mirror of
https://github.com/huggingface/diffusers.git
synced 2026-02-24 11:50:35 +08:00
Compare commits
32 Commits
fix-peft-g
...
fix/lora-l
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
f9c7b327cb | ||
|
|
255adf0466 | ||
|
|
5d04eebd1f | ||
|
|
f145d48ed7 | ||
|
|
765fef7134 | ||
|
|
8c98a187c7 | ||
|
|
ece6d89cf2 | ||
|
|
16ac1b2f4f | ||
|
|
ec9df6fc48 | ||
|
|
09618d09a6 | ||
|
|
d24e7d3ea9 | ||
|
|
57a16f35ee | ||
|
|
f4adaae5cb | ||
|
|
49a0f3ab02 | ||
|
|
24cb282d36 | ||
|
|
bcf0f4a789 | ||
|
|
fdb114618d | ||
|
|
ed333f06ae | ||
|
|
32212b6df6 | ||
|
|
9ecb271ac8 | ||
|
|
a2792cd942 | ||
|
|
c341111d69 | ||
|
|
b868e8a2fc | ||
|
|
41b9cd8787 | ||
|
|
0d08249c9f | ||
|
|
3b27b23082 | ||
|
|
e4c00bc5c2 | ||
|
|
cf132fb6b0 | ||
|
|
981ea82591 | ||
|
|
20fac7bc9d | ||
|
|
79b16373b7 | ||
|
|
ff3d380824 |
1
.github/workflows/push_tests_fast.yml
vendored
1
.github/workflows/push_tests_fast.yml
vendored
@@ -98,7 +98,6 @@ jobs:
|
||||
- name: Run example PyTorch CPU tests
|
||||
if: ${{ matrix.config.framework == 'pytorch_examples' }}
|
||||
run: |
|
||||
python -m pip install peft
|
||||
python -m pytest -n 2 --max-worker-restart=0 --dist=loadfile \
|
||||
--make-reports=tests_${{ matrix.config.report }} \
|
||||
examples
|
||||
|
||||
@@ -162,25 +162,6 @@ class LCMLoRATextToImageBenchmark(TextToImageBenchmark):
|
||||
guidance_scale=1.0,
|
||||
)
|
||||
|
||||
def benchmark(self, args):
|
||||
flush()
|
||||
|
||||
print(f"[INFO] {self.pipe.__class__.__name__}: Running benchmark with: {vars(args)}\n")
|
||||
|
||||
time = benchmark_fn(self.run_inference, self.pipe, args) # in seconds.
|
||||
memory = bytes_to_giga_bytes(torch.cuda.max_memory_allocated()) # in GBs.
|
||||
benchmark_info = BenchmarkInfo(time=time, memory=memory)
|
||||
|
||||
pipeline_class_name = str(self.pipe.__class__.__name__)
|
||||
flush()
|
||||
csv_dict = generate_csv_dict(
|
||||
pipeline_cls=pipeline_class_name, ckpt=self.lora_id, args=args, benchmark_info=benchmark_info
|
||||
)
|
||||
filepath = self.get_result_filepath(args)
|
||||
write_to_csv(filepath, csv_dict)
|
||||
print(f"Logs written to: {filepath}")
|
||||
flush()
|
||||
|
||||
|
||||
class ImageToImageBenchmark(TextToImageBenchmark):
|
||||
pipeline_class = AutoPipelineForImage2Image
|
||||
|
||||
@@ -244,10 +244,14 @@
|
||||
- sections:
|
||||
- local: api/pipelines/overview
|
||||
title: Overview
|
||||
- local: api/pipelines/alt_diffusion
|
||||
title: AltDiffusion
|
||||
- local: api/pipelines/animatediff
|
||||
title: AnimateDiff
|
||||
- local: api/pipelines/attend_and_excite
|
||||
title: Attend-and-Excite
|
||||
- local: api/pipelines/audio_diffusion
|
||||
title: Audio Diffusion
|
||||
- local: api/pipelines/audioldm
|
||||
title: AudioLDM
|
||||
- local: api/pipelines/audioldm2
|
||||
@@ -266,6 +270,8 @@
|
||||
title: ControlNet-XS
|
||||
- local: api/pipelines/controlnetxs_sdxl
|
||||
title: ControlNet-XS with Stable Diffusion XL
|
||||
- local: api/pipelines/cycle_diffusion
|
||||
title: Cycle Diffusion
|
||||
- local: api/pipelines/dance_diffusion
|
||||
title: Dance Diffusion
|
||||
- local: api/pipelines/ddim
|
||||
@@ -296,14 +302,26 @@
|
||||
title: MusicLDM
|
||||
- local: api/pipelines/paint_by_example
|
||||
title: Paint by Example
|
||||
- local: api/pipelines/paradigms
|
||||
title: Parallel Sampling of Diffusion Models
|
||||
- local: api/pipelines/pix2pix_zero
|
||||
title: Pix2Pix Zero
|
||||
- local: api/pipelines/pixart
|
||||
title: PixArt-α
|
||||
- local: api/pipelines/pndm
|
||||
title: PNDM
|
||||
- local: api/pipelines/repaint
|
||||
title: RePaint
|
||||
- local: api/pipelines/score_sde_ve
|
||||
title: Score SDE VE
|
||||
- local: api/pipelines/self_attention_guidance
|
||||
title: Self-Attention Guidance
|
||||
- local: api/pipelines/semantic_stable_diffusion
|
||||
title: Semantic Guidance
|
||||
- local: api/pipelines/shap_e
|
||||
title: Shap-E
|
||||
- local: api/pipelines/spectrogram_diffusion
|
||||
title: Spectrogram Diffusion
|
||||
- sections:
|
||||
- local: api/pipelines/stable_diffusion/overview
|
||||
title: Overview
|
||||
@@ -338,16 +356,26 @@
|
||||
title: Stable Diffusion
|
||||
- local: api/pipelines/stable_unclip
|
||||
title: Stable unCLIP
|
||||
- local: api/pipelines/stochastic_karras_ve
|
||||
title: Stochastic Karras VE
|
||||
- local: api/pipelines/model_editing
|
||||
title: Text-to-image model editing
|
||||
- local: api/pipelines/text_to_video
|
||||
title: Text-to-video
|
||||
- local: api/pipelines/text_to_video_zero
|
||||
title: Text2Video-Zero
|
||||
- local: api/pipelines/unclip
|
||||
title: unCLIP
|
||||
- local: api/pipelines/latent_diffusion_uncond
|
||||
title: Unconditional Latent Diffusion
|
||||
- local: api/pipelines/unidiffuser
|
||||
title: UniDiffuser
|
||||
- local: api/pipelines/value_guided_sampling
|
||||
title: Value-guided sampling
|
||||
- local: api/pipelines/versatile_diffusion
|
||||
title: Versatile Diffusion
|
||||
- local: api/pipelines/vq_diffusion
|
||||
title: VQ Diffusion
|
||||
- local: api/pipelines/wuerstchen
|
||||
title: Wuerstchen
|
||||
title: Pipelines
|
||||
|
||||
@@ -49,12 +49,12 @@ make_image_grid([original_image, mask_image, image], rows=1, cols=3)
|
||||
|
||||
## AsymmetricAutoencoderKL
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_asym_kl.AsymmetricAutoencoderKL
|
||||
[[autodoc]] models.autoencoder_asym_kl.AsymmetricAutoencoderKL
|
||||
|
||||
## AutoencoderKLOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_kl.AutoencoderKLOutput
|
||||
[[autodoc]] models.autoencoder_kl.AutoencoderKLOutput
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
[[autodoc]] models.vae.DecoderOutput
|
||||
|
||||
@@ -54,4 +54,4 @@ image
|
||||
|
||||
## AutoencoderTinyOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_tiny.AutoencoderTinyOutput
|
||||
[[autodoc]] models.autoencoder_tiny.AutoencoderTinyOutput
|
||||
|
||||
@@ -36,11 +36,11 @@ model = AutoencoderKL.from_single_file(url)
|
||||
|
||||
## AutoencoderKLOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_kl.AutoencoderKLOutput
|
||||
[[autodoc]] models.autoencoder_kl.AutoencoderKLOutput
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
[[autodoc]] models.vae.DecoderOutput
|
||||
|
||||
## FlaxAutoencoderKL
|
||||
|
||||
|
||||
47
docs/source/en/api/pipelines/alt_diffusion.md
Normal file
47
docs/source/en/api/pipelines/alt_diffusion.md
Normal file
@@ -0,0 +1,47 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# AltDiffusion
|
||||
|
||||
AltDiffusion was proposed in [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://huggingface.co/papers/2211.06679) by Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*In this work, we present a conceptually simple and effective method to train a strong bilingual/multilingual multimodal representation model. Starting from the pre-trained multimodal representation model CLIP released by OpenAI, we altered its text encoder with a pre-trained multilingual text encoder XLM-R, and aligned both languages and image representations by a two-stage training schema consisting of teacher learning and contrastive learning. We validate our method through evaluations of a wide range of tasks. We set new state-of-the-art performances on a bunch of tasks including ImageNet-CN, Flicker30k-CN, COCO-CN and XTD. Further, we obtain very close performances with CLIP on almost all tasks, suggesting that one can simply alter the text encoder in CLIP for extended capabilities such as multilingual understanding. Our models and code are available at [this https URL](https://github.com/FlagAI-Open/FlagAI).*
|
||||
|
||||
## Tips
|
||||
|
||||
`AltDiffusion` is conceptually the same as [Stable Diffusion](./stable_diffusion/overview).
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## AltDiffusionPipeline
|
||||
|
||||
[[autodoc]] AltDiffusionPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## AltDiffusionImg2ImgPipeline
|
||||
|
||||
[[autodoc]] AltDiffusionImg2ImgPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## AltDiffusionPipelineOutput
|
||||
|
||||
[[autodoc]] pipelines.alt_diffusion.AltDiffusionPipelineOutput
|
||||
- all
|
||||
- __call__
|
||||
35
docs/source/en/api/pipelines/audio_diffusion.md
Normal file
35
docs/source/en/api/pipelines/audio_diffusion.md
Normal file
@@ -0,0 +1,35 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Audio Diffusion
|
||||
|
||||
[Audio Diffusion](https://github.com/teticio/audio-diffusion) is by Robert Dargavel Smith, and it leverages the recent advances in image generation from diffusion models by converting audio samples to and from Mel spectrogram images.
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## AudioDiffusionPipeline
|
||||
[[autodoc]] AudioDiffusionPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## AudioPipelineOutput
|
||||
[[autodoc]] pipelines.AudioPipelineOutput
|
||||
|
||||
## ImagePipelineOutput
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
|
||||
## Mel
|
||||
[[autodoc]] Mel
|
||||
33
docs/source/en/api/pipelines/cycle_diffusion.md
Normal file
33
docs/source/en/api/pipelines/cycle_diffusion.md
Normal file
@@ -0,0 +1,33 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Cycle Diffusion
|
||||
|
||||
Cycle Diffusion is a text guided image-to-image generation model proposed in [Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance](https://huggingface.co/papers/2210.05559) by Chen Henry Wu, Fernando De la Torre.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Diffusion models have achieved unprecedented performance in generative modeling. The commonly-adopted formulation of the latent code of diffusion models is a sequence of gradually denoised samples, as opposed to the simpler (e.g., Gaussian) latent space of GANs, VAEs, and normalizing flows. This paper provides an alternative, Gaussian formulation of the latent space of various diffusion models, as well as an invertible DPM-Encoder that maps images into the latent space. While our formulation is purely based on the definition of diffusion models, we demonstrate several intriguing consequences. (1) Empirically, we observe that a common latent space emerges from two diffusion models trained independently on related domains. In light of this finding, we propose CycleDiffusion, which uses DPM-Encoder for unpaired image-to-image translation. Furthermore, applying CycleDiffusion to text-to-image diffusion models, we show that large-scale text-to-image diffusion models can be used as zero-shot image-to-image editors. (2) One can guide pre-trained diffusion models and GANs by controlling the latent codes in a unified, plug-and-play formulation based on energy-based models. Using the CLIP model and a face recognition model as guidance, we demonstrate that diffusion models have better coverage of low-density sub-populations and individuals than GANs. The code is publicly available at [this https URL](https://github.com/ChenWu98/cycle-diffusion).*
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## CycleDiffusionPipeline
|
||||
[[autodoc]] CycleDiffusionPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## StableDiffusionPiplineOutput
|
||||
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
|
||||
35
docs/source/en/api/pipelines/latent_diffusion_uncond.md
Normal file
35
docs/source/en/api/pipelines/latent_diffusion_uncond.md
Normal file
@@ -0,0 +1,35 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Unconditional Latent Diffusion
|
||||
|
||||
Unconditional Latent Diffusion was proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://huggingface.co/papers/2112.10752) by Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs.*
|
||||
|
||||
The original codebase can be found at [CompVis/latent-diffusion](https://github.com/CompVis/latent-diffusion).
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## LDMPipeline
|
||||
[[autodoc]] LDMPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## ImagePipelineOutput
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
35
docs/source/en/api/pipelines/model_editing.md
Normal file
35
docs/source/en/api/pipelines/model_editing.md
Normal file
@@ -0,0 +1,35 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Text-to-image model editing
|
||||
|
||||
[Editing Implicit Assumptions in Text-to-Image Diffusion Models](https://huggingface.co/papers/2303.08084) is by Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov. This pipeline enables editing diffusion model weights, such that its assumptions of a given concept are changed. The resulting change is expected to take effect in all prompt generations related to the edited concept.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Text-to-image diffusion models often make implicit assumptions about the world when generating images. While some assumptions are useful (e.g., the sky is blue), they can also be outdated, incorrect, or reflective of social biases present in the training data. Thus, there is a need to control these assumptions without requiring explicit user input or costly re-training. In this work, we aim to edit a given implicit assumption in a pre-trained diffusion model. Our Text-to-Image Model Editing method, TIME for short, receives a pair of inputs: a "source" under-specified prompt for which the model makes an implicit assumption (e.g., "a pack of roses"), and a "destination" prompt that describes the same setting, but with a specified desired attribute (e.g., "a pack of blue roses"). TIME then updates the model's cross-attention layers, as these layers assign visual meaning to textual tokens. We edit the projection matrices in these layers such that the source prompt is projected close to the destination prompt. Our method is highly efficient, as it modifies a mere 2.2% of the model's parameters in under one second. To evaluate model editing approaches, we introduce TIMED (TIME Dataset), containing 147 source and destination prompt pairs from various domains. Our experiments (using Stable Diffusion) show that TIME is successful in model editing, generalizes well for related prompts unseen during editing, and imposes minimal effect on unrelated generations.*
|
||||
|
||||
You can find additional information about model editing on the [project page](https://time-diffusion.github.io/), [original codebase](https://github.com/bahjat-kawar/time-diffusion), and try it out in a [demo](https://huggingface.co/spaces/bahjat-kawar/time-diffusion).
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## StableDiffusionModelEditingPipeline
|
||||
[[autodoc]] StableDiffusionModelEditingPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
## StableDiffusionPipelineOutput
|
||||
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
|
||||
51
docs/source/en/api/pipelines/paradigms.md
Normal file
51
docs/source/en/api/pipelines/paradigms.md
Normal file
@@ -0,0 +1,51 @@
|
||||
<!--Copyright 2023 ParaDiGMS authors and The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Parallel Sampling of Diffusion Models
|
||||
|
||||
[Parallel Sampling of Diffusion Models](https://huggingface.co/papers/2305.16317) is by Andy Shih, Suneel Belkhale, Stefano Ermon, Dorsa Sadigh, Nima Anari.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Diffusion models are powerful generative models but suffer from slow sampling, often taking 1000 sequential denoising steps for one sample. As a result, considerable efforts have been directed toward reducing the number of denoising steps, but these methods hurt sample quality. Instead of reducing the number of denoising steps (trading quality for speed), in this paper we explore an orthogonal approach: can we run the denoising steps in parallel (trading compute for speed)? In spite of the sequential nature of the denoising steps, we show that surprisingly it is possible to parallelize sampling via Picard iterations, by guessing the solution of future denoising steps and iteratively refining until convergence. With this insight, we present ParaDiGMS, a novel method to accelerate the sampling of pretrained diffusion models by denoising multiple steps in parallel. ParaDiGMS is the first diffusion sampling method that enables trading compute for speed and is even compatible with existing fast sampling techniques such as DDIM and DPMSolver. Using ParaDiGMS, we improve sampling speed by 2-4x across a range of robotics and image generation models, giving state-of-the-art sampling speeds of 0.2s on 100-step DiffusionPolicy and 14.6s on 1000-step StableDiffusion-v2 with no measurable degradation of task reward, FID score, or CLIP score.*
|
||||
|
||||
The original codebase can be found at [AndyShih12/paradigms](https://github.com/AndyShih12/paradigms), and the pipeline was contributed by [AndyShih12](https://github.com/AndyShih12). ❤️
|
||||
|
||||
## Tips
|
||||
|
||||
This pipeline improves sampling speed by running denoising steps in parallel, at the cost of increased total FLOPs.
|
||||
Therefore, it is better to call this pipeline when running on multiple GPUs. Otherwise, without enough GPU bandwidth
|
||||
sampling may be even slower than sequential sampling.
|
||||
|
||||
The two parameters to play with are `parallel` (batch size) and `tolerance`.
|
||||
- If it fits in memory, for a 1000-step DDPM you can aim for a batch size of around 100 (for example, 8 GPUs and `batch_per_device=12` to get `parallel=96`). A higher batch size may not fit in memory, and lower batch size gives less parallelism.
|
||||
- For tolerance, using a higher tolerance may get better speedups but can risk sample quality degradation. If there is quality degradation with the default tolerance, then use a lower tolerance like `0.001`.
|
||||
|
||||
For a 1000-step DDPM on 8 A100 GPUs, you can expect around a 3x speedup from [`StableDiffusionParadigmsPipeline`] compared to the [`StableDiffusionPipeline`]
|
||||
by setting `parallel=80` and `tolerance=0.1`.
|
||||
|
||||
🤗 Diffusers offers [distributed inference support](../../training/distributed_inference) for generating multiple prompts
|
||||
in parallel on multiple GPUs. But [`StableDiffusionParadigmsPipeline`] is designed for speeding up sampling of a single prompt by using multiple GPUs.
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## StableDiffusionParadigmsPipeline
|
||||
[[autodoc]] StableDiffusionParadigmsPipeline
|
||||
- __call__
|
||||
- all
|
||||
|
||||
## StableDiffusionPipelineOutput
|
||||
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
|
||||
289
docs/source/en/api/pipelines/pix2pix_zero.md
Normal file
289
docs/source/en/api/pipelines/pix2pix_zero.md
Normal file
@@ -0,0 +1,289 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Pix2Pix Zero
|
||||
|
||||
[Zero-shot Image-to-Image Translation](https://huggingface.co/papers/2302.03027) is by Gaurav Parmar, Krishna Kumar Singh, Richard Zhang, Yijun Li, Jingwan Lu, and Jun-Yan Zhu.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Large-scale text-to-image generative models have shown their remarkable ability to synthesize diverse and high-quality images. However, it is still challenging to directly apply these models for editing real images for two reasons. First, it is hard for users to come up with a perfect text prompt that accurately describes every visual detail in the input image. Second, while existing models can introduce desirable changes in certain regions, they often dramatically alter the input content and introduce unexpected changes in unwanted regions. In this work, we propose pix2pix-zero, an image-to-image translation method that can preserve the content of the original image without manual prompting. We first automatically discover editing directions that reflect desired edits in the text embedding space. To preserve the general content structure after editing, we further propose cross-attention guidance, which aims to retain the cross-attention maps of the input image throughout the diffusion process. In addition, our method does not need additional training for these edits and can directly use the existing pre-trained text-to-image diffusion model. We conduct extensive experiments and show that our method outperforms existing and concurrent works for both real and synthetic image editing.*
|
||||
|
||||
You can find additional information about Pix2Pix Zero on the [project page](https://pix2pixzero.github.io/), [original codebase](https://github.com/pix2pixzero/pix2pix-zero), and try it out in a [demo](https://huggingface.co/spaces/pix2pix-zero-library/pix2pix-zero-demo).
|
||||
|
||||
## Tips
|
||||
|
||||
* The pipeline can be conditioned on real input images. Check out the code examples below to know more.
|
||||
* The pipeline exposes two arguments namely `source_embeds` and `target_embeds`
|
||||
that let you control the direction of the semantic edits in the final image to be generated. Let's say,
|
||||
you wanted to translate from "cat" to "dog". In this case, the edit direction will be "cat -> dog". To reflect
|
||||
this in the pipeline, you simply have to set the embeddings related to the phrases including "cat" to
|
||||
`source_embeds` and "dog" to `target_embeds`. Refer to the code example below for more details.
|
||||
* When you're using this pipeline from a prompt, specify the _source_ concept in the prompt. Taking
|
||||
the above example, a valid input prompt would be: "a high resolution painting of a **cat** in the style of van gogh".
|
||||
* If you wanted to reverse the direction in the example above, i.e., "dog -> cat", then it's recommended to:
|
||||
* Swap the `source_embeds` and `target_embeds`.
|
||||
* Change the input prompt to include "dog".
|
||||
* To learn more about how the source and target embeddings are generated, refer to the [original paper](https://arxiv.org/abs/2302.03027). Below, we also provide some directions on how to generate the embeddings.
|
||||
* Note that the quality of the outputs generated with this pipeline is dependent on how good the `source_embeds` and `target_embeds` are. Please, refer to [this discussion](#generating-source-and-target-embeddings) for some suggestions on the topic.
|
||||
|
||||
## Available Pipelines:
|
||||
|
||||
| Pipeline | Tasks | Demo
|
||||
|---|---|:---:|
|
||||
| [StableDiffusionPix2PixZeroPipeline](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_pix2pix_zero.py) | *Text-Based Image Editing* | [🤗 Space](https://huggingface.co/spaces/pix2pix-zero-library/pix2pix-zero-demo) |
|
||||
|
||||
<!-- TODO: add Colab -->
|
||||
|
||||
## Usage example
|
||||
|
||||
### Based on an image generated with the input prompt
|
||||
|
||||
```python
|
||||
import requests
|
||||
import torch
|
||||
|
||||
from diffusers import DDIMScheduler, StableDiffusionPix2PixZeroPipeline
|
||||
|
||||
|
||||
def download(embedding_url, local_filepath):
|
||||
r = requests.get(embedding_url)
|
||||
with open(local_filepath, "wb") as f:
|
||||
f.write(r.content)
|
||||
|
||||
|
||||
model_ckpt = "CompVis/stable-diffusion-v1-4"
|
||||
pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
|
||||
model_ckpt, conditions_input_image=False, torch_dtype=torch.float16
|
||||
)
|
||||
pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
|
||||
pipeline.to("cuda")
|
||||
|
||||
prompt = "a high resolution painting of a cat in the style of van gogh"
|
||||
src_embs_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/embeddings_sd_1.4/cat.pt"
|
||||
target_embs_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/embeddings_sd_1.4/dog.pt"
|
||||
|
||||
for url in [src_embs_url, target_embs_url]:
|
||||
download(url, url.split("/")[-1])
|
||||
|
||||
src_embeds = torch.load(src_embs_url.split("/")[-1])
|
||||
target_embeds = torch.load(target_embs_url.split("/")[-1])
|
||||
|
||||
image = pipeline(
|
||||
prompt,
|
||||
source_embeds=src_embeds,
|
||||
target_embeds=target_embeds,
|
||||
num_inference_steps=50,
|
||||
cross_attention_guidance_amount=0.15,
|
||||
).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
### Based on an input image
|
||||
|
||||
When the pipeline is conditioned on an input image, we first obtain an inverted
|
||||
noise from it using a `DDIMInverseScheduler` with the help of a generated caption. Then the inverted noise is used to start the generation process.
|
||||
|
||||
First, let's load our pipeline:
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import BlipForConditionalGeneration, BlipProcessor
|
||||
from diffusers import DDIMScheduler, DDIMInverseScheduler, StableDiffusionPix2PixZeroPipeline
|
||||
|
||||
captioner_id = "Salesforce/blip-image-captioning-base"
|
||||
processor = BlipProcessor.from_pretrained(captioner_id)
|
||||
model = BlipForConditionalGeneration.from_pretrained(captioner_id, torch_dtype=torch.float16, low_cpu_mem_usage=True)
|
||||
|
||||
sd_model_ckpt = "CompVis/stable-diffusion-v1-4"
|
||||
pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
|
||||
sd_model_ckpt,
|
||||
caption_generator=model,
|
||||
caption_processor=processor,
|
||||
torch_dtype=torch.float16,
|
||||
safety_checker=None,
|
||||
)
|
||||
pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
|
||||
pipeline.inverse_scheduler = DDIMInverseScheduler.from_config(pipeline.scheduler.config)
|
||||
pipeline.enable_model_cpu_offload()
|
||||
```
|
||||
|
||||
Then, we load an input image for conditioning and obtain a suitable caption for it:
|
||||
|
||||
```py
|
||||
from diffusers.utils import load_image
|
||||
|
||||
img_url = "https://github.com/pix2pixzero/pix2pix-zero/raw/main/assets/test_images/cats/cat_6.png"
|
||||
raw_image = load_image(url).resize((512, 512))
|
||||
caption = pipeline.generate_caption(raw_image)
|
||||
caption
|
||||
```
|
||||
|
||||
Then we employ the generated caption and the input image to get the inverted noise:
|
||||
|
||||
```py
|
||||
generator = torch.manual_seed(0)
|
||||
inv_latents = pipeline.invert(caption, image=raw_image, generator=generator).latents
|
||||
```
|
||||
|
||||
Now, generate the image with edit directions:
|
||||
|
||||
```py
|
||||
# See the "Generating source and target embeddings" section below to
|
||||
# automate the generation of these captions with a pre-trained model like Flan-T5 as explained below.
|
||||
source_prompts = ["a cat sitting on the street", "a cat playing in the field", "a face of a cat"]
|
||||
target_prompts = ["a dog sitting on the street", "a dog playing in the field", "a face of a dog"]
|
||||
|
||||
source_embeds = pipeline.get_embeds(source_prompts, batch_size=2)
|
||||
target_embeds = pipeline.get_embeds(target_prompts, batch_size=2)
|
||||
|
||||
|
||||
image = pipeline(
|
||||
caption,
|
||||
source_embeds=source_embeds,
|
||||
target_embeds=target_embeds,
|
||||
num_inference_steps=50,
|
||||
cross_attention_guidance_amount=0.15,
|
||||
generator=generator,
|
||||
latents=inv_latents,
|
||||
negative_prompt=caption,
|
||||
).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
## Generating source and target embeddings
|
||||
|
||||
The authors originally used the [GPT-3 API](https://openai.com/api/) to generate the source and target captions for discovering
|
||||
edit directions. However, we can also leverage open source and public models for the same purpose.
|
||||
Below, we provide an end-to-end example with the [Flan-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5) model
|
||||
for generating captions and [CLIP](https://huggingface.co/docs/transformers/model_doc/clip) for
|
||||
computing embeddings on the generated captions.
|
||||
|
||||
**1. Load the generation model**:
|
||||
|
||||
```py
|
||||
import torch
|
||||
from transformers import AutoTokenizer, T5ForConditionalGeneration
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-xl")
|
||||
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-xl", device_map="auto", torch_dtype=torch.float16)
|
||||
```
|
||||
|
||||
**2. Construct a starting prompt**:
|
||||
|
||||
```py
|
||||
source_concept = "cat"
|
||||
target_concept = "dog"
|
||||
|
||||
source_text = f"Provide a caption for images containing a {source_concept}. "
|
||||
"The captions should be in English and should be no longer than 150 characters."
|
||||
|
||||
target_text = f"Provide a caption for images containing a {target_concept}. "
|
||||
"The captions should be in English and should be no longer than 150 characters."
|
||||
```
|
||||
|
||||
Here, we're interested in the "cat -> dog" direction.
|
||||
|
||||
**3. Generate captions**:
|
||||
|
||||
We can use a utility like so for this purpose.
|
||||
|
||||
```py
|
||||
def generate_captions(input_prompt):
|
||||
input_ids = tokenizer(input_prompt, return_tensors="pt").input_ids.to("cuda")
|
||||
|
||||
outputs = model.generate(
|
||||
input_ids, temperature=0.8, num_return_sequences=16, do_sample=True, max_new_tokens=128, top_k=10
|
||||
)
|
||||
return tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
||||
```
|
||||
|
||||
And then we just call it to generate our captions:
|
||||
|
||||
```py
|
||||
source_captions = generate_captions(source_text)
|
||||
target_captions = generate_captions(target_concept)
|
||||
print(source_captions, target_captions, sep='\n')
|
||||
```
|
||||
|
||||
We encourage you to play around with the different parameters supported by the
|
||||
`generate()` method ([documentation](https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.generation_tf_utils.TFGenerationMixin.generate)) for the generation quality you are looking for.
|
||||
|
||||
**4. Load the embedding model**:
|
||||
|
||||
Here, we need to use the same text encoder model used by the subsequent Stable Diffusion model.
|
||||
|
||||
```py
|
||||
from diffusers import StableDiffusionPix2PixZeroPipeline
|
||||
|
||||
pipeline = StableDiffusionPix2PixZeroPipeline.from_pretrained(
|
||||
"CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16
|
||||
)
|
||||
pipeline = pipeline.to("cuda")
|
||||
tokenizer = pipeline.tokenizer
|
||||
text_encoder = pipeline.text_encoder
|
||||
```
|
||||
|
||||
**5. Compute embeddings**:
|
||||
|
||||
```py
|
||||
import torch
|
||||
|
||||
def embed_captions(sentences, tokenizer, text_encoder, device="cuda"):
|
||||
with torch.no_grad():
|
||||
embeddings = []
|
||||
for sent in sentences:
|
||||
text_inputs = tokenizer(
|
||||
sent,
|
||||
padding="max_length",
|
||||
max_length=tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
text_input_ids = text_inputs.input_ids
|
||||
prompt_embeds = text_encoder(text_input_ids.to(device), attention_mask=None)[0]
|
||||
embeddings.append(prompt_embeds)
|
||||
return torch.concatenate(embeddings, dim=0).mean(dim=0).unsqueeze(0)
|
||||
|
||||
source_embeddings = embed_captions(source_captions, tokenizer, text_encoder)
|
||||
target_embeddings = embed_captions(target_captions, tokenizer, text_encoder)
|
||||
```
|
||||
|
||||
And you're done! [Here](https://colab.research.google.com/drive/1tz2C1EdfZYAPlzXXbTnf-5PRBiR8_R1F?usp=sharing) is a Colab Notebook that you can use to interact with the entire process.
|
||||
|
||||
Now, you can use these embeddings directly while calling the pipeline:
|
||||
|
||||
```py
|
||||
from diffusers import DDIMScheduler
|
||||
|
||||
pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
|
||||
|
||||
image = pipeline(
|
||||
prompt,
|
||||
source_embeds=source_embeddings,
|
||||
target_embeds=target_embeddings,
|
||||
num_inference_steps=50,
|
||||
cross_attention_guidance_amount=0.15,
|
||||
).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## StableDiffusionPix2PixZeroPipeline
|
||||
[[autodoc]] StableDiffusionPix2PixZeroPipeline
|
||||
- __call__
|
||||
- all
|
||||
35
docs/source/en/api/pipelines/pndm.md
Normal file
35
docs/source/en/api/pipelines/pndm.md
Normal file
@@ -0,0 +1,35 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# PNDM
|
||||
|
||||
[Pseudo Numerical Methods for Diffusion Models on Manifolds](https://huggingface.co/papers/2202.09778) (PNDM) is by Luping Liu, Yi Ren, Zhijie Lin and Zhou Zhao.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Denoising Diffusion Probabilistic Models (DDPMs) can generate high-quality samples such as image and audio samples. However, DDPMs require hundreds to thousands of iterations to produce final samples. Several prior works have successfully accelerated DDPMs through adjusting the variance schedule (e.g., Improved Denoising Diffusion Probabilistic Models) or the denoising equation (e.g., Denoising Diffusion Implicit Models (DDIMs)). However, these acceleration methods cannot maintain the quality of samples and even introduce new noise at a high speedup rate, which limit their practicability. To accelerate the inference process while keeping the sample quality, we provide a fresh perspective that DDPMs should be treated as solving differential equations on manifolds. Under such a perspective, we propose pseudo numerical methods for diffusion models (PNDMs). Specifically, we figure out how to solve differential equations on manifolds and show that DDIMs are simple cases of pseudo numerical methods. We change several classical numerical methods to corresponding pseudo numerical methods and find that the pseudo linear multi-step method is the best in most situations. According to our experiments, by directly using pre-trained models on Cifar10, CelebA and LSUN, PNDMs can generate higher quality synthetic images with only 50 steps compared with 1000-step DDIMs (20x speedup), significantly outperform DDIMs with 250 steps (by around 0.4 in FID) and have good generalization on different variance schedules.*
|
||||
|
||||
The original codebase can be found at [luping-liu/PNDM](https://github.com/luping-liu/PNDM).
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## PNDMPipeline
|
||||
[[autodoc]] PNDMPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## ImagePipelineOutput
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
37
docs/source/en/api/pipelines/repaint.md
Normal file
37
docs/source/en/api/pipelines/repaint.md
Normal file
@@ -0,0 +1,37 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# RePaint
|
||||
|
||||
[RePaint: Inpainting using Denoising Diffusion Probabilistic Models](https://huggingface.co/papers/2201.09865) is by Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, Luc Van Gool.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks.
|
||||
RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions.*
|
||||
|
||||
The original codebase can be found at [andreas128/RePaint](https://github.com/andreas128/RePaint).
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
## RePaintPipeline
|
||||
[[autodoc]] RePaintPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## ImagePipelineOutput
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
35
docs/source/en/api/pipelines/score_sde_ve.md
Normal file
35
docs/source/en/api/pipelines/score_sde_ve.md
Normal file
@@ -0,0 +1,35 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Score SDE VE
|
||||
|
||||
[Score-Based Generative Modeling through Stochastic Differential Equations](https://huggingface.co/papers/2011.13456) (Score SDE) is by Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon and Ben Poole. This pipeline implements the variance expanding (VE) variant of the stochastic differential equation method.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Creating noise from data is easy; creating data from noise is generative modeling. We present a stochastic differential equation (SDE) that smoothly transforms a complex data distribution to a known prior distribution by slowly injecting noise, and a corresponding reverse-time SDE that transforms the prior distribution back into the data distribution by slowly removing the noise. Crucially, the reverse-time SDE depends only on the time-dependent gradient field (\aka, score) of the perturbed data distribution. By leveraging advances in score-based generative modeling, we can accurately estimate these scores with neural networks, and use numerical SDE solvers to generate samples. We show that this framework encapsulates previous approaches in score-based generative modeling and diffusion probabilistic modeling, allowing for new sampling procedures and new modeling capabilities. In particular, we introduce a predictor-corrector framework to correct errors in the evolution of the discretized reverse-time SDE. We also derive an equivalent neural ODE that samples from the same distribution as the SDE, but additionally enables exact likelihood computation, and improved sampling efficiency. In addition, we provide a new way to solve inverse problems with score-based models, as demonstrated with experiments on class-conditional generation, image inpainting, and colorization. Combined with multiple architectural improvements, we achieve record-breaking performance for unconditional image generation on CIFAR-10 with an Inception score of 9.89 and FID of 2.20, a competitive likelihood of 2.99 bits/dim, and demonstrate high fidelity generation of 1024 x 1024 images for the first time from a score-based generative model.*
|
||||
|
||||
The original codebase can be found at [yang-song/score_sde_pytorch](https://github.com/yang-song/score_sde_pytorch).
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## ScoreSdeVePipeline
|
||||
[[autodoc]] ScoreSdeVePipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## ImagePipelineOutput
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
37
docs/source/en/api/pipelines/spectrogram_diffusion.md
Normal file
37
docs/source/en/api/pipelines/spectrogram_diffusion.md
Normal file
@@ -0,0 +1,37 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Spectrogram Diffusion
|
||||
|
||||
[Spectrogram Diffusion](https://huggingface.co/papers/2206.05408) is by Curtis Hawthorne, Ian Simon, Adam Roberts, Neil Zeghidour, Josh Gardner, Ethan Manilow, and Jesse Engel.
|
||||
|
||||
*An ideal music synthesizer should be both interactive and expressive, generating high-fidelity audio in realtime for arbitrary combinations of instruments and notes. Recent neural synthesizers have exhibited a tradeoff between domain-specific models that offer detailed control of only specific instruments, or raw waveform models that can train on any music but with minimal control and slow generation. In this work, we focus on a middle ground of neural synthesizers that can generate audio from MIDI sequences with arbitrary combinations of instruments in realtime. This enables training on a wide range of transcription datasets with a single model, which in turn offers note-level control of composition and instrumentation across a wide range of instruments. We use a simple two-stage process: MIDI to spectrograms with an encoder-decoder Transformer, then spectrograms to audio with a generative adversarial network (GAN) spectrogram inverter. We compare training the decoder as an autoregressive model and as a Denoising Diffusion Probabilistic Model (DDPM) and find that the DDPM approach is superior both qualitatively and as measured by audio reconstruction and Fréchet distance metrics. Given the interactivity and generality of this approach, we find this to be a promising first step towards interactive and expressive neural synthesis for arbitrary combinations of instruments and notes.*
|
||||
|
||||
The original codebase can be found at [magenta/music-spectrogram-diffusion](https://github.com/magenta/music-spectrogram-diffusion).
|
||||
|
||||
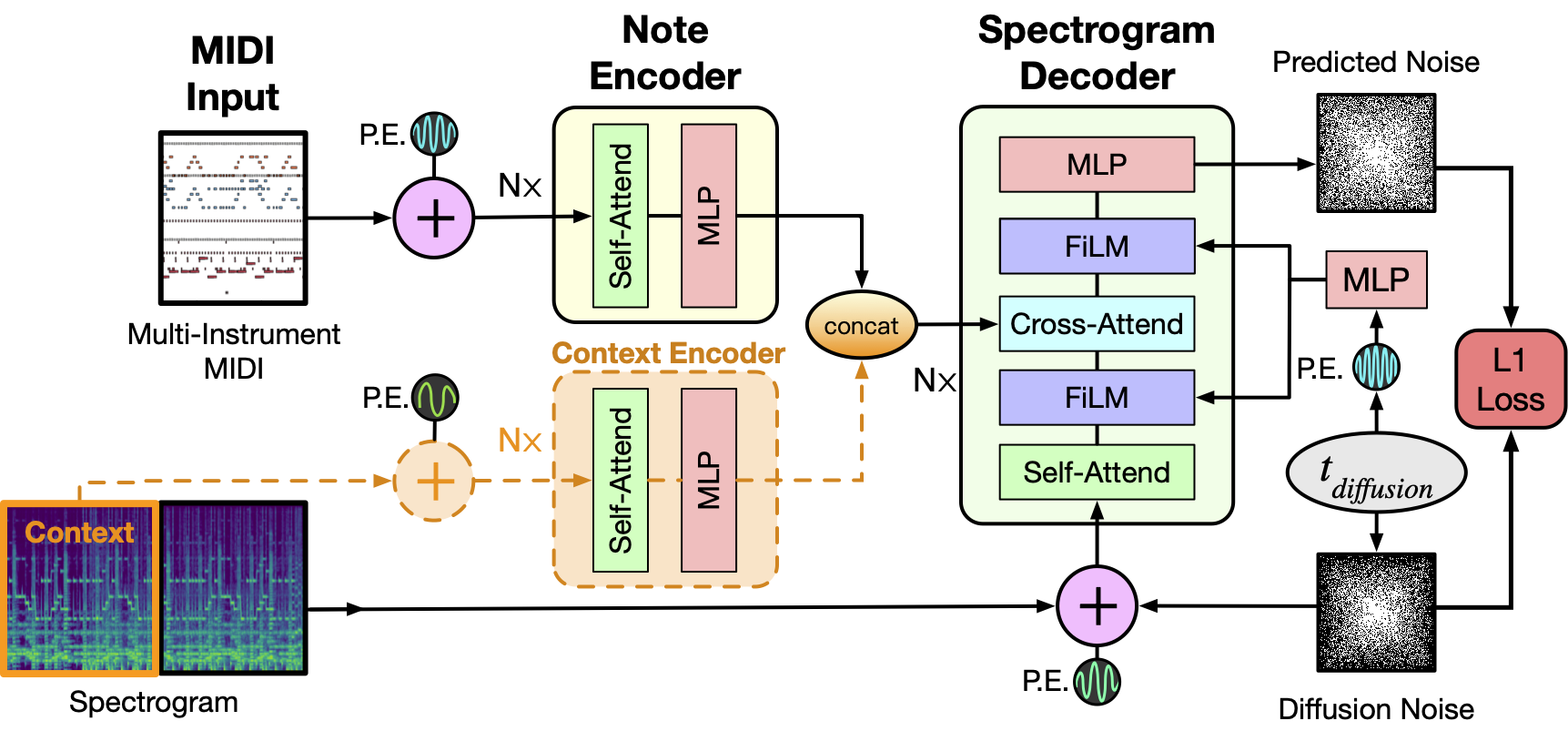
|
||||
|
||||
As depicted above the model takes as input a MIDI file and tokenizes it into a sequence of 5 second intervals. Each tokenized interval then together with positional encodings is passed through the Note Encoder and its representation is concatenated with the previous window's generated spectrogram representation obtained via the Context Encoder. For the initial 5 second window this is set to zero. The resulting context is then used as conditioning to sample the denoised Spectrogram from the MIDI window and we concatenate this spectrogram to the final output as well as use it for the context of the next MIDI window. The process repeats till we have gone over all the MIDI inputs. Finally a MelGAN decoder converts the potentially long spectrogram to audio which is the final result of this pipeline.
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## SpectrogramDiffusionPipeline
|
||||
[[autodoc]] SpectrogramDiffusionPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## AudioPipelineOutput
|
||||
[[autodoc]] pipelines.AudioPipelineOutput
|
||||
33
docs/source/en/api/pipelines/stochastic_karras_ve.md
Normal file
33
docs/source/en/api/pipelines/stochastic_karras_ve.md
Normal file
@@ -0,0 +1,33 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Stochastic Karras VE
|
||||
|
||||
[Elucidating the Design Space of Diffusion-Based Generative Models](https://huggingface.co/papers/2206.00364) is by Tero Karras, Miika Aittala, Timo Aila and Samuli Laine. This pipeline implements the stochastic sampling tailored to variance expanding (VE) models.
|
||||
|
||||
The abstract from the paper:
|
||||
|
||||
*We argue that the theory and practice of diffusion-based generative models are currently unnecessarily convoluted and seek to remedy the situation by presenting a design space that clearly separates the concrete design choices. This lets us identify several changes to both the sampling and training processes, as well as preconditioning of the score networks. Together, our improvements yield new state-of-the-art FID of 1.79 for CIFAR-10 in a class-conditional setting and 1.97 in an unconditional setting, with much faster sampling (35 network evaluations per image) than prior designs. To further demonstrate their modular nature, we show that our design changes dramatically improve both the efficiency and quality obtainable with pre-trained score networks from previous work, including improving the FID of a previously trained ImageNet-64 model from 2.07 to near-SOTA 1.55, and after re-training with our proposed improvements to a new SOTA of 1.36.*
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## KarrasVePipeline
|
||||
[[autodoc]] KarrasVePipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## ImagePipelineOutput
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
54
docs/source/en/api/pipelines/versatile_diffusion.md
Normal file
54
docs/source/en/api/pipelines/versatile_diffusion.md
Normal file
@@ -0,0 +1,54 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Versatile Diffusion
|
||||
|
||||
Versatile Diffusion was proposed in [Versatile Diffusion: Text, Images and Variations All in One Diffusion Model](https://huggingface.co/papers/2211.08332) by Xingqian Xu, Zhangyang Wang, Eric Zhang, Kai Wang, Humphrey Shi.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Recent advances in diffusion models have set an impressive milestone in many generation tasks, and trending works such as DALL-E2, Imagen, and Stable Diffusion have attracted great interest. Despite the rapid landscape changes, recent new approaches focus on extensions and performance rather than capacity, thus requiring separate models for separate tasks. In this work, we expand the existing single-flow diffusion pipeline into a multi-task multimodal network, dubbed Versatile Diffusion (VD), that handles multiple flows of text-to-image, image-to-text, and variations in one unified model. The pipeline design of VD instantiates a unified multi-flow diffusion framework, consisting of sharable and swappable layer modules that enable the crossmodal generality beyond images and text. Through extensive experiments, we demonstrate that VD successfully achieves the following: a) VD outperforms the baseline approaches and handles all its base tasks with competitive quality; b) VD enables novel extensions such as disentanglement of style and semantics, dual- and multi-context blending, etc.; c) The success of our multi-flow multimodal framework over images and text may inspire further diffusion-based universal AI research.*
|
||||
|
||||
## Tips
|
||||
|
||||
You can load the more memory intensive "all-in-one" [`VersatileDiffusionPipeline`] that supports all the tasks or use the individual pipelines which are more memory efficient.
|
||||
|
||||
| **Pipeline** | **Supported tasks** |
|
||||
|------------------------------------------------------|-----------------------------------|
|
||||
| [`VersatileDiffusionPipeline`] | all of the below |
|
||||
| [`VersatileDiffusionTextToImagePipeline`] | text-to-image |
|
||||
| [`VersatileDiffusionImageVariationPipeline`] | image variation |
|
||||
| [`VersatileDiffusionDualGuidedPipeline`] | image-text dual guided generation |
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## VersatileDiffusionPipeline
|
||||
[[autodoc]] VersatileDiffusionPipeline
|
||||
|
||||
## VersatileDiffusionTextToImagePipeline
|
||||
[[autodoc]] VersatileDiffusionTextToImagePipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## VersatileDiffusionImageVariationPipeline
|
||||
[[autodoc]] VersatileDiffusionImageVariationPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## VersatileDiffusionDualGuidedPipeline
|
||||
[[autodoc]] VersatileDiffusionDualGuidedPipeline
|
||||
- all
|
||||
- __call__
|
||||
35
docs/source/en/api/pipelines/vq_diffusion.md
Normal file
35
docs/source/en/api/pipelines/vq_diffusion.md
Normal file
@@ -0,0 +1,35 @@
|
||||
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# VQ Diffusion
|
||||
|
||||
[Vector Quantized Diffusion Model for Text-to-Image Synthesis](https://huggingface.co/papers/2111.14822) is by Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, Baining Guo.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*We present the vector quantized diffusion (VQ-Diffusion) model for text-to-image generation. This method is based on a vector quantized variational autoencoder (VQ-VAE) whose latent space is modeled by a conditional variant of the recently developed Denoising Diffusion Probabilistic Model (DDPM). We find that this latent-space method is well-suited for text-to-image generation tasks because it not only eliminates the unidirectional bias with existing methods but also allows us to incorporate a mask-and-replace diffusion strategy to avoid the accumulation of errors, which is a serious problem with existing methods. Our experiments show that the VQ-Diffusion produces significantly better text-to-image generation results when compared with conventional autoregressive (AR) models with similar numbers of parameters. Compared with previous GAN-based text-to-image methods, our VQ-Diffusion can handle more complex scenes and improve the synthesized image quality by a large margin. Finally, we show that the image generation computation in our method can be made highly efficient by reparameterization. With traditional AR methods, the text-to-image generation time increases linearly with the output image resolution and hence is quite time consuming even for normal size images. The VQ-Diffusion allows us to achieve a better trade-off between quality and speed. Our experiments indicate that the VQ-Diffusion model with the reparameterization is fifteen times faster than traditional AR methods while achieving a better image quality.*
|
||||
|
||||
The original codebase can be found at [microsoft/VQ-Diffusion](https://github.com/microsoft/VQ-Diffusion).
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
|
||||
</Tip>
|
||||
|
||||
## VQDiffusionPipeline
|
||||
[[autodoc]] VQDiffusionPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## ImagePipelineOutput
|
||||
[[autodoc]] pipelines.ImagePipelineOutput
|
||||
@@ -224,4 +224,4 @@ image.save("./output.png")
|
||||
|
||||
Congratulations on training a T2I-Adapter model! 🎉 To learn more:
|
||||
|
||||
- Read the [Efficient Controllable Generation for SDXL with T2I-Adapters](https://huggingface.co/blog/t2i-sdxl-adapters) blog post to learn more details about the experimental results from the T2I-Adapter team.
|
||||
- Read the [Efficient Controllable Generation for SDXL with T2I-Adapters](https://www.cs.cmu.edu/~custom-diffusion/) blog post to learn more details about the experimental results from the T2I-Adapter team.
|
||||
|
||||
@@ -186,7 +186,7 @@ accelerate launch train_unconditional.py \
|
||||
If you're training with more than one GPU, add the `--multi_gpu` parameter to the training command:
|
||||
|
||||
```bash
|
||||
accelerate launch --multi_gpu train_unconditional.py \
|
||||
accelerate launch --mixed_precision="fp16" --multi_gpu train_unconditional.py \
|
||||
--dataset_name="huggan/flowers-102-categories" \
|
||||
--output_dir="ddpm-ema-flowers-64" \
|
||||
--mixed_precision="fp16" \
|
||||
|
||||
@@ -203,7 +203,7 @@ def make_inpaint_condition(image, image_mask):
|
||||
image_mask = np.array(image_mask.convert("L")).astype(np.float32) / 255.0
|
||||
|
||||
assert image.shape[0:1] == image_mask.shape[0:1]
|
||||
image[image_mask > 0.5] = -1.0 # set as masked pixel
|
||||
image[image_mask > 0.5] = 1.0 # set as masked pixel
|
||||
image = np.expand_dims(image, 0).transpose(0, 3, 1, 2)
|
||||
image = torch.from_numpy(image)
|
||||
return image
|
||||
|
||||
@@ -41,20 +41,6 @@ Now, define four different `Generator`s and assign each `Generator` a seed (`0`
|
||||
generator = [torch.Generator(device="cuda").manual_seed(i) for i in range(4)]
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
To create a batched seed, you should use a list comprehension that iterates over the length specified in `range()`. This creates a unique `Generator` object for each image in the batch. If you only multiply the `Generator` by the batch size, this only creates one `Generator` object that is used sequentially for each image in the batch.
|
||||
|
||||
For example, if you want to use the same seed to create 4 identical images:
|
||||
|
||||
```py
|
||||
❌ [torch.Generator().manual_seed(seed)] * 4
|
||||
|
||||
✅ [torch.Generator().manual_seed(seed) for _ in range(4)]
|
||||
```
|
||||
|
||||
</Tip>
|
||||
|
||||
Generate the images and have a look:
|
||||
|
||||
```python
|
||||
|
||||
@@ -41,7 +41,7 @@ If a community doesn't work as expected, please open an issue and ping the autho
|
||||
| TensorRT Stable Diffusion Inpainting Pipeline | Accelerates the Stable Diffusion Inpainting Pipeline using TensorRT | [TensorRT Stable Diffusion Inpainting Pipeline](#tensorrt-inpainting-stable-diffusion-pipeline) | - | [Asfiya Baig](https://github.com/asfiyab-nvidia) |
|
||||
| IADB Pipeline | Implementation of [Iterative α-(de)Blending: a Minimalist Deterministic Diffusion Model](https://arxiv.org/abs/2305.03486) | [IADB Pipeline](#iadb-pipeline) | - | [Thomas Chambon](https://github.com/tchambon)
|
||||
| Zero1to3 Pipeline | Implementation of [Zero-1-to-3: Zero-shot One Image to 3D Object](https://arxiv.org/abs/2303.11328) | [Zero1to3 Pipeline](#Zero1to3-pipeline) | - | [Xin Kong](https://github.com/kxhit) |
|
||||
| Stable Diffusion XL Long Weighted Prompt Pipeline | A pipeline support unlimited length of prompt and negative prompt, use A1111 style of prompt weighting | [Stable Diffusion XL Long Weighted Prompt Pipeline](#stable-diffusion-xl-long-weighted-prompt-pipeline) | [](https://colab.research.google.com/drive/1LsqilswLR40XLLcp6XFOl5nKb_wOe26W?usp=sharing) | [Andrew Zhu](https://xhinker.medium.com/) |
|
||||
Stable Diffusion XL Long Weighted Prompt Pipeline | A pipeline support unlimited length of prompt and negative prompt, use A1111 style of prompt weighting | [Stable Diffusion XL Long Weighted Prompt Pipeline](#stable-diffusion-xl-long-weighted-prompt-pipeline) | - | [Andrew Zhu](https://xhinker.medium.com/) |
|
||||
FABRIC - Stable Diffusion with feedback Pipeline | pipeline supports feedback from liked and disliked images | [Stable Diffusion Fabric Pipeline](#stable-diffusion-fabric-pipeline) | - | [Shauray Singh](https://shauray8.github.io/about_shauray/) |
|
||||
sketch inpaint - Inpainting with non-inpaint Stable Diffusion | sketch inpaint much like in automatic1111 | [Masked Im2Im Stable Diffusion Pipeline](#stable-diffusion-masked-im2im) | - | [Anatoly Belikov](https://github.com/noskill) |
|
||||
prompt-to-prompt | change parts of a prompt and retain image structure (see [paper page](https://prompt-to-prompt.github.io/)) | [Prompt2Prompt Pipeline](#prompt2prompt-pipeline) | - | [Umer H. Adil](https://twitter.com/UmerHAdil) |
|
||||
@@ -1619,11 +1619,10 @@ This approach is using (optional) CoCa model to avoid writing image description.
|
||||
|
||||
This SDXL pipeline support unlimited length prompt and negative prompt, compatible with A1111 prompt weighted style.
|
||||
|
||||
You can provide both `prompt` and `prompt_2`. If only one prompt is provided, `prompt_2` will be a copy of the provided `prompt`. Here is a sample code to use this pipeline.
|
||||
You can provide both `prompt` and `prompt_2`. if only one prompt is provided, `prompt_2` will be a copy of the provided `prompt`. Here is a sample code to use this pipeline.
|
||||
|
||||
```python
|
||||
from diffusers import DiffusionPipeline
|
||||
from diffusers.utils import load_image
|
||||
import torch
|
||||
|
||||
pipe = DiffusionPipeline.from_pretrained(
|
||||
@@ -1634,52 +1633,25 @@ pipe = DiffusionPipeline.from_pretrained(
|
||||
, custom_pipeline = "lpw_stable_diffusion_xl",
|
||||
)
|
||||
|
||||
prompt = "photo of a cute (white) cat running on the grass" * 20
|
||||
prompt2 = "chasing (birds:1.5)" * 20
|
||||
prompt = "photo of a cute (white) cat running on the grass"*20
|
||||
prompt2 = "chasing (birds:1.5)"*20
|
||||
prompt = f"{prompt},{prompt2}"
|
||||
neg_prompt = "blur, low quality, carton, animate"
|
||||
|
||||
pipe.to("cuda")
|
||||
|
||||
# text2img
|
||||
t2i_images = pipe(
|
||||
prompt=prompt,
|
||||
negative_prompt=neg_prompt,
|
||||
).images # alternatively, you can call the .text2img() function
|
||||
|
||||
# img2img
|
||||
input_image = load_image("/path/to/local/image.png") # or URL to your input image
|
||||
i2i_images = pipe.img2img(
|
||||
prompt=prompt,
|
||||
negative_prompt=neg_prompt,
|
||||
image=input_image,
|
||||
strength=0.8, # higher strength will result in more variation compared to original image
|
||||
).images
|
||||
|
||||
# inpaint
|
||||
input_mask = load_image("/path/to/local/mask.png") # or URL to your input inpainting mask
|
||||
inpaint_images = pipe.inpaint(
|
||||
prompt="photo of a cute (black) cat running on the grass" * 20,
|
||||
negative_prompt=neg_prompt,
|
||||
image=input_image,
|
||||
mask=input_mask,
|
||||
strength=0.6, # higher strength will result in more variation compared to original image
|
||||
).images
|
||||
images = pipe(
|
||||
prompt = prompt
|
||||
, negative_prompt = neg_prompt
|
||||
).images[0]
|
||||
|
||||
pipe.to("cpu")
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
from IPython.display import display # assuming you are using this code in a notebook
|
||||
display(t2i_images[0])
|
||||
display(i2i_images[0])
|
||||
display(inpaint_images[0])
|
||||
images
|
||||
```
|
||||
|
||||
In the above code, the `prompt2` is appended to the `prompt`, which is more than 77 tokens. "birds" are showing up in the result.
|
||||

|
||||
|
||||
For more results, checkout [PR #6114](https://github.com/huggingface/diffusers/pull/6114).
|
||||
|
||||
## Example Images Mixing (with CoCa)
|
||||
```python
|
||||
import requests
|
||||
|
||||
@@ -11,11 +11,10 @@ import os
|
||||
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
from PIL import Image
|
||||
from transformers import CLIPTextModel, CLIPTextModelWithProjection, CLIPTokenizer
|
||||
|
||||
from diffusers import DiffusionPipeline, StableDiffusionXLPipeline
|
||||
from diffusers.image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from diffusers.image_processor import VaeImageProcessor
|
||||
from diffusers.loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from diffusers.models import AutoencoderKL, UNet2DConditionModel
|
||||
from diffusers.models.attention_processor import (
|
||||
@@ -24,7 +23,7 @@ from diffusers.models.attention_processor import (
|
||||
LoRAXFormersAttnProcessor,
|
||||
XFormersAttnProcessor,
|
||||
)
|
||||
from diffusers.pipelines.stable_diffusion_xl.pipeline_output import StableDiffusionXLPipelineOutput
|
||||
from diffusers.pipelines.stable_diffusion_xl import StableDiffusionXLPipelineOutput
|
||||
from diffusers.schedulers import KarrasDiffusionSchedulers
|
||||
from diffusers.utils import (
|
||||
is_accelerate_available,
|
||||
@@ -462,65 +461,6 @@ def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
|
||||
return noise_cfg
|
||||
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.retrieve_latents
|
||||
def retrieve_latents(
|
||||
encoder_output: torch.Tensor, generator: Optional[torch.Generator] = None, sample_mode: str = "sample"
|
||||
):
|
||||
if hasattr(encoder_output, "latent_dist") and sample_mode == "sample":
|
||||
return encoder_output.latent_dist.sample(generator)
|
||||
elif hasattr(encoder_output, "latent_dist") and sample_mode == "argmax":
|
||||
return encoder_output.latent_dist.mode()
|
||||
elif hasattr(encoder_output, "latents"):
|
||||
return encoder_output.latents
|
||||
else:
|
||||
raise AttributeError("Could not access latents of provided encoder_output")
|
||||
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.retrieve_timesteps
|
||||
def retrieve_timesteps(
|
||||
scheduler,
|
||||
num_inference_steps: Optional[int] = None,
|
||||
device: Optional[Union[str, torch.device]] = None,
|
||||
timesteps: Optional[List[int]] = None,
|
||||
**kwargs,
|
||||
):
|
||||
"""
|
||||
Calls the scheduler's `set_timesteps` method and retrieves timesteps from the scheduler after the call. Handles
|
||||
custom timesteps. Any kwargs will be supplied to `scheduler.set_timesteps`.
|
||||
|
||||
Args:
|
||||
scheduler (`SchedulerMixin`):
|
||||
The scheduler to get timesteps from.
|
||||
num_inference_steps (`int`):
|
||||
The number of diffusion steps used when generating samples with a pre-trained model. If used,
|
||||
`timesteps` must be `None`.
|
||||
device (`str` or `torch.device`, *optional*):
|
||||
The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
|
||||
timesteps (`List[int]`, *optional*):
|
||||
Custom timesteps used to support arbitrary spacing between timesteps. If `None`, then the default
|
||||
timestep spacing strategy of the scheduler is used. If `timesteps` is passed, `num_inference_steps`
|
||||
must be `None`.
|
||||
|
||||
Returns:
|
||||
`Tuple[torch.Tensor, int]`: A tuple where the first element is the timestep schedule from the scheduler and the
|
||||
second element is the number of inference steps.
|
||||
"""
|
||||
if timesteps is not None:
|
||||
accepts_timesteps = "timesteps" in set(inspect.signature(scheduler.set_timesteps).parameters.keys())
|
||||
if not accepts_timesteps:
|
||||
raise ValueError(
|
||||
f"The current scheduler class {scheduler.__class__}'s `set_timesteps` does not support custom"
|
||||
f" timestep schedules. Please check whether you are using the correct scheduler."
|
||||
)
|
||||
scheduler.set_timesteps(timesteps=timesteps, device=device, **kwargs)
|
||||
timesteps = scheduler.timesteps
|
||||
num_inference_steps = len(timesteps)
|
||||
else:
|
||||
scheduler.set_timesteps(num_inference_steps, device=device, **kwargs)
|
||||
timesteps = scheduler.timesteps
|
||||
return timesteps, num_inference_steps
|
||||
|
||||
|
||||
class SDXLLongPromptWeightingPipeline(DiffusionPipeline, FromSingleFileMixin, LoraLoaderMixin):
|
||||
r"""
|
||||
Pipeline for text-to-image generation using Stable Diffusion XL.
|
||||
@@ -586,9 +526,6 @@ class SDXLLongPromptWeightingPipeline(DiffusionPipeline, FromSingleFileMixin, Lo
|
||||
self.register_to_config(force_zeros_for_empty_prompt=force_zeros_for_empty_prompt)
|
||||
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
|
||||
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
|
||||
self.mask_processor = VaeImageProcessor(
|
||||
vae_scale_factor=self.vae_scale_factor, do_normalize=False, do_binarize=True, do_convert_grayscale=True
|
||||
)
|
||||
self.default_sample_size = self.unet.config.sample_size
|
||||
|
||||
add_watermarker = add_watermarker if add_watermarker is not None else is_invisible_watermark_available()
|
||||
@@ -876,7 +813,6 @@ class SDXLLongPromptWeightingPipeline(DiffusionPipeline, FromSingleFileMixin, Lo
|
||||
prompt_2,
|
||||
height,
|
||||
width,
|
||||
strength,
|
||||
callback_steps,
|
||||
negative_prompt=None,
|
||||
negative_prompt_2=None,
|
||||
@@ -888,9 +824,6 @@ class SDXLLongPromptWeightingPipeline(DiffusionPipeline, FromSingleFileMixin, Lo
|
||||
if height % 8 != 0 or width % 8 != 0:
|
||||
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
|
||||
|
||||
if strength < 0 or strength > 1:
|
||||
raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
|
||||
|
||||
if (callback_steps is None) or (
|
||||
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
|
||||
):
|
||||
@@ -947,263 +880,23 @@ class SDXLLongPromptWeightingPipeline(DiffusionPipeline, FromSingleFileMixin, Lo
|
||||
"If `negative_prompt_embeds` are provided, `negative_pooled_prompt_embeds` also have to be passed. Make sure to generate `negative_pooled_prompt_embeds` from the same text encoder that was used to generate `negative_prompt_embeds`."
|
||||
)
|
||||
|
||||
def get_timesteps(self, num_inference_steps, strength, device, denoising_start=None):
|
||||
# get the original timestep using init_timestep
|
||||
if denoising_start is None:
|
||||
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
|
||||
t_start = max(num_inference_steps - init_timestep, 0)
|
||||
else:
|
||||
t_start = 0
|
||||
|
||||
timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
|
||||
|
||||
# Strength is irrelevant if we directly request a timestep to start at;
|
||||
# that is, strength is determined by the denoising_start instead.
|
||||
if denoising_start is not None:
|
||||
discrete_timestep_cutoff = int(
|
||||
round(
|
||||
self.scheduler.config.num_train_timesteps
|
||||
- (denoising_start * self.scheduler.config.num_train_timesteps)
|
||||
)
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
|
||||
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
|
||||
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
|
||||
if isinstance(generator, list) and len(generator) != batch_size:
|
||||
raise ValueError(
|
||||
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
||||
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
||||
)
|
||||
|
||||
num_inference_steps = (timesteps < discrete_timestep_cutoff).sum().item()
|
||||
if self.scheduler.order == 2 and num_inference_steps % 2 == 0:
|
||||
# if the scheduler is a 2nd order scheduler we might have to do +1
|
||||
# because `num_inference_steps` might be even given that every timestep
|
||||
# (except the highest one) is duplicated. If `num_inference_steps` is even it would
|
||||
# mean that we cut the timesteps in the middle of the denoising step
|
||||
# (between 1st and 2nd devirative) which leads to incorrect results. By adding 1
|
||||
# we ensure that the denoising process always ends after the 2nd derivate step of the scheduler
|
||||
num_inference_steps = num_inference_steps + 1
|
||||
|
||||
# because t_n+1 >= t_n, we slice the timesteps starting from the end
|
||||
timesteps = timesteps[-num_inference_steps:]
|
||||
return timesteps, num_inference_steps
|
||||
|
||||
return timesteps, num_inference_steps - t_start
|
||||
|
||||
def prepare_latents(
|
||||
self,
|
||||
image,
|
||||
mask,
|
||||
width,
|
||||
height,
|
||||
num_channels_latents,
|
||||
timestep,
|
||||
batch_size,
|
||||
num_images_per_prompt,
|
||||
dtype,
|
||||
device,
|
||||
generator=None,
|
||||
add_noise=True,
|
||||
latents=None,
|
||||
is_strength_max=True,
|
||||
return_noise=False,
|
||||
return_image_latents=False,
|
||||
):
|
||||
batch_size *= num_images_per_prompt
|
||||
|
||||
if image is None:
|
||||
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
|
||||
if isinstance(generator, list) and len(generator) != batch_size:
|
||||
raise ValueError(
|
||||
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
||||
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
||||
)
|
||||
|
||||
if latents is None:
|
||||
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
else:
|
||||
latents = latents.to(device)
|
||||
|
||||
# scale the initial noise by the standard deviation required by the scheduler
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
elif mask is None:
|
||||
if not isinstance(image, (torch.Tensor, Image.Image, list)):
|
||||
raise ValueError(
|
||||
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
|
||||
)
|
||||
|
||||
# Offload text encoder if `enable_model_cpu_offload` was enabled
|
||||
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
|
||||
self.text_encoder_2.to("cpu")
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
image = image.to(device=device, dtype=dtype)
|
||||
|
||||
if image.shape[1] == 4:
|
||||
init_latents = image
|
||||
|
||||
else:
|
||||
# make sure the VAE is in float32 mode, as it overflows in float16
|
||||
if self.vae.config.force_upcast:
|
||||
image = image.float()
|
||||
self.vae.to(dtype=torch.float32)
|
||||
|
||||
if isinstance(generator, list) and len(generator) != batch_size:
|
||||
raise ValueError(
|
||||
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
||||
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
||||
)
|
||||
|
||||
elif isinstance(generator, list):
|
||||
init_latents = [
|
||||
retrieve_latents(self.vae.encode(image[i : i + 1]), generator=generator[i])
|
||||
for i in range(batch_size)
|
||||
]
|
||||
init_latents = torch.cat(init_latents, dim=0)
|
||||
else:
|
||||
init_latents = retrieve_latents(self.vae.encode(image), generator=generator)
|
||||
|
||||
if self.vae.config.force_upcast:
|
||||
self.vae.to(dtype)
|
||||
|
||||
init_latents = init_latents.to(dtype)
|
||||
init_latents = self.vae.config.scaling_factor * init_latents
|
||||
|
||||
if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
|
||||
# expand init_latents for batch_size
|
||||
additional_image_per_prompt = batch_size // init_latents.shape[0]
|
||||
init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
|
||||
elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
|
||||
raise ValueError(
|
||||
f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
|
||||
)
|
||||
else:
|
||||
init_latents = torch.cat([init_latents], dim=0)
|
||||
|
||||
if add_noise:
|
||||
shape = init_latents.shape
|
||||
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
# get latents
|
||||
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
|
||||
|
||||
latents = init_latents
|
||||
return latents
|
||||
|
||||
if latents is None:
|
||||
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
else:
|
||||
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
|
||||
if isinstance(generator, list) and len(generator) != batch_size:
|
||||
raise ValueError(
|
||||
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
|
||||
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
|
||||
)
|
||||
latents = latents.to(device)
|
||||
|
||||
if (image is None or timestep is None) and not is_strength_max:
|
||||
raise ValueError(
|
||||
"Since strength < 1. initial latents are to be initialised as a combination of Image + Noise."
|
||||
"However, either the image or the noise timestep has not been provided."
|
||||
)
|
||||
|
||||
if image.shape[1] == 4:
|
||||
image_latents = image.to(device=device, dtype=dtype)
|
||||
image_latents = image_latents.repeat(batch_size // image_latents.shape[0], 1, 1, 1)
|
||||
elif return_image_latents or (latents is None and not is_strength_max):
|
||||
image = image.to(device=device, dtype=dtype)
|
||||
image_latents = self._encode_vae_image(image=image, generator=generator)
|
||||
image_latents = image_latents.repeat(batch_size // image_latents.shape[0], 1, 1, 1)
|
||||
|
||||
if latents is None and add_noise:
|
||||
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
# if strength is 1. then initialise the latents to noise, else initial to image + noise
|
||||
latents = noise if is_strength_max else self.scheduler.add_noise(image_latents, noise, timestep)
|
||||
# if pure noise then scale the initial latents by the Scheduler's init sigma
|
||||
latents = latents * self.scheduler.init_noise_sigma if is_strength_max else latents
|
||||
elif add_noise:
|
||||
noise = latents.to(device)
|
||||
latents = noise * self.scheduler.init_noise_sigma
|
||||
else:
|
||||
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
|
||||
latents = image_latents.to(device)
|
||||
|
||||
outputs = (latents,)
|
||||
|
||||
if return_noise:
|
||||
outputs += (noise,)
|
||||
|
||||
if return_image_latents:
|
||||
outputs += (image_latents,)
|
||||
|
||||
return outputs
|
||||
|
||||
def _encode_vae_image(self, image: torch.Tensor, generator: torch.Generator):
|
||||
dtype = image.dtype
|
||||
if self.vae.config.force_upcast:
|
||||
image = image.float()
|
||||
self.vae.to(dtype=torch.float32)
|
||||
|
||||
if isinstance(generator, list):
|
||||
image_latents = [
|
||||
retrieve_latents(self.vae.encode(image[i : i + 1]), generator=generator[i])
|
||||
for i in range(image.shape[0])
|
||||
]
|
||||
image_latents = torch.cat(image_latents, dim=0)
|
||||
else:
|
||||
image_latents = retrieve_latents(self.vae.encode(image), generator=generator)
|
||||
|
||||
if self.vae.config.force_upcast:
|
||||
self.vae.to(dtype)
|
||||
|
||||
image_latents = image_latents.to(dtype)
|
||||
image_latents = self.vae.config.scaling_factor * image_latents
|
||||
|
||||
return image_latents
|
||||
|
||||
def prepare_mask_latents(
|
||||
self, mask, masked_image, batch_size, height, width, dtype, device, generator, do_classifier_free_guidance
|
||||
):
|
||||
# resize the mask to latents shape as we concatenate the mask to the latents
|
||||
# we do that before converting to dtype to avoid breaking in case we're using cpu_offload
|
||||
# and half precision
|
||||
mask = torch.nn.functional.interpolate(
|
||||
mask, size=(height // self.vae_scale_factor, width // self.vae_scale_factor)
|
||||
)
|
||||
mask = mask.to(device=device, dtype=dtype)
|
||||
|
||||
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
|
||||
if mask.shape[0] < batch_size:
|
||||
if not batch_size % mask.shape[0] == 0:
|
||||
raise ValueError(
|
||||
"The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
|
||||
f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
|
||||
" of masks that you pass is divisible by the total requested batch size."
|
||||
)
|
||||
mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
|
||||
|
||||
mask = torch.cat([mask] * 2) if do_classifier_free_guidance else mask
|
||||
|
||||
if masked_image is not None and masked_image.shape[1] == 4:
|
||||
masked_image_latents = masked_image
|
||||
else:
|
||||
masked_image_latents = None
|
||||
|
||||
if masked_image is not None:
|
||||
if masked_image_latents is None:
|
||||
masked_image = masked_image.to(device=device, dtype=dtype)
|
||||
masked_image_latents = self._encode_vae_image(masked_image, generator=generator)
|
||||
|
||||
if masked_image_latents.shape[0] < batch_size:
|
||||
if not batch_size % masked_image_latents.shape[0] == 0:
|
||||
raise ValueError(
|
||||
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
|
||||
f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
|
||||
" Make sure the number of images that you pass is divisible by the total requested batch size."
|
||||
)
|
||||
masked_image_latents = masked_image_latents.repeat(
|
||||
batch_size // masked_image_latents.shape[0], 1, 1, 1
|
||||
)
|
||||
|
||||
masked_image_latents = (
|
||||
torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
|
||||
)
|
||||
|
||||
# aligning device to prevent device errors when concating it with the latent model input
|
||||
masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
|
||||
|
||||
return mask, masked_image_latents
|
||||
# scale the initial noise by the standard deviation required by the scheduler
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
def _get_add_time_ids(self, original_size, crops_coords_top_left, target_size, dtype):
|
||||
add_time_ids = list(original_size + crops_coords_top_left + target_size)
|
||||
@@ -1241,52 +934,15 @@ class SDXLLongPromptWeightingPipeline(DiffusionPipeline, FromSingleFileMixin, Lo
|
||||
self.vae.decoder.conv_in.to(dtype)
|
||||
self.vae.decoder.mid_block.to(dtype)
|
||||
|
||||
@property
|
||||
def guidance_scale(self):
|
||||
return self._guidance_scale
|
||||
|
||||
@property
|
||||
def guidance_rescale(self):
|
||||
return self._guidance_rescale
|
||||
|
||||
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
||||
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
||||
# corresponds to doing no classifier free guidance.
|
||||
@property
|
||||
def do_classifier_free_guidance(self):
|
||||
return self._guidance_scale > 1 and self.unet.config.time_cond_proj_dim is None
|
||||
|
||||
@property
|
||||
def cross_attention_kwargs(self):
|
||||
return self._cross_attention_kwargs
|
||||
|
||||
@property
|
||||
def denoising_end(self):
|
||||
return self._denoising_end
|
||||
|
||||
@property
|
||||
def denoising_start(self):
|
||||
return self._denoising_start
|
||||
|
||||
@property
|
||||
def num_timesteps(self):
|
||||
return self._num_timesteps
|
||||
|
||||
@torch.no_grad()
|
||||
@replace_example_docstring(EXAMPLE_DOC_STRING)
|
||||
def __call__(
|
||||
self,
|
||||
prompt: str = None,
|
||||
prompt_2: Optional[str] = None,
|
||||
image: Optional[PipelineImageInput] = None,
|
||||
mask_image: Optional[PipelineImageInput] = None,
|
||||
masked_image_latents: Optional[torch.FloatTensor] = None,
|
||||
height: Optional[int] = None,
|
||||
width: Optional[int] = None,
|
||||
strength: float = 0.8,
|
||||
num_inference_steps: int = 50,
|
||||
timesteps: List[int] = None,
|
||||
denoising_start: Optional[float] = None,
|
||||
denoising_end: Optional[float] = None,
|
||||
guidance_scale: float = 5.0,
|
||||
negative_prompt: Optional[str] = None,
|
||||
@@ -1319,46 +975,20 @@ class SDXLLongPromptWeightingPipeline(DiffusionPipeline, FromSingleFileMixin, Lo
|
||||
prompt_2 (`str`):
|
||||
The prompt to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
|
||||
used in both text-encoders
|
||||
image (`PipelineImageInput`, *optional*):
|
||||
`Image`, or tensor representing an image batch, that will be used as the starting point for the
|
||||
process.
|
||||
mask_image (`PipelineImageInput`, *optional*):
|
||||
`Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
|
||||
replaced by noise and therefore repainted, while black pixels will be preserved. If `mask_image` is a
|
||||
PIL image, it will be converted to a single channel (luminance) before use. If it's a tensor, it should
|
||||
contain one color channel (L) instead of 3, so the expected shape would be `(B, H, W, 1)`.
|
||||
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
|
||||
The height in pixels of the generated image.
|
||||
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
|
||||
The width in pixels of the generated image.
|
||||
strength (`float`, *optional*, defaults to 0.8):
|
||||
Conceptually, indicates how much to transform the reference `image`. Must be between 0 and 1.
|
||||
`image` will be used as a starting point, adding more noise to it the larger the `strength`. The
|
||||
number of denoising steps depends on the amount of noise initially added. When `strength` is 1, added
|
||||
noise will be maximum and the denoising process will run for the full number of iterations specified in
|
||||
`num_inference_steps`. A value of 1, therefore, essentially ignores `image`.
|
||||
num_inference_steps (`int`, *optional*, defaults to 50):
|
||||
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
|
||||
expense of slower inference.
|
||||
timesteps (`List[int]`, *optional*):
|
||||
Custom timesteps to use for the denoising process with schedulers which support a `timesteps` argument
|
||||
in their `set_timesteps` method. If not defined, the default behavior when `num_inference_steps` is
|
||||
passed will be used. Must be in descending order.
|
||||
denoising_start (`float`, *optional*):
|
||||
When specified, indicates the fraction (between 0.0 and 1.0) of the total denoising process to be
|
||||
bypassed before it is initiated. Consequently, the initial part of the denoising process is skipped and
|
||||
it is assumed that the passed `image` is a partly denoised image. Note that when this is specified,
|
||||
strength will be ignored. The `denoising_start` parameter is particularly beneficial when this pipeline
|
||||
is integrated into a "Mixture of Denoisers" multi-pipeline setup, as detailed in [**Refine Image
|
||||
Quality**](https://huggingface.co/docs/diffusers/using-diffusers/sdxl#refine-image-quality).
|
||||
denoising_end (`float`, *optional*):
|
||||
When specified, determines the fraction (between 0.0 and 1.0) of the total denoising process to be
|
||||
completed before it is intentionally prematurely terminated. As a result, the returned sample will
|
||||
still retain a substantial amount of noise (ca. final 20% of timesteps still needed) and should be
|
||||
denoised by a successor pipeline that has `denoising_start` set to 0.8 so that it only denoises the
|
||||
final 20% of the scheduler. The denoising_end parameter should ideally be utilized when this pipeline
|
||||
forms a part of a "Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refine Image
|
||||
Quality**](https://huggingface.co/docs/diffusers/using-diffusers/sdxl#refine-image-quality).
|
||||
still retain a substantial amount of noise as determined by the discrete timesteps selected by the
|
||||
scheduler. The denoising_end parameter should ideally be utilized when this pipeline forms a part of a
|
||||
"Mixture of Denoisers" multi-pipeline setup, as elaborated in [**Refining the Image
|
||||
Output**](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl#refining-the-image-output)
|
||||
guidance_scale (`float`, *optional*, defaults to 5.0):
|
||||
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
|
||||
`guidance_scale` is defined as `w` of equation 2. of [Imagen
|
||||
@@ -1454,7 +1084,6 @@ class SDXLLongPromptWeightingPipeline(DiffusionPipeline, FromSingleFileMixin, Lo
|
||||
prompt_2,
|
||||
height,
|
||||
width,
|
||||
strength,
|
||||
callback_steps,
|
||||
negative_prompt,
|
||||
negative_prompt_2,
|
||||
@@ -1464,12 +1093,6 @@ class SDXLLongPromptWeightingPipeline(DiffusionPipeline, FromSingleFileMixin, Lo
|
||||
negative_pooled_prompt_embeds,
|
||||
)
|
||||
|
||||
self._guidance_scale = guidance_scale
|
||||
self._guidance_rescale = guidance_rescale
|
||||
self._cross_attention_kwargs = cross_attention_kwargs
|
||||
self._denoising_end = denoising_end
|
||||
self._denoising_start = denoising_start
|
||||
|
||||
# 2. Define call parameters
|
||||
if prompt is not None and isinstance(prompt, str):
|
||||
batch_size = 1
|
||||
@@ -1498,126 +1121,28 @@ class SDXLLongPromptWeightingPipeline(DiffusionPipeline, FromSingleFileMixin, Lo
|
||||
) = get_weighted_text_embeddings_sdxl(
|
||||
pipe=self, prompt=prompt, neg_prompt=negative_prompt, num_images_per_prompt=num_images_per_prompt
|
||||
)
|
||||
dtype = prompt_embeds.dtype
|
||||
|
||||
if isinstance(image, Image.Image):
|
||||
image = self.image_processor.preprocess(image, height=height, width=width)
|
||||
if image is not None:
|
||||
image = image.to(device=self.device, dtype=dtype)
|
||||
|
||||
if isinstance(mask_image, Image.Image):
|
||||
mask = self.mask_processor.preprocess(mask_image, height=height, width=width)
|
||||
else:
|
||||
mask = mask_image
|
||||
if mask_image is not None:
|
||||
mask = mask.to(device=self.device, dtype=dtype)
|
||||
|
||||
if masked_image_latents is not None:
|
||||
masked_image = masked_image_latents
|
||||
elif image.shape[1] == 4:
|
||||
# if image is in latent space, we can't mask it
|
||||
masked_image = None
|
||||
else:
|
||||
masked_image = image * (mask < 0.5)
|
||||
else:
|
||||
mask = None
|
||||
|
||||
# 4. Prepare timesteps
|
||||
def denoising_value_valid(dnv):
|
||||
return isinstance(self.denoising_end, float) and 0 < dnv < 1
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
|
||||
timesteps, num_inference_steps = retrieve_timesteps(self.scheduler, num_inference_steps, device, timesteps)
|
||||
if image is not None:
|
||||
timesteps, num_inference_steps = self.get_timesteps(
|
||||
num_inference_steps,
|
||||
strength,
|
||||
device,
|
||||
denoising_start=self.denoising_start if denoising_value_valid else None,
|
||||
)
|
||||
|
||||
# check that number of inference steps is not < 1 - as this doesn't make sense
|
||||
if num_inference_steps < 1:
|
||||
raise ValueError(
|
||||
f"After adjusting the num_inference_steps by strength parameter: {strength}, the number of pipeline"
|
||||
f"steps is {num_inference_steps} which is < 1 and not appropriate for this pipeline."
|
||||
)
|
||||
|
||||
latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
|
||||
is_strength_max = strength == 1.0
|
||||
add_noise = True if self.denoising_start is None else False
|
||||
timesteps = self.scheduler.timesteps
|
||||
|
||||
# 5. Prepare latent variables
|
||||
num_channels_latents = self.vae.config.latent_channels
|
||||
num_channels_unet = self.unet.config.in_channels
|
||||
return_image_latents = num_channels_unet == 4
|
||||
|
||||
num_channels_latents = self.unet.config.in_channels
|
||||
latents = self.prepare_latents(
|
||||
image=image,
|
||||
mask=mask,
|
||||
width=width,
|
||||
height=height,
|
||||
num_channels_latents=num_channels_unet,
|
||||
timestep=latent_timestep,
|
||||
batch_size=batch_size,
|
||||
num_images_per_prompt=num_images_per_prompt,
|
||||
dtype=prompt_embeds.dtype,
|
||||
device=device,
|
||||
generator=generator,
|
||||
add_noise=add_noise,
|
||||
latents=latents,
|
||||
is_strength_max=is_strength_max,
|
||||
return_noise=True,
|
||||
return_image_latents=return_image_latents,
|
||||
batch_size * num_images_per_prompt,
|
||||
num_channels_latents,
|
||||
height,
|
||||
width,
|
||||
prompt_embeds.dtype,
|
||||
device,
|
||||
generator,
|
||||
latents,
|
||||
)
|
||||
|
||||
if mask is not None:
|
||||
if return_image_latents:
|
||||
latents, noise, image_latents = latents
|
||||
else:
|
||||
latents, noise = latents
|
||||
|
||||
# 5.1. Prepare mask latent variables
|
||||
if mask is not None:
|
||||
mask, masked_image_latents = self.prepare_mask_latents(
|
||||
mask=mask,
|
||||
masked_image=masked_image,
|
||||
batch_size=batch_size * num_images_per_prompt,
|
||||
height=height,
|
||||
width=width,
|
||||
dtype=prompt_embeds.dtype,
|
||||
device=device,
|
||||
generator=generator,
|
||||
do_classifier_free_guidance=self.do_classifier_free_guidance,
|
||||
)
|
||||
|
||||
# 8. Check that sizes of mask, masked image and latents match
|
||||
if num_channels_unet == 9:
|
||||
# default case for runwayml/stable-diffusion-inpainting
|
||||
num_channels_mask = mask.shape[1]
|
||||
num_channels_masked_image = masked_image_latents.shape[1]
|
||||
if num_channels_latents + num_channels_mask + num_channels_masked_image != num_channels_unet:
|
||||
raise ValueError(
|
||||
f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
|
||||
f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
|
||||
f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
|
||||
f" = {num_channels_latents+num_channels_masked_image+num_channels_mask}. Please verify the config of"
|
||||
" `pipeline.unet` or your `mask_image` or `image` input."
|
||||
)
|
||||
elif num_channels_unet != 4:
|
||||
raise ValueError(
|
||||
f"The unet {self.unet.__class__} should have either 4 or 9 input channels, not {self.unet.config.in_channels}."
|
||||
)
|
||||
|
||||
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
||||
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
|
||||
|
||||
height, width = latents.shape[-2:]
|
||||
height = height * self.vae_scale_factor
|
||||
width = width * self.vae_scale_factor
|
||||
|
||||
original_size = original_size or (height, width)
|
||||
target_size = target_size or (height, width)
|
||||
|
||||
# 7. Prepare added time ids & embeddings
|
||||
add_text_embeds = pooled_prompt_embeds
|
||||
add_time_ids = self._get_add_time_ids(
|
||||
@@ -1633,41 +1158,20 @@ class SDXLLongPromptWeightingPipeline(DiffusionPipeline, FromSingleFileMixin, Lo
|
||||
add_text_embeds = add_text_embeds.to(device)
|
||||
add_time_ids = add_time_ids.to(device).repeat(batch_size * num_images_per_prompt, 1)
|
||||
|
||||
# 8. Denoising loop
|
||||
num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
|
||||
|
||||
# 7.1 Apply denoising_end
|
||||
if (
|
||||
self.denoising_end is not None
|
||||
and self.denoising_start is not None
|
||||
and denoising_value_valid(self.denoising_end)
|
||||
and denoising_value_valid(self.denoising_start)
|
||||
and self.denoising_start >= self.denoising_end
|
||||
):
|
||||
raise ValueError(
|
||||
f"`denoising_start`: {self.denoising_start} cannot be larger than or equal to `denoising_end`: "
|
||||
+ f" {self.denoising_end} when using type float."
|
||||
)
|
||||
elif self.denoising_end is not None and denoising_value_valid(self.denoising_end):
|
||||
if denoising_end is not None and isinstance(denoising_end, float) and denoising_end > 0 and denoising_end < 1:
|
||||
discrete_timestep_cutoff = int(
|
||||
round(
|
||||
self.scheduler.config.num_train_timesteps
|
||||
- (self.denoising_end * self.scheduler.config.num_train_timesteps)
|
||||
- (denoising_end * self.scheduler.config.num_train_timesteps)
|
||||
)
|
||||
)
|
||||
num_inference_steps = len(list(filter(lambda ts: ts >= discrete_timestep_cutoff, timesteps)))
|
||||
timesteps = timesteps[:num_inference_steps]
|
||||
|
||||
# 8. Optionally get Guidance Scale Embedding
|
||||
timestep_cond = None
|
||||
if self.unet.config.time_cond_proj_dim is not None:
|
||||
guidance_scale_tensor = torch.tensor(self.guidance_scale - 1).repeat(batch_size * num_images_per_prompt)
|
||||
timestep_cond = self.get_guidance_scale_embedding(
|
||||
guidance_scale_tensor, embedding_dim=self.unet.config.time_cond_proj_dim
|
||||
).to(device=device, dtype=latents.dtype)
|
||||
|
||||
self._num_timesteps = len(timesteps)
|
||||
|
||||
# 9. Denoising loop
|
||||
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
||||
for i, t in enumerate(timesteps):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
@@ -1675,17 +1179,13 @@ class SDXLLongPromptWeightingPipeline(DiffusionPipeline, FromSingleFileMixin, Lo
|
||||
|
||||
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
||||
|
||||
if mask is not None and num_channels_unet == 9:
|
||||
latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
|
||||
|
||||
# predict the noise residual
|
||||
added_cond_kwargs = {"text_embeds": add_text_embeds, "time_ids": add_time_ids}
|
||||
noise_pred = self.unet(
|
||||
latent_model_input,
|
||||
t,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep_cond=timestep_cond,
|
||||
cross_attention_kwargs=self.cross_attention_kwargs,
|
||||
cross_attention_kwargs=cross_attention_kwargs,
|
||||
added_cond_kwargs=added_cond_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
@@ -1702,22 +1202,6 @@ class SDXLLongPromptWeightingPipeline(DiffusionPipeline, FromSingleFileMixin, Lo
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
|
||||
|
||||
if mask is not None and num_channels_unet == 4:
|
||||
init_latents_proper = image_latents
|
||||
|
||||
if self.do_classifier_free_guidance:
|
||||
init_mask, _ = mask.chunk(2)
|
||||
else:
|
||||
init_mask = mask
|
||||
|
||||
if i < len(timesteps) - 1:
|
||||
noise_timestep = timesteps[i + 1]
|
||||
init_latents_proper = self.scheduler.add_noise(
|
||||
init_latents_proper, noise, torch.tensor([noise_timestep])
|
||||
)
|
||||
|
||||
latents = (1 - init_mask) * init_latents_proper + init_mask * latents
|
||||
|
||||
# call the callback, if provided
|
||||
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
|
||||
progress_bar.update()
|
||||
@@ -1757,204 +1241,6 @@ class SDXLLongPromptWeightingPipeline(DiffusionPipeline, FromSingleFileMixin, Lo
|
||||
|
||||
return StableDiffusionXLPipelineOutput(images=image)
|
||||
|
||||
def text2img(
|
||||
self,
|
||||
prompt: str = None,
|
||||
prompt_2: Optional[str] = None,
|
||||
height: Optional[int] = None,
|
||||
width: Optional[int] = None,
|
||||
num_inference_steps: int = 50,
|
||||
timesteps: List[int] = None,
|
||||
denoising_start: Optional[float] = None,
|
||||
denoising_end: Optional[float] = None,
|
||||
guidance_scale: float = 5.0,
|
||||
negative_prompt: Optional[str] = None,
|
||||
negative_prompt_2: Optional[str] = None,
|
||||
num_images_per_prompt: Optional[int] = 1,
|
||||
eta: float = 0.0,
|
||||
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
||||
latents: Optional[torch.FloatTensor] = None,
|
||||
prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
output_type: Optional[str] = "pil",
|
||||
return_dict: bool = True,
|
||||
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
|
||||
callback_steps: int = 1,
|
||||
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
||||
guidance_rescale: float = 0.0,
|
||||
original_size: Optional[Tuple[int, int]] = None,
|
||||
crops_coords_top_left: Tuple[int, int] = (0, 0),
|
||||
target_size: Optional[Tuple[int, int]] = None,
|
||||
):
|
||||
return self.__call__(
|
||||
prompt=prompt,
|
||||
prompt_2=prompt_2,
|
||||
height=height,
|
||||
width=width,
|
||||
num_inference_steps=num_inference_steps,
|
||||
timesteps=timesteps,
|
||||
denoising_start=denoising_start,
|
||||
denoising_end=denoising_end,
|
||||
guidance_scale=guidance_scale,
|
||||
negative_prompt=negative_prompt,
|
||||
negative_prompt_2=negative_prompt_2,
|
||||
num_images_per_prompt=num_images_per_prompt,
|
||||
eta=eta,
|
||||
generator=generator,
|
||||
latents=latents,
|
||||
prompt_embeds=prompt_embeds,
|
||||
negative_prompt_embeds=negative_prompt_embeds,
|
||||
pooled_prompt_embeds=pooled_prompt_embeds,
|
||||
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
||||
output_type=output_type,
|
||||
return_dict=return_dict,
|
||||
callback=callback,
|
||||
callback_steps=callback_steps,
|
||||
cross_attention_kwargs=cross_attention_kwargs,
|
||||
guidance_rescale=guidance_rescale,
|
||||
original_size=original_size,
|
||||
crops_coords_top_left=crops_coords_top_left,
|
||||
target_size=target_size,
|
||||
)
|
||||
|
||||
def img2img(
|
||||
self,
|
||||
prompt: str = None,
|
||||
prompt_2: Optional[str] = None,
|
||||
image: Optional[PipelineImageInput] = None,
|
||||
height: Optional[int] = None,
|
||||
width: Optional[int] = None,
|
||||
strength: float = 0.8,
|
||||
num_inference_steps: int = 50,
|
||||
timesteps: List[int] = None,
|
||||
denoising_start: Optional[float] = None,
|
||||
denoising_end: Optional[float] = None,
|
||||
guidance_scale: float = 5.0,
|
||||
negative_prompt: Optional[str] = None,
|
||||
negative_prompt_2: Optional[str] = None,
|
||||
num_images_per_prompt: Optional[int] = 1,
|
||||
eta: float = 0.0,
|
||||
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
||||
latents: Optional[torch.FloatTensor] = None,
|
||||
prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
output_type: Optional[str] = "pil",
|
||||
return_dict: bool = True,
|
||||
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
|
||||
callback_steps: int = 1,
|
||||
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
||||
guidance_rescale: float = 0.0,
|
||||
original_size: Optional[Tuple[int, int]] = None,
|
||||
crops_coords_top_left: Tuple[int, int] = (0, 0),
|
||||
target_size: Optional[Tuple[int, int]] = None,
|
||||
):
|
||||
return self.__call__(
|
||||
prompt=prompt,
|
||||
prompt_2=prompt_2,
|
||||
image=image,
|
||||
height=height,
|
||||
width=width,
|
||||
strength=strength,
|
||||
num_inference_steps=num_inference_steps,
|
||||
timesteps=timesteps,
|
||||
denoising_start=denoising_start,
|
||||
denoising_end=denoising_end,
|
||||
guidance_scale=guidance_scale,
|
||||
negative_prompt=negative_prompt,
|
||||
negative_prompt_2=negative_prompt_2,
|
||||
num_images_per_prompt=num_images_per_prompt,
|
||||
eta=eta,
|
||||
generator=generator,
|
||||
latents=latents,
|
||||
prompt_embeds=prompt_embeds,
|
||||
negative_prompt_embeds=negative_prompt_embeds,
|
||||
pooled_prompt_embeds=pooled_prompt_embeds,
|
||||
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
||||
output_type=output_type,
|
||||
return_dict=return_dict,
|
||||
callback=callback,
|
||||
callback_steps=callback_steps,
|
||||
cross_attention_kwargs=cross_attention_kwargs,
|
||||
guidance_rescale=guidance_rescale,
|
||||
original_size=original_size,
|
||||
crops_coords_top_left=crops_coords_top_left,
|
||||
target_size=target_size,
|
||||
)
|
||||
|
||||
def inpaint(
|
||||
self,
|
||||
prompt: str = None,
|
||||
prompt_2: Optional[str] = None,
|
||||
image: Optional[PipelineImageInput] = None,
|
||||
mask_image: Optional[PipelineImageInput] = None,
|
||||
masked_image_latents: Optional[torch.FloatTensor] = None,
|
||||
height: Optional[int] = None,
|
||||
width: Optional[int] = None,
|
||||
strength: float = 0.8,
|
||||
num_inference_steps: int = 50,
|
||||
timesteps: List[int] = None,
|
||||
denoising_start: Optional[float] = None,
|
||||
denoising_end: Optional[float] = None,
|
||||
guidance_scale: float = 5.0,
|
||||
negative_prompt: Optional[str] = None,
|
||||
negative_prompt_2: Optional[str] = None,
|
||||
num_images_per_prompt: Optional[int] = 1,
|
||||
eta: float = 0.0,
|
||||
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
|
||||
latents: Optional[torch.FloatTensor] = None,
|
||||
prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
negative_pooled_prompt_embeds: Optional[torch.FloatTensor] = None,
|
||||
output_type: Optional[str] = "pil",
|
||||
return_dict: bool = True,
|
||||
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
|
||||
callback_steps: int = 1,
|
||||
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
|
||||
guidance_rescale: float = 0.0,
|
||||
original_size: Optional[Tuple[int, int]] = None,
|
||||
crops_coords_top_left: Tuple[int, int] = (0, 0),
|
||||
target_size: Optional[Tuple[int, int]] = None,
|
||||
):
|
||||
return self.__call__(
|
||||
prompt=prompt,
|
||||
prompt_2=prompt_2,
|
||||
image=image,
|
||||
mask_image=mask_image,
|
||||
masked_image_latents=masked_image_latents,
|
||||
height=height,
|
||||
width=width,
|
||||
strength=strength,
|
||||
num_inference_steps=num_inference_steps,
|
||||
timesteps=timesteps,
|
||||
denoising_start=denoising_start,
|
||||
denoising_end=denoising_end,
|
||||
guidance_scale=guidance_scale,
|
||||
negative_prompt=negative_prompt,
|
||||
negative_prompt_2=negative_prompt_2,
|
||||
num_images_per_prompt=num_images_per_prompt,
|
||||
eta=eta,
|
||||
generator=generator,
|
||||
latents=latents,
|
||||
prompt_embeds=prompt_embeds,
|
||||
negative_prompt_embeds=negative_prompt_embeds,
|
||||
pooled_prompt_embeds=pooled_prompt_embeds,
|
||||
negative_pooled_prompt_embeds=negative_pooled_prompt_embeds,
|
||||
output_type=output_type,
|
||||
return_dict=return_dict,
|
||||
callback=callback,
|
||||
callback_steps=callback_steps,
|
||||
cross_attention_kwargs=cross_attention_kwargs,
|
||||
guidance_rescale=guidance_rescale,
|
||||
original_size=original_size,
|
||||
crops_coords_top_left=crops_coords_top_left,
|
||||
target_size=target_size,
|
||||
)
|
||||
|
||||
# Overrride to properly handle the loading and unloading of the additional text encoder.
|
||||
def load_lora_weights(self, pretrained_model_name_or_path_or_dict: Union[str, Dict[str, torch.Tensor]], **kwargs):
|
||||
# We could have accessed the unet config from `lora_state_dict()` too. We pass
|
||||
|
||||
@@ -73,14 +73,7 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
|
||||
requires_safety_checker: bool = True,
|
||||
):
|
||||
super().__init__(
|
||||
vae,
|
||||
text_encoder,
|
||||
tokenizer,
|
||||
unet,
|
||||
scheduler,
|
||||
safety_checker,
|
||||
feature_extractor,
|
||||
requires_safety_checker,
|
||||
vae, text_encoder, tokenizer, unet, scheduler, safety_checker, feature_extractor, requires_safety_checker
|
||||
)
|
||||
self.register_modules(
|
||||
vae=vae,
|
||||
@@ -109,22 +102,22 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
|
||||
return_dict: bool = True,
|
||||
rp_args: Dict[str, str] = None,
|
||||
):
|
||||
active = KBRK in prompt[0] if isinstance(prompt, list) else KBRK in prompt
|
||||
active = KBRK in prompt[0] if type(prompt) == list else KBRK in prompt # noqa: E721
|
||||
if negative_prompt is None:
|
||||
negative_prompt = "" if isinstance(prompt, str) else [""] * len(prompt)
|
||||
negative_prompt = "" if type(prompt) == str else [""] * len(prompt) # noqa: E721
|
||||
|
||||
device = self._execution_device
|
||||
regions = 0
|
||||
|
||||
self.power = int(rp_args["power"]) if "power" in rp_args else 1
|
||||
|
||||
prompts = prompt if isinstance(prompt, list) else [prompt]
|
||||
n_prompts = negative_prompt if isinstance(prompt, str) else [negative_prompt]
|
||||
prompts = prompt if type(prompt) == list else [prompt] # noqa: E721
|
||||
n_prompts = negative_prompt if type(negative_prompt) == list else [negative_prompt] # noqa: E721
|
||||
self.batch = batch = num_images_per_prompt * len(prompts)
|
||||
all_prompts_cn, all_prompts_p = promptsmaker(prompts, num_images_per_prompt)
|
||||
all_n_prompts_cn, _ = promptsmaker(n_prompts, num_images_per_prompt)
|
||||
|
||||
equal = len(all_prompts_cn) == len(all_n_prompts_cn)
|
||||
cn = len(all_prompts_cn) == len(all_n_prompts_cn)
|
||||
|
||||
if Compel:
|
||||
compel = Compel(tokenizer=self.tokenizer, text_encoder=self.text_encoder)
|
||||
@@ -136,7 +129,7 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
|
||||
return torch.cat(embl)
|
||||
|
||||
conds = getcompelembs(all_prompts_cn)
|
||||
unconds = getcompelembs(all_n_prompts_cn)
|
||||
unconds = getcompelembs(all_n_prompts_cn) if cn else getcompelembs(n_prompts)
|
||||
embs = getcompelembs(prompts)
|
||||
n_embs = getcompelembs(n_prompts)
|
||||
prompt = negative_prompt = None
|
||||
@@ -144,7 +137,7 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
|
||||
conds = self.encode_prompt(prompts, device, 1, True)[0]
|
||||
unconds = (
|
||||
self.encode_prompt(n_prompts, device, 1, True)[0]
|
||||
if equal
|
||||
if cn
|
||||
else self.encode_prompt(all_n_prompts_cn, device, 1, True)[0]
|
||||
)
|
||||
embs = n_embs = None
|
||||
@@ -213,11 +206,8 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
|
||||
else:
|
||||
px, nx = hidden_states.chunk(2)
|
||||
|
||||
if equal:
|
||||
hidden_states = torch.cat(
|
||||
[px for i in range(regions)] + [nx for i in range(regions)],
|
||||
0,
|
||||
)
|
||||
if cn:
|
||||
hidden_states = torch.cat([px for i in range(regions)] + [nx for i in range(regions)], 0)
|
||||
encoder_hidden_states = torch.cat([conds] + [unconds])
|
||||
else:
|
||||
hidden_states = torch.cat([px for i in range(regions)] + [nx], 0)
|
||||
@@ -299,9 +289,9 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
|
||||
if any(x in mode for x in ["COL", "ROW"]):
|
||||
reshaped = hidden_states.reshape(hidden_states.size()[0], h, w, hidden_states.size()[2])
|
||||
center = reshaped.shape[0] // 2
|
||||
px = reshaped[0:center] if equal else reshaped[0:-batch]
|
||||
nx = reshaped[center:] if equal else reshaped[-batch:]
|
||||
outs = [px, nx] if equal else [px]
|
||||
px = reshaped[0:center] if cn else reshaped[0:-batch]
|
||||
nx = reshaped[center:] if cn else reshaped[-batch:]
|
||||
outs = [px, nx] if cn else [px]
|
||||
for out in outs:
|
||||
c = 0
|
||||
for i, ocell in enumerate(ocells):
|
||||
@@ -331,16 +321,15 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
|
||||
:,
|
||||
]
|
||||
c += 1
|
||||
px, nx = (px[0:batch], nx[0:batch]) if equal else (px[0:batch], nx)
|
||||
px, nx = (px[0:batch], nx[0:batch]) if cn else (px[0:batch], nx)
|
||||
hidden_states = torch.cat([nx, px], 0) if revers else torch.cat([px, nx], 0)
|
||||
hidden_states = hidden_states.reshape(xshape)
|
||||
|
||||
#### Regional Prompting Prompt mode
|
||||
elif "PRO" in mode:
|
||||
px, nx = (
|
||||
torch.chunk(hidden_states) if equal else hidden_states[0:-batch],
|
||||
hidden_states[-batch:],
|
||||
)
|
||||
center = reshaped.shape[0] // 2
|
||||
px = reshaped[0:center] if cn else reshaped[0:-batch]
|
||||
nx = reshaped[center:] if cn else reshaped[-batch:]
|
||||
|
||||
if (h, w) in self.attnmasks and self.maskready:
|
||||
|
||||
@@ -351,8 +340,8 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
|
||||
out[b] = out[b] + out[r * batch + b]
|
||||
return out
|
||||
|
||||
px, nx = (mask(px), mask(nx)) if equal else (mask(px), nx)
|
||||
px, nx = (px[0:batch], nx[0:batch]) if equal else (px[0:batch], nx)
|
||||
px, nx = (mask(px), mask(nx)) if cn else (mask(px), nx)
|
||||
px, nx = (px[0:batch], nx[0:batch]) if cn else (px[0:batch], nx)
|
||||
hidden_states = torch.cat([nx, px], 0) if revers else torch.cat([px, nx], 0)
|
||||
return hidden_states
|
||||
|
||||
@@ -389,15 +378,7 @@ class RegionalPromptingStableDiffusionPipeline(StableDiffusionPipeline):
|
||||
save_mask = False
|
||||
|
||||
if mode == "PROMPT" and save_mask:
|
||||
saveattnmaps(
|
||||
self,
|
||||
output,
|
||||
height,
|
||||
width,
|
||||
thresholds,
|
||||
num_inference_steps // 2,
|
||||
regions,
|
||||
)
|
||||
saveattnmaps(self, output, height, width, thresholds, num_inference_steps // 2, regions)
|
||||
|
||||
return output
|
||||
|
||||
@@ -456,11 +437,7 @@ def make_cells(ratios):
|
||||
def make_emblist(self, prompts):
|
||||
with torch.no_grad():
|
||||
tokens = self.tokenizer(
|
||||
prompts,
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
padding=True,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
prompts, max_length=self.tokenizer.model_max_length, padding=True, truncation=True, return_tensors="pt"
|
||||
).input_ids.to(self.device)
|
||||
embs = self.text_encoder(tokens, output_hidden_states=True).last_hidden_state.to(self.device, dtype=self.dtype)
|
||||
return embs
|
||||
@@ -586,15 +563,7 @@ def tokendealer(self, all_prompts):
|
||||
|
||||
|
||||
def scaled_dot_product_attention(
|
||||
self,
|
||||
query,
|
||||
key,
|
||||
value,
|
||||
attn_mask=None,
|
||||
dropout_p=0.0,
|
||||
is_causal=False,
|
||||
scale=None,
|
||||
getattn=False,
|
||||
self, query, key, value, attn_mask=None, dropout_p=0.0, is_causal=False, scale=None, getattn=False
|
||||
) -> torch.Tensor:
|
||||
# Efficient implementation equivalent to the following:
|
||||
L, S = query.size(-2), key.size(-2)
|
||||
|
||||
@@ -64,6 +64,39 @@ check_min_version("0.25.0.dev0")
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
# TODO: This function should be removed once training scripts are rewritten in PEFT
|
||||
def text_encoder_lora_state_dict(text_encoder):
|
||||
state_dict = {}
|
||||
|
||||
def text_encoder_attn_modules(text_encoder):
|
||||
from transformers import CLIPTextModel, CLIPTextModelWithProjection
|
||||
|
||||
attn_modules = []
|
||||
|
||||
if isinstance(text_encoder, (CLIPTextModel, CLIPTextModelWithProjection)):
|
||||
for i, layer in enumerate(text_encoder.text_model.encoder.layers):
|
||||
name = f"text_model.encoder.layers.{i}.self_attn"
|
||||
mod = layer.self_attn
|
||||
attn_modules.append((name, mod))
|
||||
|
||||
return attn_modules
|
||||
|
||||
for name, module in text_encoder_attn_modules(text_encoder):
|
||||
for k, v in module.q_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.q_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
for k, v in module.k_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.k_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
for k, v in module.v_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.v_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
for k, v in module.out_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.out_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
return state_dict
|
||||
|
||||
|
||||
def save_model_card(
|
||||
repo_id: str,
|
||||
images=None,
|
||||
@@ -847,11 +880,16 @@ def main(args):
|
||||
unet_lora_layers_to_save = None
|
||||
text_encoder_lora_layers_to_save = None
|
||||
|
||||
unet_lora_config = None
|
||||
text_encoder_lora_config = None
|
||||
|
||||
for model in models:
|
||||
if isinstance(model, type(accelerator.unwrap_model(unet))):
|
||||
unet_lora_layers_to_save = get_peft_model_state_dict(model)
|
||||
unet_lora_config = model.peft_config["default"]
|
||||
elif isinstance(model, type(accelerator.unwrap_model(text_encoder))):
|
||||
text_encoder_lora_layers_to_save = get_peft_model_state_dict(model)
|
||||
text_encoder_lora_config = model.peft_config["default"]
|
||||
else:
|
||||
raise ValueError(f"unexpected save model: {model.__class__}")
|
||||
|
||||
@@ -862,6 +900,8 @@ def main(args):
|
||||
output_dir,
|
||||
unet_lora_layers=unet_lora_layers_to_save,
|
||||
text_encoder_lora_layers=text_encoder_lora_layers_to_save,
|
||||
unet_lora_config=unet_lora_config,
|
||||
text_encoder_lora_config=text_encoder_lora_config,
|
||||
)
|
||||
|
||||
def load_model_hook(models, input_dir):
|
||||
@@ -878,10 +918,12 @@ def main(args):
|
||||
else:
|
||||
raise ValueError(f"unexpected save model: {model.__class__}")
|
||||
|
||||
lora_state_dict, network_alphas = LoraLoaderMixin.lora_state_dict(input_dir)
|
||||
LoraLoaderMixin.load_lora_into_unet(lora_state_dict, network_alphas=network_alphas, unet=unet_)
|
||||
lora_state_dict, network_alphas, metadata = LoraLoaderMixin.lora_state_dict(input_dir)
|
||||
LoraLoaderMixin.load_lora_into_unet(
|
||||
lora_state_dict, network_alphas=network_alphas, unet=unet_, config=metadata
|
||||
)
|
||||
LoraLoaderMixin.load_lora_into_text_encoder(
|
||||
lora_state_dict, network_alphas=network_alphas, text_encoder=text_encoder_
|
||||
lora_state_dict, network_alphas=network_alphas, text_encoder=text_encoder_, config=metadata
|
||||
)
|
||||
|
||||
accelerator.register_save_state_pre_hook(save_model_hook)
|
||||
@@ -1282,17 +1324,22 @@ def main(args):
|
||||
unet = unet.to(torch.float32)
|
||||
|
||||
unet_lora_state_dict = get_peft_model_state_dict(unet)
|
||||
unet_lora_config = unet.peft_config["default"]
|
||||
|
||||
if args.train_text_encoder:
|
||||
text_encoder = accelerator.unwrap_model(text_encoder)
|
||||
text_encoder_state_dict = get_peft_model_state_dict(text_encoder)
|
||||
text_encoder_lora_config = text_encoder.peft_config["default"]
|
||||
else:
|
||||
text_encoder_state_dict = None
|
||||
text_encoder_lora_config = None
|
||||
|
||||
LoraLoaderMixin.save_lora_weights(
|
||||
save_directory=args.output_dir,
|
||||
unet_lora_layers=unet_lora_state_dict,
|
||||
text_encoder_lora_layers=text_encoder_state_dict,
|
||||
unet_lora_config=unet_lora_config,
|
||||
text_encoder_lora_config=text_encoder_lora_config,
|
||||
)
|
||||
|
||||
# Final inference
|
||||
|
||||
@@ -64,6 +64,39 @@ check_min_version("0.25.0.dev0")
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
# TODO: This function should be removed once training scripts are rewritten in PEFT
|
||||
def text_encoder_lora_state_dict(text_encoder):
|
||||
state_dict = {}
|
||||
|
||||
def text_encoder_attn_modules(text_encoder):
|
||||
from transformers import CLIPTextModel, CLIPTextModelWithProjection
|
||||
|
||||
attn_modules = []
|
||||
|
||||
if isinstance(text_encoder, (CLIPTextModel, CLIPTextModelWithProjection)):
|
||||
for i, layer in enumerate(text_encoder.text_model.encoder.layers):
|
||||
name = f"text_model.encoder.layers.{i}.self_attn"
|
||||
mod = layer.self_attn
|
||||
attn_modules.append((name, mod))
|
||||
|
||||
return attn_modules
|
||||
|
||||
for name, module in text_encoder_attn_modules(text_encoder):
|
||||
for k, v in module.q_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.q_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
for k, v in module.k_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.k_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
for k, v in module.v_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.v_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
for k, v in module.out_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.out_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
return state_dict
|
||||
|
||||
|
||||
def save_model_card(
|
||||
repo_id: str,
|
||||
images=None,
|
||||
@@ -991,17 +1024,6 @@ def main(args):
|
||||
text_encoder_one.add_adapter(text_lora_config)
|
||||
text_encoder_two.add_adapter(text_lora_config)
|
||||
|
||||
# Make sure the trainable params are in float32.
|
||||
if args.mixed_precision == "fp16":
|
||||
models = [unet]
|
||||
if args.train_text_encoder:
|
||||
models.extend([text_encoder_one, text_encoder_two])
|
||||
for model in models:
|
||||
for param in model.parameters():
|
||||
# only upcast trainable parameters (LoRA) into fp32
|
||||
if param.requires_grad:
|
||||
param.data = param.to(torch.float32)
|
||||
|
||||
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
|
||||
def save_model_hook(models, weights, output_dir):
|
||||
if accelerator.is_main_process:
|
||||
@@ -1011,13 +1033,20 @@ def main(args):
|
||||
text_encoder_one_lora_layers_to_save = None
|
||||
text_encoder_two_lora_layers_to_save = None
|
||||
|
||||
unet_lora_config = None
|
||||
text_encoder_one_lora_config = None
|
||||
text_encoder_two_lora_config = None
|
||||
|
||||
for model in models:
|
||||
if isinstance(model, type(accelerator.unwrap_model(unet))):
|
||||
unet_lora_layers_to_save = get_peft_model_state_dict(model)
|
||||
unet_lora_config = model.peft_config["default"]
|
||||
elif isinstance(model, type(accelerator.unwrap_model(text_encoder_one))):
|
||||
text_encoder_one_lora_layers_to_save = get_peft_model_state_dict(model)
|
||||
text_encoder_one_lora_config = model.peft_config["default"]
|
||||
elif isinstance(model, type(accelerator.unwrap_model(text_encoder_two))):
|
||||
text_encoder_two_lora_layers_to_save = get_peft_model_state_dict(model)
|
||||
text_encoder_two_lora_config = model.peft_config["default"]
|
||||
else:
|
||||
raise ValueError(f"unexpected save model: {model.__class__}")
|
||||
|
||||
@@ -1029,6 +1058,9 @@ def main(args):
|
||||
unet_lora_layers=unet_lora_layers_to_save,
|
||||
text_encoder_lora_layers=text_encoder_one_lora_layers_to_save,
|
||||
text_encoder_2_lora_layers=text_encoder_two_lora_layers_to_save,
|
||||
unet_lora_config=unet_lora_config,
|
||||
text_encoder_lora_config=text_encoder_one_lora_config,
|
||||
text_encoder_2_lora_config=text_encoder_two_lora_config,
|
||||
)
|
||||
|
||||
def load_model_hook(models, input_dir):
|
||||
@@ -1048,17 +1080,19 @@ def main(args):
|
||||
else:
|
||||
raise ValueError(f"unexpected save model: {model.__class__}")
|
||||
|
||||
lora_state_dict, network_alphas = LoraLoaderMixin.lora_state_dict(input_dir)
|
||||
LoraLoaderMixin.load_lora_into_unet(lora_state_dict, network_alphas=network_alphas, unet=unet_)
|
||||
lora_state_dict, network_alphas, metadata = LoraLoaderMixin.lora_state_dict(input_dir)
|
||||
LoraLoaderMixin.load_lora_into_unet(
|
||||
lora_state_dict, network_alphas=network_alphas, unet=unet_, config=metadata
|
||||
)
|
||||
|
||||
text_encoder_state_dict = {k: v for k, v in lora_state_dict.items() if "text_encoder." in k}
|
||||
LoraLoaderMixin.load_lora_into_text_encoder(
|
||||
text_encoder_state_dict, network_alphas=network_alphas, text_encoder=text_encoder_one_
|
||||
text_encoder_state_dict, network_alphas=network_alphas, text_encoder=text_encoder_one_, config=metadata
|
||||
)
|
||||
|
||||
text_encoder_2_state_dict = {k: v for k, v in lora_state_dict.items() if "text_encoder_2." in k}
|
||||
LoraLoaderMixin.load_lora_into_text_encoder(
|
||||
text_encoder_2_state_dict, network_alphas=network_alphas, text_encoder=text_encoder_two_
|
||||
text_encoder_2_state_dict, network_alphas=network_alphas, text_encoder=text_encoder_two_, config=metadata
|
||||
)
|
||||
|
||||
accelerator.register_save_state_pre_hook(save_model_hook)
|
||||
@@ -1594,21 +1628,29 @@ def main(args):
|
||||
unet = accelerator.unwrap_model(unet)
|
||||
unet = unet.to(torch.float32)
|
||||
unet_lora_layers = get_peft_model_state_dict(unet)
|
||||
unet_lora_config = unet.peft_config["default"]
|
||||
|
||||
if args.train_text_encoder:
|
||||
text_encoder_one = accelerator.unwrap_model(text_encoder_one)
|
||||
text_encoder_lora_layers = get_peft_model_state_dict(text_encoder_one.to(torch.float32))
|
||||
text_encoder_two = accelerator.unwrap_model(text_encoder_two)
|
||||
text_encoder_2_lora_layers = get_peft_model_state_dict(text_encoder_two.to(torch.float32))
|
||||
text_encoder_one_lora_config = text_encoder_one.peft_config["default"]
|
||||
text_encoder_two_lora_config = text_encoder_two.peft_config["default"]
|
||||
else:
|
||||
text_encoder_lora_layers = None
|
||||
text_encoder_2_lora_layers = None
|
||||
text_encoder_one_lora_config = None
|
||||
text_encoder_two_lora_config = None
|
||||
|
||||
StableDiffusionXLPipeline.save_lora_weights(
|
||||
save_directory=args.output_dir,
|
||||
unet_lora_layers=unet_lora_layers,
|
||||
text_encoder_lora_layers=text_encoder_lora_layers,
|
||||
text_encoder_2_lora_layers=text_encoder_2_lora_layers,
|
||||
unet_lora_config=unet_lora_config,
|
||||
text_encoder_lora_config=text_encoder_one_lora_config,
|
||||
text_encoder_2_lora_config=text_encoder_two_lora_config,
|
||||
)
|
||||
|
||||
# Final inference
|
||||
|
||||
@@ -101,8 +101,8 @@ accelerate launch --mixed_precision="fp16" train_text_to_image.py \
|
||||
|
||||
Once the training is finished the model will be saved in the `output_dir` specified in the command. In this example it's `sd-pokemon-model`. To load the fine-tuned model for inference just pass that path to `StableDiffusionPipeline`
|
||||
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
model_path = "path_to_saved_model"
|
||||
@@ -114,13 +114,12 @@ image.save("yoda-pokemon.png")
|
||||
```
|
||||
|
||||
Checkpoints only save the unet, so to run inference from a checkpoint, just load the unet
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import StableDiffusionPipeline, UNet2DConditionModel
|
||||
|
||||
model_path = "path_to_saved_model"
|
||||
unet = UNet2DConditionModel.from_pretrained(model_path + "/checkpoint-<N>/unet", torch_dtype=torch.float16)
|
||||
|
||||
unet = UNet2DConditionModel.from_pretrained(model_path + "/checkpoint-<N>/unet")
|
||||
|
||||
pipe = StableDiffusionPipeline.from_pretrained("<initial model>", unet=unet, torch_dtype=torch.float16)
|
||||
pipe.to("cuda")
|
||||
|
||||
@@ -54,6 +54,39 @@ check_min_version("0.25.0.dev0")
|
||||
logger = get_logger(__name__, log_level="INFO")
|
||||
|
||||
|
||||
# TODO: This function should be removed once training scripts are rewritten in PEFT
|
||||
def text_encoder_lora_state_dict(text_encoder):
|
||||
state_dict = {}
|
||||
|
||||
def text_encoder_attn_modules(text_encoder):
|
||||
from transformers import CLIPTextModel, CLIPTextModelWithProjection
|
||||
|
||||
attn_modules = []
|
||||
|
||||
if isinstance(text_encoder, (CLIPTextModel, CLIPTextModelWithProjection)):
|
||||
for i, layer in enumerate(text_encoder.text_model.encoder.layers):
|
||||
name = f"text_model.encoder.layers.{i}.self_attn"
|
||||
mod = layer.self_attn
|
||||
attn_modules.append((name, mod))
|
||||
|
||||
return attn_modules
|
||||
|
||||
for name, module in text_encoder_attn_modules(text_encoder):
|
||||
for k, v in module.q_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.q_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
for k, v in module.k_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.k_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
for k, v in module.v_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.v_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
for k, v in module.out_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.out_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
return state_dict
|
||||
|
||||
|
||||
def save_model_card(repo_id: str, images=None, base_model=str, dataset_name=str, repo_folder=None):
|
||||
img_str = ""
|
||||
for i, image in enumerate(images):
|
||||
@@ -460,13 +493,7 @@ def main():
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
text_encoder.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
# Add adapter and make sure the trainable params are in float32.
|
||||
unet.add_adapter(unet_lora_config)
|
||||
if args.mixed_precision == "fp16":
|
||||
for param in unet.parameters():
|
||||
# only upcast trainable parameters (LoRA) into fp32
|
||||
if param.requires_grad:
|
||||
param.data = param.to(torch.float32)
|
||||
|
||||
if args.enable_xformers_memory_efficient_attention:
|
||||
if is_xformers_available():
|
||||
@@ -805,12 +832,13 @@ def main():
|
||||
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
|
||||
accelerator.save_state(save_path)
|
||||
|
||||
unwrapped_unet = accelerator.unwrap_model(unet)
|
||||
unet_lora_state_dict = get_peft_model_state_dict(unwrapped_unet)
|
||||
unet_lora_state_dict = get_peft_model_state_dict(unet)
|
||||
unet_lora_config = unet.peft_config["default"]
|
||||
|
||||
StableDiffusionPipeline.save_lora_weights(
|
||||
save_directory=save_path,
|
||||
unet_lora_layers=unet_lora_state_dict,
|
||||
unet_lora_config=unet_lora_config,
|
||||
safe_serialization=True,
|
||||
)
|
||||
|
||||
@@ -871,12 +899,13 @@ def main():
|
||||
if accelerator.is_main_process:
|
||||
unet = unet.to(torch.float32)
|
||||
|
||||
unwrapped_unet = accelerator.unwrap_model(unet)
|
||||
unet_lora_state_dict = get_peft_model_state_dict(unwrapped_unet)
|
||||
unet_lora_state_dict = get_peft_model_state_dict(unet)
|
||||
unet_lora_config = unet.peft_config["default"]
|
||||
StableDiffusionPipeline.save_lora_weights(
|
||||
save_directory=args.output_dir,
|
||||
unet_lora_layers=unet_lora_state_dict,
|
||||
safe_serialization=True,
|
||||
unet_lora_config=unet_lora_config,
|
||||
)
|
||||
|
||||
if args.push_to_hub:
|
||||
@@ -894,42 +923,39 @@ def main():
|
||||
ignore_patterns=["step_*", "epoch_*"],
|
||||
)
|
||||
|
||||
# Final inference
|
||||
# Load previous pipeline
|
||||
if args.validation_prompt is not None:
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
revision=args.revision,
|
||||
variant=args.variant,
|
||||
torch_dtype=weight_dtype,
|
||||
)
|
||||
pipeline = pipeline.to(accelerator.device)
|
||||
# Final inference
|
||||
# Load previous pipeline
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
args.pretrained_model_name_or_path, revision=args.revision, variant=args.variant, torch_dtype=weight_dtype
|
||||
)
|
||||
pipeline = pipeline.to(accelerator.device)
|
||||
|
||||
# load attention processors
|
||||
pipeline.load_lora_weights(args.output_dir)
|
||||
# load attention processors
|
||||
pipeline.unet.load_attn_procs(args.output_dir)
|
||||
|
||||
# run inference
|
||||
generator = torch.Generator(device=accelerator.device)
|
||||
if args.seed is not None:
|
||||
generator = generator.manual_seed(args.seed)
|
||||
images = []
|
||||
for _ in range(args.num_validation_images):
|
||||
images.append(pipeline(args.validation_prompt, num_inference_steps=30, generator=generator).images[0])
|
||||
# run inference
|
||||
generator = torch.Generator(device=accelerator.device)
|
||||
if args.seed is not None:
|
||||
generator = generator.manual_seed(args.seed)
|
||||
images = []
|
||||
for _ in range(args.num_validation_images):
|
||||
images.append(pipeline(args.validation_prompt, num_inference_steps=30, generator=generator).images[0])
|
||||
|
||||
for tracker in accelerator.trackers:
|
||||
if len(images) != 0:
|
||||
if tracker.name == "tensorboard":
|
||||
np_images = np.stack([np.asarray(img) for img in images])
|
||||
tracker.writer.add_images("test", np_images, epoch, dataformats="NHWC")
|
||||
if tracker.name == "wandb":
|
||||
tracker.log(
|
||||
{
|
||||
"test": [
|
||||
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
|
||||
for i, image in enumerate(images)
|
||||
]
|
||||
}
|
||||
)
|
||||
if accelerator.is_main_process:
|
||||
for tracker in accelerator.trackers:
|
||||
if len(images) != 0:
|
||||
if tracker.name == "tensorboard":
|
||||
np_images = np.stack([np.asarray(img) for img in images])
|
||||
tracker.writer.add_images("test", np_images, epoch, dataformats="NHWC")
|
||||
if tracker.name == "wandb":
|
||||
tracker.log(
|
||||
{
|
||||
"test": [
|
||||
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
|
||||
for i, image in enumerate(images)
|
||||
]
|
||||
}
|
||||
)
|
||||
|
||||
accelerator.end_training()
|
||||
|
||||
|
||||
@@ -63,6 +63,39 @@ check_min_version("0.25.0.dev0")
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
# TODO: This function should be removed once training scripts are rewritten in PEFT
|
||||
def text_encoder_lora_state_dict(text_encoder):
|
||||
state_dict = {}
|
||||
|
||||
def text_encoder_attn_modules(text_encoder):
|
||||
from transformers import CLIPTextModel, CLIPTextModelWithProjection
|
||||
|
||||
attn_modules = []
|
||||
|
||||
if isinstance(text_encoder, (CLIPTextModel, CLIPTextModelWithProjection)):
|
||||
for i, layer in enumerate(text_encoder.text_model.encoder.layers):
|
||||
name = f"text_model.encoder.layers.{i}.self_attn"
|
||||
mod = layer.self_attn
|
||||
attn_modules.append((name, mod))
|
||||
|
||||
return attn_modules
|
||||
|
||||
for name, module in text_encoder_attn_modules(text_encoder):
|
||||
for k, v in module.q_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.q_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
for k, v in module.k_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.k_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
for k, v in module.v_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.v_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
for k, v in module.out_proj.lora_linear_layer.state_dict().items():
|
||||
state_dict[f"{name}.out_proj.lora_linear_layer.{k}"] = v
|
||||
|
||||
return state_dict
|
||||
|
||||
|
||||
def save_model_card(
|
||||
repo_id: str,
|
||||
images=None,
|
||||
@@ -649,13 +682,20 @@ def main(args):
|
||||
text_encoder_one_lora_layers_to_save = None
|
||||
text_encoder_two_lora_layers_to_save = None
|
||||
|
||||
unet_lora_config = None
|
||||
text_encoder_one_lora_config = None
|
||||
text_encoder_two_lora_config = None
|
||||
|
||||
for model in models:
|
||||
if isinstance(model, type(accelerator.unwrap_model(unet))):
|
||||
unet_lora_layers_to_save = get_peft_model_state_dict(model)
|
||||
unet_lora_config = model.peft_config["default"]
|
||||
elif isinstance(model, type(accelerator.unwrap_model(text_encoder_one))):
|
||||
text_encoder_one_lora_layers_to_save = get_peft_model_state_dict(model)
|
||||
text_encoder_one_lora_config = model.peft_config["default"]
|
||||
elif isinstance(model, type(accelerator.unwrap_model(text_encoder_two))):
|
||||
text_encoder_two_lora_layers_to_save = get_peft_model_state_dict(model)
|
||||
text_encoder_two_lora_config = model.peft_config["default"]
|
||||
else:
|
||||
raise ValueError(f"unexpected save model: {model.__class__}")
|
||||
|
||||
@@ -667,6 +707,9 @@ def main(args):
|
||||
unet_lora_layers=unet_lora_layers_to_save,
|
||||
text_encoder_lora_layers=text_encoder_one_lora_layers_to_save,
|
||||
text_encoder_2_lora_layers=text_encoder_two_lora_layers_to_save,
|
||||
unet_lora_config=unet_lora_config,
|
||||
text_encoder_lora_config=text_encoder_one_lora_config,
|
||||
text_encoder_2_lora_config=text_encoder_two_lora_config,
|
||||
)
|
||||
|
||||
def load_model_hook(models, input_dir):
|
||||
@@ -686,17 +729,19 @@ def main(args):
|
||||
else:
|
||||
raise ValueError(f"unexpected save model: {model.__class__}")
|
||||
|
||||
lora_state_dict, network_alphas = LoraLoaderMixin.lora_state_dict(input_dir)
|
||||
LoraLoaderMixin.load_lora_into_unet(lora_state_dict, network_alphas=network_alphas, unet=unet_)
|
||||
lora_state_dict, network_alphas, metadata = LoraLoaderMixin.lora_state_dict(input_dir)
|
||||
LoraLoaderMixin.load_lora_into_unet(
|
||||
lora_state_dict, network_alphas=network_alphas, unet=unet_, config=metadata
|
||||
)
|
||||
|
||||
text_encoder_state_dict = {k: v for k, v in lora_state_dict.items() if "text_encoder." in k}
|
||||
LoraLoaderMixin.load_lora_into_text_encoder(
|
||||
text_encoder_state_dict, network_alphas=network_alphas, text_encoder=text_encoder_one_
|
||||
text_encoder_state_dict, network_alphas=network_alphas, text_encoder=text_encoder_one_, config=metadata
|
||||
)
|
||||
|
||||
text_encoder_2_state_dict = {k: v for k, v in lora_state_dict.items() if "text_encoder_2." in k}
|
||||
LoraLoaderMixin.load_lora_into_text_encoder(
|
||||
text_encoder_2_state_dict, network_alphas=network_alphas, text_encoder=text_encoder_two_
|
||||
text_encoder_2_state_dict, network_alphas=network_alphas, text_encoder=text_encoder_two_, config=metadata
|
||||
)
|
||||
|
||||
accelerator.register_save_state_pre_hook(save_model_hook)
|
||||
@@ -1161,6 +1206,7 @@ def main(args):
|
||||
if accelerator.is_main_process:
|
||||
unet = accelerator.unwrap_model(unet)
|
||||
unet_lora_state_dict = get_peft_model_state_dict(unet)
|
||||
unet_lora_config = unet.peft_config["default"]
|
||||
|
||||
if args.train_text_encoder:
|
||||
text_encoder_one = accelerator.unwrap_model(text_encoder_one)
|
||||
@@ -1168,15 +1214,23 @@ def main(args):
|
||||
|
||||
text_encoder_lora_layers = get_peft_model_state_dict(text_encoder_one)
|
||||
text_encoder_2_lora_layers = get_peft_model_state_dict(text_encoder_two)
|
||||
|
||||
text_encoder_one_lora_config = text_encoder_one.peft_config["default"]
|
||||
text_encoder_two_lora_config = text_encoder_two.peft_config["default"]
|
||||
else:
|
||||
text_encoder_lora_layers = None
|
||||
text_encoder_2_lora_layers = None
|
||||
text_encoder_one_lora_config = None
|
||||
text_encoder_two_lora_config = None
|
||||
|
||||
StableDiffusionXLPipeline.save_lora_weights(
|
||||
save_directory=args.output_dir,
|
||||
unet_lora_layers=unet_lora_state_dict,
|
||||
text_encoder_lora_layers=text_encoder_lora_layers,
|
||||
text_encoder_2_lora_layers=text_encoder_2_lora_layers,
|
||||
unet_lora_config=unet_lora_config,
|
||||
text_encoder_lora_config=text_encoder_one_lora_config,
|
||||
text_encoder_2_lora_config=text_encoder_two_lora_config,
|
||||
)
|
||||
|
||||
del unet
|
||||
|
||||
@@ -77,7 +77,7 @@ First, you need to set up your development environment as explained in the [inst
|
||||
```bash
|
||||
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
|
||||
|
||||
accelerate launch train_text_to_image_lora_prior.py \
|
||||
accelerate launch train_text_to_image_prior_lora.py \
|
||||
--mixed_precision="fp16" \
|
||||
--dataset_name=$DATASET_NAME --caption_column="text" \
|
||||
--resolution=768 \
|
||||
|
||||
@@ -12,9 +12,9 @@ from safetensors.torch import load_file as stl
|
||||
from tqdm import tqdm
|
||||
|
||||
from diffusers import AutoencoderKL, ConsistencyDecoderVAE, DiffusionPipeline, StableDiffusionPipeline, UNet2DModel
|
||||
from diffusers.models.autoencoders.vae import Encoder
|
||||
from diffusers.models.embeddings import TimestepEmbedding
|
||||
from diffusers.models.unet_2d_blocks import ResnetDownsampleBlock2D, ResnetUpsampleBlock2D, UNetMidBlock2D
|
||||
from diffusers.models.vae import Encoder
|
||||
|
||||
|
||||
args = ArgumentParser()
|
||||
|
||||
@@ -159,14 +159,6 @@ vae_conversion_map_attn = [
|
||||
("proj_out.", "proj_attn."),
|
||||
]
|
||||
|
||||
# This is probably not the most ideal solution, but it does work.
|
||||
vae_extra_conversion_map = [
|
||||
("to_q", "q"),
|
||||
("to_k", "k"),
|
||||
("to_v", "v"),
|
||||
("to_out.0", "proj_out"),
|
||||
]
|
||||
|
||||
|
||||
def reshape_weight_for_sd(w):
|
||||
# convert HF linear weights to SD conv2d weights
|
||||
@@ -186,20 +178,11 @@ def convert_vae_state_dict(vae_state_dict):
|
||||
mapping[k] = v
|
||||
new_state_dict = {v: vae_state_dict[k] for k, v in mapping.items()}
|
||||
weights_to_convert = ["q", "k", "v", "proj_out"]
|
||||
keys_to_rename = {}
|
||||
for k, v in new_state_dict.items():
|
||||
for weight_name in weights_to_convert:
|
||||
if f"mid.attn_1.{weight_name}.weight" in k:
|
||||
print(f"Reshaping {k} for SD format")
|
||||
new_state_dict[k] = reshape_weight_for_sd(v)
|
||||
for weight_name, real_weight_name in vae_extra_conversion_map:
|
||||
if f"mid.attn_1.{weight_name}.weight" in k or f"mid.attn_1.{weight_name}.bias" in k:
|
||||
keys_to_rename[k] = k.replace(weight_name, real_weight_name)
|
||||
for k, v in keys_to_rename.items():
|
||||
if k in new_state_dict:
|
||||
print(f"Renaming {k} to {v}")
|
||||
new_state_dict[v] = reshape_weight_for_sd(new_state_dict[k])
|
||||
del new_state_dict[k]
|
||||
return new_state_dict
|
||||
|
||||
|
||||
|
||||
@@ -11,6 +11,7 @@
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import json
|
||||
import os
|
||||
from contextlib import nullcontext
|
||||
from typing import Callable, Dict, List, Optional, Union
|
||||
@@ -103,7 +104,7 @@ class LoraLoaderMixin:
|
||||
`default_{i}` where i is the total number of adapters being loaded.
|
||||
"""
|
||||
# First, ensure that the checkpoint is a compatible one and can be successfully loaded.
|
||||
state_dict, network_alphas = self.lora_state_dict(pretrained_model_name_or_path_or_dict, **kwargs)
|
||||
state_dict, network_alphas, metadata = self.lora_state_dict(pretrained_model_name_or_path_or_dict, **kwargs)
|
||||
|
||||
is_correct_format = all("lora" in key for key in state_dict.keys())
|
||||
if not is_correct_format:
|
||||
@@ -114,6 +115,7 @@ class LoraLoaderMixin:
|
||||
self.load_lora_into_unet(
|
||||
state_dict,
|
||||
network_alphas=network_alphas,
|
||||
config=metadata,
|
||||
unet=getattr(self, self.unet_name) if not hasattr(self, "unet") else self.unet,
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
adapter_name=adapter_name,
|
||||
@@ -125,6 +127,7 @@ class LoraLoaderMixin:
|
||||
text_encoder=getattr(self, self.text_encoder_name)
|
||||
if not hasattr(self, "text_encoder")
|
||||
else self.text_encoder,
|
||||
config=metadata,
|
||||
lora_scale=self.lora_scale,
|
||||
low_cpu_mem_usage=low_cpu_mem_usage,
|
||||
adapter_name=adapter_name,
|
||||
@@ -219,6 +222,7 @@ class LoraLoaderMixin:
|
||||
}
|
||||
|
||||
model_file = None
|
||||
metadata = None
|
||||
if not isinstance(pretrained_model_name_or_path_or_dict, dict):
|
||||
# Let's first try to load .safetensors weights
|
||||
if (use_safetensors and weight_name is None) or (
|
||||
@@ -248,6 +252,8 @@ class LoraLoaderMixin:
|
||||
user_agent=user_agent,
|
||||
)
|
||||
state_dict = safetensors.torch.load_file(model_file, device="cpu")
|
||||
with safetensors.safe_open(model_file, framework="pt", device="cpu") as f:
|
||||
metadata = f.metadata()
|
||||
except (IOError, safetensors.SafetensorError) as e:
|
||||
if not allow_pickle:
|
||||
raise e
|
||||
@@ -294,7 +300,7 @@ class LoraLoaderMixin:
|
||||
state_dict = _maybe_map_sgm_blocks_to_diffusers(state_dict, unet_config)
|
||||
state_dict, network_alphas = _convert_kohya_lora_to_diffusers(state_dict)
|
||||
|
||||
return state_dict, network_alphas
|
||||
return state_dict, network_alphas, metadata
|
||||
|
||||
@classmethod
|
||||
def _best_guess_weight_name(
|
||||
@@ -370,7 +376,7 @@ class LoraLoaderMixin:
|
||||
|
||||
@classmethod
|
||||
def load_lora_into_unet(
|
||||
cls, state_dict, network_alphas, unet, low_cpu_mem_usage=None, adapter_name=None, _pipeline=None
|
||||
cls, state_dict, network_alphas, unet, config=None, low_cpu_mem_usage=None, adapter_name=None, _pipeline=None
|
||||
):
|
||||
"""
|
||||
This will load the LoRA layers specified in `state_dict` into `unet`.
|
||||
@@ -384,6 +390,8 @@ class LoraLoaderMixin:
|
||||
See `LoRALinearLayer` for more details.
|
||||
unet (`UNet2DConditionModel`):
|
||||
The UNet model to load the LoRA layers into.
|
||||
config: (`Dict`):
|
||||
LoRA configuration parsed from the state dict.
|
||||
low_cpu_mem_usage (`bool`, *optional*, defaults to `True` if torch version >= 1.9.0 else `False`):
|
||||
Speed up model loading only loading the pretrained weights and not initializing the weights. This also
|
||||
tries to not use more than 1x model size in CPU memory (including peak memory) while loading the model.
|
||||
@@ -443,7 +451,9 @@ class LoraLoaderMixin:
|
||||
if "lora_B" in key:
|
||||
rank[key] = val.shape[1]
|
||||
|
||||
lora_config_kwargs = get_peft_kwargs(rank, network_alphas, state_dict, is_unet=True)
|
||||
if config is not None and isinstance(config, dict) and len(config) > 0:
|
||||
config = json.loads(config["unet"])
|
||||
lora_config_kwargs = get_peft_kwargs(rank, network_alphas, state_dict, config=config, is_unet=True)
|
||||
lora_config = LoraConfig(**lora_config_kwargs)
|
||||
|
||||
# adapter_name
|
||||
@@ -484,6 +494,7 @@ class LoraLoaderMixin:
|
||||
network_alphas,
|
||||
text_encoder,
|
||||
prefix=None,
|
||||
config=None,
|
||||
lora_scale=1.0,
|
||||
low_cpu_mem_usage=None,
|
||||
adapter_name=None,
|
||||
@@ -502,6 +513,8 @@ class LoraLoaderMixin:
|
||||
The text encoder model to load the LoRA layers into.
|
||||
prefix (`str`):
|
||||
Expected prefix of the `text_encoder` in the `state_dict`.
|
||||
config (`Dict`):
|
||||
LoRA configuration parsed from state dict.
|
||||
lora_scale (`float`):
|
||||
How much to scale the output of the lora linear layer before it is added with the output of the regular
|
||||
lora layer.
|
||||
@@ -575,10 +588,11 @@ class LoraLoaderMixin:
|
||||
if USE_PEFT_BACKEND:
|
||||
from peft import LoraConfig
|
||||
|
||||
if config is not None and len(config) > 0:
|
||||
config = json.loads(config[prefix])
|
||||
lora_config_kwargs = get_peft_kwargs(
|
||||
rank, network_alphas, text_encoder_lora_state_dict, is_unet=False
|
||||
rank, network_alphas, text_encoder_lora_state_dict, config=config, is_unet=False
|
||||
)
|
||||
|
||||
lora_config = LoraConfig(**lora_config_kwargs)
|
||||
|
||||
# adapter_name
|
||||
@@ -786,6 +800,8 @@ class LoraLoaderMixin:
|
||||
save_directory: Union[str, os.PathLike],
|
||||
unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
|
||||
text_encoder_lora_layers: Dict[str, torch.nn.Module] = None,
|
||||
unet_lora_config=None,
|
||||
text_encoder_lora_config=None,
|
||||
is_main_process: bool = True,
|
||||
weight_name: str = None,
|
||||
save_function: Callable = None,
|
||||
@@ -813,21 +829,54 @@ class LoraLoaderMixin:
|
||||
safe_serialization (`bool`, *optional*, defaults to `True`):
|
||||
Whether to save the model using `safetensors` or the traditional PyTorch way with `pickle`.
|
||||
"""
|
||||
if not USE_PEFT_BACKEND and not safe_serialization:
|
||||
if unet_lora_config or text_encoder_lora_config:
|
||||
raise ValueError(
|
||||
"Without `peft`, passing `unet_lora_config` or `text_encoder_lora_config` is not possible. Please install `peft`."
|
||||
)
|
||||
elif USE_PEFT_BACKEND and safe_serialization:
|
||||
from peft import LoraConfig
|
||||
|
||||
if not (unet_lora_layers or text_encoder_lora_layers):
|
||||
raise ValueError("You must pass at least one of `unet_lora_layers` or `text_encoder_lora_layers`.")
|
||||
|
||||
state_dict = {}
|
||||
metadata = {}
|
||||
|
||||
def pack_weights(layers, prefix):
|
||||
layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
|
||||
layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
|
||||
|
||||
return layers_state_dict
|
||||
|
||||
if not (unet_lora_layers or text_encoder_lora_layers):
|
||||
raise ValueError("You must pass at least one of `unet_lora_layers`, `text_encoder_lora_layers`.")
|
||||
def pack_metadata(config, prefix):
|
||||
local_metadata = {}
|
||||
if config is not None:
|
||||
if isinstance(config, LoraConfig):
|
||||
config = config.to_dict()
|
||||
for key, value in config.items():
|
||||
if isinstance(value, set):
|
||||
config[key] = list(value)
|
||||
|
||||
config_as_string = json.dumps(config, indent=2, sort_keys=True)
|
||||
local_metadata[prefix] = config_as_string
|
||||
return local_metadata
|
||||
|
||||
if unet_lora_layers:
|
||||
state_dict.update(pack_weights(unet_lora_layers, "unet"))
|
||||
prefix = "unet"
|
||||
unet_state_dict = pack_weights(unet_lora_layers, prefix)
|
||||
state_dict.update(unet_state_dict)
|
||||
if unet_lora_config is not None:
|
||||
unet_metadata = pack_metadata(unet_lora_config, prefix)
|
||||
metadata.update(unet_metadata)
|
||||
|
||||
if text_encoder_lora_layers:
|
||||
state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
|
||||
prefix = "text_encoder"
|
||||
text_encoder_state_dict = pack_weights(text_encoder_lora_layers, "text_encoder")
|
||||
state_dict.update(text_encoder_state_dict)
|
||||
if text_encoder_lora_config is not None:
|
||||
text_encoder_metadata = pack_metadata(text_encoder_lora_config, prefix)
|
||||
metadata.update(text_encoder_metadata)
|
||||
|
||||
# Save the model
|
||||
cls.write_lora_layers(
|
||||
@@ -837,6 +886,7 @@ class LoraLoaderMixin:
|
||||
weight_name=weight_name,
|
||||
save_function=save_function,
|
||||
safe_serialization=safe_serialization,
|
||||
metadata=metadata,
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
@@ -847,7 +897,11 @@ class LoraLoaderMixin:
|
||||
weight_name: str,
|
||||
save_function: Callable,
|
||||
safe_serialization: bool,
|
||||
metadata=None,
|
||||
):
|
||||
if not safe_serialization and isinstance(metadata, dict) and len(metadata) > 0:
|
||||
raise ValueError("Passing `metadata` is not possible when `safe_serialization` is False.")
|
||||
|
||||
if os.path.isfile(save_directory):
|
||||
logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
|
||||
return
|
||||
@@ -855,8 +909,10 @@ class LoraLoaderMixin:
|
||||
if save_function is None:
|
||||
if safe_serialization:
|
||||
|
||||
def save_function(weights, filename):
|
||||
return safetensors.torch.save_file(weights, filename, metadata={"format": "pt"})
|
||||
def save_function(weights, filename, metadata):
|
||||
if metadata is None:
|
||||
metadata = {"format": "pt"}
|
||||
return safetensors.torch.save_file(weights, filename, metadata=metadata)
|
||||
|
||||
else:
|
||||
save_function = torch.save
|
||||
@@ -869,7 +925,10 @@ class LoraLoaderMixin:
|
||||
else:
|
||||
weight_name = LORA_WEIGHT_NAME
|
||||
|
||||
save_function(state_dict, os.path.join(save_directory, weight_name))
|
||||
if save_function != torch.save:
|
||||
save_function(state_dict, os.path.join(save_directory, weight_name), metadata)
|
||||
else:
|
||||
save_function(state_dict, os.path.join(save_directory, weight_name))
|
||||
logger.info(f"Model weights saved in {os.path.join(save_directory, weight_name)}")
|
||||
|
||||
def unload_lora_weights(self):
|
||||
@@ -1301,7 +1360,7 @@ class StableDiffusionXLLoraLoaderMixin(LoraLoaderMixin):
|
||||
# pipeline.
|
||||
|
||||
# First, ensure that the checkpoint is a compatible one and can be successfully loaded.
|
||||
state_dict, network_alphas = self.lora_state_dict(
|
||||
state_dict, network_alphas, metadata = self.lora_state_dict(
|
||||
pretrained_model_name_or_path_or_dict,
|
||||
unet_config=self.unet.config,
|
||||
**kwargs,
|
||||
@@ -1311,7 +1370,12 @@ class StableDiffusionXLLoraLoaderMixin(LoraLoaderMixin):
|
||||
raise ValueError("Invalid LoRA checkpoint.")
|
||||
|
||||
self.load_lora_into_unet(
|
||||
state_dict, network_alphas=network_alphas, unet=self.unet, adapter_name=adapter_name, _pipeline=self
|
||||
state_dict,
|
||||
network_alphas=network_alphas,
|
||||
unet=self.unet,
|
||||
config=metadata,
|
||||
adapter_name=adapter_name,
|
||||
_pipeline=self,
|
||||
)
|
||||
text_encoder_state_dict = {k: v for k, v in state_dict.items() if "text_encoder." in k}
|
||||
if len(text_encoder_state_dict) > 0:
|
||||
@@ -1319,6 +1383,7 @@ class StableDiffusionXLLoraLoaderMixin(LoraLoaderMixin):
|
||||
text_encoder_state_dict,
|
||||
network_alphas=network_alphas,
|
||||
text_encoder=self.text_encoder,
|
||||
config=metadata,
|
||||
prefix="text_encoder",
|
||||
lora_scale=self.lora_scale,
|
||||
adapter_name=adapter_name,
|
||||
@@ -1331,6 +1396,7 @@ class StableDiffusionXLLoraLoaderMixin(LoraLoaderMixin):
|
||||
text_encoder_2_state_dict,
|
||||
network_alphas=network_alphas,
|
||||
text_encoder=self.text_encoder_2,
|
||||
config=metadata,
|
||||
prefix="text_encoder_2",
|
||||
lora_scale=self.lora_scale,
|
||||
adapter_name=adapter_name,
|
||||
@@ -1344,6 +1410,9 @@ class StableDiffusionXLLoraLoaderMixin(LoraLoaderMixin):
|
||||
unet_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
|
||||
text_encoder_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
|
||||
text_encoder_2_lora_layers: Dict[str, Union[torch.nn.Module, torch.Tensor]] = None,
|
||||
unet_lora_config=None,
|
||||
text_encoder_lora_config=None,
|
||||
text_encoder_2_lora_config=None,
|
||||
is_main_process: bool = True,
|
||||
weight_name: str = None,
|
||||
save_function: Callable = None,
|
||||
@@ -1371,24 +1440,63 @@ class StableDiffusionXLLoraLoaderMixin(LoraLoaderMixin):
|
||||
safe_serialization (`bool`, *optional*, defaults to `True`):
|
||||
Whether to save the model using `safetensors` or the traditional PyTorch way with `pickle`.
|
||||
"""
|
||||
state_dict = {}
|
||||
|
||||
def pack_weights(layers, prefix):
|
||||
layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
|
||||
layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
|
||||
return layers_state_dict
|
||||
if not USE_PEFT_BACKEND and not safe_serialization:
|
||||
if unet_lora_config or text_encoder_lora_config or text_encoder_2_lora_config:
|
||||
raise ValueError(
|
||||
"Without `peft`, passing `unet_lora_config` or `text_encoder_lora_config` or `text_encoder_2_lora_config` is not possible. Please install `peft`."
|
||||
)
|
||||
elif USE_PEFT_BACKEND and safe_serialization:
|
||||
from peft import LoraConfig
|
||||
|
||||
if not (unet_lora_layers or text_encoder_lora_layers or text_encoder_2_lora_layers):
|
||||
raise ValueError(
|
||||
"You must pass at least one of `unet_lora_layers`, `text_encoder_lora_layers` or `text_encoder_2_lora_layers`."
|
||||
)
|
||||
|
||||
state_dict = {}
|
||||
metadata = {}
|
||||
|
||||
def pack_weights(layers, prefix):
|
||||
layers_weights = layers.state_dict() if isinstance(layers, torch.nn.Module) else layers
|
||||
layers_state_dict = {f"{prefix}.{module_name}": param for module_name, param in layers_weights.items()}
|
||||
|
||||
return layers_state_dict
|
||||
|
||||
def pack_metadata(config, prefix):
|
||||
local_metadata = {}
|
||||
if config is not None:
|
||||
if isinstance(config, LoraConfig):
|
||||
config = config.to_dict()
|
||||
for key, value in config.items():
|
||||
if isinstance(value, set):
|
||||
config[key] = list(value)
|
||||
|
||||
config_as_string = json.dumps(config, indent=2, sort_keys=True)
|
||||
local_metadata[prefix] = config_as_string
|
||||
return local_metadata
|
||||
|
||||
if unet_lora_layers:
|
||||
state_dict.update(pack_weights(unet_lora_layers, "unet"))
|
||||
prefix = "unet"
|
||||
unet_state_dict = pack_weights(unet_lora_layers, prefix)
|
||||
state_dict.update(unet_state_dict)
|
||||
if unet_lora_config is not None:
|
||||
unet_metadata = pack_metadata(unet_lora_config, prefix)
|
||||
metadata.update(unet_metadata)
|
||||
|
||||
if text_encoder_lora_layers and text_encoder_2_lora_layers:
|
||||
state_dict.update(pack_weights(text_encoder_lora_layers, "text_encoder"))
|
||||
state_dict.update(pack_weights(text_encoder_2_lora_layers, "text_encoder_2"))
|
||||
prefix = "text_encoder"
|
||||
text_encoder_state_dict = pack_weights(text_encoder_lora_layers, "text_encoder")
|
||||
state_dict.update(text_encoder_state_dict)
|
||||
if text_encoder_lora_config is not None:
|
||||
text_encoder_metadata = pack_metadata(text_encoder_lora_config, prefix)
|
||||
metadata.update(text_encoder_metadata)
|
||||
|
||||
prefix = "text_encoder_2"
|
||||
text_encoder_2_state_dict = pack_weights(text_encoder_2_lora_layers, prefix)
|
||||
state_dict.update(text_encoder_2_state_dict)
|
||||
if text_encoder_2_lora_config is not None:
|
||||
text_encoder_2_metadata = pack_metadata(text_encoder_2_lora_config, prefix)
|
||||
metadata.update(text_encoder_2_metadata)
|
||||
|
||||
cls.write_lora_layers(
|
||||
state_dict=state_dict,
|
||||
@@ -1397,6 +1505,7 @@ class StableDiffusionXLLoraLoaderMixin(LoraLoaderMixin):
|
||||
weight_name=weight_name,
|
||||
save_function=save_function,
|
||||
safe_serialization=safe_serialization,
|
||||
metadata=metadata,
|
||||
)
|
||||
|
||||
def _remove_text_encoder_monkey_patch(self):
|
||||
|
||||
@@ -169,12 +169,10 @@ class FromSingleFileMixin:
|
||||
load_safety_checker = kwargs.pop("load_safety_checker", True)
|
||||
prediction_type = kwargs.pop("prediction_type", None)
|
||||
text_encoder = kwargs.pop("text_encoder", None)
|
||||
text_encoder_2 = kwargs.pop("text_encoder_2", None)
|
||||
vae = kwargs.pop("vae", None)
|
||||
controlnet = kwargs.pop("controlnet", None)
|
||||
adapter = kwargs.pop("adapter", None)
|
||||
tokenizer = kwargs.pop("tokenizer", None)
|
||||
tokenizer_2 = kwargs.pop("tokenizer_2", None)
|
||||
|
||||
torch_dtype = kwargs.pop("torch_dtype", None)
|
||||
|
||||
@@ -276,10 +274,8 @@ class FromSingleFileMixin:
|
||||
load_safety_checker=load_safety_checker,
|
||||
prediction_type=prediction_type,
|
||||
text_encoder=text_encoder,
|
||||
text_encoder_2=text_encoder_2,
|
||||
vae=vae,
|
||||
tokenizer=tokenizer,
|
||||
tokenizer_2=tokenizer_2,
|
||||
original_config_file=original_config_file,
|
||||
config_files=config_files,
|
||||
local_files_only=local_files_only,
|
||||
|
||||
@@ -12,7 +12,7 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
import os
|
||||
from collections import defaultdict
|
||||
from collections import OrderedDict, defaultdict
|
||||
from contextlib import nullcontext
|
||||
from typing import Callable, Dict, List, Optional, Union
|
||||
|
||||
@@ -664,80 +664,6 @@ class UNet2DConditionLoadersMixin:
|
||||
if hasattr(self, "peft_config"):
|
||||
self.peft_config.pop(adapter_name, None)
|
||||
|
||||
def _convert_ip_adapter_image_proj_to_diffusers(self, state_dict):
|
||||
updated_state_dict = {}
|
||||
image_projection = None
|
||||
|
||||
if "proj.weight" in state_dict:
|
||||
# IP-Adapter
|
||||
num_image_text_embeds = 4
|
||||
clip_embeddings_dim = state_dict["proj.weight"].shape[-1]
|
||||
cross_attention_dim = state_dict["proj.weight"].shape[0] // 4
|
||||
|
||||
image_projection = ImageProjection(
|
||||
cross_attention_dim=cross_attention_dim,
|
||||
image_embed_dim=clip_embeddings_dim,
|
||||
num_image_text_embeds=num_image_text_embeds,
|
||||
)
|
||||
|
||||
for key, value in state_dict.items():
|
||||
diffusers_name = key.replace("proj", "image_embeds")
|
||||
updated_state_dict[diffusers_name] = value
|
||||
|
||||
elif "proj.3.weight" in state_dict:
|
||||
# IP-Adapter Full
|
||||
clip_embeddings_dim = state_dict["proj.0.weight"].shape[0]
|
||||
cross_attention_dim = state_dict["proj.3.weight"].shape[0]
|
||||
|
||||
image_projection = MLPProjection(
|
||||
cross_attention_dim=cross_attention_dim, image_embed_dim=clip_embeddings_dim
|
||||
)
|
||||
|
||||
for key, value in state_dict.items():
|
||||
diffusers_name = key.replace("proj.0", "ff.net.0.proj")
|
||||
diffusers_name = diffusers_name.replace("proj.2", "ff.net.2")
|
||||
diffusers_name = diffusers_name.replace("proj.3", "norm")
|
||||
updated_state_dict[diffusers_name] = value
|
||||
|
||||
else:
|
||||
# IP-Adapter Plus
|
||||
num_image_text_embeds = state_dict["latents"].shape[1]
|
||||
embed_dims = state_dict["proj_in.weight"].shape[1]
|
||||
output_dims = state_dict["proj_out.weight"].shape[0]
|
||||
hidden_dims = state_dict["latents"].shape[2]
|
||||
heads = state_dict["layers.0.0.to_q.weight"].shape[0] // 64
|
||||
|
||||
image_projection = Resampler(
|
||||
embed_dims=embed_dims,
|
||||
output_dims=output_dims,
|
||||
hidden_dims=hidden_dims,
|
||||
heads=heads,
|
||||
num_queries=num_image_text_embeds,
|
||||
)
|
||||
|
||||
for key, value in state_dict.items():
|
||||
diffusers_name = key.replace("0.to", "2.to")
|
||||
diffusers_name = diffusers_name.replace("1.0.weight", "3.0.weight")
|
||||
diffusers_name = diffusers_name.replace("1.0.bias", "3.0.bias")
|
||||
diffusers_name = diffusers_name.replace("1.1.weight", "3.1.net.0.proj.weight")
|
||||
diffusers_name = diffusers_name.replace("1.3.weight", "3.1.net.2.weight")
|
||||
|
||||
if "norm1" in diffusers_name:
|
||||
updated_state_dict[diffusers_name.replace("0.norm1", "0")] = value
|
||||
elif "norm2" in diffusers_name:
|
||||
updated_state_dict[diffusers_name.replace("0.norm2", "1")] = value
|
||||
elif "to_kv" in diffusers_name:
|
||||
v_chunk = value.chunk(2, dim=0)
|
||||
updated_state_dict[diffusers_name.replace("to_kv", "to_k")] = v_chunk[0]
|
||||
updated_state_dict[diffusers_name.replace("to_kv", "to_v")] = v_chunk[1]
|
||||
elif "to_out" in diffusers_name:
|
||||
updated_state_dict[diffusers_name.replace("to_out", "to_out.0")] = value
|
||||
else:
|
||||
updated_state_dict[diffusers_name] = value
|
||||
|
||||
image_projection.load_state_dict(updated_state_dict)
|
||||
return image_projection
|
||||
|
||||
def _load_ip_adapter_weights(self, state_dict):
|
||||
from ..models.attention_processor import (
|
||||
AttnProcessor,
|
||||
@@ -798,8 +724,103 @@ class UNet2DConditionLoadersMixin:
|
||||
|
||||
self.set_attn_processor(attn_procs)
|
||||
|
||||
# convert IP-Adapter Image Projection layers to diffusers
|
||||
image_projection = self._convert_ip_adapter_image_proj_to_diffusers(state_dict["image_proj"])
|
||||
# create image projection layers.
|
||||
if "proj.weight" in state_dict["image_proj"]:
|
||||
# IP-Adapter
|
||||
clip_embeddings_dim = state_dict["image_proj"]["proj.weight"].shape[-1]
|
||||
cross_attention_dim = state_dict["image_proj"]["proj.weight"].shape[0] // 4
|
||||
|
||||
image_projection = ImageProjection(
|
||||
cross_attention_dim=cross_attention_dim,
|
||||
image_embed_dim=clip_embeddings_dim,
|
||||
num_image_text_embeds=num_image_text_embeds,
|
||||
)
|
||||
image_projection.to(dtype=self.dtype, device=self.device)
|
||||
|
||||
# load image projection layer weights
|
||||
image_proj_state_dict = {}
|
||||
image_proj_state_dict.update(
|
||||
{
|
||||
"image_embeds.weight": state_dict["image_proj"]["proj.weight"],
|
||||
"image_embeds.bias": state_dict["image_proj"]["proj.bias"],
|
||||
"norm.weight": state_dict["image_proj"]["norm.weight"],
|
||||
"norm.bias": state_dict["image_proj"]["norm.bias"],
|
||||
}
|
||||
)
|
||||
image_projection.load_state_dict(image_proj_state_dict)
|
||||
del image_proj_state_dict
|
||||
|
||||
elif "proj.3.weight" in state_dict["image_proj"]:
|
||||
clip_embeddings_dim = state_dict["image_proj"]["proj.0.weight"].shape[0]
|
||||
cross_attention_dim = state_dict["image_proj"]["proj.3.weight"].shape[0]
|
||||
|
||||
image_projection = MLPProjection(
|
||||
cross_attention_dim=cross_attention_dim, image_embed_dim=clip_embeddings_dim
|
||||
)
|
||||
image_projection.to(dtype=self.dtype, device=self.device)
|
||||
|
||||
# load image projection layer weights
|
||||
image_proj_state_dict = {}
|
||||
image_proj_state_dict.update(
|
||||
{
|
||||
"ff.net.0.proj.weight": state_dict["image_proj"]["proj.0.weight"],
|
||||
"ff.net.0.proj.bias": state_dict["image_proj"]["proj.0.bias"],
|
||||
"ff.net.2.weight": state_dict["image_proj"]["proj.2.weight"],
|
||||
"ff.net.2.bias": state_dict["image_proj"]["proj.2.bias"],
|
||||
"norm.weight": state_dict["image_proj"]["proj.3.weight"],
|
||||
"norm.bias": state_dict["image_proj"]["proj.3.bias"],
|
||||
}
|
||||
)
|
||||
image_projection.load_state_dict(image_proj_state_dict)
|
||||
del image_proj_state_dict
|
||||
|
||||
else:
|
||||
# IP-Adapter Plus
|
||||
embed_dims = state_dict["image_proj"]["proj_in.weight"].shape[1]
|
||||
output_dims = state_dict["image_proj"]["proj_out.weight"].shape[0]
|
||||
hidden_dims = state_dict["image_proj"]["latents"].shape[2]
|
||||
heads = state_dict["image_proj"]["layers.0.0.to_q.weight"].shape[0] // 64
|
||||
|
||||
image_projection = Resampler(
|
||||
embed_dims=embed_dims,
|
||||
output_dims=output_dims,
|
||||
hidden_dims=hidden_dims,
|
||||
heads=heads,
|
||||
num_queries=num_image_text_embeds,
|
||||
)
|
||||
|
||||
image_proj_state_dict = state_dict["image_proj"]
|
||||
|
||||
new_sd = OrderedDict()
|
||||
for k, v in image_proj_state_dict.items():
|
||||
if "0.to" in k:
|
||||
k = k.replace("0.to", "2.to")
|
||||
elif "1.0.weight" in k:
|
||||
k = k.replace("1.0.weight", "3.0.weight")
|
||||
elif "1.0.bias" in k:
|
||||
k = k.replace("1.0.bias", "3.0.bias")
|
||||
elif "1.1.weight" in k:
|
||||
k = k.replace("1.1.weight", "3.1.net.0.proj.weight")
|
||||
elif "1.3.weight" in k:
|
||||
k = k.replace("1.3.weight", "3.1.net.2.weight")
|
||||
|
||||
if "norm1" in k:
|
||||
new_sd[k.replace("0.norm1", "0")] = v
|
||||
elif "norm2" in k:
|
||||
new_sd[k.replace("0.norm2", "1")] = v
|
||||
elif "to_kv" in k:
|
||||
v_chunk = v.chunk(2, dim=0)
|
||||
new_sd[k.replace("to_kv", "to_k")] = v_chunk[0]
|
||||
new_sd[k.replace("to_kv", "to_v")] = v_chunk[1]
|
||||
elif "to_out" in k:
|
||||
new_sd[k.replace("to_out", "to_out.0")] = v
|
||||
else:
|
||||
new_sd[k] = v
|
||||
|
||||
image_projection.load_state_dict(new_sd)
|
||||
del image_proj_state_dict
|
||||
|
||||
self.encoder_hid_proj = image_projection.to(device=self.device, dtype=self.dtype)
|
||||
self.config.encoder_hid_dim_type = "ip_image_proj"
|
||||
|
||||
delete_adapter_layers
|
||||
|
||||
@@ -26,11 +26,11 @@ _import_structure = {}
|
||||
|
||||
if is_torch_available():
|
||||
_import_structure["adapter"] = ["MultiAdapter", "T2IAdapter"]
|
||||
_import_structure["autoencoders.autoencoder_asym_kl"] = ["AsymmetricAutoencoderKL"]
|
||||
_import_structure["autoencoders.autoencoder_kl"] = ["AutoencoderKL"]
|
||||
_import_structure["autoencoders.autoencoder_kl_temporal_decoder"] = ["AutoencoderKLTemporalDecoder"]
|
||||
_import_structure["autoencoders.autoencoder_tiny"] = ["AutoencoderTiny"]
|
||||
_import_structure["autoencoders.consistency_decoder_vae"] = ["ConsistencyDecoderVAE"]
|
||||
_import_structure["autoencoder_asym_kl"] = ["AsymmetricAutoencoderKL"]
|
||||
_import_structure["autoencoder_kl"] = ["AutoencoderKL"]
|
||||
_import_structure["autoencoder_kl_temporal_decoder"] = ["AutoencoderKLTemporalDecoder"]
|
||||
_import_structure["autoencoder_tiny"] = ["AutoencoderTiny"]
|
||||
_import_structure["consistency_decoder_vae"] = ["ConsistencyDecoderVAE"]
|
||||
_import_structure["controlnet"] = ["ControlNetModel"]
|
||||
_import_structure["controlnetxs"] = ["ControlNetXSModel"]
|
||||
_import_structure["dual_transformer_2d"] = ["DualTransformer2DModel"]
|
||||
@@ -58,13 +58,11 @@ if is_flax_available():
|
||||
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
if is_torch_available():
|
||||
from .adapter import MultiAdapter, T2IAdapter
|
||||
from .autoencoders import (
|
||||
AsymmetricAutoencoderKL,
|
||||
AutoencoderKL,
|
||||
AutoencoderKLTemporalDecoder,
|
||||
AutoencoderTiny,
|
||||
ConsistencyDecoderVAE,
|
||||
)
|
||||
from .autoencoder_asym_kl import AsymmetricAutoencoderKL
|
||||
from .autoencoder_kl import AutoencoderKL
|
||||
from .autoencoder_kl_temporal_decoder import AutoencoderKLTemporalDecoder
|
||||
from .autoencoder_tiny import AutoencoderTiny
|
||||
from .consistency_decoder_vae import ConsistencyDecoderVAE
|
||||
from .controlnet import ControlNetModel
|
||||
from .controlnetxs import ControlNetXSModel
|
||||
from .dual_transformer_2d import DualTransformer2DModel
|
||||
|
||||
@@ -16,10 +16,10 @@ from typing import Optional, Tuple, Union
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...utils.accelerate_utils import apply_forward_hook
|
||||
from ..modeling_outputs import AutoencoderKLOutput
|
||||
from ..modeling_utils import ModelMixin
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..utils.accelerate_utils import apply_forward_hook
|
||||
from .modeling_outputs import AutoencoderKLOutput
|
||||
from .modeling_utils import ModelMixin
|
||||
from .vae import DecoderOutput, DiagonalGaussianDistribution, Encoder, MaskConditionDecoder
|
||||
|
||||
|
||||
@@ -16,10 +16,10 @@ from typing import Dict, Optional, Tuple, Union
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...loaders import FromOriginalVAEMixin
|
||||
from ...utils.accelerate_utils import apply_forward_hook
|
||||
from ..attention_processor import (
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..loaders import FromOriginalVAEMixin
|
||||
from ..utils.accelerate_utils import apply_forward_hook
|
||||
from .attention_processor import (
|
||||
ADDED_KV_ATTENTION_PROCESSORS,
|
||||
CROSS_ATTENTION_PROCESSORS,
|
||||
Attention,
|
||||
@@ -27,8 +27,8 @@ from ..attention_processor import (
|
||||
AttnAddedKVProcessor,
|
||||
AttnProcessor,
|
||||
)
|
||||
from ..modeling_outputs import AutoencoderKLOutput
|
||||
from ..modeling_utils import ModelMixin
|
||||
from .modeling_outputs import AutoencoderKLOutput
|
||||
from .modeling_utils import ModelMixin
|
||||
from .vae import Decoder, DecoderOutput, DiagonalGaussianDistribution, Encoder
|
||||
|
||||
|
||||
@@ -16,14 +16,14 @@ from typing import Dict, Optional, Tuple, Union
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...loaders import FromOriginalVAEMixin
|
||||
from ...utils import is_torch_version
|
||||
from ...utils.accelerate_utils import apply_forward_hook
|
||||
from ..attention_processor import CROSS_ATTENTION_PROCESSORS, AttentionProcessor, AttnProcessor
|
||||
from ..modeling_outputs import AutoencoderKLOutput
|
||||
from ..modeling_utils import ModelMixin
|
||||
from ..unet_3d_blocks import MidBlockTemporalDecoder, UpBlockTemporalDecoder
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..loaders import FromOriginalVAEMixin
|
||||
from ..utils import is_torch_version
|
||||
from ..utils.accelerate_utils import apply_forward_hook
|
||||
from .attention_processor import CROSS_ATTENTION_PROCESSORS, AttentionProcessor, AttnProcessor
|
||||
from .modeling_outputs import AutoencoderKLOutput
|
||||
from .modeling_utils import ModelMixin
|
||||
from .unet_3d_blocks import MidBlockTemporalDecoder, UpBlockTemporalDecoder
|
||||
from .vae import DecoderOutput, DiagonalGaussianDistribution, Encoder
|
||||
|
||||
|
||||
@@ -18,10 +18,10 @@ from typing import Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...utils import BaseOutput
|
||||
from ...utils.accelerate_utils import apply_forward_hook
|
||||
from ..modeling_utils import ModelMixin
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..utils import BaseOutput
|
||||
from ..utils.accelerate_utils import apply_forward_hook
|
||||
from .modeling_utils import ModelMixin
|
||||
from .vae import DecoderOutput, DecoderTiny, EncoderTiny
|
||||
|
||||
|
||||
@@ -1,5 +0,0 @@
|
||||
from .autoencoder_asym_kl import AsymmetricAutoencoderKL
|
||||
from .autoencoder_kl import AutoencoderKL
|
||||
from .autoencoder_kl_temporal_decoder import AutoencoderKLTemporalDecoder
|
||||
from .autoencoder_tiny import AutoencoderTiny
|
||||
from .consistency_decoder_vae import ConsistencyDecoderVAE
|
||||
@@ -18,20 +18,20 @@ import torch
|
||||
import torch.nn.functional as F
|
||||
from torch import nn
|
||||
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...schedulers import ConsistencyDecoderScheduler
|
||||
from ...utils import BaseOutput
|
||||
from ...utils.accelerate_utils import apply_forward_hook
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..attention_processor import (
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..schedulers import ConsistencyDecoderScheduler
|
||||
from ..utils import BaseOutput
|
||||
from ..utils.accelerate_utils import apply_forward_hook
|
||||
from ..utils.torch_utils import randn_tensor
|
||||
from .attention_processor import (
|
||||
ADDED_KV_ATTENTION_PROCESSORS,
|
||||
CROSS_ATTENTION_PROCESSORS,
|
||||
AttentionProcessor,
|
||||
AttnAddedKVProcessor,
|
||||
AttnProcessor,
|
||||
)
|
||||
from ..modeling_utils import ModelMixin
|
||||
from ..unet_2d import UNet2DModel
|
||||
from .modeling_utils import ModelMixin
|
||||
from .unet_2d import UNet2DModel
|
||||
from .vae import DecoderOutput, DiagonalGaussianDistribution, Encoder
|
||||
|
||||
|
||||
@@ -153,7 +153,7 @@ class ConsistencyDecoderVAE(ModelMixin, ConfigMixin):
|
||||
self.use_slicing = False
|
||||
self.use_tiling = False
|
||||
|
||||
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.enable_tiling
|
||||
# Copied from diffusers.models.autoencoder_kl.AutoencoderKL.enable_tiling
|
||||
def enable_tiling(self, use_tiling: bool = True):
|
||||
r"""
|
||||
Enable tiled VAE decoding. When this option is enabled, the VAE will split the input tensor into tiles to
|
||||
@@ -162,7 +162,7 @@ class ConsistencyDecoderVAE(ModelMixin, ConfigMixin):
|
||||
"""
|
||||
self.use_tiling = use_tiling
|
||||
|
||||
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.disable_tiling
|
||||
# Copied from diffusers.models.autoencoder_kl.AutoencoderKL.disable_tiling
|
||||
def disable_tiling(self):
|
||||
r"""
|
||||
Disable tiled VAE decoding. If `enable_tiling` was previously enabled, this method will go back to computing
|
||||
@@ -170,7 +170,7 @@ class ConsistencyDecoderVAE(ModelMixin, ConfigMixin):
|
||||
"""
|
||||
self.enable_tiling(False)
|
||||
|
||||
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.enable_slicing
|
||||
# Copied from diffusers.models.autoencoder_kl.AutoencoderKL.enable_slicing
|
||||
def enable_slicing(self):
|
||||
r"""
|
||||
Enable sliced VAE decoding. When this option is enabled, the VAE will split the input tensor in slices to
|
||||
@@ -178,7 +178,7 @@ class ConsistencyDecoderVAE(ModelMixin, ConfigMixin):
|
||||
"""
|
||||
self.use_slicing = True
|
||||
|
||||
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.disable_slicing
|
||||
# Copied from diffusers.models.autoencoder_kl.AutoencoderKL.disable_slicing
|
||||
def disable_slicing(self):
|
||||
r"""
|
||||
Disable sliced VAE decoding. If `enable_slicing` was previously enabled, this method will go back to computing
|
||||
@@ -333,14 +333,14 @@ class ConsistencyDecoderVAE(ModelMixin, ConfigMixin):
|
||||
|
||||
return DecoderOutput(sample=x_0)
|
||||
|
||||
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.blend_v
|
||||
# Copied from diffusers.models.autoencoder_kl.AutoencoderKL.blend_v
|
||||
def blend_v(self, a: torch.Tensor, b: torch.Tensor, blend_extent: int) -> torch.Tensor:
|
||||
blend_extent = min(a.shape[2], b.shape[2], blend_extent)
|
||||
for y in range(blend_extent):
|
||||
b[:, :, y, :] = a[:, :, -blend_extent + y, :] * (1 - y / blend_extent) + b[:, :, y, :] * (y / blend_extent)
|
||||
return b
|
||||
|
||||
# Copied from diffusers.models.autoencoders.autoencoder_kl.AutoencoderKL.blend_h
|
||||
# Copied from diffusers.models.autoencoder_kl.AutoencoderKL.blend_h
|
||||
def blend_h(self, a: torch.Tensor, b: torch.Tensor, blend_extent: int) -> torch.Tensor:
|
||||
blend_extent = min(a.shape[3], b.shape[3], blend_extent)
|
||||
for x in range(blend_extent):
|
||||
@@ -23,8 +23,10 @@ from torch.nn.modules.normalization import GroupNorm
|
||||
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..utils import BaseOutput, logging
|
||||
from .attention_processor import USE_PEFT_BACKEND, AttentionProcessor
|
||||
from .autoencoders import AutoencoderKL
|
||||
from .attention_processor import (
|
||||
AttentionProcessor,
|
||||
)
|
||||
from .autoencoder_kl import AutoencoderKL
|
||||
from .lora import LoRACompatibleConv
|
||||
from .modeling_utils import ModelMixin
|
||||
from .unet_2d_blocks import (
|
||||
@@ -815,23 +817,11 @@ def increase_block_input_in_encoder_resnet(unet: UNet2DConditionModel, block_no,
|
||||
norm_kwargs = {a: getattr(old_norm1, a) for a in norm_args}
|
||||
norm_kwargs["num_channels"] += by # surgery done here
|
||||
# conv1
|
||||
conv1_args = [
|
||||
"in_channels",
|
||||
"out_channels",
|
||||
"kernel_size",
|
||||
"stride",
|
||||
"padding",
|
||||
"dilation",
|
||||
"groups",
|
||||
"bias",
|
||||
"padding_mode",
|
||||
]
|
||||
if not USE_PEFT_BACKEND:
|
||||
conv1_args.append("lora_layer")
|
||||
|
||||
conv1_args = (
|
||||
"in_channels out_channels kernel_size stride padding dilation groups bias padding_mode lora_layer".split(" ")
|
||||
)
|
||||
for a in conv1_args:
|
||||
assert hasattr(old_conv1, a)
|
||||
|
||||
conv1_kwargs = {a: getattr(old_conv1, a) for a in conv1_args}
|
||||
conv1_kwargs["bias"] = "bias" in conv1_kwargs # as param, bias is a boolean, but as attr, it's a tensor.
|
||||
conv1_kwargs["in_channels"] += by # surgery done here
|
||||
@@ -849,42 +839,25 @@ def increase_block_input_in_encoder_resnet(unet: UNet2DConditionModel, block_no,
|
||||
}
|
||||
# swap old with new modules
|
||||
unet.down_blocks[block_no].resnets[resnet_idx].norm1 = GroupNorm(**norm_kwargs)
|
||||
unet.down_blocks[block_no].resnets[resnet_idx].conv1 = (
|
||||
nn.Conv2d(**conv1_kwargs) if USE_PEFT_BACKEND else LoRACompatibleConv(**conv1_kwargs)
|
||||
)
|
||||
unet.down_blocks[block_no].resnets[resnet_idx].conv_shortcut = (
|
||||
nn.Conv2d(**conv_shortcut_args_kwargs) if USE_PEFT_BACKEND else LoRACompatibleConv(**conv_shortcut_args_kwargs)
|
||||
)
|
||||
unet.down_blocks[block_no].resnets[resnet_idx].conv1 = LoRACompatibleConv(**conv1_kwargs)
|
||||
unet.down_blocks[block_no].resnets[resnet_idx].conv_shortcut = LoRACompatibleConv(**conv_shortcut_args_kwargs)
|
||||
unet.down_blocks[block_no].resnets[resnet_idx].in_channels += by # surgery done here
|
||||
|
||||
|
||||
def increase_block_input_in_encoder_downsampler(unet: UNet2DConditionModel, block_no, by):
|
||||
"""Increase channels sizes to allow for additional concatted information from base model"""
|
||||
old_down = unet.down_blocks[block_no].downsamplers[0].conv
|
||||
|
||||
args = [
|
||||
"in_channels",
|
||||
"out_channels",
|
||||
"kernel_size",
|
||||
"stride",
|
||||
"padding",
|
||||
"dilation",
|
||||
"groups",
|
||||
"bias",
|
||||
"padding_mode",
|
||||
]
|
||||
if not USE_PEFT_BACKEND:
|
||||
args.append("lora_layer")
|
||||
|
||||
# conv1
|
||||
args = "in_channels out_channels kernel_size stride padding dilation groups bias padding_mode lora_layer".split(
|
||||
" "
|
||||
)
|
||||
for a in args:
|
||||
assert hasattr(old_down, a)
|
||||
kwargs = {a: getattr(old_down, a) for a in args}
|
||||
kwargs["bias"] = "bias" in kwargs # as param, bias is a boolean, but as attr, it's a tensor.
|
||||
kwargs["in_channels"] += by # surgery done here
|
||||
# swap old with new modules
|
||||
unet.down_blocks[block_no].downsamplers[0].conv = (
|
||||
nn.Conv2d(**kwargs) if USE_PEFT_BACKEND else LoRACompatibleConv(**kwargs)
|
||||
)
|
||||
unet.down_blocks[block_no].downsamplers[0].conv = LoRACompatibleConv(**kwargs)
|
||||
unet.down_blocks[block_no].downsamplers[0].channels += by # surgery done here
|
||||
|
||||
|
||||
@@ -898,20 +871,12 @@ def increase_block_input_in_mid_resnet(unet: UNet2DConditionModel, by):
|
||||
assert hasattr(old_norm1, a)
|
||||
norm_kwargs = {a: getattr(old_norm1, a) for a in norm_args}
|
||||
norm_kwargs["num_channels"] += by # surgery done here
|
||||
conv1_args = [
|
||||
"in_channels",
|
||||
"out_channels",
|
||||
"kernel_size",
|
||||
"stride",
|
||||
"padding",
|
||||
"dilation",
|
||||
"groups",
|
||||
"bias",
|
||||
"padding_mode",
|
||||
]
|
||||
if not USE_PEFT_BACKEND:
|
||||
conv1_args.append("lora_layer")
|
||||
|
||||
# conv1
|
||||
conv1_args = (
|
||||
"in_channels out_channels kernel_size stride padding dilation groups bias padding_mode lora_layer".split(" ")
|
||||
)
|
||||
for a in conv1_args:
|
||||
assert hasattr(old_conv1, a)
|
||||
conv1_kwargs = {a: getattr(old_conv1, a) for a in conv1_args}
|
||||
conv1_kwargs["bias"] = "bias" in conv1_kwargs # as param, bias is a boolean, but as attr, it's a tensor.
|
||||
conv1_kwargs["in_channels"] += by # surgery done here
|
||||
@@ -929,12 +894,8 @@ def increase_block_input_in_mid_resnet(unet: UNet2DConditionModel, by):
|
||||
}
|
||||
# swap old with new modules
|
||||
unet.mid_block.resnets[0].norm1 = GroupNorm(**norm_kwargs)
|
||||
unet.mid_block.resnets[0].conv1 = (
|
||||
nn.Conv2d(**conv1_kwargs) if USE_PEFT_BACKEND else LoRACompatibleConv(**conv1_kwargs)
|
||||
)
|
||||
unet.mid_block.resnets[0].conv_shortcut = (
|
||||
nn.Conv2d(**conv_shortcut_args_kwargs) if USE_PEFT_BACKEND else LoRACompatibleConv(**conv_shortcut_args_kwargs)
|
||||
)
|
||||
unet.mid_block.resnets[0].conv1 = LoRACompatibleConv(**conv1_kwargs)
|
||||
unet.mid_block.resnets[0].conv_shortcut = LoRACompatibleConv(**conv_shortcut_args_kwargs)
|
||||
unet.mid_block.resnets[0].in_channels += by # surgery done here
|
||||
|
||||
|
||||
|
||||
@@ -729,7 +729,7 @@ class PositionNet(nn.Module):
|
||||
return objs
|
||||
|
||||
|
||||
class PixArtAlphaCombinedTimestepSizeEmbeddings(nn.Module):
|
||||
class CombinedTimestepSizeEmbeddings(nn.Module):
|
||||
"""
|
||||
For PixArt-Alpha.
|
||||
|
||||
@@ -746,27 +746,45 @@ class PixArtAlphaCombinedTimestepSizeEmbeddings(nn.Module):
|
||||
|
||||
self.use_additional_conditions = use_additional_conditions
|
||||
if use_additional_conditions:
|
||||
self.use_additional_conditions = True
|
||||
self.additional_condition_proj = Timesteps(num_channels=256, flip_sin_to_cos=True, downscale_freq_shift=0)
|
||||
self.resolution_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=size_emb_dim)
|
||||
self.aspect_ratio_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=size_emb_dim)
|
||||
|
||||
def apply_condition(self, size: torch.Tensor, batch_size: int, embedder: nn.Module):
|
||||
if size.ndim == 1:
|
||||
size = size[:, None]
|
||||
|
||||
if size.shape[0] != batch_size:
|
||||
size = size.repeat(batch_size // size.shape[0], 1)
|
||||
if size.shape[0] != batch_size:
|
||||
raise ValueError(f"`batch_size` should be {size.shape[0]} but found {batch_size}.")
|
||||
|
||||
current_batch_size, dims = size.shape[0], size.shape[1]
|
||||
size = size.reshape(-1)
|
||||
size_freq = self.additional_condition_proj(size).to(size.dtype)
|
||||
|
||||
size_emb = embedder(size_freq)
|
||||
size_emb = size_emb.reshape(current_batch_size, dims * self.outdim)
|
||||
return size_emb
|
||||
|
||||
def forward(self, timestep, resolution, aspect_ratio, batch_size, hidden_dtype):
|
||||
timesteps_proj = self.time_proj(timestep)
|
||||
timesteps_emb = self.timestep_embedder(timesteps_proj.to(dtype=hidden_dtype)) # (N, D)
|
||||
|
||||
if self.use_additional_conditions:
|
||||
resolution_emb = self.additional_condition_proj(resolution.flatten()).to(hidden_dtype)
|
||||
resolution_emb = self.resolution_embedder(resolution_emb).reshape(batch_size, -1)
|
||||
aspect_ratio_emb = self.additional_condition_proj(aspect_ratio.flatten()).to(hidden_dtype)
|
||||
aspect_ratio_emb = self.aspect_ratio_embedder(aspect_ratio_emb).reshape(batch_size, -1)
|
||||
conditioning = timesteps_emb + torch.cat([resolution_emb, aspect_ratio_emb], dim=1)
|
||||
resolution = self.apply_condition(resolution, batch_size=batch_size, embedder=self.resolution_embedder)
|
||||
aspect_ratio = self.apply_condition(
|
||||
aspect_ratio, batch_size=batch_size, embedder=self.aspect_ratio_embedder
|
||||
)
|
||||
conditioning = timesteps_emb + torch.cat([resolution, aspect_ratio], dim=1)
|
||||
else:
|
||||
conditioning = timesteps_emb
|
||||
|
||||
return conditioning
|
||||
|
||||
|
||||
class PixArtAlphaTextProjection(nn.Module):
|
||||
class CaptionProjection(nn.Module):
|
||||
"""
|
||||
Projects caption embeddings. Also handles dropout for classifier-free guidance.
|
||||
|
||||
@@ -778,8 +796,9 @@ class PixArtAlphaTextProjection(nn.Module):
|
||||
self.linear_1 = nn.Linear(in_features=in_features, out_features=hidden_size, bias=True)
|
||||
self.act_1 = nn.GELU(approximate="tanh")
|
||||
self.linear_2 = nn.Linear(in_features=hidden_size, out_features=hidden_size, bias=True)
|
||||
self.register_buffer("y_embedding", nn.Parameter(torch.randn(num_tokens, in_features) / in_features**0.5))
|
||||
|
||||
def forward(self, caption):
|
||||
def forward(self, caption, force_drop_ids=None):
|
||||
hidden_states = self.linear_1(caption)
|
||||
hidden_states = self.act_1(hidden_states)
|
||||
hidden_states = self.linear_2(hidden_states)
|
||||
|
||||
@@ -202,24 +202,23 @@ class ModelMixin(torch.nn.Module, PushToHubMixin):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
# def __getattr__(self, name: str) -> Any:
|
||||
# """The only reason we overwrite `getattr` here is to gracefully deprecate accessing
|
||||
# config attributes directly. See https://github.com/huggingface/diffusers/pull/3129 We need to overwrite
|
||||
# __getattr__ here in addition so that we don't trigger `torch.nn.Module`'s __getattr__':
|
||||
# https://pytorch.org/docs/stable/_modules/torch/nn/modules/module.html#Module
|
||||
# """
|
||||
def __getattr__(self, name: str) -> Any:
|
||||
"""The only reason we overwrite `getattr` here is to gracefully deprecate accessing
|
||||
config attributes directly. See https://github.com/huggingface/diffusers/pull/3129 We need to overwrite
|
||||
__getattr__ here in addition so that we don't trigger `torch.nn.Module`'s __getattr__':
|
||||
https://pytorch.org/docs/stable/_modules/torch/nn/modules/module.html#Module
|
||||
"""
|
||||
|
||||
# internal_keys = self.__dict__.keys()
|
||||
# is_in_config = "_internal_dict" in internal_keys and hasattr(self.__dict__["_internal_dict"], name)
|
||||
# is_attribute = name in internal_keys
|
||||
is_in_config = "_internal_dict" in self.__dict__ and hasattr(self.__dict__["_internal_dict"], name)
|
||||
is_attribute = name in self.__dict__
|
||||
|
||||
# if is_in_config and not is_attribute:
|
||||
# deprecation_message = f"Accessing config attribute `{name}` directly via '{type(self).__name__}' object attribute is deprecated. Please access '{name}' over '{type(self).__name__}'s config object instead, e.g. 'unet.config.{name}'."
|
||||
# deprecate("direct config name access", "1.0.0", deprecation_message, standard_warn=False, stacklevel=3)
|
||||
# return self._internal_dict[name]
|
||||
if is_in_config and not is_attribute:
|
||||
deprecation_message = f"Accessing config attribute `{name}` directly via '{type(self).__name__}' object attribute is deprecated. Please access '{name}' over '{type(self).__name__}'s config object instead, e.g. 'unet.config.{name}'."
|
||||
deprecate("direct config name access", "1.0.0", deprecation_message, standard_warn=False, stacklevel=3)
|
||||
return self._internal_dict[name]
|
||||
|
||||
# # call PyTorch's https://pytorch.org/docs/stable/_modules/torch/nn/modules/module.html#Module
|
||||
# return super().__getattr__(name)
|
||||
# call PyTorch's https://pytorch.org/docs/stable/_modules/torch/nn/modules/module.html#Module
|
||||
return super().__getattr__(name)
|
||||
|
||||
@property
|
||||
def is_gradient_checkpointing(self) -> bool:
|
||||
|
||||
@@ -20,7 +20,7 @@ import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
from .activations import get_activation
|
||||
from .embeddings import CombinedTimestepLabelEmbeddings, PixArtAlphaCombinedTimestepSizeEmbeddings
|
||||
from .embeddings import CombinedTimestepLabelEmbeddings, CombinedTimestepSizeEmbeddings
|
||||
|
||||
|
||||
class AdaLayerNorm(nn.Module):
|
||||
@@ -91,7 +91,7 @@ class AdaLayerNormSingle(nn.Module):
|
||||
def __init__(self, embedding_dim: int, use_additional_conditions: bool = False):
|
||||
super().__init__()
|
||||
|
||||
self.emb = PixArtAlphaCombinedTimestepSizeEmbeddings(
|
||||
self.emb = CombinedTimestepSizeEmbeddings(
|
||||
embedding_dim, size_emb_dim=embedding_dim // 3, use_additional_conditions=use_additional_conditions
|
||||
)
|
||||
|
||||
|
||||
@@ -22,7 +22,7 @@ from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..models.embeddings import ImagePositionalEmbeddings
|
||||
from ..utils import USE_PEFT_BACKEND, BaseOutput, deprecate, is_torch_version
|
||||
from .attention import BasicTransformerBlock
|
||||
from .embeddings import PatchEmbed, PixArtAlphaTextProjection
|
||||
from .embeddings import CaptionProjection, PatchEmbed
|
||||
from .lora import LoRACompatibleConv, LoRACompatibleLinear
|
||||
from .modeling_utils import ModelMixin
|
||||
from .normalization import AdaLayerNormSingle
|
||||
@@ -235,7 +235,7 @@ class Transformer2DModel(ModelMixin, ConfigMixin):
|
||||
|
||||
self.caption_projection = None
|
||||
if caption_channels is not None:
|
||||
self.caption_projection = PixArtAlphaTextProjection(in_features=caption_channels, hidden_size=inner_dim)
|
||||
self.caption_projection = CaptionProjection(in_features=caption_channels, hidden_size=inner_dim)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
|
||||
@@ -18,11 +18,11 @@ import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from ...utils import BaseOutput, is_torch_version
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..activations import get_activation
|
||||
from ..attention_processor import SpatialNorm
|
||||
from ..unet_2d_blocks import (
|
||||
from ..utils import BaseOutput, is_torch_version
|
||||
from ..utils.torch_utils import randn_tensor
|
||||
from .activations import get_activation
|
||||
from .attention_processor import SpatialNorm
|
||||
from .unet_2d_blocks import (
|
||||
AutoencoderTinyBlock,
|
||||
UNetMidBlock2D,
|
||||
get_down_block,
|
||||
@@ -20,8 +20,8 @@ import torch.nn as nn
|
||||
from ..configuration_utils import ConfigMixin, register_to_config
|
||||
from ..utils import BaseOutput
|
||||
from ..utils.accelerate_utils import apply_forward_hook
|
||||
from .autoencoders.vae import Decoder, DecoderOutput, Encoder, VectorQuantizer
|
||||
from .modeling_utils import ModelMixin
|
||||
from .vae import Decoder, DecoderOutput, Encoder, VectorQuantizer
|
||||
|
||||
|
||||
@dataclass
|
||||
|
||||
@@ -20,7 +20,6 @@ _dummy_objects = {}
|
||||
_import_structure = {
|
||||
"controlnet": [],
|
||||
"controlnet_xs": [],
|
||||
"deprecated": [],
|
||||
"latent_diffusion": [],
|
||||
"stable_diffusion": [],
|
||||
"stable_diffusion_xl": [],
|
||||
@@ -45,20 +44,16 @@ else:
|
||||
_import_structure["ddpm"] = ["DDPMPipeline"]
|
||||
_import_structure["dit"] = ["DiTPipeline"]
|
||||
_import_structure["latent_diffusion"].extend(["LDMSuperResolutionPipeline"])
|
||||
_import_structure["latent_diffusion_uncond"] = ["LDMPipeline"]
|
||||
_import_structure["pipeline_utils"] = [
|
||||
"AudioPipelineOutput",
|
||||
"DiffusionPipeline",
|
||||
"ImagePipelineOutput",
|
||||
]
|
||||
_import_structure["deprecated"].extend(
|
||||
[
|
||||
"PNDMPipeline",
|
||||
"LDMPipeline",
|
||||
"RePaintPipeline",
|
||||
"ScoreSdeVePipeline",
|
||||
"KarrasVePipeline",
|
||||
]
|
||||
)
|
||||
_import_structure["pndm"] = ["PNDMPipeline"]
|
||||
_import_structure["repaint"] = ["RePaintPipeline"]
|
||||
_import_structure["score_sde_ve"] = ["ScoreSdeVePipeline"]
|
||||
_import_structure["stochastic_karras_ve"] = ["KarrasVePipeline"]
|
||||
try:
|
||||
if not (is_torch_available() and is_librosa_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
@@ -67,23 +62,7 @@ except OptionalDependencyNotAvailable:
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_torch_and_librosa_objects))
|
||||
else:
|
||||
_import_structure["deprecated"].extend(["AudioDiffusionPipeline", "Mel"])
|
||||
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ..utils import dummy_transformers_and_torch_and_note_seq_objects # noqa F403
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_transformers_and_torch_and_note_seq_objects))
|
||||
else:
|
||||
_import_structure["deprecated"].extend(
|
||||
[
|
||||
"MidiProcessor",
|
||||
"SpectrogramDiffusionPipeline",
|
||||
]
|
||||
)
|
||||
|
||||
_import_structure["audio_diffusion"] = ["AudioDiffusionPipeline", "Mel"]
|
||||
try:
|
||||
if not (is_torch_available() and is_transformers_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
@@ -92,22 +71,10 @@ except OptionalDependencyNotAvailable:
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
|
||||
else:
|
||||
_import_structure["deprecated"].extend(
|
||||
[
|
||||
"VQDiffusionPipeline",
|
||||
"AltDiffusionPipeline",
|
||||
"AltDiffusionImg2ImgPipeline",
|
||||
"CycleDiffusionPipeline",
|
||||
"StableDiffusionInpaintPipelineLegacy",
|
||||
"StableDiffusionPix2PixZeroPipeline",
|
||||
"StableDiffusionParadigmsPipeline",
|
||||
"StableDiffusionModelEditingPipeline",
|
||||
"VersatileDiffusionDualGuidedPipeline",
|
||||
"VersatileDiffusionImageVariationPipeline",
|
||||
"VersatileDiffusionPipeline",
|
||||
"VersatileDiffusionTextToImagePipeline",
|
||||
]
|
||||
)
|
||||
_import_structure["alt_diffusion"] = [
|
||||
"AltDiffusionImg2ImgPipeline",
|
||||
"AltDiffusionPipeline",
|
||||
]
|
||||
_import_structure["animatediff"] = ["AnimateDiffPipeline"]
|
||||
_import_structure["audioldm"] = ["AudioLDMPipeline"]
|
||||
_import_structure["audioldm2"] = [
|
||||
@@ -179,6 +146,7 @@ else:
|
||||
_import_structure["stable_diffusion"].extend(
|
||||
[
|
||||
"CLIPImageProjection",
|
||||
"CycleDiffusionPipeline",
|
||||
"StableDiffusionAttendAndExcitePipeline",
|
||||
"StableDiffusionDepth2ImgPipeline",
|
||||
"StableDiffusionDiffEditPipeline",
|
||||
@@ -188,11 +156,15 @@ else:
|
||||
"StableDiffusionImageVariationPipeline",
|
||||
"StableDiffusionImg2ImgPipeline",
|
||||
"StableDiffusionInpaintPipeline",
|
||||
"StableDiffusionInpaintPipelineLegacy",
|
||||
"StableDiffusionInstructPix2PixPipeline",
|
||||
"StableDiffusionLatentUpscalePipeline",
|
||||
"StableDiffusionLDM3DPipeline",
|
||||
"StableDiffusionModelEditingPipeline",
|
||||
"StableDiffusionPanoramaPipeline",
|
||||
"StableDiffusionParadigmsPipeline",
|
||||
"StableDiffusionPipeline",
|
||||
"StableDiffusionPix2PixZeroPipeline",
|
||||
"StableDiffusionSAGPipeline",
|
||||
"StableDiffusionUpscalePipeline",
|
||||
"StableUnCLIPImg2ImgPipeline",
|
||||
@@ -226,6 +198,13 @@ else:
|
||||
"UniDiffuserPipeline",
|
||||
"UniDiffuserTextDecoder",
|
||||
]
|
||||
_import_structure["versatile_diffusion"] = [
|
||||
"VersatileDiffusionDualGuidedPipeline",
|
||||
"VersatileDiffusionImageVariationPipeline",
|
||||
"VersatileDiffusionPipeline",
|
||||
"VersatileDiffusionTextToImagePipeline",
|
||||
]
|
||||
_import_structure["vq_diffusion"] = ["VQDiffusionPipeline"]
|
||||
_import_structure["wuerstchen"] = [
|
||||
"WuerstchenCombinedPipeline",
|
||||
"WuerstchenDecoderPipeline",
|
||||
@@ -252,6 +231,7 @@ else:
|
||||
[
|
||||
"OnnxStableDiffusionImg2ImgPipeline",
|
||||
"OnnxStableDiffusionInpaintPipeline",
|
||||
"OnnxStableDiffusionInpaintPipelineLegacy",
|
||||
"OnnxStableDiffusionPipeline",
|
||||
"OnnxStableDiffusionUpscalePipeline",
|
||||
"StableDiffusionOnnxPipeline",
|
||||
@@ -299,6 +279,18 @@ else:
|
||||
"FlaxStableDiffusionXLPipeline",
|
||||
]
|
||||
)
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ..utils import dummy_transformers_and_torch_and_note_seq_objects # noqa F403
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_transformers_and_torch_and_note_seq_objects))
|
||||
else:
|
||||
_import_structure["spectrogram_diffusion"] = [
|
||||
"MidiProcessor",
|
||||
"SpectrogramDiffusionPipeline",
|
||||
]
|
||||
|
||||
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
try:
|
||||
@@ -317,14 +309,18 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
from .dance_diffusion import DanceDiffusionPipeline
|
||||
from .ddim import DDIMPipeline
|
||||
from .ddpm import DDPMPipeline
|
||||
from .deprecated import KarrasVePipeline, LDMPipeline, PNDMPipeline, RePaintPipeline, ScoreSdeVePipeline
|
||||
from .dit import DiTPipeline
|
||||
from .latent_diffusion import LDMSuperResolutionPipeline
|
||||
from .latent_diffusion_uncond import LDMPipeline
|
||||
from .pipeline_utils import (
|
||||
AudioPipelineOutput,
|
||||
DiffusionPipeline,
|
||||
ImagePipelineOutput,
|
||||
)
|
||||
from .pndm import PNDMPipeline
|
||||
from .repaint import RePaintPipeline
|
||||
from .score_sde_ve import ScoreSdeVePipeline
|
||||
from .stochastic_karras_ve import KarrasVePipeline
|
||||
|
||||
try:
|
||||
if not (is_torch_available() and is_librosa_available()):
|
||||
@@ -332,7 +328,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ..utils.dummy_torch_and_librosa_objects import *
|
||||
else:
|
||||
from .deprecated import AudioDiffusionPipeline, Mel
|
||||
from .audio_diffusion import AudioDiffusionPipeline, Mel
|
||||
|
||||
try:
|
||||
if not (is_torch_available() and is_transformers_available()):
|
||||
@@ -340,6 +336,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ..utils.dummy_torch_and_transformers_objects import *
|
||||
else:
|
||||
from .alt_diffusion import AltDiffusionImg2ImgPipeline, AltDiffusionPipeline
|
||||
from .animatediff import AnimateDiffPipeline
|
||||
from .audioldm import AudioLDMPipeline
|
||||
from .audioldm2 import (
|
||||
@@ -369,20 +366,6 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
IFPipeline,
|
||||
IFSuperResolutionPipeline,
|
||||
)
|
||||
from .deprecated import (
|
||||
AltDiffusionImg2ImgPipeline,
|
||||
AltDiffusionPipeline,
|
||||
CycleDiffusionPipeline,
|
||||
StableDiffusionInpaintPipelineLegacy,
|
||||
StableDiffusionModelEditingPipeline,
|
||||
StableDiffusionParadigmsPipeline,
|
||||
StableDiffusionPix2PixZeroPipeline,
|
||||
VersatileDiffusionDualGuidedPipeline,
|
||||
VersatileDiffusionImageVariationPipeline,
|
||||
VersatileDiffusionPipeline,
|
||||
VersatileDiffusionTextToImagePipeline,
|
||||
VQDiffusionPipeline,
|
||||
)
|
||||
from .kandinsky import (
|
||||
KandinskyCombinedPipeline,
|
||||
KandinskyImg2ImgCombinedPipeline,
|
||||
@@ -420,6 +403,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
from .shap_e import ShapEImg2ImgPipeline, ShapEPipeline
|
||||
from .stable_diffusion import (
|
||||
CLIPImageProjection,
|
||||
CycleDiffusionPipeline,
|
||||
StableDiffusionAttendAndExcitePipeline,
|
||||
StableDiffusionDepth2ImgPipeline,
|
||||
StableDiffusionDiffEditPipeline,
|
||||
@@ -428,11 +412,15 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
StableDiffusionImageVariationPipeline,
|
||||
StableDiffusionImg2ImgPipeline,
|
||||
StableDiffusionInpaintPipeline,
|
||||
StableDiffusionInpaintPipelineLegacy,
|
||||
StableDiffusionInstructPix2PixPipeline,
|
||||
StableDiffusionLatentUpscalePipeline,
|
||||
StableDiffusionLDM3DPipeline,
|
||||
StableDiffusionModelEditingPipeline,
|
||||
StableDiffusionPanoramaPipeline,
|
||||
StableDiffusionParadigmsPipeline,
|
||||
StableDiffusionPipeline,
|
||||
StableDiffusionPix2PixZeroPipeline,
|
||||
StableDiffusionSAGPipeline,
|
||||
StableDiffusionUpscalePipeline,
|
||||
StableUnCLIPImg2ImgPipeline,
|
||||
@@ -463,6 +451,13 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
UniDiffuserPipeline,
|
||||
UniDiffuserTextDecoder,
|
||||
)
|
||||
from .versatile_diffusion import (
|
||||
VersatileDiffusionDualGuidedPipeline,
|
||||
VersatileDiffusionImageVariationPipeline,
|
||||
VersatileDiffusionPipeline,
|
||||
VersatileDiffusionTextToImagePipeline,
|
||||
)
|
||||
from .vq_diffusion import VQDiffusionPipeline
|
||||
from .wuerstchen import (
|
||||
WuerstchenCombinedPipeline,
|
||||
WuerstchenDecoderPipeline,
|
||||
@@ -487,6 +482,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
from .stable_diffusion import (
|
||||
OnnxStableDiffusionImg2ImgPipeline,
|
||||
OnnxStableDiffusionInpaintPipeline,
|
||||
OnnxStableDiffusionInpaintPipelineLegacy,
|
||||
OnnxStableDiffusionPipeline,
|
||||
OnnxStableDiffusionUpscalePipeline,
|
||||
StableDiffusionOnnxPipeline,
|
||||
@@ -531,7 +527,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
from ..utils.dummy_transformers_and_torch_and_note_seq_objects import * # noqa F403
|
||||
|
||||
else:
|
||||
from .deprecated import (
|
||||
from .spectrogram_diffusion import (
|
||||
MidiProcessor,
|
||||
SpectrogramDiffusionPipeline,
|
||||
)
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import (
|
||||
from ...utils import (
|
||||
DIFFUSERS_SLOW_IMPORT,
|
||||
OptionalDependencyNotAvailable,
|
||||
_LazyModule,
|
||||
@@ -17,7 +17,7 @@ try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils import dummy_torch_and_transformers_objects
|
||||
from ...utils import dummy_torch_and_transformers_objects
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
|
||||
else:
|
||||
@@ -32,7 +32,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils.dummy_torch_and_transformers_objects import *
|
||||
from ...utils.dummy_torch_and_transformers_objects import *
|
||||
|
||||
else:
|
||||
from .modeling_roberta_series import RobertaSeriesModelWithTransformation
|
||||
@@ -19,14 +19,13 @@ import torch
|
||||
from packaging import version
|
||||
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection, XLMRobertaTokenizer
|
||||
|
||||
from ....configuration_utils import FrozenDict
|
||||
from ....image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ....loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ....models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ....models.attention_processor import FusedAttnProcessor2_0
|
||||
from ....models.lora import adjust_lora_scale_text_encoder
|
||||
from ....schedulers import KarrasDiffusionSchedulers
|
||||
from ....utils import (
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ...loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import (
|
||||
USE_PEFT_BACKEND,
|
||||
deprecate,
|
||||
logging,
|
||||
@@ -34,9 +33,9 @@ from ....utils import (
|
||||
scale_lora_layers,
|
||||
unscale_lora_layers,
|
||||
)
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from .modeling_roberta_series import RobertaSeriesModelWithTransformation
|
||||
from .pipeline_output import AltDiffusionPipelineOutput
|
||||
|
||||
@@ -119,6 +118,7 @@ def retrieve_timesteps(
|
||||
return timesteps, num_inference_steps
|
||||
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline with Stable->Alt, CLIPTextModel->RobertaSeriesModelWithTransformation, CLIPTokenizer->XLMRobertaTokenizer, AltDiffusionSafetyChecker->StableDiffusionSafetyChecker
|
||||
class AltDiffusionPipeline(
|
||||
DiffusionPipeline, TextualInversionLoaderMixin, LoraLoaderMixin, IPAdapterMixin, FromSingleFileMixin
|
||||
):
|
||||
@@ -155,7 +155,7 @@ class AltDiffusionPipeline(
|
||||
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
|
||||
"""
|
||||
|
||||
model_cpu_offload_seq = "text_encoder->image_encoder->unet->vae"
|
||||
model_cpu_offload_seq = "text_encoder->unet->vae"
|
||||
_optional_components = ["safety_checker", "feature_extractor", "image_encoder"]
|
||||
_exclude_from_cpu_offload = ["safety_checker"]
|
||||
_callback_tensor_inputs = ["latents", "prompt_embeds", "negative_prompt_embeds"]
|
||||
@@ -655,65 +655,6 @@ class AltDiffusionPipeline(
|
||||
"""Disables the FreeU mechanism if enabled."""
|
||||
self.unet.disable_freeu()
|
||||
|
||||
def fuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""
|
||||
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
||||
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
"""
|
||||
self.fusing_unet = False
|
||||
self.fusing_vae = False
|
||||
|
||||
if unet:
|
||||
self.fusing_unet = True
|
||||
self.unet.fuse_qkv_projections()
|
||||
self.unet.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
if vae:
|
||||
if not isinstance(self.vae, AutoencoderKL):
|
||||
raise ValueError("`fuse_qkv_projections()` is only supported for the VAE of type `AutoencoderKL`.")
|
||||
|
||||
self.fusing_vae = True
|
||||
self.vae.fuse_qkv_projections()
|
||||
self.vae.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
def unfuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""Disable QKV projection fusion if enabled.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
|
||||
"""
|
||||
if unet:
|
||||
if not self.fusing_unet:
|
||||
logger.warning("The UNet was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.unet.unfuse_qkv_projections()
|
||||
self.fusing_unet = False
|
||||
|
||||
if vae:
|
||||
if not self.fusing_vae:
|
||||
logger.warning("The VAE was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.vae.unfuse_qkv_projections()
|
||||
self.fusing_vae = False
|
||||
|
||||
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
||||
"""
|
||||
See https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
|
||||
@@ -21,14 +21,13 @@ import torch
|
||||
from packaging import version
|
||||
from transformers import CLIPImageProcessor, CLIPVisionModelWithProjection, XLMRobertaTokenizer
|
||||
|
||||
from ....configuration_utils import FrozenDict
|
||||
from ....image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ....loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ....models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ....models.attention_processor import FusedAttnProcessor2_0
|
||||
from ....models.lora import adjust_lora_scale_text_encoder
|
||||
from ....schedulers import KarrasDiffusionSchedulers
|
||||
from ....utils import (
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ...loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import (
|
||||
PIL_INTERPOLATION,
|
||||
USE_PEFT_BACKEND,
|
||||
deprecate,
|
||||
@@ -37,9 +36,9 @@ from ....utils import (
|
||||
scale_lora_layers,
|
||||
unscale_lora_layers,
|
||||
)
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from .modeling_roberta_series import RobertaSeriesModelWithTransformation
|
||||
from .pipeline_output import AltDiffusionPipelineOutput
|
||||
|
||||
@@ -159,6 +158,7 @@ def retrieve_timesteps(
|
||||
return timesteps, num_inference_steps
|
||||
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline with Stable->Alt, CLIPTextModel->RobertaSeriesModelWithTransformation, CLIPTokenizer->XLMRobertaTokenizer, AltDiffusionSafetyChecker->StableDiffusionSafetyChecker
|
||||
class AltDiffusionImg2ImgPipeline(
|
||||
DiffusionPipeline, TextualInversionLoaderMixin, IPAdapterMixin, LoraLoaderMixin, FromSingleFileMixin
|
||||
):
|
||||
@@ -195,7 +195,7 @@ class AltDiffusionImg2ImgPipeline(
|
||||
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
|
||||
"""
|
||||
|
||||
model_cpu_offload_seq = "text_encoder->image_encoder->unet->vae"
|
||||
model_cpu_offload_seq = "text_encoder->unet->vae"
|
||||
_optional_components = ["safety_checker", "feature_extractor", "image_encoder"]
|
||||
_exclude_from_cpu_offload = ["safety_checker"]
|
||||
_callback_tensor_inputs = ["latents", "prompt_embeds", "negative_prompt_embeds"]
|
||||
@@ -715,65 +715,6 @@ class AltDiffusionImg2ImgPipeline(
|
||||
"""Disables the FreeU mechanism if enabled."""
|
||||
self.unet.disable_freeu()
|
||||
|
||||
def fuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""
|
||||
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
||||
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
"""
|
||||
self.fusing_unet = False
|
||||
self.fusing_vae = False
|
||||
|
||||
if unet:
|
||||
self.fusing_unet = True
|
||||
self.unet.fuse_qkv_projections()
|
||||
self.unet.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
if vae:
|
||||
if not isinstance(self.vae, AutoencoderKL):
|
||||
raise ValueError("`fuse_qkv_projections()` is only supported for the VAE of type `AutoencoderKL`.")
|
||||
|
||||
self.fusing_vae = True
|
||||
self.vae.fuse_qkv_projections()
|
||||
self.vae.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
def unfuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""Disable QKV projection fusion if enabled.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
|
||||
"""
|
||||
if unet:
|
||||
if not self.fusing_unet:
|
||||
logger.warning("The UNet was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.unet.unfuse_qkv_projections()
|
||||
self.fusing_unet = False
|
||||
|
||||
if vae:
|
||||
if not self.fusing_vae:
|
||||
logger.warning("The VAE was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.vae.unfuse_qkv_projections()
|
||||
self.fusing_vae = False
|
||||
|
||||
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
||||
"""
|
||||
See https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
|
||||
@@ -4,7 +4,7 @@ from typing import List, Optional, Union
|
||||
import numpy as np
|
||||
import PIL.Image
|
||||
|
||||
from ....utils import (
|
||||
from ...utils import (
|
||||
BaseOutput,
|
||||
)
|
||||
|
||||
@@ -106,7 +106,7 @@ class AnimateDiffPipeline(DiffusionPipeline, TextualInversionLoaderMixin, IPAdap
|
||||
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
|
||||
"""
|
||||
|
||||
model_cpu_offload_seq = "text_encoder->image_encoder->unet->vae"
|
||||
model_cpu_offload_seq = "text_encoder->unet->vae"
|
||||
_optional_components = ["feature_extractor", "image_encoder"]
|
||||
|
||||
def __init__(
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
from ...utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
|
||||
|
||||
_import_structure = {
|
||||
@@ -15,8 +15,8 @@
|
||||
|
||||
import numpy as np # noqa: E402
|
||||
|
||||
from ....configuration_utils import ConfigMixin, register_to_config
|
||||
from ....schedulers.scheduling_utils import SchedulerMixin
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...schedulers.scheduling_utils import SchedulerMixin
|
||||
|
||||
|
||||
try:
|
||||
@@ -20,10 +20,10 @@ import numpy as np
|
||||
import torch
|
||||
from PIL import Image
|
||||
|
||||
from ....models import AutoencoderKL, UNet2DConditionModel
|
||||
from ....schedulers import DDIMScheduler, DDPMScheduler
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import AudioPipelineOutput, BaseOutput, DiffusionPipeline, ImagePipelineOutput
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...schedulers import DDIMScheduler, DDPMScheduler
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import AudioPipelineOutput, BaseOutput, DiffusionPipeline, ImagePipelineOutput
|
||||
from .mel import Mel
|
||||
|
||||
|
||||
@@ -176,7 +176,7 @@ class StableDiffusionControlNetPipeline(
|
||||
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
|
||||
"""
|
||||
|
||||
model_cpu_offload_seq = "text_encoder->image_encoder->unet->vae"
|
||||
model_cpu_offload_seq = "text_encoder->unet->vae"
|
||||
_optional_components = ["safety_checker", "feature_extractor", "image_encoder"]
|
||||
_exclude_from_cpu_offload = ["safety_checker"]
|
||||
_callback_tensor_inputs = ["latents", "prompt_embeds", "negative_prompt_embeds"]
|
||||
|
||||
@@ -291,7 +291,7 @@ class StableDiffusionControlNetInpaintPipeline(
|
||||
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
|
||||
"""
|
||||
|
||||
model_cpu_offload_seq = "text_encoder->image_encoder->unet->vae"
|
||||
model_cpu_offload_seq = "text_encoder->unet->vae"
|
||||
_optional_components = ["safety_checker", "feature_extractor", "image_encoder"]
|
||||
_exclude_from_cpu_offload = ["safety_checker"]
|
||||
_callback_tensor_inputs = ["latents", "prompt_embeds", "negative_prompt_embeds"]
|
||||
|
||||
@@ -165,7 +165,7 @@ class StableDiffusionXLControlNetPipeline(
|
||||
"""
|
||||
|
||||
# leave controlnet out on purpose because it iterates with unet
|
||||
model_cpu_offload_seq = "text_encoder->text_encoder_2->image_encoder->unet->vae"
|
||||
model_cpu_offload_seq = "text_encoder->text_encoder_2->unet->vae"
|
||||
_optional_components = [
|
||||
"tokenizer",
|
||||
"tokenizer_2",
|
||||
|
||||
@@ -1,3 +0,0 @@
|
||||
# Deprecated Pipelines
|
||||
|
||||
This folder contains pipelines that have very low usage as measured by model downloads, issues and PRs. While you can still use the pipelines just as before, we will stop testing the pipelines and will not accept any changes to existing files.
|
||||
@@ -1,153 +0,0 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ...utils import (
|
||||
DIFFUSERS_SLOW_IMPORT,
|
||||
OptionalDependencyNotAvailable,
|
||||
_LazyModule,
|
||||
get_objects_from_module,
|
||||
is_librosa_available,
|
||||
is_note_seq_available,
|
||||
is_torch_available,
|
||||
is_transformers_available,
|
||||
)
|
||||
|
||||
|
||||
_dummy_objects = {}
|
||||
_import_structure = {}
|
||||
|
||||
try:
|
||||
if not is_torch_available():
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils import dummy_pt_objects
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_pt_objects))
|
||||
else:
|
||||
_import_structure["latent_diffusion_uncond"] = ["LDMPipeline"]
|
||||
_import_structure["pndm"] = ["PNDMPipeline"]
|
||||
_import_structure["repaint"] = ["RePaintPipeline"]
|
||||
_import_structure["score_sde_ve"] = ["ScoreSdeVePipeline"]
|
||||
_import_structure["stochastic_karras_ve"] = ["KarrasVePipeline"]
|
||||
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils import dummy_torch_and_transformers_objects
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
|
||||
else:
|
||||
_import_structure["alt_diffusion"] = [
|
||||
"AltDiffusionImg2ImgPipeline",
|
||||
"AltDiffusionPipeline",
|
||||
"AltDiffusionPipelineOutput",
|
||||
]
|
||||
_import_structure["versatile_diffusion"] = [
|
||||
"VersatileDiffusionDualGuidedPipeline",
|
||||
"VersatileDiffusionImageVariationPipeline",
|
||||
"VersatileDiffusionPipeline",
|
||||
"VersatileDiffusionTextToImagePipeline",
|
||||
]
|
||||
_import_structure["vq_diffusion"] = ["VQDiffusionPipeline"]
|
||||
_import_structure["stable_diffusion_variants"] = [
|
||||
"CycleDiffusionPipeline",
|
||||
"StableDiffusionInpaintPipelineLegacy",
|
||||
"StableDiffusionPix2PixZeroPipeline",
|
||||
"StableDiffusionParadigmsPipeline",
|
||||
"StableDiffusionModelEditingPipeline",
|
||||
]
|
||||
|
||||
try:
|
||||
if not (is_torch_available() and is_librosa_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils import dummy_torch_and_librosa_objects # noqa F403
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_torch_and_librosa_objects))
|
||||
|
||||
else:
|
||||
_import_structure["audio_diffusion"] = ["AudioDiffusionPipeline", "Mel"]
|
||||
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils import dummy_transformers_and_torch_and_note_seq_objects # noqa F403
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_transformers_and_torch_and_note_seq_objects))
|
||||
|
||||
else:
|
||||
_import_structure["spectrogram_diffusion"] = ["MidiProcessor", "SpectrogramDiffusionPipeline"]
|
||||
|
||||
|
||||
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
try:
|
||||
if not is_torch_available():
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils.dummy_pt_objects import *
|
||||
|
||||
else:
|
||||
from .latent_diffusion_uncond import LDMPipeline
|
||||
from .pndm import PNDMPipeline
|
||||
from .repaint import RePaintPipeline
|
||||
from .score_sde_ve import ScoreSdeVePipeline
|
||||
from .stochastic_karras_ve import KarrasVePipeline
|
||||
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils.dummy_torch_and_transformers_objects import *
|
||||
|
||||
else:
|
||||
from .alt_diffusion import AltDiffusionImg2ImgPipeline, AltDiffusionPipeline, AltDiffusionPipelineOutput
|
||||
from .audio_diffusion import AudioDiffusionPipeline, Mel
|
||||
from .spectrogram_diffusion import SpectrogramDiffusionPipeline
|
||||
from .stable_diffusion_variants import (
|
||||
CycleDiffusionPipeline,
|
||||
StableDiffusionInpaintPipelineLegacy,
|
||||
StableDiffusionModelEditingPipeline,
|
||||
StableDiffusionParadigmsPipeline,
|
||||
StableDiffusionPix2PixZeroPipeline,
|
||||
)
|
||||
from .stochastic_karras_ve import KarrasVePipeline
|
||||
from .versatile_diffusion import (
|
||||
VersatileDiffusionDualGuidedPipeline,
|
||||
VersatileDiffusionImageVariationPipeline,
|
||||
VersatileDiffusionPipeline,
|
||||
VersatileDiffusionTextToImagePipeline,
|
||||
)
|
||||
from .vq_diffusion import VQDiffusionPipeline
|
||||
|
||||
try:
|
||||
if not (is_torch_available() and is_librosa_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils.dummy_torch_and_librosa_objects import *
|
||||
else:
|
||||
from .audio_diffusion import AudioDiffusionPipeline, Mel
|
||||
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils.dummy_transformers_and_torch_and_note_seq_objects import * # noqa F403
|
||||
else:
|
||||
from .spectrogram_diffusion import (
|
||||
MidiProcessor,
|
||||
SpectrogramDiffusionPipeline,
|
||||
)
|
||||
|
||||
|
||||
else:
|
||||
import sys
|
||||
|
||||
sys.modules[__name__] = _LazyModule(
|
||||
__name__,
|
||||
globals()["__file__"],
|
||||
_import_structure,
|
||||
module_spec=__spec__,
|
||||
)
|
||||
for name, value in _dummy_objects.items():
|
||||
setattr(sys.modules[__name__], name, value)
|
||||
@@ -1,55 +0,0 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import (
|
||||
DIFFUSERS_SLOW_IMPORT,
|
||||
OptionalDependencyNotAvailable,
|
||||
_LazyModule,
|
||||
get_objects_from_module,
|
||||
is_torch_available,
|
||||
is_transformers_available,
|
||||
)
|
||||
|
||||
|
||||
_dummy_objects = {}
|
||||
_import_structure = {}
|
||||
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils import dummy_torch_and_transformers_objects
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
|
||||
else:
|
||||
_import_structure["pipeline_cycle_diffusion"] = ["CycleDiffusionPipeline"]
|
||||
_import_structure["pipeline_stable_diffusion_inpaint_legacy"] = ["StableDiffusionInpaintPipelineLegacy"]
|
||||
_import_structure["pipeline_stable_diffusion_model_editing"] = ["StableDiffusionModelEditingPipeline"]
|
||||
|
||||
_import_structure["pipeline_stable_diffusion_paradigms"] = ["StableDiffusionParadigmsPipeline"]
|
||||
_import_structure["pipeline_stable_diffusion_pix2pix_zero"] = ["StableDiffusionPix2PixZeroPipeline"]
|
||||
|
||||
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils.dummy_torch_and_transformers_objects import *
|
||||
|
||||
else:
|
||||
from .pipeline_cycle_diffusion import CycleDiffusionPipeline
|
||||
from .pipeline_stable_diffusion_inpaint_legacy import StableDiffusionInpaintPipelineLegacy
|
||||
from .pipeline_stable_diffusion_model_editing import StableDiffusionModelEditingPipeline
|
||||
from .pipeline_stable_diffusion_paradigms import StableDiffusionParadigmsPipeline
|
||||
from .pipeline_stable_diffusion_pix2pix_zero import StableDiffusionPix2PixZeroPipeline
|
||||
|
||||
else:
|
||||
import sys
|
||||
|
||||
sys.modules[__name__] = _LazyModule(
|
||||
__name__,
|
||||
globals()["__file__"],
|
||||
_import_structure,
|
||||
module_spec=__spec__,
|
||||
)
|
||||
for name, value in _dummy_objects.items():
|
||||
setattr(sys.modules[__name__], name, value)
|
||||
@@ -1,6 +1,6 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
from ...utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
|
||||
|
||||
_import_structure = {"pipeline_latent_diffusion_uncond": ["LDMPipeline"]}
|
||||
@@ -17,10 +17,10 @@ from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ....models import UNet2DModel, VQModel
|
||||
from ....schedulers import DDIMScheduler
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
from ...models import UNet2DModel, VQModel
|
||||
from ...schedulers import DDIMScheduler
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
|
||||
|
||||
class LDMPipeline(DiffusionPipeline):
|
||||
@@ -853,11 +853,6 @@ class PixArtAlphaPipeline(DiffusionPipeline):
|
||||
aspect_ratio = torch.tensor([float(height / width)]).repeat(batch_size * num_images_per_prompt, 1)
|
||||
resolution = resolution.to(dtype=prompt_embeds.dtype, device=device)
|
||||
aspect_ratio = aspect_ratio.to(dtype=prompt_embeds.dtype, device=device)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
resolution = torch.cat([resolution, resolution], dim=0)
|
||||
aspect_ratio = torch.cat([aspect_ratio, aspect_ratio], dim=0)
|
||||
|
||||
added_cond_kwargs = {"resolution": resolution, "aspect_ratio": aspect_ratio}
|
||||
|
||||
# 7. Denoising loop
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
from ...utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
|
||||
|
||||
_import_structure = {"pipeline_pndm": ["PNDMPipeline"]}
|
||||
@@ -17,10 +17,10 @@ from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ....models import UNet2DModel
|
||||
from ....schedulers import PNDMScheduler
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
from ...models import UNet2DModel
|
||||
from ...schedulers import PNDMScheduler
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
|
||||
|
||||
class PNDMPipeline(DiffusionPipeline):
|
||||
@@ -1,6 +1,6 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
from ...utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
|
||||
|
||||
_import_structure = {"pipeline_repaint": ["RePaintPipeline"]}
|
||||
@@ -19,11 +19,11 @@ import numpy as np
|
||||
import PIL.Image
|
||||
import torch
|
||||
|
||||
from ....models import UNet2DModel
|
||||
from ....schedulers import RePaintScheduler
|
||||
from ....utils import PIL_INTERPOLATION, deprecate, logging
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
from ...models import UNet2DModel
|
||||
from ...schedulers import RePaintScheduler
|
||||
from ...utils import PIL_INTERPOLATION, deprecate, logging
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
@@ -1,6 +1,6 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
from ...utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
|
||||
|
||||
_import_structure = {"pipeline_score_sde_ve": ["ScoreSdeVePipeline"]}
|
||||
@@ -16,10 +16,10 @@ from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ....models import UNet2DModel
|
||||
from ....schedulers import ScoreSdeVeScheduler
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
from ...models import UNet2DModel
|
||||
from ...schedulers import ScoreSdeVeScheduler
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
|
||||
|
||||
|
||||
class ScoreSdeVePipeline(DiffusionPipeline):
|
||||
@@ -283,9 +283,6 @@ class ShapEImg2ImgPipeline(DiffusionPipeline):
|
||||
f"Only the output types `pil`, `np`, `latent` and `mesh` are supported not output_type={output_type}"
|
||||
)
|
||||
|
||||
# Offload all models
|
||||
self.maybe_free_model_hooks()
|
||||
|
||||
if output_type == "latent":
|
||||
return ShapEPipelineOutput(images=latents)
|
||||
|
||||
@@ -315,6 +312,9 @@ class ShapEImg2ImgPipeline(DiffusionPipeline):
|
||||
if output_type == "pil":
|
||||
images = [self.numpy_to_pil(image) for image in images]
|
||||
|
||||
# Offload all models
|
||||
self.maybe_free_model_hooks()
|
||||
|
||||
if not return_dict:
|
||||
return (images,)
|
||||
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
# flake8: noqa
|
||||
from typing import TYPE_CHECKING
|
||||
from ....utils import (
|
||||
DIFFUSERS_SLOW_IMPORT,
|
||||
from ...utils import DIFFUSERS_SLOW_IMPORT
|
||||
from ...utils import (
|
||||
_LazyModule,
|
||||
is_note_seq_available,
|
||||
OptionalDependencyNotAvailable,
|
||||
@@ -17,7 +17,7 @@ try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils import dummy_torch_and_transformers_objects # noqa F403
|
||||
from ...utils import dummy_torch_and_transformers_objects # noqa F403
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
|
||||
else:
|
||||
@@ -32,7 +32,7 @@ try:
|
||||
if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils import dummy_transformers_and_torch_and_note_seq_objects
|
||||
from ...utils import dummy_transformers_and_torch_and_note_seq_objects
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_transformers_and_torch_and_note_seq_objects))
|
||||
else:
|
||||
@@ -45,7 +45,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
raise OptionalDependencyNotAvailable()
|
||||
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils.dummy_torch_and_transformers_objects import *
|
||||
from ...utils.dummy_torch_and_transformers_objects import *
|
||||
else:
|
||||
from .pipeline_spectrogram_diffusion import SpectrogramDiffusionPipeline
|
||||
from .pipeline_spectrogram_diffusion import SpectrogramContEncoder
|
||||
@@ -56,7 +56,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
if not (is_transformers_available() and is_torch_available() and is_note_seq_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ....utils.dummy_transformers_and_torch_and_note_seq_objects import *
|
||||
from ...utils.dummy_transformers_and_torch_and_note_seq_objects import *
|
||||
|
||||
else:
|
||||
from .midi_utils import MidiProcessor
|
||||
@@ -22,8 +22,8 @@ from transformers.models.t5.modeling_t5 import (
|
||||
T5LayerNorm,
|
||||
)
|
||||
|
||||
from ....configuration_utils import ConfigMixin, register_to_config
|
||||
from ....models import ModelMixin
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...models import ModelMixin
|
||||
|
||||
|
||||
class SpectrogramContEncoder(ModelMixin, ConfigMixin, ModuleUtilsMixin):
|
||||
@@ -22,7 +22,7 @@ import numpy as np
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
from ....utils import is_note_seq_available
|
||||
from ...utils import is_note_seq_available
|
||||
from .pipeline_spectrogram_diffusion import TARGET_FEATURE_LENGTH
|
||||
|
||||
|
||||
@@ -18,8 +18,8 @@ import torch.nn as nn
|
||||
from transformers.modeling_utils import ModuleUtilsMixin
|
||||
from transformers.models.t5.modeling_t5 import T5Block, T5Config, T5LayerNorm
|
||||
|
||||
from ....configuration_utils import ConfigMixin, register_to_config
|
||||
from ....models import ModelMixin
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...models import ModelMixin
|
||||
|
||||
|
||||
class SpectrogramNotesEncoder(ModelMixin, ConfigMixin, ModuleUtilsMixin):
|
||||
@@ -19,16 +19,16 @@ from typing import Any, Callable, List, Optional, Tuple, Union
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
from ....models import T5FilmDecoder
|
||||
from ....schedulers import DDPMScheduler
|
||||
from ....utils import is_onnx_available, logging
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...models import T5FilmDecoder
|
||||
from ...schedulers import DDPMScheduler
|
||||
from ...utils import is_onnx_available, logging
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
|
||||
|
||||
if is_onnx_available():
|
||||
from ...onnx_utils import OnnxRuntimeModel
|
||||
from ..onnx_utils import OnnxRuntimeModel
|
||||
|
||||
from ...pipeline_utils import AudioPipelineOutput, DiffusionPipeline
|
||||
from ..pipeline_utils import AudioPipelineOutput, DiffusionPipeline
|
||||
from .continuous_encoder import SpectrogramContEncoder
|
||||
from .notes_encoder import SpectrogramNotesEncoder
|
||||
|
||||
@@ -134,6 +134,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
|
||||
else:
|
||||
from .clip_image_project_model import CLIPImageProjection
|
||||
from .pipeline_cycle_diffusion import CycleDiffusionPipeline
|
||||
from .pipeline_stable_diffusion import (
|
||||
StableDiffusionPipeline,
|
||||
StableDiffusionPipelineOutput,
|
||||
@@ -148,6 +149,9 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
)
|
||||
from .pipeline_stable_diffusion_img2img import StableDiffusionImg2ImgPipeline
|
||||
from .pipeline_stable_diffusion_inpaint import StableDiffusionInpaintPipeline
|
||||
from .pipeline_stable_diffusion_inpaint_legacy import (
|
||||
StableDiffusionInpaintPipelineLegacy,
|
||||
)
|
||||
from .pipeline_stable_diffusion_instruct_pix2pix import (
|
||||
StableDiffusionInstructPix2PixPipeline,
|
||||
)
|
||||
@@ -155,7 +159,13 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
StableDiffusionLatentUpscalePipeline,
|
||||
)
|
||||
from .pipeline_stable_diffusion_ldm3d import StableDiffusionLDM3DPipeline
|
||||
from .pipeline_stable_diffusion_model_editing import (
|
||||
StableDiffusionModelEditingPipeline,
|
||||
)
|
||||
from .pipeline_stable_diffusion_panorama import StableDiffusionPanoramaPipeline
|
||||
from .pipeline_stable_diffusion_paradigms import (
|
||||
StableDiffusionParadigmsPipeline,
|
||||
)
|
||||
from .pipeline_stable_diffusion_sag import StableDiffusionSAGPipeline
|
||||
from .pipeline_stable_diffusion_upscale import StableDiffusionUpscalePipeline
|
||||
from .pipeline_stable_unclip import StableUnCLIPPipeline
|
||||
@@ -189,6 +199,9 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
StableDiffusionDepth2ImgPipeline,
|
||||
)
|
||||
from .pipeline_stable_diffusion_diffedit import StableDiffusionDiffEditPipeline
|
||||
from .pipeline_stable_diffusion_pix2pix_zero import (
|
||||
StableDiffusionPix2PixZeroPipeline,
|
||||
)
|
||||
|
||||
try:
|
||||
if not (
|
||||
@@ -221,6 +234,9 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
from .pipeline_onnx_stable_diffusion_inpaint import (
|
||||
OnnxStableDiffusionInpaintPipeline,
|
||||
)
|
||||
from .pipeline_onnx_stable_diffusion_inpaint_legacy import (
|
||||
OnnxStableDiffusionInpaintPipelineLegacy,
|
||||
)
|
||||
from .pipeline_onnx_stable_diffusion_upscale import (
|
||||
OnnxStableDiffusionUpscalePipeline,
|
||||
)
|
||||
|
||||
@@ -1153,9 +1153,7 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
vae_path=None,
|
||||
vae=None,
|
||||
text_encoder=None,
|
||||
text_encoder_2=None,
|
||||
tokenizer=None,
|
||||
tokenizer_2=None,
|
||||
config_files=None,
|
||||
) -> DiffusionPipeline:
|
||||
"""
|
||||
@@ -1234,9 +1232,7 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
StableDiffusionInpaintPipeline,
|
||||
StableDiffusionPipeline,
|
||||
StableDiffusionUpscalePipeline,
|
||||
StableDiffusionXLControlNetInpaintPipeline,
|
||||
StableDiffusionXLImg2ImgPipeline,
|
||||
StableDiffusionXLInpaintPipeline,
|
||||
StableDiffusionXLPipeline,
|
||||
StableUnCLIPImg2ImgPipeline,
|
||||
StableUnCLIPPipeline,
|
||||
@@ -1343,11 +1339,7 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
else:
|
||||
pipeline_class = StableDiffusionXLPipeline if model_type == "SDXL" else StableDiffusionXLImg2ImgPipeline
|
||||
|
||||
if num_in_channels is None and pipeline_class in [
|
||||
StableDiffusionInpaintPipeline,
|
||||
StableDiffusionXLInpaintPipeline,
|
||||
StableDiffusionXLControlNetInpaintPipeline,
|
||||
]:
|
||||
if num_in_channels is None and pipeline_class == StableDiffusionInpaintPipeline:
|
||||
num_in_channels = 9
|
||||
if num_in_channels is None and pipeline_class == StableDiffusionUpscalePipeline:
|
||||
num_in_channels = 7
|
||||
@@ -1694,9 +1686,7 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
feature_extractor=feature_extractor,
|
||||
)
|
||||
elif model_type in ["SDXL", "SDXL-Refiner"]:
|
||||
is_refiner = model_type == "SDXL-Refiner"
|
||||
|
||||
if (is_refiner is False) and (tokenizer is None):
|
||||
if model_type == "SDXL":
|
||||
try:
|
||||
tokenizer = CLIPTokenizer.from_pretrained(
|
||||
"openai/clip-vit-large-patch14", local_files_only=local_files_only
|
||||
@@ -1705,11 +1695,7 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
raise ValueError(
|
||||
f"With local_files_only set to {local_files_only}, you must first locally save the tokenizer in the following path: 'openai/clip-vit-large-patch14'."
|
||||
)
|
||||
|
||||
if (is_refiner is False) and (text_encoder is None):
|
||||
text_encoder = convert_ldm_clip_checkpoint(checkpoint, local_files_only=local_files_only)
|
||||
|
||||
if tokenizer_2 is None:
|
||||
try:
|
||||
tokenizer_2 = CLIPTokenizer.from_pretrained(
|
||||
"laion/CLIP-ViT-bigG-14-laion2B-39B-b160k", pad_token="!", local_files_only=local_files_only
|
||||
@@ -1719,69 +1705,95 @@ def download_from_original_stable_diffusion_ckpt(
|
||||
f"With local_files_only set to {local_files_only}, you must first locally save the tokenizer in the following path: 'laion/CLIP-ViT-bigG-14-laion2B-39B-b160k' with `pad_token` set to '!'."
|
||||
)
|
||||
|
||||
if text_encoder_2 is None:
|
||||
config_name = "laion/CLIP-ViT-bigG-14-laion2B-39B-b160k"
|
||||
config_kwargs = {"projection_dim": 1280}
|
||||
prefix = "conditioner.embedders.0.model." if is_refiner else "conditioner.embedders.1.model."
|
||||
|
||||
text_encoder_2 = convert_open_clip_checkpoint(
|
||||
checkpoint,
|
||||
config_name,
|
||||
prefix=prefix,
|
||||
prefix="conditioner.embedders.1.model.",
|
||||
has_projection=True,
|
||||
local_files_only=local_files_only,
|
||||
**config_kwargs,
|
||||
)
|
||||
|
||||
if is_accelerate_available(): # SBM Now move model to cpu.
|
||||
for param_name, param in converted_unet_checkpoint.items():
|
||||
set_module_tensor_to_device(unet, param_name, "cpu", value=param)
|
||||
|
||||
if controlnet:
|
||||
pipe = pipeline_class(
|
||||
vae=vae,
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
text_encoder_2=text_encoder_2,
|
||||
tokenizer_2=tokenizer_2,
|
||||
unet=unet,
|
||||
controlnet=controlnet,
|
||||
scheduler=scheduler,
|
||||
force_zeros_for_empty_prompt=True,
|
||||
)
|
||||
elif adapter:
|
||||
pipe = pipeline_class(
|
||||
vae=vae,
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
text_encoder_2=text_encoder_2,
|
||||
tokenizer_2=tokenizer_2,
|
||||
unet=unet,
|
||||
adapter=adapter,
|
||||
scheduler=scheduler,
|
||||
force_zeros_for_empty_prompt=True,
|
||||
)
|
||||
if is_accelerate_available(): # SBM Now move model to cpu.
|
||||
if model_type in ["SDXL", "SDXL-Refiner"]:
|
||||
for param_name, param in converted_unet_checkpoint.items():
|
||||
set_module_tensor_to_device(unet, param_name, "cpu", value=param)
|
||||
|
||||
if controlnet:
|
||||
pipe = pipeline_class(
|
||||
vae=vae,
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
text_encoder_2=text_encoder_2,
|
||||
tokenizer_2=tokenizer_2,
|
||||
unet=unet,
|
||||
controlnet=controlnet,
|
||||
scheduler=scheduler,
|
||||
force_zeros_for_empty_prompt=True,
|
||||
)
|
||||
elif adapter:
|
||||
pipe = pipeline_class(
|
||||
vae=vae,
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
text_encoder_2=text_encoder_2,
|
||||
tokenizer_2=tokenizer_2,
|
||||
unet=unet,
|
||||
adapter=adapter,
|
||||
scheduler=scheduler,
|
||||
force_zeros_for_empty_prompt=True,
|
||||
)
|
||||
else:
|
||||
pipe = pipeline_class(
|
||||
vae=vae,
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
text_encoder_2=text_encoder_2,
|
||||
tokenizer_2=tokenizer_2,
|
||||
unet=unet,
|
||||
scheduler=scheduler,
|
||||
force_zeros_for_empty_prompt=True,
|
||||
)
|
||||
else:
|
||||
pipeline_kwargs = {
|
||||
"vae": vae,
|
||||
"text_encoder": text_encoder,
|
||||
"tokenizer": tokenizer,
|
||||
"text_encoder_2": text_encoder_2,
|
||||
"tokenizer_2": tokenizer_2,
|
||||
"unet": unet,
|
||||
"scheduler": scheduler,
|
||||
}
|
||||
tokenizer = None
|
||||
text_encoder = None
|
||||
try:
|
||||
tokenizer_2 = CLIPTokenizer.from_pretrained(
|
||||
"laion/CLIP-ViT-bigG-14-laion2B-39B-b160k", pad_token="!", local_files_only=local_files_only
|
||||
)
|
||||
except Exception:
|
||||
raise ValueError(
|
||||
f"With local_files_only set to {local_files_only}, you must first locally save the tokenizer in the following path: 'laion/CLIP-ViT-bigG-14-laion2B-39B-b160k' with `pad_token` set to '!'."
|
||||
)
|
||||
config_name = "laion/CLIP-ViT-bigG-14-laion2B-39B-b160k"
|
||||
config_kwargs = {"projection_dim": 1280}
|
||||
text_encoder_2 = convert_open_clip_checkpoint(
|
||||
checkpoint,
|
||||
config_name,
|
||||
prefix="conditioner.embedders.0.model.",
|
||||
has_projection=True,
|
||||
local_files_only=local_files_only,
|
||||
**config_kwargs,
|
||||
)
|
||||
|
||||
if (pipeline_class == StableDiffusionXLImg2ImgPipeline) or (
|
||||
pipeline_class == StableDiffusionXLInpaintPipeline
|
||||
):
|
||||
pipeline_kwargs.update({"requires_aesthetics_score": is_refiner})
|
||||
if is_accelerate_available(): # SBM Now move model to cpu.
|
||||
if model_type in ["SDXL", "SDXL-Refiner"]:
|
||||
for param_name, param in converted_unet_checkpoint.items():
|
||||
set_module_tensor_to_device(unet, param_name, "cpu", value=param)
|
||||
|
||||
if is_refiner:
|
||||
pipeline_kwargs.update({"force_zeros_for_empty_prompt": False})
|
||||
|
||||
pipe = pipeline_class(**pipeline_kwargs)
|
||||
pipe = StableDiffusionXLImg2ImgPipeline(
|
||||
vae=vae,
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
text_encoder_2=text_encoder_2,
|
||||
tokenizer_2=tokenizer_2,
|
||||
unet=unet,
|
||||
scheduler=scheduler,
|
||||
requires_aesthetics_score=True,
|
||||
force_zeros_for_empty_prompt=False,
|
||||
)
|
||||
else:
|
||||
text_config = create_ldm_bert_config(original_config)
|
||||
text_model = convert_ldm_bert_checkpoint(checkpoint, text_config)
|
||||
|
||||
@@ -21,17 +21,17 @@ import torch
|
||||
from packaging import version
|
||||
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from ....configuration_utils import FrozenDict
|
||||
from ....image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ....loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ....models import AutoencoderKL, UNet2DConditionModel
|
||||
from ....models.lora import adjust_lora_scale_text_encoder
|
||||
from ....schedulers import DDIMScheduler
|
||||
from ....utils import PIL_INTERPOLATION, USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
|
||||
from ...stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ...loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import DDIMScheduler
|
||||
from ...utils import PIL_INTERPOLATION, USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from .pipeline_output import StableDiffusionPipelineOutput
|
||||
from .safety_checker import StableDiffusionSafetyChecker
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
@@ -6,12 +6,12 @@ import PIL.Image
|
||||
import torch
|
||||
from transformers import CLIPImageProcessor, CLIPTokenizer
|
||||
|
||||
from ....configuration_utils import FrozenDict
|
||||
from ....schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
|
||||
from ....utils import deprecate, logging
|
||||
from ...onnx_utils import ORT_TO_NP_TYPE, OnnxRuntimeModel
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
|
||||
from ...utils import deprecate, logging
|
||||
from ..onnx_utils import ORT_TO_NP_TYPE, OnnxRuntimeModel
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from . import StableDiffusionPipelineOutput
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
@@ -23,7 +23,6 @@ from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ...loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ...models.attention_processor import FusedAttnProcessor2_0
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import (
|
||||
@@ -151,7 +150,7 @@ class StableDiffusionPipeline(
|
||||
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
|
||||
"""
|
||||
|
||||
model_cpu_offload_seq = "text_encoder->image_encoder->unet->vae"
|
||||
model_cpu_offload_seq = "text_encoder->unet->vae"
|
||||
_optional_components = ["safety_checker", "feature_extractor", "image_encoder"]
|
||||
_exclude_from_cpu_offload = ["safety_checker"]
|
||||
_callback_tensor_inputs = ["latents", "prompt_embeds", "negative_prompt_embeds"]
|
||||
@@ -651,67 +650,6 @@ class StableDiffusionPipeline(
|
||||
"""Disables the FreeU mechanism if enabled."""
|
||||
self.unet.disable_freeu()
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.fuse_qkv_projections
|
||||
def fuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""
|
||||
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
||||
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
"""
|
||||
self.fusing_unet = False
|
||||
self.fusing_vae = False
|
||||
|
||||
if unet:
|
||||
self.fusing_unet = True
|
||||
self.unet.fuse_qkv_projections()
|
||||
self.unet.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
if vae:
|
||||
if not isinstance(self.vae, AutoencoderKL):
|
||||
raise ValueError("`fuse_qkv_projections()` is only supported for the VAE of type `AutoencoderKL`.")
|
||||
|
||||
self.fusing_vae = True
|
||||
self.vae.fuse_qkv_projections()
|
||||
self.vae.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.unfuse_qkv_projections
|
||||
def unfuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""Disable QKV projection fusion if enabled.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
|
||||
"""
|
||||
if unet:
|
||||
if not self.fusing_unet:
|
||||
logger.warning("The UNet was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.unet.unfuse_qkv_projections()
|
||||
self.fusing_unet = False
|
||||
|
||||
if vae:
|
||||
if not self.fusing_vae:
|
||||
logger.warning("The VAE was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.vae.unfuse_qkv_projections()
|
||||
self.fusing_vae = False
|
||||
|
||||
# Copied from diffusers.pipelines.latent_consistency_models.pipeline_latent_consistency_text2img.LatentConsistencyModelPipeline.get_guidance_scale_embedding
|
||||
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
||||
"""
|
||||
|
||||
@@ -788,6 +788,7 @@ class StableDiffusionDiffEditPipeline(DiffusionPipeline, TextualInversionLoaderM
|
||||
latents = latents * self.scheduler.init_noise_sigma
|
||||
return latents
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_pix2pix_zero.StableDiffusionPix2PixZeroPipeline.prepare_image_latents
|
||||
def prepare_image_latents(self, image, batch_size, dtype, device, generator=None):
|
||||
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
|
||||
raise ValueError(
|
||||
|
||||
@@ -25,7 +25,6 @@ from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ...loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ...models.attention_processor import FusedAttnProcessor2_0
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import (
|
||||
@@ -191,7 +190,7 @@ class StableDiffusionImg2ImgPipeline(
|
||||
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
|
||||
"""
|
||||
|
||||
model_cpu_offload_seq = "text_encoder->image_encoder->unet->vae"
|
||||
model_cpu_offload_seq = "text_encoder->unet->vae"
|
||||
_optional_components = ["safety_checker", "feature_extractor", "image_encoder"]
|
||||
_exclude_from_cpu_offload = ["safety_checker"]
|
||||
_callback_tensor_inputs = ["latents", "prompt_embeds", "negative_prompt_embeds"]
|
||||
@@ -719,67 +718,6 @@ class StableDiffusionImg2ImgPipeline(
|
||||
"""Disables the FreeU mechanism if enabled."""
|
||||
self.unet.disable_freeu()
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.fuse_qkv_projections
|
||||
def fuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""
|
||||
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
||||
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
"""
|
||||
self.fusing_unet = False
|
||||
self.fusing_vae = False
|
||||
|
||||
if unet:
|
||||
self.fusing_unet = True
|
||||
self.unet.fuse_qkv_projections()
|
||||
self.unet.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
if vae:
|
||||
if not isinstance(self.vae, AutoencoderKL):
|
||||
raise ValueError("`fuse_qkv_projections()` is only supported for the VAE of type `AutoencoderKL`.")
|
||||
|
||||
self.fusing_vae = True
|
||||
self.vae.fuse_qkv_projections()
|
||||
self.vae.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.unfuse_qkv_projections
|
||||
def unfuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""Disable QKV projection fusion if enabled.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
|
||||
"""
|
||||
if unet:
|
||||
if not self.fusing_unet:
|
||||
logger.warning("The UNet was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.unet.unfuse_qkv_projections()
|
||||
self.fusing_unet = False
|
||||
|
||||
if vae:
|
||||
if not self.fusing_vae:
|
||||
logger.warning("The VAE was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.vae.unfuse_qkv_projections()
|
||||
self.fusing_vae = False
|
||||
|
||||
# Copied from diffusers.pipelines.latent_consistency_models.pipeline_latent_consistency_text2img.LatentConsistencyModelPipeline.get_guidance_scale_embedding
|
||||
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
||||
"""
|
||||
|
||||
@@ -25,7 +25,6 @@ from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ...loaders import FromSingleFileMixin, IPAdapterMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AsymmetricAutoencoderKL, AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ...models.attention_processor import FusedAttnProcessor2_0
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
@@ -255,7 +254,7 @@ class StableDiffusionInpaintPipeline(
|
||||
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
|
||||
"""
|
||||
|
||||
model_cpu_offload_seq = "text_encoder->image_encoder->unet->vae"
|
||||
model_cpu_offload_seq = "text_encoder->unet->vae"
|
||||
_optional_components = ["safety_checker", "feature_extractor", "image_encoder"]
|
||||
_exclude_from_cpu_offload = ["safety_checker"]
|
||||
_callback_tensor_inputs = ["latents", "prompt_embeds", "negative_prompt_embeds", "mask", "masked_image_latents"]
|
||||
@@ -845,67 +844,6 @@ class StableDiffusionInpaintPipeline(
|
||||
"""Disables the FreeU mechanism if enabled."""
|
||||
self.unet.disable_freeu()
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.fuse_qkv_projections
|
||||
def fuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""
|
||||
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
||||
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
"""
|
||||
self.fusing_unet = False
|
||||
self.fusing_vae = False
|
||||
|
||||
if unet:
|
||||
self.fusing_unet = True
|
||||
self.unet.fuse_qkv_projections()
|
||||
self.unet.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
if vae:
|
||||
if not isinstance(self.vae, AutoencoderKL):
|
||||
raise ValueError("`fuse_qkv_projections()` is only supported for the VAE of type `AutoencoderKL`.")
|
||||
|
||||
self.fusing_vae = True
|
||||
self.vae.fuse_qkv_projections()
|
||||
self.vae.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.unfuse_qkv_projections
|
||||
def unfuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""Disable QKV projection fusion if enabled.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
|
||||
"""
|
||||
if unet:
|
||||
if not self.fusing_unet:
|
||||
logger.warning("The UNet was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.unet.unfuse_qkv_projections()
|
||||
self.fusing_unet = False
|
||||
|
||||
if vae:
|
||||
if not self.fusing_vae:
|
||||
logger.warning("The VAE was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.vae.unfuse_qkv_projections()
|
||||
self.fusing_vae = False
|
||||
|
||||
# Copied from diffusers.pipelines.latent_consistency_models.pipeline_latent_consistency_text2img.LatentConsistencyModelPipeline.get_guidance_scale_embedding
|
||||
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
||||
"""
|
||||
|
||||
@@ -21,17 +21,17 @@ import torch
|
||||
from packaging import version
|
||||
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from ....configuration_utils import FrozenDict
|
||||
from ....image_processor import VaeImageProcessor
|
||||
from ....loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ....models import AutoencoderKL, UNet2DConditionModel
|
||||
from ....models.lora import adjust_lora_scale_text_encoder
|
||||
from ....schedulers import KarrasDiffusionSchedulers
|
||||
from ....utils import PIL_INTERPOLATION, USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion import StableDiffusionPipelineOutput
|
||||
from ...stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import VaeImageProcessor
|
||||
from ...loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import PIL_INTERPOLATION, USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from . import StableDiffusionPipelineOutput
|
||||
from .safety_checker import StableDiffusionSafetyChecker
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
@@ -18,17 +18,17 @@ from typing import Any, Callable, Dict, List, Optional, Union
|
||||
import torch
|
||||
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from ....image_processor import VaeImageProcessor
|
||||
from ....loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ....models import AutoencoderKL, UNet2DConditionModel
|
||||
from ....models.lora import adjust_lora_scale_text_encoder
|
||||
from ....schedulers import PNDMScheduler
|
||||
from ....schedulers.scheduling_utils import SchedulerMixin
|
||||
from ....utils import USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
|
||||
from ...stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from ...image_processor import VaeImageProcessor
|
||||
from ...loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import PNDMScheduler
|
||||
from ...schedulers.scheduling_utils import SchedulerMixin
|
||||
from ...utils import USE_PEFT_BACKEND, deprecate, logging, scale_lora_layers, unscale_lora_layers
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from . import StableDiffusionPipelineOutput
|
||||
from .safety_checker import StableDiffusionSafetyChecker
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
@@ -18,12 +18,12 @@ from typing import Any, Callable, Dict, List, Optional, Union
|
||||
import torch
|
||||
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
|
||||
|
||||
from ....image_processor import VaeImageProcessor
|
||||
from ....loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ....models import AutoencoderKL, UNet2DConditionModel
|
||||
from ....models.lora import adjust_lora_scale_text_encoder
|
||||
from ....schedulers import KarrasDiffusionSchedulers
|
||||
from ....utils import (
|
||||
from ...image_processor import VaeImageProcessor
|
||||
from ...loaders import FromSingleFileMixin, LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import KarrasDiffusionSchedulers
|
||||
from ...utils import (
|
||||
USE_PEFT_BACKEND,
|
||||
deprecate,
|
||||
logging,
|
||||
@@ -31,10 +31,10 @@ from ....utils import (
|
||||
scale_lora_layers,
|
||||
unscale_lora_layers,
|
||||
)
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
|
||||
from ...stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from . import StableDiffusionPipelineOutput
|
||||
from .safety_checker import StableDiffusionSafetyChecker
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
@@ -28,14 +28,14 @@ from transformers import (
|
||||
CLIPTokenizer,
|
||||
)
|
||||
|
||||
from ....image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ....loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ....models import AutoencoderKL, UNet2DConditionModel
|
||||
from ....models.attention_processor import Attention
|
||||
from ....models.lora import adjust_lora_scale_text_encoder
|
||||
from ....schedulers import DDIMScheduler, DDPMScheduler, EulerAncestralDiscreteScheduler, LMSDiscreteScheduler
|
||||
from ....schedulers.scheduling_ddim_inverse import DDIMInverseScheduler
|
||||
from ....utils import (
|
||||
from ...image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ...loaders import LoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, UNet2DConditionModel
|
||||
from ...models.attention_processor import Attention
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...schedulers import DDIMScheduler, DDPMScheduler, EulerAncestralDiscreteScheduler, LMSDiscreteScheduler
|
||||
from ...schedulers.scheduling_ddim_inverse import DDIMInverseScheduler
|
||||
from ...utils import (
|
||||
PIL_INTERPOLATION,
|
||||
USE_PEFT_BACKEND,
|
||||
BaseOutput,
|
||||
@@ -45,10 +45,10 @@ from ....utils import (
|
||||
scale_lora_layers,
|
||||
unscale_lora_layers,
|
||||
)
|
||||
from ....utils.torch_utils import randn_tensor
|
||||
from ...pipeline_utils import DiffusionPipeline
|
||||
from ...stable_diffusion.pipeline_output import StableDiffusionPipelineOutput
|
||||
from ...stable_diffusion.safety_checker import StableDiffusionSafetyChecker
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
from . import StableDiffusionPipelineOutput
|
||||
from .safety_checker import StableDiffusionSafetyChecker
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
@@ -198,7 +198,7 @@ class StableDiffusionXLPipeline(
|
||||
watermarker will be used.
|
||||
"""
|
||||
|
||||
model_cpu_offload_seq = "text_encoder->text_encoder_2->image_encoder->unet->vae"
|
||||
model_cpu_offload_seq = "text_encoder->text_encoder_2->unet->vae"
|
||||
_optional_components = [
|
||||
"tokenizer",
|
||||
"tokenizer_2",
|
||||
|
||||
@@ -35,7 +35,6 @@ from ...loaders import (
|
||||
from ...models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ...models.attention_processor import (
|
||||
AttnProcessor2_0,
|
||||
FusedAttnProcessor2_0,
|
||||
LoRAAttnProcessor2_0,
|
||||
LoRAXFormersAttnProcessor,
|
||||
XFormersAttnProcessor,
|
||||
@@ -219,7 +218,7 @@ class StableDiffusionXLImg2ImgPipeline(
|
||||
watermarker will be used.
|
||||
"""
|
||||
|
||||
model_cpu_offload_seq = "text_encoder->text_encoder_2->image_encoder->unet->vae"
|
||||
model_cpu_offload_seq = "text_encoder->text_encoder_2->unet->vae"
|
||||
_optional_components = [
|
||||
"tokenizer",
|
||||
"tokenizer_2",
|
||||
@@ -865,67 +864,6 @@ class StableDiffusionXLImg2ImgPipeline(
|
||||
"""Disables the FreeU mechanism if enabled."""
|
||||
self.unet.disable_freeu()
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.fuse_qkv_projections
|
||||
def fuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""
|
||||
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
||||
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
"""
|
||||
self.fusing_unet = False
|
||||
self.fusing_vae = False
|
||||
|
||||
if unet:
|
||||
self.fusing_unet = True
|
||||
self.unet.fuse_qkv_projections()
|
||||
self.unet.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
if vae:
|
||||
if not isinstance(self.vae, AutoencoderKL):
|
||||
raise ValueError("`fuse_qkv_projections()` is only supported for the VAE of type `AutoencoderKL`.")
|
||||
|
||||
self.fusing_vae = True
|
||||
self.vae.fuse_qkv_projections()
|
||||
self.vae.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.unfuse_qkv_projections
|
||||
def unfuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""Disable QKV projection fusion if enabled.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
|
||||
"""
|
||||
if unet:
|
||||
if not self.fusing_unet:
|
||||
logger.warning("The UNet was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.unet.unfuse_qkv_projections()
|
||||
self.fusing_unet = False
|
||||
|
||||
if vae:
|
||||
if not self.fusing_vae:
|
||||
logger.warning("The VAE was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.vae.unfuse_qkv_projections()
|
||||
self.fusing_vae = False
|
||||
|
||||
# Copied from diffusers.pipelines.latent_consistency_models.pipeline_latent_consistency_text2img.LatentConsistencyModelPipeline.get_guidance_scale_embedding
|
||||
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
||||
"""
|
||||
|
||||
@@ -36,7 +36,6 @@ from ...loaders import (
|
||||
from ...models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ...models.attention_processor import (
|
||||
AttnProcessor2_0,
|
||||
FusedAttnProcessor2_0,
|
||||
LoRAAttnProcessor2_0,
|
||||
LoRAXFormersAttnProcessor,
|
||||
XFormersAttnProcessor,
|
||||
@@ -364,7 +363,7 @@ class StableDiffusionXLInpaintPipeline(
|
||||
watermarker will be used.
|
||||
"""
|
||||
|
||||
model_cpu_offload_seq = "text_encoder->text_encoder_2->image_encoder->unet->vae"
|
||||
model_cpu_offload_seq = "text_encoder->text_encoder_2->unet->vae"
|
||||
|
||||
_optional_components = [
|
||||
"tokenizer",
|
||||
@@ -1085,67 +1084,6 @@ class StableDiffusionXLInpaintPipeline(
|
||||
"""Disables the FreeU mechanism if enabled."""
|
||||
self.unet.disable_freeu()
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.fuse_qkv_projections
|
||||
def fuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""
|
||||
Enables fused QKV projections. For self-attention modules, all projection matrices (i.e., query,
|
||||
key, value) are fused. For cross-attention modules, key and value projection matrices are fused.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
"""
|
||||
self.fusing_unet = False
|
||||
self.fusing_vae = False
|
||||
|
||||
if unet:
|
||||
self.fusing_unet = True
|
||||
self.unet.fuse_qkv_projections()
|
||||
self.unet.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
if vae:
|
||||
if not isinstance(self.vae, AutoencoderKL):
|
||||
raise ValueError("`fuse_qkv_projections()` is only supported for the VAE of type `AutoencoderKL`.")
|
||||
|
||||
self.fusing_vae = True
|
||||
self.vae.fuse_qkv_projections()
|
||||
self.vae.set_attn_processor(FusedAttnProcessor2_0())
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl.StableDiffusionXLPipeline.unfuse_qkv_projections
|
||||
def unfuse_qkv_projections(self, unet: bool = True, vae: bool = True):
|
||||
"""Disable QKV projection fusion if enabled.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This API is 🧪 experimental.
|
||||
|
||||
</Tip>
|
||||
|
||||
Args:
|
||||
unet (`bool`, defaults to `True`): To apply fusion on the UNet.
|
||||
vae (`bool`, defaults to `True`): To apply fusion on the VAE.
|
||||
|
||||
"""
|
||||
if unet:
|
||||
if not self.fusing_unet:
|
||||
logger.warning("The UNet was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.unet.unfuse_qkv_projections()
|
||||
self.fusing_unet = False
|
||||
|
||||
if vae:
|
||||
if not self.fusing_vae:
|
||||
logger.warning("The VAE was not initially fused for QKV projections. Doing nothing.")
|
||||
else:
|
||||
self.vae.unfuse_qkv_projections()
|
||||
self.fusing_vae = False
|
||||
|
||||
# Copied from diffusers.pipelines.latent_consistency_models.pipeline_latent_consistency_text2img.LatentConsistencyModelPipeline.get_guidance_scale_embedding
|
||||
def get_guidance_scale_embedding(self, w, embedding_dim=512, dtype=torch.float32):
|
||||
"""
|
||||
|
||||
@@ -25,7 +25,7 @@ from ...image_processor import VaeImageProcessor
|
||||
from ...models import AutoencoderKLTemporalDecoder, UNetSpatioTemporalConditionModel
|
||||
from ...schedulers import EulerDiscreteScheduler
|
||||
from ...utils import BaseOutput, logging
|
||||
from ...utils.torch_utils import is_compiled_module, randn_tensor
|
||||
from ...utils.torch_utils import randn_tensor
|
||||
from ..pipeline_utils import DiffusionPipeline
|
||||
|
||||
|
||||
@@ -211,8 +211,7 @@ class StableVideoDiffusionPipeline(DiffusionPipeline):
|
||||
|
||||
latents = 1 / self.vae.config.scaling_factor * latents
|
||||
|
||||
forward_vae_fn = self.vae._orig_mod.forward if is_compiled_module(self.vae) else self.vae.forward
|
||||
accepts_num_frames = "num_frames" in set(inspect.signature(forward_vae_fn).parameters.keys())
|
||||
accepts_num_frames = "num_frames" in set(inspect.signature(self.vae.forward).parameters.keys())
|
||||
|
||||
# decode decode_chunk_size frames at a time to avoid OOM
|
||||
frames = []
|
||||
@@ -291,9 +290,7 @@ class StableVideoDiffusionPipeline(DiffusionPipeline):
|
||||
# corresponds to doing no classifier free guidance.
|
||||
@property
|
||||
def do_classifier_free_guidance(self):
|
||||
if isinstance(self.guidance_scale, (int, float)):
|
||||
return self.guidance_scale
|
||||
return self.guidance_scale.max() > 1
|
||||
return self._guidance_scale > 1 and self.unet.config.time_cond_proj_dim is None
|
||||
|
||||
@property
|
||||
def num_timesteps(self):
|
||||
@@ -418,10 +415,10 @@ class StableVideoDiffusionPipeline(DiffusionPipeline):
|
||||
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
|
||||
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
||||
# corresponds to doing no classifier free guidance.
|
||||
self._guidance_scale = max_guidance_scale
|
||||
do_classifier_free_guidance = max_guidance_scale > 1.0
|
||||
|
||||
# 3. Encode input image
|
||||
image_embeddings = self._encode_image(image, device, num_videos_per_prompt, self.do_classifier_free_guidance)
|
||||
image_embeddings = self._encode_image(image, device, num_videos_per_prompt, do_classifier_free_guidance)
|
||||
|
||||
# NOTE: Stable Diffusion Video was conditioned on fps - 1, which
|
||||
# is why it is reduced here.
|
||||
@@ -437,7 +434,7 @@ class StableVideoDiffusionPipeline(DiffusionPipeline):
|
||||
if needs_upcasting:
|
||||
self.vae.to(dtype=torch.float32)
|
||||
|
||||
image_latents = self._encode_vae_image(image, device, num_videos_per_prompt, self.do_classifier_free_guidance)
|
||||
image_latents = self._encode_vae_image(image, device, num_videos_per_prompt, do_classifier_free_guidance)
|
||||
image_latents = image_latents.to(image_embeddings.dtype)
|
||||
|
||||
# cast back to fp16 if needed
|
||||
@@ -456,7 +453,7 @@ class StableVideoDiffusionPipeline(DiffusionPipeline):
|
||||
image_embeddings.dtype,
|
||||
batch_size,
|
||||
num_videos_per_prompt,
|
||||
self.do_classifier_free_guidance,
|
||||
do_classifier_free_guidance,
|
||||
)
|
||||
added_time_ids = added_time_ids.to(device)
|
||||
|
||||
@@ -492,7 +489,7 @@ class StableVideoDiffusionPipeline(DiffusionPipeline):
|
||||
with self.progress_bar(total=num_inference_steps) as progress_bar:
|
||||
for i, t in enumerate(timesteps):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = torch.cat([latents] * 2) if self.do_classifier_free_guidance else latents
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
||||
|
||||
# Concatenate image_latents over channels dimention
|
||||
@@ -508,7 +505,7 @@ class StableVideoDiffusionPipeline(DiffusionPipeline):
|
||||
)[0]
|
||||
|
||||
# perform guidance
|
||||
if self.do_classifier_free_guidance:
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred_uncond, noise_pred_cond = noise_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_cond - noise_pred_uncond)
|
||||
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
from ...utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
|
||||
|
||||
|
||||
_import_structure = {"pipeline_stochastic_karras_ve": ["KarrasVePipeline"]}
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user