mirror of
https://github.com/huggingface/diffusers.git
synced 2025-12-06 20:44:33 +08:00
Compare commits
363 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
0e5f2daee7 | ||
|
|
416749ff96 | ||
|
|
b1b99b59ac | ||
|
|
606ac57e50 | ||
|
|
394243ce98 | ||
|
|
fe98574622 | ||
|
|
c5c9399610 | ||
|
|
836f3f35c2 | ||
|
|
9c3820d05a | ||
|
|
13e37cabe0 | ||
|
|
760dcb1ffc | ||
|
|
889aa6008c | ||
|
|
76f9b52289 | ||
|
|
6b275fca49 | ||
|
|
1b42732ced | ||
|
|
9e9d2dbc59 | ||
|
|
8b4371f70f | ||
|
|
919e27d357 | ||
|
|
ad9d252596 | ||
|
|
7e11392dfd | ||
|
|
1f49a343b5 | ||
|
|
936cd08488 | ||
|
|
3a32b8c916 | ||
|
|
c3a15437f8 | ||
|
|
8c31925b3b | ||
|
|
33344ed916 | ||
|
|
7353b74ec2 | ||
|
|
44bb38fd8b | ||
|
|
2ea64a08ed | ||
|
|
37fe8e00b2 | ||
|
|
0ea78f0d3b | ||
|
|
0e5a99bb5a | ||
|
|
e3c982ee29 | ||
|
|
ab00f5d3e1 | ||
|
|
3f0b44b322 | ||
|
|
cb90fd69b4 | ||
|
|
f794432e81 | ||
|
|
182b164f32 | ||
|
|
8b42c7cecc | ||
|
|
66d5a1804c | ||
|
|
d5acb4110a | ||
|
|
6cabc599a2 | ||
|
|
36b459f6e6 | ||
|
|
1820024005 | ||
|
|
ffe7b93b60 | ||
|
|
f82ebb9a03 | ||
|
|
63c68d979a | ||
|
|
ba3c9a9a3a | ||
|
|
b5c684f042 | ||
|
|
da8e87e201 | ||
|
|
43bbc78123 | ||
|
|
1c14ce9509 | ||
|
|
29628acbec | ||
|
|
9d2fc6b535 | ||
|
|
3f1e95928e | ||
|
|
87060e6a9c | ||
|
|
e5f3415fbd | ||
|
|
f5ca5af6ce | ||
|
|
2ac19ff190 | ||
|
|
badc5517ff | ||
|
|
a8fc1560c6 | ||
|
|
f448360bd0 | ||
|
|
97e1e3ba76 | ||
|
|
dacabaa47f | ||
|
|
6d5ef87e6b | ||
|
|
e7fe901e5e | ||
|
|
c3d78cd306 | ||
|
|
2a69c0b7b8 | ||
|
|
c8c0c0e846 | ||
|
|
5e12d5c691 | ||
|
|
8aed37c1bd | ||
|
|
06c79730d0 | ||
|
|
ea8d58ea91 | ||
|
|
c352faeae3 | ||
|
|
107986639d | ||
|
|
d9316bf8bc | ||
|
|
3abf4bc439 | ||
|
|
94566e6dd8 | ||
|
|
4e2674934f | ||
|
|
53a42d0a0c | ||
|
|
321f9791d6 | ||
|
|
c524244f49 | ||
|
|
d224c6373f | ||
|
|
44705a648b | ||
|
|
a7b0047e0f | ||
|
|
dcb9070bc2 | ||
|
|
11667d08d3 | ||
|
|
221de0edee | ||
|
|
0eac7bd682 | ||
|
|
1e7e23a9c6 | ||
|
|
b8415bb480 | ||
|
|
3a15afacab | ||
|
|
571e4062e5 | ||
|
|
14bd3567b0 | ||
|
|
c2bc59d2b1 | ||
|
|
ab946575b1 | ||
|
|
1468f754e0 | ||
|
|
fa7443c899 | ||
|
|
8d7771d8b0 | ||
|
|
a1b5ef5ddc | ||
|
|
f26d3011c7 | ||
|
|
9da575d63c | ||
|
|
979c48be04 | ||
|
|
099d3eab49 | ||
|
|
61dc657461 | ||
|
|
23904d54d0 | ||
|
|
c691bb2f42 | ||
|
|
4c293e0e1b | ||
|
|
516cb9e7f8 | ||
|
|
60a981343e | ||
|
|
db5a05742e | ||
|
|
0dbc4779c8 | ||
|
|
5018abff6e | ||
|
|
f1aade0596 | ||
|
|
abedfb08f1 | ||
|
|
61ea57c5a7 | ||
|
|
810c0e4fda | ||
|
|
db7ec72dd8 | ||
|
|
52e0c5b294 | ||
|
|
fb188cd3f5 | ||
|
|
efe1e60e12 | ||
|
|
fd6f93b2b1 | ||
|
|
db934c6750 | ||
|
|
185347e411 | ||
|
|
c1c4dea98d | ||
|
|
f4cd5a20d0 | ||
|
|
3dbd6a8f4d | ||
|
|
c54f36f087 | ||
|
|
8b0bc596de | ||
|
|
f35387b33f | ||
|
|
3e2cff4da2 | ||
|
|
639b861129 | ||
|
|
663393e28a | ||
|
|
c50d997591 | ||
|
|
f1cb807496 | ||
|
|
13ac40ed8e | ||
|
|
ebe683432f | ||
|
|
b897008122 | ||
|
|
8830af1168 | ||
|
|
81e7144783 | ||
|
|
c9bd4d4338 | ||
|
|
7e0fd19ffe | ||
|
|
21aac1aca9 | ||
|
|
b65eb377dd | ||
|
|
26ce60c46d | ||
|
|
358531be9d | ||
|
|
66ee73eebc | ||
|
|
32b93da875 | ||
|
|
597b7ae2fb | ||
|
|
519bd41ff3 | ||
|
|
eb90d3be13 | ||
|
|
df2e145e5f | ||
|
|
046dc43075 | ||
|
|
c174bcf4bf | ||
|
|
466214d2d6 | ||
|
|
4e125f72ab | ||
|
|
0926dc2418 | ||
|
|
8cba133f36 | ||
|
|
f47066f707 | ||
|
|
859ffea2b1 | ||
|
|
65788e46ed | ||
|
|
eceeb97242 | ||
|
|
333a8da678 | ||
|
|
814133ec9c | ||
|
|
f15ab901a0 | ||
|
|
d1f2e3e47b | ||
|
|
1899457b24 | ||
|
|
ebf3717c37 | ||
|
|
976173a4bf | ||
|
|
bae04ea9d8 | ||
|
|
0b7daa6de9 | ||
|
|
99568c5a39 | ||
|
|
2ac9b02609 | ||
|
|
17e5b4921a | ||
|
|
36e1893c6f | ||
|
|
4d1536bb2e | ||
|
|
e5d9baf0fe | ||
|
|
c482d7bd4f | ||
|
|
e47c97a451 | ||
|
|
740326d2a2 | ||
|
|
31d1f3c8c0 | ||
|
|
635da72374 | ||
|
|
79db3eb6ca | ||
|
|
e372767c4d | ||
|
|
c45fd7498c | ||
|
|
9dccc7dc42 | ||
|
|
52b3ff5eb9 | ||
|
|
fff981df2f | ||
|
|
a42b900d27 | ||
|
|
bdecc3cffd | ||
|
|
0efac0aac9 | ||
|
|
d74b804d05 | ||
|
|
a859b1992b | ||
|
|
22b63d155a | ||
|
|
85d991a12a | ||
|
|
3a5c87055c | ||
|
|
a2b72faff7 | ||
|
|
c9504bba10 | ||
|
|
26ea58d4e1 | ||
|
|
d1fb309381 | ||
|
|
7b9b946cb2 | ||
|
|
b9de7172ba | ||
|
|
4261c3aadf | ||
|
|
932ce05d97 | ||
|
|
4e08e0ca42 | ||
|
|
af6c143919 | ||
|
|
07ff0abff4 | ||
|
|
3286dac6bf | ||
|
|
1cf7933ea2 | ||
|
|
d726857f7e | ||
|
|
ee010726ab | ||
|
|
abcb25978a | ||
|
|
183056f243 | ||
|
|
dc7c49e4e4 | ||
|
|
c991ffd4f0 | ||
|
|
3986741b8b | ||
|
|
0e13d3293c | ||
|
|
3f9e3d8ad6 | ||
|
|
e13ee8b5b3 | ||
|
|
0027993e91 | ||
|
|
6846ee2ac4 | ||
|
|
c7a39d38ad | ||
|
|
02a76c2c81 | ||
|
|
9b9afc9726 | ||
|
|
b7f0ce5b39 | ||
|
|
6921393ae2 | ||
|
|
17bf65e186 | ||
|
|
014ebc594d | ||
|
|
168e5b7ffa | ||
|
|
43bf361a7a | ||
|
|
8199f09c22 | ||
|
|
7c120874be | ||
|
|
3562a3e661 | ||
|
|
1a0331a78a | ||
|
|
fbb103deb6 | ||
|
|
45a09bebf3 | ||
|
|
0183bf13c7 | ||
|
|
f6e8c8c09c | ||
|
|
9a4d53a476 | ||
|
|
ba264419f4 | ||
|
|
dc6d028654 | ||
|
|
d5c527a499 | ||
|
|
135acd83af | ||
|
|
433cb3f801 | ||
|
|
de810814da | ||
|
|
bc2d586dcb | ||
|
|
49a81f9f1a | ||
|
|
78e99a997b | ||
|
|
fc67917a18 | ||
|
|
7ca832cac9 | ||
|
|
b296f2d4f3 | ||
|
|
ac796924df | ||
|
|
3618d33039 | ||
|
|
c3c1bdf8e2 | ||
|
|
bd9c9fbfbe | ||
|
|
f941fc9917 | ||
|
|
e29fc44635 | ||
|
|
7b4e049eb0 | ||
|
|
4fbf8c815e | ||
|
|
0244e2af4c | ||
|
|
6e456b7a7a | ||
|
|
3a17775454 | ||
|
|
40e28e8bf4 | ||
|
|
fc596c8625 | ||
|
|
48269070d2 | ||
|
|
c31736a4a4 | ||
|
|
7b43035bcb | ||
|
|
e45dae7dc0 | ||
|
|
d0032c6095 | ||
|
|
33abc79515 | ||
|
|
0d80fe9327 | ||
|
|
848c86ca0a | ||
|
|
320506c75a | ||
|
|
30fbd39f0c | ||
|
|
62c2c547db | ||
|
|
9e31c6a749 | ||
|
|
e3bf932404 | ||
|
|
dc966cc447 | ||
|
|
ac00dad756 | ||
|
|
072d75196c | ||
|
|
da4aebeda7 | ||
|
|
71289ba06e | ||
|
|
bfb4ddca35 | ||
|
|
c982fb8262 | ||
|
|
0417baf23d | ||
|
|
9c82c32ba7 | ||
|
|
1a099e5e0e | ||
|
|
b09b152f77 | ||
|
|
a2117cb797 | ||
|
|
ee902ddf3a | ||
|
|
e1ef122260 | ||
|
|
4497e78d00 | ||
|
|
49718b4704 | ||
|
|
77aadfee6a | ||
|
|
452339e20e | ||
|
|
80898b5234 | ||
|
|
e5675fad5d | ||
|
|
27359ae049 | ||
|
|
95a45f5b3a | ||
|
|
646e16fe06 | ||
|
|
08c852290a | ||
|
|
2b8bc91cf8 | ||
|
|
5b8ce1e7e6 | ||
|
|
05e265fbc8 | ||
|
|
694ad9849b | ||
|
|
808b49a7dc | ||
|
|
1c953bc3ea | ||
|
|
e007c797b1 | ||
|
|
44e64f9464 | ||
|
|
a677565f16 | ||
|
|
ff885b0e26 | ||
|
|
b4e6a7403d | ||
|
|
d182a6ad91 | ||
|
|
12da0fe10d | ||
|
|
cf6cd39572 | ||
|
|
eef2327a47 | ||
|
|
9c96682a51 | ||
|
|
1997b90838 | ||
|
|
b2274ece73 | ||
|
|
7dc71897b3 | ||
|
|
800b27703e | ||
|
|
d76bc43720 | ||
|
|
de22d4cd5d | ||
|
|
8c1f51978c | ||
|
|
dcb23b2d72 | ||
|
|
13a78b3cd3 | ||
|
|
fe7d136324 | ||
|
|
e660a05fed | ||
|
|
5e6f500038 | ||
|
|
0ffda1dfcc | ||
|
|
20c722c601 | ||
|
|
7cabc0cddc | ||
|
|
c2e48b23f8 | ||
|
|
ace07110c1 | ||
|
|
988369a01c | ||
|
|
5a3467e623 | ||
|
|
e26782759c | ||
|
|
1d2551d716 | ||
|
|
8007393614 | ||
|
|
cdf26c55f5 | ||
|
|
bed32182f6 | ||
|
|
cf3fdb8479 | ||
|
|
d2940c23fe | ||
|
|
13f003c9bd | ||
|
|
a1e1806575 | ||
|
|
cc45831ec6 | ||
|
|
2d8d82f93e | ||
|
|
71ecc7aed8 | ||
|
|
3f2d46a14e | ||
|
|
ebbba62c36 | ||
|
|
7b55d334d5 | ||
|
|
986cc9b2f4 | ||
|
|
c3cc8eb23c | ||
|
|
926658665f | ||
|
|
acb2faaefa | ||
|
|
4c16b3a5fd | ||
|
|
c5e54c200a | ||
|
|
4bf6bea52a | ||
|
|
7d4bafa8a4 | ||
|
|
57aba1ef50 | ||
|
|
71c6b36254 | ||
|
|
1112699149 | ||
|
|
52a9acfa8e |
17
.github/workflows/build_documentation.yml
vendored
Normal file
17
.github/workflows/build_documentation.yml
vendored
Normal file
@@ -0,0 +1,17 @@
|
||||
name: Build documentation
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
- doc-builder*
|
||||
- v*-release
|
||||
|
||||
jobs:
|
||||
build:
|
||||
uses: huggingface/doc-builder/.github/workflows/build_main_documentation.yml@main
|
||||
with:
|
||||
commit_sha: ${{ github.sha }}
|
||||
package: diffusers
|
||||
secrets:
|
||||
token: ${{ secrets.HUGGINGFACE_PUSH }}
|
||||
16
.github/workflows/build_pr_documentation.yml
vendored
Normal file
16
.github/workflows/build_pr_documentation.yml
vendored
Normal file
@@ -0,0 +1,16 @@
|
||||
name: Build PR Documentation
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
build:
|
||||
uses: huggingface/doc-builder/.github/workflows/build_pr_documentation.yml@main
|
||||
with:
|
||||
commit_sha: ${{ github.event.pull_request.head.sha }}
|
||||
pr_number: ${{ github.event.number }}
|
||||
package: diffusers
|
||||
13
.github/workflows/delete_doc_comment.yml
vendored
Normal file
13
.github/workflows/delete_doc_comment.yml
vendored
Normal file
@@ -0,0 +1,13 @@
|
||||
name: Delete dev documentation
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
types: [ closed ]
|
||||
|
||||
|
||||
jobs:
|
||||
delete:
|
||||
uses: huggingface/doc-builder/.github/workflows/delete_doc_comment.yml@main
|
||||
with:
|
||||
pr_number: ${{ github.event.number }}
|
||||
package: diffusers
|
||||
1
MANIFEST.in
Normal file
1
MANIFEST.in
Normal file
@@ -0,0 +1 @@
|
||||
include diffusers/utils/model_card_template.md
|
||||
13
Makefile
13
Makefile
@@ -34,30 +34,23 @@ autogenerate_code: deps_table_update
|
||||
# Check that the repo is in a good state
|
||||
|
||||
repo-consistency:
|
||||
python utils/check_copies.py
|
||||
python utils/check_table.py
|
||||
python utils/check_dummies.py
|
||||
python utils/check_repo.py
|
||||
python utils/check_inits.py
|
||||
python utils/check_config_docstrings.py
|
||||
python utils/tests_fetcher.py --sanity_check
|
||||
|
||||
# this target runs checks on all files
|
||||
|
||||
quality:
|
||||
black --check --preview $(check_dirs)
|
||||
isort --check-only $(check_dirs)
|
||||
python utils/custom_init_isort.py --check_only
|
||||
python utils/sort_auto_mappings.py --check_only
|
||||
flake8 $(check_dirs)
|
||||
doc-builder style src/transformers docs/source --max_len 119 --check_only --path_to_docs docs/source
|
||||
doc-builder style src/diffusers docs/source --max_len 119 --check_only --path_to_docs docs/source
|
||||
|
||||
# Format source code automatically and check is there are any problems left that need manual fixing
|
||||
|
||||
extra_style_checks:
|
||||
python utils/custom_init_isort.py
|
||||
python utils/sort_auto_mappings.py
|
||||
doc-builder style src/transformers docs/source --max_len 119 --path_to_docs docs/source
|
||||
doc-builder style src/diffusers docs/source --max_len 119 --path_to_docs docs/source
|
||||
|
||||
# this target runs checks on all files and potentially modifies some of them
|
||||
|
||||
@@ -74,8 +67,6 @@ fixup: modified_only_fixup extra_style_checks autogenerate_code repo-consistency
|
||||
# Make marked copies of snippets of codes conform to the original
|
||||
|
||||
fix-copies:
|
||||
python utils/check_copies.py --fix_and_overwrite
|
||||
python utils/check_table.py --fix_and_overwrite
|
||||
python utils/check_dummies.py --fix_and_overwrite
|
||||
|
||||
# Run tests for the library
|
||||
|
||||
244
README.md
244
README.md
@@ -27,42 +27,52 @@ More precisely, 🤗 Diffusers offers:
|
||||
|
||||
## Definitions
|
||||
|
||||
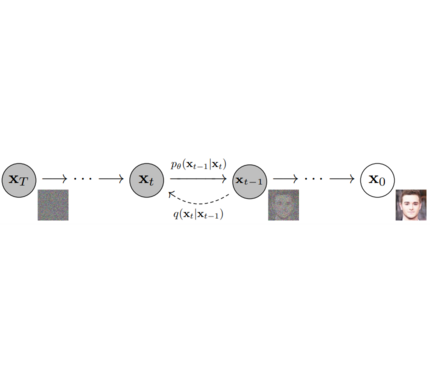
**Models**: Neural network that models **p_θ(x_t-1|x_t)** (see image below) and is trained end-to-end to *denoise* a noisy input to an image.
|
||||
**Models**: Neural network that models $p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)$ (see image below) and is trained end-to-end to *denoise* a noisy input to an image.
|
||||
*Examples*: UNet, Conditioned UNet, 3D UNet, Transformer UNet
|
||||
|
||||
|
||||
|
||||
<p align="center">
|
||||
<img src="https://user-images.githubusercontent.com/10695622/174349667-04e9e485-793b-429a-affe-096e8199ad5b.png" width="800"/>
|
||||
<br>
|
||||
<em> Figure from DDPM paper (https://arxiv.org/abs/2006.11239). </em>
|
||||
<p>
|
||||
|
||||
**Schedulers**: Algorithm class for both **inference** and **training**.
|
||||
The class provides functionality to compute previous image according to alpha, beta schedule as well as predict noise for training.
|
||||
*Examples*: [DDPM](https://arxiv.org/abs/2006.11239), [DDIM](https://arxiv.org/abs/2010.02502), [PNDM](https://arxiv.org/abs/2202.09778), [DEIS](https://arxiv.org/abs/2204.13902)
|
||||
|
||||

|
||||

|
||||
<p align="center">
|
||||
<img src="https://user-images.githubusercontent.com/10695622/174349706-53d58acc-a4d1-4cda-b3e8-432d9dc7ad38.png" width="800"/>
|
||||
<br>
|
||||
<em> Sampling and training algorithms. Figure from DDPM paper (https://arxiv.org/abs/2006.11239). </em>
|
||||
<p>
|
||||
|
||||
|
||||
**Diffusion Pipeline**: End-to-end pipeline that includes multiple diffusion models, possible text encoders, ...
|
||||
*Examples*: GLIDE, Latent-Diffusion, Imagen, DALL-E 2
|
||||
|
||||
|
||||
|
||||
*Examples*: Glide, Latent-Diffusion, Imagen, DALL-E 2
|
||||
|
||||
<p align="center">
|
||||
<img src="https://user-images.githubusercontent.com/10695622/174348898-481bd7c2-5457-4830-89bc-f0907756f64c.jpeg" width="550"/>
|
||||
<br>
|
||||
<em> Figure from ImageGen (https://imagen.research.google/). </em>
|
||||
<p>
|
||||
|
||||
## Philosophy
|
||||
|
||||
- Readability and clarity is prefered over highly optimized code. A strong importance is put on providing readable, intuitive and elementary code desgin. *E.g.*, the provided [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) are separated from the provided [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models) and provide well-commented code that can be read alongside the original paper.
|
||||
- Readability and clarity is prefered over highly optimized code. A strong importance is put on providing readable, intuitive and elementary code design. *E.g.*, the provided [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) are separated from the provided [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models) and provide well-commented code that can be read alongside the original paper.
|
||||
- Diffusers is **modality independent** and focusses on providing pretrained models and tools to build systems that generate **continous outputs**, *e.g.* vision and audio.
|
||||
- Diffusion models and schedulers are provided as consise, elementary building blocks whereas diffusion pipelines are a collection of end-to-end diffusion systems that can be used out-of-the-box, should stay as close as possible to their original implementation and can include components of other library, such as text-encoders. Examples for diffusion pipelines are [Glide](https://github.com/openai/glide-text2im) and [Latent Diffusion](https://github.com/CompVis/latent-diffusion).
|
||||
|
||||
## Quickstart
|
||||
|
||||
**Check out this notebook: https://colab.research.google.com/drive/1nMfF04cIxg6FujxsNYi9kiTRrzj4_eZU?usp=sharing**
|
||||
|
||||
### Installation
|
||||
|
||||
**Note**: If you want to run PyTorch on GPU on a CUDA-compatible machine, please make sure to install the corresponding `torch` version from the
|
||||
[official website](https://pytorch.org/).
|
||||
```
|
||||
git clone https://github.com/huggingface/diffusers.git
|
||||
cd diffusers && pip install -e .
|
||||
pip install diffusers # should install diffusers 0.0.4
|
||||
```
|
||||
|
||||
### 1. `diffusers` as a toolbox for schedulers and models.
|
||||
### 1. `diffusers` as a toolbox for schedulers and models
|
||||
|
||||
`diffusers` is more modularized than `transformers`. The idea is that researchers and engineers can use only parts of the library easily for the own use cases.
|
||||
It could become a central place for all kinds of models, schedulers, training utils and processors that one can mix and match for one's own use case.
|
||||
@@ -70,216 +80,56 @@ Both models and schedulers should be load- and saveable from the Hub.
|
||||
|
||||
For more examples see [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) and [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models)
|
||||
|
||||
#### **Example for [DDPM](https://arxiv.org/abs/2006.11239):**
|
||||
#### **Example for Unconditonal Image generation [DDPM](https://arxiv.org/abs/2006.11239):**
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import UNetModel, DDPMScheduler
|
||||
import PIL
|
||||
from diffusers import UNet2DModel, DDIMScheduler
|
||||
import PIL.Image
|
||||
import numpy as np
|
||||
import tqdm
|
||||
|
||||
generator = torch.manual_seed(0)
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
# 1. Load models
|
||||
noise_scheduler = DDPMScheduler.from_config("fusing/ddpm-lsun-church", tensor_format="pt")
|
||||
unet = UNetModel.from_pretrained("fusing/ddpm-lsun-church").to(torch_device)
|
||||
scheduler = DDIMScheduler.from_config("fusing/ddpm-celeba-hq", tensor_format="pt")
|
||||
unet = UNet2DModel.from_pretrained("fusing/ddpm-celeba-hq", ddpm=True).to(torch_device)
|
||||
|
||||
# 2. Sample gaussian noise
|
||||
generator = torch.manual_seed(23)
|
||||
unet.image_size = unet.resolution
|
||||
image = torch.randn(
|
||||
(1, unet.in_channels, unet.resolution, unet.resolution),
|
||||
generator=generator,
|
||||
(1, unet.in_channels, unet.image_size, unet.image_size),
|
||||
generator=generator,
|
||||
)
|
||||
image = image.to(torch_device)
|
||||
|
||||
# 3. Denoise
|
||||
num_prediction_steps = len(noise_scheduler)
|
||||
for t in tqdm.tqdm(reversed(range(num_prediction_steps)), total=num_prediction_steps):
|
||||
# predict noise residual
|
||||
with torch.no_grad():
|
||||
residual = unet(image, t)
|
||||
|
||||
# predict previous mean of image x_t-1
|
||||
pred_prev_image = noise_scheduler.step(residual, image, t)
|
||||
|
||||
# optionally sample variance
|
||||
variance = 0
|
||||
if t > 0:
|
||||
noise = torch.randn(image.shape, generator=generator).to(image.device)
|
||||
variance = noise_scheduler.get_variance(t).sqrt() * noise
|
||||
|
||||
# set current image to prev_image: x_t -> x_t-1
|
||||
image = pred_prev_image + variance
|
||||
|
||||
# 5. process image to PIL
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = (image_processed + 1.0) * 127.5
|
||||
image_processed = image_processed.numpy().astype(np.uint8)
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# 6. save image
|
||||
image_pil.save("test.png")
|
||||
```
|
||||
|
||||
#### **Example for [DDIM](https://arxiv.org/abs/2010.02502):**
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import UNetModel, DDIMScheduler
|
||||
import PIL
|
||||
import numpy as np
|
||||
import tqdm
|
||||
|
||||
generator = torch.manual_seed(0)
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
# 1. Load models
|
||||
noise_scheduler = DDIMScheduler.from_config("fusing/ddpm-celeba-hq", tensor_format="pt")
|
||||
unet = UNetModel.from_pretrained("fusing/ddpm-celeba-hq").to(torch_device)
|
||||
|
||||
# 2. Sample gaussian noise
|
||||
image = torch.randn(
|
||||
(1, unet.in_channels, unet.resolution, unet.resolution),
|
||||
generator=generator,
|
||||
)
|
||||
image = image.to(torch_device)
|
||||
|
||||
# 3. Denoise
|
||||
num_inference_steps = 50
|
||||
eta = 0.0 # <- deterministic sampling
|
||||
scheduler.set_timesteps(num_inference_steps)
|
||||
|
||||
for t in tqdm.tqdm(reversed(range(num_inference_steps)), total=num_inference_steps):
|
||||
# 1. predict noise residual
|
||||
orig_t = noise_scheduler.get_orig_t(t, num_inference_steps)
|
||||
with torch.no_grad():
|
||||
residual = unet(image, orig_t)
|
||||
for t in tqdm.tqdm(scheduler.timesteps):
|
||||
# 1. predict noise residual
|
||||
with torch.no_grad():
|
||||
residual = unet(image, t)["sample"]
|
||||
|
||||
# 2. predict previous mean of image x_t-1
|
||||
pred_prev_image = noise_scheduler.step(residual, image, t, num_inference_steps, eta)
|
||||
prev_image = scheduler.step(residual, t, image, eta)["prev_sample"]
|
||||
|
||||
# 3. optionally sample variance
|
||||
variance = 0
|
||||
if eta > 0:
|
||||
noise = torch.randn(image.shape, generator=generator).to(image.device)
|
||||
variance = noise_scheduler.get_variance(t).sqrt() * eta * noise
|
||||
# 3. set current image to prev_image: x_t -> x_t-1
|
||||
image = prev_image
|
||||
|
||||
# 4. set current image to prev_image: x_t -> x_t-1
|
||||
image = pred_prev_image + variance
|
||||
|
||||
# 5. process image to PIL
|
||||
# 4. process image to PIL
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = (image_processed + 1.0) * 127.5
|
||||
image_processed = image_processed.numpy().astype(np.uint8)
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# 6. save image
|
||||
image_pil.save("test.png")
|
||||
```
|
||||
# 5. save image
|
||||
image_pil.save("generated_image.png")
|
||||
```
|
||||
|
||||
### 2. `diffusers` as a collection of popula Diffusion systems (GLIDE, Dalle, ...)
|
||||
|
||||
For more examples see [pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines).
|
||||
|
||||
#### **Example image generation with PNDM**
|
||||
#### **Example for Unconditonal Image generation [LDM](https://github.com/CompVis/latent-diffusion):**
|
||||
|
||||
```python
|
||||
from diffusers import PNDM, UNetModel, PNDMScheduler
|
||||
import PIL.Image
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
model_id = "fusing/ddim-celeba-hq"
|
||||
|
||||
model = UNetModel.from_pretrained(model_id)
|
||||
scheduler = PNDMScheduler()
|
||||
|
||||
# load model and scheduler
|
||||
pndm = PNDM(unet=model, noise_scheduler=scheduler)
|
||||
|
||||
# run pipeline in inference (sample random noise and denoise)
|
||||
with torch.no_grad():
|
||||
image = pndm()
|
||||
|
||||
# process image to PIL
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = (image_processed + 1.0) / 2
|
||||
image_processed = torch.clamp(image_processed, 0.0, 1.0)
|
||||
image_processed = image_processed * 255
|
||||
image_processed = image_processed.numpy().astype(np.uint8)
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# save image
|
||||
image_pil.save("test.png")
|
||||
```
|
||||
|
||||
#### **Text to Image generation with Latent Diffusion**
|
||||
|
||||
_Note: To use latent diffusion install transformers from [this branch](https://github.com/patil-suraj/transformers/tree/ldm-bert)._
|
||||
|
||||
```python
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
ldm = DiffusionPipeline.from_pretrained("fusing/latent-diffusion-text2im-large")
|
||||
|
||||
generator = torch.manual_seed(42)
|
||||
|
||||
prompt = "A painting of a squirrel eating a burger"
|
||||
image = ldm([prompt], generator=generator, eta=0.3, guidance_scale=6.0, num_inference_steps=50)
|
||||
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = image_processed * 255.
|
||||
image_processed = image_processed.numpy().astype(np.uint8)
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# save image
|
||||
image_pil.save("test.png")
|
||||
```
|
||||
|
||||
#### **Text to speech with BDDM**
|
||||
|
||||
_Follow the isnstructions [here](https://pytorch.org/hub/nvidia_deeplearningexamples_tacotron2/) to load tacotron2 model._
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import BDDM, DiffusionPipeline
|
||||
|
||||
torch_device = "cuda"
|
||||
|
||||
# load the BDDM pipeline
|
||||
bddm = DiffusionPipeline.from_pretrained("fusing/diffwave-vocoder-ljspeech")
|
||||
|
||||
# load tacotron2 to get the mel spectograms
|
||||
tacotron2 = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tacotron2', model_math='fp16')
|
||||
tacotron2 = tacotron2.to(torch_device).eval()
|
||||
|
||||
text = "Hello world, I missed you so much."
|
||||
|
||||
utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tts_utils')
|
||||
sequences, lengths = utils.prepare_input_sequence([text])
|
||||
|
||||
# generate mel spectograms using text
|
||||
with torch.no_grad():
|
||||
mel_spec, _, _ = tacotron2.infer(sequences, lengths)
|
||||
|
||||
# generate the speech by passing mel spectograms to BDDM pipeline
|
||||
generator = torch.manual_seed(0)
|
||||
audio = bddm(mel_spec, generator, torch_device)
|
||||
|
||||
# save generated audio
|
||||
from scipy.io.wavfile import write as wavwrite
|
||||
sampling_rate = 22050
|
||||
wavwrite("generated_audio.wav", sampling_rate, audio.squeeze().cpu().numpy())
|
||||
```
|
||||
|
||||
## TODO
|
||||
|
||||
- Create common API for models [ ]
|
||||
- Add tests for models [ ]
|
||||
- Adapt schedulers for training [ ]
|
||||
- Write google colab for training [ ]
|
||||
- Write docs / Think about how to structure docs [ ]
|
||||
- Add tests to circle ci [ ]
|
||||
- Add more vision models [ ]
|
||||
- Add more speech models [ ]
|
||||
- Add RL model [ ]
|
||||
|
||||
40
docs/source/_toctree.yml
Normal file
40
docs/source/_toctree.yml
Normal file
@@ -0,0 +1,40 @@
|
||||
- sections:
|
||||
- local: index
|
||||
title: 🧨 Diffusers
|
||||
- local: quicktour
|
||||
title: Quicktour
|
||||
- local: philosophy
|
||||
title: Philosophy
|
||||
title: Get started
|
||||
- sections:
|
||||
- sections:
|
||||
- local: examples/diffusers_for_vision
|
||||
title: Diffusers for Vision
|
||||
- local: examples/diffusers_for_audio
|
||||
title: Diffusers for Audio
|
||||
- local: examples/diffusers_for_other
|
||||
title: Diffusers for Other Modalities
|
||||
title: Examples
|
||||
title: Using Diffusers
|
||||
- sections:
|
||||
- sections:
|
||||
- local: pipelines
|
||||
title: Pipelines
|
||||
- local: schedulers
|
||||
title: Schedulers
|
||||
- local: models
|
||||
title: Models
|
||||
title: Main Classes
|
||||
- sections:
|
||||
- local: pipelines/glide
|
||||
title: "Glide"
|
||||
title: Pipelines
|
||||
- sections:
|
||||
- local: schedulers/ddpm
|
||||
title: "DDPM"
|
||||
title: Schedulers
|
||||
- sections:
|
||||
- local: models/unet
|
||||
title: "Unet"
|
||||
title: Models
|
||||
title: API
|
||||
13
docs/source/examples/diffusers_for_audio.mdx
Normal file
13
docs/source/examples/diffusers_for_audio.mdx
Normal file
@@ -0,0 +1,13 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Diffusers for audio
|
||||
20
docs/source/examples/diffusers_for_other.mdx
Normal file
20
docs/source/examples/diffusers_for_other.mdx
Normal file
@@ -0,0 +1,20 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Diffusers for other modalities
|
||||
|
||||
Diffusers offers support to other modalities than vision and audio.
|
||||
Currently, some examples include:
|
||||
- [Diffuser](https://diffusion-planning.github.io/) for planning in reinforcement learning (currenlty only inference): [](https://colab.research.google.com/drive/1TmBmlYeKUZSkUZoJqfBmaicVTKx6nN1R?usp=sharing)
|
||||
|
||||
If you are interested in contributing to under-construction examples, you can explore:
|
||||
- [GeoDiff](https://github.com/MinkaiXu/GeoDiff) for generating 3D configurations of molecule diagrams [](https://colab.research.google.com/drive/1pLYYWQhdLuv1q-JtEHGZybxp2RBF8gPs?usp=sharing).
|
||||
150
docs/source/examples/diffusers_for_vision.mdx
Normal file
150
docs/source/examples/diffusers_for_vision.mdx
Normal file
@@ -0,0 +1,150 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Diffusers for vision
|
||||
|
||||
## Direct image generation
|
||||
|
||||
#### **Example image generation with PNDM**
|
||||
|
||||
```python
|
||||
from diffusers import PNDM, UNetModel, PNDMScheduler
|
||||
import PIL.Image
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
model_id = "fusing/ddim-celeba-hq"
|
||||
|
||||
model = UNetModel.from_pretrained(model_id)
|
||||
scheduler = PNDMScheduler()
|
||||
|
||||
# load model and scheduler
|
||||
pndm = PNDM(unet=model, noise_scheduler=scheduler)
|
||||
|
||||
# run pipeline in inference (sample random noise and denoise)
|
||||
with torch.no_grad():
|
||||
image = pndm()
|
||||
|
||||
# process image to PIL
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = (image_processed + 1.0) / 2
|
||||
image_processed = torch.clamp(image_processed, 0.0, 1.0)
|
||||
image_processed = image_processed * 255
|
||||
image_processed = image_processed.numpy().astype(np.uint8)
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# save image
|
||||
image_pil.save("test.png")
|
||||
```
|
||||
|
||||
#### **Example 1024x1024 image generation with SDE VE**
|
||||
|
||||
See [paper](https://arxiv.org/abs/2011.13456) for more information on SDE VE.
|
||||
|
||||
```python
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
import PIL.Image
|
||||
import numpy as np
|
||||
|
||||
torch.manual_seed(32)
|
||||
|
||||
score_sde_sv = DiffusionPipeline.from_pretrained("fusing/ffhq_ncsnpp")
|
||||
|
||||
# Note this might take up to 3 minutes on a GPU
|
||||
image = score_sde_sv(num_inference_steps=2000)
|
||||
|
||||
image = image.permute(0, 2, 3, 1).cpu().numpy()
|
||||
image = np.clip(image * 255, 0, 255).astype(np.uint8)
|
||||
image_pil = PIL.Image.fromarray(image[0])
|
||||
|
||||
# save image
|
||||
image_pil.save("test.png")
|
||||
```
|
||||
#### **Example 32x32 image generation with SDE VP**
|
||||
|
||||
See [paper](https://arxiv.org/abs/2011.13456) for more information on SDE VE.
|
||||
|
||||
```python
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
import PIL.Image
|
||||
import numpy as np
|
||||
|
||||
torch.manual_seed(32)
|
||||
|
||||
score_sde_sv = DiffusionPipeline.from_pretrained("fusing/cifar10-ddpmpp-deep-vp")
|
||||
|
||||
# Note this might take up to 3 minutes on a GPU
|
||||
image = score_sde_sv(num_inference_steps=1000)
|
||||
|
||||
image = image.permute(0, 2, 3, 1).cpu().numpy()
|
||||
image = np.clip(image * 255, 0, 255).astype(np.uint8)
|
||||
image_pil = PIL.Image.fromarray(image[0])
|
||||
|
||||
# save image
|
||||
image_pil.save("test.png")
|
||||
```
|
||||
|
||||
|
||||
#### **Text to Image generation with Latent Diffusion**
|
||||
|
||||
_Note: To use latent diffusion install transformers from [this branch](https://github.com/patil-suraj/transformers/tree/ldm-bert)._
|
||||
|
||||
```python
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
ldm = DiffusionPipeline.from_pretrained("fusing/latent-diffusion-text2im-large")
|
||||
|
||||
generator = torch.manual_seed(42)
|
||||
|
||||
prompt = "A painting of a squirrel eating a burger"
|
||||
image = ldm([prompt], generator=generator, eta=0.3, guidance_scale=6.0, num_inference_steps=50)
|
||||
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = image_processed * 255.0
|
||||
image_processed = image_processed.numpy().astype(np.uint8)
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# save image
|
||||
image_pil.save("test.png")
|
||||
```
|
||||
|
||||
|
||||
## Text to image generation
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import BDDMPipeline, GradTTSPipeline
|
||||
|
||||
torch_device = "cuda"
|
||||
|
||||
# load grad tts and bddm pipelines
|
||||
grad_tts = GradTTSPipeline.from_pretrained("fusing/grad-tts-libri-tts")
|
||||
bddm = BDDMPipeline.from_pretrained("fusing/diffwave-vocoder-ljspeech")
|
||||
|
||||
text = "Hello world, I missed you so much."
|
||||
|
||||
# generate mel spectograms using text
|
||||
mel_spec = grad_tts(text, torch_device=torch_device)
|
||||
|
||||
# generate the speech by passing mel spectograms to BDDMPipeline pipeline
|
||||
generator = torch.manual_seed(42)
|
||||
audio = bddm(mel_spec, generator, torch_device=torch_device)
|
||||
|
||||
# save generated audio
|
||||
from scipy.io.wavfile import write as wavwrite
|
||||
|
||||
sampling_rate = 22050
|
||||
wavwrite("generated_audio.wav", sampling_rate, audio.squeeze().cpu().numpy())
|
||||
```
|
||||
|
||||
110
docs/source/index.mdx
Normal file
110
docs/source/index.mdx
Normal file
@@ -0,0 +1,110 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<img src="https://raw.githubusercontent.com/huggingface/diffusers/77aadfee6a891ab9fcfb780f87c693f7a5beeb8e/docs/source/imgs/diffusers_library.jpg" width="400"/>
|
||||
<br>
|
||||
</p>
|
||||
|
||||
# 🧨 Diffusers
|
||||
|
||||
|
||||
🤗 Diffusers provides pretrained diffusion models across multiple modalities, such as vision and audio, and serves
|
||||
as a modular toolbox for inference and training of diffusion models.
|
||||
|
||||
More precisely, 🤗 Diffusers offers:
|
||||
|
||||
- State-of-the-art diffusion pipelines that can be run in inference with just a couple of lines of code (see [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines)).
|
||||
- Various noise schedulers that can be used interchangeably for the prefered speed vs. quality trade-off in inference (see [src/diffusers/schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers)).
|
||||
- Multiple types of models, such as UNet, that can be used as building blocks in an end-to-end diffusion system (see [src/diffusers/models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models)).
|
||||
- Training examples to show how to train the most popular diffusion models (see [examples](https://github.com/huggingface/diffusers/tree/main/examples)).
|
||||
|
||||
# Installation
|
||||
|
||||
Install Diffusers for with PyTorch. Support for other libraries will come in the future
|
||||
|
||||
🤗 Diffusers is tested on Python 3.6+, and PyTorch 1.4.0+.
|
||||
|
||||
## Install with pip
|
||||
|
||||
You should install 🤗 Diffusers in a [virtual environment](https://docs.python.org/3/library/venv.html).
|
||||
If you're unfamiliar with Python virtual environments, take a look at this [guide](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
|
||||
A virtual environment makes it easier to manage different projects, and avoid compatibility issues between dependencies.
|
||||
|
||||
Start by creating a virtual environment in your project directory:
|
||||
|
||||
```bash
|
||||
python -m venv .env
|
||||
```
|
||||
|
||||
Activate the virtual environment:
|
||||
|
||||
```bash
|
||||
source .env/bin/activate
|
||||
```
|
||||
|
||||
Now you're ready to install 🤗 Diffusers with the following command:
|
||||
|
||||
```bash
|
||||
pip install diffusers
|
||||
```
|
||||
|
||||
## Install from source
|
||||
|
||||
Install 🤗 Diffusers from source with the following command:
|
||||
|
||||
```bash
|
||||
pip install git+https://github.com/huggingface/diffusers
|
||||
```
|
||||
|
||||
This command installs the bleeding edge `main` version rather than the latest `stable` version.
|
||||
The `main` version is useful for staying up-to-date with the latest developments.
|
||||
For instance, if a bug has been fixed since the last official release but a new release hasn't been rolled out yet.
|
||||
However, this means the `main` version may not always be stable.
|
||||
We strive to keep the `main` version operational, and most issues are usually resolved within a few hours or a day.
|
||||
If you run into a problem, please open an [Issue](https://github.com/huggingface/transformers/issues) so we can fix it even sooner!
|
||||
|
||||
## Editable install
|
||||
|
||||
You will need an editable install if you'd like to:
|
||||
|
||||
* Use the `main` version of the source code.
|
||||
* Contribute to 🤗 Diffusers and need to test changes in the code.
|
||||
|
||||
Clone the repository and install 🤗 Diffusers with the following commands:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers.git
|
||||
cd transformers
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
These commands will link the folder you cloned the repository to and your Python library paths.
|
||||
Python will now look inside the folder you cloned to in addition to the normal library paths.
|
||||
For example, if your Python packages are typically installed in `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python will also search the folder you cloned to: `~/diffusers/`.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
You must keep the `diffusers` folder if you want to keep using the library.
|
||||
|
||||
</Tip>
|
||||
|
||||
Now you can easily update your clone to the latest version of 🤗 Diffusers with the following command:
|
||||
|
||||
```bash
|
||||
cd ~/diffusers/
|
||||
git pull
|
||||
```
|
||||
|
||||
Your Python environment will find the `main` version of 🤗 Diffuers on the next run.
|
||||
|
||||
28
docs/source/models.mdx
Normal file
28
docs/source/models.mdx
Normal file
@@ -0,0 +1,28 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Models
|
||||
|
||||
Diffusers contains pretrained models for popular algorithms and modules for creating the next set of diffusion models.
|
||||
The primary function of these models is to denoise an input sample, by modeling the distribution $p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)$.
|
||||
The models are built on the base class ['ModelMixin'] that is a `torch.nn.module` with basic functionality for saving and loading models both locally and from the HuggingFace hub.
|
||||
|
||||
## API
|
||||
|
||||
Models should provide the `def forward` function and initialization of the model.
|
||||
All saving, loading, and utilities should be in the base ['ModelMixin'] class.
|
||||
|
||||
## Examples
|
||||
|
||||
- The ['UNetModel'] was proposed in [TODO](https://arxiv.org/) and has been used in paper1, paper2, paper3.
|
||||
- Extensions of the ['UNetModel'] include the ['UNetGlideModel'] that uses attention and timestep embeddings for the [GLIDE](https://arxiv.org/abs/2112.10741) paper, the ['UNetGradTTS'] model from this [paper](https://arxiv.org/abs/2105.06337) for text-to-speech, ['UNetLDMModel'] for latent-diffusion models in this [paper](https://arxiv.org/abs/2112.10752), and the ['TemporalUNet'] used for time-series prediciton in this reinforcement learning [paper](https://arxiv.org/abs/2205.09991).
|
||||
- TODO: mention VAE / SDE score estimation
|
||||
4
docs/source/models/unet.mdx
Normal file
4
docs/source/models/unet.mdx
Normal file
@@ -0,0 +1,4 @@
|
||||
# UNet
|
||||
|
||||
The UNet is an example often used in diffusion models.
|
||||
It was originally published [here](https://www.google.com).
|
||||
17
docs/source/philosophy.mdx
Normal file
17
docs/source/philosophy.mdx
Normal file
@@ -0,0 +1,17 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Philosophy
|
||||
|
||||
- Readability and clarity is prefered over highly optimized code. A strong importance is put on providing readable, intuitive and elementary code design. *E.g.*, the provided [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers) are separated from the provided [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models) and provide well-commented code that can be read alongside the original paper.
|
||||
- Diffusers is **modality independent** and focusses on providing pretrained models and tools to build systems that generate **continous outputs**, *e.g.* vision and audio.
|
||||
- Diffusion models and schedulers are provided as consise, elementary building blocks whereas diffusion pipelines are a collection of end-to-end diffusion systems that can be used out-of-the-box, should stay as close as possible to their original implementation and can include components of other library, such as text-encoders. Examples for diffusion pipelines are [Glide](https://github.com/openai/glide-text2im) and [Latent Diffusion](https://github.com/CompVis/latent-diffusion).
|
||||
31
docs/source/pipelines.mdx
Normal file
31
docs/source/pipelines.mdx
Normal file
@@ -0,0 +1,31 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Pipelines
|
||||
|
||||
- Pipelines are a collection of end-to-end diffusion systems that can be used out-of-the-box
|
||||
- Pipelines should stay as close as possible to their original implementation
|
||||
- Pipelines can include components of other library, such as text-encoders.
|
||||
|
||||
## API
|
||||
|
||||
TODO(Patrick, Anton, Suraj)
|
||||
|
||||
## Examples
|
||||
|
||||
- DDPM for unconditional image generation in [pipeline_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_ddpm.py).
|
||||
- DDIM for unconditional image generation in [pipeline_ddim](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_ddim.py).
|
||||
- PNDM for unconditional image generation in [pipeline_pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_pndm.py).
|
||||
- Latent diffusion for text to image generation / conditional image generation in [pipeline_latent_diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_latent_diffusion.py).
|
||||
- Glide for text to image generation / conditional image generation in [pipeline_glide](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_glide.py).
|
||||
- BDDMPipeline for spectrogram-to-sound vocoding in [pipeline_bddm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_bddm.py).
|
||||
- Grad-TTS for text to audio generation / conditional audio generation in [pipeline_grad_tts](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_grad_tts.py).
|
||||
1
docs/source/pipelines/glide.mdx
Normal file
1
docs/source/pipelines/glide.mdx
Normal file
@@ -0,0 +1 @@
|
||||
# GLIDE MODEL
|
||||
32
docs/source/quicktour.mdx
Normal file
32
docs/source/quicktour.mdx
Normal file
@@ -0,0 +1,32 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
|
||||
|
||||
# Quicktour
|
||||
|
||||
Start using Diffusers🧨 quickly!
|
||||
To start, use the [`DiffusionPipeline`] for quick inference and sample generations!
|
||||
|
||||
```
|
||||
pip install diffusers
|
||||
```
|
||||
|
||||
## Main classes
|
||||
|
||||
### Models
|
||||
|
||||
### Schedulers
|
||||
|
||||
### Pipeliens
|
||||
|
||||
|
||||
33
docs/source/schedulers.mdx
Normal file
33
docs/source/schedulers.mdx
Normal file
@@ -0,0 +1,33 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Schedulers
|
||||
|
||||
The base class ['SchedulerMixin'] implements low level utilities used by multiple schedulers.
|
||||
At a high level:
|
||||
- Schedulers are the algorithms to use diffusion models in inference as well as for training. They include the noise schedules and define algorithm-specific diffusion steps.
|
||||
- Schedulers can be used interchangable between diffusion models in inference to find the preferred tradef-off between speed and generation quality.
|
||||
- Schedulers are available in numpy, but can easily be transformed into PyTorch.
|
||||
|
||||
## API
|
||||
|
||||
- Schedulers should provide one or more `def step(...)` functions that should be called iteratively to unroll the diffusion loop during
|
||||
the forward pass.
|
||||
- Schedulers should be framework-agonstic, but provide a simple functionality to convert the scheduler into a specific framework, such as PyTorch
|
||||
with a `set_format(...)` method.
|
||||
|
||||
## Examples
|
||||
|
||||
- The ['DDPMScheduler'] was proposed in [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239) and can be found in [scheduling_ddpm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddpm.py).
|
||||
An example of how to use this scheduler can be found in [pipeline_ddpm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_ddpm.py).
|
||||
- The ['DDIMScheduler'] was proposed in [Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502) and can be found in [scheduling_ddim.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py). An example of how to use this scheduler can be found in [pipeline_ddim.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_ddim.py).
|
||||
- The ['PNMDScheduler'] was proposed in [Pseudo Numerical Methods for Diffusion Models on Manifolds](https://arxiv.org/abs/2202.09778) and can be found in [scheduling_pndm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py). An example of how to use this scheduler can be found in [pipeline_pndm.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_pndm.py).
|
||||
3
docs/source/schedulers/ddpm.mdx
Normal file
3
docs/source/schedulers/ddpm.mdx
Normal file
@@ -0,0 +1,3 @@
|
||||
# DDPM
|
||||
|
||||
DDPM is a scheduler.
|
||||
46
examples/README.md
Normal file
46
examples/README.md
Normal file
@@ -0,0 +1,46 @@
|
||||
## Training examples
|
||||
|
||||
### Unconditional Flowers
|
||||
|
||||
The command to train a DDPM UNet model on the Oxford Flowers dataset:
|
||||
|
||||
```bash
|
||||
accelerate launch train_unconditional.py \
|
||||
--dataset="huggan/flowers-102-categories" \
|
||||
--resolution=64 \
|
||||
--output_dir="ddpm-ema-flowers-64" \
|
||||
--train_batch_size=16 \
|
||||
--num_epochs=100 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=1e-4 \
|
||||
--lr_warmup_steps=500 \
|
||||
--mixed_precision=no \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
A full training run takes 2 hours on 4xV100 GPUs.
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26864830/173855866-5628989f-856b-4725-a944-d6c09490b2df.png" width="500" />
|
||||
|
||||
|
||||
### Unconditional Pokemon
|
||||
|
||||
The command to train a DDPM UNet model on the Pokemon dataset:
|
||||
|
||||
```bash
|
||||
accelerate launch train_unconditional.py \
|
||||
--dataset="huggan/pokemon" \
|
||||
--resolution=64 \
|
||||
--output_dir="ddpm-ema-pokemon-64" \
|
||||
--train_batch_size=16 \
|
||||
--num_epochs=100 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=1e-4 \
|
||||
--lr_warmup_steps=500 \
|
||||
--mixed_precision=no \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
A full training run takes 2 hours on 4xV100 GPUs.
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/26864830/173856733-4f117f8c-97bd-4f51-8002-56b488c96df9.png" width="500" />
|
||||
201
examples/experimental/train_glide_text_to_image.py
Normal file
201
examples/experimental/train_glide_text_to_image.py
Normal file
@@ -0,0 +1,201 @@
|
||||
import argparse
|
||||
import os
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
import bitsandbytes as bnb
|
||||
import PIL.Image
|
||||
from accelerate import Accelerator
|
||||
from datasets import load_dataset
|
||||
from diffusers import DDPMScheduler, Glide, GlideUNetModel
|
||||
from diffusers.hub_utils import init_git_repo, push_to_hub
|
||||
from diffusers.optimization import get_scheduler
|
||||
from diffusers.utils import logging
|
||||
from torchvision.transforms import (
|
||||
CenterCrop,
|
||||
Compose,
|
||||
InterpolationMode,
|
||||
Normalize,
|
||||
RandomHorizontalFlip,
|
||||
Resize,
|
||||
ToTensor,
|
||||
)
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
def main(args):
|
||||
accelerator = Accelerator(mixed_precision=args.mixed_precision)
|
||||
|
||||
pipeline = Glide.from_pretrained("fusing/glide-base")
|
||||
model = pipeline.text_unet
|
||||
noise_scheduler = DDPMScheduler(timesteps=1000, tensor_format="pt")
|
||||
optimizer = bnb.optim.Adam8bit(model.parameters(), lr=args.lr)
|
||||
|
||||
augmentations = Compose(
|
||||
[
|
||||
Resize(args.resolution, interpolation=InterpolationMode.BILINEAR),
|
||||
CenterCrop(args.resolution),
|
||||
RandomHorizontalFlip(),
|
||||
ToTensor(),
|
||||
Normalize([0.5], [0.5]),
|
||||
]
|
||||
)
|
||||
dataset = load_dataset(args.dataset, split="train")
|
||||
|
||||
text_encoder = pipeline.text_encoder.eval()
|
||||
|
||||
def transforms(examples):
|
||||
images = [augmentations(image.convert("RGB")) for image in examples["image"]]
|
||||
text_inputs = pipeline.tokenizer(examples["caption"], padding="max_length", max_length=77, return_tensors="pt")
|
||||
text_inputs = text_inputs.input_ids.to(accelerator.device)
|
||||
with torch.no_grad():
|
||||
text_embeddings = accelerator.unwrap_model(text_encoder)(text_inputs).last_hidden_state
|
||||
return {"images": images, "text_embeddings": text_embeddings}
|
||||
|
||||
dataset.set_transform(transforms)
|
||||
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=args.batch_size, shuffle=True)
|
||||
|
||||
lr_scheduler = get_scheduler(
|
||||
"linear",
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=args.warmup_steps,
|
||||
num_training_steps=(len(train_dataloader) * args.num_epochs) // args.gradient_accumulation_steps,
|
||||
)
|
||||
|
||||
model, text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
model, text_encoder, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
|
||||
if args.push_to_hub:
|
||||
repo = init_git_repo(args, at_init=True)
|
||||
|
||||
# Train!
|
||||
is_distributed = torch.distributed.is_available() and torch.distributed.is_initialized()
|
||||
world_size = torch.distributed.get_world_size() if is_distributed else 1
|
||||
total_train_batch_size = args.batch_size * args.gradient_accumulation_steps * world_size
|
||||
max_steps = len(train_dataloader) // args.gradient_accumulation_steps * args.num_epochs
|
||||
logger.info("***** Running training *****")
|
||||
logger.info(f" Num examples = {len(train_dataloader.dataset)}")
|
||||
logger.info(f" Num Epochs = {args.num_epochs}")
|
||||
logger.info(f" Instantaneous batch size per device = {args.batch_size}")
|
||||
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_train_batch_size}")
|
||||
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
|
||||
logger.info(f" Total optimization steps = {max_steps}")
|
||||
|
||||
for epoch in range(args.num_epochs):
|
||||
model.train()
|
||||
with tqdm(total=len(train_dataloader), unit="ba") as pbar:
|
||||
pbar.set_description(f"Epoch {epoch}")
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
clean_images = batch["images"]
|
||||
batch_size, n_channels, height, width = clean_images.shape
|
||||
noise_samples = torch.randn(clean_images.shape).to(clean_images.device)
|
||||
timesteps = torch.randint(
|
||||
0, noise_scheduler.timesteps, (batch_size,), device=clean_images.device
|
||||
).long()
|
||||
|
||||
# add noise onto the clean images according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_images = noise_scheduler.training_step(clean_images, noise_samples, timesteps)
|
||||
|
||||
if step % args.gradient_accumulation_steps != 0:
|
||||
with accelerator.no_sync(model):
|
||||
model_output = model(noisy_images, timesteps, batch["text_embeddings"])
|
||||
model_output, model_var_values = torch.split(model_output, n_channels, dim=1)
|
||||
# Learn the variance using the variational bound, but don't let
|
||||
# it affect our mean prediction.
|
||||
frozen_out = torch.cat([model_output.detach(), model_var_values], dim=1)
|
||||
|
||||
# predict the noise residual
|
||||
loss = F.mse_loss(model_output, noise_samples)
|
||||
|
||||
loss = loss / args.gradient_accumulation_steps
|
||||
|
||||
accelerator.backward(loss)
|
||||
optimizer.step()
|
||||
else:
|
||||
model_output = model(noisy_images, timesteps, batch["text_embeddings"])
|
||||
model_output, model_var_values = torch.split(model_output, n_channels, dim=1)
|
||||
# Learn the variance using the variational bound, but don't let
|
||||
# it affect our mean prediction.
|
||||
frozen_out = torch.cat([model_output.detach(), model_var_values], dim=1)
|
||||
|
||||
# predict the noise residual
|
||||
loss = F.mse_loss(model_output, noise_samples)
|
||||
loss = loss / args.gradient_accumulation_steps
|
||||
accelerator.backward(loss)
|
||||
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
pbar.update(1)
|
||||
pbar.set_postfix(loss=loss.detach().item(), lr=optimizer.param_groups[0]["lr"])
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# Generate a sample image for visual inspection
|
||||
if accelerator.is_main_process:
|
||||
model.eval()
|
||||
with torch.no_grad():
|
||||
pipeline.unet = accelerator.unwrap_model(model)
|
||||
|
||||
generator = torch.manual_seed(0)
|
||||
# run pipeline in inference (sample random noise and denoise)
|
||||
image = pipeline("a clip art of a corgi", generator=generator, num_upscale_inference_steps=50)
|
||||
|
||||
# process image to PIL
|
||||
image_processed = image.squeeze(0)
|
||||
image_processed = ((image_processed + 1) * 127.5).round().clamp(0, 255).to(torch.uint8).cpu().numpy()
|
||||
image_pil = PIL.Image.fromarray(image_processed)
|
||||
|
||||
# save image
|
||||
test_dir = os.path.join(args.output_dir, "test_samples")
|
||||
os.makedirs(test_dir, exist_ok=True)
|
||||
image_pil.save(f"{test_dir}/{epoch:04d}.png")
|
||||
|
||||
# save the model
|
||||
if args.push_to_hub:
|
||||
push_to_hub(args, pipeline, repo, commit_message=f"Epoch {epoch}", blocking=False)
|
||||
else:
|
||||
pipeline.save_pretrained(args.output_dir)
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="Simple example of a training script.")
|
||||
parser.add_argument("--local_rank", type=int, default=-1)
|
||||
parser.add_argument("--dataset", type=str, default="fusing/dog_captions")
|
||||
parser.add_argument("--output_dir", type=str, default="glide-text2image")
|
||||
parser.add_argument("--overwrite_output_dir", action="store_true")
|
||||
parser.add_argument("--resolution", type=int, default=64)
|
||||
parser.add_argument("--batch_size", type=int, default=4)
|
||||
parser.add_argument("--num_epochs", type=int, default=100)
|
||||
parser.add_argument("--gradient_accumulation_steps", type=int, default=4)
|
||||
parser.add_argument("--lr", type=float, default=1e-4)
|
||||
parser.add_argument("--warmup_steps", type=int, default=500)
|
||||
parser.add_argument("--push_to_hub", action="store_true")
|
||||
parser.add_argument("--hub_token", type=str, default=None)
|
||||
parser.add_argument("--hub_model_id", type=str, default=None)
|
||||
parser.add_argument("--hub_private_repo", action="store_true")
|
||||
parser.add_argument(
|
||||
"--mixed_precision",
|
||||
type=str,
|
||||
default="no",
|
||||
choices=["no", "fp16", "bf16"],
|
||||
help=(
|
||||
"Whether to use mixed precision. Choose"
|
||||
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
|
||||
"and an Nvidia Ampere GPU."
|
||||
),
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
|
||||
if env_local_rank != -1 and env_local_rank != args.local_rank:
|
||||
args.local_rank = env_local_rank
|
||||
|
||||
main(args)
|
||||
216
examples/experimental/train_latent_text_to_image.py
Normal file
216
examples/experimental/train_latent_text_to_image.py
Normal file
@@ -0,0 +1,216 @@
|
||||
import argparse
|
||||
import os
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
import bitsandbytes as bnb
|
||||
import PIL.Image
|
||||
from accelerate import Accelerator
|
||||
from datasets import load_dataset
|
||||
from diffusers import DDPMScheduler, LatentDiffusion, UNetLDMModel
|
||||
from diffusers.hub_utils import init_git_repo, push_to_hub
|
||||
from diffusers.optimization import get_scheduler
|
||||
from diffusers.utils import logging
|
||||
from torchvision.transforms import (
|
||||
CenterCrop,
|
||||
Compose,
|
||||
InterpolationMode,
|
||||
Normalize,
|
||||
RandomHorizontalFlip,
|
||||
Resize,
|
||||
ToTensor,
|
||||
)
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
def main(args):
|
||||
accelerator = Accelerator(mixed_precision=args.mixed_precision)
|
||||
|
||||
pipeline = LatentDiffusion.from_pretrained("fusing/latent-diffusion-text2im-large")
|
||||
pipeline.unet = None # this model will be trained from scratch now
|
||||
model = UNetLDMModel(
|
||||
attention_resolutions=[4, 2, 1],
|
||||
channel_mult=[1, 2, 4, 4],
|
||||
context_dim=1280,
|
||||
conv_resample=True,
|
||||
dims=2,
|
||||
dropout=0,
|
||||
image_size=8,
|
||||
in_channels=4,
|
||||
model_channels=320,
|
||||
num_heads=8,
|
||||
num_res_blocks=2,
|
||||
out_channels=4,
|
||||
resblock_updown=False,
|
||||
transformer_depth=1,
|
||||
use_new_attention_order=False,
|
||||
use_scale_shift_norm=False,
|
||||
use_spatial_transformer=True,
|
||||
legacy=False,
|
||||
)
|
||||
noise_scheduler = DDPMScheduler(timesteps=1000, tensor_format="pt")
|
||||
optimizer = bnb.optim.Adam8bit(model.parameters(), lr=args.lr)
|
||||
|
||||
augmentations = Compose(
|
||||
[
|
||||
Resize(args.resolution, interpolation=InterpolationMode.BILINEAR),
|
||||
CenterCrop(args.resolution),
|
||||
RandomHorizontalFlip(),
|
||||
ToTensor(),
|
||||
Normalize([0.5], [0.5]),
|
||||
]
|
||||
)
|
||||
dataset = load_dataset(args.dataset, split="train")
|
||||
|
||||
text_encoder = pipeline.bert.eval()
|
||||
vqvae = pipeline.vqvae.eval()
|
||||
|
||||
def transforms(examples):
|
||||
images = [augmentations(image.convert("RGB")) for image in examples["image"]]
|
||||
text_inputs = pipeline.tokenizer(examples["caption"], padding="max_length", max_length=77, return_tensors="pt")
|
||||
with torch.no_grad():
|
||||
text_embeddings = accelerator.unwrap_model(text_encoder)(text_inputs.input_ids.cpu()).last_hidden_state
|
||||
images = 1 / 0.18215 * torch.stack(images, dim=0)
|
||||
latents = accelerator.unwrap_model(vqvae).encode(images.cpu()).mode()
|
||||
return {"images": images, "text_embeddings": text_embeddings, "latents": latents}
|
||||
|
||||
dataset.set_transform(transforms)
|
||||
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=args.batch_size, shuffle=True)
|
||||
|
||||
lr_scheduler = get_scheduler(
|
||||
"linear",
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=args.warmup_steps,
|
||||
num_training_steps=(len(train_dataloader) * args.num_epochs) // args.gradient_accumulation_steps,
|
||||
)
|
||||
|
||||
model, text_encoder, vqvae, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
model, text_encoder, vqvae, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
text_encoder = text_encoder.cpu()
|
||||
vqvae = vqvae.cpu()
|
||||
|
||||
if args.push_to_hub:
|
||||
repo = init_git_repo(args, at_init=True)
|
||||
|
||||
# Train!
|
||||
is_distributed = torch.distributed.is_available() and torch.distributed.is_initialized()
|
||||
world_size = torch.distributed.get_world_size() if is_distributed else 1
|
||||
total_train_batch_size = args.batch_size * args.gradient_accumulation_steps * world_size
|
||||
max_steps = len(train_dataloader) // args.gradient_accumulation_steps * args.num_epochs
|
||||
logger.info("***** Running training *****")
|
||||
logger.info(f" Num examples = {len(train_dataloader.dataset)}")
|
||||
logger.info(f" Num Epochs = {args.num_epochs}")
|
||||
logger.info(f" Instantaneous batch size per device = {args.batch_size}")
|
||||
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_train_batch_size}")
|
||||
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
|
||||
logger.info(f" Total optimization steps = {max_steps}")
|
||||
|
||||
global_step = 0
|
||||
for epoch in range(args.num_epochs):
|
||||
model.train()
|
||||
with tqdm(total=len(train_dataloader), unit="ba") as pbar:
|
||||
pbar.set_description(f"Epoch {epoch}")
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
clean_latents = batch["latents"]
|
||||
noise_samples = torch.randn(clean_latents.shape).to(clean_latents.device)
|
||||
bsz = clean_latents.shape[0]
|
||||
timesteps = torch.randint(0, noise_scheduler.timesteps, (bsz,), device=clean_latents.device).long()
|
||||
|
||||
# add noise onto the clean latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_latents = noise_scheduler.training_step(clean_latents, noise_samples, timesteps)
|
||||
|
||||
if step % args.gradient_accumulation_steps != 0:
|
||||
with accelerator.no_sync(model):
|
||||
output = model(noisy_latents, timesteps, context=batch["text_embeddings"])
|
||||
# predict the noise residual
|
||||
loss = F.mse_loss(output, noise_samples)
|
||||
loss = loss / args.gradient_accumulation_steps
|
||||
accelerator.backward(loss)
|
||||
optimizer.step()
|
||||
else:
|
||||
output = model(noisy_latents, timesteps, context=batch["text_embeddings"])
|
||||
# predict the noise residual
|
||||
loss = F.mse_loss(output, noise_samples)
|
||||
loss = loss / args.gradient_accumulation_steps
|
||||
accelerator.backward(loss)
|
||||
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
pbar.update(1)
|
||||
pbar.set_postfix(loss=loss.detach().item(), lr=optimizer.param_groups[0]["lr"])
|
||||
global_step += 1
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# Generate a sample image for visual inspection
|
||||
if accelerator.is_main_process:
|
||||
model.eval()
|
||||
with torch.no_grad():
|
||||
pipeline.unet = accelerator.unwrap_model(model)
|
||||
|
||||
generator = torch.manual_seed(0)
|
||||
# run pipeline in inference (sample random noise and denoise)
|
||||
image = pipeline(
|
||||
["a clip art of a corgi"], generator=generator, eta=0.3, guidance_scale=6.0, num_inference_steps=50
|
||||
)
|
||||
|
||||
# process image to PIL
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = image_processed * 255.0
|
||||
image_processed = image_processed.type(torch.uint8).numpy()
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# save image
|
||||
test_dir = os.path.join(args.output_dir, "test_samples")
|
||||
os.makedirs(test_dir, exist_ok=True)
|
||||
image_pil.save(f"{test_dir}/{epoch:04d}.png")
|
||||
|
||||
# save the model
|
||||
if args.push_to_hub:
|
||||
push_to_hub(args, pipeline, repo, commit_message=f"Epoch {epoch}", blocking=False)
|
||||
else:
|
||||
pipeline.save_pretrained(args.output_dir)
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="Simple example of a training script.")
|
||||
parser.add_argument("--local_rank", type=int, default=-1)
|
||||
parser.add_argument("--dataset", type=str, default="fusing/dog_captions")
|
||||
parser.add_argument("--output_dir", type=str, default="ldm-text2image")
|
||||
parser.add_argument("--overwrite_output_dir", action="store_true")
|
||||
parser.add_argument("--resolution", type=int, default=128)
|
||||
parser.add_argument("--batch_size", type=int, default=1)
|
||||
parser.add_argument("--num_epochs", type=int, default=100)
|
||||
parser.add_argument("--gradient_accumulation_steps", type=int, default=16)
|
||||
parser.add_argument("--lr", type=float, default=1e-4)
|
||||
parser.add_argument("--warmup_steps", type=int, default=500)
|
||||
parser.add_argument("--push_to_hub", action="store_true")
|
||||
parser.add_argument("--hub_token", type=str, default=None)
|
||||
parser.add_argument("--hub_model_id", type=str, default=None)
|
||||
parser.add_argument("--hub_private_repo", action="store_true")
|
||||
parser.add_argument(
|
||||
"--mixed_precision",
|
||||
type=str,
|
||||
default="no",
|
||||
choices=["no", "fp16", "bf16"],
|
||||
help=(
|
||||
"Whether to use mixed precision. Choose"
|
||||
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
|
||||
"and an Nvidia Ampere GPU."
|
||||
),
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
|
||||
if env_local_rank != -1 and env_local_rank != args.local_rank:
|
||||
args.local_rank = env_local_rank
|
||||
|
||||
main(args)
|
||||
@@ -1,159 +0,0 @@
|
||||
import argparse
|
||||
import os
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
import PIL.Image
|
||||
from accelerate import Accelerator
|
||||
from datasets import load_dataset
|
||||
from diffusers import DDPM, DDPMScheduler, UNetModel
|
||||
from torchvision.transforms import (
|
||||
CenterCrop,
|
||||
Compose,
|
||||
InterpolationMode,
|
||||
Lambda,
|
||||
RandomHorizontalFlip,
|
||||
Resize,
|
||||
ToTensor,
|
||||
)
|
||||
from tqdm.auto import tqdm
|
||||
from transformers import get_linear_schedule_with_warmup
|
||||
|
||||
|
||||
def main(args):
|
||||
accelerator = Accelerator(mixed_precision=args.mixed_precision)
|
||||
|
||||
model = UNetModel(
|
||||
attn_resolutions=(16,),
|
||||
ch=128,
|
||||
ch_mult=(1, 2, 4, 8),
|
||||
dropout=0.0,
|
||||
num_res_blocks=2,
|
||||
resamp_with_conv=True,
|
||||
resolution=args.resolution,
|
||||
)
|
||||
noise_scheduler = DDPMScheduler(timesteps=1000)
|
||||
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)
|
||||
|
||||
augmentations = Compose(
|
||||
[
|
||||
Resize(args.resolution, interpolation=InterpolationMode.BILINEAR),
|
||||
CenterCrop(args.resolution),
|
||||
RandomHorizontalFlip(),
|
||||
ToTensor(),
|
||||
Lambda(lambda x: x * 2 - 1),
|
||||
]
|
||||
)
|
||||
dataset = load_dataset(args.dataset, split="train")
|
||||
|
||||
def transforms(examples):
|
||||
images = [augmentations(image.convert("RGB")) for image in examples["image"]]
|
||||
return {"input": images}
|
||||
|
||||
dataset.set_transform(transforms)
|
||||
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=args.batch_size, shuffle=True)
|
||||
|
||||
lr_scheduler = get_linear_schedule_with_warmup(
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=args.warmup_steps,
|
||||
num_training_steps=(len(train_dataloader) * args.num_epochs) // args.gradient_accumulation_steps,
|
||||
)
|
||||
|
||||
model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
model, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
|
||||
for epoch in range(args.num_epochs):
|
||||
model.train()
|
||||
with tqdm(total=len(train_dataloader), unit="ba") as pbar:
|
||||
pbar.set_description(f"Epoch {epoch}")
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
clean_images = batch["input"]
|
||||
noisy_images = torch.empty_like(clean_images)
|
||||
noise_samples = torch.empty_like(clean_images)
|
||||
bsz = clean_images.shape[0]
|
||||
|
||||
timesteps = torch.randint(0, noise_scheduler.timesteps, (bsz,), device=clean_images.device).long()
|
||||
for idx in range(bsz):
|
||||
noise = torch.randn(clean_images.shape[1:]).to(clean_images.device)
|
||||
noise_samples[idx] = noise
|
||||
noisy_images[idx] = noise_scheduler.forward_step(clean_images[idx], noise, timesteps[idx])
|
||||
|
||||
if step % args.gradient_accumulation_steps != 0:
|
||||
with accelerator.no_sync(model):
|
||||
output = model(noisy_images, timesteps)
|
||||
# predict the noise residual
|
||||
loss = F.mse_loss(output, noise_samples)
|
||||
accelerator.backward(loss)
|
||||
else:
|
||||
output = model(noisy_images, timesteps)
|
||||
# predict the noise residual
|
||||
loss = F.mse_loss(output, noise_samples)
|
||||
accelerator.backward(loss)
|
||||
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad()
|
||||
pbar.update(1)
|
||||
pbar.set_postfix(loss=loss.detach().item(), lr=optimizer.param_groups[0]["lr"])
|
||||
|
||||
optimizer.step()
|
||||
|
||||
# Generate a sample image for visual inspection
|
||||
torch.distributed.barrier()
|
||||
if args.local_rank in [-1, 0]:
|
||||
model.eval()
|
||||
with torch.no_grad():
|
||||
if isinstance(model, torch.nn.parallel.DistributedDataParallel):
|
||||
pipeline = DDPM(unet=model.module, noise_scheduler=noise_scheduler)
|
||||
else:
|
||||
pipeline = DDPM(unet=model, noise_scheduler=noise_scheduler)
|
||||
pipeline.save_pretrained(args.output_path)
|
||||
|
||||
generator = torch.manual_seed(0)
|
||||
# run pipeline in inference (sample random noise and denoise)
|
||||
image = pipeline(generator=generator)
|
||||
|
||||
# process image to PIL
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = (image_processed + 1.0) * 127.5
|
||||
image_processed = image_processed.type(torch.uint8).numpy()
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# save image
|
||||
test_dir = os.path.join(args.output_path, "test_samples")
|
||||
os.makedirs(test_dir, exist_ok=True)
|
||||
image_pil.save(f"{test_dir}/{epoch}.png")
|
||||
torch.distributed.barrier()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="Simple example of a training script.")
|
||||
parser.add_argument("--local_rank", type=int)
|
||||
parser.add_argument("--dataset", type=str, default="huggan/flowers-102-categories")
|
||||
parser.add_argument("--resolution", type=int, default=64)
|
||||
parser.add_argument("--output_path", type=str, default="ddpm-model")
|
||||
parser.add_argument("--batch_size", type=int, default=16)
|
||||
parser.add_argument("--num_epochs", type=int, default=100)
|
||||
parser.add_argument("--gradient_accumulation_steps", type=int, default=1)
|
||||
parser.add_argument("--lr", type=float, default=1e-4)
|
||||
parser.add_argument("--warmup_steps", type=int, default=500)
|
||||
parser.add_argument(
|
||||
"--mixed_precision",
|
||||
type=str,
|
||||
default="no",
|
||||
choices=["no", "fp16", "bf16"],
|
||||
help=(
|
||||
"Whether to use mixed precision. Choose"
|
||||
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
|
||||
"and an Nvidia Ampere GPU."
|
||||
),
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
|
||||
if env_local_rank != -1 and env_local_rank != args.local_rank:
|
||||
args.local_rank = env_local_rank
|
||||
|
||||
main(args)
|
||||
224
examples/train_unconditional.py
Normal file
224
examples/train_unconditional.py
Normal file
@@ -0,0 +1,224 @@
|
||||
import argparse
|
||||
import os
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
from accelerate import Accelerator
|
||||
from accelerate.logging import get_logger
|
||||
from datasets import load_dataset
|
||||
from diffusers import DDPMPipeline, DDPMScheduler, UNetUnconditionalModel
|
||||
from diffusers.hub_utils import init_git_repo, push_to_hub
|
||||
from diffusers.optimization import get_scheduler
|
||||
from diffusers.training_utils import EMAModel
|
||||
from torchvision.transforms import (
|
||||
CenterCrop,
|
||||
Compose,
|
||||
InterpolationMode,
|
||||
Normalize,
|
||||
RandomHorizontalFlip,
|
||||
Resize,
|
||||
ToTensor,
|
||||
)
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
def main(args):
|
||||
logging_dir = os.path.join(args.output_dir, args.logging_dir)
|
||||
accelerator = Accelerator(
|
||||
mixed_precision=args.mixed_precision,
|
||||
log_with="tensorboard",
|
||||
logging_dir=logging_dir,
|
||||
)
|
||||
|
||||
model = UNetUnconditionalModel(
|
||||
image_size=args.resolution,
|
||||
in_channels=3,
|
||||
out_channels=3,
|
||||
num_res_blocks=2,
|
||||
block_channels=(128, 128, 256, 256, 512, 512),
|
||||
down_blocks=(
|
||||
"UNetResDownBlock2D",
|
||||
"UNetResDownBlock2D",
|
||||
"UNetResDownBlock2D",
|
||||
"UNetResDownBlock2D",
|
||||
"UNetResAttnDownBlock2D",
|
||||
"UNetResDownBlock2D",
|
||||
),
|
||||
up_blocks=(
|
||||
"UNetResUpBlock2D",
|
||||
"UNetResAttnUpBlock2D",
|
||||
"UNetResUpBlock2D",
|
||||
"UNetResUpBlock2D",
|
||||
"UNetResUpBlock2D",
|
||||
"UNetResUpBlock2D",
|
||||
),
|
||||
)
|
||||
noise_scheduler = DDPMScheduler(num_train_timesteps=1000, tensor_format="pt")
|
||||
optimizer = torch.optim.AdamW(
|
||||
model.parameters(),
|
||||
lr=args.learning_rate,
|
||||
betas=(args.adam_beta1, args.adam_beta2),
|
||||
weight_decay=args.adam_weight_decay,
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
|
||||
augmentations = Compose(
|
||||
[
|
||||
Resize(args.resolution, interpolation=InterpolationMode.BILINEAR),
|
||||
CenterCrop(args.resolution),
|
||||
RandomHorizontalFlip(),
|
||||
ToTensor(),
|
||||
Normalize([0.5], [0.5]),
|
||||
]
|
||||
)
|
||||
dataset = load_dataset(args.dataset, split="train")
|
||||
|
||||
def transforms(examples):
|
||||
images = [augmentations(image.convert("RGB")) for image in examples["image"]]
|
||||
return {"input": images}
|
||||
|
||||
dataset.set_transform(transforms)
|
||||
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=args.train_batch_size, shuffle=True)
|
||||
|
||||
lr_scheduler = get_scheduler(
|
||||
args.lr_scheduler,
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=args.lr_warmup_steps,
|
||||
num_training_steps=(len(train_dataloader) * args.num_epochs) // args.gradient_accumulation_steps,
|
||||
)
|
||||
|
||||
model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
model, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
|
||||
ema_model = EMAModel(model, inv_gamma=args.ema_inv_gamma, power=args.ema_power, max_value=args.ema_max_decay)
|
||||
|
||||
if args.push_to_hub:
|
||||
repo = init_git_repo(args, at_init=True)
|
||||
|
||||
if accelerator.is_main_process:
|
||||
run = os.path.split(__file__)[-1].split(".")[0]
|
||||
accelerator.init_trackers(run)
|
||||
|
||||
global_step = 0
|
||||
for epoch in range(args.num_epochs):
|
||||
model.train()
|
||||
progress_bar = tqdm(total=len(train_dataloader), disable=not accelerator.is_local_main_process)
|
||||
progress_bar.set_description(f"Epoch {epoch}")
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
clean_images = batch["input"]
|
||||
# Sample noise that we'll add to the images
|
||||
noise = torch.randn(clean_images.shape).to(clean_images.device)
|
||||
bsz = clean_images.shape[0]
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(
|
||||
0, noise_scheduler.num_train_timesteps, (bsz,), device=clean_images.device
|
||||
).long()
|
||||
|
||||
# Add noise to the clean images according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)
|
||||
|
||||
with accelerator.accumulate(model):
|
||||
# Predict the noise residual
|
||||
noise_pred = model(noisy_images, timesteps)["sample"]
|
||||
loss = F.mse_loss(noise_pred, noise)
|
||||
accelerator.backward(loss)
|
||||
|
||||
accelerator.clip_grad_norm_(model.parameters(), 1.0)
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
if args.use_ema:
|
||||
ema_model.step(model)
|
||||
optimizer.zero_grad()
|
||||
|
||||
progress_bar.update(1)
|
||||
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0], "step": global_step}
|
||||
if args.use_ema:
|
||||
logs["ema_decay"] = ema_model.decay
|
||||
progress_bar.set_postfix(**logs)
|
||||
accelerator.log(logs, step=global_step)
|
||||
global_step += 1
|
||||
progress_bar.close()
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# Generate a sample image for visual inspection
|
||||
if accelerator.is_main_process:
|
||||
with torch.no_grad():
|
||||
pipeline = DDPMPipeline(
|
||||
unet=accelerator.unwrap_model(ema_model.averaged_model if args.use_ema else model),
|
||||
scheduler=noise_scheduler,
|
||||
)
|
||||
|
||||
generator = torch.manual_seed(0)
|
||||
# run pipeline in inference (sample random noise and denoise)
|
||||
images = pipeline(generator=generator, batch_size=args.eval_batch_size)
|
||||
|
||||
# denormalize the images and save to tensorboard
|
||||
images_processed = (images.cpu() + 1.0) * 127.5
|
||||
images_processed = images_processed.clamp(0, 255).type(torch.uint8).numpy()
|
||||
|
||||
accelerator.trackers[0].writer.add_images("test_samples", images_processed, epoch)
|
||||
|
||||
if epoch % args.save_model_epochs == 0 or epoch == args.num_epochs - 1:
|
||||
# save the model
|
||||
if args.push_to_hub:
|
||||
push_to_hub(args, pipeline, repo, commit_message=f"Epoch {epoch}", blocking=False)
|
||||
else:
|
||||
pipeline.save_pretrained(args.output_dir)
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
accelerator.end_training()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="Simple example of a training script.")
|
||||
parser.add_argument("--local_rank", type=int, default=-1)
|
||||
parser.add_argument("--dataset", type=str, default="huggan/flowers-102-categories")
|
||||
parser.add_argument("--output_dir", type=str, default="ddpm-flowers-64")
|
||||
parser.add_argument("--overwrite_output_dir", action="store_true")
|
||||
parser.add_argument("--resolution", type=int, default=64)
|
||||
parser.add_argument("--train_batch_size", type=int, default=16)
|
||||
parser.add_argument("--eval_batch_size", type=int, default=16)
|
||||
parser.add_argument("--num_epochs", type=int, default=100)
|
||||
parser.add_argument("--save_model_epochs", type=int, default=5)
|
||||
parser.add_argument("--gradient_accumulation_steps", type=int, default=1)
|
||||
parser.add_argument("--learning_rate", type=float, default=1e-4)
|
||||
parser.add_argument("--lr_scheduler", type=str, default="cosine")
|
||||
parser.add_argument("--lr_warmup_steps", type=int, default=500)
|
||||
parser.add_argument("--adam_beta1", type=float, default=0.95)
|
||||
parser.add_argument("--adam_beta2", type=float, default=0.999)
|
||||
parser.add_argument("--adam_weight_decay", type=float, default=1e-6)
|
||||
parser.add_argument("--adam_epsilon", type=float, default=1e-3)
|
||||
parser.add_argument("--use_ema", action="store_true", default=True)
|
||||
parser.add_argument("--ema_inv_gamma", type=float, default=1.0)
|
||||
parser.add_argument("--ema_power", type=float, default=3 / 4)
|
||||
parser.add_argument("--ema_max_decay", type=float, default=0.9999)
|
||||
parser.add_argument("--push_to_hub", action="store_true")
|
||||
parser.add_argument("--hub_token", type=str, default=None)
|
||||
parser.add_argument("--hub_model_id", type=str, default=None)
|
||||
parser.add_argument("--hub_private_repo", action="store_true")
|
||||
parser.add_argument("--logging_dir", type=str, default="logs")
|
||||
parser.add_argument(
|
||||
"--mixed_precision",
|
||||
type=str,
|
||||
default="no",
|
||||
choices=["no", "fp16", "bf16"],
|
||||
help=(
|
||||
"Whether to use mixed precision. Choose"
|
||||
"between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
|
||||
"and an Nvidia Ampere GPU."
|
||||
),
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
|
||||
if env_local_rank != -1 and env_local_rank != args.local_rank:
|
||||
args.local_rank = env_local_rank
|
||||
|
||||
main(args)
|
||||
112
scripts/change_naming_configs_and_checkpoints.py
Normal file
112
scripts/change_naming_configs_and_checkpoints.py
Normal file
@@ -0,0 +1,112 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" Conversion script for the LDM checkpoints. """
|
||||
|
||||
import argparse
|
||||
import os
|
||||
import json
|
||||
import torch
|
||||
from diffusers import UNet2DModel, UNet2DConditionModel
|
||||
from transformers.file_utils import has_file
|
||||
|
||||
do_only_config = False
|
||||
do_only_weights = True
|
||||
do_only_renaming = False
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument(
|
||||
"--repo_path",
|
||||
default=None,
|
||||
type=str,
|
||||
required=True,
|
||||
help="The config json file corresponding to the architecture.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--dump_path", default=None, type=str, required=True, help="Path to the output model."
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
config_parameters_to_change = {
|
||||
"image_size": "sample_size",
|
||||
"num_res_blocks": "layers_per_block",
|
||||
"block_channels": "block_out_channels",
|
||||
"down_blocks": "down_block_types",
|
||||
"up_blocks": "up_block_types",
|
||||
"downscale_freq_shift": "freq_shift",
|
||||
"resnet_num_groups": "norm_num_groups",
|
||||
"resnet_act_fn": "act_fn",
|
||||
"resnet_eps": "norm_eps",
|
||||
"num_head_channels": "attention_head_dim",
|
||||
}
|
||||
|
||||
key_parameters_to_change = {
|
||||
"time_steps": "time_proj",
|
||||
"mid": "mid_block",
|
||||
"downsample_blocks": "down_blocks",
|
||||
"upsample_blocks": "up_blocks",
|
||||
}
|
||||
|
||||
subfolder = "" if has_file(args.repo_path, "config.json") else "unet"
|
||||
|
||||
with open(os.path.join(args.repo_path, subfolder, "config.json"), "r", encoding="utf-8") as reader:
|
||||
text = reader.read()
|
||||
config = json.loads(text)
|
||||
|
||||
if do_only_config:
|
||||
for key in config_parameters_to_change.keys():
|
||||
config.pop(key, None)
|
||||
|
||||
if has_file(args.repo_path, "config.json"):
|
||||
model = UNet2DModel(**config)
|
||||
else:
|
||||
class_name = UNet2DConditionModel if "ldm-text2im-large-256" in args.repo_path else UNet2DModel
|
||||
model = class_name(**config)
|
||||
|
||||
if do_only_config:
|
||||
model.save_config(os.path.join(args.repo_path, subfolder))
|
||||
|
||||
config = dict(model.config)
|
||||
|
||||
if do_only_renaming:
|
||||
for key, value in config_parameters_to_change.items():
|
||||
if key in config:
|
||||
config[value] = config[key]
|
||||
del config[key]
|
||||
|
||||
config["down_block_types"] = [k.replace("UNetRes", "") for k in config["down_block_types"]]
|
||||
config["up_block_types"] = [k.replace("UNetRes", "") for k in config["up_block_types"]]
|
||||
|
||||
if do_only_weights:
|
||||
state_dict = torch.load(os.path.join(args.repo_path, subfolder, "diffusion_pytorch_model.bin"))
|
||||
|
||||
new_state_dict = {}
|
||||
for param_key, param_value in state_dict.items():
|
||||
if param_key.endswith(".op.bias") or param_key.endswith(".op.weight"):
|
||||
continue
|
||||
has_changed = False
|
||||
for key, new_key in key_parameters_to_change.items():
|
||||
if not has_changed and param_key.split(".")[0] == key:
|
||||
new_state_dict[".".join([new_key] + param_key.split(".")[1:])] = param_value
|
||||
has_changed = True
|
||||
if not has_changed:
|
||||
new_state_dict[param_key] = param_value
|
||||
|
||||
model.load_state_dict(new_state_dict)
|
||||
model.save_pretrained(os.path.join(args.repo_path, subfolder))
|
||||
56
scripts/conversion_ldm_uncond.py
Normal file
56
scripts/conversion_ldm_uncond.py
Normal file
@@ -0,0 +1,56 @@
|
||||
import argparse
|
||||
|
||||
import OmegaConf
|
||||
import torch
|
||||
|
||||
from diffusers import UNetLDMModel, VQModel, LDMPipeline, DDIMScheduler
|
||||
|
||||
def convert_ldm_original(checkpoint_path, config_path, output_path):
|
||||
config = OmegaConf.load(config_path)
|
||||
state_dict = torch.load(checkpoint_path, map_location="cpu")["model"]
|
||||
keys = list(state_dict.keys())
|
||||
|
||||
# extract state_dict for VQVAE
|
||||
first_stage_dict = {}
|
||||
first_stage_key = "first_stage_model."
|
||||
for key in keys:
|
||||
if key.startswith(first_stage_key):
|
||||
first_stage_dict[key.replace(first_stage_key, "")] = state_dict[key]
|
||||
|
||||
# extract state_dict for UNetLDM
|
||||
unet_state_dict = {}
|
||||
unet_key = "model.diffusion_model."
|
||||
for key in keys:
|
||||
if key.startswith(unet_key):
|
||||
unet_state_dict[key.replace(unet_key, "")] = state_dict[key]
|
||||
|
||||
vqvae_init_args = config.model.params.first_stage_config.params
|
||||
unet_init_args = config.model.params.unet_config.params
|
||||
|
||||
vqvae = VQModel(**vqvae_init_args).eval()
|
||||
vqvae.load_state_dict(first_stage_dict)
|
||||
|
||||
unet = UNetLDMModel(**unet_init_args).eval()
|
||||
unet.load_state_dict(unet_state_dict)
|
||||
|
||||
noise_scheduler = DDIMScheduler(
|
||||
timesteps=config.model.params.timesteps,
|
||||
beta_schedule="scaled_linear",
|
||||
beta_start=config.model.params.linear_start,
|
||||
beta_end=config.model.params.linear_end,
|
||||
clip_sample=False,
|
||||
)
|
||||
|
||||
pipeline = LDMPipeline(vqvae, unet, noise_scheduler)
|
||||
pipeline.save_pretrained(output_path)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--checkpoint_path", type=str, required=True)
|
||||
parser.add_argument("--config_path", type=str, required=True)
|
||||
parser.add_argument("--output_path", type=str, required=True)
|
||||
args = parser.parse_args()
|
||||
|
||||
convert_ldm_original(args.checkpoint_path, args.config_path, args.output_path)
|
||||
|
||||
234
scripts/convert_ddpm_original_checkpoint_to_diffusers.py
Normal file
234
scripts/convert_ddpm_original_checkpoint_to_diffusers.py
Normal file
@@ -0,0 +1,234 @@
|
||||
from diffusers import UNet2DModel, DDPMScheduler, DDPMPipeline
|
||||
import argparse
|
||||
import json
|
||||
import torch
|
||||
|
||||
|
||||
def shave_segments(path, n_shave_prefix_segments=1):
|
||||
"""
|
||||
Removes segments. Positive values shave the first segments, negative shave the last segments.
|
||||
"""
|
||||
if n_shave_prefix_segments >= 0:
|
||||
return '.'.join(path.split('.')[n_shave_prefix_segments:])
|
||||
else:
|
||||
return '.'.join(path.split('.')[:n_shave_prefix_segments])
|
||||
|
||||
|
||||
def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
|
||||
mapping = []
|
||||
for old_item in old_list:
|
||||
new_item = old_item
|
||||
new_item = new_item.replace('block.', 'resnets.')
|
||||
new_item = new_item.replace('conv_shorcut', 'conv1')
|
||||
new_item = new_item.replace('nin_shortcut', 'conv_shortcut')
|
||||
new_item = new_item.replace('temb_proj', 'time_emb_proj')
|
||||
|
||||
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
|
||||
|
||||
mapping.append({'old': old_item, 'new': new_item})
|
||||
|
||||
return mapping
|
||||
|
||||
|
||||
def renew_attention_paths(old_list, n_shave_prefix_segments=0, in_mid=False):
|
||||
mapping = []
|
||||
for old_item in old_list:
|
||||
new_item = old_item
|
||||
|
||||
# In `model.mid`, the layer is called `attn`.
|
||||
if not in_mid:
|
||||
new_item = new_item.replace('attn', 'attentions')
|
||||
new_item = new_item.replace('.k.', '.key.')
|
||||
new_item = new_item.replace('.v.', '.value.')
|
||||
new_item = new_item.replace('.q.', '.query.')
|
||||
|
||||
new_item = new_item.replace('proj_out', 'proj_attn')
|
||||
new_item = new_item.replace('norm', 'group_norm')
|
||||
|
||||
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
|
||||
mapping.append({'old': old_item, 'new': new_item})
|
||||
|
||||
return mapping
|
||||
|
||||
|
||||
def assign_to_checkpoint(paths, checkpoint, old_checkpoint, attention_paths_to_split=None, additional_replacements=None, config=None):
|
||||
assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
|
||||
|
||||
if attention_paths_to_split is not None:
|
||||
if config is None:
|
||||
raise ValueError("Please specify the config if setting 'attention_paths_to_split' to 'True'.")
|
||||
|
||||
for path, path_map in attention_paths_to_split.items():
|
||||
old_tensor = old_checkpoint[path]
|
||||
channels = old_tensor.shape[0] // 3
|
||||
|
||||
target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
|
||||
|
||||
num_heads = old_tensor.shape[0] // config["num_head_channels"] // 3
|
||||
|
||||
old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
|
||||
query, key, value = old_tensor.split(channels // num_heads, dim=1)
|
||||
|
||||
checkpoint[path_map['query']] = query.reshape(target_shape).squeeze()
|
||||
checkpoint[path_map['key']] = key.reshape(target_shape).squeeze()
|
||||
checkpoint[path_map['value']] = value.reshape(target_shape).squeeze()
|
||||
|
||||
for path in paths:
|
||||
new_path = path['new']
|
||||
|
||||
if attention_paths_to_split is not None and new_path in attention_paths_to_split:
|
||||
continue
|
||||
|
||||
new_path = new_path.replace('down.', 'downsample_blocks.')
|
||||
new_path = new_path.replace('up.', 'up_blocks.')
|
||||
|
||||
if additional_replacements is not None:
|
||||
for replacement in additional_replacements:
|
||||
new_path = new_path.replace(replacement['old'], replacement['new'])
|
||||
|
||||
if 'attentions' in new_path:
|
||||
checkpoint[new_path] = old_checkpoint[path['old']].squeeze()
|
||||
else:
|
||||
checkpoint[new_path] = old_checkpoint[path['old']]
|
||||
|
||||
|
||||
def convert_ddpm_checkpoint(checkpoint, config):
|
||||
"""
|
||||
Takes a state dict and a config, and returns a converted checkpoint.
|
||||
"""
|
||||
new_checkpoint = {}
|
||||
|
||||
new_checkpoint['time_embedding.linear_1.weight'] = checkpoint['temb.dense.0.weight']
|
||||
new_checkpoint['time_embedding.linear_1.bias'] = checkpoint['temb.dense.0.bias']
|
||||
new_checkpoint['time_embedding.linear_2.weight'] = checkpoint['temb.dense.1.weight']
|
||||
new_checkpoint['time_embedding.linear_2.bias'] = checkpoint['temb.dense.1.bias']
|
||||
|
||||
new_checkpoint['conv_norm_out.weight'] = checkpoint['norm_out.weight']
|
||||
new_checkpoint['conv_norm_out.bias'] = checkpoint['norm_out.bias']
|
||||
|
||||
new_checkpoint['conv_in.weight'] = checkpoint['conv_in.weight']
|
||||
new_checkpoint['conv_in.bias'] = checkpoint['conv_in.bias']
|
||||
new_checkpoint['conv_out.weight'] = checkpoint['conv_out.weight']
|
||||
new_checkpoint['conv_out.bias'] = checkpoint['conv_out.bias']
|
||||
|
||||
num_downsample_blocks = len({'.'.join(layer.split('.')[:2]) for layer in checkpoint if 'down' in layer})
|
||||
downsample_blocks = {layer_id: [key for key in checkpoint if f'down.{layer_id}' in key] for layer_id in range(num_downsample_blocks)}
|
||||
|
||||
num_up_blocks = len({'.'.join(layer.split('.')[:2]) for layer in checkpoint if 'up' in layer})
|
||||
up_blocks = {layer_id: [key for key in checkpoint if f'up.{layer_id}' in key] for layer_id in range(num_up_blocks)}
|
||||
|
||||
for i in range(num_downsample_blocks):
|
||||
block_id = (i - 1) // (config['num_res_blocks'] + 1)
|
||||
|
||||
if any('downsample' in layer for layer in downsample_blocks[i]):
|
||||
new_checkpoint[f'downsample_blocks.{i}.downsamplers.0.conv.weight'] = checkpoint[f'down.{i}.downsample.conv.weight']
|
||||
new_checkpoint[f'downsample_blocks.{i}.downsamplers.0.conv.bias'] = checkpoint[f'down.{i}.downsample.conv.bias']
|
||||
new_checkpoint[f'downsample_blocks.{i}.downsamplers.0.op.weight'] = checkpoint[f'down.{i}.downsample.conv.weight']
|
||||
new_checkpoint[f'downsample_blocks.{i}.downsamplers.0.op.bias'] = checkpoint[f'down.{i}.downsample.conv.bias']
|
||||
|
||||
if any('block' in layer for layer in downsample_blocks[i]):
|
||||
num_blocks = len({'.'.join(shave_segments(layer, 2).split('.')[:2]) for layer in downsample_blocks[i] if 'block' in layer})
|
||||
blocks = {layer_id: [key for key in downsample_blocks[i] if f'block.{layer_id}' in key] for layer_id in range(num_blocks)}
|
||||
|
||||
if num_blocks > 0:
|
||||
for j in range(config['num_res_blocks']):
|
||||
paths = renew_resnet_paths(blocks[j])
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint)
|
||||
|
||||
if any('attn' in layer for layer in downsample_blocks[i]):
|
||||
num_attn = len({'.'.join(shave_segments(layer, 2).split('.')[:2]) for layer in downsample_blocks[i] if 'attn' in layer})
|
||||
attns = {layer_id: [key for key in downsample_blocks[i] if f'attn.{layer_id}' in key] for layer_id in range(num_blocks)}
|
||||
|
||||
if num_attn > 0:
|
||||
for j in range(config['num_res_blocks']):
|
||||
paths = renew_attention_paths(attns[j])
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint, config=config)
|
||||
|
||||
mid_block_1_layers = [key for key in checkpoint if "mid.block_1" in key]
|
||||
mid_block_2_layers = [key for key in checkpoint if "mid.block_2" in key]
|
||||
mid_attn_1_layers = [key for key in checkpoint if "mid.attn_1" in key]
|
||||
|
||||
# Mid new 2
|
||||
paths = renew_resnet_paths(mid_block_1_layers)
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[
|
||||
{'old': 'mid.', 'new': 'mid_new_2.'}, {'old': 'block_1', 'new': 'resnets.0'}
|
||||
])
|
||||
|
||||
paths = renew_resnet_paths(mid_block_2_layers)
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[
|
||||
{'old': 'mid.', 'new': 'mid_new_2.'}, {'old': 'block_2', 'new': 'resnets.1'}
|
||||
])
|
||||
|
||||
paths = renew_attention_paths(mid_attn_1_layers, in_mid=True)
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[
|
||||
{'old': 'mid.', 'new': 'mid_new_2.'}, {'old': 'attn_1', 'new': 'attentions.0'}
|
||||
])
|
||||
|
||||
for i in range(num_up_blocks):
|
||||
block_id = num_up_blocks - 1 - i
|
||||
|
||||
if any('upsample' in layer for layer in up_blocks[i]):
|
||||
new_checkpoint[f'up_blocks.{block_id}.upsamplers.0.conv.weight'] = checkpoint[f'up.{i}.upsample.conv.weight']
|
||||
new_checkpoint[f'up_blocks.{block_id}.upsamplers.0.conv.bias'] = checkpoint[f'up.{i}.upsample.conv.bias']
|
||||
|
||||
if any('block' in layer for layer in up_blocks[i]):
|
||||
num_blocks = len({'.'.join(shave_segments(layer, 2).split('.')[:2]) for layer in up_blocks[i] if 'block' in layer})
|
||||
blocks = {layer_id: [key for key in up_blocks[i] if f'block.{layer_id}' in key] for layer_id in range(num_blocks)}
|
||||
|
||||
if num_blocks > 0:
|
||||
for j in range(config['num_res_blocks'] + 1):
|
||||
replace_indices = {'old': f'up_blocks.{i}', 'new': f'up_blocks.{block_id}'}
|
||||
paths = renew_resnet_paths(blocks[j])
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[replace_indices])
|
||||
|
||||
if any('attn' in layer for layer in up_blocks[i]):
|
||||
num_attn = len({'.'.join(shave_segments(layer, 2).split('.')[:2]) for layer in up_blocks[i] if 'attn' in layer})
|
||||
attns = {layer_id: [key for key in up_blocks[i] if f'attn.{layer_id}' in key] for layer_id in range(num_blocks)}
|
||||
|
||||
if num_attn > 0:
|
||||
for j in range(config['num_res_blocks'] + 1):
|
||||
replace_indices = {'old': f'up_blocks.{i}', 'new': f'up_blocks.{block_id}'}
|
||||
paths = renew_attention_paths(attns[j])
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[replace_indices])
|
||||
|
||||
new_checkpoint = {k.replace('mid_new_2', 'mid_block'): v for k, v in new_checkpoint.items()}
|
||||
return new_checkpoint
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument(
|
||||
"--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--config_file",
|
||||
default=None,
|
||||
type=str,
|
||||
required=True,
|
||||
help="The config json file corresponding to the architecture.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--dump_path", default=None, type=str, required=True, help="Path to the output model."
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
checkpoint = torch.load(args.checkpoint_path)
|
||||
|
||||
with open(args.config_file) as f:
|
||||
config = json.loads(f.read())
|
||||
|
||||
converted_checkpoint = convert_ddpm_checkpoint(checkpoint, config)
|
||||
|
||||
if "ddpm" in config:
|
||||
del config["ddpm"]
|
||||
|
||||
model = UNet2DModel(**config)
|
||||
model.load_state_dict(converted_checkpoint)
|
||||
|
||||
scheduler = DDPMScheduler.from_config("/".join(args.checkpoint_path.split("/")[:-1]))
|
||||
|
||||
pipe = DDPMPipeline(unet=model, scheduler=scheduler)
|
||||
pipe.save_pretrained(args.dump_path)
|
||||
332
scripts/convert_ldm_original_checkpoint_to_diffusers.py
Normal file
332
scripts/convert_ldm_original_checkpoint_to_diffusers.py
Normal file
@@ -0,0 +1,332 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" Conversion script for the LDM checkpoints. """
|
||||
|
||||
import argparse
|
||||
import json
|
||||
import torch
|
||||
from diffusers import VQModel, DDPMScheduler, UNet2DModel, LDMPipeline
|
||||
|
||||
|
||||
def shave_segments(path, n_shave_prefix_segments=1):
|
||||
"""
|
||||
Removes segments. Positive values shave the first segments, negative shave the last segments.
|
||||
"""
|
||||
if n_shave_prefix_segments >= 0:
|
||||
return '.'.join(path.split('.')[n_shave_prefix_segments:])
|
||||
else:
|
||||
return '.'.join(path.split('.')[:n_shave_prefix_segments])
|
||||
|
||||
|
||||
def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
|
||||
"""
|
||||
Updates paths inside resnets to the new naming scheme (local renaming)
|
||||
"""
|
||||
mapping = []
|
||||
for old_item in old_list:
|
||||
new_item = old_item.replace('in_layers.0', 'norm1')
|
||||
new_item = new_item.replace('in_layers.2', 'conv1')
|
||||
|
||||
new_item = new_item.replace('out_layers.0', 'norm2')
|
||||
new_item = new_item.replace('out_layers.3', 'conv2')
|
||||
|
||||
new_item = new_item.replace('emb_layers.1', 'time_emb_proj')
|
||||
new_item = new_item.replace('skip_connection', 'conv_shortcut')
|
||||
|
||||
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
|
||||
|
||||
mapping.append({'old': old_item, 'new': new_item})
|
||||
|
||||
return mapping
|
||||
|
||||
|
||||
def renew_attention_paths(old_list, n_shave_prefix_segments=0):
|
||||
"""
|
||||
Updates paths inside attentions to the new naming scheme (local renaming)
|
||||
"""
|
||||
mapping = []
|
||||
for old_item in old_list:
|
||||
new_item = old_item
|
||||
|
||||
new_item = new_item.replace('norm.weight', 'group_norm.weight')
|
||||
new_item = new_item.replace('norm.bias', 'group_norm.bias')
|
||||
|
||||
new_item = new_item.replace('proj_out.weight', 'proj_attn.weight')
|
||||
new_item = new_item.replace('proj_out.bias', 'proj_attn.bias')
|
||||
|
||||
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
|
||||
|
||||
mapping.append({'old': old_item, 'new': new_item})
|
||||
|
||||
return mapping
|
||||
|
||||
|
||||
def assign_to_checkpoint(paths, checkpoint, old_checkpoint, attention_paths_to_split=None, additional_replacements=None, config=None):
|
||||
"""
|
||||
This does the final conversion step: take locally converted weights and apply a global renaming
|
||||
to them. It splits attention layers, and takes into account additional replacements
|
||||
that may arise.
|
||||
|
||||
Assigns the weights to the new checkpoint.
|
||||
"""
|
||||
assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
|
||||
|
||||
# Splits the attention layers into three variables.
|
||||
if attention_paths_to_split is not None:
|
||||
for path, path_map in attention_paths_to_split.items():
|
||||
old_tensor = old_checkpoint[path]
|
||||
channels = old_tensor.shape[0] // 3
|
||||
|
||||
target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
|
||||
|
||||
num_heads = old_tensor.shape[0] // config["num_head_channels"] // 3
|
||||
|
||||
old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
|
||||
query, key, value = old_tensor.split(channels // num_heads, dim=1)
|
||||
|
||||
checkpoint[path_map['query']] = query.reshape(target_shape)
|
||||
checkpoint[path_map['key']] = key.reshape(target_shape)
|
||||
checkpoint[path_map['value']] = value.reshape(target_shape)
|
||||
|
||||
for path in paths:
|
||||
new_path = path['new']
|
||||
|
||||
# These have already been assigned
|
||||
if attention_paths_to_split is not None and new_path in attention_paths_to_split:
|
||||
continue
|
||||
|
||||
# Global renaming happens here
|
||||
new_path = new_path.replace('middle_block.0', 'mid.resnets.0')
|
||||
new_path = new_path.replace('middle_block.1', 'mid.attentions.0')
|
||||
new_path = new_path.replace('middle_block.2', 'mid.resnets.1')
|
||||
|
||||
if additional_replacements is not None:
|
||||
for replacement in additional_replacements:
|
||||
new_path = new_path.replace(replacement['old'], replacement['new'])
|
||||
|
||||
# proj_attn.weight has to be converted from conv 1D to linear
|
||||
if "proj_attn.weight" in new_path:
|
||||
checkpoint[new_path] = old_checkpoint[path['old']][:, :, 0]
|
||||
else:
|
||||
checkpoint[new_path] = old_checkpoint[path['old']]
|
||||
|
||||
|
||||
def convert_ldm_checkpoint(checkpoint, config):
|
||||
"""
|
||||
Takes a state dict and a config, and returns a converted checkpoint.
|
||||
"""
|
||||
new_checkpoint = {}
|
||||
|
||||
new_checkpoint['time_embedding.linear_1.weight'] = checkpoint['time_embed.0.weight']
|
||||
new_checkpoint['time_embedding.linear_1.bias'] = checkpoint['time_embed.0.bias']
|
||||
new_checkpoint['time_embedding.linear_2.weight'] = checkpoint['time_embed.2.weight']
|
||||
new_checkpoint['time_embedding.linear_2.bias'] = checkpoint['time_embed.2.bias']
|
||||
|
||||
new_checkpoint['conv_in.weight'] = checkpoint['input_blocks.0.0.weight']
|
||||
new_checkpoint['conv_in.bias'] = checkpoint['input_blocks.0.0.bias']
|
||||
|
||||
new_checkpoint['conv_norm_out.weight'] = checkpoint['out.0.weight']
|
||||
new_checkpoint['conv_norm_out.bias'] = checkpoint['out.0.bias']
|
||||
new_checkpoint['conv_out.weight'] = checkpoint['out.2.weight']
|
||||
new_checkpoint['conv_out.bias'] = checkpoint['out.2.bias']
|
||||
|
||||
# Retrieves the keys for the input blocks only
|
||||
num_input_blocks = len({'.'.join(layer.split('.')[:2]) for layer in checkpoint if 'input_blocks' in layer})
|
||||
input_blocks = {layer_id: [key for key in checkpoint if f'input_blocks.{layer_id}' in key] for layer_id in range(num_input_blocks)}
|
||||
|
||||
# Retrieves the keys for the middle blocks only
|
||||
num_middle_blocks = len({'.'.join(layer.split('.')[:2]) for layer in checkpoint if 'middle_block' in layer})
|
||||
middle_blocks = {layer_id: [key for key in checkpoint if f'middle_block.{layer_id}' in key] for layer_id in range(num_middle_blocks)}
|
||||
|
||||
# Retrieves the keys for the output blocks only
|
||||
num_output_blocks = len({'.'.join(layer.split('.')[:2]) for layer in checkpoint if 'output_blocks' in layer})
|
||||
output_blocks = {layer_id: [key for key in checkpoint if f'output_blocks.{layer_id}' in key] for layer_id in range(num_output_blocks)}
|
||||
|
||||
for i in range(1, num_input_blocks):
|
||||
block_id = (i - 1) // (config['num_res_blocks'] + 1)
|
||||
layer_in_block_id = (i - 1) % (config['num_res_blocks'] + 1)
|
||||
|
||||
resnets = [key for key in input_blocks[i] if f'input_blocks.{i}.0' in key]
|
||||
attentions = [key for key in input_blocks[i] if f'input_blocks.{i}.1' in key]
|
||||
|
||||
if f'input_blocks.{i}.0.op.weight' in checkpoint:
|
||||
new_checkpoint[f'downsample_blocks.{block_id}.downsamplers.0.conv.weight'] = checkpoint[f'input_blocks.{i}.0.op.weight']
|
||||
new_checkpoint[f'downsample_blocks.{block_id}.downsamplers.0.conv.bias'] = checkpoint[f'input_blocks.{i}.0.op.bias']
|
||||
|
||||
paths = renew_resnet_paths(resnets)
|
||||
meta_path = {'old': f'input_blocks.{i}.0', 'new': f'downsample_blocks.{block_id}.resnets.{layer_in_block_id}'}
|
||||
resnet_op = {'old': 'resnets.2.op', 'new': 'downsamplers.0.op'}
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[meta_path, resnet_op], config=config)
|
||||
|
||||
if len(attentions):
|
||||
paths = renew_attention_paths(attentions)
|
||||
meta_path = {'old': f'input_blocks.{i}.1', 'new': f'downsample_blocks.{block_id}.attentions.{layer_in_block_id}'}
|
||||
to_split = {
|
||||
f'input_blocks.{i}.1.qkv.bias': {
|
||||
'key': f'downsample_blocks.{block_id}.attentions.{layer_in_block_id}.key.bias',
|
||||
'query': f'downsample_blocks.{block_id}.attentions.{layer_in_block_id}.query.bias',
|
||||
'value': f'downsample_blocks.{block_id}.attentions.{layer_in_block_id}.value.bias',
|
||||
},
|
||||
f'input_blocks.{i}.1.qkv.weight': {
|
||||
'key': f'downsample_blocks.{block_id}.attentions.{layer_in_block_id}.key.weight',
|
||||
'query': f'downsample_blocks.{block_id}.attentions.{layer_in_block_id}.query.weight',
|
||||
'value': f'downsample_blocks.{block_id}.attentions.{layer_in_block_id}.value.weight',
|
||||
},
|
||||
}
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
checkpoint,
|
||||
additional_replacements=[meta_path],
|
||||
attention_paths_to_split=to_split,
|
||||
config=config
|
||||
)
|
||||
|
||||
resnet_0 = middle_blocks[0]
|
||||
attentions = middle_blocks[1]
|
||||
resnet_1 = middle_blocks[2]
|
||||
|
||||
resnet_0_paths = renew_resnet_paths(resnet_0)
|
||||
assign_to_checkpoint(resnet_0_paths, new_checkpoint, checkpoint, config=config)
|
||||
|
||||
resnet_1_paths = renew_resnet_paths(resnet_1)
|
||||
assign_to_checkpoint(resnet_1_paths, new_checkpoint, checkpoint, config=config)
|
||||
|
||||
attentions_paths = renew_attention_paths(attentions)
|
||||
to_split = {
|
||||
'middle_block.1.qkv.bias': {
|
||||
'key': 'mid_block.attentions.0.key.bias',
|
||||
'query': 'mid_block.attentions.0.query.bias',
|
||||
'value': 'mid_block.attentions.0.value.bias',
|
||||
},
|
||||
'middle_block.1.qkv.weight': {
|
||||
'key': 'mid_block.attentions.0.key.weight',
|
||||
'query': 'mid_block.attentions.0.query.weight',
|
||||
'value': 'mid_block.attentions.0.value.weight',
|
||||
},
|
||||
}
|
||||
assign_to_checkpoint(attentions_paths, new_checkpoint, checkpoint, attention_paths_to_split=to_split, config=config)
|
||||
|
||||
for i in range(num_output_blocks):
|
||||
block_id = i // (config['num_res_blocks'] + 1)
|
||||
layer_in_block_id = i % (config['num_res_blocks'] + 1)
|
||||
output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
|
||||
output_block_list = {}
|
||||
|
||||
for layer in output_block_layers:
|
||||
layer_id, layer_name = layer.split('.')[0], shave_segments(layer, 1)
|
||||
if layer_id in output_block_list:
|
||||
output_block_list[layer_id].append(layer_name)
|
||||
else:
|
||||
output_block_list[layer_id] = [layer_name]
|
||||
|
||||
if len(output_block_list) > 1:
|
||||
resnets = [key for key in output_blocks[i] if f'output_blocks.{i}.0' in key]
|
||||
attentions = [key for key in output_blocks[i] if f'output_blocks.{i}.1' in key]
|
||||
|
||||
resnet_0_paths = renew_resnet_paths(resnets)
|
||||
paths = renew_resnet_paths(resnets)
|
||||
|
||||
meta_path = {'old': f'output_blocks.{i}.0', 'new': f'up_blocks.{block_id}.resnets.{layer_in_block_id}'}
|
||||
assign_to_checkpoint(paths, new_checkpoint, checkpoint, additional_replacements=[meta_path], config=config)
|
||||
|
||||
if ['conv.weight', 'conv.bias'] in output_block_list.values():
|
||||
index = list(output_block_list.values()).index(['conv.weight', 'conv.bias'])
|
||||
new_checkpoint[f'up_blocks.{block_id}.upsamplers.0.conv.weight'] = checkpoint[f'output_blocks.{i}.{index}.conv.weight']
|
||||
new_checkpoint[f'up_blocks.{block_id}.upsamplers.0.conv.bias'] = checkpoint[f'output_blocks.{i}.{index}.conv.bias']
|
||||
|
||||
# Clear attentions as they have been attributed above.
|
||||
if len(attentions) == 2:
|
||||
attentions = []
|
||||
|
||||
if len(attentions):
|
||||
paths = renew_attention_paths(attentions)
|
||||
meta_path = {
|
||||
'old': f'output_blocks.{i}.1',
|
||||
'new': f'up_blocks.{block_id}.attentions.{layer_in_block_id}'
|
||||
}
|
||||
to_split = {
|
||||
f'output_blocks.{i}.1.qkv.bias': {
|
||||
'key': f'up_blocks.{block_id}.attentions.{layer_in_block_id}.key.bias',
|
||||
'query': f'up_blocks.{block_id}.attentions.{layer_in_block_id}.query.bias',
|
||||
'value': f'up_blocks.{block_id}.attentions.{layer_in_block_id}.value.bias',
|
||||
},
|
||||
f'output_blocks.{i}.1.qkv.weight': {
|
||||
'key': f'up_blocks.{block_id}.attentions.{layer_in_block_id}.key.weight',
|
||||
'query': f'up_blocks.{block_id}.attentions.{layer_in_block_id}.query.weight',
|
||||
'value': f'up_blocks.{block_id}.attentions.{layer_in_block_id}.value.weight',
|
||||
},
|
||||
}
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
checkpoint,
|
||||
additional_replacements=[meta_path],
|
||||
attention_paths_to_split=to_split if any('qkv' in key for key in attentions) else None,
|
||||
config=config,
|
||||
)
|
||||
else:
|
||||
resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
|
||||
for path in resnet_0_paths:
|
||||
old_path = '.'.join(['output_blocks', str(i), path['old']])
|
||||
new_path = '.'.join(['up_blocks', str(block_id), 'resnets', str(layer_in_block_id), path['new']])
|
||||
|
||||
new_checkpoint[new_path] = checkpoint[old_path]
|
||||
|
||||
return new_checkpoint
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument(
|
||||
"--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--config_file",
|
||||
default=None,
|
||||
type=str,
|
||||
required=True,
|
||||
help="The config json file corresponding to the architecture.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--dump_path", default=None, type=str, required=True, help="Path to the output model."
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
checkpoint = torch.load(args.checkpoint_path)
|
||||
|
||||
with open(args.config_file) as f:
|
||||
config = json.loads(f.read())
|
||||
|
||||
converted_checkpoint = convert_ldm_checkpoint(checkpoint, config)
|
||||
|
||||
if "ldm" in config:
|
||||
del config["ldm"]
|
||||
|
||||
model = UNet2DModel(**config)
|
||||
model.load_state_dict(converted_checkpoint)
|
||||
|
||||
try:
|
||||
scheduler = DDPMScheduler.from_config("/".join(args.checkpoint_path.split("/")[:-1]))
|
||||
vqvae = VQModel.from_pretrained("/".join(args.checkpoint_path.split("/")[:-1]))
|
||||
|
||||
pipe = LDMPipeline(unet=model, scheduler=scheduler, vae=vqvae)
|
||||
pipe.save_pretrained(args.dump_path)
|
||||
except:
|
||||
model.save_pretrained(args.dump_path)
|
||||
183
scripts/convert_ncsnpp_original_checkpoint_to_diffusers.py
Normal file
183
scripts/convert_ncsnpp_original_checkpoint_to_diffusers.py
Normal file
@@ -0,0 +1,183 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" Conversion script for the NCSNPP checkpoints. """
|
||||
|
||||
import argparse
|
||||
import json
|
||||
import torch
|
||||
from diffusers import UNet2DModel
|
||||
|
||||
|
||||
def convert_ncsnpp_checkpoint(checkpoint, config):
|
||||
"""
|
||||
Takes a state dict and the path to
|
||||
"""
|
||||
new_model_architecture = UNet2DModel(**config)
|
||||
new_model_architecture.time_proj.W.data = checkpoint["all_modules.0.W"].data
|
||||
new_model_architecture.time_proj.weight.data = checkpoint["all_modules.0.W"].data
|
||||
new_model_architecture.time_embedding.linear_1.weight.data = checkpoint["all_modules.1.weight"].data
|
||||
new_model_architecture.time_embedding.linear_1.bias.data = checkpoint["all_modules.1.bias"].data
|
||||
|
||||
new_model_architecture.time_embedding.linear_2.weight.data = checkpoint["all_modules.2.weight"].data
|
||||
new_model_architecture.time_embedding.linear_2.bias.data = checkpoint["all_modules.2.bias"].data
|
||||
|
||||
new_model_architecture.conv_in.weight.data = checkpoint["all_modules.3.weight"].data
|
||||
new_model_architecture.conv_in.bias.data = checkpoint["all_modules.3.bias"].data
|
||||
|
||||
new_model_architecture.conv_norm_out.weight.data = checkpoint[list(checkpoint.keys())[-4]].data
|
||||
new_model_architecture.conv_norm_out.bias.data = checkpoint[list(checkpoint.keys())[-3]].data
|
||||
new_model_architecture.conv_out.weight.data = checkpoint[list(checkpoint.keys())[-2]].data
|
||||
new_model_architecture.conv_out.bias.data = checkpoint[list(checkpoint.keys())[-1]].data
|
||||
|
||||
module_index = 4
|
||||
|
||||
def set_attention_weights(new_layer, old_checkpoint, index):
|
||||
new_layer.query.weight.data = old_checkpoint[f"all_modules.{index}.NIN_0.W"].data.T
|
||||
new_layer.key.weight.data = old_checkpoint[f"all_modules.{index}.NIN_1.W"].data.T
|
||||
new_layer.value.weight.data = old_checkpoint[f"all_modules.{index}.NIN_2.W"].data.T
|
||||
|
||||
new_layer.query.bias.data = old_checkpoint[f"all_modules.{index}.NIN_0.b"].data
|
||||
new_layer.key.bias.data = old_checkpoint[f"all_modules.{index}.NIN_1.b"].data
|
||||
new_layer.value.bias.data = old_checkpoint[f"all_modules.{index}.NIN_2.b"].data
|
||||
|
||||
new_layer.proj_attn.weight.data = old_checkpoint[f"all_modules.{index}.NIN_3.W"].data.T
|
||||
new_layer.proj_attn.bias.data = old_checkpoint[f"all_modules.{index}.NIN_3.b"].data
|
||||
|
||||
new_layer.group_norm.weight.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.weight"].data
|
||||
new_layer.group_norm.bias.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.bias"].data
|
||||
|
||||
def set_resnet_weights(new_layer, old_checkpoint, index):
|
||||
new_layer.conv1.weight.data = old_checkpoint[f"all_modules.{index}.Conv_0.weight"].data
|
||||
new_layer.conv1.bias.data = old_checkpoint[f"all_modules.{index}.Conv_0.bias"].data
|
||||
new_layer.norm1.weight.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.weight"].data
|
||||
new_layer.norm1.bias.data = old_checkpoint[f"all_modules.{index}.GroupNorm_0.bias"].data
|
||||
|
||||
new_layer.conv2.weight.data = old_checkpoint[f"all_modules.{index}.Conv_1.weight"].data
|
||||
new_layer.conv2.bias.data = old_checkpoint[f"all_modules.{index}.Conv_1.bias"].data
|
||||
new_layer.norm2.weight.data = old_checkpoint[f"all_modules.{index}.GroupNorm_1.weight"].data
|
||||
new_layer.norm2.bias.data = old_checkpoint[f"all_modules.{index}.GroupNorm_1.bias"].data
|
||||
|
||||
new_layer.time_emb_proj.weight.data = old_checkpoint[f"all_modules.{index}.Dense_0.weight"].data
|
||||
new_layer.time_emb_proj.bias.data = old_checkpoint[f"all_modules.{index}.Dense_0.bias"].data
|
||||
|
||||
if new_layer.in_channels != new_layer.out_channels or new_layer.up or new_layer.down:
|
||||
new_layer.conv_shortcut.weight.data = old_checkpoint[f"all_modules.{index}.Conv_2.weight"].data
|
||||
new_layer.conv_shortcut.bias.data = old_checkpoint[f"all_modules.{index}.Conv_2.bias"].data
|
||||
|
||||
for i, block in enumerate(new_model_architecture.downsample_blocks):
|
||||
has_attentions = hasattr(block, "attentions")
|
||||
for j in range(len(block.resnets)):
|
||||
set_resnet_weights(block.resnets[j], checkpoint, module_index)
|
||||
module_index += 1
|
||||
if has_attentions:
|
||||
set_attention_weights(block.attentions[j], checkpoint, module_index)
|
||||
module_index += 1
|
||||
|
||||
if hasattr(block, "downsamplers") and block.downsamplers is not None:
|
||||
set_resnet_weights(block.resnet_down, checkpoint, module_index)
|
||||
module_index += 1
|
||||
block.skip_conv.weight.data = checkpoint[f"all_modules.{module_index}.Conv_0.weight"].data
|
||||
block.skip_conv.bias.data = checkpoint[f"all_modules.{module_index}.Conv_0.bias"].data
|
||||
module_index += 1
|
||||
|
||||
set_resnet_weights(new_model_architecture.mid_block.resnets[0], checkpoint, module_index)
|
||||
module_index += 1
|
||||
set_attention_weights(new_model_architecture.mid_block.attentions[0], checkpoint, module_index)
|
||||
module_index += 1
|
||||
set_resnet_weights(new_model_architecture.mid_block.resnets[1], checkpoint, module_index)
|
||||
module_index += 1
|
||||
|
||||
for i, block in enumerate(new_model_architecture.up_blocks):
|
||||
has_attentions = hasattr(block, "attentions")
|
||||
for j in range(len(block.resnets)):
|
||||
set_resnet_weights(block.resnets[j], checkpoint, module_index)
|
||||
module_index += 1
|
||||
if has_attentions:
|
||||
set_attention_weights(
|
||||
block.attentions[0], checkpoint, module_index
|
||||
) # why can there only be a single attention layer for up?
|
||||
module_index += 1
|
||||
|
||||
if hasattr(block, "resnet_up") and block.resnet_up is not None:
|
||||
block.skip_norm.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
|
||||
block.skip_norm.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
|
||||
module_index += 1
|
||||
block.skip_conv.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
|
||||
block.skip_conv.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
|
||||
module_index += 1
|
||||
set_resnet_weights(block.resnet_up, checkpoint, module_index)
|
||||
module_index += 1
|
||||
|
||||
new_model_architecture.conv_norm_out.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
|
||||
new_model_architecture.conv_norm_out.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
|
||||
module_index += 1
|
||||
new_model_architecture.conv_out.weight.data = checkpoint[f"all_modules.{module_index}.weight"].data
|
||||
new_model_architecture.conv_out.bias.data = checkpoint[f"all_modules.{module_index}.bias"].data
|
||||
|
||||
return new_model_architecture.state_dict()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument(
|
||||
"--checkpoint_path",
|
||||
default="/Users/arthurzucker/Work/diffusers/ArthurZ/diffusion_pytorch_model.bin",
|
||||
type=str,
|
||||
required=False,
|
||||
help="Path to the checkpoint to convert.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--config_file",
|
||||
default="/Users/arthurzucker/Work/diffusers/ArthurZ/config.json",
|
||||
type=str,
|
||||
required=False,
|
||||
help="The config json file corresponding to the architecture.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--dump_path",
|
||||
default="/Users/arthurzucker/Work/diffusers/ArthurZ/diffusion_model_new.pt",
|
||||
type=str,
|
||||
required=False,
|
||||
help="Path to the output model.",
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
checkpoint = torch.load(args.checkpoint_path, map_location="cpu")
|
||||
|
||||
with open(args.config_file) as f:
|
||||
config = json.loads(f.read())
|
||||
|
||||
converted_checkpoint = convert_ncsnpp_checkpoint(
|
||||
checkpoint,
|
||||
config,
|
||||
)
|
||||
|
||||
if "sde" in config:
|
||||
del config["sde"]
|
||||
|
||||
model = UNet2DModel(**config)
|
||||
model.load_state_dict(converted_checkpoint)
|
||||
|
||||
try:
|
||||
scheduler = ScoreSdeVeScheduler.from_config("/".join(args.checkpoint_path.split("/")[:-1]))
|
||||
|
||||
pipe = ScoreSdeVePipeline(unet=model, scheduler=scheduler)
|
||||
pipe.save_pretrained(args.dump_path)
|
||||
except:
|
||||
model.save_pretrained(args.dump_path)
|
||||
91
scripts/generate_logits.py
Normal file
91
scripts/generate_logits.py
Normal file
@@ -0,0 +1,91 @@
|
||||
from huggingface_hub import HfApi
|
||||
from transformers.file_utils import has_file
|
||||
from diffusers import UNet2DModel
|
||||
import random
|
||||
import torch
|
||||
api = HfApi()
|
||||
|
||||
results = {}
|
||||
results["google_ddpm_cifar10_32"] = torch.tensor([-0.7515, -1.6883, 0.2420, 0.0300, 0.6347, 1.3433, -1.1743, -3.7467,
|
||||
1.2342, -2.2485, 0.4636, 0.8076, -0.7991, 0.3969, 0.8498, 0.9189,
|
||||
-1.8887, -3.3522, 0.7639, 0.2040, 0.6271, -2.7148, -1.6316, 3.0839,
|
||||
0.3186, 0.2721, -0.9759, -1.2461, 2.6257, 1.3557])
|
||||
results["google_ddpm_ema_bedroom_256"] = torch.tensor([-2.3639, -2.5344, 0.0054, -0.6674, 1.5990, 1.0158, 0.3124, -2.1436,
|
||||
1.8795, -2.5429, -0.1566, -0.3973, 1.2490, 2.6447, 1.2283, -0.5208,
|
||||
-2.8154, -3.5119, 2.3838, 1.2033, 1.7201, -2.1256, -1.4576, 2.7948,
|
||||
2.4204, -0.9752, -1.2546, 0.8027, 3.2758, 3.1365])
|
||||
results["CompVis_ldm_celebahq_256"] = torch.tensor([-0.6531, -0.6891, -0.3172, -0.5375, -0.9140, -0.5367, -0.1175, -0.7869,
|
||||
-0.3808, -0.4513, -0.2098, -0.0083, 0.3183, 0.5140, 0.2247, -0.1304,
|
||||
-0.1302, -0.2802, -0.2084, -0.2025, -0.4967, -0.4873, -0.0861, 0.6925,
|
||||
0.0250, 0.1290, -0.1543, 0.6316, 1.0460, 1.4943])
|
||||
results["google_ncsnpp_ffhq_1024"] = torch.tensor([ 0.0911, 0.1107, 0.0182, 0.0435, -0.0805, -0.0608, 0.0381, 0.2172,
|
||||
-0.0280, 0.1327, -0.0299, -0.0255, -0.0050, -0.1170, -0.1046, 0.0309,
|
||||
0.1367, 0.1728, -0.0533, -0.0748, -0.0534, 0.1624, 0.0384, -0.1805,
|
||||
-0.0707, 0.0642, 0.0220, -0.0134, -0.1333, -0.1505])
|
||||
results["google_ncsnpp_bedroom_256"] = torch.tensor([ 0.1321, 0.1337, 0.0440, 0.0622, -0.0591, -0.0370, 0.0503, 0.2133,
|
||||
-0.0177, 0.1415, -0.0116, -0.0112, 0.0044, -0.0980, -0.0789, 0.0395,
|
||||
0.1502, 0.1785, -0.0488, -0.0514, -0.0404, 0.1539, 0.0454, -0.1559,
|
||||
-0.0665, 0.0659, 0.0383, -0.0005, -0.1266, -0.1386])
|
||||
results["google_ncsnpp_celebahq_256"] = torch.tensor([ 0.1154, 0.1218, 0.0307, 0.0526, -0.0711, -0.0541, 0.0366, 0.2078,
|
||||
-0.0267, 0.1317, -0.0226, -0.0193, -0.0014, -0.1055, -0.0902, 0.0330,
|
||||
0.1391, 0.1709, -0.0562, -0.0693, -0.0560, 0.1482, 0.0381, -0.1683,
|
||||
-0.0681, 0.0661, 0.0331, -0.0046, -0.1268, -0.1431])
|
||||
results["google_ncsnpp_church_256"] = torch.tensor([ 0.1192, 0.1240, 0.0414, 0.0606, -0.0557, -0.0412, 0.0430, 0.2042,
|
||||
-0.0200, 0.1385, -0.0115, -0.0132, 0.0017, -0.0965, -0.0802, 0.0398,
|
||||
0.1433, 0.1747, -0.0458, -0.0533, -0.0407, 0.1545, 0.0419, -0.1574,
|
||||
-0.0645, 0.0626, 0.0341, -0.0010, -0.1199, -0.1390])
|
||||
results["google_ncsnpp_ffhq_256"] = torch.tensor([ 0.1075, 0.1074, 0.0205, 0.0431, -0.0774, -0.0607, 0.0298, 0.2042,
|
||||
-0.0320, 0.1267, -0.0281, -0.0250, -0.0064, -0.1091, -0.0946, 0.0290,
|
||||
0.1328, 0.1650, -0.0580, -0.0738, -0.0586, 0.1440, 0.0337, -0.1746,
|
||||
-0.0712, 0.0605, 0.0250, -0.0099, -0.1316, -0.1473])
|
||||
results["google_ddpm_cat_256"] = torch.tensor([-1.4572, -2.0481, -0.0414, -0.6005, 1.4136, 0.5848, 0.4028, -2.7330,
|
||||
1.2212, -2.1228, 0.2155, 0.4039, 0.7662, 2.0535, 0.7477, -0.3243,
|
||||
-2.1758, -2.7648, 1.6947, 0.7026, 1.2338, -1.6078, -0.8682, 2.2810,
|
||||
1.8574, -0.5718, -0.5586, -0.0186, 2.3415, 2.1251])
|
||||
results["google_ddpm_celebahq_256"] = torch.tensor([-1.3690, -1.9720, -0.4090, -0.6966, 1.4660, 0.9938, -0.1385, -2.7324,
|
||||
0.7736, -1.8917, 0.2923, 0.4293, 0.1693, 1.4112, 1.1887, -0.3181,
|
||||
-2.2160, -2.6381, 1.3170, 0.8163, 0.9240, -1.6544, -0.6099, 2.5259,
|
||||
1.6430, -0.9090, -0.9392, -0.0126, 2.4268, 2.3266])
|
||||
results["google_ddpm_ema_celebahq_256"] = torch.tensor([-1.3525, -1.9628, -0.3956, -0.6860, 1.4664, 1.0014, -0.1259, -2.7212,
|
||||
0.7772, -1.8811, 0.2996, 0.4388, 0.1704, 1.4029, 1.1701, -0.3027,
|
||||
-2.2053, -2.6287, 1.3350, 0.8131, 0.9274, -1.6292, -0.6098, 2.5131,
|
||||
1.6505, -0.8958, -0.9298, -0.0151, 2.4257, 2.3355])
|
||||
results["google_ddpm_church_256"] = torch.tensor([-2.0585, -2.7897, -0.2850, -0.8940, 1.9052, 0.5702, 0.6345, -3.8959,
|
||||
1.5932, -3.2319, 0.1974, 0.0287, 1.7566, 2.6543, 0.8387, -0.5351,
|
||||
-3.2736, -4.3375, 2.9029, 1.6390, 1.4640, -2.1701, -1.9013, 2.9341,
|
||||
3.4981, -0.6255, -1.1644, -0.1591, 3.7097, 3.2066])
|
||||
results["google_ddpm_bedroom_256"] = torch.tensor([-2.3139, -2.5594, -0.0197, -0.6785, 1.7001, 1.1606, 0.3075, -2.1740,
|
||||
1.8071, -2.5630, -0.0926, -0.3811, 1.2116, 2.6246, 1.2731, -0.5398,
|
||||
-2.8153, -3.6140, 2.3893, 1.3262, 1.6258, -2.1856, -1.3267, 2.8395,
|
||||
2.3779, -1.0623, -1.2468, 0.8959, 3.3367, 3.2243])
|
||||
results["google_ddpm_ema_church_256"] = torch.tensor([-2.0628, -2.7667, -0.2089, -0.8263, 2.0539, 0.5992, 0.6495, -3.8336,
|
||||
1.6025, -3.2817, 0.1721, -0.0633, 1.7516, 2.7039, 0.8100, -0.5908,
|
||||
-3.2113, -4.4343, 2.9257, 1.3632, 1.5562, -2.1489, -1.9894, 3.0560,
|
||||
3.3396, -0.7328, -1.0417, 0.0383, 3.7093, 3.2343])
|
||||
results["google_ddpm_ema_cat_256"] = torch.tensor([-1.4574, -2.0569, -0.0473, -0.6117, 1.4018, 0.5769, 0.4129, -2.7344,
|
||||
1.2241, -2.1397, 0.2000, 0.3937, 0.7616, 2.0453, 0.7324, -0.3391,
|
||||
-2.1746, -2.7744, 1.6963, 0.6921, 1.2187, -1.6172, -0.8877, 2.2439,
|
||||
1.8471, -0.5839, -0.5605, -0.0464, 2.3250, 2.1219])
|
||||
|
||||
models = api.list_models(filter="diffusers")
|
||||
for mod in models:
|
||||
if "google" in mod.author or mod.modelId == "CompVis/ldm-celebahq-256":
|
||||
local_checkpoint = "/home/patrick/google_checkpoints/" + mod.modelId.split("/")[-1]
|
||||
|
||||
print(f"Started running {mod.modelId}!!!")
|
||||
|
||||
if mod.modelId.startswith("CompVis"):
|
||||
model = UNet2DModel.from_pretrained(local_checkpoint, subfolder = "unet")
|
||||
else:
|
||||
model = UNet2DModel.from_pretrained(local_checkpoint)
|
||||
|
||||
torch.manual_seed(0)
|
||||
random.seed(0)
|
||||
|
||||
noise = torch.randn(1, model.config.in_channels, model.config.sample_size, model.config.sample_size)
|
||||
time_step = torch.tensor([10] * noise.shape[0])
|
||||
with torch.no_grad():
|
||||
logits = model(noise, time_step)['sample']
|
||||
|
||||
assert torch.allclose(logits[0, 0, 0, :30], results["_".join("_".join(mod.modelId.split("/")).split("-"))], atol=1e-3)
|
||||
print(f"{mod.modelId} has passed succesfully!!!")
|
||||
8
setup.py
8
setup.py
@@ -87,6 +87,8 @@ _deps = [
|
||||
"regex!=2019.12.17",
|
||||
"requests",
|
||||
"torch>=1.4",
|
||||
"tensorboard",
|
||||
"modelcards==0.1.4"
|
||||
]
|
||||
|
||||
# this is a lookup table with items like:
|
||||
@@ -159,10 +161,11 @@ extras = {}
|
||||
extras = {}
|
||||
extras["quality"] = ["black ~= 22.0", "isort >= 5.5.4", "flake8 >= 3.8.3"]
|
||||
extras["docs"] = []
|
||||
extras["training"] = ["tensorboard", "modelcards"]
|
||||
extras["test"] = [
|
||||
"pytest",
|
||||
]
|
||||
extras["dev"] = extras["quality"] + extras["test"]
|
||||
extras["dev"] = extras["quality"] + extras["test"] + extras["training"]
|
||||
|
||||
install_requires = [
|
||||
deps["filelock"],
|
||||
@@ -176,7 +179,7 @@ install_requires = [
|
||||
|
||||
setup(
|
||||
name="diffusers",
|
||||
version="0.0.4",
|
||||
version="0.1.0",
|
||||
description="Diffusers",
|
||||
long_description=open("README.md", "r", encoding="utf-8").read(),
|
||||
long_description_content_type="text/markdown",
|
||||
@@ -187,6 +190,7 @@ setup(
|
||||
url="https://github.com/huggingface/diffusers",
|
||||
package_dir={"": "src"},
|
||||
packages=find_packages("src"),
|
||||
include_package_data=True,
|
||||
python_requires=">=3.6.0",
|
||||
install_requires=install_requires,
|
||||
extras_require=extras,
|
||||
|
||||
@@ -1,15 +1,19 @@
|
||||
# flake8: noqa
|
||||
# There's no way to ignore "F401 '...' imported but unused" warnings in this
|
||||
# module, but to preserve other warnings. So, don't check this module at all.
|
||||
from .utils import is_inflect_available, is_transformers_available, is_unidecode_available
|
||||
|
||||
__version__ = "0.0.4"
|
||||
|
||||
__version__ = "0.1.0"
|
||||
|
||||
from .modeling_utils import ModelMixin
|
||||
from .models.unet import UNetModel
|
||||
from .models.unet_glide import GLIDESuperResUNetModel, GLIDETextToImageUNetModel, GLIDEUNetModel
|
||||
from .models.unet_grad_tts import UNetGradTTSModel
|
||||
from .models.unet_ldm import UNetLDMModel
|
||||
from .models import AutoencoderKL, UNet2DConditionModel, UNet2DModel, VQModel
|
||||
from .pipeline_utils import DiffusionPipeline
|
||||
from .pipelines import BDDM, DDIM, DDPM, GLIDE, PNDM, LatentDiffusion
|
||||
from .schedulers import DDIMScheduler, DDPMScheduler, PNDMScheduler, SchedulerMixin
|
||||
from .schedulers.classifier_free_guidance import ClassifierFreeGuidanceScheduler
|
||||
from .pipelines import DDIMPipeline, DDPMPipeline, LDMPipeline, PNDMPipeline, ScoreSdeVePipeline
|
||||
from .schedulers import DDIMScheduler, DDPMScheduler, PNDMScheduler, SchedulerMixin, ScoreSdeVeScheduler
|
||||
|
||||
|
||||
if is_transformers_available():
|
||||
from .pipelines import LDMTextToImagePipeline
|
||||
else:
|
||||
from .utils.dummy_transformers_objects import *
|
||||
|
||||
@@ -14,13 +14,12 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" ConfigMixinuration base class and utilities."""
|
||||
|
||||
|
||||
import copy
|
||||
import functools
|
||||
import inspect
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
from collections import OrderedDict
|
||||
from typing import Any, Dict, Tuple, Union
|
||||
|
||||
from huggingface_hub import hf_hub_download
|
||||
@@ -49,8 +48,9 @@ class ConfigMixin:
|
||||
|
||||
"""
|
||||
config_name = None
|
||||
ignore_for_config = []
|
||||
|
||||
def register(self, **kwargs):
|
||||
def register_to_config(self, **kwargs):
|
||||
if self.config_name is None:
|
||||
raise NotImplementedError(f"Make sure that {self.__class__} has defined a class name `config_name`")
|
||||
kwargs["_class_name"] = self.__class__.__name__
|
||||
@@ -63,10 +63,14 @@ class ConfigMixin:
|
||||
logger.error(f"Can't set {key} with value {value} for {self}")
|
||||
raise err
|
||||
|
||||
if not hasattr(self, "_dict_to_save"):
|
||||
self._dict_to_save = {}
|
||||
if not hasattr(self, "_internal_dict"):
|
||||
internal_dict = kwargs
|
||||
else:
|
||||
previous_dict = dict(self._internal_dict)
|
||||
internal_dict = {**self._internal_dict, **kwargs}
|
||||
logger.debug(f"Updating config from {previous_dict} to {internal_dict}")
|
||||
|
||||
self._dict_to_save.update(kwargs)
|
||||
self._internal_dict = FrozenDict(internal_dict)
|
||||
|
||||
def save_config(self, save_directory: Union[str, os.PathLike], push_to_hub: bool = False, **kwargs):
|
||||
"""
|
||||
@@ -114,6 +118,7 @@ class ConfigMixin:
|
||||
use_auth_token = kwargs.pop("use_auth_token", None)
|
||||
local_files_only = kwargs.pop("local_files_only", False)
|
||||
revision = kwargs.pop("revision", None)
|
||||
subfolder = kwargs.pop("subfolder", None)
|
||||
|
||||
user_agent = {"file_type": "config"}
|
||||
|
||||
@@ -131,6 +136,10 @@ class ConfigMixin:
|
||||
if os.path.isfile(os.path.join(pretrained_model_name_or_path, cls.config_name)):
|
||||
# Load from a PyTorch checkpoint
|
||||
config_file = os.path.join(pretrained_model_name_or_path, cls.config_name)
|
||||
elif subfolder is not None and os.path.isfile(
|
||||
os.path.join(pretrained_model_name_or_path, subfolder, cls.config_name)
|
||||
):
|
||||
config_file = os.path.join(pretrained_model_name_or_path, subfolder, cls.config_name)
|
||||
else:
|
||||
raise EnvironmentError(
|
||||
f"Error no file named {cls.config_name} found in directory {pretrained_model_name_or_path}."
|
||||
@@ -148,14 +157,15 @@ class ConfigMixin:
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
user_agent=user_agent,
|
||||
subfolder=subfolder,
|
||||
)
|
||||
|
||||
except RepositoryNotFoundError:
|
||||
raise EnvironmentError(
|
||||
f"{pretrained_model_name_or_path} is not a local folder and is not a valid model identifier listed"
|
||||
" on 'https://huggingface.co/models'\nIf this is a private repository, make sure to pass a token"
|
||||
" having permission to this repo with `use_auth_token` or log in with `huggingface-cli login` and"
|
||||
" pass `use_auth_token=True`."
|
||||
f"{pretrained_model_name_or_path} is not a local folder and is not a valid model identifier"
|
||||
" listed on 'https://huggingface.co/models'\nIf this is a private repository, make sure to pass a"
|
||||
" token having permission to this repo with `use_auth_token` or log in with `huggingface-cli"
|
||||
" login` and pass `use_auth_token=True`."
|
||||
)
|
||||
except RevisionNotFoundError:
|
||||
raise EnvironmentError(
|
||||
@@ -200,6 +210,12 @@ class ConfigMixin:
|
||||
def extract_init_dict(cls, config_dict, **kwargs):
|
||||
expected_keys = set(dict(inspect.signature(cls.__init__).parameters).keys())
|
||||
expected_keys.remove("self")
|
||||
# remove general kwargs if present in dict
|
||||
if "kwargs" in expected_keys:
|
||||
expected_keys.remove("kwargs")
|
||||
# remove keys to be ignored
|
||||
if len(cls.ignore_for_config) > 0:
|
||||
expected_keys = expected_keys - set(cls.ignore_for_config)
|
||||
init_dict = {}
|
||||
for key in expected_keys:
|
||||
if key in kwargs:
|
||||
@@ -230,8 +246,7 @@ class ConfigMixin:
|
||||
|
||||
@property
|
||||
def config(self) -> Dict[str, Any]:
|
||||
output = copy.deepcopy(self._dict_to_save)
|
||||
return output
|
||||
return self._internal_dict
|
||||
|
||||
def to_json_string(self) -> str:
|
||||
"""
|
||||
@@ -240,7 +255,7 @@ class ConfigMixin:
|
||||
Returns:
|
||||
`str`: String containing all the attributes that make up this configuration instance in JSON format.
|
||||
"""
|
||||
config_dict = self._dict_to_save
|
||||
config_dict = self._internal_dict if hasattr(self, "_internal_dict") else {}
|
||||
return json.dumps(config_dict, indent=2, sort_keys=True) + "\n"
|
||||
|
||||
def to_json_file(self, json_file_path: Union[str, os.PathLike]):
|
||||
@@ -253,3 +268,78 @@ class ConfigMixin:
|
||||
"""
|
||||
with open(json_file_path, "w", encoding="utf-8") as writer:
|
||||
writer.write(self.to_json_string())
|
||||
|
||||
|
||||
class FrozenDict(OrderedDict):
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
for key, value in self.items():
|
||||
setattr(self, key, value)
|
||||
|
||||
self.__frozen = True
|
||||
|
||||
def __delitem__(self, *args, **kwargs):
|
||||
raise Exception(f"You cannot use ``__delitem__`` on a {self.__class__.__name__} instance.")
|
||||
|
||||
def setdefault(self, *args, **kwargs):
|
||||
raise Exception(f"You cannot use ``setdefault`` on a {self.__class__.__name__} instance.")
|
||||
|
||||
def pop(self, *args, **kwargs):
|
||||
raise Exception(f"You cannot use ``pop`` on a {self.__class__.__name__} instance.")
|
||||
|
||||
def update(self, *args, **kwargs):
|
||||
raise Exception(f"You cannot use ``update`` on a {self.__class__.__name__} instance.")
|
||||
|
||||
def __setattr__(self, name, value):
|
||||
if hasattr(self, "__frozen") and self.__frozen:
|
||||
raise Exception(f"You cannot use ``__setattr__`` on a {self.__class__.__name__} instance.")
|
||||
super().__setattr__(name, value)
|
||||
|
||||
def __setitem__(self, name, value):
|
||||
if hasattr(self, "__frozen") and self.__frozen:
|
||||
raise Exception(f"You cannot use ``__setattr__`` on a {self.__class__.__name__} instance.")
|
||||
super().__setitem__(name, value)
|
||||
|
||||
|
||||
def register_to_config(init):
|
||||
"""
|
||||
Decorator to apply on the init of classes inheriting from `ConfigMixin` so that all the arguments are automatically
|
||||
sent to `self.register_for_config`. To ignore a specific argument accepted by the init but that shouldn't be
|
||||
registered in the config, use the `ignore_for_config` class variable
|
||||
|
||||
Warning: Once decorated, all private arguments (beginning with an underscore) are trashed and not sent to the init!
|
||||
"""
|
||||
|
||||
@functools.wraps(init)
|
||||
def inner_init(self, *args, **kwargs):
|
||||
# Ignore private kwargs in the init.
|
||||
init_kwargs = {k: v for k, v in kwargs.items() if not k.startswith("_")}
|
||||
init(self, *args, **init_kwargs)
|
||||
if not isinstance(self, ConfigMixin):
|
||||
raise RuntimeError(
|
||||
f"`@register_for_config` was applied to {self.__class__.__name__} init method, but this class does "
|
||||
"not inherit from `ConfigMixin`."
|
||||
)
|
||||
|
||||
ignore = getattr(self, "ignore_for_config", [])
|
||||
# Get positional arguments aligned with kwargs
|
||||
new_kwargs = {}
|
||||
signature = inspect.signature(init)
|
||||
parameters = {
|
||||
name: p.default for i, (name, p) in enumerate(signature.parameters.items()) if i > 0 and name not in ignore
|
||||
}
|
||||
for arg, name in zip(args, parameters.keys()):
|
||||
new_kwargs[name] = arg
|
||||
|
||||
# Then add all kwargs
|
||||
new_kwargs.update(
|
||||
{
|
||||
k: init_kwargs.get(k, default)
|
||||
for k, default in parameters.items()
|
||||
if k not in ignore and k not in new_kwargs
|
||||
}
|
||||
)
|
||||
getattr(self, "register_to_config")(**new_kwargs)
|
||||
|
||||
return inner_init
|
||||
|
||||
@@ -13,4 +13,6 @@ deps = {
|
||||
"regex": "regex!=2019.12.17",
|
||||
"requests": "requests",
|
||||
"torch": "torch>=1.4",
|
||||
"tensorboard": "tensorboard",
|
||||
"modelcards": "modelcards==0.1.4",
|
||||
}
|
||||
|
||||
198
src/diffusers/hub_utils.py
Normal file
198
src/diffusers/hub_utils.py
Normal file
@@ -0,0 +1,198 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
import os
|
||||
import shutil
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from diffusers import DiffusionPipeline
|
||||
from huggingface_hub import HfFolder, Repository, whoami
|
||||
from utils import is_modelcards_available
|
||||
|
||||
|
||||
if is_modelcards_available():
|
||||
from modelcards import CardData, ModelCard
|
||||
|
||||
from .utils import logging
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
MODEL_CARD_TEMPLATE_PATH = Path(__file__).parent / "utils" / "model_card_template.md"
|
||||
|
||||
|
||||
def get_full_repo_name(model_id: str, organization: Optional[str] = None, token: Optional[str] = None):
|
||||
if token is None:
|
||||
token = HfFolder.get_token()
|
||||
if organization is None:
|
||||
username = whoami(token)["name"]
|
||||
return f"{username}/{model_id}"
|
||||
else:
|
||||
return f"{organization}/{model_id}"
|
||||
|
||||
|
||||
def init_git_repo(args, at_init: bool = False):
|
||||
"""
|
||||
Args:
|
||||
Initializes a git repo in `args.hub_model_id`.
|
||||
at_init (`bool`, *optional*, defaults to `False`):
|
||||
Whether this function is called before any training or not. If `self.args.overwrite_output_dir` is `True`
|
||||
and `at_init` is `True`, the path to the repo (which is `self.args.output_dir`) might be wiped out.
|
||||
"""
|
||||
if hasattr(args, "local_rank") and args.local_rank not in [-1, 0]:
|
||||
return
|
||||
hub_token = args.hub_token if hasattr(args, "hub_token") else None
|
||||
use_auth_token = True if hub_token is None else hub_token
|
||||
if not hasattr(args, "hub_model_id") or args.hub_model_id is None:
|
||||
repo_name = Path(args.output_dir).absolute().name
|
||||
else:
|
||||
repo_name = args.hub_model_id
|
||||
if "/" not in repo_name:
|
||||
repo_name = get_full_repo_name(repo_name, token=hub_token)
|
||||
|
||||
try:
|
||||
repo = Repository(
|
||||
args.output_dir,
|
||||
clone_from=repo_name,
|
||||
use_auth_token=use_auth_token,
|
||||
private=args.hub_private_repo,
|
||||
)
|
||||
except EnvironmentError:
|
||||
if args.overwrite_output_dir and at_init:
|
||||
# Try again after wiping output_dir
|
||||
shutil.rmtree(args.output_dir)
|
||||
repo = Repository(
|
||||
args.output_dir,
|
||||
clone_from=repo_name,
|
||||
use_auth_token=use_auth_token,
|
||||
)
|
||||
else:
|
||||
raise
|
||||
|
||||
repo.git_pull()
|
||||
|
||||
# By default, ignore the checkpoint folders
|
||||
if not os.path.exists(os.path.join(args.output_dir, ".gitignore")):
|
||||
with open(os.path.join(args.output_dir, ".gitignore"), "w", encoding="utf-8") as writer:
|
||||
writer.writelines(["checkpoint-*/"])
|
||||
|
||||
return repo
|
||||
|
||||
|
||||
def push_to_hub(
|
||||
args,
|
||||
pipeline: DiffusionPipeline,
|
||||
repo: Repository,
|
||||
commit_message: Optional[str] = "End of training",
|
||||
blocking: bool = True,
|
||||
**kwargs,
|
||||
) -> str:
|
||||
"""
|
||||
Parameters:
|
||||
Upload *self.model* and *self.tokenizer* to the 🤗 model hub on the repo *self.args.hub_model_id*.
|
||||
commit_message (`str`, *optional*, defaults to `"End of training"`):
|
||||
Message to commit while pushing.
|
||||
blocking (`bool`, *optional*, defaults to `True`):
|
||||
Whether the function should return only when the `git push` has finished.
|
||||
kwargs:
|
||||
Additional keyword arguments passed along to [`create_model_card`].
|
||||
Returns:
|
||||
The url of the commit of your model in the given repository if `blocking=False`, a tuple with the url of the
|
||||
commit and an object to track the progress of the commit if `blocking=True`
|
||||
"""
|
||||
|
||||
if not hasattr(args, "hub_model_id") or args.hub_model_id is None:
|
||||
model_name = Path(args.output_dir).name
|
||||
else:
|
||||
model_name = args.hub_model_id.split("/")[-1]
|
||||
|
||||
output_dir = args.output_dir
|
||||
os.makedirs(output_dir, exist_ok=True)
|
||||
logger.info(f"Saving pipeline checkpoint to {output_dir}")
|
||||
pipeline.save_pretrained(output_dir)
|
||||
|
||||
# Only push from one node.
|
||||
if hasattr(args, "local_rank") and args.local_rank not in [-1, 0]:
|
||||
return
|
||||
|
||||
# Cancel any async push in progress if blocking=True. The commits will all be pushed together.
|
||||
if (
|
||||
blocking
|
||||
and len(repo.command_queue) > 0
|
||||
and repo.command_queue[-1] is not None
|
||||
and not repo.command_queue[-1].is_done
|
||||
):
|
||||
repo.command_queue[-1]._process.kill()
|
||||
|
||||
git_head_commit_url = repo.push_to_hub(commit_message=commit_message, blocking=blocking, auto_lfs_prune=True)
|
||||
# push separately the model card to be independent from the rest of the model
|
||||
create_model_card(args, model_name=model_name)
|
||||
try:
|
||||
repo.push_to_hub(commit_message="update model card README.md", blocking=blocking, auto_lfs_prune=True)
|
||||
except EnvironmentError as exc:
|
||||
logger.error(f"Error pushing update to the model card. Please read logs and retry.\n${exc}")
|
||||
|
||||
return git_head_commit_url
|
||||
|
||||
|
||||
def create_model_card(args, model_name):
|
||||
if not is_modelcards_available:
|
||||
raise ValueError(
|
||||
"Please make sure to have `modelcards` installed when using the `create_model_card` function. You can"
|
||||
" install the package with `pip install modelcards`."
|
||||
)
|
||||
|
||||
if hasattr(args, "local_rank") and args.local_rank not in [-1, 0]:
|
||||
return
|
||||
|
||||
hub_token = args.hub_token if hasattr(args, "hub_token") else None
|
||||
repo_name = get_full_repo_name(model_name, token=hub_token)
|
||||
|
||||
model_card = ModelCard.from_template(
|
||||
card_data=CardData( # Card metadata object that will be converted to YAML block
|
||||
language="en",
|
||||
license="apache-2.0",
|
||||
library_name="diffusers",
|
||||
tags=[],
|
||||
datasets=args.dataset,
|
||||
metrics=[],
|
||||
),
|
||||
template_path=MODEL_CARD_TEMPLATE_PATH,
|
||||
model_name=model_name,
|
||||
repo_name=repo_name,
|
||||
dataset_name=args.dataset if hasattr(args, "dataset") else None,
|
||||
learning_rate=args.learning_rate,
|
||||
train_batch_size=args.train_batch_size,
|
||||
eval_batch_size=args.eval_batch_size,
|
||||
gradient_accumulation_steps=args.gradient_accumulation_steps
|
||||
if hasattr(args, "gradient_accumulation_steps")
|
||||
else None,
|
||||
adam_beta1=args.adam_beta1 if hasattr(args, "adam_beta1") else None,
|
||||
adam_beta2=args.adam_beta2 if hasattr(args, "adam_beta2") else None,
|
||||
adam_weight_decay=args.adam_weight_decay if hasattr(args, "adam_weight_decay") else None,
|
||||
adam_epsilon=args.adam_epsilon if hasattr(args, "adam_weight_decay") else None,
|
||||
lr_scheduler=args.lr_scheduler if hasattr(args, "lr_scheduler") else None,
|
||||
lr_warmup_steps=args.lr_warmup_steps if hasattr(args, "lr_warmup_steps") else None,
|
||||
ema_inv_gamma=args.ema_inv_gamma if hasattr(args, "ema_inv_gamma") else None,
|
||||
ema_power=args.ema_power if hasattr(args, "ema_power") else None,
|
||||
ema_max_decay=args.ema_max_decay if hasattr(args, "ema_max_decay") else None,
|
||||
mixed_precision=args.mixed_precision,
|
||||
)
|
||||
|
||||
card_path = os.path.join(args.output_dir, "README.md")
|
||||
model_card.save(card_path)
|
||||
@@ -34,7 +34,7 @@ from .utils import (
|
||||
)
|
||||
|
||||
|
||||
WEIGHTS_NAME = "diffusion_model.pt"
|
||||
WEIGHTS_NAME = "diffusion_pytorch_model.bin"
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
@@ -123,16 +123,16 @@ class ModelMixin(torch.nn.Module):
|
||||
r"""
|
||||
Base class for all models.
|
||||
|
||||
[`ModelMixin`] takes care of storing the configuration of the models and handles methods for loading,
|
||||
downloading and saving models as well as a few methods common to all models to:
|
||||
[`ModelMixin`] takes care of storing the configuration of the models and handles methods for loading, downloading
|
||||
and saving models as well as a few methods common to all models to:
|
||||
|
||||
- resize the input embeddings,
|
||||
- prune heads in the self-attention heads.
|
||||
|
||||
Class attributes (overridden by derived classes):
|
||||
|
||||
- **config_class** ([`ConfigMixin`]) -- A subclass of [`ConfigMixin`] to use as configuration class
|
||||
for this model architecture.
|
||||
- **config_class** ([`ConfigMixin`]) -- A subclass of [`ConfigMixin`] to use as configuration class for this
|
||||
model architecture.
|
||||
- **load_tf_weights** (`Callable`) -- A python *method* for loading a TensorFlow checkpoint in a PyTorch model,
|
||||
taking as arguments:
|
||||
|
||||
@@ -147,6 +147,7 @@ class ModelMixin(torch.nn.Module):
|
||||
models, `pixel_values` for vision models and `input_values` for speech models).
|
||||
"""
|
||||
config_name = CONFIG_NAME
|
||||
_automatically_saved_args = ["_diffusers_version", "_class_name", "_name_or_path"]
|
||||
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
@@ -227,8 +228,8 @@ class ModelMixin(torch.nn.Module):
|
||||
- A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
|
||||
Valid model ids can be located at the root-level, like `bert-base-uncased`, or namespaced under a
|
||||
user or organization name, like `dbmdz/bert-base-german-cased`.
|
||||
- A path to a *directory* containing model weights saved using
|
||||
[`~ModelMixin.save_pretrained`], e.g., `./my_model_directory/`.
|
||||
- A path to a *directory* containing model weights saved using [`~ModelMixin.save_pretrained`],
|
||||
e.g., `./my_model_directory/`.
|
||||
|
||||
config (`Union[ConfigMixin, str, os.PathLike]`, *optional*):
|
||||
Can be either:
|
||||
@@ -236,13 +237,13 @@ class ModelMixin(torch.nn.Module):
|
||||
- an instance of a class derived from [`ConfigMixin`],
|
||||
- a string or path valid as input to [`~ConfigMixin.from_pretrained`].
|
||||
|
||||
ConfigMixinuration for the model to use instead of an automatically loaded configuration. ConfigMixinuration can
|
||||
be automatically loaded when:
|
||||
ConfigMixinuration for the model to use instead of an automatically loaded configuration.
|
||||
ConfigMixinuration can be automatically loaded when:
|
||||
|
||||
- The model is a model provided by the library (loaded with the *model id* string of a pretrained
|
||||
model).
|
||||
- The model was saved using [`~ModelMixin.save_pretrained`] and is reloaded by supplying the
|
||||
save directory.
|
||||
- The model was saved using [`~ModelMixin.save_pretrained`] and is reloaded by supplying the save
|
||||
directory.
|
||||
- The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
|
||||
configuration JSON file named *config.json* is found in the directory.
|
||||
cache_dir (`Union[str, os.PathLike]`, *optional*):
|
||||
@@ -292,10 +293,10 @@ class ModelMixin(torch.nn.Module):
|
||||
underlying model's `__init__` method (we assume all relevant updates to the configuration have
|
||||
already been done)
|
||||
- If a configuration is not provided, `kwargs` will be first passed to the configuration class
|
||||
initialization function ([`~ConfigMixin.from_pretrained`]). Each key of `kwargs` that
|
||||
corresponds to a configuration attribute will be used to override said attribute with the
|
||||
supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
|
||||
will be passed to the underlying model's `__init__` function.
|
||||
initialization function ([`~ConfigMixin.from_pretrained`]). Each key of `kwargs` that corresponds
|
||||
to a configuration attribute will be used to override said attribute with the supplied `kwargs`
|
||||
value. Remaining keys that do not correspond to any configuration attribute will be passed to the
|
||||
underlying model's `__init__` function.
|
||||
|
||||
<Tip>
|
||||
|
||||
@@ -321,6 +322,7 @@ class ModelMixin(torch.nn.Module):
|
||||
use_auth_token = kwargs.pop("use_auth_token", None)
|
||||
revision = kwargs.pop("revision", None)
|
||||
from_auto_class = kwargs.pop("_from_auto", False)
|
||||
subfolder = kwargs.pop("subfolder", None)
|
||||
|
||||
user_agent = {"file_type": "model", "framework": "pytorch", "from_auto_class": from_auto_class}
|
||||
|
||||
@@ -336,9 +338,10 @@ class ModelMixin(torch.nn.Module):
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
subfolder=subfolder,
|
||||
**kwargs,
|
||||
)
|
||||
model.register(name_or_path=pretrained_model_name_or_path)
|
||||
model.register_to_config(_name_or_path=pretrained_model_name_or_path)
|
||||
# This variable will flag if we're loading a sharded checkpoint. In this case the archive file is just the
|
||||
# Load model
|
||||
pretrained_model_name_or_path = str(pretrained_model_name_or_path)
|
||||
@@ -346,6 +349,10 @@ class ModelMixin(torch.nn.Module):
|
||||
if os.path.isfile(os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME)):
|
||||
# Load from a PyTorch checkpoint
|
||||
model_file = os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME)
|
||||
elif subfolder is not None and os.path.isfile(
|
||||
os.path.join(pretrained_model_name_or_path, subfolder, WEIGHTS_NAME)
|
||||
):
|
||||
model_file = os.path.join(pretrained_model_name_or_path, subfolder, WEIGHTS_NAME)
|
||||
else:
|
||||
raise EnvironmentError(
|
||||
f"Error no file named {WEIGHTS_NAME} found in directory {pretrained_model_name_or_path}."
|
||||
@@ -363,6 +370,7 @@ class ModelMixin(torch.nn.Module):
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
user_agent=user_agent,
|
||||
subfolder=subfolder,
|
||||
)
|
||||
|
||||
except RepositoryNotFoundError:
|
||||
@@ -490,19 +498,20 @@ class ModelMixin(torch.nn.Module):
|
||||
raise RuntimeError(f"Error(s) in loading state_dict for {model.__class__.__name__}:\n\t{error_msg}")
|
||||
|
||||
if len(unexpected_keys) > 0:
|
||||
logger.warninging(
|
||||
logger.warning(
|
||||
f"Some weights of the model checkpoint at {pretrained_model_name_or_path} were not used when"
|
||||
f" initializing {model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are"
|
||||
f" initializing {model.__class__.__name__} from the checkpoint of a model trained on another task or"
|
||||
" with another architecture (e.g. initializing a BertForSequenceClassification model from a"
|
||||
f" initializing {model.__class__.__name__} from the checkpoint of a model trained on another task"
|
||||
" or with another architecture (e.g. initializing a BertForSequenceClassification model from a"
|
||||
" BertForPreTraining model).\n- This IS NOT expected if you are initializing"
|
||||
f" {model.__class__.__name__} from the checkpoint of a model that you expect to be exactly identical"
|
||||
" (initializing a BertForSequenceClassification model from a BertForSequenceClassification model)."
|
||||
f" {model.__class__.__name__} from the checkpoint of a model that you expect to be exactly"
|
||||
" identical (initializing a BertForSequenceClassification model from a"
|
||||
" BertForSequenceClassification model)."
|
||||
)
|
||||
else:
|
||||
logger.info(f"All model checkpoint weights were used when initializing {model.__class__.__name__}.\n")
|
||||
if len(missing_keys) > 0:
|
||||
logger.warninging(
|
||||
logger.warning(
|
||||
f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
|
||||
f" {pretrained_model_name_or_path} and are newly initialized: {missing_keys}\nYou should probably"
|
||||
" TRAIN this model on a down-stream task to be able to use it for predictions and inference."
|
||||
@@ -510,9 +519,9 @@ class ModelMixin(torch.nn.Module):
|
||||
elif len(mismatched_keys) == 0:
|
||||
logger.info(
|
||||
f"All the weights of {model.__class__.__name__} were initialized from the model checkpoint at"
|
||||
f" {pretrained_model_name_or_path}.\nIf your task is similar to the task the model of the checkpoint"
|
||||
f" was trained on, you can already use {model.__class__.__name__} for predictions without further"
|
||||
" training."
|
||||
f" {pretrained_model_name_or_path}.\nIf your task is similar to the task the model of the"
|
||||
f" checkpoint was trained on, you can already use {model.__class__.__name__} for predictions"
|
||||
" without further training."
|
||||
)
|
||||
if len(mismatched_keys) > 0:
|
||||
mismatched_warning = "\n".join(
|
||||
@@ -521,11 +530,11 @@ class ModelMixin(torch.nn.Module):
|
||||
for key, shape1, shape2 in mismatched_keys
|
||||
]
|
||||
)
|
||||
logger.warninging(
|
||||
logger.warning(
|
||||
f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
|
||||
f" {pretrained_model_name_or_path} and are newly initialized because the shapes did not"
|
||||
f" match:\n{mismatched_warning}\nYou should probably TRAIN this model on a down-stream task to be able"
|
||||
" to use it for predictions and inference."
|
||||
f" match:\n{mismatched_warning}\nYou should probably TRAIN this model on a down-stream task to be"
|
||||
" able to use it for predictions and inference."
|
||||
)
|
||||
|
||||
return model, missing_keys, unexpected_keys, mismatched_keys, error_msgs
|
||||
@@ -572,3 +581,17 @@ class ModelMixin(torch.nn.Module):
|
||||
return sum(p.numel() for p in non_embedding_parameters if p.requires_grad or not only_trainable)
|
||||
else:
|
||||
return sum(p.numel() for p in self.parameters() if p.requires_grad or not only_trainable)
|
||||
|
||||
|
||||
def unwrap_model(model: torch.nn.Module) -> torch.nn.Module:
|
||||
"""
|
||||
Recursively unwraps a model from potential containers (as used in distributed training).
|
||||
|
||||
Args:
|
||||
model (`torch.nn.Module`): The model to unwrap.
|
||||
"""
|
||||
# since there could be multiple levels of wrapping, unwrap recursively
|
||||
if hasattr(model, "module"):
|
||||
return unwrap_model(model.module)
|
||||
else:
|
||||
return model
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
# Models
|
||||
|
||||
- Models: Neural network that models p_θ(x_t-1|x_t) (see image below) and is trained end-to-end to denoise a noisy input to an image. Examples: UNet, Conditioned UNet, 3D UNet, Transformer UNet
|
||||
- Models: Neural network that models $p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)$ (see image below) and is trained end-to-end to denoise a noisy input to an image. Examples: UNet, Conditioned UNet, 3D UNet, Transformer UNet
|
||||
|
||||
## API
|
||||
|
||||
|
||||
@@ -16,7 +16,6 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from .unet import UNetModel
|
||||
from .unet_glide import GLIDESuperResUNetModel, GLIDETextToImageUNetModel, GLIDEUNetModel
|
||||
from .unet_grad_tts import UNetGradTTSModel
|
||||
from .unet_ldm import UNetLDMModel
|
||||
from .unet_2d import UNet2DModel
|
||||
from .unet_2d_condition import UNet2DConditionModel
|
||||
from .vae import AutoencoderKL, VQModel
|
||||
|
||||
434
src/diffusers/models/attention.py
Normal file
434
src/diffusers/models/attention.py
Normal file
@@ -0,0 +1,434 @@
|
||||
import math
|
||||
from inspect import isfunction
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from torch import nn
|
||||
|
||||
|
||||
class AttentionBlockNew(nn.Module):
|
||||
"""
|
||||
An attention block that allows spatial positions to attend to each other. Originally ported from here, but adapted
|
||||
to the N-d case.
|
||||
https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
|
||||
Uses three q, k, v linear layers to compute attention
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
channels,
|
||||
num_head_channels=None,
|
||||
num_groups=32,
|
||||
rescale_output_factor=1.0,
|
||||
eps=1e-5,
|
||||
):
|
||||
super().__init__()
|
||||
self.channels = channels
|
||||
|
||||
self.num_heads = channels // num_head_channels if num_head_channels is not None else 1
|
||||
self.num_head_size = num_head_channels
|
||||
self.group_norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, eps=eps, affine=True)
|
||||
|
||||
# define q,k,v as linear layers
|
||||
self.query = nn.Linear(channels, channels)
|
||||
self.key = nn.Linear(channels, channels)
|
||||
self.value = nn.Linear(channels, channels)
|
||||
|
||||
self.rescale_output_factor = rescale_output_factor
|
||||
self.proj_attn = nn.Linear(channels, channels, 1)
|
||||
|
||||
def transpose_for_scores(self, projection: torch.Tensor) -> torch.Tensor:
|
||||
new_projection_shape = projection.size()[:-1] + (self.num_heads, -1)
|
||||
# move heads to 2nd position (B, T, H * D) -> (B, T, H, D) -> (B, H, T, D)
|
||||
new_projection = projection.view(new_projection_shape).permute(0, 2, 1, 3)
|
||||
return new_projection
|
||||
|
||||
def forward(self, hidden_states):
|
||||
residual = hidden_states
|
||||
batch, channel, height, width = hidden_states.shape
|
||||
|
||||
# norm
|
||||
hidden_states = self.group_norm(hidden_states)
|
||||
|
||||
hidden_states = hidden_states.view(batch, channel, height * width).transpose(1, 2)
|
||||
|
||||
# proj to q, k, v
|
||||
query_proj = self.query(hidden_states)
|
||||
key_proj = self.key(hidden_states)
|
||||
value_proj = self.value(hidden_states)
|
||||
|
||||
# transpose
|
||||
query_states = self.transpose_for_scores(query_proj)
|
||||
key_states = self.transpose_for_scores(key_proj)
|
||||
value_states = self.transpose_for_scores(value_proj)
|
||||
|
||||
# get scores
|
||||
scale = 1 / math.sqrt(math.sqrt(self.channels / self.num_heads))
|
||||
attention_scores = torch.matmul(query_states * scale, key_states.transpose(-1, -2) * scale)
|
||||
attention_probs = torch.softmax(attention_scores.float(), dim=-1).type(attention_scores.dtype)
|
||||
|
||||
# compute attention output
|
||||
context_states = torch.matmul(attention_probs, value_states)
|
||||
|
||||
context_states = context_states.permute(0, 2, 1, 3).contiguous()
|
||||
new_context_states_shape = context_states.size()[:-2] + (self.channels,)
|
||||
context_states = context_states.view(new_context_states_shape)
|
||||
|
||||
# compute next hidden_states
|
||||
hidden_states = self.proj_attn(context_states)
|
||||
hidden_states = hidden_states.transpose(-1, -2).reshape(batch, channel, height, width)
|
||||
|
||||
# res connect and rescale
|
||||
hidden_states = (hidden_states + residual) / self.rescale_output_factor
|
||||
return hidden_states
|
||||
|
||||
def set_weight(self, attn_layer):
|
||||
self.group_norm.weight.data = attn_layer.norm.weight.data
|
||||
self.group_norm.bias.data = attn_layer.norm.bias.data
|
||||
|
||||
if hasattr(attn_layer, "q"):
|
||||
self.query.weight.data = attn_layer.q.weight.data[:, :, 0, 0]
|
||||
self.key.weight.data = attn_layer.k.weight.data[:, :, 0, 0]
|
||||
self.value.weight.data = attn_layer.v.weight.data[:, :, 0, 0]
|
||||
|
||||
self.query.bias.data = attn_layer.q.bias.data
|
||||
self.key.bias.data = attn_layer.k.bias.data
|
||||
self.value.bias.data = attn_layer.v.bias.data
|
||||
|
||||
self.proj_attn.weight.data = attn_layer.proj_out.weight.data[:, :, 0, 0]
|
||||
self.proj_attn.bias.data = attn_layer.proj_out.bias.data
|
||||
elif hasattr(attn_layer, "NIN_0"):
|
||||
self.query.weight.data = attn_layer.NIN_0.W.data.T
|
||||
self.key.weight.data = attn_layer.NIN_1.W.data.T
|
||||
self.value.weight.data = attn_layer.NIN_2.W.data.T
|
||||
|
||||
self.query.bias.data = attn_layer.NIN_0.b.data
|
||||
self.key.bias.data = attn_layer.NIN_1.b.data
|
||||
self.value.bias.data = attn_layer.NIN_2.b.data
|
||||
|
||||
self.proj_attn.weight.data = attn_layer.NIN_3.W.data.T
|
||||
self.proj_attn.bias.data = attn_layer.NIN_3.b.data
|
||||
|
||||
self.group_norm.weight.data = attn_layer.GroupNorm_0.weight.data
|
||||
self.group_norm.bias.data = attn_layer.GroupNorm_0.bias.data
|
||||
else:
|
||||
qkv_weight = attn_layer.qkv.weight.data.reshape(
|
||||
self.num_heads, 3 * self.channels // self.num_heads, self.channels
|
||||
)
|
||||
qkv_bias = attn_layer.qkv.bias.data.reshape(self.num_heads, 3 * self.channels // self.num_heads)
|
||||
|
||||
q_w, k_w, v_w = qkv_weight.split(self.channels // self.num_heads, dim=1)
|
||||
q_b, k_b, v_b = qkv_bias.split(self.channels // self.num_heads, dim=1)
|
||||
|
||||
self.query.weight.data = q_w.reshape(-1, self.channels)
|
||||
self.key.weight.data = k_w.reshape(-1, self.channels)
|
||||
self.value.weight.data = v_w.reshape(-1, self.channels)
|
||||
|
||||
self.query.bias.data = q_b.reshape(-1)
|
||||
self.key.bias.data = k_b.reshape(-1)
|
||||
self.value.bias.data = v_b.reshape(-1)
|
||||
|
||||
self.proj_attn.weight.data = attn_layer.proj.weight.data[:, :, 0]
|
||||
self.proj_attn.bias.data = attn_layer.proj.bias.data
|
||||
|
||||
|
||||
class SpatialTransformer(nn.Module):
|
||||
"""
|
||||
Transformer block for image-like data. First, project the input (aka embedding) and reshape to b, t, d. Then apply
|
||||
standard transformer action. Finally, reshape to image
|
||||
"""
|
||||
|
||||
def __init__(self, in_channels, n_heads, d_head, depth=1, dropout=0.0, context_dim=None):
|
||||
super().__init__()
|
||||
self.n_heads = n_heads
|
||||
self.d_head = d_head
|
||||
self.in_channels = in_channels
|
||||
inner_dim = n_heads * d_head
|
||||
self.norm = torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
|
||||
|
||||
self.proj_in = nn.Conv2d(in_channels, inner_dim, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
self.transformer_blocks = nn.ModuleList(
|
||||
[
|
||||
BasicTransformerBlock(inner_dim, n_heads, d_head, dropout=dropout, context_dim=context_dim)
|
||||
for d in range(depth)
|
||||
]
|
||||
)
|
||||
|
||||
self.proj_out = nn.Conv2d(inner_dim, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
def forward(self, x, context=None):
|
||||
# note: if no context is given, cross-attention defaults to self-attention
|
||||
b, c, h, w = x.shape
|
||||
x_in = x
|
||||
x = self.norm(x)
|
||||
x = self.proj_in(x)
|
||||
x = x.permute(0, 2, 3, 1).reshape(b, h * w, c)
|
||||
for block in self.transformer_blocks:
|
||||
x = block(x, context=context)
|
||||
x = x.reshape(b, h, w, c).permute(0, 3, 1, 2)
|
||||
x = self.proj_out(x)
|
||||
return x + x_in
|
||||
|
||||
def set_weight(self, layer):
|
||||
self.norm = layer.norm
|
||||
self.proj_in = layer.proj_in
|
||||
self.transformer_blocks = layer.transformer_blocks
|
||||
self.proj_out = layer.proj_out
|
||||
|
||||
|
||||
class BasicTransformerBlock(nn.Module):
|
||||
def __init__(self, dim, n_heads, d_head, dropout=0.0, context_dim=None, gated_ff=True, checkpoint=True):
|
||||
super().__init__()
|
||||
self.attn1 = CrossAttention(
|
||||
query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout
|
||||
) # is a self-attention
|
||||
self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
|
||||
self.attn2 = CrossAttention(
|
||||
query_dim=dim, context_dim=context_dim, heads=n_heads, dim_head=d_head, dropout=dropout
|
||||
) # is self-attn if context is none
|
||||
self.norm1 = nn.LayerNorm(dim)
|
||||
self.norm2 = nn.LayerNorm(dim)
|
||||
self.norm3 = nn.LayerNorm(dim)
|
||||
self.checkpoint = checkpoint
|
||||
|
||||
def forward(self, x, context=None):
|
||||
x = self.attn1(self.norm1(x)) + x
|
||||
x = self.attn2(self.norm2(x), context=context) + x
|
||||
x = self.ff(self.norm3(x)) + x
|
||||
return x
|
||||
|
||||
|
||||
class CrossAttention(nn.Module):
|
||||
def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.0):
|
||||
super().__init__()
|
||||
inner_dim = dim_head * heads
|
||||
context_dim = default(context_dim, query_dim)
|
||||
|
||||
self.scale = dim_head**-0.5
|
||||
self.heads = heads
|
||||
|
||||
self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
|
||||
self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
|
||||
self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
|
||||
|
||||
self.to_out = nn.Sequential(nn.Linear(inner_dim, query_dim), nn.Dropout(dropout))
|
||||
|
||||
def reshape_heads_to_batch_dim(self, tensor):
|
||||
batch_size, seq_len, dim = tensor.shape
|
||||
head_size = self.heads
|
||||
tensor = tensor.reshape(batch_size, seq_len, head_size, dim // head_size)
|
||||
tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size * head_size, seq_len, dim // head_size)
|
||||
return tensor
|
||||
|
||||
def reshape_batch_dim_to_heads(self, tensor):
|
||||
batch_size, seq_len, dim = tensor.shape
|
||||
head_size = self.heads
|
||||
tensor = tensor.reshape(batch_size // head_size, head_size, seq_len, dim)
|
||||
tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size // head_size, seq_len, dim * head_size)
|
||||
return tensor
|
||||
|
||||
def forward(self, x, context=None, mask=None):
|
||||
batch_size, sequence_length, dim = x.shape
|
||||
|
||||
h = self.heads
|
||||
|
||||
q = self.to_q(x)
|
||||
context = default(context, x)
|
||||
k = self.to_k(context)
|
||||
v = self.to_v(context)
|
||||
|
||||
q = self.reshape_heads_to_batch_dim(q)
|
||||
k = self.reshape_heads_to_batch_dim(k)
|
||||
v = self.reshape_heads_to_batch_dim(v)
|
||||
|
||||
sim = torch.einsum("b i d, b j d -> b i j", q, k) * self.scale
|
||||
|
||||
if exists(mask):
|
||||
mask = mask.reshape(batch_size, -1)
|
||||
max_neg_value = -torch.finfo(sim.dtype).max
|
||||
mask = mask[:, None, :].repeat(h, 1, 1)
|
||||
sim.masked_fill_(~mask, max_neg_value)
|
||||
|
||||
# attention, what we cannot get enough of
|
||||
attn = sim.softmax(dim=-1)
|
||||
|
||||
out = torch.einsum("b i j, b j d -> b i d", attn, v)
|
||||
out = self.reshape_batch_dim_to_heads(out)
|
||||
return self.to_out(out)
|
||||
|
||||
|
||||
class FeedForward(nn.Module):
|
||||
def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.0):
|
||||
super().__init__()
|
||||
inner_dim = int(dim * mult)
|
||||
dim_out = default(dim_out, dim)
|
||||
project_in = nn.Sequential(nn.Linear(dim, inner_dim), nn.GELU()) if not glu else GEGLU(dim, inner_dim)
|
||||
|
||||
self.net = nn.Sequential(project_in, nn.Dropout(dropout), nn.Linear(inner_dim, dim_out))
|
||||
|
||||
def forward(self, x):
|
||||
return self.net(x)
|
||||
|
||||
|
||||
# feedforward
|
||||
class GEGLU(nn.Module):
|
||||
def __init__(self, dim_in, dim_out):
|
||||
super().__init__()
|
||||
self.proj = nn.Linear(dim_in, dim_out * 2)
|
||||
|
||||
def forward(self, x):
|
||||
x, gate = self.proj(x).chunk(2, dim=-1)
|
||||
return x * F.gelu(gate)
|
||||
|
||||
|
||||
# TODO(Patrick) - remove once all weights have been converted -> not needed anymore then
|
||||
class NIN(nn.Module):
|
||||
def __init__(self, in_dim, num_units, init_scale=0.1):
|
||||
super().__init__()
|
||||
self.W = nn.Parameter(torch.zeros(in_dim, num_units), requires_grad=True)
|
||||
self.b = nn.Parameter(torch.zeros(num_units), requires_grad=True)
|
||||
|
||||
|
||||
def exists(val):
|
||||
return val is not None
|
||||
|
||||
|
||||
def default(val, d):
|
||||
if exists(val):
|
||||
return val
|
||||
return d() if isfunction(d) else d
|
||||
|
||||
|
||||
# the main attention block that is used for all models
|
||||
class AttentionBlock(nn.Module):
|
||||
"""
|
||||
An attention block that allows spatial positions to attend to each other.
|
||||
|
||||
Originally ported from here, but adapted to the N-d case.
|
||||
https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
channels,
|
||||
num_heads=1,
|
||||
num_head_channels=None,
|
||||
num_groups=32,
|
||||
encoder_channels=None,
|
||||
overwrite_qkv=False,
|
||||
overwrite_linear=False,
|
||||
rescale_output_factor=1.0,
|
||||
eps=1e-5,
|
||||
):
|
||||
super().__init__()
|
||||
self.channels = channels
|
||||
if num_head_channels is None:
|
||||
self.num_heads = num_heads
|
||||
else:
|
||||
assert (
|
||||
channels % num_head_channels == 0
|
||||
), f"q,k,v channels {channels} is not divisible by num_head_channels {num_head_channels}"
|
||||
self.num_heads = channels // num_head_channels
|
||||
|
||||
self.norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, eps=eps, affine=True)
|
||||
self.qkv = nn.Conv1d(channels, channels * 3, 1)
|
||||
self.n_heads = self.num_heads
|
||||
self.rescale_output_factor = rescale_output_factor
|
||||
|
||||
if encoder_channels is not None:
|
||||
self.encoder_kv = nn.Conv1d(encoder_channels, channels * 2, 1)
|
||||
|
||||
self.proj = nn.Conv1d(channels, channels, 1)
|
||||
|
||||
self.overwrite_qkv = overwrite_qkv
|
||||
self.overwrite_linear = overwrite_linear
|
||||
|
||||
if overwrite_qkv:
|
||||
in_channels = channels
|
||||
self.norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, eps=1e-6)
|
||||
self.q = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.k = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.v = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.proj_out = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
elif self.overwrite_linear:
|
||||
num_groups = min(channels // 4, 32)
|
||||
self.norm = nn.GroupNorm(num_channels=channels, num_groups=num_groups, eps=1e-6)
|
||||
self.NIN_0 = NIN(channels, channels)
|
||||
self.NIN_1 = NIN(channels, channels)
|
||||
self.NIN_2 = NIN(channels, channels)
|
||||
self.NIN_3 = NIN(channels, channels)
|
||||
|
||||
self.GroupNorm_0 = nn.GroupNorm(num_groups=num_groups, num_channels=channels, eps=1e-6)
|
||||
else:
|
||||
self.proj_out = nn.Conv1d(channels, channels, 1)
|
||||
self.set_weights(self)
|
||||
|
||||
self.is_overwritten = False
|
||||
|
||||
def set_weights(self, module):
|
||||
if self.overwrite_qkv:
|
||||
qkv_weight = torch.cat([module.q.weight.data, module.k.weight.data, module.v.weight.data], dim=0)[
|
||||
:, :, :, 0
|
||||
]
|
||||
qkv_bias = torch.cat([module.q.bias.data, module.k.bias.data, module.v.bias.data], dim=0)
|
||||
|
||||
self.qkv.weight.data = qkv_weight
|
||||
self.qkv.bias.data = qkv_bias
|
||||
|
||||
proj_out = nn.Conv1d(self.channels, self.channels, 1)
|
||||
proj_out.weight.data = module.proj_out.weight.data[:, :, :, 0]
|
||||
proj_out.bias.data = module.proj_out.bias.data
|
||||
|
||||
self.proj = proj_out
|
||||
elif self.overwrite_linear:
|
||||
self.qkv.weight.data = torch.concat(
|
||||
[self.NIN_0.W.data.T, self.NIN_1.W.data.T, self.NIN_2.W.data.T], dim=0
|
||||
)[:, :, None]
|
||||
self.qkv.bias.data = torch.concat([self.NIN_0.b.data, self.NIN_1.b.data, self.NIN_2.b.data], dim=0)
|
||||
|
||||
self.proj.weight.data = self.NIN_3.W.data.T[:, :, None]
|
||||
self.proj.bias.data = self.NIN_3.b.data
|
||||
|
||||
self.norm.weight.data = self.GroupNorm_0.weight.data
|
||||
self.norm.bias.data = self.GroupNorm_0.bias.data
|
||||
else:
|
||||
self.proj.weight.data = self.proj_out.weight.data
|
||||
self.proj.bias.data = self.proj_out.bias.data
|
||||
|
||||
def forward(self, x, encoder_out=None):
|
||||
if not self.is_overwritten and (self.overwrite_qkv or self.overwrite_linear):
|
||||
self.set_weights(self)
|
||||
self.is_overwritten = True
|
||||
|
||||
b, c, *spatial = x.shape
|
||||
hid_states = self.norm(x).view(b, c, -1)
|
||||
|
||||
qkv = self.qkv(hid_states)
|
||||
bs, width, length = qkv.shape
|
||||
assert width % (3 * self.n_heads) == 0
|
||||
ch = width // (3 * self.n_heads)
|
||||
q, k, v = qkv.reshape(bs * self.n_heads, ch * 3, length).split(ch, dim=1)
|
||||
|
||||
if encoder_out is not None:
|
||||
encoder_kv = self.encoder_kv(encoder_out)
|
||||
assert encoder_kv.shape[1] == self.n_heads * ch * 2
|
||||
ek, ev = encoder_kv.reshape(bs * self.n_heads, ch * 2, -1).split(ch, dim=1)
|
||||
k = torch.cat([ek, k], dim=-1)
|
||||
v = torch.cat([ev, v], dim=-1)
|
||||
|
||||
scale = 1 / math.sqrt(math.sqrt(ch))
|
||||
weight = torch.einsum("bct,bcs->bts", q * scale, k * scale) # More stable with f16 than dividing afterwards
|
||||
weight = torch.softmax(weight.float(), dim=-1).type(weight.dtype)
|
||||
|
||||
a = torch.einsum("bts,bcs->bct", weight, v)
|
||||
h = a.reshape(bs, -1, length)
|
||||
|
||||
h = self.proj(h)
|
||||
h = h.reshape(b, c, *spatial)
|
||||
|
||||
result = x + h
|
||||
|
||||
result = result / self.rescale_output_factor
|
||||
|
||||
return result
|
||||
110
src/diffusers/models/embeddings.py
Normal file
110
src/diffusers/models/embeddings.py
Normal file
@@ -0,0 +1,110 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import math
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from torch import nn
|
||||
|
||||
|
||||
def get_timestep_embedding(
|
||||
timesteps, embedding_dim, flip_sin_to_cos=False, downscale_freq_shift=1, scale=1, max_period=10000
|
||||
):
|
||||
"""
|
||||
This matches the implementation in Denoising Diffusion Probabilistic Models: Create sinusoidal timestep embeddings.
|
||||
|
||||
:param timesteps: a 1-D Tensor of N indices, one per batch element.
|
||||
These may be fractional.
|
||||
:param embedding_dim: the dimension of the output. :param max_period: controls the minimum frequency of the
|
||||
embeddings. :return: an [N x dim] Tensor of positional embeddings.
|
||||
"""
|
||||
assert len(timesteps.shape) == 1, "Timesteps should be a 1d-array"
|
||||
|
||||
half_dim = embedding_dim // 2
|
||||
|
||||
emb_coeff = -math.log(max_period) / (half_dim - downscale_freq_shift)
|
||||
emb = torch.arange(half_dim, dtype=torch.float32, device=timesteps.device)
|
||||
emb = torch.exp(emb * emb_coeff)
|
||||
emb = timesteps[:, None].float() * emb[None, :]
|
||||
|
||||
# scale embeddings
|
||||
emb = scale * emb
|
||||
|
||||
# concat sine and cosine embeddings
|
||||
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=-1)
|
||||
|
||||
# flip sine and cosine embeddings
|
||||
if flip_sin_to_cos:
|
||||
emb = torch.cat([emb[:, half_dim:], emb[:, :half_dim]], dim=-1)
|
||||
|
||||
# zero pad
|
||||
if embedding_dim % 2 == 1:
|
||||
emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
|
||||
return emb
|
||||
|
||||
|
||||
class TimestepEmbedding(nn.Module):
|
||||
def __init__(self, channel, time_embed_dim, act_fn="silu"):
|
||||
super().__init__()
|
||||
|
||||
self.linear_1 = nn.Linear(channel, time_embed_dim)
|
||||
self.act = None
|
||||
if act_fn == "silu":
|
||||
self.act = nn.SiLU()
|
||||
self.linear_2 = nn.Linear(time_embed_dim, time_embed_dim)
|
||||
|
||||
def forward(self, sample):
|
||||
sample = self.linear_1(sample)
|
||||
|
||||
if self.act is not None:
|
||||
sample = self.act(sample)
|
||||
|
||||
sample = self.linear_2(sample)
|
||||
return sample
|
||||
|
||||
|
||||
class Timesteps(nn.Module):
|
||||
def __init__(self, num_channels, flip_sin_to_cos, downscale_freq_shift):
|
||||
super().__init__()
|
||||
self.num_channels = num_channels
|
||||
self.flip_sin_to_cos = flip_sin_to_cos
|
||||
self.downscale_freq_shift = downscale_freq_shift
|
||||
|
||||
def forward(self, timesteps):
|
||||
t_emb = get_timestep_embedding(
|
||||
timesteps,
|
||||
self.num_channels,
|
||||
flip_sin_to_cos=self.flip_sin_to_cos,
|
||||
downscale_freq_shift=self.downscale_freq_shift,
|
||||
)
|
||||
return t_emb
|
||||
|
||||
|
||||
class GaussianFourierProjection(nn.Module):
|
||||
"""Gaussian Fourier embeddings for noise levels."""
|
||||
|
||||
def __init__(self, embedding_size=256, scale=1.0):
|
||||
super().__init__()
|
||||
self.weight = nn.Parameter(torch.randn(embedding_size) * scale, requires_grad=False)
|
||||
|
||||
# to delete later
|
||||
self.W = nn.Parameter(torch.randn(embedding_size) * scale, requires_grad=False)
|
||||
|
||||
self.weight = self.W
|
||||
|
||||
def forward(self, x):
|
||||
x = torch.log(x)
|
||||
x_proj = x[:, None] * self.weight[None, :] * 2 * np.pi
|
||||
out = torch.cat([torch.sin(x_proj), torch.cos(x_proj)], dim=-1)
|
||||
return out
|
||||
868
src/diffusers/models/resnet.py
Normal file
868
src/diffusers/models/resnet.py
Normal file
@@ -0,0 +1,868 @@
|
||||
from functools import partial
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
|
||||
class Upsample2D(nn.Module):
|
||||
"""
|
||||
An upsampling layer with an optional convolution.
|
||||
|
||||
:param channels: channels in the inputs and outputs. :param use_conv: a bool determining if a convolution is
|
||||
applied. :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
|
||||
upsampling occurs in the inner-two dimensions.
|
||||
"""
|
||||
|
||||
def __init__(self, channels, use_conv=False, use_conv_transpose=False, out_channels=None, name="conv"):
|
||||
super().__init__()
|
||||
self.channels = channels
|
||||
self.out_channels = out_channels or channels
|
||||
self.use_conv = use_conv
|
||||
self.use_conv_transpose = use_conv_transpose
|
||||
self.name = name
|
||||
|
||||
conv = None
|
||||
if use_conv_transpose:
|
||||
conv = nn.ConvTranspose2d(channels, self.out_channels, 4, 2, 1)
|
||||
elif use_conv:
|
||||
conv = nn.Conv2d(self.channels, self.out_channels, 3, padding=1)
|
||||
|
||||
# TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
|
||||
if name == "conv":
|
||||
self.conv = conv
|
||||
else:
|
||||
self.Conv2d_0 = conv
|
||||
|
||||
def forward(self, x):
|
||||
assert x.shape[1] == self.channels
|
||||
if self.use_conv_transpose:
|
||||
return self.conv(x)
|
||||
|
||||
x = F.interpolate(x, scale_factor=2.0, mode="nearest")
|
||||
|
||||
# TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
|
||||
if self.use_conv:
|
||||
if self.name == "conv":
|
||||
x = self.conv(x)
|
||||
else:
|
||||
x = self.Conv2d_0(x)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
class Downsample2D(nn.Module):
|
||||
"""
|
||||
A downsampling layer with an optional convolution.
|
||||
|
||||
:param channels: channels in the inputs and outputs. :param use_conv: a bool determining if a convolution is
|
||||
applied. :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
|
||||
downsampling occurs in the inner-two dimensions.
|
||||
"""
|
||||
|
||||
def __init__(self, channels, use_conv=False, out_channels=None, padding=1, name="conv"):
|
||||
super().__init__()
|
||||
self.channels = channels
|
||||
self.out_channels = out_channels or channels
|
||||
self.use_conv = use_conv
|
||||
self.padding = padding
|
||||
stride = 2
|
||||
self.name = name
|
||||
|
||||
if use_conv:
|
||||
conv = nn.Conv2d(self.channels, self.out_channels, 3, stride=stride, padding=padding)
|
||||
else:
|
||||
assert self.channels == self.out_channels
|
||||
conv = nn.AvgPool2d(kernel_size=stride, stride=stride)
|
||||
|
||||
# TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
|
||||
if name == "conv":
|
||||
self.Conv2d_0 = conv
|
||||
self.conv = conv
|
||||
elif name == "Conv2d_0":
|
||||
self.conv = conv
|
||||
else:
|
||||
self.conv = conv
|
||||
|
||||
def forward(self, x):
|
||||
assert x.shape[1] == self.channels
|
||||
if self.use_conv and self.padding == 0:
|
||||
pad = (0, 1, 0, 1)
|
||||
x = F.pad(x, pad, mode="constant", value=0)
|
||||
|
||||
assert x.shape[1] == self.channels
|
||||
x = self.conv(x)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
class FirUpsample2D(nn.Module):
|
||||
def __init__(self, channels=None, out_channels=None, use_conv=False, fir_kernel=(1, 3, 3, 1)):
|
||||
super().__init__()
|
||||
out_channels = out_channels if out_channels else channels
|
||||
if use_conv:
|
||||
self.Conv2d_0 = nn.Conv2d(channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
self.use_conv = use_conv
|
||||
self.fir_kernel = fir_kernel
|
||||
self.out_channels = out_channels
|
||||
|
||||
def _upsample_2d(self, x, w=None, k=None, factor=2, gain=1):
|
||||
"""Fused `upsample_2d()` followed by `Conv2d()`.
|
||||
|
||||
Args:
|
||||
Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
|
||||
efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of arbitrary:
|
||||
order.
|
||||
x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
|
||||
C]`.
|
||||
w: Weight tensor of the shape `[filterH, filterW, inChannels,
|
||||
outChannels]`. Grouped convolution can be performed by `inChannels = x.shape[0] // numGroups`.
|
||||
k: FIR filter of the shape `[firH, firW]` or `[firN]`
|
||||
(separable). The default is `[1] * factor`, which corresponds to nearest-neighbor upsampling.
|
||||
factor: Integer upsampling factor (default: 2). gain: Scaling factor for signal magnitude (default: 1.0).
|
||||
|
||||
Returns:
|
||||
Tensor of the shape `[N, C, H * factor, W * factor]` or `[N, H * factor, W * factor, C]`, and same datatype as
|
||||
`x`.
|
||||
"""
|
||||
|
||||
assert isinstance(factor, int) and factor >= 1
|
||||
|
||||
# Setup filter kernel.
|
||||
if k is None:
|
||||
k = [1] * factor
|
||||
|
||||
# setup kernel
|
||||
k = np.asarray(k, dtype=np.float32)
|
||||
if k.ndim == 1:
|
||||
k = np.outer(k, k)
|
||||
k /= np.sum(k)
|
||||
|
||||
k = k * (gain * (factor**2))
|
||||
|
||||
if self.use_conv:
|
||||
convH = w.shape[2]
|
||||
convW = w.shape[3]
|
||||
inC = w.shape[1]
|
||||
|
||||
p = (k.shape[0] - factor) - (convW - 1)
|
||||
|
||||
stride = (factor, factor)
|
||||
# Determine data dimensions.
|
||||
stride = [1, 1, factor, factor]
|
||||
output_shape = ((x.shape[2] - 1) * factor + convH, (x.shape[3] - 1) * factor + convW)
|
||||
output_padding = (
|
||||
output_shape[0] - (x.shape[2] - 1) * stride[0] - convH,
|
||||
output_shape[1] - (x.shape[3] - 1) * stride[1] - convW,
|
||||
)
|
||||
assert output_padding[0] >= 0 and output_padding[1] >= 0
|
||||
inC = w.shape[1]
|
||||
num_groups = x.shape[1] // inC
|
||||
|
||||
# Transpose weights.
|
||||
w = torch.reshape(w, (num_groups, -1, inC, convH, convW))
|
||||
w = w[..., ::-1, ::-1].permute(0, 2, 1, 3, 4)
|
||||
w = torch.reshape(w, (num_groups * inC, -1, convH, convW))
|
||||
|
||||
x = F.conv_transpose2d(x, w, stride=stride, output_padding=output_padding, padding=0)
|
||||
|
||||
x = upfirdn2d_native(x, torch.tensor(k, device=x.device), pad=((p + 1) // 2 + factor - 1, p // 2 + 1))
|
||||
else:
|
||||
p = k.shape[0] - factor
|
||||
x = upfirdn2d_native(
|
||||
x, torch.tensor(k, device=x.device), up=factor, pad=((p + 1) // 2 + factor - 1, p // 2)
|
||||
)
|
||||
|
||||
return x
|
||||
|
||||
def forward(self, x):
|
||||
if self.use_conv:
|
||||
h = self._upsample_2d(x, self.Conv2d_0.weight, k=self.fir_kernel)
|
||||
h = h + self.Conv2d_0.bias.reshape(1, -1, 1, 1)
|
||||
else:
|
||||
h = self._upsample_2d(x, k=self.fir_kernel, factor=2)
|
||||
|
||||
return h
|
||||
|
||||
|
||||
class FirDownsample2D(nn.Module):
|
||||
def __init__(self, channels=None, out_channels=None, use_conv=False, fir_kernel=(1, 3, 3, 1)):
|
||||
super().__init__()
|
||||
out_channels = out_channels if out_channels else channels
|
||||
if use_conv:
|
||||
self.Conv2d_0 = nn.Conv2d(channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
self.fir_kernel = fir_kernel
|
||||
self.use_conv = use_conv
|
||||
self.out_channels = out_channels
|
||||
|
||||
def _downsample_2d(self, x, w=None, k=None, factor=2, gain=1):
|
||||
"""Fused `Conv2d()` followed by `downsample_2d()`.
|
||||
|
||||
Args:
|
||||
Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
|
||||
efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of arbitrary:
|
||||
order.
|
||||
x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`. w: Weight tensor of the shape `[filterH,
|
||||
filterW, inChannels, outChannels]`. Grouped convolution can be performed by `inChannels = x.shape[0] //
|
||||
numGroups`. k: FIR filter of the shape `[firH, firW]` or `[firN]` (separable). The default is `[1] *
|
||||
factor`, which corresponds to average pooling. factor: Integer downsampling factor (default: 2). gain:
|
||||
Scaling factor for signal magnitude (default: 1.0).
|
||||
|
||||
Returns:
|
||||
Tensor of the shape `[N, C, H // factor, W // factor]` or `[N, H // factor, W // factor, C]`, and same
|
||||
datatype as `x`.
|
||||
"""
|
||||
|
||||
assert isinstance(factor, int) and factor >= 1
|
||||
if k is None:
|
||||
k = [1] * factor
|
||||
|
||||
# setup kernel
|
||||
k = np.asarray(k, dtype=np.float32)
|
||||
if k.ndim == 1:
|
||||
k = np.outer(k, k)
|
||||
k /= np.sum(k)
|
||||
|
||||
k = k * gain
|
||||
|
||||
if self.use_conv:
|
||||
_, _, convH, convW = w.shape
|
||||
p = (k.shape[0] - factor) + (convW - 1)
|
||||
s = [factor, factor]
|
||||
x = upfirdn2d_native(x, torch.tensor(k, device=x.device), pad=((p + 1) // 2, p // 2))
|
||||
x = F.conv2d(x, w, stride=s, padding=0)
|
||||
else:
|
||||
p = k.shape[0] - factor
|
||||
x = upfirdn2d_native(x, torch.tensor(k, device=x.device), down=factor, pad=((p + 1) // 2, p // 2))
|
||||
|
||||
return x
|
||||
|
||||
def forward(self, x):
|
||||
if self.use_conv:
|
||||
x = self._downsample_2d(x, w=self.Conv2d_0.weight, k=self.fir_kernel)
|
||||
x = x + self.Conv2d_0.bias.reshape(1, -1, 1, 1)
|
||||
else:
|
||||
x = self._downsample_2d(x, k=self.fir_kernel, factor=2)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
class ResnetBlock(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
*,
|
||||
in_channels,
|
||||
out_channels=None,
|
||||
conv_shortcut=False,
|
||||
dropout=0.0,
|
||||
temb_channels=512,
|
||||
groups=32,
|
||||
groups_out=None,
|
||||
pre_norm=True,
|
||||
eps=1e-6,
|
||||
non_linearity="swish",
|
||||
time_embedding_norm="default",
|
||||
kernel=None,
|
||||
output_scale_factor=1.0,
|
||||
use_nin_shortcut=None,
|
||||
up=False,
|
||||
down=False,
|
||||
):
|
||||
super().__init__()
|
||||
self.pre_norm = pre_norm
|
||||
self.pre_norm = True
|
||||
self.in_channels = in_channels
|
||||
out_channels = in_channels if out_channels is None else out_channels
|
||||
self.out_channels = out_channels
|
||||
self.use_conv_shortcut = conv_shortcut
|
||||
self.time_embedding_norm = time_embedding_norm
|
||||
self.up = up
|
||||
self.down = down
|
||||
self.output_scale_factor = output_scale_factor
|
||||
|
||||
if groups_out is None:
|
||||
groups_out = groups
|
||||
|
||||
self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
|
||||
|
||||
self.conv1 = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
self.time_emb_proj = torch.nn.Linear(temb_channels, out_channels)
|
||||
|
||||
self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
|
||||
self.dropout = torch.nn.Dropout(dropout)
|
||||
self.conv2 = torch.nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
if non_linearity == "swish":
|
||||
self.nonlinearity = lambda x: F.silu(x)
|
||||
elif non_linearity == "mish":
|
||||
self.nonlinearity = Mish()
|
||||
elif non_linearity == "silu":
|
||||
self.nonlinearity = nn.SiLU()
|
||||
|
||||
self.upsample = self.downsample = None
|
||||
if self.up:
|
||||
if kernel == "fir":
|
||||
fir_kernel = (1, 3, 3, 1)
|
||||
self.upsample = lambda x: upsample_2d(x, k=fir_kernel)
|
||||
elif kernel == "sde_vp":
|
||||
self.upsample = partial(F.interpolate, scale_factor=2.0, mode="nearest")
|
||||
else:
|
||||
self.upsample = Upsample2D(in_channels, use_conv=False)
|
||||
elif self.down:
|
||||
if kernel == "fir":
|
||||
fir_kernel = (1, 3, 3, 1)
|
||||
self.downsample = lambda x: downsample_2d(x, k=fir_kernel)
|
||||
elif kernel == "sde_vp":
|
||||
self.downsample = partial(F.avg_pool2d, kernel_size=2, stride=2)
|
||||
else:
|
||||
self.downsample = Downsample2D(in_channels, use_conv=False, padding=1, name="op")
|
||||
|
||||
self.use_nin_shortcut = self.in_channels != self.out_channels if use_nin_shortcut is None else use_nin_shortcut
|
||||
|
||||
self.conv_shortcut = None
|
||||
if self.use_nin_shortcut:
|
||||
self.conv_shortcut = torch.nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
def forward(self, x, temb, hey=False):
|
||||
h = x
|
||||
|
||||
h = self.norm1(h)
|
||||
h = self.nonlinearity(h)
|
||||
|
||||
if self.upsample is not None:
|
||||
x = self.upsample(x)
|
||||
h = self.upsample(h)
|
||||
elif self.downsample is not None:
|
||||
x = self.downsample(x)
|
||||
h = self.downsample(h)
|
||||
|
||||
h = self.conv1(h)
|
||||
|
||||
if temb is not None:
|
||||
temb = self.time_emb_proj(self.nonlinearity(temb))[:, :, None, None]
|
||||
h = h + temb
|
||||
|
||||
h = self.norm2(h)
|
||||
h = self.nonlinearity(h)
|
||||
|
||||
h = self.dropout(h)
|
||||
h = self.conv2(h)
|
||||
|
||||
if self.conv_shortcut is not None:
|
||||
x = self.conv_shortcut(x)
|
||||
|
||||
out = (x + h) / self.output_scale_factor
|
||||
|
||||
return out
|
||||
|
||||
def set_weight(self, resnet):
|
||||
self.norm1.weight.data = resnet.norm1.weight.data
|
||||
self.norm1.bias.data = resnet.norm1.bias.data
|
||||
|
||||
self.conv1.weight.data = resnet.conv1.weight.data
|
||||
self.conv1.bias.data = resnet.conv1.bias.data
|
||||
|
||||
self.time_emb_proj.weight.data = resnet.temb_proj.weight.data
|
||||
self.time_emb_proj.bias.data = resnet.temb_proj.bias.data
|
||||
|
||||
self.norm2.weight.data = resnet.norm2.weight.data
|
||||
self.norm2.bias.data = resnet.norm2.bias.data
|
||||
|
||||
self.conv2.weight.data = resnet.conv2.weight.data
|
||||
self.conv2.bias.data = resnet.conv2.bias.data
|
||||
|
||||
if self.use_nin_shortcut:
|
||||
self.conv_shortcut.weight.data = resnet.nin_shortcut.weight.data
|
||||
self.conv_shortcut.bias.data = resnet.nin_shortcut.bias.data
|
||||
|
||||
|
||||
# THE FOLLOWING SHOULD BE DELETED ONCE ALL CHECKPOITNS ARE CONVERTED
|
||||
|
||||
# unet.py, unet_grad_tts.py, unet_ldm.py, unet_glide.py, unet_score_vde.py
|
||||
# => All 2D-Resnets are included here now!
|
||||
class ResnetBlock2D(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
*,
|
||||
in_channels,
|
||||
out_channels=None,
|
||||
conv_shortcut=False,
|
||||
dropout=0.0,
|
||||
temb_channels=512,
|
||||
groups=32,
|
||||
groups_out=None,
|
||||
pre_norm=True,
|
||||
eps=1e-6,
|
||||
non_linearity="swish",
|
||||
time_embedding_norm="default",
|
||||
kernel=None,
|
||||
output_scale_factor=1.0,
|
||||
use_nin_shortcut=None,
|
||||
up=False,
|
||||
down=False,
|
||||
overwrite_for_grad_tts=False,
|
||||
overwrite_for_ldm=False,
|
||||
overwrite_for_glide=False,
|
||||
overwrite_for_score_vde=False,
|
||||
):
|
||||
super().__init__()
|
||||
self.pre_norm = pre_norm
|
||||
self.in_channels = in_channels
|
||||
out_channels = in_channels if out_channels is None else out_channels
|
||||
self.out_channels = out_channels
|
||||
self.use_conv_shortcut = conv_shortcut
|
||||
self.time_embedding_norm = time_embedding_norm
|
||||
self.up = up
|
||||
self.down = down
|
||||
self.output_scale_factor = output_scale_factor
|
||||
|
||||
if groups_out is None:
|
||||
groups_out = groups
|
||||
|
||||
if self.pre_norm:
|
||||
self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
|
||||
else:
|
||||
self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=out_channels, eps=eps, affine=True)
|
||||
|
||||
self.conv1 = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
if time_embedding_norm == "default" and temb_channels > 0:
|
||||
self.temb_proj = torch.nn.Linear(temb_channels, out_channels)
|
||||
elif time_embedding_norm == "scale_shift" and temb_channels > 0:
|
||||
self.temb_proj = torch.nn.Linear(temb_channels, 2 * out_channels)
|
||||
|
||||
self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
|
||||
self.dropout = torch.nn.Dropout(dropout)
|
||||
self.conv2 = torch.nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
if non_linearity == "swish":
|
||||
self.nonlinearity = lambda x: F.silu(x)
|
||||
elif non_linearity == "mish":
|
||||
self.nonlinearity = Mish()
|
||||
elif non_linearity == "silu":
|
||||
self.nonlinearity = nn.SiLU()
|
||||
|
||||
self.upsample = self.downsample = None
|
||||
if self.up:
|
||||
if kernel == "fir":
|
||||
fir_kernel = (1, 3, 3, 1)
|
||||
self.upsample = lambda x: upsample_2d(x, k=fir_kernel)
|
||||
elif kernel == "sde_vp":
|
||||
self.upsample = partial(F.interpolate, scale_factor=2.0, mode="nearest")
|
||||
else:
|
||||
self.upsample = Upsample2D(in_channels, use_conv=False)
|
||||
elif self.down:
|
||||
if kernel == "fir":
|
||||
fir_kernel = (1, 3, 3, 1)
|
||||
self.downsample = lambda x: downsample_2d(x, k=fir_kernel)
|
||||
elif kernel == "sde_vp":
|
||||
self.downsample = partial(F.avg_pool2d, kernel_size=2, stride=2)
|
||||
else:
|
||||
self.downsample = Downsample2D(in_channels, use_conv=False, padding=1, name="op")
|
||||
|
||||
self.use_nin_shortcut = self.in_channels != self.out_channels if use_nin_shortcut is None else use_nin_shortcut
|
||||
|
||||
self.nin_shortcut = None
|
||||
if self.use_nin_shortcut:
|
||||
self.nin_shortcut = torch.nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
# TODO(SURAJ, PATRICK): ALL OF THE FOLLOWING OF THE INIT METHOD CAN BE DELETED ONCE WEIGHTS ARE CONVERTED
|
||||
self.is_overwritten = False
|
||||
self.overwrite_for_glide = overwrite_for_glide
|
||||
self.overwrite_for_grad_tts = overwrite_for_grad_tts
|
||||
self.overwrite_for_ldm = overwrite_for_ldm or overwrite_for_glide
|
||||
self.overwrite_for_score_vde = overwrite_for_score_vde
|
||||
if self.overwrite_for_grad_tts:
|
||||
dim = in_channels
|
||||
dim_out = out_channels
|
||||
time_emb_dim = temb_channels
|
||||
self.mlp = torch.nn.Sequential(Mish(), torch.nn.Linear(time_emb_dim, dim_out))
|
||||
self.pre_norm = pre_norm
|
||||
|
||||
self.block1 = Block(dim, dim_out, groups=groups)
|
||||
self.block2 = Block(dim_out, dim_out, groups=groups)
|
||||
if dim != dim_out:
|
||||
self.res_conv = torch.nn.Conv2d(dim, dim_out, 1)
|
||||
else:
|
||||
self.res_conv = torch.nn.Identity()
|
||||
elif self.overwrite_for_ldm:
|
||||
channels = in_channels
|
||||
emb_channels = temb_channels
|
||||
use_scale_shift_norm = False
|
||||
non_linearity = "silu"
|
||||
|
||||
self.in_layers = nn.Sequential(
|
||||
normalization(channels, swish=1.0),
|
||||
nn.Identity(),
|
||||
nn.Conv2d(channels, self.out_channels, 3, padding=1),
|
||||
)
|
||||
self.emb_layers = nn.Sequential(
|
||||
nn.SiLU(),
|
||||
linear(
|
||||
emb_channels,
|
||||
2 * self.out_channels if self.time_embedding_norm == "scale_shift" else self.out_channels,
|
||||
),
|
||||
)
|
||||
self.out_layers = nn.Sequential(
|
||||
normalization(self.out_channels, swish=0.0 if use_scale_shift_norm else 1.0),
|
||||
nn.SiLU() if use_scale_shift_norm else nn.Identity(),
|
||||
nn.Dropout(p=dropout),
|
||||
zero_module(nn.Conv2d(self.out_channels, self.out_channels, 3, padding=1)),
|
||||
)
|
||||
if self.out_channels == in_channels:
|
||||
self.skip_connection = nn.Identity()
|
||||
else:
|
||||
self.skip_connection = nn.Conv2d(channels, self.out_channels, 1)
|
||||
self.set_weights_ldm()
|
||||
elif self.overwrite_for_score_vde:
|
||||
in_ch = in_channels
|
||||
out_ch = out_channels
|
||||
|
||||
eps = 1e-6
|
||||
num_groups = min(in_ch // 4, 32)
|
||||
num_groups_out = min(out_ch // 4, 32)
|
||||
temb_dim = temb_channels
|
||||
|
||||
self.GroupNorm_0 = nn.GroupNorm(num_groups=num_groups, num_channels=in_ch, eps=eps)
|
||||
self.up = up
|
||||
self.down = down
|
||||
self.Conv_0 = nn.Conv2d(in_ch, out_ch, kernel_size=3, padding=1)
|
||||
if temb_dim is not None:
|
||||
self.Dense_0 = nn.Linear(temb_dim, out_ch)
|
||||
nn.init.zeros_(self.Dense_0.bias)
|
||||
|
||||
self.GroupNorm_1 = nn.GroupNorm(num_groups=num_groups_out, num_channels=out_ch, eps=eps)
|
||||
self.Dropout_0 = nn.Dropout(dropout)
|
||||
self.Conv_1 = nn.Conv2d(out_ch, out_ch, kernel_size=3, padding=1)
|
||||
if in_ch != out_ch or up or down:
|
||||
# 1x1 convolution with DDPM initialization.
|
||||
self.Conv_2 = nn.Conv2d(in_ch, out_ch, kernel_size=1, padding=0)
|
||||
|
||||
self.in_ch = in_ch
|
||||
self.out_ch = out_ch
|
||||
self.set_weights_score_vde()
|
||||
|
||||
def set_weights_grad_tts(self):
|
||||
self.conv1.weight.data = self.block1.block[0].weight.data
|
||||
self.conv1.bias.data = self.block1.block[0].bias.data
|
||||
self.norm1.weight.data = self.block1.block[1].weight.data
|
||||
self.norm1.bias.data = self.block1.block[1].bias.data
|
||||
|
||||
self.conv2.weight.data = self.block2.block[0].weight.data
|
||||
self.conv2.bias.data = self.block2.block[0].bias.data
|
||||
self.norm2.weight.data = self.block2.block[1].weight.data
|
||||
self.norm2.bias.data = self.block2.block[1].bias.data
|
||||
|
||||
self.temb_proj.weight.data = self.mlp[1].weight.data
|
||||
self.temb_proj.bias.data = self.mlp[1].bias.data
|
||||
|
||||
if self.in_channels != self.out_channels:
|
||||
self.nin_shortcut.weight.data = self.res_conv.weight.data
|
||||
self.nin_shortcut.bias.data = self.res_conv.bias.data
|
||||
|
||||
def set_weights_ldm(self):
|
||||
self.norm1.weight.data = self.in_layers[0].weight.data
|
||||
self.norm1.bias.data = self.in_layers[0].bias.data
|
||||
|
||||
self.conv1.weight.data = self.in_layers[-1].weight.data
|
||||
self.conv1.bias.data = self.in_layers[-1].bias.data
|
||||
|
||||
self.temb_proj.weight.data = self.emb_layers[-1].weight.data
|
||||
self.temb_proj.bias.data = self.emb_layers[-1].bias.data
|
||||
|
||||
self.norm2.weight.data = self.out_layers[0].weight.data
|
||||
self.norm2.bias.data = self.out_layers[0].bias.data
|
||||
|
||||
self.conv2.weight.data = self.out_layers[-1].weight.data
|
||||
self.conv2.bias.data = self.out_layers[-1].bias.data
|
||||
|
||||
if self.in_channels != self.out_channels:
|
||||
self.nin_shortcut.weight.data = self.skip_connection.weight.data
|
||||
self.nin_shortcut.bias.data = self.skip_connection.bias.data
|
||||
|
||||
def set_weights_score_vde(self):
|
||||
self.conv1.weight.data = self.Conv_0.weight.data
|
||||
self.conv1.bias.data = self.Conv_0.bias.data
|
||||
self.norm1.weight.data = self.GroupNorm_0.weight.data
|
||||
self.norm1.bias.data = self.GroupNorm_0.bias.data
|
||||
|
||||
self.conv2.weight.data = self.Conv_1.weight.data
|
||||
self.conv2.bias.data = self.Conv_1.bias.data
|
||||
self.norm2.weight.data = self.GroupNorm_1.weight.data
|
||||
self.norm2.bias.data = self.GroupNorm_1.bias.data
|
||||
|
||||
self.temb_proj.weight.data = self.Dense_0.weight.data
|
||||
self.temb_proj.bias.data = self.Dense_0.bias.data
|
||||
|
||||
if self.in_channels != self.out_channels or self.up or self.down:
|
||||
self.nin_shortcut.weight.data = self.Conv_2.weight.data
|
||||
self.nin_shortcut.bias.data = self.Conv_2.bias.data
|
||||
|
||||
def forward(self, x, temb, hey=False, mask=1.0):
|
||||
# TODO(Patrick) eventually this class should be split into multiple classes
|
||||
# too many if else statements
|
||||
if self.overwrite_for_grad_tts and not self.is_overwritten:
|
||||
self.set_weights_grad_tts()
|
||||
self.is_overwritten = True
|
||||
# elif self.overwrite_for_score_vde and not self.is_overwritten:
|
||||
# self.set_weights_score_vde()
|
||||
# self.is_overwritten = True
|
||||
|
||||
# h2 tensor(110029.2109)
|
||||
# h3 tensor(49596.9492)
|
||||
|
||||
h = x
|
||||
|
||||
h = h * mask
|
||||
if self.pre_norm:
|
||||
h = self.norm1(h)
|
||||
h = self.nonlinearity(h)
|
||||
|
||||
if self.upsample is not None:
|
||||
x = self.upsample(x)
|
||||
h = self.upsample(h)
|
||||
elif self.downsample is not None:
|
||||
x = self.downsample(x)
|
||||
h = self.downsample(h)
|
||||
|
||||
h = self.conv1(h)
|
||||
|
||||
if not self.pre_norm:
|
||||
h = self.norm1(h)
|
||||
h = self.nonlinearity(h)
|
||||
h = h * mask
|
||||
|
||||
if temb is not None:
|
||||
temb = self.temb_proj(self.nonlinearity(temb))[:, :, None, None]
|
||||
else:
|
||||
temb = 0
|
||||
|
||||
if self.time_embedding_norm == "scale_shift":
|
||||
scale, shift = torch.chunk(temb, 2, dim=1)
|
||||
|
||||
h = self.norm2(h)
|
||||
h = h + h * scale + shift
|
||||
h = self.nonlinearity(h)
|
||||
elif self.time_embedding_norm == "default":
|
||||
h = h + temb
|
||||
h = h * mask
|
||||
if self.pre_norm:
|
||||
h = self.norm2(h)
|
||||
h = self.nonlinearity(h)
|
||||
|
||||
h = self.dropout(h)
|
||||
h = self.conv2(h)
|
||||
|
||||
if not self.pre_norm:
|
||||
h = self.norm2(h)
|
||||
h = self.nonlinearity(h)
|
||||
h = h * mask
|
||||
|
||||
x = x * mask
|
||||
if self.nin_shortcut is not None:
|
||||
x = self.nin_shortcut(x)
|
||||
|
||||
out = (x + h) / self.output_scale_factor
|
||||
|
||||
return out
|
||||
|
||||
|
||||
# TODO(Patrick) - just there to convert the weights; can delete afterward
|
||||
class Block(torch.nn.Module):
|
||||
def __init__(self, dim, dim_out, groups=8):
|
||||
super(Block, self).__init__()
|
||||
self.block = torch.nn.Sequential(
|
||||
torch.nn.Conv2d(dim, dim_out, 3, padding=1), torch.nn.GroupNorm(groups, dim_out), Mish()
|
||||
)
|
||||
|
||||
|
||||
# HELPER Modules
|
||||
|
||||
|
||||
def normalization(channels, swish=0.0):
|
||||
"""
|
||||
Make a standard normalization layer, with an optional swish activation.
|
||||
|
||||
:param channels: number of input channels. :return: an nn.Module for normalization.
|
||||
"""
|
||||
return GroupNorm32(num_channels=channels, num_groups=32, swish=swish)
|
||||
|
||||
|
||||
class GroupNorm32(nn.GroupNorm):
|
||||
def __init__(self, num_groups, num_channels, swish, eps=1e-5):
|
||||
super().__init__(num_groups=num_groups, num_channels=num_channels, eps=eps)
|
||||
self.swish = swish
|
||||
|
||||
def forward(self, x):
|
||||
y = super().forward(x.float()).to(x.dtype)
|
||||
if self.swish == 1.0:
|
||||
y = F.silu(y)
|
||||
elif self.swish:
|
||||
y = y * F.sigmoid(y * float(self.swish))
|
||||
return y
|
||||
|
||||
|
||||
def linear(*args, **kwargs):
|
||||
"""
|
||||
Create a linear module.
|
||||
"""
|
||||
return nn.Linear(*args, **kwargs)
|
||||
|
||||
|
||||
def zero_module(module):
|
||||
"""
|
||||
Zero out the parameters of a module and return it.
|
||||
"""
|
||||
for p in module.parameters():
|
||||
p.detach().zero_()
|
||||
return module
|
||||
|
||||
|
||||
class Mish(torch.nn.Module):
|
||||
def forward(self, x):
|
||||
return x * torch.tanh(torch.nn.functional.softplus(x))
|
||||
|
||||
|
||||
class Conv1dBlock(nn.Module):
|
||||
"""
|
||||
Conv1d --> GroupNorm --> Mish
|
||||
"""
|
||||
|
||||
def __init__(self, inp_channels, out_channels, kernel_size, n_groups=8):
|
||||
super().__init__()
|
||||
|
||||
self.block = nn.Sequential(
|
||||
nn.Conv1d(inp_channels, out_channels, kernel_size, padding=kernel_size // 2),
|
||||
RearrangeDim(),
|
||||
# Rearrange("batch channels horizon -> batch channels 1 horizon"),
|
||||
nn.GroupNorm(n_groups, out_channels),
|
||||
RearrangeDim(),
|
||||
# Rearrange("batch channels 1 horizon -> batch channels horizon"),
|
||||
nn.Mish(),
|
||||
)
|
||||
|
||||
def forward(self, x):
|
||||
return self.block(x)
|
||||
|
||||
|
||||
class RearrangeDim(nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def forward(self, tensor):
|
||||
if len(tensor.shape) == 2:
|
||||
return tensor[:, :, None]
|
||||
if len(tensor.shape) == 3:
|
||||
return tensor[:, :, None, :]
|
||||
elif len(tensor.shape) == 4:
|
||||
return tensor[:, :, 0, :]
|
||||
else:
|
||||
raise ValueError(f"`len(tensor)`: {len(tensor)} has to be 2, 3 or 4.")
|
||||
|
||||
|
||||
def upsample_2d(x, k=None, factor=2, gain=1):
|
||||
r"""Upsample2D a batch of 2D images with the given filter.
|
||||
|
||||
Args:
|
||||
Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and upsamples each image with the given
|
||||
filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the specified
|
||||
`gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its shape is a:
|
||||
multiple of the upsampling factor.
|
||||
x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
|
||||
C]`.
|
||||
k: FIR filter of the shape `[firH, firW]` or `[firN]`
|
||||
(separable). The default is `[1] * factor`, which corresponds to nearest-neighbor upsampling.
|
||||
factor: Integer upsampling factor (default: 2). gain: Scaling factor for signal magnitude (default: 1.0).
|
||||
|
||||
Returns:
|
||||
Tensor of the shape `[N, C, H * factor, W * factor]`
|
||||
"""
|
||||
assert isinstance(factor, int) and factor >= 1
|
||||
if k is None:
|
||||
k = [1] * factor
|
||||
|
||||
k = np.asarray(k, dtype=np.float32)
|
||||
if k.ndim == 1:
|
||||
k = np.outer(k, k)
|
||||
k /= np.sum(k)
|
||||
|
||||
k = k * (gain * (factor**2))
|
||||
p = k.shape[0] - factor
|
||||
return upfirdn2d_native(x, torch.tensor(k, device=x.device), up=factor, pad=((p + 1) // 2 + factor - 1, p // 2))
|
||||
|
||||
|
||||
def downsample_2d(x, k=None, factor=2, gain=1):
|
||||
r"""Downsample2D a batch of 2D images with the given filter.
|
||||
|
||||
Args:
|
||||
Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and downsamples each image with the
|
||||
given filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the
|
||||
specified `gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its
|
||||
shape is a multiple of the downsampling factor.
|
||||
x: Input tensor of the shape `[N, C, H, W]` or `[N, H, W,
|
||||
C]`.
|
||||
k: FIR filter of the shape `[firH, firW]` or `[firN]`
|
||||
(separable). The default is `[1] * factor`, which corresponds to average pooling.
|
||||
factor: Integer downsampling factor (default: 2). gain: Scaling factor for signal magnitude (default: 1.0).
|
||||
|
||||
Returns:
|
||||
Tensor of the shape `[N, C, H // factor, W // factor]`
|
||||
"""
|
||||
|
||||
assert isinstance(factor, int) and factor >= 1
|
||||
if k is None:
|
||||
k = [1] * factor
|
||||
|
||||
k = np.asarray(k, dtype=np.float32)
|
||||
if k.ndim == 1:
|
||||
k = np.outer(k, k)
|
||||
k /= np.sum(k)
|
||||
|
||||
k = k * gain
|
||||
p = k.shape[0] - factor
|
||||
return upfirdn2d_native(x, torch.tensor(k, device=x.device), down=factor, pad=((p + 1) // 2, p // 2))
|
||||
|
||||
|
||||
def upfirdn2d_native(input, kernel, up=1, down=1, pad=(0, 0)):
|
||||
up_x = up_y = up
|
||||
down_x = down_y = down
|
||||
pad_x0 = pad_y0 = pad[0]
|
||||
pad_x1 = pad_y1 = pad[1]
|
||||
|
||||
_, channel, in_h, in_w = input.shape
|
||||
input = input.reshape(-1, in_h, in_w, 1)
|
||||
|
||||
_, in_h, in_w, minor = input.shape
|
||||
kernel_h, kernel_w = kernel.shape
|
||||
|
||||
out = input.view(-1, in_h, 1, in_w, 1, minor)
|
||||
out = F.pad(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
|
||||
out = out.view(-1, in_h * up_y, in_w * up_x, minor)
|
||||
|
||||
out = F.pad(out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)])
|
||||
out = out[
|
||||
:,
|
||||
max(-pad_y0, 0) : out.shape[1] - max(-pad_y1, 0),
|
||||
max(-pad_x0, 0) : out.shape[2] - max(-pad_x1, 0),
|
||||
:,
|
||||
]
|
||||
|
||||
out = out.permute(0, 3, 1, 2)
|
||||
out = out.reshape([-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1])
|
||||
w = torch.flip(kernel, [0, 1]).view(1, 1, kernel_h, kernel_w)
|
||||
out = F.conv2d(out, w)
|
||||
out = out.reshape(
|
||||
-1,
|
||||
minor,
|
||||
in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1,
|
||||
in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1,
|
||||
)
|
||||
out = out.permute(0, 2, 3, 1)
|
||||
out = out[:, ::down_y, ::down_x, :]
|
||||
|
||||
out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
|
||||
out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
|
||||
|
||||
return out.view(-1, channel, out_h, out_w)
|
||||
@@ -1,332 +0,0 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
|
||||
# limitations under the License.
|
||||
|
||||
# helpers functions
|
||||
|
||||
import copy
|
||||
import math
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
from torch import nn
|
||||
from torch.cuda.amp import GradScaler, autocast
|
||||
from torch.optim import Adam
|
||||
from torch.utils import data
|
||||
|
||||
from PIL import Image
|
||||
from tqdm import tqdm
|
||||
|
||||
from ..configuration_utils import ConfigMixin
|
||||
from ..modeling_utils import ModelMixin
|
||||
|
||||
|
||||
def get_timestep_embedding(timesteps, embedding_dim):
|
||||
"""
|
||||
This matches the implementation in Denoising Diffusion Probabilistic Models:
|
||||
From Fairseq.
|
||||
Build sinusoidal embeddings.
|
||||
This matches the implementation in tensor2tensor, but differs slightly
|
||||
from the description in Section 3.5 of "Attention Is All You Need".
|
||||
"""
|
||||
assert len(timesteps.shape) == 1
|
||||
|
||||
half_dim = embedding_dim // 2
|
||||
emb = math.log(10000) / (half_dim - 1)
|
||||
emb = torch.exp(torch.arange(half_dim, dtype=torch.float32) * -emb)
|
||||
emb = emb.to(device=timesteps.device)
|
||||
emb = timesteps.float()[:, None] * emb[None, :]
|
||||
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
|
||||
if embedding_dim % 2 == 1: # zero pad
|
||||
emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
|
||||
return emb
|
||||
|
||||
|
||||
def nonlinearity(x):
|
||||
# swish
|
||||
return x * torch.sigmoid(x)
|
||||
|
||||
|
||||
def Normalize(in_channels):
|
||||
return torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
|
||||
|
||||
|
||||
class Upsample(nn.Module):
|
||||
def __init__(self, in_channels, with_conv):
|
||||
super().__init__()
|
||||
self.with_conv = with_conv
|
||||
if self.with_conv:
|
||||
self.conv = torch.nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
def forward(self, x):
|
||||
x = torch.nn.functional.interpolate(x, scale_factor=2.0, mode="nearest")
|
||||
if self.with_conv:
|
||||
x = self.conv(x)
|
||||
return x
|
||||
|
||||
|
||||
class Downsample(nn.Module):
|
||||
def __init__(self, in_channels, with_conv):
|
||||
super().__init__()
|
||||
self.with_conv = with_conv
|
||||
if self.with_conv:
|
||||
# no asymmetric padding in torch conv, must do it ourselves
|
||||
self.conv = torch.nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=2, padding=0)
|
||||
|
||||
def forward(self, x):
|
||||
if self.with_conv:
|
||||
pad = (0, 1, 0, 1)
|
||||
x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
|
||||
x = self.conv(x)
|
||||
else:
|
||||
x = torch.nn.functional.avg_pool2d(x, kernel_size=2, stride=2)
|
||||
return x
|
||||
|
||||
|
||||
class ResnetBlock(nn.Module):
|
||||
def __init__(self, *, in_channels, out_channels=None, conv_shortcut=False, dropout, temb_channels=512):
|
||||
super().__init__()
|
||||
self.in_channels = in_channels
|
||||
out_channels = in_channels if out_channels is None else out_channels
|
||||
self.out_channels = out_channels
|
||||
self.use_conv_shortcut = conv_shortcut
|
||||
|
||||
self.norm1 = Normalize(in_channels)
|
||||
self.conv1 = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
self.temb_proj = torch.nn.Linear(temb_channels, out_channels)
|
||||
self.norm2 = Normalize(out_channels)
|
||||
self.dropout = torch.nn.Dropout(dropout)
|
||||
self.conv2 = torch.nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
if self.in_channels != self.out_channels:
|
||||
if self.use_conv_shortcut:
|
||||
self.conv_shortcut = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
else:
|
||||
self.nin_shortcut = torch.nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
def forward(self, x, temb):
|
||||
h = x
|
||||
h = self.norm1(h)
|
||||
h = nonlinearity(h)
|
||||
h = self.conv1(h)
|
||||
|
||||
h = h + self.temb_proj(nonlinearity(temb))[:, :, None, None]
|
||||
|
||||
h = self.norm2(h)
|
||||
h = nonlinearity(h)
|
||||
h = self.dropout(h)
|
||||
h = self.conv2(h)
|
||||
|
||||
if self.in_channels != self.out_channels:
|
||||
if self.use_conv_shortcut:
|
||||
x = self.conv_shortcut(x)
|
||||
else:
|
||||
x = self.nin_shortcut(x)
|
||||
|
||||
return x + h
|
||||
|
||||
|
||||
class AttnBlock(nn.Module):
|
||||
def __init__(self, in_channels):
|
||||
super().__init__()
|
||||
self.in_channels = in_channels
|
||||
|
||||
self.norm = Normalize(in_channels)
|
||||
self.q = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.k = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.v = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.proj_out = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
def forward(self, x):
|
||||
h_ = x
|
||||
h_ = self.norm(h_)
|
||||
q = self.q(h_)
|
||||
k = self.k(h_)
|
||||
v = self.v(h_)
|
||||
|
||||
# compute attention
|
||||
b, c, h, w = q.shape
|
||||
q = q.reshape(b, c, h * w)
|
||||
q = q.permute(0, 2, 1) # b,hw,c
|
||||
k = k.reshape(b, c, h * w) # b,c,hw
|
||||
w_ = torch.bmm(q, k) # b,hw,hw w[b,i,j]=sum_c q[b,i,c]k[b,c,j]
|
||||
w_ = w_ * (int(c) ** (-0.5))
|
||||
w_ = torch.nn.functional.softmax(w_, dim=2)
|
||||
|
||||
# attend to values
|
||||
v = v.reshape(b, c, h * w)
|
||||
w_ = w_.permute(0, 2, 1) # b,hw,hw (first hw of k, second of q)
|
||||
h_ = torch.bmm(v, w_) # b, c,hw (hw of q) h_[b,c,j] = sum_i v[b,c,i] w_[b,i,j]
|
||||
h_ = h_.reshape(b, c, h, w)
|
||||
|
||||
h_ = self.proj_out(h_)
|
||||
|
||||
return x + h_
|
||||
|
||||
|
||||
class UNetModel(ModelMixin, ConfigMixin):
|
||||
def __init__(
|
||||
self,
|
||||
ch=128,
|
||||
out_ch=3,
|
||||
ch_mult=(1, 1, 2, 2, 4, 4),
|
||||
num_res_blocks=2,
|
||||
attn_resolutions=(16,),
|
||||
dropout=0.0,
|
||||
resamp_with_conv=True,
|
||||
in_channels=3,
|
||||
resolution=256,
|
||||
):
|
||||
super().__init__()
|
||||
self.register(
|
||||
ch=ch,
|
||||
out_ch=out_ch,
|
||||
ch_mult=ch_mult,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attn_resolutions=attn_resolutions,
|
||||
dropout=dropout,
|
||||
resamp_with_conv=resamp_with_conv,
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
)
|
||||
ch_mult = tuple(ch_mult)
|
||||
self.ch = ch
|
||||
self.temb_ch = self.ch * 4
|
||||
self.num_resolutions = len(ch_mult)
|
||||
self.num_res_blocks = num_res_blocks
|
||||
self.resolution = resolution
|
||||
self.in_channels = in_channels
|
||||
|
||||
# timestep embedding
|
||||
self.temb = nn.Module()
|
||||
self.temb.dense = nn.ModuleList(
|
||||
[
|
||||
torch.nn.Linear(self.ch, self.temb_ch),
|
||||
torch.nn.Linear(self.temb_ch, self.temb_ch),
|
||||
]
|
||||
)
|
||||
|
||||
# downsampling
|
||||
self.conv_in = torch.nn.Conv2d(in_channels, self.ch, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
curr_res = resolution
|
||||
in_ch_mult = (1,) + ch_mult
|
||||
self.down = nn.ModuleList()
|
||||
for i_level in range(self.num_resolutions):
|
||||
block = nn.ModuleList()
|
||||
attn = nn.ModuleList()
|
||||
block_in = ch * in_ch_mult[i_level]
|
||||
block_out = ch * ch_mult[i_level]
|
||||
for i_block in range(self.num_res_blocks):
|
||||
block.append(
|
||||
ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_out, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
)
|
||||
block_in = block_out
|
||||
if curr_res in attn_resolutions:
|
||||
attn.append(AttnBlock(block_in))
|
||||
down = nn.Module()
|
||||
down.block = block
|
||||
down.attn = attn
|
||||
if i_level != self.num_resolutions - 1:
|
||||
down.downsample = Downsample(block_in, resamp_with_conv)
|
||||
curr_res = curr_res // 2
|
||||
self.down.append(down)
|
||||
|
||||
# middle
|
||||
self.mid = nn.Module()
|
||||
self.mid.block_1 = ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
self.mid.attn_1 = AttnBlock(block_in)
|
||||
self.mid.block_2 = ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
|
||||
# upsampling
|
||||
self.up = nn.ModuleList()
|
||||
for i_level in reversed(range(self.num_resolutions)):
|
||||
block = nn.ModuleList()
|
||||
attn = nn.ModuleList()
|
||||
block_out = ch * ch_mult[i_level]
|
||||
skip_in = ch * ch_mult[i_level]
|
||||
for i_block in range(self.num_res_blocks + 1):
|
||||
if i_block == self.num_res_blocks:
|
||||
skip_in = ch * in_ch_mult[i_level]
|
||||
block.append(
|
||||
ResnetBlock(
|
||||
in_channels=block_in + skip_in,
|
||||
out_channels=block_out,
|
||||
temb_channels=self.temb_ch,
|
||||
dropout=dropout,
|
||||
)
|
||||
)
|
||||
block_in = block_out
|
||||
if curr_res in attn_resolutions:
|
||||
attn.append(AttnBlock(block_in))
|
||||
up = nn.Module()
|
||||
up.block = block
|
||||
up.attn = attn
|
||||
if i_level != 0:
|
||||
up.upsample = Upsample(block_in, resamp_with_conv)
|
||||
curr_res = curr_res * 2
|
||||
self.up.insert(0, up) # prepend to get consistent order
|
||||
|
||||
# end
|
||||
self.norm_out = Normalize(block_in)
|
||||
self.conv_out = torch.nn.Conv2d(block_in, out_ch, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
def forward(self, x, t):
|
||||
assert x.shape[2] == x.shape[3] == self.resolution
|
||||
|
||||
if not torch.is_tensor(t):
|
||||
t = torch.tensor([t], dtype=torch.long, device=x.device)
|
||||
|
||||
# timestep embedding
|
||||
temb = get_timestep_embedding(t, self.ch)
|
||||
temb = self.temb.dense[0](temb)
|
||||
temb = nonlinearity(temb)
|
||||
temb = self.temb.dense[1](temb)
|
||||
|
||||
# downsampling
|
||||
hs = [self.conv_in(x)]
|
||||
for i_level in range(self.num_resolutions):
|
||||
for i_block in range(self.num_res_blocks):
|
||||
h = self.down[i_level].block[i_block](hs[-1], temb)
|
||||
if len(self.down[i_level].attn) > 0:
|
||||
h = self.down[i_level].attn[i_block](h)
|
||||
hs.append(h)
|
||||
if i_level != self.num_resolutions - 1:
|
||||
hs.append(self.down[i_level].downsample(hs[-1]))
|
||||
|
||||
# middle
|
||||
h = hs[-1]
|
||||
h = self.mid.block_1(h, temb)
|
||||
h = self.mid.attn_1(h)
|
||||
h = self.mid.block_2(h, temb)
|
||||
|
||||
# upsampling
|
||||
for i_level in reversed(range(self.num_resolutions)):
|
||||
for i_block in range(self.num_res_blocks + 1):
|
||||
h = self.up[i_level].block[i_block](torch.cat([h, hs.pop()], dim=1), temb)
|
||||
if len(self.up[i_level].attn) > 0:
|
||||
h = self.up[i_level].attn[i_block](h)
|
||||
if i_level != 0:
|
||||
h = self.up[i_level].upsample(h)
|
||||
|
||||
# end
|
||||
h = self.norm_out(h)
|
||||
h = nonlinearity(h)
|
||||
h = self.conv_out(h)
|
||||
return h
|
||||
182
src/diffusers/models/unet_2d.py
Normal file
182
src/diffusers/models/unet_2d.py
Normal file
@@ -0,0 +1,182 @@
|
||||
from typing import Dict, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..modeling_utils import ModelMixin
|
||||
from .embeddings import GaussianFourierProjection, TimestepEmbedding, Timesteps
|
||||
from .unet_blocks import UNetMidBlock2D, get_down_block, get_up_block
|
||||
|
||||
|
||||
class UNet2DModel(ModelMixin, ConfigMixin):
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
sample_size=None,
|
||||
in_channels=3,
|
||||
out_channels=3,
|
||||
center_input_sample=False,
|
||||
time_embedding_type="positional",
|
||||
freq_shift=0,
|
||||
flip_sin_to_cos=True,
|
||||
down_block_types=("DownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D", "AttnDownBlock2D"),
|
||||
up_block_types=("AttnUpBlock2D", "AttnUpBlock2D", "AttnUpBlock2D", "UpBlock2D"),
|
||||
block_out_channels=(224, 448, 672, 896),
|
||||
layers_per_block=2,
|
||||
mid_block_scale_factor=1,
|
||||
downsample_padding=1,
|
||||
act_fn="silu",
|
||||
attention_head_dim=8,
|
||||
norm_num_groups=32,
|
||||
norm_eps=1e-5,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.sample_size = sample_size
|
||||
time_embed_dim = block_out_channels[0] * 4
|
||||
|
||||
# input
|
||||
self.conv_in = nn.Conv2d(in_channels, block_out_channels[0], kernel_size=3, padding=(1, 1))
|
||||
|
||||
# time
|
||||
if time_embedding_type == "fourier":
|
||||
self.time_proj = GaussianFourierProjection(embedding_size=block_out_channels[0], scale=16)
|
||||
timestep_input_dim = 2 * block_out_channels[0]
|
||||
elif time_embedding_type == "positional":
|
||||
self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
|
||||
timestep_input_dim = block_out_channels[0]
|
||||
|
||||
self.time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
|
||||
|
||||
self.down_blocks = nn.ModuleList([])
|
||||
self.mid_block = None
|
||||
self.up_blocks = nn.ModuleList([])
|
||||
|
||||
# down
|
||||
output_channel = block_out_channels[0]
|
||||
for i, down_block_type in enumerate(down_block_types):
|
||||
input_channel = output_channel
|
||||
output_channel = block_out_channels[i]
|
||||
is_final_block = i == len(block_out_channels) - 1
|
||||
|
||||
down_block = get_down_block(
|
||||
down_block_type,
|
||||
num_layers=layers_per_block,
|
||||
in_channels=input_channel,
|
||||
out_channels=output_channel,
|
||||
temb_channels=time_embed_dim,
|
||||
add_downsample=not is_final_block,
|
||||
resnet_eps=norm_eps,
|
||||
resnet_act_fn=act_fn,
|
||||
attn_num_head_channels=attention_head_dim,
|
||||
downsample_padding=downsample_padding,
|
||||
)
|
||||
self.down_blocks.append(down_block)
|
||||
|
||||
# mid
|
||||
self.mid_block = UNetMidBlock2D(
|
||||
in_channels=block_out_channels[-1],
|
||||
temb_channels=time_embed_dim,
|
||||
resnet_eps=norm_eps,
|
||||
resnet_act_fn=act_fn,
|
||||
output_scale_factor=mid_block_scale_factor,
|
||||
resnet_time_scale_shift="default",
|
||||
attn_num_head_channels=attention_head_dim,
|
||||
resnet_groups=norm_num_groups,
|
||||
)
|
||||
|
||||
# up
|
||||
reversed_block_out_channels = list(reversed(block_out_channels))
|
||||
output_channel = reversed_block_out_channels[0]
|
||||
for i, up_block_type in enumerate(up_block_types):
|
||||
prev_output_channel = output_channel
|
||||
output_channel = reversed_block_out_channels[i]
|
||||
input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
|
||||
|
||||
is_final_block = i == len(block_out_channels) - 1
|
||||
|
||||
up_block = get_up_block(
|
||||
up_block_type,
|
||||
num_layers=layers_per_block + 1,
|
||||
in_channels=input_channel,
|
||||
out_channels=output_channel,
|
||||
prev_output_channel=prev_output_channel,
|
||||
temb_channels=time_embed_dim,
|
||||
add_upsample=not is_final_block,
|
||||
resnet_eps=norm_eps,
|
||||
resnet_act_fn=act_fn,
|
||||
attn_num_head_channels=attention_head_dim,
|
||||
)
|
||||
self.up_blocks.append(up_block)
|
||||
prev_output_channel = output_channel
|
||||
|
||||
# out
|
||||
num_groups_out = norm_num_groups if norm_num_groups is not None else min(block_out_channels[0] // 4, 32)
|
||||
self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=num_groups_out, eps=norm_eps)
|
||||
self.conv_act = nn.SiLU()
|
||||
self.conv_out = nn.Conv2d(block_out_channels[0], out_channels, 3, padding=1)
|
||||
|
||||
def forward(
|
||||
self, sample: torch.FloatTensor, timestep: Union[torch.Tensor, float, int]
|
||||
) -> Dict[str, torch.FloatTensor]:
|
||||
|
||||
# 0. center input if necessary
|
||||
if self.config.center_input_sample:
|
||||
sample = 2 * sample - 1.0
|
||||
|
||||
# 1. time
|
||||
timesteps = timestep
|
||||
if not torch.is_tensor(timesteps):
|
||||
timesteps = torch.tensor([timesteps], dtype=torch.long, device=sample.device)
|
||||
elif torch.is_tensor(timesteps) and len(timesteps.shape) == 0:
|
||||
timesteps = timesteps[None].to(sample.device)
|
||||
|
||||
t_emb = self.time_proj(timesteps)
|
||||
emb = self.time_embedding(t_emb)
|
||||
|
||||
# 2. pre-process
|
||||
skip_sample = sample
|
||||
sample = self.conv_in(sample)
|
||||
|
||||
# 3. down
|
||||
down_block_res_samples = (sample,)
|
||||
for downsample_block in self.down_blocks:
|
||||
if hasattr(downsample_block, "skip_conv"):
|
||||
sample, res_samples, skip_sample = downsample_block(
|
||||
hidden_states=sample, temb=emb, skip_sample=skip_sample
|
||||
)
|
||||
else:
|
||||
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
||||
|
||||
down_block_res_samples += res_samples
|
||||
|
||||
# 4. mid
|
||||
sample = self.mid_block(sample, emb)
|
||||
|
||||
# 5. up
|
||||
skip_sample = None
|
||||
for upsample_block in self.up_blocks:
|
||||
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
||||
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
||||
|
||||
if hasattr(upsample_block, "skip_conv"):
|
||||
sample, skip_sample = upsample_block(sample, res_samples, emb, skip_sample)
|
||||
else:
|
||||
sample = upsample_block(sample, res_samples, emb)
|
||||
|
||||
# 6. post-process
|
||||
sample = self.conv_norm_out(sample)
|
||||
sample = self.conv_act(sample)
|
||||
sample = self.conv_out(sample)
|
||||
|
||||
if skip_sample is not None:
|
||||
sample += skip_sample
|
||||
|
||||
if self.config.time_embedding_type == "fourier":
|
||||
timesteps = timesteps.reshape((sample.shape[0], *([1] * len(sample.shape[1:]))))
|
||||
sample = sample / timesteps
|
||||
|
||||
output = {"sample": sample}
|
||||
|
||||
return output
|
||||
178
src/diffusers/models/unet_2d_condition.py
Normal file
178
src/diffusers/models/unet_2d_condition.py
Normal file
@@ -0,0 +1,178 @@
|
||||
from typing import Dict, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..modeling_utils import ModelMixin
|
||||
from .embeddings import TimestepEmbedding, Timesteps
|
||||
from .unet_blocks import UNetMidBlock2DCrossAttn, get_down_block, get_up_block
|
||||
|
||||
|
||||
class UNet2DConditionModel(ModelMixin, ConfigMixin):
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
sample_size=None,
|
||||
in_channels=4,
|
||||
out_channels=4,
|
||||
center_input_sample=False,
|
||||
flip_sin_to_cos=True,
|
||||
freq_shift=0,
|
||||
down_block_types=("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D"),
|
||||
up_block_types=("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"),
|
||||
block_out_channels=(320, 640, 1280, 1280),
|
||||
layers_per_block=2,
|
||||
downsample_padding=1,
|
||||
mid_block_scale_factor=1,
|
||||
act_fn="silu",
|
||||
norm_num_groups=32,
|
||||
norm_eps=1e-5,
|
||||
attention_head_dim=8,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.sample_size = sample_size
|
||||
time_embed_dim = block_out_channels[0] * 4
|
||||
|
||||
# input
|
||||
self.conv_in = nn.Conv2d(in_channels, block_out_channels[0], kernel_size=3, padding=(1, 1))
|
||||
|
||||
# time
|
||||
self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
|
||||
timestep_input_dim = block_out_channels[0]
|
||||
|
||||
self.time_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim)
|
||||
|
||||
self.down_blocks = nn.ModuleList([])
|
||||
self.mid_block = None
|
||||
self.up_blocks = nn.ModuleList([])
|
||||
|
||||
# down
|
||||
output_channel = block_out_channels[0]
|
||||
for i, down_block_type in enumerate(down_block_types):
|
||||
input_channel = output_channel
|
||||
output_channel = block_out_channels[i]
|
||||
is_final_block = i == len(block_out_channels) - 1
|
||||
|
||||
down_block = get_down_block(
|
||||
down_block_type,
|
||||
num_layers=layers_per_block,
|
||||
in_channels=input_channel,
|
||||
out_channels=output_channel,
|
||||
temb_channels=time_embed_dim,
|
||||
add_downsample=not is_final_block,
|
||||
resnet_eps=norm_eps,
|
||||
resnet_act_fn=act_fn,
|
||||
attn_num_head_channels=attention_head_dim,
|
||||
downsample_padding=downsample_padding,
|
||||
)
|
||||
self.down_blocks.append(down_block)
|
||||
|
||||
# mid
|
||||
self.mid_block = UNetMidBlock2DCrossAttn(
|
||||
in_channels=block_out_channels[-1],
|
||||
temb_channels=time_embed_dim,
|
||||
resnet_eps=norm_eps,
|
||||
resnet_act_fn=act_fn,
|
||||
output_scale_factor=mid_block_scale_factor,
|
||||
resnet_time_scale_shift="default",
|
||||
attn_num_head_channels=attention_head_dim,
|
||||
resnet_groups=norm_num_groups,
|
||||
)
|
||||
|
||||
# up
|
||||
reversed_block_out_channels = list(reversed(block_out_channels))
|
||||
output_channel = reversed_block_out_channels[0]
|
||||
for i, up_block_type in enumerate(up_block_types):
|
||||
prev_output_channel = output_channel
|
||||
output_channel = reversed_block_out_channels[i]
|
||||
input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
|
||||
|
||||
is_final_block = i == len(block_out_channels) - 1
|
||||
|
||||
up_block = get_up_block(
|
||||
up_block_type,
|
||||
num_layers=layers_per_block + 1,
|
||||
in_channels=input_channel,
|
||||
out_channels=output_channel,
|
||||
prev_output_channel=prev_output_channel,
|
||||
temb_channels=time_embed_dim,
|
||||
add_upsample=not is_final_block,
|
||||
resnet_eps=norm_eps,
|
||||
resnet_act_fn=act_fn,
|
||||
attn_num_head_channels=attention_head_dim,
|
||||
)
|
||||
self.up_blocks.append(up_block)
|
||||
prev_output_channel = output_channel
|
||||
|
||||
# out
|
||||
self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps)
|
||||
self.conv_act = nn.SiLU()
|
||||
self.conv_out = nn.Conv2d(block_out_channels[0], out_channels, 3, padding=1)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
sample: torch.FloatTensor,
|
||||
timestep: Union[torch.Tensor, float, int],
|
||||
encoder_hidden_states: torch.Tensor,
|
||||
) -> Dict[str, torch.FloatTensor]:
|
||||
|
||||
# 0. center input if necessary
|
||||
if self.config.center_input_sample:
|
||||
sample = 2 * sample - 1.0
|
||||
|
||||
# 1. time
|
||||
timesteps = timestep
|
||||
if not torch.is_tensor(timesteps):
|
||||
timesteps = torch.tensor([timesteps], dtype=torch.long, device=sample.device)
|
||||
elif torch.is_tensor(timesteps) and len(timesteps.shape) == 0:
|
||||
timesteps = timesteps[None].to(sample.device)
|
||||
|
||||
t_emb = self.time_proj(timesteps)
|
||||
emb = self.time_embedding(t_emb)
|
||||
|
||||
# 2. pre-process
|
||||
sample = self.conv_in(sample)
|
||||
|
||||
# 3. down
|
||||
down_block_res_samples = (sample,)
|
||||
for downsample_block in self.down_blocks:
|
||||
|
||||
if hasattr(downsample_block, "attentions") and downsample_block.attentions is not None:
|
||||
sample, res_samples = downsample_block(
|
||||
hidden_states=sample, temb=emb, encoder_hidden_states=encoder_hidden_states
|
||||
)
|
||||
else:
|
||||
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
||||
|
||||
down_block_res_samples += res_samples
|
||||
|
||||
# 4. mid
|
||||
sample = self.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states)
|
||||
|
||||
# 5. up
|
||||
for upsample_block in self.up_blocks:
|
||||
|
||||
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
||||
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
||||
|
||||
if hasattr(upsample_block, "attentions") and upsample_block.attentions is not None:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
res_hidden_states_tuple=res_samples,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
)
|
||||
else:
|
||||
sample = upsample_block(hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples)
|
||||
|
||||
# 6. post-process
|
||||
|
||||
sample = self.conv_norm_out(sample)
|
||||
sample = self.conv_act(sample)
|
||||
sample = self.conv_out(sample)
|
||||
|
||||
output = {"sample": sample}
|
||||
|
||||
return output
|
||||
1152
src/diffusers/models/unet_blocks.py
Normal file
1152
src/diffusers/models/unet_blocks.py
Normal file
File diff suppressed because it is too large
Load Diff
@@ -1,820 +0,0 @@
|
||||
import math
|
||||
from abc import abstractmethod
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
from ..configuration_utils import ConfigMixin
|
||||
from ..modeling_utils import ModelMixin
|
||||
|
||||
|
||||
def convert_module_to_f16(l):
|
||||
"""
|
||||
Convert primitive modules to float16.
|
||||
"""
|
||||
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Conv3d)):
|
||||
l.weight.data = l.weight.data.half()
|
||||
if l.bias is not None:
|
||||
l.bias.data = l.bias.data.half()
|
||||
|
||||
|
||||
def convert_module_to_f32(l):
|
||||
"""
|
||||
Convert primitive modules to float32, undoing convert_module_to_f16().
|
||||
"""
|
||||
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Conv3d)):
|
||||
l.weight.data = l.weight.data.float()
|
||||
if l.bias is not None:
|
||||
l.bias.data = l.bias.data.float()
|
||||
|
||||
|
||||
def avg_pool_nd(dims, *args, **kwargs):
|
||||
"""
|
||||
Create a 1D, 2D, or 3D average pooling module.
|
||||
"""
|
||||
if dims == 1:
|
||||
return nn.AvgPool1d(*args, **kwargs)
|
||||
elif dims == 2:
|
||||
return nn.AvgPool2d(*args, **kwargs)
|
||||
elif dims == 3:
|
||||
return nn.AvgPool3d(*args, **kwargs)
|
||||
raise ValueError(f"unsupported dimensions: {dims}")
|
||||
|
||||
|
||||
def conv_nd(dims, *args, **kwargs):
|
||||
"""
|
||||
Create a 1D, 2D, or 3D convolution module.
|
||||
"""
|
||||
if dims == 1:
|
||||
return nn.Conv1d(*args, **kwargs)
|
||||
elif dims == 2:
|
||||
return nn.Conv2d(*args, **kwargs)
|
||||
elif dims == 3:
|
||||
return nn.Conv3d(*args, **kwargs)
|
||||
raise ValueError(f"unsupported dimensions: {dims}")
|
||||
|
||||
|
||||
def linear(*args, **kwargs):
|
||||
"""
|
||||
Create a linear module.
|
||||
"""
|
||||
return nn.Linear(*args, **kwargs)
|
||||
|
||||
|
||||
class GroupNorm32(nn.GroupNorm):
|
||||
def __init__(self, num_groups, num_channels, swish, eps=1e-5):
|
||||
super().__init__(num_groups=num_groups, num_channels=num_channels, eps=eps)
|
||||
self.swish = swish
|
||||
|
||||
def forward(self, x):
|
||||
y = super().forward(x.float()).to(x.dtype)
|
||||
if self.swish == 1.0:
|
||||
y = F.silu(y)
|
||||
elif self.swish:
|
||||
y = y * F.sigmoid(y * float(self.swish))
|
||||
return y
|
||||
|
||||
|
||||
def normalization(channels, swish=0.0):
|
||||
"""
|
||||
Make a standard normalization layer, with an optional swish activation.
|
||||
|
||||
:param channels: number of input channels.
|
||||
:return: an nn.Module for normalization.
|
||||
"""
|
||||
return GroupNorm32(num_channels=channels, num_groups=32, swish=swish)
|
||||
|
||||
|
||||
def timestep_embedding(timesteps, dim, max_period=10000):
|
||||
"""
|
||||
Create sinusoidal timestep embeddings.
|
||||
|
||||
:param timesteps: a 1-D Tensor of N indices, one per batch element.
|
||||
These may be fractional.
|
||||
:param dim: the dimension of the output.
|
||||
:param max_period: controls the minimum frequency of the embeddings.
|
||||
:return: an [N x dim] Tensor of positional embeddings.
|
||||
"""
|
||||
half = dim // 2
|
||||
freqs = torch.exp(-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half).to(
|
||||
device=timesteps.device
|
||||
)
|
||||
args = timesteps[:, None].float() * freqs[None]
|
||||
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
|
||||
if dim % 2:
|
||||
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
|
||||
return embedding
|
||||
|
||||
|
||||
def zero_module(module):
|
||||
"""
|
||||
Zero out the parameters of a module and return it.
|
||||
"""
|
||||
for p in module.parameters():
|
||||
p.detach().zero_()
|
||||
return module
|
||||
|
||||
|
||||
class TimestepBlock(nn.Module):
|
||||
"""
|
||||
Any module where forward() takes timestep embeddings as a second argument.
|
||||
"""
|
||||
|
||||
@abstractmethod
|
||||
def forward(self, x, emb):
|
||||
"""
|
||||
Apply the module to `x` given `emb` timestep embeddings.
|
||||
"""
|
||||
|
||||
|
||||
class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
|
||||
"""
|
||||
A sequential module that passes timestep embeddings to the children that
|
||||
support it as an extra input.
|
||||
"""
|
||||
|
||||
def forward(self, x, emb, encoder_out=None):
|
||||
for layer in self:
|
||||
if isinstance(layer, TimestepBlock):
|
||||
x = layer(x, emb)
|
||||
elif isinstance(layer, AttentionBlock):
|
||||
x = layer(x, encoder_out)
|
||||
else:
|
||||
x = layer(x)
|
||||
return x
|
||||
|
||||
|
||||
class Upsample(nn.Module):
|
||||
"""
|
||||
An upsampling layer with an optional convolution.
|
||||
|
||||
:param channels: channels in the inputs and outputs.
|
||||
:param use_conv: a bool determining if a convolution is applied.
|
||||
:param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
|
||||
upsampling occurs in the inner-two dimensions.
|
||||
"""
|
||||
|
||||
def __init__(self, channels, use_conv, dims=2, out_channels=None):
|
||||
super().__init__()
|
||||
self.channels = channels
|
||||
self.out_channels = out_channels or channels
|
||||
self.use_conv = use_conv
|
||||
self.dims = dims
|
||||
if use_conv:
|
||||
self.conv = conv_nd(dims, self.channels, self.out_channels, 3, padding=1)
|
||||
|
||||
def forward(self, x):
|
||||
assert x.shape[1] == self.channels
|
||||
if self.dims == 3:
|
||||
x = F.interpolate(x, (x.shape[2], x.shape[3] * 2, x.shape[4] * 2), mode="nearest")
|
||||
else:
|
||||
x = F.interpolate(x, scale_factor=2, mode="nearest")
|
||||
if self.use_conv:
|
||||
x = self.conv(x)
|
||||
return x
|
||||
|
||||
|
||||
class Downsample(nn.Module):
|
||||
"""
|
||||
A downsampling layer with an optional convolution.
|
||||
|
||||
:param channels: channels in the inputs and outputs.
|
||||
:param use_conv: a bool determining if a convolution is applied.
|
||||
:param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
|
||||
downsampling occurs in the inner-two dimensions.
|
||||
"""
|
||||
|
||||
def __init__(self, channels, use_conv, dims=2, out_channels=None):
|
||||
super().__init__()
|
||||
self.channels = channels
|
||||
self.out_channels = out_channels or channels
|
||||
self.use_conv = use_conv
|
||||
self.dims = dims
|
||||
stride = 2 if dims != 3 else (1, 2, 2)
|
||||
if use_conv:
|
||||
self.op = conv_nd(dims, self.channels, self.out_channels, 3, stride=stride, padding=1)
|
||||
else:
|
||||
assert self.channels == self.out_channels
|
||||
self.op = avg_pool_nd(dims, kernel_size=stride, stride=stride)
|
||||
|
||||
def forward(self, x):
|
||||
assert x.shape[1] == self.channels
|
||||
return self.op(x)
|
||||
|
||||
|
||||
class ResBlock(TimestepBlock):
|
||||
"""
|
||||
A residual block that can optionally change the number of channels.
|
||||
|
||||
:param channels: the number of input channels.
|
||||
:param emb_channels: the number of timestep embedding channels.
|
||||
:param dropout: the rate of dropout.
|
||||
:param out_channels: if specified, the number of out channels.
|
||||
:param use_conv: if True and out_channels is specified, use a spatial
|
||||
convolution instead of a smaller 1x1 convolution to change the
|
||||
channels in the skip connection.
|
||||
:param dims: determines if the signal is 1D, 2D, or 3D.
|
||||
:param use_checkpoint: if True, use gradient checkpointing on this module.
|
||||
:param up: if True, use this block for upsampling.
|
||||
:param down: if True, use this block for downsampling.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
channels,
|
||||
emb_channels,
|
||||
dropout,
|
||||
out_channels=None,
|
||||
use_conv=False,
|
||||
use_scale_shift_norm=False,
|
||||
dims=2,
|
||||
use_checkpoint=False,
|
||||
up=False,
|
||||
down=False,
|
||||
):
|
||||
super().__init__()
|
||||
self.channels = channels
|
||||
self.emb_channels = emb_channels
|
||||
self.dropout = dropout
|
||||
self.out_channels = out_channels or channels
|
||||
self.use_conv = use_conv
|
||||
self.use_checkpoint = use_checkpoint
|
||||
self.use_scale_shift_norm = use_scale_shift_norm
|
||||
|
||||
self.in_layers = nn.Sequential(
|
||||
normalization(channels, swish=1.0),
|
||||
nn.Identity(),
|
||||
conv_nd(dims, channels, self.out_channels, 3, padding=1),
|
||||
)
|
||||
|
||||
self.updown = up or down
|
||||
|
||||
if up:
|
||||
self.h_upd = Upsample(channels, False, dims)
|
||||
self.x_upd = Upsample(channels, False, dims)
|
||||
elif down:
|
||||
self.h_upd = Downsample(channels, False, dims)
|
||||
self.x_upd = Downsample(channels, False, dims)
|
||||
else:
|
||||
self.h_upd = self.x_upd = nn.Identity()
|
||||
|
||||
self.emb_layers = nn.Sequential(
|
||||
nn.SiLU(),
|
||||
linear(
|
||||
emb_channels,
|
||||
2 * self.out_channels if use_scale_shift_norm else self.out_channels,
|
||||
),
|
||||
)
|
||||
self.out_layers = nn.Sequential(
|
||||
normalization(self.out_channels, swish=0.0 if use_scale_shift_norm else 1.0),
|
||||
nn.SiLU() if use_scale_shift_norm else nn.Identity(),
|
||||
nn.Dropout(p=dropout),
|
||||
zero_module(conv_nd(dims, self.out_channels, self.out_channels, 3, padding=1)),
|
||||
)
|
||||
|
||||
if self.out_channels == channels:
|
||||
self.skip_connection = nn.Identity()
|
||||
elif use_conv:
|
||||
self.skip_connection = conv_nd(dims, channels, self.out_channels, 3, padding=1)
|
||||
else:
|
||||
self.skip_connection = conv_nd(dims, channels, self.out_channels, 1)
|
||||
|
||||
def forward(self, x, emb):
|
||||
"""
|
||||
Apply the block to a Tensor, conditioned on a timestep embedding.
|
||||
|
||||
:param x: an [N x C x ...] Tensor of features.
|
||||
:param emb: an [N x emb_channels] Tensor of timestep embeddings.
|
||||
:return: an [N x C x ...] Tensor of outputs.
|
||||
"""
|
||||
if self.updown:
|
||||
in_rest, in_conv = self.in_layers[:-1], self.in_layers[-1]
|
||||
h = in_rest(x)
|
||||
h = self.h_upd(h)
|
||||
x = self.x_upd(x)
|
||||
h = in_conv(h)
|
||||
else:
|
||||
h = self.in_layers(x)
|
||||
emb_out = self.emb_layers(emb).type(h.dtype)
|
||||
while len(emb_out.shape) < len(h.shape):
|
||||
emb_out = emb_out[..., None]
|
||||
if self.use_scale_shift_norm:
|
||||
out_norm, out_rest = self.out_layers[0], self.out_layers[1:]
|
||||
scale, shift = torch.chunk(emb_out, 2, dim=1)
|
||||
h = out_norm(h) * (1 + scale) + shift
|
||||
h = out_rest(h)
|
||||
else:
|
||||
h = h + emb_out
|
||||
h = self.out_layers(h)
|
||||
return self.skip_connection(x) + h
|
||||
|
||||
|
||||
class AttentionBlock(nn.Module):
|
||||
"""
|
||||
An attention block that allows spatial positions to attend to each other.
|
||||
|
||||
Originally ported from here, but adapted to the N-d case.
|
||||
https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
channels,
|
||||
num_heads=1,
|
||||
num_head_channels=-1,
|
||||
use_checkpoint=False,
|
||||
encoder_channels=None,
|
||||
):
|
||||
super().__init__()
|
||||
self.channels = channels
|
||||
if num_head_channels == -1:
|
||||
self.num_heads = num_heads
|
||||
else:
|
||||
assert (
|
||||
channels % num_head_channels == 0
|
||||
), f"q,k,v channels {channels} is not divisible by num_head_channels {num_head_channels}"
|
||||
self.num_heads = channels // num_head_channels
|
||||
self.use_checkpoint = use_checkpoint
|
||||
self.norm = normalization(channels, swish=0.0)
|
||||
self.qkv = conv_nd(1, channels, channels * 3, 1)
|
||||
self.attention = QKVAttention(self.num_heads)
|
||||
|
||||
if encoder_channels is not None:
|
||||
self.encoder_kv = conv_nd(1, encoder_channels, channels * 2, 1)
|
||||
self.proj_out = zero_module(conv_nd(1, channels, channels, 1))
|
||||
|
||||
def forward(self, x, encoder_out=None):
|
||||
b, c, *spatial = x.shape
|
||||
qkv = self.qkv(self.norm(x).view(b, c, -1))
|
||||
if encoder_out is not None:
|
||||
encoder_out = self.encoder_kv(encoder_out)
|
||||
h = self.attention(qkv, encoder_out)
|
||||
else:
|
||||
h = self.attention(qkv)
|
||||
h = self.proj_out(h)
|
||||
return x + h.reshape(b, c, *spatial)
|
||||
|
||||
|
||||
class QKVAttention(nn.Module):
|
||||
"""
|
||||
A module which performs QKV attention. Matches legacy QKVAttention + input/ouput heads shaping
|
||||
"""
|
||||
|
||||
def __init__(self, n_heads):
|
||||
super().__init__()
|
||||
self.n_heads = n_heads
|
||||
|
||||
def forward(self, qkv, encoder_kv=None):
|
||||
"""
|
||||
Apply QKV attention.
|
||||
|
||||
:param qkv: an [N x (H * 3 * C) x T] tensor of Qs, Ks, and Vs.
|
||||
:return: an [N x (H * C) x T] tensor after attention.
|
||||
"""
|
||||
bs, width, length = qkv.shape
|
||||
assert width % (3 * self.n_heads) == 0
|
||||
ch = width // (3 * self.n_heads)
|
||||
q, k, v = qkv.reshape(bs * self.n_heads, ch * 3, length).split(ch, dim=1)
|
||||
if encoder_kv is not None:
|
||||
assert encoder_kv.shape[1] == self.n_heads * ch * 2
|
||||
ek, ev = encoder_kv.reshape(bs * self.n_heads, ch * 2, -1).split(ch, dim=1)
|
||||
k = torch.cat([ek, k], dim=-1)
|
||||
v = torch.cat([ev, v], dim=-1)
|
||||
scale = 1 / math.sqrt(math.sqrt(ch))
|
||||
weight = torch.einsum("bct,bcs->bts", q * scale, k * scale) # More stable with f16 than dividing afterwards
|
||||
weight = torch.softmax(weight.float(), dim=-1).type(weight.dtype)
|
||||
a = torch.einsum("bts,bcs->bct", weight, v)
|
||||
return a.reshape(bs, -1, length)
|
||||
|
||||
|
||||
class GLIDEUNetModel(ModelMixin, ConfigMixin):
|
||||
"""
|
||||
The full UNet model with attention and timestep embedding.
|
||||
|
||||
:param in_channels: channels in the input Tensor.
|
||||
:param model_channels: base channel count for the model.
|
||||
:param out_channels: channels in the output Tensor.
|
||||
:param num_res_blocks: number of residual blocks per downsample.
|
||||
:param attention_resolutions: a collection of downsample rates at which
|
||||
attention will take place. May be a set, list, or tuple.
|
||||
For example, if this contains 4, then at 4x downsampling, attention
|
||||
will be used.
|
||||
:param dropout: the dropout probability.
|
||||
:param channel_mult: channel multiplier for each level of the UNet.
|
||||
:param conv_resample: if True, use learned convolutions for upsampling and
|
||||
downsampling.
|
||||
:param dims: determines if the signal is 1D, 2D, or 3D.
|
||||
:param num_classes: if specified (as an int), then this model will be
|
||||
class-conditional with `num_classes` classes.
|
||||
:param use_checkpoint: use gradient checkpointing to reduce memory usage.
|
||||
:param num_heads: the number of attention heads in each attention layer.
|
||||
:param num_heads_channels: if specified, ignore num_heads and instead use
|
||||
a fixed channel width per attention head.
|
||||
:param num_heads_upsample: works with num_heads to set a different number
|
||||
of heads for upsampling. Deprecated.
|
||||
:param use_scale_shift_norm: use a FiLM-like conditioning mechanism.
|
||||
:param resblock_updown: use residual blocks for up/downsampling.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
in_channels=3,
|
||||
resolution=64,
|
||||
model_channels=192,
|
||||
out_channels=6,
|
||||
num_res_blocks=3,
|
||||
attention_resolutions=(2, 4, 8),
|
||||
dropout=0,
|
||||
channel_mult=(1, 2, 4, 8),
|
||||
conv_resample=True,
|
||||
dims=2,
|
||||
use_checkpoint=False,
|
||||
use_fp16=False,
|
||||
num_heads=1,
|
||||
num_head_channels=-1,
|
||||
num_heads_upsample=-1,
|
||||
use_scale_shift_norm=False,
|
||||
resblock_updown=False,
|
||||
transformer_dim=None,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
if num_heads_upsample == -1:
|
||||
num_heads_upsample = num_heads
|
||||
|
||||
self.in_channels = in_channels
|
||||
self.resolution = resolution
|
||||
self.model_channels = model_channels
|
||||
self.out_channels = out_channels
|
||||
self.num_res_blocks = num_res_blocks
|
||||
self.attention_resolutions = attention_resolutions
|
||||
self.dropout = dropout
|
||||
self.channel_mult = channel_mult
|
||||
self.conv_resample = conv_resample
|
||||
self.use_checkpoint = use_checkpoint
|
||||
# self.dtype = torch.float16 if use_fp16 else torch.float32
|
||||
self.num_heads = num_heads
|
||||
self.num_head_channels = num_head_channels
|
||||
self.num_heads_upsample = num_heads_upsample
|
||||
|
||||
time_embed_dim = model_channels * 4
|
||||
self.time_embed = nn.Sequential(
|
||||
linear(model_channels, time_embed_dim),
|
||||
nn.SiLU(),
|
||||
linear(time_embed_dim, time_embed_dim),
|
||||
)
|
||||
|
||||
ch = input_ch = int(channel_mult[0] * model_channels)
|
||||
self.input_blocks = nn.ModuleList([TimestepEmbedSequential(conv_nd(dims, in_channels, ch, 3, padding=1))])
|
||||
self._feature_size = ch
|
||||
input_block_chans = [ch]
|
||||
ds = 1
|
||||
for level, mult in enumerate(channel_mult):
|
||||
for _ in range(num_res_blocks):
|
||||
layers = [
|
||||
ResBlock(
|
||||
ch,
|
||||
time_embed_dim,
|
||||
dropout,
|
||||
out_channels=int(mult * model_channels),
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
)
|
||||
]
|
||||
ch = int(mult * model_channels)
|
||||
if ds in attention_resolutions:
|
||||
layers.append(
|
||||
AttentionBlock(
|
||||
ch,
|
||||
use_checkpoint=use_checkpoint,
|
||||
num_heads=num_heads,
|
||||
num_head_channels=num_head_channels,
|
||||
encoder_channels=transformer_dim,
|
||||
)
|
||||
)
|
||||
self.input_blocks.append(TimestepEmbedSequential(*layers))
|
||||
self._feature_size += ch
|
||||
input_block_chans.append(ch)
|
||||
if level != len(channel_mult) - 1:
|
||||
out_ch = ch
|
||||
self.input_blocks.append(
|
||||
TimestepEmbedSequential(
|
||||
ResBlock(
|
||||
ch,
|
||||
time_embed_dim,
|
||||
dropout,
|
||||
out_channels=out_ch,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
down=True,
|
||||
)
|
||||
if resblock_updown
|
||||
else Downsample(ch, conv_resample, dims=dims, out_channels=out_ch)
|
||||
)
|
||||
)
|
||||
ch = out_ch
|
||||
input_block_chans.append(ch)
|
||||
ds *= 2
|
||||
self._feature_size += ch
|
||||
|
||||
self.middle_block = TimestepEmbedSequential(
|
||||
ResBlock(
|
||||
ch,
|
||||
time_embed_dim,
|
||||
dropout,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
),
|
||||
AttentionBlock(
|
||||
ch,
|
||||
use_checkpoint=use_checkpoint,
|
||||
num_heads=num_heads,
|
||||
num_head_channels=num_head_channels,
|
||||
encoder_channels=transformer_dim,
|
||||
),
|
||||
ResBlock(
|
||||
ch,
|
||||
time_embed_dim,
|
||||
dropout,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
),
|
||||
)
|
||||
self._feature_size += ch
|
||||
|
||||
self.output_blocks = nn.ModuleList([])
|
||||
for level, mult in list(enumerate(channel_mult))[::-1]:
|
||||
for i in range(num_res_blocks + 1):
|
||||
ich = input_block_chans.pop()
|
||||
layers = [
|
||||
ResBlock(
|
||||
ch + ich,
|
||||
time_embed_dim,
|
||||
dropout,
|
||||
out_channels=int(model_channels * mult),
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
)
|
||||
]
|
||||
ch = int(model_channels * mult)
|
||||
if ds in attention_resolutions:
|
||||
layers.append(
|
||||
AttentionBlock(
|
||||
ch,
|
||||
use_checkpoint=use_checkpoint,
|
||||
num_heads=num_heads_upsample,
|
||||
num_head_channels=num_head_channels,
|
||||
encoder_channels=transformer_dim,
|
||||
)
|
||||
)
|
||||
if level and i == num_res_blocks:
|
||||
out_ch = ch
|
||||
layers.append(
|
||||
ResBlock(
|
||||
ch,
|
||||
time_embed_dim,
|
||||
dropout,
|
||||
out_channels=out_ch,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
up=True,
|
||||
)
|
||||
if resblock_updown
|
||||
else Upsample(ch, conv_resample, dims=dims, out_channels=out_ch)
|
||||
)
|
||||
ds //= 2
|
||||
self.output_blocks.append(TimestepEmbedSequential(*layers))
|
||||
self._feature_size += ch
|
||||
|
||||
self.out = nn.Sequential(
|
||||
normalization(ch, swish=1.0),
|
||||
nn.Identity(),
|
||||
zero_module(conv_nd(dims, input_ch, out_channels, 3, padding=1)),
|
||||
)
|
||||
self.use_fp16 = use_fp16
|
||||
|
||||
def convert_to_fp16(self):
|
||||
"""
|
||||
Convert the torso of the model to float16.
|
||||
"""
|
||||
self.input_blocks.apply(convert_module_to_f16)
|
||||
self.middle_block.apply(convert_module_to_f16)
|
||||
self.output_blocks.apply(convert_module_to_f16)
|
||||
|
||||
def convert_to_fp32(self):
|
||||
"""
|
||||
Convert the torso of the model to float32.
|
||||
"""
|
||||
self.input_blocks.apply(convert_module_to_f32)
|
||||
self.middle_block.apply(convert_module_to_f32)
|
||||
self.output_blocks.apply(convert_module_to_f32)
|
||||
|
||||
def forward(self, x, timesteps):
|
||||
"""
|
||||
Apply the model to an input batch.
|
||||
|
||||
:param x: an [N x C x ...] Tensor of inputs.
|
||||
:param timesteps: a 1-D batch of timesteps.
|
||||
:param y: an [N] Tensor of labels, if class-conditional.
|
||||
:return: an [N x C x ...] Tensor of outputs.
|
||||
"""
|
||||
|
||||
hs = []
|
||||
emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
|
||||
|
||||
h = x.type(self.dtype)
|
||||
for module in self.input_blocks:
|
||||
h = module(h, emb)
|
||||
hs.append(h)
|
||||
h = self.middle_block(h, emb)
|
||||
for module in self.output_blocks:
|
||||
h = torch.cat([h, hs.pop()], dim=1)
|
||||
h = module(h, emb)
|
||||
h = h.type(x.dtype)
|
||||
return self.out(h)
|
||||
|
||||
|
||||
class GLIDETextToImageUNetModel(GLIDEUNetModel):
|
||||
"""
|
||||
A UNetModel that performs super-resolution.
|
||||
|
||||
Expects an extra kwarg `low_res` to condition on a low-resolution image.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
in_channels=3,
|
||||
resolution=64,
|
||||
model_channels=192,
|
||||
out_channels=6,
|
||||
num_res_blocks=3,
|
||||
attention_resolutions=(2, 4, 8),
|
||||
dropout=0,
|
||||
channel_mult=(1, 2, 4, 8),
|
||||
conv_resample=True,
|
||||
dims=2,
|
||||
use_checkpoint=False,
|
||||
use_fp16=False,
|
||||
num_heads=1,
|
||||
num_head_channels=-1,
|
||||
num_heads_upsample=-1,
|
||||
use_scale_shift_norm=False,
|
||||
resblock_updown=False,
|
||||
transformer_dim=512,
|
||||
):
|
||||
super().__init__(
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
model_channels=model_channels,
|
||||
out_channels=out_channels,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attention_resolutions=attention_resolutions,
|
||||
dropout=dropout,
|
||||
channel_mult=channel_mult,
|
||||
conv_resample=conv_resample,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_fp16=use_fp16,
|
||||
num_heads=num_heads,
|
||||
num_head_channels=num_head_channels,
|
||||
num_heads_upsample=num_heads_upsample,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
resblock_updown=resblock_updown,
|
||||
transformer_dim=transformer_dim,
|
||||
)
|
||||
self.register(
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
model_channels=model_channels,
|
||||
out_channels=out_channels,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attention_resolutions=attention_resolutions,
|
||||
dropout=dropout,
|
||||
channel_mult=channel_mult,
|
||||
conv_resample=conv_resample,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_fp16=use_fp16,
|
||||
num_heads=num_heads,
|
||||
num_head_channels=num_head_channels,
|
||||
num_heads_upsample=num_heads_upsample,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
resblock_updown=resblock_updown,
|
||||
transformer_dim=transformer_dim,
|
||||
)
|
||||
|
||||
self.transformer_proj = nn.Linear(transformer_dim, self.model_channels * 4)
|
||||
|
||||
def forward(self, x, timesteps, transformer_out=None):
|
||||
hs = []
|
||||
emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
|
||||
|
||||
# project the last token
|
||||
transformer_proj = self.transformer_proj(transformer_out[:, -1])
|
||||
transformer_out = transformer_out.permute(0, 2, 1) # NLC -> NCL
|
||||
|
||||
emb = emb + transformer_proj.to(emb)
|
||||
|
||||
h = x
|
||||
for module in self.input_blocks:
|
||||
h = module(h, emb, transformer_out)
|
||||
hs.append(h)
|
||||
h = self.middle_block(h, emb, transformer_out)
|
||||
for module in self.output_blocks:
|
||||
other = hs.pop()
|
||||
h = torch.cat([h, other], dim=1)
|
||||
h = module(h, emb, transformer_out)
|
||||
return self.out(h)
|
||||
|
||||
|
||||
class GLIDESuperResUNetModel(GLIDEUNetModel):
|
||||
"""
|
||||
A UNetModel that performs super-resolution.
|
||||
|
||||
Expects an extra kwarg `low_res` to condition on a low-resolution image.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
in_channels=3,
|
||||
resolution=256,
|
||||
model_channels=192,
|
||||
out_channels=6,
|
||||
num_res_blocks=3,
|
||||
attention_resolutions=(2, 4, 8),
|
||||
dropout=0,
|
||||
channel_mult=(1, 2, 4, 8),
|
||||
conv_resample=True,
|
||||
dims=2,
|
||||
use_checkpoint=False,
|
||||
use_fp16=False,
|
||||
num_heads=1,
|
||||
num_head_channels=-1,
|
||||
num_heads_upsample=-1,
|
||||
use_scale_shift_norm=False,
|
||||
resblock_updown=False,
|
||||
):
|
||||
super().__init__(
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
model_channels=model_channels,
|
||||
out_channels=out_channels,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attention_resolutions=attention_resolutions,
|
||||
dropout=dropout,
|
||||
channel_mult=channel_mult,
|
||||
conv_resample=conv_resample,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_fp16=use_fp16,
|
||||
num_heads=num_heads,
|
||||
num_head_channels=num_head_channels,
|
||||
num_heads_upsample=num_heads_upsample,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
resblock_updown=resblock_updown,
|
||||
)
|
||||
self.register(
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
model_channels=model_channels,
|
||||
out_channels=out_channels,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attention_resolutions=attention_resolutions,
|
||||
dropout=dropout,
|
||||
channel_mult=channel_mult,
|
||||
conv_resample=conv_resample,
|
||||
dims=dims,
|
||||
use_checkpoint=use_checkpoint,
|
||||
use_fp16=use_fp16,
|
||||
num_heads=num_heads,
|
||||
num_head_channels=num_head_channels,
|
||||
num_heads_upsample=num_heads_upsample,
|
||||
use_scale_shift_norm=use_scale_shift_norm,
|
||||
resblock_updown=resblock_updown,
|
||||
)
|
||||
|
||||
def forward(self, x, timesteps, low_res=None):
|
||||
_, _, new_height, new_width = x.shape
|
||||
upsampled = F.interpolate(low_res, (new_height, new_width), mode="bilinear")
|
||||
x = torch.cat([x, upsampled], dim=1)
|
||||
|
||||
hs = []
|
||||
emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
|
||||
|
||||
h = x
|
||||
for module in self.input_blocks:
|
||||
h = module(h, emb)
|
||||
hs.append(h)
|
||||
h = self.middle_block(h, emb)
|
||||
for module in self.output_blocks:
|
||||
h = torch.cat([h, hs.pop()], dim=1)
|
||||
h = module(h, emb)
|
||||
|
||||
return self.out(h)
|
||||
@@ -1,233 +0,0 @@
|
||||
import math
|
||||
|
||||
import torch
|
||||
|
||||
|
||||
try:
|
||||
from einops import rearrange, repeat
|
||||
except:
|
||||
print("Einops is not installed")
|
||||
pass
|
||||
|
||||
from ..configuration_utils import ConfigMixin
|
||||
from ..modeling_utils import ModelMixin
|
||||
|
||||
|
||||
class Mish(torch.nn.Module):
|
||||
def forward(self, x):
|
||||
return x * torch.tanh(torch.nn.functional.softplus(x))
|
||||
|
||||
|
||||
class Upsample(torch.nn.Module):
|
||||
def __init__(self, dim):
|
||||
super(Upsample, self).__init__()
|
||||
self.conv = torch.nn.ConvTranspose2d(dim, dim, 4, 2, 1)
|
||||
|
||||
def forward(self, x):
|
||||
return self.conv(x)
|
||||
|
||||
|
||||
class Downsample(torch.nn.Module):
|
||||
def __init__(self, dim):
|
||||
super(Downsample, self).__init__()
|
||||
self.conv = torch.nn.Conv2d(dim, dim, 3, 2, 1)
|
||||
|
||||
def forward(self, x):
|
||||
return self.conv(x)
|
||||
|
||||
|
||||
class Rezero(torch.nn.Module):
|
||||
def __init__(self, fn):
|
||||
super(Rezero, self).__init__()
|
||||
self.fn = fn
|
||||
self.g = torch.nn.Parameter(torch.zeros(1))
|
||||
|
||||
def forward(self, x):
|
||||
return self.fn(x) * self.g
|
||||
|
||||
|
||||
class Block(torch.nn.Module):
|
||||
def __init__(self, dim, dim_out, groups=8):
|
||||
super(Block, self).__init__()
|
||||
self.block = torch.nn.Sequential(
|
||||
torch.nn.Conv2d(dim, dim_out, 3, padding=1), torch.nn.GroupNorm(groups, dim_out), Mish()
|
||||
)
|
||||
|
||||
def forward(self, x, mask):
|
||||
output = self.block(x * mask)
|
||||
return output * mask
|
||||
|
||||
|
||||
class ResnetBlock(torch.nn.Module):
|
||||
def __init__(self, dim, dim_out, time_emb_dim, groups=8):
|
||||
super(ResnetBlock, self).__init__()
|
||||
self.mlp = torch.nn.Sequential(Mish(), torch.nn.Linear(time_emb_dim, dim_out))
|
||||
|
||||
self.block1 = Block(dim, dim_out, groups=groups)
|
||||
self.block2 = Block(dim_out, dim_out, groups=groups)
|
||||
if dim != dim_out:
|
||||
self.res_conv = torch.nn.Conv2d(dim, dim_out, 1)
|
||||
else:
|
||||
self.res_conv = torch.nn.Identity()
|
||||
|
||||
def forward(self, x, mask, time_emb):
|
||||
h = self.block1(x, mask)
|
||||
h += self.mlp(time_emb).unsqueeze(-1).unsqueeze(-1)
|
||||
h = self.block2(h, mask)
|
||||
output = h + self.res_conv(x * mask)
|
||||
return output
|
||||
|
||||
|
||||
class LinearAttention(torch.nn.Module):
|
||||
def __init__(self, dim, heads=4, dim_head=32):
|
||||
super(LinearAttention, self).__init__()
|
||||
self.heads = heads
|
||||
hidden_dim = dim_head * heads
|
||||
self.to_qkv = torch.nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
|
||||
self.to_out = torch.nn.Conv2d(hidden_dim, dim, 1)
|
||||
|
||||
def forward(self, x):
|
||||
b, c, h, w = x.shape
|
||||
qkv = self.to_qkv(x)
|
||||
q, k, v = rearrange(qkv, "b (qkv heads c) h w -> qkv b heads c (h w)", heads=self.heads, qkv=3)
|
||||
k = k.softmax(dim=-1)
|
||||
context = torch.einsum("bhdn,bhen->bhde", k, v)
|
||||
out = torch.einsum("bhde,bhdn->bhen", context, q)
|
||||
out = rearrange(out, "b heads c (h w) -> b (heads c) h w", heads=self.heads, h=h, w=w)
|
||||
return self.to_out(out)
|
||||
|
||||
|
||||
class Residual(torch.nn.Module):
|
||||
def __init__(self, fn):
|
||||
super(Residual, self).__init__()
|
||||
self.fn = fn
|
||||
|
||||
def forward(self, x, *args, **kwargs):
|
||||
output = self.fn(x, *args, **kwargs) + x
|
||||
return output
|
||||
|
||||
|
||||
class SinusoidalPosEmb(torch.nn.Module):
|
||||
def __init__(self, dim):
|
||||
super(SinusoidalPosEmb, self).__init__()
|
||||
self.dim = dim
|
||||
|
||||
def forward(self, x, scale=1000):
|
||||
device = x.device
|
||||
half_dim = self.dim // 2
|
||||
emb = math.log(10000) / (half_dim - 1)
|
||||
emb = torch.exp(torch.arange(half_dim, device=device).float() * -emb)
|
||||
emb = scale * x.unsqueeze(1) * emb.unsqueeze(0)
|
||||
emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
|
||||
return emb
|
||||
|
||||
|
||||
class UNetGradTTSModel(ModelMixin, ConfigMixin):
|
||||
def __init__(self, dim, dim_mults=(1, 2, 4), groups=8, n_spks=None, spk_emb_dim=64, n_feats=80, pe_scale=1000):
|
||||
super(UNetGradTTSModel, self).__init__()
|
||||
|
||||
self.register(
|
||||
dim=dim,
|
||||
dim_mults=dim_mults,
|
||||
groups=groups,
|
||||
n_spks=n_spks,
|
||||
spk_emb_dim=spk_emb_dim,
|
||||
n_feats=n_feats,
|
||||
pe_scale=pe_scale,
|
||||
)
|
||||
|
||||
self.dim = dim
|
||||
self.dim_mults = dim_mults
|
||||
self.groups = groups
|
||||
self.n_spks = n_spks if not isinstance(n_spks, type(None)) else 1
|
||||
self.spk_emb_dim = spk_emb_dim
|
||||
self.pe_scale = pe_scale
|
||||
|
||||
if n_spks > 1:
|
||||
self.spk_mlp = torch.nn.Sequential(
|
||||
torch.nn.Linear(spk_emb_dim, spk_emb_dim * 4), Mish(), torch.nn.Linear(spk_emb_dim * 4, n_feats)
|
||||
)
|
||||
self.time_pos_emb = SinusoidalPosEmb(dim)
|
||||
self.mlp = torch.nn.Sequential(torch.nn.Linear(dim, dim * 4), Mish(), torch.nn.Linear(dim * 4, dim))
|
||||
|
||||
dims = [2 + (1 if n_spks > 1 else 0), *map(lambda m: dim * m, dim_mults)]
|
||||
in_out = list(zip(dims[:-1], dims[1:]))
|
||||
self.downs = torch.nn.ModuleList([])
|
||||
self.ups = torch.nn.ModuleList([])
|
||||
num_resolutions = len(in_out)
|
||||
|
||||
for ind, (dim_in, dim_out) in enumerate(in_out):
|
||||
is_last = ind >= (num_resolutions - 1)
|
||||
self.downs.append(
|
||||
torch.nn.ModuleList(
|
||||
[
|
||||
ResnetBlock(dim_in, dim_out, time_emb_dim=dim),
|
||||
ResnetBlock(dim_out, dim_out, time_emb_dim=dim),
|
||||
Residual(Rezero(LinearAttention(dim_out))),
|
||||
Downsample(dim_out) if not is_last else torch.nn.Identity(),
|
||||
]
|
||||
)
|
||||
)
|
||||
|
||||
mid_dim = dims[-1]
|
||||
self.mid_block1 = ResnetBlock(mid_dim, mid_dim, time_emb_dim=dim)
|
||||
self.mid_attn = Residual(Rezero(LinearAttention(mid_dim)))
|
||||
self.mid_block2 = ResnetBlock(mid_dim, mid_dim, time_emb_dim=dim)
|
||||
|
||||
for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])):
|
||||
self.ups.append(
|
||||
torch.nn.ModuleList(
|
||||
[
|
||||
ResnetBlock(dim_out * 2, dim_in, time_emb_dim=dim),
|
||||
ResnetBlock(dim_in, dim_in, time_emb_dim=dim),
|
||||
Residual(Rezero(LinearAttention(dim_in))),
|
||||
Upsample(dim_in),
|
||||
]
|
||||
)
|
||||
)
|
||||
self.final_block = Block(dim, dim)
|
||||
self.final_conv = torch.nn.Conv2d(dim, 1, 1)
|
||||
|
||||
def forward(self, x, mask, mu, t, spk=None):
|
||||
if not isinstance(spk, type(None)):
|
||||
s = self.spk_mlp(spk)
|
||||
|
||||
t = self.time_pos_emb(t, scale=self.pe_scale)
|
||||
t = self.mlp(t)
|
||||
|
||||
if self.n_spks < 2:
|
||||
x = torch.stack([mu, x], 1)
|
||||
else:
|
||||
s = s.unsqueeze(-1).repeat(1, 1, x.shape[-1])
|
||||
x = torch.stack([mu, x, s], 1)
|
||||
mask = mask.unsqueeze(1)
|
||||
|
||||
hiddens = []
|
||||
masks = [mask]
|
||||
for resnet1, resnet2, attn, downsample in self.downs:
|
||||
mask_down = masks[-1]
|
||||
x = resnet1(x, mask_down, t)
|
||||
x = resnet2(x, mask_down, t)
|
||||
x = attn(x)
|
||||
hiddens.append(x)
|
||||
x = downsample(x * mask_down)
|
||||
masks.append(mask_down[:, :, :, ::2])
|
||||
|
||||
masks = masks[:-1]
|
||||
mask_mid = masks[-1]
|
||||
x = self.mid_block1(x, mask_mid, t)
|
||||
x = self.mid_attn(x)
|
||||
x = self.mid_block2(x, mask_mid, t)
|
||||
|
||||
for resnet1, resnet2, attn, upsample in self.ups:
|
||||
mask_up = masks.pop()
|
||||
x = torch.cat((x, hiddens.pop()), dim=1)
|
||||
x = resnet1(x, mask_up, t)
|
||||
x = resnet2(x, mask_up, t)
|
||||
x = attn(x)
|
||||
x = upsample(x * mask_up)
|
||||
|
||||
x = self.final_block(x, mask)
|
||||
output = self.final_conv(x * mask)
|
||||
|
||||
return (output * mask).squeeze(1)
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,35 +1,11 @@
|
||||
# pytorch_diffusion + derived encoder decoder
|
||||
import math
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
import tqdm
|
||||
from diffusers import DiffusionPipeline
|
||||
from diffusers.configuration_utils import ConfigMixin
|
||||
from diffusers.modeling_utils import ModelMixin
|
||||
|
||||
|
||||
def get_timestep_embedding(timesteps, embedding_dim):
|
||||
"""
|
||||
This matches the implementation in Denoising Diffusion Probabilistic Models:
|
||||
From Fairseq.
|
||||
Build sinusoidal embeddings.
|
||||
This matches the implementation in tensor2tensor, but differs slightly
|
||||
from the description in Section 3.5 of "Attention Is All You Need".
|
||||
"""
|
||||
assert len(timesteps.shape) == 1
|
||||
|
||||
half_dim = embedding_dim // 2
|
||||
emb = math.log(10000) / (half_dim - 1)
|
||||
emb = torch.exp(torch.arange(half_dim, dtype=torch.float32) * -emb)
|
||||
emb = emb.to(device=timesteps.device)
|
||||
emb = timesteps.float()[:, None] * emb[None, :]
|
||||
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
|
||||
if embedding_dim % 2 == 1: # zero pad
|
||||
emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
|
||||
return emb
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..modeling_utils import ModelMixin
|
||||
from .attention import AttentionBlock
|
||||
from .resnet import Downsample2D, ResnetBlock2D, Upsample2D
|
||||
|
||||
|
||||
def nonlinearity(x):
|
||||
@@ -41,277 +17,11 @@ def Normalize(in_channels):
|
||||
return torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
|
||||
|
||||
|
||||
class Upsample(nn.Module):
|
||||
def __init__(self, in_channels, with_conv):
|
||||
super().__init__()
|
||||
self.with_conv = with_conv
|
||||
if self.with_conv:
|
||||
self.conv = torch.nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
def forward(self, x):
|
||||
x = torch.nn.functional.interpolate(x, scale_factor=2.0, mode="nearest")
|
||||
if self.with_conv:
|
||||
x = self.conv(x)
|
||||
return x
|
||||
|
||||
|
||||
class Downsample(nn.Module):
|
||||
def __init__(self, in_channels, with_conv):
|
||||
super().__init__()
|
||||
self.with_conv = with_conv
|
||||
if self.with_conv:
|
||||
# no asymmetric padding in torch conv, must do it ourselves
|
||||
self.conv = torch.nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=2, padding=0)
|
||||
|
||||
def forward(self, x):
|
||||
if self.with_conv:
|
||||
pad = (0, 1, 0, 1)
|
||||
x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
|
||||
x = self.conv(x)
|
||||
else:
|
||||
x = torch.nn.functional.avg_pool2d(x, kernel_size=2, stride=2)
|
||||
return x
|
||||
|
||||
|
||||
class ResnetBlock(nn.Module):
|
||||
def __init__(self, *, in_channels, out_channels=None, conv_shortcut=False, dropout, temb_channels=512):
|
||||
super().__init__()
|
||||
self.in_channels = in_channels
|
||||
out_channels = in_channels if out_channels is None else out_channels
|
||||
self.out_channels = out_channels
|
||||
self.use_conv_shortcut = conv_shortcut
|
||||
|
||||
self.norm1 = Normalize(in_channels)
|
||||
self.conv1 = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
if temb_channels > 0:
|
||||
self.temb_proj = torch.nn.Linear(temb_channels, out_channels)
|
||||
self.norm2 = Normalize(out_channels)
|
||||
self.dropout = torch.nn.Dropout(dropout)
|
||||
self.conv2 = torch.nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
if self.in_channels != self.out_channels:
|
||||
if self.use_conv_shortcut:
|
||||
self.conv_shortcut = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
else:
|
||||
self.nin_shortcut = torch.nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
def forward(self, x, temb):
|
||||
h = x
|
||||
h = self.norm1(h)
|
||||
h = nonlinearity(h)
|
||||
h = self.conv1(h)
|
||||
|
||||
if temb is not None:
|
||||
h = h + self.temb_proj(nonlinearity(temb))[:, :, None, None]
|
||||
|
||||
h = self.norm2(h)
|
||||
h = nonlinearity(h)
|
||||
h = self.dropout(h)
|
||||
h = self.conv2(h)
|
||||
|
||||
if self.in_channels != self.out_channels:
|
||||
if self.use_conv_shortcut:
|
||||
x = self.conv_shortcut(x)
|
||||
else:
|
||||
x = self.nin_shortcut(x)
|
||||
|
||||
return x + h
|
||||
|
||||
|
||||
class AttnBlock(nn.Module):
|
||||
def __init__(self, in_channels):
|
||||
super().__init__()
|
||||
self.in_channels = in_channels
|
||||
|
||||
self.norm = Normalize(in_channels)
|
||||
self.q = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.k = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.v = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.proj_out = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
def forward(self, x):
|
||||
h_ = x
|
||||
h_ = self.norm(h_)
|
||||
q = self.q(h_)
|
||||
k = self.k(h_)
|
||||
v = self.v(h_)
|
||||
|
||||
# compute attention
|
||||
b, c, h, w = q.shape
|
||||
q = q.reshape(b, c, h * w)
|
||||
q = q.permute(0, 2, 1) # b,hw,c
|
||||
k = k.reshape(b, c, h * w) # b,c,hw
|
||||
w_ = torch.bmm(q, k) # b,hw,hw w[b,i,j]=sum_c q[b,i,c]k[b,c,j]
|
||||
w_ = w_ * (int(c) ** (-0.5))
|
||||
w_ = torch.nn.functional.softmax(w_, dim=2)
|
||||
|
||||
# attend to values
|
||||
v = v.reshape(b, c, h * w)
|
||||
w_ = w_.permute(0, 2, 1) # b,hw,hw (first hw of k, second of q)
|
||||
h_ = torch.bmm(v, w_) # b, c,hw (hw of q) h_[b,c,j] = sum_i v[b,c,i] w_[b,i,j]
|
||||
h_ = h_.reshape(b, c, h, w)
|
||||
|
||||
h_ = self.proj_out(h_)
|
||||
|
||||
return x + h_
|
||||
|
||||
|
||||
class Model(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
*,
|
||||
ch,
|
||||
out_ch,
|
||||
ch_mult=(1, 2, 4, 8),
|
||||
num_res_blocks,
|
||||
attn_resolutions,
|
||||
dropout=0.0,
|
||||
resamp_with_conv=True,
|
||||
in_channels,
|
||||
resolution,
|
||||
use_timestep=True,
|
||||
):
|
||||
super().__init__()
|
||||
self.ch = ch
|
||||
self.temb_ch = self.ch * 4
|
||||
self.num_resolutions = len(ch_mult)
|
||||
self.num_res_blocks = num_res_blocks
|
||||
self.resolution = resolution
|
||||
self.in_channels = in_channels
|
||||
|
||||
self.use_timestep = use_timestep
|
||||
if self.use_timestep:
|
||||
# timestep embedding
|
||||
self.temb = nn.Module()
|
||||
self.temb.dense = nn.ModuleList(
|
||||
[
|
||||
torch.nn.Linear(self.ch, self.temb_ch),
|
||||
torch.nn.Linear(self.temb_ch, self.temb_ch),
|
||||
]
|
||||
)
|
||||
|
||||
# downsampling
|
||||
self.conv_in = torch.nn.Conv2d(in_channels, self.ch, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
curr_res = resolution
|
||||
in_ch_mult = (1,) + tuple(ch_mult)
|
||||
self.down = nn.ModuleList()
|
||||
for i_level in range(self.num_resolutions):
|
||||
block = nn.ModuleList()
|
||||
attn = nn.ModuleList()
|
||||
block_in = ch * in_ch_mult[i_level]
|
||||
block_out = ch * ch_mult[i_level]
|
||||
for i_block in range(self.num_res_blocks):
|
||||
block.append(
|
||||
ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_out, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
)
|
||||
block_in = block_out
|
||||
if curr_res in attn_resolutions:
|
||||
attn.append(AttnBlock(block_in))
|
||||
down = nn.Module()
|
||||
down.block = block
|
||||
down.attn = attn
|
||||
if i_level != self.num_resolutions - 1:
|
||||
down.downsample = Downsample(block_in, resamp_with_conv)
|
||||
curr_res = curr_res // 2
|
||||
self.down.append(down)
|
||||
|
||||
# middle
|
||||
self.mid = nn.Module()
|
||||
self.mid.block_1 = ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
self.mid.attn_1 = AttnBlock(block_in)
|
||||
self.mid.block_2 = ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
|
||||
# upsampling
|
||||
self.up = nn.ModuleList()
|
||||
for i_level in reversed(range(self.num_resolutions)):
|
||||
block = nn.ModuleList()
|
||||
attn = nn.ModuleList()
|
||||
block_out = ch * ch_mult[i_level]
|
||||
skip_in = ch * ch_mult[i_level]
|
||||
for i_block in range(self.num_res_blocks + 1):
|
||||
if i_block == self.num_res_blocks:
|
||||
skip_in = ch * in_ch_mult[i_level]
|
||||
block.append(
|
||||
ResnetBlock(
|
||||
in_channels=block_in + skip_in,
|
||||
out_channels=block_out,
|
||||
temb_channels=self.temb_ch,
|
||||
dropout=dropout,
|
||||
)
|
||||
)
|
||||
block_in = block_out
|
||||
if curr_res in attn_resolutions:
|
||||
attn.append(AttnBlock(block_in))
|
||||
up = nn.Module()
|
||||
up.block = block
|
||||
up.attn = attn
|
||||
if i_level != 0:
|
||||
up.upsample = Upsample(block_in, resamp_with_conv)
|
||||
curr_res = curr_res * 2
|
||||
self.up.insert(0, up) # prepend to get consistent order
|
||||
|
||||
# end
|
||||
self.norm_out = Normalize(block_in)
|
||||
self.conv_out = torch.nn.Conv2d(block_in, out_ch, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
def forward(self, x, t=None):
|
||||
# assert x.shape[2] == x.shape[3] == self.resolution
|
||||
|
||||
if self.use_timestep:
|
||||
# timestep embedding
|
||||
assert t is not None
|
||||
temb = get_timestep_embedding(t, self.ch)
|
||||
temb = self.temb.dense[0](temb)
|
||||
temb = nonlinearity(temb)
|
||||
temb = self.temb.dense[1](temb)
|
||||
else:
|
||||
temb = None
|
||||
|
||||
# downsampling
|
||||
hs = [self.conv_in(x)]
|
||||
for i_level in range(self.num_resolutions):
|
||||
for i_block in range(self.num_res_blocks):
|
||||
h = self.down[i_level].block[i_block](hs[-1], temb)
|
||||
if len(self.down[i_level].attn) > 0:
|
||||
h = self.down[i_level].attn[i_block](h)
|
||||
hs.append(h)
|
||||
if i_level != self.num_resolutions - 1:
|
||||
hs.append(self.down[i_level].downsample(hs[-1]))
|
||||
|
||||
# middle
|
||||
h = hs[-1]
|
||||
h = self.mid.block_1(h, temb)
|
||||
h = self.mid.attn_1(h)
|
||||
h = self.mid.block_2(h, temb)
|
||||
|
||||
# upsampling
|
||||
for i_level in reversed(range(self.num_resolutions)):
|
||||
for i_block in range(self.num_res_blocks + 1):
|
||||
h = self.up[i_level].block[i_block](torch.cat([h, hs.pop()], dim=1), temb)
|
||||
if len(self.up[i_level].attn) > 0:
|
||||
h = self.up[i_level].attn[i_block](h)
|
||||
if i_level != 0:
|
||||
h = self.up[i_level].upsample(h)
|
||||
|
||||
# end
|
||||
h = self.norm_out(h)
|
||||
h = nonlinearity(h)
|
||||
h = self.conv_out(h)
|
||||
return h
|
||||
|
||||
|
||||
class Encoder(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
*,
|
||||
ch,
|
||||
out_ch,
|
||||
ch_mult=(1, 2, 4, 8),
|
||||
num_res_blocks,
|
||||
attn_resolutions,
|
||||
@@ -344,28 +54,28 @@ class Encoder(nn.Module):
|
||||
block_out = ch * ch_mult[i_level]
|
||||
for i_block in range(self.num_res_blocks):
|
||||
block.append(
|
||||
ResnetBlock(
|
||||
ResnetBlock2D(
|
||||
in_channels=block_in, out_channels=block_out, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
)
|
||||
block_in = block_out
|
||||
if curr_res in attn_resolutions:
|
||||
attn.append(AttnBlock(block_in))
|
||||
attn.append(AttentionBlock(block_in, overwrite_qkv=True))
|
||||
down = nn.Module()
|
||||
down.block = block
|
||||
down.attn = attn
|
||||
if i_level != self.num_resolutions - 1:
|
||||
down.downsample = Downsample(block_in, resamp_with_conv)
|
||||
down.downsample = Downsample2D(block_in, use_conv=resamp_with_conv, padding=0)
|
||||
curr_res = curr_res // 2
|
||||
self.down.append(down)
|
||||
|
||||
# middle
|
||||
self.mid = nn.Module()
|
||||
self.mid.block_1 = ResnetBlock(
|
||||
self.mid.block_1 = ResnetBlock2D(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
self.mid.attn_1 = AttnBlock(block_in)
|
||||
self.mid.block_2 = ResnetBlock(
|
||||
self.mid.attn_1 = AttentionBlock(block_in, overwrite_qkv=True)
|
||||
self.mid.block_2 = ResnetBlock2D(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
|
||||
@@ -432,22 +142,21 @@ class Decoder(nn.Module):
|
||||
self.give_pre_end = give_pre_end
|
||||
|
||||
# compute in_ch_mult, block_in and curr_res at lowest res
|
||||
in_ch_mult = (1,) + tuple(ch_mult)
|
||||
block_in = ch * ch_mult[self.num_resolutions - 1]
|
||||
curr_res = resolution // 2 ** (self.num_resolutions - 1)
|
||||
self.z_shape = (1, z_channels, curr_res, curr_res)
|
||||
print("Working with z of shape {} = {} dimensions.".format(self.z_shape, np.prod(self.z_shape)))
|
||||
# print("Working with z of shape {} = {} dimensions.".format(self.z_shape, np.prod(self.z_shape)))
|
||||
|
||||
# z to block_in
|
||||
self.conv_in = torch.nn.Conv2d(z_channels, block_in, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
# middle
|
||||
self.mid = nn.Module()
|
||||
self.mid.block_1 = ResnetBlock(
|
||||
self.mid.block_1 = ResnetBlock2D(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
self.mid.attn_1 = AttnBlock(block_in)
|
||||
self.mid.block_2 = ResnetBlock(
|
||||
self.mid.attn_1 = AttentionBlock(block_in, overwrite_qkv=True)
|
||||
self.mid.block_2 = ResnetBlock2D(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
|
||||
@@ -459,18 +168,18 @@ class Decoder(nn.Module):
|
||||
block_out = ch * ch_mult[i_level]
|
||||
for i_block in range(self.num_res_blocks + 1):
|
||||
block.append(
|
||||
ResnetBlock(
|
||||
ResnetBlock2D(
|
||||
in_channels=block_in, out_channels=block_out, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
)
|
||||
block_in = block_out
|
||||
if curr_res in attn_resolutions:
|
||||
attn.append(AttnBlock(block_in))
|
||||
attn.append(AttentionBlock(block_in, overwrite_qkv=True))
|
||||
up = nn.Module()
|
||||
up.block = block
|
||||
up.attn = attn
|
||||
if i_level != 0:
|
||||
up.upsample = Upsample(block_in, resamp_with_conv)
|
||||
up.upsample = Upsample2D(block_in, use_conv=resamp_with_conv)
|
||||
curr_res = curr_res * 2
|
||||
self.up.insert(0, up) # prepend to get consistent order
|
||||
|
||||
@@ -514,8 +223,8 @@ class Decoder(nn.Module):
|
||||
|
||||
class VectorQuantizer(nn.Module):
|
||||
"""
|
||||
Improved version over VectorQuantizer, can be used as a drop-in replacement. Mostly
|
||||
avoids costly matrix multiplications and allows for post-hoc remapping of indices.
|
||||
Improved version over VectorQuantizer, can be used as a drop-in replacement. Mostly avoids costly matrix
|
||||
multiplications and allows for post-hoc remapping of indices.
|
||||
"""
|
||||
|
||||
# NOTE: due to a bug the beta term was applied to the wrong term. for
|
||||
@@ -572,19 +281,16 @@ class VectorQuantizer(nn.Module):
|
||||
back = torch.gather(used[None, :][inds.shape[0] * [0], :], 1, inds)
|
||||
return back.reshape(ishape)
|
||||
|
||||
def forward(self, z, temp=None, rescale_logits=False, return_logits=False):
|
||||
assert temp is None or temp == 1.0, "Only for interface compatible with Gumbel"
|
||||
assert rescale_logits == False, "Only for interface compatible with Gumbel"
|
||||
assert return_logits == False, "Only for interface compatible with Gumbel"
|
||||
def forward(self, z):
|
||||
# reshape z -> (batch, height, width, channel) and flatten
|
||||
z = rearrange(z, "b c h w -> b h w c").contiguous()
|
||||
z = z.permute(0, 2, 3, 1).contiguous()
|
||||
z_flattened = z.view(-1, self.e_dim)
|
||||
# distances from z to embeddings e_j (z - e)^2 = z^2 + e^2 - 2 e * z
|
||||
|
||||
d = (
|
||||
torch.sum(z_flattened**2, dim=1, keepdim=True)
|
||||
+ torch.sum(self.embedding.weight**2, dim=1)
|
||||
- 2 * torch.einsum("bd,dn->bn", z_flattened, rearrange(self.embedding.weight, "n d -> d n"))
|
||||
- 2 * torch.einsum("bd,dn->bn", z_flattened, self.embedding.weight.t())
|
||||
)
|
||||
|
||||
min_encoding_indices = torch.argmin(d, dim=1)
|
||||
@@ -602,7 +308,7 @@ class VectorQuantizer(nn.Module):
|
||||
z_q = z + (z_q - z).detach()
|
||||
|
||||
# reshape back to match original input shape
|
||||
z_q = rearrange(z_q, "b h w c -> b c h w").contiguous()
|
||||
z_q = z_q.permute(0, 3, 1, 2).contiguous()
|
||||
|
||||
if self.remap is not None:
|
||||
min_encoding_indices = min_encoding_indices.reshape(z.shape[0], -1) # add batch axis
|
||||
@@ -632,97 +338,6 @@ class VectorQuantizer(nn.Module):
|
||||
return z_q
|
||||
|
||||
|
||||
class VQModel(ModelMixin, ConfigMixin):
|
||||
def __init__(
|
||||
self,
|
||||
ch,
|
||||
out_ch,
|
||||
num_res_blocks,
|
||||
attn_resolutions,
|
||||
in_channels,
|
||||
resolution,
|
||||
z_channels,
|
||||
n_embed,
|
||||
embed_dim,
|
||||
remap=None,
|
||||
sane_index_shape=False, # tell vector quantizer to return indices as bhw
|
||||
ch_mult=(1, 2, 4, 8),
|
||||
dropout=0.0,
|
||||
double_z=True,
|
||||
resamp_with_conv=True,
|
||||
give_pre_end=False,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
# register all __init__ params with self.register
|
||||
self.register(
|
||||
ch=ch,
|
||||
out_ch=out_ch,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attn_resolutions=attn_resolutions,
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
z_channels=z_channels,
|
||||
n_embed=n_embed,
|
||||
embed_dim=embed_dim,
|
||||
remap=remap,
|
||||
sane_index_shape=sane_index_shape,
|
||||
ch_mult=ch_mult,
|
||||
dropout=dropout,
|
||||
double_z=double_z,
|
||||
resamp_with_conv=resamp_with_conv,
|
||||
give_pre_end=give_pre_end,
|
||||
)
|
||||
|
||||
# pass init params to Encoder
|
||||
self.encoder = Encoder(
|
||||
ch=ch,
|
||||
out_ch=out_ch,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attn_resolutions=attn_resolutions,
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
z_channels=z_channels,
|
||||
ch_mult=ch_mult,
|
||||
dropout=dropout,
|
||||
resamp_with_conv=resamp_with_conv,
|
||||
double_z=double_z,
|
||||
give_pre_end=give_pre_end,
|
||||
)
|
||||
|
||||
self.quantize = VectorQuantizer(n_embed, embed_dim, beta=0.25, remap=remap, sane_index_shape=sane_index_shape)
|
||||
|
||||
# pass init params to Decoder
|
||||
self.decoder = Decoder(
|
||||
ch=ch,
|
||||
out_ch=out_ch,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attn_resolutions=attn_resolutions,
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
z_channels=z_channels,
|
||||
ch_mult=ch_mult,
|
||||
dropout=dropout,
|
||||
resamp_with_conv=resamp_with_conv,
|
||||
give_pre_end=give_pre_end,
|
||||
)
|
||||
|
||||
def encode(self, x):
|
||||
h = self.encoder(x)
|
||||
h = self.quant_conv(h)
|
||||
return h
|
||||
|
||||
def decode(self, h, force_not_quantize=False):
|
||||
# also go through quantization layer
|
||||
if not force_not_quantize:
|
||||
quant, emb_loss, info = self.quantize(h)
|
||||
else:
|
||||
quant = h
|
||||
quant = self.post_quant_conv(quant)
|
||||
dec = self.decoder(quant)
|
||||
return dec
|
||||
|
||||
|
||||
class DiagonalGaussianDistribution(object):
|
||||
def __init__(self, parameters, deterministic=False):
|
||||
self.parameters = parameters
|
||||
@@ -764,7 +379,87 @@ class DiagonalGaussianDistribution(object):
|
||||
return self.mean
|
||||
|
||||
|
||||
class VQModel(ModelMixin, ConfigMixin):
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
ch,
|
||||
out_ch,
|
||||
num_res_blocks,
|
||||
attn_resolutions,
|
||||
in_channels,
|
||||
resolution,
|
||||
z_channels,
|
||||
n_embed,
|
||||
embed_dim,
|
||||
remap=None,
|
||||
sane_index_shape=False, # tell vector quantizer to return indices as bhw
|
||||
ch_mult=(1, 2, 4, 8),
|
||||
dropout=0.0,
|
||||
double_z=True,
|
||||
resamp_with_conv=True,
|
||||
give_pre_end=False,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
# pass init params to Encoder
|
||||
self.encoder = Encoder(
|
||||
ch=ch,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attn_resolutions=attn_resolutions,
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
z_channels=z_channels,
|
||||
ch_mult=ch_mult,
|
||||
dropout=dropout,
|
||||
resamp_with_conv=resamp_with_conv,
|
||||
double_z=double_z,
|
||||
give_pre_end=give_pre_end,
|
||||
)
|
||||
|
||||
self.quant_conv = torch.nn.Conv2d(z_channels, embed_dim, 1)
|
||||
self.quantize = VectorQuantizer(n_embed, embed_dim, beta=0.25, remap=remap, sane_index_shape=sane_index_shape)
|
||||
self.post_quant_conv = torch.nn.Conv2d(embed_dim, z_channels, 1)
|
||||
|
||||
# pass init params to Decoder
|
||||
self.decoder = Decoder(
|
||||
ch=ch,
|
||||
out_ch=out_ch,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attn_resolutions=attn_resolutions,
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
z_channels=z_channels,
|
||||
ch_mult=ch_mult,
|
||||
dropout=dropout,
|
||||
resamp_with_conv=resamp_with_conv,
|
||||
give_pre_end=give_pre_end,
|
||||
)
|
||||
|
||||
def encode(self, x):
|
||||
h = self.encoder(x)
|
||||
h = self.quant_conv(h)
|
||||
return h
|
||||
|
||||
def decode(self, h, force_not_quantize=False):
|
||||
# also go through quantization layer
|
||||
if not force_not_quantize:
|
||||
quant, emb_loss, info = self.quantize(h)
|
||||
else:
|
||||
quant = h
|
||||
quant = self.post_quant_conv(quant)
|
||||
dec = self.decoder(quant)
|
||||
return dec
|
||||
|
||||
def forward(self, sample):
|
||||
x = sample
|
||||
h = self.encode(x)
|
||||
dec = self.decode(h)
|
||||
return dec
|
||||
|
||||
|
||||
class AutoencoderKL(ModelMixin, ConfigMixin):
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
ch,
|
||||
@@ -785,25 +480,6 @@ class AutoencoderKL(ModelMixin, ConfigMixin):
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
# register all __init__ params with self.register
|
||||
self.register(
|
||||
ch=ch,
|
||||
out_ch=out_ch,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attn_resolutions=attn_resolutions,
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
z_channels=z_channels,
|
||||
embed_dim=embed_dim,
|
||||
remap=remap,
|
||||
sane_index_shape=sane_index_shape,
|
||||
ch_mult=ch_mult,
|
||||
dropout=dropout,
|
||||
double_z=double_z,
|
||||
resamp_with_conv=resamp_with_conv,
|
||||
give_pre_end=give_pre_end,
|
||||
)
|
||||
|
||||
# pass init params to Encoder
|
||||
self.encoder = Encoder(
|
||||
ch=ch,
|
||||
@@ -849,11 +525,12 @@ class AutoencoderKL(ModelMixin, ConfigMixin):
|
||||
dec = self.decoder(z)
|
||||
return dec
|
||||
|
||||
def forward(self, input, sample_posterior=True):
|
||||
posterior = self.encode(input)
|
||||
def forward(self, sample, sample_posterior=False):
|
||||
x = sample
|
||||
posterior = self.encode(x)
|
||||
if sample_posterior:
|
||||
z = posterior.sample()
|
||||
else:
|
||||
z = posterior.mode()
|
||||
dec = self.decode(z)
|
||||
return dec, posterior
|
||||
return dec
|
||||
276
src/diffusers/optimization.py
Normal file
276
src/diffusers/optimization.py
Normal file
@@ -0,0 +1,276 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""PyTorch optimization for diffusion models."""
|
||||
|
||||
import math
|
||||
from enum import Enum
|
||||
from typing import Optional, Union
|
||||
|
||||
import torch
|
||||
from torch.optim import Optimizer
|
||||
from torch.optim.lr_scheduler import LambdaLR
|
||||
|
||||
from .utils import logging
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
class SchedulerType(Enum):
|
||||
LINEAR = "linear"
|
||||
COSINE = "cosine"
|
||||
COSINE_WITH_RESTARTS = "cosine_with_restarts"
|
||||
POLYNOMIAL = "polynomial"
|
||||
CONSTANT = "constant"
|
||||
CONSTANT_WITH_WARMUP = "constant_with_warmup"
|
||||
|
||||
|
||||
def get_constant_schedule(optimizer: Optimizer, last_epoch: int = -1):
|
||||
"""
|
||||
Create a schedule with a constant learning rate, using the learning rate set in optimizer.
|
||||
|
||||
Args:
|
||||
optimizer ([`~torch.optim.Optimizer`]):
|
||||
The optimizer for which to schedule the learning rate.
|
||||
last_epoch (`int`, *optional*, defaults to -1):
|
||||
The index of the last epoch when resuming training.
|
||||
|
||||
Return:
|
||||
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
|
||||
"""
|
||||
return LambdaLR(optimizer, lambda _: 1, last_epoch=last_epoch)
|
||||
|
||||
|
||||
def get_constant_schedule_with_warmup(optimizer: Optimizer, num_warmup_steps: int, last_epoch: int = -1):
|
||||
"""
|
||||
Create a schedule with a constant learning rate preceded by a warmup period during which the learning rate
|
||||
increases linearly between 0 and the initial lr set in the optimizer.
|
||||
|
||||
Args:
|
||||
optimizer ([`~torch.optim.Optimizer`]):
|
||||
The optimizer for which to schedule the learning rate.
|
||||
num_warmup_steps (`int`):
|
||||
The number of steps for the warmup phase.
|
||||
last_epoch (`int`, *optional*, defaults to -1):
|
||||
The index of the last epoch when resuming training.
|
||||
|
||||
Return:
|
||||
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
|
||||
"""
|
||||
|
||||
def lr_lambda(current_step: int):
|
||||
if current_step < num_warmup_steps:
|
||||
return float(current_step) / float(max(1.0, num_warmup_steps))
|
||||
return 1.0
|
||||
|
||||
return LambdaLR(optimizer, lr_lambda, last_epoch=last_epoch)
|
||||
|
||||
|
||||
def get_linear_schedule_with_warmup(optimizer, num_warmup_steps, num_training_steps, last_epoch=-1):
|
||||
"""
|
||||
Create a schedule with a learning rate that decreases linearly from the initial lr set in the optimizer to 0, after
|
||||
a warmup period during which it increases linearly from 0 to the initial lr set in the optimizer.
|
||||
|
||||
Args:
|
||||
optimizer ([`~torch.optim.Optimizer`]):
|
||||
The optimizer for which to schedule the learning rate.
|
||||
num_warmup_steps (`int`):
|
||||
The number of steps for the warmup phase.
|
||||
num_training_steps (`int`):
|
||||
The total number of training steps.
|
||||
last_epoch (`int`, *optional*, defaults to -1):
|
||||
The index of the last epoch when resuming training.
|
||||
|
||||
Return:
|
||||
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
|
||||
"""
|
||||
|
||||
def lr_lambda(current_step: int):
|
||||
if current_step < num_warmup_steps:
|
||||
return float(current_step) / float(max(1, num_warmup_steps))
|
||||
return max(
|
||||
0.0, float(num_training_steps - current_step) / float(max(1, num_training_steps - num_warmup_steps))
|
||||
)
|
||||
|
||||
return LambdaLR(optimizer, lr_lambda, last_epoch)
|
||||
|
||||
|
||||
def get_cosine_schedule_with_warmup(
|
||||
optimizer: Optimizer, num_warmup_steps: int, num_training_steps: int, num_cycles: float = 0.5, last_epoch: int = -1
|
||||
):
|
||||
"""
|
||||
Create a schedule with a learning rate that decreases following the values of the cosine function between the
|
||||
initial lr set in the optimizer to 0, after a warmup period during which it increases linearly between 0 and the
|
||||
initial lr set in the optimizer.
|
||||
|
||||
Args:
|
||||
optimizer ([`~torch.optim.Optimizer`]):
|
||||
The optimizer for which to schedule the learning rate.
|
||||
num_warmup_steps (`int`):
|
||||
The number of steps for the warmup phase.
|
||||
num_training_steps (`int`):
|
||||
The total number of training steps.
|
||||
num_cycles (`float`, *optional*, defaults to 0.5):
|
||||
The number of waves in the cosine schedule (the defaults is to just decrease from the max value to 0
|
||||
following a half-cosine).
|
||||
last_epoch (`int`, *optional*, defaults to -1):
|
||||
The index of the last epoch when resuming training.
|
||||
|
||||
Return:
|
||||
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
|
||||
"""
|
||||
|
||||
def lr_lambda(current_step):
|
||||
if current_step < num_warmup_steps:
|
||||
return float(current_step) / float(max(1, num_warmup_steps))
|
||||
progress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))
|
||||
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress)))
|
||||
|
||||
return LambdaLR(optimizer, lr_lambda, last_epoch)
|
||||
|
||||
|
||||
def get_cosine_with_hard_restarts_schedule_with_warmup(
|
||||
optimizer: Optimizer, num_warmup_steps: int, num_training_steps: int, num_cycles: int = 1, last_epoch: int = -1
|
||||
):
|
||||
"""
|
||||
Create a schedule with a learning rate that decreases following the values of the cosine function between the
|
||||
initial lr set in the optimizer to 0, with several hard restarts, after a warmup period during which it increases
|
||||
linearly between 0 and the initial lr set in the optimizer.
|
||||
|
||||
Args:
|
||||
optimizer ([`~torch.optim.Optimizer`]):
|
||||
The optimizer for which to schedule the learning rate.
|
||||
num_warmup_steps (`int`):
|
||||
The number of steps for the warmup phase.
|
||||
num_training_steps (`int`):
|
||||
The total number of training steps.
|
||||
num_cycles (`int`, *optional*, defaults to 1):
|
||||
The number of hard restarts to use.
|
||||
last_epoch (`int`, *optional*, defaults to -1):
|
||||
The index of the last epoch when resuming training.
|
||||
|
||||
Return:
|
||||
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
|
||||
"""
|
||||
|
||||
def lr_lambda(current_step):
|
||||
if current_step < num_warmup_steps:
|
||||
return float(current_step) / float(max(1, num_warmup_steps))
|
||||
progress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))
|
||||
if progress >= 1.0:
|
||||
return 0.0
|
||||
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * ((float(num_cycles) * progress) % 1.0))))
|
||||
|
||||
return LambdaLR(optimizer, lr_lambda, last_epoch)
|
||||
|
||||
|
||||
def get_polynomial_decay_schedule_with_warmup(
|
||||
optimizer, num_warmup_steps, num_training_steps, lr_end=1e-7, power=1.0, last_epoch=-1
|
||||
):
|
||||
"""
|
||||
Create a schedule with a learning rate that decreases as a polynomial decay from the initial lr set in the
|
||||
optimizer to end lr defined by *lr_end*, after a warmup period during which it increases linearly from 0 to the
|
||||
initial lr set in the optimizer.
|
||||
|
||||
Args:
|
||||
optimizer ([`~torch.optim.Optimizer`]):
|
||||
The optimizer for which to schedule the learning rate.
|
||||
num_warmup_steps (`int`):
|
||||
The number of steps for the warmup phase.
|
||||
num_training_steps (`int`):
|
||||
The total number of training steps.
|
||||
lr_end (`float`, *optional*, defaults to 1e-7):
|
||||
The end LR.
|
||||
power (`float`, *optional*, defaults to 1.0):
|
||||
Power factor.
|
||||
last_epoch (`int`, *optional*, defaults to -1):
|
||||
The index of the last epoch when resuming training.
|
||||
|
||||
Note: *power* defaults to 1.0 as in the fairseq implementation, which in turn is based on the original BERT
|
||||
implementation at
|
||||
https://github.com/google-research/bert/blob/f39e881b169b9d53bea03d2d341b31707a6c052b/optimization.py#L37
|
||||
|
||||
Return:
|
||||
`torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.
|
||||
|
||||
"""
|
||||
|
||||
lr_init = optimizer.defaults["lr"]
|
||||
if not (lr_init > lr_end):
|
||||
raise ValueError(f"lr_end ({lr_end}) must be be smaller than initial lr ({lr_init})")
|
||||
|
||||
def lr_lambda(current_step: int):
|
||||
if current_step < num_warmup_steps:
|
||||
return float(current_step) / float(max(1, num_warmup_steps))
|
||||
elif current_step > num_training_steps:
|
||||
return lr_end / lr_init # as LambdaLR multiplies by lr_init
|
||||
else:
|
||||
lr_range = lr_init - lr_end
|
||||
decay_steps = num_training_steps - num_warmup_steps
|
||||
pct_remaining = 1 - (current_step - num_warmup_steps) / decay_steps
|
||||
decay = lr_range * pct_remaining**power + lr_end
|
||||
return decay / lr_init # as LambdaLR multiplies by lr_init
|
||||
|
||||
return LambdaLR(optimizer, lr_lambda, last_epoch)
|
||||
|
||||
|
||||
TYPE_TO_SCHEDULER_FUNCTION = {
|
||||
SchedulerType.LINEAR: get_linear_schedule_with_warmup,
|
||||
SchedulerType.COSINE: get_cosine_schedule_with_warmup,
|
||||
SchedulerType.COSINE_WITH_RESTARTS: get_cosine_with_hard_restarts_schedule_with_warmup,
|
||||
SchedulerType.POLYNOMIAL: get_polynomial_decay_schedule_with_warmup,
|
||||
SchedulerType.CONSTANT: get_constant_schedule,
|
||||
SchedulerType.CONSTANT_WITH_WARMUP: get_constant_schedule_with_warmup,
|
||||
}
|
||||
|
||||
|
||||
def get_scheduler(
|
||||
name: Union[str, SchedulerType],
|
||||
optimizer: Optimizer,
|
||||
num_warmup_steps: Optional[int] = None,
|
||||
num_training_steps: Optional[int] = None,
|
||||
):
|
||||
"""
|
||||
Unified API to get any scheduler from its name.
|
||||
|
||||
Args:
|
||||
name (`str` or `SchedulerType`):
|
||||
The name of the scheduler to use.
|
||||
optimizer (`torch.optim.Optimizer`):
|
||||
The optimizer that will be used during training.
|
||||
num_warmup_steps (`int`, *optional*):
|
||||
The number of warmup steps to do. This is not required by all schedulers (hence the argument being
|
||||
optional), the function will raise an error if it's unset and the scheduler type requires it.
|
||||
num_training_steps (`int``, *optional*):
|
||||
The number of training steps to do. This is not required by all schedulers (hence the argument being
|
||||
optional), the function will raise an error if it's unset and the scheduler type requires it.
|
||||
"""
|
||||
name = SchedulerType(name)
|
||||
schedule_func = TYPE_TO_SCHEDULER_FUNCTION[name]
|
||||
if name == SchedulerType.CONSTANT:
|
||||
return schedule_func(optimizer)
|
||||
|
||||
# All other schedulers require `num_warmup_steps`
|
||||
if num_warmup_steps is None:
|
||||
raise ValueError(f"{name} requires `num_warmup_steps`, please provide that argument.")
|
||||
|
||||
if name == SchedulerType.CONSTANT_WITH_WARMUP:
|
||||
return schedule_func(optimizer, num_warmup_steps=num_warmup_steps)
|
||||
|
||||
# All other schedulers require `num_training_steps`
|
||||
if num_training_steps is None:
|
||||
raise ValueError(f"{name} requires `num_training_steps`, please provide that argument.")
|
||||
|
||||
return schedule_func(optimizer, num_warmup_steps=num_warmup_steps, num_training_steps=num_training_steps)
|
||||
@@ -19,13 +19,13 @@ import os
|
||||
from typing import Optional, Union
|
||||
|
||||
from huggingface_hub import snapshot_download
|
||||
from PIL import Image
|
||||
|
||||
from .configuration_utils import ConfigMixin
|
||||
from .dynamic_modules_utils import get_class_from_dynamic_module
|
||||
from .utils import DIFFUSERS_CACHE, logging
|
||||
|
||||
|
||||
INDEX_FILE = "diffusion_model.pt"
|
||||
INDEX_FILE = "diffusion_pytorch_model.bin"
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
@@ -36,7 +36,6 @@ LOADABLE_CLASSES = {
|
||||
"ModelMixin": ["save_pretrained", "from_pretrained"],
|
||||
"SchedulerMixin": ["save_config", "from_config"],
|
||||
"DiffusionPipeline": ["save_pretrained", "from_pretrained"],
|
||||
"ClassifierFreeGuidanceScheduler": ["save_config", "from_config"],
|
||||
},
|
||||
"transformers": {
|
||||
"PreTrainedTokenizer": ["save_pretrained", "from_pretrained"],
|
||||
@@ -59,17 +58,19 @@ class DiffusionPipeline(ConfigMixin):
|
||||
from diffusers import pipelines
|
||||
|
||||
for name, module in kwargs.items():
|
||||
# check if the module is a pipeline module
|
||||
is_pipeline_module = hasattr(pipelines, module.__module__.split(".")[-1])
|
||||
|
||||
# retrive library
|
||||
library = module.__module__.split(".")[0]
|
||||
|
||||
# check if the module is a pipeline module
|
||||
pipeline_file = module.__module__.split(".")[-1]
|
||||
pipeline_dir = module.__module__.split(".")[-2]
|
||||
is_pipeline_module = pipeline_file == "pipeline_" + pipeline_dir and hasattr(pipelines, pipeline_dir)
|
||||
|
||||
# if library is not in LOADABLE_CLASSES, then it is a custom module.
|
||||
# Or if it's a pipeline module, then the module is inside the pipeline
|
||||
# so we set the library to module name.
|
||||
# folder so we set the library to module name.
|
||||
if library not in LOADABLE_CLASSES or is_pipeline_module:
|
||||
library = module.__module__.split(".")[-1]
|
||||
library = pipeline_dir
|
||||
|
||||
# retrive class_name
|
||||
class_name = module.__class__.__name__
|
||||
@@ -77,21 +78,18 @@ class DiffusionPipeline(ConfigMixin):
|
||||
register_dict = {name: (library, class_name)}
|
||||
|
||||
# save model index config
|
||||
self.register(**register_dict)
|
||||
self.register_to_config(**register_dict)
|
||||
|
||||
# set models
|
||||
setattr(self, name, module)
|
||||
|
||||
register_dict = {"_module": self.__module__.split(".")[-1]}
|
||||
self.register(**register_dict)
|
||||
|
||||
def save_pretrained(self, save_directory: Union[str, os.PathLike]):
|
||||
self.save_config(save_directory)
|
||||
|
||||
model_index_dict = self.config
|
||||
model_index_dict = dict(self.config)
|
||||
model_index_dict.pop("_class_name")
|
||||
model_index_dict.pop("_diffusers_version")
|
||||
model_index_dict.pop("_module")
|
||||
model_index_dict.pop("_module", None)
|
||||
|
||||
for pipeline_component_name in model_index_dict.keys():
|
||||
sub_model = getattr(self, pipeline_component_name)
|
||||
@@ -123,6 +121,7 @@ class DiffusionPipeline(ConfigMixin):
|
||||
proxies = kwargs.pop("proxies", None)
|
||||
local_files_only = kwargs.pop("local_files_only", False)
|
||||
use_auth_token = kwargs.pop("use_auth_token", None)
|
||||
revision = kwargs.pop("revision", None)
|
||||
|
||||
# 1. Download the checkpoints and configs
|
||||
# use snapshot download here to get it working from from_pretrained
|
||||
@@ -134,17 +133,14 @@ class DiffusionPipeline(ConfigMixin):
|
||||
proxies=proxies,
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
)
|
||||
else:
|
||||
cached_folder = pretrained_model_name_or_path
|
||||
|
||||
config_dict = cls.get_config_dict(cached_folder)
|
||||
|
||||
# 2. Get class name and module candidates to load custom models
|
||||
module_candidate_name = config_dict["_module"]
|
||||
module_candidate = module_candidate_name + ".py"
|
||||
|
||||
# 3. Load the pipeline class, if using custom module then load it from the hub
|
||||
# 2. Load the pipeline class, if using custom module then load it from the hub
|
||||
# if we load from explicit class, let's use it
|
||||
if cls != DiffusionPipeline:
|
||||
pipeline_class = cls
|
||||
@@ -152,11 +148,6 @@ class DiffusionPipeline(ConfigMixin):
|
||||
diffusers_module = importlib.import_module(cls.__module__.split(".")[0])
|
||||
pipeline_class = getattr(diffusers_module, config_dict["_class_name"])
|
||||
|
||||
# (TODO - we should allow to load custom pipelines
|
||||
# else we need to load the correct module from the Hub
|
||||
# module = module_candidate
|
||||
# pipeline_class = get_class_from_dynamic_module(cached_folder, module, class_name_, cached_folder)
|
||||
|
||||
init_dict, _ = pipeline_class.extract_init_dict(config_dict, **kwargs)
|
||||
|
||||
init_kwargs = {}
|
||||
@@ -164,7 +155,7 @@ class DiffusionPipeline(ConfigMixin):
|
||||
# import it here to avoid circular import
|
||||
from diffusers import pipelines
|
||||
|
||||
# 4. Load each module in the pipeline
|
||||
# 3. Load each module in the pipeline
|
||||
for name, (library_name, class_name) in init_dict.items():
|
||||
is_pipeline_module = hasattr(pipelines, library_name)
|
||||
# if the model is in a pipeline module, then we load it from the pipeline
|
||||
@@ -172,14 +163,7 @@ class DiffusionPipeline(ConfigMixin):
|
||||
pipeline_module = getattr(pipelines, library_name)
|
||||
class_obj = getattr(pipeline_module, class_name)
|
||||
importable_classes = ALL_IMPORTABLE_CLASSES
|
||||
class_candidates = {c: class_obj for c in ALL_IMPORTABLE_CLASSES.keys()}
|
||||
elif library_name == module_candidate_name:
|
||||
# if the model is not in diffusers or transformers, we need to load it from the hub
|
||||
# assumes that it's a subclass of ModelMixin
|
||||
class_obj = get_class_from_dynamic_module(cached_folder, module_candidate, class_name, cached_folder)
|
||||
# since it's not from a library, we need to check class candidates for all importable classes
|
||||
importable_classes = ALL_IMPORTABLE_CLASSES
|
||||
class_candidates = {c: class_obj for c in ALL_IMPORTABLE_CLASSES.keys()}
|
||||
class_candidates = {c: class_obj for c in importable_classes.keys()}
|
||||
else:
|
||||
# else we just import it from the library.
|
||||
library = importlib.import_module(library_name)
|
||||
@@ -206,3 +190,15 @@ class DiffusionPipeline(ConfigMixin):
|
||||
# 5. Instantiate the pipeline
|
||||
model = pipeline_class(**init_kwargs)
|
||||
return model
|
||||
|
||||
@staticmethod
|
||||
def numpy_to_pil(images):
|
||||
"""
|
||||
Convert a numpy image or a batch of images to a PIL image.
|
||||
"""
|
||||
if images.ndim == 3:
|
||||
images = images[None, ...]
|
||||
images = (images * 255).round().astype("uint8")
|
||||
pil_images = [Image.fromarray(image) for image in images]
|
||||
|
||||
return pil_images
|
||||
|
||||
@@ -1,19 +0,0 @@
|
||||
# Pipelines
|
||||
|
||||
- Pipelines are a collection of end-to-end diffusion systems that can be used out-of-the-box
|
||||
- Pipelines should stay as close as possible to their original implementation
|
||||
- Pipelines can include components of other library, such as text-encoders.
|
||||
|
||||
## API
|
||||
|
||||
TODO(Patrick, Anton, Suraj)
|
||||
|
||||
## Examples
|
||||
|
||||
- DDPM for unconditional image generation in [pipeline_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_ddpm.py).
|
||||
- DDIM for unconditional image generation in [pipeline_ddim](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_ddim.py).
|
||||
- PNDM for unconditional image generation in [pipeline_pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_pndm.py).
|
||||
- Latent diffusion for text to image generation / conditional image generation in [pipeline_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_bddm.py).
|
||||
- Glide for text to image generation / conditional image generation in [pipeline_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_bddm.py).
|
||||
- BDDM for spectrogram-to-sound vocoding in [pipeline_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_bddm.py).
|
||||
- Grad-TTS for text to audio generation / conditional audio generation in [pipeline_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_bddm.py).
|
||||
@@ -15,5 +15,5 @@ TODO(Patrick, Anton, Suraj)
|
||||
- PNDM for unconditional image generation in [pipeline_pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_pndm.py).
|
||||
- Latent diffusion for text to image generation / conditional image generation in [pipeline_latent_diffusion](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_latent_diffusion.py).
|
||||
- Glide for text to image generation / conditional image generation in [pipeline_glide](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_glide.py).
|
||||
- BDDM for spectrogram-to-sound vocoding in [pipeline_bddm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_bddm.py).
|
||||
- BDDMPipeline for spectrogram-to-sound vocoding in [pipeline_bddm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_bddm.py).
|
||||
- Grad-TTS for text to audio generation / conditional audio generation in [pipeline_grad_tts](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_grad_tts.py).
|
||||
|
||||
@@ -1,15 +1,10 @@
|
||||
from .pipeline_bddm import BDDM
|
||||
from .pipeline_ddim import DDIM
|
||||
from .pipeline_ddpm import DDPM
|
||||
from ..utils import is_inflect_available, is_transformers_available, is_unidecode_available
|
||||
from .ddim import DDIMPipeline
|
||||
from .ddpm import DDPMPipeline
|
||||
from .latent_diffusion_uncond import LDMPipeline
|
||||
from .pndm import PNDMPipeline
|
||||
from .score_sde_ve import ScoreSdeVePipeline
|
||||
|
||||
|
||||
try:
|
||||
from .pipeline_glide import GLIDE
|
||||
except (NameError, ImportError):
|
||||
|
||||
class GLIDE:
|
||||
pass
|
||||
|
||||
|
||||
from .pipeline_latent_diffusion import LatentDiffusion
|
||||
from .pipeline_pndm import PNDM
|
||||
if is_transformers_available():
|
||||
from .latent_diffusion import LDMTextToImagePipeline
|
||||
|
||||
@@ -1,113 +0,0 @@
|
||||
import torch
|
||||
from torch import nn
|
||||
|
||||
from diffusers import ClassifierFreeGuidanceScheduler, DDIMScheduler, GLIDESuperResUNetModel, GLIDETextToImageUNetModel
|
||||
from diffusers.pipelines.pipeline_glide import GLIDE, CLIPTextModel
|
||||
from transformers import CLIPTextConfig, GPT2Tokenizer
|
||||
|
||||
|
||||
# wget https://openaipublic.blob.core.windows.net/diffusion/dec-2021/base.pt
|
||||
state_dict = torch.load("base.pt", map_location="cpu")
|
||||
state_dict = {k: nn.Parameter(v) for k, v in state_dict.items()}
|
||||
|
||||
### Convert the text encoder
|
||||
|
||||
config = CLIPTextConfig(
|
||||
vocab_size=50257,
|
||||
max_position_embeddings=128,
|
||||
hidden_size=512,
|
||||
intermediate_size=2048,
|
||||
num_hidden_layers=16,
|
||||
num_attention_heads=8,
|
||||
use_padding_embeddings=True,
|
||||
)
|
||||
model = CLIPTextModel(config).eval()
|
||||
tokenizer = GPT2Tokenizer(
|
||||
"./glide-base/tokenizer/vocab.json", "./glide-base/tokenizer/merges.txt", pad_token="<|endoftext|>"
|
||||
)
|
||||
|
||||
hf_encoder = model.text_model
|
||||
|
||||
hf_encoder.embeddings.token_embedding.weight = state_dict["token_embedding.weight"]
|
||||
hf_encoder.embeddings.position_embedding.weight.data = state_dict["positional_embedding"]
|
||||
hf_encoder.embeddings.padding_embedding.weight.data = state_dict["padding_embedding"]
|
||||
|
||||
hf_encoder.final_layer_norm.weight = state_dict["final_ln.weight"]
|
||||
hf_encoder.final_layer_norm.bias = state_dict["final_ln.bias"]
|
||||
|
||||
for layer_idx in range(config.num_hidden_layers):
|
||||
hf_layer = hf_encoder.encoder.layers[layer_idx]
|
||||
hf_layer.self_attn.qkv_proj.weight = state_dict[f"transformer.resblocks.{layer_idx}.attn.c_qkv.weight"]
|
||||
hf_layer.self_attn.qkv_proj.bias = state_dict[f"transformer.resblocks.{layer_idx}.attn.c_qkv.bias"]
|
||||
|
||||
hf_layer.self_attn.out_proj.weight = state_dict[f"transformer.resblocks.{layer_idx}.attn.c_proj.weight"]
|
||||
hf_layer.self_attn.out_proj.bias = state_dict[f"transformer.resblocks.{layer_idx}.attn.c_proj.bias"]
|
||||
|
||||
hf_layer.layer_norm1.weight = state_dict[f"transformer.resblocks.{layer_idx}.ln_1.weight"]
|
||||
hf_layer.layer_norm1.bias = state_dict[f"transformer.resblocks.{layer_idx}.ln_1.bias"]
|
||||
hf_layer.layer_norm2.weight = state_dict[f"transformer.resblocks.{layer_idx}.ln_2.weight"]
|
||||
hf_layer.layer_norm2.bias = state_dict[f"transformer.resblocks.{layer_idx}.ln_2.bias"]
|
||||
|
||||
hf_layer.mlp.fc1.weight = state_dict[f"transformer.resblocks.{layer_idx}.mlp.c_fc.weight"]
|
||||
hf_layer.mlp.fc1.bias = state_dict[f"transformer.resblocks.{layer_idx}.mlp.c_fc.bias"]
|
||||
hf_layer.mlp.fc2.weight = state_dict[f"transformer.resblocks.{layer_idx}.mlp.c_proj.weight"]
|
||||
hf_layer.mlp.fc2.bias = state_dict[f"transformer.resblocks.{layer_idx}.mlp.c_proj.bias"]
|
||||
|
||||
### Convert the Text-to-Image UNet
|
||||
|
||||
text2im_model = GLIDETextToImageUNetModel(
|
||||
in_channels=3,
|
||||
model_channels=192,
|
||||
out_channels=6,
|
||||
num_res_blocks=3,
|
||||
attention_resolutions=(2, 4, 8),
|
||||
dropout=0.1,
|
||||
channel_mult=(1, 2, 3, 4),
|
||||
num_heads=1,
|
||||
num_head_channels=64,
|
||||
num_heads_upsample=1,
|
||||
use_scale_shift_norm=True,
|
||||
resblock_updown=True,
|
||||
transformer_dim=512,
|
||||
)
|
||||
|
||||
text2im_model.load_state_dict(state_dict, strict=False)
|
||||
|
||||
text_scheduler = ClassifierFreeGuidanceScheduler(timesteps=1000, beta_schedule="squaredcos_cap_v2")
|
||||
|
||||
### Convert the Super-Resolution UNet
|
||||
|
||||
# wget https://openaipublic.blob.core.windows.net/diffusion/dec-2021/upsample.pt
|
||||
ups_state_dict = torch.load("upsample.pt", map_location="cpu")
|
||||
|
||||
superres_model = GLIDESuperResUNetModel(
|
||||
in_channels=6,
|
||||
model_channels=192,
|
||||
out_channels=6,
|
||||
num_res_blocks=2,
|
||||
attention_resolutions=(8, 16, 32),
|
||||
dropout=0.1,
|
||||
channel_mult=(1, 1, 2, 2, 4, 4),
|
||||
num_heads=1,
|
||||
num_head_channels=64,
|
||||
num_heads_upsample=1,
|
||||
use_scale_shift_norm=True,
|
||||
resblock_updown=True,
|
||||
)
|
||||
|
||||
superres_model.load_state_dict(ups_state_dict, strict=False)
|
||||
|
||||
upscale_scheduler = DDIMScheduler(
|
||||
timesteps=1000, beta_schedule="linear", beta_start=0.0001, beta_end=0.02, tensor_format="pt"
|
||||
)
|
||||
|
||||
glide = GLIDE(
|
||||
text_unet=text2im_model,
|
||||
text_noise_scheduler=text_scheduler,
|
||||
text_encoder=model,
|
||||
tokenizer=tokenizer,
|
||||
upscale_unet=superres_model,
|
||||
upscale_noise_scheduler=upscale_scheduler,
|
||||
)
|
||||
|
||||
glide.save_pretrained("./glide-base")
|
||||
1
src/diffusers/pipelines/ddim/__init__.py
Normal file
1
src/diffusers/pipelines/ddim/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
from .pipeline_ddim import DDIMPipeline
|
||||
63
src/diffusers/pipelines/ddim/pipeline_ddim.py
Normal file
63
src/diffusers/pipelines/ddim/pipeline_ddim.py
Normal file
@@ -0,0 +1,63 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
import torch
|
||||
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
|
||||
|
||||
class DDIMPipeline(DiffusionPipeline):
|
||||
def __init__(self, unet, scheduler):
|
||||
super().__init__()
|
||||
scheduler = scheduler.set_format("pt")
|
||||
self.register_modules(unet=unet, scheduler=scheduler)
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(
|
||||
self, batch_size=1, generator=None, torch_device=None, eta=0.0, num_inference_steps=50, output_type="pil"
|
||||
):
|
||||
# eta corresponds to η in paper and should be between [0, 1]
|
||||
if torch_device is None:
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
self.unet.to(torch_device)
|
||||
|
||||
# Sample gaussian noise to begin loop
|
||||
image = torch.randn(
|
||||
(batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size),
|
||||
generator=generator,
|
||||
)
|
||||
image = image.to(torch_device)
|
||||
|
||||
# set step values
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
|
||||
for t in tqdm(self.scheduler.timesteps):
|
||||
# 1. predict noise model_output
|
||||
model_output = self.unet(image, t)["sample"]
|
||||
|
||||
# 2. predict previous mean of image x_t-1 and add variance depending on eta
|
||||
# do x_t -> x_t-1
|
||||
image = self.scheduler.step(model_output, t, image, eta)["prev_sample"]
|
||||
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).numpy()
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
return {"sample": image}
|
||||
1
src/diffusers/pipelines/ddpm/__init__.py
Normal file
1
src/diffusers/pipelines/ddpm/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
from .pipeline_ddpm import DDPMPipeline
|
||||
59
src/diffusers/pipelines/ddpm/pipeline_ddpm.py
Normal file
59
src/diffusers/pipelines/ddpm/pipeline_ddpm.py
Normal file
@@ -0,0 +1,59 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
import torch
|
||||
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
|
||||
|
||||
class DDPMPipeline(DiffusionPipeline):
|
||||
def __init__(self, unet, scheduler):
|
||||
super().__init__()
|
||||
scheduler = scheduler.set_format("pt")
|
||||
self.register_modules(unet=unet, scheduler=scheduler)
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, batch_size=1, generator=None, torch_device=None, output_type="pil"):
|
||||
if torch_device is None:
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
self.unet.to(torch_device)
|
||||
|
||||
# Sample gaussian noise to begin loop
|
||||
image = torch.randn(
|
||||
(batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size),
|
||||
generator=generator,
|
||||
)
|
||||
image = image.to(torch_device)
|
||||
|
||||
# set step values
|
||||
self.scheduler.set_timesteps(1000)
|
||||
|
||||
for t in tqdm(self.scheduler.timesteps):
|
||||
# 1. predict noise model_output
|
||||
model_output = self.unet(image, t)["sample"]
|
||||
|
||||
# 2. compute previous image: x_t -> t_t-1
|
||||
image = self.scheduler.step(model_output, t, image)["prev_sample"]
|
||||
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).numpy()
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
return {"sample": image}
|
||||
5
src/diffusers/pipelines/latent_diffusion/__init__.py
Normal file
5
src/diffusers/pipelines/latent_diffusion/__init__.py
Normal file
@@ -0,0 +1,5 @@
|
||||
from ...utils import is_transformers_available
|
||||
|
||||
|
||||
if is_transformers_available():
|
||||
from .pipeline_latent_diffusion import LDMBertModel, LDMTextToImagePipeline
|
||||
@@ -1,78 +1,167 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The Fairseq Authors and The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" PyTorch LDMBERT model."""
|
||||
import copy
|
||||
import math
|
||||
import random
|
||||
import warnings
|
||||
from typing import List, Optional, Tuple, Union
|
||||
from typing import Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.utils.checkpoint
|
||||
from torch import nn
|
||||
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
|
||||
|
||||
from tqdm.auto import tqdm
|
||||
from transformers.activations import ACT2FN
|
||||
from transformers.modeling_outputs import (
|
||||
BaseModelOutput,
|
||||
BaseModelOutputWithPastAndCrossAttentions,
|
||||
CausalLMOutputWithCrossAttentions,
|
||||
Seq2SeqLMOutput,
|
||||
Seq2SeqModelOutput,
|
||||
Seq2SeqQuestionAnsweringModelOutput,
|
||||
Seq2SeqSequenceClassifierOutput,
|
||||
)
|
||||
from transformers.configuration_utils import PretrainedConfig
|
||||
from transformers.modeling_outputs import BaseModelOutput
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
from transformers.utils import (
|
||||
add_code_sample_docstrings,
|
||||
add_end_docstrings,
|
||||
add_start_docstrings,
|
||||
add_start_docstrings_to_model_forward,
|
||||
logging,
|
||||
replace_return_docstrings,
|
||||
)
|
||||
from transformers.utils import logging
|
||||
|
||||
from .configuration_ldmbert import LDMBertConfig
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
|
||||
|
||||
class LDMTextToImagePipeline(DiffusionPipeline):
|
||||
def __init__(self, vqvae, bert, tokenizer, unet, scheduler):
|
||||
super().__init__()
|
||||
scheduler = scheduler.set_format("pt")
|
||||
self.register_modules(vqvae=vqvae, bert=bert, tokenizer=tokenizer, unet=unet, scheduler=scheduler)
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(
|
||||
self,
|
||||
prompt,
|
||||
batch_size=1,
|
||||
generator=None,
|
||||
torch_device=None,
|
||||
eta=0.0,
|
||||
guidance_scale=1.0,
|
||||
num_inference_steps=50,
|
||||
output_type="pil",
|
||||
):
|
||||
# eta corresponds to η in paper and should be between [0, 1]
|
||||
|
||||
if torch_device is None:
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
batch_size = len(prompt)
|
||||
|
||||
self.unet.to(torch_device)
|
||||
self.vqvae.to(torch_device)
|
||||
self.bert.to(torch_device)
|
||||
|
||||
# get unconditional embeddings for classifier free guidance
|
||||
if guidance_scale != 1.0:
|
||||
uncond_input = self.tokenizer([""] * batch_size, padding="max_length", max_length=77, return_tensors="pt")
|
||||
uncond_embeddings = self.bert(uncond_input.input_ids.to(torch_device))
|
||||
|
||||
# get prompt text embeddings
|
||||
text_input = self.tokenizer(prompt, padding="max_length", max_length=77, return_tensors="pt")
|
||||
text_embeddings = self.bert(text_input.input_ids.to(torch_device))
|
||||
|
||||
latents = torch.randn(
|
||||
(batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size),
|
||||
generator=generator,
|
||||
)
|
||||
latents = latents.to(torch_device)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
|
||||
for t in tqdm(self.scheduler.timesteps):
|
||||
if guidance_scale == 1.0:
|
||||
# guidance_scale of 1 means no guidance
|
||||
latents_input = latents
|
||||
context = text_embeddings
|
||||
else:
|
||||
# For classifier free guidance, we need to do two forward passes.
|
||||
# Here we concatenate the unconditional and text embeddings into a single batch
|
||||
# to avoid doing two forward passes
|
||||
latents_input = torch.cat([latents] * 2)
|
||||
context = torch.cat([uncond_embeddings, text_embeddings])
|
||||
|
||||
# predict the noise residual
|
||||
noise_pred = self.unet(latents_input, t, encoder_hidden_states=context)["sample"]
|
||||
# perform guidance
|
||||
if guidance_scale != 1.0:
|
||||
noise_pred_uncond, noise_prediction_text = noise_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_prediction_text - noise_pred_uncond)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(noise_pred, t, latents, eta)["prev_sample"]
|
||||
|
||||
# scale and decode the image latents with vae
|
||||
latents = 1 / 0.18215 * latents
|
||||
image = self.vqvae.decode(latents)
|
||||
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).numpy()
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
return {"sample": image}
|
||||
|
||||
|
||||
################################################################################
|
||||
# Code for the text transformer model
|
||||
################################################################################
|
||||
""" PyTorch LDMBERT model."""
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
_CHECKPOINT_FOR_DOC = "ldm-bert"
|
||||
_CONFIG_FOR_DOC = "LDMBertConfig"
|
||||
_TOKENIZER_FOR_DOC = "BartTokenizer"
|
||||
|
||||
# Base model docstring
|
||||
_EXPECTED_OUTPUT_SHAPE = [1, 8, 768]
|
||||
|
||||
# SequenceClassification docstring
|
||||
_CHECKPOINT_FOR_SEQUENCE_CLASSIFICATION = "valhalla/ldmbert-large-sst2"
|
||||
_SEQ_CLASS_EXPECTED_LOSS = 0.0
|
||||
_SEQ_CLASS_EXPECTED_OUTPUT = "'POSITIVE'"
|
||||
|
||||
# QuestionAsnwering docstring
|
||||
_CHECKPOINT_FOR_QA = "valhalla/ldmbert-large-finetuned-squadv1"
|
||||
_QA_EXPECTED_LOSS = 0.59
|
||||
_QA_EXPECTED_OUTPUT = "' nice puppet'"
|
||||
|
||||
|
||||
LDMBERT_PRETRAINED_MODEL_ARCHIVE_LIST = [
|
||||
"ldm-bert",
|
||||
# See all LDMBert models at https://huggingface.co/models?filter=ldmbert
|
||||
]
|
||||
|
||||
|
||||
LDMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
|
||||
"ldm-bert": "https://huggingface.co/ldm-bert/resolve/main/config.json",
|
||||
}
|
||||
|
||||
|
||||
""" LDMBERT model configuration"""
|
||||
|
||||
|
||||
class LDMBertConfig(PretrainedConfig):
|
||||
model_type = "ldmbert"
|
||||
keys_to_ignore_at_inference = ["past_key_values"]
|
||||
attribute_map = {"num_attention_heads": "encoder_attention_heads", "hidden_size": "d_model"}
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_size=30522,
|
||||
max_position_embeddings=77,
|
||||
encoder_layers=32,
|
||||
encoder_ffn_dim=5120,
|
||||
encoder_attention_heads=8,
|
||||
head_dim=64,
|
||||
encoder_layerdrop=0.0,
|
||||
activation_function="gelu",
|
||||
d_model=1280,
|
||||
dropout=0.1,
|
||||
attention_dropout=0.0,
|
||||
activation_dropout=0.0,
|
||||
init_std=0.02,
|
||||
classifier_dropout=0.0,
|
||||
scale_embedding=False,
|
||||
use_cache=True,
|
||||
pad_token_id=0,
|
||||
**kwargs,
|
||||
):
|
||||
self.vocab_size = vocab_size
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.d_model = d_model
|
||||
self.encoder_ffn_dim = encoder_ffn_dim
|
||||
self.encoder_layers = encoder_layers
|
||||
self.encoder_attention_heads = encoder_attention_heads
|
||||
self.head_dim = head_dim
|
||||
self.dropout = dropout
|
||||
self.attention_dropout = attention_dropout
|
||||
self.activation_dropout = activation_dropout
|
||||
self.activation_function = activation_function
|
||||
self.init_std = init_std
|
||||
self.encoder_layerdrop = encoder_layerdrop
|
||||
self.classifier_dropout = classifier_dropout
|
||||
self.use_cache = use_cache
|
||||
self.num_hidden_layers = encoder_layers
|
||||
self.scale_embedding = scale_embedding # scale factor will be sqrt(d_model) if True
|
||||
|
||||
super().__init__(pad_token_id=pad_token_id, **kwargs)
|
||||
|
||||
|
||||
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
|
||||
"""
|
||||
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
||||
@@ -320,7 +409,7 @@ class LDMBertPreTrainedModel(PreTrainedModel):
|
||||
module.weight.data[module.padding_idx].zero_()
|
||||
|
||||
def _set_gradient_checkpointing(self, module, value=False):
|
||||
if isinstance(module, (LDMBertDecoder, LDMBertEncoder)):
|
||||
if isinstance(module, (LDMBertEncoder,)):
|
||||
module.gradient_checkpointing = value
|
||||
|
||||
@property
|
||||
@@ -334,163 +423,6 @@ class LDMBertPreTrainedModel(PreTrainedModel):
|
||||
return dummy_inputs
|
||||
|
||||
|
||||
LDMBERT_START_DOCSTRING = r"""
|
||||
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
|
||||
etc.)
|
||||
|
||||
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
|
||||
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
|
||||
and behavior.
|
||||
|
||||
Parameters:
|
||||
config ([`LDMBertConfig`]):
|
||||
Model configuration class with all the parameters of the model. Initializing with a config file does not
|
||||
load the weights associated with the model, only the configuration. Check out the
|
||||
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
||||
"""
|
||||
|
||||
LDMBERT_GENERATION_EXAMPLE = r"""
|
||||
Summarization example:
|
||||
|
||||
```python
|
||||
>>> from transformers import BartTokenizer, LDMBertForConditionalGeneration
|
||||
|
||||
>>> model = LDMBertForConditionalGeneration.from_pretrained("facebook/ldmbert-large-cnn")
|
||||
>>> tokenizer = BartTokenizer.from_pretrained("facebook/ldmbert-large-cnn")
|
||||
|
||||
>>> ARTICLE_TO_SUMMARIZE = (
|
||||
... "PG&E stated it scheduled the blackouts in response to forecasts for high winds "
|
||||
... "amid dry conditions. The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were "
|
||||
... "scheduled to be affected by the shutoffs which were expected to last through at least midday tomorrow."
|
||||
... )
|
||||
>>> inputs = tokenizer([ARTICLE_TO_SUMMARIZE], max_length=1024, return_tensors="pt")
|
||||
|
||||
>>> # Generate Summary
|
||||
>>> summary_ids = model.generate(inputs["input_ids"], num_beams=2, min_length=0, max_length=20)
|
||||
>>> tokenizer.batch_decode(summary_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
||||
'PG&E scheduled the blackouts in response to forecasts for high winds amid dry conditions'
|
||||
```
|
||||
|
||||
Mask filling example:
|
||||
|
||||
```python
|
||||
>>> from transformers import BartTokenizer, LDMBertForConditionalGeneration
|
||||
|
||||
>>> tokenizer = BartTokenizer.from_pretrained("ldm-bert")
|
||||
>>> model = LDMBertForConditionalGeneration.from_pretrained("ldm-bert")
|
||||
|
||||
>>> TXT = "My friends are <mask> but they eat too many carbs."
|
||||
>>> input_ids = tokenizer([TXT], return_tensors="pt")["input_ids"]
|
||||
>>> logits = model(input_ids).logits
|
||||
|
||||
>>> masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
|
||||
>>> probs = logits[0, masked_index].softmax(dim=0)
|
||||
>>> values, predictions = probs.topk(5)
|
||||
|
||||
>>> tokenizer.decode(predictions).split()
|
||||
['not', 'good', 'healthy', 'great', 'very']
|
||||
```
|
||||
"""
|
||||
|
||||
LDMBERT_INPUTS_DOCSTRING = r"""
|
||||
Args:
|
||||
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
||||
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
||||
it.
|
||||
|
||||
Indices can be obtained using [`BartTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
||||
[`PreTrainedTokenizer.__call__`] for details.
|
||||
|
||||
[What are input IDs?](../glossary#input-ids)
|
||||
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
||||
|
||||
- 1 for tokens that are **not masked**,
|
||||
- 0 for tokens that are **masked**.
|
||||
|
||||
[What are attention masks?](../glossary#attention-mask)
|
||||
decoder_input_ids (`torch.LongTensor` of shape `(batch_size, target_sequence_length)`, *optional*):
|
||||
Indices of decoder input sequence tokens in the vocabulary.
|
||||
|
||||
Indices can be obtained using [`BartTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
||||
[`PreTrainedTokenizer.__call__`] for details.
|
||||
|
||||
[What are decoder input IDs?](../glossary#decoder-input-ids)
|
||||
|
||||
LDMBert uses the `eos_token_id` as the starting token for `decoder_input_ids` generation. If
|
||||
`past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
|
||||
`past_key_values`).
|
||||
|
||||
For translation and summarization training, `decoder_input_ids` should be provided. If no
|
||||
`decoder_input_ids` is provided, the model will create this tensor by shifting the `input_ids` to the right
|
||||
for denoising pre-training following the paper.
|
||||
decoder_attention_mask (`torch.LongTensor` of shape `(batch_size, target_sequence_length)`, *optional*):
|
||||
Default behavior: generate a tensor that ignores pad tokens in `decoder_input_ids`. Causal mask will also
|
||||
be used by default.
|
||||
|
||||
If you want to change padding behavior, you should read
|
||||
[`modeling_ldmbert._prepare_decoder_attention_mask`] and modify to your needs. See diagram 1 in [the
|
||||
paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
|
||||
head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
|
||||
Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in `[0, 1]`:
|
||||
|
||||
- 1 indicates the head is **not masked**,
|
||||
- 0 indicates the head is **masked**.
|
||||
|
||||
decoder_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
|
||||
Mask to nullify selected heads of the attention modules in the decoder. Mask values selected in `[0, 1]`:
|
||||
|
||||
- 1 indicates the head is **not masked**,
|
||||
- 0 indicates the head is **masked**.
|
||||
|
||||
cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
|
||||
Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in `[0,
|
||||
1]`:
|
||||
|
||||
- 1 indicates the head is **not masked**,
|
||||
- 0 indicates the head is **masked**.
|
||||
|
||||
encoder_outputs (`tuple(tuple(torch.FloatTensor)`, *optional*):
|
||||
Tuple consists of (`last_hidden_state`, *optional*: `hidden_states`, *optional*: `attentions`)
|
||||
`last_hidden_state` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) is a sequence of
|
||||
hidden-states at the output of the last layer of the encoder. Used in the cross-attention of the decoder.
|
||||
past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
|
||||
Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
|
||||
`(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
|
||||
`(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
|
||||
|
||||
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
|
||||
blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
|
||||
|
||||
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
|
||||
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
|
||||
`decoder_input_ids` of shape `(batch_size, sequence_length)`. inputs_embeds (`torch.FloatTensor` of shape
|
||||
`(batch_size, sequence_length, hidden_size)`, *optional*): Optionally, instead of passing `input_ids` you
|
||||
can choose to directly pass an embedded representation. This is useful if you want more control over how to
|
||||
convert `input_ids` indices into associated vectors than the model's internal embedding lookup matrix.
|
||||
decoder_inputs_embeds (`torch.FloatTensor` of shape `(batch_size, target_sequence_length, hidden_size)`, *optional*):
|
||||
Optionally, instead of passing `decoder_input_ids` you can choose to directly pass an embedded
|
||||
representation. If `past_key_values` is used, optionally only the last `decoder_inputs_embeds` have to be
|
||||
input (see `past_key_values`). This is useful if you want more control over how to convert
|
||||
`decoder_input_ids` indices into associated vectors than the model's internal embedding lookup matrix.
|
||||
|
||||
If `decoder_input_ids` and `decoder_inputs_embeds` are both unset, `decoder_inputs_embeds` takes the value
|
||||
of `inputs_embeds`.
|
||||
use_cache (`bool`, *optional*):
|
||||
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
|
||||
`past_key_values`).
|
||||
output_attentions (`bool`, *optional*):
|
||||
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
||||
tensors for more detail.
|
||||
output_hidden_states (`bool`, *optional*):
|
||||
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
||||
more detail.
|
||||
return_dict (`bool`, *optional*):
|
||||
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
||||
"""
|
||||
|
||||
|
||||
class LDMBertEncoder(LDMBertPreTrainedModel):
|
||||
"""
|
||||
Transformer encoder consisting of *config.encoder_layers* self attention layers. Each layer is a
|
||||
@@ -671,7 +603,6 @@ class LDMBertModel(LDMBertPreTrainedModel):
|
||||
position_ids=None,
|
||||
head_mask=None,
|
||||
inputs_embeds=None,
|
||||
labels=None,
|
||||
output_attentions=None,
|
||||
output_hidden_states=None,
|
||||
return_dict=None,
|
||||
@@ -688,19 +619,4 @@ class LDMBertModel(LDMBertPreTrainedModel):
|
||||
return_dict=return_dict,
|
||||
)
|
||||
sequence_output = outputs[0]
|
||||
# logits = self.to_logits(sequence_output)
|
||||
# outputs = (logits,) + outputs[1:]
|
||||
|
||||
# if labels is not None:
|
||||
# loss_fct = CrossEntropyLoss()
|
||||
# loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
|
||||
# outputs = (loss,) + outputs
|
||||
|
||||
# if not return_dict:
|
||||
# return outputs
|
||||
|
||||
return BaseModelOutput(
|
||||
last_hidden_state=sequence_output,
|
||||
# hidden_states=outputs[1],
|
||||
# attentions=outputs[2],
|
||||
)
|
||||
return sequence_output
|
||||
@@ -0,0 +1 @@
|
||||
from .pipeline_latent_diffusion_uncond import LDMPipeline
|
||||
@@ -0,0 +1,48 @@
|
||||
import torch
|
||||
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
|
||||
|
||||
class LDMPipeline(DiffusionPipeline):
|
||||
def __init__(self, vqvae, unet, scheduler):
|
||||
super().__init__()
|
||||
scheduler = scheduler.set_format("pt")
|
||||
self.register_modules(vqvae=vqvae, unet=unet, scheduler=scheduler)
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(
|
||||
self, batch_size=1, generator=None, torch_device=None, eta=0.0, num_inference_steps=50, output_type="pil"
|
||||
):
|
||||
# eta corresponds to η in paper and should be between [0, 1]
|
||||
|
||||
if torch_device is None:
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
self.unet.to(torch_device)
|
||||
self.vqvae.to(torch_device)
|
||||
|
||||
latents = torch.randn(
|
||||
(batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size),
|
||||
generator=generator,
|
||||
)
|
||||
latents = latents.to(torch_device)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
|
||||
for t in tqdm(self.scheduler.timesteps):
|
||||
# predict the noise residual
|
||||
noise_prediction = self.unet(latents, t)["sample"]
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(noise_prediction, t, latents, eta)["prev_sample"]
|
||||
|
||||
# decode the image latents with the VAE
|
||||
image = self.vqvae.decode(latents)
|
||||
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).numpy()
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
return {"sample": image}
|
||||
@@ -1,28 +0,0 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Denoising Diffusion Implicit Models (DDIM)
|
||||
|
||||
## Overview
|
||||
|
||||
DDPM was proposed in [Denoising Diffusion Implicit Models](https://arxiv.org/abs/2010.02502) by *Jiaming Song, Chenlin Meng, Stefano Ermon*
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*Denoising diffusion probabilistic models (DDPMs) have achieved high quality image generation without adversarial training, yet they require simulating a Markov chain for many steps to produce a sample. To accelerate sampling, we present denoising diffusion implicit models (DDIMs), a more efficient class of iterative implicit probabilistic models with the same training procedure as DDPMs. In DDPMs, the generative process is defined as the reverse of a Markovian diffusion process. We construct a class of non-Markovian diffusion processes that lead to the same training objective, but whose reverse process can be much faster to sample from. We empirically demonstrate that DDIMs can produce high quality samples 10× to 50× faster in terms of wall-clock time compared to DDPMs, allow us to trade off computation for sample quality, and can perform semantically meaningful image interpolation directly in the latent space.*
|
||||
|
||||
Tips:
|
||||
|
||||
- ...
|
||||
- ...
|
||||
|
||||
This model was contributed by [???](https://huggingface.co/???). The original code can be found [here](https://github.com/hojonathanho/diffusion).
|
||||
@@ -1 +0,0 @@
|
||||
from .pipeline_ddim import DDIM
|
||||
@@ -1,26 +0,0 @@
|
||||
#!/usr/bin/env python3
|
||||
import os
|
||||
import pathlib
|
||||
|
||||
import numpy as np
|
||||
|
||||
import PIL.Image
|
||||
from modeling_ddim import DDIM
|
||||
|
||||
|
||||
model_ids = ["ddim-celeba-hq", "ddim-lsun-church", "ddim-lsun-bedroom"]
|
||||
|
||||
for model_id in model_ids:
|
||||
path = os.path.join("/home/patrick/images/hf", model_id)
|
||||
pathlib.Path(path).mkdir(parents=True, exist_ok=True)
|
||||
|
||||
ddpm = DDIM.from_pretrained("fusing/" + model_id)
|
||||
image = ddpm(batch_size=4)
|
||||
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = (image_processed + 1.0) * 127.5
|
||||
image_processed = image_processed.numpy().astype(np.uint8)
|
||||
|
||||
for i in range(image_processed.shape[0]):
|
||||
image_pil = PIL.Image.fromarray(image_processed[i])
|
||||
image_pil.save(os.path.join(path, f"image_{i}.png"))
|
||||
@@ -1,17 +0,0 @@
|
||||
#!/usr/bin/env python3
|
||||
import torch
|
||||
|
||||
from diffusers import DDPMScheduler, UNetModel
|
||||
|
||||
|
||||
model = UNetModel(dim=64, dim_mults=(1, 2, 4, 8))
|
||||
|
||||
diffusion = DDPMScheduler(model, image_size=128, timesteps=1000, loss_type="l1") # number of steps # L1 or L2
|
||||
|
||||
training_images = torch.randn(8, 3, 128, 128) # your images need to be normalized from a range of -1 to +1
|
||||
loss = diffusion(training_images)
|
||||
loss.backward()
|
||||
# after a lot of training
|
||||
|
||||
sampled_images = diffusion.sample(batch_size=4)
|
||||
sampled_images.shape # (4, 3, 128, 128)
|
||||
@@ -1,25 +0,0 @@
|
||||
#!/usr/bin/env python3
|
||||
# !pip install diffusers
|
||||
import numpy as np
|
||||
|
||||
import PIL.Image
|
||||
from modeling_ddim import DDIM
|
||||
|
||||
|
||||
model_id = "fusing/ddpm-cifar10"
|
||||
model_id = "fusing/ddpm-lsun-bedroom"
|
||||
|
||||
# load model and scheduler
|
||||
ddpm = DDIM.from_pretrained(model_id)
|
||||
|
||||
# run pipeline in inference (sample random noise and denoise)
|
||||
image = ddpm()
|
||||
|
||||
# process image to PIL
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = (image_processed + 1.0) * 127.5
|
||||
image_processed = image_processed.numpy().astype(np.uint8)
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# save image
|
||||
image_pil.save("/home/patrick/images/show.png")
|
||||
@@ -1,30 +0,0 @@
|
||||
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Denoising Diffusion Probabilistic Models (DDPM)
|
||||
|
||||
## Overview
|
||||
|
||||
DDPM was proposed in [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239) by *Jonathan Ho, Ajay Jain, Pieter Abbeel*.
|
||||
|
||||
The abstract from the paper is the following:
|
||||
|
||||
*We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN. Our implementation is available at this https URL*
|
||||
|
||||
Tips:
|
||||
|
||||
- ...
|
||||
- ...
|
||||
|
||||
This model was contributed by [???](https://huggingface.co/???). The original code can be found [here](https://github.com/hojonathanho/diffusion).
|
||||
|
||||

|
||||
@@ -1,37 +0,0 @@
|
||||
#!/usr/bin/env python3
|
||||
import os
|
||||
import pathlib
|
||||
|
||||
import numpy as np
|
||||
|
||||
import PIL.Image
|
||||
from modeling_ddpm import DDPM
|
||||
|
||||
|
||||
model_ids = [
|
||||
"ddpm-lsun-cat",
|
||||
"ddpm-lsun-cat-ema",
|
||||
"ddpm-lsun-church-ema",
|
||||
"ddpm-lsun-church",
|
||||
"ddpm-lsun-bedroom",
|
||||
"ddpm-lsun-bedroom-ema",
|
||||
"ddpm-cifar10-ema",
|
||||
"ddpm-cifar10",
|
||||
"ddpm-celeba-hq",
|
||||
"ddpm-celeba-hq-ema",
|
||||
]
|
||||
|
||||
for model_id in model_ids:
|
||||
path = os.path.join("/home/patrick/images/hf", model_id)
|
||||
pathlib.Path(path).mkdir(parents=True, exist_ok=True)
|
||||
|
||||
ddpm = DDPM.from_pretrained("fusing/" + model_id)
|
||||
image = ddpm(batch_size=4)
|
||||
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = (image_processed + 1.0) * 127.5
|
||||
image_processed = image_processed.numpy().astype(np.uint8)
|
||||
|
||||
for i in range(image_processed.shape[0]):
|
||||
image_pil = PIL.Image.fromarray(image_processed[i])
|
||||
image_pil.save(os.path.join(path, f"image_{i}.png"))
|
||||
@@ -1,17 +0,0 @@
|
||||
#!/usr/bin/env python3
|
||||
import torch
|
||||
|
||||
from diffusers import DDPMScheduler, UNetModel
|
||||
|
||||
|
||||
model = UNetModel(dim=64, dim_mults=(1, 2, 4, 8))
|
||||
|
||||
diffusion = DDPMScheduler(model, image_size=128, timesteps=1000, loss_type="l1") # number of steps # L1 or L2
|
||||
|
||||
training_images = torch.randn(8, 3, 128, 128) # your images need to be normalized from a range of -1 to +1
|
||||
loss = diffusion(training_images)
|
||||
loss.backward()
|
||||
# after a lot of training
|
||||
|
||||
sampled_images = diffusion.sample(batch_size=4)
|
||||
sampled_images.shape # (4, 3, 128, 128)
|
||||
@@ -1,4 +0,0 @@
|
||||
# References
|
||||
|
||||
[GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models](https://arxiv.org/pdf/2112.10741.pdf)
|
||||
[Diffusion Models Beat GANs on Image Synthesis](https://arxiv.org/pdf/2105.05233.pdf)
|
||||
@@ -1,111 +0,0 @@
|
||||
import torch
|
||||
from torch import nn
|
||||
|
||||
from diffusers import ClassifierFreeGuidanceScheduler, GLIDESuperResUNetModel, GLIDETextToImageUNetModel
|
||||
from modeling_glide import GLIDE, CLIPTextModel
|
||||
from transformers import CLIPTextConfig, GPT2Tokenizer
|
||||
|
||||
|
||||
# wget https://openaipublic.blob.core.windows.net/diffusion/dec-2021/base.pt
|
||||
state_dict = torch.load("base.pt", map_location="cpu")
|
||||
state_dict = {k: nn.Parameter(v) for k, v in state_dict.items()}
|
||||
|
||||
### Convert the text encoder
|
||||
|
||||
config = CLIPTextConfig(
|
||||
vocab_size=50257,
|
||||
max_position_embeddings=128,
|
||||
hidden_size=512,
|
||||
intermediate_size=2048,
|
||||
num_hidden_layers=16,
|
||||
num_attention_heads=8,
|
||||
use_padding_embeddings=True,
|
||||
)
|
||||
model = CLIPTextModel(config).eval()
|
||||
tokenizer = GPT2Tokenizer(
|
||||
"./glide-base/tokenizer/vocab.json", "./glide-base/tokenizer/merges.txt", pad_token="<|endoftext|>"
|
||||
)
|
||||
|
||||
hf_encoder = model.text_model
|
||||
|
||||
hf_encoder.embeddings.token_embedding.weight = state_dict["token_embedding.weight"]
|
||||
hf_encoder.embeddings.position_embedding.weight.data = state_dict["positional_embedding"]
|
||||
hf_encoder.embeddings.padding_embedding.weight.data = state_dict["padding_embedding"]
|
||||
|
||||
hf_encoder.final_layer_norm.weight = state_dict["final_ln.weight"]
|
||||
hf_encoder.final_layer_norm.bias = state_dict["final_ln.bias"]
|
||||
|
||||
for layer_idx in range(config.num_hidden_layers):
|
||||
hf_layer = hf_encoder.encoder.layers[layer_idx]
|
||||
hf_layer.self_attn.qkv_proj.weight = state_dict[f"transformer.resblocks.{layer_idx}.attn.c_qkv.weight"]
|
||||
hf_layer.self_attn.qkv_proj.bias = state_dict[f"transformer.resblocks.{layer_idx}.attn.c_qkv.bias"]
|
||||
|
||||
hf_layer.self_attn.out_proj.weight = state_dict[f"transformer.resblocks.{layer_idx}.attn.c_proj.weight"]
|
||||
hf_layer.self_attn.out_proj.bias = state_dict[f"transformer.resblocks.{layer_idx}.attn.c_proj.bias"]
|
||||
|
||||
hf_layer.layer_norm1.weight = state_dict[f"transformer.resblocks.{layer_idx}.ln_1.weight"]
|
||||
hf_layer.layer_norm1.bias = state_dict[f"transformer.resblocks.{layer_idx}.ln_1.bias"]
|
||||
hf_layer.layer_norm2.weight = state_dict[f"transformer.resblocks.{layer_idx}.ln_2.weight"]
|
||||
hf_layer.layer_norm2.bias = state_dict[f"transformer.resblocks.{layer_idx}.ln_2.bias"]
|
||||
|
||||
hf_layer.mlp.fc1.weight = state_dict[f"transformer.resblocks.{layer_idx}.mlp.c_fc.weight"]
|
||||
hf_layer.mlp.fc1.bias = state_dict[f"transformer.resblocks.{layer_idx}.mlp.c_fc.bias"]
|
||||
hf_layer.mlp.fc2.weight = state_dict[f"transformer.resblocks.{layer_idx}.mlp.c_proj.weight"]
|
||||
hf_layer.mlp.fc2.bias = state_dict[f"transformer.resblocks.{layer_idx}.mlp.c_proj.bias"]
|
||||
|
||||
### Convert the Text-to-Image UNet
|
||||
|
||||
text2im_model = GLIDETextToImageUNetModel(
|
||||
in_channels=3,
|
||||
model_channels=192,
|
||||
out_channels=6,
|
||||
num_res_blocks=3,
|
||||
attention_resolutions=(2, 4, 8),
|
||||
dropout=0.1,
|
||||
channel_mult=(1, 2, 3, 4),
|
||||
num_heads=1,
|
||||
num_head_channels=64,
|
||||
num_heads_upsample=1,
|
||||
use_scale_shift_norm=True,
|
||||
resblock_updown=True,
|
||||
transformer_dim=512,
|
||||
)
|
||||
|
||||
text2im_model.load_state_dict(state_dict, strict=False)
|
||||
|
||||
text_scheduler = ClassifierFreeGuidanceScheduler(timesteps=1000, beta_schedule="squaredcos_cap_v2")
|
||||
|
||||
### Convert the Super-Resolution UNet
|
||||
|
||||
# wget https://openaipublic.blob.core.windows.net/diffusion/dec-2021/upsample.pt
|
||||
ups_state_dict = torch.load("upsample.pt", map_location="cpu")
|
||||
|
||||
superres_model = GLIDESuperResUNetModel(
|
||||
in_channels=6,
|
||||
model_channels=192,
|
||||
out_channels=6,
|
||||
num_res_blocks=2,
|
||||
attention_resolutions=(8, 16, 32),
|
||||
dropout=0.1,
|
||||
channel_mult=(1, 1, 2, 2, 4, 4),
|
||||
num_heads=1,
|
||||
num_head_channels=64,
|
||||
num_heads_upsample=1,
|
||||
use_scale_shift_norm=True,
|
||||
resblock_updown=True,
|
||||
)
|
||||
|
||||
superres_model.load_state_dict(ups_state_dict, strict=False)
|
||||
|
||||
upscale_scheduler = DDIMScheduler(timesteps=1000, beta_schedule="linear")
|
||||
|
||||
glide = GLIDE(
|
||||
text_unet=text2im_model,
|
||||
text_noise_scheduler=text_scheduler,
|
||||
text_encoder=model,
|
||||
tokenizer=tokenizer,
|
||||
upscale_unet=superres_model,
|
||||
upscale_noise_scheduler=upscale_scheduler,
|
||||
)
|
||||
|
||||
glide.save_pretrained("./glide-base")
|
||||
@@ -1,923 +0,0 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The OpenAI Team Authors and The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" PyTorch CLIP model."""
|
||||
|
||||
import math
|
||||
from dataclasses import dataclass
|
||||
from typing import Any, Optional, Tuple, Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.utils.checkpoint
|
||||
from torch import nn
|
||||
|
||||
import tqdm
|
||||
from diffusers import (
|
||||
ClassifierFreeGuidanceScheduler,
|
||||
DDIMScheduler,
|
||||
DiffusionPipeline,
|
||||
GLIDESuperResUNetModel,
|
||||
GLIDETextToImageUNetModel,
|
||||
)
|
||||
from transformers import CLIPConfig, CLIPModel, CLIPTextConfig, CLIPVisionConfig, GPT2Tokenizer
|
||||
from transformers.activations import ACT2FN
|
||||
from transformers.modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
from transformers.utils import (
|
||||
ModelOutput,
|
||||
add_start_docstrings,
|
||||
add_start_docstrings_to_model_forward,
|
||||
logging,
|
||||
replace_return_docstrings,
|
||||
)
|
||||
|
||||
|
||||
#####################
|
||||
# START OF THE CLIP MODEL COPY-PASTE (with a modified attention module)
|
||||
#####################
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
_CHECKPOINT_FOR_DOC = "fusing/glide-base"
|
||||
|
||||
CLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
|
||||
"fusing/glide-base",
|
||||
# See all CLIP models at https://huggingface.co/models?filter=clip
|
||||
]
|
||||
|
||||
|
||||
# Copied from transformers.models.bart.modeling_bart._expand_mask
|
||||
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
|
||||
"""
|
||||
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
||||
"""
|
||||
bsz, src_len = mask.size()
|
||||
tgt_len = tgt_len if tgt_len is not None else src_len
|
||||
|
||||
expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
|
||||
|
||||
inverted_mask = 1.0 - expanded_mask
|
||||
|
||||
return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
|
||||
|
||||
|
||||
# contrastive loss function, adapted from
|
||||
# https://sachinruk.github.io/blog/pytorch/pytorch%20lightning/loss%20function/gpu/2021/03/07/CLIP.html
|
||||
def contrastive_loss(logits: torch.Tensor) -> torch.Tensor:
|
||||
return nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device))
|
||||
|
||||
|
||||
def clip_loss(similarity: torch.Tensor) -> torch.Tensor:
|
||||
caption_loss = contrastive_loss(similarity)
|
||||
image_loss = contrastive_loss(similarity.T)
|
||||
return (caption_loss + image_loss) / 2.0
|
||||
|
||||
|
||||
@dataclass
|
||||
class CLIPOutput(ModelOutput):
|
||||
"""
|
||||
Args:
|
||||
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
|
||||
Contrastive loss for image-text similarity.
|
||||
logits_per_image:(`torch.FloatTensor` of shape `(image_batch_size, text_batch_size)`):
|
||||
The scaled dot product scores between `image_embeds` and `text_embeds`. This represents the image-text
|
||||
similarity scores.
|
||||
logits_per_text:(`torch.FloatTensor` of shape `(text_batch_size, image_batch_size)`):
|
||||
The scaled dot product scores between `text_embeds` and `image_embeds`. This represents the text-image
|
||||
similarity scores.
|
||||
text_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
|
||||
The text embeddings obtained by applying the projection layer to the pooled output of [`CLIPTextModel`].
|
||||
image_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
|
||||
The image embeddings obtained by applying the projection layer to the pooled output of [`CLIPVisionModel`].
|
||||
text_model_output(`BaseModelOutputWithPooling`):
|
||||
The output of the [`CLIPTextModel`].
|
||||
vision_model_output(`BaseModelOutputWithPooling`):
|
||||
The output of the [`CLIPVisionModel`].
|
||||
"""
|
||||
|
||||
loss: Optional[torch.FloatTensor] = None
|
||||
logits_per_image: torch.FloatTensor = None
|
||||
logits_per_text: torch.FloatTensor = None
|
||||
text_embeds: torch.FloatTensor = None
|
||||
image_embeds: torch.FloatTensor = None
|
||||
text_model_output: BaseModelOutputWithPooling = None
|
||||
vision_model_output: BaseModelOutputWithPooling = None
|
||||
|
||||
def to_tuple(self) -> Tuple[Any]:
|
||||
return tuple(
|
||||
self[k] if k not in ["text_model_output", "vision_model_output"] else getattr(self, k).to_tuple()
|
||||
for k in self.keys()
|
||||
)
|
||||
|
||||
|
||||
class CLIPVisionEmbeddings(nn.Module):
|
||||
def __init__(self, config: CLIPVisionConfig):
|
||||
super().__init__()
|
||||
self.config = config
|
||||
self.embed_dim = config.hidden_size
|
||||
self.image_size = config.image_size
|
||||
self.patch_size = config.patch_size
|
||||
|
||||
self.class_embedding = nn.Parameter(torch.randn(self.embed_dim))
|
||||
|
||||
self.patch_embedding = nn.Conv2d(
|
||||
in_channels=3, out_channels=self.embed_dim, kernel_size=self.patch_size, stride=self.patch_size, bias=False
|
||||
)
|
||||
|
||||
self.num_patches = (self.image_size // self.patch_size) ** 2
|
||||
self.num_positions = self.num_patches + 1
|
||||
self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
|
||||
self.register_buffer("position_ids", torch.arange(self.num_positions).expand((1, -1)))
|
||||
|
||||
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
|
||||
batch_size = pixel_values.shape[0]
|
||||
patch_embeds = self.patch_embedding(pixel_values) # shape = [*, width, grid, grid]
|
||||
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
|
||||
|
||||
class_embeds = self.class_embedding.expand(batch_size, 1, -1)
|
||||
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
|
||||
embeddings = embeddings + self.position_embedding(self.position_ids)
|
||||
return embeddings
|
||||
|
||||
|
||||
class CLIPTextEmbeddings(nn.Module):
|
||||
def __init__(self, config: CLIPTextConfig):
|
||||
super().__init__()
|
||||
embed_dim = config.hidden_size
|
||||
|
||||
self.token_embedding = nn.Embedding(config.vocab_size, embed_dim)
|
||||
self.position_embedding = nn.Embedding(config.max_position_embeddings, embed_dim)
|
||||
self.use_padding_embeddings = config.use_padding_embeddings
|
||||
if self.use_padding_embeddings:
|
||||
self.padding_embedding = nn.Embedding(config.max_position_embeddings, embed_dim)
|
||||
|
||||
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
|
||||
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
) -> torch.Tensor:
|
||||
seq_length = input_ids.shape[-1] if input_ids is not None else inputs_embeds.shape[-2]
|
||||
|
||||
if position_ids is None:
|
||||
position_ids = self.position_ids[:, :seq_length]
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.token_embedding(input_ids)
|
||||
|
||||
position_embeddings = self.position_embedding(position_ids)
|
||||
embeddings = inputs_embeds + position_embeddings
|
||||
|
||||
if self.use_padding_embeddings and attention_mask is not None:
|
||||
padding_embeddings = self.padding_embedding(position_ids)
|
||||
embeddings = torch.where(attention_mask.bool().unsqueeze(-1), embeddings, padding_embeddings)
|
||||
|
||||
return embeddings
|
||||
|
||||
|
||||
class CLIPAttention(nn.Module):
|
||||
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__()
|
||||
self.config = config
|
||||
self.embed_dim = config.hidden_size
|
||||
self.num_heads = config.num_attention_heads
|
||||
self.head_dim = self.embed_dim // self.num_heads
|
||||
if self.head_dim * self.num_heads != self.embed_dim:
|
||||
raise ValueError(
|
||||
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
|
||||
f" {self.num_heads})."
|
||||
)
|
||||
self.scale = 1 / math.sqrt(math.sqrt(self.head_dim))
|
||||
|
||||
self.qkv_proj = nn.Linear(self.embed_dim, self.embed_dim * 3)
|
||||
self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
causal_attention_mask: Optional[torch.Tensor] = None,
|
||||
output_attentions: Optional[bool] = False,
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
||||
"""Input shape: Batch x Time x Channel"""
|
||||
|
||||
bsz, tgt_len, embed_dim = hidden_states.size()
|
||||
|
||||
qkv_states = self.qkv_proj(hidden_states)
|
||||
qkv_states = qkv_states.view(bsz, tgt_len, self.num_heads, -1)
|
||||
query_states, key_states, value_states = torch.split(qkv_states, self.head_dim, dim=-1)
|
||||
|
||||
attn_weights = torch.einsum("bthc,bshc->bhts", query_states * self.scale, key_states * self.scale)
|
||||
|
||||
wdtype = attn_weights.dtype
|
||||
attn_weights = nn.functional.softmax(attn_weights.float(), dim=-1).type(wdtype)
|
||||
|
||||
attn_output = torch.einsum("bhts,bshc->bthc", attn_weights, value_states)
|
||||
attn_output = attn_output.reshape(bsz, tgt_len, -1)
|
||||
|
||||
attn_output = self.out_proj(attn_output)
|
||||
|
||||
return attn_output, attn_weights
|
||||
|
||||
|
||||
class CLIPMLP(nn.Module):
|
||||
def __init__(self, config):
|
||||
super().__init__()
|
||||
self.config = config
|
||||
self.activation_fn = ACT2FN[config.hidden_act]
|
||||
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
|
||||
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
|
||||
|
||||
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
||||
hidden_states = self.fc1(hidden_states)
|
||||
hidden_states = self.activation_fn(hidden_states)
|
||||
hidden_states = self.fc2(hidden_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
class CLIPEncoderLayer(nn.Module):
|
||||
def __init__(self, config: CLIPConfig):
|
||||
super().__init__()
|
||||
self.embed_dim = config.hidden_size
|
||||
self.self_attn = CLIPAttention(config)
|
||||
self.layer_norm1 = nn.LayerNorm(self.embed_dim)
|
||||
self.mlp = CLIPMLP(config)
|
||||
self.layer_norm2 = nn.LayerNorm(self.embed_dim)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: torch.Tensor,
|
||||
causal_attention_mask: torch.Tensor,
|
||||
output_attentions: Optional[bool] = False,
|
||||
) -> Tuple[torch.FloatTensor]:
|
||||
"""
|
||||
Args:
|
||||
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
||||
attention_mask (`torch.FloatTensor`): attention mask of size
|
||||
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
|
||||
`(config.encoder_attention_heads,)`.
|
||||
output_attentions (`bool`, *optional*):
|
||||
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
||||
returned tensors for more detail.
|
||||
"""
|
||||
residual = hidden_states
|
||||
|
||||
hidden_states = self.layer_norm1(hidden_states)
|
||||
hidden_states, attn_weights = self.self_attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
causal_attention_mask=causal_attention_mask,
|
||||
output_attentions=output_attentions,
|
||||
)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
residual = hidden_states
|
||||
hidden_states = self.layer_norm2(hidden_states)
|
||||
hidden_states = self.mlp(hidden_states)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
outputs = (hidden_states,)
|
||||
|
||||
if output_attentions:
|
||||
outputs += (attn_weights,)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
class CLIPPreTrainedModel(PreTrainedModel):
|
||||
"""
|
||||
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
|
||||
models.
|
||||
"""
|
||||
|
||||
config_class = CLIPConfig
|
||||
base_model_prefix = "clip"
|
||||
supports_gradient_checkpointing = True
|
||||
_keys_to_ignore_on_load_missing = [r"position_ids"]
|
||||
|
||||
def _init_weights(self, module):
|
||||
"""Initialize the weights"""
|
||||
factor = self.config.initializer_factor
|
||||
if isinstance(module, CLIPTextEmbeddings):
|
||||
module.token_embedding.weight.data.normal_(mean=0.0, std=factor * 0.02)
|
||||
module.position_embedding.weight.data.normal_(mean=0.0, std=factor * 0.02)
|
||||
if hasattr(module, "padding_embedding"):
|
||||
module.padding_embedding.weight.data.normal_(mean=0.0, std=factor * 0.02)
|
||||
elif isinstance(module, CLIPVisionEmbeddings):
|
||||
factor = self.config.initializer_factor
|
||||
nn.init.normal_(module.class_embedding, mean=0.0, std=module.embed_dim**-0.5 * factor)
|
||||
nn.init.normal_(module.patch_embedding.weight, std=module.config.initializer_range * factor)
|
||||
nn.init.normal_(module.position_embedding.weight, std=module.config.initializer_range * factor)
|
||||
elif isinstance(module, CLIPAttention):
|
||||
factor = self.config.initializer_factor
|
||||
in_proj_std = (module.embed_dim**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
|
||||
out_proj_std = (module.embed_dim**-0.5) * factor
|
||||
nn.init.normal_(module.qkv_proj.weight, std=in_proj_std)
|
||||
nn.init.normal_(module.out_proj.weight, std=out_proj_std)
|
||||
elif isinstance(module, CLIPMLP):
|
||||
factor = self.config.initializer_factor
|
||||
in_proj_std = (
|
||||
(module.config.hidden_size**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
|
||||
)
|
||||
fc_std = (2 * module.config.hidden_size) ** -0.5 * factor
|
||||
nn.init.normal_(module.fc1.weight, std=fc_std)
|
||||
nn.init.normal_(module.fc2.weight, std=in_proj_std)
|
||||
elif isinstance(module, CLIPModel):
|
||||
nn.init.normal_(
|
||||
module.text_projection.weight,
|
||||
std=module.text_embed_dim**-0.5 * self.config.initializer_factor,
|
||||
)
|
||||
nn.init.normal_(
|
||||
module.visual_projection.weight,
|
||||
std=module.vision_embed_dim**-0.5 * self.config.initializer_factor,
|
||||
)
|
||||
|
||||
if isinstance(module, nn.LayerNorm):
|
||||
module.bias.data.zero_()
|
||||
module.weight.data.fill_(1.0)
|
||||
if isinstance(module, nn.Linear) and module.bias is not None:
|
||||
module.bias.data.zero_()
|
||||
|
||||
def _set_gradient_checkpointing(self, module, value=False):
|
||||
if isinstance(module, CLIPEncoder):
|
||||
module.gradient_checkpointing = value
|
||||
|
||||
|
||||
CLIP_START_DOCSTRING = r"""
|
||||
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
|
||||
as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
|
||||
behavior.
|
||||
|
||||
Parameters:
|
||||
config ([`CLIPConfig`]): Model configuration class with all the parameters of the model.
|
||||
Initializing with a config file does not load the weights associated with the model, only the
|
||||
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
||||
"""
|
||||
|
||||
CLIP_TEXT_INPUTS_DOCSTRING = r"""
|
||||
Args:
|
||||
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
||||
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
||||
it.
|
||||
|
||||
Indices can be obtained using [`CLIPTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
||||
[`PreTrainedTokenizer.__call__`] for details.
|
||||
|
||||
[What are input IDs?](../glossary#input-ids)
|
||||
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
||||
|
||||
- 1 for tokens that are **not masked**,
|
||||
- 0 for tokens that are **masked**.
|
||||
|
||||
[What are attention masks?](../glossary#attention-mask)
|
||||
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
||||
config.max_position_embeddings - 1]`.
|
||||
|
||||
[What are position IDs?](../glossary#position-ids)
|
||||
output_attentions (`bool`, *optional*):
|
||||
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
||||
tensors for more detail.
|
||||
output_hidden_states (`bool`, *optional*):
|
||||
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
||||
more detail.
|
||||
return_dict (`bool`, *optional*):
|
||||
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
||||
"""
|
||||
|
||||
CLIP_VISION_INPUTS_DOCSTRING = r"""
|
||||
Args:
|
||||
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
||||
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
|
||||
[`CLIPFeatureExtractor`]. See [`CLIPFeatureExtractor.__call__`] for details.
|
||||
output_attentions (`bool`, *optional*):
|
||||
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
||||
tensors for more detail.
|
||||
output_hidden_states (`bool`, *optional*):
|
||||
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
||||
more detail.
|
||||
return_dict (`bool`, *optional*):
|
||||
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
||||
"""
|
||||
|
||||
CLIP_INPUTS_DOCSTRING = r"""
|
||||
Args:
|
||||
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
||||
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
||||
it.
|
||||
|
||||
Indices can be obtained using [`CLIPTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
||||
[`PreTrainedTokenizer.__call__`] for details.
|
||||
|
||||
[What are input IDs?](../glossary#input-ids)
|
||||
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
||||
|
||||
- 1 for tokens that are **not masked**,
|
||||
- 0 for tokens that are **masked**.
|
||||
|
||||
[What are attention masks?](../glossary#attention-mask)
|
||||
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
||||
config.max_position_embeddings - 1]`.
|
||||
|
||||
[What are position IDs?](../glossary#position-ids)
|
||||
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
||||
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
|
||||
[`CLIPFeatureExtractor`]. See [`CLIPFeatureExtractor.__call__`] for details.
|
||||
return_loss (`bool`, *optional*):
|
||||
Whether or not to return the contrastive loss.
|
||||
output_attentions (`bool`, *optional*):
|
||||
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
||||
tensors for more detail.
|
||||
output_hidden_states (`bool`, *optional*):
|
||||
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
||||
more detail.
|
||||
return_dict (`bool`, *optional*):
|
||||
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
||||
"""
|
||||
|
||||
|
||||
class CLIPEncoder(nn.Module):
|
||||
"""
|
||||
Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
|
||||
[`CLIPEncoderLayer`].
|
||||
|
||||
Args:
|
||||
config: CLIPConfig
|
||||
"""
|
||||
|
||||
def __init__(self, config: CLIPConfig):
|
||||
super().__init__()
|
||||
self.config = config
|
||||
self.layers = nn.ModuleList([CLIPEncoderLayer(config) for _ in range(config.num_hidden_layers)])
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
def forward(
|
||||
self,
|
||||
inputs_embeds,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
causal_attention_mask: Optional[torch.Tensor] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, BaseModelOutput]:
|
||||
r"""
|
||||
Args:
|
||||
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
||||
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
|
||||
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
|
||||
than the model's internal embedding lookup matrix.
|
||||
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
||||
|
||||
- 1 for tokens that are **not masked**,
|
||||
- 0 for tokens that are **masked**.
|
||||
|
||||
[What are attention masks?](../glossary#attention-mask)
|
||||
causal_attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Causal mask for the text model. Mask values selected in `[0, 1]`:
|
||||
|
||||
- 1 for tokens that are **not masked**,
|
||||
- 0 for tokens that are **masked**.
|
||||
|
||||
[What are attention masks?](../glossary#attention-mask)
|
||||
output_attentions (`bool`, *optional*):
|
||||
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
||||
returned tensors for more detail.
|
||||
output_hidden_states (`bool`, *optional*):
|
||||
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
|
||||
for more detail.
|
||||
return_dict (`bool`, *optional*):
|
||||
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
||||
"""
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
encoder_states = () if output_hidden_states else None
|
||||
all_attentions = () if output_attentions else None
|
||||
|
||||
hidden_states = inputs_embeds
|
||||
for idx, encoder_layer in enumerate(self.layers):
|
||||
if output_hidden_states:
|
||||
encoder_states = encoder_states + (hidden_states,)
|
||||
if self.gradient_checkpointing and self.training:
|
||||
|
||||
def create_custom_forward(module):
|
||||
def custom_forward(*inputs):
|
||||
return module(*inputs, output_attentions)
|
||||
|
||||
return custom_forward
|
||||
|
||||
layer_outputs = torch.utils.checkpoint.checkpoint(
|
||||
create_custom_forward(encoder_layer),
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
causal_attention_mask,
|
||||
)
|
||||
else:
|
||||
layer_outputs = encoder_layer(
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
causal_attention_mask,
|
||||
output_attentions=output_attentions,
|
||||
)
|
||||
|
||||
hidden_states = layer_outputs[0]
|
||||
|
||||
if output_attentions:
|
||||
all_attentions = all_attentions + (layer_outputs[1],)
|
||||
|
||||
if output_hidden_states:
|
||||
encoder_states = encoder_states + (hidden_states,)
|
||||
|
||||
if not return_dict:
|
||||
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
|
||||
return BaseModelOutput(
|
||||
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
|
||||
)
|
||||
|
||||
|
||||
class CLIPTextTransformer(nn.Module):
|
||||
def __init__(self, config: CLIPTextConfig):
|
||||
super().__init__()
|
||||
self.config = config
|
||||
embed_dim = config.hidden_size
|
||||
self.embeddings = CLIPTextEmbeddings(config)
|
||||
self.encoder = CLIPEncoder(config)
|
||||
self.final_layer_norm = nn.LayerNorm(embed_dim)
|
||||
|
||||
@add_start_docstrings_to_model_forward(CLIP_TEXT_INPUTS_DOCSTRING)
|
||||
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPTextConfig)
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.Tensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.Tensor] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
||||
r"""
|
||||
Returns:
|
||||
|
||||
"""
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
if input_ids is None:
|
||||
raise ValueError("You have to specify either input_ids")
|
||||
|
||||
input_shape = input_ids.size()
|
||||
input_ids = input_ids.view(-1, input_shape[-1])
|
||||
|
||||
hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids, attention_mask=attention_mask)
|
||||
|
||||
bsz, seq_len = input_shape
|
||||
# CLIP's text model uses causal mask, prepare it here.
|
||||
# https://github.com/openai/CLIP/blob/cfcffb90e69f37bf2ff1e988237a0fbe41f33c04/clip/model.py#L324
|
||||
causal_attention_mask = self._build_causal_attention_mask(bsz, seq_len).to(hidden_states.device)
|
||||
|
||||
# expand attention_mask
|
||||
if attention_mask is not None:
|
||||
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
||||
attention_mask = _expand_mask(attention_mask, hidden_states.dtype)
|
||||
|
||||
encoder_outputs = self.encoder(
|
||||
inputs_embeds=hidden_states,
|
||||
attention_mask=None,
|
||||
causal_attention_mask=None,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict,
|
||||
)
|
||||
|
||||
last_hidden_state = encoder_outputs[0]
|
||||
last_hidden_state = self.final_layer_norm(last_hidden_state)
|
||||
|
||||
# text_embeds.shape = [batch_size, sequence_length, transformer.width]
|
||||
# take features from the eot embedding (eot_token is the highest number in each sequence)
|
||||
pooled_output = last_hidden_state[torch.arange(last_hidden_state.shape[0]), input_ids.argmax(dim=-1)]
|
||||
|
||||
if not return_dict:
|
||||
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
|
||||
|
||||
return BaseModelOutputWithPooling(
|
||||
last_hidden_state=last_hidden_state,
|
||||
pooler_output=pooled_output,
|
||||
hidden_states=encoder_outputs.hidden_states,
|
||||
attentions=encoder_outputs.attentions,
|
||||
)
|
||||
|
||||
def _build_causal_attention_mask(self, bsz, seq_len):
|
||||
# lazily create causal attention mask, with full attention between the vision tokens
|
||||
# pytorch uses additive attention mask; fill with -inf
|
||||
mask = torch.empty(bsz, seq_len, seq_len)
|
||||
mask.fill_(torch.tensor(float("-inf")))
|
||||
mask.triu_(1) # zero out the lower diagonal
|
||||
mask = mask.unsqueeze(1) # expand mask
|
||||
return mask
|
||||
|
||||
|
||||
class CLIPTextModel(CLIPPreTrainedModel):
|
||||
config_class = CLIPTextConfig
|
||||
|
||||
def __init__(self, config: CLIPTextConfig):
|
||||
super().__init__(config)
|
||||
self.text_model = CLIPTextTransformer(config)
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self) -> nn.Module:
|
||||
return self.text_model.embeddings.token_embedding
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.text_model.embeddings.token_embedding = value
|
||||
|
||||
@add_start_docstrings_to_model_forward(CLIP_TEXT_INPUTS_DOCSTRING)
|
||||
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPTextConfig)
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.Tensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.Tensor] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
||||
r"""
|
||||
Returns:
|
||||
|
||||
Examples:
|
||||
|
||||
```python
|
||||
>>> from transformers import CLIPTokenizer, CLIPTextModel
|
||||
|
||||
>>> model = CLIPTextModel.from_pretrained("openai/clip-vit-base-patch32")
|
||||
>>> tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-base-patch32")
|
||||
|
||||
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding=True, return_tensors="pt")
|
||||
|
||||
>>> outputs = model(**inputs)
|
||||
>>> last_hidden_state = outputs.last_hidden_state
|
||||
>>> pooled_output = outputs.pooler_output # pooled (EOS token) states
|
||||
```"""
|
||||
return self.text_model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict,
|
||||
)
|
||||
|
||||
|
||||
#####################
|
||||
# END OF THE CLIP MODEL COPY-PASTE
|
||||
#####################
|
||||
|
||||
|
||||
def _extract_into_tensor(arr, timesteps, broadcast_shape):
|
||||
"""
|
||||
Extract values from a 1-D numpy array for a batch of indices.
|
||||
|
||||
:param arr: the 1-D numpy array.
|
||||
:param timesteps: a tensor of indices into the array to extract.
|
||||
:param broadcast_shape: a larger shape of K dimensions with the batch
|
||||
dimension equal to the length of timesteps.
|
||||
:return: a tensor of shape [batch_size, 1, ...] where the shape has K dims.
|
||||
"""
|
||||
res = torch.from_numpy(arr).to(device=timesteps.device)[timesteps].float()
|
||||
while len(res.shape) < len(broadcast_shape):
|
||||
res = res[..., None]
|
||||
return res + torch.zeros(broadcast_shape, device=timesteps.device)
|
||||
|
||||
|
||||
class GLIDE(DiffusionPipeline):
|
||||
def __init__(
|
||||
self,
|
||||
text_unet: GLIDETextToImageUNetModel,
|
||||
text_noise_scheduler: ClassifierFreeGuidanceScheduler,
|
||||
text_encoder: CLIPTextModel,
|
||||
tokenizer: GPT2Tokenizer,
|
||||
upscale_unet: GLIDESuperResUNetModel,
|
||||
upscale_noise_scheduler: DDIMScheduler,
|
||||
):
|
||||
super().__init__()
|
||||
self.register_modules(
|
||||
text_unet=text_unet,
|
||||
text_noise_scheduler=text_noise_scheduler,
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
upscale_unet=upscale_unet,
|
||||
upscale_noise_scheduler=upscale_noise_scheduler,
|
||||
)
|
||||
|
||||
def q_posterior_mean_variance(self, scheduler, x_start, x_t, t):
|
||||
"""
|
||||
Compute the mean and variance of the diffusion posterior:
|
||||
|
||||
q(x_{t-1} | x_t, x_0)
|
||||
|
||||
"""
|
||||
assert x_start.shape == x_t.shape
|
||||
posterior_mean = (
|
||||
_extract_into_tensor(scheduler.posterior_mean_coef1, t, x_t.shape) * x_start
|
||||
+ _extract_into_tensor(scheduler.posterior_mean_coef2, t, x_t.shape) * x_t
|
||||
)
|
||||
posterior_variance = _extract_into_tensor(scheduler.posterior_variance, t, x_t.shape)
|
||||
posterior_log_variance_clipped = _extract_into_tensor(scheduler.posterior_log_variance_clipped, t, x_t.shape)
|
||||
assert (
|
||||
posterior_mean.shape[0]
|
||||
== posterior_variance.shape[0]
|
||||
== posterior_log_variance_clipped.shape[0]
|
||||
== x_start.shape[0]
|
||||
)
|
||||
return posterior_mean, posterior_variance, posterior_log_variance_clipped
|
||||
|
||||
def p_mean_variance(self, model, scheduler, x, t, transformer_out=None, low_res=None, clip_denoised=True):
|
||||
"""
|
||||
Apply the model to get p(x_{t-1} | x_t), as well as a prediction of
|
||||
the initial x, x_0.
|
||||
|
||||
:param model: the model, which takes a signal and a batch of timesteps
|
||||
as input.
|
||||
:param x: the [N x C x ...] tensor at time t.
|
||||
:param t: a 1-D Tensor of timesteps.
|
||||
:param clip_denoised: if True, clip the denoised signal into [-1, 1].
|
||||
:param model_kwargs: if not None, a dict of extra keyword arguments to
|
||||
pass to the model. This can be used for conditioning.
|
||||
:return: a dict with the following keys:
|
||||
- 'mean': the model mean output.
|
||||
- 'variance': the model variance output.
|
||||
- 'log_variance': the log of 'variance'.
|
||||
- 'pred_xstart': the prediction for x_0.
|
||||
"""
|
||||
|
||||
B, C = x.shape[:2]
|
||||
assert t.shape == (B,)
|
||||
if transformer_out is None:
|
||||
# super-res model
|
||||
model_output = model(x, t, low_res)
|
||||
else:
|
||||
# text2image model
|
||||
model_output = model(x, t, transformer_out)
|
||||
|
||||
assert model_output.shape == (B, C * 2, *x.shape[2:])
|
||||
model_output, model_var_values = torch.split(model_output, C, dim=1)
|
||||
min_log = _extract_into_tensor(scheduler.posterior_log_variance_clipped, t, x.shape)
|
||||
max_log = _extract_into_tensor(np.log(scheduler.betas), t, x.shape)
|
||||
# The model_var_values is [-1, 1] for [min_var, max_var].
|
||||
frac = (model_var_values + 1) / 2
|
||||
model_log_variance = frac * max_log + (1 - frac) * min_log
|
||||
model_variance = torch.exp(model_log_variance)
|
||||
|
||||
pred_xstart = self._predict_xstart_from_eps(scheduler, x_t=x, t=t, eps=model_output)
|
||||
if clip_denoised:
|
||||
pred_xstart = pred_xstart.clamp(-1, 1)
|
||||
model_mean, _, _ = self.q_posterior_mean_variance(scheduler, x_start=pred_xstart, x_t=x, t=t)
|
||||
|
||||
assert model_mean.shape == model_log_variance.shape == pred_xstart.shape == x.shape
|
||||
return model_mean, model_variance, model_log_variance, pred_xstart
|
||||
|
||||
def _predict_xstart_from_eps(self, scheduler, x_t, t, eps):
|
||||
assert x_t.shape == eps.shape
|
||||
return (
|
||||
_extract_into_tensor(scheduler.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t
|
||||
- _extract_into_tensor(scheduler.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * eps
|
||||
)
|
||||
|
||||
def _predict_eps_from_xstart(self, scheduler, x_t, t, pred_xstart):
|
||||
return (
|
||||
_extract_into_tensor(scheduler.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t - pred_xstart
|
||||
) / _extract_into_tensor(scheduler.sqrt_recipm1_alphas_cumprod, t, x_t.shape)
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, prompt, generator=None, torch_device=None):
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
self.text_unet.to(torch_device)
|
||||
self.text_encoder.to(torch_device)
|
||||
self.upscale_unet.to(torch_device)
|
||||
|
||||
# Create a classifier-free guidance sampling function
|
||||
guidance_scale = 3.0
|
||||
|
||||
def text_model_fn(x_t, ts, transformer_out, **kwargs):
|
||||
half = x_t[: len(x_t) // 2]
|
||||
combined = torch.cat([half, half], dim=0)
|
||||
model_out = self.text_unet(combined, ts, transformer_out, **kwargs)
|
||||
eps, rest = model_out[:, :3], model_out[:, 3:]
|
||||
cond_eps, uncond_eps = torch.split(eps, len(eps) // 2, dim=0)
|
||||
half_eps = uncond_eps + guidance_scale * (cond_eps - uncond_eps)
|
||||
eps = torch.cat([half_eps, half_eps], dim=0)
|
||||
return torch.cat([eps, rest], dim=1)
|
||||
|
||||
# 1. Sample gaussian noise
|
||||
batch_size = 2 # second image is empty for classifier-free guidance
|
||||
image = self.text_noise_scheduler.sample_noise(
|
||||
(batch_size, self.text_unet.in_channels, 64, 64), device=torch_device, generator=generator
|
||||
)
|
||||
|
||||
# 2. Encode tokens
|
||||
# an empty input is needed to guide the model away from (
|
||||
inputs = self.tokenizer([prompt, ""], padding="max_length", max_length=128, return_tensors="pt")
|
||||
input_ids = inputs["input_ids"].to(torch_device)
|
||||
attention_mask = inputs["attention_mask"].to(torch_device)
|
||||
transformer_out = self.text_encoder(input_ids, attention_mask).last_hidden_state
|
||||
|
||||
# 3. Run the text2image generation step
|
||||
num_timesteps = len(self.text_noise_scheduler)
|
||||
for i in tqdm.tqdm(reversed(range(num_timesteps)), total=num_timesteps):
|
||||
t = torch.tensor([i] * image.shape[0], device=torch_device)
|
||||
mean, variance, log_variance, pred_xstart = self.p_mean_variance(
|
||||
text_model_fn, self.text_noise_scheduler, image, t, transformer_out=transformer_out
|
||||
)
|
||||
noise = self.text_noise_scheduler.sample_noise(image.shape, device=torch_device, generator=generator)
|
||||
nonzero_mask = (t != 0).float().view(-1, *([1] * (len(image.shape) - 1))) # no noise when t == 0
|
||||
image = mean + nonzero_mask * torch.exp(0.5 * log_variance) * noise
|
||||
|
||||
# 4. Run the upscaling step
|
||||
batch_size = 1
|
||||
image = image[:1]
|
||||
low_res = ((image + 1) * 127.5).round() / 127.5 - 1
|
||||
eta = 0.0
|
||||
|
||||
# Tune this parameter to control the sharpness of 256x256 images.
|
||||
# A value of 1.0 is sharper, but sometimes results in grainy artifacts.
|
||||
upsample_temp = 0.997
|
||||
|
||||
image = (
|
||||
self.upscale_noise_scheduler.sample_noise(
|
||||
(batch_size, 3, 256, 256), device=torch_device, generator=generator
|
||||
)
|
||||
* upsample_temp
|
||||
)
|
||||
|
||||
num_timesteps = len(self.upscale_noise_scheduler)
|
||||
for t in tqdm.tqdm(
|
||||
reversed(range(len(self.upscale_noise_scheduler))), total=len(self.upscale_noise_scheduler)
|
||||
):
|
||||
# i) define coefficients for time step t
|
||||
clipped_image_coeff = 1 / torch.sqrt(self.upscale_noise_scheduler.get_alpha_prod(t))
|
||||
clipped_noise_coeff = torch.sqrt(1 / self.upscale_noise_scheduler.get_alpha_prod(t) - 1)
|
||||
image_coeff = (
|
||||
(1 - self.upscale_noise_scheduler.get_alpha_prod(t - 1))
|
||||
* torch.sqrt(self.upscale_noise_scheduler.get_alpha(t))
|
||||
/ (1 - self.upscale_noise_scheduler.get_alpha_prod(t))
|
||||
)
|
||||
clipped_coeff = (
|
||||
torch.sqrt(self.upscale_noise_scheduler.get_alpha_prod(t - 1))
|
||||
* self.upscale_noise_scheduler.get_beta(t)
|
||||
/ (1 - self.upscale_noise_scheduler.get_alpha_prod(t))
|
||||
)
|
||||
|
||||
# ii) predict noise residual
|
||||
time_input = torch.tensor([t] * image.shape[0], device=torch_device)
|
||||
model_output = self.upscale_unet(image, time_input, low_res)
|
||||
noise_residual, pred_variance = torch.split(model_output, 3, dim=1)
|
||||
|
||||
# iii) compute predicted image from residual
|
||||
# See 2nd formula at https://github.com/hojonathanho/diffusion/issues/5#issue-896554416 for comparison
|
||||
pred_mean = clipped_image_coeff * image - clipped_noise_coeff * noise_residual
|
||||
pred_mean = torch.clamp(pred_mean, -1, 1)
|
||||
prev_image = clipped_coeff * pred_mean + image_coeff * image
|
||||
|
||||
# iv) sample variance
|
||||
prev_variance = self.upscale_noise_scheduler.sample_variance(
|
||||
t, prev_image.shape, device=torch_device, generator=generator
|
||||
)
|
||||
|
||||
# v) sample x_{t-1} ~ N(prev_image, prev_variance)
|
||||
sampled_prev_image = prev_image + prev_variance
|
||||
image = sampled_prev_image
|
||||
|
||||
image = image.permute(0, 2, 3, 1)
|
||||
|
||||
return image
|
||||
@@ -1,24 +0,0 @@
|
||||
import torch
|
||||
|
||||
import PIL.Image
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
|
||||
generator = torch.Generator()
|
||||
generator = generator.manual_seed(0)
|
||||
|
||||
model_id = "fusing/glide-base"
|
||||
|
||||
# load model and scheduler
|
||||
pipeline = DiffusionPipeline.from_pretrained(model_id)
|
||||
|
||||
# run inference (text-conditioned denoising + upscaling)
|
||||
img = pipeline("a crayon drawing of a corgi", generator)
|
||||
|
||||
# process image to PIL
|
||||
img = img.squeeze(0)
|
||||
img = ((img + 1) * 127.5).round().clamp(0, 255).to(torch.uint8).cpu().numpy()
|
||||
image_pil = PIL.Image.fromarray(img)
|
||||
|
||||
# save image
|
||||
image_pil.save("test.png")
|
||||
@@ -1,146 +0,0 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The Fairseq Authors and The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" LDMBERT model configuration"""
|
||||
|
||||
from transformers.configuration_utils import PretrainedConfig
|
||||
from transformers.utils import logging
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
LDMBERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
|
||||
"ldm-bert": "https://huggingface.co/ldm-bert/resolve/main/config.json",
|
||||
}
|
||||
|
||||
|
||||
class LDMBertConfig(PretrainedConfig):
|
||||
r"""
|
||||
This is the configuration class to store the configuration of a [`LDMBertModel`]. It is used to instantiate a
|
||||
LDMBERT model according to the specified arguments, defining the model architecture. Instantiating a configuration
|
||||
with the defaults will yield a similar configuration to that of the LDMBERT
|
||||
[facebook/ldmbert-large](https://huggingface.co/facebook/ldmbert-large) architecture.
|
||||
|
||||
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
||||
documentation from [`PretrainedConfig`] for more information.
|
||||
|
||||
|
||||
Args:
|
||||
vocab_size (`int`, *optional*, defaults to 50265):
|
||||
Vocabulary size of the LDMBERT model. Defines the number of different tokens that can be represented by the
|
||||
`inputs_ids` passed when calling [`LDMBertModel`] or [`TFLDMBertModel`].
|
||||
d_model (`int`, *optional*, defaults to 1024):
|
||||
Dimensionality of the layers and the pooler layer.
|
||||
encoder_layers (`int`, *optional*, defaults to 12):
|
||||
Number of encoder layers.
|
||||
decoder_layers (`int`, *optional*, defaults to 12):
|
||||
Number of decoder layers.
|
||||
encoder_attention_heads (`int`, *optional*, defaults to 16):
|
||||
Number of attention heads for each attention layer in the Transformer encoder.
|
||||
decoder_attention_heads (`int`, *optional*, defaults to 16):
|
||||
Number of attention heads for each attention layer in the Transformer decoder.
|
||||
decoder_ffn_dim (`int`, *optional*, defaults to 4096):
|
||||
Dimensionality of the "intermediate" (often named feed-forward) layer in decoder.
|
||||
encoder_ffn_dim (`int`, *optional*, defaults to 4096):
|
||||
Dimensionality of the "intermediate" (often named feed-forward) layer in decoder.
|
||||
activation_function (`str` or `function`, *optional*, defaults to `"gelu"`):
|
||||
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
|
||||
`"relu"`, `"silu"` and `"gelu_new"` are supported.
|
||||
dropout (`float`, *optional*, defaults to 0.1):
|
||||
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
|
||||
attention_dropout (`float`, *optional*, defaults to 0.0):
|
||||
The dropout ratio for the attention probabilities.
|
||||
activation_dropout (`float`, *optional*, defaults to 0.0):
|
||||
The dropout ratio for activations inside the fully connected layer.
|
||||
classifier_dropout (`float`, *optional*, defaults to 0.0):
|
||||
The dropout ratio for classifier.
|
||||
max_position_embeddings (`int`, *optional*, defaults to 1024):
|
||||
The maximum sequence length that this model might ever be used with. Typically set this to something large
|
||||
just in case (e.g., 512 or 1024 or 2048).
|
||||
init_std (`float`, *optional*, defaults to 0.02):
|
||||
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
||||
encoder_layerdrop: (`float`, *optional*, defaults to 0.0):
|
||||
The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
|
||||
for more details.
|
||||
decoder_layerdrop: (`float`, *optional*, defaults to 0.0):
|
||||
The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
|
||||
for more details.
|
||||
scale_embedding (`bool`, *optional*, defaults to `False`):
|
||||
Scale embeddings by diving by sqrt(d_model).
|
||||
use_cache (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not the model should return the last key/values attentions (not used by all models).
|
||||
num_labels: (`int`, *optional*, defaults to 3):
|
||||
The number of labels to use in [`LDMBertForSequenceClassification`].
|
||||
forced_eos_token_id (`int`, *optional*, defaults to 2):
|
||||
The id of the token to force as the last generated token when `max_length` is reached. Usually set to
|
||||
`eos_token_id`.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
>>> from transformers import LDMBertModel, LDMBertConfig
|
||||
|
||||
>>> # Initializing a LDMBERT facebook/ldmbert-large style configuration
|
||||
>>> configuration = LDMBertConfig()
|
||||
|
||||
>>> # Initializing a model from the facebook/ldmbert-large style configuration
|
||||
>>> model = LDMBertModel(configuration)
|
||||
|
||||
>>> # Accessing the model configuration
|
||||
>>> configuration = model.config
|
||||
```"""
|
||||
model_type = "ldmbert"
|
||||
keys_to_ignore_at_inference = ["past_key_values"]
|
||||
attribute_map = {"num_attention_heads": "encoder_attention_heads", "hidden_size": "d_model"}
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_size=30522,
|
||||
max_position_embeddings=77,
|
||||
encoder_layers=32,
|
||||
encoder_ffn_dim=5120,
|
||||
encoder_attention_heads=8,
|
||||
head_dim=64,
|
||||
encoder_layerdrop=0.0,
|
||||
activation_function="gelu",
|
||||
d_model=1280,
|
||||
dropout=0.1,
|
||||
attention_dropout=0.0,
|
||||
activation_dropout=0.0,
|
||||
init_std=0.02,
|
||||
classifier_dropout=0.0,
|
||||
scale_embedding=False,
|
||||
use_cache=True,
|
||||
pad_token_id=0,
|
||||
**kwargs,
|
||||
):
|
||||
self.vocab_size = vocab_size
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.d_model = d_model
|
||||
self.encoder_ffn_dim = encoder_ffn_dim
|
||||
self.encoder_layers = encoder_layers
|
||||
self.encoder_attention_heads = encoder_attention_heads
|
||||
self.head_dim = head_dim
|
||||
self.dropout = dropout
|
||||
self.attention_dropout = attention_dropout
|
||||
self.activation_dropout = activation_dropout
|
||||
self.activation_function = activation_function
|
||||
self.init_std = init_std
|
||||
self.encoder_layerdrop = encoder_layerdrop
|
||||
self.classifier_dropout = classifier_dropout
|
||||
self.use_cache = use_cache
|
||||
self.num_hidden_layers = encoder_layers
|
||||
self.scale_embedding = scale_embedding # scale factor will be sqrt(d_model) if True
|
||||
|
||||
super().__init__(pad_token_id=pad_token_id, **kwargs)
|
||||
@@ -1,107 +0,0 @@
|
||||
import torch
|
||||
|
||||
import tqdm
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
from .configuration_ldmbert import LDMBertConfig # NOQA
|
||||
from .modeling_ldmbert import LDMBertModel # NOQA
|
||||
|
||||
# add these relative imports here, so we can load from hub
|
||||
from .modeling_vae import AutoencoderKL # NOQA
|
||||
|
||||
|
||||
class LatentDiffusion(DiffusionPipeline):
|
||||
def __init__(self, vqvae, bert, tokenizer, unet, noise_scheduler):
|
||||
super().__init__()
|
||||
self.register_modules(vqvae=vqvae, bert=bert, tokenizer=tokenizer, unet=unet, noise_scheduler=noise_scheduler)
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(
|
||||
self,
|
||||
prompt,
|
||||
batch_size=1,
|
||||
generator=None,
|
||||
torch_device=None,
|
||||
eta=0.0,
|
||||
guidance_scale=1.0,
|
||||
num_inference_steps=50,
|
||||
):
|
||||
# eta corresponds to η in paper and should be between [0, 1]
|
||||
|
||||
if torch_device is None:
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
self.unet.to(torch_device)
|
||||
self.vqvae.to(torch_device)
|
||||
self.bert.to(torch_device)
|
||||
|
||||
# get unconditional embeddings for classifier free guidence
|
||||
if guidance_scale != 1.0:
|
||||
uncond_input = self.tokenizer([""], padding="max_length", max_length=77, return_tensors="pt").to(
|
||||
torch_device
|
||||
)
|
||||
uncond_embeddings = self.bert(uncond_input.input_ids)[0]
|
||||
|
||||
# get text embedding
|
||||
text_input = self.tokenizer(prompt, padding="max_length", max_length=77, return_tensors="pt").to(torch_device)
|
||||
text_embedding = self.bert(text_input.input_ids)[0]
|
||||
|
||||
num_trained_timesteps = self.noise_scheduler.timesteps
|
||||
inference_step_times = range(0, num_trained_timesteps, num_trained_timesteps // num_inference_steps)
|
||||
|
||||
image = self.noise_scheduler.sample_noise(
|
||||
(batch_size, self.unet.in_channels, self.unet.image_size, self.unet.image_size),
|
||||
device=torch_device,
|
||||
generator=generator,
|
||||
)
|
||||
|
||||
# See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
|
||||
# Ideally, read DDIM paper in-detail understanding
|
||||
|
||||
# Notation (<variable name> -> <name in paper>
|
||||
# - pred_noise_t -> e_theta(x_t, t)
|
||||
# - pred_original_image -> f_theta(x_t, t) or x_0
|
||||
# - std_dev_t -> sigma_t
|
||||
# - eta -> η
|
||||
# - pred_image_direction -> "direction pointingc to x_t"
|
||||
# - pred_prev_image -> "x_t-1"
|
||||
for t in tqdm.tqdm(reversed(range(num_inference_steps)), total=num_inference_steps):
|
||||
# guidance_scale of 1 means no guidance
|
||||
if guidance_scale == 1.0:
|
||||
image_in = image
|
||||
context = text_embedding
|
||||
timesteps = torch.tensor([inference_step_times[t]] * image.shape[0], device=torch_device)
|
||||
else:
|
||||
# for classifier free guidance, we need to do two forward passes
|
||||
# here we concanate embedding and unconditioned embedding in a single batch
|
||||
# to avoid doing two forward passes
|
||||
image_in = torch.cat([image] * 2)
|
||||
context = torch.cat([uncond_embeddings, text_embedding])
|
||||
timesteps = torch.tensor([inference_step_times[t]] * image.shape[0], device=torch_device)
|
||||
|
||||
# 1. predict noise residual
|
||||
pred_noise_t = self.unet(image_in, timesteps, context=context)
|
||||
|
||||
# perform guidance
|
||||
if guidance_scale != 1.0:
|
||||
pred_noise_t_uncond, pred_noise_t = pred_noise_t.chunk(2)
|
||||
pred_noise_t = pred_noise_t_uncond + guidance_scale * (pred_noise_t - pred_noise_t_uncond)
|
||||
|
||||
# 2. predict previous mean of image x_t-1
|
||||
pred_prev_image = self.noise_scheduler.step(pred_noise_t, image, t, num_inference_steps, eta)
|
||||
|
||||
# 3. optionally sample variance
|
||||
variance = 0
|
||||
if eta > 0:
|
||||
noise = self.noise_scheduler.sample_noise(image.shape, device=image.device, generator=generator)
|
||||
variance = self.noise_scheduler.get_variance(t, num_inference_steps).sqrt() * eta * noise
|
||||
|
||||
# 4. set current image to prev_image: x_t -> x_t-1
|
||||
image = pred_prev_image + variance
|
||||
|
||||
# scale and decode image with vae
|
||||
image = 1 / 0.18215 * image
|
||||
image = self.vqvae.decode(image)
|
||||
image = torch.clamp((image + 1.0) / 2.0, min=0.0, max=1.0)
|
||||
|
||||
return image
|
||||
@@ -1,313 +0,0 @@
|
||||
#!/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
########################################################################
|
||||
#
|
||||
# DiffWave: A Versatile Diffusion Model for Audio Synthesis
|
||||
# (https://arxiv.org/abs/2009.09761)
|
||||
# Modified from https://github.com/philsyn/DiffWave-Vocoder
|
||||
#
|
||||
# Author: Max W. Y. Lam (maxwylam@tencent.com)
|
||||
# Copyright (c) 2021Tencent. All Rights Reserved
|
||||
#
|
||||
########################################################################
|
||||
|
||||
|
||||
import math
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
import tqdm
|
||||
|
||||
from ..configuration_utils import ConfigMixin
|
||||
from ..modeling_utils import ModelMixin
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
|
||||
|
||||
def calc_diffusion_step_embedding(diffusion_steps, diffusion_step_embed_dim_in):
|
||||
"""
|
||||
Embed a diffusion step $t$ into a higher dimensional space
|
||||
E.g. the embedding vector in the 128-dimensional space is
|
||||
[sin(t * 10^(0*4/63)), ... , sin(t * 10^(63*4/63)),
|
||||
cos(t * 10^(0*4/63)), ... , cos(t * 10^(63*4/63))]
|
||||
|
||||
Parameters:
|
||||
diffusion_steps (torch.long tensor, shape=(batchsize, 1)):
|
||||
diffusion steps for batch data
|
||||
diffusion_step_embed_dim_in (int, default=128):
|
||||
dimensionality of the embedding space for discrete diffusion steps
|
||||
Returns:
|
||||
the embedding vectors (torch.tensor, shape=(batchsize, diffusion_step_embed_dim_in)):
|
||||
"""
|
||||
|
||||
assert diffusion_step_embed_dim_in % 2 == 0
|
||||
|
||||
half_dim = diffusion_step_embed_dim_in // 2
|
||||
_embed = np.log(10000) / (half_dim - 1)
|
||||
_embed = torch.exp(torch.arange(half_dim) * -_embed).cuda()
|
||||
_embed = diffusion_steps * _embed
|
||||
diffusion_step_embed = torch.cat((torch.sin(_embed), torch.cos(_embed)), 1)
|
||||
return diffusion_step_embed
|
||||
|
||||
|
||||
"""
|
||||
Below scripts were borrowed from
|
||||
https://github.com/philsyn/DiffWave-Vocoder/blob/master/WaveNet.py
|
||||
"""
|
||||
|
||||
|
||||
def swish(x):
|
||||
return x * torch.sigmoid(x)
|
||||
|
||||
|
||||
# dilated conv layer with kaiming_normal initialization
|
||||
# from https://github.com/ksw0306/FloWaveNet/blob/master/modules.py
|
||||
class Conv(nn.Module):
|
||||
def __init__(self, in_channels, out_channels, kernel_size=3, dilation=1):
|
||||
super().__init__()
|
||||
self.padding = dilation * (kernel_size - 1) // 2
|
||||
self.conv = nn.Conv1d(in_channels, out_channels, kernel_size, dilation=dilation, padding=self.padding)
|
||||
self.conv = nn.utils.weight_norm(self.conv)
|
||||
nn.init.kaiming_normal_(self.conv.weight)
|
||||
|
||||
def forward(self, x):
|
||||
out = self.conv(x)
|
||||
return out
|
||||
|
||||
|
||||
# conv1x1 layer with zero initialization
|
||||
# from https://github.com/ksw0306/FloWaveNet/blob/master/modules.py but the scale parameter is removed
|
||||
class ZeroConv1d(nn.Module):
|
||||
def __init__(self, in_channel, out_channel):
|
||||
super().__init__()
|
||||
self.conv = nn.Conv1d(in_channel, out_channel, kernel_size=1, padding=0)
|
||||
self.conv.weight.data.zero_()
|
||||
self.conv.bias.data.zero_()
|
||||
|
||||
def forward(self, x):
|
||||
out = self.conv(x)
|
||||
return out
|
||||
|
||||
|
||||
# every residual block (named residual layer in paper)
|
||||
# contains one noncausal dilated conv
|
||||
class ResidualBlock(nn.Module):
|
||||
def __init__(self, res_channels, skip_channels, dilation, diffusion_step_embed_dim_out):
|
||||
super().__init__()
|
||||
self.res_channels = res_channels
|
||||
|
||||
# Use a FC layer for diffusion step embedding
|
||||
self.fc_t = nn.Linear(diffusion_step_embed_dim_out, self.res_channels)
|
||||
|
||||
# Dilated conv layer
|
||||
self.dilated_conv_layer = Conv(self.res_channels, 2 * self.res_channels, kernel_size=3, dilation=dilation)
|
||||
|
||||
# Add mel spectrogram upsampler and conditioner conv1x1 layer
|
||||
self.upsample_conv2d = nn.ModuleList()
|
||||
for s in [16, 16]:
|
||||
conv_trans2d = nn.ConvTranspose2d(1, 1, (3, 2 * s), padding=(1, s // 2), stride=(1, s))
|
||||
conv_trans2d = nn.utils.weight_norm(conv_trans2d)
|
||||
nn.init.kaiming_normal_(conv_trans2d.weight)
|
||||
self.upsample_conv2d.append(conv_trans2d)
|
||||
|
||||
# 80 is mel bands
|
||||
self.mel_conv = Conv(80, 2 * self.res_channels, kernel_size=1)
|
||||
|
||||
# Residual conv1x1 layer, connect to next residual layer
|
||||
self.res_conv = nn.Conv1d(res_channels, res_channels, kernel_size=1)
|
||||
self.res_conv = nn.utils.weight_norm(self.res_conv)
|
||||
nn.init.kaiming_normal_(self.res_conv.weight)
|
||||
|
||||
# Skip conv1x1 layer, add to all skip outputs through skip connections
|
||||
self.skip_conv = nn.Conv1d(res_channels, skip_channels, kernel_size=1)
|
||||
self.skip_conv = nn.utils.weight_norm(self.skip_conv)
|
||||
nn.init.kaiming_normal_(self.skip_conv.weight)
|
||||
|
||||
def forward(self, input_data):
|
||||
x, mel_spec, diffusion_step_embed = input_data
|
||||
h = x
|
||||
batch_size, n_channels, seq_len = x.shape
|
||||
assert n_channels == self.res_channels
|
||||
|
||||
# Add in diffusion step embedding
|
||||
part_t = self.fc_t(diffusion_step_embed)
|
||||
part_t = part_t.view([batch_size, self.res_channels, 1])
|
||||
h += part_t
|
||||
|
||||
# Dilated conv layer
|
||||
h = self.dilated_conv_layer(h)
|
||||
|
||||
# Upsample spectrogram to size of audio
|
||||
mel_spec = torch.unsqueeze(mel_spec, dim=1)
|
||||
mel_spec = F.leaky_relu(self.upsample_conv2d[0](mel_spec), 0.4, inplace=False)
|
||||
mel_spec = F.leaky_relu(self.upsample_conv2d[1](mel_spec), 0.4, inplace=False)
|
||||
mel_spec = torch.squeeze(mel_spec, dim=1)
|
||||
|
||||
assert mel_spec.size(2) >= seq_len
|
||||
if mel_spec.size(2) > seq_len:
|
||||
mel_spec = mel_spec[:, :, :seq_len]
|
||||
|
||||
mel_spec = self.mel_conv(mel_spec)
|
||||
h += mel_spec
|
||||
|
||||
# Gated-tanh nonlinearity
|
||||
out = torch.tanh(h[:, : self.res_channels, :]) * torch.sigmoid(h[:, self.res_channels :, :])
|
||||
|
||||
# Residual and skip outputs
|
||||
res = self.res_conv(out)
|
||||
assert x.shape == res.shape
|
||||
skip = self.skip_conv(out)
|
||||
|
||||
# Normalize for training stability
|
||||
return (x + res) * math.sqrt(0.5), skip
|
||||
|
||||
|
||||
class ResidualGroup(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
res_channels,
|
||||
skip_channels,
|
||||
num_res_layers,
|
||||
dilation_cycle,
|
||||
diffusion_step_embed_dim_in,
|
||||
diffusion_step_embed_dim_mid,
|
||||
diffusion_step_embed_dim_out,
|
||||
):
|
||||
super().__init__()
|
||||
self.num_res_layers = num_res_layers
|
||||
self.diffusion_step_embed_dim_in = diffusion_step_embed_dim_in
|
||||
|
||||
# Use the shared two FC layers for diffusion step embedding
|
||||
self.fc_t1 = nn.Linear(diffusion_step_embed_dim_in, diffusion_step_embed_dim_mid)
|
||||
self.fc_t2 = nn.Linear(diffusion_step_embed_dim_mid, diffusion_step_embed_dim_out)
|
||||
|
||||
# Stack all residual blocks with dilations 1, 2, ... , 512, ... , 1, 2, ..., 512
|
||||
self.residual_blocks = nn.ModuleList()
|
||||
for n in range(self.num_res_layers):
|
||||
self.residual_blocks.append(
|
||||
ResidualBlock(
|
||||
res_channels,
|
||||
skip_channels,
|
||||
dilation=2 ** (n % dilation_cycle),
|
||||
diffusion_step_embed_dim_out=diffusion_step_embed_dim_out,
|
||||
)
|
||||
)
|
||||
|
||||
def forward(self, input_data):
|
||||
x, mel_spectrogram, diffusion_steps = input_data
|
||||
|
||||
# Embed diffusion step t
|
||||
diffusion_step_embed = calc_diffusion_step_embedding(diffusion_steps, self.diffusion_step_embed_dim_in)
|
||||
diffusion_step_embed = swish(self.fc_t1(diffusion_step_embed))
|
||||
diffusion_step_embed = swish(self.fc_t2(diffusion_step_embed))
|
||||
|
||||
# Pass all residual layers
|
||||
h = x
|
||||
skip = 0
|
||||
for n in range(self.num_res_layers):
|
||||
# Use the output from last residual layer
|
||||
h, skip_n = self.residual_blocks[n]((h, mel_spectrogram, diffusion_step_embed))
|
||||
# Accumulate all skip outputs
|
||||
skip += skip_n
|
||||
|
||||
# Normalize for training stability
|
||||
return skip * math.sqrt(1.0 / self.num_res_layers)
|
||||
|
||||
|
||||
class DiffWave(ModelMixin, ConfigMixin):
|
||||
def __init__(
|
||||
self,
|
||||
in_channels=1,
|
||||
res_channels=128,
|
||||
skip_channels=128,
|
||||
out_channels=1,
|
||||
num_res_layers=30,
|
||||
dilation_cycle=10,
|
||||
diffusion_step_embed_dim_in=128,
|
||||
diffusion_step_embed_dim_mid=512,
|
||||
diffusion_step_embed_dim_out=512,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
# register all init arguments with self.register
|
||||
self.register(
|
||||
in_channels=in_channels,
|
||||
res_channels=res_channels,
|
||||
skip_channels=skip_channels,
|
||||
out_channels=out_channels,
|
||||
num_res_layers=num_res_layers,
|
||||
dilation_cycle=dilation_cycle,
|
||||
diffusion_step_embed_dim_in=diffusion_step_embed_dim_in,
|
||||
diffusion_step_embed_dim_mid=diffusion_step_embed_dim_mid,
|
||||
diffusion_step_embed_dim_out=diffusion_step_embed_dim_out,
|
||||
)
|
||||
|
||||
# Initial conv1x1 with relu
|
||||
self.init_conv = nn.Sequential(Conv(in_channels, res_channels, kernel_size=1), nn.ReLU(inplace=False))
|
||||
# All residual layers
|
||||
self.residual_layer = ResidualGroup(
|
||||
res_channels,
|
||||
skip_channels,
|
||||
num_res_layers,
|
||||
dilation_cycle,
|
||||
diffusion_step_embed_dim_in,
|
||||
diffusion_step_embed_dim_mid,
|
||||
diffusion_step_embed_dim_out,
|
||||
)
|
||||
# Final conv1x1 -> relu -> zeroconv1x1
|
||||
self.final_conv = nn.Sequential(
|
||||
Conv(skip_channels, skip_channels, kernel_size=1),
|
||||
nn.ReLU(inplace=False),
|
||||
ZeroConv1d(skip_channels, out_channels),
|
||||
)
|
||||
|
||||
def forward(self, input_data):
|
||||
audio, mel_spectrogram, diffusion_steps = input_data
|
||||
x = audio
|
||||
x = self.init_conv(x).clone()
|
||||
x = self.residual_layer((x, mel_spectrogram, diffusion_steps))
|
||||
return self.final_conv(x)
|
||||
|
||||
|
||||
class BDDM(DiffusionPipeline):
|
||||
def __init__(self, diffwave, noise_scheduler):
|
||||
super().__init__()
|
||||
noise_scheduler = noise_scheduler.set_format("pt")
|
||||
self.register_modules(diffwave=diffwave, noise_scheduler=noise_scheduler)
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, mel_spectrogram, generator, torch_device=None):
|
||||
if torch_device is None:
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
self.diffwave.to(torch_device)
|
||||
|
||||
mel_spectrogram = mel_spectrogram.to(torch_device)
|
||||
audio_length = mel_spectrogram.size(-1) * 256
|
||||
audio_size = (1, 1, audio_length)
|
||||
|
||||
# Sample gaussian noise to begin loop
|
||||
audio = torch.normal(0, 1, size=audio_size, generator=generator).to(torch_device)
|
||||
|
||||
timestep_values = self.noise_scheduler.timestep_values
|
||||
num_prediction_steps = len(self.noise_scheduler)
|
||||
for t in tqdm.tqdm(reversed(range(num_prediction_steps)), total=num_prediction_steps):
|
||||
# 1. predict noise residual
|
||||
ts = (torch.tensor(timestep_values[t]) * torch.ones((1, 1))).to(torch_device)
|
||||
residual = self.diffwave((audio, mel_spectrogram, ts))
|
||||
|
||||
# 2. predict previous mean of audio x_t-1
|
||||
pred_prev_audio = self.noise_scheduler.step(residual, audio, t)
|
||||
|
||||
# 3. optionally sample variance
|
||||
variance = 0
|
||||
if t > 0:
|
||||
noise = torch.normal(0, 1, size=audio_size, generator=generator).to(torch_device)
|
||||
variance = self.noise_scheduler.get_variance(t).sqrt() * noise
|
||||
|
||||
# 4. set current audio to prev_audio: x_t -> x_t-1
|
||||
audio = pred_prev_audio + variance
|
||||
|
||||
return audio
|
||||
@@ -1,74 +0,0 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
import torch
|
||||
|
||||
import tqdm
|
||||
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
|
||||
|
||||
class DDIM(DiffusionPipeline):
|
||||
def __init__(self, unet, noise_scheduler):
|
||||
super().__init__()
|
||||
noise_scheduler = noise_scheduler.set_format("pt")
|
||||
self.register_modules(unet=unet, noise_scheduler=noise_scheduler)
|
||||
|
||||
def __call__(self, batch_size=1, generator=None, torch_device=None, eta=0.0, num_inference_steps=50):
|
||||
# eta corresponds to η in paper and should be between [0, 1]
|
||||
if torch_device is None:
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
num_trained_timesteps = self.noise_scheduler.timesteps
|
||||
inference_step_times = range(0, num_trained_timesteps, num_trained_timesteps // num_inference_steps)
|
||||
|
||||
self.unet.to(torch_device)
|
||||
|
||||
# Sample gaussian noise to begin loop
|
||||
image = torch.randn(
|
||||
(batch_size, self.unet.in_channels, self.unet.resolution, self.unet.resolution),
|
||||
generator=generator,
|
||||
)
|
||||
image = image.to(torch_device)
|
||||
|
||||
# See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
|
||||
# Ideally, read DDIM paper in-detail understanding
|
||||
|
||||
# Notation (<variable name> -> <name in paper>
|
||||
# - pred_noise_t -> e_theta(x_t, t)
|
||||
# - pred_original_image -> f_theta(x_t, t) or x_0
|
||||
# - std_dev_t -> sigma_t
|
||||
# - eta -> η
|
||||
# - pred_image_direction -> "direction pointingc to x_t"
|
||||
# - pred_prev_image -> "x_t-1"
|
||||
for t in tqdm.tqdm(reversed(range(num_inference_steps)), total=num_inference_steps):
|
||||
# 1. predict noise residual
|
||||
with torch.no_grad():
|
||||
residual = self.unet(image, inference_step_times[t])
|
||||
|
||||
# 2. predict previous mean of image x_t-1
|
||||
pred_prev_image = self.noise_scheduler.step(residual, image, t, num_inference_steps, eta)
|
||||
|
||||
# 3. optionally sample variance
|
||||
variance = 0
|
||||
if eta > 0:
|
||||
noise = torch.randn(image.shape, generator=generator).to(image.device)
|
||||
variance = self.noise_scheduler.get_variance(t, num_inference_steps).sqrt() * eta * noise
|
||||
|
||||
# 4. set current image to prev_image: x_t -> x_t-1
|
||||
image = pred_prev_image + variance
|
||||
|
||||
return image
|
||||
@@ -1,61 +0,0 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
import torch
|
||||
|
||||
import tqdm
|
||||
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
|
||||
|
||||
class DDPM(DiffusionPipeline):
|
||||
def __init__(self, unet, noise_scheduler):
|
||||
super().__init__()
|
||||
noise_scheduler = noise_scheduler.set_format("pt")
|
||||
self.register_modules(unet=unet, noise_scheduler=noise_scheduler)
|
||||
|
||||
def __call__(self, batch_size=1, generator=None, torch_device=None):
|
||||
if torch_device is None:
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
self.unet.to(torch_device)
|
||||
|
||||
# Sample gaussian noise to begin loop
|
||||
image = torch.randn(
|
||||
(batch_size, self.unet.in_channels, self.unet.resolution, self.unet.resolution),
|
||||
generator=generator,
|
||||
)
|
||||
image = image.to(torch_device)
|
||||
|
||||
num_prediction_steps = len(self.noise_scheduler)
|
||||
for t in tqdm.tqdm(reversed(range(num_prediction_steps)), total=num_prediction_steps):
|
||||
# 1. predict noise residual
|
||||
with torch.no_grad():
|
||||
residual = self.unet(image, t)
|
||||
|
||||
# 2. predict previous mean of image x_t-1
|
||||
pred_prev_image = self.noise_scheduler.step(residual, image, t)
|
||||
|
||||
# 3. optionally sample variance
|
||||
variance = 0
|
||||
if t > 0:
|
||||
noise = torch.randn(image.shape, generator=generator).to(image.device)
|
||||
variance = self.noise_scheduler.get_variance(t).sqrt() * noise
|
||||
|
||||
# 4. set current image to prev_image: x_t -> x_t-1
|
||||
image = pred_prev_image + variance
|
||||
|
||||
return image
|
||||
@@ -1,914 +0,0 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2022 The OpenAI Team Authors and The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
""" PyTorch CLIP model."""
|
||||
|
||||
import math
|
||||
from dataclasses import dataclass
|
||||
from typing import Any, Optional, Tuple, Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.utils.checkpoint
|
||||
from torch import nn
|
||||
|
||||
import tqdm
|
||||
|
||||
|
||||
try:
|
||||
from transformers import CLIPConfig, CLIPModel, CLIPTextConfig, CLIPVisionConfig, GPT2Tokenizer
|
||||
from transformers.activations import ACT2FN
|
||||
from transformers.modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
from transformers.utils import ModelOutput, add_start_docstrings_to_model_forward, replace_return_docstrings
|
||||
except:
|
||||
print("Transformers is not installed")
|
||||
pass
|
||||
|
||||
from ..models import GLIDESuperResUNetModel, GLIDETextToImageUNetModel
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from ..schedulers import ClassifierFreeGuidanceScheduler, DDIMScheduler
|
||||
from ..utils import logging
|
||||
|
||||
|
||||
#####################
|
||||
# START OF THE CLIP MODEL COPY-PASTE (with a modified attention module)
|
||||
#####################
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
_CHECKPOINT_FOR_DOC = "fusing/glide-base"
|
||||
|
||||
CLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
|
||||
"fusing/glide-base",
|
||||
# See all CLIP models at https://huggingface.co/models?filter=clip
|
||||
]
|
||||
|
||||
|
||||
# Copied from transformers.models.bart.modeling_bart._expand_mask
|
||||
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
|
||||
"""
|
||||
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
||||
"""
|
||||
bsz, src_len = mask.size()
|
||||
tgt_len = tgt_len if tgt_len is not None else src_len
|
||||
|
||||
expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
|
||||
|
||||
inverted_mask = 1.0 - expanded_mask
|
||||
|
||||
return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
|
||||
|
||||
|
||||
# contrastive loss function, adapted from
|
||||
# https://sachinruk.github.io/blog/pytorch/pytorch%20lightning/loss%20function/gpu/2021/03/07/CLIP.html
|
||||
def contrastive_loss(logits: torch.Tensor) -> torch.Tensor:
|
||||
return nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device))
|
||||
|
||||
|
||||
def clip_loss(similarity: torch.Tensor) -> torch.Tensor:
|
||||
caption_loss = contrastive_loss(similarity)
|
||||
image_loss = contrastive_loss(similarity.T)
|
||||
return (caption_loss + image_loss) / 2.0
|
||||
|
||||
|
||||
@dataclass
|
||||
class CLIPOutput(ModelOutput):
|
||||
"""
|
||||
Args:
|
||||
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
|
||||
Contrastive loss for image-text similarity.
|
||||
logits_per_image:(`torch.FloatTensor` of shape `(image_batch_size, text_batch_size)`):
|
||||
The scaled dot product scores between `image_embeds` and `text_embeds`. This represents the image-text
|
||||
similarity scores.
|
||||
logits_per_text:(`torch.FloatTensor` of shape `(text_batch_size, image_batch_size)`):
|
||||
The scaled dot product scores between `text_embeds` and `image_embeds`. This represents the text-image
|
||||
similarity scores.
|
||||
text_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
|
||||
The text embeddings obtained by applying the projection layer to the pooled output of [`CLIPTextModel`].
|
||||
image_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
|
||||
The image embeddings obtained by applying the projection layer to the pooled output of [`CLIPVisionModel`].
|
||||
text_model_output(`BaseModelOutputWithPooling`):
|
||||
The output of the [`CLIPTextModel`].
|
||||
vision_model_output(`BaseModelOutputWithPooling`):
|
||||
The output of the [`CLIPVisionModel`].
|
||||
"""
|
||||
|
||||
loss: Optional[torch.FloatTensor] = None
|
||||
logits_per_image: torch.FloatTensor = None
|
||||
logits_per_text: torch.FloatTensor = None
|
||||
text_embeds: torch.FloatTensor = None
|
||||
image_embeds: torch.FloatTensor = None
|
||||
text_model_output: BaseModelOutputWithPooling = None
|
||||
vision_model_output: BaseModelOutputWithPooling = None
|
||||
|
||||
def to_tuple(self) -> Tuple[Any]:
|
||||
return tuple(
|
||||
self[k] if k not in ["text_model_output", "vision_model_output"] else getattr(self, k).to_tuple()
|
||||
for k in self.keys()
|
||||
)
|
||||
|
||||
|
||||
class CLIPVisionEmbeddings(nn.Module):
|
||||
def __init__(self, config: CLIPVisionConfig):
|
||||
super().__init__()
|
||||
self.config = config
|
||||
self.embed_dim = config.hidden_size
|
||||
self.image_size = config.image_size
|
||||
self.patch_size = config.patch_size
|
||||
|
||||
self.class_embedding = nn.Parameter(torch.randn(self.embed_dim))
|
||||
|
||||
self.patch_embedding = nn.Conv2d(
|
||||
in_channels=3, out_channels=self.embed_dim, kernel_size=self.patch_size, stride=self.patch_size, bias=False
|
||||
)
|
||||
|
||||
self.num_patches = (self.image_size // self.patch_size) ** 2
|
||||
self.num_positions = self.num_patches + 1
|
||||
self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
|
||||
self.register_buffer("position_ids", torch.arange(self.num_positions).expand((1, -1)))
|
||||
|
||||
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
|
||||
batch_size = pixel_values.shape[0]
|
||||
patch_embeds = self.patch_embedding(pixel_values) # shape = [*, width, grid, grid]
|
||||
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
|
||||
|
||||
class_embeds = self.class_embedding.expand(batch_size, 1, -1)
|
||||
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
|
||||
embeddings = embeddings + self.position_embedding(self.position_ids)
|
||||
return embeddings
|
||||
|
||||
|
||||
class CLIPTextEmbeddings(nn.Module):
|
||||
def __init__(self, config: CLIPTextConfig):
|
||||
super().__init__()
|
||||
embed_dim = config.hidden_size
|
||||
|
||||
self.token_embedding = nn.Embedding(config.vocab_size, embed_dim)
|
||||
self.position_embedding = nn.Embedding(config.max_position_embeddings, embed_dim)
|
||||
self.use_padding_embeddings = config.use_padding_embeddings
|
||||
if self.use_padding_embeddings:
|
||||
self.padding_embedding = nn.Embedding(config.max_position_embeddings, embed_dim)
|
||||
|
||||
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
|
||||
self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
) -> torch.Tensor:
|
||||
seq_length = input_ids.shape[-1] if input_ids is not None else inputs_embeds.shape[-2]
|
||||
|
||||
if position_ids is None:
|
||||
position_ids = self.position_ids[:, :seq_length]
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.token_embedding(input_ids)
|
||||
|
||||
position_embeddings = self.position_embedding(position_ids)
|
||||
embeddings = inputs_embeds + position_embeddings
|
||||
|
||||
if self.use_padding_embeddings and attention_mask is not None:
|
||||
padding_embeddings = self.padding_embedding(position_ids)
|
||||
embeddings = torch.where(attention_mask.bool().unsqueeze(-1), embeddings, padding_embeddings)
|
||||
|
||||
return embeddings
|
||||
|
||||
|
||||
class CLIPAttention(nn.Module):
|
||||
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__()
|
||||
self.config = config
|
||||
self.embed_dim = config.hidden_size
|
||||
self.num_heads = config.num_attention_heads
|
||||
self.head_dim = self.embed_dim // self.num_heads
|
||||
if self.head_dim * self.num_heads != self.embed_dim:
|
||||
raise ValueError(
|
||||
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
|
||||
f" {self.num_heads})."
|
||||
)
|
||||
self.scale = 1 / math.sqrt(math.sqrt(self.head_dim))
|
||||
|
||||
self.qkv_proj = nn.Linear(self.embed_dim, self.embed_dim * 3)
|
||||
self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
causal_attention_mask: Optional[torch.Tensor] = None,
|
||||
output_attentions: Optional[bool] = False,
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
||||
"""Input shape: Batch x Time x Channel"""
|
||||
|
||||
bsz, tgt_len, embed_dim = hidden_states.size()
|
||||
|
||||
qkv_states = self.qkv_proj(hidden_states)
|
||||
qkv_states = qkv_states.view(bsz, tgt_len, self.num_heads, -1)
|
||||
query_states, key_states, value_states = torch.split(qkv_states, self.head_dim, dim=-1)
|
||||
|
||||
attn_weights = torch.einsum("bthc,bshc->bhts", query_states * self.scale, key_states * self.scale)
|
||||
|
||||
wdtype = attn_weights.dtype
|
||||
attn_weights = nn.functional.softmax(attn_weights.float(), dim=-1).type(wdtype)
|
||||
|
||||
attn_output = torch.einsum("bhts,bshc->bthc", attn_weights, value_states)
|
||||
attn_output = attn_output.reshape(bsz, tgt_len, -1)
|
||||
|
||||
attn_output = self.out_proj(attn_output)
|
||||
|
||||
return attn_output, attn_weights
|
||||
|
||||
|
||||
class CLIPMLP(nn.Module):
|
||||
def __init__(self, config):
|
||||
super().__init__()
|
||||
self.config = config
|
||||
self.activation_fn = ACT2FN[config.hidden_act]
|
||||
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
|
||||
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
|
||||
|
||||
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
||||
hidden_states = self.fc1(hidden_states)
|
||||
hidden_states = self.activation_fn(hidden_states)
|
||||
hidden_states = self.fc2(hidden_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
class CLIPEncoderLayer(nn.Module):
|
||||
def __init__(self, config: CLIPConfig):
|
||||
super().__init__()
|
||||
self.embed_dim = config.hidden_size
|
||||
self.self_attn = CLIPAttention(config)
|
||||
self.layer_norm1 = nn.LayerNorm(self.embed_dim)
|
||||
self.mlp = CLIPMLP(config)
|
||||
self.layer_norm2 = nn.LayerNorm(self.embed_dim)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: torch.Tensor,
|
||||
causal_attention_mask: torch.Tensor,
|
||||
output_attentions: Optional[bool] = False,
|
||||
) -> Tuple[torch.FloatTensor]:
|
||||
"""
|
||||
Args:
|
||||
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
||||
attention_mask (`torch.FloatTensor`): attention mask of size
|
||||
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
|
||||
`(config.encoder_attention_heads,)`.
|
||||
output_attentions (`bool`, *optional*):
|
||||
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
||||
returned tensors for more detail.
|
||||
"""
|
||||
residual = hidden_states
|
||||
|
||||
hidden_states = self.layer_norm1(hidden_states)
|
||||
hidden_states, attn_weights = self.self_attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
causal_attention_mask=causal_attention_mask,
|
||||
output_attentions=output_attentions,
|
||||
)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
residual = hidden_states
|
||||
hidden_states = self.layer_norm2(hidden_states)
|
||||
hidden_states = self.mlp(hidden_states)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
outputs = (hidden_states,)
|
||||
|
||||
if output_attentions:
|
||||
outputs += (attn_weights,)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
class CLIPPreTrainedModel(PreTrainedModel):
|
||||
"""
|
||||
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
|
||||
models.
|
||||
"""
|
||||
|
||||
config_class = CLIPConfig
|
||||
base_model_prefix = "clip"
|
||||
supports_gradient_checkpointing = True
|
||||
_keys_to_ignore_on_load_missing = [r"position_ids"]
|
||||
|
||||
def _init_weights(self, module):
|
||||
"""Initialize the weights"""
|
||||
factor = self.config.initializer_factor
|
||||
if isinstance(module, CLIPTextEmbeddings):
|
||||
module.token_embedding.weight.data.normal_(mean=0.0, std=factor * 0.02)
|
||||
module.position_embedding.weight.data.normal_(mean=0.0, std=factor * 0.02)
|
||||
if hasattr(module, "padding_embedding"):
|
||||
module.padding_embedding.weight.data.normal_(mean=0.0, std=factor * 0.02)
|
||||
elif isinstance(module, CLIPVisionEmbeddings):
|
||||
factor = self.config.initializer_factor
|
||||
nn.init.normal_(module.class_embedding, mean=0.0, std=module.embed_dim**-0.5 * factor)
|
||||
nn.init.normal_(module.patch_embedding.weight, std=module.config.initializer_range * factor)
|
||||
nn.init.normal_(module.position_embedding.weight, std=module.config.initializer_range * factor)
|
||||
elif isinstance(module, CLIPAttention):
|
||||
factor = self.config.initializer_factor
|
||||
in_proj_std = (module.embed_dim**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
|
||||
out_proj_std = (module.embed_dim**-0.5) * factor
|
||||
nn.init.normal_(module.qkv_proj.weight, std=in_proj_std)
|
||||
nn.init.normal_(module.out_proj.weight, std=out_proj_std)
|
||||
elif isinstance(module, CLIPMLP):
|
||||
factor = self.config.initializer_factor
|
||||
in_proj_std = (
|
||||
(module.config.hidden_size**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
|
||||
)
|
||||
fc_std = (2 * module.config.hidden_size) ** -0.5 * factor
|
||||
nn.init.normal_(module.fc1.weight, std=fc_std)
|
||||
nn.init.normal_(module.fc2.weight, std=in_proj_std)
|
||||
elif isinstance(module, CLIPModel):
|
||||
nn.init.normal_(
|
||||
module.text_projection.weight,
|
||||
std=module.text_embed_dim**-0.5 * self.config.initializer_factor,
|
||||
)
|
||||
nn.init.normal_(
|
||||
module.visual_projection.weight,
|
||||
std=module.vision_embed_dim**-0.5 * self.config.initializer_factor,
|
||||
)
|
||||
|
||||
if isinstance(module, nn.LayerNorm):
|
||||
module.bias.data.zero_()
|
||||
module.weight.data.fill_(1.0)
|
||||
if isinstance(module, nn.Linear) and module.bias is not None:
|
||||
module.bias.data.zero_()
|
||||
|
||||
def _set_gradient_checkpointing(self, module, value=False):
|
||||
if isinstance(module, CLIPEncoder):
|
||||
module.gradient_checkpointing = value
|
||||
|
||||
|
||||
CLIP_START_DOCSTRING = r"""
|
||||
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
|
||||
as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
|
||||
behavior.
|
||||
|
||||
Parameters:
|
||||
config ([`CLIPConfig`]): Model configuration class with all the parameters of the model.
|
||||
Initializing with a config file does not load the weights associated with the model, only the
|
||||
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
||||
"""
|
||||
|
||||
CLIP_TEXT_INPUTS_DOCSTRING = r"""
|
||||
Args:
|
||||
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
||||
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
||||
it.
|
||||
|
||||
Indices can be obtained using [`CLIPTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
||||
[`PreTrainedTokenizer.__call__`] for details.
|
||||
|
||||
[What are input IDs?](../glossary#input-ids)
|
||||
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
||||
|
||||
- 1 for tokens that are **not masked**,
|
||||
- 0 for tokens that are **masked**.
|
||||
|
||||
[What are attention masks?](../glossary#attention-mask)
|
||||
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
||||
config.max_position_embeddings - 1]`.
|
||||
|
||||
[What are position IDs?](../glossary#position-ids)
|
||||
output_attentions (`bool`, *optional*):
|
||||
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
||||
tensors for more detail.
|
||||
output_hidden_states (`bool`, *optional*):
|
||||
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
||||
more detail.
|
||||
return_dict (`bool`, *optional*):
|
||||
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
||||
"""
|
||||
|
||||
CLIP_VISION_INPUTS_DOCSTRING = r"""
|
||||
Args:
|
||||
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
||||
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
|
||||
[`CLIPFeatureExtractor`]. See [`CLIPFeatureExtractor.__call__`] for details.
|
||||
output_attentions (`bool`, *optional*):
|
||||
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
||||
tensors for more detail.
|
||||
output_hidden_states (`bool`, *optional*):
|
||||
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
||||
more detail.
|
||||
return_dict (`bool`, *optional*):
|
||||
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
||||
"""
|
||||
|
||||
CLIP_INPUTS_DOCSTRING = r"""
|
||||
Args:
|
||||
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
||||
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
||||
it.
|
||||
|
||||
Indices can be obtained using [`CLIPTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
||||
[`PreTrainedTokenizer.__call__`] for details.
|
||||
|
||||
[What are input IDs?](../glossary#input-ids)
|
||||
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
||||
|
||||
- 1 for tokens that are **not masked**,
|
||||
- 0 for tokens that are **masked**.
|
||||
|
||||
[What are attention masks?](../glossary#attention-mask)
|
||||
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
||||
config.max_position_embeddings - 1]`.
|
||||
|
||||
[What are position IDs?](../glossary#position-ids)
|
||||
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
||||
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
|
||||
[`CLIPFeatureExtractor`]. See [`CLIPFeatureExtractor.__call__`] for details.
|
||||
return_loss (`bool`, *optional*):
|
||||
Whether or not to return the contrastive loss.
|
||||
output_attentions (`bool`, *optional*):
|
||||
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
||||
tensors for more detail.
|
||||
output_hidden_states (`bool`, *optional*):
|
||||
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
||||
more detail.
|
||||
return_dict (`bool`, *optional*):
|
||||
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
||||
"""
|
||||
|
||||
|
||||
class CLIPEncoder(nn.Module):
|
||||
"""
|
||||
Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
|
||||
[`CLIPEncoderLayer`].
|
||||
|
||||
Args:
|
||||
config: CLIPConfig
|
||||
"""
|
||||
|
||||
def __init__(self, config: CLIPConfig):
|
||||
super().__init__()
|
||||
self.config = config
|
||||
self.layers = nn.ModuleList([CLIPEncoderLayer(config) for _ in range(config.num_hidden_layers)])
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
def forward(
|
||||
self,
|
||||
inputs_embeds,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
causal_attention_mask: Optional[torch.Tensor] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, BaseModelOutput]:
|
||||
r"""
|
||||
Args:
|
||||
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
||||
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
|
||||
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
|
||||
than the model's internal embedding lookup matrix.
|
||||
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
||||
|
||||
- 1 for tokens that are **not masked**,
|
||||
- 0 for tokens that are **masked**.
|
||||
|
||||
[What are attention masks?](../glossary#attention-mask)
|
||||
causal_attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Causal mask for the text model. Mask values selected in `[0, 1]`:
|
||||
|
||||
- 1 for tokens that are **not masked**,
|
||||
- 0 for tokens that are **masked**.
|
||||
|
||||
[What are attention masks?](../glossary#attention-mask)
|
||||
output_attentions (`bool`, *optional*):
|
||||
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
||||
returned tensors for more detail.
|
||||
output_hidden_states (`bool`, *optional*):
|
||||
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
|
||||
for more detail.
|
||||
return_dict (`bool`, *optional*):
|
||||
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
||||
"""
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
encoder_states = () if output_hidden_states else None
|
||||
all_attentions = () if output_attentions else None
|
||||
|
||||
hidden_states = inputs_embeds
|
||||
for idx, encoder_layer in enumerate(self.layers):
|
||||
if output_hidden_states:
|
||||
encoder_states = encoder_states + (hidden_states,)
|
||||
if self.gradient_checkpointing and self.training:
|
||||
|
||||
def create_custom_forward(module):
|
||||
def custom_forward(*inputs):
|
||||
return module(*inputs, output_attentions)
|
||||
|
||||
return custom_forward
|
||||
|
||||
layer_outputs = torch.utils.checkpoint.checkpoint(
|
||||
create_custom_forward(encoder_layer),
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
causal_attention_mask,
|
||||
)
|
||||
else:
|
||||
layer_outputs = encoder_layer(
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
causal_attention_mask,
|
||||
output_attentions=output_attentions,
|
||||
)
|
||||
|
||||
hidden_states = layer_outputs[0]
|
||||
|
||||
if output_attentions:
|
||||
all_attentions = all_attentions + (layer_outputs[1],)
|
||||
|
||||
if output_hidden_states:
|
||||
encoder_states = encoder_states + (hidden_states,)
|
||||
|
||||
if not return_dict:
|
||||
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
|
||||
return BaseModelOutput(
|
||||
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
|
||||
)
|
||||
|
||||
|
||||
class CLIPTextTransformer(nn.Module):
|
||||
def __init__(self, config: CLIPTextConfig):
|
||||
super().__init__()
|
||||
self.config = config
|
||||
embed_dim = config.hidden_size
|
||||
self.embeddings = CLIPTextEmbeddings(config)
|
||||
self.encoder = CLIPEncoder(config)
|
||||
self.final_layer_norm = nn.LayerNorm(embed_dim)
|
||||
|
||||
@add_start_docstrings_to_model_forward(CLIP_TEXT_INPUTS_DOCSTRING)
|
||||
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPTextConfig)
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.Tensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.Tensor] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
||||
r"""
|
||||
Returns:
|
||||
|
||||
"""
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
if input_ids is None:
|
||||
raise ValueError("You have to specify either input_ids")
|
||||
|
||||
input_shape = input_ids.size()
|
||||
input_ids = input_ids.view(-1, input_shape[-1])
|
||||
|
||||
hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids, attention_mask=attention_mask)
|
||||
|
||||
bsz, seq_len = input_shape
|
||||
# CLIP's text model uses causal mask, prepare it here.
|
||||
# https://github.com/openai/CLIP/blob/cfcffb90e69f37bf2ff1e988237a0fbe41f33c04/clip/model.py#L324
|
||||
causal_attention_mask = self._build_causal_attention_mask(bsz, seq_len).to(hidden_states.device)
|
||||
|
||||
# expand attention_mask
|
||||
if attention_mask is not None:
|
||||
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
||||
attention_mask = _expand_mask(attention_mask, hidden_states.dtype)
|
||||
|
||||
encoder_outputs = self.encoder(
|
||||
inputs_embeds=hidden_states,
|
||||
attention_mask=None,
|
||||
causal_attention_mask=None,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict,
|
||||
)
|
||||
|
||||
last_hidden_state = encoder_outputs[0]
|
||||
last_hidden_state = self.final_layer_norm(last_hidden_state)
|
||||
|
||||
# text_embeds.shape = [batch_size, sequence_length, transformer.width]
|
||||
# take features from the eot embedding (eot_token is the highest number in each sequence)
|
||||
pooled_output = last_hidden_state[torch.arange(last_hidden_state.shape[0]), input_ids.argmax(dim=-1)]
|
||||
|
||||
if not return_dict:
|
||||
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
|
||||
|
||||
return BaseModelOutputWithPooling(
|
||||
last_hidden_state=last_hidden_state,
|
||||
pooler_output=pooled_output,
|
||||
hidden_states=encoder_outputs.hidden_states,
|
||||
attentions=encoder_outputs.attentions,
|
||||
)
|
||||
|
||||
def _build_causal_attention_mask(self, bsz, seq_len):
|
||||
# lazily create causal attention mask, with full attention between the vision tokens
|
||||
# pytorch uses additive attention mask; fill with -inf
|
||||
mask = torch.empty(bsz, seq_len, seq_len)
|
||||
mask.fill_(torch.tensor(float("-inf")))
|
||||
mask.triu_(1) # zero out the lower diagonal
|
||||
mask = mask.unsqueeze(1) # expand mask
|
||||
return mask
|
||||
|
||||
|
||||
class CLIPTextModel(CLIPPreTrainedModel):
|
||||
config_class = CLIPTextConfig
|
||||
|
||||
def __init__(self, config: CLIPTextConfig):
|
||||
super().__init__(config)
|
||||
self.text_model = CLIPTextTransformer(config)
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self) -> nn.Module:
|
||||
return self.text_model.embeddings.token_embedding
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.text_model.embeddings.token_embedding = value
|
||||
|
||||
@add_start_docstrings_to_model_forward(CLIP_TEXT_INPUTS_DOCSTRING)
|
||||
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPTextConfig)
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.Tensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.Tensor] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
||||
r"""
|
||||
Returns:
|
||||
|
||||
Examples:
|
||||
|
||||
```python
|
||||
>>> from transformers import CLIPTokenizer, CLIPTextModel
|
||||
|
||||
>>> model = CLIPTextModel.from_pretrained("openai/clip-vit-base-patch32")
|
||||
>>> tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-base-patch32")
|
||||
|
||||
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding=True, return_tensors="pt")
|
||||
|
||||
>>> outputs = model(**inputs)
|
||||
>>> last_hidden_state = outputs.last_hidden_state
|
||||
>>> pooled_output = outputs.pooler_output # pooled (EOS token) states
|
||||
```"""
|
||||
return self.text_model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict,
|
||||
)
|
||||
|
||||
|
||||
#####################
|
||||
# END OF THE CLIP MODEL COPY-PASTE
|
||||
#####################
|
||||
|
||||
|
||||
def _extract_into_tensor(arr, timesteps, broadcast_shape):
|
||||
"""
|
||||
Extract values from a 1-D numpy array for a batch of indices.
|
||||
|
||||
:param arr: the 1-D numpy array.
|
||||
:param timesteps: a tensor of indices into the array to extract.
|
||||
:param broadcast_shape: a larger shape of K dimensions with the batch
|
||||
dimension equal to the length of timesteps.
|
||||
:return: a tensor of shape [batch_size, 1, ...] where the shape has K dims.
|
||||
"""
|
||||
res = torch.from_numpy(arr).to(device=timesteps.device)[timesteps].float()
|
||||
while len(res.shape) < len(broadcast_shape):
|
||||
res = res[..., None]
|
||||
return res + torch.zeros(broadcast_shape, device=timesteps.device)
|
||||
|
||||
|
||||
class GLIDE(DiffusionPipeline):
|
||||
def __init__(
|
||||
self,
|
||||
text_unet: GLIDETextToImageUNetModel,
|
||||
text_noise_scheduler: ClassifierFreeGuidanceScheduler,
|
||||
text_encoder: CLIPTextModel,
|
||||
tokenizer: GPT2Tokenizer,
|
||||
upscale_unet: GLIDESuperResUNetModel,
|
||||
upscale_noise_scheduler: DDIMScheduler,
|
||||
):
|
||||
super().__init__()
|
||||
self.register_modules(
|
||||
text_unet=text_unet,
|
||||
text_noise_scheduler=text_noise_scheduler,
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
upscale_unet=upscale_unet,
|
||||
upscale_noise_scheduler=upscale_noise_scheduler,
|
||||
)
|
||||
|
||||
def q_posterior_mean_variance(self, scheduler, x_start, x_t, t):
|
||||
"""
|
||||
Compute the mean and variance of the diffusion posterior:
|
||||
|
||||
q(x_{t-1} | x_t, x_0)
|
||||
|
||||
"""
|
||||
assert x_start.shape == x_t.shape
|
||||
posterior_mean = (
|
||||
_extract_into_tensor(scheduler.posterior_mean_coef1, t, x_t.shape) * x_start
|
||||
+ _extract_into_tensor(scheduler.posterior_mean_coef2, t, x_t.shape) * x_t
|
||||
)
|
||||
posterior_variance = _extract_into_tensor(scheduler.posterior_variance, t, x_t.shape)
|
||||
posterior_log_variance_clipped = _extract_into_tensor(scheduler.posterior_log_variance_clipped, t, x_t.shape)
|
||||
assert (
|
||||
posterior_mean.shape[0]
|
||||
== posterior_variance.shape[0]
|
||||
== posterior_log_variance_clipped.shape[0]
|
||||
== x_start.shape[0]
|
||||
)
|
||||
return posterior_mean, posterior_variance, posterior_log_variance_clipped
|
||||
|
||||
def p_mean_variance(self, model, scheduler, x, t, transformer_out=None, low_res=None, clip_denoised=True):
|
||||
"""
|
||||
Apply the model to get p(x_{t-1} | x_t), as well as a prediction of
|
||||
the initial x, x_0.
|
||||
|
||||
:param model: the model, which takes a signal and a batch of timesteps
|
||||
as input.
|
||||
:param x: the [N x C x ...] tensor at time t.
|
||||
:param t: a 1-D Tensor of timesteps.
|
||||
:param clip_denoised: if True, clip the denoised signal into [-1, 1].
|
||||
:param model_kwargs: if not None, a dict of extra keyword arguments to
|
||||
pass to the model. This can be used for conditioning.
|
||||
:return: a dict with the following keys:
|
||||
- 'mean': the model mean output.
|
||||
- 'variance': the model variance output.
|
||||
- 'log_variance': the log of 'variance'.
|
||||
- 'pred_xstart': the prediction for x_0.
|
||||
"""
|
||||
|
||||
B, C = x.shape[:2]
|
||||
assert t.shape == (B,)
|
||||
if transformer_out is None:
|
||||
# super-res model
|
||||
model_output = model(x, t, low_res)
|
||||
else:
|
||||
# text2image model
|
||||
model_output = model(x, t, transformer_out)
|
||||
|
||||
assert model_output.shape == (B, C * 2, *x.shape[2:])
|
||||
model_output, model_var_values = torch.split(model_output, C, dim=1)
|
||||
min_log = _extract_into_tensor(scheduler.posterior_log_variance_clipped, t, x.shape)
|
||||
max_log = _extract_into_tensor(np.log(scheduler.betas), t, x.shape)
|
||||
# The model_var_values is [-1, 1] for [min_var, max_var].
|
||||
frac = (model_var_values + 1) / 2
|
||||
model_log_variance = frac * max_log + (1 - frac) * min_log
|
||||
model_variance = torch.exp(model_log_variance)
|
||||
|
||||
pred_xstart = self._predict_xstart_from_eps(scheduler, x_t=x, t=t, eps=model_output)
|
||||
if clip_denoised:
|
||||
pred_xstart = pred_xstart.clamp(-1, 1)
|
||||
model_mean, _, _ = self.q_posterior_mean_variance(scheduler, x_start=pred_xstart, x_t=x, t=t)
|
||||
|
||||
assert model_mean.shape == model_log_variance.shape == pred_xstart.shape == x.shape
|
||||
return model_mean, model_variance, model_log_variance, pred_xstart
|
||||
|
||||
def _predict_xstart_from_eps(self, scheduler, x_t, t, eps):
|
||||
assert x_t.shape == eps.shape
|
||||
return (
|
||||
_extract_into_tensor(scheduler.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t
|
||||
- _extract_into_tensor(scheduler.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * eps
|
||||
)
|
||||
|
||||
def _predict_eps_from_xstart(self, scheduler, x_t, t, pred_xstart):
|
||||
return (
|
||||
_extract_into_tensor(scheduler.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t - pred_xstart
|
||||
) / _extract_into_tensor(scheduler.sqrt_recipm1_alphas_cumprod, t, x_t.shape)
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, prompt, generator=None, torch_device=None, num_inference_steps_upscale=50):
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
self.text_unet.to(torch_device)
|
||||
self.text_encoder.to(torch_device)
|
||||
self.upscale_unet.to(torch_device)
|
||||
|
||||
# Create a classifier-free guidance sampling function
|
||||
guidance_scale = 3.0
|
||||
|
||||
def text_model_fn(x_t, ts, transformer_out, **kwargs):
|
||||
half = x_t[: len(x_t) // 2]
|
||||
combined = torch.cat([half, half], dim=0)
|
||||
model_out = self.text_unet(combined, ts, transformer_out, **kwargs)
|
||||
eps, rest = model_out[:, :3], model_out[:, 3:]
|
||||
cond_eps, uncond_eps = torch.split(eps, len(eps) // 2, dim=0)
|
||||
half_eps = uncond_eps + guidance_scale * (cond_eps - uncond_eps)
|
||||
eps = torch.cat([half_eps, half_eps], dim=0)
|
||||
return torch.cat([eps, rest], dim=1)
|
||||
|
||||
# 1. Sample gaussian noise
|
||||
batch_size = 2 # second image is empty for classifier-free guidance
|
||||
image = torch.randn((batch_size, self.text_unet.in_channels, 64, 64), generator=generator).to(torch_device)
|
||||
|
||||
# 2. Encode tokens
|
||||
# an empty input is needed to guide the model away from it
|
||||
inputs = self.tokenizer([prompt, ""], padding="max_length", max_length=128, return_tensors="pt")
|
||||
input_ids = inputs["input_ids"].to(torch_device)
|
||||
attention_mask = inputs["attention_mask"].to(torch_device)
|
||||
transformer_out = self.text_encoder(input_ids, attention_mask).last_hidden_state
|
||||
|
||||
# 3. Run the text2image generation step
|
||||
num_timesteps = len(self.text_noise_scheduler)
|
||||
for i in tqdm.tqdm(reversed(range(num_timesteps)), total=num_timesteps):
|
||||
t = torch.tensor([i] * image.shape[0], device=torch_device)
|
||||
mean, variance, log_variance, pred_xstart = self.p_mean_variance(
|
||||
text_model_fn, self.text_noise_scheduler, image, t, transformer_out=transformer_out
|
||||
)
|
||||
noise = torch.randn(image.shape, generator=generator).to(torch_device)
|
||||
nonzero_mask = (t != 0).float().view(-1, *([1] * (len(image.shape) - 1))) # no noise when t == 0
|
||||
image = mean + nonzero_mask * torch.exp(0.5 * log_variance) * noise
|
||||
|
||||
# 4. Run the upscaling step
|
||||
batch_size = 1
|
||||
image = image[:1]
|
||||
low_res = ((image + 1) * 127.5).round() / 127.5 - 1
|
||||
eta = 0.0
|
||||
|
||||
# Tune this parameter to control the sharpness of 256x256 images.
|
||||
# A value of 1.0 is sharper, but sometimes results in grainy artifacts.
|
||||
upsample_temp = 0.997
|
||||
|
||||
# Sample gaussian noise to begin loop
|
||||
image = torch.randn(
|
||||
(
|
||||
batch_size,
|
||||
self.upscale_unet.in_channels // 2,
|
||||
self.upscale_unet.resolution,
|
||||
self.upscale_unet.resolution,
|
||||
),
|
||||
generator=generator,
|
||||
).to(torch_device)
|
||||
image = image * upsample_temp
|
||||
|
||||
num_trained_timesteps = self.upscale_noise_scheduler.timesteps
|
||||
inference_step_times = range(0, num_trained_timesteps, num_trained_timesteps // num_inference_steps_upscale)
|
||||
# adapt the beta schedule to the number of steps
|
||||
# self.upscale_noise_scheduler.rescale_betas(num_inference_steps_upscale)
|
||||
|
||||
for t in tqdm.tqdm(reversed(range(num_inference_steps_upscale)), total=num_inference_steps_upscale):
|
||||
# 1. predict noise residual
|
||||
with torch.no_grad():
|
||||
time_input = torch.tensor([inference_step_times[t]] * image.shape[0], device=torch_device)
|
||||
model_output = self.upscale_unet(image, time_input, low_res)
|
||||
noise_residual, pred_variance = torch.split(model_output, 3, dim=1)
|
||||
|
||||
# 2. predict previous mean of image x_t-1
|
||||
pred_prev_image = self.upscale_noise_scheduler.step(
|
||||
noise_residual, image, t, num_inference_steps_upscale, eta, use_clipped_residual=True
|
||||
)
|
||||
|
||||
# 3. optionally sample variance
|
||||
variance = 0
|
||||
if eta > 0:
|
||||
noise = torch.randn(image.shape, generator=generator).to(torch_device)
|
||||
variance = (
|
||||
self.upscale_noise_scheduler.get_variance(t, num_inference_steps_upscale).sqrt() * eta * noise
|
||||
)
|
||||
|
||||
# 4. set current image to prev_image: x_t -> x_t-1
|
||||
image = pred_prev_image + variance
|
||||
|
||||
image = image.clamp(-1, 1).permute(0, 2, 3, 1)
|
||||
|
||||
return image
|
||||
@@ -1,416 +0,0 @@
|
||||
""" from https://github.com/jaywalnut310/glow-tts """
|
||||
|
||||
import math
|
||||
|
||||
import torch
|
||||
from torch import nn
|
||||
|
||||
from diffusers.configuration_utils import ConfigMixin
|
||||
from diffusers.modeling_utils import ModelMixin
|
||||
|
||||
|
||||
def sequence_mask(length, max_length=None):
|
||||
if max_length is None:
|
||||
max_length = length.max()
|
||||
x = torch.arange(int(max_length), dtype=length.dtype, device=length.device)
|
||||
return x.unsqueeze(0) < length.unsqueeze(1)
|
||||
|
||||
|
||||
def fix_len_compatibility(length, num_downsamplings_in_unet=2):
|
||||
while True:
|
||||
if length % (2**num_downsamplings_in_unet) == 0:
|
||||
return length
|
||||
length += 1
|
||||
|
||||
|
||||
def convert_pad_shape(pad_shape):
|
||||
l = pad_shape[::-1]
|
||||
pad_shape = [item for sublist in l for item in sublist]
|
||||
return pad_shape
|
||||
|
||||
|
||||
def generate_path(duration, mask):
|
||||
device = duration.device
|
||||
|
||||
b, t_x, t_y = mask.shape
|
||||
cum_duration = torch.cumsum(duration, 1)
|
||||
path = torch.zeros(b, t_x, t_y, dtype=mask.dtype).to(device=device)
|
||||
|
||||
cum_duration_flat = cum_duration.view(b * t_x)
|
||||
path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
|
||||
path = path.view(b, t_x, t_y)
|
||||
path = path - torch.nn.functional.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
|
||||
path = path * mask
|
||||
return path
|
||||
|
||||
|
||||
def duration_loss(logw, logw_, lengths):
|
||||
loss = torch.sum((logw - logw_) ** 2) / torch.sum(lengths)
|
||||
return loss
|
||||
|
||||
|
||||
class LayerNorm(nn.Module):
|
||||
def __init__(self, channels, eps=1e-4):
|
||||
super(LayerNorm, self).__init__()
|
||||
self.channels = channels
|
||||
self.eps = eps
|
||||
|
||||
self.gamma = torch.nn.Parameter(torch.ones(channels))
|
||||
self.beta = torch.nn.Parameter(torch.zeros(channels))
|
||||
|
||||
def forward(self, x):
|
||||
n_dims = len(x.shape)
|
||||
mean = torch.mean(x, 1, keepdim=True)
|
||||
variance = torch.mean((x - mean) ** 2, 1, keepdim=True)
|
||||
|
||||
x = (x - mean) * torch.rsqrt(variance + self.eps)
|
||||
|
||||
shape = [1, -1] + [1] * (n_dims - 2)
|
||||
x = x * self.gamma.view(*shape) + self.beta.view(*shape)
|
||||
return x
|
||||
|
||||
|
||||
class ConvReluNorm(nn.Module):
|
||||
def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
|
||||
super(ConvReluNorm, self).__init__()
|
||||
self.in_channels = in_channels
|
||||
self.hidden_channels = hidden_channels
|
||||
self.out_channels = out_channels
|
||||
self.kernel_size = kernel_size
|
||||
self.n_layers = n_layers
|
||||
self.p_dropout = p_dropout
|
||||
|
||||
self.conv_layers = torch.nn.ModuleList()
|
||||
self.norm_layers = torch.nn.ModuleList()
|
||||
self.conv_layers.append(torch.nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size // 2))
|
||||
self.norm_layers.append(LayerNorm(hidden_channels))
|
||||
self.relu_drop = torch.nn.Sequential(torch.nn.ReLU(), torch.nn.Dropout(p_dropout))
|
||||
for _ in range(n_layers - 1):
|
||||
self.conv_layers.append(
|
||||
torch.nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size // 2)
|
||||
)
|
||||
self.norm_layers.append(LayerNorm(hidden_channels))
|
||||
self.proj = torch.nn.Conv1d(hidden_channels, out_channels, 1)
|
||||
self.proj.weight.data.zero_()
|
||||
self.proj.bias.data.zero_()
|
||||
|
||||
def forward(self, x, x_mask):
|
||||
x_org = x
|
||||
for i in range(self.n_layers):
|
||||
x = self.conv_layers[i](x * x_mask)
|
||||
x = self.norm_layers[i](x)
|
||||
x = self.relu_drop(x)
|
||||
x = x_org + self.proj(x)
|
||||
return x * x_mask
|
||||
|
||||
|
||||
class DurationPredictor(nn.Module):
|
||||
def __init__(self, in_channels, filter_channels, kernel_size, p_dropout):
|
||||
super(DurationPredictor, self).__init__()
|
||||
self.in_channels = in_channels
|
||||
self.filter_channels = filter_channels
|
||||
self.p_dropout = p_dropout
|
||||
|
||||
self.drop = torch.nn.Dropout(p_dropout)
|
||||
self.conv_1 = torch.nn.Conv1d(in_channels, filter_channels, kernel_size, padding=kernel_size // 2)
|
||||
self.norm_1 = LayerNorm(filter_channels)
|
||||
self.conv_2 = torch.nn.Conv1d(filter_channels, filter_channels, kernel_size, padding=kernel_size // 2)
|
||||
self.norm_2 = LayerNorm(filter_channels)
|
||||
self.proj = torch.nn.Conv1d(filter_channels, 1, 1)
|
||||
|
||||
def forward(self, x, x_mask):
|
||||
x = self.conv_1(x * x_mask)
|
||||
x = torch.relu(x)
|
||||
x = self.norm_1(x)
|
||||
x = self.drop(x)
|
||||
x = self.conv_2(x * x_mask)
|
||||
x = torch.relu(x)
|
||||
x = self.norm_2(x)
|
||||
x = self.drop(x)
|
||||
x = self.proj(x * x_mask)
|
||||
return x * x_mask
|
||||
|
||||
|
||||
class MultiHeadAttention(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
channels,
|
||||
out_channels,
|
||||
n_heads,
|
||||
window_size=None,
|
||||
heads_share=True,
|
||||
p_dropout=0.0,
|
||||
proximal_bias=False,
|
||||
proximal_init=False,
|
||||
):
|
||||
super(MultiHeadAttention, self).__init__()
|
||||
assert channels % n_heads == 0
|
||||
|
||||
self.channels = channels
|
||||
self.out_channels = out_channels
|
||||
self.n_heads = n_heads
|
||||
self.window_size = window_size
|
||||
self.heads_share = heads_share
|
||||
self.proximal_bias = proximal_bias
|
||||
self.p_dropout = p_dropout
|
||||
self.attn = None
|
||||
|
||||
self.k_channels = channels // n_heads
|
||||
self.conv_q = torch.nn.Conv1d(channels, channels, 1)
|
||||
self.conv_k = torch.nn.Conv1d(channels, channels, 1)
|
||||
self.conv_v = torch.nn.Conv1d(channels, channels, 1)
|
||||
if window_size is not None:
|
||||
n_heads_rel = 1 if heads_share else n_heads
|
||||
rel_stddev = self.k_channels**-0.5
|
||||
self.emb_rel_k = torch.nn.Parameter(
|
||||
torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels) * rel_stddev
|
||||
)
|
||||
self.emb_rel_v = torch.nn.Parameter(
|
||||
torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels) * rel_stddev
|
||||
)
|
||||
self.conv_o = torch.nn.Conv1d(channels, out_channels, 1)
|
||||
self.drop = torch.nn.Dropout(p_dropout)
|
||||
|
||||
torch.nn.init.xavier_uniform_(self.conv_q.weight)
|
||||
torch.nn.init.xavier_uniform_(self.conv_k.weight)
|
||||
if proximal_init:
|
||||
self.conv_k.weight.data.copy_(self.conv_q.weight.data)
|
||||
self.conv_k.bias.data.copy_(self.conv_q.bias.data)
|
||||
torch.nn.init.xavier_uniform_(self.conv_v.weight)
|
||||
|
||||
def forward(self, x, c, attn_mask=None):
|
||||
q = self.conv_q(x)
|
||||
k = self.conv_k(c)
|
||||
v = self.conv_v(c)
|
||||
|
||||
x, self.attn = self.attention(q, k, v, mask=attn_mask)
|
||||
|
||||
x = self.conv_o(x)
|
||||
return x
|
||||
|
||||
def attention(self, query, key, value, mask=None):
|
||||
b, d, t_s, t_t = (*key.size(), query.size(2))
|
||||
query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
|
||||
key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
||||
value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
||||
|
||||
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(self.k_channels)
|
||||
if self.window_size is not None:
|
||||
assert t_s == t_t, "Relative attention is only available for self-attention."
|
||||
key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
|
||||
rel_logits = self._matmul_with_relative_keys(query, key_relative_embeddings)
|
||||
rel_logits = self._relative_position_to_absolute_position(rel_logits)
|
||||
scores_local = rel_logits / math.sqrt(self.k_channels)
|
||||
scores = scores + scores_local
|
||||
if self.proximal_bias:
|
||||
assert t_s == t_t, "Proximal bias is only available for self-attention."
|
||||
scores = scores + self._attention_bias_proximal(t_s).to(device=scores.device, dtype=scores.dtype)
|
||||
if mask is not None:
|
||||
scores = scores.masked_fill(mask == 0, -1e4)
|
||||
p_attn = torch.nn.functional.softmax(scores, dim=-1)
|
||||
p_attn = self.drop(p_attn)
|
||||
output = torch.matmul(p_attn, value)
|
||||
if self.window_size is not None:
|
||||
relative_weights = self._absolute_position_to_relative_position(p_attn)
|
||||
value_relative_embeddings = self._get_relative_embeddings(self.emb_rel_v, t_s)
|
||||
output = output + self._matmul_with_relative_values(relative_weights, value_relative_embeddings)
|
||||
output = output.transpose(2, 3).contiguous().view(b, d, t_t)
|
||||
return output, p_attn
|
||||
|
||||
def _matmul_with_relative_values(self, x, y):
|
||||
ret = torch.matmul(x, y.unsqueeze(0))
|
||||
return ret
|
||||
|
||||
def _matmul_with_relative_keys(self, x, y):
|
||||
ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
|
||||
return ret
|
||||
|
||||
def _get_relative_embeddings(self, relative_embeddings, length):
|
||||
pad_length = max(length - (self.window_size + 1), 0)
|
||||
slice_start_position = max((self.window_size + 1) - length, 0)
|
||||
slice_end_position = slice_start_position + 2 * length - 1
|
||||
if pad_length > 0:
|
||||
padded_relative_embeddings = torch.nn.functional.pad(
|
||||
relative_embeddings, convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]])
|
||||
)
|
||||
else:
|
||||
padded_relative_embeddings = relative_embeddings
|
||||
used_relative_embeddings = padded_relative_embeddings[:, slice_start_position:slice_end_position]
|
||||
return used_relative_embeddings
|
||||
|
||||
def _relative_position_to_absolute_position(self, x):
|
||||
batch, heads, length, _ = x.size()
|
||||
x = torch.nn.functional.pad(x, convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, 1]]))
|
||||
x_flat = x.view([batch, heads, length * 2 * length])
|
||||
x_flat = torch.nn.functional.pad(x_flat, convert_pad_shape([[0, 0], [0, 0], [0, length - 1]]))
|
||||
x_final = x_flat.view([batch, heads, length + 1, 2 * length - 1])[:, :, :length, length - 1 :]
|
||||
return x_final
|
||||
|
||||
def _absolute_position_to_relative_position(self, x):
|
||||
batch, heads, length, _ = x.size()
|
||||
x = torch.nn.functional.pad(x, convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length - 1]]))
|
||||
x_flat = x.view([batch, heads, length**2 + length * (length - 1)])
|
||||
x_flat = torch.nn.functional.pad(x_flat, convert_pad_shape([[0, 0], [0, 0], [length, 0]]))
|
||||
x_final = x_flat.view([batch, heads, length, 2 * length])[:, :, :, 1:]
|
||||
return x_final
|
||||
|
||||
def _attention_bias_proximal(self, length):
|
||||
r = torch.arange(length, dtype=torch.float32)
|
||||
diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
|
||||
return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
|
||||
|
||||
|
||||
class FFN(nn.Module):
|
||||
def __init__(self, in_channels, out_channels, filter_channels, kernel_size, p_dropout=0.0):
|
||||
super(FFN, self).__init__()
|
||||
self.in_channels = in_channels
|
||||
self.out_channels = out_channels
|
||||
self.filter_channels = filter_channels
|
||||
self.kernel_size = kernel_size
|
||||
self.p_dropout = p_dropout
|
||||
|
||||
self.conv_1 = torch.nn.Conv1d(in_channels, filter_channels, kernel_size, padding=kernel_size // 2)
|
||||
self.conv_2 = torch.nn.Conv1d(filter_channels, out_channels, kernel_size, padding=kernel_size // 2)
|
||||
self.drop = torch.nn.Dropout(p_dropout)
|
||||
|
||||
def forward(self, x, x_mask):
|
||||
x = self.conv_1(x * x_mask)
|
||||
x = torch.relu(x)
|
||||
x = self.drop(x)
|
||||
x = self.conv_2(x * x_mask)
|
||||
return x * x_mask
|
||||
|
||||
|
||||
class Encoder(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
hidden_channels,
|
||||
filter_channels,
|
||||
n_heads,
|
||||
n_layers,
|
||||
kernel_size=1,
|
||||
p_dropout=0.0,
|
||||
window_size=None,
|
||||
**kwargs,
|
||||
):
|
||||
super(Encoder, self).__init__()
|
||||
self.hidden_channels = hidden_channels
|
||||
self.filter_channels = filter_channels
|
||||
self.n_heads = n_heads
|
||||
self.n_layers = n_layers
|
||||
self.kernel_size = kernel_size
|
||||
self.p_dropout = p_dropout
|
||||
self.window_size = window_size
|
||||
|
||||
self.drop = torch.nn.Dropout(p_dropout)
|
||||
self.attn_layers = torch.nn.ModuleList()
|
||||
self.norm_layers_1 = torch.nn.ModuleList()
|
||||
self.ffn_layers = torch.nn.ModuleList()
|
||||
self.norm_layers_2 = torch.nn.ModuleList()
|
||||
for _ in range(self.n_layers):
|
||||
self.attn_layers.append(
|
||||
MultiHeadAttention(
|
||||
hidden_channels, hidden_channels, n_heads, window_size=window_size, p_dropout=p_dropout
|
||||
)
|
||||
)
|
||||
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
||||
self.ffn_layers.append(
|
||||
FFN(hidden_channels, hidden_channels, filter_channels, kernel_size, p_dropout=p_dropout)
|
||||
)
|
||||
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
||||
|
||||
def forward(self, x, x_mask):
|
||||
attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
||||
for i in range(self.n_layers):
|
||||
x = x * x_mask
|
||||
y = self.attn_layers[i](x, x, attn_mask)
|
||||
y = self.drop(y)
|
||||
x = self.norm_layers_1[i](x + y)
|
||||
y = self.ffn_layers[i](x, x_mask)
|
||||
y = self.drop(y)
|
||||
x = self.norm_layers_2[i](x + y)
|
||||
x = x * x_mask
|
||||
return x
|
||||
|
||||
|
||||
class TextEncoder(ModelMixin, ConfigMixin):
|
||||
def __init__(
|
||||
self,
|
||||
n_vocab,
|
||||
n_feats,
|
||||
n_channels,
|
||||
filter_channels,
|
||||
filter_channels_dp,
|
||||
n_heads,
|
||||
n_layers,
|
||||
kernel_size,
|
||||
p_dropout,
|
||||
window_size=None,
|
||||
spk_emb_dim=64,
|
||||
n_spks=1,
|
||||
):
|
||||
super(TextEncoder, self).__init__()
|
||||
|
||||
self.register(
|
||||
n_vocab=n_vocab,
|
||||
n_feats=n_feats,
|
||||
n_channels=n_channels,
|
||||
filter_channels=filter_channels,
|
||||
filter_channels_dp=filter_channels_dp,
|
||||
n_heads=n_heads,
|
||||
n_layers=n_layers,
|
||||
kernel_size=kernel_size,
|
||||
p_dropout=p_dropout,
|
||||
window_size=window_size,
|
||||
spk_emb_dim=spk_emb_dim,
|
||||
n_spks=n_spks,
|
||||
)
|
||||
|
||||
self.n_vocab = n_vocab
|
||||
self.n_feats = n_feats
|
||||
self.n_channels = n_channels
|
||||
self.filter_channels = filter_channels
|
||||
self.filter_channels_dp = filter_channels_dp
|
||||
self.n_heads = n_heads
|
||||
self.n_layers = n_layers
|
||||
self.kernel_size = kernel_size
|
||||
self.p_dropout = p_dropout
|
||||
self.window_size = window_size
|
||||
self.spk_emb_dim = spk_emb_dim
|
||||
self.n_spks = n_spks
|
||||
|
||||
self.emb = torch.nn.Embedding(n_vocab, n_channels)
|
||||
torch.nn.init.normal_(self.emb.weight, 0.0, n_channels**-0.5)
|
||||
|
||||
self.prenet = ConvReluNorm(n_channels, n_channels, n_channels, kernel_size=5, n_layers=3, p_dropout=0.5)
|
||||
|
||||
self.encoder = Encoder(
|
||||
n_channels + (spk_emb_dim if n_spks > 1 else 0),
|
||||
filter_channels,
|
||||
n_heads,
|
||||
n_layers,
|
||||
kernel_size,
|
||||
p_dropout,
|
||||
window_size=window_size,
|
||||
)
|
||||
|
||||
self.proj_m = torch.nn.Conv1d(n_channels + (spk_emb_dim if n_spks > 1 else 0), n_feats, 1)
|
||||
self.proj_w = DurationPredictor(
|
||||
n_channels + (spk_emb_dim if n_spks > 1 else 0), filter_channels_dp, kernel_size, p_dropout
|
||||
)
|
||||
|
||||
def forward(self, x, x_lengths, spk=None):
|
||||
x = self.emb(x) * math.sqrt(self.n_channels)
|
||||
x = torch.transpose(x, 1, -1)
|
||||
x_mask = torch.unsqueeze(sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
|
||||
|
||||
x = self.prenet(x, x_mask)
|
||||
if self.n_spks > 1:
|
||||
x = torch.cat([x, spk.unsqueeze(-1).repeat(1, 1, x.shape[-1])], dim=1)
|
||||
x = self.encoder(x, x_mask)
|
||||
mu = self.proj_m(x) * x_mask
|
||||
|
||||
x_dp = torch.detach(x)
|
||||
logw = self.proj_w(x_dp, x_mask)
|
||||
|
||||
return mu, logw, x_mask
|
||||
@@ -1,957 +0,0 @@
|
||||
# pytorch_diffusion + derived encoder decoder
|
||||
import math
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
import tqdm
|
||||
|
||||
from ..configuration_utils import ConfigMixin
|
||||
from ..modeling_utils import ModelMixin
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
|
||||
|
||||
def get_timestep_embedding(timesteps, embedding_dim):
|
||||
"""
|
||||
This matches the implementation in Denoising Diffusion Probabilistic Models:
|
||||
From Fairseq.
|
||||
Build sinusoidal embeddings.
|
||||
This matches the implementation in tensor2tensor, but differs slightly
|
||||
from the description in Section 3.5 of "Attention Is All You Need".
|
||||
"""
|
||||
assert len(timesteps.shape) == 1
|
||||
|
||||
half_dim = embedding_dim // 2
|
||||
emb = math.log(10000) / (half_dim - 1)
|
||||
emb = torch.exp(torch.arange(half_dim, dtype=torch.float32) * -emb)
|
||||
emb = emb.to(device=timesteps.device)
|
||||
emb = timesteps.float()[:, None] * emb[None, :]
|
||||
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
|
||||
if embedding_dim % 2 == 1: # zero pad
|
||||
emb = torch.nn.functional.pad(emb, (0, 1, 0, 0))
|
||||
return emb
|
||||
|
||||
|
||||
def nonlinearity(x):
|
||||
# swish
|
||||
return x * torch.sigmoid(x)
|
||||
|
||||
|
||||
def Normalize(in_channels):
|
||||
return torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
|
||||
|
||||
|
||||
class Upsample(nn.Module):
|
||||
def __init__(self, in_channels, with_conv):
|
||||
super().__init__()
|
||||
self.with_conv = with_conv
|
||||
if self.with_conv:
|
||||
self.conv = torch.nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
def forward(self, x):
|
||||
x = torch.nn.functional.interpolate(x, scale_factor=2.0, mode="nearest")
|
||||
if self.with_conv:
|
||||
x = self.conv(x)
|
||||
return x
|
||||
|
||||
|
||||
class Downsample(nn.Module):
|
||||
def __init__(self, in_channels, with_conv):
|
||||
super().__init__()
|
||||
self.with_conv = with_conv
|
||||
if self.with_conv:
|
||||
# no asymmetric padding in torch conv, must do it ourselves
|
||||
self.conv = torch.nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=2, padding=0)
|
||||
|
||||
def forward(self, x):
|
||||
if self.with_conv:
|
||||
pad = (0, 1, 0, 1)
|
||||
x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
|
||||
x = self.conv(x)
|
||||
else:
|
||||
x = torch.nn.functional.avg_pool2d(x, kernel_size=2, stride=2)
|
||||
return x
|
||||
|
||||
|
||||
class ResnetBlock(nn.Module):
|
||||
def __init__(self, *, in_channels, out_channels=None, conv_shortcut=False, dropout, temb_channels=512):
|
||||
super().__init__()
|
||||
self.in_channels = in_channels
|
||||
out_channels = in_channels if out_channels is None else out_channels
|
||||
self.out_channels = out_channels
|
||||
self.use_conv_shortcut = conv_shortcut
|
||||
|
||||
self.norm1 = Normalize(in_channels)
|
||||
self.conv1 = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
if temb_channels > 0:
|
||||
self.temb_proj = torch.nn.Linear(temb_channels, out_channels)
|
||||
self.norm2 = Normalize(out_channels)
|
||||
self.dropout = torch.nn.Dropout(dropout)
|
||||
self.conv2 = torch.nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
if self.in_channels != self.out_channels:
|
||||
if self.use_conv_shortcut:
|
||||
self.conv_shortcut = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
else:
|
||||
self.nin_shortcut = torch.nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
def forward(self, x, temb):
|
||||
h = x
|
||||
h = self.norm1(h)
|
||||
h = nonlinearity(h)
|
||||
h = self.conv1(h)
|
||||
|
||||
if temb is not None:
|
||||
h = h + self.temb_proj(nonlinearity(temb))[:, :, None, None]
|
||||
|
||||
h = self.norm2(h)
|
||||
h = nonlinearity(h)
|
||||
h = self.dropout(h)
|
||||
h = self.conv2(h)
|
||||
|
||||
if self.in_channels != self.out_channels:
|
||||
if self.use_conv_shortcut:
|
||||
x = self.conv_shortcut(x)
|
||||
else:
|
||||
x = self.nin_shortcut(x)
|
||||
|
||||
return x + h
|
||||
|
||||
|
||||
class AttnBlock(nn.Module):
|
||||
def __init__(self, in_channels):
|
||||
super().__init__()
|
||||
self.in_channels = in_channels
|
||||
|
||||
self.norm = Normalize(in_channels)
|
||||
self.q = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.k = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.v = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.proj_out = torch.nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
def forward(self, x):
|
||||
h_ = x
|
||||
h_ = self.norm(h_)
|
||||
q = self.q(h_)
|
||||
k = self.k(h_)
|
||||
v = self.v(h_)
|
||||
|
||||
# compute attention
|
||||
b, c, h, w = q.shape
|
||||
q = q.reshape(b, c, h * w)
|
||||
q = q.permute(0, 2, 1) # b,hw,c
|
||||
k = k.reshape(b, c, h * w) # b,c,hw
|
||||
w_ = torch.bmm(q, k) # b,hw,hw w[b,i,j]=sum_c q[b,i,c]k[b,c,j]
|
||||
w_ = w_ * (int(c) ** (-0.5))
|
||||
w_ = torch.nn.functional.softmax(w_, dim=2)
|
||||
|
||||
# attend to values
|
||||
v = v.reshape(b, c, h * w)
|
||||
w_ = w_.permute(0, 2, 1) # b,hw,hw (first hw of k, second of q)
|
||||
h_ = torch.bmm(v, w_) # b, c,hw (hw of q) h_[b,c,j] = sum_i v[b,c,i] w_[b,i,j]
|
||||
h_ = h_.reshape(b, c, h, w)
|
||||
|
||||
h_ = self.proj_out(h_)
|
||||
|
||||
return x + h_
|
||||
|
||||
|
||||
class Model(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
*,
|
||||
ch,
|
||||
out_ch,
|
||||
ch_mult=(1, 2, 4, 8),
|
||||
num_res_blocks,
|
||||
attn_resolutions,
|
||||
dropout=0.0,
|
||||
resamp_with_conv=True,
|
||||
in_channels,
|
||||
resolution,
|
||||
use_timestep=True,
|
||||
):
|
||||
super().__init__()
|
||||
self.ch = ch
|
||||
self.temb_ch = self.ch * 4
|
||||
self.num_resolutions = len(ch_mult)
|
||||
self.num_res_blocks = num_res_blocks
|
||||
self.resolution = resolution
|
||||
self.in_channels = in_channels
|
||||
|
||||
self.use_timestep = use_timestep
|
||||
if self.use_timestep:
|
||||
# timestep embedding
|
||||
self.temb = nn.Module()
|
||||
self.temb.dense = nn.ModuleList(
|
||||
[
|
||||
torch.nn.Linear(self.ch, self.temb_ch),
|
||||
torch.nn.Linear(self.temb_ch, self.temb_ch),
|
||||
]
|
||||
)
|
||||
|
||||
# downsampling
|
||||
self.conv_in = torch.nn.Conv2d(in_channels, self.ch, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
curr_res = resolution
|
||||
in_ch_mult = (1,) + tuple(ch_mult)
|
||||
self.down = nn.ModuleList()
|
||||
for i_level in range(self.num_resolutions):
|
||||
block = nn.ModuleList()
|
||||
attn = nn.ModuleList()
|
||||
block_in = ch * in_ch_mult[i_level]
|
||||
block_out = ch * ch_mult[i_level]
|
||||
for i_block in range(self.num_res_blocks):
|
||||
block.append(
|
||||
ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_out, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
)
|
||||
block_in = block_out
|
||||
if curr_res in attn_resolutions:
|
||||
attn.append(AttnBlock(block_in))
|
||||
down = nn.Module()
|
||||
down.block = block
|
||||
down.attn = attn
|
||||
if i_level != self.num_resolutions - 1:
|
||||
down.downsample = Downsample(block_in, resamp_with_conv)
|
||||
curr_res = curr_res // 2
|
||||
self.down.append(down)
|
||||
|
||||
# middle
|
||||
self.mid = nn.Module()
|
||||
self.mid.block_1 = ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
self.mid.attn_1 = AttnBlock(block_in)
|
||||
self.mid.block_2 = ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
|
||||
# upsampling
|
||||
self.up = nn.ModuleList()
|
||||
for i_level in reversed(range(self.num_resolutions)):
|
||||
block = nn.ModuleList()
|
||||
attn = nn.ModuleList()
|
||||
block_out = ch * ch_mult[i_level]
|
||||
skip_in = ch * ch_mult[i_level]
|
||||
for i_block in range(self.num_res_blocks + 1):
|
||||
if i_block == self.num_res_blocks:
|
||||
skip_in = ch * in_ch_mult[i_level]
|
||||
block.append(
|
||||
ResnetBlock(
|
||||
in_channels=block_in + skip_in,
|
||||
out_channels=block_out,
|
||||
temb_channels=self.temb_ch,
|
||||
dropout=dropout,
|
||||
)
|
||||
)
|
||||
block_in = block_out
|
||||
if curr_res in attn_resolutions:
|
||||
attn.append(AttnBlock(block_in))
|
||||
up = nn.Module()
|
||||
up.block = block
|
||||
up.attn = attn
|
||||
if i_level != 0:
|
||||
up.upsample = Upsample(block_in, resamp_with_conv)
|
||||
curr_res = curr_res * 2
|
||||
self.up.insert(0, up) # prepend to get consistent order
|
||||
|
||||
# end
|
||||
self.norm_out = Normalize(block_in)
|
||||
self.conv_out = torch.nn.Conv2d(block_in, out_ch, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
def forward(self, x, t=None):
|
||||
# assert x.shape[2] == x.shape[3] == self.resolution
|
||||
|
||||
if self.use_timestep:
|
||||
# timestep embedding
|
||||
assert t is not None
|
||||
temb = get_timestep_embedding(t, self.ch)
|
||||
temb = self.temb.dense[0](temb)
|
||||
temb = nonlinearity(temb)
|
||||
temb = self.temb.dense[1](temb)
|
||||
else:
|
||||
temb = None
|
||||
|
||||
# downsampling
|
||||
hs = [self.conv_in(x)]
|
||||
for i_level in range(self.num_resolutions):
|
||||
for i_block in range(self.num_res_blocks):
|
||||
h = self.down[i_level].block[i_block](hs[-1], temb)
|
||||
if len(self.down[i_level].attn) > 0:
|
||||
h = self.down[i_level].attn[i_block](h)
|
||||
hs.append(h)
|
||||
if i_level != self.num_resolutions - 1:
|
||||
hs.append(self.down[i_level].downsample(hs[-1]))
|
||||
|
||||
# middle
|
||||
h = hs[-1]
|
||||
h = self.mid.block_1(h, temb)
|
||||
h = self.mid.attn_1(h)
|
||||
h = self.mid.block_2(h, temb)
|
||||
|
||||
# upsampling
|
||||
for i_level in reversed(range(self.num_resolutions)):
|
||||
for i_block in range(self.num_res_blocks + 1):
|
||||
h = self.up[i_level].block[i_block](torch.cat([h, hs.pop()], dim=1), temb)
|
||||
if len(self.up[i_level].attn) > 0:
|
||||
h = self.up[i_level].attn[i_block](h)
|
||||
if i_level != 0:
|
||||
h = self.up[i_level].upsample(h)
|
||||
|
||||
# end
|
||||
h = self.norm_out(h)
|
||||
h = nonlinearity(h)
|
||||
h = self.conv_out(h)
|
||||
return h
|
||||
|
||||
|
||||
class Encoder(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
*,
|
||||
ch,
|
||||
out_ch,
|
||||
ch_mult=(1, 2, 4, 8),
|
||||
num_res_blocks,
|
||||
attn_resolutions,
|
||||
dropout=0.0,
|
||||
resamp_with_conv=True,
|
||||
in_channels,
|
||||
resolution,
|
||||
z_channels,
|
||||
double_z=True,
|
||||
**ignore_kwargs,
|
||||
):
|
||||
super().__init__()
|
||||
self.ch = ch
|
||||
self.temb_ch = 0
|
||||
self.num_resolutions = len(ch_mult)
|
||||
self.num_res_blocks = num_res_blocks
|
||||
self.resolution = resolution
|
||||
self.in_channels = in_channels
|
||||
|
||||
# downsampling
|
||||
self.conv_in = torch.nn.Conv2d(in_channels, self.ch, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
curr_res = resolution
|
||||
in_ch_mult = (1,) + tuple(ch_mult)
|
||||
self.down = nn.ModuleList()
|
||||
for i_level in range(self.num_resolutions):
|
||||
block = nn.ModuleList()
|
||||
attn = nn.ModuleList()
|
||||
block_in = ch * in_ch_mult[i_level]
|
||||
block_out = ch * ch_mult[i_level]
|
||||
for i_block in range(self.num_res_blocks):
|
||||
block.append(
|
||||
ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_out, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
)
|
||||
block_in = block_out
|
||||
if curr_res in attn_resolutions:
|
||||
attn.append(AttnBlock(block_in))
|
||||
down = nn.Module()
|
||||
down.block = block
|
||||
down.attn = attn
|
||||
if i_level != self.num_resolutions - 1:
|
||||
down.downsample = Downsample(block_in, resamp_with_conv)
|
||||
curr_res = curr_res // 2
|
||||
self.down.append(down)
|
||||
|
||||
# middle
|
||||
self.mid = nn.Module()
|
||||
self.mid.block_1 = ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
self.mid.attn_1 = AttnBlock(block_in)
|
||||
self.mid.block_2 = ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
|
||||
# end
|
||||
self.norm_out = Normalize(block_in)
|
||||
self.conv_out = torch.nn.Conv2d(
|
||||
block_in, 2 * z_channels if double_z else z_channels, kernel_size=3, stride=1, padding=1
|
||||
)
|
||||
|
||||
def forward(self, x):
|
||||
# assert x.shape[2] == x.shape[3] == self.resolution, "{}, {}, {}".format(x.shape[2], x.shape[3], self.resolution)
|
||||
|
||||
# timestep embedding
|
||||
temb = None
|
||||
|
||||
# downsampling
|
||||
hs = [self.conv_in(x)]
|
||||
for i_level in range(self.num_resolutions):
|
||||
for i_block in range(self.num_res_blocks):
|
||||
h = self.down[i_level].block[i_block](hs[-1], temb)
|
||||
if len(self.down[i_level].attn) > 0:
|
||||
h = self.down[i_level].attn[i_block](h)
|
||||
hs.append(h)
|
||||
if i_level != self.num_resolutions - 1:
|
||||
hs.append(self.down[i_level].downsample(hs[-1]))
|
||||
|
||||
# middle
|
||||
h = hs[-1]
|
||||
h = self.mid.block_1(h, temb)
|
||||
h = self.mid.attn_1(h)
|
||||
h = self.mid.block_2(h, temb)
|
||||
|
||||
# end
|
||||
h = self.norm_out(h)
|
||||
h = nonlinearity(h)
|
||||
h = self.conv_out(h)
|
||||
return h
|
||||
|
||||
|
||||
class Decoder(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
*,
|
||||
ch,
|
||||
out_ch,
|
||||
ch_mult=(1, 2, 4, 8),
|
||||
num_res_blocks,
|
||||
attn_resolutions,
|
||||
dropout=0.0,
|
||||
resamp_with_conv=True,
|
||||
in_channels,
|
||||
resolution,
|
||||
z_channels,
|
||||
give_pre_end=False,
|
||||
**ignorekwargs,
|
||||
):
|
||||
super().__init__()
|
||||
self.ch = ch
|
||||
self.temb_ch = 0
|
||||
self.num_resolutions = len(ch_mult)
|
||||
self.num_res_blocks = num_res_blocks
|
||||
self.resolution = resolution
|
||||
self.in_channels = in_channels
|
||||
self.give_pre_end = give_pre_end
|
||||
|
||||
# compute in_ch_mult, block_in and curr_res at lowest res
|
||||
in_ch_mult = (1,) + tuple(ch_mult)
|
||||
block_in = ch * ch_mult[self.num_resolutions - 1]
|
||||
curr_res = resolution // 2 ** (self.num_resolutions - 1)
|
||||
self.z_shape = (1, z_channels, curr_res, curr_res)
|
||||
print("Working with z of shape {} = {} dimensions.".format(self.z_shape, np.prod(self.z_shape)))
|
||||
|
||||
# z to block_in
|
||||
self.conv_in = torch.nn.Conv2d(z_channels, block_in, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
# middle
|
||||
self.mid = nn.Module()
|
||||
self.mid.block_1 = ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
self.mid.attn_1 = AttnBlock(block_in)
|
||||
self.mid.block_2 = ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_in, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
|
||||
# upsampling
|
||||
self.up = nn.ModuleList()
|
||||
for i_level in reversed(range(self.num_resolutions)):
|
||||
block = nn.ModuleList()
|
||||
attn = nn.ModuleList()
|
||||
block_out = ch * ch_mult[i_level]
|
||||
for i_block in range(self.num_res_blocks + 1):
|
||||
block.append(
|
||||
ResnetBlock(
|
||||
in_channels=block_in, out_channels=block_out, temb_channels=self.temb_ch, dropout=dropout
|
||||
)
|
||||
)
|
||||
block_in = block_out
|
||||
if curr_res in attn_resolutions:
|
||||
attn.append(AttnBlock(block_in))
|
||||
up = nn.Module()
|
||||
up.block = block
|
||||
up.attn = attn
|
||||
if i_level != 0:
|
||||
up.upsample = Upsample(block_in, resamp_with_conv)
|
||||
curr_res = curr_res * 2
|
||||
self.up.insert(0, up) # prepend to get consistent order
|
||||
|
||||
# end
|
||||
self.norm_out = Normalize(block_in)
|
||||
self.conv_out = torch.nn.Conv2d(block_in, out_ch, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
def forward(self, z):
|
||||
# assert z.shape[1:] == self.z_shape[1:]
|
||||
self.last_z_shape = z.shape
|
||||
|
||||
# timestep embedding
|
||||
temb = None
|
||||
|
||||
# z to block_in
|
||||
h = self.conv_in(z)
|
||||
|
||||
# middle
|
||||
h = self.mid.block_1(h, temb)
|
||||
h = self.mid.attn_1(h)
|
||||
h = self.mid.block_2(h, temb)
|
||||
|
||||
# upsampling
|
||||
for i_level in reversed(range(self.num_resolutions)):
|
||||
for i_block in range(self.num_res_blocks + 1):
|
||||
h = self.up[i_level].block[i_block](h, temb)
|
||||
if len(self.up[i_level].attn) > 0:
|
||||
h = self.up[i_level].attn[i_block](h)
|
||||
if i_level != 0:
|
||||
h = self.up[i_level].upsample(h)
|
||||
|
||||
# end
|
||||
if self.give_pre_end:
|
||||
return h
|
||||
|
||||
h = self.norm_out(h)
|
||||
h = nonlinearity(h)
|
||||
h = self.conv_out(h)
|
||||
return h
|
||||
|
||||
|
||||
class VectorQuantizer(nn.Module):
|
||||
"""
|
||||
Improved version over VectorQuantizer, can be used as a drop-in replacement. Mostly
|
||||
avoids costly matrix multiplications and allows for post-hoc remapping of indices.
|
||||
"""
|
||||
|
||||
# NOTE: due to a bug the beta term was applied to the wrong term. for
|
||||
# backwards compatibility we use the buggy version by default, but you can
|
||||
# specify legacy=False to fix it.
|
||||
def __init__(self, n_e, e_dim, beta, remap=None, unknown_index="random", sane_index_shape=False, legacy=True):
|
||||
super().__init__()
|
||||
self.n_e = n_e
|
||||
self.e_dim = e_dim
|
||||
self.beta = beta
|
||||
self.legacy = legacy
|
||||
|
||||
self.embedding = nn.Embedding(self.n_e, self.e_dim)
|
||||
self.embedding.weight.data.uniform_(-1.0 / self.n_e, 1.0 / self.n_e)
|
||||
|
||||
self.remap = remap
|
||||
if self.remap is not None:
|
||||
self.register_buffer("used", torch.tensor(np.load(self.remap)))
|
||||
self.re_embed = self.used.shape[0]
|
||||
self.unknown_index = unknown_index # "random" or "extra" or integer
|
||||
if self.unknown_index == "extra":
|
||||
self.unknown_index = self.re_embed
|
||||
self.re_embed = self.re_embed + 1
|
||||
print(
|
||||
f"Remapping {self.n_e} indices to {self.re_embed} indices. "
|
||||
f"Using {self.unknown_index} for unknown indices."
|
||||
)
|
||||
else:
|
||||
self.re_embed = n_e
|
||||
|
||||
self.sane_index_shape = sane_index_shape
|
||||
|
||||
def remap_to_used(self, inds):
|
||||
ishape = inds.shape
|
||||
assert len(ishape) > 1
|
||||
inds = inds.reshape(ishape[0], -1)
|
||||
used = self.used.to(inds)
|
||||
match = (inds[:, :, None] == used[None, None, ...]).long()
|
||||
new = match.argmax(-1)
|
||||
unknown = match.sum(2) < 1
|
||||
if self.unknown_index == "random":
|
||||
new[unknown] = torch.randint(0, self.re_embed, size=new[unknown].shape).to(device=new.device)
|
||||
else:
|
||||
new[unknown] = self.unknown_index
|
||||
return new.reshape(ishape)
|
||||
|
||||
def unmap_to_all(self, inds):
|
||||
ishape = inds.shape
|
||||
assert len(ishape) > 1
|
||||
inds = inds.reshape(ishape[0], -1)
|
||||
used = self.used.to(inds)
|
||||
if self.re_embed > self.used.shape[0]: # extra token
|
||||
inds[inds >= self.used.shape[0]] = 0 # simply set to zero
|
||||
back = torch.gather(used[None, :][inds.shape[0] * [0], :], 1, inds)
|
||||
return back.reshape(ishape)
|
||||
|
||||
def forward(self, z, temp=None, rescale_logits=False, return_logits=False):
|
||||
assert temp is None or temp == 1.0, "Only for interface compatible with Gumbel"
|
||||
assert rescale_logits == False, "Only for interface compatible with Gumbel"
|
||||
assert return_logits == False, "Only for interface compatible with Gumbel"
|
||||
# reshape z -> (batch, height, width, channel) and flatten
|
||||
z = rearrange(z, "b c h w -> b h w c").contiguous()
|
||||
z_flattened = z.view(-1, self.e_dim)
|
||||
# distances from z to embeddings e_j (z - e)^2 = z^2 + e^2 - 2 e * z
|
||||
|
||||
d = (
|
||||
torch.sum(z_flattened**2, dim=1, keepdim=True)
|
||||
+ torch.sum(self.embedding.weight**2, dim=1)
|
||||
- 2 * torch.einsum("bd,dn->bn", z_flattened, rearrange(self.embedding.weight, "n d -> d n"))
|
||||
)
|
||||
|
||||
min_encoding_indices = torch.argmin(d, dim=1)
|
||||
z_q = self.embedding(min_encoding_indices).view(z.shape)
|
||||
perplexity = None
|
||||
min_encodings = None
|
||||
|
||||
# compute loss for embedding
|
||||
if not self.legacy:
|
||||
loss = self.beta * torch.mean((z_q.detach() - z) ** 2) + torch.mean((z_q - z.detach()) ** 2)
|
||||
else:
|
||||
loss = torch.mean((z_q.detach() - z) ** 2) + self.beta * torch.mean((z_q - z.detach()) ** 2)
|
||||
|
||||
# preserve gradients
|
||||
z_q = z + (z_q - z).detach()
|
||||
|
||||
# reshape back to match original input shape
|
||||
z_q = rearrange(z_q, "b h w c -> b c h w").contiguous()
|
||||
|
||||
if self.remap is not None:
|
||||
min_encoding_indices = min_encoding_indices.reshape(z.shape[0], -1) # add batch axis
|
||||
min_encoding_indices = self.remap_to_used(min_encoding_indices)
|
||||
min_encoding_indices = min_encoding_indices.reshape(-1, 1) # flatten
|
||||
|
||||
if self.sane_index_shape:
|
||||
min_encoding_indices = min_encoding_indices.reshape(z_q.shape[0], z_q.shape[2], z_q.shape[3])
|
||||
|
||||
return z_q, loss, (perplexity, min_encodings, min_encoding_indices)
|
||||
|
||||
def get_codebook_entry(self, indices, shape):
|
||||
# shape specifying (batch, height, width, channel)
|
||||
if self.remap is not None:
|
||||
indices = indices.reshape(shape[0], -1) # add batch axis
|
||||
indices = self.unmap_to_all(indices)
|
||||
indices = indices.reshape(-1) # flatten again
|
||||
|
||||
# get quantized latent vectors
|
||||
z_q = self.embedding(indices)
|
||||
|
||||
if shape is not None:
|
||||
z_q = z_q.view(shape)
|
||||
# reshape back to match original input shape
|
||||
z_q = z_q.permute(0, 3, 1, 2).contiguous()
|
||||
|
||||
return z_q
|
||||
|
||||
|
||||
class VQModel(ModelMixin, ConfigMixin):
|
||||
def __init__(
|
||||
self,
|
||||
ch,
|
||||
out_ch,
|
||||
num_res_blocks,
|
||||
attn_resolutions,
|
||||
in_channels,
|
||||
resolution,
|
||||
z_channels,
|
||||
n_embed,
|
||||
embed_dim,
|
||||
remap=None,
|
||||
sane_index_shape=False, # tell vector quantizer to return indices as bhw
|
||||
ch_mult=(1, 2, 4, 8),
|
||||
dropout=0.0,
|
||||
double_z=True,
|
||||
resamp_with_conv=True,
|
||||
give_pre_end=False,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
# register all __init__ params with self.register
|
||||
self.register(
|
||||
ch=ch,
|
||||
out_ch=out_ch,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attn_resolutions=attn_resolutions,
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
z_channels=z_channels,
|
||||
n_embed=n_embed,
|
||||
embed_dim=embed_dim,
|
||||
remap=remap,
|
||||
sane_index_shape=sane_index_shape,
|
||||
ch_mult=ch_mult,
|
||||
dropout=dropout,
|
||||
double_z=double_z,
|
||||
resamp_with_conv=resamp_with_conv,
|
||||
give_pre_end=give_pre_end,
|
||||
)
|
||||
|
||||
# pass init params to Encoder
|
||||
self.encoder = Encoder(
|
||||
ch=ch,
|
||||
out_ch=out_ch,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attn_resolutions=attn_resolutions,
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
z_channels=z_channels,
|
||||
ch_mult=ch_mult,
|
||||
dropout=dropout,
|
||||
resamp_with_conv=resamp_with_conv,
|
||||
double_z=double_z,
|
||||
give_pre_end=give_pre_end,
|
||||
)
|
||||
|
||||
self.quantize = VectorQuantizer(n_embed, embed_dim, beta=0.25, remap=remap, sane_index_shape=sane_index_shape)
|
||||
|
||||
# pass init params to Decoder
|
||||
self.decoder = Decoder(
|
||||
ch=ch,
|
||||
out_ch=out_ch,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attn_resolutions=attn_resolutions,
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
z_channels=z_channels,
|
||||
ch_mult=ch_mult,
|
||||
dropout=dropout,
|
||||
resamp_with_conv=resamp_with_conv,
|
||||
give_pre_end=give_pre_end,
|
||||
)
|
||||
|
||||
def encode(self, x):
|
||||
h = self.encoder(x)
|
||||
h = self.quant_conv(h)
|
||||
return h
|
||||
|
||||
def decode(self, h, force_not_quantize=False):
|
||||
# also go through quantization layer
|
||||
if not force_not_quantize:
|
||||
quant, emb_loss, info = self.quantize(h)
|
||||
else:
|
||||
quant = h
|
||||
quant = self.post_quant_conv(quant)
|
||||
dec = self.decoder(quant)
|
||||
return dec
|
||||
|
||||
|
||||
class DiagonalGaussianDistribution(object):
|
||||
def __init__(self, parameters, deterministic=False):
|
||||
self.parameters = parameters
|
||||
self.mean, self.logvar = torch.chunk(parameters, 2, dim=1)
|
||||
self.logvar = torch.clamp(self.logvar, -30.0, 20.0)
|
||||
self.deterministic = deterministic
|
||||
self.std = torch.exp(0.5 * self.logvar)
|
||||
self.var = torch.exp(self.logvar)
|
||||
if self.deterministic:
|
||||
self.var = self.std = torch.zeros_like(self.mean).to(device=self.parameters.device)
|
||||
|
||||
def sample(self):
|
||||
x = self.mean + self.std * torch.randn(self.mean.shape).to(device=self.parameters.device)
|
||||
return x
|
||||
|
||||
def kl(self, other=None):
|
||||
if self.deterministic:
|
||||
return torch.Tensor([0.0])
|
||||
else:
|
||||
if other is None:
|
||||
return 0.5 * torch.sum(torch.pow(self.mean, 2) + self.var - 1.0 - self.logvar, dim=[1, 2, 3])
|
||||
else:
|
||||
return 0.5 * torch.sum(
|
||||
torch.pow(self.mean - other.mean, 2) / other.var
|
||||
+ self.var / other.var
|
||||
- 1.0
|
||||
- self.logvar
|
||||
+ other.logvar,
|
||||
dim=[1, 2, 3],
|
||||
)
|
||||
|
||||
def nll(self, sample, dims=[1, 2, 3]):
|
||||
if self.deterministic:
|
||||
return torch.Tensor([0.0])
|
||||
logtwopi = np.log(2.0 * np.pi)
|
||||
return 0.5 * torch.sum(logtwopi + self.logvar + torch.pow(sample - self.mean, 2) / self.var, dim=dims)
|
||||
|
||||
def mode(self):
|
||||
return self.mean
|
||||
|
||||
|
||||
class AutoencoderKL(ModelMixin, ConfigMixin):
|
||||
def __init__(
|
||||
self,
|
||||
ch,
|
||||
out_ch,
|
||||
num_res_blocks,
|
||||
attn_resolutions,
|
||||
in_channels,
|
||||
resolution,
|
||||
z_channels,
|
||||
embed_dim,
|
||||
remap=None,
|
||||
sane_index_shape=False, # tell vector quantizer to return indices as bhw
|
||||
ch_mult=(1, 2, 4, 8),
|
||||
dropout=0.0,
|
||||
double_z=True,
|
||||
resamp_with_conv=True,
|
||||
give_pre_end=False,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
# register all __init__ params with self.register
|
||||
self.register(
|
||||
ch=ch,
|
||||
out_ch=out_ch,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attn_resolutions=attn_resolutions,
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
z_channels=z_channels,
|
||||
embed_dim=embed_dim,
|
||||
remap=remap,
|
||||
sane_index_shape=sane_index_shape,
|
||||
ch_mult=ch_mult,
|
||||
dropout=dropout,
|
||||
double_z=double_z,
|
||||
resamp_with_conv=resamp_with_conv,
|
||||
give_pre_end=give_pre_end,
|
||||
)
|
||||
|
||||
# pass init params to Encoder
|
||||
self.encoder = Encoder(
|
||||
ch=ch,
|
||||
out_ch=out_ch,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attn_resolutions=attn_resolutions,
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
z_channels=z_channels,
|
||||
ch_mult=ch_mult,
|
||||
dropout=dropout,
|
||||
resamp_with_conv=resamp_with_conv,
|
||||
double_z=double_z,
|
||||
give_pre_end=give_pre_end,
|
||||
)
|
||||
|
||||
# pass init params to Decoder
|
||||
self.decoder = Decoder(
|
||||
ch=ch,
|
||||
out_ch=out_ch,
|
||||
num_res_blocks=num_res_blocks,
|
||||
attn_resolutions=attn_resolutions,
|
||||
in_channels=in_channels,
|
||||
resolution=resolution,
|
||||
z_channels=z_channels,
|
||||
ch_mult=ch_mult,
|
||||
dropout=dropout,
|
||||
resamp_with_conv=resamp_with_conv,
|
||||
give_pre_end=give_pre_end,
|
||||
)
|
||||
|
||||
self.quant_conv = torch.nn.Conv2d(2 * z_channels, 2 * embed_dim, 1)
|
||||
self.post_quant_conv = torch.nn.Conv2d(embed_dim, z_channels, 1)
|
||||
|
||||
def encode(self, x):
|
||||
h = self.encoder(x)
|
||||
moments = self.quant_conv(h)
|
||||
posterior = DiagonalGaussianDistribution(moments)
|
||||
return posterior
|
||||
|
||||
def decode(self, z):
|
||||
z = self.post_quant_conv(z)
|
||||
dec = self.decoder(z)
|
||||
return dec
|
||||
|
||||
def forward(self, input, sample_posterior=True):
|
||||
posterior = self.encode(input)
|
||||
if sample_posterior:
|
||||
z = posterior.sample()
|
||||
else:
|
||||
z = posterior.mode()
|
||||
dec = self.decode(z)
|
||||
return dec, posterior
|
||||
|
||||
|
||||
class LatentDiffusion(DiffusionPipeline):
|
||||
def __init__(self, vqvae, bert, tokenizer, unet, noise_scheduler):
|
||||
super().__init__()
|
||||
noise_scheduler = noise_scheduler.set_format("pt")
|
||||
self.register_modules(vqvae=vqvae, bert=bert, tokenizer=tokenizer, unet=unet, noise_scheduler=noise_scheduler)
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(
|
||||
self,
|
||||
prompt,
|
||||
batch_size=1,
|
||||
generator=None,
|
||||
torch_device=None,
|
||||
eta=0.0,
|
||||
guidance_scale=1.0,
|
||||
num_inference_steps=50,
|
||||
):
|
||||
# eta corresponds to η in paper and should be between [0, 1]
|
||||
|
||||
if torch_device is None:
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
self.unet.to(torch_device)
|
||||
self.vqvae.to(torch_device)
|
||||
self.bert.to(torch_device)
|
||||
|
||||
# get unconditional embeddings for classifier free guidence
|
||||
if guidance_scale != 1.0:
|
||||
uncond_input = self.tokenizer([""], padding="max_length", max_length=77, return_tensors="pt").to(
|
||||
torch_device
|
||||
)
|
||||
uncond_embeddings = self.bert(uncond_input.input_ids)[0]
|
||||
|
||||
# get text embedding
|
||||
text_input = self.tokenizer(prompt, padding="max_length", max_length=77, return_tensors="pt").to(torch_device)
|
||||
text_embedding = self.bert(text_input.input_ids)[0]
|
||||
|
||||
num_trained_timesteps = self.noise_scheduler.timesteps
|
||||
inference_step_times = range(0, num_trained_timesteps, num_trained_timesteps // num_inference_steps)
|
||||
|
||||
image = torch.randn(
|
||||
(batch_size, self.unet.in_channels, self.unet.image_size, self.unet.image_size),
|
||||
generator=generator,
|
||||
).to(torch_device)
|
||||
|
||||
# See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
|
||||
# Ideally, read DDIM paper in-detail understanding
|
||||
|
||||
# Notation (<variable name> -> <name in paper>
|
||||
# - pred_noise_t -> e_theta(x_t, t)
|
||||
# - pred_original_image -> f_theta(x_t, t) or x_0
|
||||
# - std_dev_t -> sigma_t
|
||||
# - eta -> η
|
||||
# - pred_image_direction -> "direction pointingc to x_t"
|
||||
# - pred_prev_image -> "x_t-1"
|
||||
for t in tqdm.tqdm(reversed(range(num_inference_steps)), total=num_inference_steps):
|
||||
# guidance_scale of 1 means no guidance
|
||||
if guidance_scale == 1.0:
|
||||
image_in = image
|
||||
context = text_embedding
|
||||
timesteps = torch.tensor([inference_step_times[t]] * image.shape[0], device=torch_device)
|
||||
else:
|
||||
# for classifier free guidance, we need to do two forward passes
|
||||
# here we concanate embedding and unconditioned embedding in a single batch
|
||||
# to avoid doing two forward passes
|
||||
image_in = torch.cat([image] * 2)
|
||||
context = torch.cat([uncond_embeddings, text_embedding])
|
||||
timesteps = torch.tensor([inference_step_times[t]] * image.shape[0], device=torch_device)
|
||||
|
||||
# 1. predict noise residual
|
||||
pred_noise_t = self.unet(image_in, timesteps, context=context)
|
||||
|
||||
# perform guidance
|
||||
if guidance_scale != 1.0:
|
||||
pred_noise_t_uncond, pred_noise_t = pred_noise_t.chunk(2)
|
||||
pred_noise_t = pred_noise_t_uncond + guidance_scale * (pred_noise_t - pred_noise_t_uncond)
|
||||
|
||||
# 2. predict previous mean of image x_t-1
|
||||
pred_prev_image = self.noise_scheduler.step(pred_noise_t, image, t, num_inference_steps, eta)
|
||||
|
||||
# 3. optionally sample variance
|
||||
variance = 0
|
||||
if eta > 0:
|
||||
noise = torch.randn(image.shape, generator=generator).to(image.device)
|
||||
variance = self.noise_scheduler.get_variance(t, num_inference_steps).sqrt() * eta * noise
|
||||
|
||||
# 4. set current image to prev_image: x_t -> x_t-1
|
||||
image = pred_prev_image + variance
|
||||
|
||||
# scale and decode image with vae
|
||||
image = 1 / 0.18215 * image
|
||||
image = self.vqvae.decode(image)
|
||||
image = torch.clamp((image + 1.0) / 2.0, min=0.0, max=1.0)
|
||||
|
||||
return image
|
||||
1
src/diffusers/pipelines/pndm/__init__.py
Normal file
1
src/diffusers/pipelines/pndm/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
from .pipeline_pndm import PNDMPipeline
|
||||
@@ -16,18 +16,19 @@
|
||||
|
||||
import torch
|
||||
|
||||
import tqdm
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
|
||||
|
||||
class PNDM(DiffusionPipeline):
|
||||
def __init__(self, unet, noise_scheduler):
|
||||
class PNDMPipeline(DiffusionPipeline):
|
||||
def __init__(self, unet, scheduler):
|
||||
super().__init__()
|
||||
noise_scheduler = noise_scheduler.set_format("pt")
|
||||
self.register_modules(unet=unet, noise_scheduler=noise_scheduler)
|
||||
scheduler = scheduler.set_format("pt")
|
||||
self.register_modules(unet=unet, scheduler=scheduler)
|
||||
|
||||
def __call__(self, batch_size=1, generator=None, torch_device=None, num_inference_steps=50):
|
||||
@torch.no_grad()
|
||||
def __call__(self, batch_size=1, generator=None, torch_device=None, num_inference_steps=50, output_type="pil"):
|
||||
# For more information on the sampling method you can take a look at Algorithm 2 of
|
||||
# the official paper: https://arxiv.org/pdf/2202.09778.pdf
|
||||
if torch_device is None:
|
||||
@@ -37,23 +38,20 @@ class PNDM(DiffusionPipeline):
|
||||
|
||||
# Sample gaussian noise to begin loop
|
||||
image = torch.randn(
|
||||
(batch_size, self.unet.in_channels, self.unet.resolution, self.unet.resolution),
|
||||
(batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size),
|
||||
generator=generator,
|
||||
)
|
||||
image = image.to(torch_device)
|
||||
|
||||
warmup_time_steps = self.noise_scheduler.get_warmup_time_steps(num_inference_steps)
|
||||
for t in tqdm.tqdm(range(len(warmup_time_steps))):
|
||||
t_orig = warmup_time_steps[t]
|
||||
residual = self.unet(image, t_orig)
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
for t in tqdm(self.scheduler.timesteps):
|
||||
model_output = self.unet(image, t)["sample"]
|
||||
|
||||
image = self.noise_scheduler.step_prk(residual, image, t, num_inference_steps)
|
||||
image = self.scheduler.step(model_output, t, image)["prev_sample"]
|
||||
|
||||
timesteps = self.noise_scheduler.get_time_steps(num_inference_steps)
|
||||
for t in tqdm.tqdm(range(len(timesteps))):
|
||||
t_orig = timesteps[t]
|
||||
residual = self.unet(image, t_orig)
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).numpy()
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
image = self.noise_scheduler.step_plms(residual, image, t, num_inference_steps)
|
||||
|
||||
return image
|
||||
return {"sample": image}
|
||||
1
src/diffusers/pipelines/score_sde_ve/__init__.py
Normal file
1
src/diffusers/pipelines/score_sde_ve/__init__.py
Normal file
@@ -0,0 +1 @@
|
||||
from .pipeline_score_sde_ve import ScoreSdeVePipeline
|
||||
@@ -0,0 +1,47 @@
|
||||
#!/usr/bin/env python3
|
||||
import torch
|
||||
|
||||
from diffusers import DiffusionPipeline
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
|
||||
class ScoreSdeVePipeline(DiffusionPipeline):
|
||||
def __init__(self, model, scheduler):
|
||||
super().__init__()
|
||||
self.register_modules(model=model, scheduler=scheduler)
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, num_inference_steps=2000, generator=None, output_type="pil"):
|
||||
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
|
||||
|
||||
img_size = self.model.config.sample_size
|
||||
shape = (1, 3, img_size, img_size)
|
||||
|
||||
model = self.model.to(device)
|
||||
|
||||
sample = torch.randn(*shape) * self.scheduler.config.sigma_max
|
||||
sample = sample.to(device)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps)
|
||||
self.scheduler.set_sigmas(num_inference_steps)
|
||||
|
||||
for i, t in tqdm(enumerate(self.scheduler.timesteps)):
|
||||
sigma_t = self.scheduler.sigmas[i] * torch.ones(shape[0], device=device)
|
||||
|
||||
# correction step
|
||||
for _ in range(self.scheduler.correct_steps):
|
||||
model_output = self.model(sample, sigma_t)["sample"]
|
||||
sample = self.scheduler.step_correct(model_output, sample)["prev_sample"]
|
||||
|
||||
# prediction step
|
||||
model_output = model(sample, sigma_t)["sample"]
|
||||
output = self.scheduler.step_pred(model_output, t, sample)
|
||||
|
||||
sample, sample_mean = output["prev_sample"], output["prev_sample_mean"]
|
||||
|
||||
sample = sample.clamp(0, 1)
|
||||
sample = sample.cpu().permute(0, 2, 3, 1).numpy()
|
||||
if output_type == "pil":
|
||||
sample = self.numpy_to_pil(sample)
|
||||
|
||||
return {"sample": sample}
|
||||
@@ -16,8 +16,9 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from .classifier_free_guidance import ClassifierFreeGuidanceScheduler
|
||||
from .scheduling_ddim import DDIMScheduler
|
||||
from .scheduling_ddpm import DDPMScheduler
|
||||
from .scheduling_pndm import PNDMScheduler
|
||||
from .scheduling_sde_ve import ScoreSdeVeScheduler
|
||||
from .scheduling_sde_vp import ScoreSdeVpScheduler
|
||||
from .scheduling_utils import SchedulerMixin
|
||||
|
||||
@@ -1,97 +0,0 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import math
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from torch import nn
|
||||
|
||||
from ..configuration_utils import ConfigMixin
|
||||
|
||||
|
||||
SAMPLING_CONFIG_NAME = "scheduler_config.json"
|
||||
|
||||
|
||||
def linear_beta_schedule(timesteps, beta_start, beta_end):
|
||||
return torch.linspace(beta_start, beta_end, timesteps, dtype=torch.float64)
|
||||
|
||||
|
||||
def betas_for_alpha_bar(num_diffusion_timesteps, alpha_bar, max_beta=0.999):
|
||||
"""
|
||||
Create a beta schedule that discretizes the given alpha_t_bar function,
|
||||
which defines the cumulative product of (1-beta) over time from t = [0,1].
|
||||
|
||||
:param num_diffusion_timesteps: the number of betas to produce.
|
||||
:param alpha_bar: a lambda that takes an argument t from 0 to 1 and
|
||||
produces the cumulative product of (1-beta) up to that
|
||||
part of the diffusion process.
|
||||
:param max_beta: the maximum beta to use; use values lower than 1 to
|
||||
prevent singularities.
|
||||
"""
|
||||
betas = []
|
||||
for i in range(num_diffusion_timesteps):
|
||||
t1 = i / num_diffusion_timesteps
|
||||
t2 = (i + 1) / num_diffusion_timesteps
|
||||
betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
|
||||
return np.array(betas, dtype=np.float64)
|
||||
|
||||
|
||||
class ClassifierFreeGuidanceScheduler(nn.Module, ConfigMixin):
|
||||
|
||||
config_name = SAMPLING_CONFIG_NAME
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
timesteps=1000,
|
||||
beta_schedule="squaredcos_cap_v2",
|
||||
):
|
||||
super().__init__()
|
||||
self.register(
|
||||
timesteps=timesteps,
|
||||
beta_schedule=beta_schedule,
|
||||
)
|
||||
self.timesteps = int(timesteps)
|
||||
|
||||
if beta_schedule == "squaredcos_cap_v2":
|
||||
# GLIDE cosine schedule
|
||||
self.betas = betas_for_alpha_bar(
|
||||
timesteps,
|
||||
lambda t: math.cos((t + 0.008) / 1.008 * math.pi / 2) ** 2,
|
||||
)
|
||||
else:
|
||||
raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
|
||||
|
||||
alphas = 1.0 - self.betas
|
||||
self.alphas_cumprod = np.cumprod(alphas, axis=0)
|
||||
self.alphas_cumprod_prev = np.append(1.0, self.alphas_cumprod[:-1])
|
||||
|
||||
# calculations for diffusion q(x_t | x_{t-1}) and others
|
||||
self.sqrt_recip_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod)
|
||||
self.sqrt_recipm1_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod - 1)
|
||||
|
||||
# calculations for posterior q(x_{t-1} | x_t, x_0)
|
||||
self.posterior_variance = self.betas * (1.0 - self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod)
|
||||
# below: log calculation clipped because the posterior variance is 0 at the beginning of the diffusion chain
|
||||
self.posterior_log_variance_clipped = np.log(
|
||||
np.append(self.posterior_variance[1], self.posterior_variance[1:])
|
||||
)
|
||||
self.posterior_mean_coef1 = self.betas * np.sqrt(self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod)
|
||||
self.posterior_mean_coef2 = (1.0 - self.alphas_cumprod_prev) * np.sqrt(alphas) / (1.0 - self.alphas_cumprod)
|
||||
|
||||
def sample_noise(self, shape, device, generator=None):
|
||||
# always sample on CPU to be deterministic
|
||||
return torch.randn(shape, generator=generator).to(device)
|
||||
|
||||
def __len__(self):
|
||||
return self.timesteps
|
||||
@@ -1,4 +1,4 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
# Copyright 2022 Stanford University Team and The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@@ -11,45 +11,65 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pytorch_diffusion
|
||||
# and https://github.com/hojonathanho/diffusion
|
||||
|
||||
import math
|
||||
from typing import Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
from ..configuration_utils import ConfigMixin
|
||||
from .scheduling_utils import SchedulerMixin, betas_for_alpha_bar, linear_beta_schedule
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from .scheduling_utils import SchedulerMixin
|
||||
|
||||
|
||||
def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
|
||||
"""
|
||||
Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
|
||||
(1-beta) over time from t = [0,1].
|
||||
|
||||
:param num_diffusion_timesteps: the number of betas to produce. :param alpha_bar: a lambda that takes an argument t
|
||||
from 0 to 1 and
|
||||
produces the cumulative product of (1-beta) up to that part of the diffusion process.
|
||||
:param max_beta: the maximum beta to use; use values lower than 1 to
|
||||
prevent singularities.
|
||||
"""
|
||||
|
||||
def alpha_bar(time_step):
|
||||
return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
|
||||
|
||||
betas = []
|
||||
for i in range(num_diffusion_timesteps):
|
||||
t1 = i / num_diffusion_timesteps
|
||||
t2 = (i + 1) / num_diffusion_timesteps
|
||||
betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
|
||||
return np.array(betas, dtype=np.float32)
|
||||
|
||||
|
||||
class DDIMScheduler(SchedulerMixin, ConfigMixin):
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
timesteps=1000,
|
||||
num_train_timesteps=1000,
|
||||
beta_start=0.0001,
|
||||
beta_end=0.02,
|
||||
beta_schedule="linear",
|
||||
trained_betas=None,
|
||||
timestep_values=None,
|
||||
clip_predicted_image=True,
|
||||
tensor_format="np",
|
||||
clip_sample=True,
|
||||
tensor_format="pt",
|
||||
):
|
||||
super().__init__()
|
||||
self.register(
|
||||
timesteps=timesteps,
|
||||
beta_start=beta_start,
|
||||
beta_end=beta_end,
|
||||
beta_schedule=beta_schedule,
|
||||
)
|
||||
self.timesteps = int(timesteps)
|
||||
self.timestep_values = timestep_values # save the fixed timestep values for BDDM
|
||||
self.clip_image = clip_predicted_image
|
||||
|
||||
if beta_schedule == "linear":
|
||||
self.betas = linear_beta_schedule(timesteps, beta_start=beta_start, beta_end=beta_end)
|
||||
self.betas = np.linspace(beta_start, beta_end, num_train_timesteps, dtype=np.float32)
|
||||
elif beta_schedule == "scaled_linear":
|
||||
# this schedule is very specific to the latent diffusion model.
|
||||
self.betas = np.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=np.float32) ** 2
|
||||
elif beta_schedule == "squaredcos_cap_v2":
|
||||
# GLIDE cosine schedule
|
||||
self.betas = betas_for_alpha_bar(
|
||||
timesteps,
|
||||
lambda t: math.cos((t + 0.008) / 1.008 * math.pi / 2) ** 2,
|
||||
)
|
||||
# Glide cosine schedule
|
||||
self.betas = betas_for_alpha_bar(num_train_timesteps)
|
||||
else:
|
||||
raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
|
||||
|
||||
@@ -57,53 +77,16 @@ class DDIMScheduler(SchedulerMixin, ConfigMixin):
|
||||
self.alphas_cumprod = np.cumprod(self.alphas, axis=0)
|
||||
self.one = np.array(1.0)
|
||||
|
||||
# setable values
|
||||
self.num_inference_steps = None
|
||||
self.timesteps = np.arange(0, num_train_timesteps)[::-1].copy()
|
||||
|
||||
self.tensor_format = tensor_format
|
||||
self.set_format(tensor_format=tensor_format)
|
||||
|
||||
# alphas_cumprod_prev = torch.nn.functional.pad(alphas_cumprod[:-1], (1, 0), value=1.0)
|
||||
# TODO(PVP) - check how much of these is actually necessary!
|
||||
# LDM only uses "fixed_small"; glide seems to use a weird mix of the two, ...
|
||||
# https://github.com/openai/glide-text2im/blob/69b530740eb6cef69442d6180579ef5ba9ef063e/glide_text2im/gaussian_diffusion.py#L246
|
||||
# variance = betas * (1.0 - alphas_cumprod_prev) / (1.0 - alphas_cumprod)
|
||||
# if variance_type == "fixed_small":
|
||||
# log_variance = torch.log(variance.clamp(min=1e-20))
|
||||
# elif variance_type == "fixed_large":
|
||||
# log_variance = torch.log(torch.cat([variance[1:2], betas[1:]], dim=0))
|
||||
#
|
||||
#
|
||||
# self.register_buffer("log_variance", log_variance.to(torch.float32))
|
||||
|
||||
# def rescale_betas(self, num_timesteps):
|
||||
# # GLIDE scaling
|
||||
# if self.beta_schedule == "linear":
|
||||
# scale = self.timesteps / num_timesteps
|
||||
# self.betas = linear_beta_schedule(
|
||||
# num_timesteps, beta_start=self.beta_start * scale, beta_end=self.beta_end * scale
|
||||
# )
|
||||
# self.alphas = 1.0 - self.betas
|
||||
# self.alphas_cumprod = np.cumprod(self.alphas, axis=0)
|
||||
|
||||
def get_alpha(self, time_step):
|
||||
return self.alphas[time_step]
|
||||
|
||||
def get_beta(self, time_step):
|
||||
return self.betas[time_step]
|
||||
|
||||
def get_alpha_prod(self, time_step):
|
||||
if time_step < 0:
|
||||
return self.one
|
||||
return self.alphas_cumprod[time_step]
|
||||
|
||||
def get_orig_t(self, t, num_inference_steps):
|
||||
if t < 0:
|
||||
return -1
|
||||
return self.timesteps // num_inference_steps * t
|
||||
|
||||
def get_variance(self, t, num_inference_steps):
|
||||
orig_t = self.get_orig_t(t, num_inference_steps)
|
||||
orig_prev_t = self.get_orig_t(t - 1, num_inference_steps)
|
||||
|
||||
alpha_prod_t = self.get_alpha_prod(orig_t)
|
||||
alpha_prod_t_prev = self.get_alpha_prod(orig_prev_t)
|
||||
def _get_variance(self, timestep, prev_timestep):
|
||||
alpha_prod_t = self.alphas_cumprod[timestep]
|
||||
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.one
|
||||
beta_prod_t = 1 - alpha_prod_t
|
||||
beta_prod_t_prev = 1 - alpha_prod_t_prev
|
||||
|
||||
@@ -111,51 +94,84 @@ class DDIMScheduler(SchedulerMixin, ConfigMixin):
|
||||
|
||||
return variance
|
||||
|
||||
def step(self, residual, image, t, num_inference_steps, eta, use_clipped_residual=False):
|
||||
def set_timesteps(self, num_inference_steps):
|
||||
self.num_inference_steps = num_inference_steps
|
||||
self.timesteps = np.arange(
|
||||
0, self.config.num_train_timesteps, self.config.num_train_timesteps // self.num_inference_steps
|
||||
)[::-1].copy()
|
||||
self.set_format(tensor_format=self.tensor_format)
|
||||
|
||||
def step(
|
||||
self,
|
||||
model_output: Union[torch.FloatTensor, np.ndarray],
|
||||
timestep: int,
|
||||
sample: Union[torch.FloatTensor, np.ndarray],
|
||||
eta: float = 0.0,
|
||||
use_clipped_model_output: bool = False,
|
||||
generator=None,
|
||||
):
|
||||
# See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
|
||||
# Ideally, read DDIM paper in-detail understanding
|
||||
|
||||
# Notation (<variable name> -> <name in paper>
|
||||
# - pred_noise_t -> e_theta(x_t, t)
|
||||
# - pred_original_image -> f_theta(x_t, t) or x_0
|
||||
# - pred_original_sample -> f_theta(x_t, t) or x_0
|
||||
# - std_dev_t -> sigma_t
|
||||
# - eta -> η
|
||||
# - pred_image_direction -> "direction pointingc to x_t"
|
||||
# - pred_prev_image -> "x_t-1"
|
||||
# - pred_sample_direction -> "direction pointingc to x_t"
|
||||
# - pred_prev_sample -> "x_t-1"
|
||||
|
||||
# 1. get actual t and t-1
|
||||
orig_t = self.get_orig_t(t, num_inference_steps)
|
||||
orig_prev_t = self.get_orig_t(t - 1, num_inference_steps)
|
||||
# 1. get previous step value (=t-1)
|
||||
prev_timestep = timestep - self.config.num_train_timesteps // self.num_inference_steps
|
||||
|
||||
# 2. compute alphas, betas
|
||||
alpha_prod_t = self.get_alpha_prod(orig_t)
|
||||
alpha_prod_t_prev = self.get_alpha_prod(orig_prev_t)
|
||||
alpha_prod_t = self.alphas_cumprod[timestep]
|
||||
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.one
|
||||
beta_prod_t = 1 - alpha_prod_t
|
||||
|
||||
# 3. compute predicted original image from predicted noise also called
|
||||
# 3. compute predicted original sample from predicted noise also called
|
||||
# "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
|
||||
pred_original_image = (image - beta_prod_t ** (0.5) * residual) / alpha_prod_t ** (0.5)
|
||||
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
|
||||
|
||||
# 4. Clip "predicted x_0"
|
||||
if self.clip_image:
|
||||
pred_original_image = self.clip(pred_original_image, -1, 1)
|
||||
if self.config.clip_sample:
|
||||
pred_original_sample = self.clip(pred_original_sample, -1, 1)
|
||||
|
||||
# 5. compute variance: "sigma_t(η)" -> see formula (16)
|
||||
# σ_t = sqrt((1 − α_t−1)/(1 − α_t)) * sqrt(1 − α_t/α_t−1)
|
||||
variance = self.get_variance(t, num_inference_steps)
|
||||
variance = self._get_variance(timestep, prev_timestep)
|
||||
std_dev_t = eta * variance ** (0.5)
|
||||
|
||||
if use_clipped_residual:
|
||||
# the residual is always re-derived from the clipped x_0 in GLIDE
|
||||
residual = (image - alpha_prod_t ** (0.5) * pred_original_image) / beta_prod_t ** (0.5)
|
||||
if use_clipped_model_output:
|
||||
# the model_output is always re-derived from the clipped x_0 in Glide
|
||||
model_output = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
|
||||
|
||||
# 6. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
|
||||
pred_image_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * residual
|
||||
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * model_output
|
||||
|
||||
# 7. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
|
||||
pred_prev_image = alpha_prod_t_prev ** (0.5) * pred_original_image + pred_image_direction
|
||||
prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
|
||||
|
||||
return pred_prev_image
|
||||
if eta > 0:
|
||||
device = model_output.device if torch.is_tensor(model_output) else "cpu"
|
||||
noise = torch.randn(model_output.shape, generator=generator).to(device)
|
||||
variance = self._get_variance(timestep, prev_timestep) ** (0.5) * eta * noise
|
||||
|
||||
if not torch.is_tensor(model_output):
|
||||
variance = variance.numpy()
|
||||
|
||||
prev_sample = prev_sample + variance
|
||||
|
||||
return {"prev_sample": prev_sample}
|
||||
|
||||
def add_noise(self, original_samples, noise, timesteps):
|
||||
sqrt_alpha_prod = self.alphas_cumprod[timesteps] ** 0.5
|
||||
sqrt_alpha_prod = self.match_shape(sqrt_alpha_prod, original_samples)
|
||||
sqrt_one_minus_alpha_prod = (1 - self.alphas_cumprod[timesteps]) ** 0.5
|
||||
sqrt_one_minus_alpha_prod = self.match_shape(sqrt_one_minus_alpha_prod, original_samples)
|
||||
|
||||
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
|
||||
return noisy_samples
|
||||
|
||||
def __len__(self):
|
||||
return self.timesteps
|
||||
return self.config.num_train_timesteps
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
# Copyright 2022 UC Berkely Team and The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@@ -11,53 +11,63 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# DISCLAIMER: This file is strongly influenced by https://github.com/ermongroup/ddim
|
||||
|
||||
import math
|
||||
from typing import Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
from ..configuration_utils import ConfigMixin
|
||||
from .scheduling_utils import SchedulerMixin, betas_for_alpha_bar, linear_beta_schedule
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from .scheduling_utils import SchedulerMixin
|
||||
|
||||
|
||||
def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
|
||||
"""
|
||||
Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
|
||||
(1-beta) over time from t = [0,1].
|
||||
|
||||
:param num_diffusion_timesteps: the number of betas to produce. :param alpha_bar: a lambda that takes an argument t
|
||||
from 0 to 1 and
|
||||
produces the cumulative product of (1-beta) up to that part of the diffusion process.
|
||||
:param max_beta: the maximum beta to use; use values lower than 1 to
|
||||
prevent singularities.
|
||||
"""
|
||||
|
||||
def alpha_bar(time_step):
|
||||
return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
|
||||
|
||||
betas = []
|
||||
for i in range(num_diffusion_timesteps):
|
||||
t1 = i / num_diffusion_timesteps
|
||||
t2 = (i + 1) / num_diffusion_timesteps
|
||||
betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
|
||||
return np.array(betas, dtype=np.float32)
|
||||
|
||||
|
||||
class DDPMScheduler(SchedulerMixin, ConfigMixin):
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
timesteps=1000,
|
||||
num_train_timesteps=1000,
|
||||
beta_start=0.0001,
|
||||
beta_end=0.02,
|
||||
beta_schedule="linear",
|
||||
trained_betas=None,
|
||||
timestep_values=None,
|
||||
variance_type="fixed_small",
|
||||
clip_predicted_image=True,
|
||||
tensor_format="np",
|
||||
clip_sample=True,
|
||||
tensor_format="pt",
|
||||
):
|
||||
super().__init__()
|
||||
self.register(
|
||||
timesteps=timesteps,
|
||||
beta_start=beta_start,
|
||||
beta_end=beta_end,
|
||||
beta_schedule=beta_schedule,
|
||||
trained_betas=trained_betas,
|
||||
timestep_values=timestep_values,
|
||||
variance_type=variance_type,
|
||||
clip_predicted_image=clip_predicted_image,
|
||||
)
|
||||
self.timesteps = int(timesteps)
|
||||
self.timestep_values = timestep_values # save the fixed timestep values for BDDM
|
||||
self.clip_image = clip_predicted_image
|
||||
self.variance_type = variance_type
|
||||
|
||||
if trained_betas is not None:
|
||||
self.betas = np.asarray(trained_betas)
|
||||
elif beta_schedule == "linear":
|
||||
self.betas = linear_beta_schedule(timesteps, beta_start=beta_start, beta_end=beta_end)
|
||||
self.betas = np.linspace(beta_start, beta_end, num_train_timesteps, dtype=np.float32)
|
||||
elif beta_schedule == "squaredcos_cap_v2":
|
||||
# GLIDE cosine schedule
|
||||
self.betas = betas_for_alpha_bar(
|
||||
timesteps,
|
||||
lambda t: math.cos((t + 0.008) / 1.008 * math.pi / 2) ** 2,
|
||||
)
|
||||
# Glide cosine schedule
|
||||
self.betas = betas_for_alpha_bar(num_train_timesteps)
|
||||
else:
|
||||
raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
|
||||
|
||||
@@ -65,84 +75,100 @@ class DDPMScheduler(SchedulerMixin, ConfigMixin):
|
||||
self.alphas_cumprod = np.cumprod(self.alphas, axis=0)
|
||||
self.one = np.array(1.0)
|
||||
|
||||
# setable values
|
||||
self.num_inference_steps = None
|
||||
self.timesteps = np.arange(0, num_train_timesteps)[::-1].copy()
|
||||
|
||||
self.tensor_format = tensor_format
|
||||
self.set_format(tensor_format=tensor_format)
|
||||
|
||||
# self.register_buffer("betas", betas.to(torch.float32))
|
||||
# self.register_buffer("alphas", alphas.to(torch.float32))
|
||||
# self.register_buffer("alphas_cumprod", alphas_cumprod.to(torch.float32))
|
||||
def set_timesteps(self, num_inference_steps):
|
||||
num_inference_steps = min(self.config.num_train_timesteps, num_inference_steps)
|
||||
self.num_inference_steps = num_inference_steps
|
||||
self.timesteps = np.arange(
|
||||
0, self.config.num_train_timesteps, self.config.num_train_timesteps // self.num_inference_steps
|
||||
)[::-1].copy()
|
||||
self.set_format(tensor_format=self.tensor_format)
|
||||
|
||||
# alphas_cumprod_prev = torch.nn.functional.pad(alphas_cumprod[:-1], (1, 0), value=1.0)
|
||||
# TODO(PVP) - check how much of these is actually necessary!
|
||||
# LDM only uses "fixed_small"; glide seems to use a weird mix of the two, ...
|
||||
# https://github.com/openai/glide-text2im/blob/69b530740eb6cef69442d6180579ef5ba9ef063e/glide_text2im/gaussian_diffusion.py#L246
|
||||
# variance = betas * (1.0 - alphas_cumprod_prev) / (1.0 - alphas_cumprod)
|
||||
# if variance_type == "fixed_small":
|
||||
# log_variance = torch.log(variance.clamp(min=1e-20))
|
||||
# elif variance_type == "fixed_large":
|
||||
# log_variance = torch.log(torch.cat([variance[1:2], betas[1:]], dim=0))
|
||||
#
|
||||
#
|
||||
# self.register_buffer("log_variance", log_variance.to(torch.float32))
|
||||
def _get_variance(self, t, variance_type=None):
|
||||
alpha_prod_t = self.alphas_cumprod[t]
|
||||
alpha_prod_t_prev = self.alphas_cumprod[t - 1] if t > 0 else self.one
|
||||
|
||||
def get_alpha(self, time_step):
|
||||
return self.alphas[time_step]
|
||||
# For t > 0, compute predicted variance βt (see formula (6) and (7) from https://arxiv.org/pdf/2006.11239.pdf)
|
||||
# and sample from it to get previous sample
|
||||
# x_{t-1} ~ N(pred_prev_sample, variance) == add variance to pred_sample
|
||||
variance = (1 - alpha_prod_t_prev) / (1 - alpha_prod_t) * self.betas[t]
|
||||
|
||||
def get_beta(self, time_step):
|
||||
return self.betas[time_step]
|
||||
|
||||
def get_alpha_prod(self, time_step):
|
||||
if time_step < 0:
|
||||
return self.one
|
||||
return self.alphas_cumprod[time_step]
|
||||
|
||||
def get_variance(self, t):
|
||||
alpha_prod_t = self.get_alpha_prod(t)
|
||||
alpha_prod_t_prev = self.get_alpha_prod(t - 1)
|
||||
|
||||
# For t > 0, compute predicted variance βt (see formala (6) and (7) from https://arxiv.org/pdf/2006.11239.pdf)
|
||||
# and sample from it to get previous image
|
||||
# x_{t-1} ~ N(pred_prev_image, variance) == add variane to pred_image
|
||||
variance = (1 - alpha_prod_t_prev) / (1 - alpha_prod_t) * self.get_beta(t)
|
||||
if variance_type is None:
|
||||
variance_type = self.config.variance_type
|
||||
|
||||
# hacks - were probs added for training stability
|
||||
if self.variance_type == "fixed_small":
|
||||
if variance_type == "fixed_small":
|
||||
variance = self.clip(variance, min_value=1e-20)
|
||||
elif self.variance_type == "fixed_large":
|
||||
variance = self.get_beta(t)
|
||||
# for rl-diffuser https://arxiv.org/abs/2205.09991
|
||||
elif variance_type == "fixed_small_log":
|
||||
variance = self.log(self.clip(variance, min_value=1e-20))
|
||||
elif variance_type == "fixed_large":
|
||||
variance = self.betas[t]
|
||||
elif variance_type == "fixed_large_log":
|
||||
# Glide max_log
|
||||
variance = self.log(self.betas[t])
|
||||
|
||||
return variance
|
||||
|
||||
def step(self, residual, image, t):
|
||||
def step(
|
||||
self,
|
||||
model_output: Union[torch.FloatTensor, np.ndarray],
|
||||
timestep: int,
|
||||
sample: Union[torch.FloatTensor, np.ndarray],
|
||||
predict_epsilon=True,
|
||||
generator=None,
|
||||
):
|
||||
t = timestep
|
||||
# 1. compute alphas, betas
|
||||
alpha_prod_t = self.get_alpha_prod(t)
|
||||
alpha_prod_t_prev = self.get_alpha_prod(t - 1)
|
||||
alpha_prod_t = self.alphas_cumprod[t]
|
||||
alpha_prod_t_prev = self.alphas_cumprod[t - 1] if t > 0 else self.one
|
||||
beta_prod_t = 1 - alpha_prod_t
|
||||
beta_prod_t_prev = 1 - alpha_prod_t_prev
|
||||
|
||||
# 2. compute predicted original image from predicted noise also called
|
||||
# 2. compute predicted original sample from predicted noise also called
|
||||
# "predicted x_0" of formula (15) from https://arxiv.org/pdf/2006.11239.pdf
|
||||
pred_original_image = (image - beta_prod_t ** (0.5) * residual) / alpha_prod_t ** (0.5)
|
||||
if predict_epsilon:
|
||||
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
|
||||
else:
|
||||
pred_original_sample = model_output
|
||||
|
||||
# 3. Clip "predicted x_0"
|
||||
if self.clip_predicted_image:
|
||||
pred_original_image = self.clip(pred_original_image, -1, 1)
|
||||
if self.config.clip_sample:
|
||||
pred_original_sample = self.clip(pred_original_sample, -1, 1)
|
||||
|
||||
# 4. Compute coefficients for pred_original_image x_0 and current image x_t
|
||||
# 4. Compute coefficients for pred_original_sample x_0 and current sample x_t
|
||||
# See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
|
||||
pred_original_image_coeff = (alpha_prod_t_prev ** (0.5) * self.get_beta(t)) / beta_prod_t
|
||||
current_image_coeff = self.get_alpha(t) ** (0.5) * beta_prod_t_prev / beta_prod_t
|
||||
pred_original_sample_coeff = (alpha_prod_t_prev ** (0.5) * self.betas[t]) / beta_prod_t
|
||||
current_sample_coeff = self.alphas[t] ** (0.5) * beta_prod_t_prev / beta_prod_t
|
||||
|
||||
# 5. Compute predicted previous image µ_t
|
||||
# 5. Compute predicted previous sample µ_t
|
||||
# See formula (7) from https://arxiv.org/pdf/2006.11239.pdf
|
||||
pred_prev_image = pred_original_image_coeff * pred_original_image + current_image_coeff * image
|
||||
pred_prev_sample = pred_original_sample_coeff * pred_original_sample + current_sample_coeff * sample
|
||||
|
||||
return pred_prev_image
|
||||
# 6. Add noise
|
||||
variance = 0
|
||||
if t > 0:
|
||||
noise = self.randn_like(model_output, generator=generator)
|
||||
variance = (self._get_variance(t) ** 0.5) * noise
|
||||
|
||||
def forward_step(self, original_image, noise, t):
|
||||
sqrt_alpha_prod = self.get_alpha_prod(t) ** 0.5
|
||||
sqrt_one_minus_alpha_prod = (1 - self.get_alpha_prod(t)) ** 0.5
|
||||
noisy_image = sqrt_alpha_prod * original_image + sqrt_one_minus_alpha_prod * noise
|
||||
return noisy_image
|
||||
pred_prev_sample = pred_prev_sample + variance
|
||||
|
||||
return {"prev_sample": pred_prev_sample}
|
||||
|
||||
def add_noise(self, original_samples, noise, timesteps):
|
||||
sqrt_alpha_prod = self.alphas_cumprod[timesteps] ** 0.5
|
||||
sqrt_alpha_prod = self.match_shape(sqrt_alpha_prod, original_samples)
|
||||
sqrt_one_minus_alpha_prod = (1 - self.alphas_cumprod[timesteps]) ** 0.5
|
||||
sqrt_one_minus_alpha_prod = self.match_shape(sqrt_one_minus_alpha_prod, original_samples)
|
||||
|
||||
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
|
||||
return noisy_samples
|
||||
|
||||
def __len__(self):
|
||||
return self.timesteps
|
||||
return self.config.num_train_timesteps
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
# Copyright 2022 Zhejiang University Team and The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
@@ -11,40 +11,58 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# DISCLAIMER: This file is strongly influenced by https://github.com/ermongroup/ddim
|
||||
|
||||
import math
|
||||
from typing import Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
from ..configuration_utils import ConfigMixin
|
||||
from .scheduling_utils import SchedulerMixin, betas_for_alpha_bar, linear_beta_schedule
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from .scheduling_utils import SchedulerMixin
|
||||
|
||||
|
||||
def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999):
|
||||
"""
|
||||
Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
|
||||
(1-beta) over time from t = [0,1].
|
||||
|
||||
:param num_diffusion_timesteps: the number of betas to produce. :param alpha_bar: a lambda that takes an argument t
|
||||
from 0 to 1 and
|
||||
produces the cumulative product of (1-beta) up to that part of the diffusion process.
|
||||
:param max_beta: the maximum beta to use; use values lower than 1 to
|
||||
prevent singularities.
|
||||
"""
|
||||
|
||||
def alpha_bar(time_step):
|
||||
return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
|
||||
|
||||
betas = []
|
||||
for i in range(num_diffusion_timesteps):
|
||||
t1 = i / num_diffusion_timesteps
|
||||
t2 = (i + 1) / num_diffusion_timesteps
|
||||
betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
|
||||
return np.array(betas, dtype=np.float32)
|
||||
|
||||
|
||||
class PNDMScheduler(SchedulerMixin, ConfigMixin):
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
timesteps=1000,
|
||||
num_train_timesteps=1000,
|
||||
beta_start=0.0001,
|
||||
beta_end=0.02,
|
||||
beta_schedule="linear",
|
||||
tensor_format="np",
|
||||
tensor_format="pt",
|
||||
):
|
||||
super().__init__()
|
||||
self.register(
|
||||
timesteps=timesteps,
|
||||
beta_start=beta_start,
|
||||
beta_end=beta_end,
|
||||
beta_schedule=beta_schedule,
|
||||
)
|
||||
self.timesteps = int(timesteps)
|
||||
|
||||
if beta_schedule == "linear":
|
||||
self.betas = linear_beta_schedule(timesteps, beta_start=beta_start, beta_end=beta_end)
|
||||
self.betas = np.linspace(beta_start, beta_end, num_train_timesteps, dtype=np.float32)
|
||||
elif beta_schedule == "squaredcos_cap_v2":
|
||||
# GLIDE cosine schedule
|
||||
self.betas = betas_for_alpha_bar(
|
||||
timesteps,
|
||||
lambda t: math.cos((t + 0.008) / 1.008 * math.pi / 2) ** 2,
|
||||
)
|
||||
# Glide cosine schedule
|
||||
self.betas = betas_for_alpha_bar(num_train_timesteps)
|
||||
else:
|
||||
raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
|
||||
|
||||
@@ -53,99 +71,151 @@ class PNDMScheduler(SchedulerMixin, ConfigMixin):
|
||||
|
||||
self.one = np.array(1.0)
|
||||
|
||||
self.set_format(tensor_format=tensor_format)
|
||||
|
||||
# For now we only support F-PNDM, i.e. the runge-kutta method
|
||||
# For more information on the algorithm please take a look at the paper: https://arxiv.org/pdf/2202.09778.pdf
|
||||
# mainly at equations (12) and (13) and the Algorithm 2.
|
||||
# mainly at formula (9), (12), (13) and the Algorithm 2.
|
||||
self.pndm_order = 4
|
||||
|
||||
# running values
|
||||
self.cur_residual = 0
|
||||
self.cur_image = None
|
||||
self.cur_model_output = 0
|
||||
self.counter = 0
|
||||
self.cur_sample = None
|
||||
self.ets = []
|
||||
self.warmup_time_steps = {}
|
||||
self.time_steps = {}
|
||||
|
||||
def get_alpha(self, time_step):
|
||||
return self.alphas[time_step]
|
||||
# setable values
|
||||
self.num_inference_steps = None
|
||||
self._timesteps = np.arange(0, num_train_timesteps)[::-1].copy()
|
||||
self.prk_timesteps = None
|
||||
self.plms_timesteps = None
|
||||
self.timesteps = None
|
||||
|
||||
def get_beta(self, time_step):
|
||||
return self.betas[time_step]
|
||||
self.tensor_format = tensor_format
|
||||
self.set_format(tensor_format=tensor_format)
|
||||
|
||||
def get_alpha_prod(self, time_step):
|
||||
if time_step < 0:
|
||||
return self.one
|
||||
return self.alphas_cumprod[time_step]
|
||||
|
||||
def get_warmup_time_steps(self, num_inference_steps):
|
||||
if num_inference_steps in self.warmup_time_steps:
|
||||
return self.warmup_time_steps[num_inference_steps]
|
||||
|
||||
inference_step_times = list(range(0, self.timesteps, self.timesteps // num_inference_steps))
|
||||
|
||||
warmup_time_steps = np.array(inference_step_times[-self.pndm_order :]).repeat(2) + np.tile(
|
||||
np.array([0, self.timesteps // num_inference_steps // 2]), self.pndm_order
|
||||
)
|
||||
self.warmup_time_steps[num_inference_steps] = list(reversed(warmup_time_steps[:-1].repeat(2)[1:-1]))
|
||||
|
||||
return self.warmup_time_steps[num_inference_steps]
|
||||
|
||||
def get_time_steps(self, num_inference_steps):
|
||||
if num_inference_steps in self.time_steps:
|
||||
return self.time_steps[num_inference_steps]
|
||||
|
||||
inference_step_times = list(range(0, self.timesteps, self.timesteps // num_inference_steps))
|
||||
self.time_steps[num_inference_steps] = list(reversed(inference_step_times[:-3]))
|
||||
|
||||
return self.time_steps[num_inference_steps]
|
||||
|
||||
def step_prk(self, residual, image, t, num_inference_steps):
|
||||
# TODO(Patrick) - need to rethink whether the "warmup" way is the correct API design here
|
||||
warmup_time_steps = self.get_warmup_time_steps(num_inference_steps)
|
||||
|
||||
t_prev = warmup_time_steps[t // 4 * 4]
|
||||
t_next = warmup_time_steps[min(t + 1, len(warmup_time_steps) - 1)]
|
||||
|
||||
if t % 4 == 0:
|
||||
self.cur_residual += 1 / 6 * residual
|
||||
self.ets.append(residual)
|
||||
self.cur_image = image
|
||||
elif (t - 1) % 4 == 0:
|
||||
self.cur_residual += 1 / 3 * residual
|
||||
elif (t - 2) % 4 == 0:
|
||||
self.cur_residual += 1 / 3 * residual
|
||||
elif (t - 3) % 4 == 0:
|
||||
residual = self.cur_residual + 1 / 6 * residual
|
||||
self.cur_residual = 0
|
||||
|
||||
return self.transfer(self.cur_image, t_prev, t_next, residual)
|
||||
|
||||
def step_plms(self, residual, image, t, num_inference_steps):
|
||||
timesteps = self.get_time_steps(num_inference_steps)
|
||||
|
||||
t_prev = timesteps[t]
|
||||
t_next = timesteps[min(t + 1, len(timesteps) - 1)]
|
||||
self.ets.append(residual)
|
||||
|
||||
residual = (1 / 24) * (55 * self.ets[-1] - 59 * self.ets[-2] + 37 * self.ets[-3] - 9 * self.ets[-4])
|
||||
|
||||
return self.transfer(image, t_prev, t_next, residual)
|
||||
|
||||
def transfer(self, x, t, t_next, et):
|
||||
# TODO(Patrick): clean up to be compatible with numpy and give better names
|
||||
|
||||
alphas_cump = self.alphas_cumprod.to(x.device)
|
||||
at = alphas_cump[t + 1].view(-1, 1, 1, 1)
|
||||
at_next = alphas_cump[t_next + 1].view(-1, 1, 1, 1)
|
||||
|
||||
x_delta = (at_next - at) * (
|
||||
(1 / (at.sqrt() * (at.sqrt() + at_next.sqrt()))) * x
|
||||
- 1 / (at.sqrt() * (((1 - at_next) * at).sqrt() + ((1 - at) * at_next).sqrt())) * et
|
||||
def set_timesteps(self, num_inference_steps):
|
||||
self.num_inference_steps = num_inference_steps
|
||||
self._timesteps = list(
|
||||
range(0, self.config.num_train_timesteps, self.config.num_train_timesteps // num_inference_steps)
|
||||
)
|
||||
|
||||
x_next = x + x_delta
|
||||
return x_next
|
||||
prk_timesteps = np.array(self._timesteps[-self.pndm_order :]).repeat(2) + np.tile(
|
||||
np.array([0, self.config.num_train_timesteps // num_inference_steps // 2]), self.pndm_order
|
||||
)
|
||||
self.prk_timesteps = list(reversed(prk_timesteps[:-1].repeat(2)[1:-1]))
|
||||
self.plms_timesteps = list(reversed(self._timesteps[:-3]))
|
||||
self.timesteps = self.prk_timesteps + self.plms_timesteps
|
||||
|
||||
self.counter = 0
|
||||
self.set_format(tensor_format=self.tensor_format)
|
||||
|
||||
def step(
|
||||
self,
|
||||
model_output: Union[torch.FloatTensor, np.ndarray],
|
||||
timestep: int,
|
||||
sample: Union[torch.FloatTensor, np.ndarray],
|
||||
):
|
||||
if self.counter < len(self.prk_timesteps):
|
||||
return self.step_prk(model_output=model_output, timestep=timestep, sample=sample)
|
||||
else:
|
||||
return self.step_plms(model_output=model_output, timestep=timestep, sample=sample)
|
||||
|
||||
def step_prk(
|
||||
self,
|
||||
model_output: Union[torch.FloatTensor, np.ndarray],
|
||||
timestep: int,
|
||||
sample: Union[torch.FloatTensor, np.ndarray],
|
||||
):
|
||||
"""
|
||||
Step function propagating the sample with the Runge-Kutta method. RK takes 4 forward passes to approximate the
|
||||
solution to the differential equation.
|
||||
"""
|
||||
diff_to_prev = 0 if self.counter % 2 else self.config.num_train_timesteps // self.num_inference_steps // 2
|
||||
prev_timestep = max(timestep - diff_to_prev, self.prk_timesteps[-1])
|
||||
timestep = self.prk_timesteps[self.counter // 4 * 4]
|
||||
|
||||
if self.counter % 4 == 0:
|
||||
self.cur_model_output += 1 / 6 * model_output
|
||||
self.ets.append(model_output)
|
||||
self.cur_sample = sample
|
||||
elif (self.counter - 1) % 4 == 0:
|
||||
self.cur_model_output += 1 / 3 * model_output
|
||||
elif (self.counter - 2) % 4 == 0:
|
||||
self.cur_model_output += 1 / 3 * model_output
|
||||
elif (self.counter - 3) % 4 == 0:
|
||||
model_output = self.cur_model_output + 1 / 6 * model_output
|
||||
self.cur_model_output = 0
|
||||
|
||||
# cur_sample should not be `None`
|
||||
cur_sample = self.cur_sample if self.cur_sample is not None else sample
|
||||
|
||||
prev_sample = self._get_prev_sample(cur_sample, timestep, prev_timestep, model_output)
|
||||
self.counter += 1
|
||||
|
||||
return {"prev_sample": prev_sample}
|
||||
|
||||
def step_plms(
|
||||
self,
|
||||
model_output: Union[torch.FloatTensor, np.ndarray],
|
||||
timestep: int,
|
||||
sample: Union[torch.FloatTensor, np.ndarray],
|
||||
):
|
||||
"""
|
||||
Step function propagating the sample with the linear multi-step method. This has one forward pass with multiple
|
||||
times to approximate the solution.
|
||||
"""
|
||||
if len(self.ets) < 3:
|
||||
raise ValueError(
|
||||
f"{self.__class__} can only be run AFTER scheduler has been run "
|
||||
"in 'prk' mode for at least 12 iterations "
|
||||
"See: https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_pndm.py "
|
||||
"for more information."
|
||||
)
|
||||
|
||||
prev_timestep = max(timestep - self.config.num_train_timesteps // self.num_inference_steps, 0)
|
||||
self.ets.append(model_output)
|
||||
|
||||
model_output = (1 / 24) * (55 * self.ets[-1] - 59 * self.ets[-2] + 37 * self.ets[-3] - 9 * self.ets[-4])
|
||||
|
||||
prev_sample = self._get_prev_sample(sample, timestep, prev_timestep, model_output)
|
||||
self.counter += 1
|
||||
|
||||
return {"prev_sample": prev_sample}
|
||||
|
||||
def _get_prev_sample(self, sample, timestep, timestep_prev, model_output):
|
||||
# See formula (9) of PNDM paper https://arxiv.org/pdf/2202.09778.pdf
|
||||
# this function computes x_(t−δ) using the formula of (9)
|
||||
# Note that x_t needs to be added to both sides of the equation
|
||||
|
||||
# Notation (<variable name> -> <name in paper>
|
||||
# alpha_prod_t -> α_t
|
||||
# alpha_prod_t_prev -> α_(t−δ)
|
||||
# beta_prod_t -> (1 - α_t)
|
||||
# beta_prod_t_prev -> (1 - α_(t−δ))
|
||||
# sample -> x_t
|
||||
# model_output -> e_θ(x_t, t)
|
||||
# prev_sample -> x_(t−δ)
|
||||
alpha_prod_t = self.alphas_cumprod[timestep + 1]
|
||||
alpha_prod_t_prev = self.alphas_cumprod[timestep_prev + 1]
|
||||
beta_prod_t = 1 - alpha_prod_t
|
||||
beta_prod_t_prev = 1 - alpha_prod_t_prev
|
||||
|
||||
# corresponds to (α_(t−δ) - α_t) divided by
|
||||
# denominator of x_t in formula (9) and plus 1
|
||||
# Note: (α_(t−δ) - α_t) / (sqrt(α_t) * (sqrt(α_(t−δ)) + sqr(α_t))) =
|
||||
# sqrt(α_(t−δ)) / sqrt(α_t))
|
||||
sample_coeff = (alpha_prod_t_prev / alpha_prod_t) ** (0.5)
|
||||
|
||||
# corresponds to denominator of e_θ(x_t, t) in formula (9)
|
||||
model_output_denom_coeff = alpha_prod_t * beta_prod_t_prev ** (0.5) + (
|
||||
alpha_prod_t * beta_prod_t * alpha_prod_t_prev
|
||||
) ** (0.5)
|
||||
|
||||
# full formula (9)
|
||||
prev_sample = (
|
||||
sample_coeff * sample - (alpha_prod_t_prev - alpha_prod_t) * model_output / model_output_denom_coeff
|
||||
)
|
||||
|
||||
return prev_sample
|
||||
|
||||
def __len__(self):
|
||||
return self.timesteps
|
||||
return self.config.num_train_timesteps
|
||||
|
||||
176
src/diffusers/schedulers/scheduling_sde_ve.py
Normal file
176
src/diffusers/schedulers/scheduling_sde_ve.py
Normal file
@@ -0,0 +1,176 @@
|
||||
# Copyright 2022 Google Brain and The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# DISCLAIMER: This file is strongly influenced by https://github.com/yang-song/score_sde_pytorch
|
||||
|
||||
# TODO(Patrick, Anton, Suraj) - make scheduler framework indepedent and clean-up a bit
|
||||
from typing import Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from .scheduling_utils import SchedulerMixin
|
||||
|
||||
|
||||
class ScoreSdeVeScheduler(SchedulerMixin, ConfigMixin):
|
||||
"""
|
||||
The variance exploding stochastic differential equation (SDE) scheduler.
|
||||
|
||||
:param snr: coefficient weighting the step from the model_output sample (from the network) to the random noise.
|
||||
:param sigma_min: initial noise scale for sigma sequence in sampling procedure. The minimum sigma should mirror the
|
||||
distribution of the data.
|
||||
:param sigma_max: :param sampling_eps: the end value of sampling, where timesteps decrease progessively from 1 to
|
||||
epsilon. :param correct_steps: number of correction steps performed on a produced sample. :param tensor_format:
|
||||
"np" or "pt" for the expected format of samples passed to the Scheduler.
|
||||
"""
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
num_train_timesteps=2000,
|
||||
snr=0.15,
|
||||
sigma_min=0.01,
|
||||
sigma_max=1348,
|
||||
sampling_eps=1e-5,
|
||||
correct_steps=1,
|
||||
tensor_format="pt",
|
||||
):
|
||||
# self.sigmas = None
|
||||
# self.discrete_sigmas = None
|
||||
#
|
||||
# # setable values
|
||||
# self.num_inference_steps = None
|
||||
self.timesteps = None
|
||||
|
||||
self.set_sigmas(num_train_timesteps, sigma_min, sigma_max, sampling_eps)
|
||||
|
||||
self.tensor_format = tensor_format
|
||||
self.set_format(tensor_format=tensor_format)
|
||||
|
||||
def set_timesteps(self, num_inference_steps, sampling_eps=None):
|
||||
sampling_eps = sampling_eps if sampling_eps is not None else self.config.sampling_eps
|
||||
tensor_format = getattr(self, "tensor_format", "pt")
|
||||
if tensor_format == "np":
|
||||
self.timesteps = np.linspace(1, sampling_eps, num_inference_steps)
|
||||
elif tensor_format == "pt":
|
||||
self.timesteps = torch.linspace(1, sampling_eps, num_inference_steps)
|
||||
else:
|
||||
raise ValueError(f"`self.tensor_format`: {self.tensor_format} is not valid.")
|
||||
|
||||
def set_sigmas(self, num_inference_steps, sigma_min=None, sigma_max=None, sampling_eps=None):
|
||||
sigma_min = sigma_min if sigma_min is not None else self.config.sigma_min
|
||||
sigma_max = sigma_max if sigma_max is not None else self.config.sigma_max
|
||||
sampling_eps = sampling_eps if sampling_eps is not None else self.config.sampling_eps
|
||||
if self.timesteps is None:
|
||||
self.set_timesteps(num_inference_steps, sampling_eps)
|
||||
|
||||
tensor_format = getattr(self, "tensor_format", "pt")
|
||||
if tensor_format == "np":
|
||||
self.discrete_sigmas = np.exp(np.linspace(np.log(sigma_min), np.log(sigma_max), num_inference_steps))
|
||||
self.sigmas = np.array([sigma_min * (sigma_max / sigma_min) ** t for t in self.timesteps])
|
||||
elif tensor_format == "pt":
|
||||
self.discrete_sigmas = torch.exp(torch.linspace(np.log(sigma_min), np.log(sigma_max), num_inference_steps))
|
||||
self.sigmas = torch.tensor([sigma_min * (sigma_max / sigma_min) ** t for t in self.timesteps])
|
||||
else:
|
||||
raise ValueError(f"`self.tensor_format`: {self.tensor_format} is not valid.")
|
||||
|
||||
def get_adjacent_sigma(self, timesteps, t):
|
||||
tensor_format = getattr(self, "tensor_format", "pt")
|
||||
if tensor_format == "np":
|
||||
return np.where(timesteps == 0, np.zeros_like(t), self.discrete_sigmas[timesteps - 1])
|
||||
elif tensor_format == "pt":
|
||||
return torch.where(
|
||||
timesteps == 0, torch.zeros_like(t), self.discrete_sigmas[timesteps - 1].to(timesteps.device)
|
||||
)
|
||||
|
||||
raise ValueError(f"`self.tensor_format`: {self.tensor_format} is not valid.")
|
||||
|
||||
def set_seed(self, seed):
|
||||
tensor_format = getattr(self, "tensor_format", "pt")
|
||||
if tensor_format == "np":
|
||||
np.random.seed(seed)
|
||||
elif tensor_format == "pt":
|
||||
torch.manual_seed(seed)
|
||||
else:
|
||||
raise ValueError(f"`self.tensor_format`: {self.tensor_format} is not valid.")
|
||||
|
||||
def step_pred(
|
||||
self,
|
||||
model_output: Union[torch.FloatTensor, np.ndarray],
|
||||
timestep: int,
|
||||
sample: Union[torch.FloatTensor, np.ndarray],
|
||||
seed=None,
|
||||
):
|
||||
"""
|
||||
Predict the sample at the previous timestep by reversing the SDE.
|
||||
"""
|
||||
if seed is not None:
|
||||
self.set_seed(seed)
|
||||
# TODO(Patrick) non-PyTorch
|
||||
|
||||
timestep = timestep * torch.ones(
|
||||
sample.shape[0], device=sample.device
|
||||
) # torch.repeat_interleave(timestep, sample.shape[0])
|
||||
timesteps = (timestep * (len(self.timesteps) - 1)).long()
|
||||
|
||||
sigma = self.discrete_sigmas[timesteps].to(sample.device)
|
||||
adjacent_sigma = self.get_adjacent_sigma(timesteps, timestep)
|
||||
drift = self.zeros_like(sample)
|
||||
diffusion = (sigma**2 - adjacent_sigma**2) ** 0.5
|
||||
|
||||
# equation 6 in the paper: the model_output modeled by the network is grad_x log pt(x)
|
||||
# also equation 47 shows the analog from SDE models to ancestral sampling methods
|
||||
drift = drift - diffusion[:, None, None, None] ** 2 * model_output
|
||||
|
||||
# equation 6: sample noise for the diffusion term of
|
||||
noise = self.randn_like(sample)
|
||||
prev_sample_mean = sample - drift # subtract because `dt` is a small negative timestep
|
||||
# TODO is the variable diffusion the correct scaling term for the noise?
|
||||
prev_sample = prev_sample_mean + diffusion[:, None, None, None] * noise # add impact of diffusion field g
|
||||
|
||||
return {"prev_sample": prev_sample, "prev_sample_mean": prev_sample_mean}
|
||||
|
||||
def step_correct(
|
||||
self,
|
||||
model_output: Union[torch.FloatTensor, np.ndarray],
|
||||
sample: Union[torch.FloatTensor, np.ndarray],
|
||||
seed=None,
|
||||
):
|
||||
"""
|
||||
Correct the predicted sample based on the output model_output of the network. This is often run repeatedly
|
||||
after making the prediction for the previous timestep.
|
||||
"""
|
||||
if seed is not None:
|
||||
self.set_seed(seed)
|
||||
|
||||
# For small batch sizes, the paper "suggest replacing norm(z) with sqrt(d), where d is the dim. of z"
|
||||
# sample noise for correction
|
||||
noise = self.randn_like(sample)
|
||||
|
||||
# compute step size from the model_output, the noise, and the snr
|
||||
grad_norm = self.norm(model_output)
|
||||
noise_norm = self.norm(noise)
|
||||
step_size = (self.config.snr * noise_norm / grad_norm) ** 2 * 2
|
||||
step_size = step_size * torch.ones(sample.shape[0]).to(sample.device)
|
||||
# self.repeat_scalar(step_size, sample.shape[0])
|
||||
|
||||
# compute corrected sample: model_output term and noise term
|
||||
prev_sample_mean = sample + step_size[:, None, None, None] * model_output
|
||||
prev_sample = prev_sample_mean + ((step_size * 2) ** 0.5)[:, None, None, None] * noise
|
||||
|
||||
return {"prev_sample": prev_sample}
|
||||
|
||||
def __len__(self):
|
||||
return self.config.num_train_timesteps
|
||||
62
src/diffusers/schedulers/scheduling_sde_vp.py
Normal file
62
src/diffusers/schedulers/scheduling_sde_vp.py
Normal file
@@ -0,0 +1,62 @@
|
||||
# Copyright 2022 Google Brain and The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# DISCLAIMER: This file is strongly influenced by https://github.com/yang-song/score_sde_pytorch
|
||||
|
||||
# TODO(Patrick, Anton, Suraj) - make scheduler framework indepedent and clean-up a bit
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from .scheduling_utils import SchedulerMixin
|
||||
|
||||
|
||||
class ScoreSdeVpScheduler(SchedulerMixin, ConfigMixin):
|
||||
@register_to_config
|
||||
def __init__(self, num_train_timesteps=2000, beta_min=0.1, beta_max=20, sampling_eps=1e-3, tensor_format="np"):
|
||||
|
||||
self.sigmas = None
|
||||
self.discrete_sigmas = None
|
||||
self.timesteps = None
|
||||
|
||||
def set_timesteps(self, num_inference_steps):
|
||||
self.timesteps = torch.linspace(1, self.config.sampling_eps, num_inference_steps)
|
||||
|
||||
def step_pred(self, score, x, t):
|
||||
# TODO(Patrick) better comments + non-PyTorch
|
||||
# postprocess model score
|
||||
log_mean_coeff = (
|
||||
-0.25 * t**2 * (self.config.beta_max - self.config.beta_min) - 0.5 * t * self.config.beta_min
|
||||
)
|
||||
std = torch.sqrt(1.0 - torch.exp(2.0 * log_mean_coeff))
|
||||
score = -score / std[:, None, None, None]
|
||||
|
||||
# compute
|
||||
dt = -1.0 / len(self.timesteps)
|
||||
|
||||
beta_t = self.config.beta_min + t * (self.config.beta_max - self.config.beta_min)
|
||||
drift = -0.5 * beta_t[:, None, None, None] * x
|
||||
diffusion = torch.sqrt(beta_t)
|
||||
drift = drift - diffusion[:, None, None, None] ** 2 * score
|
||||
x_mean = x + drift * dt
|
||||
|
||||
# add noise
|
||||
noise = torch.randn_like(x)
|
||||
x = x_mean + diffusion[:, None, None, None] * np.sqrt(-dt) * noise
|
||||
|
||||
return x, x_mean
|
||||
|
||||
def __len__(self):
|
||||
return self.config.num_train_timesteps
|
||||
@@ -11,6 +11,8 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
from typing import Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
@@ -18,33 +20,10 @@ import torch
|
||||
SCHEDULER_CONFIG_NAME = "scheduler_config.json"
|
||||
|
||||
|
||||
def linear_beta_schedule(timesteps, beta_start, beta_end):
|
||||
return np.linspace(beta_start, beta_end, timesteps, dtype=np.float32)
|
||||
|
||||
|
||||
def betas_for_alpha_bar(num_diffusion_timesteps, alpha_bar, max_beta=0.999):
|
||||
"""
|
||||
Create a beta schedule that discretizes the given alpha_t_bar function,
|
||||
which defines the cumulative product of (1-beta) over time from t = [0,1].
|
||||
|
||||
:param num_diffusion_timesteps: the number of betas to produce.
|
||||
:param alpha_bar: a lambda that takes an argument t from 0 to 1 and
|
||||
produces the cumulative product of (1-beta) up to that
|
||||
part of the diffusion process.
|
||||
:param max_beta: the maximum beta to use; use values lower than 1 to
|
||||
prevent singularities.
|
||||
"""
|
||||
betas = []
|
||||
for i in range(num_diffusion_timesteps):
|
||||
t1 = i / num_diffusion_timesteps
|
||||
t2 = (i + 1) / num_diffusion_timesteps
|
||||
betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
|
||||
return np.array(betas, dtype=np.float32)
|
||||
|
||||
|
||||
class SchedulerMixin:
|
||||
|
||||
config_name = SCHEDULER_CONFIG_NAME
|
||||
ignore_for_config = ["tensor_format"]
|
||||
|
||||
def set_format(self, tensor_format="pt"):
|
||||
self.tensor_format = tensor_format
|
||||
@@ -64,3 +43,63 @@ class SchedulerMixin:
|
||||
return torch.clamp(tensor, min_value, max_value)
|
||||
|
||||
raise ValueError(f"`self.tensor_format`: {self.tensor_format} is not valid.")
|
||||
|
||||
def log(self, tensor):
|
||||
tensor_format = getattr(self, "tensor_format", "pt")
|
||||
|
||||
if tensor_format == "np":
|
||||
return np.log(tensor)
|
||||
elif tensor_format == "pt":
|
||||
return torch.log(tensor)
|
||||
|
||||
raise ValueError(f"`self.tensor_format`: {self.tensor_format} is not valid.")
|
||||
|
||||
def match_shape(self, values: Union[np.ndarray, torch.Tensor], broadcast_array: Union[np.ndarray, torch.Tensor]):
|
||||
"""
|
||||
Turns a 1-D array into an array or tensor with len(broadcast_array.shape) dims.
|
||||
|
||||
Args:
|
||||
values: an array or tensor of values to extract.
|
||||
broadcast_array: an array with a larger shape of K dimensions with the batch
|
||||
dimension equal to the length of timesteps.
|
||||
Returns:
|
||||
a tensor of shape [batch_size, 1, ...] where the shape has K dims.
|
||||
"""
|
||||
|
||||
tensor_format = getattr(self, "tensor_format", "pt")
|
||||
values = values.flatten()
|
||||
|
||||
while len(values.shape) < len(broadcast_array.shape):
|
||||
values = values[..., None]
|
||||
if tensor_format == "pt":
|
||||
values = values.to(broadcast_array.device)
|
||||
|
||||
return values
|
||||
|
||||
def norm(self, tensor):
|
||||
tensor_format = getattr(self, "tensor_format", "pt")
|
||||
if tensor_format == "np":
|
||||
return np.linalg.norm(tensor)
|
||||
elif tensor_format == "pt":
|
||||
return torch.norm(tensor.reshape(tensor.shape[0], -1), dim=-1).mean()
|
||||
|
||||
raise ValueError(f"`self.tensor_format`: {self.tensor_format} is not valid.")
|
||||
|
||||
def randn_like(self, tensor, generator=None):
|
||||
tensor_format = getattr(self, "tensor_format", "pt")
|
||||
if tensor_format == "np":
|
||||
return np.random.randn(*np.shape(tensor))
|
||||
elif tensor_format == "pt":
|
||||
# return torch.randn_like(tensor)
|
||||
return torch.randn(tensor.shape, layout=tensor.layout, generator=generator).to(tensor.device)
|
||||
|
||||
raise ValueError(f"`self.tensor_format`: {self.tensor_format} is not valid.")
|
||||
|
||||
def zeros_like(self, tensor):
|
||||
tensor_format = getattr(self, "tensor_format", "pt")
|
||||
if tensor_format == "np":
|
||||
return np.zeros_like(tensor)
|
||||
elif tensor_format == "pt":
|
||||
return torch.zeros_like(tensor)
|
||||
|
||||
raise ValueError(f"`self.tensor_format`: {self.tensor_format} is not valid.")
|
||||
|
||||
89
src/diffusers/training_utils.py
Normal file
89
src/diffusers/training_utils.py
Normal file
@@ -0,0 +1,89 @@
|
||||
import copy
|
||||
|
||||
import torch
|
||||
|
||||
|
||||
class EMAModel:
|
||||
"""
|
||||
Exponential Moving Average of models weights
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model,
|
||||
update_after_step=0,
|
||||
inv_gamma=1.0,
|
||||
power=2 / 3,
|
||||
min_value=0.0,
|
||||
max_value=0.9999,
|
||||
device=None,
|
||||
):
|
||||
"""
|
||||
@crowsonkb's notes on EMA Warmup:
|
||||
If gamma=1 and power=1, implements a simple average. gamma=1, power=2/3 are good values for models you plan
|
||||
to train for a million or more steps (reaches decay factor 0.999 at 31.6K steps, 0.9999 at 1M steps),
|
||||
gamma=1, power=3/4 for models you plan to train for less (reaches decay factor 0.999 at 10K steps, 0.9999
|
||||
at 215.4k steps).
|
||||
Args:
|
||||
inv_gamma (float): Inverse multiplicative factor of EMA warmup. Default: 1.
|
||||
power (float): Exponential factor of EMA warmup. Default: 2/3.
|
||||
min_value (float): The minimum EMA decay rate. Default: 0.
|
||||
"""
|
||||
|
||||
self.averaged_model = copy.deepcopy(model).eval()
|
||||
self.averaged_model.requires_grad_(False)
|
||||
|
||||
self.update_after_step = update_after_step
|
||||
self.inv_gamma = inv_gamma
|
||||
self.power = power
|
||||
self.min_value = min_value
|
||||
self.max_value = max_value
|
||||
|
||||
if device is not None:
|
||||
self.averaged_model = self.averaged_model.to(device=device)
|
||||
|
||||
self.decay = 0.0
|
||||
self.optimization_step = 0
|
||||
|
||||
def get_decay(self, optimization_step):
|
||||
"""
|
||||
Compute the decay factor for the exponential moving average.
|
||||
"""
|
||||
step = max(0, optimization_step - self.update_after_step - 1)
|
||||
value = 1 - (1 + step / self.inv_gamma) ** -self.power
|
||||
|
||||
if step <= 0:
|
||||
return 0.0
|
||||
|
||||
return max(self.min_value, min(value, self.max_value))
|
||||
|
||||
@torch.no_grad()
|
||||
def step(self, new_model):
|
||||
ema_state_dict = {}
|
||||
ema_params = self.averaged_model.state_dict()
|
||||
|
||||
self.decay = self.get_decay(self.optimization_step)
|
||||
|
||||
for key, param in new_model.named_parameters():
|
||||
if isinstance(param, dict):
|
||||
continue
|
||||
try:
|
||||
ema_param = ema_params[key]
|
||||
except KeyError:
|
||||
ema_param = param.float().clone() if param.ndim == 1 else copy.deepcopy(param)
|
||||
ema_params[key] = ema_param
|
||||
|
||||
if not param.requires_grad:
|
||||
ema_params[key].copy_(param.to(dtype=ema_param.dtype).data)
|
||||
ema_param = ema_params[key]
|
||||
else:
|
||||
ema_param.mul_(self.decay)
|
||||
ema_param.add_(param.data.to(dtype=ema_param.dtype), alpha=1 - self.decay)
|
||||
|
||||
ema_state_dict[key] = ema_param
|
||||
|
||||
for key, param in new_model.named_buffers():
|
||||
ema_state_dict[key] = param
|
||||
|
||||
self.averaged_model.load_state_dict(ema_state_dict, strict=False)
|
||||
self.optimization_step += 1
|
||||
@@ -1,12 +1,3 @@
|
||||
#!/usr/bin/env python
|
||||
# coding=utf-8
|
||||
|
||||
# flake8: noqa
|
||||
# There's no way to ignore "F401 '...' imported but unused" warnings in this
|
||||
# module, but to preserve other warnings. So, don't check this module at all.
|
||||
|
||||
import os
|
||||
|
||||
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
@@ -20,8 +11,18 @@ import os
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import importlib
|
||||
import os
|
||||
from collections import OrderedDict
|
||||
|
||||
import importlib_metadata
|
||||
from requests.exceptions import HTTPError
|
||||
|
||||
from .logging import get_logger
|
||||
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
hf_cache_home = os.path.expanduser(
|
||||
os.getenv("HF_HOME", os.path.join(os.getenv("XDG_CACHE_HOME", "~/.cache"), "huggingface"))
|
||||
@@ -36,6 +37,54 @@ DIFFUSERS_DYNAMIC_MODULE_NAME = "diffusers_modules"
|
||||
HF_MODULES_CACHE = os.getenv("HF_MODULES_CACHE", os.path.join(hf_cache_home, "modules"))
|
||||
|
||||
|
||||
_transformers_available = importlib.util.find_spec("transformers") is not None
|
||||
try:
|
||||
_transformers_version = importlib_metadata.version("transformers")
|
||||
logger.debug(f"Successfully imported transformers version {_transformers_version}")
|
||||
except importlib_metadata.PackageNotFoundError:
|
||||
_transformers_available = False
|
||||
|
||||
|
||||
_inflect_available = importlib.util.find_spec("inflect") is not None
|
||||
try:
|
||||
_inflect_version = importlib_metadata.version("inflect")
|
||||
logger.debug(f"Successfully imported inflect version {_inflect_version}")
|
||||
except importlib_metadata.PackageNotFoundError:
|
||||
_inflect_available = False
|
||||
|
||||
|
||||
_unidecode_available = importlib.util.find_spec("unidecode") is not None
|
||||
try:
|
||||
_unidecode_version = importlib_metadata.version("unidecode")
|
||||
logger.debug(f"Successfully imported unidecode version {_unidecode_version}")
|
||||
except importlib_metadata.PackageNotFoundError:
|
||||
_unidecode_available = False
|
||||
|
||||
|
||||
_modelcards_available = importlib.util.find_spec("modelcards") is not None
|
||||
try:
|
||||
_modelcards_version = importlib_metadata.version("modelcards")
|
||||
logger.debug(f"Successfully imported modelcards version {_modelcards_version}")
|
||||
except importlib_metadata.PackageNotFoundError:
|
||||
_modelcards_available = False
|
||||
|
||||
|
||||
def is_transformers_available():
|
||||
return _transformers_available
|
||||
|
||||
|
||||
def is_inflect_available():
|
||||
return _inflect_available
|
||||
|
||||
|
||||
def is_unidecode_available():
|
||||
return _unidecode_available
|
||||
|
||||
|
||||
def is_modelcards_available():
|
||||
return _modelcards_available
|
||||
|
||||
|
||||
class RepositoryNotFoundError(HTTPError):
|
||||
"""
|
||||
Raised when trying to access a hf.co URL with an invalid repository name, or with a private repo name the user does
|
||||
@@ -49,3 +98,53 @@ class EntryNotFoundError(HTTPError):
|
||||
|
||||
class RevisionNotFoundError(HTTPError):
|
||||
"""Raised when trying to access a hf.co URL with a valid repository but an invalid revision."""
|
||||
|
||||
|
||||
TRANSFORMERS_IMPORT_ERROR = """
|
||||
{0} requires the transformers library but it was not found in your environment. You can install it with pip: `pip
|
||||
install transformers`
|
||||
"""
|
||||
|
||||
|
||||
UNIDECODE_IMPORT_ERROR = """
|
||||
{0} requires the unidecode library but it was not found in your environment. You can install it with pip: `pip install
|
||||
Unidecode`
|
||||
"""
|
||||
|
||||
|
||||
INFLECT_IMPORT_ERROR = """
|
||||
{0} requires the inflect library but it was not found in your environment. You can install it with pip: `pip install
|
||||
inflect`
|
||||
"""
|
||||
|
||||
|
||||
BACKENDS_MAPPING = OrderedDict(
|
||||
[
|
||||
("transformers", (is_transformers_available, TRANSFORMERS_IMPORT_ERROR)),
|
||||
("unidecode", (is_unidecode_available, UNIDECODE_IMPORT_ERROR)),
|
||||
("inflect", (is_inflect_available, INFLECT_IMPORT_ERROR)),
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
def requires_backends(obj, backends):
|
||||
if not isinstance(backends, (list, tuple)):
|
||||
backends = [backends]
|
||||
|
||||
name = obj.__name__ if hasattr(obj, "__name__") else obj.__class__.__name__
|
||||
checks = (BACKENDS_MAPPING[backend] for backend in backends)
|
||||
failed = [msg.format(name) for available, msg in checks if not available()]
|
||||
if failed:
|
||||
raise ImportError("".join(failed))
|
||||
|
||||
|
||||
class DummyObject(type):
|
||||
"""
|
||||
Metaclass for the dummy objects. Any class inheriting from it will return the ImportError generated by
|
||||
`requires_backend` each time a user tries to access any method of that class.
|
||||
"""
|
||||
|
||||
def __getattr__(cls, key):
|
||||
if key.startswith("_"):
|
||||
return super().__getattr__(cls, key)
|
||||
requires_backends(cls, cls._backends)
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user