mirror of
https://github.com/huggingface/diffusers.git
synced 2026-03-05 16:20:39 +08:00
Compare commits
27 Commits
fix_custom
...
temp/debug
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
fe6c903373 | ||
|
|
7ba7c65700 | ||
|
|
af7d5a6914 | ||
|
|
aa58d7a570 | ||
|
|
1a60865487 | ||
|
|
a1eb20c577 | ||
|
|
eada18a8c2 | ||
|
|
66d38f6eaa | ||
|
|
bc6b677a6a | ||
|
|
641e94da44 | ||
|
|
a86aa73aa1 | ||
|
|
893ef35bf1 | ||
|
|
1d813f6ebe | ||
|
|
ce4e6edefc | ||
|
|
a202bb1fca | ||
|
|
74483b9f14 | ||
|
|
dc42933feb | ||
|
|
eba1df08fb | ||
|
|
8e76e1269d | ||
|
|
a559b33eda | ||
|
|
3872e12d99 | ||
|
|
c83935a716 | ||
|
|
fe2501e540 | ||
|
|
5c3601b7a8 | ||
|
|
9658b24834 | ||
|
|
a1b6e29288 | ||
|
|
9bd4fda920 |
@@ -125,14 +125,14 @@ Awesome! Tell us what problem it solved for you.
|
||||
|
||||
You can open a feature request [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=).
|
||||
|
||||
#### 2.3 Feedback.
|
||||
#### 2.3 Feedback.
|
||||
|
||||
Feedback about the library design and why it is good or not good helps the core maintainers immensely to build a user-friendly library. To understand the philosophy behind the current design philosophy, please have a look [here](https://huggingface.co/docs/diffusers/conceptual/philosophy). If you feel like a certain design choice does not fit with the current design philosophy, please explain why and how it should be changed. If a certain design choice follows the design philosophy too much, hence restricting use cases, explain why and how it should be changed.
|
||||
If a certain design choice is very useful for you, please also leave a note as this is great feedback for future design decisions.
|
||||
|
||||
You can open an issue about feedback [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
|
||||
|
||||
#### 2.4 Technical questions.
|
||||
#### 2.4 Technical questions.
|
||||
|
||||
Technical questions are mainly about why certain code of the library was written in a certain way, or what a certain part of the code does. Please make sure to link to the code in question and please provide detail on
|
||||
why this part of the code is difficult to understand.
|
||||
@@ -394,8 +394,8 @@ passes. You should run the tests impacted by your changes like this:
|
||||
```bash
|
||||
$ pytest tests/<TEST_TO_RUN>.py
|
||||
```
|
||||
|
||||
Before you run the tests, please make sure you install the dependencies required for testing. You can do so
|
||||
|
||||
Before you run the tests, please make sure you install the dependencies required for testing. You can do so
|
||||
with this command:
|
||||
|
||||
```bash
|
||||
|
||||
@@ -27,18 +27,18 @@ In a nutshell, Diffusers is built to be a natural extension of PyTorch. Therefor
|
||||
|
||||
## Simple over easy
|
||||
|
||||
As PyTorch states, **explicit is better than implicit** and **simple is better than complex**. This design philosophy is reflected in multiple parts of the library:
|
||||
As PyTorch states, **explicit is better than implicit** and **simple is better than complex**. This design philosophy is reflected in multiple parts of the library:
|
||||
- We follow PyTorch's API with methods like [`DiffusionPipeline.to`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.to) to let the user handle device management.
|
||||
- Raising concise error messages is preferred to silently correct erroneous input. Diffusers aims at teaching the user, rather than making the library as easy to use as possible.
|
||||
- Complex model vs. scheduler logic is exposed instead of magically handled inside. Schedulers/Samplers are separated from diffusion models with minimal dependencies on each other. This forces the user to write the unrolled denoising loop. However, the separation allows for easier debugging and gives the user more control over adapting the denoising process or switching out diffusion models or schedulers.
|
||||
- Separately trained components of the diffusion pipeline, *e.g.* the text encoder, the unet, and the variational autoencoder, each have their own model class. This forces the user to handle the interaction between the different model components, and the serialization format separates the model components into different files. However, this allows for easier debugging and customization. Dreambooth or textual inversion training
|
||||
- Separately trained components of the diffusion pipeline, *e.g.* the text encoder, the unet, and the variational autoencoder, each have their own model class. This forces the user to handle the interaction between the different model components, and the serialization format separates the model components into different files. However, this allows for easier debugging and customization. Dreambooth or textual inversion training
|
||||
is very simple thanks to diffusers' ability to separate single components of the diffusion pipeline.
|
||||
|
||||
## Tweakable, contributor-friendly over abstraction
|
||||
|
||||
For large parts of the library, Diffusers adopts an important design principle of the [Transformers library](https://github.com/huggingface/transformers), which is to prefer copy-pasted code over hasty abstractions. This design principle is very opinionated and stands in stark contrast to popular design principles such as [Don't repeat yourself (DRY)](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself).
|
||||
For large parts of the library, Diffusers adopts an important design principle of the [Transformers library](https://github.com/huggingface/transformers), which is to prefer copy-pasted code over hasty abstractions. This design principle is very opinionated and stands in stark contrast to popular design principles such as [Don't repeat yourself (DRY)](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself).
|
||||
In short, just like Transformers does for modeling files, diffusers prefers to keep an extremely low level of abstraction and very self-contained code for pipelines and schedulers.
|
||||
Functions, long code blocks, and even classes can be copied across multiple files which at first can look like a bad, sloppy design choice that makes the library unmaintainable.
|
||||
Functions, long code blocks, and even classes can be copied across multiple files which at first can look like a bad, sloppy design choice that makes the library unmaintainable.
|
||||
**However**, this design has proven to be extremely successful for Transformers and makes a lot of sense for community-driven, open-source machine learning libraries because:
|
||||
- Machine Learning is an extremely fast-moving field in which paradigms, model architectures, and algorithms are changing rapidly, which therefore makes it very difficult to define long-lasting code abstractions.
|
||||
- Machine Learning practitioners like to be able to quickly tweak existing code for ideation and research and therefore prefer self-contained code over one that contains many abstractions.
|
||||
@@ -47,10 +47,10 @@ Functions, long code blocks, and even classes can be copied across multiple file
|
||||
At Hugging Face, we call this design the **single-file policy** which means that almost all of the code of a certain class should be written in a single, self-contained file. To read more about the philosophy, you can have a look
|
||||
at [this blog post](https://huggingface.co/blog/transformers-design-philosophy).
|
||||
|
||||
In diffusers, we follow this philosophy for both pipelines and schedulers, but only partly for diffusion models. The reason we don't follow this design fully for diffusion models is because almost all diffusion pipelines, such
|
||||
In diffusers, we follow this philosophy for both pipelines and schedulers, but only partly for diffusion models. The reason we don't follow this design fully for diffusion models is because almost all diffusion pipelines, such
|
||||
as [DDPM](https://huggingface.co/docs/diffusers/v0.12.0/en/api/pipelines/ddpm), [Stable Diffusion](https://huggingface.co/docs/diffusers/v0.12.0/en/api/pipelines/stable_diffusion/overview#stable-diffusion-pipelines), [UnCLIP (Dalle-2)](https://huggingface.co/docs/diffusers/v0.12.0/en/api/pipelines/unclip#overview) and [Imagen](https://imagen.research.google/) all rely on the same diffusion model, the [UNet](https://huggingface.co/docs/diffusers/api/models#diffusers.UNet2DConditionModel).
|
||||
|
||||
Great, now you should have generally understood why 🧨 Diffusers is designed the way it is 🤗.
|
||||
Great, now you should have generally understood why 🧨 Diffusers is designed the way it is 🤗.
|
||||
We try to apply these design principles consistently across the library. Nevertheless, there are some minor exceptions to the philosophy or some unlucky design choices. If you have feedback regarding the design, we would ❤️ to hear it [directly on GitHub](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
|
||||
|
||||
## Design Philosophy in Details
|
||||
@@ -89,7 +89,7 @@ The following design principles are followed:
|
||||
- Models should by default have the highest precision and lowest performance setting.
|
||||
- To integrate new model checkpoints whose general architecture can be classified as an architecture that already exists in Diffusers, the existing model architecture shall be adapted to make it work with the new checkpoint. One should only create a new file if the model architecture is fundamentally different.
|
||||
- Models should be designed to be easily extendable to future changes. This can be achieved by limiting public function arguments, configuration arguments, and "foreseeing" future changes, *e.g.* it is usually better to add `string` "...type" arguments that can easily be extended to new future types instead of boolean `is_..._type` arguments. Only the minimum amount of changes shall be made to existing architectures to make a new model checkpoint work.
|
||||
- The model design is a difficult trade-off between keeping code readable and concise and supporting many model checkpoints. For most parts of the modeling code, classes shall be adapted for new model checkpoints, while there are some exceptions where it is preferred to add new classes to make sure the code is kept concise and
|
||||
- The model design is a difficult trade-off between keeping code readable and concise and supporting many model checkpoints. For most parts of the modeling code, classes shall be adapted for new model checkpoints, while there are some exceptions where it is preferred to add new classes to make sure the code is kept concise and
|
||||
readable longterm, such as [UNet blocks](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/unet_2d_blocks.py) and [Attention processors](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
|
||||
### Schedulers
|
||||
@@ -97,9 +97,9 @@ readable longterm, such as [UNet blocks](https://github.com/huggingface/diffuser
|
||||
Schedulers are responsible to guide the denoising process for inference as well as to define a noise schedule for training. They are designed as individual classes with loadable configuration files and strongly follow the **single-file policy**.
|
||||
|
||||
The following design principles are followed:
|
||||
- All schedulers are found in [`src/diffusers/schedulers`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers).
|
||||
- Schedulers are **not** allowed to import from large utils files and shall be kept very self-contained.
|
||||
- One scheduler python file corresponds to one scheduler algorithm (as might be defined in a paper).
|
||||
- All schedulers are found in [`src/diffusers/schedulers`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers).
|
||||
- Schedulers are **not** allowed to import from large utils files and shall be kept very self-contained.
|
||||
- One scheduler python file corresponds to one scheduler algorithm (as might be defined in a paper).
|
||||
- If schedulers share similar functionalities, we can make use of the `#Copied from` mechanism.
|
||||
- Schedulers all inherit from `SchedulerMixin` and `ConfigMixin`.
|
||||
- Schedulers can be easily swapped out with the [`ConfigMixin.from_config`](https://huggingface.co/docs/diffusers/main/en/api/configuration#diffusers.ConfigMixin.from_config) method as explained in detail [here](./using-diffusers/schedulers.mdx).
|
||||
|
||||
40
README.md
40
README.md
@@ -1,6 +1,6 @@
|
||||
<p align="center">
|
||||
<br>
|
||||
<img src="https://github.com/huggingface/diffusers/blob/main/docs/source/en/imgs/diffusers_library.jpg" width="400"/>
|
||||
<img src="./docs/source/en/imgs/diffusers_library.jpg" width="400"/>
|
||||
<br>
|
||||
<p>
|
||||
<p align="center">
|
||||
@@ -30,7 +30,7 @@ We recommend installing 🤗 Diffusers in a virtual environment from PyPi or Con
|
||||
### PyTorch
|
||||
|
||||
With `pip` (official package):
|
||||
|
||||
|
||||
```bash
|
||||
pip install --upgrade diffusers[torch]
|
||||
```
|
||||
@@ -107,7 +107,7 @@ Check out the [Quickstart](https://huggingface.co/docs/diffusers/quicktour) to l
|
||||
| [Training](https://huggingface.co/docs/diffusers/training/overview) | Guides for how to train a diffusion model for different tasks with different training techniques. |
|
||||
## Contribution
|
||||
|
||||
We ❤️ contributions from the open-source community!
|
||||
We ❤️ contributions from the open-source community!
|
||||
If you want to contribute to this library, please check out our [Contribution guide](https://github.com/huggingface/diffusers/blob/main/CONTRIBUTING.md).
|
||||
You can look out for [issues](https://github.com/huggingface/diffusers/issues) you'd like to tackle to contribute to the library.
|
||||
- See [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) for general opportunities to contribute
|
||||
@@ -128,70 +128,70 @@ just hang out ☕.
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td>Unconditional Image Generation</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/ddpm"> DDPM </a></td>
|
||||
<td><a href="./api/pipelines/ddpm"> DDPM </a></td>
|
||||
<td><a href="https://huggingface.co/google/ddpm-ema-church-256"> google/ddpm-ema-church-256 </a></td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td>Text-to-Image</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/text2img">Stable Diffusion Text-to-Image</a></td>
|
||||
<td><a href="./api/pipelines/stable_diffusion/text2img">Stable Diffusion Text-to-Image</a></td>
|
||||
<td><a href="https://huggingface.co/runwayml/stable-diffusion-v1-5"> runwayml/stable-diffusion-v1-5 </a></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Text-to-Image</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/unclip">unclip</a></td>
|
||||
<td><a href="./api/pipelines/unclip">unclip</a></td>
|
||||
<td><a href="https://huggingface.co/kakaobrain/karlo-v1-alpha"> kakaobrain/karlo-v1-alpha </a></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Text-to-Image</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/if">if</a></td>
|
||||
<td><a href="./api/pipelines/if">if</a></td>
|
||||
<td><a href="https://huggingface.co/DeepFloyd/IF-I-XL-v1.0"> DeepFloyd/IF-I-XL-v1.0 </a></td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td>Text-guided Image-to-Image</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/controlnet">Controlnet</a></td>
|
||||
<td><a href="./api/pipelines/stable_diffusion/controlnet">Controlnet</a></td>
|
||||
<td><a href="https://huggingface.co/lllyasviel/sd-controlnet-canny"> lllyasviel/sd-controlnet-canny </a></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Text-guided Image-to-Image</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/pix2pix">Instruct Pix2Pix</a></td>
|
||||
<td><a href="./api/pipelines/stable_diffusion/pix2pix">Instruct Pix2Pix</a></td>
|
||||
<td><a href="https://huggingface.co/timbrooks/instruct-pix2pix"> timbrooks/instruct-pix2pix </a></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Text-guided Image-to-Image</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/img2img">Stable Diffusion Image-to-Image</a></td>
|
||||
<td><a href="./api/pipelines/stable_diffusion/img2img">Stable Diffusion Image-to-Image</a></td>
|
||||
<td><a href="https://huggingface.co/runwayml/stable-diffusion-v1-5"> runwayml/stable-diffusion-v1-5 </a></td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td>Text-guided Image Inpainting</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/inpaint">Stable Diffusion Inpaint</a></td>
|
||||
<td><a href="./api/pipelines/stable_diffusion/inpaint">Stable Diffusion Inpaint</a></td>
|
||||
<td><a href="https://huggingface.co/runwayml/stable-diffusion-inpainting"> runwayml/stable-diffusion-inpainting </a></td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td>Image Variation</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/image_variation">Stable Diffusion Image Variation</a></td>
|
||||
<td><a href="./stable_diffusion/image_variation">Stable Diffusion Image Variation</a></td>
|
||||
<td><a href="https://huggingface.co/lambdalabs/sd-image-variations-diffusers"> lambdalabs/sd-image-variations-diffusers </a></td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td>Super Resolution</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/upscale">Stable Diffusion Upscale</a></td>
|
||||
<td><a href="./stable_diffusion/stable_diffusion/upscale">Stable Diffusion Upscale</a></td>
|
||||
<td><a href="https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler"> stabilityai/stable-diffusion-x4-upscaler </a></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Super Resolution</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/latent_upscale">Stable Diffusion Latent Upscale</a></td>
|
||||
<td><a href="./stable_diffusion/latent_upscale">Stable Diffusion Latent Upscale</a></td>
|
||||
<td><a href="https://huggingface.co/stabilityai/sd-x2-latent-upscaler"> stabilityai/sd-x2-latent-upscaler </a></td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
## Popular libraries using 🧨 Diffusers
|
||||
|
||||
- https://github.com/microsoft/TaskMatrix
|
||||
- https://github.com/invoke-ai/InvokeAI
|
||||
- https://github.com/apple/ml-stable-diffusion
|
||||
- https://github.com/Sanster/lama-cleaner
|
||||
- https://github.com/microsoft/TaskMatrix
|
||||
- https://github.com/invoke-ai/InvokeAI
|
||||
- https://github.com/apple/ml-stable-diffusion
|
||||
- https://github.com/Sanster/lama-cleaner
|
||||
- https://github.com/IDEA-Research/Grounded-Segment-Anything
|
||||
- https://github.com/ashawkey/stable-dreamfusion
|
||||
- https://github.com/deep-floyd/IF
|
||||
- https://github.com/ashawkey/stable-dreamfusion
|
||||
- https://github.com/deep-floyd/IF
|
||||
- https://github.com/bentoml/BentoML
|
||||
- https://github.com/bmaltais/kohya_ss
|
||||
- +3000 other amazing GitHub repositories 💪
|
||||
|
||||
@@ -38,8 +38,6 @@ RUN python3 -m pip install --no-cache-dir --upgrade pip && \
|
||||
scipy \
|
||||
tensorboard \
|
||||
transformers \
|
||||
omegaconf \
|
||||
pytorch-lightning \
|
||||
xformers
|
||||
omegaconf
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
|
||||
@@ -6,4 +6,4 @@ INSTALL_CONTENT = """
|
||||
# ! pip install git+https://github.com/huggingface/diffusers.git
|
||||
"""
|
||||
|
||||
notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
|
||||
notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
|
||||
@@ -28,8 +28,8 @@
|
||||
title: Load community pipelines
|
||||
- local: using-diffusers/using_safetensors
|
||||
title: Load safetensors
|
||||
- local: using-diffusers/other-formats
|
||||
title: Load different Stable Diffusion formats
|
||||
- local: using-diffusers/kerascv
|
||||
title: Load KerasCV Stable Diffusion checkpoints
|
||||
title: Loading & Hub
|
||||
- sections:
|
||||
- local: using-diffusers/pipeline_overview
|
||||
@@ -132,8 +132,6 @@
|
||||
- sections:
|
||||
- local: api/models
|
||||
title: Models
|
||||
- local: api/attnprocessor
|
||||
title: Attention Processor
|
||||
- local: api/diffusion_pipeline
|
||||
title: Diffusion Pipeline
|
||||
- local: api/logging
|
||||
@@ -144,16 +142,12 @@
|
||||
title: Outputs
|
||||
- local: api/loaders
|
||||
title: Loaders
|
||||
- local: api/utilities
|
||||
title: Utilities
|
||||
title: Main Classes
|
||||
- sections:
|
||||
- local: api/pipelines/overview
|
||||
title: Overview
|
||||
- local: api/pipelines/alt_diffusion
|
||||
title: AltDiffusion
|
||||
- local: api/pipelines/attend_and_excite
|
||||
title: Attend and Excite
|
||||
- local: api/pipelines/audio_diffusion
|
||||
title: Audio Diffusion
|
||||
- local: api/pipelines/audioldm
|
||||
@@ -168,32 +162,22 @@
|
||||
title: DDIM
|
||||
- local: api/pipelines/ddpm
|
||||
title: DDPM
|
||||
- local: api/pipelines/diffedit
|
||||
title: DiffEdit
|
||||
- local: api/pipelines/dit
|
||||
title: DiT
|
||||
- local: api/pipelines/if
|
||||
title: IF
|
||||
- local: api/pipelines/pix2pix
|
||||
title: InstructPix2Pix
|
||||
- local: api/pipelines/kandinsky
|
||||
title: Kandinsky
|
||||
- local: api/pipelines/latent_diffusion
|
||||
title: Latent Diffusion
|
||||
- local: api/pipelines/panorama
|
||||
title: MultiDiffusion Panorama
|
||||
- local: api/pipelines/paint_by_example
|
||||
title: PaintByExample
|
||||
- local: api/pipelines/pix2pix_zero
|
||||
title: Pix2Pix Zero
|
||||
- local: api/pipelines/pndm
|
||||
title: PNDM
|
||||
- local: api/pipelines/repaint
|
||||
title: RePaint
|
||||
- local: api/pipelines/stable_diffusion_safe
|
||||
title: Safe Stable Diffusion
|
||||
- local: api/pipelines/score_sde_ve
|
||||
title: Score SDE VE
|
||||
- local: api/pipelines/self_attention_guidance
|
||||
title: Self-Attention Guidance
|
||||
- local: api/pipelines/semantic_stable_diffusion
|
||||
title: Semantic Guidance
|
||||
- local: api/pipelines/spectrogram_diffusion
|
||||
@@ -211,21 +195,31 @@
|
||||
title: Depth-to-Image
|
||||
- local: api/pipelines/stable_diffusion/image_variation
|
||||
title: Image-Variation
|
||||
- local: api/pipelines/stable_diffusion/stable_diffusion_safe
|
||||
title: Safe Stable Diffusion
|
||||
- local: api/pipelines/stable_diffusion/stable_diffusion_2
|
||||
title: Stable Diffusion 2
|
||||
- local: api/pipelines/stable_diffusion/latent_upscale
|
||||
title: Stable-Diffusion-Latent-Upscaler
|
||||
- local: api/pipelines/stable_diffusion/upscale
|
||||
title: Super-Resolution
|
||||
- local: api/pipelines/stable_diffusion/latent_upscale
|
||||
title: Stable-Diffusion-Latent-Upscaler
|
||||
- local: api/pipelines/stable_diffusion/pix2pix
|
||||
title: InstructPix2Pix
|
||||
- local: api/pipelines/stable_diffusion/attend_and_excite
|
||||
title: Attend and Excite
|
||||
- local: api/pipelines/stable_diffusion/pix2pix_zero
|
||||
title: Pix2Pix Zero
|
||||
- local: api/pipelines/stable_diffusion/self_attention_guidance
|
||||
title: Self-Attention Guidance
|
||||
- local: api/pipelines/stable_diffusion/panorama
|
||||
title: MultiDiffusion Panorama
|
||||
- local: api/pipelines/stable_diffusion/model_editing
|
||||
title: Text-to-Image Model Editing
|
||||
- local: api/pipelines/stable_diffusion/diffedit
|
||||
title: DiffEdit
|
||||
title: Stable Diffusion
|
||||
- local: api/pipelines/stable_diffusion_2
|
||||
title: Stable Diffusion 2
|
||||
- local: api/pipelines/stable_unclip
|
||||
title: Stable unCLIP
|
||||
- local: api/pipelines/stochastic_karras_ve
|
||||
title: Stochastic Karras VE
|
||||
- local: api/pipelines/model_editing
|
||||
title: Text-to-Image Model Editing
|
||||
- local: api/pipelines/text_to_video
|
||||
title: Text-to-Video
|
||||
- local: api/pipelines/text_to_video_zero
|
||||
@@ -234,8 +228,6 @@
|
||||
title: UnCLIP
|
||||
- local: api/pipelines/latent_diffusion_uncond
|
||||
title: Unconditional Latent Diffusion
|
||||
- local: api/pipelines/unidiffuser
|
||||
title: UniDiffuser
|
||||
- local: api/pipelines/versatile_diffusion
|
||||
title: Versatile Diffusion
|
||||
- local: api/pipelines/vq_diffusion
|
||||
|
||||
@@ -1,42 +0,0 @@
|
||||
# Attention Processor
|
||||
|
||||
An attention processor is a class for applying different types of attention mechanisms.
|
||||
|
||||
## AttnProcessor
|
||||
[[autodoc]] models.attention_processor.AttnProcessor
|
||||
|
||||
## AttnProcessor2_0
|
||||
[[autodoc]] models.attention_processor.AttnProcessor2_0
|
||||
|
||||
## LoRAAttnProcessor
|
||||
[[autodoc]] models.attention_processor.LoRAAttnProcessor
|
||||
|
||||
## LoRAAttnProcessor2_0
|
||||
[[autodoc]] models.attention_processor.LoRAAttnProcessor2_0
|
||||
|
||||
## CustomDiffusionAttnProcessor
|
||||
[[autodoc]] models.attention_processor.CustomDiffusionAttnProcessor
|
||||
|
||||
## AttnAddedKVProcessor
|
||||
[[autodoc]] models.attention_processor.AttnAddedKVProcessor
|
||||
|
||||
## AttnAddedKVProcessor2_0
|
||||
[[autodoc]] models.attention_processor.AttnAddedKVProcessor2_0
|
||||
|
||||
## LoRAAttnAddedKVProcessor
|
||||
[[autodoc]] models.attention_processor.LoRAAttnAddedKVProcessor
|
||||
|
||||
## XFormersAttnProcessor
|
||||
[[autodoc]] models.attention_processor.XFormersAttnProcessor
|
||||
|
||||
## LoRAXFormersAttnProcessor
|
||||
[[autodoc]] models.attention_processor.LoRAXFormersAttnProcessor
|
||||
|
||||
## CustomDiffusionXFormersAttnProcessor
|
||||
[[autodoc]] models.attention_processor.CustomDiffusionXFormersAttnProcessor
|
||||
|
||||
## SlicedAttnProcessor
|
||||
[[autodoc]] models.attention_processor.SlicedAttnProcessor
|
||||
|
||||
## SlicedAttnAddedKVProcessor
|
||||
[[autodoc]] models.attention_processor.SlicedAttnAddedKVProcessor
|
||||
@@ -12,25 +12,36 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
# Pipelines
|
||||
|
||||
The [`DiffusionPipeline`] is the easiest way to load any pretrained diffusion pipeline from the [Hub](https://huggingface.co/models?library=diffusers) and use it for inference.
|
||||
The [`DiffusionPipeline`] is the easiest way to load any pretrained diffusion pipeline from the [Hub](https://huggingface.co/models?library=diffusers) and to use it in inference.
|
||||
|
||||
<Tip>
|
||||
|
||||
You shouldn't use the [`DiffusionPipeline`] class for training or finetuning a diffusion model. Individual
|
||||
components (for example, [`UNetModel`] and [`UNetConditionModel`]) of diffusion pipelines are usually trained individually, so we suggest directly working with instead.
|
||||
One should not use the Diffusion Pipeline class for training or fine-tuning a diffusion model. Individual
|
||||
components of diffusion pipelines are usually trained individually, so we suggest to directly work
|
||||
with [`UNetModel`] and [`UNetConditionModel`].
|
||||
|
||||
</Tip>
|
||||
|
||||
The pipeline type (for example [`StableDiffusionPipeline`]) of any diffusion pipeline loaded with [`~DiffusionPipeline.from_pretrained`] is automatically
|
||||
detected and pipeline components are loaded and passed to the `__init__` function of the pipeline.
|
||||
Any diffusion pipeline that is loaded with [`~DiffusionPipeline.from_pretrained`] will automatically
|
||||
detect the pipeline type, *e.g.* [`StableDiffusionPipeline`] and consequently load each component of the
|
||||
pipeline and pass them into the `__init__` function of the pipeline, *e.g.* [`~StableDiffusionPipeline.__init__`].
|
||||
|
||||
Any pipeline object can be saved locally with [`~DiffusionPipeline.save_pretrained`].
|
||||
|
||||
## DiffusionPipeline
|
||||
|
||||
[[autodoc]] DiffusionPipeline
|
||||
- all
|
||||
- __call__
|
||||
- device
|
||||
- to
|
||||
- components
|
||||
|
||||
## ImagePipelineOutput
|
||||
By default diffusion pipelines return an object of class
|
||||
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
|
||||
## AudioPipelineOutput
|
||||
By default diffusion pipelines return an object of class
|
||||
|
||||
[[autodoc]] pipelines.AudioPipelineOutput
|
||||
|
||||
@@ -13,7 +13,7 @@ specific language governing permissions and limitations under the License.
|
||||
# Models
|
||||
|
||||
Diffusers contains pretrained models for popular algorithms and modules for creating the next set of diffusion models.
|
||||
The primary function of these models is to denoise an input sample, by modeling the distribution \\(p_{\theta}(x_{t-1}|x_{t})\\).
|
||||
The primary function of these models is to denoise an input sample, by modeling the distribution $p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)$.
|
||||
The models are built on the base class ['ModelMixin'] that is a `torch.nn.module` with basic functionality for saving and loading models both locally and from the HuggingFace hub.
|
||||
|
||||
## ModelMixin
|
||||
|
||||
@@ -12,11 +12,11 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
# BaseOutputs
|
||||
|
||||
All models have outputs that are subclasses of [`~utils.BaseOutput`]. Those are
|
||||
data structures containing all the information returned by the model, but they can also be used as tuples or
|
||||
All models have outputs that are instances of subclasses of [`~utils.BaseOutput`]. Those are
|
||||
data structures containing all the information returned by the model, but that can also be used as tuples or
|
||||
dictionaries.
|
||||
|
||||
For example:
|
||||
Let's see how this looks in an example:
|
||||
|
||||
```python
|
||||
from diffusers import DDIMPipeline
|
||||
@@ -25,45 +25,31 @@ pipeline = DDIMPipeline.from_pretrained("google/ddpm-cifar10-32")
|
||||
outputs = pipeline()
|
||||
```
|
||||
|
||||
The `outputs` object is a [`~pipelines.ImagePipelineOutput`] which means it has an image attribute.
|
||||
The `outputs` object is a [`~pipelines.ImagePipelineOutput`], as we can see in the
|
||||
documentation of that class below, it means it has an image attribute.
|
||||
|
||||
You can access each attribute as you normally would or with a keyword lookup, and if that attribute is not returned by the model, you will get `None`:
|
||||
You can access each attribute as you would usually do, and if that attribute has not been returned by the model, you will get `None`:
|
||||
|
||||
```python
|
||||
outputs.images
|
||||
```
|
||||
|
||||
or via keyword lookup
|
||||
|
||||
```python
|
||||
outputs["images"]
|
||||
```
|
||||
|
||||
When considering the `outputs` object as a tuple, it only considers the attributes that don't have `None` values.
|
||||
For instance, retrieving an image by indexing into it returns the tuple `(outputs.images)`:
|
||||
When considering our `outputs` object as tuple, it only considers the attributes that don't have `None` values.
|
||||
Here for instance, we could retrieve images via indexing:
|
||||
|
||||
```python
|
||||
outputs[:1]
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
To check a specific pipeline or model output, refer to its corresponding API documentation.
|
||||
|
||||
</Tip>
|
||||
which will return the tuple `(outputs.images)` for instance.
|
||||
|
||||
## BaseOutput
|
||||
|
||||
[[autodoc]] utils.BaseOutput
|
||||
- to_tuple
|
||||
|
||||
## ImagePipelineOutput
|
||||
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
|
||||
## FlaxImagePipelineOutput
|
||||
|
||||
[[autodoc]] pipelines.pipeline_flax_utils.FlaxImagePipelineOutput
|
||||
|
||||
## AudioPipelineOutput
|
||||
|
||||
[[autodoc]] pipelines.AudioPipelineOutput
|
||||
|
||||
## ImageTextPipelineOutput
|
||||
|
||||
[[autodoc]] ImageTextPipelineOutput
|
||||
@@ -1,351 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Kandinsky
|
||||
|
||||
## Overview
|
||||
|
||||
Kandinsky 2.1 inherits best practices from [DALL-E 2](https://arxiv.org/abs/2204.06125) and [Latent Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/latent_diffusion), while introducing some new ideas.
|
||||
|
||||
It uses [CLIP](https://huggingface.co/docs/transformers/model_doc/clip) for encoding images and text, and a diffusion image prior (mapping) between latent spaces of CLIP modalities. This approach enhances the visual performance of the model and unveils new horizons in blending images and text-guided image manipulation.
|
||||
|
||||
The Kandinsky model is created by [Arseniy Shakhmatov](https://github.com/cene555), [Anton Razzhigaev](https://github.com/razzant), [Aleksandr Nikolich](https://github.com/AlexWortega), [Igor Pavlov](https://github.com/boomb0om), [Andrey Kuznetsov](https://github.com/kuznetsoffandrey) and [Denis Dimitrov](https://github.com/denndimitrov) and the original codebase can be found [here](https://github.com/ai-forever/Kandinsky-2)
|
||||
|
||||
## Available Pipelines:
|
||||
|
||||
| Pipeline | Tasks |
|
||||
|---|---|
|
||||
| [pipeline_kandinsky.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/kandinsky/pipeline_kandinsky.py) | *Text-to-Image Generation* |
|
||||
| [pipeline_kandinsky_inpaint.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_inpaint.py) | *Image-Guided Image Generation* |
|
||||
| [pipeline_kandinsky_img2img.py](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/kandinsky/pipeline_kandinsky_img2img.py) | *Image-Guided Image Generation* |
|
||||
|
||||
## Usage example
|
||||
|
||||
In the following, we will walk you through some examples of how to use the Kandinsky pipelines to create some visually aesthetic artwork.
|
||||
|
||||
### Text-to-Image Generation
|
||||
|
||||
For text-to-image generation, we need to use both [`KandinskyPriorPipeline`] and [`KandinskyPipeline`].
|
||||
The first step is to encode text prompts with CLIP and then diffuse the CLIP text embeddings to CLIP image embeddings,
|
||||
as first proposed in [DALL-E 2](https://cdn.openai.com/papers/dall-e-2.pdf).
|
||||
Let's throw a fun prompt at Kandinsky to see what it comes up with.
|
||||
|
||||
```py
|
||||
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
|
||||
```
|
||||
|
||||
First, let's instantiate the prior pipeline and the text-to-image pipeline. Both
|
||||
pipelines are diffusion models.
|
||||
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
|
||||
pipe_prior = DiffusionPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16)
|
||||
pipe_prior.to("cuda")
|
||||
|
||||
t2i_pipe = DiffusionPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
|
||||
t2i_pipe.to("cuda")
|
||||
```
|
||||
|
||||
Now we pass the prompt through the prior to generate image embeddings. The prior
|
||||
returns both the image embeddings corresponding to the prompt and negative/unconditional image
|
||||
embeddings corresponding to an empty string.
|
||||
|
||||
```py
|
||||
generator = torch.Generator(device="cuda").manual_seed(12)
|
||||
image_embeds, negative_image_embeds = pipe_prior(prompt, generator=generator).to_tuple()
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
The text-to-image pipeline expects both `image_embeds`, `negative_image_embeds` and the original
|
||||
`prompt` as the text-to-image pipeline uses another text encoder to better guide the second diffusion
|
||||
process of `t2i_pipe`.
|
||||
|
||||
By default, the prior returns unconditioned negative image embeddings corresponding to the negative prompt of `""`.
|
||||
For better results, you can also pass a `negative_prompt` to the prior. This will increase the effective batch size
|
||||
of the prior by a factor of 2.
|
||||
|
||||
```py
|
||||
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
|
||||
negative_prompt = "low quality, bad quality"
|
||||
|
||||
image_embeds, negative_image_embeds = pipe_prior(prompt, negative_prompt, generator=generator).to_tuple()
|
||||
```
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
Next, we can pass the embeddings as well as the prompt to the text-to-image pipeline. Remember that
|
||||
in case you are using a customized negative prompt, that you should pass this one also to the text-to-image pipelines
|
||||
with `negative_prompt=negative_prompt`:
|
||||
|
||||
```py
|
||||
image = t2i_pipe(prompt, image_embeds=image_embeds, negative_image_embeds=negative_image_embeds).images[0]
|
||||
image.save("cheeseburger_monster.png")
|
||||
```
|
||||
|
||||
One cheeseburger monster coming up! Enjoy!
|
||||
|
||||

|
||||
|
||||
The Kandinsky model works extremely well with creative prompts. Here is some of the amazing art that can be created using the exact same process but with different prompts.
|
||||
|
||||
```python
|
||||
prompt = "bird eye view shot of a full body woman with cyan light orange magenta makeup, digital art, long braided hair her face separated by makeup in the style of yin Yang surrealism, symmetrical face, real image, contrasting tone, pastel gradient background"
|
||||
```
|
||||

|
||||
|
||||
```python
|
||||
prompt = "A car exploding into colorful dust"
|
||||
```
|
||||

|
||||
|
||||
```python
|
||||
prompt = "editorial photography of an organic, almost liquid smoke style armchair"
|
||||
```
|
||||
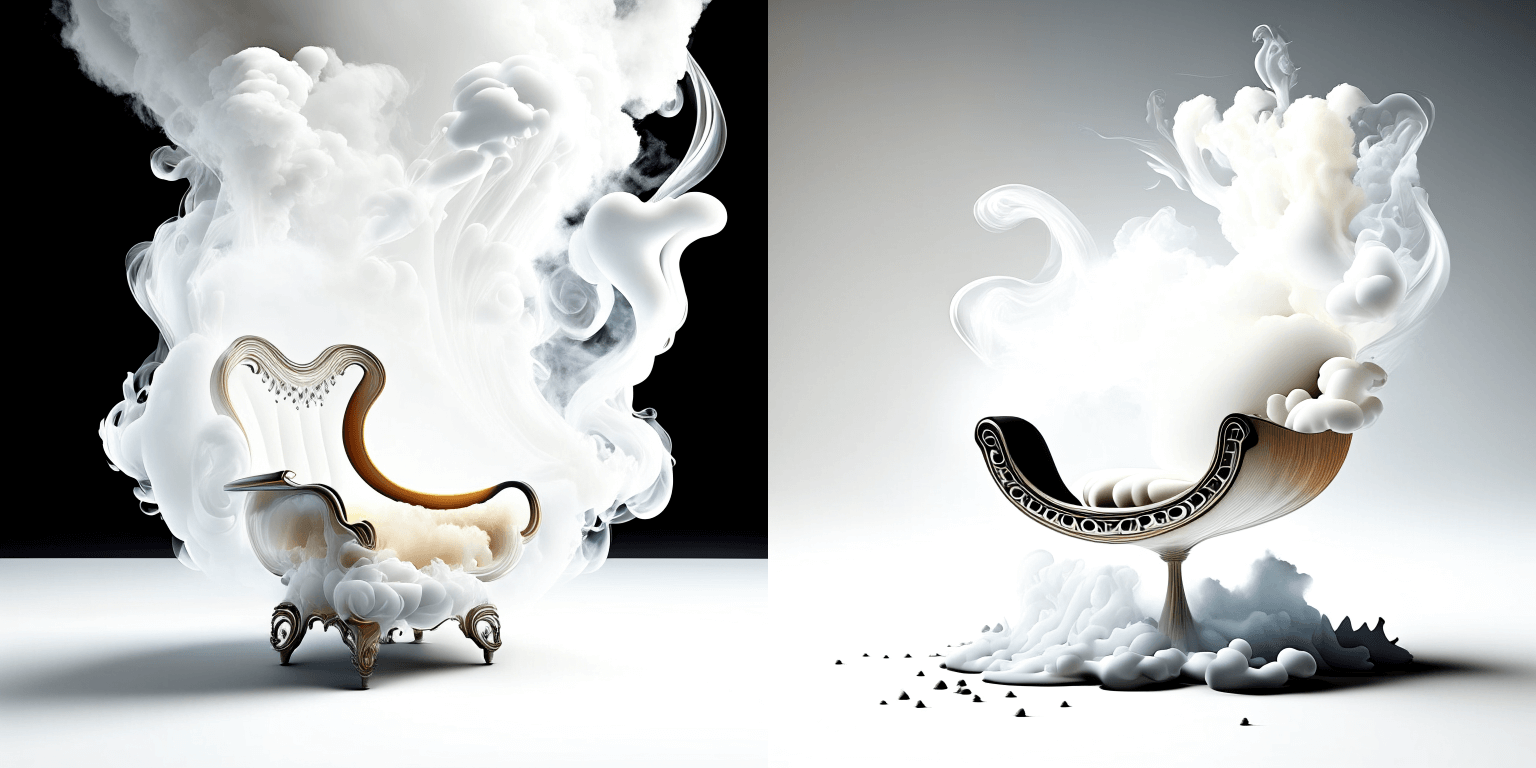
|
||||
|
||||
```python
|
||||
prompt = "birds eye view of a quilted paper style alien planet landscape, vibrant colours, Cinematic lighting"
|
||||
```
|
||||

|
||||
|
||||
|
||||
### Text Guided Image-to-Image Generation
|
||||
|
||||
The same Kandinsky model weights can be used for text-guided image-to-image translation. In this case, just make sure to load the weights using the [`KandinskyImg2ImgPipeline`] pipeline.
|
||||
|
||||
**Note**: You can also directly move the weights of the text-to-image pipelines to the image-to-image pipelines
|
||||
without loading them twice by making use of the [`~DiffusionPipeline.components`] function as explained [here](#converting-between-different-pipelines).
|
||||
|
||||
Let's download an image.
|
||||
|
||||
```python
|
||||
from PIL import Image
|
||||
import requests
|
||||
from io import BytesIO
|
||||
|
||||
# download image
|
||||
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
|
||||
response = requests.get(url)
|
||||
original_image = Image.open(BytesIO(response.content)).convert("RGB")
|
||||
original_image = original_image.resize((768, 512))
|
||||
```
|
||||
|
||||

|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import KandinskyImg2ImgPipeline, KandinskyPriorPipeline
|
||||
|
||||
# create prior
|
||||
pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
"kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
)
|
||||
pipe_prior.to("cuda")
|
||||
|
||||
# create img2img pipeline
|
||||
pipe = KandinskyImg2ImgPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
|
||||
pipe.to("cuda")
|
||||
|
||||
prompt = "A fantasy landscape, Cinematic lighting"
|
||||
negative_prompt = "low quality, bad quality"
|
||||
|
||||
generator = torch.Generator(device="cuda").manual_seed(30)
|
||||
image_embeds, negative_image_embeds = pipe_prior(prompt, negative_prompt, generator=generator).to_tuple()
|
||||
|
||||
out = pipe(
|
||||
prompt,
|
||||
image=original_image,
|
||||
image_embeds=image_embeds,
|
||||
negative_image_embeds=negative_image_embeds,
|
||||
height=768,
|
||||
width=768,
|
||||
strength=0.3,
|
||||
)
|
||||
|
||||
out.images[0].save("fantasy_land.png")
|
||||
```
|
||||
|
||||

|
||||
|
||||
|
||||
### Text Guided Inpainting Generation
|
||||
|
||||
You can use [`KandinskyInpaintPipeline`] to edit images. In this example, we will add a hat to the portrait of a cat.
|
||||
|
||||
```py
|
||||
from diffusers import KandinskyInpaintPipeline, KandinskyPriorPipeline
|
||||
from diffusers.utils import load_image
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
"kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
)
|
||||
pipe_prior.to("cuda")
|
||||
|
||||
prompt = "a hat"
|
||||
prior_output = pipe_prior(prompt)
|
||||
|
||||
pipe = KandinskyInpaintPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-inpaint", torch_dtype=torch.float16)
|
||||
pipe.to("cuda")
|
||||
|
||||
init_image = load_image(
|
||||
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
|
||||
)
|
||||
|
||||
mask = np.ones((768, 768), dtype=np.float32)
|
||||
# Let's mask out an area above the cat's head
|
||||
mask[:250, 250:-250] = 0
|
||||
|
||||
out = pipe(
|
||||
prompt,
|
||||
image=init_image,
|
||||
mask_image=mask,
|
||||
**prior_output,
|
||||
height=768,
|
||||
width=768,
|
||||
num_inference_steps=150,
|
||||
)
|
||||
|
||||
image = out.images[0]
|
||||
image.save("cat_with_hat.png")
|
||||
```
|
||||

|
||||
|
||||
### Interpolate
|
||||
|
||||
The [`KandinskyPriorPipeline`] also comes with a cool utility function that will allow you to interpolate the latent space of different images and texts super easily. Here is an example of how you can create an Impressionist-style portrait for your pet based on "The Starry Night".
|
||||
|
||||
Note that you can interpolate between texts and images - in the below example, we passed a text prompt "a cat" and two images to the `interplate` function, along with a `weights` variable containing the corresponding weights for each condition we interplate.
|
||||
|
||||
```python
|
||||
from diffusers import KandinskyPriorPipeline, KandinskyPipeline
|
||||
from diffusers.utils import load_image
|
||||
import PIL
|
||||
|
||||
import torch
|
||||
|
||||
pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
"kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
)
|
||||
pipe_prior.to("cuda")
|
||||
|
||||
img1 = load_image(
|
||||
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
|
||||
)
|
||||
|
||||
img2 = load_image(
|
||||
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/starry_night.jpeg"
|
||||
)
|
||||
|
||||
# add all the conditions we want to interpolate, can be either text or image
|
||||
images_texts = ["a cat", img1, img2]
|
||||
|
||||
# specify the weights for each condition in images_texts
|
||||
weights = [0.3, 0.3, 0.4]
|
||||
|
||||
# We can leave the prompt empty
|
||||
prompt = ""
|
||||
prior_out = pipe_prior.interpolate(images_texts, weights)
|
||||
|
||||
pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
|
||||
pipe.to("cuda")
|
||||
|
||||
image = pipe(prompt, **prior_out, height=768, width=768).images[0]
|
||||
|
||||
image.save("starry_cat.png")
|
||||
```
|
||||

|
||||
|
||||
|
||||
## Optimization
|
||||
|
||||
Running Kandinsky in inference requires running both a first prior pipeline: [`KandinskyPriorPipeline`]
|
||||
and a second image decoding pipeline which is one of [`KandinskyPipeline`], [`KandinskyImg2ImgPipeline`], or [`KandinskyInpaintPipeline`].
|
||||
|
||||
The bulk of the computation time will always be the second image decoding pipeline, so when looking
|
||||
into optimizing the model, one should look into the second image decoding pipeline.
|
||||
|
||||
When running with PyTorch < 2.0, we strongly recommend making use of [`xformers`](https://github.com/facebookresearch/xformers)
|
||||
to speed-up the optimization. This can be done by simply running:
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
|
||||
t2i_pipe = DiffusionPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
|
||||
t2i_pipe.enable_xformers_memory_efficient_attention()
|
||||
```
|
||||
|
||||
When running on PyTorch >= 2.0, PyTorch's SDPA attention will automatically be used. For more information on
|
||||
PyTorch's SDPA, feel free to have a look at [this blog post](https://pytorch.org/blog/accelerated-diffusers-pt-20/).
|
||||
|
||||
To have explicit control , you can also manually set the pipeline to use PyTorch's 2.0 efficient attention:
|
||||
|
||||
```py
|
||||
from diffusers.models.attention_processor import AttnAddedKVProcessor2_0
|
||||
|
||||
t2i_pipe.unet.set_attn_processor(AttnAddedKVProcessor2_0())
|
||||
```
|
||||
|
||||
The slowest and most memory intense attention processor is the default `AttnAddedKVProcessor` processor.
|
||||
We do **not** recommend using it except for testing purposes or cases where very high determistic behaviour is desired.
|
||||
You can set it with:
|
||||
|
||||
```py
|
||||
from diffusers.models.attention_processor import AttnAddedKVProcessor
|
||||
|
||||
t2i_pipe.unet.set_attn_processor(AttnAddedKVProcessor())
|
||||
```
|
||||
|
||||
With PyTorch >= 2.0, you can also use Kandinsky with `torch.compile` which depending
|
||||
on your hardware can signficantly speed-up your inference time once the model is compiled.
|
||||
To use Kandinsksy with `torch.compile`, you can do:
|
||||
|
||||
```py
|
||||
t2i_pipe.unet.to(memory_format=torch.channels_last)
|
||||
t2i_pipe.unet = torch.compile(t2i_pipe.unet, mode="reduce-overhead", fullgraph=True)
|
||||
```
|
||||
|
||||
After compilation you should see a very fast inference time. For more information,
|
||||
feel free to have a look at [Our PyTorch 2.0 benchmark](https://huggingface.co/docs/diffusers/main/en/optimization/torch2.0).
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## KandinskyPriorPipeline
|
||||
|
||||
[[autodoc]] KandinskyPriorPipeline
|
||||
- all
|
||||
- __call__
|
||||
- interpolate
|
||||
|
||||
## KandinskyPipeline
|
||||
|
||||
[[autodoc]] KandinskyPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## KandinskyImg2ImgPipeline
|
||||
|
||||
[[autodoc]] KandinskyImg2ImgPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## KandinskyInpaintPipeline
|
||||
|
||||
[[autodoc]] KandinskyInpaintPipeline
|
||||
- all
|
||||
- __call__
|
||||
@@ -113,3 +113,105 @@ each pipeline, one should look directly into the respective pipeline.
|
||||
|
||||
**Note**: All pipelines have PyTorch's autograd disabled by decorating the `__call__` method with a [`torch.no_grad`](https://pytorch.org/docs/stable/generated/torch.no_grad.html) decorator because pipelines should
|
||||
not be used for training. If you want to store the gradients during the forward pass, we recommend writing your own pipeline, see also our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community).
|
||||
|
||||
## Contribution
|
||||
|
||||
We are more than happy about any contribution to the officially supported pipelines 🤗. We aspire
|
||||
all of our pipelines to be **self-contained**, **easy-to-tweak**, **beginner-friendly** and for **one-purpose-only**.
|
||||
|
||||
- **Self-contained**: A pipeline shall be as self-contained as possible. More specifically, this means that all functionality should be either directly defined in the pipeline file itself, should be inherited from (and only from) the [`DiffusionPipeline` class](.../diffusion_pipeline) or be directly attached to the model and scheduler components of the pipeline.
|
||||
- **Easy-to-use**: Pipelines should be extremely easy to use - one should be able to load the pipeline and
|
||||
use it for its designated task, *e.g.* text-to-image generation, in just a couple of lines of code. Most
|
||||
logic including pre-processing, an unrolled diffusion loop, and post-processing should all happen inside the `__call__` method.
|
||||
- **Easy-to-tweak**: Certain pipelines will not be able to handle all use cases and tasks that you might like them to. If you want to use a certain pipeline for a specific use case that is not yet supported, you might have to copy the pipeline file and tweak the code to your needs. We try to make the pipeline code as readable as possible so that each part –from pre-processing to diffusing to post-processing– can easily be adapted. If you would like the community to benefit from your customized pipeline, we would love to see a contribution to our [community-examples](https://github.com/huggingface/diffusers/tree/main/examples/community). If you feel that an important pipeline should be part of the official pipelines but isn't, a contribution to the [official pipelines](./overview) would be even better.
|
||||
- **One-purpose-only**: Pipelines should be used for one task and one task only. Even if two tasks are very similar from a modeling point of view, *e.g.* image2image translation and in-painting, pipelines shall be used for one task only to keep them *easy-to-tweak* and *readable*.
|
||||
|
||||
## Examples
|
||||
|
||||
### Text-to-Image generation with Stable Diffusion
|
||||
|
||||
```python
|
||||
# make sure you're logged in with `huggingface-cli login`
|
||||
from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
image = pipe(prompt).images[0]
|
||||
|
||||
image.save("astronaut_rides_horse.png")
|
||||
```
|
||||
|
||||
### Image-to-Image text-guided generation with Stable Diffusion
|
||||
|
||||
The `StableDiffusionImg2ImgPipeline` lets you pass a text prompt and an initial image to condition the generation of new images.
|
||||
|
||||
```python
|
||||
import requests
|
||||
from PIL import Image
|
||||
from io import BytesIO
|
||||
|
||||
from diffusers import StableDiffusionImg2ImgPipeline
|
||||
|
||||
# load the pipeline
|
||||
device = "cuda"
|
||||
pipe = StableDiffusionImg2ImgPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to(
|
||||
device
|
||||
)
|
||||
|
||||
# let's download an initial image
|
||||
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
|
||||
|
||||
response = requests.get(url)
|
||||
init_image = Image.open(BytesIO(response.content)).convert("RGB")
|
||||
init_image = init_image.resize((768, 512))
|
||||
|
||||
prompt = "A fantasy landscape, trending on artstation"
|
||||
|
||||
images = pipe(prompt=prompt, image=init_image, strength=0.75, guidance_scale=7.5).images
|
||||
|
||||
images[0].save("fantasy_landscape.png")
|
||||
```
|
||||
You can also run this example on colab [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/image_2_image_using_diffusers.ipynb)
|
||||
|
||||
### Tweak prompts reusing seeds and latents
|
||||
|
||||
You can generate your own latents to reproduce results, or tweak your prompt on a specific result you liked. [This notebook](https://github.com/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb) shows how to do it step by step. You can also run it in Google Colab [](https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb)
|
||||
|
||||
|
||||
### In-painting using Stable Diffusion
|
||||
|
||||
The `StableDiffusionInpaintPipeline` lets you edit specific parts of an image by providing a mask and text prompt.
|
||||
|
||||
```python
|
||||
import PIL
|
||||
import requests
|
||||
import torch
|
||||
from io import BytesIO
|
||||
|
||||
from diffusers import StableDiffusionInpaintPipeline
|
||||
|
||||
|
||||
def download_image(url):
|
||||
response = requests.get(url)
|
||||
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
|
||||
|
||||
|
||||
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
|
||||
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
|
||||
|
||||
init_image = download_image(img_url).resize((512, 512))
|
||||
mask_image = download_image(mask_url).resize((512, 512))
|
||||
|
||||
pipe = StableDiffusionInpaintPipeline.from_pretrained(
|
||||
"runwayml/stable-diffusion-inpainting",
|
||||
torch_dtype=torch.float16,
|
||||
)
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
|
||||
image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
|
||||
```
|
||||
|
||||
You can also run this example on colab [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
|
||||
|
||||
@@ -52,14 +52,6 @@ image = pipe(prompt).images[0]
|
||||
image.save("dolomites.png")
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
While calling this pipeline, it's possible to specify the `view_batch_size` to have a >1 value.
|
||||
For some GPUs with high performance, higher a `view_batch_size`, can speedup the generation
|
||||
and increase the VRAM usage.
|
||||
|
||||
</Tip>
|
||||
|
||||
## StableDiffusionPanoramaPipeline
|
||||
[[autodoc]] StableDiffusionPanoramaPipeline
|
||||
- __call__
|
||||
@@ -1,204 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# UniDiffuser
|
||||
|
||||
The UniDiffuser model was proposed in [One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale](https://arxiv.org/abs/2303.06555) by Fan Bao, Shen Nie, Kaiwen Xue, Chongxuan Li, Shi Pu, Yaole Wang, Gang Yue, Yue Cao, Hang Su, Jun Zhu.
|
||||
|
||||
The abstract of the [paper](https://arxiv.org/abs/2303.06555) is the following:
|
||||
|
||||
*This paper proposes a unified diffusion framework (dubbed UniDiffuser) to fit all distributions relevant to a set of multi-modal data in one model. Our key insight is -- learning diffusion models for marginal, conditional, and joint distributions can be unified as predicting the noise in the perturbed data, where the perturbation levels (i.e. timesteps) can be different for different modalities. Inspired by the unified view, UniDiffuser learns all distributions simultaneously with a minimal modification to the original diffusion model -- perturbs data in all modalities instead of a single modality, inputs individual timesteps in different modalities, and predicts the noise of all modalities instead of a single modality. UniDiffuser is parameterized by a transformer for diffusion models to handle input types of different modalities. Implemented on large-scale paired image-text data, UniDiffuser is able to perform image, text, text-to-image, image-to-text, and image-text pair generation by setting proper timesteps without additional overhead. In particular, UniDiffuser is able to produce perceptually realistic samples in all tasks and its quantitative results (e.g., the FID and CLIP score) are not only superior to existing general-purpose models but also comparable to the bespoken models (e.g., Stable Diffusion and DALL-E 2) in representative tasks (e.g., text-to-image generation).*
|
||||
|
||||
Resources:
|
||||
|
||||
* [Paper](https://arxiv.org/abs/2303.06555).
|
||||
* [Original Code](https://github.com/thu-ml/unidiffuser).
|
||||
|
||||
Available Checkpoints are:
|
||||
- *UniDiffuser-v0 (512x512 resolution)* [thu-ml/unidiffuser-v0](https://huggingface.co/thu-ml/unidiffuser-v0)
|
||||
- *UniDiffuser-v1 (512x512 resolution)* [thu-ml/unidiffuser-v1](https://huggingface.co/thu-ml/unidiffuser-v1)
|
||||
|
||||
This pipeline was contributed by our community member [dg845](https://github.com/dg845).
|
||||
|
||||
## Available Pipelines:
|
||||
|
||||
| Pipeline | Tasks | Demo | Colab |
|
||||
|:---:|:---:|:---:|:---:|
|
||||
| [UniDiffuserPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/pipeline_unidiffuser.py) | *Joint Image-Text Gen*, *Text-to-Image*, *Image-to-Text*,<br> *Image Gen*, *Text Gen*, *Image Variation*, *Text Variation* | [🤗 Spaces](https://huggingface.co/spaces/thu-ml/unidiffuser) | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/unidiffuser.ipynb) |
|
||||
|
||||
## Usage Examples
|
||||
|
||||
Because the UniDiffuser model is trained to model the joint distribution of (image, text) pairs, it is capable of performing a diverse range of generation tasks.
|
||||
|
||||
### Unconditional Image and Text Generation
|
||||
|
||||
Unconditional generation (where we start from only latents sampled from a standard Gaussian prior) from a [`UniDiffuserPipeline`] will produce a (image, text) pair:
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
from diffusers import UniDiffuserPipeline
|
||||
|
||||
device = "cuda"
|
||||
model_id_or_path = "thu-ml/unidiffuser-v1"
|
||||
pipe = UniDiffuserPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
|
||||
pipe.to(device)
|
||||
|
||||
# Unconditional image and text generation. The generation task is automatically inferred.
|
||||
sample = pipe(num_inference_steps=20, guidance_scale=8.0)
|
||||
image = sample.images[0]
|
||||
text = sample.text[0]
|
||||
image.save("unidiffuser_joint_sample_image.png")
|
||||
print(text)
|
||||
```
|
||||
|
||||
This is also called "joint" generation in the UniDiffusers paper, since we are sampling from the joint image-text distribution.
|
||||
|
||||
Note that the generation task is inferred from the inputs used when calling the pipeline.
|
||||
It is also possible to manually specify the unconditional generation task ("mode") manually with [`UniDiffuserPipeline.set_joint_mode`]:
|
||||
|
||||
```python
|
||||
# Equivalent to the above.
|
||||
pipe.set_joint_mode()
|
||||
sample = pipe(num_inference_steps=20, guidance_scale=8.0)
|
||||
```
|
||||
|
||||
When the mode is set manually, subsequent calls to the pipeline will use the set mode without attempting the infer the mode.
|
||||
You can reset the mode with [`UniDiffuserPipeline.reset_mode`], after which the pipeline will once again infer the mode.
|
||||
|
||||
You can also generate only an image or only text (which the UniDiffuser paper calls "marginal" generation since we sample from the marginal distribution of images and text, respectively):
|
||||
|
||||
```python
|
||||
# Unlike other generation tasks, image-only and text-only generation don't use classifier-free guidance
|
||||
# Image-only generation
|
||||
pipe.set_image_mode()
|
||||
sample_image = pipe(num_inference_steps=20).images[0]
|
||||
# Text-only generation
|
||||
pipe.set_text_mode()
|
||||
sample_text = pipe(num_inference_steps=20).text[0]
|
||||
```
|
||||
|
||||
### Text-to-Image Generation
|
||||
|
||||
UniDiffuser is also capable of sampling from conditional distributions; that is, the distribution of images conditioned on a text prompt or the distribution of texts conditioned on an image.
|
||||
Here is an example of sampling from the conditional image distribution (text-to-image generation or text-conditioned image generation):
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
from diffusers import UniDiffuserPipeline
|
||||
|
||||
device = "cuda"
|
||||
model_id_or_path = "thu-ml/unidiffuser-v1"
|
||||
pipe = UniDiffuserPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
|
||||
pipe.to(device)
|
||||
|
||||
# Text-to-image generation
|
||||
prompt = "an elephant under the sea"
|
||||
|
||||
sample = pipe(prompt=prompt, num_inference_steps=20, guidance_scale=8.0)
|
||||
t2i_image = sample.images[0]
|
||||
t2i_image.save("unidiffuser_text2img_sample_image.png")
|
||||
```
|
||||
|
||||
The `text2img` mode requires that either an input `prompt` or `prompt_embeds` be supplied. You can set the `text2img` mode manually with [`UniDiffuserPipeline.set_text_to_image_mode`].
|
||||
|
||||
### Image-to-Text Generation
|
||||
|
||||
Similarly, UniDiffuser can also produce text samples given an image (image-to-text or image-conditioned text generation):
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
from diffusers import UniDiffuserPipeline
|
||||
from diffusers.utils import load_image
|
||||
|
||||
device = "cuda"
|
||||
model_id_or_path = "thu-ml/unidiffuser-v1"
|
||||
pipe = UniDiffuserPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
|
||||
pipe.to(device)
|
||||
|
||||
# Image-to-text generation
|
||||
image_url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/unidiffuser/unidiffuser_example_image.jpg"
|
||||
init_image = load_image(image_url).resize((512, 512))
|
||||
|
||||
sample = pipe(image=init_image, num_inference_steps=20, guidance_scale=8.0)
|
||||
i2t_text = sample.text[0]
|
||||
print(i2t_text)
|
||||
```
|
||||
|
||||
The `img2text` mode requires that an input `image` be supplied. You can set the `img2text` mode manually with [`UniDiffuserPipeline.set_image_to_text_mode`].
|
||||
|
||||
### Image Variation
|
||||
|
||||
The UniDiffuser authors suggest performing image variation through a "round-trip" generation method, where given an input image, we first perform an image-to-text generation, and the perform a text-to-image generation on the outputs of the first generation.
|
||||
This produces a new image which is semantically similar to the input image:
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
from diffusers import UniDiffuserPipeline
|
||||
from diffusers.utils import load_image
|
||||
|
||||
device = "cuda"
|
||||
model_id_or_path = "thu-ml/unidiffuser-v1"
|
||||
pipe = UniDiffuserPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
|
||||
pipe.to(device)
|
||||
|
||||
# Image variation can be performed with a image-to-text generation followed by a text-to-image generation:
|
||||
# 1. Image-to-text generation
|
||||
image_url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/unidiffuser/unidiffuser_example_image.jpg"
|
||||
init_image = load_image(image_url).resize((512, 512))
|
||||
|
||||
sample = pipe(image=init_image, num_inference_steps=20, guidance_scale=8.0)
|
||||
i2t_text = sample.text[0]
|
||||
print(i2t_text)
|
||||
|
||||
# 2. Text-to-image generation
|
||||
sample = pipe(prompt=i2t_text, num_inference_steps=20, guidance_scale=8.0)
|
||||
final_image = sample.images[0]
|
||||
final_image.save("unidiffuser_image_variation_sample.png")
|
||||
```
|
||||
|
||||
### Text Variation
|
||||
|
||||
|
||||
Similarly, text variation can be performed on an input prompt with a text-to-image generation followed by a image-to-text generation:
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
from diffusers import UniDiffuserPipeline
|
||||
|
||||
device = "cuda"
|
||||
model_id_or_path = "thu-ml/unidiffuser-v1"
|
||||
pipe = UniDiffuserPipeline.from_pretrained(model_id_or_path, torch_dtype=torch.float16)
|
||||
pipe.to(device)
|
||||
|
||||
# Text variation can be performed with a text-to-image generation followed by a image-to-text generation:
|
||||
# 1. Text-to-image generation
|
||||
prompt = "an elephant under the sea"
|
||||
|
||||
sample = pipe(prompt=prompt, num_inference_steps=20, guidance_scale=8.0)
|
||||
t2i_image = sample.images[0]
|
||||
t2i_image.save("unidiffuser_text2img_sample_image.png")
|
||||
|
||||
# 2. Image-to-text generation
|
||||
sample = pipe(image=t2i_image, num_inference_steps=20, guidance_scale=8.0)
|
||||
final_prompt = sample.text[0]
|
||||
print(final_prompt)
|
||||
```
|
||||
|
||||
## UniDiffuserPipeline
|
||||
[[autodoc]] UniDiffuserPipeline
|
||||
- all
|
||||
- __call__
|
||||
@@ -1,23 +0,0 @@
|
||||
# Utilities
|
||||
|
||||
Utility and helper functions for working with 🤗 Diffusers.
|
||||
|
||||
## randn_tensor
|
||||
|
||||
[[autodoc]] diffusers.utils.randn_tensor
|
||||
|
||||
## numpy_to_pil
|
||||
|
||||
[[autodoc]] utils.pil_utils.numpy_to_pil
|
||||
|
||||
## pt_to_pil
|
||||
|
||||
[[autodoc]] utils.pil_utils.pt_to_pil
|
||||
|
||||
## load_image
|
||||
|
||||
[[autodoc]] utils.testing_utils.load_image
|
||||
|
||||
## export_to_video
|
||||
|
||||
[[autodoc]] utils.testing_utils.export_to_video
|
||||
@@ -14,7 +14,7 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
We ❤️ contributions from the open-source community! Everyone is welcome, and all types of participation –not just code– are valued and appreciated. Answering questions, helping others, reaching out, and improving the documentation are all immensely valuable to the community, so don't be afraid and get involved if you're up for it!
|
||||
|
||||
Everyone is encouraged to start by saying 👋 in our public Discord channel. We discuss the latest trends in diffusion models, ask questions, show off personal projects, help each other with contributions, or just hang out ☕. <a href="https://Discord.gg/G7tWnz98XR"><img alt="Join us on Discord" src="https://img.shields.io/discord/823813159592001537?color=5865F2&logo=discord&logoColor=white"></a>
|
||||
Everyone is encouraged to start by saying 👋 in our public Discord channel. We discuss the latest trends in diffusion models, ask questions, show off personal projects, help each other with contributions, or just hang out ☕. <a href="https://Discord.gg/G7tWnz98XR"><img alt="Join us on Discord" src="https://img.shields.io/Discord/823813159592001537?color=5865F2&logo=Discord&logoColor=white"></a>
|
||||
|
||||
Whichever way you choose to contribute, we strive to be part of an open, welcoming, and kind community. Please, read our [code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md) and be mindful to respect it during your interactions. We also recommend you become familiar with the [ethical guidelines](https://huggingface.co/docs/diffusers/conceptual/ethical_guidelines) that guide our project and ask you to adhere to the same principles of transparency and responsibility.
|
||||
|
||||
|
||||
@@ -37,8 +37,7 @@ We cover Diffusion models with the following pipelines:
|
||||
|
||||
## Qualitative Evaluation
|
||||
|
||||
Qualitative evaluation typically involves human assessment of generated images. Quality is measured across aspects such as compositionality, image-text alignment, and spatial relations. Common prompts provide a degree of uniformity for subjective metrics.
|
||||
DrawBench and PartiPrompts are prompt datasets used for qualitative benchmarking. DrawBench and PartiPrompts were introduced by [Imagen](https://imagen.research.google/) and [Parti](https://parti.research.google/) respectively.
|
||||
Qualitative evaluation typically involves human assessment of generated images. Quality is measured across aspects such as compositionality, image-text alignment, and spatial relations. Common prompts provide a degree of uniformity for subjective metrics. DrawBench and PartiPrompts are prompt datasets used for qualitative benchmarking. DrawBench and PartiPrompts were introduced by [Imagen](https://imagen.research.google/) and [Parti](https://parti.research.google/) respectively.
|
||||
|
||||
From the [official Parti website](https://parti.research.google/):
|
||||
|
||||
@@ -52,13 +51,7 @@ PartiPrompts has the following columns:
|
||||
- Category of the prompt (such as “Abstract”, “World Knowledge”, etc.)
|
||||
- Challenge reflecting the difficulty (such as “Basic”, “Complex”, “Writing & Symbols”, etc.)
|
||||
|
||||
These benchmarks allow for side-by-side human evaluation of different image generation models.
|
||||
|
||||
For this, the 🧨 Diffusers team has built **Open Parti Prompts**, which is a community-driven qualitative benchmark based on Parti Prompts to compare state-of-the-art open-source diffusion models:
|
||||
- [Open Parti Prompts Game](https://huggingface.co/spaces/OpenGenAI/open-parti-prompts): For 10 parti prompts, 4 generated images are shown and the user selects the image that suits the prompt best.
|
||||
- [Open Parti Prompts Leaderboard](https://huggingface.co/spaces/OpenGenAI/parti-prompts-leaderboard): The leaderboard comparing the currently best open-sourced diffusion models to each other.
|
||||
|
||||
To manually compare images, let’s see how we can use `diffusers` on a couple of PartiPrompts.
|
||||
These benchmarks allow for side-by-side human evaluation of different image generation models. Let’s see how we can use `diffusers` on a couple of PartiPrompts.
|
||||
|
||||
Below we show some prompts sampled across different challenges: Basic, Complex, Linguistic Structures, Imagination, and Writing & Symbols. Here we are using PartiPrompts as a [dataset](https://huggingface.co/datasets/nateraw/parti-prompts).
|
||||
|
||||
|
||||
@@ -50,6 +50,7 @@ from diffusers import DiffusionPipeline
|
||||
|
||||
pipe = DiffusionPipeline.from_pretrained(
|
||||
"runwayml/stable-diffusion-v1-5",
|
||||
|
||||
torch_dtype=torch.float16,
|
||||
)
|
||||
pipe = pipe.to("cuda")
|
||||
@@ -84,6 +85,7 @@ from diffusers import DiffusionPipeline
|
||||
|
||||
pipe = DiffusionPipeline.from_pretrained(
|
||||
"runwayml/stable-diffusion-v1-5",
|
||||
|
||||
torch_dtype=torch.float16,
|
||||
)
|
||||
pipe = pipe.to("cuda")
|
||||
@@ -110,6 +112,7 @@ from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained(
|
||||
"runwayml/stable-diffusion-v1-5",
|
||||
|
||||
torch_dtype=torch.float16,
|
||||
)
|
||||
pipe = pipe.to("cuda")
|
||||
@@ -163,6 +166,7 @@ from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained(
|
||||
"runwayml/stable-diffusion-v1-5",
|
||||
|
||||
torch_dtype=torch.float16,
|
||||
)
|
||||
|
||||
@@ -187,6 +191,7 @@ from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained(
|
||||
"runwayml/stable-diffusion-v1-5",
|
||||
|
||||
torch_dtype=torch.float16,
|
||||
)
|
||||
|
||||
@@ -404,14 +409,7 @@ Here are the speedups we obtain on a few Nvidia GPUs when running the inference
|
||||
| A100-SXM4-40GB | 18.6it/s | 29.it/s |
|
||||
| A100-SXM-80GB | 18.7it/s | 29.5it/s |
|
||||
|
||||
To leverage it just make sure you have:
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
If you have PyTorch 2.0 installed, you shouldn't use xFormers!
|
||||
|
||||
</Tip>
|
||||
|
||||
To leverage it just make sure you have:
|
||||
- PyTorch > 1.12
|
||||
- Cuda available
|
||||
- [Installed the xformers library](xformers).
|
||||
|
||||
@@ -23,7 +23,7 @@ To benefit from the accelerated attention implementation and `torch.compile()`,
|
||||
when PyTorch 2.0 is available.
|
||||
|
||||
```bash
|
||||
pip install --upgrade torch diffusers
|
||||
pip install --upgrade torch torchvision diffusers
|
||||
```
|
||||
|
||||
## Using accelerated transformers and `torch.compile`.
|
||||
|
||||
@@ -266,6 +266,6 @@ image_grid(images)
|
||||
|
||||
In this tutorial, you learned how to optimize a [`DiffusionPipeline`] for computational and memory efficiency as well as improving the quality of generated outputs. If you're interested in making your pipeline even faster, take a look at the following resources:
|
||||
|
||||
- Learn how [PyTorch 2.0](./optimization/torch2.0) and [`torch.compile`](https://pytorch.org/docs/stable/generated/torch.compile.html) can yield 5 - 300% faster inference speed. On an A100 GPU, inference can be up to 50% faster!
|
||||
- Learn how [PyTorch 2.0](./optimization/torch2.0) and [`torch.compile`](https://pytorch.org/docs/stable/generated/torch.compile.html) can yield 5 - 300% faster inference speed.
|
||||
- If you can't use PyTorch 2, we recommend you install [xFormers](./optimization/xformers). Its memory-efficient attention mechanism works great with PyTorch 1.13.1 for faster speed and reduced memory consumption.
|
||||
- Other optimization techniques, such as model offloading, are covered in [this guide](./optimization/fp16).
|
||||
|
||||
@@ -97,8 +97,7 @@ accelerate launch train_controlnet.py \
|
||||
--learning_rate=1e-5 \
|
||||
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
|
||||
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
|
||||
--train_batch_size=4 \
|
||||
--push_to_hub
|
||||
--train_batch_size=4
|
||||
```
|
||||
|
||||
This default configuration requires ~38GB VRAM.
|
||||
@@ -121,8 +120,7 @@ accelerate launch train_controlnet.py \
|
||||
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
|
||||
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--push_to_hub
|
||||
--gradient_accumulation_steps=4
|
||||
```
|
||||
|
||||
## Training with multiple GPUs
|
||||
@@ -145,8 +143,7 @@ accelerate launch --mixed_precision="fp16" --multi_gpu train_controlnet.py \
|
||||
--train_batch_size=4 \
|
||||
--mixed_precision="fp16" \
|
||||
--tracker_project_name="controlnet-demo" \
|
||||
--report_to=wandb \
|
||||
--push_to_hub
|
||||
--report_to=wandb
|
||||
```
|
||||
|
||||
## Example results
|
||||
@@ -194,8 +191,7 @@ accelerate launch train_controlnet.py \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--gradient_checkpointing \
|
||||
--use_8bit_adam \
|
||||
--push_to_hub
|
||||
--use_8bit_adam
|
||||
```
|
||||
|
||||
## Training on a 12 GB GPU
|
||||
@@ -223,8 +219,7 @@ accelerate launch train_controlnet.py \
|
||||
--gradient_checkpointing \
|
||||
--use_8bit_adam \
|
||||
--enable_xformers_memory_efficient_attention \
|
||||
--set_grads_to_none \
|
||||
--push_to_hub
|
||||
--set_grads_to_none
|
||||
```
|
||||
|
||||
When using `enable_xformers_memory_efficient_attention`, please make sure to install `xformers` by `pip install xformers`.
|
||||
@@ -288,8 +283,7 @@ accelerate launch train_controlnet.py \
|
||||
--gradient_checkpointing \
|
||||
--enable_xformers_memory_efficient_attention \
|
||||
--set_grads_to_none \
|
||||
--mixed_precision fp16 \
|
||||
--push_to_hub
|
||||
--mixed_precision fp16
|
||||
```
|
||||
|
||||
## Inference
|
||||
|
||||
@@ -100,8 +100,7 @@ accelerate launch train_custom_diffusion.py \
|
||||
--lr_warmup_steps=0 \
|
||||
--max_train_steps=250 \
|
||||
--scale_lr --hflip \
|
||||
--modifier_token "<new1>" \
|
||||
--push_to_hub
|
||||
--modifier_token "<new1>"
|
||||
```
|
||||
|
||||
**Use `--enable_xformers_memory_efficient_attention` for faster training with lower VRAM requirement (16GB per GPU). Follow [this guide](https://github.com/facebookresearch/xformers) for installation instructions.**
|
||||
@@ -133,8 +132,7 @@ accelerate launch train_custom_diffusion.py \
|
||||
--scale_lr --hflip \
|
||||
--modifier_token "<new1>" \
|
||||
--validation_prompt="<new1> cat sitting in a bucket" \
|
||||
--report_to="wandb" \
|
||||
--push_to_hub
|
||||
--report_to="wandb"
|
||||
```
|
||||
|
||||
Here is an example [Weights and Biases page](https://wandb.ai/sayakpaul/custom-diffusion/runs/26ghrcau) where you can check out the intermediate results along with other training details.
|
||||
@@ -170,8 +168,7 @@ accelerate launch train_custom_diffusion.py \
|
||||
--max_train_steps=500 \
|
||||
--num_class_images=200 \
|
||||
--scale_lr --hflip \
|
||||
--modifier_token "<new1>+<new2>" \
|
||||
--push_to_hub
|
||||
--modifier_token "<new1>+<new2>"
|
||||
```
|
||||
|
||||
Here is an example [Weights and Biases page](https://wandb.ai/sayakpaul/custom-diffusion/runs/3990tzkg) where you can check out the intermediate results along with other training details.
|
||||
@@ -210,8 +207,7 @@ accelerate launch train_custom_diffusion.py \
|
||||
--scale_lr --hflip --noaug \
|
||||
--freeze_model crossattn \
|
||||
--modifier_token "<new1>" \
|
||||
--enable_xformers_memory_efficient_attention \
|
||||
--push_to_hub
|
||||
--enable_xformers_memory_efficient_attention
|
||||
```
|
||||
|
||||
## Inference
|
||||
|
||||
@@ -130,8 +130,7 @@ python train_dreambooth_flax.py \
|
||||
--resolution=512 \
|
||||
--train_batch_size=1 \
|
||||
--learning_rate=5e-6 \
|
||||
--max_train_steps=400 \
|
||||
--push_to_hub
|
||||
--max_train_steps=400
|
||||
```
|
||||
</jax>
|
||||
</frameworkcontent>
|
||||
@@ -188,8 +187,7 @@ python train_dreambooth_flax.py \
|
||||
--train_batch_size=1 \
|
||||
--learning_rate=5e-6 \
|
||||
--num_class_images=200 \
|
||||
--max_train_steps=800 \
|
||||
--push_to_hub
|
||||
--max_train_steps=800
|
||||
```
|
||||
</jax>
|
||||
</frameworkcontent>
|
||||
@@ -225,7 +223,7 @@ accelerate launch train_dreambooth.py \
|
||||
--class_prompt="a photo of dog" \
|
||||
--resolution=512 \
|
||||
--train_batch_size=1 \
|
||||
--use_8bit_adam \
|
||||
--use_8bit_adam
|
||||
--gradient_checkpointing \
|
||||
--learning_rate=2e-6 \
|
||||
--lr_scheduler="constant" \
|
||||
@@ -255,8 +253,7 @@ python train_dreambooth_flax.py \
|
||||
--train_batch_size=1 \
|
||||
--learning_rate=2e-6 \
|
||||
--num_class_images=200 \
|
||||
--max_train_steps=800 \
|
||||
--push_to_hub
|
||||
--max_train_steps=800
|
||||
```
|
||||
</jax>
|
||||
</frameworkcontent>
|
||||
@@ -502,68 +499,9 @@ You may also run inference from any of the [saved training checkpoints](#inferen
|
||||
|
||||
## IF
|
||||
|
||||
You can use the lora and full dreambooth scripts to train the text to image [IF model](https://huggingface.co/DeepFloyd/IF-I-XL-v1.0) and the stage II upscaler
|
||||
[IF model](https://huggingface.co/DeepFloyd/IF-II-L-v1.0).
|
||||
You can use the lora and full dreambooth scripts to also train the text to image [IF model](https://huggingface.co/DeepFloyd/IF-I-XL-v1.0). A few alternative cli flags are needed due to the model size, the expected input resolution, and the text encoder conventions.
|
||||
|
||||
Note that IF has a predicted variance, and our finetuning scripts only train the models predicted error, so for finetuned IF models we switch to a fixed
|
||||
variance schedule. The full finetuning scripts will update the scheduler config for the full saved model. However, when loading saved LoRA weights, you
|
||||
must also update the pipeline's scheduler config.
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipe = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0")
|
||||
|
||||
pipe.load_lora_weights("<lora weights path>")
|
||||
|
||||
# Update scheduler config to fixed variance schedule
|
||||
pipe.scheduler = pipe.scheduler.__class__.from_config(pipe.scheduler.config, variance_type="fixed_small")
|
||||
```
|
||||
|
||||
Additionally, a few alternative cli flags are needed for IF.
|
||||
|
||||
`--resolution=64`: IF is a pixel space diffusion model. In order to operate on un-compressed pixels, the input images are of a much smaller resolution.
|
||||
|
||||
`--pre_compute_text_embeddings`: IF uses [T5](https://huggingface.co/docs/transformers/model_doc/t5) for its text encoder. In order to save GPU memory, we pre compute all text embeddings and then de-allocate
|
||||
T5.
|
||||
|
||||
`--tokenizer_max_length=77`: T5 has a longer default text length, but the default IF encoding procedure uses a smaller number.
|
||||
|
||||
`--text_encoder_use_attention_mask`: T5 passes the attention mask to the text encoder.
|
||||
|
||||
### Tips and Tricks
|
||||
We find LoRA to be sufficient for finetuning the stage I model as the low resolution of the model makes representing finegrained detail hard regardless.
|
||||
|
||||
For common and/or not-visually complex object concepts, you can get away with not-finetuning the upscaler. Just be sure to adjust the prompt passed to the
|
||||
upscaler to remove the new token from the instance prompt. I.e. if your stage I prompt is "a sks dog", use "a dog" for your stage II prompt.
|
||||
|
||||
For finegrained detail like faces that aren't present in the original training set, we find that full finetuning of the stage II upscaler is better than
|
||||
LoRA finetuning stage II.
|
||||
|
||||
For finegrained detail like faces, we find that lower learning rates along with larger batch sizes work best.
|
||||
|
||||
For stage II, we find that lower learning rates are also needed.
|
||||
|
||||
We found experimentally that the DDPM scheduler with the default larger number of denoising steps to sometimes work better than the DPM Solver scheduler
|
||||
used in the training scripts.
|
||||
|
||||
### Stage II additional validation images
|
||||
|
||||
The stage II validation requires images to upscale, we can download a downsized version of the training set:
|
||||
|
||||
```py
|
||||
from huggingface_hub import snapshot_download
|
||||
|
||||
local_dir = "./dog_downsized"
|
||||
snapshot_download(
|
||||
"diffusers/dog-example-downsized",
|
||||
local_dir=local_dir,
|
||||
repo_type="dataset",
|
||||
ignore_patterns=".gitattributes",
|
||||
)
|
||||
```
|
||||
|
||||
### IF stage I LoRA Dreambooth
|
||||
### LoRA Dreambooth
|
||||
This training configuration requires ~28 GB VRAM.
|
||||
|
||||
```sh
|
||||
@@ -577,7 +515,7 @@ accelerate launch train_dreambooth_lora.py \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--instance_prompt="a sks dog" \
|
||||
--resolution=64 \
|
||||
--resolution=64 \ # The input resolution of the IF unet is 64x64
|
||||
--train_batch_size=4 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=5e-6 \
|
||||
@@ -586,58 +524,16 @@ accelerate launch train_dreambooth_lora.py \
|
||||
--validation_prompt="a sks dog" \
|
||||
--validation_epochs=25 \
|
||||
--checkpointing_steps=100 \
|
||||
--pre_compute_text_embeddings \
|
||||
--tokenizer_max_length=77 \
|
||||
--text_encoder_use_attention_mask
|
||||
--pre_compute_text_embeddings \ # Pre compute text embeddings to that T5 doesn't have to be kept in memory
|
||||
--tokenizer_max_length=77 \ # IF expects an override of the max token length
|
||||
--text_encoder_use_attention_mask # IF expects attention mask for text embeddings
|
||||
```
|
||||
|
||||
### IF stage II LoRA Dreambooth
|
||||
### Full Dreambooth
|
||||
Due to the size of the optimizer states, we recommend training the full XL IF model with 8bit adam.
|
||||
Using 8bit adam and the rest of the following config, the model can be trained in ~48 GB VRAM.
|
||||
|
||||
`--validation_images`: These images are upscaled during validation steps.
|
||||
|
||||
`--class_labels_conditioning=timesteps`: Pass additional conditioning to the UNet needed for stage II.
|
||||
|
||||
`--learning_rate=1e-6`: Lower learning rate than stage I.
|
||||
|
||||
`--resolution=256`: The upscaler expects higher resolution inputs
|
||||
|
||||
```sh
|
||||
export MODEL_NAME="DeepFloyd/IF-II-L-v1.0"
|
||||
export INSTANCE_DIR="dog"
|
||||
export OUTPUT_DIR="dreambooth_dog_upscale"
|
||||
export VALIDATION_IMAGES="dog_downsized/image_1.png dog_downsized/image_2.png dog_downsized/image_3.png dog_downsized/image_4.png"
|
||||
|
||||
python train_dreambooth_lora.py \
|
||||
--report_to wandb \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--instance_prompt="a sks dog" \
|
||||
--resolution=256 \
|
||||
--train_batch_size=4 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=1e-6 \
|
||||
--max_train_steps=2000 \
|
||||
--validation_prompt="a sks dog" \
|
||||
--validation_epochs=100 \
|
||||
--checkpointing_steps=500 \
|
||||
--pre_compute_text_embeddings \
|
||||
--tokenizer_max_length=77 \
|
||||
--text_encoder_use_attention_mask \
|
||||
--validation_images $VALIDATION_IMAGES \
|
||||
--class_labels_conditioning=timesteps
|
||||
```
|
||||
|
||||
### IF Stage I Full Dreambooth
|
||||
`--skip_save_text_encoder`: When training the full model, this will skip saving the entire T5 with the finetuned model. You can still load the pipeline
|
||||
with a T5 loaded from the original model.
|
||||
|
||||
`use_8bit_adam`: Due to the size of the optimizer states, we recommend training the full XL IF model with 8bit adam.
|
||||
|
||||
`--learning_rate=1e-7`: For full dreambooth, IF requires very low learning rates. With higher learning rates model quality will degrade. Note that it is
|
||||
likely the learning rate can be increased with larger batch sizes.
|
||||
|
||||
Using 8bit adam and a batch size of 4, the model can be trained in ~48 GB VRAM.
|
||||
For full dreambooth, IF requires very low learning rates. With higher learning rates model quality will degrade.
|
||||
|
||||
```sh
|
||||
export MODEL_NAME="DeepFloyd/IF-I-XL-v1.0"
|
||||
@@ -650,56 +546,17 @@ accelerate launch train_dreambooth.py \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--instance_prompt="a photo of sks dog" \
|
||||
--resolution=64 \
|
||||
--resolution=64 \ # The input resolution of the IF unet is 64x64
|
||||
--train_batch_size=4 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=1e-7 \
|
||||
--max_train_steps=150 \
|
||||
--validation_prompt "a photo of sks dog" \
|
||||
--validation_steps 25 \
|
||||
--text_encoder_use_attention_mask \
|
||||
--tokenizer_max_length 77 \
|
||||
--pre_compute_text_embeddings \
|
||||
--use_8bit_adam \
|
||||
--text_encoder_use_attention_mask \ # IF expects attention mask for text embeddings
|
||||
--tokenizer_max_length 77 \ # IF expects an override of the max token length
|
||||
--pre_compute_text_embeddings \ # Pre compute text embeddings to that T5 doesn't have to be kept in memory
|
||||
--use_8bit_adam \ #
|
||||
--set_grads_to_none \
|
||||
--skip_save_text_encoder \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
### IF Stage II Full Dreambooth
|
||||
|
||||
`--learning_rate=5e-6`: With a smaller effective batch size of 4, we found that we required learning rates as low as
|
||||
1e-8.
|
||||
|
||||
`--resolution=256`: The upscaler expects higher resolution inputs
|
||||
|
||||
`--train_batch_size=2` and `--gradient_accumulation_steps=6`: We found that full training of stage II particularly with
|
||||
faces required large effective batch sizes.
|
||||
|
||||
```sh
|
||||
export MODEL_NAME="DeepFloyd/IF-II-L-v1.0"
|
||||
export INSTANCE_DIR="dog"
|
||||
export OUTPUT_DIR="dreambooth_dog_upscale"
|
||||
export VALIDATION_IMAGES="dog_downsized/image_1.png dog_downsized/image_2.png dog_downsized/image_3.png dog_downsized/image_4.png"
|
||||
|
||||
accelerate launch train_dreambooth.py \
|
||||
--report_to wandb \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--instance_prompt="a sks dog" \
|
||||
--resolution=256 \
|
||||
--train_batch_size=2 \
|
||||
--gradient_accumulation_steps=6 \
|
||||
--learning_rate=5e-6 \
|
||||
--max_train_steps=2000 \
|
||||
--validation_prompt="a sks dog" \
|
||||
--validation_steps=150 \
|
||||
--checkpointing_steps=500 \
|
||||
--pre_compute_text_embeddings \
|
||||
--tokenizer_max_length=77 \
|
||||
--text_encoder_use_attention_mask \
|
||||
--validation_images $VALIDATION_IMAGES \
|
||||
--class_labels_conditioning timesteps \
|
||||
--push_to_hub
|
||||
```
|
||||
--skip_save_text_encoder # do not save the full T5 text encoder with the model
|
||||
```
|
||||
@@ -100,8 +100,7 @@ accelerate launch --mixed_precision="fp16" train_instruct_pix2pix.py \
|
||||
--learning_rate=5e-05 --max_grad_norm=1 --lr_warmup_steps=0 \
|
||||
--conditioning_dropout_prob=0.05 \
|
||||
--mixed_precision=fp16 \
|
||||
--seed=42 \
|
||||
--push_to_hub
|
||||
--seed=42
|
||||
```
|
||||
|
||||
Additionally, we support performing validation inference to monitor training progress
|
||||
@@ -122,8 +121,7 @@ accelerate launch --mixed_precision="fp16" train_instruct_pix2pix.py \
|
||||
--val_image_url="https://hf.co/datasets/diffusers/diffusers-images-docs/resolve/main/mountain.png" \
|
||||
--validation_prompt="make the mountains snowy" \
|
||||
--seed=42 \
|
||||
--report_to=wandb \
|
||||
--push_to_hub
|
||||
--report_to=wandb
|
||||
```
|
||||
|
||||
We recommend this type of validation as it can be useful for model debugging. Note that you need `wandb` installed to use this. You can install `wandb` by running `pip install wandb`.
|
||||
@@ -150,8 +148,7 @@ accelerate launch --mixed_precision="fp16" --multi_gpu train_instruct_pix2pix.py
|
||||
--learning_rate=5e-05 --lr_warmup_steps=0 \
|
||||
--conditioning_dropout_prob=0.05 \
|
||||
--mixed_precision=fp16 \
|
||||
--seed=42 \
|
||||
--push_to_hub
|
||||
--seed=42
|
||||
```
|
||||
|
||||
## Inference
|
||||
@@ -207,5 +204,3 @@ speed and quality during performance:
|
||||
|
||||
Particularly, `image_guidance_scale` and `guidance_scale` can have a profound impact
|
||||
on the generated ("edited") image (see [here](https://twitter.com/RisingSayak/status/1628392199196151808?s=20) for an example).
|
||||
|
||||
If you're looking for some interesting ways to use the InstructPix2Pix training methodology, we welcome you to check out this blog post: [Instruction-tuning Stable Diffusion with InstructPix2Pix](https://huggingface.co/blog/instruction-tuning-sd).
|
||||
@@ -260,14 +260,6 @@ pipe.load_lora_weights(lora_model_id)
|
||||
image = pipe("A picture of a sks dog in a bucket", num_inference_steps=25).images[0]
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
If your LoRA parameters involve the UNet as well as the Text Encoder, then passing
|
||||
`cross_attention_kwargs={"scale": 0.5}` will apply the `scale` value to both the UNet
|
||||
and the Text Encoder.
|
||||
|
||||
</Tip>
|
||||
|
||||
Note that the use of [`~diffusers.loaders.LoraLoaderMixin.load_lora_weights`] is preferred to [`~diffusers.loaders.UNet2DConditionLoadersMixin.load_attn_procs`] for loading LoRA parameters. This is because
|
||||
[`~diffusers.loaders.LoraLoaderMixin.load_lora_weights`] can handle the following situations:
|
||||
|
||||
@@ -280,75 +272,4 @@ Note that the use of [`~diffusers.loaders.LoraLoaderMixin.load_lora_weights`] is
|
||||
* LoRA parameters that have separate identifiers for the UNet and the text encoder such as: [`"sayakpaul/dreambooth"`](https://huggingface.co/sayakpaul/dreambooth).
|
||||
|
||||
**Note** that it is possible to provide a local directory path to [`~diffusers.loaders.LoraLoaderMixin.load_lora_weights`] as well as [`~diffusers.loaders.UNet2DConditionLoadersMixin.load_attn_procs`]. To know about the supported inputs,
|
||||
refer to the respective docstrings.
|
||||
|
||||
## Supporting A1111 themed LoRA checkpoints from Diffusers
|
||||
|
||||
To provide seamless interoperability with A1111 to our users, we support loading A1111 formatted
|
||||
LoRA checkpoints using [`~diffusers.loaders.LoraLoaderMixin.load_lora_weights`] in a limited capacity.
|
||||
In this section, we explain how to load an A1111 formatted LoRA checkpoint from [CivitAI](https://civitai.com/)
|
||||
in Diffusers and perform inference with it.
|
||||
|
||||
First, download a checkpoint. We'll use
|
||||
[this one](https://civitai.com/models/13239/light-and-shadow) for demonstration purposes.
|
||||
|
||||
```bash
|
||||
wget https://civitai.com/api/download/models/15603 -O light_and_shadow.safetensors
|
||||
```
|
||||
|
||||
Next, we initialize a [`~DiffusionPipeline`]:
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
|
||||
|
||||
pipeline = StableDiffusionPipeline.from_pretrained(
|
||||
"gsdf/Counterfeit-V2.5", torch_dtype=torch.float16, safety_checker=None
|
||||
).to("cuda")
|
||||
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(
|
||||
pipeline.scheduler.config, use_karras_sigmas=True
|
||||
)
|
||||
```
|
||||
|
||||
We then load the checkpoint downloaded from CivitAI:
|
||||
|
||||
```python
|
||||
pipeline.load_lora_weights(".", weight_name="light_and_shadow.safetensors")
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
If you're loading a checkpoint in the `safetensors` format, please ensure you have `safetensors` installed.
|
||||
|
||||
</Tip>
|
||||
|
||||
And then it's time for running inference:
|
||||
|
||||
```python
|
||||
prompt = "masterpiece, best quality, 1girl, at dusk"
|
||||
negative_prompt = ("(low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), "
|
||||
"bad composition, inaccurate eyes, extra digit, fewer digits, (extra arms:1.2), large breasts")
|
||||
|
||||
images = pipeline(prompt=prompt,
|
||||
negative_prompt=negative_prompt,
|
||||
width=512,
|
||||
height=768,
|
||||
num_inference_steps=15,
|
||||
num_images_per_prompt=4,
|
||||
generator=torch.manual_seed(0)
|
||||
).images
|
||||
```
|
||||
|
||||
Below is a comparison between the LoRA and the non-LoRA results:
|
||||
|
||||

|
||||
|
||||
You have a similar checkpoint stored on the Hugging Face Hub, you can load it
|
||||
directly with [`~diffusers.loaders.LoraLoaderMixin.load_lora_weights`] like so:
|
||||
|
||||
```python
|
||||
lora_model_id = "sayakpaul/civitai-light-shadow-lora"
|
||||
lora_filename = "light_and_shadow.safetensors"
|
||||
pipeline.load_lora_weights(lora_model_id, weight_name=lora_filename)
|
||||
```
|
||||
refer to the respective docstrings.
|
||||
@@ -76,25 +76,13 @@ Launch the [PyTorch training script](https://github.com/huggingface/diffusers/bl
|
||||
|
||||
Specify the `MODEL_NAME` environment variable (either a Hub model repository id or a path to the directory containing the model weights) and pass it to the [`pretrained_model_name_or_path`](https://huggingface.co/docs/diffusers/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.from_pretrained.pretrained_model_name_or_path) argument.
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
|
||||
export dataset_name="lambdalabs/pokemon-blip-captions"
|
||||
|
||||
accelerate launch --mixed_precision="fp16" train_text_to_image.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--dataset_name=$dataset_name \
|
||||
--use_ema \
|
||||
--resolution=512 --center_crop --random_flip \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--gradient_checkpointing \
|
||||
--max_train_steps=15000 \
|
||||
--learning_rate=1e-05 \
|
||||
--max_grad_norm=1 \
|
||||
--lr_scheduler="constant" --lr_warmup_steps=0 \
|
||||
--output_dir="sd-pokemon-model" \
|
||||
--push_to_hub
|
||||
```
|
||||
<literalinclude>
|
||||
{"path": "../../../../examples/text_to_image/README.md",
|
||||
"language": "bash",
|
||||
"start-after": "accelerate_snippet_start",
|
||||
"end-before": "accelerate_snippet_end",
|
||||
"dedent": 0}
|
||||
</literalinclude>
|
||||
|
||||
To finetune on your own dataset, prepare the dataset according to the format required by 🤗 [Datasets](https://huggingface.co/docs/datasets/index). You can [upload your dataset to the Hub](https://huggingface.co/docs/datasets/image_dataset#upload-dataset-to-the-hub), or you can [prepare a local folder with your files](https://huggingface.co/docs/datasets/image_dataset#imagefolder).
|
||||
|
||||
@@ -117,10 +105,8 @@ accelerate launch train_text_to_image.py \
|
||||
--max_train_steps=15000 \
|
||||
--learning_rate=1e-05 \
|
||||
--max_grad_norm=1 \
|
||||
--lr_scheduler="constant"
|
||||
--lr_warmup_steps=0 \
|
||||
--output_dir=${OUTPUT_DIR} \
|
||||
--push_to_hub
|
||||
--lr_scheduler="constant" --lr_warmup_steps=0 \
|
||||
--output_dir=${OUTPUT_DIR}
|
||||
```
|
||||
|
||||
#### Training with multiple GPUs
|
||||
@@ -143,10 +129,8 @@ accelerate launch --mixed_precision="fp16" --multi_gpu train_text_to_image.py \
|
||||
--max_train_steps=15000 \
|
||||
--learning_rate=1e-05 \
|
||||
--max_grad_norm=1 \
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--output_dir="sd-pokemon-model" \
|
||||
--push_to_hub
|
||||
--lr_scheduler="constant" --lr_warmup_steps=0 \
|
||||
--output_dir="sd-pokemon-model"
|
||||
```
|
||||
|
||||
</pt>
|
||||
@@ -175,8 +159,7 @@ python train_text_to_image_flax.py \
|
||||
--max_train_steps=15000 \
|
||||
--learning_rate=1e-05 \
|
||||
--max_grad_norm=1 \
|
||||
--output_dir="sd-pokemon-model" \
|
||||
--push_to_hub
|
||||
--output_dir="sd-pokemon-model"
|
||||
```
|
||||
|
||||
To finetune on your own dataset, prepare the dataset according to the format required by 🤗 [Datasets](https://huggingface.co/docs/datasets/index). You can [upload your dataset to the Hub](https://huggingface.co/docs/datasets/image_dataset#upload-dataset-to-the-hub), or you can [prepare a local folder with your files](https://huggingface.co/docs/datasets/image_dataset#imagefolder).
|
||||
@@ -196,8 +179,7 @@ python train_text_to_image_flax.py \
|
||||
--max_train_steps=15000 \
|
||||
--learning_rate=1e-05 \
|
||||
--max_grad_norm=1 \
|
||||
--output_dir="sd-pokemon-model" \
|
||||
--push_to_hub
|
||||
--output_dir="sd-pokemon-model"
|
||||
```
|
||||
</jax>
|
||||
</frameworkcontent>
|
||||
|
||||
@@ -120,8 +120,7 @@ accelerate launch textual_inversion.py \
|
||||
--learning_rate=5.0e-04 --scale_lr \
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--output_dir="textual_inversion_cat" \
|
||||
--push_to_hub
|
||||
--output_dir="textual_inversion_cat"
|
||||
```
|
||||
|
||||
<Tip>
|
||||
@@ -162,8 +161,7 @@ python textual_inversion_flax.py \
|
||||
--train_batch_size=1 \
|
||||
--max_train_steps=3000 \
|
||||
--learning_rate=5.0e-04 --scale_lr \
|
||||
--output_dir="textual_inversion_cat" \
|
||||
--push_to_hub
|
||||
--output_dir="textual_inversion_cat"
|
||||
```
|
||||
</jax>
|
||||
</frameworkcontent>
|
||||
|
||||
@@ -141,6 +141,5 @@ accelerate launch --mixed_precision="fp16" --multi_gpu train_unconditional.py \
|
||||
--learning_rate=1e-4 \
|
||||
--lr_warmup_steps=500 \
|
||||
--mixed_precision="fp16" \
|
||||
--logger="wandb" \
|
||||
--push_to_hub
|
||||
--logger="wandb"
|
||||
```
|
||||
@@ -407,9 +407,9 @@ Once training is complete, take a look at the final 🦋 images 🦋 generated b
|
||||
|
||||
## Next steps
|
||||
|
||||
Unconditional image generation is one example of a task that can be trained. You can explore other tasks and training techniques by visiting the [🧨 Diffusers Training Examples](../training/overview) page. Here are some examples of what you can learn:
|
||||
Unconditional image generation is one example of a task that can be trained. You can explore other tasks and training techniques by visiting the [🧨 Diffusers Training Examples](./training/overview) page. Here are some examples of what you can learn:
|
||||
|
||||
* [Textual Inversion](../training/text_inversion), an algorithm that teaches a model a specific visual concept and integrates it into the generated image.
|
||||
* [DreamBooth](../training/dreambooth), a technique for generating personalized images of a subject given several input images of the subject.
|
||||
* [Guide](../training/text2image) to finetuning a Stable Diffusion model on your own dataset.
|
||||
* [Guide](../training/lora) to using LoRA, a memory-efficient technique for finetuning really large models faster.
|
||||
* [Textual Inversion](./training/text_inversion), an algorithm that teaches a model a specific visual concept and integrates it into the generated image.
|
||||
* [DreamBooth](./training/dreambooth), a technique for generating personalized images of a subject given several input images of the subject.
|
||||
* [Guide](./training/text2image) to finetuning a Stable Diffusion model on your own dataset.
|
||||
* [Guide](./training/lora) to using LoRA, a memory-efficient technique for finetuning really large models faster.
|
||||
|
||||
@@ -20,12 +20,12 @@ The [`DiffusionPipeline`] is the easiest way to use a pre-trained diffusion syst
|
||||
|
||||
Start by creating an instance of [`DiffusionPipeline`] and specify which pipeline [checkpoint](https://huggingface.co/models?library=diffusers&sort=downloads) you would like to download.
|
||||
|
||||
In this guide, you'll use [`DiffusionPipeline`] for text-to-image generation with [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5):
|
||||
In this guide, you'll use [`DiffusionPipeline`] for text-to-image generation with [Latent Diffusion](https://huggingface.co/CompVis/ldm-text2im-large-256):
|
||||
|
||||
```python
|
||||
>>> from diffusers import DiffusionPipeline
|
||||
|
||||
>>> generator = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
|
||||
>>> generator = DiffusionPipeline.from_pretrained("CompVis/ldm-text2im-large-256")
|
||||
```
|
||||
|
||||
The [`DiffusionPipeline`] downloads and caches all modeling, tokenization, and scheduling components.
|
||||
|
||||
179
docs/source/en/using-diffusers/kerascv.mdx
Normal file
179
docs/source/en/using-diffusers/kerascv.mdx
Normal file
@@ -0,0 +1,179 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Using KerasCV Stable Diffusion Checkpoints in Diffusers
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This is an experimental feature.
|
||||
|
||||
</Tip>
|
||||
|
||||
[KerasCV](https://github.com/keras-team/keras-cv/) provides APIs for implementing various computer vision workflows. It
|
||||
also provides the Stable Diffusion [v1 and v2](https://github.com/keras-team/keras-cv/blob/master/keras_cv/models/stable_diffusion)
|
||||
models. Many practitioners find it easy to fine-tune the Stable Diffusion models shipped by KerasCV. However, as of this writing, KerasCV offers limited support to experiment with Stable Diffusion models for inference and deployment. On the other hand,
|
||||
Diffusers provides tooling dedicated to this purpose (and more), such as different [noise schedulers](https://huggingface.co/docs/diffusers/using-diffusers/schedulers), [flash attention](https://huggingface.co/docs/diffusers/optimization/xformers), and [other
|
||||
optimization techniques](https://huggingface.co/docs/diffusers/optimization/fp16).
|
||||
|
||||
How about fine-tuning Stable Diffusion models in KerasCV and exporting them such that they become compatible with Diffusers to combine the
|
||||
best of both worlds? We have created a [tool](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers) that
|
||||
lets you do just that! It takes KerasCV Stable Diffusion checkpoints and exports them to Diffusers-compatible checkpoints.
|
||||
More specifically, it first converts the checkpoints to PyTorch and then wraps them into a
|
||||
[`StableDiffusionPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview) which is ready
|
||||
for inference. Finally, it pushes the converted checkpoints to a repository on the Hugging Face Hub.
|
||||
|
||||
We welcome you to try out the tool [here](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers)
|
||||
and share feedback via [discussions](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers/discussions/new).
|
||||
|
||||
## Getting Started
|
||||
|
||||
First, you need to obtain the fine-tuned KerasCV Stable Diffusion checkpoints. We provide an
|
||||
overview of the different ways Stable Diffusion models can be fine-tuned [using `diffusers`](https://huggingface.co/docs/diffusers/training/overview). For the Keras implementation of some of these methods, you can check out these resources:
|
||||
|
||||
* [Teach StableDiffusion new concepts via Textual Inversion](https://keras.io/examples/generative/fine_tune_via_textual_inversion/)
|
||||
* [Fine-tuning Stable Diffusion](https://keras.io/examples/generative/finetune_stable_diffusion/)
|
||||
* [DreamBooth](https://keras.io/examples/generative/dreambooth/)
|
||||
* [Prompt-to-Prompt editing](https://github.com/miguelCalado/prompt-to-prompt-tensorflow)
|
||||
|
||||
Stable Diffusion is comprised of the following models:
|
||||
|
||||
* Text encoder
|
||||
* UNet
|
||||
* VAE
|
||||
|
||||
Depending on the fine-tuning task, we may fine-tune one or more of these components (the VAE is almost always left untouched). Here are some common combinations:
|
||||
|
||||
* DreamBooth: UNet and text encoder
|
||||
* Classical text to image fine-tuning: UNet
|
||||
* Textual Inversion: Just the newly initialized embeddings in the text encoder
|
||||
|
||||
### Performing the Conversion
|
||||
|
||||
Let's use [this checkpoint](https://huggingface.co/sayakpaul/textual-inversion-kerasio/resolve/main/textual_inversion_kerasio.h5) which was generated
|
||||
by conducting Textual Inversion with the following "placeholder token": `<my-funny-cat-token>`.
|
||||
|
||||
On the tool, we supply the following things:
|
||||
|
||||
* Path(s) to download the fine-tuned checkpoint(s) (KerasCV)
|
||||
* An HF token
|
||||
* Placeholder token (only applicable for Textual Inversion)
|
||||
|
||||
<div align="center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/space_snap.png"/>
|
||||
</div>
|
||||
|
||||
As soon as you hit "Submit", the conversion process will begin. Once it's complete, you should see the following:
|
||||
|
||||
<div align="center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/model_push_success.png"/>
|
||||
</div>
|
||||
|
||||
If you click the [link](https://huggingface.co/sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline/tree/main), you
|
||||
should see something like so:
|
||||
|
||||
<div align="center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/model_repo_contents.png"/>
|
||||
</div>
|
||||
|
||||
If you head over to the [model card of the repository](https://huggingface.co/sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline), the
|
||||
following should appear:
|
||||
|
||||
<div align="center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/model_card.png"/>
|
||||
</div>
|
||||
|
||||
<Tip>
|
||||
|
||||
Note that we're not specifying the UNet weights here since the UNet is not fine-tuned during Textual Inversion.
|
||||
|
||||
</Tip>
|
||||
|
||||
And that's it! You now have your fine-tuned KerasCV Stable Diffusion model in Diffusers 🧨.
|
||||
|
||||
## Using the Converted Model in Diffusers
|
||||
|
||||
Just beside the model card of the [repository](https://huggingface.co/sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline),
|
||||
you'd notice an inference widget to try out the model directly from the UI 🤗
|
||||
|
||||
<div align="center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/inference_widget_output.png"/>
|
||||
</div>
|
||||
|
||||
On the top right hand side, we provide a "Use in Diffusers" button. If you click the button, you should see the following code-snippet:
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained("sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline")
|
||||
```
|
||||
|
||||
The model is in standard `diffusers` format. Let's perform inference!
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained("sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline")
|
||||
pipeline.to("cuda")
|
||||
|
||||
placeholder_token = "<my-funny-cat-token>"
|
||||
prompt = f"two {placeholder_token} getting married, photorealistic, high quality"
|
||||
image = pipeline(prompt, num_inference_steps=50).images[0]
|
||||
```
|
||||
|
||||
And we get:
|
||||
|
||||
<div align="center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/diffusers_output_one.png"/>
|
||||
</div>
|
||||
|
||||
_**Note that if you specified a `placeholder_token` while performing the conversion, the tool will log it accordingly. Refer
|
||||
to the model card of [this repository](https://huggingface.co/sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline)
|
||||
as an example.**_
|
||||
|
||||
We welcome you to use the tool for various Stable Diffusion fine-tuning scenarios and let us know your feedback! Here are some examples
|
||||
of Diffusers checkpoints that were obtained using the tool:
|
||||
|
||||
* [sayakpaul/text-unet-dogs-kerascv_sd_diffusers_pipeline](https://huggingface.co/sayakpaul/text-unet-dogs-kerascv_sd_diffusers_pipeline) (DreamBooth with both the text encoder and UNet fine-tuned)
|
||||
* [sayakpaul/unet-dogs-kerascv_sd_diffusers_pipeline](https://huggingface.co/sayakpaul/unet-dogs-kerascv_sd_diffusers_pipeline) (DreamBooth with only the UNet fine-tuned)
|
||||
|
||||
## Incorporating Diffusers Goodies 🎁
|
||||
|
||||
Diffusers provides various options that one can leverage to experiment with different inference setups. One particularly
|
||||
useful option is the use of a different noise scheduler during inference other than what was used during fine-tuning.
|
||||
Let's try out the [`DPMSolverMultistepScheduler`](https://huggingface.co/docs/diffusers/main/en/api/schedulers/multistep_dpm_solver)
|
||||
which is different from the one ([`DDPMScheduler`](https://huggingface.co/docs/diffusers/main/en/api/schedulers/ddpm)) used during
|
||||
fine-tuning.
|
||||
|
||||
You can read more details about this process in [this section](https://huggingface.co/docs/diffusers/using-diffusers/schedulers).
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained("sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline")
|
||||
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
|
||||
pipeline.to("cuda")
|
||||
|
||||
placeholder_token = "<my-funny-cat-token>"
|
||||
prompt = f"two {placeholder_token} getting married, photorealistic, high quality"
|
||||
image = pipeline(prompt, num_inference_steps=50).images[0]
|
||||
```
|
||||
|
||||
<div align="center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/diffusers_output_two.png"/>
|
||||
</div>
|
||||
|
||||
One can also continue fine-tuning from these Diffusers checkpoints by leveraging some relevant tools from Diffusers. Refer [here](https://huggingface.co/docs/diffusers/training/overview) for
|
||||
more details. For inference-specific optimizations, refer [here](https://huggingface.co/docs/diffusers/main/en/optimization/fp16).
|
||||
|
||||
## Known Limitations
|
||||
|
||||
* Only Stable Diffusion v1 checkpoints are supported for conversion in this tool.
|
||||
@@ -1,191 +0,0 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Load different Stable Diffusion formats
|
||||
|
||||
Stable Diffusion models are available in different formats depending on the framework they're trained and saved with, and where you download them from. Converting these formats for use in 🤗 Diffusers allows you to use all the features supported by the library, such as [using different schedulers](schedulers) for inference, [building your custom pipeline](write_own_pipeline), and a variety of techniques and methods for [optimizing inference speed](./optimization/opt_overview).
|
||||
|
||||
<Tip>
|
||||
|
||||
We highly recommend using the `.safetensors` format because it is more secure than traditional pickled files which are vulnerable and can be exploited to execute any code on your machine (learn more in the [Load safetensors](using_safetensors) guide).
|
||||
|
||||
</Tip>
|
||||
|
||||
This guide will show you how to convert other Stable Diffusion formats to be compatible with 🤗 Diffusers.
|
||||
|
||||
## PyTorch .ckpt
|
||||
|
||||
The checkpoint - or `.ckpt` - format is commonly used to store and save models. The `.ckpt` file contains the entire model and is typically several GBs in size. While you can load and use a `.ckpt` file directly with the [`~StableDiffusionPipeline.from_ckpt`] method, it is generally better to convert the `.ckpt` file to 🤗 Diffusers so both formats are available.
|
||||
|
||||
There are two options for converting a `.ckpt` file; use a Space to convert the checkpoint or convert the `.ckpt` file with a script.
|
||||
|
||||
### Convert with a Space
|
||||
|
||||
The easiest and most convenient way to convert a `.ckpt` file is to use the [SD to Diffusers](https://huggingface.co/spaces/diffusers/sd-to-diffusers) Space. You can follow the instructions on the Space to convert the `.ckpt` file.
|
||||
|
||||
This approach works well for basic models, but it may struggle with more customized models. You'll know the Space failed if it returns an empty pull request or error. In this case, you can try converting the `.ckpt` file with a script.
|
||||
|
||||
### Convert with a script
|
||||
|
||||
🤗 Diffusers provides a [conversion script](https://github.com/huggingface/diffusers/blob/main/scripts/convert_original_stable_diffusion_to_diffusers.py) for converting `.ckpt` files. This approach is more reliable than the Space above.
|
||||
|
||||
Before you start, make sure you have a local clone of 🤗 Diffusers to run the script and log in to your Hugging Face account so you can open pull requests and push your converted model to the Hub.
|
||||
|
||||
```bash
|
||||
huggingface-cli login
|
||||
```
|
||||
|
||||
To use the script:
|
||||
|
||||
1. Git clone the repository containing the `.ckpt` file you want to convert. For this example, let's convert this [TemporalNet](https://huggingface.co/CiaraRowles/TemporalNet) `.ckpt` file:
|
||||
|
||||
```bash
|
||||
git lfs install
|
||||
git clone https://huggingface.co/CiaraRowles/TemporalNet
|
||||
```
|
||||
|
||||
2. Open a pull request on the repository where you're converting the checkpoint from:
|
||||
|
||||
```bash
|
||||
cd TemporalNet && git fetch origin refs/pr/13:pr/13
|
||||
git checkout pr/13
|
||||
```
|
||||
|
||||
3. There are several input arguments to configure in the conversion script, but the most important ones are:
|
||||
|
||||
- `checkpoint_path`: the path to the `.ckpt` file to convert.
|
||||
- `original_config_file`: a YAML file defining the configuration of the original architecture. If you can't find this file, try searching for the YAML file in the GitHub repository where you found the `.ckpt` file.
|
||||
- `dump_path`: the path to the converted model.
|
||||
|
||||
For example, you can take the `cldm_v15.yaml` file from the [ControlNet](https://github.com/lllyasviel/ControlNet/tree/main/models) repository because the TemporalNet model is a Stable Diffusion v1.5 and ControlNet model.
|
||||
|
||||
4. Now you can run the script to convert the `.ckpt` file:
|
||||
|
||||
```bash
|
||||
python ../diffusers/scripts/convert_original_stable_diffusion_to_diffusers.py --checkpoint_path temporalnetv3.ckpt --original_config_file cldm_v15.yaml --dump_path ./ --controlnet
|
||||
```
|
||||
|
||||
5. Once the conversion is done, upload your converted model and test out the resulting [pull request](https://huggingface.co/CiaraRowles/TemporalNet/discussions/13)!
|
||||
|
||||
```bash
|
||||
git push origin pr/13:refs/pr/13
|
||||
```
|
||||
|
||||
## Keras .pb or .h5
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
🧪 This is an experimental feature. Only Stable Diffusion v1 checkpoints are supported by the Convert KerasCV Space at the moment.
|
||||
|
||||
</Tip>
|
||||
|
||||
[KerasCV](https://keras.io/keras_cv/) supports training for [Stable Diffusion](https://github.com/keras-team/keras-cv/blob/master/keras_cv/models/stable_diffusion) v1 and v2. However, it offers limited support for experimenting with Stable Diffusion models for inference and deployment whereas 🤗 Diffusers has a more complete set of features for this purpose, such as different [noise schedulers](https://huggingface.co/docs/diffusers/using-diffusers/schedulers), [flash attention](https://huggingface.co/docs/diffusers/optimization/xformers), and [other
|
||||
optimization techniques](https://huggingface.co/docs/diffusers/optimization/fp16).
|
||||
|
||||
The [Convert KerasCV](https://huggingface.co/spaces/sayakpaul/convert-kerascv-sd-diffusers) Space converts `.pb` or `.h5` files to PyTorch, and then wraps them in a [`StableDiffusionPipeline`] so it is ready for inference. The converted checkpoint is stored in a repository on the Hugging Face Hub.
|
||||
|
||||
For this example, let's convert the [`sayakpaul/textual-inversion-kerasio`](https://huggingface.co/sayakpaul/textual-inversion-kerasio/tree/main) checkpoint which was trained with Textual Inversion. It uses the special token `<my-funny-cat>` to personalize images with cats.
|
||||
|
||||
The Convert KerasCV Space allows you to input the following:
|
||||
|
||||
* Your Hugging Face token.
|
||||
* Paths to download the UNet and text encoder weights from. Depending on how the model was trained, you don't necessarily need to provide the paths to both the UNet and text encoder. For example, Textual Inversion only requires the embeddings from the text encoder and a text-to-image model only requires the UNet weights.
|
||||
* Placeholder token is only applicable for textual inversion models.
|
||||
* The `output_repo_prefix` is the name of the repository where the converted model is stored.
|
||||
|
||||
Click the **Submit** button to automatically convert the KerasCV checkpoint! Once the checkpoint is successfully converted, you'll see a link to the new repository containing the converted checkpoint. Follow the link to the new repository, and you'll see the Convert KerasCV Space generated a model card with an inference widget to try out the converted model.
|
||||
|
||||
If you prefer to run inference with code, click on the **Use in Diffusers** button in the upper right corner of the model card to copy and paste the code snippet:
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained("sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline")
|
||||
```
|
||||
|
||||
Then you can generate an image like:
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained("sayakpaul/textual-inversion-cat-kerascv_sd_diffusers_pipeline")
|
||||
pipeline.to("cuda")
|
||||
|
||||
placeholder_token = "<my-funny-cat-token>"
|
||||
prompt = f"two {placeholder_token} getting married, photorealistic, high quality"
|
||||
image = pipeline(prompt, num_inference_steps=50).images[0]
|
||||
```
|
||||
|
||||
## A1111 LoRA files
|
||||
|
||||
[Automatic1111](https://github.com/AUTOMATIC1111/stable-diffusion-webui) (A1111) is a popular web UI for Stable Diffusion that supports model sharing platforms like [Civitai](https://civitai.com/). Models trained with the Low-Rank Adaptation (LoRA) technique are especially popular because they're fast to train and have a much smaller file size than a fully finetuned model. 🤗 Diffusers supports loading A1111 LoRA checkpoints with [`~loaders.LoraLoaderMixin.load_lora_weights`]:
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline, UniPCMultistepScheduler
|
||||
import torch
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"andite/anything-v4.0", torch_dtype=torch.float16, safety_checker=None
|
||||
).to("cuda")
|
||||
pipeline.scheduler = UniPCMultistepScheduler.from_config(pipeline.scheduler.config)
|
||||
```
|
||||
|
||||
Download a LoRA checkpoint from Civitai; this example uses the [Howls Moving Castle,Interior/Scenery LoRA (Ghibli Stlye)](https://civitai.com/models/14605?modelVersionId=19998) checkpoint, but feel free to try out any LoRA checkpoint!
|
||||
|
||||
```bash
|
||||
!wget https://civitai.com/api/download/models/19998 -O howls_moving_castle.safetensors
|
||||
```
|
||||
|
||||
Load the LoRA checkpoint into the pipeline with the [`~loaders.LoraLoaderMixin.load_lora_weights`] method:
|
||||
|
||||
```py
|
||||
pipeline.load_lora_weights(".", weight_name="howls_moving_castle.safetensors")
|
||||
```
|
||||
|
||||
Now you can use the pipeline to generate images:
|
||||
|
||||
```py
|
||||
prompt = "masterpiece, illustration, ultra-detailed, cityscape, san francisco, golden gate bridge, california, bay area, in the snow, beautiful detailed starry sky"
|
||||
negative_prompt = "lowres, cropped, worst quality, low quality, normal quality, artifacts, signature, watermark, username, blurry, more than one bridge, bad architecture"
|
||||
|
||||
images = pipeline(
|
||||
prompt=prompt,
|
||||
negative_prompt=negative_prompt,
|
||||
width=512,
|
||||
height=512,
|
||||
num_inference_steps=25,
|
||||
num_images_per_prompt=4,
|
||||
generator=torch.manual_seed(0),
|
||||
).images
|
||||
```
|
||||
|
||||
Finally, create a helper function to display the images:
|
||||
|
||||
```py
|
||||
from PIL import Image
|
||||
|
||||
|
||||
def image_grid(imgs, rows=2, cols=2):
|
||||
w, h = imgs[0].size
|
||||
grid = Image.new("RGB", size=(cols * w, rows * h))
|
||||
|
||||
for i, img in enumerate(imgs):
|
||||
grid.paste(img, box=(i % cols * w, i // cols * h))
|
||||
return grid
|
||||
|
||||
|
||||
image_grid(images)
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/a1111-lora-sf.png"/>
|
||||
</div>
|
||||
@@ -111,7 +111,7 @@ print(np.abs(image).sum())
|
||||
|
||||
The result is not the same even though you're using an identical seed because the GPU uses a different random number generator than the CPU.
|
||||
|
||||
To circumvent this problem, 🧨 Diffusers has a [`~diffusers.utils.randn_tensor`] function for creating random noise on the CPU, and then moving the tensor to a GPU if necessary. The `randn_tensor` function is used everywhere inside the pipeline, allowing the user to **always** pass a CPU `Generator` even if the pipeline is run on a GPU.
|
||||
To circumvent this problem, 🧨 Diffusers has a [`randn_tensor`](#diffusers.utils.randn_tensor) function for creating random noise on the CPU, and then moving the tensor to a GPU if necessary. The `randn_tensor` function is used everywhere inside the pipeline, allowing the user to **always** pass a CPU `Generator` even if the pipeline is run on a GPU.
|
||||
|
||||
You'll see the results are much closer now!
|
||||
|
||||
@@ -147,6 +147,9 @@ susceptible to precision error propagation. Don't expect similar results across
|
||||
different GPU hardware or PyTorch versions. In this case, you'll need to run
|
||||
exactly the same hardware and PyTorch version for full reproducibility.
|
||||
|
||||
### randn_tensor
|
||||
[[autodoc]] diffusers.utils.randn_tensor
|
||||
|
||||
## Deterministic algorithms
|
||||
|
||||
You can also configure PyTorch to use deterministic algorithms to create a reproducible pipeline. However, you should be aware that deterministic algorithms may be slower than nondeterministic ones and you may observe a decrease in performance. But if reproducibility is important to you, then this is the way to go!
|
||||
|
||||
@@ -28,15 +28,18 @@ The following paragraphs show how to do so with the 🧨 Diffusers library.
|
||||
|
||||
## Load pipeline
|
||||
|
||||
Let's start by loading the [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5) model in the [`DiffusionPipeline`]:
|
||||
Let's start by loading the stable diffusion pipeline.
|
||||
Remember that you have to be a registered user on the 🤗 Hugging Face Hub, and have "click-accepted" the [license](https://huggingface.co/runwayml/stable-diffusion-v1-5) in order to use stable diffusion.
|
||||
|
||||
```python
|
||||
from huggingface_hub import login
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
|
||||
# first we need to login with our access token
|
||||
login()
|
||||
|
||||
# Now we can download the pipeline
|
||||
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16)
|
||||
```
|
||||
|
||||
|
||||
@@ -30,7 +30,14 @@ pipeline = StableDiffusionPipeline.from_ckpt(
|
||||
|
||||
## Convert to safetensors
|
||||
|
||||
Not all weights on the Hub are available in the `.safetensors` format, and you may encounter weights stored as `.bin`. In this case, use the [Convert Space](https://huggingface.co/spaces/diffusers/convert) to convert the weights to `.safetensors`. The Convert Space downloads the pickled weights, converts them, and opens a Pull Request to upload the newly converted `.safetensors` file on the Hub. This way, if there is any malicious code contained in the pickled files, they're uploaded to the Hub - which has a [security scanner](https://huggingface.co/docs/hub/security-pickle#hubs-security-scanner) to detect unsafe files and suspicious pickle imports - instead of your computer.
|
||||
Not all weights on the Hub are available in the `.safetensors` format, and you may encounter weights stored as `.bin`. In this case, use the Space below to convert the weights to `.safetensors`. The Convert Space downloads the pickled weights, converts them, and opens a Pull Request to upload the newly converted `.safetensors` file on the Hub. This way, if there is any malicious code contained in the pickled files, they're uploaded to the Hub - which has a [security scanner](https://huggingface.co/docs/hub/security-pickle#hubs-security-scanner) to detect unsafe files and suspicious pickle imports - instead of your computer.
|
||||
|
||||
<iframe
|
||||
src="https://safetensors-convert.hf.space"
|
||||
frameborder="0"
|
||||
width="850"
|
||||
height="450"
|
||||
></iframe>
|
||||
|
||||
You can use the model with the new `.safetensors` weights by specifying the reference to the Pull Request in the `revision` parameter (you can also test it in this [Check PR](https://huggingface.co/spaces/diffusers/check_pr) Space on the Hub), for example `refs/pr/22`:
|
||||
|
||||
|
||||
@@ -94,15 +94,5 @@ a try!
|
||||
If your favorite pipeline does not have a `prompt_embeds` input, please make sure to open an issue, the
|
||||
diffusers team tries to be as responsive as possible.
|
||||
|
||||
Compel 1.1.6 adds a utility class to simplify using textual inversions. Instantiate a `DiffusersTextualInversionManager` and pass it to Compel init:
|
||||
|
||||
```
|
||||
textual_inversion_manager = DiffusersTextualInversionManager(pipe)
|
||||
compel = Compel(
|
||||
tokenizer=pipe.tokenizer,
|
||||
text_encoder=pipe.text_encoder,
|
||||
textual_inversion_manager=textual_inversion_manager)
|
||||
```
|
||||
|
||||
Also, please check out the documentation of the [compel](https://github.com/damian0815/compel) library for
|
||||
more information.
|
||||
|
||||
@@ -36,7 +36,7 @@ A pipeline is a quick and easy way to run a model for inference, requiring no mo
|
||||
|
||||
That was super easy, but how did the pipeline do that? Let's breakdown the pipeline and take a look at what's happening under the hood.
|
||||
|
||||
In the example above, the pipeline contains a [`UNet2DModel`] model and a [`DDPMScheduler`]. The pipeline denoises an image by taking random noise the size of the desired output and passing it through the model several times. At each timestep, the model predicts the *noise residual* and the scheduler uses it to predict a less noisy image. The pipeline repeats this process until it reaches the end of the specified number of inference steps.
|
||||
In the example above, the pipeline contains a UNet model and a DDPM scheduler. The pipeline denoises an image by taking random noise the size of the desired output and passing it through the model several times. At each timestep, the model predicts the *noise residual* and the scheduler uses it to predict a less noisy image. The pipeline repeats this process until it reaches the end of the specified number of inference steps.
|
||||
|
||||
To recreate the pipeline with the model and scheduler separately, let's write our own denoising process.
|
||||
|
||||
|
||||
@@ -36,8 +36,6 @@ If a community doesn't work as expected, please open an issue and ping the autho
|
||||
| Stable Diffusion RePaint | Stable Diffusion pipeline using [RePaint](https://arxiv.org/abs/2201.0986) for inpainting. | [Stable Diffusion RePaint](#stable-diffusion-repaint ) | - | [Markus Pobitzer](https://github.com/Markus-Pobitzer) |
|
||||
| TensorRT Stable Diffusion Image to Image Pipeline | Accelerates the Stable Diffusion Image2Image Pipeline using TensorRT | [TensorRT Stable Diffusion Image to Image Pipeline](#tensorrt-image2image-stable-diffusion-pipeline) | - | [Asfiya Baig](https://github.com/asfiyab-nvidia) |
|
||||
| Stable Diffusion IPEX Pipeline | Accelerate Stable Diffusion inference pipeline with BF16/FP32 precision on Intel Xeon CPUs with [IPEX](https://github.com/intel/intel-extension-for-pytorch) | [Stable Diffusion on IPEX](#stable-diffusion-on-ipex) | - | [Yingjie Han](https://github.com/yingjie-han/) |
|
||||
| CLIP Guided Images Mixing Stable Diffusion Pipeline | Сombine images using usual diffusion models. | [CLIP Guided Images Mixing Using Stable Diffusion](#clip-guided-images-mixing-with-stable-diffusion) | - | [Karachev Denis](https://github.com/TheDenk) |
|
||||
| TensorRT Stable Diffusion Inpainting Pipeline | Accelerates the Stable Diffusion Inpainting Pipeline using TensorRT | [TensorRT Stable Diffusion Inpainting Pipeline](#tensorrt-inpainting-stable-diffusion-pipeline) | - | [Asfiya Baig](https://github.com/asfiyab-nvidia) |
|
||||
|
||||
To load a custom pipeline you just need to pass the `custom_pipeline` argument to `DiffusionPipeline`, as one of the files in `diffusers/examples/community`. Feel free to send a PR with your own pipelines, we will merge them quickly.
|
||||
```py
|
||||
@@ -1328,8 +1326,6 @@ image.save('tensorrt_img2img_new_zealand_hills.png')
|
||||
|
||||
This pipeline uses the Reference Control. Refer to the [sd-webui-controlnet discussion: Reference-only Control](https://github.com/Mikubill/sd-webui-controlnet/discussions/1236)[sd-webui-controlnet discussion: Reference-adain Control](https://github.com/Mikubill/sd-webui-controlnet/discussions/1280).
|
||||
|
||||
Based on [this issue](https://github.com/huggingface/diffusers/issues/3566),
|
||||
- `EulerAncestralDiscreteScheduler` got poor results.
|
||||
|
||||
```py
|
||||
import torch
|
||||
@@ -1373,9 +1369,6 @@ Output Image of `reference_attn=True` and `reference_adain=True`
|
||||
|
||||
This pipeline uses the Reference Control with ControlNet. Refer to the [sd-webui-controlnet discussion: Reference-only Control](https://github.com/Mikubill/sd-webui-controlnet/discussions/1236)[sd-webui-controlnet discussion: Reference-adain Control](https://github.com/Mikubill/sd-webui-controlnet/discussions/1280).
|
||||
|
||||
Based on [this issue](https://github.com/huggingface/diffusers/issues/3566),
|
||||
- `EulerAncestralDiscreteScheduler` got poor results.
|
||||
- `guess_mode=True` works well for ControlNet v1.1
|
||||
|
||||
```py
|
||||
import cv2
|
||||
@@ -1517,159 +1510,3 @@ latency = elapsed_time(pipe4)
|
||||
print("Latency of StableDiffusionPipeline--fp32",latency)
|
||||
|
||||
```
|
||||
|
||||
### CLIP Guided Images Mixing With Stable Diffusion
|
||||
|
||||

|
||||
|
||||
CLIP guided stable diffusion images mixing pipline allows to combine two images using standard diffusion models.
|
||||
This approach is using (optional) CoCa model to avoid writing image description.
|
||||
[More code examples](https://github.com/TheDenk/images_mixing)
|
||||
|
||||
## Example Images Mixing (with CoCa)
|
||||
```python
|
||||
import requests
|
||||
from io import BytesIO
|
||||
|
||||
import PIL
|
||||
import torch
|
||||
import open_clip
|
||||
from open_clip import SimpleTokenizer
|
||||
from diffusers import DiffusionPipeline
|
||||
from transformers import CLIPFeatureExtractor, CLIPModel
|
||||
|
||||
|
||||
def download_image(url):
|
||||
response = requests.get(url)
|
||||
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
|
||||
|
||||
# Loading additional models
|
||||
feature_extractor = CLIPFeatureExtractor.from_pretrained(
|
||||
"laion/CLIP-ViT-B-32-laion2B-s34B-b79K"
|
||||
)
|
||||
clip_model = CLIPModel.from_pretrained(
|
||||
"laion/CLIP-ViT-B-32-laion2B-s34B-b79K", torch_dtype=torch.float16
|
||||
)
|
||||
coca_model = open_clip.create_model('coca_ViT-L-14', pretrained='laion2B-s13B-b90k').to('cuda')
|
||||
coca_model.dtype = torch.float16
|
||||
coca_transform = open_clip.image_transform(
|
||||
coca_model.visual.image_size,
|
||||
is_train = False,
|
||||
mean = getattr(coca_model.visual, 'image_mean', None),
|
||||
std = getattr(coca_model.visual, 'image_std', None),
|
||||
)
|
||||
coca_tokenizer = SimpleTokenizer()
|
||||
|
||||
# Pipline creating
|
||||
mixing_pipeline = DiffusionPipeline.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4",
|
||||
custom_pipeline="clip_guided_images_mixing_stable_diffusion",
|
||||
clip_model=clip_model,
|
||||
feature_extractor=feature_extractor,
|
||||
coca_model=coca_model,
|
||||
coca_tokenizer=coca_tokenizer,
|
||||
coca_transform=coca_transform,
|
||||
torch_dtype=torch.float16,
|
||||
)
|
||||
mixing_pipeline.enable_attention_slicing()
|
||||
mixing_pipeline = mixing_pipeline.to("cuda")
|
||||
|
||||
# Pipline running
|
||||
generator = torch.Generator(device="cuda").manual_seed(17)
|
||||
|
||||
def download_image(url):
|
||||
response = requests.get(url)
|
||||
return PIL.Image.open(BytesIO(response.content)).convert("RGB")
|
||||
|
||||
content_image = download_image("https://huggingface.co/datasets/TheDenk/images_mixing/resolve/main/boromir.jpg")
|
||||
style_image = download_image("https://huggingface.co/datasets/TheDenk/images_mixing/resolve/main/gigachad.jpg")
|
||||
|
||||
pipe_images = mixing_pipeline(
|
||||
num_inference_steps=50,
|
||||
content_image=content_image,
|
||||
style_image=style_image,
|
||||
noise_strength=0.65,
|
||||
slerp_latent_style_strength=0.9,
|
||||
slerp_prompt_style_strength=0.1,
|
||||
slerp_clip_image_style_strength=0.1,
|
||||
guidance_scale=9.0,
|
||||
batch_size=1,
|
||||
clip_guidance_scale=100,
|
||||
generator=generator,
|
||||
).images
|
||||
```
|
||||
|
||||

|
||||
|
||||
### Stable Diffusion Mixture
|
||||
|
||||
This pipeline uses the Mixture. Refer to the [Mixture](https://arxiv.org/abs/2302.02412) paper for more details.
|
||||
|
||||
```python
|
||||
from diffusers import LMSDiscreteScheduler, DiffusionPipeline
|
||||
|
||||
# Creater scheduler and model (similar to StableDiffusionPipeline)
|
||||
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
|
||||
pipeline = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", scheduler=scheduler, custom_pipeline="mixture_tiling")
|
||||
pipeline.to("cuda")
|
||||
|
||||
# Mixture of Diffusers generation
|
||||
image = pipeline(
|
||||
prompt=[[
|
||||
"A charming house in the countryside, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece",
|
||||
"A dirt road in the countryside crossing pastures, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece",
|
||||
"An old and rusty giant robot lying on a dirt road, by jakub rozalski, dark sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece"
|
||||
]],
|
||||
tile_height=640,
|
||||
tile_width=640,
|
||||
tile_row_overlap=0,
|
||||
tile_col_overlap=256,
|
||||
guidance_scale=8,
|
||||
seed=7178915308,
|
||||
num_inference_steps=50,
|
||||
)["images"][0]
|
||||
```
|
||||

|
||||
|
||||
### TensorRT Inpainting Stable Diffusion Pipeline
|
||||
|
||||
The TensorRT Pipeline can be used to accelerate the Inpainting Stable Diffusion Inference run.
|
||||
|
||||
NOTE: The ONNX conversions and TensorRT engine build may take up to 30 minutes.
|
||||
|
||||
```python
|
||||
import requests
|
||||
from io import BytesIO
|
||||
from PIL import Image
|
||||
import torch
|
||||
from diffusers import PNDMScheduler
|
||||
from diffusers.pipelines.stable_diffusion import StableDiffusionImg2ImgPipeline
|
||||
|
||||
# Use the PNDMScheduler scheduler here instead
|
||||
scheduler = PNDMScheduler.from_pretrained("stabilityai/stable-diffusion-2-inpainting", subfolder="scheduler")
|
||||
|
||||
|
||||
pipe = StableDiffusionImg2ImgPipeline.from_pretrained("stabilityai/stable-diffusion-2-inpainting",
|
||||
custom_pipeline="stable_diffusion_tensorrt_inpaint",
|
||||
revision='fp16',
|
||||
torch_dtype=torch.float16,
|
||||
scheduler=scheduler,
|
||||
)
|
||||
|
||||
# re-use cached folder to save ONNX models and TensorRT Engines
|
||||
pipe.set_cached_folder("stabilityai/stable-diffusion-2-inpainting", revision='fp16',)
|
||||
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
|
||||
response = requests.get(url)
|
||||
input_image = Image.open(BytesIO(response.content)).convert("RGB")
|
||||
|
||||
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
|
||||
response = requests.get(mask_url)
|
||||
mask_image = Image.open(BytesIO(response.content)).convert("RGB")
|
||||
|
||||
prompt = "a mecha robot sitting on a bench"
|
||||
image = pipe(prompt, image=input_image, mask_image=mask_image, strength=0.75,).images[0]
|
||||
image.save('tensorrt_inpaint_mecha_robot.png')
|
||||
```
|
||||
@@ -1,456 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
import inspect
|
||||
from typing import Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import PIL
|
||||
import torch
|
||||
from torch.nn import functional as F
|
||||
from torchvision import transforms
|
||||
from transformers import CLIPFeatureExtractor, CLIPModel, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from diffusers import (
|
||||
AutoencoderKL,
|
||||
DDIMScheduler,
|
||||
DiffusionPipeline,
|
||||
DPMSolverMultistepScheduler,
|
||||
LMSDiscreteScheduler,
|
||||
PNDMScheduler,
|
||||
UNet2DConditionModel,
|
||||
)
|
||||
from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion import StableDiffusionPipelineOutput
|
||||
from diffusers.utils import (
|
||||
PIL_INTERPOLATION,
|
||||
randn_tensor,
|
||||
)
|
||||
|
||||
|
||||
def preprocess(image, w, h):
|
||||
if isinstance(image, torch.Tensor):
|
||||
return image
|
||||
elif isinstance(image, PIL.Image.Image):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image[0], PIL.Image.Image):
|
||||
image = [np.array(i.resize((w, h), resample=PIL_INTERPOLATION["lanczos"]))[None, :] for i in image]
|
||||
image = np.concatenate(image, axis=0)
|
||||
image = np.array(image).astype(np.float32) / 255.0
|
||||
image = image.transpose(0, 3, 1, 2)
|
||||
image = 2.0 * image - 1.0
|
||||
image = torch.from_numpy(image)
|
||||
elif isinstance(image[0], torch.Tensor):
|
||||
image = torch.cat(image, dim=0)
|
||||
return image
|
||||
|
||||
|
||||
def slerp(t, v0, v1, DOT_THRESHOLD=0.9995):
|
||||
if not isinstance(v0, np.ndarray):
|
||||
inputs_are_torch = True
|
||||
input_device = v0.device
|
||||
v0 = v0.cpu().numpy()
|
||||
v1 = v1.cpu().numpy()
|
||||
|
||||
dot = np.sum(v0 * v1 / (np.linalg.norm(v0) * np.linalg.norm(v1)))
|
||||
if np.abs(dot) > DOT_THRESHOLD:
|
||||
v2 = (1 - t) * v0 + t * v1
|
||||
else:
|
||||
theta_0 = np.arccos(dot)
|
||||
sin_theta_0 = np.sin(theta_0)
|
||||
theta_t = theta_0 * t
|
||||
sin_theta_t = np.sin(theta_t)
|
||||
s0 = np.sin(theta_0 - theta_t) / sin_theta_0
|
||||
s1 = sin_theta_t / sin_theta_0
|
||||
v2 = s0 * v0 + s1 * v1
|
||||
|
||||
if inputs_are_torch:
|
||||
v2 = torch.from_numpy(v2).to(input_device)
|
||||
|
||||
return v2
|
||||
|
||||
|
||||
def spherical_dist_loss(x, y):
|
||||
x = F.normalize(x, dim=-1)
|
||||
y = F.normalize(y, dim=-1)
|
||||
return (x - y).norm(dim=-1).div(2).arcsin().pow(2).mul(2)
|
||||
|
||||
|
||||
def set_requires_grad(model, value):
|
||||
for param in model.parameters():
|
||||
param.requires_grad = value
|
||||
|
||||
|
||||
class CLIPGuidedImagesMixingStableDiffusion(DiffusionPipeline):
|
||||
def __init__(
|
||||
self,
|
||||
vae: AutoencoderKL,
|
||||
text_encoder: CLIPTextModel,
|
||||
clip_model: CLIPModel,
|
||||
tokenizer: CLIPTokenizer,
|
||||
unet: UNet2DConditionModel,
|
||||
scheduler: Union[PNDMScheduler, LMSDiscreteScheduler, DDIMScheduler, DPMSolverMultistepScheduler],
|
||||
feature_extractor: CLIPFeatureExtractor,
|
||||
coca_model=None,
|
||||
coca_tokenizer=None,
|
||||
coca_transform=None,
|
||||
):
|
||||
super().__init__()
|
||||
self.register_modules(
|
||||
vae=vae,
|
||||
text_encoder=text_encoder,
|
||||
clip_model=clip_model,
|
||||
tokenizer=tokenizer,
|
||||
unet=unet,
|
||||
scheduler=scheduler,
|
||||
feature_extractor=feature_extractor,
|
||||
coca_model=coca_model,
|
||||
coca_tokenizer=coca_tokenizer,
|
||||
coca_transform=coca_transform,
|
||||
)
|
||||
self.feature_extractor_size = (
|
||||
feature_extractor.size
|
||||
if isinstance(feature_extractor.size, int)
|
||||
else feature_extractor.size["shortest_edge"]
|
||||
)
|
||||
self.normalize = transforms.Normalize(mean=feature_extractor.image_mean, std=feature_extractor.image_std)
|
||||
set_requires_grad(self.text_encoder, False)
|
||||
set_requires_grad(self.clip_model, False)
|
||||
|
||||
def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
|
||||
if slice_size == "auto":
|
||||
# half the attention head size is usually a good trade-off between
|
||||
# speed and memory
|
||||
slice_size = self.unet.config.attention_head_dim // 2
|
||||
self.unet.set_attention_slice(slice_size)
|
||||
|
||||
def disable_attention_slicing(self):
|
||||
self.enable_attention_slicing(None)
|
||||
|
||||
def freeze_vae(self):
|
||||
set_requires_grad(self.vae, False)
|
||||
|
||||
def unfreeze_vae(self):
|
||||
set_requires_grad(self.vae, True)
|
||||
|
||||
def freeze_unet(self):
|
||||
set_requires_grad(self.unet, False)
|
||||
|
||||
def unfreeze_unet(self):
|
||||
set_requires_grad(self.unet, True)
|
||||
|
||||
def get_timesteps(self, num_inference_steps, strength, device):
|
||||
# get the original timestep using init_timestep
|
||||
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
|
||||
|
||||
t_start = max(num_inference_steps - init_timestep, 0)
|
||||
timesteps = self.scheduler.timesteps[t_start:]
|
||||
|
||||
return timesteps, num_inference_steps - t_start
|
||||
|
||||
def prepare_latents(self, image, timestep, batch_size, dtype, device, generator=None):
|
||||
if not isinstance(image, torch.Tensor):
|
||||
raise ValueError(f"`image` has to be of type `torch.Tensor` but is {type(image)}")
|
||||
|
||||
image = image.to(device=device, dtype=dtype)
|
||||
|
||||
if isinstance(generator, list):
|
||||
init_latents = [
|
||||
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
|
||||
]
|
||||
init_latents = torch.cat(init_latents, dim=0)
|
||||
else:
|
||||
init_latents = self.vae.encode(image).latent_dist.sample(generator)
|
||||
|
||||
# Hardcode 0.18215 because stable-diffusion-2-base has not self.vae.config.scaling_factor
|
||||
init_latents = 0.18215 * init_latents
|
||||
init_latents = init_latents.repeat_interleave(batch_size, dim=0)
|
||||
|
||||
noise = randn_tensor(init_latents.shape, generator=generator, device=device, dtype=dtype)
|
||||
|
||||
# get latents
|
||||
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
|
||||
latents = init_latents
|
||||
|
||||
return latents
|
||||
|
||||
def get_image_description(self, image):
|
||||
transformed_image = self.coca_transform(image).unsqueeze(0)
|
||||
with torch.no_grad(), torch.cuda.amp.autocast():
|
||||
generated = self.coca_model.generate(transformed_image.to(device=self.device, dtype=self.coca_model.dtype))
|
||||
generated = self.coca_tokenizer.decode(generated[0].cpu().numpy())
|
||||
return generated.split("<end_of_text>")[0].replace("<start_of_text>", "").rstrip(" .,")
|
||||
|
||||
def get_clip_image_embeddings(self, image, batch_size):
|
||||
clip_image_input = self.feature_extractor.preprocess(image)
|
||||
clip_image_features = torch.from_numpy(clip_image_input["pixel_values"][0]).unsqueeze(0).to(self.device).half()
|
||||
image_embeddings_clip = self.clip_model.get_image_features(clip_image_features)
|
||||
image_embeddings_clip = image_embeddings_clip / image_embeddings_clip.norm(p=2, dim=-1, keepdim=True)
|
||||
image_embeddings_clip = image_embeddings_clip.repeat_interleave(batch_size, dim=0)
|
||||
return image_embeddings_clip
|
||||
|
||||
@torch.enable_grad()
|
||||
def cond_fn(
|
||||
self,
|
||||
latents,
|
||||
timestep,
|
||||
index,
|
||||
text_embeddings,
|
||||
noise_pred_original,
|
||||
original_image_embeddings_clip,
|
||||
clip_guidance_scale,
|
||||
):
|
||||
latents = latents.detach().requires_grad_()
|
||||
|
||||
latent_model_input = self.scheduler.scale_model_input(latents, timestep)
|
||||
|
||||
# predict the noise residual
|
||||
noise_pred = self.unet(latent_model_input, timestep, encoder_hidden_states=text_embeddings).sample
|
||||
|
||||
if isinstance(self.scheduler, (PNDMScheduler, DDIMScheduler, DPMSolverMultistepScheduler)):
|
||||
alpha_prod_t = self.scheduler.alphas_cumprod[timestep]
|
||||
beta_prod_t = 1 - alpha_prod_t
|
||||
# compute predicted original sample from predicted noise also called
|
||||
# "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
|
||||
pred_original_sample = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
|
||||
|
||||
fac = torch.sqrt(beta_prod_t)
|
||||
sample = pred_original_sample * (fac) + latents * (1 - fac)
|
||||
elif isinstance(self.scheduler, LMSDiscreteScheduler):
|
||||
sigma = self.scheduler.sigmas[index]
|
||||
sample = latents - sigma * noise_pred
|
||||
else:
|
||||
raise ValueError(f"scheduler type {type(self.scheduler)} not supported")
|
||||
|
||||
# Hardcode 0.18215 because stable-diffusion-2-base has not self.vae.config.scaling_factor
|
||||
sample = 1 / 0.18215 * sample
|
||||
image = self.vae.decode(sample).sample
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
|
||||
image = transforms.Resize(self.feature_extractor_size)(image)
|
||||
image = self.normalize(image).to(latents.dtype)
|
||||
|
||||
image_embeddings_clip = self.clip_model.get_image_features(image)
|
||||
image_embeddings_clip = image_embeddings_clip / image_embeddings_clip.norm(p=2, dim=-1, keepdim=True)
|
||||
|
||||
loss = spherical_dist_loss(image_embeddings_clip, original_image_embeddings_clip).mean() * clip_guidance_scale
|
||||
|
||||
grads = -torch.autograd.grad(loss, latents)[0]
|
||||
|
||||
if isinstance(self.scheduler, LMSDiscreteScheduler):
|
||||
latents = latents.detach() + grads * (sigma**2)
|
||||
noise_pred = noise_pred_original
|
||||
else:
|
||||
noise_pred = noise_pred_original - torch.sqrt(beta_prod_t) * grads
|
||||
return noise_pred, latents
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(
|
||||
self,
|
||||
style_image: Union[torch.FloatTensor, PIL.Image.Image],
|
||||
content_image: Union[torch.FloatTensor, PIL.Image.Image],
|
||||
style_prompt: Optional[str] = None,
|
||||
content_prompt: Optional[str] = None,
|
||||
height: Optional[int] = 512,
|
||||
width: Optional[int] = 512,
|
||||
noise_strength: float = 0.6,
|
||||
num_inference_steps: Optional[int] = 50,
|
||||
guidance_scale: Optional[float] = 7.5,
|
||||
batch_size: Optional[int] = 1,
|
||||
eta: float = 0.0,
|
||||
clip_guidance_scale: Optional[float] = 100,
|
||||
generator: Optional[torch.Generator] = None,
|
||||
output_type: Optional[str] = "pil",
|
||||
return_dict: bool = True,
|
||||
slerp_latent_style_strength: float = 0.8,
|
||||
slerp_prompt_style_strength: float = 0.1,
|
||||
slerp_clip_image_style_strength: float = 0.1,
|
||||
):
|
||||
if isinstance(generator, list) and len(generator) != batch_size:
|
||||
raise ValueError(f"You have passed {batch_size} batch_size, but only {len(generator)} generators.")
|
||||
|
||||
if height % 8 != 0 or width % 8 != 0:
|
||||
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
|
||||
|
||||
if isinstance(generator, torch.Generator) and batch_size > 1:
|
||||
generator = [generator] + [None] * (batch_size - 1)
|
||||
|
||||
coca_is_none = [
|
||||
("model", self.coca_model is None),
|
||||
("tokenizer", self.coca_tokenizer is None),
|
||||
("transform", self.coca_transform is None),
|
||||
]
|
||||
coca_is_none = [x[0] for x in coca_is_none if x[1]]
|
||||
coca_is_none_str = ", ".join(coca_is_none)
|
||||
# generate prompts with coca model if prompt is None
|
||||
if content_prompt is None:
|
||||
if len(coca_is_none):
|
||||
raise ValueError(
|
||||
f"Content prompt is None and CoCa [{coca_is_none_str}] is None."
|
||||
f"Set prompt or pass Coca [{coca_is_none_str}] to DiffusionPipeline."
|
||||
)
|
||||
content_prompt = self.get_image_description(content_image)
|
||||
if style_prompt is None:
|
||||
if len(coca_is_none):
|
||||
raise ValueError(
|
||||
f"Style prompt is None and CoCa [{coca_is_none_str}] is None."
|
||||
f" Set prompt or pass Coca [{coca_is_none_str}] to DiffusionPipeline."
|
||||
)
|
||||
style_prompt = self.get_image_description(style_image)
|
||||
|
||||
# get prompt text embeddings for content and style
|
||||
content_text_input = self.tokenizer(
|
||||
content_prompt,
|
||||
padding="max_length",
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
content_text_embeddings = self.text_encoder(content_text_input.input_ids.to(self.device))[0]
|
||||
|
||||
style_text_input = self.tokenizer(
|
||||
style_prompt,
|
||||
padding="max_length",
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
style_text_embeddings = self.text_encoder(style_text_input.input_ids.to(self.device))[0]
|
||||
|
||||
text_embeddings = slerp(slerp_prompt_style_strength, content_text_embeddings, style_text_embeddings)
|
||||
|
||||
# duplicate text embeddings for each generation per prompt
|
||||
text_embeddings = text_embeddings.repeat_interleave(batch_size, dim=0)
|
||||
|
||||
# set timesteps
|
||||
accepts_offset = "offset" in set(inspect.signature(self.scheduler.set_timesteps).parameters.keys())
|
||||
extra_set_kwargs = {}
|
||||
if accepts_offset:
|
||||
extra_set_kwargs["offset"] = 1
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
|
||||
# Some schedulers like PNDM have timesteps as arrays
|
||||
# It's more optimized to move all timesteps to correct device beforehand
|
||||
self.scheduler.timesteps.to(self.device)
|
||||
|
||||
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, noise_strength, self.device)
|
||||
latent_timestep = timesteps[:1].repeat(batch_size)
|
||||
|
||||
# Preprocess image
|
||||
preprocessed_content_image = preprocess(content_image, width, height)
|
||||
content_latents = self.prepare_latents(
|
||||
preprocessed_content_image, latent_timestep, batch_size, text_embeddings.dtype, self.device, generator
|
||||
)
|
||||
|
||||
preprocessed_style_image = preprocess(style_image, width, height)
|
||||
style_latents = self.prepare_latents(
|
||||
preprocessed_style_image, latent_timestep, batch_size, text_embeddings.dtype, self.device, generator
|
||||
)
|
||||
|
||||
latents = slerp(slerp_latent_style_strength, content_latents, style_latents)
|
||||
|
||||
if clip_guidance_scale > 0:
|
||||
content_clip_image_embedding = self.get_clip_image_embeddings(content_image, batch_size)
|
||||
style_clip_image_embedding = self.get_clip_image_embeddings(style_image, batch_size)
|
||||
clip_image_embeddings = slerp(
|
||||
slerp_clip_image_style_strength, content_clip_image_embedding, style_clip_image_embedding
|
||||
)
|
||||
|
||||
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
||||
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
||||
# corresponds to doing no classifier free guidance.
|
||||
do_classifier_free_guidance = guidance_scale > 1.0
|
||||
# get unconditional embeddings for classifier free guidance
|
||||
if do_classifier_free_guidance:
|
||||
max_length = content_text_input.input_ids.shape[-1]
|
||||
uncond_input = self.tokenizer([""], padding="max_length", max_length=max_length, return_tensors="pt")
|
||||
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
|
||||
# duplicate unconditional embeddings for each generation per prompt
|
||||
uncond_embeddings = uncond_embeddings.repeat_interleave(batch_size, dim=0)
|
||||
|
||||
# For classifier free guidance, we need to do two forward passes.
|
||||
# Here we concatenate the unconditional and text embeddings into a single batch
|
||||
# to avoid doing two forward passes
|
||||
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
|
||||
|
||||
# get the initial random noise unless the user supplied it
|
||||
|
||||
# Unlike in other pipelines, latents need to be generated in the target device
|
||||
# for 1-to-1 results reproducibility with the CompVis implementation.
|
||||
# However this currently doesn't work in `mps`.
|
||||
latents_shape = (batch_size, self.unet.config.in_channels, height // 8, width // 8)
|
||||
latents_dtype = text_embeddings.dtype
|
||||
if latents is None:
|
||||
if self.device.type == "mps":
|
||||
# randn does not work reproducibly on mps
|
||||
latents = torch.randn(latents_shape, generator=generator, device="cpu", dtype=latents_dtype).to(
|
||||
self.device
|
||||
)
|
||||
else:
|
||||
latents = torch.randn(latents_shape, generator=generator, device=self.device, dtype=latents_dtype)
|
||||
else:
|
||||
if latents.shape != latents_shape:
|
||||
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
|
||||
latents = latents.to(self.device)
|
||||
|
||||
# scale the initial noise by the standard deviation required by the scheduler
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
|
||||
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
|
||||
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
|
||||
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
|
||||
# and should be between [0, 1]
|
||||
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
|
||||
extra_step_kwargs = {}
|
||||
if accepts_eta:
|
||||
extra_step_kwargs["eta"] = eta
|
||||
|
||||
# check if the scheduler accepts generator
|
||||
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
|
||||
if accepts_generator:
|
||||
extra_step_kwargs["generator"] = generator
|
||||
|
||||
with self.progress_bar(total=num_inference_steps):
|
||||
for i, t in enumerate(timesteps):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
||||
|
||||
# predict the noise residual
|
||||
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
|
||||
|
||||
# perform classifier free guidance
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
|
||||
# perform clip guidance
|
||||
if clip_guidance_scale > 0:
|
||||
text_embeddings_for_guidance = (
|
||||
text_embeddings.chunk(2)[1] if do_classifier_free_guidance else text_embeddings
|
||||
)
|
||||
noise_pred, latents = self.cond_fn(
|
||||
latents,
|
||||
t,
|
||||
i,
|
||||
text_embeddings_for_guidance,
|
||||
noise_pred,
|
||||
clip_image_embeddings,
|
||||
clip_guidance_scale,
|
||||
)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
|
||||
|
||||
# Hardcode 0.18215 because stable-diffusion-2-base has not self.vae.config.scaling_factor
|
||||
latents = 1 / 0.18215 * latents
|
||||
image = self.vae.decode(latents).sample
|
||||
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).numpy()
|
||||
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
if not return_dict:
|
||||
return (image, None)
|
||||
|
||||
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=None)
|
||||
@@ -1,401 +0,0 @@
|
||||
import inspect
|
||||
from copy import deepcopy
|
||||
from enum import Enum
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
from ligo.segments import segment
|
||||
from tqdm.auto import tqdm
|
||||
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from diffusers.models import AutoencoderKL, UNet2DConditionModel
|
||||
from diffusers.pipeline_utils import DiffusionPipeline
|
||||
from diffusers.pipelines.stable_diffusion import StableDiffusionSafetyChecker
|
||||
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
|
||||
from diffusers.utils import logging
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
EXAMPLE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> from diffusers import LMSDiscreteScheduler
|
||||
>>> from mixdiff import StableDiffusionTilingPipeline
|
||||
|
||||
>>> scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
|
||||
>>> pipeline = StableDiffusionTilingPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", scheduler=scheduler)
|
||||
>>> pipeline.to("cuda:0")
|
||||
|
||||
>>> image = pipeline(
|
||||
>>> prompt=[[
|
||||
>>> "A charming house in the countryside, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece",
|
||||
>>> "A dirt road in the countryside crossing pastures, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece",
|
||||
>>> "An old and rusty giant robot lying on a dirt road, by jakub rozalski, dark sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece"
|
||||
>>> ]],
|
||||
>>> tile_height=640,
|
||||
>>> tile_width=640,
|
||||
>>> tile_row_overlap=0,
|
||||
>>> tile_col_overlap=256,
|
||||
>>> guidance_scale=8,
|
||||
>>> seed=7178915308,
|
||||
>>> num_inference_steps=50,
|
||||
>>> )["images"][0]
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
def _tile2pixel_indices(tile_row, tile_col, tile_width, tile_height, tile_row_overlap, tile_col_overlap):
|
||||
"""Given a tile row and column numbers returns the range of pixels affected by that tiles in the overall image
|
||||
|
||||
Returns a tuple with:
|
||||
- Starting coordinates of rows in pixel space
|
||||
- Ending coordinates of rows in pixel space
|
||||
- Starting coordinates of columns in pixel space
|
||||
- Ending coordinates of columns in pixel space
|
||||
"""
|
||||
px_row_init = 0 if tile_row == 0 else tile_row * (tile_height - tile_row_overlap)
|
||||
px_row_end = px_row_init + tile_height
|
||||
px_col_init = 0 if tile_col == 0 else tile_col * (tile_width - tile_col_overlap)
|
||||
px_col_end = px_col_init + tile_width
|
||||
return px_row_init, px_row_end, px_col_init, px_col_end
|
||||
|
||||
|
||||
def _pixel2latent_indices(px_row_init, px_row_end, px_col_init, px_col_end):
|
||||
"""Translates coordinates in pixel space to coordinates in latent space"""
|
||||
return px_row_init // 8, px_row_end // 8, px_col_init // 8, px_col_end // 8
|
||||
|
||||
|
||||
def _tile2latent_indices(tile_row, tile_col, tile_width, tile_height, tile_row_overlap, tile_col_overlap):
|
||||
"""Given a tile row and column numbers returns the range of latents affected by that tiles in the overall image
|
||||
|
||||
Returns a tuple with:
|
||||
- Starting coordinates of rows in latent space
|
||||
- Ending coordinates of rows in latent space
|
||||
- Starting coordinates of columns in latent space
|
||||
- Ending coordinates of columns in latent space
|
||||
"""
|
||||
px_row_init, px_row_end, px_col_init, px_col_end = _tile2pixel_indices(
|
||||
tile_row, tile_col, tile_width, tile_height, tile_row_overlap, tile_col_overlap
|
||||
)
|
||||
return _pixel2latent_indices(px_row_init, px_row_end, px_col_init, px_col_end)
|
||||
|
||||
|
||||
def _tile2latent_exclusive_indices(
|
||||
tile_row, tile_col, tile_width, tile_height, tile_row_overlap, tile_col_overlap, rows, columns
|
||||
):
|
||||
"""Given a tile row and column numbers returns the range of latents affected only by that tile in the overall image
|
||||
|
||||
Returns a tuple with:
|
||||
- Starting coordinates of rows in latent space
|
||||
- Ending coordinates of rows in latent space
|
||||
- Starting coordinates of columns in latent space
|
||||
- Ending coordinates of columns in latent space
|
||||
"""
|
||||
row_init, row_end, col_init, col_end = _tile2latent_indices(
|
||||
tile_row, tile_col, tile_width, tile_height, tile_row_overlap, tile_col_overlap
|
||||
)
|
||||
row_segment = segment(row_init, row_end)
|
||||
col_segment = segment(col_init, col_end)
|
||||
# Iterate over the rest of tiles, clipping the region for the current tile
|
||||
for row in range(rows):
|
||||
for column in range(columns):
|
||||
if row != tile_row and column != tile_col:
|
||||
clip_row_init, clip_row_end, clip_col_init, clip_col_end = _tile2latent_indices(
|
||||
row, column, tile_width, tile_height, tile_row_overlap, tile_col_overlap
|
||||
)
|
||||
row_segment = row_segment - segment(clip_row_init, clip_row_end)
|
||||
col_segment = col_segment - segment(clip_col_init, clip_col_end)
|
||||
# return row_init, row_end, col_init, col_end
|
||||
return row_segment[0], row_segment[1], col_segment[0], col_segment[1]
|
||||
|
||||
|
||||
class StableDiffusionExtrasMixin:
|
||||
"""Mixin providing additional convenience method to Stable Diffusion pipelines"""
|
||||
|
||||
def decode_latents(self, latents, cpu_vae=False):
|
||||
"""Decodes a given array of latents into pixel space"""
|
||||
# scale and decode the image latents with vae
|
||||
if cpu_vae:
|
||||
lat = deepcopy(latents).cpu()
|
||||
vae = deepcopy(self.vae).cpu()
|
||||
else:
|
||||
lat = latents
|
||||
vae = self.vae
|
||||
|
||||
lat = 1 / 0.18215 * lat
|
||||
image = vae.decode(lat).sample
|
||||
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).numpy()
|
||||
|
||||
return self.numpy_to_pil(image)
|
||||
|
||||
|
||||
class StableDiffusionTilingPipeline(DiffusionPipeline, StableDiffusionExtrasMixin):
|
||||
def __init__(
|
||||
self,
|
||||
vae: AutoencoderKL,
|
||||
text_encoder: CLIPTextModel,
|
||||
tokenizer: CLIPTokenizer,
|
||||
unet: UNet2DConditionModel,
|
||||
scheduler: Union[DDIMScheduler, PNDMScheduler],
|
||||
safety_checker: StableDiffusionSafetyChecker,
|
||||
feature_extractor: CLIPFeatureExtractor,
|
||||
):
|
||||
super().__init__()
|
||||
self.register_modules(
|
||||
vae=vae,
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
unet=unet,
|
||||
scheduler=scheduler,
|
||||
safety_checker=safety_checker,
|
||||
feature_extractor=feature_extractor,
|
||||
)
|
||||
|
||||
class SeedTilesMode(Enum):
|
||||
"""Modes in which the latents of a particular tile can be re-seeded"""
|
||||
|
||||
FULL = "full"
|
||||
EXCLUSIVE = "exclusive"
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(
|
||||
self,
|
||||
prompt: Union[str, List[List[str]]],
|
||||
num_inference_steps: Optional[int] = 50,
|
||||
guidance_scale: Optional[float] = 7.5,
|
||||
eta: Optional[float] = 0.0,
|
||||
seed: Optional[int] = None,
|
||||
tile_height: Optional[int] = 512,
|
||||
tile_width: Optional[int] = 512,
|
||||
tile_row_overlap: Optional[int] = 256,
|
||||
tile_col_overlap: Optional[int] = 256,
|
||||
guidance_scale_tiles: Optional[List[List[float]]] = None,
|
||||
seed_tiles: Optional[List[List[int]]] = None,
|
||||
seed_tiles_mode: Optional[Union[str, List[List[str]]]] = "full",
|
||||
seed_reroll_regions: Optional[List[Tuple[int, int, int, int, int]]] = None,
|
||||
cpu_vae: Optional[bool] = False,
|
||||
):
|
||||
r"""
|
||||
Function to run the diffusion pipeline with tiling support.
|
||||
|
||||
Args:
|
||||
prompt: either a single string (no tiling) or a list of lists with all the prompts to use (one list for each row of tiles). This will also define the tiling structure.
|
||||
num_inference_steps: number of diffusions steps.
|
||||
guidance_scale: classifier-free guidance.
|
||||
seed: general random seed to initialize latents.
|
||||
tile_height: height in pixels of each grid tile.
|
||||
tile_width: width in pixels of each grid tile.
|
||||
tile_row_overlap: number of overlap pixels between tiles in consecutive rows.
|
||||
tile_col_overlap: number of overlap pixels between tiles in consecutive columns.
|
||||
guidance_scale_tiles: specific weights for classifier-free guidance in each tile.
|
||||
guidance_scale_tiles: specific weights for classifier-free guidance in each tile. If None, the value provided in guidance_scale will be used.
|
||||
seed_tiles: specific seeds for the initialization latents in each tile. These will override the latents generated for the whole canvas using the standard seed parameter.
|
||||
seed_tiles_mode: either "full" "exclusive". If "full", all the latents affected by the tile be overriden. If "exclusive", only the latents that are affected exclusively by this tile (and no other tiles) will be overrriden.
|
||||
seed_reroll_regions: a list of tuples in the form (start row, end row, start column, end column, seed) defining regions in pixel space for which the latents will be overriden using the given seed. Takes priority over seed_tiles.
|
||||
cpu_vae: the decoder from latent space to pixel space can require too mucho GPU RAM for large images. If you find out of memory errors at the end of the generation process, try setting this parameter to True to run the decoder in CPU. Slower, but should run without memory issues.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
A PIL image with the generated image.
|
||||
|
||||
"""
|
||||
if not isinstance(prompt, list) or not all(isinstance(row, list) for row in prompt):
|
||||
raise ValueError(f"`prompt` has to be a list of lists but is {type(prompt)}")
|
||||
grid_rows = len(prompt)
|
||||
grid_cols = len(prompt[0])
|
||||
if not all(len(row) == grid_cols for row in prompt):
|
||||
raise ValueError("All prompt rows must have the same number of prompt columns")
|
||||
if not isinstance(seed_tiles_mode, str) and (
|
||||
not isinstance(seed_tiles_mode, list) or not all(isinstance(row, list) for row in seed_tiles_mode)
|
||||
):
|
||||
raise ValueError(f"`seed_tiles_mode` has to be a string or list of lists but is {type(prompt)}")
|
||||
if isinstance(seed_tiles_mode, str):
|
||||
seed_tiles_mode = [[seed_tiles_mode for _ in range(len(row))] for row in prompt]
|
||||
modes = [mode.value for mode in self.SeedTilesMode]
|
||||
if any(mode not in modes for row in seed_tiles_mode for mode in row):
|
||||
raise ValueError(f"Seed tiles mode must be one of {modes}")
|
||||
if seed_reroll_regions is None:
|
||||
seed_reroll_regions = []
|
||||
batch_size = 1
|
||||
|
||||
# create original noisy latents using the timesteps
|
||||
height = tile_height + (grid_rows - 1) * (tile_height - tile_row_overlap)
|
||||
width = tile_width + (grid_cols - 1) * (tile_width - tile_col_overlap)
|
||||
latents_shape = (batch_size, self.unet.config.in_channels, height // 8, width // 8)
|
||||
generator = torch.Generator("cuda").manual_seed(seed)
|
||||
latents = torch.randn(latents_shape, generator=generator, device=self.device)
|
||||
|
||||
# overwrite latents for specific tiles if provided
|
||||
if seed_tiles is not None:
|
||||
for row in range(grid_rows):
|
||||
for col in range(grid_cols):
|
||||
if (seed_tile := seed_tiles[row][col]) is not None:
|
||||
mode = seed_tiles_mode[row][col]
|
||||
if mode == self.SeedTilesMode.FULL.value:
|
||||
row_init, row_end, col_init, col_end = _tile2latent_indices(
|
||||
row, col, tile_width, tile_height, tile_row_overlap, tile_col_overlap
|
||||
)
|
||||
else:
|
||||
row_init, row_end, col_init, col_end = _tile2latent_exclusive_indices(
|
||||
row,
|
||||
col,
|
||||
tile_width,
|
||||
tile_height,
|
||||
tile_row_overlap,
|
||||
tile_col_overlap,
|
||||
grid_rows,
|
||||
grid_cols,
|
||||
)
|
||||
tile_generator = torch.Generator("cuda").manual_seed(seed_tile)
|
||||
tile_shape = (latents_shape[0], latents_shape[1], row_end - row_init, col_end - col_init)
|
||||
latents[:, :, row_init:row_end, col_init:col_end] = torch.randn(
|
||||
tile_shape, generator=tile_generator, device=self.device
|
||||
)
|
||||
|
||||
# overwrite again for seed reroll regions
|
||||
for row_init, row_end, col_init, col_end, seed_reroll in seed_reroll_regions:
|
||||
row_init, row_end, col_init, col_end = _pixel2latent_indices(
|
||||
row_init, row_end, col_init, col_end
|
||||
) # to latent space coordinates
|
||||
reroll_generator = torch.Generator("cuda").manual_seed(seed_reroll)
|
||||
region_shape = (latents_shape[0], latents_shape[1], row_end - row_init, col_end - col_init)
|
||||
latents[:, :, row_init:row_end, col_init:col_end] = torch.randn(
|
||||
region_shape, generator=reroll_generator, device=self.device
|
||||
)
|
||||
|
||||
# Prepare scheduler
|
||||
accepts_offset = "offset" in set(inspect.signature(self.scheduler.set_timesteps).parameters.keys())
|
||||
extra_set_kwargs = {}
|
||||
if accepts_offset:
|
||||
extra_set_kwargs["offset"] = 1
|
||||
self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
|
||||
# if we use LMSDiscreteScheduler, let's make sure latents are multiplied by sigmas
|
||||
if isinstance(self.scheduler, LMSDiscreteScheduler):
|
||||
latents = latents * self.scheduler.sigmas[0]
|
||||
|
||||
# get prompts text embeddings
|
||||
text_input = [
|
||||
[
|
||||
self.tokenizer(
|
||||
col,
|
||||
padding="max_length",
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
for col in row
|
||||
]
|
||||
for row in prompt
|
||||
]
|
||||
text_embeddings = [[self.text_encoder(col.input_ids.to(self.device))[0] for col in row] for row in text_input]
|
||||
|
||||
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
||||
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
||||
# corresponds to doing no classifier free guidance.
|
||||
do_classifier_free_guidance = guidance_scale > 1.0 # TODO: also active if any tile has guidance scale
|
||||
# get unconditional embeddings for classifier free guidance
|
||||
if do_classifier_free_guidance:
|
||||
for i in range(grid_rows):
|
||||
for j in range(grid_cols):
|
||||
max_length = text_input[i][j].input_ids.shape[-1]
|
||||
uncond_input = self.tokenizer(
|
||||
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
|
||||
)
|
||||
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
|
||||
|
||||
# For classifier free guidance, we need to do two forward passes.
|
||||
# Here we concatenate the unconditional and text embeddings into a single batch
|
||||
# to avoid doing two forward passes
|
||||
text_embeddings[i][j] = torch.cat([uncond_embeddings, text_embeddings[i][j]])
|
||||
|
||||
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
|
||||
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
|
||||
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
|
||||
# and should be between [0, 1]
|
||||
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
|
||||
extra_step_kwargs = {}
|
||||
if accepts_eta:
|
||||
extra_step_kwargs["eta"] = eta
|
||||
|
||||
# Mask for tile weights strenght
|
||||
tile_weights = self._gaussian_weights(tile_width, tile_height, batch_size)
|
||||
|
||||
# Diffusion timesteps
|
||||
for i, t in tqdm(enumerate(self.scheduler.timesteps)):
|
||||
# Diffuse each tile
|
||||
noise_preds = []
|
||||
for row in range(grid_rows):
|
||||
noise_preds_row = []
|
||||
for col in range(grid_cols):
|
||||
px_row_init, px_row_end, px_col_init, px_col_end = _tile2latent_indices(
|
||||
row, col, tile_width, tile_height, tile_row_overlap, tile_col_overlap
|
||||
)
|
||||
tile_latents = latents[:, :, px_row_init:px_row_end, px_col_init:px_col_end]
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([tile_latents] * 2) if do_classifier_free_guidance else tile_latents
|
||||
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
||||
# predict the noise residual
|
||||
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings[row][col])[
|
||||
"sample"
|
||||
]
|
||||
# perform guidance
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
guidance = (
|
||||
guidance_scale
|
||||
if guidance_scale_tiles is None or guidance_scale_tiles[row][col] is None
|
||||
else guidance_scale_tiles[row][col]
|
||||
)
|
||||
noise_pred_tile = noise_pred_uncond + guidance * (noise_pred_text - noise_pred_uncond)
|
||||
noise_preds_row.append(noise_pred_tile)
|
||||
noise_preds.append(noise_preds_row)
|
||||
# Stitch noise predictions for all tiles
|
||||
noise_pred = torch.zeros(latents.shape, device=self.device)
|
||||
contributors = torch.zeros(latents.shape, device=self.device)
|
||||
# Add each tile contribution to overall latents
|
||||
for row in range(grid_rows):
|
||||
for col in range(grid_cols):
|
||||
px_row_init, px_row_end, px_col_init, px_col_end = _tile2latent_indices(
|
||||
row, col, tile_width, tile_height, tile_row_overlap, tile_col_overlap
|
||||
)
|
||||
noise_pred[:, :, px_row_init:px_row_end, px_col_init:px_col_end] += (
|
||||
noise_preds[row][col] * tile_weights
|
||||
)
|
||||
contributors[:, :, px_row_init:px_row_end, px_col_init:px_col_end] += tile_weights
|
||||
# Average overlapping areas with more than 1 contributor
|
||||
noise_pred /= contributors
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(noise_pred, t, latents).prev_sample
|
||||
|
||||
# scale and decode the image latents with vae
|
||||
image = self.decode_latents(latents, cpu_vae)
|
||||
|
||||
return {"images": image}
|
||||
|
||||
def _gaussian_weights(self, tile_width, tile_height, nbatches):
|
||||
"""Generates a gaussian mask of weights for tile contributions"""
|
||||
import numpy as np
|
||||
from numpy import exp, pi, sqrt
|
||||
|
||||
latent_width = tile_width // 8
|
||||
latent_height = tile_height // 8
|
||||
|
||||
var = 0.01
|
||||
midpoint = (latent_width - 1) / 2 # -1 because index goes from 0 to latent_width - 1
|
||||
x_probs = [
|
||||
exp(-(x - midpoint) * (x - midpoint) / (latent_width * latent_width) / (2 * var)) / sqrt(2 * pi * var)
|
||||
for x in range(latent_width)
|
||||
]
|
||||
midpoint = latent_height / 2
|
||||
y_probs = [
|
||||
exp(-(y - midpoint) * (y - midpoint) / (latent_height * latent_height) / (2 * var)) / sqrt(2 * pi * var)
|
||||
for y in range(latent_height)
|
||||
]
|
||||
|
||||
weights = np.outer(y_probs, x_probs)
|
||||
return torch.tile(torch.tensor(weights, device=self.device), (nbatches, self.unet.config.in_channels, 1, 1))
|
||||
@@ -1,405 +0,0 @@
|
||||
import inspect
|
||||
from copy import deepcopy
|
||||
from enum import Enum
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
from diffusers.models import AutoencoderKL, UNet2DConditionModel
|
||||
from diffusers.pipeline_utils import DiffusionPipeline
|
||||
from diffusers.pipelines.stable_diffusion import StableDiffusionSafetyChecker
|
||||
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
|
||||
from diffusers.utils import logging
|
||||
|
||||
|
||||
try:
|
||||
from ligo.segments import segment
|
||||
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
|
||||
except ImportError:
|
||||
raise ImportError("Please install transformers and ligo-segments to use the mixture pipeline")
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
EXAMPLE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> from diffusers import LMSDiscreteScheduler, DiffusionPipeline
|
||||
|
||||
>>> scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
|
||||
>>> pipeline = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", scheduler=scheduler, custom_pipeline="mixture_tiling")
|
||||
>>> pipeline.to("cuda")
|
||||
|
||||
>>> image = pipeline(
|
||||
>>> prompt=[[
|
||||
>>> "A charming house in the countryside, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece",
|
||||
>>> "A dirt road in the countryside crossing pastures, by jakub rozalski, sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece",
|
||||
>>> "An old and rusty giant robot lying on a dirt road, by jakub rozalski, dark sunset lighting, elegant, highly detailed, smooth, sharp focus, artstation, stunning masterpiece"
|
||||
>>> ]],
|
||||
>>> tile_height=640,
|
||||
>>> tile_width=640,
|
||||
>>> tile_row_overlap=0,
|
||||
>>> tile_col_overlap=256,
|
||||
>>> guidance_scale=8,
|
||||
>>> seed=7178915308,
|
||||
>>> num_inference_steps=50,
|
||||
>>> )["images"][0]
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
def _tile2pixel_indices(tile_row, tile_col, tile_width, tile_height, tile_row_overlap, tile_col_overlap):
|
||||
"""Given a tile row and column numbers returns the range of pixels affected by that tiles in the overall image
|
||||
|
||||
Returns a tuple with:
|
||||
- Starting coordinates of rows in pixel space
|
||||
- Ending coordinates of rows in pixel space
|
||||
- Starting coordinates of columns in pixel space
|
||||
- Ending coordinates of columns in pixel space
|
||||
"""
|
||||
px_row_init = 0 if tile_row == 0 else tile_row * (tile_height - tile_row_overlap)
|
||||
px_row_end = px_row_init + tile_height
|
||||
px_col_init = 0 if tile_col == 0 else tile_col * (tile_width - tile_col_overlap)
|
||||
px_col_end = px_col_init + tile_width
|
||||
return px_row_init, px_row_end, px_col_init, px_col_end
|
||||
|
||||
|
||||
def _pixel2latent_indices(px_row_init, px_row_end, px_col_init, px_col_end):
|
||||
"""Translates coordinates in pixel space to coordinates in latent space"""
|
||||
return px_row_init // 8, px_row_end // 8, px_col_init // 8, px_col_end // 8
|
||||
|
||||
|
||||
def _tile2latent_indices(tile_row, tile_col, tile_width, tile_height, tile_row_overlap, tile_col_overlap):
|
||||
"""Given a tile row and column numbers returns the range of latents affected by that tiles in the overall image
|
||||
|
||||
Returns a tuple with:
|
||||
- Starting coordinates of rows in latent space
|
||||
- Ending coordinates of rows in latent space
|
||||
- Starting coordinates of columns in latent space
|
||||
- Ending coordinates of columns in latent space
|
||||
"""
|
||||
px_row_init, px_row_end, px_col_init, px_col_end = _tile2pixel_indices(
|
||||
tile_row, tile_col, tile_width, tile_height, tile_row_overlap, tile_col_overlap
|
||||
)
|
||||
return _pixel2latent_indices(px_row_init, px_row_end, px_col_init, px_col_end)
|
||||
|
||||
|
||||
def _tile2latent_exclusive_indices(
|
||||
tile_row, tile_col, tile_width, tile_height, tile_row_overlap, tile_col_overlap, rows, columns
|
||||
):
|
||||
"""Given a tile row and column numbers returns the range of latents affected only by that tile in the overall image
|
||||
|
||||
Returns a tuple with:
|
||||
- Starting coordinates of rows in latent space
|
||||
- Ending coordinates of rows in latent space
|
||||
- Starting coordinates of columns in latent space
|
||||
- Ending coordinates of columns in latent space
|
||||
"""
|
||||
row_init, row_end, col_init, col_end = _tile2latent_indices(
|
||||
tile_row, tile_col, tile_width, tile_height, tile_row_overlap, tile_col_overlap
|
||||
)
|
||||
row_segment = segment(row_init, row_end)
|
||||
col_segment = segment(col_init, col_end)
|
||||
# Iterate over the rest of tiles, clipping the region for the current tile
|
||||
for row in range(rows):
|
||||
for column in range(columns):
|
||||
if row != tile_row and column != tile_col:
|
||||
clip_row_init, clip_row_end, clip_col_init, clip_col_end = _tile2latent_indices(
|
||||
row, column, tile_width, tile_height, tile_row_overlap, tile_col_overlap
|
||||
)
|
||||
row_segment = row_segment - segment(clip_row_init, clip_row_end)
|
||||
col_segment = col_segment - segment(clip_col_init, clip_col_end)
|
||||
# return row_init, row_end, col_init, col_end
|
||||
return row_segment[0], row_segment[1], col_segment[0], col_segment[1]
|
||||
|
||||
|
||||
class StableDiffusionExtrasMixin:
|
||||
"""Mixin providing additional convenience method to Stable Diffusion pipelines"""
|
||||
|
||||
def decode_latents(self, latents, cpu_vae=False):
|
||||
"""Decodes a given array of latents into pixel space"""
|
||||
# scale and decode the image latents with vae
|
||||
if cpu_vae:
|
||||
lat = deepcopy(latents).cpu()
|
||||
vae = deepcopy(self.vae).cpu()
|
||||
else:
|
||||
lat = latents
|
||||
vae = self.vae
|
||||
|
||||
lat = 1 / 0.18215 * lat
|
||||
image = vae.decode(lat).sample
|
||||
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).numpy()
|
||||
|
||||
return self.numpy_to_pil(image)
|
||||
|
||||
|
||||
class StableDiffusionTilingPipeline(DiffusionPipeline, StableDiffusionExtrasMixin):
|
||||
def __init__(
|
||||
self,
|
||||
vae: AutoencoderKL,
|
||||
text_encoder: CLIPTextModel,
|
||||
tokenizer: CLIPTokenizer,
|
||||
unet: UNet2DConditionModel,
|
||||
scheduler: Union[DDIMScheduler, PNDMScheduler],
|
||||
safety_checker: StableDiffusionSafetyChecker,
|
||||
feature_extractor: CLIPFeatureExtractor,
|
||||
):
|
||||
super().__init__()
|
||||
self.register_modules(
|
||||
vae=vae,
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
unet=unet,
|
||||
scheduler=scheduler,
|
||||
safety_checker=safety_checker,
|
||||
feature_extractor=feature_extractor,
|
||||
)
|
||||
|
||||
class SeedTilesMode(Enum):
|
||||
"""Modes in which the latents of a particular tile can be re-seeded"""
|
||||
|
||||
FULL = "full"
|
||||
EXCLUSIVE = "exclusive"
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(
|
||||
self,
|
||||
prompt: Union[str, List[List[str]]],
|
||||
num_inference_steps: Optional[int] = 50,
|
||||
guidance_scale: Optional[float] = 7.5,
|
||||
eta: Optional[float] = 0.0,
|
||||
seed: Optional[int] = None,
|
||||
tile_height: Optional[int] = 512,
|
||||
tile_width: Optional[int] = 512,
|
||||
tile_row_overlap: Optional[int] = 256,
|
||||
tile_col_overlap: Optional[int] = 256,
|
||||
guidance_scale_tiles: Optional[List[List[float]]] = None,
|
||||
seed_tiles: Optional[List[List[int]]] = None,
|
||||
seed_tiles_mode: Optional[Union[str, List[List[str]]]] = "full",
|
||||
seed_reroll_regions: Optional[List[Tuple[int, int, int, int, int]]] = None,
|
||||
cpu_vae: Optional[bool] = False,
|
||||
):
|
||||
r"""
|
||||
Function to run the diffusion pipeline with tiling support.
|
||||
|
||||
Args:
|
||||
prompt: either a single string (no tiling) or a list of lists with all the prompts to use (one list for each row of tiles). This will also define the tiling structure.
|
||||
num_inference_steps: number of diffusions steps.
|
||||
guidance_scale: classifier-free guidance.
|
||||
seed: general random seed to initialize latents.
|
||||
tile_height: height in pixels of each grid tile.
|
||||
tile_width: width in pixels of each grid tile.
|
||||
tile_row_overlap: number of overlap pixels between tiles in consecutive rows.
|
||||
tile_col_overlap: number of overlap pixels between tiles in consecutive columns.
|
||||
guidance_scale_tiles: specific weights for classifier-free guidance in each tile.
|
||||
guidance_scale_tiles: specific weights for classifier-free guidance in each tile. If None, the value provided in guidance_scale will be used.
|
||||
seed_tiles: specific seeds for the initialization latents in each tile. These will override the latents generated for the whole canvas using the standard seed parameter.
|
||||
seed_tiles_mode: either "full" "exclusive". If "full", all the latents affected by the tile be overriden. If "exclusive", only the latents that are affected exclusively by this tile (and no other tiles) will be overrriden.
|
||||
seed_reroll_regions: a list of tuples in the form (start row, end row, start column, end column, seed) defining regions in pixel space for which the latents will be overriden using the given seed. Takes priority over seed_tiles.
|
||||
cpu_vae: the decoder from latent space to pixel space can require too mucho GPU RAM for large images. If you find out of memory errors at the end of the generation process, try setting this parameter to True to run the decoder in CPU. Slower, but should run without memory issues.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
A PIL image with the generated image.
|
||||
|
||||
"""
|
||||
if not isinstance(prompt, list) or not all(isinstance(row, list) for row in prompt):
|
||||
raise ValueError(f"`prompt` has to be a list of lists but is {type(prompt)}")
|
||||
grid_rows = len(prompt)
|
||||
grid_cols = len(prompt[0])
|
||||
if not all(len(row) == grid_cols for row in prompt):
|
||||
raise ValueError("All prompt rows must have the same number of prompt columns")
|
||||
if not isinstance(seed_tiles_mode, str) and (
|
||||
not isinstance(seed_tiles_mode, list) or not all(isinstance(row, list) for row in seed_tiles_mode)
|
||||
):
|
||||
raise ValueError(f"`seed_tiles_mode` has to be a string or list of lists but is {type(prompt)}")
|
||||
if isinstance(seed_tiles_mode, str):
|
||||
seed_tiles_mode = [[seed_tiles_mode for _ in range(len(row))] for row in prompt]
|
||||
|
||||
modes = [mode.value for mode in self.SeedTilesMode]
|
||||
if any(mode not in modes for row in seed_tiles_mode for mode in row):
|
||||
raise ValueError(f"Seed tiles mode must be one of {modes}")
|
||||
if seed_reroll_regions is None:
|
||||
seed_reroll_regions = []
|
||||
batch_size = 1
|
||||
|
||||
# create original noisy latents using the timesteps
|
||||
height = tile_height + (grid_rows - 1) * (tile_height - tile_row_overlap)
|
||||
width = tile_width + (grid_cols - 1) * (tile_width - tile_col_overlap)
|
||||
latents_shape = (batch_size, self.unet.config.in_channels, height // 8, width // 8)
|
||||
generator = torch.Generator("cuda").manual_seed(seed)
|
||||
latents = torch.randn(latents_shape, generator=generator, device=self.device)
|
||||
|
||||
# overwrite latents for specific tiles if provided
|
||||
if seed_tiles is not None:
|
||||
for row in range(grid_rows):
|
||||
for col in range(grid_cols):
|
||||
if (seed_tile := seed_tiles[row][col]) is not None:
|
||||
mode = seed_tiles_mode[row][col]
|
||||
if mode == self.SeedTilesMode.FULL.value:
|
||||
row_init, row_end, col_init, col_end = _tile2latent_indices(
|
||||
row, col, tile_width, tile_height, tile_row_overlap, tile_col_overlap
|
||||
)
|
||||
else:
|
||||
row_init, row_end, col_init, col_end = _tile2latent_exclusive_indices(
|
||||
row,
|
||||
col,
|
||||
tile_width,
|
||||
tile_height,
|
||||
tile_row_overlap,
|
||||
tile_col_overlap,
|
||||
grid_rows,
|
||||
grid_cols,
|
||||
)
|
||||
tile_generator = torch.Generator("cuda").manual_seed(seed_tile)
|
||||
tile_shape = (latents_shape[0], latents_shape[1], row_end - row_init, col_end - col_init)
|
||||
latents[:, :, row_init:row_end, col_init:col_end] = torch.randn(
|
||||
tile_shape, generator=tile_generator, device=self.device
|
||||
)
|
||||
|
||||
# overwrite again for seed reroll regions
|
||||
for row_init, row_end, col_init, col_end, seed_reroll in seed_reroll_regions:
|
||||
row_init, row_end, col_init, col_end = _pixel2latent_indices(
|
||||
row_init, row_end, col_init, col_end
|
||||
) # to latent space coordinates
|
||||
reroll_generator = torch.Generator("cuda").manual_seed(seed_reroll)
|
||||
region_shape = (latents_shape[0], latents_shape[1], row_end - row_init, col_end - col_init)
|
||||
latents[:, :, row_init:row_end, col_init:col_end] = torch.randn(
|
||||
region_shape, generator=reroll_generator, device=self.device
|
||||
)
|
||||
|
||||
# Prepare scheduler
|
||||
accepts_offset = "offset" in set(inspect.signature(self.scheduler.set_timesteps).parameters.keys())
|
||||
extra_set_kwargs = {}
|
||||
if accepts_offset:
|
||||
extra_set_kwargs["offset"] = 1
|
||||
self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
|
||||
# if we use LMSDiscreteScheduler, let's make sure latents are multiplied by sigmas
|
||||
if isinstance(self.scheduler, LMSDiscreteScheduler):
|
||||
latents = latents * self.scheduler.sigmas[0]
|
||||
|
||||
# get prompts text embeddings
|
||||
text_input = [
|
||||
[
|
||||
self.tokenizer(
|
||||
col,
|
||||
padding="max_length",
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
for col in row
|
||||
]
|
||||
for row in prompt
|
||||
]
|
||||
text_embeddings = [[self.text_encoder(col.input_ids.to(self.device))[0] for col in row] for row in text_input]
|
||||
|
||||
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
||||
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
||||
# corresponds to doing no classifier free guidance.
|
||||
do_classifier_free_guidance = guidance_scale > 1.0 # TODO: also active if any tile has guidance scale
|
||||
# get unconditional embeddings for classifier free guidance
|
||||
if do_classifier_free_guidance:
|
||||
for i in range(grid_rows):
|
||||
for j in range(grid_cols):
|
||||
max_length = text_input[i][j].input_ids.shape[-1]
|
||||
uncond_input = self.tokenizer(
|
||||
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
|
||||
)
|
||||
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
|
||||
|
||||
# For classifier free guidance, we need to do two forward passes.
|
||||
# Here we concatenate the unconditional and text embeddings into a single batch
|
||||
# to avoid doing two forward passes
|
||||
text_embeddings[i][j] = torch.cat([uncond_embeddings, text_embeddings[i][j]])
|
||||
|
||||
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
|
||||
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
|
||||
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
|
||||
# and should be between [0, 1]
|
||||
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
|
||||
extra_step_kwargs = {}
|
||||
if accepts_eta:
|
||||
extra_step_kwargs["eta"] = eta
|
||||
|
||||
# Mask for tile weights strenght
|
||||
tile_weights = self._gaussian_weights(tile_width, tile_height, batch_size)
|
||||
|
||||
# Diffusion timesteps
|
||||
for i, t in tqdm(enumerate(self.scheduler.timesteps)):
|
||||
# Diffuse each tile
|
||||
noise_preds = []
|
||||
for row in range(grid_rows):
|
||||
noise_preds_row = []
|
||||
for col in range(grid_cols):
|
||||
px_row_init, px_row_end, px_col_init, px_col_end = _tile2latent_indices(
|
||||
row, col, tile_width, tile_height, tile_row_overlap, tile_col_overlap
|
||||
)
|
||||
tile_latents = latents[:, :, px_row_init:px_row_end, px_col_init:px_col_end]
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([tile_latents] * 2) if do_classifier_free_guidance else tile_latents
|
||||
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
||||
# predict the noise residual
|
||||
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings[row][col])[
|
||||
"sample"
|
||||
]
|
||||
# perform guidance
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
guidance = (
|
||||
guidance_scale
|
||||
if guidance_scale_tiles is None or guidance_scale_tiles[row][col] is None
|
||||
else guidance_scale_tiles[row][col]
|
||||
)
|
||||
noise_pred_tile = noise_pred_uncond + guidance * (noise_pred_text - noise_pred_uncond)
|
||||
noise_preds_row.append(noise_pred_tile)
|
||||
noise_preds.append(noise_preds_row)
|
||||
# Stitch noise predictions for all tiles
|
||||
noise_pred = torch.zeros(latents.shape, device=self.device)
|
||||
contributors = torch.zeros(latents.shape, device=self.device)
|
||||
# Add each tile contribution to overall latents
|
||||
for row in range(grid_rows):
|
||||
for col in range(grid_cols):
|
||||
px_row_init, px_row_end, px_col_init, px_col_end = _tile2latent_indices(
|
||||
row, col, tile_width, tile_height, tile_row_overlap, tile_col_overlap
|
||||
)
|
||||
noise_pred[:, :, px_row_init:px_row_end, px_col_init:px_col_end] += (
|
||||
noise_preds[row][col] * tile_weights
|
||||
)
|
||||
contributors[:, :, px_row_init:px_row_end, px_col_init:px_col_end] += tile_weights
|
||||
# Average overlapping areas with more than 1 contributor
|
||||
noise_pred /= contributors
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(noise_pred, t, latents).prev_sample
|
||||
|
||||
# scale and decode the image latents with vae
|
||||
image = self.decode_latents(latents, cpu_vae)
|
||||
|
||||
return {"images": image}
|
||||
|
||||
def _gaussian_weights(self, tile_width, tile_height, nbatches):
|
||||
"""Generates a gaussian mask of weights for tile contributions"""
|
||||
import numpy as np
|
||||
from numpy import exp, pi, sqrt
|
||||
|
||||
latent_width = tile_width // 8
|
||||
latent_height = tile_height // 8
|
||||
|
||||
var = 0.01
|
||||
midpoint = (latent_width - 1) / 2 # -1 because index goes from 0 to latent_width - 1
|
||||
x_probs = [
|
||||
exp(-(x - midpoint) * (x - midpoint) / (latent_width * latent_width) / (2 * var)) / sqrt(2 * pi * var)
|
||||
for x in range(latent_width)
|
||||
]
|
||||
midpoint = latent_height / 2
|
||||
y_probs = [
|
||||
exp(-(y - midpoint) * (y - midpoint) / (latent_height * latent_height) / (2 * var)) / sqrt(2 * pi * var)
|
||||
for y in range(latent_height)
|
||||
]
|
||||
|
||||
weights = np.outer(y_probs, x_probs)
|
||||
return torch.tile(torch.tensor(weights, device=self.device), (nbatches, self.unet.config.in_channels, 1, 1))
|
||||
@@ -505,8 +505,8 @@ class StableDiffusionControlNetReferencePipeline(StableDiffusionControlNetPipeli
|
||||
if MODE == "write":
|
||||
if gn_auto_machine_weight >= self.gn_weight:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
self.mean_bank.append([mean])
|
||||
self.var_bank.append([var])
|
||||
self.mean_bank.append(mean)
|
||||
self.var_bank.append(var)
|
||||
if MODE == "read":
|
||||
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
@@ -545,8 +545,8 @@ class StableDiffusionControlNetReferencePipeline(StableDiffusionControlNetPipeli
|
||||
if MODE == "write":
|
||||
if gn_auto_machine_weight >= self.gn_weight:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
self.mean_bank.append([mean])
|
||||
self.var_bank.append([var])
|
||||
self.mean_bank.append(mean)
|
||||
self.var_bank.append(var)
|
||||
if MODE == "read":
|
||||
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
@@ -605,8 +605,8 @@ class StableDiffusionControlNetReferencePipeline(StableDiffusionControlNetPipeli
|
||||
if MODE == "write":
|
||||
if gn_auto_machine_weight >= self.gn_weight:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
self.mean_bank.append([mean])
|
||||
self.var_bank.append([var])
|
||||
self.mean_bank.append(mean)
|
||||
self.var_bank.append(var)
|
||||
if MODE == "read":
|
||||
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
@@ -642,8 +642,8 @@ class StableDiffusionControlNetReferencePipeline(StableDiffusionControlNetPipeli
|
||||
if MODE == "write":
|
||||
if gn_auto_machine_weight >= self.gn_weight:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
self.mean_bank.append([mean])
|
||||
self.var_bank.append([var])
|
||||
self.mean_bank.append(mean)
|
||||
self.var_bank.append(var)
|
||||
if MODE == "read":
|
||||
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
|
||||
@@ -499,8 +499,8 @@ class StableDiffusionReferencePipeline(StableDiffusionPipeline):
|
||||
if MODE == "write":
|
||||
if gn_auto_machine_weight >= self.gn_weight:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
self.mean_bank.append([mean])
|
||||
self.var_bank.append([var])
|
||||
self.mean_bank.append(mean)
|
||||
self.var_bank.append(var)
|
||||
if MODE == "read":
|
||||
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
@@ -539,8 +539,8 @@ class StableDiffusionReferencePipeline(StableDiffusionPipeline):
|
||||
if MODE == "write":
|
||||
if gn_auto_machine_weight >= self.gn_weight:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
self.mean_bank.append([mean])
|
||||
self.var_bank.append([var])
|
||||
self.mean_bank.append(mean)
|
||||
self.var_bank.append(var)
|
||||
if MODE == "read":
|
||||
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
@@ -599,8 +599,8 @@ class StableDiffusionReferencePipeline(StableDiffusionPipeline):
|
||||
if MODE == "write":
|
||||
if gn_auto_machine_weight >= self.gn_weight:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
self.mean_bank.append([mean])
|
||||
self.var_bank.append([var])
|
||||
self.mean_bank.append(mean)
|
||||
self.var_bank.append(var)
|
||||
if MODE == "read":
|
||||
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
@@ -636,8 +636,8 @@ class StableDiffusionReferencePipeline(StableDiffusionPipeline):
|
||||
if MODE == "write":
|
||||
if gn_auto_machine_weight >= self.gn_weight:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
self.mean_bank.append([mean])
|
||||
self.var_bank.append([var])
|
||||
self.mean_bank.append(mean)
|
||||
self.var_bank.append(var)
|
||||
if MODE == "read":
|
||||
if len(self.mean_bank) > 0 and len(self.var_bank) > 0:
|
||||
var, mean = torch.var_mean(hidden_states, dim=(2, 3), keepdim=True, correction=0)
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -536,68 +536,9 @@ You can refer to [this blog post](https://huggingface.co/blog/dreambooth) that d
|
||||
|
||||
## IF
|
||||
|
||||
You can use the lora and full dreambooth scripts to train the text to image [IF model](https://huggingface.co/DeepFloyd/IF-I-XL-v1.0) and the stage II upscaler
|
||||
[IF model](https://huggingface.co/DeepFloyd/IF-II-L-v1.0).
|
||||
You can use the lora and full dreambooth scripts to also train the text to image [IF model](https://huggingface.co/DeepFloyd/IF-I-XL-v1.0). A few alternative cli flags are needed due to the model size, the expected input resolution, and the text encoder conventions.
|
||||
|
||||
Note that IF has a predicted variance, and our finetuning scripts only train the models predicted error, so for finetuned IF models we switch to a fixed
|
||||
variance schedule. The full finetuning scripts will update the scheduler config for the full saved model. However, when loading saved LoRA weights, you
|
||||
must also update the pipeline's scheduler config.
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipe = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0")
|
||||
|
||||
pipe.load_lora_weights("<lora weights path>")
|
||||
|
||||
# Update scheduler config to fixed variance schedule
|
||||
pipe.scheduler = pipe.scheduler.__class__.from_config(pipe.scheduler.config, variance_type="fixed_small")
|
||||
```
|
||||
|
||||
Additionally, a few alternative cli flags are needed for IF.
|
||||
|
||||
`--resolution=64`: IF is a pixel space diffusion model. In order to operate on un-compressed pixels, the input images are of a much smaller resolution.
|
||||
|
||||
`--pre_compute_text_embeddings`: IF uses [T5](https://huggingface.co/docs/transformers/model_doc/t5) for its text encoder. In order to save GPU memory, we pre compute all text embeddings and then de-allocate
|
||||
T5.
|
||||
|
||||
`--tokenizer_max_length=77`: T5 has a longer default text length, but the default IF encoding procedure uses a smaller number.
|
||||
|
||||
`--text_encoder_use_attention_mask`: T5 passes the attention mask to the text encoder.
|
||||
|
||||
### Tips and Tricks
|
||||
We find LoRA to be sufficient for finetuning the stage I model as the low resolution of the model makes representing finegrained detail hard regardless.
|
||||
|
||||
For common and/or not-visually complex object concepts, you can get away with not-finetuning the upscaler. Just be sure to adjust the prompt passed to the
|
||||
upscaler to remove the new token from the instance prompt. I.e. if your stage I prompt is "a sks dog", use "a dog" for your stage II prompt.
|
||||
|
||||
For finegrained detail like faces that aren't present in the original training set, we find that full finetuning of the stage II upscaler is better than
|
||||
LoRA finetuning stage II.
|
||||
|
||||
For finegrained detail like faces, we find that lower learning rates along with larger batch sizes work best.
|
||||
|
||||
For stage II, we find that lower learning rates are also needed.
|
||||
|
||||
We found experimentally that the DDPM scheduler with the default larger number of denoising steps to sometimes work better than the DPM Solver scheduler
|
||||
used in the training scripts.
|
||||
|
||||
### Stage II additional validation images
|
||||
|
||||
The stage II validation requires images to upscale, we can download a downsized version of the training set:
|
||||
|
||||
```py
|
||||
from huggingface_hub import snapshot_download
|
||||
|
||||
local_dir = "./dog_downsized"
|
||||
snapshot_download(
|
||||
"diffusers/dog-example-downsized",
|
||||
local_dir=local_dir,
|
||||
repo_type="dataset",
|
||||
ignore_patterns=".gitattributes",
|
||||
)
|
||||
```
|
||||
|
||||
### IF stage I LoRA Dreambooth
|
||||
### LoRA Dreambooth
|
||||
This training configuration requires ~28 GB VRAM.
|
||||
|
||||
```sh
|
||||
@@ -611,7 +552,7 @@ accelerate launch train_dreambooth_lora.py \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--instance_prompt="a sks dog" \
|
||||
--resolution=64 \
|
||||
--resolution=64 \ # The input resolution of the IF unet is 64x64
|
||||
--train_batch_size=4 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=5e-6 \
|
||||
@@ -620,58 +561,16 @@ accelerate launch train_dreambooth_lora.py \
|
||||
--validation_prompt="a sks dog" \
|
||||
--validation_epochs=25 \
|
||||
--checkpointing_steps=100 \
|
||||
--pre_compute_text_embeddings \
|
||||
--tokenizer_max_length=77 \
|
||||
--text_encoder_use_attention_mask
|
||||
--pre_compute_text_embeddings \ # Pre compute text embeddings to that T5 doesn't have to be kept in memory
|
||||
--tokenizer_max_length=77 \ # IF expects an override of the max token length
|
||||
--text_encoder_use_attention_mask # IF expects attention mask for text embeddings
|
||||
```
|
||||
|
||||
### IF stage II LoRA Dreambooth
|
||||
### Full Dreambooth
|
||||
Due to the size of the optimizer states, we recommend training the full XL IF model with 8bit adam.
|
||||
Using 8bit adam and the rest of the following config, the model can be trained in ~48 GB VRAM.
|
||||
|
||||
`--validation_images`: These images are upscaled during validation steps.
|
||||
|
||||
`--class_labels_conditioning=timesteps`: Pass additional conditioning to the UNet needed for stage II.
|
||||
|
||||
`--learning_rate=1e-6`: Lower learning rate than stage I.
|
||||
|
||||
`--resolution=256`: The upscaler expects higher resolution inputs
|
||||
|
||||
```sh
|
||||
export MODEL_NAME="DeepFloyd/IF-II-L-v1.0"
|
||||
export INSTANCE_DIR="dog"
|
||||
export OUTPUT_DIR="dreambooth_dog_upscale"
|
||||
export VALIDATION_IMAGES="dog_downsized/image_1.png dog_downsized/image_2.png dog_downsized/image_3.png dog_downsized/image_4.png"
|
||||
|
||||
python train_dreambooth_lora.py \
|
||||
--report_to wandb \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--instance_prompt="a sks dog" \
|
||||
--resolution=256 \
|
||||
--train_batch_size=4 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=1e-6 \
|
||||
--max_train_steps=2000 \
|
||||
--validation_prompt="a sks dog" \
|
||||
--validation_epochs=100 \
|
||||
--checkpointing_steps=500 \
|
||||
--pre_compute_text_embeddings \
|
||||
--tokenizer_max_length=77 \
|
||||
--text_encoder_use_attention_mask \
|
||||
--validation_images $VALIDATION_IMAGES \
|
||||
--class_labels_conditioning=timesteps
|
||||
```
|
||||
|
||||
### IF Stage I Full Dreambooth
|
||||
`--skip_save_text_encoder`: When training the full model, this will skip saving the entire T5 with the finetuned model. You can still load the pipeline
|
||||
with a T5 loaded from the original model.
|
||||
|
||||
`use_8bit_adam`: Due to the size of the optimizer states, we recommend training the full XL IF model with 8bit adam.
|
||||
|
||||
`--learning_rate=1e-7`: For full dreambooth, IF requires very low learning rates. With higher learning rates model quality will degrade. Note that it is
|
||||
likely the learning rate can be increased with larger batch sizes.
|
||||
|
||||
Using 8bit adam and a batch size of 4, the model can be trained in ~48 GB VRAM.
|
||||
For full dreambooth, IF requires very low learning rates. With higher learning rates model quality will degrade.
|
||||
|
||||
```sh
|
||||
export MODEL_NAME="DeepFloyd/IF-I-XL-v1.0"
|
||||
@@ -684,56 +583,17 @@ accelerate launch train_dreambooth.py \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--instance_prompt="a photo of sks dog" \
|
||||
--resolution=64 \
|
||||
--resolution=64 \ # The input resolution of the IF unet is 64x64
|
||||
--train_batch_size=4 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=1e-7 \
|
||||
--max_train_steps=150 \
|
||||
--validation_prompt "a photo of sks dog" \
|
||||
--validation_steps 25 \
|
||||
--text_encoder_use_attention_mask \
|
||||
--tokenizer_max_length 77 \
|
||||
--pre_compute_text_embeddings \
|
||||
--use_8bit_adam \
|
||||
--text_encoder_use_attention_mask \ # IF expects attention mask for text embeddings
|
||||
--tokenizer_max_length 77 \ # IF expects an override of the max token length
|
||||
--pre_compute_text_embeddings \ # Pre compute text embeddings to that T5 doesn't have to be kept in memory
|
||||
--use_8bit_adam \ #
|
||||
--set_grads_to_none \
|
||||
--skip_save_text_encoder \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
### IF Stage II Full Dreambooth
|
||||
|
||||
`--learning_rate=5e-6`: With a smaller effective batch size of 4, we found that we required learning rates as low as
|
||||
1e-8.
|
||||
|
||||
`--resolution=256`: The upscaler expects higher resolution inputs
|
||||
|
||||
`--train_batch_size=2` and `--gradient_accumulation_steps=6`: We found that full training of stage II particularly with
|
||||
faces required large effective batch sizes.
|
||||
|
||||
```sh
|
||||
export MODEL_NAME="DeepFloyd/IF-II-L-v1.0"
|
||||
export INSTANCE_DIR="dog"
|
||||
export OUTPUT_DIR="dreambooth_dog_upscale"
|
||||
export VALIDATION_IMAGES="dog_downsized/image_1.png dog_downsized/image_2.png dog_downsized/image_3.png dog_downsized/image_4.png"
|
||||
|
||||
accelerate launch train_dreambooth.py \
|
||||
--report_to wandb \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--instance_prompt="a sks dog" \
|
||||
--resolution=256 \
|
||||
--train_batch_size=2 \
|
||||
--gradient_accumulation_steps=6 \
|
||||
--learning_rate=5e-6 \
|
||||
--max_train_steps=2000 \
|
||||
--validation_prompt="a sks dog" \
|
||||
--validation_steps=150 \
|
||||
--checkpointing_steps=500 \
|
||||
--pre_compute_text_embeddings \
|
||||
--tokenizer_max_length=77 \
|
||||
--text_encoder_use_attention_mask \
|
||||
--validation_images $VALIDATION_IMAGES \
|
||||
--class_labels_conditioning timesteps \
|
||||
--push_to_hub
|
||||
--skip_save_text_encoder # do not save the full T5 text encoder with the model
|
||||
```
|
||||
|
||||
@@ -46,7 +46,6 @@ from diffusers import (
|
||||
DDPMScheduler,
|
||||
DiffusionPipeline,
|
||||
DPMSolverMultistepScheduler,
|
||||
StableDiffusionPipeline,
|
||||
UNet2DConditionModel,
|
||||
)
|
||||
from diffusers.optimization import get_scheduler
|
||||
@@ -63,15 +62,7 @@ check_min_version("0.17.0.dev0")
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
def save_model_card(
|
||||
repo_id: str,
|
||||
images=None,
|
||||
base_model=str,
|
||||
train_text_encoder=False,
|
||||
prompt=str,
|
||||
repo_folder=None,
|
||||
pipeline: DiffusionPipeline = None,
|
||||
):
|
||||
def save_model_card(repo_id: str, images=None, base_model=str, train_text_encoder=False, prompt=str, repo_folder=None):
|
||||
img_str = ""
|
||||
for i, image in enumerate(images):
|
||||
image.save(os.path.join(repo_folder, f"image_{i}.png"))
|
||||
@@ -83,8 +74,8 @@ license: creativeml-openrail-m
|
||||
base_model: {base_model}
|
||||
instance_prompt: {prompt}
|
||||
tags:
|
||||
- {'stable-diffusion' if isinstance(pipeline, StableDiffusionPipeline) else 'if'}
|
||||
- {'stable-diffusion-diffusers' if isinstance(pipeline, StableDiffusionPipeline) else 'if-diffusers'}
|
||||
- stable-diffusion
|
||||
- stable-diffusion-diffusers
|
||||
- text-to-image
|
||||
- diffusers
|
||||
- dreambooth
|
||||
@@ -114,17 +105,16 @@ def log_validation(
|
||||
|
||||
pipeline_args = {}
|
||||
|
||||
if text_encoder is not None:
|
||||
pipeline_args["text_encoder"] = accelerator.unwrap_model(text_encoder)
|
||||
|
||||
if vae is not None:
|
||||
pipeline_args["vae"] = vae
|
||||
|
||||
if text_encoder is not None:
|
||||
text_encoder = accelerator.unwrap_model(text_encoder)
|
||||
|
||||
# create pipeline (note: unet and vae are loaded again in float32)
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
tokenizer=tokenizer,
|
||||
text_encoder=text_encoder,
|
||||
unet=accelerator.unwrap_model(unet),
|
||||
revision=args.revision,
|
||||
torch_dtype=weight_dtype,
|
||||
@@ -157,16 +147,10 @@ def log_validation(
|
||||
# run inference
|
||||
generator = None if args.seed is None else torch.Generator(device=accelerator.device).manual_seed(args.seed)
|
||||
images = []
|
||||
if args.validation_images is None:
|
||||
for _ in range(args.num_validation_images):
|
||||
with torch.autocast("cuda"):
|
||||
image = pipeline(**pipeline_args, num_inference_steps=25, generator=generator).images[0]
|
||||
images.append(image)
|
||||
else:
|
||||
for image in args.validation_images:
|
||||
image = Image.open(image)
|
||||
image = pipeline(**pipeline_args, image=image, generator=generator).images[0]
|
||||
images.append(image)
|
||||
for _ in range(args.num_validation_images):
|
||||
with torch.autocast("cuda"):
|
||||
image = pipeline(**pipeline_args, num_inference_steps=25, generator=generator).images[0]
|
||||
images.append(image)
|
||||
|
||||
for tracker in accelerator.trackers:
|
||||
if tracker.name == "tensorboard":
|
||||
@@ -532,19 +516,6 @@ def parse_args(input_args=None):
|
||||
parser.add_argument(
|
||||
"--skip_save_text_encoder", action="store_true", required=False, help="Set to not save text encoder"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--validation_images",
|
||||
required=False,
|
||||
default=None,
|
||||
nargs="+",
|
||||
help="Optional set of images to use for validation. Used when the target pipeline takes an initial image as input such as when training image variation or superresolution.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--class_labels_conditioning",
|
||||
required=False,
|
||||
default=None,
|
||||
help="The optional `class_label` conditioning to pass to the unet, available values are `timesteps`.",
|
||||
)
|
||||
|
||||
if input_args is not None:
|
||||
args = parser.parse_args(input_args)
|
||||
@@ -701,7 +672,6 @@ def collate_fn(examples, with_prior_preservation=False):
|
||||
}
|
||||
|
||||
if has_attention_mask:
|
||||
attention_mask = torch.cat(attention_mask, dim=0)
|
||||
batch["attention_mask"] = attention_mask
|
||||
|
||||
return batch
|
||||
@@ -1189,7 +1159,7 @@ def main(args):
|
||||
)
|
||||
else:
|
||||
noise = torch.randn_like(model_input)
|
||||
bsz, channels, height, width = model_input.shape
|
||||
bsz = model_input.shape[0]
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(
|
||||
0, noise_scheduler.config.num_train_timesteps, (bsz,), device=model_input.device
|
||||
@@ -1211,18 +1181,8 @@ def main(args):
|
||||
text_encoder_use_attention_mask=args.text_encoder_use_attention_mask,
|
||||
)
|
||||
|
||||
if accelerator.unwrap_model(unet).config.in_channels == channels * 2:
|
||||
noisy_model_input = torch.cat([noisy_model_input, noisy_model_input], dim=1)
|
||||
|
||||
if args.class_labels_conditioning == "timesteps":
|
||||
class_labels = timesteps
|
||||
else:
|
||||
class_labels = None
|
||||
|
||||
# Predict the noise residual
|
||||
model_pred = unet(
|
||||
noisy_model_input, timesteps, encoder_hidden_states, class_labels=class_labels
|
||||
).sample
|
||||
model_pred = unet(noisy_model_input, timesteps, encoder_hidden_states).sample
|
||||
|
||||
if model_pred.shape[1] == 6:
|
||||
model_pred, _ = torch.chunk(model_pred, 2, dim=1)
|
||||
@@ -1337,7 +1297,6 @@ def main(args):
|
||||
train_text_encoder=args.train_text_encoder,
|
||||
prompt=args.instance_prompt,
|
||||
repo_folder=args.output_dir,
|
||||
pipeline=pipeline,
|
||||
)
|
||||
upload_folder(
|
||||
repo_id=repo_id,
|
||||
|
||||
@@ -46,7 +46,6 @@ from diffusers import (
|
||||
DDPMScheduler,
|
||||
DiffusionPipeline,
|
||||
DPMSolverMultistepScheduler,
|
||||
StableDiffusionPipeline,
|
||||
UNet2DConditionModel,
|
||||
)
|
||||
from diffusers.loaders import AttnProcsLayers, LoraLoaderMixin
|
||||
@@ -55,11 +54,10 @@ from diffusers.models.attention_processor import (
|
||||
AttnAddedKVProcessor2_0,
|
||||
LoRAAttnAddedKVProcessor,
|
||||
LoRAAttnProcessor,
|
||||
LoRAAttnProcessor2_0,
|
||||
SlicedAttnAddedKVProcessor,
|
||||
)
|
||||
from diffusers.optimization import get_scheduler
|
||||
from diffusers.utils import TEXT_ENCODER_ATTN_MODULE, check_min_version, is_wandb_available
|
||||
from diffusers.utils import TEXT_ENCODER_TARGET_MODULES, check_min_version, is_wandb_available
|
||||
from diffusers.utils.import_utils import is_xformers_available
|
||||
|
||||
|
||||
@@ -69,15 +67,7 @@ check_min_version("0.17.0.dev0")
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
def save_model_card(
|
||||
repo_id: str,
|
||||
images=None,
|
||||
base_model=str,
|
||||
train_text_encoder=False,
|
||||
prompt=str,
|
||||
repo_folder=None,
|
||||
pipeline: DiffusionPipeline = None,
|
||||
):
|
||||
def save_model_card(repo_id: str, images=None, base_model=str, train_text_encoder=False, prompt=str, repo_folder=None):
|
||||
img_str = ""
|
||||
for i, image in enumerate(images):
|
||||
image.save(os.path.join(repo_folder, f"image_{i}.png"))
|
||||
@@ -89,8 +79,8 @@ license: creativeml-openrail-m
|
||||
base_model: {base_model}
|
||||
instance_prompt: {prompt}
|
||||
tags:
|
||||
- {'stable-diffusion' if isinstance(pipeline, StableDiffusionPipeline) else 'if'}
|
||||
- {'stable-diffusion-diffusers' if isinstance(pipeline, StableDiffusionPipeline) else 'if-diffusers'}
|
||||
- stable-diffusion
|
||||
- stable-diffusion-diffusers
|
||||
- text-to-image
|
||||
- diffusers
|
||||
- lora
|
||||
@@ -426,19 +416,6 @@ def parse_args(input_args=None):
|
||||
required=False,
|
||||
help="Whether to use attention mask for the text encoder",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--validation_images",
|
||||
required=False,
|
||||
default=None,
|
||||
nargs="+",
|
||||
help="Optional set of images to use for validation. Used when the target pipeline takes an initial image as input such as when training image variation or superresolution.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--class_labels_conditioning",
|
||||
required=False,
|
||||
default=None,
|
||||
help="The optional `class_label` conditioning to pass to the unet, available values are `timesteps`.",
|
||||
)
|
||||
|
||||
if input_args is not None:
|
||||
args = parser.parse_args(input_args)
|
||||
@@ -845,15 +822,15 @@ def main(args):
|
||||
if isinstance(attn_processor, (AttnAddedKVProcessor, SlicedAttnAddedKVProcessor, AttnAddedKVProcessor2_0)):
|
||||
lora_attn_processor_class = LoRAAttnAddedKVProcessor
|
||||
else:
|
||||
lora_attn_processor_class = (
|
||||
LoRAAttnProcessor2_0 if hasattr(F, "scaled_dot_product_attention") else LoRAAttnProcessor
|
||||
)
|
||||
lora_attn_processor_class = LoRAAttnProcessor
|
||||
|
||||
unet_lora_attn_procs[name] = lora_attn_processor_class(
|
||||
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim
|
||||
)
|
||||
|
||||
unet.set_attn_processor(unet_lora_attn_procs)
|
||||
unet_lora_layers = AttnProcsLayers(unet.attn_processors)
|
||||
unet_lora_layers.state_dict()
|
||||
|
||||
# The text encoder comes from 🤗 transformers, so we cannot directly modify it.
|
||||
# So, instead, we monkey-patch the forward calls of its attention-blocks. For this,
|
||||
@@ -862,9 +839,9 @@ def main(args):
|
||||
if args.train_text_encoder:
|
||||
text_lora_attn_procs = {}
|
||||
for name, module in text_encoder.named_modules():
|
||||
if name.endswith(TEXT_ENCODER_ATTN_MODULE):
|
||||
if any(x in name for x in TEXT_ENCODER_TARGET_MODULES):
|
||||
text_lora_attn_procs[name] = LoRAAttnProcessor(
|
||||
hidden_size=module.out_proj.out_features, cross_attention_dim=None
|
||||
hidden_size=module.out_features, cross_attention_dim=None
|
||||
)
|
||||
text_encoder_lora_layers = AttnProcsLayers(text_lora_attn_procs)
|
||||
temp_pipeline = DiffusionPipeline.from_pretrained(
|
||||
@@ -1136,7 +1113,7 @@ def main(args):
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(model_input)
|
||||
bsz, channels, height, width = model_input.shape
|
||||
bsz = model_input.shape[0]
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(
|
||||
0, noise_scheduler.config.num_train_timesteps, (bsz,), device=model_input.device
|
||||
@@ -1158,18 +1135,8 @@ def main(args):
|
||||
text_encoder_use_attention_mask=args.text_encoder_use_attention_mask,
|
||||
)
|
||||
|
||||
if accelerator.unwrap_model(unet).config.in_channels == channels * 2:
|
||||
noisy_model_input = torch.cat([noisy_model_input, noisy_model_input], dim=1)
|
||||
|
||||
if args.class_labels_conditioning == "timesteps":
|
||||
class_labels = timesteps
|
||||
else:
|
||||
class_labels = None
|
||||
|
||||
# Predict the noise residual
|
||||
model_pred = unet(
|
||||
noisy_model_input, timesteps, encoder_hidden_states, class_labels=class_labels
|
||||
).sample
|
||||
model_pred = unet(noisy_model_input, timesteps, encoder_hidden_states).sample
|
||||
|
||||
# if model predicts variance, throw away the prediction. we will only train on the
|
||||
# simplified training objective. This means that all schedulers using the fine tuned
|
||||
@@ -1273,18 +1240,9 @@ def main(args):
|
||||
}
|
||||
else:
|
||||
pipeline_args = {"prompt": args.validation_prompt}
|
||||
|
||||
if args.validation_images is None:
|
||||
images = [
|
||||
pipeline(**pipeline_args, generator=generator).images[0]
|
||||
for _ in range(args.num_validation_images)
|
||||
]
|
||||
else:
|
||||
images = []
|
||||
for image in args.validation_images:
|
||||
image = Image.open(image)
|
||||
image = pipeline(**pipeline_args, image=image, generator=generator).images[0]
|
||||
images.append(image)
|
||||
images = [
|
||||
pipeline(**pipeline_args, generator=generator).images[0] for _ in range(args.num_validation_images)
|
||||
]
|
||||
|
||||
for tracker in accelerator.trackers:
|
||||
if tracker.name == "tensorboard":
|
||||
@@ -1313,8 +1271,10 @@ def main(args):
|
||||
text_encoder = text_encoder.to(torch.float32)
|
||||
text_encoder_lora_layers = accelerator.unwrap_model(text_encoder_lora_layers)
|
||||
|
||||
print(f"Text encoder layers: {text_encoder_lora_layers}")
|
||||
LoraLoaderMixin.save_lora_weights(
|
||||
save_directory=args.output_dir,
|
||||
# unet_lora_layers=AttnProcsLayers(unet.attn_processors),
|
||||
unet_lora_layers=unet_lora_layers,
|
||||
text_encoder_lora_layers=text_encoder_lora_layers,
|
||||
)
|
||||
@@ -1342,13 +1302,19 @@ def main(args):
|
||||
|
||||
# load attention processors
|
||||
pipeline.load_lora_weights(args.output_dir)
|
||||
trained_state_dict = unet_lora_layers.state_dict()
|
||||
unet_attn_proc_state_dict = AttnProcsLayers(pipeline.unet.attn_processors).state_dict()
|
||||
for k in unet_attn_proc_state_dict:
|
||||
from_unet = unet_attn_proc_state_dict[k]
|
||||
orig = trained_state_dict[k]
|
||||
print(f"Assertion: {torch.allclose(from_unet, orig.to(from_unet.dtype))}")
|
||||
|
||||
# run inference
|
||||
images = []
|
||||
if args.validation_prompt and args.num_validation_images > 0:
|
||||
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed) if args.seed else None
|
||||
images = [
|
||||
pipeline(args.validation_prompt, num_inference_steps=25, generator=generator).images[0]
|
||||
pipeline(args.validation_prompt, generator=generator).images[0]
|
||||
for _ in range(args.num_validation_images)
|
||||
]
|
||||
|
||||
@@ -1374,7 +1340,6 @@ def main(args):
|
||||
train_text_encoder=args.train_text_encoder,
|
||||
prompt=args.instance_prompt,
|
||||
repo_folder=args.output_dir,
|
||||
pipeline=pipeline,
|
||||
)
|
||||
upload_folder(
|
||||
repo_id=repo_id,
|
||||
|
||||
@@ -185,5 +185,3 @@ speed and quality during performance:
|
||||
|
||||
Particularly, `image_guidance_scale` and `guidance_scale` can have a profound impact
|
||||
on the generated ("edited") image (see [here](https://twitter.com/RisingSayak/status/1628392199196151808?s=20) for an example).
|
||||
|
||||
If you're looking for some interesting ways to use the InstructPix2Pix training methodology, we welcome you to check out this blog post: [Instruction-tuning Stable Diffusion with InstructPix2Pix](https://huggingface.co/blog/instruction-tuning-sd).
|
||||
@@ -20,7 +20,6 @@ import os
|
||||
import random
|
||||
from pathlib import Path
|
||||
|
||||
import accelerate
|
||||
import datasets
|
||||
import numpy as np
|
||||
import torch
|
||||
@@ -29,96 +28,30 @@ import torch.utils.checkpoint
|
||||
import transformers
|
||||
from accelerate import Accelerator
|
||||
from accelerate.logging import get_logger
|
||||
from accelerate.state import AcceleratorState
|
||||
from accelerate.utils import ProjectConfiguration, set_seed
|
||||
from datasets import load_dataset
|
||||
from huggingface_hub import create_repo, upload_folder
|
||||
from onnxruntime.training.optim.fp16_optimizer import FP16_Optimizer as ORT_FP16_Optimizer
|
||||
from onnxruntime.training.ortmodule import ORTModule
|
||||
from packaging import version
|
||||
from torchvision import transforms
|
||||
from tqdm.auto import tqdm
|
||||
from transformers import CLIPTextModel, CLIPTokenizer
|
||||
from transformers.utils import ContextManagers
|
||||
|
||||
import diffusers
|
||||
from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionPipeline, UNet2DConditionModel
|
||||
from diffusers.optimization import get_scheduler
|
||||
from diffusers.training_utils import EMAModel
|
||||
from diffusers.utils import check_min_version, deprecate, is_wandb_available
|
||||
from diffusers.utils import check_min_version
|
||||
from diffusers.utils.import_utils import is_xformers_available
|
||||
|
||||
|
||||
if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.17.0.dev0")
|
||||
check_min_version("0.13.0.dev0")
|
||||
|
||||
logger = get_logger(__name__, log_level="INFO")
|
||||
|
||||
DATASET_NAME_MAPPING = {
|
||||
"lambdalabs/pokemon-blip-captions": ("image", "text"),
|
||||
}
|
||||
|
||||
|
||||
def log_validation(vae, text_encoder, tokenizer, unet, args, accelerator, weight_dtype, epoch):
|
||||
logger.info("Running validation... ")
|
||||
|
||||
pipeline = StableDiffusionPipeline.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
vae=accelerator.unwrap_model(vae),
|
||||
text_encoder=accelerator.unwrap_model(text_encoder),
|
||||
tokenizer=tokenizer,
|
||||
unet=accelerator.unwrap_model(unet),
|
||||
safety_checker=None,
|
||||
revision=args.revision,
|
||||
torch_dtype=weight_dtype,
|
||||
)
|
||||
pipeline = pipeline.to(accelerator.device)
|
||||
pipeline.set_progress_bar_config(disable=True)
|
||||
|
||||
if args.enable_xformers_memory_efficient_attention:
|
||||
pipeline.enable_xformers_memory_efficient_attention()
|
||||
|
||||
if args.seed is None:
|
||||
generator = None
|
||||
else:
|
||||
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
|
||||
|
||||
images = []
|
||||
for i in range(len(args.validation_prompts)):
|
||||
with torch.autocast("cuda"):
|
||||
image = pipeline(args.validation_prompts[i], num_inference_steps=20, generator=generator).images[0]
|
||||
|
||||
images.append(image)
|
||||
|
||||
for tracker in accelerator.trackers:
|
||||
if tracker.name == "tensorboard":
|
||||
np_images = np.stack([np.asarray(img) for img in images])
|
||||
tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
|
||||
elif tracker.name == "wandb":
|
||||
tracker.log(
|
||||
{
|
||||
"validation": [
|
||||
wandb.Image(image, caption=f"{i}: {args.validation_prompts[i]}")
|
||||
for i, image in enumerate(images)
|
||||
]
|
||||
}
|
||||
)
|
||||
else:
|
||||
logger.warn(f"image logging not implemented for {tracker.name}")
|
||||
|
||||
del pipeline
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser(description="Simple example of a training script.")
|
||||
parser.add_argument(
|
||||
"--input_pertubation", type=float, default=0, help="The scale of input pretubation. Recommended 0.1."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--pretrained_model_name_or_path",
|
||||
type=str,
|
||||
@@ -177,13 +110,6 @@ def parse_args():
|
||||
"value if set."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--validation_prompts",
|
||||
type=str,
|
||||
default=None,
|
||||
nargs="+",
|
||||
help=("A set of prompts evaluated every `--validation_epochs` and logged to `--report_to`."),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--output_dir",
|
||||
type=str,
|
||||
@@ -265,13 +191,6 @@ def parse_args():
|
||||
parser.add_argument(
|
||||
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--snr_gamma",
|
||||
type=float,
|
||||
default=None,
|
||||
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
|
||||
"More details here: https://arxiv.org/abs/2303.09556.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
|
||||
)
|
||||
@@ -376,22 +295,6 @@ def parse_args():
|
||||
parser.add_argument(
|
||||
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
|
||||
)
|
||||
parser.add_argument("--noise_offset", type=float, default=0, help="The scale of noise offset.")
|
||||
parser.add_argument(
|
||||
"--validation_epochs",
|
||||
type=int,
|
||||
default=5,
|
||||
help="Run validation every X epochs.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--tracker_project_name",
|
||||
type=str,
|
||||
default="text2image-fine-tune",
|
||||
help=(
|
||||
"The `project_name` argument passed to Accelerator.init_trackers for"
|
||||
" more information see https://huggingface.co/docs/accelerate/v0.17.0/en/package_reference/accelerator#accelerate.Accelerator"
|
||||
),
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
|
||||
@@ -409,18 +312,13 @@ def parse_args():
|
||||
return args
|
||||
|
||||
|
||||
dataset_name_mapping = {
|
||||
"lambdalabs/pokemon-blip-captions": ("image", "text"),
|
||||
}
|
||||
|
||||
|
||||
def main():
|
||||
args = parse_args()
|
||||
|
||||
if args.non_ema_revision is not None:
|
||||
deprecate(
|
||||
"non_ema_revision!=None",
|
||||
"0.15.0",
|
||||
message=(
|
||||
"Downloading 'non_ema' weights from revision branches of the Hub is deprecated. Please make sure to"
|
||||
" use `--variant=non_ema` instead."
|
||||
),
|
||||
)
|
||||
logging_dir = os.path.join(args.output_dir, args.logging_dir)
|
||||
|
||||
accelerator_project_config = ProjectConfiguration(total_limit=args.checkpoints_total_limit)
|
||||
@@ -468,34 +366,10 @@ def main():
|
||||
tokenizer = CLIPTokenizer.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
|
||||
)
|
||||
|
||||
def deepspeed_zero_init_disabled_context_manager():
|
||||
"""
|
||||
returns either a context list that includes one that will disable zero.Init or an empty context list
|
||||
"""
|
||||
deepspeed_plugin = AcceleratorState().deepspeed_plugin if accelerate.state.is_initialized() else None
|
||||
if deepspeed_plugin is None:
|
||||
return []
|
||||
|
||||
return [deepspeed_plugin.zero3_init_context_manager(enable=False)]
|
||||
|
||||
# Currently Accelerate doesn't know how to handle multiple models under Deepspeed ZeRO stage 3.
|
||||
# For this to work properly all models must be run through `accelerate.prepare`. But accelerate
|
||||
# will try to assign the same optimizer with the same weights to all models during
|
||||
# `deepspeed.initialize`, which of course doesn't work.
|
||||
#
|
||||
# For now the following workaround will partially support Deepspeed ZeRO-3, by excluding the 2
|
||||
# frozen models from being partitioned during `zero.Init` which gets called during
|
||||
# `from_pretrained` So CLIPTextModel and AutoencoderKL will not enjoy the parameter sharding
|
||||
# across multiple gpus and only UNet2DConditionModel will get ZeRO sharded.
|
||||
with ContextManagers(deepspeed_zero_init_disabled_context_manager()):
|
||||
text_encoder = CLIPTextModel.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
|
||||
)
|
||||
vae = AutoencoderKL.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision
|
||||
)
|
||||
|
||||
text_encoder = CLIPTextModel.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
|
||||
)
|
||||
vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
|
||||
unet = UNet2DConditionModel.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="unet", revision=args.non_ema_revision
|
||||
)
|
||||
@@ -509,81 +383,17 @@ def main():
|
||||
ema_unet = UNet2DConditionModel.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
|
||||
)
|
||||
ema_unet = EMAModel(ema_unet.parameters(), model_cls=UNet2DConditionModel, model_config=ema_unet.config)
|
||||
ema_unet = EMAModel(ema_unet.parameters())
|
||||
|
||||
if args.enable_xformers_memory_efficient_attention:
|
||||
if is_xformers_available():
|
||||
import xformers
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
else:
|
||||
raise ValueError("xformers is not available. Make sure it is installed correctly")
|
||||
|
||||
def compute_snr(timesteps):
|
||||
"""
|
||||
Computes SNR as per https://github.com/TiankaiHang/Min-SNR-Diffusion-Training/blob/521b624bd70c67cee4bdf49225915f5945a872e3/guided_diffusion/gaussian_diffusion.py#L847-L849
|
||||
"""
|
||||
alphas_cumprod = noise_scheduler.alphas_cumprod
|
||||
sqrt_alphas_cumprod = alphas_cumprod**0.5
|
||||
sqrt_one_minus_alphas_cumprod = (1.0 - alphas_cumprod) ** 0.5
|
||||
|
||||
# Expand the tensors.
|
||||
# Adapted from https://github.com/TiankaiHang/Min-SNR-Diffusion-Training/blob/521b624bd70c67cee4bdf49225915f5945a872e3/guided_diffusion/gaussian_diffusion.py#L1026
|
||||
sqrt_alphas_cumprod = sqrt_alphas_cumprod.to(device=timesteps.device)[timesteps].float()
|
||||
while len(sqrt_alphas_cumprod.shape) < len(timesteps.shape):
|
||||
sqrt_alphas_cumprod = sqrt_alphas_cumprod[..., None]
|
||||
alpha = sqrt_alphas_cumprod.expand(timesteps.shape)
|
||||
|
||||
sqrt_one_minus_alphas_cumprod = sqrt_one_minus_alphas_cumprod.to(device=timesteps.device)[timesteps].float()
|
||||
while len(sqrt_one_minus_alphas_cumprod.shape) < len(timesteps.shape):
|
||||
sqrt_one_minus_alphas_cumprod = sqrt_one_minus_alphas_cumprod[..., None]
|
||||
sigma = sqrt_one_minus_alphas_cumprod.expand(timesteps.shape)
|
||||
|
||||
# Compute SNR.
|
||||
snr = (alpha / sigma) ** 2
|
||||
return snr
|
||||
|
||||
# `accelerate` 0.16.0 will have better support for customized saving
|
||||
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
|
||||
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
|
||||
def save_model_hook(models, weights, output_dir):
|
||||
if args.use_ema:
|
||||
ema_unet.save_pretrained(os.path.join(output_dir, "unet_ema"))
|
||||
|
||||
for i, model in enumerate(models):
|
||||
model.save_pretrained(os.path.join(output_dir, "unet"))
|
||||
|
||||
# make sure to pop weight so that corresponding model is not saved again
|
||||
weights.pop()
|
||||
|
||||
def load_model_hook(models, input_dir):
|
||||
if args.use_ema:
|
||||
load_model = EMAModel.from_pretrained(os.path.join(input_dir, "unet_ema"), UNet2DConditionModel)
|
||||
ema_unet.load_state_dict(load_model.state_dict())
|
||||
ema_unet.to(accelerator.device)
|
||||
del load_model
|
||||
|
||||
for i in range(len(models)):
|
||||
# pop models so that they are not loaded again
|
||||
model = models.pop()
|
||||
|
||||
# load diffusers style into model
|
||||
load_model = UNet2DConditionModel.from_pretrained(input_dir, subfolder="unet")
|
||||
model.register_to_config(**load_model.config)
|
||||
|
||||
model.load_state_dict(load_model.state_dict())
|
||||
del load_model
|
||||
|
||||
accelerator.register_save_state_pre_hook(save_model_hook)
|
||||
accelerator.register_load_state_pre_hook(load_model_hook)
|
||||
|
||||
if args.gradient_checkpointing:
|
||||
unet.enable_gradient_checkpointing()
|
||||
vae.enable_gradient_checkpointing()
|
||||
|
||||
# Enable TF32 for faster training on Ampere GPUs,
|
||||
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
|
||||
@@ -616,8 +426,6 @@ def main():
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
|
||||
optimizer = ORT_FP16_Optimizer(optimizer)
|
||||
|
||||
# Get the datasets: you can either provide your own training and evaluation files (see below)
|
||||
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
|
||||
|
||||
@@ -647,7 +455,7 @@ def main():
|
||||
column_names = dataset["train"].column_names
|
||||
|
||||
# 6. Get the column names for input/target.
|
||||
dataset_columns = DATASET_NAME_MAPPING.get(args.dataset_name, None)
|
||||
dataset_columns = dataset_name_mapping.get(args.dataset_name, None)
|
||||
if args.image_column is None:
|
||||
image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
|
||||
else:
|
||||
@@ -741,11 +549,11 @@ def main():
|
||||
unet, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
|
||||
if args.use_ema:
|
||||
ema_unet.to(accelerator.device)
|
||||
|
||||
unet = ORTModule(unet)
|
||||
|
||||
if args.use_ema:
|
||||
accelerator.register_for_checkpointing(ema_unet)
|
||||
|
||||
# For mixed precision training we cast the text_encoder and vae weights to half-precision
|
||||
# as these models are only used for inference, keeping weights in full precision is not required.
|
||||
weight_dtype = torch.float32
|
||||
@@ -757,6 +565,8 @@ def main():
|
||||
# Move text_encode and vae to gpu and cast to weight_dtype
|
||||
text_encoder.to(accelerator.device, dtype=weight_dtype)
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
if args.use_ema:
|
||||
ema_unet.to(accelerator.device)
|
||||
|
||||
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
@@ -768,9 +578,7 @@ def main():
|
||||
# We need to initialize the trackers we use, and also store our configuration.
|
||||
# The trackers initializes automatically on the main process.
|
||||
if accelerator.is_main_process:
|
||||
tracker_config = dict(vars(args))
|
||||
tracker_config.pop("validation_prompts")
|
||||
accelerator.init_trackers(args.tracker_project_name, tracker_config)
|
||||
accelerator.init_trackers("text2image-fine-tune", config=vars(args))
|
||||
|
||||
# Train!
|
||||
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
@@ -831,13 +639,6 @@ def main():
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents)
|
||||
if args.noise_offset:
|
||||
# https://www.crosslabs.org//blog/diffusion-with-offset-noise
|
||||
noise += args.noise_offset * torch.randn(
|
||||
(latents.shape[0], latents.shape[1], 1, 1), device=latents.device
|
||||
)
|
||||
if args.input_pertubation:
|
||||
new_noise = noise + args.input_pertubation * torch.randn_like(noise)
|
||||
bsz = latents.shape[0]
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
|
||||
@@ -845,10 +646,7 @@ def main():
|
||||
|
||||
# Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
if args.input_pertubation:
|
||||
noisy_latents = noise_scheduler.add_noise(latents, new_noise, timesteps)
|
||||
else:
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
|
||||
# Get the text embedding for conditioning
|
||||
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
|
||||
@@ -862,24 +660,8 @@ def main():
|
||||
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
|
||||
|
||||
# Predict the noise residual and compute loss
|
||||
model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
|
||||
|
||||
if args.snr_gamma is None:
|
||||
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
|
||||
else:
|
||||
# Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
|
||||
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
|
||||
# This is discussed in Section 4.2 of the same paper.
|
||||
snr = compute_snr(timesteps)
|
||||
mse_loss_weights = (
|
||||
torch.stack([snr, args.snr_gamma * torch.ones_like(timesteps)], dim=1).min(dim=1)[0] / snr
|
||||
)
|
||||
# We first calculate the original loss. Then we mean over the non-batch dimensions and
|
||||
# rebalance the sample-wise losses with their respective loss weights.
|
||||
# Finally, we take the mean of the rebalanced loss.
|
||||
loss = F.mse_loss(model_pred.float(), target.float(), reduction="none")
|
||||
loss = loss.mean(dim=list(range(1, len(loss.shape)))) * mse_loss_weights
|
||||
loss = loss.mean()
|
||||
model_pred = unet(noisy_latents, timesteps, encoder_hidden_states, return_dict=False)[0]
|
||||
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
|
||||
|
||||
# Gather the losses across all processes for logging (if we use distributed training).
|
||||
avg_loss = accelerator.gather(loss.repeat(args.train_batch_size)).mean()
|
||||
@@ -914,26 +696,6 @@ def main():
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
if accelerator.is_main_process:
|
||||
if args.validation_prompts is not None and epoch % args.validation_epochs == 0:
|
||||
if args.use_ema:
|
||||
# Store the UNet parameters temporarily and load the EMA parameters to perform inference.
|
||||
ema_unet.store(unet.parameters())
|
||||
ema_unet.copy_to(unet.parameters())
|
||||
log_validation(
|
||||
vae,
|
||||
text_encoder,
|
||||
tokenizer,
|
||||
unet,
|
||||
args,
|
||||
accelerator,
|
||||
weight_dtype,
|
||||
global_step,
|
||||
)
|
||||
if args.use_ema:
|
||||
# Switch back to the original UNet parameters.
|
||||
ema_unet.restore(unet.parameters())
|
||||
|
||||
# Create the pipeline using the trained modules and save it.
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
|
||||
@@ -53,19 +53,7 @@ If you have already cloned the repo, then you won't need to go through these ste
|
||||
|
||||
<br>
|
||||
|
||||
Now let's get our dataset. For this example we will use some cat images: https://huggingface.co/datasets/diffusers/cat_toy_example .
|
||||
|
||||
Let's first download it locally:
|
||||
|
||||
```py
|
||||
from huggingface_hub import snapshot_download
|
||||
|
||||
local_dir = "./cat"
|
||||
snapshot_download("diffusers/cat_toy_example", local_dir=local_dir, repo_type="dataset", ignore_patterns=".gitattributes")
|
||||
```
|
||||
|
||||
This will be our training data.
|
||||
Now we can launch the training using
|
||||
Now let's get our dataset.Download 3-4 images from [here](https://drive.google.com/drive/folders/1fmJMs25nxS_rSNqS5hTcRdLem_YQXbq5) and save them in a directory. This will be our training data.
|
||||
|
||||
## Use ONNXRuntime to accelerate training
|
||||
In order to leverage onnxruntime to accelerate training, please use textual_inversion.py
|
||||
|
||||
@@ -18,9 +18,9 @@ import logging
|
||||
import math
|
||||
import os
|
||||
import random
|
||||
import warnings
|
||||
from pathlib import Path
|
||||
|
||||
import datasets
|
||||
import numpy as np
|
||||
import PIL
|
||||
import torch
|
||||
@@ -31,7 +31,6 @@ from accelerate import Accelerator
|
||||
from accelerate.logging import get_logger
|
||||
from accelerate.utils import ProjectConfiguration, set_seed
|
||||
from huggingface_hub import create_repo, upload_folder
|
||||
from onnxruntime.training.optim.fp16_optimizer import FP16_Optimizer as ORT_FP16_Optimizer
|
||||
from onnxruntime.training.ortmodule import ORTModule
|
||||
|
||||
# TODO: remove and import from diffusers.utils when the new version of diffusers is released
|
||||
@@ -56,9 +55,6 @@ from diffusers.utils import check_min_version, is_wandb_available
|
||||
from diffusers.utils.import_utils import is_xformers_available
|
||||
|
||||
|
||||
if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
if version.parse(version.parse(PIL.__version__).base_version) >= version.parse("9.1.0"):
|
||||
PIL_INTERPOLATION = {
|
||||
"linear": PIL.Image.Resampling.BILINEAR,
|
||||
@@ -79,92 +75,14 @@ else:
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.17.0.dev0")
|
||||
check_min_version("0.13.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
def save_model_card(repo_id: str, images=None, base_model=str, repo_folder=None):
|
||||
img_str = ""
|
||||
for i, image in enumerate(images):
|
||||
image.save(os.path.join(repo_folder, f"image_{i}.png"))
|
||||
img_str += f"\n"
|
||||
|
||||
yaml = f"""
|
||||
---
|
||||
license: creativeml-openrail-m
|
||||
base_model: {base_model}
|
||||
tags:
|
||||
- stable-diffusion
|
||||
- stable-diffusion-diffusers
|
||||
- text-to-image
|
||||
- diffusers
|
||||
- textual_inversion
|
||||
inference: true
|
||||
---
|
||||
"""
|
||||
model_card = f"""
|
||||
# Textual inversion text2image fine-tuning - {repo_id}
|
||||
These are textual inversion adaption weights for {base_model}. You can find some example images in the following. \n
|
||||
{img_str}
|
||||
"""
|
||||
with open(os.path.join(repo_folder, "README.md"), "w") as f:
|
||||
f.write(yaml + model_card)
|
||||
|
||||
|
||||
def log_validation(text_encoder, tokenizer, unet, vae, args, accelerator, weight_dtype, epoch):
|
||||
logger.info(
|
||||
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
|
||||
f" {args.validation_prompt}."
|
||||
)
|
||||
# create pipeline (note: unet and vae are loaded again in float32)
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
text_encoder=accelerator.unwrap_model(text_encoder),
|
||||
tokenizer=tokenizer,
|
||||
unet=unet,
|
||||
vae=vae,
|
||||
safety_checker=None,
|
||||
revision=args.revision,
|
||||
torch_dtype=weight_dtype,
|
||||
)
|
||||
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
|
||||
pipeline = pipeline.to(accelerator.device)
|
||||
pipeline.set_progress_bar_config(disable=True)
|
||||
|
||||
# run inference
|
||||
generator = None if args.seed is None else torch.Generator(device=accelerator.device).manual_seed(args.seed)
|
||||
images = []
|
||||
for _ in range(args.num_validation_images):
|
||||
with torch.autocast("cuda"):
|
||||
image = pipeline(args.validation_prompt, num_inference_steps=25, generator=generator).images[0]
|
||||
images.append(image)
|
||||
|
||||
for tracker in accelerator.trackers:
|
||||
if tracker.name == "tensorboard":
|
||||
np_images = np.stack([np.asarray(img) for img in images])
|
||||
tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
|
||||
if tracker.name == "wandb":
|
||||
tracker.log(
|
||||
{
|
||||
"validation": [
|
||||
wandb.Image(image, caption=f"{i}: {args.validation_prompt}") for i, image in enumerate(images)
|
||||
]
|
||||
}
|
||||
)
|
||||
|
||||
del pipeline
|
||||
torch.cuda.empty_cache()
|
||||
return images
|
||||
|
||||
|
||||
def save_progress(text_encoder, placeholder_token_ids, accelerator, args, save_path):
|
||||
def save_progress(text_encoder, placeholder_token_id, accelerator, args, save_path):
|
||||
logger.info("Saving embeddings")
|
||||
learned_embeds = (
|
||||
accelerator.unwrap_model(text_encoder)
|
||||
.get_input_embeddings()
|
||||
.weight[min(placeholder_token_ids) : max(placeholder_token_ids) + 1]
|
||||
)
|
||||
learned_embeds = accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[placeholder_token_id]
|
||||
learned_embeds_dict = {args.placeholder_token: learned_embeds.detach().cpu()}
|
||||
torch.save(learned_embeds_dict, save_path)
|
||||
|
||||
@@ -178,15 +96,10 @@ def parse_args():
|
||||
help="Save learned_embeds.bin every X updates steps.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--save_as_full_pipeline",
|
||||
"--only_save_embeds",
|
||||
action="store_true",
|
||||
help="Save the complete stable diffusion pipeline.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--num_vectors",
|
||||
type=int,
|
||||
default=1,
|
||||
help="How many textual inversion vectors shall be used to learn the concept.",
|
||||
default=False,
|
||||
help="Save only the embeddings for the new concept.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--pretrained_model_name_or_path",
|
||||
@@ -356,22 +269,12 @@ def parse_args():
|
||||
default=4,
|
||||
help="Number of images that should be generated during validation with `validation_prompt`.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--validation_steps",
|
||||
type=int,
|
||||
default=100,
|
||||
help=(
|
||||
"Run validation every X steps. Validation consists of running the prompt"
|
||||
" `args.validation_prompt` multiple times: `args.num_validation_images`"
|
||||
" and logging the images."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--validation_epochs",
|
||||
type=int,
|
||||
default=None,
|
||||
default=50,
|
||||
help=(
|
||||
"Deprecated in favor of validation_steps. Run validation every X epochs. Validation consists of running the prompt"
|
||||
"Run validation every X epochs. Validation consists of running the prompt"
|
||||
" `args.validation_prompt` multiple times: `args.num_validation_images`"
|
||||
" and logging the images."
|
||||
),
|
||||
@@ -576,6 +479,7 @@ def main():
|
||||
if args.report_to == "wandb":
|
||||
if not is_wandb_available():
|
||||
raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
|
||||
import wandb
|
||||
|
||||
# Make one log on every process with the configuration for debugging.
|
||||
logging.basicConfig(
|
||||
@@ -585,9 +489,11 @@ def main():
|
||||
)
|
||||
logger.info(accelerator.state, main_process_only=False)
|
||||
if accelerator.is_local_main_process:
|
||||
datasets.utils.logging.set_verbosity_warning()
|
||||
transformers.utils.logging.set_verbosity_warning()
|
||||
diffusers.utils.logging.set_verbosity_info()
|
||||
else:
|
||||
datasets.utils.logging.set_verbosity_error()
|
||||
transformers.utils.logging.set_verbosity_error()
|
||||
diffusers.utils.logging.set_verbosity_error()
|
||||
|
||||
@@ -622,19 +528,8 @@ def main():
|
||||
)
|
||||
|
||||
# Add the placeholder token in tokenizer
|
||||
placeholder_tokens = [args.placeholder_token]
|
||||
|
||||
if args.num_vectors < 1:
|
||||
raise ValueError(f"--num_vectors has to be larger or equal to 1, but is {args.num_vectors}")
|
||||
|
||||
# add dummy tokens for multi-vector
|
||||
additional_tokens = []
|
||||
for i in range(1, args.num_vectors):
|
||||
additional_tokens.append(f"{args.placeholder_token}_{i}")
|
||||
placeholder_tokens += additional_tokens
|
||||
|
||||
num_added_tokens = tokenizer.add_tokens(placeholder_tokens)
|
||||
if num_added_tokens != args.num_vectors:
|
||||
num_added_tokens = tokenizer.add_tokens(args.placeholder_token)
|
||||
if num_added_tokens == 0:
|
||||
raise ValueError(
|
||||
f"The tokenizer already contains the token {args.placeholder_token}. Please pass a different"
|
||||
" `placeholder_token` that is not already in the tokenizer."
|
||||
@@ -647,16 +542,14 @@ def main():
|
||||
raise ValueError("The initializer token must be a single token.")
|
||||
|
||||
initializer_token_id = token_ids[0]
|
||||
placeholder_token_ids = tokenizer.convert_tokens_to_ids(placeholder_tokens)
|
||||
placeholder_token_id = tokenizer.convert_tokens_to_ids(args.placeholder_token)
|
||||
|
||||
# Resize the token embeddings as we are adding new special tokens to the tokenizer
|
||||
text_encoder.resize_token_embeddings(len(tokenizer))
|
||||
|
||||
# Initialise the newly added placeholder token with the embeddings of the initializer token
|
||||
token_embeds = text_encoder.get_input_embeddings().weight.data
|
||||
with torch.no_grad():
|
||||
for token_id in placeholder_token_ids:
|
||||
token_embeds[token_id] = token_embeds[initializer_token_id].clone()
|
||||
token_embeds[placeholder_token_id] = token_embeds[initializer_token_id]
|
||||
|
||||
# Freeze vae and unet
|
||||
vae.requires_grad_(False)
|
||||
@@ -675,13 +568,6 @@ def main():
|
||||
|
||||
if args.enable_xformers_memory_efficient_attention:
|
||||
if is_xformers_available():
|
||||
import xformers
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
unet.enable_xformers_memory_efficient_attention()
|
||||
else:
|
||||
raise ValueError("xformers is not available. Make sure it is installed correctly")
|
||||
@@ -705,8 +591,6 @@ def main():
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
|
||||
optimizer = ORT_FP16_Optimizer(optimizer)
|
||||
|
||||
# Dataset and DataLoaders creation:
|
||||
train_dataset = TextualInversionDataset(
|
||||
data_root=args.train_data_dir,
|
||||
@@ -721,15 +605,6 @@ def main():
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset, batch_size=args.train_batch_size, shuffle=True, num_workers=args.dataloader_num_workers
|
||||
)
|
||||
if args.validation_epochs is not None:
|
||||
warnings.warn(
|
||||
f"FutureWarning: You are doing logging with validation_epochs={args.validation_epochs}."
|
||||
" Deprecated validation_epochs in favor of `validation_steps`"
|
||||
f"Setting `args.validation_steps` to {args.validation_epochs * len(train_dataset)}",
|
||||
FutureWarning,
|
||||
stacklevel=2,
|
||||
)
|
||||
args.validation_steps = args.validation_epochs * len(train_dataset)
|
||||
|
||||
# Scheduler and math around the number of training steps.
|
||||
overrode_max_train_steps = False
|
||||
@@ -751,8 +626,6 @@ def main():
|
||||
)
|
||||
|
||||
text_encoder = ORTModule(text_encoder)
|
||||
unet = ORTModule(unet)
|
||||
vae = ORTModule(vae)
|
||||
|
||||
# For mixed precision training we cast the unet and vae weights to half-precision
|
||||
# as these models are only used for inference, keeping weights in full precision is not required.
|
||||
@@ -790,6 +663,7 @@ def main():
|
||||
logger.info(f" Total optimization steps = {args.max_train_steps}")
|
||||
global_step = 0
|
||||
first_epoch = 0
|
||||
|
||||
# Potentially load in the weights and states from a previous save
|
||||
if args.resume_from_checkpoint:
|
||||
if args.resume_from_checkpoint != "latest":
|
||||
@@ -870,9 +744,7 @@ def main():
|
||||
optimizer.zero_grad()
|
||||
|
||||
# Let's make sure we don't update any embedding weights besides the newly added token
|
||||
index_no_updates = torch.ones((len(tokenizer),), dtype=torch.bool)
|
||||
index_no_updates[min(placeholder_token_ids) : max(placeholder_token_ids) + 1] = False
|
||||
|
||||
index_no_updates = torch.arange(len(tokenizer)) != placeholder_token_id
|
||||
with torch.no_grad():
|
||||
accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[
|
||||
index_no_updates
|
||||
@@ -880,38 +752,72 @@ def main():
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
if accelerator.sync_gradients:
|
||||
images = []
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
if global_step % args.save_steps == 0:
|
||||
save_path = os.path.join(args.output_dir, f"learned_embeds-steps-{global_step}.bin")
|
||||
save_progress(text_encoder, placeholder_token_ids, accelerator, args, save_path)
|
||||
save_progress(text_encoder, placeholder_token_id, accelerator, args, save_path)
|
||||
|
||||
if accelerator.is_main_process:
|
||||
if global_step % args.checkpointing_steps == 0:
|
||||
if global_step % args.checkpointing_steps == 0:
|
||||
if accelerator.is_main_process:
|
||||
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
|
||||
accelerator.save_state(save_path)
|
||||
logger.info(f"Saved state to {save_path}")
|
||||
|
||||
if args.validation_prompt is not None and global_step % args.validation_steps == 0:
|
||||
images = log_validation(
|
||||
text_encoder, tokenizer, unet, vae, args, accelerator, weight_dtype, epoch
|
||||
)
|
||||
|
||||
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
# Create the pipeline using the trained modules and save it.
|
||||
|
||||
if accelerator.is_main_process and args.validation_prompt is not None and epoch % args.validation_epochs == 0:
|
||||
logger.info(
|
||||
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
|
||||
f" {args.validation_prompt}."
|
||||
)
|
||||
# create pipeline (note: unet and vae are loaded again in float32)
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
text_encoder=accelerator.unwrap_model(text_encoder),
|
||||
revision=args.revision,
|
||||
)
|
||||
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
|
||||
pipeline = pipeline.to(accelerator.device)
|
||||
pipeline.set_progress_bar_config(disable=True)
|
||||
|
||||
# run inference
|
||||
generator = (
|
||||
None if args.seed is None else torch.Generator(device=accelerator.device).manual_seed(args.seed)
|
||||
)
|
||||
prompt = args.num_validation_images * [args.validation_prompt]
|
||||
images = pipeline(prompt, num_inference_steps=25, generator=generator).images
|
||||
|
||||
for tracker in accelerator.trackers:
|
||||
if tracker.name == "tensorboard":
|
||||
np_images = np.stack([np.asarray(img) for img in images])
|
||||
tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
|
||||
if tracker.name == "wandb":
|
||||
tracker.log(
|
||||
{
|
||||
"validation": [
|
||||
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
|
||||
for i, image in enumerate(images)
|
||||
]
|
||||
}
|
||||
)
|
||||
|
||||
del pipeline
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
# Create the pipeline using using the trained modules and save it.
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
if args.push_to_hub and not args.save_as_full_pipeline:
|
||||
if args.push_to_hub and args.only_save_embeds:
|
||||
logger.warn("Enabling full model saving because --push_to_hub=True was specified.")
|
||||
save_full_model = True
|
||||
else:
|
||||
save_full_model = args.save_as_full_pipeline
|
||||
save_full_model = not args.only_save_embeds
|
||||
if save_full_model:
|
||||
pipeline = StableDiffusionPipeline.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
@@ -923,15 +829,9 @@ def main():
|
||||
pipeline.save_pretrained(args.output_dir)
|
||||
# Save the newly trained embeddings
|
||||
save_path = os.path.join(args.output_dir, "learned_embeds.bin")
|
||||
save_progress(text_encoder, placeholder_token_ids, accelerator, args, save_path)
|
||||
save_progress(text_encoder, placeholder_token_id, accelerator, args, save_path)
|
||||
|
||||
if args.push_to_hub:
|
||||
save_model_card(
|
||||
repo_id,
|
||||
images=images,
|
||||
base_model=args.pretrained_model_name_or_path,
|
||||
repo_folder=args.output_dir,
|
||||
)
|
||||
upload_folder(
|
||||
repo_id=repo_id,
|
||||
folder_path=args.output_dir,
|
||||
|
||||
@@ -34,7 +34,7 @@ In order to leverage onnxruntime to accelerate training, please use train_uncond
|
||||
The command to train a DDPM UNet model on the Oxford Flowers dataset with onnxruntime:
|
||||
|
||||
```bash
|
||||
accelerate launch train_unconditional.py \
|
||||
accelerate launch train_unconditional_ort.py \
|
||||
--dataset_name="huggan/flowers-102-categories" \
|
||||
--resolution=64 --center_crop --random_flip \
|
||||
--output_dir="ddpm-ema-flowers-64" \
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
accelerate>=0.16.0
|
||||
torchvision
|
||||
datasets
|
||||
tensorboard
|
||||
@@ -6,7 +6,6 @@ import os
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
import accelerate
|
||||
import datasets
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
@@ -15,9 +14,7 @@ from accelerate.logging import get_logger
|
||||
from accelerate.utils import ProjectConfiguration
|
||||
from datasets import load_dataset
|
||||
from huggingface_hub import HfFolder, Repository, create_repo, whoami
|
||||
from onnxruntime.training.optim.fp16_optimizer import FP16_Optimizer as ORT_FP16_Optimizer
|
||||
from onnxruntime.training.ortmodule import ORTModule
|
||||
from packaging import version
|
||||
from torchvision import transforms
|
||||
from tqdm.auto import tqdm
|
||||
|
||||
@@ -25,12 +22,11 @@ import diffusers
|
||||
from diffusers import DDPMPipeline, DDPMScheduler, UNet2DModel
|
||||
from diffusers.optimization import get_scheduler
|
||||
from diffusers.training_utils import EMAModel
|
||||
from diffusers.utils import check_min_version, is_accelerate_version, is_tensorboard_available, is_wandb_available
|
||||
from diffusers.utils.import_utils import is_xformers_available
|
||||
from diffusers.utils import check_min_version, is_tensorboard_available, is_wandb_available
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.17.0.dev0")
|
||||
check_min_version("0.13.0.dev0")
|
||||
|
||||
logger = get_logger(__name__, log_level="INFO")
|
||||
|
||||
@@ -38,7 +34,6 @@ logger = get_logger(__name__, log_level="INFO")
|
||||
def _extract_into_tensor(arr, timesteps, broadcast_shape):
|
||||
"""
|
||||
Extract values from a 1-D numpy array for a batch of indices.
|
||||
|
||||
:param arr: the 1-D numpy array.
|
||||
:param timesteps: a tensor of indices into the array to extract.
|
||||
:param broadcast_shape: a larger shape of K dimensions with the batch
|
||||
@@ -71,12 +66,6 @@ def parse_args():
|
||||
default=None,
|
||||
help="The config of the Dataset, leave as None if there's only one config.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--model_config_name_or_path",
|
||||
type=str,
|
||||
default=None,
|
||||
help="The config of the UNet model to train, leave as None to use standard DDPM configuration.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--train_data_dir",
|
||||
type=str,
|
||||
@@ -262,9 +251,6 @@ def parse_args():
|
||||
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
|
||||
@@ -309,40 +295,6 @@ def main(args):
|
||||
raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
|
||||
import wandb
|
||||
|
||||
# `accelerate` 0.16.0 will have better support for customized saving
|
||||
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
|
||||
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
|
||||
def save_model_hook(models, weights, output_dir):
|
||||
if args.use_ema:
|
||||
ema_model.save_pretrained(os.path.join(output_dir, "unet_ema"))
|
||||
|
||||
for i, model in enumerate(models):
|
||||
model.save_pretrained(os.path.join(output_dir, "unet"))
|
||||
|
||||
# make sure to pop weight so that corresponding model is not saved again
|
||||
weights.pop()
|
||||
|
||||
def load_model_hook(models, input_dir):
|
||||
if args.use_ema:
|
||||
load_model = EMAModel.from_pretrained(os.path.join(input_dir, "unet_ema"), UNet2DModel)
|
||||
ema_model.load_state_dict(load_model.state_dict())
|
||||
ema_model.to(accelerator.device)
|
||||
del load_model
|
||||
|
||||
for i in range(len(models)):
|
||||
# pop models so that they are not loaded again
|
||||
model = models.pop()
|
||||
|
||||
# load diffusers style into model
|
||||
load_model = UNet2DModel.from_pretrained(input_dir, subfolder="unet")
|
||||
model.register_to_config(**load_model.config)
|
||||
|
||||
model.load_state_dict(load_model.state_dict())
|
||||
del load_model
|
||||
|
||||
accelerator.register_save_state_pre_hook(save_model_hook)
|
||||
accelerator.register_load_state_pre_hook(load_model_hook)
|
||||
|
||||
# Make one log on every process with the configuration for debugging.
|
||||
logging.basicConfig(
|
||||
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
|
||||
@@ -376,33 +328,29 @@ def main(args):
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
|
||||
# Initialize the model
|
||||
if args.model_config_name_or_path is None:
|
||||
model = UNet2DModel(
|
||||
sample_size=args.resolution,
|
||||
in_channels=3,
|
||||
out_channels=3,
|
||||
layers_per_block=2,
|
||||
block_out_channels=(128, 128, 256, 256, 512, 512),
|
||||
down_block_types=(
|
||||
"DownBlock2D",
|
||||
"DownBlock2D",
|
||||
"DownBlock2D",
|
||||
"DownBlock2D",
|
||||
"AttnDownBlock2D",
|
||||
"DownBlock2D",
|
||||
),
|
||||
up_block_types=(
|
||||
"UpBlock2D",
|
||||
"AttnUpBlock2D",
|
||||
"UpBlock2D",
|
||||
"UpBlock2D",
|
||||
"UpBlock2D",
|
||||
"UpBlock2D",
|
||||
),
|
||||
)
|
||||
else:
|
||||
config = UNet2DModel.load_config(args.model_config_name_or_path)
|
||||
model = UNet2DModel.from_config(config)
|
||||
model = UNet2DModel(
|
||||
sample_size=args.resolution,
|
||||
in_channels=3,
|
||||
out_channels=3,
|
||||
layers_per_block=2,
|
||||
block_out_channels=(128, 128, 256, 256, 512, 512),
|
||||
down_block_types=(
|
||||
"DownBlock2D",
|
||||
"DownBlock2D",
|
||||
"DownBlock2D",
|
||||
"DownBlock2D",
|
||||
"AttnDownBlock2D",
|
||||
"DownBlock2D",
|
||||
),
|
||||
up_block_types=(
|
||||
"UpBlock2D",
|
||||
"AttnUpBlock2D",
|
||||
"UpBlock2D",
|
||||
"UpBlock2D",
|
||||
"UpBlock2D",
|
||||
"UpBlock2D",
|
||||
),
|
||||
)
|
||||
|
||||
# Create EMA for the model.
|
||||
if args.use_ema:
|
||||
@@ -412,23 +360,8 @@ def main(args):
|
||||
use_ema_warmup=True,
|
||||
inv_gamma=args.ema_inv_gamma,
|
||||
power=args.ema_power,
|
||||
model_cls=UNet2DModel,
|
||||
model_config=model.config,
|
||||
)
|
||||
|
||||
if args.enable_xformers_memory_efficient_attention:
|
||||
if is_xformers_available():
|
||||
import xformers
|
||||
|
||||
xformers_version = version.parse(xformers.__version__)
|
||||
if xformers_version == version.parse("0.0.16"):
|
||||
logger.warn(
|
||||
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
|
||||
)
|
||||
model.enable_xformers_memory_efficient_attention()
|
||||
else:
|
||||
raise ValueError("xformers is not available. Make sure it is installed correctly")
|
||||
|
||||
# Initialize the scheduler
|
||||
accepts_prediction_type = "prediction_type" in set(inspect.signature(DDPMScheduler.__init__).parameters.keys())
|
||||
if accepts_prediction_type:
|
||||
@@ -449,8 +382,6 @@ def main(args):
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
|
||||
optimizer = ORT_FP16_Optimizer(optimizer)
|
||||
|
||||
# Get the datasets: you can either provide your own training and evaluation files (see below)
|
||||
# or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
|
||||
|
||||
@@ -503,7 +434,10 @@ def main(args):
|
||||
model, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
|
||||
model = ORTModule(model)
|
||||
|
||||
if args.use_ema:
|
||||
accelerator.register_for_checkpointing(ema_model)
|
||||
ema_model.to(accelerator.device)
|
||||
|
||||
# We need to initialize the trackers we use, and also store our configuration.
|
||||
@@ -512,8 +446,6 @@ def main(args):
|
||||
run = os.path.split(__file__)[-1].split(".")[0]
|
||||
accelerator.init_trackers(run)
|
||||
|
||||
model = ORTModule(model)
|
||||
|
||||
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
max_train_steps = args.num_epochs * num_update_steps_per_epoch
|
||||
@@ -620,7 +552,7 @@ def main(args):
|
||||
|
||||
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0], "step": global_step}
|
||||
if args.use_ema:
|
||||
logs["ema_decay"] = ema_model.cur_decay_value
|
||||
logs["ema_decay"] = ema_model.decay
|
||||
progress_bar.set_postfix(**logs)
|
||||
accelerator.log(logs, step=global_step)
|
||||
progress_bar.close()
|
||||
@@ -631,11 +563,8 @@ def main(args):
|
||||
if accelerator.is_main_process:
|
||||
if epoch % args.save_images_epochs == 0 or epoch == args.num_epochs - 1:
|
||||
unet = accelerator.unwrap_model(model)
|
||||
|
||||
if args.use_ema:
|
||||
ema_model.store(unet.parameters())
|
||||
ema_model.copy_to(unet.parameters())
|
||||
|
||||
pipeline = DDPMPipeline(
|
||||
unet=unet,
|
||||
scheduler=noise_scheduler,
|
||||
@@ -646,24 +575,18 @@ def main(args):
|
||||
images = pipeline(
|
||||
generator=generator,
|
||||
batch_size=args.eval_batch_size,
|
||||
num_inference_steps=args.ddpm_num_inference_steps,
|
||||
output_type="numpy",
|
||||
num_inference_steps=args.ddpm_num_inference_steps,
|
||||
).images
|
||||
|
||||
if args.use_ema:
|
||||
ema_model.restore(unet.parameters())
|
||||
|
||||
# denormalize the images and save to tensorboard
|
||||
images_processed = (images * 255).round().astype("uint8")
|
||||
|
||||
if args.logger == "tensorboard":
|
||||
if is_accelerate_version(">=", "0.17.0.dev0"):
|
||||
tracker = accelerator.get_tracker("tensorboard", unwrap=True)
|
||||
else:
|
||||
tracker = accelerator.get_tracker("tensorboard")
|
||||
tracker.add_images("test_samples", images_processed.transpose(0, 3, 1, 2), epoch)
|
||||
accelerator.get_tracker("tensorboard").add_images(
|
||||
"test_samples", images_processed.transpose(0, 3, 1, 2), epoch
|
||||
)
|
||||
elif args.logger == "wandb":
|
||||
# Upcoming `log_images` helper coming in https://github.com/huggingface/accelerate/pull/962/files
|
||||
accelerator.get_tracker("wandb").log(
|
||||
{"test_samples": [wandb.Image(img) for img in images_processed], "epoch": epoch},
|
||||
step=global_step,
|
||||
@@ -671,22 +594,7 @@ def main(args):
|
||||
|
||||
if epoch % args.save_model_epochs == 0 or epoch == args.num_epochs - 1:
|
||||
# save the model
|
||||
unet = accelerator.unwrap_model(model)
|
||||
|
||||
if args.use_ema:
|
||||
ema_model.store(unet.parameters())
|
||||
ema_model.copy_to(unet.parameters())
|
||||
|
||||
pipeline = DDPMPipeline(
|
||||
unet=unet,
|
||||
scheduler=noise_scheduler,
|
||||
)
|
||||
|
||||
pipeline.save_pretrained(args.output_dir)
|
||||
|
||||
if args.use_ema:
|
||||
ema_model.restore(unet.parameters())
|
||||
|
||||
if args.push_to_hub:
|
||||
repo.push_to_hub(commit_message=f"Epoch {epoch}", blocking=False)
|
||||
|
||||
|
||||
@@ -115,7 +115,7 @@ def log_validation(vae, text_encoder, tokenizer, unet, args, accelerator, weight
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser(description="Simple example of a training script.")
|
||||
parser.add_argument(
|
||||
"--input_perturbation", type=float, default=0, help="The scale of input perturbation. Recommended 0.1."
|
||||
"--input_pertubation", type=float, default=0, help="The scale of input pretubation. Recommended 0.1."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--pretrained_model_name_or_path",
|
||||
@@ -830,8 +830,8 @@ def main():
|
||||
noise += args.noise_offset * torch.randn(
|
||||
(latents.shape[0], latents.shape[1], 1, 1), device=latents.device
|
||||
)
|
||||
if args.input_perturbation:
|
||||
new_noise = noise + args.input_perturbation * torch.randn_like(noise)
|
||||
if args.input_pertubation:
|
||||
new_noise = noise + args.input_pertubation * torch.randn_like(noise)
|
||||
bsz = latents.shape[0]
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
|
||||
@@ -839,7 +839,7 @@ def main():
|
||||
|
||||
# Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
if args.input_perturbation:
|
||||
if args.input_pertubation:
|
||||
noisy_latents = noise_scheduler.add_noise(latents, new_noise, timesteps)
|
||||
else:
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
|
||||
@@ -285,12 +285,6 @@ def parse_args():
|
||||
parser.add_argument(
|
||||
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--lr_num_cycles",
|
||||
type=int,
|
||||
default=1,
|
||||
help="Number of hard resets of the lr in cosine_with_restarts scheduler.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--dataloader_num_workers",
|
||||
type=int,
|
||||
@@ -745,7 +739,6 @@ def main():
|
||||
optimizer=optimizer,
|
||||
num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
|
||||
num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
|
||||
num_cycles=args.lr_num_cycles * args.gradient_accumulation_steps,
|
||||
)
|
||||
|
||||
# Prepare everything with our `accelerator`.
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -75,22 +75,6 @@ if __name__ == "__main__":
|
||||
)
|
||||
parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
|
||||
parser.add_argument("--device", type=str, help="Device to use (e.g. cpu, cuda:0, cuda:1, etc.)")
|
||||
|
||||
# small workaround to get argparser to parse a boolean input as either true _or_ false
|
||||
def parse_bool(string):
|
||||
if string == "True":
|
||||
return True
|
||||
elif string == "False":
|
||||
return False
|
||||
else:
|
||||
raise ValueError(f"could not parse string as bool {string}")
|
||||
|
||||
parser.add_argument(
|
||||
"--use_linear_projection", help="Override for use linear projection", required=False, type=parse_bool
|
||||
)
|
||||
|
||||
parser.add_argument("--cross_attention_dim", help="Override for cross attention_dim", required=False, type=int)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
controlnet = download_controlnet_from_original_ckpt(
|
||||
@@ -102,8 +86,6 @@ if __name__ == "__main__":
|
||||
upcast_attention=args.upcast_attention,
|
||||
from_safetensors=args.from_safetensors,
|
||||
device=args.device,
|
||||
use_linear_projection=args.use_linear_projection,
|
||||
cross_attention_dim=args.cross_attention_dim,
|
||||
)
|
||||
|
||||
controlnet.save_pretrained(args.dump_path, safe_serialization=args.to_safetensors)
|
||||
|
||||
@@ -1,776 +0,0 @@
|
||||
# Convert the original UniDiffuser checkpoints into diffusers equivalents.
|
||||
|
||||
import argparse
|
||||
from argparse import Namespace
|
||||
|
||||
import torch
|
||||
from transformers import (
|
||||
CLIPImageProcessor,
|
||||
CLIPTextConfig,
|
||||
CLIPTextModel,
|
||||
CLIPTokenizer,
|
||||
CLIPVisionConfig,
|
||||
CLIPVisionModelWithProjection,
|
||||
GPT2Tokenizer,
|
||||
)
|
||||
|
||||
from diffusers import (
|
||||
AutoencoderKL,
|
||||
DPMSolverMultistepScheduler,
|
||||
UniDiffuserModel,
|
||||
UniDiffuserPipeline,
|
||||
UniDiffuserTextDecoder,
|
||||
)
|
||||
|
||||
|
||||
SCHEDULER_CONFIG = Namespace(
|
||||
**{
|
||||
"beta_start": 0.00085,
|
||||
"beta_end": 0.012,
|
||||
"beta_schedule": "scaled_linear",
|
||||
"solver_order": 3,
|
||||
}
|
||||
)
|
||||
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.convert_from_ckpt.shave_segments
|
||||
def shave_segments(path, n_shave_prefix_segments=1):
|
||||
"""
|
||||
Removes segments. Positive values shave the first segments, negative shave the last segments.
|
||||
"""
|
||||
if n_shave_prefix_segments >= 0:
|
||||
return ".".join(path.split(".")[n_shave_prefix_segments:])
|
||||
else:
|
||||
return ".".join(path.split(".")[:n_shave_prefix_segments])
|
||||
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.convert_from_ckpt.renew_vae_resnet_paths
|
||||
def renew_vae_resnet_paths(old_list, n_shave_prefix_segments=0):
|
||||
"""
|
||||
Updates paths inside resnets to the new naming scheme (local renaming)
|
||||
"""
|
||||
mapping = []
|
||||
for old_item in old_list:
|
||||
new_item = old_item
|
||||
|
||||
new_item = new_item.replace("nin_shortcut", "conv_shortcut")
|
||||
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
|
||||
|
||||
mapping.append({"old": old_item, "new": new_item})
|
||||
|
||||
return mapping
|
||||
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.convert_from_ckpt.renew_vae_attention_paths
|
||||
def renew_vae_attention_paths(old_list, n_shave_prefix_segments=0):
|
||||
"""
|
||||
Updates paths inside attentions to the new naming scheme (local renaming)
|
||||
"""
|
||||
mapping = []
|
||||
for old_item in old_list:
|
||||
new_item = old_item
|
||||
|
||||
new_item = new_item.replace("norm.weight", "group_norm.weight")
|
||||
new_item = new_item.replace("norm.bias", "group_norm.bias")
|
||||
|
||||
new_item = new_item.replace("q.weight", "query.weight")
|
||||
new_item = new_item.replace("q.bias", "query.bias")
|
||||
|
||||
new_item = new_item.replace("k.weight", "key.weight")
|
||||
new_item = new_item.replace("k.bias", "key.bias")
|
||||
|
||||
new_item = new_item.replace("v.weight", "value.weight")
|
||||
new_item = new_item.replace("v.bias", "value.bias")
|
||||
|
||||
new_item = new_item.replace("proj_out.weight", "proj_attn.weight")
|
||||
new_item = new_item.replace("proj_out.bias", "proj_attn.bias")
|
||||
|
||||
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
|
||||
|
||||
mapping.append({"old": old_item, "new": new_item})
|
||||
|
||||
return mapping
|
||||
|
||||
|
||||
# Modified from diffusers.pipelines.stable_diffusion.convert_from_ckpt.assign_to_checkpoint
|
||||
# config.num_head_channels => num_head_channels
|
||||
def assign_to_checkpoint(
|
||||
paths,
|
||||
checkpoint,
|
||||
old_checkpoint,
|
||||
attention_paths_to_split=None,
|
||||
additional_replacements=None,
|
||||
num_head_channels=1,
|
||||
):
|
||||
"""
|
||||
This does the final conversion step: take locally converted weights and apply a global renaming to them. It splits
|
||||
attention layers, and takes into account additional replacements that may arise. Assigns the weights to the new
|
||||
checkpoint.
|
||||
"""
|
||||
assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
|
||||
|
||||
# Splits the attention layers into three variables.
|
||||
if attention_paths_to_split is not None:
|
||||
for path, path_map in attention_paths_to_split.items():
|
||||
old_tensor = old_checkpoint[path]
|
||||
channels = old_tensor.shape[0] // 3
|
||||
|
||||
target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
|
||||
|
||||
num_heads = old_tensor.shape[0] // num_head_channels // 3
|
||||
|
||||
old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
|
||||
query, key, value = old_tensor.split(channels // num_heads, dim=1)
|
||||
|
||||
checkpoint[path_map["query"]] = query.reshape(target_shape)
|
||||
checkpoint[path_map["key"]] = key.reshape(target_shape)
|
||||
checkpoint[path_map["value"]] = value.reshape(target_shape)
|
||||
|
||||
for path in paths:
|
||||
new_path = path["new"]
|
||||
|
||||
# These have already been assigned
|
||||
if attention_paths_to_split is not None and new_path in attention_paths_to_split:
|
||||
continue
|
||||
|
||||
# Global renaming happens here
|
||||
new_path = new_path.replace("middle_block.0", "mid_block.resnets.0")
|
||||
new_path = new_path.replace("middle_block.1", "mid_block.attentions.0")
|
||||
new_path = new_path.replace("middle_block.2", "mid_block.resnets.1")
|
||||
|
||||
if additional_replacements is not None:
|
||||
for replacement in additional_replacements:
|
||||
new_path = new_path.replace(replacement["old"], replacement["new"])
|
||||
|
||||
# proj_attn.weight has to be converted from conv 1D to linear
|
||||
if "proj_attn.weight" in new_path:
|
||||
checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0]
|
||||
else:
|
||||
checkpoint[new_path] = old_checkpoint[path["old"]]
|
||||
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.convert_from_ckpt.conv_attn_to_linear
|
||||
def conv_attn_to_linear(checkpoint):
|
||||
keys = list(checkpoint.keys())
|
||||
attn_keys = ["query.weight", "key.weight", "value.weight"]
|
||||
for key in keys:
|
||||
if ".".join(key.split(".")[-2:]) in attn_keys:
|
||||
if checkpoint[key].ndim > 2:
|
||||
checkpoint[key] = checkpoint[key][:, :, 0, 0]
|
||||
elif "proj_attn.weight" in key:
|
||||
if checkpoint[key].ndim > 2:
|
||||
checkpoint[key] = checkpoint[key][:, :, 0]
|
||||
|
||||
|
||||
def create_vae_diffusers_config(config_type):
|
||||
# Hardcoded for now
|
||||
if args.config_type == "test":
|
||||
vae_config = create_vae_diffusers_config_test()
|
||||
elif args.config_type == "big":
|
||||
vae_config = create_vae_diffusers_config_big()
|
||||
else:
|
||||
raise NotImplementedError(
|
||||
f"Config type {config_type} is not implemented, currently only config types"
|
||||
" 'test' and 'big' are available."
|
||||
)
|
||||
return vae_config
|
||||
|
||||
|
||||
def create_unidiffuser_unet_config(config_type, version):
|
||||
# Hardcoded for now
|
||||
if args.config_type == "test":
|
||||
unet_config = create_unidiffuser_unet_config_test()
|
||||
elif args.config_type == "big":
|
||||
unet_config = create_unidiffuser_unet_config_big()
|
||||
else:
|
||||
raise NotImplementedError(
|
||||
f"Config type {config_type} is not implemented, currently only config types"
|
||||
" 'test' and 'big' are available."
|
||||
)
|
||||
# Unidiffuser-v1 uses data type embeddings
|
||||
if version == 1:
|
||||
unet_config["use_data_type_embedding"] = True
|
||||
return unet_config
|
||||
|
||||
|
||||
def create_text_decoder_config(config_type):
|
||||
# Hardcoded for now
|
||||
if args.config_type == "test":
|
||||
text_decoder_config = create_text_decoder_config_test()
|
||||
elif args.config_type == "big":
|
||||
text_decoder_config = create_text_decoder_config_big()
|
||||
else:
|
||||
raise NotImplementedError(
|
||||
f"Config type {config_type} is not implemented, currently only config types"
|
||||
" 'test' and 'big' are available."
|
||||
)
|
||||
return text_decoder_config
|
||||
|
||||
|
||||
# Hardcoded configs for test versions of the UniDiffuser models, corresponding to those in the fast default tests.
|
||||
def create_vae_diffusers_config_test():
|
||||
vae_config = {
|
||||
"sample_size": 32,
|
||||
"in_channels": 3,
|
||||
"out_channels": 3,
|
||||
"down_block_types": ["DownEncoderBlock2D", "DownEncoderBlock2D"],
|
||||
"up_block_types": ["UpDecoderBlock2D", "UpDecoderBlock2D"],
|
||||
"block_out_channels": [32, 64],
|
||||
"latent_channels": 4,
|
||||
"layers_per_block": 1,
|
||||
}
|
||||
return vae_config
|
||||
|
||||
|
||||
def create_unidiffuser_unet_config_test():
|
||||
unet_config = {
|
||||
"text_dim": 32,
|
||||
"clip_img_dim": 32,
|
||||
"num_text_tokens": 77,
|
||||
"num_attention_heads": 2,
|
||||
"attention_head_dim": 8,
|
||||
"in_channels": 4,
|
||||
"out_channels": 4,
|
||||
"num_layers": 2,
|
||||
"dropout": 0.0,
|
||||
"norm_num_groups": 32,
|
||||
"attention_bias": False,
|
||||
"sample_size": 16,
|
||||
"patch_size": 2,
|
||||
"activation_fn": "gelu",
|
||||
"num_embeds_ada_norm": 1000,
|
||||
"norm_type": "layer_norm",
|
||||
"block_type": "unidiffuser",
|
||||
"pre_layer_norm": False,
|
||||
"use_timestep_embedding": False,
|
||||
"norm_elementwise_affine": True,
|
||||
"use_patch_pos_embed": False,
|
||||
"ff_final_dropout": True,
|
||||
"use_data_type_embedding": False,
|
||||
}
|
||||
return unet_config
|
||||
|
||||
|
||||
def create_text_decoder_config_test():
|
||||
text_decoder_config = {
|
||||
"prefix_length": 77,
|
||||
"prefix_inner_dim": 32,
|
||||
"prefix_hidden_dim": 32,
|
||||
"vocab_size": 1025, # 1024 + 1 for new EOS token
|
||||
"n_positions": 1024,
|
||||
"n_embd": 32,
|
||||
"n_layer": 5,
|
||||
"n_head": 4,
|
||||
"n_inner": 37,
|
||||
"activation_function": "gelu",
|
||||
"resid_pdrop": 0.1,
|
||||
"embd_pdrop": 0.1,
|
||||
"attn_pdrop": 0.1,
|
||||
"layer_norm_epsilon": 1e-5,
|
||||
"initializer_range": 0.02,
|
||||
}
|
||||
return text_decoder_config
|
||||
|
||||
|
||||
# Hardcoded configs for the UniDiffuser V1 model at https://huggingface.co/thu-ml/unidiffuser-v1
|
||||
# See also https://github.com/thu-ml/unidiffuser/blob/main/configs/sample_unidiffuser_v1.py
|
||||
def create_vae_diffusers_config_big():
|
||||
vae_config = {
|
||||
"sample_size": 256,
|
||||
"in_channels": 3,
|
||||
"out_channels": 3,
|
||||
"down_block_types": ["DownEncoderBlock2D", "DownEncoderBlock2D", "DownEncoderBlock2D", "DownEncoderBlock2D"],
|
||||
"up_block_types": ["UpDecoderBlock2D", "UpDecoderBlock2D", "UpDecoderBlock2D", "UpDecoderBlock2D"],
|
||||
"block_out_channels": [128, 256, 512, 512],
|
||||
"latent_channels": 4,
|
||||
"layers_per_block": 2,
|
||||
}
|
||||
return vae_config
|
||||
|
||||
|
||||
def create_unidiffuser_unet_config_big():
|
||||
unet_config = {
|
||||
"text_dim": 64,
|
||||
"clip_img_dim": 512,
|
||||
"num_text_tokens": 77,
|
||||
"num_attention_heads": 24,
|
||||
"attention_head_dim": 64,
|
||||
"in_channels": 4,
|
||||
"out_channels": 4,
|
||||
"num_layers": 30,
|
||||
"dropout": 0.0,
|
||||
"norm_num_groups": 32,
|
||||
"attention_bias": False,
|
||||
"sample_size": 64,
|
||||
"patch_size": 2,
|
||||
"activation_fn": "gelu",
|
||||
"num_embeds_ada_norm": 1000,
|
||||
"norm_type": "layer_norm",
|
||||
"block_type": "unidiffuser",
|
||||
"pre_layer_norm": False,
|
||||
"use_timestep_embedding": False,
|
||||
"norm_elementwise_affine": True,
|
||||
"use_patch_pos_embed": False,
|
||||
"ff_final_dropout": True,
|
||||
"use_data_type_embedding": False,
|
||||
}
|
||||
return unet_config
|
||||
|
||||
|
||||
# From https://huggingface.co/gpt2/blob/main/config.json, the GPT2 checkpoint used by UniDiffuser
|
||||
def create_text_decoder_config_big():
|
||||
text_decoder_config = {
|
||||
"prefix_length": 77,
|
||||
"prefix_inner_dim": 768,
|
||||
"prefix_hidden_dim": 64,
|
||||
"vocab_size": 50258, # 50257 + 1 for new EOS token
|
||||
"n_positions": 1024,
|
||||
"n_embd": 768,
|
||||
"n_layer": 12,
|
||||
"n_head": 12,
|
||||
"n_inner": 3072,
|
||||
"activation_function": "gelu",
|
||||
"resid_pdrop": 0.1,
|
||||
"embd_pdrop": 0.1,
|
||||
"attn_pdrop": 0.1,
|
||||
"layer_norm_epsilon": 1e-5,
|
||||
"initializer_range": 0.02,
|
||||
}
|
||||
return text_decoder_config
|
||||
|
||||
|
||||
# Based on diffusers.pipelines.stable_diffusion.convert_from_ckpt.shave_segments.convert_ldm_vae_checkpoint
|
||||
def convert_vae_to_diffusers(ckpt, diffusers_model, num_head_channels=1):
|
||||
"""
|
||||
Converts a UniDiffuser autoencoder_kl.pth checkpoint to a diffusers AutoencoderKL.
|
||||
"""
|
||||
# autoencoder_kl.pth ckpt is a torch state dict
|
||||
vae_state_dict = torch.load(ckpt, map_location="cpu")
|
||||
|
||||
new_checkpoint = {}
|
||||
|
||||
new_checkpoint["encoder.conv_in.weight"] = vae_state_dict["encoder.conv_in.weight"]
|
||||
new_checkpoint["encoder.conv_in.bias"] = vae_state_dict["encoder.conv_in.bias"]
|
||||
new_checkpoint["encoder.conv_out.weight"] = vae_state_dict["encoder.conv_out.weight"]
|
||||
new_checkpoint["encoder.conv_out.bias"] = vae_state_dict["encoder.conv_out.bias"]
|
||||
new_checkpoint["encoder.conv_norm_out.weight"] = vae_state_dict["encoder.norm_out.weight"]
|
||||
new_checkpoint["encoder.conv_norm_out.bias"] = vae_state_dict["encoder.norm_out.bias"]
|
||||
|
||||
new_checkpoint["decoder.conv_in.weight"] = vae_state_dict["decoder.conv_in.weight"]
|
||||
new_checkpoint["decoder.conv_in.bias"] = vae_state_dict["decoder.conv_in.bias"]
|
||||
new_checkpoint["decoder.conv_out.weight"] = vae_state_dict["decoder.conv_out.weight"]
|
||||
new_checkpoint["decoder.conv_out.bias"] = vae_state_dict["decoder.conv_out.bias"]
|
||||
new_checkpoint["decoder.conv_norm_out.weight"] = vae_state_dict["decoder.norm_out.weight"]
|
||||
new_checkpoint["decoder.conv_norm_out.bias"] = vae_state_dict["decoder.norm_out.bias"]
|
||||
|
||||
new_checkpoint["quant_conv.weight"] = vae_state_dict["quant_conv.weight"]
|
||||
new_checkpoint["quant_conv.bias"] = vae_state_dict["quant_conv.bias"]
|
||||
new_checkpoint["post_quant_conv.weight"] = vae_state_dict["post_quant_conv.weight"]
|
||||
new_checkpoint["post_quant_conv.bias"] = vae_state_dict["post_quant_conv.bias"]
|
||||
|
||||
# Retrieves the keys for the encoder down blocks only
|
||||
num_down_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "encoder.down" in layer})
|
||||
down_blocks = {
|
||||
layer_id: [key for key in vae_state_dict if f"down.{layer_id}" in key] for layer_id in range(num_down_blocks)
|
||||
}
|
||||
|
||||
# Retrieves the keys for the decoder up blocks only
|
||||
num_up_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "decoder.up" in layer})
|
||||
up_blocks = {
|
||||
layer_id: [key for key in vae_state_dict if f"up.{layer_id}" in key] for layer_id in range(num_up_blocks)
|
||||
}
|
||||
|
||||
for i in range(num_down_blocks):
|
||||
resnets = [key for key in down_blocks[i] if f"down.{i}" in key and f"down.{i}.downsample" not in key]
|
||||
|
||||
if f"encoder.down.{i}.downsample.conv.weight" in vae_state_dict:
|
||||
new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.weight"] = vae_state_dict.pop(
|
||||
f"encoder.down.{i}.downsample.conv.weight"
|
||||
)
|
||||
new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.bias"] = vae_state_dict.pop(
|
||||
f"encoder.down.{i}.downsample.conv.bias"
|
||||
)
|
||||
|
||||
paths = renew_vae_resnet_paths(resnets)
|
||||
meta_path = {"old": f"down.{i}.block", "new": f"down_blocks.{i}.resnets"}
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
vae_state_dict,
|
||||
additional_replacements=[meta_path],
|
||||
num_head_channels=num_head_channels, # not used in vae
|
||||
)
|
||||
|
||||
mid_resnets = [key for key in vae_state_dict if "encoder.mid.block" in key]
|
||||
num_mid_res_blocks = 2
|
||||
for i in range(1, num_mid_res_blocks + 1):
|
||||
resnets = [key for key in mid_resnets if f"encoder.mid.block_{i}" in key]
|
||||
|
||||
paths = renew_vae_resnet_paths(resnets)
|
||||
meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
vae_state_dict,
|
||||
additional_replacements=[meta_path],
|
||||
num_head_channels=num_head_channels, # not used in vae
|
||||
)
|
||||
|
||||
mid_attentions = [key for key in vae_state_dict if "encoder.mid.attn" in key]
|
||||
paths = renew_vae_attention_paths(mid_attentions)
|
||||
meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
vae_state_dict,
|
||||
additional_replacements=[meta_path],
|
||||
num_head_channels=num_head_channels, # not used in vae
|
||||
)
|
||||
conv_attn_to_linear(new_checkpoint)
|
||||
|
||||
for i in range(num_up_blocks):
|
||||
block_id = num_up_blocks - 1 - i
|
||||
resnets = [
|
||||
key for key in up_blocks[block_id] if f"up.{block_id}" in key and f"up.{block_id}.upsample" not in key
|
||||
]
|
||||
|
||||
if f"decoder.up.{block_id}.upsample.conv.weight" in vae_state_dict:
|
||||
new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.weight"] = vae_state_dict[
|
||||
f"decoder.up.{block_id}.upsample.conv.weight"
|
||||
]
|
||||
new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.bias"] = vae_state_dict[
|
||||
f"decoder.up.{block_id}.upsample.conv.bias"
|
||||
]
|
||||
|
||||
paths = renew_vae_resnet_paths(resnets)
|
||||
meta_path = {"old": f"up.{block_id}.block", "new": f"up_blocks.{i}.resnets"}
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
vae_state_dict,
|
||||
additional_replacements=[meta_path],
|
||||
num_head_channels=num_head_channels, # not used in vae
|
||||
)
|
||||
|
||||
mid_resnets = [key for key in vae_state_dict if "decoder.mid.block" in key]
|
||||
num_mid_res_blocks = 2
|
||||
for i in range(1, num_mid_res_blocks + 1):
|
||||
resnets = [key for key in mid_resnets if f"decoder.mid.block_{i}" in key]
|
||||
|
||||
paths = renew_vae_resnet_paths(resnets)
|
||||
meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
vae_state_dict,
|
||||
additional_replacements=[meta_path],
|
||||
num_head_channels=num_head_channels, # not used in vae
|
||||
)
|
||||
|
||||
mid_attentions = [key for key in vae_state_dict if "decoder.mid.attn" in key]
|
||||
paths = renew_vae_attention_paths(mid_attentions)
|
||||
meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
|
||||
assign_to_checkpoint(
|
||||
paths,
|
||||
new_checkpoint,
|
||||
vae_state_dict,
|
||||
additional_replacements=[meta_path],
|
||||
num_head_channels=num_head_channels, # not used in vae
|
||||
)
|
||||
conv_attn_to_linear(new_checkpoint)
|
||||
|
||||
missing_keys, unexpected_keys = diffusers_model.load_state_dict(new_checkpoint)
|
||||
for missing_key in missing_keys:
|
||||
print(f"Missing key: {missing_key}")
|
||||
for unexpected_key in unexpected_keys:
|
||||
print(f"Unexpected key: {unexpected_key}")
|
||||
|
||||
return diffusers_model
|
||||
|
||||
|
||||
def convert_uvit_block_to_diffusers_block(
|
||||
uvit_state_dict,
|
||||
new_state_dict,
|
||||
block_prefix,
|
||||
new_prefix="transformer.transformer_",
|
||||
skip_connection=False,
|
||||
):
|
||||
"""
|
||||
Maps the keys in a UniDiffuser transformer block (`Block`) to the keys in a diffusers transformer block
|
||||
(`UTransformerBlock`/`UniDiffuserBlock`).
|
||||
"""
|
||||
prefix = new_prefix + block_prefix
|
||||
if skip_connection:
|
||||
new_state_dict[prefix + ".skip.skip_linear.weight"] = uvit_state_dict[block_prefix + ".skip_linear.weight"]
|
||||
new_state_dict[prefix + ".skip.skip_linear.bias"] = uvit_state_dict[block_prefix + ".skip_linear.bias"]
|
||||
new_state_dict[prefix + ".skip.norm.weight"] = uvit_state_dict[block_prefix + ".norm1.weight"]
|
||||
new_state_dict[prefix + ".skip.norm.bias"] = uvit_state_dict[block_prefix + ".norm1.bias"]
|
||||
|
||||
# Create the prefix string for out_blocks.
|
||||
prefix += ".block"
|
||||
|
||||
# Split up attention qkv.weight into to_q.weight, to_k.weight, to_v.weight
|
||||
qkv = uvit_state_dict[block_prefix + ".attn.qkv.weight"]
|
||||
new_attn_keys = [".attn1.to_q.weight", ".attn1.to_k.weight", ".attn1.to_v.weight"]
|
||||
new_attn_keys = [prefix + key for key in new_attn_keys]
|
||||
shape = qkv.shape[0] // len(new_attn_keys)
|
||||
for i, attn_key in enumerate(new_attn_keys):
|
||||
new_state_dict[attn_key] = qkv[i * shape : (i + 1) * shape]
|
||||
|
||||
new_state_dict[prefix + ".attn1.to_out.0.weight"] = uvit_state_dict[block_prefix + ".attn.proj.weight"]
|
||||
new_state_dict[prefix + ".attn1.to_out.0.bias"] = uvit_state_dict[block_prefix + ".attn.proj.bias"]
|
||||
new_state_dict[prefix + ".norm1.weight"] = uvit_state_dict[block_prefix + ".norm2.weight"]
|
||||
new_state_dict[prefix + ".norm1.bias"] = uvit_state_dict[block_prefix + ".norm2.bias"]
|
||||
new_state_dict[prefix + ".ff.net.0.proj.weight"] = uvit_state_dict[block_prefix + ".mlp.fc1.weight"]
|
||||
new_state_dict[prefix + ".ff.net.0.proj.bias"] = uvit_state_dict[block_prefix + ".mlp.fc1.bias"]
|
||||
new_state_dict[prefix + ".ff.net.2.weight"] = uvit_state_dict[block_prefix + ".mlp.fc2.weight"]
|
||||
new_state_dict[prefix + ".ff.net.2.bias"] = uvit_state_dict[block_prefix + ".mlp.fc2.bias"]
|
||||
new_state_dict[prefix + ".norm3.weight"] = uvit_state_dict[block_prefix + ".norm3.weight"]
|
||||
new_state_dict[prefix + ".norm3.bias"] = uvit_state_dict[block_prefix + ".norm3.bias"]
|
||||
|
||||
return uvit_state_dict, new_state_dict
|
||||
|
||||
|
||||
def convert_uvit_to_diffusers(ckpt, diffusers_model):
|
||||
"""
|
||||
Converts a UniDiffuser uvit_v*.pth checkpoint to a diffusers UniDiffusersModel.
|
||||
"""
|
||||
# uvit_v*.pth ckpt is a torch state dict
|
||||
uvit_state_dict = torch.load(ckpt, map_location="cpu")
|
||||
|
||||
new_state_dict = {}
|
||||
|
||||
# Input layers
|
||||
new_state_dict["vae_img_in.proj.weight"] = uvit_state_dict["patch_embed.proj.weight"]
|
||||
new_state_dict["vae_img_in.proj.bias"] = uvit_state_dict["patch_embed.proj.bias"]
|
||||
new_state_dict["clip_img_in.weight"] = uvit_state_dict["clip_img_embed.weight"]
|
||||
new_state_dict["clip_img_in.bias"] = uvit_state_dict["clip_img_embed.bias"]
|
||||
new_state_dict["text_in.weight"] = uvit_state_dict["text_embed.weight"]
|
||||
new_state_dict["text_in.bias"] = uvit_state_dict["text_embed.bias"]
|
||||
|
||||
new_state_dict["pos_embed"] = uvit_state_dict["pos_embed"]
|
||||
|
||||
# Handle data type token embeddings for UniDiffuser-v1
|
||||
if "token_embedding.weight" in uvit_state_dict and diffusers_model.use_data_type_embedding:
|
||||
new_state_dict["data_type_pos_embed_token"] = uvit_state_dict["pos_embed_token"]
|
||||
new_state_dict["data_type_token_embedding.weight"] = uvit_state_dict["token_embedding.weight"]
|
||||
|
||||
# Also initialize the PatchEmbedding in UTransformer2DModel with the PatchEmbedding from the checkpoint.
|
||||
# This isn't used in the current implementation, so might want to remove.
|
||||
new_state_dict["transformer.pos_embed.proj.weight"] = uvit_state_dict["patch_embed.proj.weight"]
|
||||
new_state_dict["transformer.pos_embed.proj.bias"] = uvit_state_dict["patch_embed.proj.bias"]
|
||||
|
||||
# Output layers
|
||||
new_state_dict["transformer.norm_out.weight"] = uvit_state_dict["norm.weight"]
|
||||
new_state_dict["transformer.norm_out.bias"] = uvit_state_dict["norm.bias"]
|
||||
|
||||
new_state_dict["vae_img_out.weight"] = uvit_state_dict["decoder_pred.weight"]
|
||||
new_state_dict["vae_img_out.bias"] = uvit_state_dict["decoder_pred.bias"]
|
||||
new_state_dict["clip_img_out.weight"] = uvit_state_dict["clip_img_out.weight"]
|
||||
new_state_dict["clip_img_out.bias"] = uvit_state_dict["clip_img_out.bias"]
|
||||
new_state_dict["text_out.weight"] = uvit_state_dict["text_out.weight"]
|
||||
new_state_dict["text_out.bias"] = uvit_state_dict["text_out.bias"]
|
||||
|
||||
# in_blocks
|
||||
in_blocks_prefixes = {".".join(layer.split(".")[:2]) for layer in uvit_state_dict if "in_blocks" in layer}
|
||||
for in_block_prefix in list(in_blocks_prefixes):
|
||||
convert_uvit_block_to_diffusers_block(uvit_state_dict, new_state_dict, in_block_prefix)
|
||||
|
||||
# mid_block
|
||||
# Assume there's only one mid block
|
||||
convert_uvit_block_to_diffusers_block(uvit_state_dict, new_state_dict, "mid_block")
|
||||
|
||||
# out_blocks
|
||||
out_blocks_prefixes = {".".join(layer.split(".")[:2]) for layer in uvit_state_dict if "out_blocks" in layer}
|
||||
for out_block_prefix in list(out_blocks_prefixes):
|
||||
convert_uvit_block_to_diffusers_block(uvit_state_dict, new_state_dict, out_block_prefix, skip_connection=True)
|
||||
|
||||
missing_keys, unexpected_keys = diffusers_model.load_state_dict(new_state_dict)
|
||||
for missing_key in missing_keys:
|
||||
print(f"Missing key: {missing_key}")
|
||||
for unexpected_key in unexpected_keys:
|
||||
print(f"Unexpected key: {unexpected_key}")
|
||||
|
||||
return diffusers_model
|
||||
|
||||
|
||||
def convert_caption_decoder_to_diffusers(ckpt, diffusers_model):
|
||||
"""
|
||||
Converts a UniDiffuser caption_decoder.pth checkpoint to a diffusers UniDiffuserTextDecoder.
|
||||
"""
|
||||
# caption_decoder.pth ckpt is a torch state dict
|
||||
checkpoint_state_dict = torch.load(ckpt, map_location="cpu")
|
||||
decoder_state_dict = {}
|
||||
# Remove the "module." prefix, if necessary
|
||||
caption_decoder_key = "module."
|
||||
for key in checkpoint_state_dict:
|
||||
if key.startswith(caption_decoder_key):
|
||||
decoder_state_dict[key.replace(caption_decoder_key, "")] = checkpoint_state_dict.get(key)
|
||||
else:
|
||||
decoder_state_dict[key] = checkpoint_state_dict.get(key)
|
||||
|
||||
new_state_dict = {}
|
||||
|
||||
# Encoder and Decoder
|
||||
new_state_dict["encode_prefix.weight"] = decoder_state_dict["encode_prefix.weight"]
|
||||
new_state_dict["encode_prefix.bias"] = decoder_state_dict["encode_prefix.bias"]
|
||||
new_state_dict["decode_prefix.weight"] = decoder_state_dict["decode_prefix.weight"]
|
||||
new_state_dict["decode_prefix.bias"] = decoder_state_dict["decode_prefix.bias"]
|
||||
|
||||
# Internal GPT2LMHeadModel transformer model
|
||||
for key, val in decoder_state_dict.items():
|
||||
if key.startswith("gpt"):
|
||||
suffix = key[len("gpt") :]
|
||||
new_state_dict["transformer" + suffix] = val
|
||||
|
||||
missing_keys, unexpected_keys = diffusers_model.load_state_dict(new_state_dict)
|
||||
for missing_key in missing_keys:
|
||||
print(f"Missing key: {missing_key}")
|
||||
for unexpected_key in unexpected_keys:
|
||||
print(f"Unexpected key: {unexpected_key}")
|
||||
|
||||
return diffusers_model
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument(
|
||||
"--caption_decoder_checkpoint_path",
|
||||
default=None,
|
||||
type=str,
|
||||
required=False,
|
||||
help="Path to caption decoder checkpoint to convert.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--uvit_checkpoint_path", default=None, type=str, required=False, help="Path to U-ViT checkpoint to convert."
|
||||
)
|
||||
parser.add_argument(
|
||||
"--vae_checkpoint_path",
|
||||
default=None,
|
||||
type=str,
|
||||
required=False,
|
||||
help="Path to VAE checkpoint to convert.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--pipeline_output_path",
|
||||
default=None,
|
||||
type=str,
|
||||
required=True,
|
||||
help="Path to save the output pipeline to.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--config_type",
|
||||
default="test",
|
||||
type=str,
|
||||
help=(
|
||||
"Config type to use. Should be 'test' to create small models for testing or 'big' to convert a full"
|
||||
" checkpoint."
|
||||
),
|
||||
)
|
||||
parser.add_argument(
|
||||
"--version",
|
||||
default=0,
|
||||
type=int,
|
||||
help="The UniDiffuser model type to convert to. Should be 0 for UniDiffuser-v0 and 1 for UniDiffuser-v1.",
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
# Convert the VAE model.
|
||||
if args.vae_checkpoint_path is not None:
|
||||
vae_config = create_vae_diffusers_config(args.config_type)
|
||||
vae = AutoencoderKL(**vae_config)
|
||||
vae = convert_vae_to_diffusers(args.vae_checkpoint_path, vae)
|
||||
|
||||
# Convert the U-ViT ("unet") model.
|
||||
if args.uvit_checkpoint_path is not None:
|
||||
unet_config = create_unidiffuser_unet_config(args.config_type, args.version)
|
||||
unet = UniDiffuserModel(**unet_config)
|
||||
unet = convert_uvit_to_diffusers(args.uvit_checkpoint_path, unet)
|
||||
|
||||
# Convert the caption decoder ("text_decoder") model.
|
||||
if args.caption_decoder_checkpoint_path is not None:
|
||||
text_decoder_config = create_text_decoder_config(args.config_type)
|
||||
text_decoder = UniDiffuserTextDecoder(**text_decoder_config)
|
||||
text_decoder = convert_caption_decoder_to_diffusers(args.caption_decoder_checkpoint_path, text_decoder)
|
||||
|
||||
# Scheduler is the same for both the test and big models.
|
||||
scheduler_config = SCHEDULER_CONFIG
|
||||
scheduler = DPMSolverMultistepScheduler(
|
||||
beta_start=scheduler_config.beta_start,
|
||||
beta_end=scheduler_config.beta_end,
|
||||
beta_schedule=scheduler_config.beta_schedule,
|
||||
solver_order=scheduler_config.solver_order,
|
||||
)
|
||||
|
||||
if args.config_type == "test":
|
||||
# Make a small random CLIPTextModel
|
||||
torch.manual_seed(0)
|
||||
clip_text_encoder_config = CLIPTextConfig(
|
||||
bos_token_id=0,
|
||||
eos_token_id=2,
|
||||
hidden_size=32,
|
||||
intermediate_size=37,
|
||||
layer_norm_eps=1e-05,
|
||||
num_attention_heads=4,
|
||||
num_hidden_layers=5,
|
||||
pad_token_id=1,
|
||||
vocab_size=1000,
|
||||
)
|
||||
text_encoder = CLIPTextModel(clip_text_encoder_config)
|
||||
clip_tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
|
||||
|
||||
# Make a small random CLIPVisionModel and accompanying CLIPImageProcessor
|
||||
torch.manual_seed(0)
|
||||
clip_image_encoder_config = CLIPVisionConfig(
|
||||
image_size=32,
|
||||
patch_size=2,
|
||||
num_channels=3,
|
||||
hidden_size=32,
|
||||
projection_dim=32,
|
||||
num_hidden_layers=5,
|
||||
num_attention_heads=4,
|
||||
intermediate_size=37,
|
||||
dropout=0.1,
|
||||
attention_dropout=0.1,
|
||||
initializer_range=0.02,
|
||||
)
|
||||
image_encoder = CLIPVisionModelWithProjection(clip_image_encoder_config)
|
||||
image_processor = CLIPImageProcessor(crop_size=32, size=32)
|
||||
|
||||
# Note that the text_decoder should already have its token embeddings resized.
|
||||
text_tokenizer = GPT2Tokenizer.from_pretrained("hf-internal-testing/tiny-random-GPT2Model")
|
||||
eos = "<|EOS|>"
|
||||
special_tokens_dict = {"eos_token": eos}
|
||||
text_tokenizer.add_special_tokens(special_tokens_dict)
|
||||
elif args.config_type == "big":
|
||||
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
|
||||
clip_tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
|
||||
|
||||
image_encoder = CLIPVisionModelWithProjection.from_pretrained("openai/clip-vit-base-patch32")
|
||||
image_processor = CLIPImageProcessor.from_pretrained("openai/clip-vit-base-patch32")
|
||||
|
||||
# Note that the text_decoder should already have its token embeddings resized.
|
||||
text_tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
|
||||
eos = "<|EOS|>"
|
||||
special_tokens_dict = {"eos_token": eos}
|
||||
text_tokenizer.add_special_tokens(special_tokens_dict)
|
||||
else:
|
||||
raise NotImplementedError(
|
||||
f"Config type {args.config_type} is not implemented, currently only config types"
|
||||
" 'test' and 'big' are available."
|
||||
)
|
||||
|
||||
pipeline = UniDiffuserPipeline(
|
||||
vae=vae,
|
||||
text_encoder=text_encoder,
|
||||
image_encoder=image_encoder,
|
||||
image_processor=image_processor,
|
||||
clip_tokenizer=clip_tokenizer,
|
||||
text_decoder=text_decoder,
|
||||
text_tokenizer=text_tokenizer,
|
||||
unet=unet,
|
||||
scheduler=scheduler,
|
||||
)
|
||||
pipeline.save_pretrained(args.pipeline_output_path)
|
||||
@@ -129,11 +129,6 @@ else:
|
||||
IFInpaintingSuperResolutionPipeline,
|
||||
IFPipeline,
|
||||
IFSuperResolutionPipeline,
|
||||
ImageTextPipelineOutput,
|
||||
KandinskyImg2ImgPipeline,
|
||||
KandinskyInpaintPipeline,
|
||||
KandinskyPipeline,
|
||||
KandinskyPriorPipeline,
|
||||
LDMTextToImagePipeline,
|
||||
PaintByExamplePipeline,
|
||||
SemanticStableDiffusionPipeline,
|
||||
@@ -162,9 +157,6 @@ else:
|
||||
TextToVideoZeroPipeline,
|
||||
UnCLIPImageVariationPipeline,
|
||||
UnCLIPPipeline,
|
||||
UniDiffuserModel,
|
||||
UniDiffuserPipeline,
|
||||
UniDiffuserTextDecoder,
|
||||
VersatileDiffusionDualGuidedPipeline,
|
||||
VersatileDiffusionImageVariationPipeline,
|
||||
VersatileDiffusionPipeline,
|
||||
|
||||
@@ -160,7 +160,7 @@ class ConfigMixin:
|
||||
@classmethod
|
||||
def from_config(cls, config: Union[FrozenDict, Dict[str, Any]] = None, return_unused_kwargs=False, **kwargs):
|
||||
r"""
|
||||
Instantiate a Python class from a config dictionary.
|
||||
Instantiate a Python class from a config dictionary
|
||||
|
||||
Parameters:
|
||||
config (`Dict[str, Any]`):
|
||||
@@ -170,13 +170,9 @@ class ConfigMixin:
|
||||
Whether kwargs that are not consumed by the Python class should be returned or not.
|
||||
|
||||
kwargs (remaining dictionary of keyword arguments, *optional*):
|
||||
Can be used to update the configuration object (after it is loaded) and initiate the Python class.
|
||||
`**kwargs` are directly passed to the underlying scheduler/model's `__init__` method and eventually
|
||||
overwrite same named arguments in `config`.
|
||||
|
||||
Returns:
|
||||
[`ModelMixin`] or [`SchedulerMixin`]:
|
||||
A model or scheduler object instantiated from a config dictionary.
|
||||
Can be used to update the configuration object (after it being loaded) and initiate the Python class.
|
||||
`**kwargs` will be directly passed to the underlying scheduler/model's `__init__` method and eventually
|
||||
overwrite same named arguments of `config`.
|
||||
|
||||
Examples:
|
||||
|
||||
@@ -262,57 +258,59 @@ class ConfigMixin:
|
||||
**kwargs,
|
||||
) -> Tuple[Dict[str, Any], Dict[str, Any]]:
|
||||
r"""
|
||||
Load a model or scheduler configuration.
|
||||
Instantiate a Python class from a config dictionary
|
||||
|
||||
Parameters:
|
||||
pretrained_model_name_or_path (`str` or `os.PathLike`, *optional*):
|
||||
Can be either:
|
||||
|
||||
- A string, the *model id* (for example `google/ddpm-celebahq-256`) of a pretrained model hosted on
|
||||
the Hub.
|
||||
- A path to a *directory* (for example `./my_model_directory`) containing model weights saved with
|
||||
[`~ConfigMixin.save_config`].
|
||||
- A string, the *model id* of a model repo on huggingface.co. Valid model ids should have an
|
||||
organization name, like `google/ddpm-celebahq-256`.
|
||||
- A path to a *directory* containing model weights saved using [`~ConfigMixin.save_config`], e.g.,
|
||||
`./my_model_directory/`.
|
||||
|
||||
cache_dir (`Union[str, os.PathLike]`, *optional*):
|
||||
Path to a directory where a downloaded pretrained model configuration is cached if the standard cache
|
||||
is not used.
|
||||
Path to a directory in which a downloaded pretrained model configuration should be cached if the
|
||||
standard cache should not be used.
|
||||
force_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
|
||||
cached versions if they exist.
|
||||
resume_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to resume downloading the model weights and configuration files. If set to False, any
|
||||
incompletely downloaded files are deleted.
|
||||
Whether or not to delete incompletely received files. Will attempt to resume the download if such a
|
||||
file exists.
|
||||
proxies (`Dict[str, str]`, *optional*):
|
||||
A dictionary of proxy servers to use by protocol or endpoint, for example, `{'http': 'foo.bar:3128',
|
||||
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
|
||||
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
|
||||
output_loading_info(`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
|
||||
local_files_only(`bool`, *optional*, defaults to `False`):
|
||||
Whether to only load local model weights and configuration files or not. If set to True, the model
|
||||
won’t be downloaded from the Hub.
|
||||
Whether or not to only look at local files (i.e., do not try to download the model).
|
||||
use_auth_token (`str` or *bool*, *optional*):
|
||||
The token to use as HTTP bearer authorization for remote files. If `True`, the token generated from
|
||||
`diffusers-cli login` (stored in `~/.huggingface`) is used.
|
||||
The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
|
||||
when running `transformers-cli login` (stored in `~/.huggingface`).
|
||||
revision (`str`, *optional*, defaults to `"main"`):
|
||||
The specific model version to use. It can be a branch name, a tag name, a commit id, or any identifier
|
||||
allowed by Git.
|
||||
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
|
||||
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
|
||||
identifier allowed by git.
|
||||
subfolder (`str`, *optional*, defaults to `""`):
|
||||
The subfolder location of a model file within a larger model repository on the Hub or locally.
|
||||
In case the relevant files are located inside a subfolder of the model repo (either remote in
|
||||
huggingface.co or downloaded locally), you can specify the folder name here.
|
||||
return_unused_kwargs (`bool`, *optional*, defaults to `False):
|
||||
Whether unused keyword arguments of the config are returned.
|
||||
Whether unused keyword arguments of the config shall be returned.
|
||||
return_commit_hash (`bool`, *optional*, defaults to `False):
|
||||
Whether the `commit_hash` of the loaded configuration are returned.
|
||||
|
||||
Returns:
|
||||
`dict`:
|
||||
A dictionary of all the parameters stored in a JSON configuration file.
|
||||
Whether the commit_hash of the loaded configuration shall be returned.
|
||||
|
||||
<Tip>
|
||||
|
||||
To use private or [gated models](https://huggingface.co/docs/hub/models-gated#gated-models), log-in with
|
||||
`huggingface-cli login`. You can also activate the special
|
||||
["offline-mode"](https://huggingface.co/transformers/installation.html#offline-mode) to use this method in a
|
||||
firewalled environment.
|
||||
It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
|
||||
models](https://huggingface.co/docs/hub/models-gated#gated-models).
|
||||
|
||||
</Tip>
|
||||
|
||||
<Tip>
|
||||
|
||||
Activate the special ["offline-mode"](https://huggingface.co/transformers/installation.html#offline-mode) to
|
||||
use this method in a firewalled environment.
|
||||
|
||||
</Tip>
|
||||
"""
|
||||
|
||||
@@ -30,8 +30,7 @@ class VaeImageProcessor(ConfigMixin):
|
||||
|
||||
Args:
|
||||
do_resize (`bool`, *optional*, defaults to `True`):
|
||||
Whether to downscale the image's (height, width) dimensions to multiples of `vae_scale_factor`. Can accept
|
||||
`height` and `width` arguments from `preprocess` method
|
||||
Whether to downscale the image's (height, width) dimensions to multiples of `vae_scale_factor`.
|
||||
vae_scale_factor (`int`, *optional*, defaults to `8`):
|
||||
VAE scale factor. If `do_resize` is True, the image will be automatically resized to multiples of this
|
||||
factor.
|
||||
@@ -39,8 +38,6 @@ class VaeImageProcessor(ConfigMixin):
|
||||
Resampling filter to use when resizing the image.
|
||||
do_normalize (`bool`, *optional*, defaults to `True`):
|
||||
Whether to normalize the image to [-1,1]
|
||||
do_convert_rgb (`bool`, *optional*, defaults to be `False`):
|
||||
Whether to convert the images to RGB format.
|
||||
"""
|
||||
|
||||
config_name = CONFIG_NAME
|
||||
@@ -52,12 +49,11 @@ class VaeImageProcessor(ConfigMixin):
|
||||
vae_scale_factor: int = 8,
|
||||
resample: str = "lanczos",
|
||||
do_normalize: bool = True,
|
||||
do_convert_rgb: bool = False,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
@staticmethod
|
||||
def numpy_to_pil(images: np.ndarray) -> PIL.Image.Image:
|
||||
def numpy_to_pil(images):
|
||||
"""
|
||||
Convert a numpy image or a batch of images to a PIL image.
|
||||
"""
|
||||
@@ -73,19 +69,7 @@ class VaeImageProcessor(ConfigMixin):
|
||||
return pil_images
|
||||
|
||||
@staticmethod
|
||||
def pil_to_numpy(images: Union[List[PIL.Image.Image], PIL.Image.Image]) -> np.ndarray:
|
||||
"""
|
||||
Convert a PIL image or a list of PIL images to numpy arrays.
|
||||
"""
|
||||
if not isinstance(images, list):
|
||||
images = [images]
|
||||
images = [np.array(image).astype(np.float32) / 255.0 for image in images]
|
||||
images = np.stack(images, axis=0)
|
||||
|
||||
return images
|
||||
|
||||
@staticmethod
|
||||
def numpy_to_pt(images: np.ndarray) -> torch.FloatTensor:
|
||||
def numpy_to_pt(images):
|
||||
"""
|
||||
Convert a numpy image to a pytorch tensor
|
||||
"""
|
||||
@@ -96,7 +80,7 @@ class VaeImageProcessor(ConfigMixin):
|
||||
return images
|
||||
|
||||
@staticmethod
|
||||
def pt_to_numpy(images: torch.FloatTensor) -> np.ndarray:
|
||||
def pt_to_numpy(images):
|
||||
"""
|
||||
Convert a pytorch tensor to a numpy image
|
||||
"""
|
||||
@@ -117,39 +101,18 @@ class VaeImageProcessor(ConfigMixin):
|
||||
"""
|
||||
return (images / 2 + 0.5).clamp(0, 1)
|
||||
|
||||
@staticmethod
|
||||
def convert_to_rgb(image: PIL.Image.Image) -> PIL.Image.Image:
|
||||
"""
|
||||
Converts an image to RGB format.
|
||||
"""
|
||||
image = image.convert("RGB")
|
||||
return image
|
||||
|
||||
def resize(
|
||||
self,
|
||||
image: PIL.Image.Image,
|
||||
height: Optional[int] = None,
|
||||
width: Optional[int] = None,
|
||||
) -> PIL.Image.Image:
|
||||
def resize(self, images: PIL.Image.Image) -> PIL.Image.Image:
|
||||
"""
|
||||
Resize a PIL image. Both height and width will be downscaled to the next integer multiple of `vae_scale_factor`
|
||||
"""
|
||||
if height is None:
|
||||
height = image.height
|
||||
if width is None:
|
||||
width = image.width
|
||||
|
||||
width, height = (
|
||||
x - x % self.config.vae_scale_factor for x in (width, height)
|
||||
) # resize to integer multiple of vae_scale_factor
|
||||
image = image.resize((width, height), resample=PIL_INTERPOLATION[self.config.resample])
|
||||
return image
|
||||
w, h = images.size
|
||||
w, h = (x - x % self.config.vae_scale_factor for x in (w, h)) # resize to integer multiple of vae_scale_factor
|
||||
images = images.resize((w, h), resample=PIL_INTERPOLATION[self.config.resample])
|
||||
return images
|
||||
|
||||
def preprocess(
|
||||
self,
|
||||
image: Union[torch.FloatTensor, PIL.Image.Image, np.ndarray],
|
||||
height: Optional[int] = None,
|
||||
width: Optional[int] = None,
|
||||
) -> torch.Tensor:
|
||||
"""
|
||||
Preprocess the image input, accepted formats are PIL images, numpy arrays or pytorch tensors"
|
||||
@@ -163,11 +126,10 @@ class VaeImageProcessor(ConfigMixin):
|
||||
)
|
||||
|
||||
if isinstance(image[0], PIL.Image.Image):
|
||||
if self.config.do_convert_rgb:
|
||||
image = [self.convert_to_rgb(i) for i in image]
|
||||
if self.config.do_resize:
|
||||
image = [self.resize(i, height, width) for i in image]
|
||||
image = self.pil_to_numpy(image) # to np
|
||||
image = [self.resize(i) for i in image]
|
||||
image = [np.array(i).astype(np.float32) / 255.0 for i in image]
|
||||
image = np.stack(image, axis=0) # to np
|
||||
image = self.numpy_to_pt(image) # to pt
|
||||
|
||||
elif isinstance(image[0], np.ndarray):
|
||||
@@ -184,12 +146,7 @@ class VaeImageProcessor(ConfigMixin):
|
||||
|
||||
elif isinstance(image[0], torch.Tensor):
|
||||
image = torch.cat(image, axis=0) if image[0].ndim == 4 else torch.stack(image, axis=0)
|
||||
_, channel, height, width = image.shape
|
||||
|
||||
# don't need any preprocess if the image is latents
|
||||
if channel == 4:
|
||||
return image
|
||||
|
||||
_, _, height, width = image.shape
|
||||
if self.config.do_resize and (
|
||||
height % self.config.vae_scale_factor != 0 or width % self.config.vae_scale_factor != 0
|
||||
):
|
||||
|
||||
@@ -18,7 +18,6 @@ from pathlib import Path
|
||||
from typing import Callable, Dict, List, Optional, Union
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from huggingface_hub import hf_hub_download
|
||||
|
||||
from .models.attention_processor import (
|
||||
@@ -28,15 +27,12 @@ from .models.attention_processor import (
|
||||
CustomDiffusionXFormersAttnProcessor,
|
||||
LoRAAttnAddedKVProcessor,
|
||||
LoRAAttnProcessor,
|
||||
LoRAAttnProcessor2_0,
|
||||
LoRAXFormersAttnProcessor,
|
||||
SlicedAttnAddedKVProcessor,
|
||||
XFormersAttnProcessor,
|
||||
)
|
||||
from .utils import (
|
||||
DIFFUSERS_CACHE,
|
||||
HF_HUB_OFFLINE,
|
||||
TEXT_ENCODER_ATTN_MODULE,
|
||||
TEXT_ENCODER_TARGET_MODULES,
|
||||
_get_model_file,
|
||||
deprecate,
|
||||
is_safetensors_available,
|
||||
@@ -74,8 +70,8 @@ class AttnProcsLayers(torch.nn.Module):
|
||||
self.mapping = dict(enumerate(state_dict.keys()))
|
||||
self.rev_mapping = {v: k for k, v in enumerate(state_dict.keys())}
|
||||
|
||||
# .processor for unet, .self_attn for text encoder
|
||||
self.split_keys = [".processor", ".self_attn"]
|
||||
# .processor for unet, .k_proj, ".q_proj", ".v_proj", and ".out_proj" for text encoder
|
||||
self.split_keys = [".processor", ".k_proj", ".q_proj", ".v_proj", ".out_proj"]
|
||||
|
||||
# we add a hook to state_dict() and load_state_dict() so that the
|
||||
# naming fits with `unet.attn_processors`
|
||||
@@ -184,9 +180,6 @@ class UNet2DConditionLoadersMixin:
|
||||
subfolder = kwargs.pop("subfolder", None)
|
||||
weight_name = kwargs.pop("weight_name", None)
|
||||
use_safetensors = kwargs.pop("use_safetensors", None)
|
||||
# This value has the same meaning as the `--network_alpha` option in the kohya-ss trainer script.
|
||||
# See https://github.com/darkstorm2150/sd-scripts/blob/main/docs/train_network_README-en.md#execute-learning
|
||||
network_alpha = kwargs.pop("network_alpha", None)
|
||||
|
||||
if use_safetensors and not is_safetensors_available():
|
||||
raise ValueError(
|
||||
@@ -286,18 +279,10 @@ class UNet2DConditionLoadersMixin:
|
||||
attn_processor_class = LoRAAttnAddedKVProcessor
|
||||
else:
|
||||
cross_attention_dim = value_dict["to_k_lora.down.weight"].shape[1]
|
||||
if isinstance(attn_processor, (XFormersAttnProcessor, LoRAXFormersAttnProcessor)):
|
||||
attn_processor_class = LoRAXFormersAttnProcessor
|
||||
else:
|
||||
attn_processor_class = (
|
||||
LoRAAttnProcessor2_0 if hasattr(F, "scaled_dot_product_attention") else LoRAAttnProcessor
|
||||
)
|
||||
attn_processor_class = LoRAAttnProcessor
|
||||
|
||||
attn_processors[key] = attn_processor_class(
|
||||
hidden_size=hidden_size,
|
||||
cross_attention_dim=cross_attention_dim,
|
||||
rank=rank,
|
||||
network_alpha=network_alpha,
|
||||
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim, rank=rank
|
||||
)
|
||||
attn_processors[key].load_state_dict(value_dict)
|
||||
elif is_custom_diffusion:
|
||||
@@ -337,6 +322,10 @@ class UNet2DConditionLoadersMixin:
|
||||
attn_processors = {k: v.to(device=self.device, dtype=self.dtype) for k, v in attn_processors.items()}
|
||||
|
||||
# set layers
|
||||
print(
|
||||
"All processors are of type: LoRAAttnAddedKVProcessor: ",
|
||||
all(isinstance(attn_processors[k], LoRAAttnAddedKVProcessor) for k in attn_processors),
|
||||
)
|
||||
self.set_attn_processor(attn_processors)
|
||||
|
||||
def save_attn_procs(
|
||||
@@ -466,8 +455,7 @@ class TextualInversionLoaderMixin:
|
||||
`str`: The converted prompt
|
||||
"""
|
||||
tokens = tokenizer.tokenize(prompt)
|
||||
unique_tokens = set(tokens)
|
||||
for token in unique_tokens:
|
||||
for token in tokens:
|
||||
if token in tokenizer.added_tokens_encoder:
|
||||
replacement = token
|
||||
i = 1
|
||||
@@ -481,7 +469,7 @@ class TextualInversionLoaderMixin:
|
||||
|
||||
def load_textual_inversion(
|
||||
self,
|
||||
pretrained_model_name_or_path: Union[str, List[str], Dict[str, torch.Tensor], List[Dict[str, torch.Tensor]]],
|
||||
pretrained_model_name_or_path: Union[str, List[str]],
|
||||
token: Optional[Union[str, List[str]]] = None,
|
||||
**kwargs,
|
||||
):
|
||||
@@ -496,7 +484,7 @@ class TextualInversionLoaderMixin:
|
||||
</Tip>
|
||||
|
||||
Parameters:
|
||||
pretrained_model_name_or_path (`str` or `os.PathLike` or `List[str or os.PathLike]` or `Dict` or `List[Dict]`):
|
||||
pretrained_model_name_or_path (`str` or `os.PathLike` or `List[str or os.PathLike]`):
|
||||
Can be either:
|
||||
|
||||
- A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
|
||||
@@ -505,8 +493,6 @@ class TextualInversionLoaderMixin:
|
||||
- A path to a *directory* containing textual inversion weights, e.g.
|
||||
`./my_text_inversion_directory/`.
|
||||
- A path to a *file* containing textual inversion weights, e.g. `./my_text_inversions.pt`.
|
||||
- A [torch state
|
||||
dict](https://pytorch.org/tutorials/beginner/saving_loading_models.html#what-is-a-state-dict).
|
||||
|
||||
Or a list of those elements.
|
||||
token (`str` or `List[str]`, *optional*):
|
||||
@@ -631,7 +617,7 @@ class TextualInversionLoaderMixin:
|
||||
"framework": "pytorch",
|
||||
}
|
||||
|
||||
if not isinstance(pretrained_model_name_or_path, list):
|
||||
if isinstance(pretrained_model_name_or_path, str):
|
||||
pretrained_model_name_or_paths = [pretrained_model_name_or_path]
|
||||
else:
|
||||
pretrained_model_name_or_paths = pretrained_model_name_or_path
|
||||
@@ -656,38 +642,16 @@ class TextualInversionLoaderMixin:
|
||||
token_ids_and_embeddings = []
|
||||
|
||||
for pretrained_model_name_or_path, token in zip(pretrained_model_name_or_paths, tokens):
|
||||
if not isinstance(pretrained_model_name_or_path, dict):
|
||||
# 1. Load textual inversion file
|
||||
model_file = None
|
||||
# Let's first try to load .safetensors weights
|
||||
if (use_safetensors and weight_name is None) or (
|
||||
weight_name is not None and weight_name.endswith(".safetensors")
|
||||
):
|
||||
try:
|
||||
model_file = _get_model_file(
|
||||
pretrained_model_name_or_path,
|
||||
weights_name=weight_name or TEXT_INVERSION_NAME_SAFE,
|
||||
cache_dir=cache_dir,
|
||||
force_download=force_download,
|
||||
resume_download=resume_download,
|
||||
proxies=proxies,
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
subfolder=subfolder,
|
||||
user_agent=user_agent,
|
||||
)
|
||||
state_dict = safetensors.torch.load_file(model_file, device="cpu")
|
||||
except Exception as e:
|
||||
if not allow_pickle:
|
||||
raise e
|
||||
|
||||
model_file = None
|
||||
|
||||
if model_file is None:
|
||||
# 1. Load textual inversion file
|
||||
model_file = None
|
||||
# Let's first try to load .safetensors weights
|
||||
if (use_safetensors and weight_name is None) or (
|
||||
weight_name is not None and weight_name.endswith(".safetensors")
|
||||
):
|
||||
try:
|
||||
model_file = _get_model_file(
|
||||
pretrained_model_name_or_path,
|
||||
weights_name=weight_name or TEXT_INVERSION_NAME,
|
||||
weights_name=weight_name or TEXT_INVERSION_NAME_SAFE,
|
||||
cache_dir=cache_dir,
|
||||
force_download=force_download,
|
||||
resume_download=resume_download,
|
||||
@@ -698,12 +662,30 @@ class TextualInversionLoaderMixin:
|
||||
subfolder=subfolder,
|
||||
user_agent=user_agent,
|
||||
)
|
||||
state_dict = torch.load(model_file, map_location="cpu")
|
||||
else:
|
||||
state_dict = pretrained_model_name_or_path
|
||||
state_dict = safetensors.torch.load_file(model_file, device="cpu")
|
||||
except Exception as e:
|
||||
if not allow_pickle:
|
||||
raise e
|
||||
|
||||
model_file = None
|
||||
|
||||
if model_file is None:
|
||||
model_file = _get_model_file(
|
||||
pretrained_model_name_or_path,
|
||||
weights_name=weight_name or TEXT_INVERSION_NAME,
|
||||
cache_dir=cache_dir,
|
||||
force_download=force_download,
|
||||
resume_download=resume_download,
|
||||
proxies=proxies,
|
||||
local_files_only=local_files_only,
|
||||
use_auth_token=use_auth_token,
|
||||
revision=revision,
|
||||
subfolder=subfolder,
|
||||
user_agent=user_agent,
|
||||
)
|
||||
state_dict = torch.load(model_file, map_location="cpu")
|
||||
|
||||
# 2. Load token and embedding correcly from file
|
||||
loaded_token = None
|
||||
if isinstance(state_dict, torch.Tensor):
|
||||
if token is None:
|
||||
raise ValueError(
|
||||
@@ -785,8 +767,6 @@ class LoraLoaderMixin:
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
We support loading A1111 formatted LoRA checkpoints in a limited capacity.
|
||||
|
||||
This function is experimental and might change in the future.
|
||||
|
||||
</Tip>
|
||||
@@ -852,9 +832,6 @@ class LoraLoaderMixin:
|
||||
weight_name = kwargs.pop("weight_name", None)
|
||||
use_safetensors = kwargs.pop("use_safetensors", None)
|
||||
|
||||
# set lora scale to a reasonable default
|
||||
self._lora_scale = 1.0
|
||||
|
||||
if use_safetensors and not is_safetensors_available():
|
||||
raise ValueError(
|
||||
"`use_safetensors`=True but safetensors is not installed. Please install safetensors with `pip install safetenstors"
|
||||
@@ -914,11 +891,6 @@ class LoraLoaderMixin:
|
||||
else:
|
||||
state_dict = pretrained_model_name_or_path_or_dict
|
||||
|
||||
# Convert kohya-ss Style LoRA attn procs to diffusers attn procs
|
||||
network_alpha = None
|
||||
if all((k.startswith("lora_te_") or k.startswith("lora_unet_")) for k in state_dict.keys()):
|
||||
state_dict, network_alpha = self._convert_kohya_lora_to_diffusers(state_dict)
|
||||
|
||||
# If the serialization format is new (introduced in https://github.com/huggingface/diffusers/pull/2918),
|
||||
# then the `state_dict` keys should have `self.unet_name` and/or `self.text_encoder_name` as
|
||||
# their prefixes.
|
||||
@@ -930,18 +902,17 @@ class LoraLoaderMixin:
|
||||
unet_lora_state_dict = {
|
||||
k.replace(f"{self.unet_name}.", ""): v for k, v in state_dict.items() if k in unet_keys
|
||||
}
|
||||
self.unet.load_attn_procs(unet_lora_state_dict, network_alpha=network_alpha)
|
||||
self.unet.load_attn_procs(unet_lora_state_dict)
|
||||
|
||||
# Load the layers corresponding to text encoder and make necessary adjustments.
|
||||
text_encoder_keys = [k for k in keys if k.startswith(self.text_encoder_name)]
|
||||
text_encoder_lora_state_dict = {
|
||||
k.replace(f"{self.text_encoder_name}.", ""): v for k, v in state_dict.items() if k in text_encoder_keys
|
||||
}
|
||||
print(f"text_encoder_lora_state_dict: {text_encoder_lora_state_dict.keys()}")
|
||||
if len(text_encoder_lora_state_dict) > 0:
|
||||
logger.info(f"Loading {self.text_encoder_name}.")
|
||||
attn_procs_text_encoder = self._load_text_encoder_attn_procs(
|
||||
text_encoder_lora_state_dict, network_alpha=network_alpha
|
||||
)
|
||||
attn_procs_text_encoder = self._load_text_encoder_attn_procs(text_encoder_lora_state_dict)
|
||||
self._modify_text_encoder(attn_procs_text_encoder)
|
||||
|
||||
# save lora attn procs of text encoder so that it can be easily retrieved
|
||||
@@ -956,31 +927,12 @@ class LoraLoaderMixin:
|
||||
warn_message = "You have saved the LoRA weights using the old format. To convert the old LoRA weights to the new format, you can first load them in a dictionary and then create a new dictionary like the following: `new_state_dict = {f'unet'.{module_name}: params for module_name, params in old_state_dict.items()}`."
|
||||
warnings.warn(warn_message)
|
||||
|
||||
@property
|
||||
def lora_scale(self) -> float:
|
||||
# property function that returns the lora scale which can be set at run time by the pipeline.
|
||||
# if _lora_scale has not been set, return 1
|
||||
return self._lora_scale if hasattr(self, "_lora_scale") else 1.0
|
||||
|
||||
@property
|
||||
def text_encoder_lora_attn_procs(self):
|
||||
if hasattr(self, "_text_encoder_lora_attn_procs"):
|
||||
return self._text_encoder_lora_attn_procs
|
||||
return
|
||||
|
||||
def _remove_text_encoder_monkey_patch(self):
|
||||
# Loop over the CLIPAttention module of text_encoder
|
||||
for name, attn_module in self.text_encoder.named_modules():
|
||||
if name.endswith(TEXT_ENCODER_ATTN_MODULE):
|
||||
# Loop over the LoRA layers
|
||||
for _, text_encoder_attr in self._lora_attn_processor_attr_to_text_encoder_attr.items():
|
||||
# Retrieve the q/k/v/out projection of CLIPAttention
|
||||
module = attn_module.get_submodule(text_encoder_attr)
|
||||
if hasattr(module, "old_forward"):
|
||||
# restore original `forward` to remove monkey-patch
|
||||
module.forward = module.old_forward
|
||||
delattr(module, "old_forward")
|
||||
|
||||
def _modify_text_encoder(self, attn_processors: Dict[str, LoRAAttnProcessor]):
|
||||
r"""
|
||||
Monkey-patches the forward passes of attention modules of the text encoder.
|
||||
@@ -989,42 +941,31 @@ class LoraLoaderMixin:
|
||||
attn_processors: Dict[str, `LoRAAttnProcessor`]:
|
||||
A dictionary mapping the module names and their corresponding [`~LoRAAttnProcessor`].
|
||||
"""
|
||||
# Loop over the original attention modules.
|
||||
for name, _ in self.text_encoder.named_modules():
|
||||
if any(x in name for x in TEXT_ENCODER_TARGET_MODULES):
|
||||
# Retrieve the module and its corresponding LoRA processor.
|
||||
module = self.text_encoder.get_submodule(name)
|
||||
# Construct a new function that performs the LoRA merging. We will monkey patch
|
||||
# this forward pass.
|
||||
lora_layer = getattr(attn_processors[name], self._get_lora_layer_attribute(name))
|
||||
old_forward = module.forward
|
||||
|
||||
# First, remove any monkey-patch that might have been applied before
|
||||
self._remove_text_encoder_monkey_patch()
|
||||
def new_forward(x):
|
||||
return old_forward(x) + lora_layer(x)
|
||||
|
||||
# Loop over the CLIPAttention module of text_encoder
|
||||
for name, attn_module in self.text_encoder.named_modules():
|
||||
if name.endswith(TEXT_ENCODER_ATTN_MODULE):
|
||||
# Loop over the LoRA layers
|
||||
for attn_proc_attr, text_encoder_attr in self._lora_attn_processor_attr_to_text_encoder_attr.items():
|
||||
# Retrieve the q/k/v/out projection of CLIPAttention and its corresponding LoRA layer.
|
||||
module = attn_module.get_submodule(text_encoder_attr)
|
||||
lora_layer = attn_processors[name].get_submodule(attn_proc_attr)
|
||||
# Monkey-patch.
|
||||
module.forward = new_forward
|
||||
|
||||
# save old_forward to module that can be used to remove monkey-patch
|
||||
old_forward = module.old_forward = module.forward
|
||||
|
||||
# create a new scope that locks in the old_forward, lora_layer value for each new_forward function
|
||||
# for more detail, see https://github.com/huggingface/diffusers/pull/3490#issuecomment-1555059060
|
||||
def make_new_forward(old_forward, lora_layer):
|
||||
def new_forward(x):
|
||||
result = old_forward(x) + self.lora_scale * lora_layer(x)
|
||||
return result
|
||||
|
||||
return new_forward
|
||||
|
||||
# Monkey-patch.
|
||||
module.forward = make_new_forward(old_forward, lora_layer)
|
||||
|
||||
@property
|
||||
def _lora_attn_processor_attr_to_text_encoder_attr(self):
|
||||
return {
|
||||
"to_q_lora": "q_proj",
|
||||
"to_k_lora": "k_proj",
|
||||
"to_v_lora": "v_proj",
|
||||
"to_out_lora": "out_proj",
|
||||
}
|
||||
def _get_lora_layer_attribute(self, name: str) -> str:
|
||||
if "q_proj" in name:
|
||||
return "to_q_lora"
|
||||
elif "v_proj" in name:
|
||||
return "to_v_lora"
|
||||
elif "k_proj" in name:
|
||||
return "to_k_lora"
|
||||
else:
|
||||
return "to_out_lora"
|
||||
|
||||
def _load_text_encoder_attn_procs(
|
||||
self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs
|
||||
@@ -1101,7 +1042,6 @@ class LoraLoaderMixin:
|
||||
subfolder = kwargs.pop("subfolder", None)
|
||||
weight_name = kwargs.pop("weight_name", None)
|
||||
use_safetensors = kwargs.pop("use_safetensors", None)
|
||||
network_alpha = kwargs.pop("network_alpha", None)
|
||||
|
||||
if use_safetensors and not is_safetensors_available():
|
||||
raise ValueError(
|
||||
@@ -1178,14 +1118,8 @@ class LoraLoaderMixin:
|
||||
cross_attention_dim = value_dict["to_k_lora.down.weight"].shape[1]
|
||||
hidden_size = value_dict["to_k_lora.up.weight"].shape[0]
|
||||
|
||||
attn_processor_class = (
|
||||
LoRAAttnProcessor2_0 if hasattr(F, "scaled_dot_product_attention") else LoRAAttnProcessor
|
||||
)
|
||||
attn_processors[key] = attn_processor_class(
|
||||
hidden_size=hidden_size,
|
||||
cross_attention_dim=cross_attention_dim,
|
||||
rank=rank,
|
||||
network_alpha=network_alpha,
|
||||
attn_processors[key] = LoRAAttnProcessor(
|
||||
hidden_size=hidden_size, cross_attention_dim=cross_attention_dim, rank=rank
|
||||
)
|
||||
attn_processors[key].load_state_dict(value_dict)
|
||||
|
||||
@@ -1279,56 +1213,6 @@ class LoraLoaderMixin:
|
||||
save_function(state_dict, os.path.join(save_directory, weight_name))
|
||||
logger.info(f"Model weights saved in {os.path.join(save_directory, weight_name)}")
|
||||
|
||||
def _convert_kohya_lora_to_diffusers(self, state_dict):
|
||||
unet_state_dict = {}
|
||||
te_state_dict = {}
|
||||
network_alpha = None
|
||||
|
||||
for key, value in state_dict.items():
|
||||
if "lora_down" in key:
|
||||
lora_name = key.split(".")[0]
|
||||
lora_name_up = lora_name + ".lora_up.weight"
|
||||
lora_name_alpha = lora_name + ".alpha"
|
||||
if lora_name_alpha in state_dict:
|
||||
alpha = state_dict[lora_name_alpha].item()
|
||||
if network_alpha is None:
|
||||
network_alpha = alpha
|
||||
elif network_alpha != alpha:
|
||||
raise ValueError("Network alpha is not consistent")
|
||||
|
||||
if lora_name.startswith("lora_unet_"):
|
||||
diffusers_name = key.replace("lora_unet_", "").replace("_", ".")
|
||||
diffusers_name = diffusers_name.replace("down.blocks", "down_blocks")
|
||||
diffusers_name = diffusers_name.replace("mid.block", "mid_block")
|
||||
diffusers_name = diffusers_name.replace("up.blocks", "up_blocks")
|
||||
diffusers_name = diffusers_name.replace("transformer.blocks", "transformer_blocks")
|
||||
diffusers_name = diffusers_name.replace("to.q.lora", "to_q_lora")
|
||||
diffusers_name = diffusers_name.replace("to.k.lora", "to_k_lora")
|
||||
diffusers_name = diffusers_name.replace("to.v.lora", "to_v_lora")
|
||||
diffusers_name = diffusers_name.replace("to.out.0.lora", "to_out_lora")
|
||||
if "transformer_blocks" in diffusers_name:
|
||||
if "attn1" in diffusers_name or "attn2" in diffusers_name:
|
||||
diffusers_name = diffusers_name.replace("attn1", "attn1.processor")
|
||||
diffusers_name = diffusers_name.replace("attn2", "attn2.processor")
|
||||
unet_state_dict[diffusers_name] = value
|
||||
unet_state_dict[diffusers_name.replace(".down.", ".up.")] = state_dict[lora_name_up]
|
||||
elif lora_name.startswith("lora_te_"):
|
||||
diffusers_name = key.replace("lora_te_", "").replace("_", ".")
|
||||
diffusers_name = diffusers_name.replace("text.model", "text_model")
|
||||
diffusers_name = diffusers_name.replace("self.attn", "self_attn")
|
||||
diffusers_name = diffusers_name.replace("q.proj.lora", "to_q_lora")
|
||||
diffusers_name = diffusers_name.replace("k.proj.lora", "to_k_lora")
|
||||
diffusers_name = diffusers_name.replace("v.proj.lora", "to_v_lora")
|
||||
diffusers_name = diffusers_name.replace("out.proj.lora", "to_out_lora")
|
||||
if "self_attn" in diffusers_name:
|
||||
te_state_dict[diffusers_name] = value
|
||||
te_state_dict[diffusers_name.replace(".down.", ".up.")] = state_dict[lora_name_up]
|
||||
|
||||
unet_state_dict = {f"{UNET_NAME}.{module_name}": params for module_name, params in unet_state_dict.items()}
|
||||
te_state_dict = {f"{TEXT_ENCODER_NAME}.{module_name}": params for module_name, params in te_state_dict.items()}
|
||||
new_state_dict = {**unet_state_dict, **te_state_dict}
|
||||
return new_state_dict, network_alpha
|
||||
|
||||
|
||||
class FromCkptMixin:
|
||||
"""This helper class allows to directly load .ckpt stable diffusion file_extension
|
||||
@@ -1452,25 +1336,23 @@ class FromCkptMixin:
|
||||
|
||||
# TODO: For now we only support stable diffusion
|
||||
stable_unclip = None
|
||||
model_type = None
|
||||
controlnet = False
|
||||
|
||||
if pipeline_name == "StableDiffusionControlNetPipeline":
|
||||
# Model type will be inferred from the checkpoint.
|
||||
model_type = "FrozenCLIPEmbedder"
|
||||
controlnet = True
|
||||
elif "StableDiffusion" in pipeline_name:
|
||||
# Model type will be inferred from the checkpoint.
|
||||
pass
|
||||
model_type = "FrozenCLIPEmbedder"
|
||||
elif pipeline_name == "StableUnCLIPPipeline":
|
||||
model_type = "FrozenOpenCLIPEmbedder"
|
||||
model_type == "FrozenOpenCLIPEmbedder"
|
||||
stable_unclip = "txt2img"
|
||||
elif pipeline_name == "StableUnCLIPImg2ImgPipeline":
|
||||
model_type = "FrozenOpenCLIPEmbedder"
|
||||
model_type == "FrozenOpenCLIPEmbedder"
|
||||
stable_unclip = "img2img"
|
||||
elif pipeline_name == "PaintByExamplePipeline":
|
||||
model_type = "PaintByExample"
|
||||
model_type == "PaintByExample"
|
||||
elif pipeline_name == "LDMTextToImagePipeline":
|
||||
model_type = "LDMTextToImage"
|
||||
model_type == "LDMTextToImage"
|
||||
else:
|
||||
raise ValueError(f"Unhandled pipeline class: {pipeline_name}")
|
||||
|
||||
@@ -1483,8 +1365,8 @@ class FromCkptMixin:
|
||||
ckpt_path = Path(pretrained_model_link_or_path)
|
||||
if not ckpt_path.is_file():
|
||||
# get repo_id and (potentially nested) file path of ckpt in repo
|
||||
repo_id = "/".join(ckpt_path.parts[:2])
|
||||
file_path = "/".join(ckpt_path.parts[2:])
|
||||
repo_id = str(Path().joinpath(*ckpt_path.parts[:2]))
|
||||
file_path = str(Path().joinpath(*ckpt_path.parts[2:]))
|
||||
|
||||
if file_path.startswith("blob/"):
|
||||
file_path = file_path[len("blob/") :]
|
||||
|
||||
@@ -1,12 +0,0 @@
|
||||
from torch import nn
|
||||
|
||||
|
||||
def get_activation(act_fn):
|
||||
if act_fn in ["swish", "silu"]:
|
||||
return nn.SiLU()
|
||||
elif act_fn == "mish":
|
||||
return nn.Mish()
|
||||
elif act_fn == "gelu":
|
||||
return nn.GELU()
|
||||
else:
|
||||
raise ValueError(f"Unsupported activation function: {act_fn}")
|
||||
@@ -18,7 +18,6 @@ import torch.nn.functional as F
|
||||
from torch import nn
|
||||
|
||||
from ..utils import maybe_allow_in_graph
|
||||
from .activations import get_activation
|
||||
from .attention_processor import Attention
|
||||
from .embeddings import CombinedTimestepLabelEmbeddings
|
||||
|
||||
@@ -346,11 +345,15 @@ class AdaGroupNorm(nn.Module):
|
||||
super().__init__()
|
||||
self.num_groups = num_groups
|
||||
self.eps = eps
|
||||
|
||||
if act_fn is None:
|
||||
self.act = None
|
||||
else:
|
||||
self.act = get_activation(act_fn)
|
||||
self.act = None
|
||||
if act_fn == "swish":
|
||||
self.act = lambda x: F.silu(x)
|
||||
elif act_fn == "mish":
|
||||
self.act = nn.Mish()
|
||||
elif act_fn == "silu":
|
||||
self.act = nn.SiLU()
|
||||
elif act_fn == "gelu":
|
||||
self.act = nn.GELU()
|
||||
|
||||
self.linear = nn.Linear(embedding_dim, out_dim * 2)
|
||||
|
||||
|
||||
@@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import warnings
|
||||
from typing import Callable, Optional, Union
|
||||
|
||||
import torch
|
||||
@@ -61,7 +62,6 @@ class Attention(nn.Module):
|
||||
cross_attention_norm_num_groups: int = 32,
|
||||
added_kv_proj_dim: Optional[int] = None,
|
||||
norm_num_groups: Optional[int] = None,
|
||||
spatial_norm_dim: Optional[int] = None,
|
||||
out_bias: bool = True,
|
||||
scale_qk: bool = True,
|
||||
only_cross_attention: bool = False,
|
||||
@@ -105,11 +105,6 @@ class Attention(nn.Module):
|
||||
else:
|
||||
self.group_norm = None
|
||||
|
||||
if spatial_norm_dim is not None:
|
||||
self.spatial_norm = SpatialNorm(f_channels=query_dim, zq_channels=spatial_norm_dim)
|
||||
else:
|
||||
self.spatial_norm = None
|
||||
|
||||
if cross_attention_norm is None:
|
||||
self.norm_cross = None
|
||||
elif cross_attention_norm == "layer_norm":
|
||||
@@ -165,29 +160,22 @@ class Attention(nn.Module):
|
||||
self, use_memory_efficient_attention_xformers: bool, attention_op: Optional[Callable] = None
|
||||
):
|
||||
is_lora = hasattr(self, "processor") and isinstance(
|
||||
self.processor,
|
||||
(LoRAAttnProcessor, LoRAAttnProcessor2_0, LoRAXFormersAttnProcessor, LoRAAttnAddedKVProcessor),
|
||||
self.processor, (LoRAAttnProcessor, LoRAXFormersAttnProcessor)
|
||||
)
|
||||
is_custom_diffusion = hasattr(self, "processor") and isinstance(
|
||||
self.processor, (CustomDiffusionAttnProcessor, CustomDiffusionXFormersAttnProcessor)
|
||||
)
|
||||
is_added_kv_processor = hasattr(self, "processor") and isinstance(
|
||||
self.processor,
|
||||
(
|
||||
AttnAddedKVProcessor,
|
||||
AttnAddedKVProcessor2_0,
|
||||
SlicedAttnAddedKVProcessor,
|
||||
XFormersAttnAddedKVProcessor,
|
||||
LoRAAttnAddedKVProcessor,
|
||||
),
|
||||
)
|
||||
|
||||
if use_memory_efficient_attention_xformers:
|
||||
if is_added_kv_processor and (is_lora or is_custom_diffusion):
|
||||
if self.added_kv_proj_dim is not None:
|
||||
# TODO(Anton, Patrick, Suraj, William) - currently xformers doesn't work for UnCLIP
|
||||
# which uses this type of cross attention ONLY because the attention mask of format
|
||||
# [0, ..., -10.000, ..., 0, ...,] is not supported
|
||||
raise NotImplementedError(
|
||||
f"Memory efficient attention is currently not supported for LoRA or custom diffuson for attention processor type {self.processor}"
|
||||
"Memory efficient attention with `xformers` is currently not supported when"
|
||||
" `self.added_kv_proj_dim` is defined."
|
||||
)
|
||||
if not is_xformers_available():
|
||||
elif not is_xformers_available():
|
||||
raise ModuleNotFoundError(
|
||||
(
|
||||
"Refer to https://github.com/facebookresearch/xformers for more information on how to install"
|
||||
@@ -200,6 +188,14 @@ class Attention(nn.Module):
|
||||
"torch.cuda.is_available() should be True but is False. xformers' memory efficient attention is"
|
||||
" only available for GPU "
|
||||
)
|
||||
elif hasattr(F, "scaled_dot_product_attention") and self.scale_qk:
|
||||
warnings.warn(
|
||||
"You have specified using flash attention using xFormers but you have PyTorch 2.0 already installed. "
|
||||
"We will default to PyTorch's native efficient flash attention implementation (`F.scaled_dot_product_attention`) "
|
||||
"introduced in PyTorch 2.0. In case you are using LoRA or Custom Diffusion, we will fall "
|
||||
"back to their respective attention processors i.e., we will NOT use the PyTorch 2.0 "
|
||||
"native efficient flash attention."
|
||||
)
|
||||
else:
|
||||
try:
|
||||
# Make sure we can run the memory efficient attention
|
||||
@@ -212,8 +208,6 @@ class Attention(nn.Module):
|
||||
raise e
|
||||
|
||||
if is_lora:
|
||||
# TODO (sayakpaul): should we throw a warning if someone wants to use the xformers
|
||||
# variant when using PT 2.0 now that we have LoRAAttnProcessor2_0?
|
||||
processor = LoRAXFormersAttnProcessor(
|
||||
hidden_size=self.processor.hidden_size,
|
||||
cross_attention_dim=self.processor.cross_attention_dim,
|
||||
@@ -222,6 +216,9 @@ class Attention(nn.Module):
|
||||
)
|
||||
processor.load_state_dict(self.processor.state_dict())
|
||||
processor.to(self.processor.to_q_lora.up.weight.device)
|
||||
print(
|
||||
f"is_lora is set to {is_lora}, type: LoRAXFormersAttnProcessor: {isinstance(processor, LoRAXFormersAttnProcessor)}"
|
||||
)
|
||||
elif is_custom_diffusion:
|
||||
processor = CustomDiffusionXFormersAttnProcessor(
|
||||
train_kv=self.processor.train_kv,
|
||||
@@ -233,23 +230,11 @@ class Attention(nn.Module):
|
||||
processor.load_state_dict(self.processor.state_dict())
|
||||
if hasattr(self.processor, "to_k_custom_diffusion"):
|
||||
processor.to(self.processor.to_k_custom_diffusion.weight.device)
|
||||
elif is_added_kv_processor:
|
||||
# TODO(Patrick, Suraj, William) - currently xformers doesn't work for UnCLIP
|
||||
# which uses this type of cross attention ONLY because the attention mask of format
|
||||
# [0, ..., -10.000, ..., 0, ...,] is not supported
|
||||
# throw warning
|
||||
logger.info(
|
||||
"Memory efficient attention with `xformers` might currently not work correctly if an attention mask is required for the attention operation."
|
||||
)
|
||||
processor = XFormersAttnAddedKVProcessor(attention_op=attention_op)
|
||||
else:
|
||||
processor = XFormersAttnProcessor(attention_op=attention_op)
|
||||
else:
|
||||
if is_lora:
|
||||
attn_processor_class = (
|
||||
LoRAAttnProcessor2_0 if hasattr(F, "scaled_dot_product_attention") else LoRAAttnProcessor
|
||||
)
|
||||
processor = attn_processor_class(
|
||||
processor = LoRAAttnProcessor(
|
||||
hidden_size=self.processor.hidden_size,
|
||||
cross_attention_dim=self.processor.cross_attention_dim,
|
||||
rank=self.processor.rank,
|
||||
@@ -271,6 +256,7 @@ class Attention(nn.Module):
|
||||
# We use the AttnProcessor2_0 by default when torch 2.x is used which uses
|
||||
# torch.nn.functional.scaled_dot_product_attention for native Flash/memory_efficient_attention
|
||||
# but only if it has the default `scale` argument. TODO remove scale_qk check when we move to torch 2.1
|
||||
print("Still defaulting to: AttnProcessor2_0 :O")
|
||||
processor = (
|
||||
AttnProcessor2_0()
|
||||
if hasattr(F, "scaled_dot_product_attention") and self.scale_qk
|
||||
@@ -311,6 +297,7 @@ class Attention(nn.Module):
|
||||
logger.info(f"You are removing possibly trained weights of {self.processor} with {processor}")
|
||||
self._modules.pop("processor")
|
||||
|
||||
# print(f"Processor type: {type(processor)}")
|
||||
self.processor = processor
|
||||
|
||||
def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, **cross_attention_kwargs):
|
||||
@@ -439,23 +426,15 @@ class Attention(nn.Module):
|
||||
|
||||
|
||||
class AttnProcessor:
|
||||
r"""
|
||||
Default processor for performing attention-related computations.
|
||||
"""
|
||||
|
||||
def __call__(
|
||||
self,
|
||||
attn: Attention,
|
||||
hidden_states,
|
||||
encoder_hidden_states=None,
|
||||
attention_mask=None,
|
||||
temb=None,
|
||||
):
|
||||
residual = hidden_states
|
||||
|
||||
if attn.spatial_norm is not None:
|
||||
hidden_states = attn.spatial_norm(hidden_states, temb)
|
||||
|
||||
input_ndim = hidden_states.ndim
|
||||
|
||||
if input_ndim == 4:
|
||||
@@ -505,7 +484,7 @@ class AttnProcessor:
|
||||
|
||||
|
||||
class LoRALinearLayer(nn.Module):
|
||||
def __init__(self, in_features, out_features, rank=4, network_alpha=None):
|
||||
def __init__(self, in_features, out_features, rank=4):
|
||||
super().__init__()
|
||||
|
||||
if rank > min(in_features, out_features):
|
||||
@@ -513,10 +492,6 @@ class LoRALinearLayer(nn.Module):
|
||||
|
||||
self.down = nn.Linear(in_features, rank, bias=False)
|
||||
self.up = nn.Linear(rank, out_features, bias=False)
|
||||
# This value has the same meaning as the `--network_alpha` option in the kohya-ss trainer script.
|
||||
# See https://github.com/darkstorm2150/sd-scripts/blob/main/docs/train_network_README-en.md#execute-learning
|
||||
self.network_alpha = network_alpha
|
||||
self.rank = rank
|
||||
|
||||
nn.init.normal_(self.down.weight, std=1 / rank)
|
||||
nn.init.zeros_(self.up.weight)
|
||||
@@ -528,47 +503,25 @@ class LoRALinearLayer(nn.Module):
|
||||
down_hidden_states = self.down(hidden_states.to(dtype))
|
||||
up_hidden_states = self.up(down_hidden_states)
|
||||
|
||||
if self.network_alpha is not None:
|
||||
up_hidden_states *= self.network_alpha / self.rank
|
||||
|
||||
return up_hidden_states.to(orig_dtype)
|
||||
|
||||
|
||||
class LoRAAttnProcessor(nn.Module):
|
||||
r"""
|
||||
Processor for implementing the LoRA attention mechanism.
|
||||
|
||||
Args:
|
||||
hidden_size (`int`, *optional*):
|
||||
The hidden size of the attention layer.
|
||||
cross_attention_dim (`int`, *optional*):
|
||||
The number of channels in the `encoder_hidden_states`.
|
||||
rank (`int`, defaults to 4):
|
||||
The dimension of the LoRA update matrices.
|
||||
network_alpha (`int`, *optional*):
|
||||
Equivalent to `alpha` but it's usage is specific to Kohya (A1111) style LoRAs.
|
||||
"""
|
||||
|
||||
def __init__(self, hidden_size, cross_attention_dim=None, rank=4, network_alpha=None):
|
||||
def __init__(self, hidden_size, cross_attention_dim=None, rank=4):
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.cross_attention_dim = cross_attention_dim
|
||||
self.rank = rank
|
||||
|
||||
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
||||
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
||||
self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
||||
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
||||
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
|
||||
self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
|
||||
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
|
||||
def __call__(
|
||||
self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None, scale=1.0, temb=None
|
||||
):
|
||||
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None, scale=1.0):
|
||||
residual = hidden_states
|
||||
|
||||
if attn.spatial_norm is not None:
|
||||
hidden_states = attn.spatial_norm(hidden_states, temb)
|
||||
|
||||
input_ndim = hidden_states.ndim
|
||||
|
||||
if input_ndim == 4:
|
||||
@@ -618,24 +571,6 @@ class LoRAAttnProcessor(nn.Module):
|
||||
|
||||
|
||||
class CustomDiffusionAttnProcessor(nn.Module):
|
||||
r"""
|
||||
Processor for implementing attention for the Custom Diffusion method.
|
||||
|
||||
Args:
|
||||
train_kv (`bool`, defaults to `True`):
|
||||
Whether to newly train the key and value matrices corresponding to the text features.
|
||||
train_q_out (`bool`, defaults to `True`):
|
||||
Whether to newly train query matrices corresponding to the latent image features.
|
||||
hidden_size (`int`, *optional*, defaults to `None`):
|
||||
The hidden size of the attention layer.
|
||||
cross_attention_dim (`int`, *optional*, defaults to `None`):
|
||||
The number of channels in the `encoder_hidden_states`.
|
||||
out_bias (`bool`, defaults to `True`):
|
||||
Whether to include the bias parameter in `train_q_out`.
|
||||
dropout (`float`, *optional*, defaults to 0.0):
|
||||
The dropout probability to use.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
train_kv=True,
|
||||
@@ -714,11 +649,6 @@ class CustomDiffusionAttnProcessor(nn.Module):
|
||||
|
||||
|
||||
class AttnAddedKVProcessor:
|
||||
r"""
|
||||
Processor for performing attention-related computations with extra learnable key and value matrices for the text
|
||||
encoder.
|
||||
"""
|
||||
|
||||
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
residual = hidden_states
|
||||
hidden_states = hidden_states.view(hidden_states.shape[0], hidden_states.shape[1], -1).transpose(1, 2)
|
||||
@@ -768,11 +698,6 @@ class AttnAddedKVProcessor:
|
||||
|
||||
|
||||
class AttnAddedKVProcessor2_0:
|
||||
r"""
|
||||
Processor for performing scaled dot-product attention (enabled by default if you're using PyTorch 2.0), with extra
|
||||
learnable key and value matrices for the text encoder.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
if not hasattr(F, "scaled_dot_product_attention"):
|
||||
raise ImportError(
|
||||
@@ -831,35 +756,22 @@ class AttnAddedKVProcessor2_0:
|
||||
|
||||
|
||||
class LoRAAttnAddedKVProcessor(nn.Module):
|
||||
r"""
|
||||
Processor for implementing the LoRA attention mechanism with extra learnable key and value matrices for the text
|
||||
encoder.
|
||||
|
||||
Args:
|
||||
hidden_size (`int`, *optional*):
|
||||
The hidden size of the attention layer.
|
||||
cross_attention_dim (`int`, *optional*, defaults to `None`):
|
||||
The number of channels in the `encoder_hidden_states`.
|
||||
rank (`int`, defaults to 4):
|
||||
The dimension of the LoRA update matrices.
|
||||
|
||||
"""
|
||||
|
||||
def __init__(self, hidden_size, cross_attention_dim=None, rank=4, network_alpha=None):
|
||||
def __init__(self, hidden_size, cross_attention_dim=None, rank=4):
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.cross_attention_dim = cross_attention_dim
|
||||
self.rank = rank
|
||||
|
||||
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
||||
self.add_k_proj_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
||||
self.add_v_proj_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
||||
self.to_k_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
||||
self.to_v_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
||||
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
||||
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
self.add_k_proj_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
|
||||
self.add_v_proj_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
|
||||
self.to_k_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
self.to_v_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
|
||||
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None, scale=1.0):
|
||||
# print(f"{self.__class__.__name__} have been called.")
|
||||
residual = hidden_states
|
||||
hidden_states = hidden_states.view(hidden_states.shape[0], hidden_states.shape[1], -1).transpose(1, 2)
|
||||
batch_size, sequence_length, _ = hidden_states.shape
|
||||
@@ -911,83 +823,7 @@ class LoRAAttnAddedKVProcessor(nn.Module):
|
||||
return hidden_states
|
||||
|
||||
|
||||
class XFormersAttnAddedKVProcessor:
|
||||
r"""
|
||||
Processor for implementing memory efficient attention using xFormers.
|
||||
|
||||
Args:
|
||||
attention_op (`Callable`, *optional*, defaults to `None`):
|
||||
The base
|
||||
[operator](https://facebookresearch.github.io/xformers/components/ops.html#xformers.ops.AttentionOpBase) to
|
||||
use as the attention operator. It is recommended to set to `None`, and allow xFormers to choose the best
|
||||
operator.
|
||||
"""
|
||||
|
||||
def __init__(self, attention_op: Optional[Callable] = None):
|
||||
self.attention_op = attention_op
|
||||
|
||||
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
residual = hidden_states
|
||||
hidden_states = hidden_states.view(hidden_states.shape[0], hidden_states.shape[1], -1).transpose(1, 2)
|
||||
batch_size, sequence_length, _ = hidden_states.shape
|
||||
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.norm_cross:
|
||||
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
||||
|
||||
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
query = attn.head_to_batch_dim(query)
|
||||
|
||||
encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
|
||||
encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
|
||||
encoder_hidden_states_key_proj = attn.head_to_batch_dim(encoder_hidden_states_key_proj)
|
||||
encoder_hidden_states_value_proj = attn.head_to_batch_dim(encoder_hidden_states_value_proj)
|
||||
|
||||
if not attn.only_cross_attention:
|
||||
key = attn.to_k(hidden_states)
|
||||
value = attn.to_v(hidden_states)
|
||||
key = attn.head_to_batch_dim(key)
|
||||
value = attn.head_to_batch_dim(value)
|
||||
key = torch.cat([encoder_hidden_states_key_proj, key], dim=1)
|
||||
value = torch.cat([encoder_hidden_states_value_proj, value], dim=1)
|
||||
else:
|
||||
key = encoder_hidden_states_key_proj
|
||||
value = encoder_hidden_states_value_proj
|
||||
|
||||
hidden_states = xformers.ops.memory_efficient_attention(
|
||||
query, key, value, attn_bias=attention_mask, op=self.attention_op, scale=attn.scale
|
||||
)
|
||||
hidden_states = hidden_states.to(query.dtype)
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
hidden_states = hidden_states.transpose(-1, -2).reshape(residual.shape)
|
||||
hidden_states = hidden_states + residual
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class XFormersAttnProcessor:
|
||||
r"""
|
||||
Processor for implementing memory efficient attention using xFormers.
|
||||
|
||||
Args:
|
||||
attention_op (`Callable`, *optional*, defaults to `None`):
|
||||
The base
|
||||
[operator](https://facebookresearch.github.io/xformers/components/ops.html#xformers.ops.AttentionOpBase) to
|
||||
use as the attention operator. It is recommended to set to `None`, and allow xFormers to choose the best
|
||||
operator.
|
||||
"""
|
||||
|
||||
def __init__(self, attention_op: Optional[Callable] = None):
|
||||
self.attention_op = attention_op
|
||||
|
||||
@@ -997,13 +833,9 @@ class XFormersAttnProcessor:
|
||||
hidden_states: torch.FloatTensor,
|
||||
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
||||
attention_mask: Optional[torch.FloatTensor] = None,
|
||||
temb: Optional[torch.FloatTensor] = None,
|
||||
):
|
||||
residual = hidden_states
|
||||
|
||||
if attn.spatial_norm is not None:
|
||||
hidden_states = attn.spatial_norm(hidden_states, temb)
|
||||
|
||||
input_ndim = hidden_states.ndim
|
||||
|
||||
if input_ndim == 4:
|
||||
@@ -1065,27 +897,13 @@ class XFormersAttnProcessor:
|
||||
|
||||
|
||||
class AttnProcessor2_0:
|
||||
r"""
|
||||
Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
if not hasattr(F, "scaled_dot_product_attention"):
|
||||
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
||||
|
||||
def __call__(
|
||||
self,
|
||||
attn: Attention,
|
||||
hidden_states,
|
||||
encoder_hidden_states=None,
|
||||
attention_mask=None,
|
||||
temb=None,
|
||||
):
|
||||
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
residual = hidden_states
|
||||
|
||||
if attn.spatial_norm is not None:
|
||||
hidden_states = attn.spatial_norm(hidden_states, temb)
|
||||
|
||||
input_ndim = hidden_states.ndim
|
||||
|
||||
if input_ndim == 4:
|
||||
@@ -1147,29 +965,7 @@ class AttnProcessor2_0:
|
||||
|
||||
|
||||
class LoRAXFormersAttnProcessor(nn.Module):
|
||||
r"""
|
||||
Processor for implementing the LoRA attention mechanism with memory efficient attention using xFormers.
|
||||
|
||||
Args:
|
||||
hidden_size (`int`, *optional*):
|
||||
The hidden size of the attention layer.
|
||||
cross_attention_dim (`int`, *optional*):
|
||||
The number of channels in the `encoder_hidden_states`.
|
||||
rank (`int`, defaults to 4):
|
||||
The dimension of the LoRA update matrices.
|
||||
attention_op (`Callable`, *optional*, defaults to `None`):
|
||||
The base
|
||||
[operator](https://facebookresearch.github.io/xformers/components/ops.html#xformers.ops.AttentionOpBase) to
|
||||
use as the attention operator. It is recommended to set to `None`, and allow xFormers to choose the best
|
||||
operator.
|
||||
network_alpha (`int`, *optional*):
|
||||
Equivalent to `alpha` but it's usage is specific to Kohya (A1111) style LoRAs.
|
||||
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self, hidden_size, cross_attention_dim, rank=4, attention_op: Optional[Callable] = None, network_alpha=None
|
||||
):
|
||||
def __init__(self, hidden_size, cross_attention_dim, rank=4, attention_op: Optional[Callable] = None):
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
@@ -1177,19 +973,14 @@ class LoRAXFormersAttnProcessor(nn.Module):
|
||||
self.rank = rank
|
||||
self.attention_op = attention_op
|
||||
|
||||
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
||||
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
||||
self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
||||
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
||||
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
|
||||
self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank)
|
||||
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank)
|
||||
|
||||
def __call__(
|
||||
self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None, scale=1.0, temb=None
|
||||
):
|
||||
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None, scale=1.0):
|
||||
residual = hidden_states
|
||||
|
||||
if attn.spatial_norm is not None:
|
||||
hidden_states = attn.spatial_norm(hidden_states, temb)
|
||||
|
||||
input_ndim = hidden_states.ndim
|
||||
|
||||
if input_ndim == 4:
|
||||
@@ -1239,120 +1030,7 @@ class LoRAXFormersAttnProcessor(nn.Module):
|
||||
return hidden_states
|
||||
|
||||
|
||||
class LoRAAttnProcessor2_0(nn.Module):
|
||||
r"""
|
||||
Processor for implementing the LoRA attention mechanism using PyTorch 2.0's memory-efficient scaled dot-product
|
||||
attention.
|
||||
|
||||
Args:
|
||||
hidden_size (`int`):
|
||||
The hidden size of the attention layer.
|
||||
cross_attention_dim (`int`, *optional*):
|
||||
The number of channels in the `encoder_hidden_states`.
|
||||
rank (`int`, defaults to 4):
|
||||
The dimension of the LoRA update matrices.
|
||||
network_alpha (`int`, *optional*):
|
||||
Equivalent to `alpha` but it's usage is specific to Kohya (A1111) style LoRAs.
|
||||
"""
|
||||
|
||||
def __init__(self, hidden_size, cross_attention_dim=None, rank=4, network_alpha=None):
|
||||
super().__init__()
|
||||
if not hasattr(F, "scaled_dot_product_attention"):
|
||||
raise ImportError("AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.cross_attention_dim = cross_attention_dim
|
||||
self.rank = rank
|
||||
|
||||
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
||||
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
||||
self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
|
||||
self.to_out_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
|
||||
|
||||
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None, scale=1.0):
|
||||
residual = hidden_states
|
||||
|
||||
input_ndim = hidden_states.ndim
|
||||
|
||||
if input_ndim == 4:
|
||||
batch_size, channel, height, width = hidden_states.shape
|
||||
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
||||
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
||||
)
|
||||
inner_dim = hidden_states.shape[-1]
|
||||
|
||||
if attention_mask is not None:
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
# scaled_dot_product_attention expects attention_mask shape to be
|
||||
# (batch, heads, source_length, target_length)
|
||||
attention_mask = attention_mask.view(batch_size, attn.heads, -1, attention_mask.shape[-1])
|
||||
|
||||
if attn.group_norm is not None:
|
||||
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
||||
|
||||
query = attn.to_q(hidden_states) + scale * self.to_q_lora(hidden_states)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.norm_cross:
|
||||
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(encoder_hidden_states) + scale * self.to_k_lora(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states) + scale * self.to_v_lora(encoder_hidden_states)
|
||||
|
||||
head_dim = inner_dim // attn.heads
|
||||
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
|
||||
# TODO: add support for attn.scale when we move to Torch 2.1
|
||||
hidden_states = F.scaled_dot_product_attention(
|
||||
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
|
||||
hidden_states = hidden_states.to(query.dtype)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states) + scale * self.to_out_lora(hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
if input_ndim == 4:
|
||||
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
||||
|
||||
if attn.residual_connection:
|
||||
hidden_states = hidden_states + residual
|
||||
|
||||
hidden_states = hidden_states / attn.rescale_output_factor
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class CustomDiffusionXFormersAttnProcessor(nn.Module):
|
||||
r"""
|
||||
Processor for implementing memory efficient attention using xFormers for the Custom Diffusion method.
|
||||
|
||||
Args:
|
||||
train_kv (`bool`, defaults to `True`):
|
||||
Whether to newly train the key and value matrices corresponding to the text features.
|
||||
train_q_out (`bool`, defaults to `True`):
|
||||
Whether to newly train query matrices corresponding to the latent image features.
|
||||
hidden_size (`int`, *optional*, defaults to `None`):
|
||||
The hidden size of the attention layer.
|
||||
cross_attention_dim (`int`, *optional*, defaults to `None`):
|
||||
The number of channels in the `encoder_hidden_states`.
|
||||
out_bias (`bool`, defaults to `True`):
|
||||
Whether to include the bias parameter in `train_q_out`.
|
||||
dropout (`float`, *optional*, defaults to 0.0):
|
||||
The dropout probability to use.
|
||||
attention_op (`Callable`, *optional*, defaults to `None`):
|
||||
The base
|
||||
[operator](https://facebookresearch.github.io/xformers/components/ops.html#xformers.ops.AttentionOpBase) to use
|
||||
as the attention operator. It is recommended to set to `None`, and allow xFormers to choose the best operator.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
train_kv=True,
|
||||
@@ -1438,15 +1116,6 @@ class CustomDiffusionXFormersAttnProcessor(nn.Module):
|
||||
|
||||
|
||||
class SlicedAttnProcessor:
|
||||
r"""
|
||||
Processor for implementing sliced attention.
|
||||
|
||||
Args:
|
||||
slice_size (`int`, *optional*):
|
||||
The number of steps to compute attention. Uses as many slices as `attention_head_dim // slice_size`, and
|
||||
`attention_head_dim` must be a multiple of the `slice_size`.
|
||||
"""
|
||||
|
||||
def __init__(self, slice_size):
|
||||
self.slice_size = slice_size
|
||||
|
||||
@@ -1519,24 +1188,11 @@ class SlicedAttnProcessor:
|
||||
|
||||
|
||||
class SlicedAttnAddedKVProcessor:
|
||||
r"""
|
||||
Processor for implementing sliced attention with extra learnable key and value matrices for the text encoder.
|
||||
|
||||
Args:
|
||||
slice_size (`int`, *optional*):
|
||||
The number of steps to compute attention. Uses as many slices as `attention_head_dim // slice_size`, and
|
||||
`attention_head_dim` must be a multiple of the `slice_size`.
|
||||
"""
|
||||
|
||||
def __init__(self, slice_size):
|
||||
self.slice_size = slice_size
|
||||
|
||||
def __call__(self, attn: "Attention", hidden_states, encoder_hidden_states=None, attention_mask=None, temb=None):
|
||||
def __call__(self, attn: "Attention", hidden_states, encoder_hidden_states=None, attention_mask=None):
|
||||
residual = hidden_states
|
||||
|
||||
if attn.spatial_norm is not None:
|
||||
hidden_states = attn.spatial_norm(hidden_states, temb)
|
||||
|
||||
hidden_states = hidden_states.view(hidden_states.shape[0], hidden_states.shape[1], -1).transpose(1, 2)
|
||||
|
||||
batch_size, sequence_length, _ = hidden_states.shape
|
||||
@@ -1611,34 +1267,9 @@ AttentionProcessor = Union[
|
||||
AttnAddedKVProcessor,
|
||||
SlicedAttnAddedKVProcessor,
|
||||
AttnAddedKVProcessor2_0,
|
||||
XFormersAttnAddedKVProcessor,
|
||||
LoRAAttnProcessor,
|
||||
LoRAXFormersAttnProcessor,
|
||||
LoRAAttnProcessor2_0,
|
||||
LoRAAttnAddedKVProcessor,
|
||||
CustomDiffusionAttnProcessor,
|
||||
CustomDiffusionXFormersAttnProcessor,
|
||||
]
|
||||
|
||||
|
||||
class SpatialNorm(nn.Module):
|
||||
"""
|
||||
Spatially conditioned normalization as defined in https://arxiv.org/abs/2209.09002
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
f_channels,
|
||||
zq_channels,
|
||||
):
|
||||
super().__init__()
|
||||
self.norm_layer = nn.GroupNorm(num_channels=f_channels, num_groups=32, eps=1e-6, affine=True)
|
||||
self.conv_y = nn.Conv2d(zq_channels, f_channels, kernel_size=1, stride=1, padding=0)
|
||||
self.conv_b = nn.Conv2d(zq_channels, f_channels, kernel_size=1, stride=1, padding=0)
|
||||
|
||||
def forward(self, f, zq):
|
||||
f_size = f.shape[-2:]
|
||||
zq = F.interpolate(zq, size=f_size, mode="nearest")
|
||||
norm_f = self.norm_layer(f)
|
||||
new_f = norm_f * self.conv_y(zq) + self.conv_b(zq)
|
||||
return new_f
|
||||
|
||||
@@ -18,8 +18,6 @@ import numpy as np
|
||||
import torch
|
||||
from torch import nn
|
||||
|
||||
from .activations import get_activation
|
||||
|
||||
|
||||
def get_timestep_embedding(
|
||||
timesteps: torch.Tensor,
|
||||
@@ -173,7 +171,14 @@ class TimestepEmbedding(nn.Module):
|
||||
else:
|
||||
self.cond_proj = None
|
||||
|
||||
self.act = get_activation(act_fn)
|
||||
if act_fn == "silu":
|
||||
self.act = nn.SiLU()
|
||||
elif act_fn == "mish":
|
||||
self.act = nn.Mish()
|
||||
elif act_fn == "gelu":
|
||||
self.act = nn.GELU()
|
||||
else:
|
||||
raise ValueError(f"{act_fn} does not exist. Make sure to define one of 'silu', 'mish', or 'gelu'")
|
||||
|
||||
if out_dim is not None:
|
||||
time_embed_dim_out = out_dim
|
||||
@@ -183,8 +188,14 @@ class TimestepEmbedding(nn.Module):
|
||||
|
||||
if post_act_fn is None:
|
||||
self.post_act = None
|
||||
elif post_act_fn == "silu":
|
||||
self.post_act = nn.SiLU()
|
||||
elif post_act_fn == "mish":
|
||||
self.post_act = nn.Mish()
|
||||
elif post_act_fn == "gelu":
|
||||
self.post_act = nn.GELU()
|
||||
else:
|
||||
self.post_act = get_activation(post_act_fn)
|
||||
raise ValueError(f"{post_act_fn} does not exist. Make sure to define one of 'silu', 'mish', or 'gelu'")
|
||||
|
||||
def forward(self, sample, condition=None):
|
||||
if condition is not None:
|
||||
@@ -349,33 +360,6 @@ class LabelEmbedding(nn.Module):
|
||||
return embeddings
|
||||
|
||||
|
||||
class TextImageProjection(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
text_embed_dim: int = 1024,
|
||||
image_embed_dim: int = 768,
|
||||
cross_attention_dim: int = 768,
|
||||
num_image_text_embeds: int = 10,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.num_image_text_embeds = num_image_text_embeds
|
||||
self.image_embeds = nn.Linear(image_embed_dim, self.num_image_text_embeds * cross_attention_dim)
|
||||
self.text_proj = nn.Linear(text_embed_dim, cross_attention_dim)
|
||||
|
||||
def forward(self, text_embeds: torch.FloatTensor, image_embeds: torch.FloatTensor):
|
||||
batch_size = text_embeds.shape[0]
|
||||
|
||||
# image
|
||||
image_text_embeds = self.image_embeds(image_embeds)
|
||||
image_text_embeds = image_text_embeds.reshape(batch_size, self.num_image_text_embeds, -1)
|
||||
|
||||
# text
|
||||
text_embeds = self.text_proj(text_embeds)
|
||||
|
||||
return torch.cat([image_text_embeds, text_embeds], dim=1)
|
||||
|
||||
|
||||
class CombinedTimestepLabelEmbeddings(nn.Module):
|
||||
def __init__(self, num_classes, embedding_dim, class_dropout_prob=0.1):
|
||||
super().__init__()
|
||||
@@ -411,24 +395,6 @@ class TextTimeEmbedding(nn.Module):
|
||||
return hidden_states
|
||||
|
||||
|
||||
class TextImageTimeEmbedding(nn.Module):
|
||||
def __init__(self, text_embed_dim: int = 768, image_embed_dim: int = 768, time_embed_dim: int = 1536):
|
||||
super().__init__()
|
||||
self.text_proj = nn.Linear(text_embed_dim, time_embed_dim)
|
||||
self.text_norm = nn.LayerNorm(time_embed_dim)
|
||||
self.image_proj = nn.Linear(image_embed_dim, time_embed_dim)
|
||||
|
||||
def forward(self, text_embeds: torch.FloatTensor, image_embeds: torch.FloatTensor):
|
||||
# text
|
||||
time_text_embeds = self.text_proj(text_embeds)
|
||||
time_text_embeds = self.text_norm(time_text_embeds)
|
||||
|
||||
# image
|
||||
time_image_embeds = self.image_proj(image_embeds)
|
||||
|
||||
return time_image_embeds + time_text_embeds
|
||||
|
||||
|
||||
class AttentionPooling(nn.Module):
|
||||
# Copied from https://github.com/deep-floyd/IF/blob/2f91391f27dd3c468bf174be5805b4cc92980c0b/deepfloyd_if/model/nn.py#L54
|
||||
|
||||
|
||||
@@ -20,9 +20,7 @@ import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
from .activations import get_activation
|
||||
from .attention import AdaGroupNorm
|
||||
from .attention_processor import SpatialNorm
|
||||
|
||||
|
||||
class Upsample1D(nn.Module):
|
||||
@@ -53,17 +51,17 @@ class Upsample1D(nn.Module):
|
||||
elif use_conv:
|
||||
self.conv = nn.Conv1d(self.channels, self.out_channels, 3, padding=1)
|
||||
|
||||
def forward(self, inputs):
|
||||
assert inputs.shape[1] == self.channels
|
||||
def forward(self, x):
|
||||
assert x.shape[1] == self.channels
|
||||
if self.use_conv_transpose:
|
||||
return self.conv(inputs)
|
||||
return self.conv(x)
|
||||
|
||||
outputs = F.interpolate(inputs, scale_factor=2.0, mode="nearest")
|
||||
x = F.interpolate(x, scale_factor=2.0, mode="nearest")
|
||||
|
||||
if self.use_conv:
|
||||
outputs = self.conv(outputs)
|
||||
x = self.conv(x)
|
||||
|
||||
return outputs
|
||||
return x
|
||||
|
||||
|
||||
class Downsample1D(nn.Module):
|
||||
@@ -435,8 +433,7 @@ class KDownsample2D(nn.Module):
|
||||
x = F.pad(x, (self.pad,) * 4, self.pad_mode)
|
||||
weight = x.new_zeros([x.shape[1], x.shape[1], self.kernel.shape[0], self.kernel.shape[1]])
|
||||
indices = torch.arange(x.shape[1], device=x.device)
|
||||
kernel = self.kernel.to(weight)[None, :].expand(x.shape[1], -1, -1)
|
||||
weight[indices, indices] = kernel
|
||||
weight[indices, indices] = self.kernel.to(weight)
|
||||
return F.conv2d(x, weight, stride=2)
|
||||
|
||||
|
||||
@@ -452,8 +449,7 @@ class KUpsample2D(nn.Module):
|
||||
x = F.pad(x, ((self.pad + 1) // 2,) * 4, self.pad_mode)
|
||||
weight = x.new_zeros([x.shape[1], x.shape[1], self.kernel.shape[0], self.kernel.shape[1]])
|
||||
indices = torch.arange(x.shape[1], device=x.device)
|
||||
kernel = self.kernel.to(weight)[None, :].expand(x.shape[1], -1, -1)
|
||||
weight[indices, indices] = kernel
|
||||
weight[indices, indices] = self.kernel.to(weight)
|
||||
return F.conv_transpose2d(x, weight, stride=2, padding=self.pad * 2 + 1)
|
||||
|
||||
|
||||
@@ -502,7 +498,7 @@ class ResnetBlock2D(nn.Module):
|
||||
eps=1e-6,
|
||||
non_linearity="swish",
|
||||
skip_time_act=False,
|
||||
time_embedding_norm="default", # default, scale_shift, ada_group, spatial
|
||||
time_embedding_norm="default", # default, scale_shift, ada_group
|
||||
kernel=None,
|
||||
output_scale_factor=1.0,
|
||||
use_in_shortcut=None,
|
||||
@@ -529,8 +525,6 @@ class ResnetBlock2D(nn.Module):
|
||||
|
||||
if self.time_embedding_norm == "ada_group":
|
||||
self.norm1 = AdaGroupNorm(temb_channels, in_channels, groups, eps=eps)
|
||||
elif self.time_embedding_norm == "spatial":
|
||||
self.norm1 = SpatialNorm(in_channels, temb_channels)
|
||||
else:
|
||||
self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
|
||||
|
||||
@@ -541,7 +535,7 @@ class ResnetBlock2D(nn.Module):
|
||||
self.time_emb_proj = torch.nn.Linear(temb_channels, out_channels)
|
||||
elif self.time_embedding_norm == "scale_shift":
|
||||
self.time_emb_proj = torch.nn.Linear(temb_channels, 2 * out_channels)
|
||||
elif self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
|
||||
elif self.time_embedding_norm == "ada_group":
|
||||
self.time_emb_proj = None
|
||||
else:
|
||||
raise ValueError(f"unknown time_embedding_norm : {self.time_embedding_norm} ")
|
||||
@@ -550,8 +544,6 @@ class ResnetBlock2D(nn.Module):
|
||||
|
||||
if self.time_embedding_norm == "ada_group":
|
||||
self.norm2 = AdaGroupNorm(temb_channels, out_channels, groups_out, eps=eps)
|
||||
elif self.time_embedding_norm == "spatial":
|
||||
self.norm2 = SpatialNorm(out_channels, temb_channels)
|
||||
else:
|
||||
self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
|
||||
|
||||
@@ -559,7 +551,14 @@ class ResnetBlock2D(nn.Module):
|
||||
conv_2d_out_channels = conv_2d_out_channels or out_channels
|
||||
self.conv2 = torch.nn.Conv2d(out_channels, conv_2d_out_channels, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
self.nonlinearity = get_activation(non_linearity)
|
||||
if non_linearity == "swish":
|
||||
self.nonlinearity = lambda x: F.silu(x)
|
||||
elif non_linearity == "mish":
|
||||
self.nonlinearity = nn.Mish()
|
||||
elif non_linearity == "silu":
|
||||
self.nonlinearity = nn.SiLU()
|
||||
elif non_linearity == "gelu":
|
||||
self.nonlinearity = nn.GELU()
|
||||
|
||||
self.upsample = self.downsample = None
|
||||
if self.up:
|
||||
@@ -590,7 +589,7 @@ class ResnetBlock2D(nn.Module):
|
||||
def forward(self, input_tensor, temb):
|
||||
hidden_states = input_tensor
|
||||
|
||||
if self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
|
||||
if self.time_embedding_norm == "ada_group":
|
||||
hidden_states = self.norm1(hidden_states, temb)
|
||||
else:
|
||||
hidden_states = self.norm1(hidden_states)
|
||||
@@ -618,7 +617,7 @@ class ResnetBlock2D(nn.Module):
|
||||
if temb is not None and self.time_embedding_norm == "default":
|
||||
hidden_states = hidden_states + temb
|
||||
|
||||
if self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
|
||||
if self.time_embedding_norm == "ada_group":
|
||||
hidden_states = self.norm2(hidden_states, temb)
|
||||
else:
|
||||
hidden_states = self.norm2(hidden_states)
|
||||
@@ -640,6 +639,11 @@ class ResnetBlock2D(nn.Module):
|
||||
return output_tensor
|
||||
|
||||
|
||||
class Mish(torch.nn.Module):
|
||||
def forward(self, hidden_states):
|
||||
return hidden_states * torch.tanh(torch.nn.functional.softplus(hidden_states))
|
||||
|
||||
|
||||
# unet_rl.py
|
||||
def rearrange_dims(tensor):
|
||||
if len(tensor.shape) == 2:
|
||||
|
||||
@@ -17,7 +17,6 @@ import torch
|
||||
import torch.nn.functional as F
|
||||
from torch import nn
|
||||
|
||||
from .activations import get_activation
|
||||
from .resnet import Downsample1D, ResidualTemporalBlock1D, Upsample1D, rearrange_dims
|
||||
|
||||
|
||||
@@ -56,10 +55,14 @@ class DownResnetBlock1D(nn.Module):
|
||||
|
||||
self.resnets = nn.ModuleList(resnets)
|
||||
|
||||
if non_linearity is None:
|
||||
self.nonlinearity = None
|
||||
if non_linearity == "swish":
|
||||
self.nonlinearity = lambda x: F.silu(x)
|
||||
elif non_linearity == "mish":
|
||||
self.nonlinearity = nn.Mish()
|
||||
elif non_linearity == "silu":
|
||||
self.nonlinearity = nn.SiLU()
|
||||
else:
|
||||
self.nonlinearity = get_activation(non_linearity)
|
||||
self.nonlinearity = None
|
||||
|
||||
self.downsample = None
|
||||
if add_downsample:
|
||||
@@ -116,10 +119,14 @@ class UpResnetBlock1D(nn.Module):
|
||||
|
||||
self.resnets = nn.ModuleList(resnets)
|
||||
|
||||
if non_linearity is None:
|
||||
self.nonlinearity = None
|
||||
if non_linearity == "swish":
|
||||
self.nonlinearity = lambda x: F.silu(x)
|
||||
elif non_linearity == "mish":
|
||||
self.nonlinearity = nn.Mish()
|
||||
elif non_linearity == "silu":
|
||||
self.nonlinearity = nn.SiLU()
|
||||
else:
|
||||
self.nonlinearity = get_activation(non_linearity)
|
||||
self.nonlinearity = None
|
||||
|
||||
self.upsample = None
|
||||
if add_upsample:
|
||||
@@ -187,10 +194,14 @@ class MidResTemporalBlock1D(nn.Module):
|
||||
|
||||
self.resnets = nn.ModuleList(resnets)
|
||||
|
||||
if non_linearity is None:
|
||||
self.nonlinearity = None
|
||||
if non_linearity == "swish":
|
||||
self.nonlinearity = lambda x: F.silu(x)
|
||||
elif non_linearity == "mish":
|
||||
self.nonlinearity = nn.Mish()
|
||||
elif non_linearity == "silu":
|
||||
self.nonlinearity = nn.SiLU()
|
||||
else:
|
||||
self.nonlinearity = get_activation(non_linearity)
|
||||
self.nonlinearity = None
|
||||
|
||||
self.upsample = None
|
||||
if add_upsample:
|
||||
@@ -221,7 +232,10 @@ class OutConv1DBlock(nn.Module):
|
||||
super().__init__()
|
||||
self.final_conv1d_1 = nn.Conv1d(embed_dim, embed_dim, 5, padding=2)
|
||||
self.final_conv1d_gn = nn.GroupNorm(num_groups_out, embed_dim)
|
||||
self.final_conv1d_act = get_activation(act_fn)
|
||||
if act_fn == "silu":
|
||||
self.final_conv1d_act = nn.SiLU()
|
||||
if act_fn == "mish":
|
||||
self.final_conv1d_act = nn.Mish()
|
||||
self.final_conv1d_2 = nn.Conv1d(embed_dim, out_channels, 1)
|
||||
|
||||
def forward(self, hidden_states, temb=None):
|
||||
|
||||
@@ -349,7 +349,6 @@ def get_up_block(
|
||||
resnet_act_fn=resnet_act_fn,
|
||||
resnet_groups=resnet_groups,
|
||||
resnet_time_scale_shift=resnet_time_scale_shift,
|
||||
temb_channels=temb_channels,
|
||||
)
|
||||
elif up_block_type == "AttnUpDecoderBlock2D":
|
||||
return AttnUpDecoderBlock2D(
|
||||
@@ -362,7 +361,6 @@ def get_up_block(
|
||||
resnet_groups=resnet_groups,
|
||||
attn_num_head_channels=attn_num_head_channels,
|
||||
resnet_time_scale_shift=resnet_time_scale_shift,
|
||||
temb_channels=temb_channels,
|
||||
)
|
||||
elif up_block_type == "KUpBlock2D":
|
||||
return KUpBlock2D(
|
||||
@@ -398,7 +396,7 @@ class UNetMidBlock2D(nn.Module):
|
||||
dropout: float = 0.0,
|
||||
num_layers: int = 1,
|
||||
resnet_eps: float = 1e-6,
|
||||
resnet_time_scale_shift: str = "default", # default, spatial
|
||||
resnet_time_scale_shift: str = "default",
|
||||
resnet_act_fn: str = "swish",
|
||||
resnet_groups: int = 32,
|
||||
resnet_pre_norm: bool = True,
|
||||
@@ -436,8 +434,7 @@ class UNetMidBlock2D(nn.Module):
|
||||
dim_head=attn_num_head_channels if attn_num_head_channels is not None else in_channels,
|
||||
rescale_output_factor=output_scale_factor,
|
||||
eps=resnet_eps,
|
||||
norm_num_groups=resnet_groups if resnet_time_scale_shift == "default" else None,
|
||||
spatial_norm_dim=temb_channels if resnet_time_scale_shift == "spatial" else None,
|
||||
norm_num_groups=resnet_groups,
|
||||
residual_connection=True,
|
||||
bias=True,
|
||||
upcast_softmax=True,
|
||||
@@ -469,7 +466,7 @@ class UNetMidBlock2D(nn.Module):
|
||||
hidden_states = self.resnets[0](hidden_states, temb)
|
||||
for attn, resnet in zip(self.attentions, self.resnets[1:]):
|
||||
if attn is not None:
|
||||
hidden_states = attn(hidden_states, temb=temb)
|
||||
hidden_states = attn(hidden_states)
|
||||
hidden_states = resnet(hidden_states, temb)
|
||||
|
||||
return hidden_states
|
||||
@@ -2119,13 +2116,12 @@ class UpDecoderBlock2D(nn.Module):
|
||||
dropout: float = 0.0,
|
||||
num_layers: int = 1,
|
||||
resnet_eps: float = 1e-6,
|
||||
resnet_time_scale_shift: str = "default", # default, spatial
|
||||
resnet_time_scale_shift: str = "default",
|
||||
resnet_act_fn: str = "swish",
|
||||
resnet_groups: int = 32,
|
||||
resnet_pre_norm: bool = True,
|
||||
output_scale_factor=1.0,
|
||||
add_upsample=True,
|
||||
temb_channels=None,
|
||||
):
|
||||
super().__init__()
|
||||
resnets = []
|
||||
@@ -2137,7 +2133,7 @@ class UpDecoderBlock2D(nn.Module):
|
||||
ResnetBlock2D(
|
||||
in_channels=input_channels,
|
||||
out_channels=out_channels,
|
||||
temb_channels=temb_channels,
|
||||
temb_channels=None,
|
||||
eps=resnet_eps,
|
||||
groups=resnet_groups,
|
||||
dropout=dropout,
|
||||
@@ -2155,9 +2151,9 @@ class UpDecoderBlock2D(nn.Module):
|
||||
else:
|
||||
self.upsamplers = None
|
||||
|
||||
def forward(self, hidden_states, temb=None):
|
||||
def forward(self, hidden_states):
|
||||
for resnet in self.resnets:
|
||||
hidden_states = resnet(hidden_states, temb=temb)
|
||||
hidden_states = resnet(hidden_states, temb=None)
|
||||
|
||||
if self.upsamplers is not None:
|
||||
for upsampler in self.upsamplers:
|
||||
@@ -2181,7 +2177,6 @@ class AttnUpDecoderBlock2D(nn.Module):
|
||||
attn_num_head_channels=1,
|
||||
output_scale_factor=1.0,
|
||||
add_upsample=True,
|
||||
temb_channels=None,
|
||||
):
|
||||
super().__init__()
|
||||
resnets = []
|
||||
@@ -2194,7 +2189,7 @@ class AttnUpDecoderBlock2D(nn.Module):
|
||||
ResnetBlock2D(
|
||||
in_channels=input_channels,
|
||||
out_channels=out_channels,
|
||||
temb_channels=temb_channels,
|
||||
temb_channels=None,
|
||||
eps=resnet_eps,
|
||||
groups=resnet_groups,
|
||||
dropout=dropout,
|
||||
@@ -2211,8 +2206,7 @@ class AttnUpDecoderBlock2D(nn.Module):
|
||||
dim_head=attn_num_head_channels if attn_num_head_channels is not None else out_channels,
|
||||
rescale_output_factor=output_scale_factor,
|
||||
eps=resnet_eps,
|
||||
norm_num_groups=resnet_groups if resnet_time_scale_shift != "spatial" else None,
|
||||
spatial_norm_dim=temb_channels if resnet_time_scale_shift == "spatial" else None,
|
||||
norm_num_groups=resnet_groups,
|
||||
residual_connection=True,
|
||||
bias=True,
|
||||
upcast_softmax=True,
|
||||
@@ -2228,10 +2222,10 @@ class AttnUpDecoderBlock2D(nn.Module):
|
||||
else:
|
||||
self.upsamplers = None
|
||||
|
||||
def forward(self, hidden_states, temb=None):
|
||||
def forward(self, hidden_states):
|
||||
for resnet, attn in zip(self.resnets, self.attentions):
|
||||
hidden_states = resnet(hidden_states, temb=temb)
|
||||
hidden_states = attn(hidden_states, temb=temb)
|
||||
hidden_states = resnet(hidden_states, temb=None)
|
||||
hidden_states = attn(hidden_states)
|
||||
|
||||
if self.upsamplers is not None:
|
||||
for upsampler in self.upsamplers:
|
||||
|
||||
@@ -16,21 +16,14 @@ from typing import Any, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
import torch.utils.checkpoint
|
||||
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..loaders import UNet2DConditionLoadersMixin
|
||||
from ..utils import BaseOutput, logging
|
||||
from .activations import get_activation
|
||||
from .attention_processor import AttentionProcessor, AttnProcessor
|
||||
from .embeddings import (
|
||||
GaussianFourierProjection,
|
||||
TextImageProjection,
|
||||
TextImageTimeEmbedding,
|
||||
TextTimeEmbedding,
|
||||
TimestepEmbedding,
|
||||
Timesteps,
|
||||
)
|
||||
from .embeddings import GaussianFourierProjection, TextTimeEmbedding, TimestepEmbedding, Timesteps
|
||||
from .modeling_utils import ModelMixin
|
||||
from .unet_2d_blocks import (
|
||||
CrossAttnDownBlock2D,
|
||||
@@ -97,11 +90,7 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
cross_attention_dim (`int` or `Tuple[int]`, *optional*, defaults to 1280):
|
||||
The dimension of the cross attention features.
|
||||
encoder_hid_dim (`int`, *optional*, defaults to None):
|
||||
If `encoder_hid_dim_type` is defined, `encoder_hidden_states` will be projected from `encoder_hid_dim`
|
||||
dimension to `cross_attention_dim`.
|
||||
encoder_hid_dim_type (`str`, *optional*, defaults to None):
|
||||
If given, the `encoder_hidden_states` and potentially other embeddings will be down-projected to text
|
||||
embeddings of dimension `cross_attention` according to `encoder_hid_dim_type`.
|
||||
If given, `encoder_hidden_states` will be projected from this dimension to `cross_attention_dim`.
|
||||
attention_head_dim (`int`, *optional*, defaults to 8): The dimension of the attention heads.
|
||||
resnet_time_scale_shift (`str`, *optional*, defaults to `"default"`): Time scale shift config
|
||||
for resnet blocks, see [`~models.resnet.ResnetBlock2D`]. Choose from `default` or `scale_shift`.
|
||||
@@ -167,7 +156,6 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
norm_eps: float = 1e-5,
|
||||
cross_attention_dim: Union[int, Tuple[int]] = 1280,
|
||||
encoder_hid_dim: Optional[int] = None,
|
||||
encoder_hid_dim_type: Optional[str] = None,
|
||||
attention_head_dim: Union[int, Tuple[int]] = 8,
|
||||
dual_cross_attention: bool = False,
|
||||
use_linear_projection: bool = False,
|
||||
@@ -259,32 +247,8 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
cond_proj_dim=time_cond_proj_dim,
|
||||
)
|
||||
|
||||
if encoder_hid_dim_type is None and encoder_hid_dim is not None:
|
||||
encoder_hid_dim_type = "text_proj"
|
||||
self.register_to_config(encoder_hid_dim_type=encoder_hid_dim_type)
|
||||
logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
|
||||
|
||||
if encoder_hid_dim is None and encoder_hid_dim_type is not None:
|
||||
raise ValueError(
|
||||
f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
|
||||
)
|
||||
|
||||
if encoder_hid_dim_type == "text_proj":
|
||||
if encoder_hid_dim is not None:
|
||||
self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
|
||||
elif encoder_hid_dim_type == "text_image_proj":
|
||||
# image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
||||
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
||||
# case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
|
||||
self.encoder_hid_proj = TextImageProjection(
|
||||
text_embed_dim=encoder_hid_dim,
|
||||
image_embed_dim=cross_attention_dim,
|
||||
cross_attention_dim=cross_attention_dim,
|
||||
)
|
||||
|
||||
elif encoder_hid_dim_type is not None:
|
||||
raise ValueError(
|
||||
f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
|
||||
)
|
||||
else:
|
||||
self.encoder_hid_proj = None
|
||||
|
||||
@@ -326,20 +290,21 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
self.add_embedding = TextTimeEmbedding(
|
||||
text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
|
||||
)
|
||||
elif addition_embed_type == "text_image":
|
||||
# text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
|
||||
# they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
|
||||
# case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
|
||||
self.add_embedding = TextImageTimeEmbedding(
|
||||
text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
|
||||
)
|
||||
elif addition_embed_type is not None:
|
||||
raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
|
||||
raise ValueError(f"addition_embed_type: {addition_embed_type} must be None or 'text'.")
|
||||
|
||||
if time_embedding_act_fn is None:
|
||||
self.time_embed_act = None
|
||||
elif time_embedding_act_fn == "swish":
|
||||
self.time_embed_act = lambda x: F.silu(x)
|
||||
elif time_embedding_act_fn == "mish":
|
||||
self.time_embed_act = nn.Mish()
|
||||
elif time_embedding_act_fn == "silu":
|
||||
self.time_embed_act = nn.SiLU()
|
||||
elif time_embedding_act_fn == "gelu":
|
||||
self.time_embed_act = nn.GELU()
|
||||
else:
|
||||
self.time_embed_act = get_activation(time_embedding_act_fn)
|
||||
raise ValueError(f"Unsupported activation function: {time_embedding_act_fn}")
|
||||
|
||||
self.down_blocks = nn.ModuleList([])
|
||||
self.up_blocks = nn.ModuleList([])
|
||||
@@ -493,7 +458,16 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
|
||||
)
|
||||
|
||||
self.conv_act = get_activation(act_fn)
|
||||
if act_fn == "swish":
|
||||
self.conv_act = lambda x: F.silu(x)
|
||||
elif act_fn == "mish":
|
||||
self.conv_act = nn.Mish()
|
||||
elif act_fn == "silu":
|
||||
self.conv_act = nn.SiLU()
|
||||
elif act_fn == "gelu":
|
||||
self.conv_act = nn.GELU()
|
||||
else:
|
||||
raise ValueError(f"Unsupported activation function: {act_fn}")
|
||||
|
||||
else:
|
||||
self.conv_norm_out = None
|
||||
@@ -544,6 +518,9 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
|
||||
f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
|
||||
)
|
||||
# print("set_attn_processor() is called.")
|
||||
# for k in processor:
|
||||
# print(f"{k}: {type(processor[k])}")
|
||||
|
||||
def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
|
||||
if hasattr(module, "set_processor"):
|
||||
@@ -642,7 +619,6 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
timestep_cond: Optional[torch.Tensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
||||
added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
|
||||
down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
|
||||
mid_block_additional_residual: Optional[torch.Tensor] = None,
|
||||
encoder_attention_mask: Optional[torch.Tensor] = None,
|
||||
@@ -663,10 +639,6 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
|
||||
`self.processor` in
|
||||
[diffusers.cross_attention](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/cross_attention.py).
|
||||
added_cond_kwargs (`dict`, *optional*):
|
||||
A kwargs dictionary that if specified includes additonal conditions that can be used for additonal time
|
||||
embeddings or encoder hidden states projections. See the configurations `encoder_hid_dim_type` and
|
||||
`addition_embed_type` for more information.
|
||||
|
||||
Returns:
|
||||
[`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
|
||||
@@ -759,33 +731,12 @@ class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin)
|
||||
if self.config.addition_embed_type == "text":
|
||||
aug_emb = self.add_embedding(encoder_hidden_states)
|
||||
emb = emb + aug_emb
|
||||
elif self.config.addition_embed_type == "text_image":
|
||||
# Kadinsky 2.1 - style
|
||||
if "image_embeds" not in added_cond_kwargs:
|
||||
raise ValueError(
|
||||
f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
|
||||
)
|
||||
|
||||
image_embs = added_cond_kwargs.get("image_embeds")
|
||||
text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
|
||||
|
||||
aug_emb = self.add_embedding(text_embs, image_embs)
|
||||
emb = emb + aug_emb
|
||||
|
||||
if self.time_embed_act is not None:
|
||||
emb = self.time_embed_act(emb)
|
||||
|
||||
if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
|
||||
if self.encoder_hid_proj is not None:
|
||||
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
|
||||
elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
|
||||
# Kadinsky 2.1 - style
|
||||
if "image_embeds" not in added_cond_kwargs:
|
||||
raise ValueError(
|
||||
f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
|
||||
)
|
||||
|
||||
image_embeds = added_cond_kwargs.get("image_embeds")
|
||||
encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
|
||||
|
||||
# 2. pre-process
|
||||
sample = self.conv_in(sample)
|
||||
|
||||
@@ -19,7 +19,6 @@ import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from ..utils import BaseOutput, is_torch_version, randn_tensor
|
||||
from .attention_processor import SpatialNorm
|
||||
from .unet_2d_blocks import UNetMidBlock2D, get_down_block, get_up_block
|
||||
|
||||
|
||||
@@ -159,7 +158,6 @@ class Decoder(nn.Module):
|
||||
layers_per_block=2,
|
||||
norm_num_groups=32,
|
||||
act_fn="silu",
|
||||
norm_type="group", # group, spatial
|
||||
):
|
||||
super().__init__()
|
||||
self.layers_per_block = layers_per_block
|
||||
@@ -175,18 +173,16 @@ class Decoder(nn.Module):
|
||||
self.mid_block = None
|
||||
self.up_blocks = nn.ModuleList([])
|
||||
|
||||
temb_channels = in_channels if norm_type == "spatial" else None
|
||||
|
||||
# mid
|
||||
self.mid_block = UNetMidBlock2D(
|
||||
in_channels=block_out_channels[-1],
|
||||
resnet_eps=1e-6,
|
||||
resnet_act_fn=act_fn,
|
||||
output_scale_factor=1,
|
||||
resnet_time_scale_shift="default" if norm_type == "group" else norm_type,
|
||||
resnet_time_scale_shift="default",
|
||||
attn_num_head_channels=None,
|
||||
resnet_groups=norm_num_groups,
|
||||
temb_channels=temb_channels,
|
||||
temb_channels=None,
|
||||
)
|
||||
|
||||
# up
|
||||
@@ -209,23 +205,19 @@ class Decoder(nn.Module):
|
||||
resnet_act_fn=act_fn,
|
||||
resnet_groups=norm_num_groups,
|
||||
attn_num_head_channels=None,
|
||||
temb_channels=temb_channels,
|
||||
resnet_time_scale_shift=norm_type,
|
||||
temb_channels=None,
|
||||
)
|
||||
self.up_blocks.append(up_block)
|
||||
prev_output_channel = output_channel
|
||||
|
||||
# out
|
||||
if norm_type == "spatial":
|
||||
self.conv_norm_out = SpatialNorm(block_out_channels[0], temb_channels)
|
||||
else:
|
||||
self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=1e-6)
|
||||
self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=1e-6)
|
||||
self.conv_act = nn.SiLU()
|
||||
self.conv_out = nn.Conv2d(block_out_channels[0], out_channels, 3, padding=1)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
def forward(self, z, latent_embeds=None):
|
||||
def forward(self, z):
|
||||
sample = z
|
||||
sample = self.conv_in(sample)
|
||||
|
||||
@@ -241,39 +233,34 @@ class Decoder(nn.Module):
|
||||
if is_torch_version(">=", "1.11.0"):
|
||||
# middle
|
||||
sample = torch.utils.checkpoint.checkpoint(
|
||||
create_custom_forward(self.mid_block), sample, latent_embeds, use_reentrant=False
|
||||
create_custom_forward(self.mid_block), sample, use_reentrant=False
|
||||
)
|
||||
sample = sample.to(upscale_dtype)
|
||||
|
||||
# up
|
||||
for up_block in self.up_blocks:
|
||||
sample = torch.utils.checkpoint.checkpoint(
|
||||
create_custom_forward(up_block), sample, latent_embeds, use_reentrant=False
|
||||
create_custom_forward(up_block), sample, use_reentrant=False
|
||||
)
|
||||
else:
|
||||
# middle
|
||||
sample = torch.utils.checkpoint.checkpoint(
|
||||
create_custom_forward(self.mid_block), sample, latent_embeds
|
||||
)
|
||||
sample = torch.utils.checkpoint.checkpoint(create_custom_forward(self.mid_block), sample)
|
||||
sample = sample.to(upscale_dtype)
|
||||
|
||||
# up
|
||||
for up_block in self.up_blocks:
|
||||
sample = torch.utils.checkpoint.checkpoint(create_custom_forward(up_block), sample, latent_embeds)
|
||||
sample = torch.utils.checkpoint.checkpoint(create_custom_forward(up_block), sample)
|
||||
else:
|
||||
# middle
|
||||
sample = self.mid_block(sample, latent_embeds)
|
||||
sample = self.mid_block(sample)
|
||||
sample = sample.to(upscale_dtype)
|
||||
|
||||
# up
|
||||
for up_block in self.up_blocks:
|
||||
sample = up_block(sample, latent_embeds)
|
||||
sample = up_block(sample)
|
||||
|
||||
# post-process
|
||||
if latent_embeds is None:
|
||||
sample = self.conv_norm_out(sample)
|
||||
else:
|
||||
sample = self.conv_norm_out(sample, latent_embeds)
|
||||
sample = self.conv_norm_out(sample)
|
||||
sample = self.conv_act(sample)
|
||||
sample = self.conv_out(sample)
|
||||
|
||||
|
||||
@@ -82,7 +82,6 @@ class VQModel(ModelMixin, ConfigMixin):
|
||||
norm_num_groups: int = 32,
|
||||
vq_embed_dim: Optional[int] = None,
|
||||
scaling_factor: float = 0.18215,
|
||||
norm_type: str = "group", # group, spatial
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
@@ -113,7 +112,6 @@ class VQModel(ModelMixin, ConfigMixin):
|
||||
layers_per_block=layers_per_block,
|
||||
act_fn=act_fn,
|
||||
norm_num_groups=norm_num_groups,
|
||||
norm_type=norm_type,
|
||||
)
|
||||
|
||||
def encode(self, x: torch.FloatTensor, return_dict: bool = True) -> VQEncoderOutput:
|
||||
@@ -133,8 +131,8 @@ class VQModel(ModelMixin, ConfigMixin):
|
||||
quant, emb_loss, info = self.quantize(h)
|
||||
else:
|
||||
quant = h
|
||||
quant2 = self.post_quant_conv(quant)
|
||||
dec = self.decoder(quant2, quant if self.config.norm_type == "spatial" else None)
|
||||
quant = self.post_quant_conv(quant)
|
||||
dec = self.decoder(quant)
|
||||
|
||||
if not return_dict:
|
||||
return (dec,)
|
||||
|
||||
@@ -318,7 +318,7 @@ def get_scheduler(
|
||||
return schedule_func(optimizer, last_epoch=last_epoch)
|
||||
|
||||
if name == SchedulerType.PIECEWISE_CONSTANT:
|
||||
return schedule_func(optimizer, step_rules=step_rules, last_epoch=last_epoch)
|
||||
return schedule_func(optimizer, rules=step_rules, last_epoch=last_epoch)
|
||||
|
||||
# All other schedulers require `num_warmup_steps`
|
||||
if num_warmup_steps is None:
|
||||
|
||||
@@ -57,12 +57,6 @@ else:
|
||||
IFPipeline,
|
||||
IFSuperResolutionPipeline,
|
||||
)
|
||||
from .kandinsky import (
|
||||
KandinskyImg2ImgPipeline,
|
||||
KandinskyInpaintPipeline,
|
||||
KandinskyPipeline,
|
||||
KandinskyPriorPipeline,
|
||||
)
|
||||
from .latent_diffusion import LDMTextToImagePipeline
|
||||
from .paint_by_example import PaintByExamplePipeline
|
||||
from .semantic_stable_diffusion import SemanticStableDiffusionPipeline
|
||||
@@ -89,7 +83,6 @@ else:
|
||||
from .stable_diffusion_safe import StableDiffusionPipelineSafe
|
||||
from .text_to_video_synthesis import TextToVideoSDPipeline, TextToVideoZeroPipeline
|
||||
from .unclip import UnCLIPImageVariationPipeline, UnCLIPPipeline
|
||||
from .unidiffuser import ImageTextPipelineOutput, UniDiffuserModel, UniDiffuserPipeline, UniDiffuserTextDecoder
|
||||
from .versatile_diffusion import (
|
||||
VersatileDiffusionDualGuidedPipeline,
|
||||
VersatileDiffusionImageVariationPipeline,
|
||||
|
||||
@@ -24,7 +24,7 @@ from diffusers.utils import is_accelerate_available, is_accelerate_version
|
||||
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import VaeImageProcessor
|
||||
from ...loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...loaders import TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import deprecate, logging, randn_tensor, replace_example_docstring
|
||||
@@ -52,7 +52,7 @@ EXAMPLE_DOC_STRING = """
|
||||
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline with Stable->Alt, CLIPTextModel->RobertaSeriesModelWithTransformation, CLIPTokenizer->XLMRobertaTokenizer, AltDiffusionSafetyChecker->StableDiffusionSafetyChecker
|
||||
class AltDiffusionPipeline(DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin):
|
||||
class AltDiffusionPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
|
||||
r"""
|
||||
Pipeline for text-to-image generation using Alt Diffusion.
|
||||
|
||||
@@ -291,7 +291,6 @@ class AltDiffusionPipeline(DiffusionPipeline, TextualInversionLoaderMixin, LoraL
|
||||
negative_prompt=None,
|
||||
prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
lora_scale: Optional[float] = None,
|
||||
):
|
||||
r"""
|
||||
Encodes the prompt into text encoder hidden states.
|
||||
@@ -316,14 +315,7 @@ class AltDiffusionPipeline(DiffusionPipeline, TextualInversionLoaderMixin, LoraL
|
||||
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
|
||||
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
|
||||
argument.
|
||||
lora_scale (`float`, *optional*):
|
||||
A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
|
||||
"""
|
||||
# set lora scale so that monkey patched LoRA
|
||||
# function of text encoder can correctly access it
|
||||
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
|
||||
self._lora_scale = lora_scale
|
||||
|
||||
if prompt is not None and isinstance(prompt, str):
|
||||
batch_size = 1
|
||||
elif prompt is not None and isinstance(prompt, list):
|
||||
@@ -661,9 +653,6 @@ class AltDiffusionPipeline(DiffusionPipeline, TextualInversionLoaderMixin, LoraL
|
||||
do_classifier_free_guidance = guidance_scale > 1.0
|
||||
|
||||
# 3. Encode input prompt
|
||||
text_encoder_lora_scale = (
|
||||
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
|
||||
)
|
||||
prompt_embeds = self._encode_prompt(
|
||||
prompt,
|
||||
device,
|
||||
@@ -672,7 +661,6 @@ class AltDiffusionPipeline(DiffusionPipeline, TextualInversionLoaderMixin, LoraL
|
||||
negative_prompt,
|
||||
prompt_embeds=prompt_embeds,
|
||||
negative_prompt_embeds=negative_prompt_embeds,
|
||||
lora_scale=text_encoder_lora_scale,
|
||||
)
|
||||
|
||||
# 4. Prepare timesteps
|
||||
|
||||
@@ -26,7 +26,7 @@ from diffusers.utils import is_accelerate_available, is_accelerate_version
|
||||
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import VaeImageProcessor
|
||||
from ...loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...loaders import TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import PIL_INTERPOLATION, deprecate, logging, randn_tensor, replace_example_docstring
|
||||
@@ -69,11 +69,6 @@ EXAMPLE_DOC_STRING = """
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.preprocess
|
||||
def preprocess(image):
|
||||
warnings.warn(
|
||||
"The preprocess method is deprecated and will be removed in a future version. Please"
|
||||
" use VaeImageProcessor.preprocess instead",
|
||||
FutureWarning,
|
||||
)
|
||||
if isinstance(image, torch.Tensor):
|
||||
return image
|
||||
elif isinstance(image, PIL.Image.Image):
|
||||
@@ -95,7 +90,7 @@ def preprocess(image):
|
||||
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline with Stable->Alt, CLIPTextModel->RobertaSeriesModelWithTransformation, CLIPTokenizer->XLMRobertaTokenizer, AltDiffusionSafetyChecker->StableDiffusionSafetyChecker
|
||||
class AltDiffusionImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin):
|
||||
class AltDiffusionImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
|
||||
r"""
|
||||
Pipeline for text-guided image to image generation using Alt Diffusion.
|
||||
|
||||
@@ -302,7 +297,6 @@ class AltDiffusionImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin
|
||||
negative_prompt=None,
|
||||
prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
lora_scale: Optional[float] = None,
|
||||
):
|
||||
r"""
|
||||
Encodes the prompt into text encoder hidden states.
|
||||
@@ -327,14 +321,7 @@ class AltDiffusionImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin
|
||||
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
|
||||
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
|
||||
argument.
|
||||
lora_scale (`float`, *optional*):
|
||||
A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
|
||||
"""
|
||||
# set lora scale so that monkey patched LoRA
|
||||
# function of text encoder can correctly access it
|
||||
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
|
||||
self._lora_scale = lora_scale
|
||||
|
||||
if prompt is not None and isinstance(prompt, str):
|
||||
batch_size = 1
|
||||
elif prompt is not None and isinstance(prompt, list):
|
||||
@@ -551,26 +538,21 @@ class AltDiffusionImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin
|
||||
image = image.to(device=device, dtype=dtype)
|
||||
|
||||
batch_size = batch_size * num_images_per_prompt
|
||||
if isinstance(generator, list) and len(generator) != batch_size:
|
||||
raise ValueError(
|
||||
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
||||
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
||||
)
|
||||
|
||||
if image.shape[1] == 4:
|
||||
init_latents = image
|
||||
|
||||
if isinstance(generator, list):
|
||||
init_latents = [
|
||||
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
|
||||
]
|
||||
init_latents = torch.cat(init_latents, dim=0)
|
||||
else:
|
||||
if isinstance(generator, list) and len(generator) != batch_size:
|
||||
raise ValueError(
|
||||
f"You have passed a list of generators of length {len(generator)}, but requested an effective"
|
||||
f" batch size of {batch_size}. Make sure the batch size matches the length of the generators."
|
||||
)
|
||||
init_latents = self.vae.encode(image).latent_dist.sample(generator)
|
||||
|
||||
elif isinstance(generator, list):
|
||||
init_latents = [
|
||||
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
|
||||
]
|
||||
init_latents = torch.cat(init_latents, dim=0)
|
||||
else:
|
||||
init_latents = self.vae.encode(image).latent_dist.sample(generator)
|
||||
|
||||
init_latents = self.vae.config.scaling_factor * init_latents
|
||||
init_latents = self.vae.config.scaling_factor * init_latents
|
||||
|
||||
if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
|
||||
# expand init_latents for batch_size
|
||||
@@ -604,14 +586,7 @@ class AltDiffusionImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin
|
||||
def __call__(
|
||||
self,
|
||||
prompt: Union[str, List[str]] = None,
|
||||
image: Union[
|
||||
torch.FloatTensor,
|
||||
PIL.Image.Image,
|
||||
np.ndarray,
|
||||
List[torch.FloatTensor],
|
||||
List[PIL.Image.Image],
|
||||
List[np.ndarray],
|
||||
] = None,
|
||||
image: Union[torch.FloatTensor, PIL.Image.Image] = None,
|
||||
strength: float = 0.8,
|
||||
num_inference_steps: Optional[int] = 50,
|
||||
guidance_scale: Optional[float] = 7.5,
|
||||
@@ -634,10 +609,9 @@ class AltDiffusionImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin
|
||||
prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
|
||||
instead.
|
||||
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, or `List[np.ndarray]`):
|
||||
image (`torch.FloatTensor` or `PIL.Image.Image`):
|
||||
`Image`, or tensor representing an image batch, that will be used as the starting point for the
|
||||
process. Can also accpet image latents as `image`, if passing latents directly, it will not be encoded
|
||||
again.
|
||||
process.
|
||||
strength (`float`, *optional*, defaults to 0.8):
|
||||
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
|
||||
will be used as a starting point, adding more noise to it the larger the `strength`. The number of
|
||||
@@ -714,9 +688,6 @@ class AltDiffusionImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin
|
||||
do_classifier_free_guidance = guidance_scale > 1.0
|
||||
|
||||
# 3. Encode input prompt
|
||||
text_encoder_lora_scale = (
|
||||
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
|
||||
)
|
||||
prompt_embeds = self._encode_prompt(
|
||||
prompt,
|
||||
device,
|
||||
@@ -725,7 +696,6 @@ class AltDiffusionImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin
|
||||
negative_prompt,
|
||||
prompt_embeds=prompt_embeds,
|
||||
negative_prompt_embeds=negative_prompt_embeds,
|
||||
lora_scale=text_encoder_lora_scale,
|
||||
)
|
||||
|
||||
# 4. Preprocess image
|
||||
|
||||
@@ -25,10 +25,11 @@ import torch.nn.functional as F
|
||||
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from ...image_processor import VaeImageProcessor
|
||||
from ...loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...loaders import TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, ControlNetModel, UNet2DConditionModel
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import (
|
||||
PIL_INTERPOLATION,
|
||||
is_accelerate_available,
|
||||
is_accelerate_version,
|
||||
is_compiled_module,
|
||||
@@ -91,7 +92,7 @@ EXAMPLE_DOC_STRING = """
|
||||
"""
|
||||
|
||||
|
||||
class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin):
|
||||
class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
|
||||
r"""
|
||||
Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
|
||||
|
||||
@@ -171,10 +172,7 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
feature_extractor=feature_extractor,
|
||||
)
|
||||
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
|
||||
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True)
|
||||
self.control_image_processor = VaeImageProcessor(
|
||||
vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False
|
||||
)
|
||||
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
|
||||
self.register_to_config(requires_safety_checker=requires_safety_checker)
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
|
||||
@@ -291,7 +289,6 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
negative_prompt=None,
|
||||
prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
lora_scale: Optional[float] = None,
|
||||
):
|
||||
r"""
|
||||
Encodes the prompt into text encoder hidden states.
|
||||
@@ -316,14 +313,7 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
|
||||
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
|
||||
argument.
|
||||
lora_scale (`float`, *optional*):
|
||||
A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
|
||||
"""
|
||||
# set lora scale so that monkey patched LoRA
|
||||
# function of text encoder can correctly access it
|
||||
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
|
||||
self._lora_scale = lora_scale
|
||||
|
||||
if prompt is not None and isinstance(prompt, str):
|
||||
batch_size = 1
|
||||
elif prompt is not None and isinstance(prompt, list):
|
||||
@@ -487,12 +477,17 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
self,
|
||||
prompt,
|
||||
image,
|
||||
height,
|
||||
width,
|
||||
callback_steps,
|
||||
negative_prompt=None,
|
||||
prompt_embeds=None,
|
||||
negative_prompt_embeds=None,
|
||||
controlnet_conditioning_scale=1.0,
|
||||
):
|
||||
if height % 8 != 0 or width % 8 != 0:
|
||||
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
|
||||
|
||||
if (callback_steps is None) or (
|
||||
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
|
||||
):
|
||||
@@ -597,26 +592,21 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
def check_image(self, image, prompt, prompt_embeds):
|
||||
image_is_pil = isinstance(image, PIL.Image.Image)
|
||||
image_is_tensor = isinstance(image, torch.Tensor)
|
||||
image_is_np = isinstance(image, np.ndarray)
|
||||
image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
|
||||
image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
|
||||
image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray)
|
||||
|
||||
if (
|
||||
not image_is_pil
|
||||
and not image_is_tensor
|
||||
and not image_is_np
|
||||
and not image_is_pil_list
|
||||
and not image_is_tensor_list
|
||||
and not image_is_np_list
|
||||
):
|
||||
if not image_is_pil and not image_is_tensor and not image_is_pil_list and not image_is_tensor_list:
|
||||
raise TypeError(
|
||||
"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors"
|
||||
"image must be passed and be one of PIL image, torch tensor, list of PIL images, or list of torch tensors"
|
||||
)
|
||||
|
||||
if image_is_pil:
|
||||
image_batch_size = 1
|
||||
else:
|
||||
elif image_is_tensor:
|
||||
image_batch_size = image.shape[0]
|
||||
elif image_is_pil_list:
|
||||
image_batch_size = len(image)
|
||||
elif image_is_tensor_list:
|
||||
image_batch_size = len(image)
|
||||
|
||||
if prompt is not None and isinstance(prompt, str):
|
||||
@@ -643,7 +633,29 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
do_classifier_free_guidance=False,
|
||||
guess_mode=False,
|
||||
):
|
||||
image = self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32)
|
||||
if not isinstance(image, torch.Tensor):
|
||||
if isinstance(image, PIL.Image.Image):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image[0], PIL.Image.Image):
|
||||
images = []
|
||||
|
||||
for image_ in image:
|
||||
image_ = image_.convert("RGB")
|
||||
image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
|
||||
image_ = np.array(image_)
|
||||
image_ = image_[None, :]
|
||||
images.append(image_)
|
||||
|
||||
image = images
|
||||
|
||||
image = np.concatenate(image, axis=0)
|
||||
image = np.array(image).astype(np.float32) / 255.0
|
||||
image = image.transpose(0, 3, 1, 2)
|
||||
image = torch.from_numpy(image)
|
||||
elif isinstance(image[0], torch.Tensor):
|
||||
image = torch.cat(image, dim=0)
|
||||
|
||||
image_batch_size = image.shape[0]
|
||||
|
||||
if image_batch_size == 1:
|
||||
@@ -679,6 +691,31 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def _default_height_width(self, height, width, image):
|
||||
# NOTE: It is possible that a list of images have different
|
||||
# dimensions for each image, so just checking the first image
|
||||
# is not _exactly_ correct, but it is simple.
|
||||
while isinstance(image, list):
|
||||
image = image[0]
|
||||
|
||||
if height is None:
|
||||
if isinstance(image, PIL.Image.Image):
|
||||
height = image.height
|
||||
elif isinstance(image, torch.Tensor):
|
||||
height = image.shape[2]
|
||||
|
||||
height = (height // 8) * 8 # round down to nearest multiple of 8
|
||||
|
||||
if width is None:
|
||||
if isinstance(image, PIL.Image.Image):
|
||||
width = image.width
|
||||
elif isinstance(image, torch.Tensor):
|
||||
width = image.shape[3]
|
||||
|
||||
width = (width // 8) * 8 # round down to nearest multiple of 8
|
||||
|
||||
return height, width
|
||||
|
||||
# override DiffusionPipeline
|
||||
def save_pretrained(
|
||||
self,
|
||||
@@ -696,14 +733,7 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
def __call__(
|
||||
self,
|
||||
prompt: Union[str, List[str]] = None,
|
||||
image: Union[
|
||||
torch.FloatTensor,
|
||||
PIL.Image.Image,
|
||||
np.ndarray,
|
||||
List[torch.FloatTensor],
|
||||
List[PIL.Image.Image],
|
||||
List[np.ndarray],
|
||||
] = None,
|
||||
image: Union[torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]] = None,
|
||||
height: Optional[int] = None,
|
||||
width: Optional[int] = None,
|
||||
num_inference_steps: int = 50,
|
||||
@@ -730,8 +760,8 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
|
||||
instead.
|
||||
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
|
||||
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
|
||||
image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`,
|
||||
`List[List[torch.FloatTensor]]`, or `List[List[PIL.Image.Image]]`):
|
||||
The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
|
||||
the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
|
||||
also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
|
||||
@@ -807,11 +837,15 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
|
||||
(nsfw) content, according to the `safety_checker`.
|
||||
"""
|
||||
# 0. Default height and width to unet
|
||||
height, width = self._default_height_width(height, width, image)
|
||||
|
||||
# 1. Check inputs. Raise error if not correct
|
||||
self.check_inputs(
|
||||
prompt,
|
||||
image,
|
||||
height,
|
||||
width,
|
||||
callback_steps,
|
||||
negative_prompt,
|
||||
prompt_embeds,
|
||||
@@ -846,9 +880,6 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
guess_mode = guess_mode or global_pool_conditions
|
||||
|
||||
# 3. Encode input prompt
|
||||
text_encoder_lora_scale = (
|
||||
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
|
||||
)
|
||||
prompt_embeds = self._encode_prompt(
|
||||
prompt,
|
||||
device,
|
||||
@@ -857,7 +888,6 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
negative_prompt,
|
||||
prompt_embeds=prompt_embeds,
|
||||
negative_prompt_embeds=negative_prompt_embeds,
|
||||
lora_scale=text_encoder_lora_scale,
|
||||
)
|
||||
|
||||
# 4. Prepare image
|
||||
@@ -873,7 +903,6 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
do_classifier_free_guidance=do_classifier_free_guidance,
|
||||
guess_mode=guess_mode,
|
||||
)
|
||||
height, width = image.shape[-2:]
|
||||
elif isinstance(controlnet, MultiControlNetModel):
|
||||
images = []
|
||||
|
||||
@@ -893,7 +922,6 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
images.append(image_)
|
||||
|
||||
image = images
|
||||
height, width = image[0].shape[-2:]
|
||||
else:
|
||||
assert False
|
||||
|
||||
@@ -928,15 +956,14 @@ class StableDiffusionControlNetPipeline(DiffusionPipeline, TextualInversionLoade
|
||||
# controlnet(s) inference
|
||||
if guess_mode and do_classifier_free_guidance:
|
||||
# Infer ControlNet only for the conditional batch.
|
||||
control_model_input = latents
|
||||
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
|
||||
controlnet_latent_model_input = latents
|
||||
controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
|
||||
else:
|
||||
control_model_input = latent_model_input
|
||||
controlnet_latent_model_input = latent_model_input
|
||||
controlnet_prompt_embeds = prompt_embeds
|
||||
|
||||
down_block_res_samples, mid_block_res_sample = self.controlnet(
|
||||
control_model_input,
|
||||
controlnet_latent_model_input,
|
||||
t,
|
||||
encoder_hidden_states=controlnet_prompt_embeds,
|
||||
controlnet_cond=image,
|
||||
|
||||
@@ -25,10 +25,11 @@ import torch.nn.functional as F
|
||||
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from ...image_processor import VaeImageProcessor
|
||||
from ...loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...loaders import TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, ControlNetModel, UNet2DConditionModel
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import (
|
||||
PIL_INTERPOLATION,
|
||||
deprecate,
|
||||
is_accelerate_available,
|
||||
is_accelerate_version,
|
||||
@@ -117,7 +118,7 @@ def prepare_image(image):
|
||||
return image
|
||||
|
||||
|
||||
class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin):
|
||||
class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
|
||||
r"""
|
||||
Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
|
||||
|
||||
@@ -197,10 +198,7 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversi
|
||||
feature_extractor=feature_extractor,
|
||||
)
|
||||
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
|
||||
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True)
|
||||
self.control_image_processor = VaeImageProcessor(
|
||||
vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False
|
||||
)
|
||||
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
|
||||
self.register_to_config(requires_safety_checker=requires_safety_checker)
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
|
||||
@@ -317,7 +315,6 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversi
|
||||
negative_prompt=None,
|
||||
prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
lora_scale: Optional[float] = None,
|
||||
):
|
||||
r"""
|
||||
Encodes the prompt into text encoder hidden states.
|
||||
@@ -342,14 +339,7 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversi
|
||||
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
|
||||
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
|
||||
argument.
|
||||
lora_scale (`float`, *optional*):
|
||||
A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
|
||||
"""
|
||||
# set lora scale so that monkey patched LoRA
|
||||
# function of text encoder can correctly access it
|
||||
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
|
||||
self._lora_scale = lora_scale
|
||||
|
||||
if prompt is not None and isinstance(prompt, str):
|
||||
batch_size = 1
|
||||
elif prompt is not None and isinstance(prompt, list):
|
||||
@@ -513,12 +503,17 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversi
|
||||
self,
|
||||
prompt,
|
||||
image,
|
||||
height,
|
||||
width,
|
||||
callback_steps,
|
||||
negative_prompt=None,
|
||||
prompt_embeds=None,
|
||||
negative_prompt_embeds=None,
|
||||
controlnet_conditioning_scale=1.0,
|
||||
):
|
||||
if height % 8 != 0 or width % 8 != 0:
|
||||
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
|
||||
|
||||
if (callback_steps is None) or (
|
||||
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
|
||||
):
|
||||
@@ -620,30 +615,24 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversi
|
||||
else:
|
||||
assert False
|
||||
|
||||
# Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.check_image
|
||||
def check_image(self, image, prompt, prompt_embeds):
|
||||
image_is_pil = isinstance(image, PIL.Image.Image)
|
||||
image_is_tensor = isinstance(image, torch.Tensor)
|
||||
image_is_np = isinstance(image, np.ndarray)
|
||||
image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
|
||||
image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
|
||||
image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray)
|
||||
|
||||
if (
|
||||
not image_is_pil
|
||||
and not image_is_tensor
|
||||
and not image_is_np
|
||||
and not image_is_pil_list
|
||||
and not image_is_tensor_list
|
||||
and not image_is_np_list
|
||||
):
|
||||
if not image_is_pil and not image_is_tensor and not image_is_pil_list and not image_is_tensor_list:
|
||||
raise TypeError(
|
||||
"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors"
|
||||
"image must be passed and be one of PIL image, torch tensor, list of PIL images, or list of torch tensors"
|
||||
)
|
||||
|
||||
if image_is_pil:
|
||||
image_batch_size = 1
|
||||
else:
|
||||
elif image_is_tensor:
|
||||
image_batch_size = image.shape[0]
|
||||
elif image_is_pil_list:
|
||||
image_batch_size = len(image)
|
||||
elif image_is_tensor_list:
|
||||
image_batch_size = len(image)
|
||||
|
||||
if prompt is not None and isinstance(prompt, str):
|
||||
@@ -671,7 +660,29 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversi
|
||||
do_classifier_free_guidance=False,
|
||||
guess_mode=False,
|
||||
):
|
||||
image = self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32)
|
||||
if not isinstance(image, torch.Tensor):
|
||||
if isinstance(image, PIL.Image.Image):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image[0], PIL.Image.Image):
|
||||
images = []
|
||||
|
||||
for image_ in image:
|
||||
image_ = image_.convert("RGB")
|
||||
image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
|
||||
image_ = np.array(image_)
|
||||
image_ = image_[None, :]
|
||||
images.append(image_)
|
||||
|
||||
image = images
|
||||
|
||||
image = np.concatenate(image, axis=0)
|
||||
image = np.array(image).astype(np.float32) / 255.0
|
||||
image = image.transpose(0, 3, 1, 2)
|
||||
image = torch.from_numpy(image)
|
||||
elif isinstance(image[0], torch.Tensor):
|
||||
image = torch.cat(image, dim=0)
|
||||
|
||||
image_batch_size = image.shape[0]
|
||||
|
||||
if image_batch_size == 1:
|
||||
@@ -709,26 +720,21 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversi
|
||||
image = image.to(device=device, dtype=dtype)
|
||||
|
||||
batch_size = batch_size * num_images_per_prompt
|
||||
if isinstance(generator, list) and len(generator) != batch_size:
|
||||
raise ValueError(
|
||||
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
||||
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
||||
)
|
||||
|
||||
if image.shape[1] == 4:
|
||||
init_latents = image
|
||||
|
||||
if isinstance(generator, list):
|
||||
init_latents = [
|
||||
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
|
||||
]
|
||||
init_latents = torch.cat(init_latents, dim=0)
|
||||
else:
|
||||
if isinstance(generator, list) and len(generator) != batch_size:
|
||||
raise ValueError(
|
||||
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
||||
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
||||
)
|
||||
init_latents = self.vae.encode(image).latent_dist.sample(generator)
|
||||
|
||||
elif isinstance(generator, list):
|
||||
init_latents = [
|
||||
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
|
||||
]
|
||||
init_latents = torch.cat(init_latents, dim=0)
|
||||
else:
|
||||
init_latents = self.vae.encode(image).latent_dist.sample(generator)
|
||||
|
||||
init_latents = self.vae.config.scaling_factor * init_latents
|
||||
init_latents = self.vae.config.scaling_factor * init_latents
|
||||
|
||||
if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
|
||||
# expand init_latents for batch_size
|
||||
@@ -757,6 +763,31 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversi
|
||||
|
||||
return latents
|
||||
|
||||
def _default_height_width(self, height, width, image):
|
||||
# NOTE: It is possible that a list of images have different
|
||||
# dimensions for each image, so just checking the first image
|
||||
# is not _exactly_ correct, but it is simple.
|
||||
while isinstance(image, list):
|
||||
image = image[0]
|
||||
|
||||
if height is None:
|
||||
if isinstance(image, PIL.Image.Image):
|
||||
height = image.height
|
||||
elif isinstance(image, torch.Tensor):
|
||||
height = image.shape[2]
|
||||
|
||||
height = (height // 8) * 8 # round down to nearest multiple of 8
|
||||
|
||||
if width is None:
|
||||
if isinstance(image, PIL.Image.Image):
|
||||
width = image.width
|
||||
elif isinstance(image, torch.Tensor):
|
||||
width = image.shape[3]
|
||||
|
||||
width = (width // 8) * 8 # round down to nearest multiple of 8
|
||||
|
||||
return height, width
|
||||
|
||||
# override DiffusionPipeline
|
||||
def save_pretrained(
|
||||
self,
|
||||
@@ -774,21 +805,9 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversi
|
||||
def __call__(
|
||||
self,
|
||||
prompt: Union[str, List[str]] = None,
|
||||
image: Union[
|
||||
torch.FloatTensor,
|
||||
PIL.Image.Image,
|
||||
np.ndarray,
|
||||
List[torch.FloatTensor],
|
||||
List[PIL.Image.Image],
|
||||
List[np.ndarray],
|
||||
] = None,
|
||||
image: Union[torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]] = None,
|
||||
control_image: Union[
|
||||
torch.FloatTensor,
|
||||
PIL.Image.Image,
|
||||
np.ndarray,
|
||||
List[torch.FloatTensor],
|
||||
List[PIL.Image.Image],
|
||||
List[np.ndarray],
|
||||
torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]
|
||||
] = None,
|
||||
height: Optional[int] = None,
|
||||
width: Optional[int] = None,
|
||||
@@ -817,12 +836,8 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversi
|
||||
prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
|
||||
instead.
|
||||
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
|
||||
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
|
||||
The initial image will be used as the starting point for the image generation process. Can also accpet
|
||||
image latents as `image`, if passing latents directly, it will not be encoded again.
|
||||
control_image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, `List[np.ndarray]`,:
|
||||
`List[List[torch.FloatTensor]]`, `List[List[np.ndarray]]` or `List[List[PIL.Image.Image]]`):
|
||||
image (`torch.FloatTensor`, `PIL.Image.Image`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`,
|
||||
`List[List[torch.FloatTensor]]`, or `List[List[PIL.Image.Image]]`):
|
||||
The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If
|
||||
the type is specified as `Torch.FloatTensor`, it is passed to ControlNet as is. `PIL.Image.Image` can
|
||||
also be accepted as an image. The dimensions of the output image defaults to `image`'s dimensions. If
|
||||
@@ -899,10 +914,15 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversi
|
||||
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
|
||||
(nsfw) content, according to the `safety_checker`.
|
||||
"""
|
||||
# 0. Default height and width to unet
|
||||
height, width = self._default_height_width(height, width, image)
|
||||
|
||||
# 1. Check inputs. Raise error if not correct
|
||||
self.check_inputs(
|
||||
prompt,
|
||||
control_image,
|
||||
height,
|
||||
width,
|
||||
callback_steps,
|
||||
negative_prompt,
|
||||
prompt_embeds,
|
||||
@@ -937,9 +957,6 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversi
|
||||
guess_mode = guess_mode or global_pool_conditions
|
||||
|
||||
# 3. Encode input prompt
|
||||
text_encoder_lora_scale = (
|
||||
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
|
||||
)
|
||||
prompt_embeds = self._encode_prompt(
|
||||
prompt,
|
||||
device,
|
||||
@@ -948,12 +965,11 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversi
|
||||
negative_prompt,
|
||||
prompt_embeds=prompt_embeds,
|
||||
negative_prompt_embeds=negative_prompt_embeds,
|
||||
lora_scale=text_encoder_lora_scale,
|
||||
)
|
||||
# 4. Prepare image
|
||||
image = self.image_processor.preprocess(image).to(dtype=torch.float32)
|
||||
# 4. Prepare image, and controlnet_conditioning_image
|
||||
image = prepare_image(image)
|
||||
|
||||
# 5. Prepare controlnet_conditioning_image
|
||||
# 5. Prepare image
|
||||
if isinstance(controlnet, ControlNetModel):
|
||||
control_image = self.prepare_control_image(
|
||||
image=control_image,
|
||||
@@ -1018,15 +1034,14 @@ class StableDiffusionControlNetImg2ImgPipeline(DiffusionPipeline, TextualInversi
|
||||
# controlnet(s) inference
|
||||
if guess_mode and do_classifier_free_guidance:
|
||||
# Infer ControlNet only for the conditional batch.
|
||||
control_model_input = latents
|
||||
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
|
||||
controlnet_latent_model_input = latents
|
||||
controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
|
||||
else:
|
||||
control_model_input = latent_model_input
|
||||
controlnet_latent_model_input = latent_model_input
|
||||
controlnet_prompt_embeds = prompt_embeds
|
||||
|
||||
down_block_res_samples, mid_block_res_sample = self.controlnet(
|
||||
control_model_input,
|
||||
controlnet_latent_model_input,
|
||||
t,
|
||||
encoder_hidden_states=controlnet_prompt_embeds,
|
||||
controlnet_cond=control_image,
|
||||
|
||||
@@ -26,10 +26,11 @@ import torch.nn.functional as F
|
||||
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from ...image_processor import VaeImageProcessor
|
||||
from ...loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...loaders import TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, ControlNetModel, UNet2DConditionModel
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import (
|
||||
PIL_INTERPOLATION,
|
||||
is_accelerate_available,
|
||||
is_accelerate_version,
|
||||
is_compiled_module,
|
||||
@@ -49,57 +50,49 @@ logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
EXAMPLE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> # !pip install transformers accelerate
|
||||
>>> from diffusers import StableDiffusionControlNetInpaintPipeline, ControlNetModel, DDIMScheduler
|
||||
>>> # !pip install opencv-python transformers accelerate
|
||||
>>> from diffusers import StableDiffusionControlNetInpaintPipeline, ControlNetModel, UniPCMultistepScheduler
|
||||
>>> from diffusers.utils import load_image
|
||||
>>> import numpy as np
|
||||
>>> import torch
|
||||
|
||||
>>> init_image = load_image(
|
||||
... "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main/stable_diffusion_inpaint/boy.png"
|
||||
... )
|
||||
>>> init_image = init_image.resize((512, 512))
|
||||
>>> import cv2
|
||||
>>> from PIL import Image
|
||||
|
||||
>>> generator = torch.Generator(device="cpu").manual_seed(1)
|
||||
>>> img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
|
||||
>>> mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
|
||||
|
||||
>>> mask_image = load_image(
|
||||
... "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main/stable_diffusion_inpaint/boy_mask.png"
|
||||
... )
|
||||
>>> mask_image = mask_image.resize((512, 512))
|
||||
>>> init_image = load_image(img_url).resize((512, 512))
|
||||
>>> mask_image = load_image(mask_url).resize((512, 512))
|
||||
|
||||
>>> image = np.array(init_image)
|
||||
|
||||
>>> def make_inpaint_condition(image, image_mask):
|
||||
... image = np.array(image.convert("RGB")).astype(np.float32) / 255.0
|
||||
... image_mask = np.array(image_mask.convert("L")).astype(np.float32) / 255.0
|
||||
>>> # get canny image
|
||||
>>> image = cv2.Canny(image, 100, 200)
|
||||
>>> image = image[:, :, None]
|
||||
>>> image = np.concatenate([image, image, image], axis=2)
|
||||
>>> canny_image = Image.fromarray(image)
|
||||
|
||||
... assert image.shape[0:1] == image_mask.shape[0:1], "image and image_mask must have the same image size"
|
||||
... image[image_mask > 0.5] = -1.0 # set as masked pixel
|
||||
... image = np.expand_dims(image, 0).transpose(0, 3, 1, 2)
|
||||
... image = torch.from_numpy(image)
|
||||
... return image
|
||||
|
||||
|
||||
>>> control_image = make_inpaint_condition(init_image, mask_image)
|
||||
|
||||
>>> controlnet = ControlNetModel.from_pretrained(
|
||||
... "lllyasviel/control_v11p_sd15_inpaint", torch_dtype=torch.float16
|
||||
... )
|
||||
>>> # load control net and stable diffusion inpainting
|
||||
>>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
|
||||
>>> pipe = StableDiffusionControlNetInpaintPipeline.from_pretrained(
|
||||
... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
|
||||
... "runwayml/stable-diffusion-inpainting", controlnet=controlnet, torch_dtype=torch.float16
|
||||
... )
|
||||
|
||||
>>> pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
|
||||
>>> # speed up diffusion process with faster scheduler and memory optimization
|
||||
>>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
|
||||
|
||||
>>> pipe.enable_model_cpu_offload()
|
||||
|
||||
>>> # generate image
|
||||
>>> generator = torch.manual_seed(0)
|
||||
>>> image = pipe(
|
||||
... "a handsome man with ray-ban sunglasses",
|
||||
... num_inference_steps=20,
|
||||
... "spiderman",
|
||||
... num_inference_steps=30,
|
||||
... generator=generator,
|
||||
... eta=1.0,
|
||||
... image=init_image,
|
||||
... mask_image=mask_image,
|
||||
... control_image=control_image,
|
||||
... control_image=canny_image,
|
||||
... ).images[0]
|
||||
```
|
||||
"""
|
||||
@@ -223,7 +216,7 @@ def prepare_mask_and_masked_image(image, mask, height, width, return_image=False
|
||||
return mask, masked_image
|
||||
|
||||
|
||||
class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin):
|
||||
class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversionLoaderMixin):
|
||||
r"""
|
||||
Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
|
||||
|
||||
@@ -233,17 +226,6 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
In addition the pipeline inherits the following loading methods:
|
||||
- *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`]
|
||||
|
||||
<Tip>
|
||||
|
||||
This pipeline can be used both with checkpoints that have been specifically fine-tuned for inpainting, such as
|
||||
[runwayml/stable-diffusion-inpainting](https://huggingface.co/runwayml/stable-diffusion-inpainting)
|
||||
as well as default text-to-image stable diffusion checkpoints, such as
|
||||
[runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5).
|
||||
Default text-to-image stable diffusion checkpoints might be preferable for controlnets that have been fine-tuned on
|
||||
those, such as [lllyasviel/control_v11p_sd15_inpaint](https://huggingface.co/lllyasviel/control_v11p_sd15_inpaint).
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
vae ([`AutoencoderKL`]):
|
||||
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
|
||||
@@ -315,9 +297,6 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
)
|
||||
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
|
||||
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
|
||||
self.control_image_processor = VaeImageProcessor(
|
||||
vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False
|
||||
)
|
||||
self.register_to_config(requires_safety_checker=requires_safety_checker)
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.enable_vae_slicing
|
||||
@@ -434,7 +413,6 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
negative_prompt=None,
|
||||
prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
lora_scale: Optional[float] = None,
|
||||
):
|
||||
r"""
|
||||
Encodes the prompt into text encoder hidden states.
|
||||
@@ -459,14 +437,7 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
|
||||
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
|
||||
argument.
|
||||
lora_scale (`float`, *optional*):
|
||||
A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
|
||||
"""
|
||||
# set lora scale so that monkey patched LoRA
|
||||
# function of text encoder can correctly access it
|
||||
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
|
||||
self._lora_scale = lora_scale
|
||||
|
||||
if prompt is not None and isinstance(prompt, str):
|
||||
batch_size = 1
|
||||
elif prompt is not None and isinstance(prompt, list):
|
||||
@@ -626,16 +597,6 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
extra_step_kwargs["generator"] = generator
|
||||
return extra_step_kwargs
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.get_timesteps
|
||||
def get_timesteps(self, num_inference_steps, strength, device):
|
||||
# get the original timestep using init_timestep
|
||||
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
|
||||
|
||||
t_start = max(num_inference_steps - init_timestep, 0)
|
||||
timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
|
||||
|
||||
return timesteps, num_inference_steps - t_start
|
||||
|
||||
def check_inputs(
|
||||
self,
|
||||
prompt,
|
||||
@@ -752,30 +713,24 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
else:
|
||||
assert False
|
||||
|
||||
# Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.check_image
|
||||
def check_image(self, image, prompt, prompt_embeds):
|
||||
image_is_pil = isinstance(image, PIL.Image.Image)
|
||||
image_is_tensor = isinstance(image, torch.Tensor)
|
||||
image_is_np = isinstance(image, np.ndarray)
|
||||
image_is_pil_list = isinstance(image, list) and isinstance(image[0], PIL.Image.Image)
|
||||
image_is_tensor_list = isinstance(image, list) and isinstance(image[0], torch.Tensor)
|
||||
image_is_np_list = isinstance(image, list) and isinstance(image[0], np.ndarray)
|
||||
|
||||
if (
|
||||
not image_is_pil
|
||||
and not image_is_tensor
|
||||
and not image_is_np
|
||||
and not image_is_pil_list
|
||||
and not image_is_tensor_list
|
||||
and not image_is_np_list
|
||||
):
|
||||
if not image_is_pil and not image_is_tensor and not image_is_pil_list and not image_is_tensor_list:
|
||||
raise TypeError(
|
||||
"image must be passed and be one of PIL image, numpy array, torch tensor, list of PIL images, list of numpy arrays or list of torch tensors"
|
||||
"image must be passed and be one of PIL image, torch tensor, list of PIL images, or list of torch tensors"
|
||||
)
|
||||
|
||||
if image_is_pil:
|
||||
image_batch_size = 1
|
||||
else:
|
||||
elif image_is_tensor:
|
||||
image_batch_size = image.shape[0]
|
||||
elif image_is_pil_list:
|
||||
image_batch_size = len(image)
|
||||
elif image_is_tensor_list:
|
||||
image_batch_size = len(image)
|
||||
|
||||
if prompt is not None and isinstance(prompt, str):
|
||||
@@ -803,7 +758,29 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
do_classifier_free_guidance=False,
|
||||
guess_mode=False,
|
||||
):
|
||||
image = self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32)
|
||||
if not isinstance(image, torch.Tensor):
|
||||
if isinstance(image, PIL.Image.Image):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image[0], PIL.Image.Image):
|
||||
images = []
|
||||
|
||||
for image_ in image:
|
||||
image_ = image_.convert("RGB")
|
||||
image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
|
||||
image_ = np.array(image_)
|
||||
image_ = image_[None, :]
|
||||
images.append(image_)
|
||||
|
||||
image = images
|
||||
|
||||
image = np.concatenate(image, axis=0)
|
||||
image = np.array(image).astype(np.float32) / 255.0
|
||||
image = image.transpose(0, 3, 1, 2)
|
||||
image = torch.from_numpy(image)
|
||||
elif isinstance(image[0], torch.Tensor):
|
||||
image = torch.cat(image, dim=0)
|
||||
|
||||
image_batch_size = image.shape[0]
|
||||
|
||||
if image_batch_size == 1:
|
||||
@@ -835,8 +812,6 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
image=None,
|
||||
timestep=None,
|
||||
is_strength_max=True,
|
||||
return_noise=False,
|
||||
return_image_latents=False,
|
||||
):
|
||||
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
|
||||
if isinstance(generator, list) and len(generator) != batch_size:
|
||||
@@ -851,29 +826,32 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
"However, either the image or the noise timestep has not been provided."
|
||||
)
|
||||
|
||||
if return_image_latents or (latents is None and not is_strength_max):
|
||||
image = image.to(device=device, dtype=dtype)
|
||||
image_latents = self._encode_vae_image(image=image, generator=generator)
|
||||
|
||||
if latents is None:
|
||||
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
# if strength is 1. then initialise the latents to noise, else initial to image + noise
|
||||
latents = noise if is_strength_max else self.scheduler.add_noise(image_latents, noise, timestep)
|
||||
# if pure noise then scale the initial latents by the Scheduler's init sigma
|
||||
latents = latents * self.scheduler.init_noise_sigma if is_strength_max else latents
|
||||
if is_strength_max:
|
||||
# if strength is 100% then simply initialise the latents to noise
|
||||
latents = noise
|
||||
else:
|
||||
# otherwise initialise latents as init image + noise
|
||||
image = image.to(device=device, dtype=dtype)
|
||||
if isinstance(generator, list):
|
||||
image_latents = [
|
||||
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator=generator[i])
|
||||
for i in range(batch_size)
|
||||
]
|
||||
else:
|
||||
image_latents = self.vae.encode(image).latent_dist.sample(generator=generator)
|
||||
|
||||
image_latents = self.vae.config.scaling_factor * image_latents
|
||||
|
||||
latents = self.scheduler.add_noise(image_latents, noise, timestep)
|
||||
else:
|
||||
noise = latents.to(device)
|
||||
latents = noise * self.scheduler.init_noise_sigma
|
||||
latents = latents.to(device)
|
||||
|
||||
outputs = (latents,)
|
||||
# scale the initial noise by the standard deviation required by the scheduler
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
|
||||
if return_noise:
|
||||
outputs += (noise,)
|
||||
|
||||
if return_image_latents:
|
||||
outputs += (image_latents,)
|
||||
|
||||
return outputs
|
||||
return latents
|
||||
|
||||
def _default_height_width(self, height, width, image):
|
||||
# NOTE: It is possible that a list of images have different
|
||||
@@ -913,7 +891,17 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
mask = mask.to(device=device, dtype=dtype)
|
||||
|
||||
masked_image = masked_image.to(device=device, dtype=dtype)
|
||||
masked_image_latents = self._encode_vae_image(masked_image, generator=generator)
|
||||
|
||||
# encode the mask image into latents space so we can concatenate it to the latents
|
||||
if isinstance(generator, list):
|
||||
masked_image_latents = [
|
||||
self.vae.encode(masked_image[i : i + 1]).latent_dist.sample(generator=generator[i])
|
||||
for i in range(batch_size)
|
||||
]
|
||||
masked_image_latents = torch.cat(masked_image_latents, dim=0)
|
||||
else:
|
||||
masked_image_latents = self.vae.encode(masked_image).latent_dist.sample(generator=generator)
|
||||
masked_image_latents = self.vae.config.scaling_factor * masked_image_latents
|
||||
|
||||
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
|
||||
if mask.shape[0] < batch_size:
|
||||
@@ -942,21 +930,6 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
|
||||
return mask, masked_image_latents
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint.StableDiffusionInpaintPipeline._encode_vae_image
|
||||
def _encode_vae_image(self, image: torch.Tensor, generator: torch.Generator):
|
||||
if isinstance(generator, list):
|
||||
image_latents = [
|
||||
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator=generator[i])
|
||||
for i in range(image.shape[0])
|
||||
]
|
||||
image_latents = torch.cat(image_latents, dim=0)
|
||||
else:
|
||||
image_latents = self.vae.encode(image).latent_dist.sample(generator=generator)
|
||||
|
||||
image_latents = self.vae.config.scaling_factor * image_latents
|
||||
|
||||
return image_latents
|
||||
|
||||
# override DiffusionPipeline
|
||||
def save_pretrained(
|
||||
self,
|
||||
@@ -977,16 +950,10 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
image: Union[torch.Tensor, PIL.Image.Image] = None,
|
||||
mask_image: Union[torch.Tensor, PIL.Image.Image] = None,
|
||||
control_image: Union[
|
||||
torch.FloatTensor,
|
||||
PIL.Image.Image,
|
||||
np.ndarray,
|
||||
List[torch.FloatTensor],
|
||||
List[PIL.Image.Image],
|
||||
List[np.ndarray],
|
||||
torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]
|
||||
] = None,
|
||||
height: Optional[int] = None,
|
||||
width: Optional[int] = None,
|
||||
strength: float = 1.0,
|
||||
num_inference_steps: int = 50,
|
||||
guidance_scale: float = 7.5,
|
||||
negative_prompt: Optional[Union[str, List[str]]] = None,
|
||||
@@ -1023,13 +990,6 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
The height in pixels of the generated image.
|
||||
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
|
||||
The width in pixels of the generated image.
|
||||
strength (`float`, *optional*, defaults to 1.):
|
||||
Conceptually, indicates how much to transform the masked portion of the reference `image`. Must be
|
||||
between 0 and 1. `image` will be used as a starting point, adding more noise to it the larger the
|
||||
`strength`. The number of denoising steps depends on the amount of noise initially added. When
|
||||
`strength` is 1, added noise will be maximum and the denoising process will run for the full number of
|
||||
iterations specified in `num_inference_steps`. A value of 1, therefore, essentially ignores the masked
|
||||
portion of the reference `image`.
|
||||
num_inference_steps (`int`, *optional*, defaults to 50):
|
||||
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
||||
expense of slower inference.
|
||||
@@ -1139,9 +1099,6 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
guess_mode = guess_mode or global_pool_conditions
|
||||
|
||||
# 3. Encode input prompt
|
||||
text_encoder_lora_scale = (
|
||||
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
|
||||
)
|
||||
prompt_embeds = self._encode_prompt(
|
||||
prompt,
|
||||
device,
|
||||
@@ -1150,7 +1107,6 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
negative_prompt,
|
||||
prompt_embeds=prompt_embeds,
|
||||
negative_prompt_embeds=negative_prompt_embeds,
|
||||
lora_scale=text_encoder_lora_scale,
|
||||
)
|
||||
|
||||
# 4. Prepare image
|
||||
@@ -1189,25 +1145,13 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
assert False
|
||||
|
||||
# 4. Preprocess mask and image - resizes image and mask w.r.t height and width
|
||||
mask, masked_image, init_image = prepare_mask_and_masked_image(
|
||||
image, mask_image, height, width, return_image=True
|
||||
)
|
||||
|
||||
# 5. Prepare timesteps
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
timesteps, num_inference_steps = self.get_timesteps(
|
||||
num_inference_steps=num_inference_steps, strength=strength, device=device
|
||||
)
|
||||
# at which timestep to set the initial noise (n.b. 50% if strength is 0.5)
|
||||
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
|
||||
# create a boolean to check if the strength is set to 1. if so then initialise the latents with pure noise
|
||||
is_strength_max = strength == 1.0
|
||||
timesteps = self.scheduler.timesteps
|
||||
|
||||
# 6. Prepare latent variables
|
||||
num_channels_latents = self.vae.config.latent_channels
|
||||
num_channels_unet = self.unet.config.in_channels
|
||||
return_image_latents = num_channels_unet == 4
|
||||
latents_outputs = self.prepare_latents(
|
||||
latents = self.prepare_latents(
|
||||
batch_size * num_images_per_prompt,
|
||||
num_channels_latents,
|
||||
height,
|
||||
@@ -1216,19 +1160,10 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
device,
|
||||
generator,
|
||||
latents,
|
||||
image=init_image,
|
||||
timestep=latent_timestep,
|
||||
is_strength_max=is_strength_max,
|
||||
return_noise=True,
|
||||
return_image_latents=return_image_latents,
|
||||
)
|
||||
|
||||
if return_image_latents:
|
||||
latents, noise, image_latents = latents_outputs
|
||||
else:
|
||||
latents, noise = latents_outputs
|
||||
|
||||
# 7. Prepare mask latent variables
|
||||
mask, masked_image = prepare_mask_and_masked_image(image, mask_image, height, width)
|
||||
mask, masked_image_latents = self.prepare_mask_latents(
|
||||
mask,
|
||||
masked_image,
|
||||
@@ -1252,18 +1187,16 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
||||
|
||||
# controlnet(s) inference
|
||||
if guess_mode and do_classifier_free_guidance:
|
||||
# Infer ControlNet only for the conditional batch.
|
||||
control_model_input = latents
|
||||
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
|
||||
controlnet_latent_model_input = latents
|
||||
controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
|
||||
else:
|
||||
control_model_input = latent_model_input
|
||||
controlnet_latent_model_input = latent_model_input
|
||||
controlnet_prompt_embeds = prompt_embeds
|
||||
|
||||
down_block_res_samples, mid_block_res_sample = self.controlnet(
|
||||
control_model_input,
|
||||
controlnet_latent_model_input,
|
||||
t,
|
||||
encoder_hidden_states=controlnet_prompt_embeds,
|
||||
controlnet_cond=control_image,
|
||||
@@ -1280,9 +1213,7 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
|
||||
|
||||
# predict the noise residual
|
||||
if num_channels_unet == 9:
|
||||
latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
|
||||
|
||||
latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
|
||||
noise_pred = self.unet(
|
||||
latent_model_input,
|
||||
t,
|
||||
@@ -1301,15 +1232,6 @@ class StableDiffusionControlNetInpaintPipeline(DiffusionPipeline, TextualInversi
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
|
||||
|
||||
if num_channels_unet == 4:
|
||||
init_latents_proper = image_latents[:1]
|
||||
init_mask = mask[:1]
|
||||
|
||||
if i < len(timesteps) - 1:
|
||||
init_latents_proper = self.scheduler.add_noise(init_latents_proper, noise, torch.tensor([t]))
|
||||
|
||||
latents = (1 - init_mask) * init_latents_proper + init_mask * latents
|
||||
|
||||
# call the callback, if provided
|
||||
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
||||
progress_bar.update()
|
||||
|
||||
@@ -10,7 +10,6 @@ import torch
|
||||
import torch.nn.functional as F
|
||||
from transformers import CLIPImageProcessor, T5EncoderModel, T5Tokenizer
|
||||
|
||||
from ...loaders import LoraLoaderMixin
|
||||
from ...models import UNet2DConditionModel
|
||||
from ...schedulers import DDPMScheduler
|
||||
from ...utils import (
|
||||
@@ -113,7 +112,7 @@ EXAMPLE_DOC_STRING = """
|
||||
"""
|
||||
|
||||
|
||||
class IFImg2ImgSuperResolutionPipeline(DiffusionPipeline, LoraLoaderMixin):
|
||||
class IFImg2ImgSuperResolutionPipeline(DiffusionPipeline):
|
||||
tokenizer: T5Tokenizer
|
||||
text_encoder: T5EncoderModel
|
||||
|
||||
@@ -760,7 +759,7 @@ class IFImg2ImgSuperResolutionPipeline(DiffusionPipeline, LoraLoaderMixin):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image[0], PIL.Image.Image):
|
||||
image = [np.array(i).astype(np.float32) / 127.5 - 1.0 for i in image]
|
||||
image = [np.array(i).astype(np.float32) / 255.0 for i in image]
|
||||
|
||||
image = np.stack(image, axis=0) # to np
|
||||
image = torch.from_numpy(image.transpose(0, 3, 1, 2))
|
||||
@@ -1048,9 +1047,6 @@ class IFImg2ImgSuperResolutionPipeline(DiffusionPipeline, LoraLoaderMixin):
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
noise_pred = torch.cat([noise_pred, predicted_variance], dim=1)
|
||||
|
||||
if self.scheduler.config.variance_type not in ["learned", "learned_range"]:
|
||||
noise_pred, _ = noise_pred.split(intermediate_images.shape[1], dim=1)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
intermediate_images = self.scheduler.step(
|
||||
noise_pred, t, intermediate_images, **extra_step_kwargs, return_dict=False
|
||||
|
||||
@@ -10,7 +10,6 @@ import torch
|
||||
import torch.nn.functional as F
|
||||
from transformers import CLIPImageProcessor, T5EncoderModel, T5Tokenizer
|
||||
|
||||
from ...loaders import LoraLoaderMixin
|
||||
from ...models import UNet2DConditionModel
|
||||
from ...schedulers import DDPMScheduler
|
||||
from ...utils import (
|
||||
@@ -115,7 +114,7 @@ EXAMPLE_DOC_STRING = """
|
||||
"""
|
||||
|
||||
|
||||
class IFInpaintingSuperResolutionPipeline(DiffusionPipeline, LoraLoaderMixin):
|
||||
class IFInpaintingSuperResolutionPipeline(DiffusionPipeline):
|
||||
tokenizer: T5Tokenizer
|
||||
text_encoder: T5EncoderModel
|
||||
|
||||
@@ -796,7 +795,7 @@ class IFInpaintingSuperResolutionPipeline(DiffusionPipeline, LoraLoaderMixin):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image[0], PIL.Image.Image):
|
||||
image = [np.array(i).astype(np.float32) / 127.5 - 1.0 for i in image]
|
||||
image = [np.array(i).astype(np.float32) / 255.0 for i in image]
|
||||
|
||||
image = np.stack(image, axis=0) # to np
|
||||
image = torch.from_numpy(image.transpose(0, 3, 1, 2))
|
||||
@@ -1155,9 +1154,6 @@ class IFInpaintingSuperResolutionPipeline(DiffusionPipeline, LoraLoaderMixin):
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
noise_pred = torch.cat([noise_pred, predicted_variance], dim=1)
|
||||
|
||||
if self.scheduler.config.variance_type not in ["learned", "learned_range"]:
|
||||
noise_pred, _ = noise_pred.split(intermediate_images.shape[1], dim=1)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
prev_intermediate_images = intermediate_images
|
||||
|
||||
|
||||
@@ -10,7 +10,6 @@ import torch
|
||||
import torch.nn.functional as F
|
||||
from transformers import CLIPImageProcessor, T5EncoderModel, T5Tokenizer
|
||||
|
||||
from ...loaders import LoraLoaderMixin
|
||||
from ...models import UNet2DConditionModel
|
||||
from ...schedulers import DDPMScheduler
|
||||
from ...utils import (
|
||||
@@ -71,7 +70,7 @@ EXAMPLE_DOC_STRING = """
|
||||
"""
|
||||
|
||||
|
||||
class IFSuperResolutionPipeline(DiffusionPipeline, LoraLoaderMixin):
|
||||
class IFSuperResolutionPipeline(DiffusionPipeline):
|
||||
tokenizer: T5Tokenizer
|
||||
text_encoder: T5EncoderModel
|
||||
|
||||
@@ -665,7 +664,7 @@ class IFSuperResolutionPipeline(DiffusionPipeline, LoraLoaderMixin):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image[0], PIL.Image.Image):
|
||||
image = [np.array(i).astype(np.float32) / 127.5 - 1.0 for i in image]
|
||||
image = [np.array(i).astype(np.float32) / 255.0 for i in image]
|
||||
|
||||
image = np.stack(image, axis=0) # to np
|
||||
image = torch.from_numpy(image.transpose(0, 3, 1, 2))
|
||||
@@ -904,9 +903,6 @@ class IFSuperResolutionPipeline(DiffusionPipeline, LoraLoaderMixin):
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
noise_pred = torch.cat([noise_pred, predicted_variance], dim=1)
|
||||
|
||||
if self.scheduler.config.variance_type not in ["learned", "learned_range"]:
|
||||
noise_pred, _ = noise_pred.split(intermediate_images.shape[1], dim=1)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
intermediate_images = self.scheduler.step(
|
||||
noise_pred, t, intermediate_images, **extra_step_kwargs, return_dict=False
|
||||
|
||||
@@ -1,19 +0,0 @@
|
||||
from ...utils import (
|
||||
OptionalDependencyNotAvailable,
|
||||
is_torch_available,
|
||||
is_transformers_available,
|
||||
is_transformers_version,
|
||||
)
|
||||
|
||||
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils.dummy_torch_and_transformers_objects import KandinskyPipeline, KandinskyPriorPipeline
|
||||
else:
|
||||
from .pipeline_kandinsky import KandinskyPipeline
|
||||
from .pipeline_kandinsky_img2img import KandinskyImg2ImgPipeline
|
||||
from .pipeline_kandinsky_inpaint import KandinskyInpaintPipeline
|
||||
from .pipeline_kandinsky_prior import KandinskyPriorPipeline
|
||||
from .text_encoder import MultilingualCLIP
|
||||
@@ -1,464 +0,0 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import torch
|
||||
from transformers import (
|
||||
XLMRobertaTokenizer,
|
||||
)
|
||||
|
||||
from ...models import UNet2DConditionModel, VQModel
|
||||
from ...pipelines import DiffusionPipeline
|
||||
from ...pipelines.pipeline_utils import ImagePipelineOutput
|
||||
from ...schedulers import DDIMScheduler
|
||||
from ...utils import (
|
||||
is_accelerate_available,
|
||||
is_accelerate_version,
|
||||
logging,
|
||||
randn_tensor,
|
||||
replace_example_docstring,
|
||||
)
|
||||
from .text_encoder import MultilingualCLIP
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
EXAMPLE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> from diffusers import KandinskyPipeline, KandinskyPriorPipeline
|
||||
>>> import torch
|
||||
|
||||
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained("kandinsky-community/Kandinsky-2-1-prior")
|
||||
>>> pipe_prior.to("cuda")
|
||||
|
||||
>>> prompt = "red cat, 4k photo"
|
||||
>>> out = pipe_prior(prompt)
|
||||
>>> image_emb = out.image_embeds
|
||||
>>> negative_image_emb = out.negative_image_embeds
|
||||
|
||||
>>> pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1")
|
||||
>>> pipe.to("cuda")
|
||||
|
||||
>>> image = pipe(
|
||||
... prompt,
|
||||
... image_embeds=image_emb,
|
||||
... negative_image_embeds=negative_image_emb,
|
||||
... height=768,
|
||||
... width=768,
|
||||
... num_inference_steps=100,
|
||||
... ).images
|
||||
|
||||
>>> image[0].save("cat.png")
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
def get_new_h_w(h, w, scale_factor=8):
|
||||
new_h = h // scale_factor**2
|
||||
if h % scale_factor**2 != 0:
|
||||
new_h += 1
|
||||
new_w = w // scale_factor**2
|
||||
if w % scale_factor**2 != 0:
|
||||
new_w += 1
|
||||
return new_h * scale_factor, new_w * scale_factor
|
||||
|
||||
|
||||
class KandinskyPipeline(DiffusionPipeline):
|
||||
"""
|
||||
Pipeline for text-to-image generation using Kandinsky
|
||||
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
Args:
|
||||
text_encoder ([`MultilingualCLIP`]):
|
||||
Frozen text-encoder.
|
||||
tokenizer ([`XLMRobertaTokenizer`]):
|
||||
Tokenizer of class
|
||||
scheduler ([`DDIMScheduler`]):
|
||||
A scheduler to be used in combination with `unet` to generate image latents.
|
||||
unet ([`UNet2DConditionModel`]):
|
||||
Conditional U-Net architecture to denoise the image embedding.
|
||||
movq ([`VQModel`]):
|
||||
MoVQ Decoder to generate the image from the latents.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
text_encoder: MultilingualCLIP,
|
||||
tokenizer: XLMRobertaTokenizer,
|
||||
unet: UNet2DConditionModel,
|
||||
scheduler: DDIMScheduler,
|
||||
movq: VQModel,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.register_modules(
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
unet=unet,
|
||||
scheduler=scheduler,
|
||||
movq=movq,
|
||||
)
|
||||
self.movq_scale_factor = 2 ** (len(self.movq.config.block_out_channels) - 1)
|
||||
|
||||
def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
|
||||
if latents is None:
|
||||
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
else:
|
||||
if latents.shape != shape:
|
||||
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
|
||||
latents = latents.to(device)
|
||||
|
||||
latents = latents * scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def _encode_prompt(
|
||||
self,
|
||||
prompt,
|
||||
device,
|
||||
num_images_per_prompt,
|
||||
do_classifier_free_guidance,
|
||||
negative_prompt=None,
|
||||
):
|
||||
batch_size = len(prompt) if isinstance(prompt, list) else 1
|
||||
# get prompt text embeddings
|
||||
text_inputs = self.tokenizer(
|
||||
prompt,
|
||||
padding="max_length",
|
||||
truncation=True,
|
||||
max_length=77,
|
||||
return_attention_mask=True,
|
||||
add_special_tokens=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
|
||||
text_input_ids = text_inputs.input_ids
|
||||
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
|
||||
|
||||
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
|
||||
removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
|
||||
logger.warning(
|
||||
"The following part of your input was truncated because CLIP can only handle sequences up to"
|
||||
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
|
||||
)
|
||||
|
||||
text_input_ids = text_input_ids.to(device)
|
||||
text_mask = text_inputs.attention_mask.to(device)
|
||||
|
||||
prompt_embeds, text_encoder_hidden_states = self.text_encoder(
|
||||
input_ids=text_input_ids, attention_mask=text_mask
|
||||
)
|
||||
|
||||
prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_encoder_hidden_states = text_encoder_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_mask = text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
uncond_tokens: List[str]
|
||||
if negative_prompt is None:
|
||||
uncond_tokens = [""] * batch_size
|
||||
elif type(prompt) is not type(negative_prompt):
|
||||
raise TypeError(
|
||||
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
|
||||
f" {type(prompt)}."
|
||||
)
|
||||
elif isinstance(negative_prompt, str):
|
||||
uncond_tokens = [negative_prompt]
|
||||
elif batch_size != len(negative_prompt):
|
||||
raise ValueError(
|
||||
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
|
||||
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
|
||||
" the batch size of `prompt`."
|
||||
)
|
||||
else:
|
||||
uncond_tokens = negative_prompt
|
||||
|
||||
uncond_input = self.tokenizer(
|
||||
uncond_tokens,
|
||||
padding="max_length",
|
||||
max_length=77,
|
||||
truncation=True,
|
||||
return_attention_mask=True,
|
||||
add_special_tokens=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
uncond_text_input_ids = uncond_input.input_ids.to(device)
|
||||
uncond_text_mask = uncond_input.attention_mask.to(device)
|
||||
|
||||
negative_prompt_embeds, uncond_text_encoder_hidden_states = self.text_encoder(
|
||||
input_ids=uncond_text_input_ids, attention_mask=uncond_text_mask
|
||||
)
|
||||
|
||||
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
|
||||
|
||||
seq_len = negative_prompt_embeds.shape[1]
|
||||
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt)
|
||||
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len)
|
||||
|
||||
seq_len = uncond_text_encoder_hidden_states.shape[1]
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.repeat(1, num_images_per_prompt, 1)
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.view(
|
||||
batch_size * num_images_per_prompt, seq_len, -1
|
||||
)
|
||||
uncond_text_mask = uncond_text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
# done duplicates
|
||||
|
||||
# For classifier free guidance, we need to do two forward passes.
|
||||
# Here we concatenate the unconditional and text embeddings into a single batch
|
||||
# to avoid doing two forward passes
|
||||
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
|
||||
text_encoder_hidden_states = torch.cat([uncond_text_encoder_hidden_states, text_encoder_hidden_states])
|
||||
|
||||
text_mask = torch.cat([uncond_text_mask, text_mask])
|
||||
|
||||
return prompt_embeds, text_encoder_hidden_states, text_mask
|
||||
|
||||
def enable_sequential_cpu_offload(self, gpu_id=0):
|
||||
r"""
|
||||
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline's
|
||||
models have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded to GPU only
|
||||
when their specific submodule has its `forward` method called.
|
||||
"""
|
||||
if is_accelerate_available():
|
||||
from accelerate import cpu_offload
|
||||
else:
|
||||
raise ImportError("Please install accelerate via `pip install accelerate`")
|
||||
|
||||
device = torch.device(f"cuda:{gpu_id}")
|
||||
|
||||
models = [
|
||||
self.unet,
|
||||
self.text_encoder,
|
||||
self.movq,
|
||||
]
|
||||
for cpu_offloaded_model in models:
|
||||
if cpu_offloaded_model is not None:
|
||||
cpu_offload(cpu_offloaded_model, device)
|
||||
|
||||
def enable_model_cpu_offload(self, gpu_id=0):
|
||||
r"""
|
||||
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
|
||||
to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
|
||||
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
|
||||
`enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
|
||||
"""
|
||||
if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
|
||||
from accelerate import cpu_offload_with_hook
|
||||
else:
|
||||
raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
|
||||
|
||||
device = torch.device(f"cuda:{gpu_id}")
|
||||
|
||||
if self.device.type != "cpu":
|
||||
self.to("cpu", silence_dtype_warnings=True)
|
||||
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
|
||||
|
||||
hook = None
|
||||
for cpu_offloaded_model in [self.text_encoder, self.unet, self.movq]:
|
||||
_, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
|
||||
|
||||
if self.safety_checker is not None:
|
||||
_, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
|
||||
|
||||
# We'll offload the last model manually.
|
||||
self.final_offload_hook = hook
|
||||
|
||||
@property
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
|
||||
def _execution_device(self):
|
||||
r"""
|
||||
Returns the device on which the pipeline's models will be executed. After calling
|
||||
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
|
||||
hooks.
|
||||
"""
|
||||
if not hasattr(self.unet, "_hf_hook"):
|
||||
return self.device
|
||||
for module in self.unet.modules():
|
||||
if (
|
||||
hasattr(module, "_hf_hook")
|
||||
and hasattr(module._hf_hook, "execution_device")
|
||||
and module._hf_hook.execution_device is not None
|
||||
):
|
||||
return torch.device(module._hf_hook.execution_device)
|
||||
return self.device
|
||||
|
||||
@torch.no_grad()
|
||||
@replace_example_docstring(EXAMPLE_DOC_STRING)
|
||||
def __call__(
|
||||
self,
|
||||
prompt: Union[str, List[str]],
|
||||
image_embeds: Union[torch.FloatTensor, List[torch.FloatTensor]],
|
||||
negative_image_embeds: Union[torch.FloatTensor, List[torch.FloatTensor]],
|
||||
negative_prompt: Optional[Union[str, List[str]]] = None,
|
||||
height: int = 512,
|
||||
width: int = 512,
|
||||
num_inference_steps: int = 100,
|
||||
guidance_scale: float = 4.0,
|
||||
num_images_per_prompt: int = 1,
|
||||
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
||||
latents: Optional[torch.FloatTensor] = None,
|
||||
output_type: Optional[str] = "pil",
|
||||
return_dict: bool = True,
|
||||
):
|
||||
"""
|
||||
Function invoked when calling the pipeline for generation.
|
||||
|
||||
Args:
|
||||
prompt (`str` or `List[str]`):
|
||||
The prompt or prompts to guide the image generation.
|
||||
image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
|
||||
The clip image embeddings for text prompt, that will be used to condition the image generation.
|
||||
negative_image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
|
||||
The clip image embeddings for negative text prompt, will be used to condition the image generation.
|
||||
negative_prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
|
||||
if `guidance_scale` is less than `1`).
|
||||
height (`int`, *optional*, defaults to 512):
|
||||
The height in pixels of the generated image.
|
||||
width (`int`, *optional*, defaults to 512):
|
||||
The width in pixels of the generated image.
|
||||
num_inference_steps (`int`, *optional*, defaults to 100):
|
||||
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
||||
expense of slower inference.
|
||||
guidance_scale (`float`, *optional*, defaults to 4.0):
|
||||
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
||||
`guidance_scale` is defined as `w` of equation 2. of [Imagen
|
||||
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
|
||||
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
|
||||
usually at the expense of lower image quality.
|
||||
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
||||
The number of images to generate per prompt.
|
||||
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
||||
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
|
||||
to make generation deterministic.
|
||||
latents (`torch.FloatTensor`, *optional*):
|
||||
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
|
||||
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
||||
tensor will ge generated by sampling using the supplied random `generator`.
|
||||
output_type (`str`, *optional*, defaults to `"pil"`):
|
||||
The output format of the generate image. Choose between: `"pil"` (`PIL.Image.Image`), `"np"`
|
||||
(`np.array`) or `"pt"` (`torch.Tensor`).
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`~pipelines.ImagePipelineOutput`] or `tuple`
|
||||
"""
|
||||
|
||||
if isinstance(prompt, str):
|
||||
batch_size = 1
|
||||
elif isinstance(prompt, list):
|
||||
batch_size = len(prompt)
|
||||
else:
|
||||
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
|
||||
|
||||
device = self._execution_device
|
||||
|
||||
batch_size = batch_size * num_images_per_prompt
|
||||
do_classifier_free_guidance = guidance_scale > 1.0
|
||||
|
||||
prompt_embeds, text_encoder_hidden_states, _ = self._encode_prompt(
|
||||
prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
|
||||
)
|
||||
|
||||
if isinstance(image_embeds, list):
|
||||
image_embeds = torch.cat(image_embeds, dim=0)
|
||||
if isinstance(negative_image_embeds, list):
|
||||
negative_image_embeds = torch.cat(negative_image_embeds, dim=0)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
negative_image_embeds = negative_image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
image_embeds = torch.cat([negative_image_embeds, image_embeds], dim=0).to(
|
||||
dtype=prompt_embeds.dtype, device=device
|
||||
)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
timesteps_tensor = self.scheduler.timesteps
|
||||
|
||||
num_channels_latents = self.unet.config.in_channels
|
||||
|
||||
height, width = get_new_h_w(height, width, self.movq_scale_factor)
|
||||
|
||||
# create initial latent
|
||||
latents = self.prepare_latents(
|
||||
(batch_size, num_channels_latents, height, width),
|
||||
text_encoder_hidden_states.dtype,
|
||||
device,
|
||||
generator,
|
||||
latents,
|
||||
self.scheduler,
|
||||
)
|
||||
|
||||
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
|
||||
added_cond_kwargs = {"text_embeds": prompt_embeds, "image_embeds": image_embeds}
|
||||
noise_pred = self.unet(
|
||||
sample=latent_model_input,
|
||||
timestep=t,
|
||||
encoder_hidden_states=text_encoder_hidden_states,
|
||||
added_cond_kwargs=added_cond_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred, variance_pred = noise_pred.split(latents.shape[1], dim=1)
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
_, variance_pred_text = variance_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
noise_pred = torch.cat([noise_pred, variance_pred_text], dim=1)
|
||||
|
||||
if not (
|
||||
hasattr(self.scheduler.config, "variance_type")
|
||||
and self.scheduler.config.variance_type in ["learned", "learned_range"]
|
||||
):
|
||||
noise_pred, _ = noise_pred.split(latents.shape[1], dim=1)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(
|
||||
noise_pred,
|
||||
t,
|
||||
latents,
|
||||
# YiYi notes: only reason this pipeline can't work with unclip scheduler is that can't pass down this argument
|
||||
# need to use DDPM scheduler instead
|
||||
# prev_timestep=prev_timestep,
|
||||
generator=generator,
|
||||
).prev_sample
|
||||
# post-processing
|
||||
image = self.movq.decode(latents, force_not_quantize=True)["sample"]
|
||||
|
||||
if output_type not in ["pt", "np", "pil"]:
|
||||
raise ValueError(f"Only the output types `pt`, `pil` and `np` are supported not output_type={output_type}")
|
||||
|
||||
if output_type in ["np", "pil"]:
|
||||
image = image * 0.5 + 0.5
|
||||
image = image.clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
|
||||
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
if not return_dict:
|
||||
return (image,)
|
||||
|
||||
return ImagePipelineOutput(images=image)
|
||||
@@ -1,548 +0,0 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import PIL
|
||||
import torch
|
||||
from PIL import Image
|
||||
from transformers import (
|
||||
XLMRobertaTokenizer,
|
||||
)
|
||||
|
||||
from ...models import UNet2DConditionModel, VQModel
|
||||
from ...pipelines import DiffusionPipeline
|
||||
from ...pipelines.pipeline_utils import ImagePipelineOutput
|
||||
from ...schedulers import DDIMScheduler
|
||||
from ...utils import (
|
||||
is_accelerate_available,
|
||||
is_accelerate_version,
|
||||
logging,
|
||||
randn_tensor,
|
||||
replace_example_docstring,
|
||||
)
|
||||
from .text_encoder import MultilingualCLIP
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
EXAMPLE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> from diffusers import KandinskyImg2ImgPipeline, KandinskyPriorPipeline
|
||||
>>> from diffusers.utils import load_image
|
||||
>>> import torch
|
||||
|
||||
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
... "kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
... )
|
||||
>>> pipe_prior.to("cuda")
|
||||
|
||||
>>> prompt = "A red cartoon frog, 4k"
|
||||
>>> image_emb, zero_image_emb = pipe_prior(prompt, return_dict=False)
|
||||
|
||||
>>> pipe = KandinskyImg2ImgPipeline.from_pretrained(
|
||||
... "kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16
|
||||
... )
|
||||
>>> pipe.to("cuda")
|
||||
|
||||
>>> init_image = load_image(
|
||||
... "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
|
||||
... "/kandinsky/frog.png"
|
||||
... )
|
||||
|
||||
>>> image = pipe(
|
||||
... prompt,
|
||||
... image=init_image,
|
||||
... image_embeds=image_emb,
|
||||
... negative_image_embeds=zero_image_emb,
|
||||
... height=768,
|
||||
... width=768,
|
||||
... num_inference_steps=100,
|
||||
... strength=0.2,
|
||||
... ).images
|
||||
|
||||
>>> image[0].save("red_frog.png")
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
def get_new_h_w(h, w, scale_factor=8):
|
||||
new_h = h // scale_factor**2
|
||||
if h % scale_factor**2 != 0:
|
||||
new_h += 1
|
||||
new_w = w // scale_factor**2
|
||||
if w % scale_factor**2 != 0:
|
||||
new_w += 1
|
||||
return new_h * scale_factor, new_w * scale_factor
|
||||
|
||||
|
||||
def prepare_image(pil_image, w=512, h=512):
|
||||
pil_image = pil_image.resize((w, h), resample=Image.BICUBIC, reducing_gap=1)
|
||||
arr = np.array(pil_image.convert("RGB"))
|
||||
arr = arr.astype(np.float32) / 127.5 - 1
|
||||
arr = np.transpose(arr, [2, 0, 1])
|
||||
image = torch.from_numpy(arr).unsqueeze(0)
|
||||
return image
|
||||
|
||||
|
||||
class KandinskyImg2ImgPipeline(DiffusionPipeline):
|
||||
"""
|
||||
Pipeline for image-to-image generation using Kandinsky
|
||||
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
Args:
|
||||
text_encoder ([`MultilingualCLIP`]):
|
||||
Frozen text-encoder.
|
||||
tokenizer ([`XLMRobertaTokenizer`]):
|
||||
Tokenizer of class
|
||||
scheduler ([`DDIMScheduler`]):
|
||||
A scheduler to be used in combination with `unet` to generate image latents.
|
||||
unet ([`UNet2DConditionModel`]):
|
||||
Conditional U-Net architecture to denoise the image embedding.
|
||||
movq ([`VQModel`]):
|
||||
MoVQ image encoder and decoder
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
text_encoder: MultilingualCLIP,
|
||||
movq: VQModel,
|
||||
tokenizer: XLMRobertaTokenizer,
|
||||
unet: UNet2DConditionModel,
|
||||
scheduler: DDIMScheduler,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.register_modules(
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
unet=unet,
|
||||
scheduler=scheduler,
|
||||
movq=movq,
|
||||
)
|
||||
self.movq_scale_factor = 2 ** (len(self.movq.config.block_out_channels) - 1)
|
||||
|
||||
def get_timesteps(self, num_inference_steps, strength, device):
|
||||
# get the original timestep using init_timestep
|
||||
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
|
||||
|
||||
t_start = max(num_inference_steps - init_timestep, 0)
|
||||
timesteps = self.scheduler.timesteps[t_start:]
|
||||
|
||||
return timesteps, num_inference_steps - t_start
|
||||
|
||||
def prepare_latents(self, latents, latent_timestep, shape, dtype, device, generator, scheduler):
|
||||
if latents is None:
|
||||
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
else:
|
||||
if latents.shape != shape:
|
||||
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
|
||||
latents = latents.to(device)
|
||||
|
||||
latents = latents * scheduler.init_noise_sigma
|
||||
|
||||
shape = latents.shape
|
||||
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
|
||||
latents = self.add_noise(latents, noise, latent_timestep)
|
||||
return latents
|
||||
|
||||
def _encode_prompt(
|
||||
self,
|
||||
prompt,
|
||||
device,
|
||||
num_images_per_prompt,
|
||||
do_classifier_free_guidance,
|
||||
negative_prompt=None,
|
||||
):
|
||||
batch_size = len(prompt) if isinstance(prompt, list) else 1
|
||||
# get prompt text embeddings
|
||||
text_inputs = self.tokenizer(
|
||||
prompt,
|
||||
padding="max_length",
|
||||
max_length=77,
|
||||
truncation=True,
|
||||
return_attention_mask=True,
|
||||
add_special_tokens=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
|
||||
text_input_ids = text_inputs.input_ids
|
||||
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
|
||||
|
||||
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
|
||||
removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
|
||||
logger.warning(
|
||||
"The following part of your input was truncated because CLIP can only handle sequences up to"
|
||||
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
|
||||
)
|
||||
|
||||
text_input_ids = text_input_ids.to(device)
|
||||
text_mask = text_inputs.attention_mask.to(device)
|
||||
|
||||
prompt_embeds, text_encoder_hidden_states = self.text_encoder(
|
||||
input_ids=text_input_ids, attention_mask=text_mask
|
||||
)
|
||||
|
||||
prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_encoder_hidden_states = text_encoder_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_mask = text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
uncond_tokens: List[str]
|
||||
if negative_prompt is None:
|
||||
uncond_tokens = [""] * batch_size
|
||||
elif type(prompt) is not type(negative_prompt):
|
||||
raise TypeError(
|
||||
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
|
||||
f" {type(prompt)}."
|
||||
)
|
||||
elif isinstance(negative_prompt, str):
|
||||
uncond_tokens = [negative_prompt]
|
||||
elif batch_size != len(negative_prompt):
|
||||
raise ValueError(
|
||||
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
|
||||
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
|
||||
" the batch size of `prompt`."
|
||||
)
|
||||
else:
|
||||
uncond_tokens = negative_prompt
|
||||
|
||||
uncond_input = self.tokenizer(
|
||||
uncond_tokens,
|
||||
padding="max_length",
|
||||
max_length=77,
|
||||
truncation=True,
|
||||
return_attention_mask=True,
|
||||
add_special_tokens=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
uncond_text_input_ids = uncond_input.input_ids.to(device)
|
||||
uncond_text_mask = uncond_input.attention_mask.to(device)
|
||||
|
||||
negative_prompt_embeds, uncond_text_encoder_hidden_states = self.text_encoder(
|
||||
input_ids=uncond_text_input_ids, attention_mask=uncond_text_mask
|
||||
)
|
||||
|
||||
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
|
||||
|
||||
seq_len = negative_prompt_embeds.shape[1]
|
||||
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt)
|
||||
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len)
|
||||
|
||||
seq_len = uncond_text_encoder_hidden_states.shape[1]
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.repeat(1, num_images_per_prompt, 1)
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.view(
|
||||
batch_size * num_images_per_prompt, seq_len, -1
|
||||
)
|
||||
uncond_text_mask = uncond_text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
# done duplicates
|
||||
|
||||
# For classifier free guidance, we need to do two forward passes.
|
||||
# Here we concatenate the unconditional and text embeddings into a single batch
|
||||
# to avoid doing two forward passes
|
||||
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
|
||||
text_encoder_hidden_states = torch.cat([uncond_text_encoder_hidden_states, text_encoder_hidden_states])
|
||||
|
||||
text_mask = torch.cat([uncond_text_mask, text_mask])
|
||||
|
||||
return prompt_embeds, text_encoder_hidden_states, text_mask
|
||||
|
||||
def enable_sequential_cpu_offload(self, gpu_id=0):
|
||||
r"""
|
||||
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline's
|
||||
models have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded to GPU only
|
||||
when their specific submodule has its `forward` method called.
|
||||
"""
|
||||
if is_accelerate_available():
|
||||
from accelerate import cpu_offload
|
||||
else:
|
||||
raise ImportError("Please install accelerate via `pip install accelerate`")
|
||||
|
||||
device = torch.device(f"cuda:{gpu_id}")
|
||||
|
||||
models = [
|
||||
self.unet,
|
||||
self.text_encoder,
|
||||
self.movq,
|
||||
]
|
||||
for cpu_offloaded_model in models:
|
||||
if cpu_offloaded_model is not None:
|
||||
cpu_offload(cpu_offloaded_model, device)
|
||||
|
||||
def enable_model_cpu_offload(self, gpu_id=0):
|
||||
r"""
|
||||
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
|
||||
to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
|
||||
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
|
||||
`enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
|
||||
"""
|
||||
if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
|
||||
from accelerate import cpu_offload_with_hook
|
||||
else:
|
||||
raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
|
||||
|
||||
device = torch.device(f"cuda:{gpu_id}")
|
||||
|
||||
if self.device.type != "cpu":
|
||||
self.to("cpu", silence_dtype_warnings=True)
|
||||
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
|
||||
|
||||
hook = None
|
||||
for cpu_offloaded_model in [self.text_encoder, self.unet, self.movq]:
|
||||
_, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
|
||||
|
||||
if self.safety_checker is not None:
|
||||
_, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
|
||||
|
||||
# We'll offload the last model manually.
|
||||
self.final_offload_hook = hook
|
||||
|
||||
@property
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
|
||||
def _execution_device(self):
|
||||
r"""
|
||||
Returns the device on which the pipeline's models will be executed. After calling
|
||||
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
|
||||
hooks.
|
||||
"""
|
||||
if not hasattr(self.unet, "_hf_hook"):
|
||||
return self.device
|
||||
for module in self.unet.modules():
|
||||
if (
|
||||
hasattr(module, "_hf_hook")
|
||||
and hasattr(module._hf_hook, "execution_device")
|
||||
and module._hf_hook.execution_device is not None
|
||||
):
|
||||
return torch.device(module._hf_hook.execution_device)
|
||||
return self.device
|
||||
|
||||
# add_noise method to overwrite the one in schedule because it use a different beta schedule for adding noise vs sampling
|
||||
def add_noise(
|
||||
self,
|
||||
original_samples: torch.FloatTensor,
|
||||
noise: torch.FloatTensor,
|
||||
timesteps: torch.IntTensor,
|
||||
) -> torch.FloatTensor:
|
||||
betas = torch.linspace(0.0001, 0.02, 1000, dtype=torch.float32)
|
||||
alphas = 1.0 - betas
|
||||
alphas_cumprod = torch.cumprod(alphas, dim=0)
|
||||
alphas_cumprod = alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
|
||||
timesteps = timesteps.to(original_samples.device)
|
||||
|
||||
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
|
||||
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
|
||||
while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
|
||||
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
|
||||
|
||||
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
|
||||
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
|
||||
while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
|
||||
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
|
||||
|
||||
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
|
||||
|
||||
return noisy_samples
|
||||
|
||||
@torch.no_grad()
|
||||
@replace_example_docstring(EXAMPLE_DOC_STRING)
|
||||
def __call__(
|
||||
self,
|
||||
prompt: Union[str, List[str]],
|
||||
image: Union[torch.FloatTensor, PIL.Image.Image, List[torch.FloatTensor], List[PIL.Image.Image]],
|
||||
image_embeds: torch.FloatTensor,
|
||||
negative_image_embeds: torch.FloatTensor,
|
||||
negative_prompt: Optional[Union[str, List[str]]] = None,
|
||||
height: int = 512,
|
||||
width: int = 512,
|
||||
num_inference_steps: int = 100,
|
||||
strength: float = 0.3,
|
||||
guidance_scale: float = 7.0,
|
||||
num_images_per_prompt: int = 1,
|
||||
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
||||
output_type: Optional[str] = "pil",
|
||||
return_dict: bool = True,
|
||||
):
|
||||
"""
|
||||
Function invoked when calling the pipeline for generation.
|
||||
|
||||
Args:
|
||||
prompt (`str` or `List[str]`):
|
||||
The prompt or prompts to guide the image generation.
|
||||
image (`torch.FloatTensor`, `PIL.Image.Image`):
|
||||
`Image`, or tensor representing an image batch, that will be used as the starting point for the
|
||||
process.
|
||||
image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
|
||||
The clip image embeddings for text prompt, that will be used to condition the image generation.
|
||||
negative_image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
|
||||
The clip image embeddings for negative text prompt, will be used to condition the image generation.
|
||||
negative_prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
|
||||
if `guidance_scale` is less than `1`).
|
||||
height (`int`, *optional*, defaults to 512):
|
||||
The height in pixels of the generated image.
|
||||
width (`int`, *optional*, defaults to 512):
|
||||
The width in pixels of the generated image.
|
||||
num_inference_steps (`int`, *optional*, defaults to 100):
|
||||
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
||||
expense of slower inference.
|
||||
strength (`float`, *optional*, defaults to 0.3):
|
||||
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1. `image`
|
||||
will be used as a starting point, adding more noise to it the larger the `strength`. The number of
|
||||
denoising steps depends on the amount of noise initially added. When `strength` is 1, added noise will
|
||||
be maximum and the denoising process will run for the full number of iterations specified in
|
||||
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
|
||||
guidance_scale (`float`, *optional*, defaults to 4.0):
|
||||
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
||||
`guidance_scale` is defined as `w` of equation 2. of [Imagen
|
||||
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
|
||||
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
|
||||
usually at the expense of lower image quality.
|
||||
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
||||
The number of images to generate per prompt.
|
||||
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
||||
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
|
||||
to make generation deterministic.
|
||||
output_type (`str`, *optional*, defaults to `"pil"`):
|
||||
The output format of the generate image. Choose between: `"pil"` (`PIL.Image.Image`), `"np"`
|
||||
(`np.array`) or `"pt"` (`torch.Tensor`).
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`~pipelines.ImagePipelineOutput`] or `tuple`
|
||||
"""
|
||||
# 1. Define call parameters
|
||||
if isinstance(prompt, str):
|
||||
batch_size = 1
|
||||
elif isinstance(prompt, list):
|
||||
batch_size = len(prompt)
|
||||
else:
|
||||
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
|
||||
|
||||
device = self._execution_device
|
||||
|
||||
batch_size = batch_size * num_images_per_prompt
|
||||
|
||||
do_classifier_free_guidance = guidance_scale > 1.0
|
||||
|
||||
# 2. get text and image embeddings
|
||||
prompt_embeds, text_encoder_hidden_states, _ = self._encode_prompt(
|
||||
prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
|
||||
)
|
||||
|
||||
if isinstance(image_embeds, list):
|
||||
image_embeds = torch.cat(image_embeds, dim=0)
|
||||
if isinstance(negative_image_embeds, list):
|
||||
negative_image_embeds = torch.cat(negative_image_embeds, dim=0)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
negative_image_embeds = negative_image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
image_embeds = torch.cat([negative_image_embeds, image_embeds], dim=0).to(
|
||||
dtype=prompt_embeds.dtype, device=device
|
||||
)
|
||||
|
||||
# 3. pre-processing initial image
|
||||
if not isinstance(image, list):
|
||||
image = [image]
|
||||
if not all(isinstance(i, (PIL.Image.Image, torch.Tensor)) for i in image):
|
||||
raise ValueError(
|
||||
f"Input is in incorrect format: {[type(i) for i in image]}. Currently, we only support PIL image and pytorch tensor"
|
||||
)
|
||||
|
||||
image = torch.cat([prepare_image(i, width, height) for i in image], dim=0)
|
||||
image = image.to(dtype=prompt_embeds.dtype, device=device)
|
||||
|
||||
latents = self.movq.encode(image)["latents"]
|
||||
latents = latents.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
# 4. set timesteps
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
|
||||
timesteps_tensor, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
|
||||
|
||||
# the formular to calculate timestep for add_noise is taken from the original kandinsky repo
|
||||
latent_timestep = int(self.scheduler.config.num_train_timesteps * strength) - 2
|
||||
|
||||
latent_timestep = torch.tensor([latent_timestep] * batch_size, dtype=timesteps_tensor.dtype, device=device)
|
||||
|
||||
num_channels_latents = self.unet.config.in_channels
|
||||
|
||||
height, width = get_new_h_w(height, width, self.movq_scale_factor)
|
||||
|
||||
# 5. Create initial latent
|
||||
latents = self.prepare_latents(
|
||||
latents,
|
||||
latent_timestep,
|
||||
(batch_size, num_channels_latents, height, width),
|
||||
text_encoder_hidden_states.dtype,
|
||||
device,
|
||||
generator,
|
||||
self.scheduler,
|
||||
)
|
||||
|
||||
# 6. Denoising loop
|
||||
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
|
||||
added_cond_kwargs = {"text_embeds": prompt_embeds, "image_embeds": image_embeds}
|
||||
noise_pred = self.unet(
|
||||
sample=latent_model_input,
|
||||
timestep=t,
|
||||
encoder_hidden_states=text_encoder_hidden_states,
|
||||
added_cond_kwargs=added_cond_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred, _ = noise_pred.split(latents.shape[1], dim=1)
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(
|
||||
noise_pred,
|
||||
t,
|
||||
latents,
|
||||
generator=generator,
|
||||
).prev_sample
|
||||
|
||||
# 7. post-processing
|
||||
image = self.movq.decode(latents, force_not_quantize=True)["sample"]
|
||||
|
||||
if output_type not in ["pt", "np", "pil"]:
|
||||
raise ValueError(f"Only the output types `pt`, `pil` and `np` are supported not output_type={output_type}")
|
||||
|
||||
if output_type in ["np", "pil"]:
|
||||
image = image * 0.5 + 0.5
|
||||
image = image.clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
|
||||
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
if not return_dict:
|
||||
return (image,)
|
||||
|
||||
return ImagePipelineOutput(images=image)
|
||||
@@ -1,673 +0,0 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from copy import deepcopy
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import PIL
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from PIL import Image
|
||||
from transformers import (
|
||||
XLMRobertaTokenizer,
|
||||
)
|
||||
|
||||
from ...models import UNet2DConditionModel, VQModel
|
||||
from ...pipelines import DiffusionPipeline
|
||||
from ...pipelines.pipeline_utils import ImagePipelineOutput
|
||||
from ...schedulers import DDIMScheduler
|
||||
from ...utils import (
|
||||
is_accelerate_available,
|
||||
is_accelerate_version,
|
||||
logging,
|
||||
randn_tensor,
|
||||
replace_example_docstring,
|
||||
)
|
||||
from .text_encoder import MultilingualCLIP
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
EXAMPLE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> from diffusers import KandinskyInpaintPipeline, KandinskyPriorPipeline
|
||||
>>> from diffusers.utils import load_image
|
||||
>>> import torch
|
||||
>>> import numpy as np
|
||||
|
||||
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
... "kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
... )
|
||||
>>> pipe_prior.to("cuda")
|
||||
|
||||
>>> prompt = "a hat"
|
||||
>>> image_emb, zero_image_emb = pipe_prior(prompt, return_dict=False)
|
||||
|
||||
>>> pipe = KandinskyInpaintPipeline.from_pretrained(
|
||||
... "kandinsky-community/kandinsky-2-1-inpaint", torch_dtype=torch.float16
|
||||
... )
|
||||
>>> pipe.to("cuda")
|
||||
|
||||
>>> init_image = load_image(
|
||||
... "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
|
||||
... "/kandinsky/cat.png"
|
||||
... )
|
||||
|
||||
>>> mask = np.ones((768, 768), dtype=np.float32)
|
||||
>>> mask[:250, 250:-250] = 0
|
||||
|
||||
>>> out = pipe(
|
||||
... prompt,
|
||||
... image=init_image,
|
||||
... mask_image=mask,
|
||||
... image_embeds=image_emb,
|
||||
... negative_image_embeds=zero_image_emb,
|
||||
... height=768,
|
||||
... width=768,
|
||||
... num_inference_steps=50,
|
||||
... )
|
||||
|
||||
>>> image = out.images[0]
|
||||
>>> image.save("cat_with_hat.png")
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
def get_new_h_w(h, w, scale_factor=8):
|
||||
new_h = h // scale_factor**2
|
||||
if h % scale_factor**2 != 0:
|
||||
new_h += 1
|
||||
new_w = w // scale_factor**2
|
||||
if w % scale_factor**2 != 0:
|
||||
new_w += 1
|
||||
return new_h * scale_factor, new_w * scale_factor
|
||||
|
||||
|
||||
def prepare_mask(masks):
|
||||
prepared_masks = []
|
||||
for mask in masks:
|
||||
old_mask = deepcopy(mask)
|
||||
for i in range(mask.shape[1]):
|
||||
for j in range(mask.shape[2]):
|
||||
if old_mask[0][i][j] == 1:
|
||||
continue
|
||||
if i != 0:
|
||||
mask[:, i - 1, j] = 0
|
||||
if j != 0:
|
||||
mask[:, i, j - 1] = 0
|
||||
if i != 0 and j != 0:
|
||||
mask[:, i - 1, j - 1] = 0
|
||||
if i != mask.shape[1] - 1:
|
||||
mask[:, i + 1, j] = 0
|
||||
if j != mask.shape[2] - 1:
|
||||
mask[:, i, j + 1] = 0
|
||||
if i != mask.shape[1] - 1 and j != mask.shape[2] - 1:
|
||||
mask[:, i + 1, j + 1] = 0
|
||||
prepared_masks.append(mask)
|
||||
return torch.stack(prepared_masks, dim=0)
|
||||
|
||||
|
||||
def prepare_mask_and_masked_image(image, mask, height, width):
|
||||
r"""
|
||||
Prepares a pair (mask, image) to be consumed by the Kandinsky inpaint pipeline. This means that those inputs will
|
||||
be converted to ``torch.Tensor`` with shapes ``batch x channels x height x width`` where ``channels`` is ``3`` for
|
||||
the ``image`` and ``1`` for the ``mask``.
|
||||
|
||||
The ``image`` will be converted to ``torch.float32`` and normalized to be in ``[-1, 1]``. The ``mask`` will be
|
||||
binarized (``mask > 0.5``) and cast to ``torch.float32`` too.
|
||||
|
||||
Args:
|
||||
image (Union[np.array, PIL.Image, torch.Tensor]): The image to inpaint.
|
||||
It can be a ``PIL.Image``, or a ``height x width x 3`` ``np.array`` or a ``channels x height x width``
|
||||
``torch.Tensor`` or a ``batch x channels x height x width`` ``torch.Tensor``.
|
||||
mask (_type_): The mask to apply to the image, i.e. regions to inpaint.
|
||||
It can be a ``PIL.Image``, or a ``height x width`` ``np.array`` or a ``1 x height x width``
|
||||
``torch.Tensor`` or a ``batch x 1 x height x width`` ``torch.Tensor``.
|
||||
height (`int`, *optional*, defaults to 512):
|
||||
The height in pixels of the generated image.
|
||||
width (`int`, *optional*, defaults to 512):
|
||||
The width in pixels of the generated image.
|
||||
|
||||
|
||||
Raises:
|
||||
ValueError: ``torch.Tensor`` images should be in the ``[-1, 1]`` range. ValueError: ``torch.Tensor`` mask
|
||||
should be in the ``[0, 1]`` range. ValueError: ``mask`` and ``image`` should have the same spatial dimensions.
|
||||
TypeError: ``mask`` is a ``torch.Tensor`` but ``image`` is not
|
||||
(ot the other way around).
|
||||
|
||||
Returns:
|
||||
tuple[torch.Tensor]: The pair (mask, image) as ``torch.Tensor`` with 4
|
||||
dimensions: ``batch x channels x height x width``.
|
||||
"""
|
||||
|
||||
if image is None:
|
||||
raise ValueError("`image` input cannot be undefined.")
|
||||
|
||||
if mask is None:
|
||||
raise ValueError("`mask_image` input cannot be undefined.")
|
||||
|
||||
if isinstance(image, torch.Tensor):
|
||||
if not isinstance(mask, torch.Tensor):
|
||||
raise TypeError(f"`image` is a torch.Tensor but `mask` (type: {type(mask)} is not")
|
||||
|
||||
# Batch single image
|
||||
if image.ndim == 3:
|
||||
assert image.shape[0] == 3, "Image outside a batch should be of shape (3, H, W)"
|
||||
image = image.unsqueeze(0)
|
||||
|
||||
# Batch and add channel dim for single mask
|
||||
if mask.ndim == 2:
|
||||
mask = mask.unsqueeze(0).unsqueeze(0)
|
||||
|
||||
# Batch single mask or add channel dim
|
||||
if mask.ndim == 3:
|
||||
# Single batched mask, no channel dim or single mask not batched but channel dim
|
||||
if mask.shape[0] == 1:
|
||||
mask = mask.unsqueeze(0)
|
||||
|
||||
# Batched masks no channel dim
|
||||
else:
|
||||
mask = mask.unsqueeze(1)
|
||||
|
||||
assert image.ndim == 4 and mask.ndim == 4, "Image and Mask must have 4 dimensions"
|
||||
assert image.shape[-2:] == mask.shape[-2:], "Image and Mask must have the same spatial dimensions"
|
||||
assert image.shape[0] == mask.shape[0], "Image and Mask must have the same batch size"
|
||||
|
||||
# Check image is in [-1, 1]
|
||||
if image.min() < -1 or image.max() > 1:
|
||||
raise ValueError("Image should be in [-1, 1] range")
|
||||
|
||||
# Check mask is in [0, 1]
|
||||
if mask.min() < 0 or mask.max() > 1:
|
||||
raise ValueError("Mask should be in [0, 1] range")
|
||||
|
||||
# Binarize mask
|
||||
mask[mask < 0.5] = 0
|
||||
mask[mask >= 0.5] = 1
|
||||
|
||||
# Image as float32
|
||||
image = image.to(dtype=torch.float32)
|
||||
elif isinstance(mask, torch.Tensor):
|
||||
raise TypeError(f"`mask` is a torch.Tensor but `image` (type: {type(image)} is not")
|
||||
else:
|
||||
# preprocess image
|
||||
if isinstance(image, (PIL.Image.Image, np.ndarray)):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
|
||||
# resize all images w.r.t passed height an width
|
||||
image = [i.resize((width, height), resample=Image.BICUBIC, reducing_gap=1) for i in image]
|
||||
image = [np.array(i.convert("RGB"))[None, :] for i in image]
|
||||
image = np.concatenate(image, axis=0)
|
||||
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
|
||||
image = np.concatenate([i[None, :] for i in image], axis=0)
|
||||
|
||||
image = image.transpose(0, 3, 1, 2)
|
||||
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
|
||||
|
||||
# preprocess mask
|
||||
if isinstance(mask, (PIL.Image.Image, np.ndarray)):
|
||||
mask = [mask]
|
||||
|
||||
if isinstance(mask, list) and isinstance(mask[0], PIL.Image.Image):
|
||||
mask = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in mask]
|
||||
mask = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask], axis=0)
|
||||
mask = mask.astype(np.float32) / 255.0
|
||||
elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
|
||||
mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
|
||||
|
||||
mask[mask < 0.5] = 0
|
||||
mask[mask >= 0.5] = 1
|
||||
mask = torch.from_numpy(mask)
|
||||
|
||||
return mask, image
|
||||
|
||||
|
||||
class KandinskyInpaintPipeline(DiffusionPipeline):
|
||||
"""
|
||||
Pipeline for text-guided image inpainting using Kandinsky2.1
|
||||
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
Args:
|
||||
text_encoder ([`MultilingualCLIP`]):
|
||||
Frozen text-encoder.
|
||||
tokenizer ([`XLMRobertaTokenizer`]):
|
||||
Tokenizer of class
|
||||
scheduler ([`DDIMScheduler`]):
|
||||
A scheduler to be used in combination with `unet` to generate image latents.
|
||||
unet ([`UNet2DConditionModel`]):
|
||||
Conditional U-Net architecture to denoise the image embedding.
|
||||
movq ([`VQModel`]):
|
||||
MoVQ image encoder and decoder
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
text_encoder: MultilingualCLIP,
|
||||
movq: VQModel,
|
||||
tokenizer: XLMRobertaTokenizer,
|
||||
unet: UNet2DConditionModel,
|
||||
scheduler: DDIMScheduler,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.register_modules(
|
||||
text_encoder=text_encoder,
|
||||
movq=movq,
|
||||
tokenizer=tokenizer,
|
||||
unet=unet,
|
||||
scheduler=scheduler,
|
||||
)
|
||||
self.movq_scale_factor = 2 ** (len(self.movq.config.block_out_channels) - 1)
|
||||
|
||||
def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
|
||||
if latents is None:
|
||||
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
else:
|
||||
if latents.shape != shape:
|
||||
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
|
||||
latents = latents.to(device)
|
||||
|
||||
latents = latents * scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def _encode_prompt(
|
||||
self,
|
||||
prompt,
|
||||
device,
|
||||
num_images_per_prompt,
|
||||
do_classifier_free_guidance,
|
||||
negative_prompt=None,
|
||||
):
|
||||
batch_size = len(prompt) if isinstance(prompt, list) else 1
|
||||
# get prompt text embeddings
|
||||
text_inputs = self.tokenizer(
|
||||
prompt,
|
||||
padding="max_length",
|
||||
max_length=77,
|
||||
truncation=True,
|
||||
return_attention_mask=True,
|
||||
add_special_tokens=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
|
||||
text_input_ids = text_inputs.input_ids
|
||||
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
|
||||
|
||||
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
|
||||
removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
|
||||
logger.warning(
|
||||
"The following part of your input was truncated because CLIP can only handle sequences up to"
|
||||
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
|
||||
)
|
||||
|
||||
text_input_ids = text_input_ids.to(device)
|
||||
text_mask = text_inputs.attention_mask.to(device)
|
||||
|
||||
prompt_embeds, text_encoder_hidden_states = self.text_encoder(
|
||||
input_ids=text_input_ids, attention_mask=text_mask
|
||||
)
|
||||
|
||||
prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_encoder_hidden_states = text_encoder_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_mask = text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
uncond_tokens: List[str]
|
||||
if negative_prompt is None:
|
||||
uncond_tokens = [""] * batch_size
|
||||
elif type(prompt) is not type(negative_prompt):
|
||||
raise TypeError(
|
||||
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
|
||||
f" {type(prompt)}."
|
||||
)
|
||||
elif isinstance(negative_prompt, str):
|
||||
uncond_tokens = [negative_prompt]
|
||||
elif batch_size != len(negative_prompt):
|
||||
raise ValueError(
|
||||
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
|
||||
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
|
||||
" the batch size of `prompt`."
|
||||
)
|
||||
else:
|
||||
uncond_tokens = negative_prompt
|
||||
|
||||
uncond_input = self.tokenizer(
|
||||
uncond_tokens,
|
||||
padding="max_length",
|
||||
max_length=77,
|
||||
truncation=True,
|
||||
return_attention_mask=True,
|
||||
add_special_tokens=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
uncond_text_input_ids = uncond_input.input_ids.to(device)
|
||||
uncond_text_mask = uncond_input.attention_mask.to(device)
|
||||
|
||||
negative_prompt_embeds, uncond_text_encoder_hidden_states = self.text_encoder(
|
||||
input_ids=uncond_text_input_ids, attention_mask=uncond_text_mask
|
||||
)
|
||||
|
||||
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
|
||||
|
||||
seq_len = negative_prompt_embeds.shape[1]
|
||||
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt)
|
||||
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len)
|
||||
|
||||
seq_len = uncond_text_encoder_hidden_states.shape[1]
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.repeat(1, num_images_per_prompt, 1)
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.view(
|
||||
batch_size * num_images_per_prompt, seq_len, -1
|
||||
)
|
||||
uncond_text_mask = uncond_text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
# done duplicates
|
||||
|
||||
# For classifier free guidance, we need to do two forward passes.
|
||||
# Here we concatenate the unconditional and text embeddings into a single batch
|
||||
# to avoid doing two forward passes
|
||||
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
|
||||
text_encoder_hidden_states = torch.cat([uncond_text_encoder_hidden_states, text_encoder_hidden_states])
|
||||
|
||||
text_mask = torch.cat([uncond_text_mask, text_mask])
|
||||
|
||||
return prompt_embeds, text_encoder_hidden_states, text_mask
|
||||
|
||||
def enable_sequential_cpu_offload(self, gpu_id=0):
|
||||
r"""
|
||||
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline's
|
||||
models have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded to GPU only
|
||||
when their specific submodule has its `forward` method called.
|
||||
"""
|
||||
if is_accelerate_available():
|
||||
from accelerate import cpu_offload
|
||||
else:
|
||||
raise ImportError("Please install accelerate via `pip install accelerate`")
|
||||
|
||||
device = torch.device(f"cuda:{gpu_id}")
|
||||
|
||||
models = [
|
||||
self.unet,
|
||||
self.text_encoder,
|
||||
self.movq,
|
||||
]
|
||||
for cpu_offloaded_model in models:
|
||||
if cpu_offloaded_model is not None:
|
||||
cpu_offload(cpu_offloaded_model, device)
|
||||
|
||||
def enable_model_cpu_offload(self, gpu_id=0):
|
||||
r"""
|
||||
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
|
||||
to `enable_sequential_cpu_offload`, this method moves one whole model at a time to the GPU when its `forward`
|
||||
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
|
||||
`enable_sequential_cpu_offload`, but performance is much better due to the iterative execution of the `unet`.
|
||||
"""
|
||||
if is_accelerate_available() and is_accelerate_version(">=", "0.17.0.dev0"):
|
||||
from accelerate import cpu_offload_with_hook
|
||||
else:
|
||||
raise ImportError("`enable_model_cpu_offload` requires `accelerate v0.17.0` or higher.")
|
||||
|
||||
device = torch.device(f"cuda:{gpu_id}")
|
||||
|
||||
if self.device.type != "cpu":
|
||||
self.to("cpu", silence_dtype_warnings=True)
|
||||
torch.cuda.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
|
||||
|
||||
hook = None
|
||||
for cpu_offloaded_model in [self.text_encoder, self.unet, self.movq]:
|
||||
_, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
|
||||
|
||||
if self.safety_checker is not None:
|
||||
_, hook = cpu_offload_with_hook(self.safety_checker, device, prev_module_hook=hook)
|
||||
|
||||
# We'll offload the last model manually.
|
||||
self.final_offload_hook = hook
|
||||
|
||||
@property
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._execution_device
|
||||
def _execution_device(self):
|
||||
r"""
|
||||
Returns the device on which the pipeline's models will be executed. After calling
|
||||
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
|
||||
hooks.
|
||||
"""
|
||||
if not hasattr(self.unet, "_hf_hook"):
|
||||
return self.device
|
||||
for module in self.unet.modules():
|
||||
if (
|
||||
hasattr(module, "_hf_hook")
|
||||
and hasattr(module._hf_hook, "execution_device")
|
||||
and module._hf_hook.execution_device is not None
|
||||
):
|
||||
return torch.device(module._hf_hook.execution_device)
|
||||
return self.device
|
||||
|
||||
@torch.no_grad()
|
||||
@replace_example_docstring(EXAMPLE_DOC_STRING)
|
||||
def __call__(
|
||||
self,
|
||||
prompt: Union[str, List[str]],
|
||||
image: Union[torch.FloatTensor, PIL.Image.Image],
|
||||
mask_image: Union[torch.FloatTensor, PIL.Image.Image, np.ndarray],
|
||||
image_embeds: torch.FloatTensor,
|
||||
negative_image_embeds: torch.FloatTensor,
|
||||
negative_prompt: Optional[Union[str, List[str]]] = None,
|
||||
height: int = 512,
|
||||
width: int = 512,
|
||||
num_inference_steps: int = 100,
|
||||
guidance_scale: float = 4.0,
|
||||
num_images_per_prompt: int = 1,
|
||||
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
||||
latents: Optional[torch.FloatTensor] = None,
|
||||
output_type: Optional[str] = "pil",
|
||||
return_dict: bool = True,
|
||||
):
|
||||
"""
|
||||
Function invoked when calling the pipeline for generation.
|
||||
|
||||
Args:
|
||||
prompt (`str` or `List[str]`):
|
||||
The prompt or prompts to guide the image generation.
|
||||
image (`torch.FloatTensor`, `PIL.Image.Image` or `np.ndarray`):
|
||||
`Image`, or tensor representing an image batch, that will be used as the starting point for the
|
||||
process.
|
||||
mask_image (`PIL.Image.Image`,`torch.FloatTensor` or `np.ndarray`):
|
||||
`Image`, or a tensor representing an image batch, to mask `image`. White pixels in the mask will be
|
||||
repainted, while black pixels will be preserved. You can pass a pytorch tensor as mask only if the
|
||||
image you passed is a pytorch tensor, and it should contain one color channel (L) instead of 3, so the
|
||||
expected shape would be either `(B, 1, H, W,)`, `(B, H, W)`, `(1, H, W)` or `(H, W)` If image is an PIL
|
||||
image or numpy array, mask should also be a either PIL image or numpy array. If it is a PIL image, it
|
||||
will be converted to a single channel (luminance) before use. If it is a nummpy array, the expected
|
||||
shape is `(H, W)`.
|
||||
image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
|
||||
The clip image embeddings for text prompt, that will be used to condition the image generation.
|
||||
negative_image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
|
||||
The clip image embeddings for negative text prompt, will be used to condition the image generation.
|
||||
negative_prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
|
||||
if `guidance_scale` is less than `1`).
|
||||
height (`int`, *optional*, defaults to 512):
|
||||
The height in pixels of the generated image.
|
||||
width (`int`, *optional*, defaults to 512):
|
||||
The width in pixels of the generated image.
|
||||
num_inference_steps (`int`, *optional*, defaults to 100):
|
||||
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
||||
expense of slower inference.
|
||||
guidance_scale (`float`, *optional*, defaults to 4.0):
|
||||
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
||||
`guidance_scale` is defined as `w` of equation 2. of [Imagen
|
||||
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
|
||||
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
|
||||
usually at the expense of lower image quality.
|
||||
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
||||
The number of images to generate per prompt.
|
||||
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
||||
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
|
||||
to make generation deterministic.
|
||||
latents (`torch.FloatTensor`, *optional*):
|
||||
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
|
||||
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
||||
tensor will ge generated by sampling using the supplied random `generator`.
|
||||
output_type (`str`, *optional*, defaults to `"pil"`):
|
||||
The output format of the generate image. Choose between: `"pil"` (`PIL.Image.Image`), `"np"`
|
||||
(`np.array`) or `"pt"` (`torch.Tensor`).
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`~pipelines.ImagePipelineOutput`] or `tuple`
|
||||
"""
|
||||
|
||||
# Define call parameters
|
||||
if isinstance(prompt, str):
|
||||
batch_size = 1
|
||||
elif isinstance(prompt, list):
|
||||
batch_size = len(prompt)
|
||||
else:
|
||||
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
|
||||
|
||||
device = self._execution_device
|
||||
|
||||
batch_size = batch_size * num_images_per_prompt
|
||||
do_classifier_free_guidance = guidance_scale > 1.0
|
||||
|
||||
prompt_embeds, text_encoder_hidden_states, _ = self._encode_prompt(
|
||||
prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
|
||||
)
|
||||
|
||||
if isinstance(image_embeds, list):
|
||||
image_embeds = torch.cat(image_embeds, dim=0)
|
||||
if isinstance(negative_image_embeds, list):
|
||||
negative_image_embeds = torch.cat(negative_image_embeds, dim=0)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
negative_image_embeds = negative_image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
image_embeds = torch.cat([negative_image_embeds, image_embeds], dim=0).to(
|
||||
dtype=prompt_embeds.dtype, device=device
|
||||
)
|
||||
|
||||
# preprocess image and mask
|
||||
mask_image, image = prepare_mask_and_masked_image(image, mask_image, height, width)
|
||||
|
||||
image = image.to(dtype=prompt_embeds.dtype, device=device)
|
||||
image = self.movq.encode(image)["latents"]
|
||||
|
||||
mask_image = mask_image.to(dtype=prompt_embeds.dtype, device=device)
|
||||
|
||||
image_shape = tuple(image.shape[-2:])
|
||||
mask_image = F.interpolate(
|
||||
mask_image,
|
||||
image_shape,
|
||||
mode="nearest",
|
||||
)
|
||||
mask_image = prepare_mask(mask_image)
|
||||
masked_image = image * mask_image
|
||||
|
||||
mask_image = mask_image.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
masked_image = masked_image.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
if do_classifier_free_guidance:
|
||||
mask_image = mask_image.repeat(2, 1, 1, 1)
|
||||
masked_image = masked_image.repeat(2, 1, 1, 1)
|
||||
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
timesteps_tensor = self.scheduler.timesteps
|
||||
|
||||
num_channels_latents = self.movq.config.latent_channels
|
||||
|
||||
# get h, w for latents
|
||||
sample_height, sample_width = get_new_h_w(height, width, self.movq_scale_factor)
|
||||
|
||||
# create initial latent
|
||||
latents = self.prepare_latents(
|
||||
(batch_size, num_channels_latents, sample_height, sample_width),
|
||||
text_encoder_hidden_states.dtype,
|
||||
device,
|
||||
generator,
|
||||
latents,
|
||||
self.scheduler,
|
||||
)
|
||||
|
||||
# Check that sizes of mask, masked image and latents match with expected
|
||||
num_channels_mask = mask_image.shape[1]
|
||||
num_channels_masked_image = masked_image.shape[1]
|
||||
if num_channels_latents + num_channels_mask + num_channels_masked_image != self.unet.config.in_channels:
|
||||
raise ValueError(
|
||||
f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
|
||||
f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
|
||||
f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
|
||||
f" = {num_channels_latents+num_channels_masked_image+num_channels_mask}. Please verify the config of"
|
||||
" `pipeline.unet` or your `mask_image` or `image` input."
|
||||
)
|
||||
|
||||
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
latent_model_input = torch.cat([latent_model_input, masked_image, mask_image], dim=1)
|
||||
|
||||
added_cond_kwargs = {"text_embeds": prompt_embeds, "image_embeds": image_embeds}
|
||||
noise_pred = self.unet(
|
||||
sample=latent_model_input,
|
||||
timestep=t,
|
||||
encoder_hidden_states=text_encoder_hidden_states,
|
||||
added_cond_kwargs=added_cond_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred, variance_pred = noise_pred.split(latents.shape[1], dim=1)
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
_, variance_pred_text = variance_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
noise_pred = torch.cat([noise_pred, variance_pred_text], dim=1)
|
||||
|
||||
if not (
|
||||
hasattr(self.scheduler.config, "variance_type")
|
||||
and self.scheduler.config.variance_type in ["learned", "learned_range"]
|
||||
):
|
||||
noise_pred, _ = noise_pred.split(latents.shape[1], dim=1)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(
|
||||
noise_pred,
|
||||
t,
|
||||
latents,
|
||||
generator=generator,
|
||||
).prev_sample
|
||||
|
||||
# post-processing
|
||||
image = self.movq.decode(latents, force_not_quantize=True)["sample"]
|
||||
|
||||
if output_type not in ["pt", "np", "pil"]:
|
||||
raise ValueError(f"Only the output types `pt`, `pil` and `np` are supported not output_type={output_type}")
|
||||
|
||||
if output_type in ["np", "pil"]:
|
||||
image = image * 0.5 + 0.5
|
||||
image = image.clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
|
||||
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
if not return_dict:
|
||||
return (image,)
|
||||
|
||||
return ImagePipelineOutput(images=image)
|
||||
@@ -1,578 +0,0 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import PIL
|
||||
import torch
|
||||
from transformers import CLIPImageProcessor, CLIPTextModelWithProjection, CLIPTokenizer, CLIPVisionModelWithProjection
|
||||
|
||||
from ...models import PriorTransformer
|
||||
from ...pipelines import DiffusionPipeline
|
||||
from ...schedulers import UnCLIPScheduler
|
||||
from ...utils import (
|
||||
BaseOutput,
|
||||
is_accelerate_available,
|
||||
logging,
|
||||
randn_tensor,
|
||||
replace_example_docstring,
|
||||
)
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
EXAMPLE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> from diffusers import KandinskyPipeline, KandinskyPriorPipeline
|
||||
>>> import torch
|
||||
|
||||
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior")
|
||||
>>> pipe_prior.to("cuda")
|
||||
|
||||
>>> prompt = "red cat, 4k photo"
|
||||
>>> out = pipe_prior(prompt)
|
||||
>>> image_emb = out.image_embeds
|
||||
>>> negative_image_emb = out.negative_image_embeds
|
||||
|
||||
>>> pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1")
|
||||
>>> pipe.to("cuda")
|
||||
|
||||
>>> image = pipe(
|
||||
... prompt,
|
||||
... image_embeds=image_emb,
|
||||
... negative_image_embeds=negative_image_emb,
|
||||
... height=768,
|
||||
... width=768,
|
||||
... num_inference_steps=100,
|
||||
... ).images
|
||||
|
||||
>>> image[0].save("cat.png")
|
||||
```
|
||||
"""
|
||||
|
||||
EXAMPLE_INTERPOLATE_DOC_STRING = """
|
||||
Examples:
|
||||
```py
|
||||
>>> from diffusers import KandinskyPriorPipeline, KandinskyPipeline
|
||||
>>> from diffusers.utils import load_image
|
||||
>>> import PIL
|
||||
|
||||
>>> import torch
|
||||
>>> from torchvision import transforms
|
||||
|
||||
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained(
|
||||
... "kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
|
||||
... )
|
||||
>>> pipe_prior.to("cuda")
|
||||
|
||||
>>> img1 = load_image(
|
||||
... "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
|
||||
... "/kandinsky/cat.png"
|
||||
... )
|
||||
|
||||
>>> img2 = load_image(
|
||||
... "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
|
||||
... "/kandinsky/starry_night.jpeg"
|
||||
... )
|
||||
|
||||
>>> images_texts = ["a cat", img1, img2]
|
||||
>>> weights = [0.3, 0.3, 0.4]
|
||||
>>> image_emb, zero_image_emb = pipe_prior.interpolate(images_texts, weights)
|
||||
|
||||
>>> pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
|
||||
>>> pipe.to("cuda")
|
||||
|
||||
>>> image = pipe(
|
||||
... "",
|
||||
... image_embeds=image_emb,
|
||||
... negative_image_embeds=zero_image_emb,
|
||||
... height=768,
|
||||
... width=768,
|
||||
... num_inference_steps=150,
|
||||
... ).images[0]
|
||||
|
||||
>>> image.save("starry_cat.png")
|
||||
```
|
||||
"""
|
||||
|
||||
|
||||
@dataclass
|
||||
class KandinskyPriorPipelineOutput(BaseOutput):
|
||||
"""
|
||||
Output class for KandinskyPriorPipeline.
|
||||
|
||||
Args:
|
||||
image_embeds (`torch.FloatTensor`)
|
||||
clip image embeddings for text prompt
|
||||
negative_image_embeds (`List[PIL.Image.Image]` or `np.ndarray`)
|
||||
clip image embeddings for unconditional tokens
|
||||
"""
|
||||
|
||||
image_embeds: Union[torch.FloatTensor, np.ndarray]
|
||||
negative_image_embeds: Union[torch.FloatTensor, np.ndarray]
|
||||
|
||||
|
||||
class KandinskyPriorPipeline(DiffusionPipeline):
|
||||
"""
|
||||
Pipeline for generating image prior for Kandinsky
|
||||
|
||||
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
|
||||
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
|
||||
|
||||
Args:
|
||||
prior ([`PriorTransformer`]):
|
||||
The canonincal unCLIP prior to approximate the image embedding from the text embedding.
|
||||
image_encoder ([`CLIPVisionModelWithProjection`]):
|
||||
Frozen image-encoder.
|
||||
text_encoder ([`CLIPTextModelWithProjection`]):
|
||||
Frozen text-encoder.
|
||||
tokenizer (`CLIPTokenizer`):
|
||||
Tokenizer of class
|
||||
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
|
||||
scheduler ([`UnCLIPScheduler`]):
|
||||
A scheduler to be used in combination with `prior` to generate image embedding.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
prior: PriorTransformer,
|
||||
image_encoder: CLIPVisionModelWithProjection,
|
||||
text_encoder: CLIPTextModelWithProjection,
|
||||
tokenizer: CLIPTokenizer,
|
||||
scheduler: UnCLIPScheduler,
|
||||
image_processor: CLIPImageProcessor,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.register_modules(
|
||||
prior=prior,
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
scheduler=scheduler,
|
||||
image_encoder=image_encoder,
|
||||
image_processor=image_processor,
|
||||
)
|
||||
|
||||
@torch.no_grad()
|
||||
@replace_example_docstring(EXAMPLE_INTERPOLATE_DOC_STRING)
|
||||
def interpolate(
|
||||
self,
|
||||
images_and_prompts: List[Union[str, PIL.Image.Image, torch.FloatTensor]],
|
||||
weights: List[float],
|
||||
num_images_per_prompt: int = 1,
|
||||
num_inference_steps: int = 25,
|
||||
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
||||
latents: Optional[torch.FloatTensor] = None,
|
||||
negative_prior_prompt: Optional[str] = None,
|
||||
negative_prompt: Union[str] = "",
|
||||
guidance_scale: float = 4.0,
|
||||
device=None,
|
||||
):
|
||||
"""
|
||||
Function invoked when using the prior pipeline for interpolation.
|
||||
|
||||
Args:
|
||||
images_and_prompts (`List[Union[str, PIL.Image.Image, torch.FloatTensor]]`):
|
||||
list of prompts and images to guide the image generation.
|
||||
weights: (`List[float]`):
|
||||
list of weights for each condition in `images_and_prompts`
|
||||
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
||||
The number of images to generate per prompt.
|
||||
num_inference_steps (`int`, *optional*, defaults to 100):
|
||||
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
||||
expense of slower inference.
|
||||
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
||||
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
|
||||
to make generation deterministic.
|
||||
latents (`torch.FloatTensor`, *optional*):
|
||||
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
|
||||
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
||||
tensor will ge generated by sampling using the supplied random `generator`.
|
||||
negative_prior_prompt (`str`, *optional*):
|
||||
The prompt not to guide the prior diffusion process. Ignored when not using guidance (i.e., ignored if
|
||||
`guidance_scale` is less than `1`).
|
||||
negative_prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt not to guide the image generation. Ignored when not using guidance (i.e., ignored if
|
||||
`guidance_scale` is less than `1`).
|
||||
guidance_scale (`float`, *optional*, defaults to 4.0):
|
||||
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
||||
`guidance_scale` is defined as `w` of equation 2. of [Imagen
|
||||
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
|
||||
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
|
||||
usually at the expense of lower image quality.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`KandinskyPriorPipelineOutput`] or `tuple`
|
||||
"""
|
||||
|
||||
device = device or self.device
|
||||
|
||||
if len(images_and_prompts) != len(weights):
|
||||
raise ValueError(
|
||||
f"`images_and_prompts` contains {len(images_and_prompts)} items and `weights` contains {len(weights)} items - they should be lists of same length"
|
||||
)
|
||||
|
||||
image_embeddings = []
|
||||
for cond, weight in zip(images_and_prompts, weights):
|
||||
if isinstance(cond, str):
|
||||
image_emb = self(
|
||||
cond,
|
||||
num_inference_steps=num_inference_steps,
|
||||
num_images_per_prompt=num_images_per_prompt,
|
||||
generator=generator,
|
||||
latents=latents,
|
||||
negative_prompt=negative_prior_prompt,
|
||||
guidance_scale=guidance_scale,
|
||||
).image_embeds
|
||||
|
||||
elif isinstance(cond, (PIL.Image.Image, torch.Tensor)):
|
||||
if isinstance(cond, PIL.Image.Image):
|
||||
cond = (
|
||||
self.image_processor(cond, return_tensors="pt")
|
||||
.pixel_values[0]
|
||||
.unsqueeze(0)
|
||||
.to(dtype=self.image_encoder.dtype, device=device)
|
||||
)
|
||||
|
||||
image_emb = self.image_encoder(cond)["image_embeds"]
|
||||
|
||||
else:
|
||||
raise ValueError(
|
||||
f"`images_and_prompts` can only contains elements to be of type `str`, `PIL.Image.Image` or `torch.Tensor` but is {type(cond)}"
|
||||
)
|
||||
|
||||
image_embeddings.append(image_emb * weight)
|
||||
|
||||
image_emb = torch.cat(image_embeddings).sum(dim=0, keepdim=True)
|
||||
|
||||
out_zero = self(
|
||||
negative_prompt,
|
||||
num_inference_steps=num_inference_steps,
|
||||
num_images_per_prompt=num_images_per_prompt,
|
||||
generator=generator,
|
||||
latents=latents,
|
||||
negative_prompt=negative_prior_prompt,
|
||||
guidance_scale=guidance_scale,
|
||||
)
|
||||
zero_image_emb = out_zero.negative_image_embeds if negative_prompt == "" else out_zero.image_embeds
|
||||
|
||||
return KandinskyPriorPipelineOutput(image_embeds=image_emb, negative_image_embeds=zero_image_emb)
|
||||
|
||||
def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
|
||||
if latents is None:
|
||||
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
else:
|
||||
if latents.shape != shape:
|
||||
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
|
||||
latents = latents.to(device)
|
||||
|
||||
latents = latents * scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def get_zero_embed(self, batch_size=1, device=None):
|
||||
device = device or self.device
|
||||
zero_img = torch.zeros(1, 3, self.image_encoder.config.image_size, self.image_encoder.config.image_size).to(
|
||||
device=device, dtype=self.image_encoder.dtype
|
||||
)
|
||||
zero_image_emb = self.image_encoder(zero_img)["image_embeds"]
|
||||
zero_image_emb = zero_image_emb.repeat(batch_size, 1)
|
||||
return zero_image_emb
|
||||
|
||||
def enable_sequential_cpu_offload(self, gpu_id=0):
|
||||
r"""
|
||||
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline's
|
||||
models have their state dicts saved to CPU and then are moved to a `torch.device('meta') and loaded to GPU only
|
||||
when their specific submodule has its `forward` method called.
|
||||
"""
|
||||
if is_accelerate_available():
|
||||
from accelerate import cpu_offload
|
||||
else:
|
||||
raise ImportError("Please install accelerate via `pip install accelerate`")
|
||||
|
||||
device = torch.device(f"cuda:{gpu_id}")
|
||||
|
||||
models = [
|
||||
self.image_encoder,
|
||||
self.text_encoder,
|
||||
]
|
||||
for cpu_offloaded_model in models:
|
||||
if cpu_offloaded_model is not None:
|
||||
cpu_offload(cpu_offloaded_model, device)
|
||||
|
||||
@property
|
||||
def _execution_device(self):
|
||||
r"""
|
||||
Returns the device on which the pipeline's models will be executed. After calling
|
||||
`pipeline.enable_sequential_cpu_offload()` the execution device can only be inferred from Accelerate's module
|
||||
hooks.
|
||||
"""
|
||||
if self.device != torch.device("meta") or not hasattr(self.text_encoder, "_hf_hook"):
|
||||
return self.device
|
||||
for module in self.text_encoder.modules():
|
||||
if (
|
||||
hasattr(module, "_hf_hook")
|
||||
and hasattr(module._hf_hook, "execution_device")
|
||||
and module._hf_hook.execution_device is not None
|
||||
):
|
||||
return torch.device(module._hf_hook.execution_device)
|
||||
return self.device
|
||||
|
||||
def _encode_prompt(
|
||||
self,
|
||||
prompt,
|
||||
device,
|
||||
num_images_per_prompt,
|
||||
do_classifier_free_guidance,
|
||||
negative_prompt=None,
|
||||
):
|
||||
batch_size = len(prompt) if isinstance(prompt, list) else 1
|
||||
# get prompt text embeddings
|
||||
text_inputs = self.tokenizer(
|
||||
prompt,
|
||||
padding="max_length",
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
text_input_ids = text_inputs.input_ids
|
||||
text_mask = text_inputs.attention_mask.bool().to(device)
|
||||
|
||||
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
|
||||
|
||||
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
|
||||
removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
|
||||
logger.warning(
|
||||
"The following part of your input was truncated because CLIP can only handle sequences up to"
|
||||
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
|
||||
)
|
||||
text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
|
||||
|
||||
text_encoder_output = self.text_encoder(text_input_ids.to(device))
|
||||
|
||||
prompt_embeds = text_encoder_output.text_embeds
|
||||
text_encoder_hidden_states = text_encoder_output.last_hidden_state
|
||||
|
||||
prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_encoder_hidden_states = text_encoder_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
text_mask = text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
uncond_tokens: List[str]
|
||||
if negative_prompt is None:
|
||||
uncond_tokens = [""] * batch_size
|
||||
elif type(prompt) is not type(negative_prompt):
|
||||
raise TypeError(
|
||||
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
|
||||
f" {type(prompt)}."
|
||||
)
|
||||
elif isinstance(negative_prompt, str):
|
||||
uncond_tokens = [negative_prompt]
|
||||
elif batch_size != len(negative_prompt):
|
||||
raise ValueError(
|
||||
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
|
||||
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
|
||||
" the batch size of `prompt`."
|
||||
)
|
||||
else:
|
||||
uncond_tokens = negative_prompt
|
||||
|
||||
uncond_input = self.tokenizer(
|
||||
uncond_tokens,
|
||||
padding="max_length",
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
uncond_text_mask = uncond_input.attention_mask.bool().to(device)
|
||||
negative_prompt_embeds_text_encoder_output = self.text_encoder(uncond_input.input_ids.to(device))
|
||||
|
||||
negative_prompt_embeds = negative_prompt_embeds_text_encoder_output.text_embeds
|
||||
uncond_text_encoder_hidden_states = negative_prompt_embeds_text_encoder_output.last_hidden_state
|
||||
|
||||
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
|
||||
|
||||
seq_len = negative_prompt_embeds.shape[1]
|
||||
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt)
|
||||
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len)
|
||||
|
||||
seq_len = uncond_text_encoder_hidden_states.shape[1]
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.repeat(1, num_images_per_prompt, 1)
|
||||
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.view(
|
||||
batch_size * num_images_per_prompt, seq_len, -1
|
||||
)
|
||||
uncond_text_mask = uncond_text_mask.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
|
||||
# done duplicates
|
||||
|
||||
# For classifier free guidance, we need to do two forward passes.
|
||||
# Here we concatenate the unconditional and text embeddings into a single batch
|
||||
# to avoid doing two forward passes
|
||||
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
|
||||
text_encoder_hidden_states = torch.cat([uncond_text_encoder_hidden_states, text_encoder_hidden_states])
|
||||
|
||||
text_mask = torch.cat([uncond_text_mask, text_mask])
|
||||
|
||||
return prompt_embeds, text_encoder_hidden_states, text_mask
|
||||
|
||||
@torch.no_grad()
|
||||
@replace_example_docstring(EXAMPLE_DOC_STRING)
|
||||
def __call__(
|
||||
self,
|
||||
prompt: Union[str, List[str]],
|
||||
negative_prompt: Optional[Union[str, List[str]]] = None,
|
||||
num_images_per_prompt: int = 1,
|
||||
num_inference_steps: int = 25,
|
||||
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
||||
latents: Optional[torch.FloatTensor] = None,
|
||||
guidance_scale: float = 4.0,
|
||||
output_type: Optional[str] = "pt", # pt only
|
||||
return_dict: bool = True,
|
||||
):
|
||||
"""
|
||||
Function invoked when calling the pipeline for generation.
|
||||
|
||||
Args:
|
||||
prompt (`str` or `List[str]`):
|
||||
The prompt or prompts to guide the image generation.
|
||||
negative_prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
|
||||
if `guidance_scale` is less than `1`).
|
||||
num_images_per_prompt (`int`, *optional*, defaults to 1):
|
||||
The number of images to generate per prompt.
|
||||
num_inference_steps (`int`, *optional*, defaults to 100):
|
||||
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
||||
expense of slower inference.
|
||||
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
|
||||
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
|
||||
to make generation deterministic.
|
||||
latents (`torch.FloatTensor`, *optional*):
|
||||
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
|
||||
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
|
||||
tensor will ge generated by sampling using the supplied random `generator`.
|
||||
guidance_scale (`float`, *optional*, defaults to 4.0):
|
||||
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
||||
`guidance_scale` is defined as `w` of equation 2. of [Imagen
|
||||
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
|
||||
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
|
||||
usually at the expense of lower image quality.
|
||||
output_type (`str`, *optional*, defaults to `"pt"`):
|
||||
The output format of the generate image. Choose between: `"np"` (`np.array`) or `"pt"`
|
||||
(`torch.Tensor`).
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
|
||||
|
||||
Examples:
|
||||
|
||||
Returns:
|
||||
[`KandinskyPriorPipelineOutput`] or `tuple`
|
||||
"""
|
||||
|
||||
if isinstance(prompt, str):
|
||||
prompt = [prompt]
|
||||
elif not isinstance(prompt, list):
|
||||
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
|
||||
|
||||
if isinstance(negative_prompt, str):
|
||||
negative_prompt = [negative_prompt]
|
||||
elif not isinstance(negative_prompt, list) and negative_prompt is not None:
|
||||
raise ValueError(f"`negative_prompt` has to be of type `str` or `list` but is {type(negative_prompt)}")
|
||||
|
||||
# if the negative prompt is defined we double the batch size to
|
||||
# directly retrieve the negative prompt embedding
|
||||
if negative_prompt is not None:
|
||||
prompt = prompt + negative_prompt
|
||||
negative_prompt = 2 * negative_prompt
|
||||
|
||||
device = self._execution_device
|
||||
|
||||
batch_size = len(prompt)
|
||||
batch_size = batch_size * num_images_per_prompt
|
||||
|
||||
do_classifier_free_guidance = guidance_scale > 1.0
|
||||
prompt_embeds, text_encoder_hidden_states, text_mask = self._encode_prompt(
|
||||
prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
|
||||
)
|
||||
|
||||
# prior
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
prior_timesteps_tensor = self.scheduler.timesteps
|
||||
|
||||
embedding_dim = self.prior.config.embedding_dim
|
||||
|
||||
latents = self.prepare_latents(
|
||||
(batch_size, embedding_dim),
|
||||
prompt_embeds.dtype,
|
||||
device,
|
||||
generator,
|
||||
latents,
|
||||
self.scheduler,
|
||||
)
|
||||
|
||||
for i, t in enumerate(self.progress_bar(prior_timesteps_tensor)):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
|
||||
predicted_image_embedding = self.prior(
|
||||
latent_model_input,
|
||||
timestep=t,
|
||||
proj_embedding=prompt_embeds,
|
||||
encoder_hidden_states=text_encoder_hidden_states,
|
||||
attention_mask=text_mask,
|
||||
).predicted_image_embedding
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
predicted_image_embedding_uncond, predicted_image_embedding_text = predicted_image_embedding.chunk(2)
|
||||
predicted_image_embedding = predicted_image_embedding_uncond + guidance_scale * (
|
||||
predicted_image_embedding_text - predicted_image_embedding_uncond
|
||||
)
|
||||
|
||||
if i + 1 == prior_timesteps_tensor.shape[0]:
|
||||
prev_timestep = None
|
||||
else:
|
||||
prev_timestep = prior_timesteps_tensor[i + 1]
|
||||
|
||||
latents = self.scheduler.step(
|
||||
predicted_image_embedding,
|
||||
timestep=t,
|
||||
sample=latents,
|
||||
generator=generator,
|
||||
prev_timestep=prev_timestep,
|
||||
).prev_sample
|
||||
|
||||
latents = self.prior.post_process_latents(latents)
|
||||
|
||||
image_embeddings = latents
|
||||
|
||||
# if negative prompt has been defined, we retrieve split the image embedding into two
|
||||
if negative_prompt is None:
|
||||
zero_embeds = self.get_zero_embed(latents.shape[0], device=latents.device)
|
||||
else:
|
||||
image_embeddings, zero_embeds = image_embeddings.chunk(2)
|
||||
|
||||
if output_type not in ["pt", "np"]:
|
||||
raise ValueError(f"Only the output types `pt` and `np` are supported not output_type={output_type}")
|
||||
|
||||
if output_type == "np":
|
||||
image_embeddings = image_embeddings.cpu().numpy()
|
||||
zero_embeds = zero_embeds.cpu().numpy()
|
||||
|
||||
if not return_dict:
|
||||
return (image_embeddings, zero_embeds)
|
||||
|
||||
return KandinskyPriorPipelineOutput(image_embeds=image_embeddings, negative_image_embeds=zero_embeds)
|
||||
@@ -1,27 +0,0 @@
|
||||
import torch
|
||||
from transformers import PreTrainedModel, XLMRobertaConfig, XLMRobertaModel
|
||||
|
||||
|
||||
class MCLIPConfig(XLMRobertaConfig):
|
||||
model_type = "M-CLIP"
|
||||
|
||||
def __init__(self, transformerDimSize=1024, imageDimSize=768, **kwargs):
|
||||
self.transformerDimensions = transformerDimSize
|
||||
self.numDims = imageDimSize
|
||||
super().__init__(**kwargs)
|
||||
|
||||
|
||||
class MultilingualCLIP(PreTrainedModel):
|
||||
config_class = MCLIPConfig
|
||||
|
||||
def __init__(self, config, *args, **kwargs):
|
||||
super().__init__(config, *args, **kwargs)
|
||||
self.transformer = XLMRobertaModel(config)
|
||||
self.LinearTransformation = torch.nn.Linear(
|
||||
in_features=config.transformerDimensions, out_features=config.numDims
|
||||
)
|
||||
|
||||
def forward(self, input_ids, attention_mask):
|
||||
embs = self.transformer(input_ids=input_ids, attention_mask=attention_mask)[0]
|
||||
embs2 = (embs * attention_mask.unsqueeze(2)).sum(dim=1) / attention_mask.sum(dim=1)[:, None]
|
||||
return self.LinearTransformation(embs2), embs
|
||||
@@ -328,7 +328,17 @@ class PaintByExamplePipeline(DiffusionPipeline):
|
||||
mask = mask.to(device=device, dtype=dtype)
|
||||
|
||||
masked_image = masked_image.to(device=device, dtype=dtype)
|
||||
masked_image_latents = self._encode_vae_image(masked_image, generator=generator)
|
||||
|
||||
# encode the mask image into latents space so we can concatenate it to the latents
|
||||
if isinstance(generator, list):
|
||||
masked_image_latents = [
|
||||
self.vae.encode(masked_image[i : i + 1]).latent_dist.sample(generator=generator[i])
|
||||
for i in range(batch_size)
|
||||
]
|
||||
masked_image_latents = torch.cat(masked_image_latents, dim=0)
|
||||
else:
|
||||
masked_image_latents = self.vae.encode(masked_image).latent_dist.sample(generator=generator)
|
||||
masked_image_latents = self.vae.config.scaling_factor * masked_image_latents
|
||||
|
||||
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
|
||||
if mask.shape[0] < batch_size:
|
||||
@@ -357,21 +367,6 @@ class PaintByExamplePipeline(DiffusionPipeline):
|
||||
masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
|
||||
return mask, masked_image_latents
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_inpaint.StableDiffusionInpaintPipeline._encode_vae_image
|
||||
def _encode_vae_image(self, image: torch.Tensor, generator: torch.Generator):
|
||||
if isinstance(generator, list):
|
||||
image_latents = [
|
||||
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator=generator[i])
|
||||
for i in range(image.shape[0])
|
||||
]
|
||||
image_latents = torch.cat(image_latents, dim=0)
|
||||
else:
|
||||
image_latents = self.vae.encode(image).latent_dist.sample(generator=generator)
|
||||
|
||||
image_latents = self.vae.config.scaling_factor * image_latents
|
||||
|
||||
return image_latents
|
||||
|
||||
def _encode_image(self, image, device, num_images_per_prompt, do_classifier_free_guidance):
|
||||
dtype = next(self.image_encoder.parameters()).dtype
|
||||
|
||||
|
||||
@@ -485,19 +485,17 @@ class DiffusionPipeline(ConfigMixin):
|
||||
if module is None:
|
||||
register_dict = {name: (None, None)}
|
||||
else:
|
||||
# register the config from the original module, not the dynamo compiled one
|
||||
# register the original module, not the dynamo compiled one
|
||||
if is_compiled_module(module):
|
||||
not_compiled_module = module._orig_mod
|
||||
else:
|
||||
not_compiled_module = module
|
||||
module = module._orig_mod
|
||||
|
||||
library = not_compiled_module.__module__.split(".")[0]
|
||||
library = module.__module__.split(".")[0]
|
||||
|
||||
# check if the module is a pipeline module
|
||||
module_path_items = not_compiled_module.__module__.split(".")
|
||||
module_path_items = module.__module__.split(".")
|
||||
pipeline_dir = module_path_items[-2] if len(module_path_items) > 2 else None
|
||||
|
||||
path = not_compiled_module.__module__.split(".")
|
||||
path = module.__module__.split(".")
|
||||
is_pipeline_module = pipeline_dir in path and hasattr(pipelines, pipeline_dir)
|
||||
|
||||
# if library is not in LOADABLE_CLASSES, then it is a custom module.
|
||||
@@ -506,10 +504,10 @@ class DiffusionPipeline(ConfigMixin):
|
||||
if is_pipeline_module:
|
||||
library = pipeline_dir
|
||||
elif library not in LOADABLE_CLASSES:
|
||||
library = not_compiled_module.__module__
|
||||
library = module.__module__
|
||||
|
||||
# retrieve class_name
|
||||
class_name = not_compiled_module.__class__.__name__
|
||||
class_name = module.__class__.__name__
|
||||
|
||||
register_dict = {name: (library, class_name)}
|
||||
|
||||
@@ -1111,78 +1109,95 @@ class DiffusionPipeline(ConfigMixin):
|
||||
@classmethod
|
||||
def download(cls, pretrained_model_name, **kwargs) -> Union[str, os.PathLike]:
|
||||
r"""
|
||||
Download and cache a PyTorch diffusion pipeline from pretrained pipeline weights.
|
||||
Download and cache a PyTorch diffusion pipeline from pre-trained pipeline weights.
|
||||
|
||||
Parameters:
|
||||
pretrained_model_name (`str` or `os.PathLike`, *optional*):
|
||||
A string, the repository id (for example `CompVis/ldm-text2im-large-256`) of a pretrained pipeline
|
||||
hosted on the Hub.
|
||||
Should be a string, the *repo id* of a pretrained pipeline hosted inside a model repo on
|
||||
https://huggingface.co/ Valid repo ids have to be located under a user or organization name, like
|
||||
`CompVis/ldm-text2im-large-256`.
|
||||
custom_pipeline (`str`, *optional*):
|
||||
Can be either:
|
||||
|
||||
- A string, the repository id (for example `CompVis/ldm-text2im-large-256`) of a pretrained
|
||||
pipeline hosted on the Hub. The repository must contain a file called `pipeline.py` that defines
|
||||
the custom pipeline.
|
||||
|
||||
- A string, the *file name* of a community pipeline hosted on GitHub under
|
||||
[Community](https://github.com/huggingface/diffusers/tree/main/examples/community). Valid file
|
||||
names must match the file name and not the pipeline script (`clip_guided_stable_diffusion`
|
||||
instead of `clip_guided_stable_diffusion.py`). Community pipelines are always loaded from the
|
||||
current `main` branch of GitHub.
|
||||
|
||||
- A path to a *directory* (`./my_pipeline_directory/`) containing a custom pipeline. The directory
|
||||
must contain a file called `pipeline.py` that defines the custom pipeline.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
🧪 This is an experimental feature and may change in the future.
|
||||
This is an experimental feature and is likely to change in the future.
|
||||
|
||||
</Tip>
|
||||
|
||||
For more information on how to load and create custom pipelines, take a look at [How to contribute a
|
||||
community pipeline](https://huggingface.co/docs/diffusers/main/en/using-diffusers/contribute_pipeline).
|
||||
Can be either:
|
||||
|
||||
- A string, the *repo id* of a custom pipeline hosted inside a model repo on
|
||||
https://huggingface.co/. Valid repo ids have to be located under a user or organization name,
|
||||
like `hf-internal-testing/diffusers-dummy-pipeline`.
|
||||
|
||||
<Tip>
|
||||
|
||||
It is required that the model repo has a file, called `pipeline.py` that defines the custom
|
||||
pipeline.
|
||||
|
||||
</Tip>
|
||||
|
||||
- A string, the *file name* of a community pipeline hosted on GitHub under
|
||||
https://github.com/huggingface/diffusers/tree/main/examples/community. Valid file names have to
|
||||
match exactly the file name without `.py` located under the above link, *e.g.*
|
||||
`clip_guided_stable_diffusion`.
|
||||
|
||||
<Tip>
|
||||
|
||||
Community pipelines are always loaded from the current `main` branch of GitHub.
|
||||
|
||||
</Tip>
|
||||
|
||||
- A path to a *directory* containing a custom pipeline, e.g., `./my_pipeline_directory/`.
|
||||
|
||||
<Tip>
|
||||
|
||||
It is required that the directory has a file, called `pipeline.py` that defines the custom
|
||||
pipeline.
|
||||
|
||||
</Tip>
|
||||
|
||||
For more information on how to load and create custom pipelines, please have a look at [Loading and
|
||||
Adding Custom
|
||||
Pipelines](https://huggingface.co/docs/diffusers/using-diffusers/custom_pipeline_overview)
|
||||
|
||||
force_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
|
||||
cached versions if they exist.
|
||||
resume_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to resume downloading the model weights and configuration files. If set to False, any
|
||||
incompletely downloaded files are deleted.
|
||||
Whether or not to delete incompletely received files. Will attempt to resume the download if such a
|
||||
file exists.
|
||||
proxies (`Dict[str, str]`, *optional*):
|
||||
A dictionary of proxy servers to use by protocol or endpoint, for example, `{'http': 'foo.bar:3128',
|
||||
A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
|
||||
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
|
||||
output_loading_info(`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
|
||||
local_files_only(`bool`, *optional*, defaults to `False`):
|
||||
Whether to only load local model weights and configuration files or not. If set to True, the model
|
||||
won’t be downloaded from the Hub.
|
||||
Whether or not to only look at local files (i.e., do not try to download the model).
|
||||
use_auth_token (`str` or *bool*, *optional*):
|
||||
The token to use as HTTP bearer authorization for remote files. If `True`, the token generated from
|
||||
`diffusers-cli login` (stored in `~/.huggingface`) is used.
|
||||
The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
|
||||
when running `huggingface-cli login` (stored in `~/.huggingface`).
|
||||
revision (`str`, *optional*, defaults to `"main"`):
|
||||
The specific model version to use. It can be a branch name, a tag name, a commit id, or any identifier
|
||||
allowed by Git.
|
||||
The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
|
||||
git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
|
||||
identifier allowed by git.
|
||||
custom_revision (`str`, *optional*, defaults to `"main"` when loading from the Hub and to local version of
|
||||
`diffusers` when loading from GitHub):
|
||||
The specific model version to use. It can be a branch name, a tag name, or a commit id similar to
|
||||
`revision` when loading a custom pipeline from the Hub. It can be a diffusers version when loading a
|
||||
custom pipeline from GitHub.
|
||||
mirror (`str`, *optional*):
|
||||
Mirror source to resolve accessibility issues if you're downloading a model in China. We do not
|
||||
guarantee the timeliness or safety of the source, and you should refer to the mirror site for more
|
||||
information.
|
||||
Mirror source to accelerate downloads in China. If you are from China and have an accessibility
|
||||
problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
|
||||
Please refer to the mirror site for more information. specify the folder name here.
|
||||
variant (`str`, *optional*):
|
||||
Load weights from a specified variant filename such as `"fp16"` or `"ema"`. This is ignored when
|
||||
loading `from_flax`.
|
||||
|
||||
Returns:
|
||||
`os.PathLike`:
|
||||
A path to the downloaded pipeline.
|
||||
If specified load weights from `variant` filename, *e.g.* pytorch_model.<variant>.bin. `variant` is
|
||||
ignored when using `from_flax`.
|
||||
|
||||
<Tip>
|
||||
|
||||
To use private or [gated models](https://huggingface.co/docs/hub/models-gated#gated-models), log-in with
|
||||
`huggingface-cli login`.
|
||||
It is required to be logged in (`huggingface-cli login`) when you want to use private or [gated
|
||||
models](https://huggingface.co/docs/hub/models-gated#gated-models)
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
@@ -13,7 +13,6 @@
|
||||
# limitations under the License.
|
||||
|
||||
|
||||
import warnings
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import numpy as np
|
||||
@@ -31,11 +30,6 @@ logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.preprocess
|
||||
def _preprocess_image(image: Union[List, PIL.Image.Image, torch.Tensor]):
|
||||
warnings.warn(
|
||||
"The preprocess method is deprecated and will be removed in a future version. Please"
|
||||
" use VaeImageProcessor.preprocess instead",
|
||||
FutureWarning,
|
||||
)
|
||||
if isinstance(image, torch.Tensor):
|
||||
return image
|
||||
elif isinstance(image, PIL.Image.Image):
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user