mirror of
https://github.com/huggingface/diffusers.git
synced 2025-12-06 20:44:33 +08:00
Compare commits
50 Commits
custom-cod
...
qwenimage-
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
9b92241cbe | ||
|
|
673d4357ff | ||
|
|
561ab54de3 | ||
|
|
b60faf456b | ||
|
|
3e73dc24a4 | ||
|
|
d03240801f | ||
|
|
e62804ffbd | ||
|
|
bb1d9a8b75 | ||
|
|
a0a4127905 | ||
|
|
603172465f | ||
|
|
91a151b5c6 | ||
|
|
4fcd0bc7eb | ||
|
|
7993be9e7f | ||
|
|
7a2b78bf0f | ||
|
|
f868d4b58b | ||
|
|
cc48b9368f | ||
|
|
dba4e007fe | ||
|
|
8d1de40891 | ||
|
|
8cc528c5e7 | ||
|
|
3c50f0cdad | ||
|
|
555b6cc34f | ||
|
|
5b53f67f06 | ||
|
|
9918d13eba | ||
|
|
e824660436 | ||
|
|
03be15e890 | ||
|
|
85cbe589a7 | ||
|
|
4d9b82297f | ||
|
|
76c809e2ef | ||
|
|
e682af2027 | ||
|
|
a58a4f665b | ||
|
|
8701e8644b | ||
|
|
58bf268261 | ||
|
|
1b48db4c8f | ||
|
|
46a0c6aa82 | ||
|
|
421ee07e33 | ||
|
|
123506ee59 | ||
|
|
8c48ec05ed | ||
|
|
a6d2fc2c1d | ||
|
|
bc2762cce9 | ||
|
|
baa9b582f3 | ||
|
|
da096a4999 | ||
|
|
480fb357a3 | ||
|
|
38740ddbd8 | ||
|
|
72282876b2 | ||
|
|
3552279a23 | ||
|
|
f8ba5cd77a | ||
|
|
c9c8217306 | ||
|
|
135df5be9d | ||
|
|
4a9dbd56f6 | ||
|
|
630d27fe5b |
@@ -5,9 +5,9 @@
|
||||
- local: installation
|
||||
title: Installation
|
||||
- local: quicktour
|
||||
title: Quicktour
|
||||
title: Quickstart
|
||||
- local: stable_diffusion
|
||||
title: Effective and efficient diffusion
|
||||
title: Basic performance
|
||||
|
||||
- title: DiffusionPipeline
|
||||
isExpanded: false
|
||||
@@ -17,7 +17,7 @@
|
||||
- local: tutorials/autopipeline
|
||||
title: AutoPipeline
|
||||
- local: using-diffusers/custom_pipeline_overview
|
||||
title: Load community pipelines and components
|
||||
title: Community pipelines and components
|
||||
- local: using-diffusers/callback
|
||||
title: Pipeline callbacks
|
||||
- local: using-diffusers/reusing_seeds
|
||||
@@ -112,22 +112,24 @@
|
||||
sections:
|
||||
- local: modular_diffusers/overview
|
||||
title: Overview
|
||||
- local: modular_diffusers/modular_pipeline
|
||||
title: Modular Pipeline
|
||||
- local: modular_diffusers/components_manager
|
||||
title: Components Manager
|
||||
- local: modular_diffusers/quickstart
|
||||
title: Quickstart
|
||||
- local: modular_diffusers/modular_diffusers_states
|
||||
title: Modular Diffusers States
|
||||
title: States
|
||||
- local: modular_diffusers/pipeline_block
|
||||
title: Pipeline Block
|
||||
title: ModularPipelineBlocks
|
||||
- local: modular_diffusers/sequential_pipeline_blocks
|
||||
title: Sequential Pipeline Blocks
|
||||
title: SequentialPipelineBlocks
|
||||
- local: modular_diffusers/loop_sequential_pipeline_blocks
|
||||
title: Loop Sequential Pipeline Blocks
|
||||
title: LoopSequentialPipelineBlocks
|
||||
- local: modular_diffusers/auto_pipeline_blocks
|
||||
title: Auto Pipeline Blocks
|
||||
- local: modular_diffusers/end_to_end_guide
|
||||
title: End-to-End Example
|
||||
title: AutoPipelineBlocks
|
||||
- local: modular_diffusers/modular_pipeline
|
||||
title: ModularPipeline
|
||||
- local: modular_diffusers/components_manager
|
||||
title: ComponentsManager
|
||||
- local: modular_diffusers/guiders
|
||||
title: Guiders
|
||||
|
||||
- title: Training
|
||||
isExpanded: false
|
||||
@@ -282,6 +284,18 @@
|
||||
title: Outputs
|
||||
- local: api/quantization
|
||||
title: Quantization
|
||||
- title: Modular
|
||||
sections:
|
||||
- local: api/modular_diffusers/pipeline
|
||||
title: Pipeline
|
||||
- local: api/modular_diffusers/pipeline_blocks
|
||||
title: Blocks
|
||||
- local: api/modular_diffusers/pipeline_states
|
||||
title: States
|
||||
- local: api/modular_diffusers/pipeline_components
|
||||
title: Components and configs
|
||||
- local: api/modular_diffusers/guiders
|
||||
title: Guiders
|
||||
- title: Loaders
|
||||
sections:
|
||||
- local: api/loaders/ip_adapter
|
||||
@@ -326,6 +340,8 @@
|
||||
title: AllegroTransformer3DModel
|
||||
- local: api/models/aura_flow_transformer2d
|
||||
title: AuraFlowTransformer2DModel
|
||||
- local: api/models/bria_transformer
|
||||
title: BriaTransformer2DModel
|
||||
- local: api/models/chroma_transformer
|
||||
title: ChromaTransformer2DModel
|
||||
- local: api/models/cogvideox_transformer3d
|
||||
@@ -454,6 +470,8 @@
|
||||
title: AutoPipeline
|
||||
- local: api/pipelines/blip_diffusion
|
||||
title: BLIP-Diffusion
|
||||
- local: api/pipelines/bria_3_2
|
||||
title: Bria 3.2
|
||||
- local: api/pipelines/chroma
|
||||
title: Chroma
|
||||
- local: api/pipelines/cogvideox
|
||||
|
||||
19
docs/source/en/api/models/bria_transformer.md
Normal file
19
docs/source/en/api/models/bria_transformer.md
Normal file
@@ -0,0 +1,19 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# BriaTransformer2DModel
|
||||
|
||||
A modified flux Transformer model from [Bria](https://huggingface.co/briaai/BRIA-3.2)
|
||||
|
||||
## BriaTransformer2DModel
|
||||
|
||||
[[autodoc]] BriaTransformer2DModel
|
||||
39
docs/source/en/api/modular_diffusers/guiders.md
Normal file
39
docs/source/en/api/modular_diffusers/guiders.md
Normal file
@@ -0,0 +1,39 @@
|
||||
# Guiders
|
||||
|
||||
Guiders are components in Modular Diffusers that control how the diffusion process is guided during generation. They implement various guidance techniques to improve generation quality and control.
|
||||
|
||||
## BaseGuidance
|
||||
|
||||
[[autodoc]] diffusers.guiders.guider_utils.BaseGuidance
|
||||
|
||||
## ClassifierFreeGuidance
|
||||
|
||||
[[autodoc]] diffusers.guiders.classifier_free_guidance.ClassifierFreeGuidance
|
||||
|
||||
## ClassifierFreeZeroStarGuidance
|
||||
|
||||
[[autodoc]] diffusers.guiders.classifier_free_zero_star_guidance.ClassifierFreeZeroStarGuidance
|
||||
|
||||
## SkipLayerGuidance
|
||||
|
||||
[[autodoc]] diffusers.guiders.skip_layer_guidance.SkipLayerGuidance
|
||||
|
||||
## SmoothedEnergyGuidance
|
||||
|
||||
[[autodoc]] diffusers.guiders.smoothed_energy_guidance.SmoothedEnergyGuidance
|
||||
|
||||
## PerturbedAttentionGuidance
|
||||
|
||||
[[autodoc]] diffusers.guiders.perturbed_attention_guidance.PerturbedAttentionGuidance
|
||||
|
||||
## AdaptiveProjectedGuidance
|
||||
|
||||
[[autodoc]] diffusers.guiders.adaptive_projected_guidance.AdaptiveProjectedGuidance
|
||||
|
||||
## AutoGuidance
|
||||
|
||||
[[autodoc]] diffusers.guiders.auto_guidance.AutoGuidance
|
||||
|
||||
## TangentialClassifierFreeGuidance
|
||||
|
||||
[[autodoc]] diffusers.guiders.tangential_classifier_free_guidance.TangentialClassifierFreeGuidance
|
||||
5
docs/source/en/api/modular_diffusers/pipeline.md
Normal file
5
docs/source/en/api/modular_diffusers/pipeline.md
Normal file
@@ -0,0 +1,5 @@
|
||||
# Pipeline
|
||||
|
||||
## ModularPipeline
|
||||
|
||||
[[autodoc]] diffusers.modular_pipelines.modular_pipeline.ModularPipeline
|
||||
17
docs/source/en/api/modular_diffusers/pipeline_blocks.md
Normal file
17
docs/source/en/api/modular_diffusers/pipeline_blocks.md
Normal file
@@ -0,0 +1,17 @@
|
||||
# Pipeline blocks
|
||||
|
||||
## ModularPipelineBlocks
|
||||
|
||||
[[autodoc]] diffusers.modular_pipelines.modular_pipeline.ModularPipelineBlocks
|
||||
|
||||
## SequentialPipelineBlocks
|
||||
|
||||
[[autodoc]] diffusers.modular_pipelines.modular_pipeline.SequentialPipelineBlocks
|
||||
|
||||
## LoopSequentialPipelineBlocks
|
||||
|
||||
[[autodoc]] diffusers.modular_pipelines.modular_pipeline.LoopSequentialPipelineBlocks
|
||||
|
||||
## AutoPipelineBlocks
|
||||
|
||||
[[autodoc]] diffusers.modular_pipelines.modular_pipeline.AutoPipelineBlocks
|
||||
17
docs/source/en/api/modular_diffusers/pipeline_components.md
Normal file
17
docs/source/en/api/modular_diffusers/pipeline_components.md
Normal file
@@ -0,0 +1,17 @@
|
||||
# Components and configs
|
||||
|
||||
## ComponentSpec
|
||||
|
||||
[[autodoc]] diffusers.modular_pipelines.modular_pipeline.ComponentSpec
|
||||
|
||||
## ConfigSpec
|
||||
|
||||
[[autodoc]] diffusers.modular_pipelines.modular_pipeline.ConfigSpec
|
||||
|
||||
## ComponentsManager
|
||||
|
||||
[[autodoc]] diffusers.modular_pipelines.components_manager.ComponentsManager
|
||||
|
||||
## InsertableDict
|
||||
|
||||
[[autodoc]] diffusers.modular_pipelines.modular_pipeline_utils.InsertableDict
|
||||
9
docs/source/en/api/modular_diffusers/pipeline_states.md
Normal file
9
docs/source/en/api/modular_diffusers/pipeline_states.md
Normal file
@@ -0,0 +1,9 @@
|
||||
# Pipeline states
|
||||
|
||||
## PipelineState
|
||||
|
||||
[[autodoc]] diffusers.modular_pipelines.modular_pipeline.PipelineState
|
||||
|
||||
## BlockState
|
||||
|
||||
[[autodoc]] diffusers.modular_pipelines.modular_pipeline.BlockState
|
||||
44
docs/source/en/api/pipelines/bria_3_2.md
Normal file
44
docs/source/en/api/pipelines/bria_3_2.md
Normal file
@@ -0,0 +1,44 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Bria 3.2
|
||||
|
||||
Bria 3.2 is the next-generation commercial-ready text-to-image model. With just 4 billion parameters, it provides exceptional aesthetics and text rendering, evaluated to provide on par results to leading open-source models, and outperforming other licensed models.
|
||||
In addition to being built entirely on licensed data, 3.2 provides several advantages for enterprise and commercial use:
|
||||
|
||||
- Efficient Compute - the model is X3 smaller than the equivalent models in the market (4B parameters vs 12B parameters other open source models)
|
||||
- Architecture Consistency: Same architecture as 3.1—ideal for users looking to upgrade without disruption.
|
||||
- Fine-tuning Speedup: 2x faster fine-tuning on L40S and A100.
|
||||
|
||||
Original model checkpoints for Bria 3.2 can be found [here](https://huggingface.co/briaai/BRIA-3.2).
|
||||
Github repo for Bria 3.2 can be found [here](https://github.com/Bria-AI/BRIA-3.2).
|
||||
|
||||
If you want to learn more about the Bria platform, and get free traril access, please visit [bria.ai](https://bria.ai).
|
||||
|
||||
|
||||
## Usage
|
||||
|
||||
_As the model is gated, before using it with diffusers you first need to go to the [Bria 3.2 Hugging Face page](https://huggingface.co/briaai/BRIA-3.2), fill in the form and accept the gate. Once you are in, you need to login so that your system knows you’ve accepted the gate._
|
||||
|
||||
Use the command below to log in:
|
||||
|
||||
```bash
|
||||
hf auth login
|
||||
```
|
||||
|
||||
|
||||
## BriaPipeline
|
||||
|
||||
[[autodoc]] BriaPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
@@ -25,6 +25,8 @@ Original model checkpoints for Flux can be found [here](https://huggingface.co/b
|
||||
|
||||
Flux can be quite expensive to run on consumer hardware devices. However, you can perform a suite of optimizations to run it faster and in a more memory-friendly manner. Check out [this section](https://huggingface.co/blog/sd3#memory-optimizations-for-sd3) for more details. Additionally, Flux can benefit from quantization for memory efficiency with a trade-off in inference latency. Refer to [this blog post](https://huggingface.co/blog/quanto-diffusers) to learn more. For an exhaustive list of resources, check out [this gist](https://gist.github.com/sayakpaul/b664605caf0aa3bf8585ab109dd5ac9c).
|
||||
|
||||
[Caching](../../optimization/cache) may also speed up inference by storing and reusing intermediate outputs.
|
||||
|
||||
</Tip>
|
||||
|
||||
Flux comes in the following variants:
|
||||
@@ -314,6 +316,67 @@ if integrity_checker.test_image(image_):
|
||||
raise ValueError("Your image has been flagged. Choose another prompt/image or try again.")
|
||||
```
|
||||
|
||||
### Kontext Inpainting
|
||||
`FluxKontextInpaintPipeline` enables image modification within a fixed mask region. It currently supports both text-based conditioning and image-reference conditioning.
|
||||
<hfoptions id="kontext-inpaint">
|
||||
<hfoption id="text-only">
|
||||
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import FluxKontextInpaintPipeline
|
||||
from diffusers.utils import load_image
|
||||
|
||||
prompt = "Change the yellow dinosaur to green one"
|
||||
img_url = (
|
||||
"https://github.com/ZenAI-Vietnam/Flux-Kontext-pipelines/blob/main/assets/dinosaur_input.jpeg?raw=true"
|
||||
)
|
||||
mask_url = (
|
||||
"https://github.com/ZenAI-Vietnam/Flux-Kontext-pipelines/blob/main/assets/dinosaur_mask.png?raw=true"
|
||||
)
|
||||
|
||||
source = load_image(img_url)
|
||||
mask = load_image(mask_url)
|
||||
|
||||
pipe = FluxKontextInpaintPipeline.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-Kontext-dev", torch_dtype=torch.bfloat16
|
||||
)
|
||||
pipe.to("cuda")
|
||||
|
||||
image = pipe(prompt=prompt, image=source, mask_image=mask, strength=1.0).images[0]
|
||||
image.save("kontext_inpainting_normal.png")
|
||||
```
|
||||
</hfoption>
|
||||
<hfoption id="image conditioning">
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import FluxKontextInpaintPipeline
|
||||
from diffusers.utils import load_image
|
||||
|
||||
pipe = FluxKontextInpaintPipeline.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-Kontext-dev", torch_dtype=torch.bfloat16
|
||||
)
|
||||
pipe.to("cuda")
|
||||
|
||||
prompt = "Replace this ball"
|
||||
img_url = "https://images.pexels.com/photos/39362/the-ball-stadion-football-the-pitch-39362.jpeg?auto=compress&cs=tinysrgb&dpr=1&w=500"
|
||||
mask_url = "https://github.com/ZenAI-Vietnam/Flux-Kontext-pipelines/blob/main/assets/ball_mask.png?raw=true"
|
||||
image_reference_url = "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTah3x6OL_ECMBaZ5ZlJJhNsyC-OSMLWAI-xw&s"
|
||||
|
||||
source = load_image(img_url)
|
||||
mask = load_image(mask_url)
|
||||
image_reference = load_image(image_reference_url)
|
||||
|
||||
mask = pipe.mask_processor.blur(mask, blur_factor=12)
|
||||
image = pipe(
|
||||
prompt=prompt, image=source, mask_image=mask, image_reference=image_reference, strength=1.0
|
||||
).images[0]
|
||||
image.save("kontext_inpainting_ref.png")
|
||||
```
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## Combining Flux Turbo LoRAs with Flux Control, Fill, and Redux
|
||||
|
||||
We can combine Flux Turbo LoRAs with Flux Control and other pipelines like Fill and Redux to enable few-steps' inference. The example below shows how to do that for Flux Control LoRA for depth and turbo LoRA from [`ByteDance/Hyper-SD`](https://hf.co/ByteDance/Hyper-SD).
|
||||
@@ -644,3 +707,15 @@ image.save("flux-fp8-dev.png")
|
||||
[[autodoc]] FluxFillPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## FluxKontextPipeline
|
||||
|
||||
[[autodoc]] FluxKontextPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## FluxKontextInpaintPipeline
|
||||
|
||||
[[autodoc]] FluxKontextInpaintPipeline
|
||||
- all
|
||||
- __call__
|
||||
@@ -18,7 +18,7 @@
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-a-pipeline) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
[Caching](../../optimization/cache) may also speed up inference by storing and reusing intermediate outputs.
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
@@ -88,7 +88,7 @@ export_to_video(video, "output.mp4", fps=24)
|
||||
</hfoption>
|
||||
<hfoption id="inference speed">
|
||||
|
||||
[Compilation](../../optimization/fp16#torchcompile) is slow the first time but subsequent calls to the pipeline are faster.
|
||||
[Compilation](../../optimization/fp16#torchcompile) is slow the first time but subsequent calls to the pipeline are faster. [Caching](../../optimization/cache) may also speed up inference by storing and reusing intermediate outputs.
|
||||
|
||||
```py
|
||||
import torch
|
||||
|
||||
@@ -37,6 +37,7 @@ The table below lists all the pipelines currently available in 🤗 Diffusers an
|
||||
| [AudioLDM2](audioldm2) | text2audio |
|
||||
| [AuraFlow](auraflow) | text2image |
|
||||
| [BLIP Diffusion](blip_diffusion) | text2image |
|
||||
| [Bria 3.2](bria_3_2) | text2image |
|
||||
| [CogVideoX](cogvideox) | text2video |
|
||||
| [Consistency Models](consistency_models) | unconditional image generation |
|
||||
| [ControlNet](controlnet) | text2image, image2image, inpainting |
|
||||
@@ -112,3 +113,17 @@ The table below lists all the pipelines currently available in 🤗 Diffusers an
|
||||
## PushToHubMixin
|
||||
|
||||
[[autodoc]] utils.PushToHubMixin
|
||||
|
||||
## Callbacks
|
||||
|
||||
[[autodoc]] callbacks.PipelineCallback
|
||||
|
||||
[[autodoc]] callbacks.SDCFGCutoffCallback
|
||||
|
||||
[[autodoc]] callbacks.SDXLCFGCutoffCallback
|
||||
|
||||
[[autodoc]] callbacks.SDXLControlnetCFGCutoffCallback
|
||||
|
||||
[[autodoc]] callbacks.IPAdapterScaleCutoffCallback
|
||||
|
||||
[[autodoc]] callbacks.SD3CFGCutoffCallback
|
||||
|
||||
@@ -14,13 +14,22 @@
|
||||
|
||||
# QwenImage
|
||||
|
||||
<div class="flex flex-wrap space-x-1">
|
||||
<img alt="LoRA" src="https://img.shields.io/badge/LoRA-d8b4fe?style=flat"/>
|
||||
</div>
|
||||
|
||||
Qwen-Image from the Qwen team is an image generation foundation model in the Qwen series that achieves significant advances in complex text rendering and precise image editing. Experiments show strong general capabilities in both image generation and editing, with exceptional performance in text rendering, especially for Chinese.
|
||||
|
||||
Check out the model card [here](https://huggingface.co/Qwen/Qwen-Image) to learn more.
|
||||
Qwen-Image comes in the following variants:
|
||||
|
||||
| model type | model id |
|
||||
|:----------:|:--------:|
|
||||
| Qwen-Image | [`Qwen/Qwen-Image`](https://huggingface.co/Qwen/Qwen-Image) |
|
||||
| Qwen-Image-Edit | [`Qwen/Qwen-Image-Edit`](https://huggingface.co/Qwen/Qwen-Image-Edit) |
|
||||
|
||||
<Tip>
|
||||
|
||||
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-a-pipeline) section to learn how to efficiently load the same components into multiple pipelines.
|
||||
[Caching](../../optimization/cache) may also speed up inference by storing and reusing intermediate outputs.
|
||||
|
||||
</Tip>
|
||||
|
||||
@@ -81,12 +90,40 @@ image.save("qwen_fewsteps.png")
|
||||
|
||||
</details>
|
||||
|
||||
<Tip>
|
||||
|
||||
The `guidance_scale` parameter in the pipeline is there to support future guidance-distilled models when they come up. Note that passing `guidance_scale` to the pipeline is ineffective. To enable classifier-free guidance, please pass `true_cfg_scale` and `negative_prompt` (even an empty negative prompt like " ") should enable classifier-free guidance computations.
|
||||
|
||||
</Tip>
|
||||
|
||||
## QwenImagePipeline
|
||||
|
||||
[[autodoc]] QwenImagePipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## QwenImageImg2ImgPipeline
|
||||
|
||||
[[autodoc]] QwenImageImg2ImgPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## QwenImageInpaintPipeline
|
||||
|
||||
[[autodoc]] QwenImageInpaintPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## QwenImageEditPipeline
|
||||
|
||||
[[autodoc]] QwenImageEditPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## QwenImaggeControlNetPipeline
|
||||
- all
|
||||
- __call__
|
||||
|
||||
## QwenImagePipelineOutput
|
||||
|
||||
[[autodoc]] pipelines.qwenimage.pipeline_output.QwenImagePipelineOutput
|
||||
[[autodoc]] pipelines.qwenimage.pipeline_output.QwenImagePipelineOutput
|
||||
@@ -119,7 +119,7 @@ export_to_video(output, "output.mp4", fps=16)
|
||||
</hfoption>
|
||||
<hfoption id="T2V inference speed">
|
||||
|
||||
[Compilation](../../optimization/fp16#torchcompile) is slow the first time but subsequent calls to the pipeline are faster.
|
||||
[Compilation](../../optimization/fp16#torchcompile) is slow the first time but subsequent calls to the pipeline are faster. [Caching](../../optimization/cache) may also speed up inference by storing and reusing intermediate outputs.
|
||||
|
||||
```py
|
||||
# pip install ftfy
|
||||
@@ -333,6 +333,8 @@ The general rule of thumb to keep in mind when preparing inputs for the VACE pip
|
||||
|
||||
- Wan 2.1 and 2.2 support using [LightX2V LoRAs](https://huggingface.co/Kijai/WanVideo_comfy/tree/main/Lightx2v) to speed up inference. Using them on Wan 2.2 is slightly more involed. Refer to [this code snippet](https://github.com/huggingface/diffusers/pull/12040#issuecomment-3144185272) to learn more.
|
||||
|
||||
- Wan 2.2 has two denoisers. By default, LoRAs are only loaded into the first denoiser. One can set `load_into_transformer_2=True` to load LoRAs into the second denoiser. Refer to [this](https://github.com/huggingface/diffusers/pull/12074#issue-3292620048) and [this](https://github.com/huggingface/diffusers/pull/12074#issuecomment-3155896144) examples to learn more.
|
||||
|
||||
## WanPipeline
|
||||
|
||||
[[autodoc]] WanPipeline
|
||||
|
||||
@@ -12,83 +12,112 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
# AutoPipelineBlocks
|
||||
|
||||
<Tip warning={true}>
|
||||
[`~modular_pipelines.AutoPipelineBlocks`] are a multi-block type containing blocks that support different workflows. It automatically selects which sub-blocks to run based on the input provided at runtime. This is typically used to package multiple workflows - text-to-image, image-to-image, inpaint - into a single pipeline for convenience.
|
||||
|
||||
🧪 **Experimental Feature**: Modular Diffusers is an experimental feature we are actively developing. The API may be subject to breaking changes.
|
||||
This guide shows how to create [`~modular_pipelines.AutoPipelineBlocks`].
|
||||
|
||||
</Tip>
|
||||
Create three [`~modular_pipelines.ModularPipelineBlocks`] for text-to-image, image-to-image, and inpainting. These represent the different workflows available in the pipeline.
|
||||
|
||||
`AutoPipelineBlocks` is a subclass of `ModularPipelineBlocks`. It is a multi-block that automatically selects which sub-blocks to run based on the inputs provided at runtime, creating conditional workflows that adapt to different scenarios. The main purpose is convenience and portability - for developers, you can package everything into one workflow, making it easier to share and use.
|
||||
|
||||
In this tutorial, we will show you how to create an `AutoPipelineBlocks` and learn more about how the conditional selection works.
|
||||
|
||||
<Tip>
|
||||
|
||||
Other types of multi-blocks include [SequentialPipelineBlocks](sequential_pipeline_blocks.md) (for linear workflows) and [LoopSequentialPipelineBlocks](loop_sequential_pipeline_blocks.md) (for iterative workflows). For information on creating individual blocks, see the [PipelineBlock guide](pipeline_block.md).
|
||||
|
||||
Additionally, like all `ModularPipelineBlocks`, `AutoPipelineBlocks` are definitions/specifications, not runnable pipelines. You need to convert them into a `ModularPipeline` to actually execute them. For information on creating and running pipelines, see the [Modular Pipeline guide](modular_pipeline.md).
|
||||
|
||||
</Tip>
|
||||
|
||||
For example, you might want to support text-to-image and image-to-image tasks. Instead of creating two separate pipelines, you can create an `AutoPipelineBlocks` that automatically chooses the workflow based on whether an `image` input is provided.
|
||||
|
||||
Let's see an example. We'll use the helper function from the [PipelineBlock guide](./pipeline_block.md) to create our blocks:
|
||||
|
||||
**Helper Function**
|
||||
<hfoptions id="auto">
|
||||
<hfoption id="text-to-image">
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import PipelineBlock, InputParam, OutputParam
|
||||
import torch
|
||||
from diffusers.modular_pipelines import ModularPipelineBlocks, InputParam, OutputParam
|
||||
|
||||
def make_block(inputs=[], intermediate_inputs=[], intermediate_outputs=[], block_fn=None, description=None):
|
||||
class TestBlock(PipelineBlock):
|
||||
model_name = "test"
|
||||
|
||||
@property
|
||||
def inputs(self):
|
||||
return inputs
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self):
|
||||
return intermediate_inputs
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self):
|
||||
return intermediate_outputs
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return description if description is not None else ""
|
||||
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
if block_fn is not None:
|
||||
block_state = block_fn(block_state, state)
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
|
||||
return TestBlock
|
||||
class TextToImageBlock(ModularPipelineBlocks):
|
||||
model_name = "text2img"
|
||||
|
||||
@property
|
||||
def inputs(self):
|
||||
return [InputParam(name="prompt")]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self):
|
||||
return []
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return "I'm a text-to-image workflow!"
|
||||
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
print("running the text-to-image workflow")
|
||||
# Add your text-to-image logic here
|
||||
# For example: generate image from prompt
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
Now let's create a dummy `AutoPipelineBlocks` that includes dummy text-to-image, image-to-image, and inpaint pipelines.
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="image-to-image">
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import AutoPipelineBlocks
|
||||
class ImageToImageBlock(ModularPipelineBlocks):
|
||||
model_name = "img2img"
|
||||
|
||||
# These are dummy blocks and we only focus on "inputs" for our purpose
|
||||
inputs = [InputParam(name="prompt")]
|
||||
# block_fn prints out which workflow is running so we can see the execution order at runtime
|
||||
block_fn = lambda x, y: print("running the text-to-image workflow")
|
||||
block_t2i_cls = make_block(inputs=inputs, block_fn=block_fn, description="I'm a text-to-image workflow!")
|
||||
@property
|
||||
def inputs(self):
|
||||
return [InputParam(name="prompt"), InputParam(name="image")]
|
||||
|
||||
inputs = [InputParam(name="prompt"), InputParam(name="image")]
|
||||
block_fn = lambda x, y: print("running the image-to-image workflow")
|
||||
block_i2i_cls = make_block(inputs=inputs, block_fn=block_fn, description="I'm a image-to-image workflow!")
|
||||
@property
|
||||
def intermediate_outputs(self):
|
||||
return []
|
||||
|
||||
inputs = [InputParam(name="prompt"), InputParam(name="image"), InputParam(name="mask")]
|
||||
block_fn = lambda x, y: print("running the inpaint workflow")
|
||||
block_inpaint_cls = make_block(inputs=inputs, block_fn=block_fn, description="I'm a inpaint workflow!")
|
||||
@property
|
||||
def description(self):
|
||||
return "I'm an image-to-image workflow!"
|
||||
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
print("running the image-to-image workflow")
|
||||
# Add your image-to-image logic here
|
||||
# For example: transform input image based on prompt
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="inpaint">
|
||||
|
||||
```py
|
||||
class InpaintBlock(ModularPipelineBlocks):
|
||||
model_name = "inpaint"
|
||||
|
||||
@property
|
||||
def inputs(self):
|
||||
return [InputParam(name="prompt"), InputParam(name="image"), InputParam(name="mask")]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self):
|
||||
return []
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return "I'm an inpaint workflow!"
|
||||
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
print("running the inpaint workflow")
|
||||
# Add your inpainting logic here
|
||||
# For example: fill masked areas based on prompt
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
Create an [`~modular_pipelines.AutoPipelineBlocks`] class that includes a list of the sub-block classes and their corresponding block names.
|
||||
|
||||
You also need to include `block_trigger_inputs`, a list of input names that trigger the corresponding block. If a trigger input is provided at runtime, then that block is selected to run. Use `None` to specify the default block to run if no trigger inputs are detected.
|
||||
|
||||
Lastly, it is important to include a `description` that clearly explains which inputs trigger which workflow. This helps users understand how to run specific workflows.
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import AutoPipelineBlocks
|
||||
|
||||
class AutoImageBlocks(AutoPipelineBlocks):
|
||||
# List of sub-block classes to choose from
|
||||
@@ -97,11 +126,11 @@ class AutoImageBlocks(AutoPipelineBlocks):
|
||||
block_names = ["inpaint", "img2img", "text2img"]
|
||||
# Trigger inputs that determine which block to run
|
||||
# - "mask" triggers inpaint workflow
|
||||
# - "image" triggers img2img workflow (but only if mask is not provided)
|
||||
# - "image" triggers img2img workflow (but only if mask is not provided)
|
||||
# - if none of above, runs the text2img workflow (default)
|
||||
block_trigger_inputs = ["mask", "image", None]
|
||||
# Description is extremely important for AutoPipelineBlocks
|
||||
@property
|
||||
|
||||
def description(self):
|
||||
return (
|
||||
"Pipeline generates images given different types of conditions!\n"
|
||||
@@ -110,207 +139,18 @@ class AutoImageBlocks(AutoPipelineBlocks):
|
||||
+ " - img2img workflow is run when `image` is provided (but only when `mask` is not provided).\n"
|
||||
+ " - text2img workflow is run when neither `image` nor `mask` is provided.\n"
|
||||
)
|
||||
```
|
||||
|
||||
# Create the blocks
|
||||
It is **very** important to include a `description` to avoid any confusion over how to run a block and what inputs are required. While [`~modular_pipelines.AutoPipelineBlocks`] are convenient, it's conditional logic may be difficult to figure out if it isn't properly explained.
|
||||
|
||||
Create an instance of `AutoImageBlocks`.
|
||||
|
||||
```py
|
||||
auto_blocks = AutoImageBlocks()
|
||||
# convert to pipeline
|
||||
auto_pipeline = auto_blocks.init_pipeline()
|
||||
```
|
||||
|
||||
Now we have created an `AutoPipelineBlocks` that contains 3 sub-blocks. Notice the warning message at the top - this automatically appears in every `ModularPipelineBlocks` that contains `AutoPipelineBlocks` to remind end users that dynamic block selection happens at runtime.
|
||||
For more complex compositions, such as nested [`~modular_pipelines.AutoPipelineBlocks`] blocks when they're used as sub-blocks in larger pipelines, use the [`~modular_pipelines.SequentialPipelineBlocks.get_execution_blocks`] method to extract the a block that is actually run based on your input.
|
||||
|
||||
```py
|
||||
AutoImageBlocks(
|
||||
Class: AutoPipelineBlocks
|
||||
|
||||
====================================================================================================
|
||||
This pipeline contains blocks that are selected at runtime based on inputs.
|
||||
Trigger Inputs: ['mask', 'image']
|
||||
====================================================================================================
|
||||
|
||||
|
||||
Description: Pipeline generates images given different types of conditions!
|
||||
This is an auto pipeline block that works for text2img, img2img and inpainting tasks.
|
||||
- inpaint workflow is run when `mask` is provided.
|
||||
- img2img workflow is run when `image` is provided (but only when `mask` is not provided).
|
||||
- text2img workflow is run when neither `image` nor `mask` is provided.
|
||||
|
||||
|
||||
|
||||
Sub-Blocks:
|
||||
• inpaint [trigger: mask] (TestBlock)
|
||||
Description: I'm a inpaint workflow!
|
||||
|
||||
• img2img [trigger: image] (TestBlock)
|
||||
Description: I'm a image-to-image workflow!
|
||||
|
||||
• text2img [default] (TestBlock)
|
||||
Description: I'm a text-to-image workflow!
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
Check out the documentation with `print(auto_pipeline.doc)`:
|
||||
|
||||
```py
|
||||
>>> print(auto_pipeline.doc)
|
||||
class AutoImageBlocks
|
||||
|
||||
Pipeline generates images given different types of conditions!
|
||||
This is an auto pipeline block that works for text2img, img2img and inpainting tasks.
|
||||
- inpaint workflow is run when `mask` is provided.
|
||||
- img2img workflow is run when `image` is provided (but only when `mask` is not provided).
|
||||
- text2img workflow is run when neither `image` nor `mask` is provided.
|
||||
|
||||
Inputs:
|
||||
|
||||
prompt (`None`, *optional*):
|
||||
|
||||
image (`None`, *optional*):
|
||||
|
||||
mask (`None`, *optional*):
|
||||
```
|
||||
|
||||
There is a fundamental trade-off of AutoPipelineBlocks: it trades clarity for convenience. While it is really easy for packaging multiple workflows, it can become confusing without proper documentation. e.g. if we just throw a pipeline at you and tell you that it contains 3 sub-blocks and takes 3 inputs `prompt`, `image` and `mask`, and ask you to run an image-to-image workflow: if you don't have any prior knowledge on how these pipelines work, you would be pretty clueless, right?
|
||||
|
||||
This pipeline we just made though, has a docstring that shows all available inputs and workflows and explains how to use each with different inputs. So it's really helpful for users. For example, it's clear that you need to pass `image` to run img2img. This is why the description field is absolutely critical for AutoPipelineBlocks. We highly recommend you to explain the conditional logic very well for each `AutoPipelineBlocks` you would make. We also recommend to always test individual pipelines first before packaging them into AutoPipelineBlocks.
|
||||
|
||||
Let's run this auto pipeline with different inputs to see if the conditional logic works as described. Remember that we have added `print` in each `PipelineBlock`'s `__call__` method to print out its workflow name, so it should be easy to tell which one is running:
|
||||
|
||||
```py
|
||||
>>> _ = auto_pipeline(image="image", mask="mask")
|
||||
running the inpaint workflow
|
||||
>>> _ = auto_pipeline(image="image")
|
||||
running the image-to-image workflow
|
||||
>>> _ = auto_pipeline(prompt="prompt")
|
||||
running the text-to-image workflow
|
||||
>>> _ = auto_pipeline(image="prompt", mask="mask")
|
||||
running the inpaint workflow
|
||||
```
|
||||
|
||||
However, even with documentation, it can become very confusing when AutoPipelineBlocks are combined with other blocks. The complexity grows quickly when you have nested AutoPipelineBlocks or use them as sub-blocks in larger pipelines.
|
||||
|
||||
Let's make another `AutoPipelineBlocks` - this one only contains one block, and it does not include `None` in its `block_trigger_inputs` (which corresponds to the default block to run when none of the trigger inputs are provided). This means this block will be skipped if the trigger input (`ip_adapter_image`) is not provided at runtime.
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import SequentialPipelineBlocks, InsertableDict
|
||||
inputs = [InputParam(name="ip_adapter_image")]
|
||||
block_fn = lambda x, y: print("running the ip-adapter workflow")
|
||||
block_ipa_cls = make_block(inputs=inputs, block_fn=block_fn, description="I'm a IP-adapter workflow!")
|
||||
|
||||
class AutoIPAdapter(AutoPipelineBlocks):
|
||||
block_classes = [block_ipa_cls]
|
||||
block_names = ["ip-adapter"]
|
||||
block_trigger_inputs = ["ip_adapter_image"]
|
||||
@property
|
||||
def description(self):
|
||||
return "Run IP Adapter step if `ip_adapter_image` is provided."
|
||||
```
|
||||
|
||||
Now let's combine these 2 auto blocks together into a `SequentialPipelineBlocks`:
|
||||
|
||||
```py
|
||||
auto_ipa_blocks = AutoIPAdapter()
|
||||
blocks_dict = InsertableDict()
|
||||
blocks_dict["ip-adapter"] = auto_ipa_blocks
|
||||
blocks_dict["image-generation"] = auto_blocks
|
||||
all_blocks = SequentialPipelineBlocks.from_blocks_dict(blocks_dict)
|
||||
pipeline = all_blocks.init_pipeline()
|
||||
```
|
||||
|
||||
Let's take a look: now things get more confusing. In this particular example, you could still try to explain the conditional logic in the `description` field here - there are only 4 possible execution paths so it's doable. However, since this is a `SequentialPipelineBlocks` that could contain many more blocks, the complexity can quickly get out of hand as the number of blocks increases.
|
||||
|
||||
```py
|
||||
>>> all_blocks
|
||||
SequentialPipelineBlocks(
|
||||
Class: ModularPipelineBlocks
|
||||
|
||||
====================================================================================================
|
||||
This pipeline contains blocks that are selected at runtime based on inputs.
|
||||
Trigger Inputs: ['image', 'mask', 'ip_adapter_image']
|
||||
Use `get_execution_blocks()` with input names to see selected blocks (e.g. `get_execution_blocks('image')`).
|
||||
====================================================================================================
|
||||
|
||||
|
||||
Description:
|
||||
|
||||
|
||||
Sub-Blocks:
|
||||
[0] ip-adapter (AutoIPAdapter)
|
||||
Description: Run IP Adapter step if `ip_adapter_image` is provided.
|
||||
|
||||
|
||||
[1] image-generation (AutoImageBlocks)
|
||||
Description: Pipeline generates images given different types of conditions!
|
||||
This is an auto pipeline block that works for text2img, img2img and inpainting tasks.
|
||||
- inpaint workflow is run when `mask` is provided.
|
||||
- img2img workflow is run when `image` is provided (but only when `mask` is not provided).
|
||||
- text2img workflow is run when neither `image` nor `mask` is provided.
|
||||
|
||||
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
This is when the `get_execution_blocks()` method comes in handy - it basically extracts a `SequentialPipelineBlocks` that only contains the blocks that are actually run based on your inputs.
|
||||
|
||||
Let's try some examples:
|
||||
|
||||
`mask`: we expect it to skip the first ip-adapter since `ip_adapter_image` is not provided, and then run the inpaint for the second block.
|
||||
|
||||
```py
|
||||
>>> all_blocks.get_execution_blocks('mask')
|
||||
SequentialPipelineBlocks(
|
||||
Class: ModularPipelineBlocks
|
||||
|
||||
Description:
|
||||
|
||||
|
||||
Sub-Blocks:
|
||||
[0] image-generation (TestBlock)
|
||||
Description: I'm a inpaint workflow!
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
Let's also actually run the pipeline to confirm:
|
||||
|
||||
```py
|
||||
>>> _ = pipeline(mask="mask")
|
||||
skipping auto block: AutoIPAdapter
|
||||
running the inpaint workflow
|
||||
```
|
||||
|
||||
Try a few more:
|
||||
|
||||
```py
|
||||
print(f"inputs: ip_adapter_image:")
|
||||
blocks_select = all_blocks.get_execution_blocks('ip_adapter_image')
|
||||
print(f"expected_execution_blocks: {blocks_select}")
|
||||
print(f"actual execution blocks:")
|
||||
_ = pipeline(ip_adapter_image="ip_adapter_image", prompt="prompt")
|
||||
# expect to see ip-adapter + text2img
|
||||
|
||||
print(f"inputs: image:")
|
||||
blocks_select = all_blocks.get_execution_blocks('image')
|
||||
print(f"expected_execution_blocks: {blocks_select}")
|
||||
print(f"actual execution blocks:")
|
||||
_ = pipeline(image="image", prompt="prompt")
|
||||
# expect to see img2img
|
||||
|
||||
print(f"inputs: prompt:")
|
||||
blocks_select = all_blocks.get_execution_blocks('prompt')
|
||||
print(f"expected_execution_blocks: {blocks_select}")
|
||||
print(f"actual execution blocks:")
|
||||
_ = pipeline(prompt="prompt")
|
||||
# expect to see text2img (prompt is not a trigger input so fallback to default)
|
||||
|
||||
print(f"inputs: mask + ip_adapter_image:")
|
||||
blocks_select = all_blocks.get_execution_blocks('mask','ip_adapter_image')
|
||||
print(f"expected_execution_blocks: {blocks_select}")
|
||||
print(f"actual execution blocks:")
|
||||
_ = pipeline(mask="mask", ip_adapter_image="ip_adapter_image")
|
||||
# expect to see ip-adapter + inpaint
|
||||
```
|
||||
|
||||
In summary, `AutoPipelineBlocks` is a good tool for packaging multiple workflows into a single, convenient interface and it can greatly simplify the user experience. However, always provide clear descriptions explaining the conditional logic, test individual pipelines first before combining them, and use `get_execution_blocks()` to understand runtime behavior in complex compositions.
|
||||
auto_blocks.get_execution_blocks("mask")
|
||||
```
|
||||
@@ -10,118 +10,123 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Components Manager
|
||||
# ComponentsManager
|
||||
|
||||
<Tip warning={true}>
|
||||
The [`ComponentsManager`] is a model registry and management system for Modular Diffusers. It adds and tracks models, stores useful metadata (model size, device placement, adapters), prevents duplicate model instances, and supports offloading.
|
||||
|
||||
🧪 **Experimental Feature**: This is an experimental feature we are actively developing. The API may be subject to breaking changes.
|
||||
This guide will show you how to use [`ComponentsManager`] to manage components and device memory.
|
||||
|
||||
</Tip>
|
||||
## Add a component
|
||||
|
||||
The Components Manager is a central model registry and management system in diffusers. It lets you add models then reuse them across multiple pipelines and workflows. It tracks all models in one place with useful metadata such as model size, device placement and loaded adapters (LoRA, IP-Adapter). It has mechanisms in place to prevent duplicate model instances, enables memory-efficient sharing. Most significantly, it offers offloading that works across pipelines — unlike regular DiffusionPipeline offloading (i.e. `enable_model_cpu_offload` and `enable_sequential_cpu_offload`) which is limited to one pipeline with predefined sequences, the Components Manager automatically manages your device memory across all your models and workflows.
|
||||
The [`ComponentsManager`] should be created alongside a [`ModularPipeline`] in either [`~ModularPipeline.from_pretrained`] or [`~ModularPipelineBlocks.init_pipeline`].
|
||||
|
||||
> [!TIP]
|
||||
> The `collection` parameter is optional but makes it easier to organize and manage components.
|
||||
|
||||
## Basic Operations
|
||||
<hfoptions id="create">
|
||||
<hfoption id="from_pretrained">
|
||||
|
||||
Let's start with the most basic operations. First, create a Components Manager:
|
||||
```py
|
||||
from diffusers import ModularPipeline, ComponentsManager
|
||||
|
||||
comp = ComponentsManager()
|
||||
pipe = ModularPipeline.from_pretrained("YiYiXu/modular-demo-auto", components_manager=comp, collection="test1")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="init_pipeline">
|
||||
|
||||
```py
|
||||
from diffusers import ComponentsManager
|
||||
comp = ComponentsManager()
|
||||
from diffusers.modular_pipelines import SequentialPipelineBlocks
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl import TEXT2IMAGE_BLOCKS
|
||||
|
||||
t2i_blocks = SequentialPipelineBlocks.from_blocks_dict(TEXT2IMAGE_BLOCKS)
|
||||
|
||||
modular_repo_id = "YiYiXu/modular-loader-t2i-0704"
|
||||
components = ComponentsManager()
|
||||
t2i_pipeline = t2i_blocks.init_pipeline(modular_repo_id, components_manager=components)
|
||||
```
|
||||
|
||||
Use the `add(name, component)` method to register a component. It returns a unique ID that combines the component name with the object's unique identifier (using Python's `id()` function):
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
Components are only loaded and registered when using [`~ModularPipeline.load_components`] or [`~ModularPipeline.load_default_components`]. The example below uses [`~ModularPipeline.load_default_components`] to create a second pipeline that reuses all the components from the first one, and assigns it to a different collection
|
||||
|
||||
```py
|
||||
pipe.load_default_components()
|
||||
pipe2 = ModularPipeline.from_pretrained("YiYiXu/modular-demo-auto", components_manager=comp, collection="test2")
|
||||
```
|
||||
|
||||
Use the [`~ModularPipeline.null_component_names`] property to identify any components that need to be loaded, retrieve them with [`~ComponentsManager.get_components_by_names`], and then call [`~ModularPipeline.update_components`] to add the missing components.
|
||||
|
||||
```py
|
||||
pipe2.null_component_names
|
||||
['text_encoder', 'text_encoder_2', 'tokenizer', 'tokenizer_2', 'image_encoder', 'unet', 'vae', 'scheduler', 'controlnet']
|
||||
|
||||
comp_dict = comp.get_components_by_names(names=pipe2.null_component_names)
|
||||
pipe2.update_components(**comp_dict)
|
||||
```
|
||||
|
||||
To add individual components, use the [`~ComponentsManager.add`] method. This registers a component with a unique id.
|
||||
|
||||
```py
|
||||
from diffusers import AutoModel
|
||||
|
||||
text_encoder = AutoModel.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", subfolder="text_encoder")
|
||||
# Returns component_id like 'text_encoder_139917733042864'
|
||||
component_id = comp.add("text_encoder", text_encoder)
|
||||
comp
|
||||
```
|
||||
|
||||
You can view all registered components and their metadata:
|
||||
|
||||
```py
|
||||
>>> comp
|
||||
Components:
|
||||
===============================================================================================================================================
|
||||
Models:
|
||||
-----------------------------------------------------------------------------------------------------------------------------------------------
|
||||
Name_ID | Class | Device: act(exec) | Dtype | Size (GB) | Load ID | Collection
|
||||
-----------------------------------------------------------------------------------------------------------------------------------------------
|
||||
text_encoder_139917733042864 | CLIPTextModel | cpu | torch.float32 | 0.46 | N/A | N/A
|
||||
-----------------------------------------------------------------------------------------------------------------------------------------------
|
||||
|
||||
Additional Component Info:
|
||||
==================================================
|
||||
```
|
||||
|
||||
And remove components using their unique ID:
|
||||
Use [`~ComponentsManager.remove`] to remove a component using their id.
|
||||
|
||||
```py
|
||||
comp.remove("text_encoder_139917733042864")
|
||||
```
|
||||
|
||||
## Duplicate Detection
|
||||
## Retrieve a component
|
||||
|
||||
The Components Manager automatically detects and prevents duplicate model instances to save memory and avoid confusion. Let's walk through how this works in practice.
|
||||
The [`ComponentsManager`] provides several methods to retrieve registered components.
|
||||
|
||||
When you try to add the same object twice, the manager will warn you and return the existing ID:
|
||||
### get_one
|
||||
|
||||
The [`~ComponentsManager.get_one`] method returns a single component and supports pattern matching for the `name` parameter. If multiple components match, [`~ComponentsManager.get_one`] returns an error.
|
||||
|
||||
| Pattern | Example | Description |
|
||||
|-------------|----------------------------------|-------------------------------------------|
|
||||
| exact | `comp.get_one(name="unet")` | exact name match |
|
||||
| wildcard | `comp.get_one(name="unet*")` | names starting with "unet" |
|
||||
| exclusion | `comp.get_one(name="!unet")` | exclude components named "unet" |
|
||||
| or | `comp.get_one(name="unet|vae")` | name is "unet" or "vae" |
|
||||
|
||||
[`~ComponentsManager.get_one`] also filters components by the `collection` argument or `load_id` argument.
|
||||
|
||||
```py
|
||||
>>> comp.add("text_encoder", text_encoder)
|
||||
'text_encoder_139917733042864'
|
||||
>>> comp.add("text_encoder", text_encoder)
|
||||
ComponentsManager: component 'text_encoder' already exists as 'text_encoder_139917733042864'
|
||||
'text_encoder_139917733042864'
|
||||
comp.get_one(name="unet", collection="sdxl")
|
||||
```
|
||||
|
||||
Even if you add the same object under a different name, it will still be detected as a duplicate:
|
||||
### get_components_by_names
|
||||
|
||||
The [`~ComponentsManager.get_components_by_names`] method accepts a list of names and returns a dictionary mapping names to components. This is especially useful with [`ModularPipeline`] since they provide lists of required component names and the returned dictionary can be passed directly to [`~ModularPipeline.update_components`].
|
||||
|
||||
```py
|
||||
>>> comp.add("clip", text_encoder)
|
||||
ComponentsManager: adding component 'clip' as 'clip_139917733042864', but it is duplicate of 'text_encoder_139917733042864'
|
||||
To remove a duplicate, call `components_manager.remove('<component_id>')`.
|
||||
'clip_139917733042864'
|
||||
component_dict = comp.get_components_by_names(names=["text_encoder", "unet", "vae"])
|
||||
{"text_encoder": component1, "unet": component2, "vae": component3}
|
||||
```
|
||||
|
||||
However, there's a more subtle case where duplicate detection becomes tricky. When you load the same model into different objects, the manager can't detect duplicates unless you use `ComponentSpec`. For example:
|
||||
## Duplicate detection
|
||||
|
||||
```py
|
||||
>>> text_encoder_2 = AutoModel.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", subfolder="text_encoder")
|
||||
>>> comp.add("text_encoder", text_encoder_2)
|
||||
'text_encoder_139917732983664'
|
||||
```
|
||||
|
||||
This creates a problem - you now have two copies of the same model consuming double the memory:
|
||||
|
||||
```py
|
||||
>>> comp
|
||||
Components:
|
||||
===============================================================================================================================================
|
||||
Models:
|
||||
-----------------------------------------------------------------------------------------------------------------------------------------------
|
||||
Name_ID | Class | Device: act(exec) | Dtype | Size (GB) | Load ID | Collection
|
||||
-----------------------------------------------------------------------------------------------------------------------------------------------
|
||||
text_encoder_139917733042864 | CLIPTextModel | cpu | torch.float32 | 0.46 | N/A | N/A
|
||||
clip_139917733042864 | CLIPTextModel | cpu | torch.float32 | 0.46 | N/A | N/A
|
||||
text_encoder_139917732983664 | CLIPTextModel | cpu | torch.float32 | 0.46 | N/A | N/A
|
||||
-----------------------------------------------------------------------------------------------------------------------------------------------
|
||||
|
||||
Additional Component Info:
|
||||
==================================================
|
||||
```
|
||||
|
||||
We recommend using `ComponentSpec` to load your models. Models loaded with `ComponentSpec` get tagged with a unique ID that encodes their loading parameters, allowing the Components Manager to detect when different objects represent the same underlying checkpoint:
|
||||
It is recommended to load model components with [`ComponentSpec`] to assign components with a unique id that encodes their loading parameters. This allows [`ComponentsManager`] to automatically detect and prevent duplicate model instances even when different objects represent the same underlying checkpoint.
|
||||
|
||||
```py
|
||||
from diffusers import ComponentSpec, ComponentsManager
|
||||
from transformers import CLIPTextModel
|
||||
|
||||
comp = ComponentsManager()
|
||||
|
||||
# Create ComponentSpec for the first text encoder
|
||||
spec = ComponentSpec(name="text_encoder", repo="stabilityai/stable-diffusion-xl-base-1.0", subfolder="text_encoder", type_hint=AutoModel)
|
||||
# Create ComponentSpec for a duplicate text encoder (it is same checkpoint, from same repo/subfolder)
|
||||
# Create ComponentSpec for a duplicate text encoder (it is same checkpoint, from the same repo/subfolder)
|
||||
spec_duplicated = ComponentSpec(name="text_encoder_duplicated", repo="stabilityai/stable-diffusion-xl-base-1.0", subfolder="text_encoder", type_hint=CLIPTextModel)
|
||||
|
||||
# Load and add both components - the manager will detect they're the same model
|
||||
@@ -129,42 +134,36 @@ comp.add("text_encoder", spec.load())
|
||||
comp.add("text_encoder_duplicated", spec_duplicated.load())
|
||||
```
|
||||
|
||||
Now the manager detects the duplicate and warns you:
|
||||
This returns a warning with instructions for removing the duplicate.
|
||||
|
||||
```out
|
||||
```py
|
||||
ComponentsManager: adding component 'text_encoder_duplicated_139917580682672', but it has duplicate load_id 'stabilityai/stable-diffusion-xl-base-1.0|text_encoder|null|null' with existing components: text_encoder_139918506246832. To remove a duplicate, call `components_manager.remove('<component_id>')`.
|
||||
'text_encoder_duplicated_139917580682672'
|
||||
```
|
||||
|
||||
Both models now show the same `load_id`, making it clear they're the same model:
|
||||
You could also add a component without using [`ComponentSpec`] and duplicate detection still works in most cases even if you're adding the same component under a different name.
|
||||
|
||||
However, [`ComponentManager`] can't detect duplicates when you load the same component into different objects. In this case, you should load a model with [`ComponentSpec`].
|
||||
|
||||
```py
|
||||
>>> comp
|
||||
Components:
|
||||
======================================================================================================================================================================================================
|
||||
Models:
|
||||
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
Name_ID | Class | Device: act(exec) | Dtype | Size (GB) | Load ID | Collection
|
||||
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
text_encoder_139918506246832 | CLIPTextModel | cpu | torch.float32 | 0.46 | stabilityai/stable-diffusion-xl-base-1.0|text_encoder|null|null | N/A
|
||||
text_encoder_duplicated_139917580682672 | CLIPTextModel | cpu | torch.float32 | 0.46 | stabilityai/stable-diffusion-xl-base-1.0|text_encoder|null|null | N/A
|
||||
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
|
||||
Additional Component Info:
|
||||
==================================================
|
||||
text_encoder_2 = AutoModel.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", subfolder="text_encoder")
|
||||
comp.add("text_encoder", text_encoder_2)
|
||||
'text_encoder_139917732983664'
|
||||
```
|
||||
|
||||
## Collections
|
||||
|
||||
Collections are labels you can assign to components for better organization and management. You add a component under a collection by passing the `collection=` parameter when you add the component to the manager, i.e. `add(name, component, collection=...)`. Within each collection, only one component per name is allowed - if you add a second component with the same name, the first one is automatically removed.
|
||||
Collections are labels assigned to components for better organization and management. Add a component to a collection with the `collection` argument in [`~ComponentsManager.add`].
|
||||
|
||||
Here's how collections work in practice:
|
||||
Only one component per name is allowed in each collection. Adding a second component with the same name automatically removes the first component.
|
||||
|
||||
```py
|
||||
from diffusers import ComponentSpec, ComponentsManager
|
||||
|
||||
comp = ComponentsManager()
|
||||
# Create ComponentSpec for the first UNet (SDXL base)
|
||||
# Create ComponentSpec for the first UNet
|
||||
spec = ComponentSpec(name="unet", repo="stabilityai/stable-diffusion-xl-base-1.0", subfolder="unet", type_hint=AutoModel)
|
||||
# Create ComponentSpec for a different UNet (Juggernaut-XL)
|
||||
# Create ComponentSpec for a different UNet
|
||||
spec2 = ComponentSpec(name="unet", repo="RunDiffusion/Juggernaut-XL-v9", subfolder="unet", type_hint=AutoModel, variant="fp16")
|
||||
|
||||
# Add both UNets to the same collection - the second one will replace the first
|
||||
@@ -172,343 +171,20 @@ comp.add("unet", spec.load(), collection="sdxl")
|
||||
comp.add("unet", spec2.load(), collection="sdxl")
|
||||
```
|
||||
|
||||
The manager automatically removes the old UNet and adds the new one:
|
||||
This makes it convenient to work with node-based systems because you can:
|
||||
|
||||
```out
|
||||
ComponentsManager: removing existing unet from collection 'sdxl': unet_139917723891888
|
||||
'unet_139917723893136'
|
||||
```
|
||||
- Mark all models as loaded from one node with the `collection` label.
|
||||
- Automatically replace models when new checkpoints are loaded under the same name.
|
||||
- Batch delete all models in a collection when a node is removed.
|
||||
|
||||
Only one UNet remains in the collection:
|
||||
## Offloading
|
||||
|
||||
```py
|
||||
>>> comp
|
||||
Components:
|
||||
====================================================================================================================================================================
|
||||
Models:
|
||||
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
Name_ID | Class | Device: act(exec) | Dtype | Size (GB) | Load ID | Collection
|
||||
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
unet_139917723893136 | UNet2DConditionModel | cpu | torch.float32 | 9.56 | RunDiffusion/Juggernaut-XL-v9|unet|fp16|null | sdxl
|
||||
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
|
||||
Additional Component Info:
|
||||
==================================================
|
||||
```
|
||||
|
||||
For example, in node-based systems, you can mark all models loaded from one node with the same collection label, automatically replace models when user loads new checkpoints under same name, batch delete all models in a collection when a node is removed.
|
||||
|
||||
## Retrieving Components
|
||||
|
||||
The Components Manager provides several methods to retrieve registered components.
|
||||
|
||||
The `get_one()` method returns a single component and supports pattern matching for the `name` parameter. You can use:
|
||||
- exact matches like `comp.get_one(name="unet")`
|
||||
- wildcards like `comp.get_one(name="unet*")` for components starting with "unet"
|
||||
- exclusion patterns like `comp.get_one(name="!unet")` to exclude components named "unet"
|
||||
- OR patterns like `comp.get_one(name="unet|vae")` to match either "unet" OR "vae".
|
||||
|
||||
Optionally, You can add collection and load_id as filters e.g. `comp.get_one(name="unet", collection="sdxl")`. If multiple components match, `get_one()` throws an error.
|
||||
|
||||
Another useful method is `get_components_by_names()`, which takes a list of names and returns a dictionary mapping names to components. This is particularly helpful with modular pipelines since they provide lists of required component names, and the returned dictionary can be directly passed to `pipeline.update_components()`.
|
||||
|
||||
```py
|
||||
# Get components by name list
|
||||
component_dict = comp.get_components_by_names(names=["text_encoder", "unet", "vae"])
|
||||
# Returns: {"text_encoder": component1, "unet": component2, "vae": component3}
|
||||
```
|
||||
|
||||
## Using Components Manager with Modular Pipelines
|
||||
|
||||
The Components Manager integrates seamlessly with Modular Pipelines. All you need to do is pass a Components Manager instance to `from_pretrained()` or `init_pipeline()` with an optional `collection` parameter:
|
||||
|
||||
```py
|
||||
from diffusers import ModularPipeline, ComponentsManager
|
||||
comp = ComponentsManager()
|
||||
pipe = ModularPipeline.from_pretrained("YiYiXu/modular-demo-auto", components_manager=comp, collection="test1")
|
||||
```
|
||||
|
||||
By default, modular pipelines don't load components immediately, so both the pipeline and Components Manager start empty:
|
||||
|
||||
```py
|
||||
>>> comp
|
||||
Components:
|
||||
==================================================
|
||||
No components registered.
|
||||
==================================================
|
||||
```
|
||||
|
||||
When you load components on the pipeline, they are automatically registered in the Components Manager:
|
||||
|
||||
```py
|
||||
>>> pipe.load_components(names="unet")
|
||||
>>> comp
|
||||
Components:
|
||||
==============================================================================================================================================================
|
||||
Models:
|
||||
--------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
Name_ID | Class | Device: act(exec) | Dtype | Size (GB) | Load ID | Collection
|
||||
--------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
unet_139917726686304 | UNet2DConditionModel | cpu | torch.float32 | 9.56 | SG161222/RealVisXL_V4.0|unet|null|null | test1
|
||||
--------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
|
||||
Additional Component Info:
|
||||
==================================================
|
||||
```
|
||||
|
||||
Now let's load all default components and then create a second pipeline that reuses all components from the first one. We pass the same Components Manager to the second pipeline but with a different collection:
|
||||
|
||||
```py
|
||||
# Load all default components
|
||||
>>> pipe.load_default_components()
|
||||
|
||||
# Create a second pipeline using the same Components Manager but with a different collection
|
||||
>>> pipe2 = ModularPipeline.from_pretrained("YiYiXu/modular-demo-auto", components_manager=comp, collection="test2")
|
||||
```
|
||||
|
||||
As mentioned earlier, `ModularPipeline` has a property `null_component_names` that returns a list of component names it needs to load. We can conveniently use this list with the `get_components_by_names` method on the Components Manager:
|
||||
|
||||
```py
|
||||
# Get the list of components that pipe2 needs to load
|
||||
>>> pipe2.null_component_names
|
||||
['text_encoder', 'text_encoder_2', 'tokenizer', 'tokenizer_2', 'image_encoder', 'unet', 'vae', 'scheduler', 'controlnet']
|
||||
|
||||
# Retrieve all required components from the Components Manager
|
||||
>>> comp_dict = comp.get_components_by_names(names=pipe2.null_component_names)
|
||||
|
||||
# Update the pipeline with the retrieved components
|
||||
>>> pipe2.update_components(**comp_dict)
|
||||
```
|
||||
|
||||
The warnings that follow are expected and indicate that the Components Manager is correctly identifying that these components already exist and will be reused rather than creating duplicates:
|
||||
|
||||
```out
|
||||
ComponentsManager: component 'text_encoder' already exists as 'text_encoder_139917586016400'
|
||||
ComponentsManager: component 'text_encoder_2' already exists as 'text_encoder_2_139917699973424'
|
||||
ComponentsManager: component 'tokenizer' already exists as 'tokenizer_139917580599504'
|
||||
ComponentsManager: component 'tokenizer_2' already exists as 'tokenizer_2_139915763443904'
|
||||
ComponentsManager: component 'image_encoder' already exists as 'image_encoder_139917722468304'
|
||||
ComponentsManager: component 'unet' already exists as 'unet_139917580609632'
|
||||
ComponentsManager: component 'vae' already exists as 'vae_139917722459040'
|
||||
ComponentsManager: component 'scheduler' already exists as 'scheduler_139916266559408'
|
||||
ComponentsManager: component 'controlnet' already exists as 'controlnet_139917722454432'
|
||||
```
|
||||
|
||||
|
||||
The pipeline is now fully loaded:
|
||||
|
||||
```py
|
||||
# null_component_names return empty list, meaning everything are loaded
|
||||
>>> pipe2.null_component_names
|
||||
[]
|
||||
```
|
||||
|
||||
No new components were added to the Components Manager - we're reusing everything. All models are now associated with both `test1` and `test2` collections, showing that these components are shared across multiple pipelines:
|
||||
```py
|
||||
>>> comp
|
||||
Components:
|
||||
========================================================================================================================================================================================
|
||||
Models:
|
||||
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
Name_ID | Class | Device: act(exec) | Dtype | Size (GB) | Load ID | Collection
|
||||
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
text_encoder_139917586016400 | CLIPTextModel | cpu | torch.float32 | 0.46 | SG161222/RealVisXL_V4.0|text_encoder|null|null | test1
|
||||
| | | | | | test2
|
||||
text_encoder_2_139917699973424 | CLIPTextModelWithProjection | cpu | torch.float32 | 2.59 | SG161222/RealVisXL_V4.0|text_encoder_2|null|null | test1
|
||||
| | | | | | test2
|
||||
unet_139917580609632 | UNet2DConditionModel | cpu | torch.float32 | 9.56 | SG161222/RealVisXL_V4.0|unet|null|null | test1
|
||||
| | | | | | test2
|
||||
controlnet_139917722454432 | ControlNetModel | cpu | torch.float32 | 4.66 | diffusers/controlnet-canny-sdxl-1.0|null|null|null | test1
|
||||
| | | | | | test2
|
||||
vae_139917722459040 | AutoencoderKL | cpu | torch.float32 | 0.31 | SG161222/RealVisXL_V4.0|vae|null|null | test1
|
||||
| | | | | | test2
|
||||
image_encoder_139917722468304 | CLIPVisionModelWithProjection | cpu | torch.float32 | 6.87 | h94/IP-Adapter|sdxl_models/image_encoder|null|null | test1
|
||||
| | | | | | test2
|
||||
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
|
||||
Other Components:
|
||||
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
ID | Class | Collection
|
||||
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
tokenizer_139917580599504 | CLIPTokenizer | test1
|
||||
| | test2
|
||||
scheduler_139916266559408 | EulerDiscreteScheduler | test1
|
||||
| | test2
|
||||
tokenizer_2_139915763443904 | CLIPTokenizer | test1
|
||||
| | test2
|
||||
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
|
||||
Additional Component Info:
|
||||
==================================================
|
||||
```
|
||||
|
||||
|
||||
## Automatic Memory Management
|
||||
|
||||
The Components Manager provides a global offloading strategy across all models, regardless of which pipeline is using them:
|
||||
The [`~ComponentsManager.enable_auto_cpu_offload`] method is a global offloading strategy that works across all models regardless of which pipeline is using them. Once enabled, you don't need to worry about device placement if you add or remove components.
|
||||
|
||||
```py
|
||||
comp.enable_auto_cpu_offload(device="cuda")
|
||||
```
|
||||
|
||||
When enabled, all models start on CPU. The manager moves models to the device right before they're used and moves other models back to CPU when GPU memory runs low. You can set your own rules for which models to offload first. This works smoothly as you add or remove components. Once it's on, you don't need to worry about device placement - you can focus on your workflow.
|
||||
|
||||
|
||||
|
||||
## Practical Example: Building Modular Workflows with Component Reuse
|
||||
|
||||
Now that we've covered the basics of the Components Manager, let's walk through a practical example that shows how to build workflows in a modular setting and use the Components Manager to reuse components across multiple pipelines. This example demonstrates the true power of Modular Diffusers by working with multiple pipelines that can share components.
|
||||
|
||||
In this example, we'll generate latents from a text-to-image pipeline, then refine them with an image-to-image pipeline.
|
||||
|
||||
Let's create a modular text-to-image workflow by separating it into three workflows: `text_blocks` for encoding prompts, `t2i_blocks` for generating latents, and `decoder_blocks` for creating final images.
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers.modular_pipelines import SequentialPipelineBlocks
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl import ALL_BLOCKS
|
||||
|
||||
# Create modular blocks and separate text encoding and decoding steps
|
||||
t2i_blocks = SequentialPipelineBlocks.from_blocks_dict(ALL_BLOCKS["text2img"])
|
||||
text_blocks = t2i_blocks.sub_blocks.pop("text_encoder")
|
||||
decoder_blocks = t2i_blocks.sub_blocks.pop("decode")
|
||||
```
|
||||
|
||||
Now we will convert them into runnalbe pipelines and set up the Components Manager with auto offloading and organize components under a "t2i" collection
|
||||
|
||||
Since we now have 3 different workflows that share components, we create a separate pipeline that serves as a dedicated loader to load all the components, register them to the component manager, and then reuse them across different workflows.
|
||||
|
||||
```py
|
||||
from diffusers import ComponentsManager, ModularPipeline
|
||||
|
||||
# Set up Components Manager with auto offloading
|
||||
components = ComponentsManager()
|
||||
components.enable_auto_cpu_offload(device="cuda")
|
||||
|
||||
# Create a new pipeline to load the components
|
||||
t2i_repo = "YiYiXu/modular-demo-auto"
|
||||
t2i_loader_pipe = ModularPipeline.from_pretrained(t2i_repo, components_manager=components, collection="t2i")
|
||||
|
||||
# convert the 3 blocks into pipelines and attach the same components manager to all 3
|
||||
text_node = text_blocks.init_pipeline(t2i_repo, components_manager=components)
|
||||
decoder_node = decoder_blocks.init_pipeline(t2i_repo, components_manager=components)
|
||||
t2i_pipe = t2i_blocks.init_pipeline(t2i_repo, components_manager=components)
|
||||
```
|
||||
|
||||
Load all components into the loader pipeline, they should all be automatically registered to Components Manager under the "t2i" collection:
|
||||
|
||||
```py
|
||||
# Load all components (including IP-Adapter and ControlNet for later use)
|
||||
t2i_loader_pipe.load_default_components(torch_dtype=torch.float16)
|
||||
```
|
||||
|
||||
Now distribute the loaded components to each pipeline:
|
||||
|
||||
```py
|
||||
# Get VAE for decoder (using get_one since there's only one)
|
||||
vae = components.get_one(load_id="SG161222/RealVisXL_V4.0|vae|null|null")
|
||||
decoder_node.update_components(vae=vae)
|
||||
|
||||
# Get text components for text node (using get_components_by_names for multiple components)
|
||||
text_components = components.get_components_by_names(text_node.null_component_names)
|
||||
text_node.update_components(**text_components)
|
||||
|
||||
# Get remaining components for t2i pipeline
|
||||
t2i_components = components.get_components_by_names(t2i_pipe.null_component_names)
|
||||
t2i_pipe.update_components(**t2i_components)
|
||||
```
|
||||
|
||||
Now we can generate images using our modular workflow:
|
||||
|
||||
```py
|
||||
# Generate text embeddings
|
||||
prompt = "an astronaut"
|
||||
text_embeddings = text_node(prompt=prompt, output=["prompt_embeds","negative_prompt_embeds", "pooled_prompt_embeds", "negative_pooled_prompt_embeds"])
|
||||
|
||||
# Generate latents and decode to image
|
||||
generator = torch.Generator(device="cuda").manual_seed(0)
|
||||
latents_t2i = t2i_pipe(**text_embeddings, num_inference_steps=25, generator=generator, output="latents")
|
||||
image = decoder_node(latents=latents_t2i, output="images")[0]
|
||||
image.save("modular_part2_t2i.png")
|
||||
```
|
||||
|
||||
Let's add a LoRA:
|
||||
|
||||
```py
|
||||
# Load LoRA weights
|
||||
>>> t2i_loader_pipe.load_lora_weights("CiroN2022/toy-face", weight_name="toy_face_sdxl.safetensors", adapter_name="toy_face")
|
||||
>>> components
|
||||
Components:
|
||||
============================================================================================================================================================
|
||||
...
|
||||
Additional Component Info:
|
||||
==================================================
|
||||
|
||||
unet:
|
||||
Adapters: ['toy_face']
|
||||
```
|
||||
|
||||
You can see that the Components Manager tracks adapters metadata for all models it manages, and in our case, only Unet has lora loaded. This means we can reuse existing text embeddings.
|
||||
|
||||
```py
|
||||
# Generate with LoRA (reusing existing text embeddings)
|
||||
generator = torch.Generator(device="cuda").manual_seed(0)
|
||||
latents_lora = t2i_pipe(**text_embeddings, num_inference_steps=25, generator=generator, output="latents")
|
||||
image = decoder_node(latents=latents_lora, output="images")[0]
|
||||
image.save("modular_part2_lora.png")
|
||||
```
|
||||
|
||||
|
||||
Now let's create a refiner pipeline that reuses components from our text-to-image workflow:
|
||||
|
||||
```py
|
||||
# Create refiner blocks (removing image_encoder and decode since we work with latents)
|
||||
refiner_blocks = SequentialPipelineBlocks.from_blocks_dict(ALL_BLOCKS["img2img"])
|
||||
refiner_blocks.sub_blocks.pop("image_encoder")
|
||||
refiner_blocks.sub_blocks.pop("decode")
|
||||
|
||||
# Create refiner pipeline with different repo and collection,
|
||||
# Attach the same component manager to it
|
||||
refiner_repo = "YiYiXu/modular_refiner"
|
||||
refiner_pipe = refiner_blocks.init_pipeline(refiner_repo, components_manager=components, collection="refiner")
|
||||
```
|
||||
|
||||
We pass the **same Components Manager** (`components`) to the refiner pipeline, but with a **different collection** (`"refiner"`). This allows the refiner to access and reuse components from the "t2i" collection while organizing its own components (like the refiner UNet) under the "refiner" collection.
|
||||
|
||||
```py
|
||||
# Load only the refiner UNet (different from t2i UNet)
|
||||
refiner_pipe.load_components(names="unet", torch_dtype=torch.float16)
|
||||
|
||||
# Reuse components from t2i pipeline using pattern matching
|
||||
reuse_components = components.search_components("text_encoder_2|scheduler|vae|tokenizer_2")
|
||||
refiner_pipe.update_components(**reuse_components)
|
||||
```
|
||||
|
||||
When we reuse components from the "t2i" collection, they automatically get added to the "refiner" collection as well. You can verify this by checking the Components Manager - you'll see components like `vae`, `scheduler`, etc. listed under both collections, indicating they're shared between workflows.
|
||||
|
||||
Now we can refine any of our generated latents:
|
||||
|
||||
```py
|
||||
# Refine all our different latents
|
||||
refined_latents = refiner_pipe(image_latents=latents_t2i, prompt=prompt, num_inference_steps=10, output="latents")
|
||||
refined_image = decoder_node(latents=refined_latents, output="images")[0]
|
||||
refined_image.save("modular_part2_t2i_refine_out.png")
|
||||
|
||||
refined_latents = refiner_pipe(image_latents=latents_lora, prompt=prompt, num_inference_steps=10, output="latents")
|
||||
refined_image = decoder_node(latents=refined_latents, output="images")[0]
|
||||
refined_image.save("modular_part2_lora_refine_out.png")
|
||||
```
|
||||
|
||||
|
||||
Here are the results from our modular pipeline examples.
|
||||
|
||||
#### Base Text-to-Image Generation
|
||||
| Base Text-to-Image | Base Text-to-Image (Refined) |
|
||||
|-------------------|------------------------------|
|
||||
|  |  |
|
||||
|
||||
#### LoRA
|
||||
| LoRA | LoRA (Refined) |
|
||||
|-------------------|------------------------------|
|
||||
|  |  |
|
||||
All models begin on the CPU and [`ComponentsManager`] moves them to the appropriate device right before they're needed, and moves other models back to the CPU when GPU memory is low.
|
||||
|
||||
You can set your own rules for which models to offload first.
|
||||
@@ -1,648 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# End-to-End Developer Guide: Building with Modular Diffusers
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
🧪 **Experimental Feature**: Modular Diffusers is an experimental feature we are actively developing. The API may be subject to breaking changes.
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
In this tutorial we will walk through the process of adding a new pipeline to the modular framework using differential diffusion as our example. We'll cover the complete workflow from implementation to deployment: implementing the new pipeline, ensuring compatibility with existing tools, sharing the code on Hugging Face Hub, and deploying it as a UI node.
|
||||
|
||||
We'll also demonstrate the 4-step framework process we use for implementing new basic pipelines in the modular system.
|
||||
|
||||
1. **Start with an existing pipeline as a base**
|
||||
- Identify which existing pipeline is most similar to the one you want to implement
|
||||
- Determine what part of the pipeline needs modification
|
||||
|
||||
2. **Build a working pipeline structure first**
|
||||
- Assemble the complete pipeline structure
|
||||
- Use existing blocks wherever possible
|
||||
- For new blocks, create placeholders (e.g. you can copy from similar blocks and change the name) without implementing custom logic just yet
|
||||
|
||||
3. **Set up an example**
|
||||
- Create a simple inference script with expected inputs/outputs
|
||||
|
||||
4. **Implement your custom logic and test incrementally**
|
||||
- Add the custom logics the blocks you want to change
|
||||
- Test incrementally, and inspect pipeline states and debug as needed
|
||||
|
||||
Let's see how this works with the Differential Diffusion example.
|
||||
|
||||
|
||||
## Differential Diffusion Pipeline
|
||||
|
||||
### Start with an existing pipeline
|
||||
|
||||
Differential diffusion (https://differential-diffusion.github.io/) is an image-to-image workflow, so it makes sense for us to start with the preset of pipeline blocks used to build img2img pipeline (`IMAGE2IMAGE_BLOCKS`) and see how we can build this new pipeline with them.
|
||||
|
||||
```py
|
||||
>>> from diffusers.modular_pipelines.stable_diffusion_xl import IMAGE2IMAGE_BLOCKS
|
||||
>>> IMAGE2IMAGE_BLOCKS = InsertableDict([
|
||||
... ("text_encoder", StableDiffusionXLTextEncoderStep),
|
||||
... ("image_encoder", StableDiffusionXLVaeEncoderStep),
|
||||
... ("input", StableDiffusionXLInputStep),
|
||||
... ("set_timesteps", StableDiffusionXLImg2ImgSetTimestepsStep),
|
||||
... ("prepare_latents", StableDiffusionXLImg2ImgPrepareLatentsStep),
|
||||
... ("prepare_add_cond", StableDiffusionXLImg2ImgPrepareAdditionalConditioningStep),
|
||||
... ("denoise", StableDiffusionXLDenoiseStep),
|
||||
... ("decode", StableDiffusionXLDecodeStep)
|
||||
... ])
|
||||
```
|
||||
|
||||
Note that "denoise" (`StableDiffusionXLDenoiseStep`) is a `LoopSequentialPipelineBlocks` that contains 3 loop blocks (more on LoopSequentialPipelineBlocks [here](https://huggingface.co/docs/diffusers/modular_diffusers/write_own_pipeline_block#loopsequentialpipelineblocks))
|
||||
|
||||
```py
|
||||
>>> denoise_blocks = IMAGE2IMAGE_BLOCKS["denoise"]()
|
||||
>>> print(denoise_blocks)
|
||||
```
|
||||
|
||||
```out
|
||||
StableDiffusionXLDenoiseStep(
|
||||
Class: StableDiffusionXLDenoiseLoopWrapper
|
||||
|
||||
Description: Denoise step that iteratively denoise the latents.
|
||||
Its loop logic is defined in `StableDiffusionXLDenoiseLoopWrapper.__call__` method
|
||||
At each iteration, it runs blocks defined in `sub_blocks` sequencially:
|
||||
- `StableDiffusionXLLoopBeforeDenoiser`
|
||||
- `StableDiffusionXLLoopDenoiser`
|
||||
- `StableDiffusionXLLoopAfterDenoiser`
|
||||
This block supports both text2img and img2img tasks.
|
||||
|
||||
|
||||
Components:
|
||||
scheduler (`EulerDiscreteScheduler`)
|
||||
guider (`ClassifierFreeGuidance`)
|
||||
unet (`UNet2DConditionModel`)
|
||||
|
||||
Sub-Blocks:
|
||||
[0] before_denoiser (StableDiffusionXLLoopBeforeDenoiser)
|
||||
Description: step within the denoising loop that prepare the latent input for the denoiser. This block should be used to compose the `sub_blocks` attribute of a `LoopSequentialPipelineBlocks` object (e.g. `StableDiffusionXLDenoiseLoopWrapper`)
|
||||
|
||||
[1] denoiser (StableDiffusionXLLoopDenoiser)
|
||||
Description: Step within the denoising loop that denoise the latents with guidance. This block should be used to compose the `sub_blocks` attribute of a `LoopSequentialPipelineBlocks` object (e.g. `StableDiffusionXLDenoiseLoopWrapper`)
|
||||
|
||||
[2] after_denoiser (StableDiffusionXLLoopAfterDenoiser)
|
||||
Description: step within the denoising loop that update the latents. This block should be used to compose the `sub_blocks` attribute of a `LoopSequentialPipelineBlocks` object (e.g. `StableDiffusionXLDenoiseLoopWrapper`)
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
Let's compare standard image-to-image and differential diffusion! The key difference in algorithm is that standard image-to-image diffusion applies uniform noise across all pixels based on a single `strength` parameter, but differential diffusion uses a change map where each pixel value determines when that region starts denoising. Regions with lower values get "frozen" earlier by replacing them with noised original latents, preserving more of the original image.
|
||||
|
||||
Therefore, the key differences when it comes to pipeline implementation would be:
|
||||
1. The `prepare_latents` step (which prepares the change map and pre-computes noised latents for all timesteps)
|
||||
2. The `denoise` step (which selectively applies denoising based on the change map)
|
||||
3. Since differential diffusion doesn't use the `strength` parameter, we'll use the text-to-image `set_timesteps` step instead of the image-to-image version
|
||||
|
||||
To implement differntial diffusion, we can reuse most blocks from image-to-image and text-to-image workflows, only modifying the `prepare_latents` step and the first part of the `denoise` step (i.e. `before_denoiser (StableDiffusionXLLoopBeforeDenoiser)`).
|
||||
|
||||
Here's a flowchart showing the pipeline structure and the changes we need to make:
|
||||
|
||||
|
||||
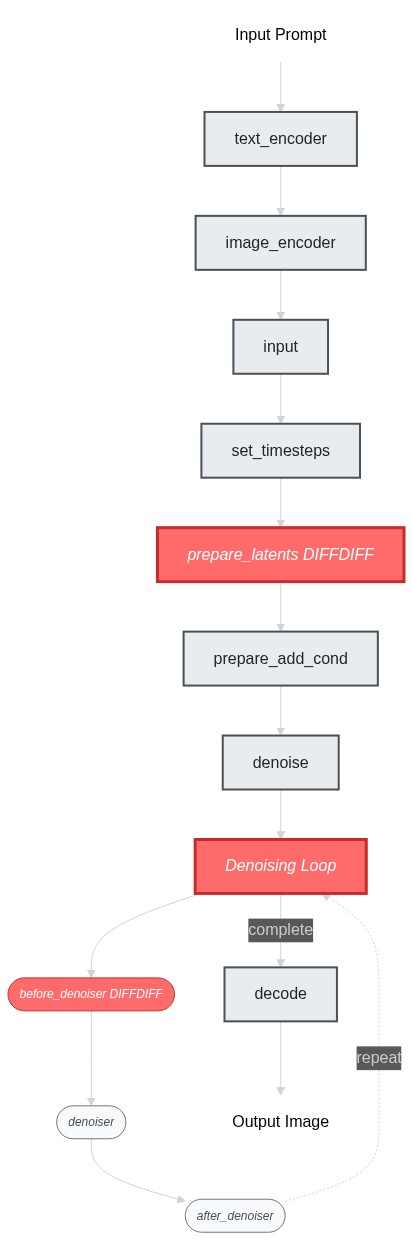
|
||||
|
||||
|
||||
### Build a Working Pipeline Structure
|
||||
|
||||
ok now we've identified the blocks to modify, let's build the pipeline skeleton first - at this stage, our goal is to get the pipeline struture working end-to-end (even though it's just doing the img2img behavior). I would simply create placeholder blocks by copying from existing ones:
|
||||
|
||||
```py
|
||||
>>> # Copy existing blocks as placeholders
|
||||
>>> class SDXLDiffDiffPrepareLatentsStep(PipelineBlock):
|
||||
... """Copied from StableDiffusionXLImg2ImgPrepareLatentsStep - will modify later"""
|
||||
... # ... same implementation as StableDiffusionXLImg2ImgPrepareLatentsStep
|
||||
...
|
||||
>>> class SDXLDiffDiffLoopBeforeDenoiser(PipelineBlock):
|
||||
... """Copied from StableDiffusionXLLoopBeforeDenoiser - will modify later"""
|
||||
... # ... same implementation as StableDiffusionXLLoopBeforeDenoiser
|
||||
```
|
||||
|
||||
`SDXLDiffDiffLoopBeforeDenoiser` is the be part of the denoise loop we need to change. Let's use it to assemble a `SDXLDiffDiffDenoiseStep`.
|
||||
|
||||
```py
|
||||
>>> class SDXLDiffDiffDenoiseStep(StableDiffusionXLDenoiseLoopWrapper):
|
||||
... block_classes = [SDXLDiffDiffLoopBeforeDenoiser, StableDiffusionXLLoopDenoiser, StableDiffusionXLLoopAfterDenoiser]
|
||||
... block_names = ["before_denoiser", "denoiser", "after_denoiser"]
|
||||
```
|
||||
|
||||
Now we can put together our differential diffusion pipeline.
|
||||
|
||||
```py
|
||||
>>> DIFFDIFF_BLOCKS = IMAGE2IMAGE_BLOCKS.copy()
|
||||
>>> DIFFDIFF_BLOCKS["set_timesteps"] = TEXT2IMAGE_BLOCKS["set_timesteps"]
|
||||
>>> DIFFDIFF_BLOCKS["prepare_latents"] = SDXLDiffDiffPrepareLatentsStep
|
||||
>>> DIFFDIFF_BLOCKS["denoise"] = SDXLDiffDiffDenoiseStep
|
||||
>>>
|
||||
>>> dd_blocks = SequentialPipelineBlocks.from_blocks_dict(DIFFDIFF_BLOCKS)
|
||||
>>> print(dd_blocks)
|
||||
>>> # At this point, the pipeline works exactly like img2img since our blocks are just copies
|
||||
```
|
||||
|
||||
### Set up an example
|
||||
|
||||
ok, so now our blocks should be able to compile without an error, we can move on to the next step. Let's setup a simple example so we can run the pipeline as we build it. diff-diff use same model checkpoints as SDXL so we can fetch the models from a regular SDXL repo.
|
||||
|
||||
```py
|
||||
>>> dd_pipeline = dd_blocks.init_pipeline("YiYiXu/modular-demo-auto", collection="diffdiff")
|
||||
>>> dd_pipeline.load_default_componenets(torch_dtype=torch.float16)
|
||||
>>> dd_pipeline.to("cuda")
|
||||
```
|
||||
|
||||
We will use this example script:
|
||||
|
||||
```py
|
||||
>>> image = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/20240329211129_4024911930.png?download=true")
|
||||
>>> mask = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/gradient_mask.png?download=true")
|
||||
>>>
|
||||
>>> prompt = "a green pear"
|
||||
>>> negative_prompt = "blurry"
|
||||
>>>
|
||||
>>> image = dd_pipeline(
|
||||
... prompt=prompt,
|
||||
... negative_prompt=negative_prompt,
|
||||
... num_inference_steps=25,
|
||||
... diffdiff_map=mask,
|
||||
... image=image,
|
||||
... output="images"
|
||||
... )[0]
|
||||
>>>
|
||||
>>> image.save("diffdiff_out.png")
|
||||
```
|
||||
|
||||
If you run the script right now, you will get a complaint about unexpected input `diffdiff_map`.
|
||||
and you would get the same result as the original img2img pipeline.
|
||||
|
||||
### implement your custom logic and test incrementally
|
||||
|
||||
Let's modify the pipeline so that we can get expected result with this example script.
|
||||
|
||||
We'll start with the `prepare_latents` step. The main changes are:
|
||||
- Requires a new user input `diffdiff_map`
|
||||
- Requires new component `mask_processor` to process the `diffdiff_map`
|
||||
- Requires new intermediate inputs:
|
||||
- Need `timestep` instead of `latent_timestep` to precompute all the latents
|
||||
- Need `num_inference_steps` to create the `diffdiff_masks`
|
||||
- create a new output `diffdiff_masks` and `original_latents`
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 use `print(dd_pipeline.doc)` to check compiled inputs and outputs of the built piepline.
|
||||
|
||||
e.g. after we added `diffdiff_map` as an input in this step, we can run `print(dd_pipeline.doc)` to verify that it shows up in the docstring as a user input.
|
||||
|
||||
</Tip>
|
||||
|
||||
Once we make sure all the variables we need are available in the block state, we can implement the diff-diff logic inside `__call__`. We created 2 new variables: the change map `diffdiff_mask` and the pre-computed noised latents for all timesteps `original_latents`.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 Implement incrementally! Run the example script as you go, and insert `print(state)` and `print(block_state)` everywhere inside the `__call__` method to inspect the intermediate results. This helps you understand what's going on and what each line you just added does.
|
||||
|
||||
</Tip>
|
||||
|
||||
Here are the key changes we made to implement differential diffusion:
|
||||
|
||||
**1. Modified `prepare_latents` step:**
|
||||
```diff
|
||||
class SDXLDiffDiffPrepareLatentsStep(PipelineBlock):
|
||||
@property
|
||||
def expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec("vae", AutoencoderKL),
|
||||
ComponentSpec("scheduler", EulerDiscreteScheduler),
|
||||
+ ComponentSpec("mask_processor", VaeImageProcessor, config=FrozenDict({"do_normalize": False, "do_convert_grayscale": True}))
|
||||
]
|
||||
|
||||
@property
|
||||
def inputs(self) -> List[Tuple[str, Any]]:
|
||||
return [
|
||||
+ InputParam("diffdiff_map", required=True),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self) -> List[InputParam]:
|
||||
return [
|
||||
InputParam("generator"),
|
||||
- InputParam("latent_timestep", required=True, type_hint=torch.Tensor),
|
||||
+ InputParam("timesteps", type_hint=torch.Tensor),
|
||||
+ InputParam("num_inference_steps", type_hint=int),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self) -> List[OutputParam]:
|
||||
return [
|
||||
+ OutputParam("original_latents", type_hint=torch.Tensor),
|
||||
+ OutputParam("diffdiff_masks", type_hint=torch.Tensor),
|
||||
]
|
||||
|
||||
def __call__(self, components, state: PipelineState):
|
||||
# ... existing logic ...
|
||||
+ # Process change map and create masks
|
||||
+ diffdiff_map = components.mask_processor.preprocess(block_state.diffdiff_map, height=latent_height, width=latent_width)
|
||||
+ thresholds = torch.arange(block_state.num_inference_steps, dtype=diffdiff_map.dtype) / block_state.num_inference_steps
|
||||
+ block_state.diffdiff_masks = diffdiff_map > (thresholds + (block_state.denoising_start or 0))
|
||||
+ block_state.original_latents = block_state.latents
|
||||
```
|
||||
|
||||
**2. Modified `before_denoiser` step:**
|
||||
```diff
|
||||
class SDXLDiffDiffLoopBeforeDenoiser(PipelineBlock):
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"Step within the denoising loop for differential diffusion that prepare the latent input for the denoiser"
|
||||
)
|
||||
|
||||
+ @property
|
||||
+ def inputs(self) -> List[Tuple[str, Any]]:
|
||||
+ return [
|
||||
+ InputParam("denoising_start"),
|
||||
+ ]
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self) -> List[str]:
|
||||
return [
|
||||
InputParam("latents", required=True, type_hint=torch.Tensor),
|
||||
+ InputParam("original_latents", type_hint=torch.Tensor),
|
||||
+ InputParam("diffdiff_masks", type_hint=torch.Tensor),
|
||||
]
|
||||
|
||||
def __call__(self, components, block_state, i, t):
|
||||
+ # Apply differential diffusion logic
|
||||
+ if i == 0 and block_state.denoising_start is None:
|
||||
+ block_state.latents = block_state.original_latents[:1]
|
||||
+ else:
|
||||
+ block_state.mask = block_state.diffdiff_masks[i].unsqueeze(0).unsqueeze(1)
|
||||
+ block_state.latents = block_state.original_latents[i] * block_state.mask + block_state.latents * (1 - block_state.mask)
|
||||
|
||||
# ... rest of existing logic ...
|
||||
```
|
||||
|
||||
That's all there is to it! We've just created a simple sequential pipeline by mix-and-match some existing and new pipeline blocks.
|
||||
|
||||
Now we use the process we've prepred in step2 to build the pipeline and inspect it.
|
||||
|
||||
|
||||
```py
|
||||
>> dd_pipeline
|
||||
SequentialPipelineBlocks(
|
||||
Class: ModularPipelineBlocks
|
||||
|
||||
Description:
|
||||
|
||||
|
||||
Components:
|
||||
text_encoder (`CLIPTextModel`)
|
||||
text_encoder_2 (`CLIPTextModelWithProjection`)
|
||||
tokenizer (`CLIPTokenizer`)
|
||||
tokenizer_2 (`CLIPTokenizer`)
|
||||
guider (`ClassifierFreeGuidance`)
|
||||
vae (`AutoencoderKL`)
|
||||
image_processor (`VaeImageProcessor`)
|
||||
scheduler (`EulerDiscreteScheduler`)
|
||||
mask_processor (`VaeImageProcessor`)
|
||||
unet (`UNet2DConditionModel`)
|
||||
|
||||
Configs:
|
||||
force_zeros_for_empty_prompt (default: True)
|
||||
requires_aesthetics_score (default: False)
|
||||
|
||||
Blocks:
|
||||
[0] text_encoder (StableDiffusionXLTextEncoderStep)
|
||||
Description: Text Encoder step that generate text_embeddings to guide the image generation
|
||||
|
||||
[1] image_encoder (StableDiffusionXLVaeEncoderStep)
|
||||
Description: Vae Encoder step that encode the input image into a latent representation
|
||||
|
||||
[2] input (StableDiffusionXLInputStep)
|
||||
Description: Input processing step that:
|
||||
1. Determines `batch_size` and `dtype` based on `prompt_embeds`
|
||||
2. Adjusts input tensor shapes based on `batch_size` (number of prompts) and `num_images_per_prompt`
|
||||
|
||||
All input tensors are expected to have either batch_size=1 or match the batch_size
|
||||
of prompt_embeds. The tensors will be duplicated across the batch dimension to
|
||||
have a final batch_size of batch_size * num_images_per_prompt.
|
||||
|
||||
[3] set_timesteps (StableDiffusionXLSetTimestepsStep)
|
||||
Description: Step that sets the scheduler's timesteps for inference
|
||||
|
||||
[4] prepare_latents (SDXLDiffDiffPrepareLatentsStep)
|
||||
Description: Step that prepares the latents for the differential diffusion generation process
|
||||
|
||||
[5] prepare_add_cond (StableDiffusionXLImg2ImgPrepareAdditionalConditioningStep)
|
||||
Description: Step that prepares the additional conditioning for the image-to-image/inpainting generation process
|
||||
|
||||
[6] denoise (SDXLDiffDiffDenoiseStep)
|
||||
Description: Pipeline block that iteratively denoise the latents over `timesteps`. The specific steps with each iteration can be customized with `sub_blocks` attributes
|
||||
|
||||
[7] decode (StableDiffusionXLDecodeStep)
|
||||
Description: Step that decodes the denoised latents into images
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
Run the example now, you should see an apple with its right half transformed into a green pear.
|
||||
|
||||

|
||||
|
||||
|
||||
## Adding IP-adapter
|
||||
|
||||
We provide an auto IP-adapter block that you can plug-and-play into your modular workflow. It's an `AutoPipelineBlocks`, so it will only run when the user passes an IP adapter image. In this tutorial, we'll focus on how to package it into your differential diffusion workflow. To learn more about `AutoPipelineBlocks`, see [here](./auto_pipeline_blocks.md)
|
||||
|
||||
We talked about how to add IP-adapter into your workflow in the [Modular Pipeline Guide](./modular_pipeline.md). Let's just go ahead to create the IP-adapter block.
|
||||
|
||||
```py
|
||||
>>> from diffusers.modular_pipelines.stable_diffusion_xl.encoders import StableDiffusionXLAutoIPAdapterStep
|
||||
>>> ip_adapter_block = StableDiffusionXLAutoIPAdapterStep()
|
||||
```
|
||||
|
||||
We can directly add the ip-adapter block instance to the `diffdiff_blocks` that we created before. The `sub_blocks` attribute is a `InsertableDict`, so we're able to insert the it at specific position (index `0` here).
|
||||
|
||||
```py
|
||||
>>> dd_blocks.sub_blocks.insert("ip_adapter", ip_adapter_block, 0)
|
||||
```
|
||||
|
||||
Take a look at the new diff-diff pipeline with ip-adapter!
|
||||
|
||||
```py
|
||||
>>> print(dd_blocks)
|
||||
```
|
||||
|
||||
The pipeline now lists ip-adapter as its first block, and tells you that it will run only if `ip_adapter_image` is provided. It also includes the two new components from ip-adpater: `image_encoder` and `feature_extractor`
|
||||
|
||||
```out
|
||||
SequentialPipelineBlocks(
|
||||
Class: ModularPipelineBlocks
|
||||
|
||||
====================================================================================================
|
||||
This pipeline contains blocks that are selected at runtime based on inputs.
|
||||
Trigger Inputs: {'ip_adapter_image'}
|
||||
Use `get_execution_blocks()` with input names to see selected blocks (e.g. `get_execution_blocks('ip_adapter_image')`).
|
||||
====================================================================================================
|
||||
|
||||
|
||||
Description:
|
||||
|
||||
|
||||
Components:
|
||||
image_encoder (`CLIPVisionModelWithProjection`)
|
||||
feature_extractor (`CLIPImageProcessor`)
|
||||
unet (`UNet2DConditionModel`)
|
||||
guider (`ClassifierFreeGuidance`)
|
||||
text_encoder (`CLIPTextModel`)
|
||||
text_encoder_2 (`CLIPTextModelWithProjection`)
|
||||
tokenizer (`CLIPTokenizer`)
|
||||
tokenizer_2 (`CLIPTokenizer`)
|
||||
vae (`AutoencoderKL`)
|
||||
image_processor (`VaeImageProcessor`)
|
||||
scheduler (`EulerDiscreteScheduler`)
|
||||
mask_processor (`VaeImageProcessor`)
|
||||
|
||||
Configs:
|
||||
force_zeros_for_empty_prompt (default: True)
|
||||
requires_aesthetics_score (default: False)
|
||||
|
||||
Blocks:
|
||||
[0] ip_adapter (StableDiffusionXLAutoIPAdapterStep)
|
||||
Description: Run IP Adapter step if `ip_adapter_image` is provided.
|
||||
|
||||
[1] text_encoder (StableDiffusionXLTextEncoderStep)
|
||||
Description: Text Encoder step that generate text_embeddings to guide the image generation
|
||||
|
||||
[2] image_encoder (StableDiffusionXLVaeEncoderStep)
|
||||
Description: Vae Encoder step that encode the input image into a latent representation
|
||||
|
||||
[3] input (StableDiffusionXLInputStep)
|
||||
Description: Input processing step that:
|
||||
1. Determines `batch_size` and `dtype` based on `prompt_embeds`
|
||||
2. Adjusts input tensor shapes based on `batch_size` (number of prompts) and `num_images_per_prompt`
|
||||
|
||||
All input tensors are expected to have either batch_size=1 or match the batch_size
|
||||
of prompt_embeds. The tensors will be duplicated across the batch dimension to
|
||||
have a final batch_size of batch_size * num_images_per_prompt.
|
||||
|
||||
[4] set_timesteps (StableDiffusionXLSetTimestepsStep)
|
||||
Description: Step that sets the scheduler's timesteps for inference
|
||||
|
||||
[5] prepare_latents (SDXLDiffDiffPrepareLatentsStep)
|
||||
Description: Step that prepares the latents for the differential diffusion generation process
|
||||
|
||||
[6] prepare_add_cond (StableDiffusionXLImg2ImgPrepareAdditionalConditioningStep)
|
||||
Description: Step that prepares the additional conditioning for the image-to-image/inpainting generation process
|
||||
|
||||
[7] denoise (SDXLDiffDiffDenoiseStep)
|
||||
Description: Pipeline block that iteratively denoise the latents over `timesteps`. The specific steps with each iteration can be customized with `sub_blocks` attributes
|
||||
|
||||
[8] decode (StableDiffusionXLDecodeStep)
|
||||
Description: Step that decodes the denoised latents into images
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
Let's test it out. We used an orange image to condition the generation via ip-addapter and we can see a slight orange color and texture in the final output.
|
||||
|
||||
|
||||
```py
|
||||
>>> ip_adapter_block = StableDiffusionXLAutoIPAdapterStep()
|
||||
>>> dd_blocks.sub_blocks.insert("ip_adapter", ip_adapter_block, 0)
|
||||
>>>
|
||||
>>> dd_pipeline = dd_blocks.init_pipeline("YiYiXu/modular-demo-auto", collection="diffdiff")
|
||||
>>> dd_pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
>>> dd_pipeline.loader.load_ip_adapter("h94/IP-Adapter", subfolder="sdxl_models", weight_name="ip-adapter_sdxl.bin")
|
||||
>>> dd_pipeline.loader.set_ip_adapter_scale(0.6)
|
||||
>>> dd_pipeline = dd_pipeline.to(device)
|
||||
>>>
|
||||
>>> ip_adapter_image = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/diffdiff_orange.jpeg")
|
||||
>>> image = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/20240329211129_4024911930.png?download=true")
|
||||
>>> mask = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/gradient_mask.png?download=true")
|
||||
>>>
|
||||
>>> prompt = "a green pear"
|
||||
>>> negative_prompt = "blurry"
|
||||
>>> generator = torch.Generator(device=device).manual_seed(42)
|
||||
>>>
|
||||
>>> image = dd_pipeline(
|
||||
... prompt=prompt,
|
||||
... negative_prompt=negative_prompt,
|
||||
... num_inference_steps=25,
|
||||
... generator=generator,
|
||||
... ip_adapter_image=ip_adapter_image,
|
||||
... diffdiff_map=mask,
|
||||
... image=image,
|
||||
... output="images"
|
||||
... )[0]
|
||||
```
|
||||
|
||||
## Working with ControlNets
|
||||
|
||||
What about controlnet? Can differential diffusion work with controlnet? The key differences between a regular pipeline and a ControlNet pipeline are:
|
||||
1. A ControlNet input step that prepares the control condition
|
||||
2. Inside the denoising loop, a modified denoiser step where the control image is first processed through ControlNet, then control information is injected into the UNet
|
||||
|
||||
From looking at the code workflow: differential diffusion only modifies the "before denoiser" step, while ControlNet operates within the "denoiser" itself. Since they intervene at different points in the pipeline, they should work together without conflicts.
|
||||
|
||||
Intuitively, these two techniques are orthogonal and should combine naturally: differential diffusion controls how much the inference process can deviate from the original in each region, while ControlNet controls in what direction that change occurs.
|
||||
|
||||
With this understanding, let's assemble the diffdiff-controlnet loop by combining the diffdiff before-denoiser step and controlnet denoiser step.
|
||||
|
||||
```py
|
||||
>>> class SDXLDiffDiffControlNetDenoiseStep(StableDiffusionXLDenoiseLoopWrapper):
|
||||
... block_classes = [SDXLDiffDiffLoopBeforeDenoiser, StableDiffusionXLControlNetLoopDenoiser, StableDiffusionXLDenoiseLoopAfterDenoiser]
|
||||
... block_names = ["before_denoiser", "denoiser", "after_denoiser"]
|
||||
>>>
|
||||
>>> controlnet_denoise_block = SDXLDiffDiffControlNetDenoiseStep()
|
||||
>>> # print(controlnet_denoise)
|
||||
```
|
||||
|
||||
We provide a auto controlnet input block that you can directly put into your workflow to proceess the `control_image`: similar to auto ip-adapter block, this step will only run if `control_image` input is passed from user. It work with both controlnet and controlnet union.
|
||||
|
||||
|
||||
```py
|
||||
>>> from diffusers.modular_pipelines.stable_diffusion_xl.modular_blocks import StableDiffusionXLAutoControlNetInputStep
|
||||
>>> control_input_block = StableDiffusionXLAutoControlNetInputStep()
|
||||
>>> print(control_input_block)
|
||||
```
|
||||
|
||||
```out
|
||||
StableDiffusionXLAutoControlNetInputStep(
|
||||
Class: AutoPipelineBlocks
|
||||
|
||||
====================================================================================================
|
||||
This pipeline contains blocks that are selected at runtime based on inputs.
|
||||
Trigger Inputs: ['control_image', 'control_mode']
|
||||
====================================================================================================
|
||||
|
||||
|
||||
Description: Controlnet Input step that prepare the controlnet input.
|
||||
This is an auto pipeline block that works for both controlnet and controlnet_union.
|
||||
(it should be called right before the denoise step) - `StableDiffusionXLControlNetUnionInputStep` is called to prepare the controlnet input when `control_mode` and `control_image` are provided.
|
||||
- `StableDiffusionXLControlNetInputStep` is called to prepare the controlnet input when `control_image` is provided. - if neither `control_mode` nor `control_image` is provided, step will be skipped.
|
||||
|
||||
|
||||
Components:
|
||||
controlnet (`ControlNetUnionModel`)
|
||||
control_image_processor (`VaeImageProcessor`)
|
||||
|
||||
Sub-Blocks:
|
||||
• controlnet_union [trigger: control_mode] (StableDiffusionXLControlNetUnionInputStep)
|
||||
Description: step that prepares inputs for the ControlNetUnion model
|
||||
|
||||
• controlnet [trigger: control_image] (StableDiffusionXLControlNetInputStep)
|
||||
Description: step that prepare inputs for controlnet
|
||||
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
Let's assemble the blocks and run an example using controlnet + differential diffusion. We used a tomato as `control_image`, so you can see that in the output, the right half that transformed into a pear had a tomato-like shape.
|
||||
|
||||
```py
|
||||
>>> dd_blocks.sub_blocks.insert("controlnet_input", control_input_block, 7)
|
||||
>>> dd_blocks.sub_blocks["denoise"] = controlnet_denoise_block
|
||||
>>>
|
||||
>>> dd_pipeline = dd_blocks.init_pipeline("YiYiXu/modular-demo-auto", collection="diffdiff")
|
||||
>>> dd_pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
>>> dd_pipeline = dd_pipeline.to(device)
|
||||
>>>
|
||||
>>> control_image = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/diffdiff_tomato_canny.jpeg")
|
||||
>>> image = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/20240329211129_4024911930.png?download=true")
|
||||
>>> mask = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/gradient_mask.png?download=true")
|
||||
>>>
|
||||
>>> prompt = "a green pear"
|
||||
>>> negative_prompt = "blurry"
|
||||
>>> generator = torch.Generator(device=device).manual_seed(42)
|
||||
>>>
|
||||
>>> image = dd_pipeline(
|
||||
... prompt=prompt,
|
||||
... negative_prompt=negative_prompt,
|
||||
... num_inference_steps=25,
|
||||
... generator=generator,
|
||||
... control_image=control_image,
|
||||
... controlnet_conditioning_scale=0.5,
|
||||
... diffdiff_map=mask,
|
||||
... image=image,
|
||||
... output="images"
|
||||
... )[0]
|
||||
```
|
||||
|
||||
Optionally, We can combine `SDXLDiffDiffControlNetDenoiseStep` and `SDXLDiffDiffDenoiseStep` into a `AutoPipelineBlocks` so that same workflow can work with or without controlnet.
|
||||
|
||||
|
||||
```py
|
||||
>>> class SDXLDiffDiffAutoDenoiseStep(AutoPipelineBlocks):
|
||||
... block_classes = [SDXLDiffDiffControlNetDenoiseStep, SDXLDiffDiffDenoiseStep]
|
||||
... block_names = ["controlnet_denoise", "denoise"]
|
||||
... block_trigger_inputs = ["controlnet_cond", None]
|
||||
```
|
||||
|
||||
`SDXLDiffDiffAutoDenoiseStep` will run the ControlNet denoise step if `control_image` input is provided, otherwise it will run the regular denoise step.
|
||||
|
||||
<Tip>
|
||||
|
||||
Note that it's perfectly fine not to use `AutoPipelineBlocks`. In fact, we recommend only using `AutoPipelineBlocks` to package your workflow at the end once you've verified all your pipelines work as expected.
|
||||
|
||||
</Tip>
|
||||
|
||||
Now you can create the differential diffusion preset that works with ip-adapter & controlnet.
|
||||
|
||||
```py
|
||||
>>> DIFFDIFF_AUTO_BLOCKS = IMAGE2IMAGE_BLOCKS.copy()
|
||||
>>> DIFFDIFF_AUTO_BLOCKS["prepare_latents"] = SDXLDiffDiffPrepareLatentsStep
|
||||
>>> DIFFDIFF_AUTO_BLOCKS["set_timesteps"] = TEXT2IMAGE_BLOCKS["set_timesteps"]
|
||||
>>> DIFFDIFF_AUTO_BLOCKS["denoise"] = SDXLDiffDiffAutoDenoiseStep
|
||||
>>> DIFFDIFF_AUTO_BLOCKS.insert("ip_adapter", StableDiffusionXLAutoIPAdapterStep, 0)
|
||||
>>> DIFFDIFF_AUTO_BLOCKS.insert("controlnet_input",StableDiffusionXLControlNetAutoInput, 7)
|
||||
>>>
|
||||
>>> print(DIFFDIFF_AUTO_BLOCKS)
|
||||
```
|
||||
|
||||
to use
|
||||
|
||||
```py
|
||||
>>> dd_auto_blocks = SequentialPipelineBlocks.from_blocks_dict(DIFFDIFF_AUTO_BLOCKS)
|
||||
>>> dd_pipeline = dd_auto_blocks.init_pipeline(...)
|
||||
```
|
||||
## Creating a Modular Repo
|
||||
|
||||
You can easily share your differential diffusion workflow on the Hub by creating a modular repo. This is one created using the code we just wrote together: https://huggingface.co/YiYiXu/modular-diffdiff
|
||||
|
||||
To create a Modular Repo and share on hub, you just need to run `save_pretrained()` along with the `push_to_hub=True` flag. Note that if your pipeline contains custom block, you need to manually upload the code to the hub. But we are working on a command line tool to help you upload it very easily.
|
||||
|
||||
```py
|
||||
dd_pipeline.save_pretrained("YiYiXu/test_modular_doc", push_to_hub=True)
|
||||
```
|
||||
|
||||
With a modular repo, it is very easy for the community to use the workflow you just created! Here is an example to use the differential-diffusion pipeline we just created and shared.
|
||||
|
||||
```py
|
||||
>>> from diffusers.modular_pipelines import ModularPipeline, ComponentsManager
|
||||
>>> import torch
|
||||
>>> from diffusers.utils import load_image
|
||||
>>>
|
||||
>>> repo_id = "YiYiXu/modular-diffdiff-0704"
|
||||
>>>
|
||||
>>> components = ComponentsManager()
|
||||
>>>
|
||||
>>> diffdiff_pipeline = ModularPipeline.from_pretrained(repo_id, trust_remote_code=True, components_manager=components, collection="diffdiff")
|
||||
>>> diffdiff_pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
>>> components.enable_auto_cpu_offload()
|
||||
```
|
||||
|
||||
see more usage example on model card.
|
||||
|
||||
## deploy a mellon node
|
||||
|
||||
[YIYI TODO: for now, here is an example of mellon node https://huggingface.co/YiYiXu/diff-diff-mellon]
|
||||
175
docs/source/en/modular_diffusers/guiders.md
Normal file
175
docs/source/en/modular_diffusers/guiders.md
Normal file
@@ -0,0 +1,175 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Guiders
|
||||
|
||||
[Classifier-free guidance](https://huggingface.co/papers/2207.12598) steers model generation that better match a prompt and is commonly used to improve generation quality, control, and adherence to prompts. There are different types of guidance methods, and in Diffusers, they are known as *guiders*. Like blocks, it is easy to switch and use different guiders for different use cases without rewriting the pipeline.
|
||||
|
||||
This guide will show you how to switch guiders, adjust guider parameters, and load and share them to the Hub.
|
||||
|
||||
## Switching guiders
|
||||
|
||||
[`ClassifierFreeGuidance`] is the default guider and created when a pipeline is initialized with [`~ModularPipelineBlocks.init_pipeline`]. It is created by `from_config` which means it doesn't require loading specifications from a modular repository. A guider won't be listed in `modular_model_index.json`.
|
||||
|
||||
Use [`~ModularPipeline.get_component_spec`] to inspect a guider.
|
||||
|
||||
```py
|
||||
t2i_pipeline.get_component_spec("guider")
|
||||
ComponentSpec(name='guider', type_hint=<class 'diffusers.guiders.classifier_free_guidance.ClassifierFreeGuidance'>, description=None, config=FrozenDict([('guidance_scale', 7.5), ('guidance_rescale', 0.0), ('use_original_formulation', False), ('start', 0.0), ('stop', 1.0), ('_use_default_values', ['start', 'guidance_rescale', 'stop', 'use_original_formulation'])]), repo=None, subfolder=None, variant=None, revision=None, default_creation_method='from_config')
|
||||
```
|
||||
|
||||
Switch to a different guider by passing the new guider to [`~ModularPipeline.update_components`].
|
||||
|
||||
> [!TIP]
|
||||
> Changing guiders will return text letting you know you're changing the guider type.
|
||||
> ```bash
|
||||
> ModularPipeline.update_components: adding guider with new type: PerturbedAttentionGuidance, previous type: ClassifierFreeGuidance
|
||||
> ```
|
||||
|
||||
```py
|
||||
from diffusers import LayerSkipConfig, PerturbedAttentionGuidance
|
||||
|
||||
config = LayerSkipConfig(indices=[2, 9], fqn="mid_block.attentions.0.transformer_blocks", skip_attention=False, skip_attention_scores=True, skip_ff=False)
|
||||
guider = PerturbedAttentionGuidance(
|
||||
guidance_scale=5.0, perturbed_guidance_scale=2.5, perturbed_guidance_config=config
|
||||
)
|
||||
t2i_pipeline.update_components(guider=guider)
|
||||
```
|
||||
|
||||
Use [`~ModularPipeline.get_component_spec`] again to verify the guider type is different.
|
||||
|
||||
```py
|
||||
t2i_pipeline.get_component_spec("guider")
|
||||
ComponentSpec(name='guider', type_hint=<class 'diffusers.guiders.perturbed_attention_guidance.PerturbedAttentionGuidance'>, description=None, config=FrozenDict([('guidance_scale', 5.0), ('perturbed_guidance_scale', 2.5), ('perturbed_guidance_start', 0.01), ('perturbed_guidance_stop', 0.2), ('perturbed_guidance_layers', None), ('perturbed_guidance_config', LayerSkipConfig(indices=[2, 9], fqn='mid_block.attentions.0.transformer_blocks', skip_attention=False, skip_attention_scores=True, skip_ff=False, dropout=1.0)), ('guidance_rescale', 0.0), ('use_original_formulation', False), ('start', 0.0), ('stop', 1.0), ('_use_default_values', ['perturbed_guidance_start', 'use_original_formulation', 'perturbed_guidance_layers', 'stop', 'start', 'guidance_rescale', 'perturbed_guidance_stop']), ('_class_name', 'PerturbedAttentionGuidance'), ('_diffusers_version', '0.35.0.dev0')]), repo=None, subfolder=None, variant=None, revision=None, default_creation_method='from_config')
|
||||
```
|
||||
|
||||
## Loading custom guiders
|
||||
|
||||
Guiders that are already saved on the Hub with a `modular_model_index.json` file are considered a `from_pretrained` component now instead of a `from_config` component.
|
||||
|
||||
```json
|
||||
{
|
||||
"guider": [
|
||||
null,
|
||||
null,
|
||||
{
|
||||
"repo": "YiYiXu/modular-loader-t2i-guider",
|
||||
"revision": null,
|
||||
"subfolder": "pag_guider",
|
||||
"type_hint": [
|
||||
"diffusers",
|
||||
"PerturbedAttentionGuidance"
|
||||
],
|
||||
"variant": null
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
The guider is only created after calling [`~ModularPipeline.load_default_components`] based on the loading specification in `modular_model_index.json`.
|
||||
|
||||
```py
|
||||
t2i_pipeline = t2i_blocks.init_pipeline("YiYiXu/modular-doc-guider")
|
||||
# not created during init
|
||||
assert t2i_pipeline.guider is None
|
||||
t2i_pipeline.load_default_components()
|
||||
# loaded as PAG guider
|
||||
t2i_pipeline.guider
|
||||
```
|
||||
|
||||
|
||||
## Changing guider parameters
|
||||
|
||||
The guider parameters can be adjusted with either the [`~ComponentSpec.create`] method or with [`~ModularPipeline.update_components`]. The example below changes the `guidance_scale` value.
|
||||
|
||||
<hfoptions id="switch">
|
||||
<hfoption id="create">
|
||||
|
||||
```py
|
||||
guider_spec = t2i_pipeline.get_component_spec("guider")
|
||||
guider = guider_spec.create(guidance_scale=10)
|
||||
t2i_pipeline.update_components(guider=guider)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="update_components">
|
||||
|
||||
```py
|
||||
guider_spec = t2i_pipeline.get_component_spec("guider")
|
||||
guider_spec.config["guidance_scale"] = 10
|
||||
t2i_pipeline.update_components(guider=guider_spec)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## Uploading custom guiders
|
||||
|
||||
Call the [`~utils.PushToHubMixin.push_to_hub`] method on a custom guider to share it to the Hub.
|
||||
|
||||
```py
|
||||
guider.push_to_hub("YiYiXu/modular-loader-t2i-guider", subfolder="pag_guider")
|
||||
```
|
||||
|
||||
To make this guider available to the pipeline, either modify the `modular_model_index.json` file or use the [`~ModularPipeline.update_components`] method.
|
||||
|
||||
<hfoptions id="upload">
|
||||
<hfoption id="modular_model_index.json">
|
||||
|
||||
Edit the `modular_model_index.json` file and add a loading specification for the guider by pointing to a folder containing the guider config.
|
||||
|
||||
```json
|
||||
{
|
||||
"guider": [
|
||||
"diffusers",
|
||||
"PerturbedAttentionGuidance",
|
||||
{
|
||||
"repo": "YiYiXu/modular-loader-t2i-guider",
|
||||
"revision": null,
|
||||
"subfolder": "pag_guider",
|
||||
"type_hint": [
|
||||
"diffusers",
|
||||
"PerturbedAttentionGuidance"
|
||||
],
|
||||
"variant": null
|
||||
}
|
||||
],
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="update_components">
|
||||
|
||||
Change the [`~ComponentSpec.default_creation_method`] to `from_pretrained` and use [`~ModularPipeline.update_components`] to update the guider and component specifications as well as the pipeline config.
|
||||
|
||||
> [!TIP]
|
||||
> Changing the creation method will return text letting you know you're changing the creation type to `from_pretrained`.
|
||||
> ```bash
|
||||
> ModularPipeline.update_components: changing the default_creation_method of guider from from_config to from_pretrained.
|
||||
> ```
|
||||
|
||||
```py
|
||||
guider_spec = t2i_pipeline.get_component_spec("guider")
|
||||
guider_spec.default_creation_method="from_pretrained"
|
||||
guider_spec.repo="YiYiXu/modular-loader-t2i-guider"
|
||||
guider_spec.subfolder="pag_guider"
|
||||
pag_guider = guider_spec.load()
|
||||
t2i_pipeline.update_components(guider=pag_guider)
|
||||
```
|
||||
|
||||
To make it the default guider for a pipeline, call [`~utils.PushToHubMixin.push_to_hub`]. This is an optional step and not necessary if you are only experimenting locally.
|
||||
|
||||
```py
|
||||
t2i_pipeline.push_to_hub("YiYiXu/modular-doc-guider")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
@@ -12,67 +12,22 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
# LoopSequentialPipelineBlocks
|
||||
|
||||
<Tip warning={true}>
|
||||
[`~modular_pipelines.LoopSequentialPipelineBlocks`] are a multi-block type that composes other [`~modular_pipelines.ModularPipelineBlocks`] together in a loop. Data flows circularly, using `intermediate_inputs` and `intermediate_outputs`, and each block is run iteratively. This is typically used to create a denoising loop which is iterative by default.
|
||||
|
||||
🧪 **Experimental Feature**: Modular Diffusers is an experimental feature we are actively developing. The API may be subject to breaking changes.
|
||||
This guide shows you how to create [`~modular_pipelines.LoopSequentialPipelineBlocks`].
|
||||
|
||||
</Tip>
|
||||
## Loop wrapper
|
||||
|
||||
`LoopSequentialPipelineBlocks` is a subclass of `ModularPipelineBlocks`. It is a multi-block that composes other blocks together in a loop, creating iterative workflows where blocks run multiple times with evolving state. It's particularly useful for denoising loops requiring repeated execution of the same blocks.
|
||||
[`~modular_pipelines.LoopSequentialPipelineBlocks`], is also known as the *loop wrapper* because it defines the loop structure, iteration variables, and configuration. Within the loop wrapper, you need the following variables.
|
||||
|
||||
<Tip>
|
||||
|
||||
Other types of multi-blocks include [SequentialPipelineBlocks](./sequential_pipeline_blocks.md) (for linear workflows) and [AutoPipelineBlocks](./auto_pipeline_blocks.md) (for conditional block selection). For information on creating individual blocks, see the [PipelineBlock guide](./pipeline_block.md).
|
||||
|
||||
Additionally, like all `ModularPipelineBlocks`, `LoopSequentialPipelineBlocks` are definitions/specifications, not runnable pipelines. You need to convert them into a `ModularPipeline` to actually execute them. For information on creating and running pipelines, see the [Modular Pipeline guide](modular_pipeline.md).
|
||||
|
||||
</Tip>
|
||||
|
||||
You could create a loop using `PipelineBlock` like this:
|
||||
|
||||
```python
|
||||
class DenoiseLoop(PipelineBlock):
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
for t in range(block_state.num_inference_steps):
|
||||
# ... loop logic here
|
||||
pass
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
But in this tutorial, we will focus on how to use `LoopSequentialPipelineBlocks` to create a "composable" denoising loop where you can add or remove blocks within the loop or reuse the same loop structure with different block combinations.
|
||||
|
||||
It involves two parts: a **loop wrapper** and **loop blocks**
|
||||
|
||||
* The **loop wrapper** (`LoopSequentialPipelineBlocks`) defines the loop structure, e.g. it defines the iteration variables, and loop configurations such as progress bar.
|
||||
|
||||
* The **loop blocks** are basically standard pipeline blocks you add to the loop wrapper.
|
||||
- they run sequentially for each iteration of the loop
|
||||
- they receive the current iteration index as an additional parameter
|
||||
- they share the same block_state throughout the entire loop
|
||||
|
||||
Unlike regular `SequentialPipelineBlocks` where each block gets its own state, loop blocks share a single state that persists and evolves across iterations.
|
||||
|
||||
We will build a simple loop block to demonstrate these concepts. Creating a loop block involves three steps:
|
||||
1. defining the loop wrapper class
|
||||
2. creating the loop blocks
|
||||
3. adding the loop blocks to the loop wrapper class to create the loop wrapper instance
|
||||
|
||||
**Step 1: Define the Loop Wrapper**
|
||||
|
||||
To create a `LoopSequentialPipelineBlocks` class, you need to define:
|
||||
|
||||
* `loop_inputs`: User input variables (equivalent to `PipelineBlock.inputs`)
|
||||
* `loop_intermediate_inputs`: Intermediate variables needed from the mutable pipeline state (equivalent to `PipelineBlock.intermediates_inputs`)
|
||||
* `loop_intermediate_outputs`: New intermediate variables this block will add to the mutable pipeline state (equivalent to `PipelineBlock.intermediates_outputs`)
|
||||
* `__call__` method: Defines the loop structure and iteration logic
|
||||
|
||||
Here is an example of a loop wrapper:
|
||||
- `loop_inputs` are user provided values and equivalent to [`~modular_pipelines.ModularPipelineBlocks.inputs`].
|
||||
- `loop_intermediate_inputs` are intermediate variables from the [`~modular_pipelines.PipelineState`] and equivalent to [`~modular_pipelines.ModularPipelineBlocks.intermediate_inputs`].
|
||||
- `loop_intermediate_outputs` are new intermediate variables created by the block and added to the [`~modular_pipelines.PipelineState`]. It is equivalent to [`~modular_pipelines.ModularPipelineBlocks.intermediate_outputs`].
|
||||
- `__call__` method defines the loop structure and iteration logic.
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers.modular_pipelines import LoopSequentialPipelineBlocks, PipelineBlock, InputParam, OutputParam
|
||||
from diffusers.modular_pipelines import LoopSequentialPipelineBlocks, ModularPipelineBlocks, InputParam, OutputParam
|
||||
|
||||
class LoopWrapper(LoopSequentialPipelineBlocks):
|
||||
model_name = "test"
|
||||
@@ -93,16 +48,20 @@ class LoopWrapper(LoopSequentialPipelineBlocks):
|
||||
return components, state
|
||||
```
|
||||
|
||||
**Step 2: Create Loop Blocks**
|
||||
The loop wrapper can pass additional arguments, like current iteration index, to the loop blocks.
|
||||
|
||||
Loop blocks are standard `PipelineBlock`s, but their `__call__` method works differently:
|
||||
* It receives the iteration variable (e.g., `i`) passed by the loop wrapper
|
||||
* It works directly with `block_state` instead of pipeline state
|
||||
* No need to call `self.get_block_state()` or `self.set_block_state()`
|
||||
## Loop blocks
|
||||
|
||||
A loop block is a [`~modular_pipelines.ModularPipelineBlocks`], but the `__call__` method behaves differently.
|
||||
|
||||
- It recieves the iteration variable from the loop wrapper.
|
||||
- It works directly with the [`~modular_pipelines.BlockState`] instead of the [`~modular_pipelines.PipelineState`].
|
||||
- It doesn't require retrieving or updating the [`~modular_pipelines.BlockState`].
|
||||
|
||||
Loop blocks share the same [`~modular_pipelines.BlockState`] to allow values to accumulate and change for each iteration in the loop.
|
||||
|
||||
```py
|
||||
class LoopBlock(PipelineBlock):
|
||||
# this is used to identify the model family, we won't worry about it in this example
|
||||
class LoopBlock(ModularPipelineBlocks):
|
||||
model_name = "test"
|
||||
@property
|
||||
def inputs(self):
|
||||
@@ -119,76 +78,16 @@ class LoopBlock(PipelineBlock):
|
||||
return components, block_state
|
||||
```
|
||||
|
||||
**Step 3: Combine Everything**
|
||||
## LoopSequentialPipelineBlocks
|
||||
|
||||
Finally, assemble your loop by adding the block(s) to the wrapper:
|
||||
Use the [`~modular_pipelines.LoopSequentialPipelineBlocks.from_blocks_dict`] method to add the loop block to the loop wrapper to create [`~modular_pipelines.LoopSequentialPipelineBlocks`].
|
||||
|
||||
```py
|
||||
loop = LoopWrapper.from_blocks_dict({"block1": LoopBlock})
|
||||
```
|
||||
|
||||
Now you've created a loop with one step:
|
||||
|
||||
```py
|
||||
>>> loop
|
||||
LoopWrapper(
|
||||
Class: LoopSequentialPipelineBlocks
|
||||
|
||||
Description: I'm a loop!!
|
||||
|
||||
Sub-Blocks:
|
||||
[0] block1 (LoopBlock)
|
||||
Description: I'm a block used inside the `LoopWrapper` class
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
It has two inputs: `x` (used at each step within the loop) and `num_steps` used to define the loop.
|
||||
|
||||
```py
|
||||
>>> print(loop.doc)
|
||||
class LoopWrapper
|
||||
|
||||
I'm a loop!!
|
||||
|
||||
Inputs:
|
||||
|
||||
x (`None`, *optional*):
|
||||
|
||||
num_steps (`None`, *optional*):
|
||||
|
||||
Outputs:
|
||||
|
||||
x (`None`):
|
||||
```
|
||||
|
||||
**Running the Loop:**
|
||||
|
||||
```py
|
||||
# run the loop
|
||||
loop_pipeline = loop.init_pipeline()
|
||||
x = loop_pipeline(num_steps=10, x=0, output="x")
|
||||
assert x == 10
|
||||
```
|
||||
|
||||
**Adding Multiple Blocks:**
|
||||
|
||||
We can add multiple blocks to run within each iteration. Let's run the loop block twice within each iteration:
|
||||
Add more loop blocks to run within each iteration with [`~modular_pipelines.LoopSequentialPipelineBlocks.from_blocks_dict`]. This allows you to modify the blocks without changing the loop logic itself.
|
||||
|
||||
```py
|
||||
loop = LoopWrapper.from_blocks_dict({"block1": LoopBlock(), "block2": LoopBlock})
|
||||
loop_pipeline = loop.init_pipeline()
|
||||
x = loop_pipeline(num_steps=10, x=0, output="x")
|
||||
assert x == 20 # Each iteration runs 2 blocks, so 10 iterations * 2 = 20
|
||||
```
|
||||
|
||||
**Key Differences from SequentialPipelineBlocks:**
|
||||
|
||||
The main difference is that loop blocks share the same `block_state` across all iterations, allowing values to accumulate and evolve throughout the loop. Loop blocks could receive additional arguments (like the current iteration index) depending on the loop wrapper's implementation, since the wrapper defines how loop blocks are called. You can easily add, remove, or reorder blocks within the loop without changing the loop logic itself.
|
||||
|
||||
The officially supported denoising loops in Modular Diffusers are implemented using `LoopSequentialPipelineBlocks`. You can explore the actual implementation to see how these concepts work in practice:
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl.denoise import StableDiffusionXLDenoiseStep
|
||||
StableDiffusionXLDenoiseStep()
|
||||
```
|
||||
@@ -10,43 +10,42 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# PipelineState and BlockState
|
||||
# States
|
||||
|
||||
<Tip warning={true}>
|
||||
Blocks rely on the [`~modular_pipelines.PipelineState`] and [`~modular_pipelines.BlockState`] data structures for communicating and sharing data.
|
||||
|
||||
🧪 **Experimental Feature**: Modular Diffusers is an experimental feature we are actively developing. The API may be subject to breaking changes.
|
||||
| State | Description |
|
||||
|-------|-------------|
|
||||
| [`~modular_pipelines.PipelineState`] | Maintains the overall data required for a pipeline's execution and allows blocks to read and update its data. |
|
||||
| [`~modular_pipelines.BlockState`] | Allows each block to perform its computation with the necessary data from `inputs`|
|
||||
|
||||
</Tip>
|
||||
This guide explains how states work and how they connect blocks.
|
||||
|
||||
In Modular Diffusers, `PipelineState` and `BlockState` are the core data structures that enable blocks to communicate and share data. The concept is fundamental to understand how blocks interact with each other and the pipeline system.
|
||||
## PipelineState
|
||||
|
||||
In the modular diffusers system, `PipelineState` acts as the global state container that all pipeline blocks operate on. It maintains the complete runtime state of the pipeline and provides a structured way for blocks to read from and write to shared data.
|
||||
The [`~modular_pipelines.PipelineState`] is a global state container for all blocks. It maintains the complete runtime state of the pipeline and provides a structured way for blocks to read from and write to shared data.
|
||||
|
||||
A `PipelineState` consists of two distinct states:
|
||||
There are two dict's in [`~modular_pipelines.PipelineState`] for structuring data.
|
||||
|
||||
- **The immutable state** (i.e. the `inputs` dict) contains a copy of values provided by users. Once a value is added to the immutable state, it cannot be changed. Blocks can read from the immutable state but cannot write to it.
|
||||
|
||||
- **The mutable state** (i.e. the `intermediates` dict) contains variables that are passed between blocks and can be modified by them.
|
||||
|
||||
Here's an example of what a `PipelineState` looks like:
|
||||
- The `values` dict is a **mutable** state containing a copy of user provided input values and intermediate output values generated by blocks. If a block modifies an `input`, it will be reflected in the `values` dict after calling `set_block_state`.
|
||||
|
||||
```py
|
||||
PipelineState(
|
||||
inputs={
|
||||
values={
|
||||
'prompt': 'a cat'
|
||||
'guidance_scale': 7.0
|
||||
'num_inference_steps': 25
|
||||
},
|
||||
intermediates={
|
||||
'prompt_embeds': Tensor(dtype=torch.float32, shape=torch.Size([1, 1, 1, 1]))
|
||||
'negative_prompt_embeds': None
|
||||
},
|
||||
)
|
||||
```
|
||||
|
||||
Each pipeline blocks define what parts of that state they can read from and write to through their `inputs`, `intermediate_inputs`, and `intermediate_outputs` properties. At run time, they gets a local view (`BlockState`) of the relevant variables it needs from `PipelineState`, performs its operations, and then updates `PipelineState` with any changes.
|
||||
## BlockState
|
||||
|
||||
For example, if a block defines an input `image`, inside the block's `__call__` method, the `BlockState` would contain:
|
||||
The [`~modular_pipelines.BlockState`] is a local view of the relevant variables an individual block needs from [`~modular_pipelines.PipelineState`] for performing it's computations.
|
||||
|
||||
Access these variables directly as attributes like `block_state.image`.
|
||||
|
||||
```py
|
||||
BlockState(
|
||||
@@ -54,6 +53,23 @@ BlockState(
|
||||
)
|
||||
```
|
||||
|
||||
You can access the variables directly as attributes: `block_state.image`.
|
||||
When a block's `__call__` method is executed, it retrieves the [`BlockState`] with `self.get_block_state(state)`, performs it's operations, and updates [`~modular_pipelines.PipelineState`] with `self.set_block_state(state, block_state)`.
|
||||
|
||||
We will explore more on how blocks interact with pipeline state through their `inputs`, `intermediate_inputs`, and `intermediate_outputs` properties, see the [PipelineBlock guide](./pipeline_block.md).
|
||||
```py
|
||||
def __call__(self, components, state):
|
||||
# retrieve BlockState
|
||||
block_state = self.get_block_state(state)
|
||||
|
||||
# computation logic on inputs
|
||||
|
||||
# update PipelineState
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
## State interaction
|
||||
|
||||
[`~modular_pipelines.PipelineState`] and [`~modular_pipelines.BlockState`] interaction is defined by a block's `inputs`, and `intermediate_outputs`.
|
||||
|
||||
- `inputs`, a block can modify an input - like `block_state.image` - and this change can be propagated globally to [`~modular_pipelines.PipelineState`] by calling `set_block_state`.
|
||||
- `intermediate_outputs`, is a new variable that a block creates. It is added to the [`~modular_pipelines.PipelineState`]'s `values` dict and is available as for subsequent blocks or accessed by users as a final output from the pipeline.
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@@ -10,33 +10,32 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Getting Started with Modular Diffusers
|
||||
# Overview
|
||||
|
||||
<Tip warning={true}>
|
||||
> [!WARNING]
|
||||
> Modular Diffusers is under active development and it's API may change.
|
||||
|
||||
🧪 **Experimental Feature**: Modular Diffusers is an experimental feature we are actively developing. The API may be subject to breaking changes.
|
||||
Modular Diffusers is a unified pipeline system that simplifies your workflow with *pipeline blocks*.
|
||||
|
||||
</Tip>
|
||||
- Blocks are reusable and you only need to create new blocks that are unique to your pipeline.
|
||||
- Blocks can be mixed and matched to adapt to or create a pipeline for a specific workflow or multiple workflows.
|
||||
|
||||
With Modular Diffusers, we introduce a unified pipeline system that simplifies how you work with diffusion models. Instead of creating separate pipelines for each task, Modular Diffusers lets you:
|
||||
The Modular Diffusers docs are organized as shown below.
|
||||
|
||||
**Write Only What's New**: You won't need to write an entire pipeline from scratch every time you have a new use case. You can create pipeline blocks just for your new workflow's unique aspects and reuse existing blocks for existing functionalities.
|
||||
## Quickstart
|
||||
|
||||
**Assemble Like LEGO®**: You can mix and match between blocks in flexible ways. This allows you to write dedicated blocks unique to specific workflows, and then assemble different blocks into a pipeline that can be used more conveniently for multiple workflows.
|
||||
- A [quickstart](./quickstart) demonstrating how to implement an example workflow with Modular Diffusers.
|
||||
|
||||
## ModularPipelineBlocks
|
||||
|
||||
Here's how our guides are organized to help you navigate the Modular Diffusers documentation:
|
||||
- [States](./modular_diffusers_states) explains how data is shared and communicated between blocks and [`ModularPipeline`].
|
||||
- [ModularPipelineBlocks](./pipeline_block) is the most basic unit of a [`ModularPipeline`] and this guide shows you how to create one.
|
||||
- [SequentialPipelineBlocks](./sequential_pipeline_blocks) is a type of block that chains multiple blocks so they run one after another, passing data along the chain. This guide shows you how to create [`~modular_pipelines.SequentialPipelineBlocks`] and how they connect and work together.
|
||||
- [LoopSequentialPipelineBlocks](./loop_sequential_pipeline_blocks) is a type of block that runs a series of blocks in a loop. This guide shows you how to create [`~modular_pipelines.LoopSequentialPipelineBlocks`].
|
||||
- [AutoPipelineBlocks](./auto_pipeline_blocks) is a type of block that automatically chooses which blocks to run based on the input. This guide shows you how to create [`~modular_pipelines.AutoPipelineBlocks`].
|
||||
|
||||
### 🚀 Running Pipelines
|
||||
- **[Modular Pipeline Guide](./modular_pipeline.md)** - How to use predefined blocks to build a pipeline and run it
|
||||
- **[Components Manager Guide](./components_manager.md)** - How to manage and reuse components across multiple pipelines
|
||||
## ModularPipeline
|
||||
|
||||
### 📚 Creating PipelineBlocks
|
||||
- **[Pipeline and Block States](./modular_diffusers_states.md)** - Understanding PipelineState and BlockState
|
||||
- **[Pipeline Block](./pipeline_block.md)** - How to write custom PipelineBlocks
|
||||
- **[SequentialPipelineBlocks](sequential_pipeline_blocks.md)** - Connecting blocks in sequence
|
||||
- **[LoopSequentialPipelineBlocks](./loop_sequential_pipeline_blocks.md)** - Creating iterative workflows
|
||||
- **[AutoPipelineBlocks](./auto_pipeline_blocks.md)** - Conditional block selection
|
||||
|
||||
### 🎯 Practical Examples
|
||||
- **[End-to-End Example](./end_to_end_guide.md)** - Complete end-to-end examples including sharing your workflow in huggingface hub and deplying UI nodes
|
||||
- [ModularPipeline](./modular_pipeline) shows you how to create and convert pipeline blocks into an executable [`ModularPipeline`].
|
||||
- [ComponentsManager](./components_manager) shows you how to manage and reuse components across multiple pipelines.
|
||||
- [Guiders](./guiders) shows you how to use different guidance methods in the pipeline.
|
||||
@@ -10,126 +10,101 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# PipelineBlock
|
||||
# ModularPipelineBlocks
|
||||
|
||||
<Tip warning={true}>
|
||||
[`~modular_pipelines.ModularPipelineBlocks`] is the basic block for building a [`ModularPipeline`]. It defines what components, inputs/outputs, and computation a block should perform for a specific step in a pipeline. A [`~modular_pipelines.ModularPipelineBlocks`] connects with other blocks, using [state](./modular_diffusers_states), to enable the modular construction of workflows.
|
||||
|
||||
🧪 **Experimental Feature**: Modular Diffusers is an experimental feature we are actively developing. The API may be subject to breaking changes.
|
||||
A [`~modular_pipelines.ModularPipelineBlocks`] on it's own can't be executed. It is a blueprint for what a step should do in a pipeline. To actually run and execute a pipeline, the [`~modular_pipelines.ModularPipelineBlocks`] needs to be converted into a [`ModularPipeline`].
|
||||
|
||||
</Tip>
|
||||
This guide will show you how to create a [`~modular_pipelines.ModularPipelineBlocks`].
|
||||
|
||||
In Modular Diffusers, you build your workflow using `ModularPipelineBlocks`. We support 4 different types of blocks: `PipelineBlock`, `SequentialPipelineBlocks`, `LoopSequentialPipelineBlocks`, and `AutoPipelineBlocks`. Among them, `PipelineBlock` is the most fundamental building block of the whole system - it's like a brick in a Lego system. These blocks are designed to easily connect with each other, allowing for modular construction of creative and potentially very complex workflows.
|
||||
## Inputs and outputs
|
||||
|
||||
<Tip>
|
||||
> [!TIP]
|
||||
> Refer to the [States](./modular_diffusers_states) guide if you aren't familiar with how state works in Modular Diffusers.
|
||||
|
||||
**Important**: `PipelineBlock`s are definitions/specifications, not runnable pipelines. They define what a block should do and what data it needs, but you need to convert them into a `ModularPipeline` to actually execute them. For information on creating and running pipelines, see the [Modular Pipeline guide](./modular_pipeline.md).
|
||||
A [`~modular_pipelines.ModularPipelineBlocks`] requires `inputs`, and `intermediate_outputs`.
|
||||
|
||||
</Tip>
|
||||
- `inputs` are values provided by a user and retrieved from the [`~modular_pipelines.PipelineState`]. This is useful because some workflows resize an image, but the original image is still required. The [`~modular_pipelines.PipelineState`] maintains the original image.
|
||||
|
||||
In this tutorial, we will focus on how to write a basic `PipelineBlock` and how it interacts with the pipeline state.
|
||||
Use `InputParam` to define `inputs`.
|
||||
|
||||
## PipelineState
|
||||
```py
|
||||
from diffusers.modular_pipelines import InputParam
|
||||
|
||||
Before we dive into creating `PipelineBlock`s, make sure you have a basic understanding of `PipelineState`. It acts as the global state container that all blocks operate on - each block gets a local view (`BlockState`) of the relevant variables it needs from `PipelineState`, performs its operations, and then updates `PipelineState` with any changes. See the [PipelineState and BlockState guide](./modular_diffusers_states.md) for more details.
|
||||
user_inputs = [
|
||||
InputParam(name="image", type_hint="PIL.Image", description="raw input image to process")
|
||||
]
|
||||
```
|
||||
|
||||
## Define a `PipelineBlock`
|
||||
- `intermediate_inputs` are values typically created from a previous block but it can also be directly provided if no preceding block generates them. Unlike `inputs`, `intermediate_inputs` can be modified.
|
||||
|
||||
To write a `PipelineBlock` class, you need to define a few properties that determine how your block interacts with the pipeline state. Understanding these properties is crucial - they define what data your block can access and what it can produce.
|
||||
Use `InputParam` to define `intermediate_inputs`.
|
||||
|
||||
The three main properties you need to define are:
|
||||
- `inputs`: Immutable values from the user that cannot be modified
|
||||
- `intermediate_inputs`: Mutable values from previous blocks that can be read and modified
|
||||
- `intermediate_outputs`: New values your block creates for subsequent blocks and user access
|
||||
```py
|
||||
user_intermediate_inputs = [
|
||||
InputParam(name="processed_image", type_hint="torch.Tensor", description="image that has been preprocessed and normalized"),
|
||||
]
|
||||
```
|
||||
|
||||
Let's explore each one and understand how they work with the pipeline state.
|
||||
- `intermediate_outputs` are new values created by a block and added to the [`~modular_pipelines.PipelineState`]. The `intermediate_outputs` are available as `intermediate_inputs` for subsequent blocks or available as the final output from running the pipeline.
|
||||
|
||||
**Inputs: Immutable User Values**
|
||||
Use `OutputParam` to define `intermediate_outputs`.
|
||||
|
||||
Inputs are variables your block needs from the immutable pipeline state - these are user-provided values that cannot be modified by any block. You define them using `InputParam`:
|
||||
```py
|
||||
from diffusers.modular_pipelines import OutputParam
|
||||
|
||||
```py
|
||||
user_inputs = [
|
||||
InputParam(name="image", type_hint="PIL.Image", description="raw input image to process")
|
||||
]
|
||||
```
|
||||
user_intermediate_outputs = [
|
||||
OutputParam(name="image_latents", description="latents representing the image")
|
||||
]
|
||||
```
|
||||
|
||||
When you list something as an input, you're saying "I need this value directly from the end user, and I will talk to them directly, telling them what I need in the 'description' field. They will provide it and it will come to me unchanged."
|
||||
The intermediate inputs and outputs share data to connect blocks. They are accessible at any point, allowing you to track the workflow's progress.
|
||||
|
||||
This is especially useful for raw values that serve as the "source of truth" in your workflow. For example, with a raw image, many workflows require preprocessing steps like resizing that a previous block might have performed. But in many cases, you also want the raw PIL image. In some inpainting workflows, you need the original image to overlay with the generated result for better control and consistency.
|
||||
## Computation logic
|
||||
|
||||
**Intermediate Inputs: Mutable Values from Previous Blocks, or Users**
|
||||
The computation a block performs is defined in the `__call__` method and it follows a specific structure.
|
||||
|
||||
Intermediate inputs are variables your block needs from the mutable pipeline state - these are values that can be read and modified. They're typically created by previous blocks, but could also be directly provided by the user if not the case:
|
||||
|
||||
```py
|
||||
user_intermediate_inputs = [
|
||||
InputParam(name="processed_image", type_hint="torch.Tensor", description="image that has been preprocessed and normalized"),
|
||||
]
|
||||
```
|
||||
|
||||
When you list something as an intermediate input, you're saying "I need this value, but I want to work with a different block that has already created it. I already know for sure that I can get it from this other block, but it's okay if other developers want use something different."
|
||||
|
||||
**Intermediate Outputs: New Values for Subsequent Blocks and User Access**
|
||||
|
||||
Intermediate outputs are new variables your block creates and adds to the mutable pipeline state. They serve two purposes:
|
||||
|
||||
1. **For subsequent blocks**: They can be used as intermediate inputs by other blocks in the pipeline
|
||||
2. **For users**: They become available as final outputs that users can access when running the pipeline
|
||||
|
||||
```py
|
||||
user_intermediate_outputs = [
|
||||
OutputParam(name="image_latents", description="latents representing the image")
|
||||
]
|
||||
```
|
||||
|
||||
Intermediate inputs and intermediate outputs work together like Lego studs and anti-studs - they're the connection points that make blocks modular. When one block produces an intermediate output, it becomes available as an intermediate input for subsequent blocks. This is where the "modular" nature of the system really shines - blocks can be connected and reconnected in different ways as long as their inputs and outputs match.
|
||||
|
||||
Additionally, all intermediate outputs are accessible to users when they run the pipeline, typically you would only need the final images, but they are also able to access intermediate results like latents, embeddings, or other processing steps.
|
||||
|
||||
**The `__call__` Method Structure**
|
||||
|
||||
Your `PipelineBlock`'s `__call__` method should follow this structure:
|
||||
1. Retrieve the [`~modular_pipelines.BlockState`] to get a local view of the `inputs` and `intermediate_inputs`.
|
||||
2. Implement the computation logic on the `inputs` and `intermediate_inputs`.
|
||||
3. Update [`~modular_pipelines.PipelineState`] to push changes from the local [`~modular_pipelines.BlockState`] back to the global [`~modular_pipelines.PipelineState`].
|
||||
4. Return the components and state which becomes available to the next block.
|
||||
|
||||
```py
|
||||
def __call__(self, components, state):
|
||||
# Get a local view of the state variables this block needs
|
||||
block_state = self.get_block_state(state)
|
||||
|
||||
|
||||
# Your computation logic here
|
||||
# block_state contains all your inputs and intermediate_inputs
|
||||
# You can access them like: block_state.image, block_state.processed_image
|
||||
|
||||
# Access them like: block_state.image, block_state.processed_image
|
||||
|
||||
# Update the pipeline state with your updated block_states
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
The `block_state` object contains all the variables you defined in `inputs` and `intermediate_inputs`, making them easily accessible for your computation.
|
||||
### Components and configs
|
||||
|
||||
**Components and Configs**
|
||||
The components and pipeline-level configs a block needs are specified in [`ComponentSpec`] and [`~modular_pipelines.ConfigSpec`].
|
||||
|
||||
You can define the components and pipeline-level configs your block needs using `ComponentSpec` and `ConfigSpec`:
|
||||
- [`ComponentSpec`] contains the expected components used by a block. You need the `name` of the component and ideally a `type_hint` that specifies exactly what the component is.
|
||||
- [`~modular_pipelines.ConfigSpec`] contains pipeline-level settings that control behavior across all blocks.
|
||||
|
||||
```py
|
||||
from diffusers import ComponentSpec, ConfigSpec
|
||||
|
||||
# Define components your block needs
|
||||
expected_components = [
|
||||
ComponentSpec(name="unet", type_hint=UNet2DConditionModel),
|
||||
ComponentSpec(name="scheduler", type_hint=EulerDiscreteScheduler)
|
||||
]
|
||||
|
||||
# Define pipeline-level configs
|
||||
expected_config = [
|
||||
ConfigSpec("force_zeros_for_empty_prompt", True)
|
||||
]
|
||||
```
|
||||
|
||||
**Components**: In the `ComponentSpec`, you must provide a `name` and ideally a `type_hint`. You can also specify a `default_creation_method` to indicate whether the component should be loaded from a pretrained model or created with default configurations. The actual loading details (`repo`, `subfolder`, `variant` and `revision` fields) are typically specified when creating the pipeline, as we covered in the [Modular Pipeline Guide](./modular_pipeline.md).
|
||||
|
||||
**Configs**: Pipeline-level settings that control behavior across all blocks.
|
||||
|
||||
When you convert your blocks into a pipeline using `blocks.init_pipeline()`, the pipeline collects all component requirements from the blocks and fetches the loading specs from the modular repository. The components are then made available to your block as the first argument of the `__call__` method. You can access any component you need using dot notation:
|
||||
When the blocks are converted into a pipeline, the components become available to the block as the first argument in `__call__`.
|
||||
|
||||
```py
|
||||
def __call__(self, components, state):
|
||||
@@ -137,156 +112,4 @@ def __call__(self, components, state):
|
||||
unet = components.unet
|
||||
vae = components.vae
|
||||
scheduler = components.scheduler
|
||||
```
|
||||
|
||||
That's all you need to define in order to create a `PipelineBlock`. There is no hidden complexity. In fact we are going to create a helper function that take exactly these variables as input and return a pipeline block. We will use this helper function through out the tutorial to create test blocks
|
||||
|
||||
Note that for `__call__` method, the only part you should implement differently is the part between `self.get_block_state()` and `self.set_block_state()`, which can be abstracted into a simple function that takes `block_state` and returns the updated state. Our helper function accepts a `block_fn` that does exactly that.
|
||||
|
||||
**Helper Function**
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import PipelineBlock, InputParam, OutputParam
|
||||
import torch
|
||||
|
||||
def make_block(inputs=[], intermediate_inputs=[], intermediate_outputs=[], block_fn=None, description=None):
|
||||
class TestBlock(PipelineBlock):
|
||||
model_name = "test"
|
||||
|
||||
@property
|
||||
def inputs(self):
|
||||
return inputs
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self):
|
||||
return intermediate_inputs
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self):
|
||||
return intermediate_outputs
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return description if description is not None else ""
|
||||
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
if block_fn is not None:
|
||||
block_state = block_fn(block_state, state)
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
|
||||
return TestBlock
|
||||
```
|
||||
|
||||
## Example: Creating a Simple Pipeline Block
|
||||
|
||||
Let's create a simple block to see how these definitions interact with the pipeline state. To better understand what's happening, we'll print out the states before and after updates to inspect them:
|
||||
|
||||
```py
|
||||
inputs = [
|
||||
InputParam(name="image", type_hint="PIL.Image", description="raw input image to process")
|
||||
]
|
||||
|
||||
intermediate_inputs = [InputParam(name="batch_size", type_hint=int)]
|
||||
|
||||
intermediate_outputs = [
|
||||
OutputParam(name="image_latents", description="latents representing the image")
|
||||
]
|
||||
|
||||
def image_encoder_block_fn(block_state, pipeline_state):
|
||||
print(f"pipeline_state (before update): {pipeline_state}")
|
||||
print(f"block_state (before update): {block_state}")
|
||||
|
||||
# Simulate processing the image
|
||||
block_state.image = torch.randn(1, 3, 512, 512)
|
||||
block_state.batch_size = block_state.batch_size * 2
|
||||
block_state.processed_image = [torch.randn(1, 3, 512, 512)] * block_state.batch_size
|
||||
block_state.image_latents = torch.randn(1, 4, 64, 64)
|
||||
|
||||
print(f"block_state (after update): {block_state}")
|
||||
return block_state
|
||||
|
||||
# Create a block with our definitions
|
||||
image_encoder_block_cls = make_block(
|
||||
inputs=inputs,
|
||||
intermediate_inputs=intermediate_inputs,
|
||||
intermediate_outputs=intermediate_outputs,
|
||||
block_fn=image_encoder_block_fn,
|
||||
description="Encode raw image into its latent presentation"
|
||||
)
|
||||
image_encoder_block = image_encoder_block_cls()
|
||||
pipe = image_encoder_block.init_pipeline()
|
||||
```
|
||||
|
||||
Let's check the pipeline's docstring to see what inputs it expects:
|
||||
```py
|
||||
>>> print(pipe.doc)
|
||||
class TestBlock
|
||||
|
||||
Encode raw image into its latent presentation
|
||||
|
||||
Inputs:
|
||||
|
||||
image (`PIL.Image`, *optional*):
|
||||
raw input image to process
|
||||
|
||||
batch_size (`int`, *optional*):
|
||||
|
||||
Outputs:
|
||||
|
||||
image_latents (`None`):
|
||||
latents representing the image
|
||||
```
|
||||
|
||||
Notice that `batch_size` appears as an input even though we defined it as an intermediate input. This happens because no previous block provided it, so the pipeline makes it available as a user input. However, unlike regular inputs, this value goes directly into the mutable intermediate state.
|
||||
|
||||
Now let's run the pipeline:
|
||||
|
||||
```py
|
||||
from diffusers.utils import load_image
|
||||
|
||||
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/image_of_squirrel_painting.png")
|
||||
state = pipe(image=image, batch_size=2)
|
||||
print(f"pipeline_state (after update): {state}")
|
||||
```
|
||||
```out
|
||||
pipeline_state (before update): PipelineState(
|
||||
inputs={
|
||||
image: <PIL.Image.Image image mode=RGB size=512x512 at 0x7F3ECC494550>
|
||||
},
|
||||
intermediates={
|
||||
batch_size: 2
|
||||
},
|
||||
)
|
||||
block_state (before update): BlockState(
|
||||
image: <PIL.Image.Image image mode=RGB size=512x512 at 0x7F3ECC494640>
|
||||
batch_size: 2
|
||||
)
|
||||
|
||||
block_state (after update): BlockState(
|
||||
image: Tensor(dtype=torch.float32, shape=torch.Size([1, 3, 512, 512]))
|
||||
batch_size: 4
|
||||
processed_image: List[4] of Tensors with shapes [torch.Size([1, 3, 512, 512]), torch.Size([1, 3, 512, 512]), torch.Size([1, 3, 512, 512]), torch.Size([1, 3, 512, 512])]
|
||||
image_latents: Tensor(dtype=torch.float32, shape=torch.Size([1, 4, 64, 64]))
|
||||
)
|
||||
pipeline_state (after update): PipelineState(
|
||||
inputs={
|
||||
image: <PIL.Image.Image image mode=RGB size=512x512 at 0x7F3ECC494550>
|
||||
},
|
||||
intermediates={
|
||||
batch_size: 4
|
||||
image_latents: Tensor(dtype=torch.float32, shape=torch.Size([1, 4, 64, 64]))
|
||||
},
|
||||
)
|
||||
```
|
||||
|
||||
**Key Observations:**
|
||||
|
||||
1. **Before the update**: `image` (the input) goes to the immutable inputs dict, while `batch_size` (the intermediate_input) goes to the mutable intermediates dict, and both are available in `block_state`.
|
||||
|
||||
2. **After the update**:
|
||||
- **`image` (inputs)** changed in `block_state` but not in `pipeline_state` - this change is local to the block only.
|
||||
- **`batch_size (intermediate_inputs)`** was updated in both `block_state` and `pipeline_state` - this change affects subsequent blocks (we didn't need to declare it as an intermediate output since it was already in the intermediates dict)
|
||||
- **`image_latents (intermediate_outputs)`** was added to `pipeline_state` because it was declared as an intermediate output
|
||||
- **`processed_image`** was not added to `pipeline_state` because it wasn't declared as an intermediate output
|
||||
```
|
||||
344
docs/source/en/modular_diffusers/quickstart.md
Normal file
344
docs/source/en/modular_diffusers/quickstart.md
Normal file
@@ -0,0 +1,344 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Quickstart
|
||||
|
||||
Modular Diffusers is a framework for quickly building flexible and customizable pipelines. At the core of Modular Diffusers are [`ModularPipelineBlocks`] that can be combined with other blocks to adapt to new workflows. The blocks are converted into a [`ModularPipeline`], a friendly user-facing interface developers can use.
|
||||
|
||||
This doc will show you how to implement a [Differential Diffusion](https://differential-diffusion.github.io/) pipeline with the modular framework.
|
||||
|
||||
## ModularPipelineBlocks
|
||||
|
||||
[`ModularPipelineBlocks`] are *definitions* that specify the components, inputs, outputs, and computation logic for a single step in a pipeline. There are four types of blocks.
|
||||
|
||||
- [`ModularPipelineBlocks`] is the most basic block for a single step.
|
||||
- [`SequentialPipelineBlocks`] is a multi-block that composes other blocks linearly. The outputs of one block are the inputs to the next block.
|
||||
- [`LoopSequentialPipelineBlocks`] is a multi-block that runs iteratively and is designed for iterative workflows.
|
||||
- [`AutoPipelineBlocks`] is a collection of blocks for different workflows and it selects which block to run based on the input. It is designed to conveniently package multiple workflows into a single pipeline.
|
||||
|
||||
[Differential Diffusion](https://differential-diffusion.github.io/) is an image-to-image workflow. Start with the `IMAGE2IMAGE_BLOCKS` preset, a collection of `ModularPipelineBlocks` for image-to-image generation.
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl import IMAGE2IMAGE_BLOCKS
|
||||
IMAGE2IMAGE_BLOCKS = InsertableDict([
|
||||
("text_encoder", StableDiffusionXLTextEncoderStep),
|
||||
("image_encoder", StableDiffusionXLVaeEncoderStep),
|
||||
("input", StableDiffusionXLInputStep),
|
||||
("set_timesteps", StableDiffusionXLImg2ImgSetTimestepsStep),
|
||||
("prepare_latents", StableDiffusionXLImg2ImgPrepareLatentsStep),
|
||||
("prepare_add_cond", StableDiffusionXLImg2ImgPrepareAdditionalConditioningStep),
|
||||
("denoise", StableDiffusionXLDenoiseStep),
|
||||
("decode", StableDiffusionXLDecodeStep)
|
||||
])
|
||||
```
|
||||
|
||||
## Pipeline and block states
|
||||
|
||||
Modular Diffusers uses *state* to communicate data between blocks. There are two types of states.
|
||||
|
||||
- [`PipelineState`] is a global state that can be used to track all inputs and outputs across all blocks.
|
||||
- [`BlockState`] is a local view of relevant variables from [`PipelineState`] for an individual block.
|
||||
|
||||
## Customizing blocks
|
||||
|
||||
[Differential Diffusion](https://differential-diffusion.github.io/) differs from standard image-to-image in its `prepare_latents` and `denoise` blocks. All the other blocks can be reused, but you'll need to modify these two.
|
||||
|
||||
Create placeholder `ModularPipelineBlocks` for `prepare_latents` and `denoise` by copying and modifying the existing ones.
|
||||
|
||||
Print the `denoise` block to see that it is composed of [`LoopSequentialPipelineBlocks`] with three sub-blocks, `before_denoiser`, `denoiser`, and `after_denoiser`. Only the `before_denoiser` sub-block needs to be modified to prepare the latent input for the denoiser based on the change map.
|
||||
|
||||
```py
|
||||
denoise_blocks = IMAGE2IMAGE_BLOCKS["denoise"]()
|
||||
print(denoise_blocks)
|
||||
```
|
||||
|
||||
Replace the `StableDiffusionXLLoopBeforeDenoiser` sub-block with the new `SDXLDiffDiffLoopBeforeDenoiser` block.
|
||||
|
||||
```py
|
||||
# Copy existing blocks as placeholders
|
||||
class SDXLDiffDiffPrepareLatentsStep(ModularPipelineBlocks):
|
||||
"""Copied from StableDiffusionXLImg2ImgPrepareLatentsStep - will modify later"""
|
||||
# ... same implementation as StableDiffusionXLImg2ImgPrepareLatentsStep
|
||||
|
||||
class SDXLDiffDiffDenoiseStep(StableDiffusionXLDenoiseLoopWrapper):
|
||||
block_classes = [SDXLDiffDiffLoopBeforeDenoiser, StableDiffusionXLLoopDenoiser, StableDiffusionXLLoopAfterDenoiser]
|
||||
block_names = ["before_denoiser", "denoiser", "after_denoiser"]
|
||||
```
|
||||
|
||||
### prepare_latents
|
||||
|
||||
The `prepare_latents` block requires the following changes.
|
||||
|
||||
- a processor to process the change map
|
||||
- a new `inputs` to accept the user-provided change map, `timestep` for precomputing all the latents and `num_inference_steps` to create the mask for updating the image regions
|
||||
- update the computation in the `__call__` method for processing the change map and creating the masks, and storing it in the [`BlockState`]
|
||||
|
||||
```diff
|
||||
class SDXLDiffDiffPrepareLatentsStep(ModularPipelineBlocks):
|
||||
@property
|
||||
def expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec("vae", AutoencoderKL),
|
||||
ComponentSpec("scheduler", EulerDiscreteScheduler),
|
||||
+ ComponentSpec("mask_processor", VaeImageProcessor, config=FrozenDict({"do_normalize": False, "do_convert_grayscale": True}))
|
||||
]
|
||||
@property
|
||||
def inputs(self) -> List[Tuple[str, Any]]:
|
||||
return [
|
||||
InputParam("generator"),
|
||||
+ InputParam("diffdiff_map", required=True),
|
||||
- InputParam("latent_timestep", required=True, type_hint=torch.Tensor),
|
||||
+ InputParam("timesteps", type_hint=torch.Tensor),
|
||||
+ InputParam("num_inference_steps", type_hint=int),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self) -> List[OutputParam]:
|
||||
return [
|
||||
+ OutputParam("original_latents", type_hint=torch.Tensor),
|
||||
+ OutputParam("diffdiff_masks", type_hint=torch.Tensor),
|
||||
]
|
||||
def __call__(self, components, state: PipelineState):
|
||||
# ... existing logic ...
|
||||
+ # Process change map and create masks
|
||||
+ diffdiff_map = components.mask_processor.preprocess(block_state.diffdiff_map, height=latent_height, width=latent_width)
|
||||
+ thresholds = torch.arange(block_state.num_inference_steps, dtype=diffdiff_map.dtype) / block_state.num_inference_steps
|
||||
+ block_state.diffdiff_masks = diffdiff_map > (thresholds + (block_state.denoising_start or 0))
|
||||
+ block_state.original_latents = block_state.latents
|
||||
```
|
||||
|
||||
### denoise
|
||||
|
||||
The `before_denoiser` sub-block requires the following changes.
|
||||
|
||||
- a new `inputs` to accept a `denoising_start` parameter, `original_latents` and `diffdiff_masks` from the `prepare_latents` block
|
||||
- update the computation in the `__call__` method for applying Differential Diffusion
|
||||
|
||||
```diff
|
||||
class SDXLDiffDiffLoopBeforeDenoiser(ModularPipelineBlocks):
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"Step within the denoising loop for differential diffusion that prepare the latent input for the denoiser"
|
||||
)
|
||||
|
||||
@property
|
||||
def inputs(self) -> List[str]:
|
||||
return [
|
||||
InputParam("latents", required=True, type_hint=torch.Tensor),
|
||||
+ InputParam("denoising_start"),
|
||||
+ InputParam("original_latents", type_hint=torch.Tensor),
|
||||
+ InputParam("diffdiff_masks", type_hint=torch.Tensor),
|
||||
]
|
||||
|
||||
def __call__(self, components, block_state, i, t):
|
||||
+ # Apply differential diffusion logic
|
||||
+ if i == 0 and block_state.denoising_start is None:
|
||||
+ block_state.latents = block_state.original_latents[:1]
|
||||
+ else:
|
||||
+ block_state.mask = block_state.diffdiff_masks[i].unsqueeze(0).unsqueeze(1)
|
||||
+ block_state.latents = block_state.original_latents[i] * block_state.mask + block_state.latents * (1 - block_state.mask)
|
||||
|
||||
# ... rest of existing logic ...
|
||||
```
|
||||
|
||||
## Assembling the blocks
|
||||
|
||||
You should have all the blocks you need at this point to create a [`ModularPipeline`].
|
||||
|
||||
Copy the existing `IMAGE2IMAGE_BLOCKS` preset and for the `set_timesteps` block, use the `set_timesteps` from the `TEXT2IMAGE_BLOCKS` because Differential Diffusion doesn't require a `strength` parameter.
|
||||
|
||||
Set the `prepare_latents` and `denoise` blocks to the `SDXLDiffDiffPrepareLatentsStep` and `SDXLDiffDiffDenoiseStep` blocks you just modified.
|
||||
|
||||
Call [`SequentialPipelineBlocks.from_blocks_dict`] on the blocks to create a `SequentialPipelineBlocks`.
|
||||
|
||||
```py
|
||||
DIFFDIFF_BLOCKS = IMAGE2IMAGE_BLOCKS.copy()
|
||||
DIFFDIFF_BLOCKS["set_timesteps"] = TEXT2IMAGE_BLOCKS["set_timesteps"]
|
||||
DIFFDIFF_BLOCKS["prepare_latents"] = SDXLDiffDiffPrepareLatentsStep
|
||||
DIFFDIFF_BLOCKS["denoise"] = SDXLDiffDiffDenoiseStep
|
||||
|
||||
dd_blocks = SequentialPipelineBlocks.from_blocks_dict(DIFFDIFF_BLOCKS)
|
||||
print(dd_blocks)
|
||||
```
|
||||
|
||||
## ModularPipeline
|
||||
|
||||
Convert the [`SequentialPipelineBlocks`] into a [`ModularPipeline`] with the [`ModularPipeline.init_pipeline`] method. This initializes the expected components to load from a `modular_model_index.json` file. Explicitly load the components by calling [`ModularPipeline.load_default_components`].
|
||||
|
||||
It is a good idea to initialize the [`ComponentManager`] with the pipeline to help manage the different components. Once you call [`~ModularPipeline.load_default_components`], the components are registered to the [`ComponentManager`] and can be shared between workflows. The example below uses the `collection` argument to assign the components a `"diffdiff"` label for better organization.
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import ComponentsManager
|
||||
|
||||
components = ComponentManager()
|
||||
|
||||
dd_pipeline = dd_blocks.init_pipeline("YiYiXu/modular-demo-auto", components_manager=components, collection="diffdiff")
|
||||
dd_pipeline.load_default_componenets(torch_dtype=torch.float16)
|
||||
dd_pipeline.to("cuda")
|
||||
```
|
||||
|
||||
## Adding workflows
|
||||
|
||||
Other workflows can be added to the [`ModularPipeline`] to support additional features without rewriting the entire pipeline from scratch.
|
||||
|
||||
This section demonstrates how to add an IP-Adapter or ControlNet.
|
||||
|
||||
### IP-Adapter
|
||||
|
||||
Stable Diffusion XL already has a preset IP-Adapter block that you can use and doesn't require any changes to the existing Differential Diffusion pipeline.
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl.encoders import StableDiffusionXLAutoIPAdapterStep
|
||||
|
||||
ip_adapter_block = StableDiffusionXLAutoIPAdapterStep()
|
||||
```
|
||||
|
||||
Use the [`sub_blocks.insert`] method to insert it into the [`ModularPipeline`]. The example below inserts the `ip_adapter_block` at position `0`. Print the pipeline to see that the `ip_adapter_block` is added and it requires an `ip_adapter_image`. This also added two components to the pipeline, the `image_encoder` and `feature_extractor`.
|
||||
|
||||
```py
|
||||
dd_blocks.sub_blocks.insert("ip_adapter", ip_adapter_block, 0)
|
||||
```
|
||||
|
||||
Call [`~ModularPipeline.init_pipeline`] to initialize a [`ModularPipeline`] and use [`~ModularPipeline.load_default_components`] to load the model components. Load and set the IP-Adapter to run the pipeline.
|
||||
|
||||
```py
|
||||
dd_pipeline = dd_blocks.init_pipeline("YiYiXu/modular-demo-auto", collection="diffdiff")
|
||||
dd_pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
dd_pipeline.loader.load_ip_adapter("h94/IP-Adapter", subfolder="sdxl_models", weight_name="ip-adapter_sdxl.bin")
|
||||
dd_pipeline.loader.set_ip_adapter_scale(0.6)
|
||||
dd_pipeline = dd_pipeline.to(device)
|
||||
|
||||
ip_adapter_image = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/diffdiff_orange.jpeg")
|
||||
image = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/20240329211129_4024911930.png?download=true")
|
||||
mask = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/gradient_mask.png?download=true")
|
||||
|
||||
prompt = "a green pear"
|
||||
negative_prompt = "blurry"
|
||||
generator = torch.Generator(device=device).manual_seed(42)
|
||||
|
||||
image = dd_pipeline(
|
||||
prompt=prompt,
|
||||
negative_prompt=negative_prompt,
|
||||
num_inference_steps=25,
|
||||
generator=generator,
|
||||
ip_adapter_image=ip_adapter_image,
|
||||
diffdiff_map=mask,
|
||||
image=image,
|
||||
output="images"
|
||||
)[0]
|
||||
```
|
||||
|
||||
### ControlNet
|
||||
|
||||
Stable Diffusion XL already has a preset ControlNet block that can readily be used.
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl.modular_blocks import StableDiffusionXLAutoControlNetInputStep
|
||||
|
||||
control_input_block = StableDiffusionXLAutoControlNetInputStep()
|
||||
```
|
||||
|
||||
However, it requires modifying the `denoise` block because that's where the ControlNet injects the control information into the UNet.
|
||||
|
||||
Modify the `denoise` block by replacing the `StableDiffusionXLLoopDenoiser` sub-block with the `StableDiffusionXLControlNetLoopDenoiser`.
|
||||
|
||||
```py
|
||||
class SDXLDiffDiffControlNetDenoiseStep(StableDiffusionXLDenoiseLoopWrapper):
|
||||
block_classes = [SDXLDiffDiffLoopBeforeDenoiser, StableDiffusionXLControlNetLoopDenoiser, StableDiffusionXLDenoiseLoopAfterDenoiser]
|
||||
block_names = ["before_denoiser", "denoiser", "after_denoiser"]
|
||||
|
||||
controlnet_denoise_block = SDXLDiffDiffControlNetDenoiseStep()
|
||||
```
|
||||
|
||||
Insert the `controlnet_input` block and replace the `denoise` block with the new `controlnet_denoise_block`. Initialize a [`ModularPipeline`] and [`~ModularPipeline.load_default_components`] into it.
|
||||
|
||||
```py
|
||||
dd_blocks.sub_blocks.insert("controlnet_input", control_input_block, 7)
|
||||
dd_blocks.sub_blocks["denoise"] = controlnet_denoise_block
|
||||
|
||||
dd_pipeline = dd_blocks.init_pipeline("YiYiXu/modular-demo-auto", collection="diffdiff")
|
||||
dd_pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
dd_pipeline = dd_pipeline.to(device)
|
||||
|
||||
control_image = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/diffdiff_tomato_canny.jpeg")
|
||||
image = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/20240329211129_4024911930.png?download=true")
|
||||
mask = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/gradient_mask.png?download=true")
|
||||
|
||||
prompt = "a green pear"
|
||||
negative_prompt = "blurry"
|
||||
generator = torch.Generator(device=device).manual_seed(42)
|
||||
|
||||
image = dd_pipeline(
|
||||
prompt=prompt,
|
||||
negative_prompt=negative_prompt,
|
||||
num_inference_steps=25,
|
||||
generator=generator,
|
||||
control_image=control_image,
|
||||
controlnet_conditioning_scale=0.5,
|
||||
diffdiff_map=mask,
|
||||
image=image,
|
||||
output="images"
|
||||
)[0]
|
||||
```
|
||||
|
||||
### AutoPipelineBlocks
|
||||
|
||||
The Differential Diffusion, IP-Adapter, and ControlNet workflows can be bundled into a single [`ModularPipeline`] by using [`AutoPipelineBlocks`]. This allows automatically selecting which sub-blocks to run based on the inputs like `control_image` or `ip_adapter_image`. If none of these inputs are passed, then it defaults to the Differential Diffusion.
|
||||
|
||||
Use `block_trigger_inputs` to only run the `SDXLDiffDiffControlNetDenoiseStep` block if a `control_image` input is provided. Otherwise, the `SDXLDiffDiffDenoiseStep` is used.
|
||||
|
||||
```py
|
||||
class SDXLDiffDiffAutoDenoiseStep(AutoPipelineBlocks):
|
||||
block_classes = [SDXLDiffDiffControlNetDenoiseStep, SDXLDiffDiffDenoiseStep]
|
||||
block_names = ["controlnet_denoise", "denoise"]
|
||||
block_trigger_inputs = ["controlnet_cond", None]
|
||||
```
|
||||
|
||||
Add the `ip_adapter` and `controlnet_input` blocks.
|
||||
|
||||
```py
|
||||
DIFFDIFF_AUTO_BLOCKS = IMAGE2IMAGE_BLOCKS.copy()
|
||||
DIFFDIFF_AUTO_BLOCKS["prepare_latents"] = SDXLDiffDiffPrepareLatentsStep
|
||||
DIFFDIFF_AUTO_BLOCKS["set_timesteps"] = TEXT2IMAGE_BLOCKS["set_timesteps"]
|
||||
DIFFDIFF_AUTO_BLOCKS["denoise"] = SDXLDiffDiffAutoDenoiseStep
|
||||
DIFFDIFF_AUTO_BLOCKS.insert("ip_adapter", StableDiffusionXLAutoIPAdapterStep, 0)
|
||||
DIFFDIFF_AUTO_BLOCKS.insert("controlnet_input",StableDiffusionXLControlNetAutoInput, 7)
|
||||
```
|
||||
|
||||
Call [`SequentialPipelineBlocks.from_blocks_dict`] to create a [`SequentialPipelineBlocks`] and create a [`ModularPipeline`] and load in the model components to run.
|
||||
|
||||
```py
|
||||
dd_auto_blocks = SequentialPipelineBlocks.from_blocks_dict(DIFFDIFF_AUTO_BLOCKS)
|
||||
dd_pipeline = dd_auto_blocks.init_pipeline("YiYiXu/modular-demo-auto", collection="diffdiff")
|
||||
dd_pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
```
|
||||
|
||||
## Share
|
||||
|
||||
Add your [`ModularPipeline`] to the Hub with [`~ModularPipeline.save_pretrained`] and set `push_to_hub` argument to `True`.
|
||||
|
||||
```py
|
||||
dd_pipeline.save_pretrained("YiYiXu/test_modular_doc", push_to_hub=True)
|
||||
```
|
||||
|
||||
Other users can load the [`ModularPipeline`] with [`~ModularPipeline.from_pretrained`].
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers.modular_pipelines import ModularPipeline, ComponentsManager
|
||||
|
||||
components = ComponentsManager()
|
||||
|
||||
diffdiff_pipeline = ModularPipeline.from_pretrained("YiYiXu/modular-diffdiff-0704", trust_remote_code=True, components_manager=components, collection="diffdiff")
|
||||
diffdiff_pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
```
|
||||
@@ -12,178 +12,102 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
# SequentialPipelineBlocks
|
||||
|
||||
<Tip warning={true}>
|
||||
[`~modular_pipelines.SequentialPipelineBlocks`] are a multi-block type that composes other [`~modular_pipelines.ModularPipelineBlocks`] together in a sequence. Data flows linearly from one block to the next using `intermediate_inputs` and `intermediate_outputs`. Each block in [`~modular_pipelines.SequentialPipelineBlocks`] usually represents a step in the pipeline, and by combining them, you gradually build a pipeline.
|
||||
|
||||
🧪 **Experimental Feature**: Modular Diffusers is an experimental feature we are actively developing. The API may be subject to breaking changes.
|
||||
This guide shows you how to connect two blocks into a [`~modular_pipelines.SequentialPipelineBlocks`].
|
||||
|
||||
</Tip>
|
||||
Create two [`~modular_pipelines.ModularPipelineBlocks`]. The first block, `InputBlock`, outputs a `batch_size` value and the second block, `ImageEncoderBlock` uses `batch_size` as `intermediate_inputs`.
|
||||
|
||||
`SequentialPipelineBlocks` is a subclass of `ModularPipelineBlocks`. Unlike `PipelineBlock`, it is a multi-block that composes other blocks together in sequence, creating modular workflows where data flows from one block to the next. It's one of the most common ways to build complex pipelines by combining simpler building blocks.
|
||||
|
||||
<Tip>
|
||||
|
||||
Other types of multi-blocks include [AutoPipelineBlocks](auto_pipeline_blocks.md) (for conditional block selection) and [LoopSequentialPipelineBlocks](loop_sequential_pipeline_blocks.md) (for iterative workflows). For information on creating individual blocks, see the [PipelineBlock guide](pipeline_block.md).
|
||||
|
||||
Additionally, like all `ModularPipelineBlocks`, `SequentialPipelineBlocks` are definitions/specifications, not runnable pipelines. You need to convert them into a `ModularPipeline` to actually execute them. For information on creating and running pipelines, see the [Modular Pipeline guide](modular_pipeline.md).
|
||||
|
||||
</Tip>
|
||||
|
||||
In this tutorial, we will focus on how to create `SequentialPipelineBlocks` and how blocks connect and work together.
|
||||
|
||||
The key insight is that blocks connect through their intermediate inputs and outputs - the "studs and anti-studs" we discussed in the [PipelineBlock guide](pipeline_block.md). When one block produces an intermediate output, it becomes available as an intermediate input for subsequent blocks.
|
||||
|
||||
Let's explore this through an example. We will use the same helper function from the PipelineBlock guide to create blocks.
|
||||
<hfoptions id="sequential">
|
||||
<hfoption id="InputBlock">
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import ModularPipelineBlocks, InputParam, OutputParam
|
||||
|
||||
class InputBlock(ModularPipelineBlocks):
|
||||
|
||||
@property
|
||||
def inputs(self):
|
||||
return [
|
||||
InputParam(name="prompt", type_hint=list, description="list of text prompts"),
|
||||
InputParam(name="num_images_per_prompt", type_hint=int, description="number of images per prompt"),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self):
|
||||
return [
|
||||
OutputParam(name="batch_size", description="calculated batch size"),
|
||||
]
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return "A block that determines batch_size based on the number of prompts and num_images_per_prompt argument."
|
||||
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
batch_size = len(block_state.prompt)
|
||||
block_state.batch_size = batch_size * block_state.num_images_per_prompt
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="ImageEncoderBlock">
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import PipelineBlock, InputParam, OutputParam
|
||||
import torch
|
||||
from diffusers.modular_pipelines import ModularPipelineBlocks, InputParam, OutputParam
|
||||
|
||||
def make_block(inputs=[], intermediate_inputs=[], intermediate_outputs=[], block_fn=None, description=None):
|
||||
class TestBlock(PipelineBlock):
|
||||
model_name = "test"
|
||||
|
||||
@property
|
||||
def inputs(self):
|
||||
return inputs
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self):
|
||||
return intermediate_inputs
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self):
|
||||
return intermediate_outputs
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return description if description is not None else ""
|
||||
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
if block_fn is not None:
|
||||
block_state = block_fn(block_state, state)
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
|
||||
return TestBlock
|
||||
class ImageEncoderBlock(ModularPipelineBlocks):
|
||||
|
||||
@property
|
||||
def inputs(self):
|
||||
return [
|
||||
InputParam(name="image", type_hint="PIL.Image", description="raw input image to process"),
|
||||
InputParam(name="batch_size", type_hint=int),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self):
|
||||
return [
|
||||
OutputParam(name="image_latents", description="latents representing the image"),
|
||||
]
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return "Encode raw image into its latent presentation"
|
||||
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
# Simulate processing the image
|
||||
# This will change the state of the image from a PIL image to a tensor for all blocks
|
||||
block_state.image = torch.randn(1, 3, 512, 512)
|
||||
block_state.batch_size = block_state.batch_size * 2
|
||||
block_state.image_latents = torch.randn(1, 4, 64, 64)
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
Let's create a block that produces `batch_size`, which we'll call "input_block":
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
```py
|
||||
def input_block_fn(block_state, pipeline_state):
|
||||
|
||||
batch_size = len(block_state.prompt)
|
||||
block_state.batch_size = batch_size * block_state.num_images_per_prompt
|
||||
|
||||
return block_state
|
||||
Connect the two blocks by defining an [`InsertableDict`] to map the block names to the block instances. Blocks are executed in the order they're registered in `blocks_dict`.
|
||||
|
||||
input_block_cls = make_block(
|
||||
inputs=[
|
||||
InputParam(name="prompt", type_hint=list, description="list of text prompts"),
|
||||
InputParam(name="num_images_per_prompt", type_hint=int, description="number of images per prompt")
|
||||
],
|
||||
intermediate_outputs=[
|
||||
OutputParam(name="batch_size", description="calculated batch size")
|
||||
],
|
||||
block_fn=input_block_fn,
|
||||
description="A block that determines batch_size based on the number of prompts and num_images_per_prompt argument."
|
||||
)
|
||||
input_block = input_block_cls()
|
||||
```
|
||||
|
||||
Now let's create a second block that uses the `batch_size` from the first block:
|
||||
|
||||
```py
|
||||
def image_encoder_block_fn(block_state, pipeline_state):
|
||||
# Simulate processing the image
|
||||
block_state.image = torch.randn(1, 3, 512, 512)
|
||||
block_state.batch_size = block_state.batch_size * 2
|
||||
block_state.image_latents = torch.randn(1, 4, 64, 64)
|
||||
return block_state
|
||||
|
||||
image_encoder_block_cls = make_block(
|
||||
inputs=[
|
||||
InputParam(name="image", type_hint="PIL.Image", description="raw input image to process")
|
||||
],
|
||||
intermediate_inputs=[
|
||||
InputParam(name="batch_size", type_hint=int)
|
||||
],
|
||||
intermediate_outputs=[
|
||||
OutputParam(name="image_latents", description="latents representing the image")
|
||||
],
|
||||
block_fn=image_encoder_block_fn,
|
||||
description="Encode raw image into its latent presentation"
|
||||
)
|
||||
image_encoder_block = image_encoder_block_cls()
|
||||
```
|
||||
|
||||
Now let's connect these blocks to create a `SequentialPipelineBlocks`:
|
||||
Use [`~modular_pipelines.SequentialPipelineBlocks.from_blocks_dict`] to create a [`~modular_pipelines.SequentialPipelineBlocks`].
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import SequentialPipelineBlocks, InsertableDict
|
||||
|
||||
# Define a dict mapping block names to block instances
|
||||
blocks_dict = InsertableDict()
|
||||
blocks_dict["input"] = input_block
|
||||
blocks_dict["image_encoder"] = image_encoder_block
|
||||
|
||||
# Create the SequentialPipelineBlocks
|
||||
blocks = SequentialPipelineBlocks.from_blocks_dict(blocks_dict)
|
||||
```
|
||||
|
||||
Now you have a `SequentialPipelineBlocks` with 2 blocks:
|
||||
Inspect the sub-blocks in [`~modular_pipelines.SequentialPipelineBlocks`] by calling `blocks`, and for more details about the inputs and outputs, access the `docs` attribute.
|
||||
|
||||
```py
|
||||
>>> blocks
|
||||
SequentialPipelineBlocks(
|
||||
Class: ModularPipelineBlocks
|
||||
|
||||
Description:
|
||||
|
||||
|
||||
Sub-Blocks:
|
||||
[0] input (TestBlock)
|
||||
Description: A block that determines batch_size based on the number of prompts and num_images_per_prompt argument.
|
||||
|
||||
[1] image_encoder (TestBlock)
|
||||
Description: Encode raw image into its latent presentation
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
When you inspect `blocks.doc`, you can see that `batch_size` is not listed as an input. The pipeline automatically detects that the `input_block` can produce `batch_size` for the `image_encoder_block`, so it doesn't ask the user to provide it.
|
||||
|
||||
```py
|
||||
>>> print(blocks.doc)
|
||||
class SequentialPipelineBlocks
|
||||
|
||||
Inputs:
|
||||
|
||||
prompt (`None`, *optional*):
|
||||
|
||||
num_images_per_prompt (`None`, *optional*):
|
||||
|
||||
image (`PIL.Image`, *optional*):
|
||||
raw input image to process
|
||||
|
||||
Outputs:
|
||||
|
||||
batch_size (`None`):
|
||||
|
||||
image_latents (`None`):
|
||||
latents representing the image
|
||||
```
|
||||
|
||||
At runtime, you have data flow like this:
|
||||
|
||||

|
||||
|
||||
**How SequentialPipelineBlocks Works:**
|
||||
|
||||
1. Blocks are executed in the order they're registered in the `blocks_dict`
|
||||
2. Outputs from one block become available as intermediate inputs to all subsequent blocks
|
||||
3. The pipeline automatically figures out which values need to be provided by the user and which will be generated by previous blocks
|
||||
4. Each block maintains its own behavior and operates through its defined interface, while collectively these interfaces determine what the entire pipeline accepts and produces
|
||||
|
||||
What happens within each block follows the same pattern we described earlier: each block gets its own `block_state` with the relevant inputs and intermediate inputs, performs its computation, and updates the pipeline state with its intermediate outputs.
|
||||
print(blocks)
|
||||
print(blocks.doc)
|
||||
```
|
||||
@@ -10,314 +10,223 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
[[open-in-colab]]
|
||||
# Quickstart
|
||||
|
||||
# Quicktour
|
||||
Diffusers is a library for developers and researchers that provides an easy inference API for generating images, videos and audio, as well as the building blocks for implementing new workflows.
|
||||
|
||||
Diffusion models are trained to denoise random Gaussian noise step-by-step to generate a sample of interest, such as an image or audio. This has sparked a tremendous amount of interest in generative AI, and you have probably seen examples of diffusion generated images on the internet. 🧨 Diffusers is a library aimed at making diffusion models widely accessible to everyone.
|
||||
Diffusers provides many optimizations out-of-the-box that makes it possible to load and run large models on setups with limited memory or to accelerate inference.
|
||||
|
||||
Whether you're a developer or an everyday user, this quicktour will introduce you to 🧨 Diffusers and help you get up and generating quickly! There are three main components of the library to know about:
|
||||
This Quickstart will give you an overview of Diffusers and get you up and generating quickly.
|
||||
|
||||
* The [`DiffusionPipeline`] is a high-level end-to-end class designed to rapidly generate samples from pretrained diffusion models for inference.
|
||||
* Popular pretrained [model](./api/models) architectures and modules that can be used as building blocks for creating diffusion systems.
|
||||
* Many different [schedulers](./api/schedulers/overview) - algorithms that control how noise is added for training, and how to generate denoised images during inference.
|
||||
> [!TIP]
|
||||
> Before you begin, make sure you have a Hugging Face [account](https://huggingface.co/join) in order to use gated models like [Flux](https://huggingface.co/black-forest-labs/FLUX.1-dev).
|
||||
|
||||
The quicktour will show you how to use the [`DiffusionPipeline`] for inference, and then walk you through how to combine a model and scheduler to replicate what's happening inside the [`DiffusionPipeline`].
|
||||
|
||||
<Tip>
|
||||
|
||||
The quicktour is a simplified version of the introductory 🧨 Diffusers [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb) to help you get started quickly. If you want to learn more about 🧨 Diffusers' goal, design philosophy, and additional details about its core API, check out the notebook!
|
||||
|
||||
</Tip>
|
||||
|
||||
Before you begin, make sure you have all the necessary libraries installed:
|
||||
|
||||
```py
|
||||
# uncomment to install the necessary libraries in Colab
|
||||
#!pip install --upgrade diffusers accelerate transformers
|
||||
```
|
||||
|
||||
- [🤗 Accelerate](https://huggingface.co/docs/accelerate/index) speeds up model loading for inference and training.
|
||||
- [🤗 Transformers](https://huggingface.co/docs/transformers/index) is required to run the most popular diffusion models, such as [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview).
|
||||
Follow the [Installation](./installation) guide to install Diffusers if it's not already installed.
|
||||
|
||||
## DiffusionPipeline
|
||||
|
||||
The [`DiffusionPipeline`] is the easiest way to use a pretrained diffusion system for inference. It is an end-to-end system containing the model and the scheduler. You can use the [`DiffusionPipeline`] out-of-the-box for many tasks. Take a look at the table below for some supported tasks, and for a complete list of supported tasks, check out the [🧨 Diffusers Summary](./api/pipelines/overview#diffusers-summary) table.
|
||||
A diffusion model combines multiple components to generate outputs in any modality based on an input, such as a text description, image or both.
|
||||
|
||||
| **Task** | **Description** | **Pipeline**
|
||||
|------------------------------|--------------------------------------------------------------------------------------------------------------|-----------------|
|
||||
| Unconditional Image Generation | generate an image from Gaussian noise | [unconditional_image_generation](./using-diffusers/unconditional_image_generation) |
|
||||
| Text-Guided Image Generation | generate an image given a text prompt | [conditional_image_generation](./using-diffusers/conditional_image_generation) |
|
||||
| Text-Guided Image-to-Image Translation | adapt an image guided by a text prompt | [img2img](./using-diffusers/img2img) |
|
||||
| Text-Guided Image-Inpainting | fill the masked part of an image given the image, the mask and a text prompt | [inpaint](./using-diffusers/inpaint) |
|
||||
| Text-Guided Depth-to-Image Translation | adapt parts of an image guided by a text prompt while preserving structure via depth estimation | [depth2img](./using-diffusers/depth2img) |
|
||||
For a standard text-to-image model:
|
||||
|
||||
Start by creating an instance of a [`DiffusionPipeline`] and specify which pipeline checkpoint you would like to download.
|
||||
You can use the [`DiffusionPipeline`] for any [checkpoint](https://huggingface.co/models?library=diffusers&sort=downloads) stored on the Hugging Face Hub.
|
||||
In this quicktour, you'll load the [`stable-diffusion-v1-5`](https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5) checkpoint for text-to-image generation.
|
||||
1. A text encoder turns a prompt into embeddings that guide the denoising process. Some models have more than one text encoder.
|
||||
2. A scheduler contains the algorithmic specifics for gradually denoising initial random noise into clean outputs. Different schedulers affect generation speed and quality.
|
||||
3. A UNet or diffusion transformer (DiT) is the workhorse of a diffusion model.
|
||||
|
||||
<Tip warning={true}>
|
||||
At each step, it performs the denoising predictions, such as how much noise to remove or the general direction in which to steer the noise to generate better quality outputs.
|
||||
|
||||
For [Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion) models, please carefully read the [license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) first before running the model. 🧨 Diffusers implements a [`safety_checker`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) to prevent offensive or harmful content, but the model's improved image generation capabilities can still produce potentially harmful content.
|
||||
The UNet or DiT repeats this loop for a set amount of steps to generate the final output.
|
||||
|
||||
4. A variational autoencoder (VAE) encodes and decodes pixels to a spatially compressed latent-space. *Latents* are compressed representations of an image and are more efficient to work with. The UNet or DiT operates on latents, and the clean latents at the end are decoded back into images.
|
||||
|
||||
</Tip>
|
||||
The [`DiffusionPipeline`] packages all these components into a single class for inference. There are several arguments in [`~DiffusionPipeline.__call__`] you can change, such as `num_inference_steps`, that affect the diffusion process. Try different values and arguments to see how they change generation quality or speed.
|
||||
|
||||
Load the model with the [`~DiffusionPipeline.from_pretrained`] method:
|
||||
Load a model with [`~DiffusionPipeline.from_pretrained`] and describe what you'd like to generate. The example below uses the default argument values.
|
||||
|
||||
```python
|
||||
>>> from diffusers import DiffusionPipeline
|
||||
<hfoptions id="diffusionpipeline">
|
||||
<hfoption id="text-to-image">
|
||||
|
||||
>>> pipeline = DiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", use_safetensors=True)
|
||||
```
|
||||
|
||||
The [`DiffusionPipeline`] downloads and caches all modeling, tokenization, and scheduling components. You'll see that the Stable Diffusion pipeline is composed of the [`UNet2DConditionModel`] and [`PNDMScheduler`] among other things:
|
||||
Use `.images[0]` to access the generated image output.
|
||||
|
||||
```py
|
||||
>>> pipeline
|
||||
StableDiffusionPipeline {
|
||||
"_class_name": "StableDiffusionPipeline",
|
||||
"_diffusers_version": "0.21.4",
|
||||
...,
|
||||
"scheduler": [
|
||||
"diffusers",
|
||||
"PNDMScheduler"
|
||||
],
|
||||
...,
|
||||
"unet": [
|
||||
"diffusers",
|
||||
"UNet2DConditionModel"
|
||||
],
|
||||
"vae": [
|
||||
"diffusers",
|
||||
"AutoencoderKL"
|
||||
]
|
||||
}
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"Qwen/Qwen-Image", torch_dtype=torch.bfloat16, device_map="cuda"
|
||||
)
|
||||
|
||||
prompt = """
|
||||
cinematic film still of a cat sipping a margarita in a pool in Palm Springs, California
|
||||
highly detailed, high budget hollywood movie, cinemascope, moody, epic, gorgeous, film grain
|
||||
"""
|
||||
pipeline(prompt).images[0]
|
||||
```
|
||||
|
||||
We strongly recommend running the pipeline on a GPU because the model consists of roughly 1.4 billion parameters.
|
||||
You can move the generator object to a GPU, just like you would in PyTorch:
|
||||
</hfoption>
|
||||
<hfoption id="text-to-video">
|
||||
|
||||
```python
|
||||
>>> pipeline.to("cuda")
|
||||
```
|
||||
|
||||
Now you can pass a text prompt to the `pipeline` to generate an image, and then access the denoised image. By default, the image output is wrapped in a [`PIL.Image`](https://pillow.readthedocs.io/en/stable/reference/Image.html?highlight=image#the-image-class) object.
|
||||
|
||||
```python
|
||||
>>> image = pipeline("An image of a squirrel in Picasso style").images[0]
|
||||
>>> image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/image_of_squirrel_painting.png"/>
|
||||
</div>
|
||||
|
||||
Save the image by calling `save`:
|
||||
|
||||
```python
|
||||
>>> image.save("image_of_squirrel_painting.png")
|
||||
```
|
||||
|
||||
### Local pipeline
|
||||
|
||||
You can also use the pipeline locally. The only difference is you need to download the weights first:
|
||||
|
||||
```bash
|
||||
!git lfs install
|
||||
!git clone https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5
|
||||
```
|
||||
|
||||
Then load the saved weights into the pipeline:
|
||||
|
||||
```python
|
||||
>>> pipeline = DiffusionPipeline.from_pretrained("./stable-diffusion-v1-5", use_safetensors=True)
|
||||
```
|
||||
|
||||
Now, you can run the pipeline as you would in the section above.
|
||||
|
||||
### Swapping schedulers
|
||||
|
||||
Different schedulers come with different denoising speeds and quality trade-offs. The best way to find out which one works best for you is to try them out! One of the main features of 🧨 Diffusers is to allow you to easily switch between schedulers. For example, to replace the default [`PNDMScheduler`] with the [`EulerDiscreteScheduler`], load it with the [`~diffusers.ConfigMixin.from_config`] method:
|
||||
Use `.frames[0]` to access the generated video output and [`~utils.export_to_video`] to save the video.
|
||||
|
||||
```py
|
||||
>>> from diffusers import EulerDiscreteScheduler
|
||||
import torch
|
||||
from diffusers import AutoencoderKLWan, DiffusionPipeline
|
||||
from diffusers.quantizers import PipelineQuantizationConfig
|
||||
from diffusers.utils import export_to_video
|
||||
|
||||
>>> pipeline = DiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", use_safetensors=True)
|
||||
>>> pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
|
||||
vae = AutoencoderKLWan.from_pretrained(
|
||||
"Wan-AI/Wan2.2-T2V-A14B-Diffusers",
|
||||
subfolder="vae",
|
||||
torch_dtype=torch.float32
|
||||
)
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"Wan-AI/Wan2.2-T2V-A14B-Diffusers",
|
||||
vae=vae
|
||||
torch_dtype=torch.bfloat16,
|
||||
device_map="cuda"
|
||||
)
|
||||
|
||||
prompt = """
|
||||
Cinematic video of a sleek cat lounging on a colorful inflatable in a crystal-clear turquoise pool in Palm Springs,
|
||||
sipping a salt-rimmed margarita through a straw. Golden-hour sunlight glows over mid-century modern homes and swaying palms.
|
||||
Shot in rich Sony a7S III: with moody, glamorous color grading, subtle lens flares, and soft vintage film grain.
|
||||
Ripples shimmer as a warm desert breeze stirs the water, blending luxury and playful charm in an epic, gorgeously composed frame.
|
||||
"""
|
||||
video = pipeline(prompt=prompt, num_frames=81, num_inference_steps=40).frames[0]
|
||||
export_to_video(video, "output.mp4", fps=16)
|
||||
```
|
||||
|
||||
Try generating an image with the new scheduler and see if you notice a difference!
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
In the next section, you'll take a closer look at the components - the model and scheduler - that make up the [`DiffusionPipeline`] and learn how to use these components to generate an image of a cat.
|
||||
## LoRA
|
||||
|
||||
## Models
|
||||
Adapters insert a small number of trainable parameters to the original base model. Only the inserted parameters are fine-tuned while the rest of the model weights remain frozen. This makes it fast and cheap to fine-tune a model on a new style. Among adapters, [LoRA's](./tutorials/using_peft_for_inference) are the most popular.
|
||||
|
||||
Most models take a noisy sample, and at each timestep it predicts the *noise residual* (other models learn to predict the previous sample directly or the velocity or [`v-prediction`](https://github.com/huggingface/diffusers/blob/5e5ce13e2f89ac45a0066cb3f369462a3cf1d9ef/src/diffusers/schedulers/scheduling_ddim.py#L110)), the difference between a less noisy image and the input image. You can mix and match models to create other diffusion systems.
|
||||
|
||||
Models are initiated with the [`~ModelMixin.from_pretrained`] method which also locally caches the model weights so it is faster the next time you load the model. For the quicktour, you'll load the [`UNet2DModel`], a basic unconditional image generation model with a checkpoint trained on cat images:
|
||||
Add a LoRA to a pipeline with the [`~loaders.QwenImageLoraLoaderMixin.load_lora_weights`] method. Some LoRA's require a special word to trigger it, such as `Realism`, in the example below. Check a LoRA's model card to see if it requires a trigger word.
|
||||
|
||||
```py
|
||||
>>> from diffusers import UNet2DModel
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
>>> repo_id = "google/ddpm-cat-256"
|
||||
>>> model = UNet2DModel.from_pretrained(repo_id, use_safetensors=True)
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"Qwen/Qwen-Image", torch_dtype=torch.bfloat16, device_map="cuda"
|
||||
)
|
||||
pipeline.load_lora_weights(
|
||||
"flymy-ai/qwen-image-realism-lora",
|
||||
)
|
||||
|
||||
prompt = """
|
||||
super Realism cinematic film still of a cat sipping a margarita in a pool in Palm Springs in the style of umempart, California
|
||||
highly detailed, high budget hollywood movie, cinemascope, moody, epic, gorgeous, film grain
|
||||
"""
|
||||
pipeline(prompt).images[0]
|
||||
```
|
||||
|
||||
Check out the [LoRA](./tutorials/using_peft_for_inference) docs or Adapters section to learn more.
|
||||
|
||||
## Quantization
|
||||
|
||||
[Quantization](./quantization/overview) stores data in fewer bits to reduce memory usage. It may also speed up inference because it takes less time to perform calculations with fewer bits.
|
||||
|
||||
Diffusers provides several quantization backends and picking one depends on your use case. For example, [bitsandbytes](./quantization/bitsandbytes) and [torchao](./quantization/torchao) are both simple and easy to use for inference, but torchao supports more [quantization types](./quantization/torchao#supported-quantization-types) like fp8.
|
||||
|
||||
Configure [`PipelineQuantizationConfig`] with the backend to use, the specific arguments (refer to the [API](./api/quantization) reference for available arguments) for that backend, and which components to quantize. The example below quantizes the model to 4-bits and only uses 14.93GB of memory.
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
from diffusers.quantizers import PipelineQuantizationConfig
|
||||
|
||||
quant_config = PipelineQuantizationConfig(
|
||||
quant_backend="bitsandbytes_4bit",
|
||||
quant_kwargs={"load_in_4bit": True, "bnb_4bit_quant_type": "nf4", "bnb_4bit_compute_dtype": torch.bfloat16},
|
||||
components_to_quantize=["transformer", "text_encoder"],
|
||||
)
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"Qwen/Qwen-Image",
|
||||
torch_dtype=torch.bfloat16,
|
||||
quantization_config=quant_config,
|
||||
device_map="cuda"
|
||||
)
|
||||
|
||||
prompt = """
|
||||
cinematic film still of a cat sipping a margarita in a pool in Palm Springs, California
|
||||
highly detailed, high budget hollywood movie, cinemascope, moody, epic, gorgeous, film grain
|
||||
"""
|
||||
pipeline(prompt).images[0]
|
||||
print(f"Max memory reserved: {torch.cuda.max_memory_allocated() / 1024**3:.2f} GB")
|
||||
```
|
||||
|
||||
Take a look at the [Quantization](./quantization/overview) section for more details.
|
||||
|
||||
## Optimizations
|
||||
|
||||
> [!TIP]
|
||||
> Use the [`AutoModel`] API to automatically select a model class if you're unsure of which one to use.
|
||||
> Optimization is dependent on hardware specs such as memory. Use this [Space](https://huggingface.co/spaces/diffusers/optimized-diffusers-code) to generate code examples that include all of Diffusers' available memory and speed optimization techniques for any model you're using.
|
||||
|
||||
To access the model parameters, call `model.config`:
|
||||
Modern diffusion models are very large and have billions of parameters. The iterative denoising process is also computationally intensive and slow. Diffusers provides techniques for reducing memory usage and boosting inference speed. These techniques can be combined with quantization to optimize for both memory usage and inference speed.
|
||||
|
||||
### Memory usage
|
||||
|
||||
The text encoders and UNet or DiT can use up as much as ~30GB of memory, exceeding the amount available on many free-tier or consumer GPUs.
|
||||
|
||||
Offloading stores weights that aren't currently used on the CPU and only moves them to the GPU when they're needed. There are a few offloading types and the example below uses [model offloading](./optimization/memory#model-offloading). This moves an entire model, like a text encoder or transformer, to the CPU when it isn't actively being used.
|
||||
|
||||
Call [`~DiffusionPipeline.enable_model_cpu_offload`] to activate it. By combining quantization and offloading, the following example only requires ~12.54GB of memory.
|
||||
|
||||
```py
|
||||
>>> model.config
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
from diffusers.quantizers import PipelineQuantizationConfig
|
||||
|
||||
quant_config = PipelineQuantizationConfig(
|
||||
quant_backend="bitsandbytes_4bit",
|
||||
quant_kwargs={"load_in_4bit": True, "bnb_4bit_quant_type": "nf4", "bnb_4bit_compute_dtype": torch.bfloat16},
|
||||
components_to_quantize=["transformer", "text_encoder"],
|
||||
)
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"Qwen/Qwen-Image",
|
||||
torch_dtype=torch.bfloat16,
|
||||
quantization_config=quant_config,
|
||||
device_map="cuda"
|
||||
)
|
||||
pipeline.enable_model_cpu_offload()
|
||||
|
||||
prompt = """
|
||||
cinematic film still of a cat sipping a margarita in a pool in Palm Springs, California
|
||||
highly detailed, high budget hollywood movie, cinemascope, moody, epic, gorgeous, film grain
|
||||
"""
|
||||
pipeline(prompt).images[0]
|
||||
print(f"Max memory reserved: {torch.cuda.max_memory_allocated() / 1024**3:.2f} GB")
|
||||
```
|
||||
|
||||
The model configuration is a 🧊 frozen 🧊 dictionary, which means those parameters can't be changed after the model is created. This is intentional and ensures that the parameters used to define the model architecture at the start remain the same, while other parameters can still be adjusted during inference.
|
||||
Refer to the [Reduce memory usage](./optimization/memory) docs to learn more about other memory reducing techniques.
|
||||
|
||||
Some of the most important parameters are:
|
||||
### Inference speed
|
||||
|
||||
* `sample_size`: the height and width dimension of the input sample.
|
||||
* `in_channels`: the number of input channels of the input sample.
|
||||
* `down_block_types` and `up_block_types`: the type of down- and upsampling blocks used to create the UNet architecture.
|
||||
* `block_out_channels`: the number of output channels of the downsampling blocks; also used in reverse order for the number of input channels of the upsampling blocks.
|
||||
* `layers_per_block`: the number of ResNet blocks present in each UNet block.
|
||||
The denoising loop performs a lot of computations and can be slow. Methods like [torch.compile](./optimization/fp16#torchcompile) increases inference speed by compiling the computations into an optimized kernel. Compilation is slow for the first generation but successive generations should be much faster.
|
||||
|
||||
To use the model for inference, create the image shape with random Gaussian noise. It should have a `batch` axis because the model can receive multiple random noises, a `channel` axis corresponding to the number of input channels, and a `sample_size` axis for the height and width of the image:
|
||||
The example below uses [regional compilation](./optimization/fp16#regional-compilation) to only compile small regions of a model. It reduces cold-start latency while also providing a runtime speed up.
|
||||
|
||||
Call [`~ModelMixin.compile_repeated_blocks`] on the model to activate it.
|
||||
|
||||
```py
|
||||
>>> import torch
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
>>> torch.manual_seed(0)
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"Qwen/Qwen-Image", torch_dtype=torch.bfloat16, device_map="cuda"
|
||||
)
|
||||
|
||||
>>> noisy_sample = torch.randn(1, model.config.in_channels, model.config.sample_size, model.config.sample_size)
|
||||
>>> noisy_sample.shape
|
||||
torch.Size([1, 3, 256, 256])
|
||||
pipeline.transformer.compile_repeated_blocks(
|
||||
fullgraph=True,
|
||||
)
|
||||
prompt = """
|
||||
cinematic film still of a cat sipping a margarita in a pool in Palm Springs, California
|
||||
highly detailed, high budget hollywood movie, cinemascope, moody, epic, gorgeous, film grain
|
||||
"""
|
||||
pipeline(prompt).images[0]
|
||||
```
|
||||
|
||||
For inference, pass the noisy image and a `timestep` to the model. The `timestep` indicates how noisy the input image is, with more noise at the beginning and less at the end. This helps the model determine its position in the diffusion process, whether it is closer to the start or the end. Use the `sample` method to get the model output:
|
||||
|
||||
```py
|
||||
>>> with torch.no_grad():
|
||||
... noisy_residual = model(sample=noisy_sample, timestep=2).sample
|
||||
```
|
||||
|
||||
To generate actual examples though, you'll need a scheduler to guide the denoising process. In the next section, you'll learn how to couple a model with a scheduler.
|
||||
|
||||
## Schedulers
|
||||
|
||||
Schedulers manage going from a noisy sample to a less noisy sample given the model output - in this case, it is the `noisy_residual`.
|
||||
|
||||
<Tip>
|
||||
|
||||
🧨 Diffusers is a toolbox for building diffusion systems. While the [`DiffusionPipeline`] is a convenient way to get started with a pre-built diffusion system, you can also choose your own model and scheduler components separately to build a custom diffusion system.
|
||||
|
||||
</Tip>
|
||||
|
||||
For the quicktour, you'll instantiate the [`DDPMScheduler`] with its [`~diffusers.ConfigMixin.from_config`] method:
|
||||
|
||||
```py
|
||||
>>> from diffusers import DDPMScheduler
|
||||
|
||||
>>> scheduler = DDPMScheduler.from_pretrained(repo_id)
|
||||
>>> scheduler
|
||||
DDPMScheduler {
|
||||
"_class_name": "DDPMScheduler",
|
||||
"_diffusers_version": "0.21.4",
|
||||
"beta_end": 0.02,
|
||||
"beta_schedule": "linear",
|
||||
"beta_start": 0.0001,
|
||||
"clip_sample": true,
|
||||
"clip_sample_range": 1.0,
|
||||
"dynamic_thresholding_ratio": 0.995,
|
||||
"num_train_timesteps": 1000,
|
||||
"prediction_type": "epsilon",
|
||||
"sample_max_value": 1.0,
|
||||
"steps_offset": 0,
|
||||
"thresholding": false,
|
||||
"timestep_spacing": "leading",
|
||||
"trained_betas": null,
|
||||
"variance_type": "fixed_small"
|
||||
}
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 Unlike a model, a scheduler does not have trainable weights and is parameter-free!
|
||||
|
||||
</Tip>
|
||||
|
||||
Some of the most important parameters are:
|
||||
|
||||
* `num_train_timesteps`: the length of the denoising process or, in other words, the number of timesteps required to process random Gaussian noise into a data sample.
|
||||
* `beta_schedule`: the type of noise schedule to use for inference and training.
|
||||
* `beta_start` and `beta_end`: the start and end noise values for the noise schedule.
|
||||
|
||||
To predict a slightly less noisy image, pass the following to the scheduler's [`~diffusers.DDPMScheduler.step`] method: model output, `timestep`, and current `sample`.
|
||||
|
||||
```py
|
||||
>>> less_noisy_sample = scheduler.step(model_output=noisy_residual, timestep=2, sample=noisy_sample).prev_sample
|
||||
>>> less_noisy_sample.shape
|
||||
torch.Size([1, 3, 256, 256])
|
||||
```
|
||||
|
||||
The `less_noisy_sample` can be passed to the next `timestep` where it'll get even less noisy! Let's bring it all together now and visualize the entire denoising process.
|
||||
|
||||
First, create a function that postprocesses and displays the denoised image as a `PIL.Image`:
|
||||
|
||||
```py
|
||||
>>> import PIL.Image
|
||||
>>> import numpy as np
|
||||
|
||||
|
||||
>>> def display_sample(sample, i):
|
||||
... image_processed = sample.cpu().permute(0, 2, 3, 1)
|
||||
... image_processed = (image_processed + 1.0) * 127.5
|
||||
... image_processed = image_processed.numpy().astype(np.uint8)
|
||||
|
||||
... image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
... display(f"Image at step {i}")
|
||||
... display(image_pil)
|
||||
```
|
||||
|
||||
To speed up the denoising process, move the input and model to a GPU:
|
||||
|
||||
```py
|
||||
>>> model.to("cuda")
|
||||
>>> noisy_sample = noisy_sample.to("cuda")
|
||||
```
|
||||
|
||||
Now create a denoising loop that predicts the residual of the less noisy sample, and computes the less noisy sample with the scheduler:
|
||||
|
||||
```py
|
||||
>>> import tqdm
|
||||
|
||||
>>> sample = noisy_sample
|
||||
|
||||
>>> for i, t in enumerate(tqdm.tqdm(scheduler.timesteps)):
|
||||
... # 1. predict noise residual
|
||||
... with torch.no_grad():
|
||||
... residual = model(sample, t).sample
|
||||
|
||||
... # 2. compute less noisy image and set x_t -> x_t-1
|
||||
... sample = scheduler.step(residual, t, sample).prev_sample
|
||||
|
||||
... # 3. optionally look at image
|
||||
... if (i + 1) % 50 == 0:
|
||||
... display_sample(sample, i + 1)
|
||||
```
|
||||
|
||||
Sit back and watch as a cat is generated from nothing but noise! 😻
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/diffusion-quicktour.png"/>
|
||||
</div>
|
||||
|
||||
## Next steps
|
||||
|
||||
Hopefully, you generated some cool images with 🧨 Diffusers in this quicktour! For your next steps, you can:
|
||||
|
||||
* Train or finetune a model to generate your own images in the [training](./tutorials/basic_training) tutorial.
|
||||
* See example official and community [training or finetuning scripts](https://github.com/huggingface/diffusers/tree/main/examples#-diffusers-examples) for a variety of use cases.
|
||||
* Learn more about loading, accessing, changing, and comparing schedulers in the [Using different Schedulers](./using-diffusers/schedulers) guide.
|
||||
* Explore prompt engineering, speed and memory optimizations, and tips and tricks for generating higher-quality images with the [Stable Diffusion](./stable_diffusion) guide.
|
||||
* Dive deeper into speeding up 🧨 Diffusers with guides on [optimized PyTorch on a GPU](./optimization/fp16), and inference guides for running [Stable Diffusion on Apple Silicon (M1/M2)](./optimization/mps) and [ONNX Runtime](./optimization/onnx).
|
||||
Check out the [Accelerate inference](./optimization/fp16) or [Caching](./optimization/cache) docs for more methods that speed up inference.
|
||||
@@ -10,252 +10,123 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Effective and efficient diffusion
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
Getting the [`DiffusionPipeline`] to generate images in a certain style or include what you want can be tricky. Often times, you have to run the [`DiffusionPipeline`] several times before you end up with an image you're happy with. But generating something out of nothing is a computationally intensive process, especially if you're running inference over and over again.
|
||||
# Basic performance
|
||||
|
||||
This is why it's important to get the most *computational* (speed) and *memory* (GPU vRAM) efficiency from the pipeline to reduce the time between inference cycles so you can iterate faster.
|
||||
Diffusion is a random process that is computationally demanding. You may need to run the [`DiffusionPipeline`] several times before getting a desired output. That's why it's important to carefully balance generation speed and memory usage in order to iterate faster,
|
||||
|
||||
This tutorial walks you through how to generate faster and better with the [`DiffusionPipeline`].
|
||||
This guide recommends some basic performance tips for using the [`DiffusionPipeline`]. Refer to the Inference Optimization section docs such as [Accelerate inference](./optimization/fp16) or [Reduce memory usage](./optimization/memory) for more detailed performance guides.
|
||||
|
||||
Begin by loading the [`stable-diffusion-v1-5/stable-diffusion-v1-5`](https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5) model:
|
||||
## Memory usage
|
||||
|
||||
```python
|
||||
Reducing the amount of memory used indirectly speeds up generation and can help a model fit on device.
|
||||
|
||||
The [`~DiffusionPipeline.enable_model_cpu_offload`] method moves a model to the CPU when it is not in use to save GPU memory.
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
model_id = "stable-diffusion-v1-5/stable-diffusion-v1-5"
|
||||
pipeline = DiffusionPipeline.from_pretrained(model_id, use_safetensors=True)
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.bfloat16,
|
||||
device_map="cuda"
|
||||
)
|
||||
pipeline.enable_model_cpu_offload()
|
||||
|
||||
prompt = """
|
||||
cinematic film still of a cat sipping a margarita in a pool in Palm Springs, California
|
||||
highly detailed, high budget hollywood movie, cinemascope, moody, epic, gorgeous, film grain
|
||||
"""
|
||||
pipeline(prompt).images[0]
|
||||
print(f"Max memory reserved: {torch.cuda.max_memory_allocated() / 1024**3:.2f} GB")
|
||||
```
|
||||
|
||||
The example prompt you'll use is a portrait of an old warrior chief, but feel free to use your own prompt:
|
||||
## Inference speed
|
||||
|
||||
```python
|
||||
prompt = "portrait photo of a old warrior chief"
|
||||
```
|
||||
Denoising is the most computationally demanding process during diffusion. Methods that optimizes this process accelerates inference speed. Try the following methods for a speed up.
|
||||
|
||||
## Speed
|
||||
- Add `device_map="cuda"` to place the pipeline on a GPU. Placing a model on an accelerator, like a GPU, increases speed because it performs computations in parallel.
|
||||
- Set `torch_dtype=torch.bfloat16` to execute the pipeline in half-precision. Reducing the data type precision increases speed because it takes less time to perform computations in a lower precision.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 If you don't have access to a GPU, you can use one for free from a GPU provider like [Colab](https://colab.research.google.com/)!
|
||||
|
||||
</Tip>
|
||||
|
||||
One of the simplest ways to speed up inference is to place the pipeline on a GPU the same way you would with any PyTorch module:
|
||||
|
||||
```python
|
||||
pipeline = pipeline.to("cuda")
|
||||
```
|
||||
|
||||
To make sure you can use the same image and improve on it, use a [`Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) and set a seed for [reproducibility](./using-diffusers/reusing_seeds):
|
||||
|
||||
```python
|
||||
```py
|
||||
import torch
|
||||
import time
|
||||
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
|
||||
|
||||
generator = torch.Generator("cuda").manual_seed(0)
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.bfloat16,
|
||||
device_map="cuda
|
||||
)
|
||||
```
|
||||
|
||||
Now you can generate an image:
|
||||
|
||||
```python
|
||||
image = pipeline(prompt, generator=generator).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/stable_diffusion_101/sd_101_1.png">
|
||||
</div>
|
||||
|
||||
This process took ~30 seconds on a T4 GPU (it might be faster if your allocated GPU is better than a T4). By default, the [`DiffusionPipeline`] runs inference with full `float32` precision for 50 inference steps. You can speed this up by switching to a lower precision like `float16` or running fewer inference steps.
|
||||
|
||||
Let's start by loading the model in `float16` and generate an image:
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16, use_safetensors=True)
|
||||
pipeline = pipeline.to("cuda")
|
||||
generator = torch.Generator("cuda").manual_seed(0)
|
||||
image = pipeline(prompt, generator=generator).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/stable_diffusion_101/sd_101_2.png">
|
||||
</div>
|
||||
|
||||
This time, it only took ~11 seconds to generate the image, which is almost 3x faster than before!
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 We strongly suggest always running your pipelines in `float16`, and so far, we've rarely seen any degradation in output quality.
|
||||
|
||||
</Tip>
|
||||
|
||||
Another option is to reduce the number of inference steps. Choosing a more efficient scheduler could help decrease the number of steps without sacrificing output quality. You can find which schedulers are compatible with the current model in the [`DiffusionPipeline`] by calling the `compatibles` method:
|
||||
|
||||
```python
|
||||
pipeline.scheduler.compatibles
|
||||
[
|
||||
diffusers.schedulers.scheduling_lms_discrete.LMSDiscreteScheduler,
|
||||
diffusers.schedulers.scheduling_unipc_multistep.UniPCMultistepScheduler,
|
||||
diffusers.schedulers.scheduling_k_dpm_2_discrete.KDPM2DiscreteScheduler,
|
||||
diffusers.schedulers.scheduling_deis_multistep.DEISMultistepScheduler,
|
||||
diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler,
|
||||
diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler,
|
||||
diffusers.schedulers.scheduling_ddpm.DDPMScheduler,
|
||||
diffusers.schedulers.scheduling_dpmsolver_singlestep.DPMSolverSinglestepScheduler,
|
||||
diffusers.schedulers.scheduling_k_dpm_2_ancestral_discrete.KDPM2AncestralDiscreteScheduler,
|
||||
diffusers.utils.dummy_torch_and_torchsde_objects.DPMSolverSDEScheduler,
|
||||
diffusers.schedulers.scheduling_heun_discrete.HeunDiscreteScheduler,
|
||||
diffusers.schedulers.scheduling_pndm.PNDMScheduler,
|
||||
diffusers.schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteScheduler,
|
||||
diffusers.schedulers.scheduling_ddim.DDIMScheduler,
|
||||
]
|
||||
```
|
||||
|
||||
The Stable Diffusion model uses the [`PNDMScheduler`] by default which usually requires ~50 inference steps, but more performant schedulers like [`DPMSolverMultistepScheduler`], require only ~20 or 25 inference steps. Use the [`~ConfigMixin.from_config`] method to load a new scheduler:
|
||||
|
||||
```python
|
||||
from diffusers import DPMSolverMultistepScheduler
|
||||
- Use a faster scheduler, such as [`DPMSolverMultistepScheduler`], which only requires ~20-25 steps.
|
||||
- Set `num_inference_steps` to a lower value. Reducing the number of inference steps reduces the overall number of computations. However, this can result in lower generation quality.
|
||||
|
||||
```py
|
||||
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
|
||||
|
||||
prompt = """
|
||||
cinematic film still of a cat sipping a margarita in a pool in Palm Springs, California
|
||||
highly detailed, high budget hollywood movie, cinemascope, moody, epic, gorgeous, film grain
|
||||
"""
|
||||
|
||||
start_time = time.perf_counter()
|
||||
image = pipeline(prompt).images[0]
|
||||
end_time = time.perf_counter()
|
||||
|
||||
print(f"Image generation took {end_time - start_time:.3f} seconds")
|
||||
```
|
||||
|
||||
Now set the `num_inference_steps` to 20:
|
||||
## Generation quality
|
||||
|
||||
```python
|
||||
generator = torch.Generator("cuda").manual_seed(0)
|
||||
image = pipeline(prompt, generator=generator, num_inference_steps=20).images[0]
|
||||
image
|
||||
```
|
||||
Many modern diffusion models deliver high-quality images out-of-the-box. However, you can still improve generation quality by trying the following.
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/stable_diffusion_101/sd_101_3.png">
|
||||
</div>
|
||||
- Try a more detailed and descriptive prompt. Include details such as the image medium, subject, style, and aesthetic. A negative prompt may also help by guiding a model away from undesirable features by using words like low quality or blurry.
|
||||
|
||||
Great, you've managed to cut the inference time to just 4 seconds! ⚡️
|
||||
```py
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
## Memory
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.bfloat16,
|
||||
device_map="cuda"
|
||||
)
|
||||
|
||||
The other key to improving pipeline performance is consuming less memory, which indirectly implies more speed, since you're often trying to maximize the number of images generated per second. The easiest way to see how many images you can generate at once is to try out different batch sizes until you get an `OutOfMemoryError` (OOM).
|
||||
prompt = """
|
||||
cinematic film still of a cat sipping a margarita in a pool in Palm Springs, California
|
||||
highly detailed, high budget hollywood movie, cinemascope, moody, epic, gorgeous, film grain
|
||||
"""
|
||||
negative_prompt = "low quality, blurry, ugly, poor details"
|
||||
pipeline(prompt, negative_prompt=negative_prompt).images[0]
|
||||
```
|
||||
|
||||
Create a function that'll generate a batch of images from a list of prompts and `Generators`. Make sure to assign each `Generator` a seed so you can reuse it if it produces a good result.
|
||||
For more details about creating better prompts, take a look at the [Prompt techniques](./using-diffusers/weighted_prompts) doc.
|
||||
|
||||
```python
|
||||
def get_inputs(batch_size=1):
|
||||
generator = [torch.Generator("cuda").manual_seed(i) for i in range(batch_size)]
|
||||
prompts = batch_size * [prompt]
|
||||
num_inference_steps = 20
|
||||
- Try a different scheduler, like [`HeunDiscreteScheduler`] or [`LMSDiscreteScheduler`], that gives up generation speed for quality.
|
||||
|
||||
return {"prompt": prompts, "generator": generator, "num_inference_steps": num_inference_steps}
|
||||
```
|
||||
```py
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline, HeunDiscreteScheduler
|
||||
|
||||
Start with `batch_size=4` and see how much memory you've consumed:
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.bfloat16,
|
||||
device_map="cuda"
|
||||
)
|
||||
pipeline.scheduler = HeunDiscreteScheduler.from_config(pipeline.scheduler.config)
|
||||
|
||||
```python
|
||||
from diffusers.utils import make_image_grid
|
||||
|
||||
images = pipeline(**get_inputs(batch_size=4)).images
|
||||
make_image_grid(images, 2, 2)
|
||||
```
|
||||
|
||||
Unless you have a GPU with more vRAM, the code above probably returned an `OOM` error! Most of the memory is taken up by the cross-attention layers. Instead of running this operation in a batch, you can run it sequentially to save a significant amount of memory. All you have to do is configure the pipeline to use the [`~DiffusionPipeline.enable_attention_slicing`] function:
|
||||
|
||||
```python
|
||||
pipeline.enable_attention_slicing()
|
||||
```
|
||||
|
||||
Now try increasing the `batch_size` to 8!
|
||||
|
||||
```python
|
||||
images = pipeline(**get_inputs(batch_size=8)).images
|
||||
make_image_grid(images, rows=2, cols=4)
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/stable_diffusion_101/sd_101_5.png">
|
||||
</div>
|
||||
|
||||
Whereas before you couldn't even generate a batch of 4 images, now you can generate a batch of 8 images at ~3.5 seconds per image! This is probably the fastest you can go on a T4 GPU without sacrificing quality.
|
||||
|
||||
## Quality
|
||||
|
||||
In the last two sections, you learned how to optimize the speed of your pipeline by using `fp16`, reducing the number of inference steps by using a more performant scheduler, and enabling attention slicing to reduce memory consumption. Now you're going to focus on how to improve the quality of generated images.
|
||||
|
||||
### Better checkpoints
|
||||
|
||||
The most obvious step is to use better checkpoints. The Stable Diffusion model is a good starting point, and since its official launch, several improved versions have also been released. However, using a newer version doesn't automatically mean you'll get better results. You'll still have to experiment with different checkpoints yourself, and do a little research (such as using [negative prompts](https://minimaxir.com/2022/11/stable-diffusion-negative-prompt/)) to get the best results.
|
||||
|
||||
As the field grows, there are more and more high-quality checkpoints finetuned to produce certain styles. Try exploring the [Hub](https://huggingface.co/models?library=diffusers&sort=downloads) and [Diffusers Gallery](https://huggingface.co/spaces/huggingface-projects/diffusers-gallery) to find one you're interested in!
|
||||
|
||||
### Better pipeline components
|
||||
|
||||
You can also try replacing the current pipeline components with a newer version. Let's try loading the latest [autoencoder](https://huggingface.co/stabilityai/stable-diffusion-2-1/tree/main/vae) from Stability AI into the pipeline, and generate some images:
|
||||
|
||||
```python
|
||||
from diffusers import AutoencoderKL
|
||||
|
||||
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse", torch_dtype=torch.float16).to("cuda")
|
||||
pipeline.vae = vae
|
||||
images = pipeline(**get_inputs(batch_size=8)).images
|
||||
make_image_grid(images, rows=2, cols=4)
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/stable_diffusion_101/sd_101_6.png">
|
||||
</div>
|
||||
|
||||
### Better prompt engineering
|
||||
|
||||
The text prompt you use to generate an image is super important, so much so that it is called *prompt engineering*. Some considerations to keep during prompt engineering are:
|
||||
|
||||
- How is the image or similar images of the one I want to generate stored on the internet?
|
||||
- What additional detail can I give that steers the model towards the style I want?
|
||||
|
||||
With this in mind, let's improve the prompt to include color and higher quality details:
|
||||
|
||||
```python
|
||||
prompt += ", tribal panther make up, blue on red, side profile, looking away, serious eyes"
|
||||
prompt += " 50mm portrait photography, hard rim lighting photography--beta --ar 2:3 --beta --upbeta"
|
||||
```
|
||||
|
||||
Generate a batch of images with the new prompt:
|
||||
|
||||
```python
|
||||
images = pipeline(**get_inputs(batch_size=8)).images
|
||||
make_image_grid(images, rows=2, cols=4)
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/stable_diffusion_101/sd_101_7.png">
|
||||
</div>
|
||||
|
||||
Pretty impressive! Let's tweak the second image - corresponding to the `Generator` with a seed of `1` - a bit more by adding some text about the age of the subject:
|
||||
|
||||
```python
|
||||
prompts = [
|
||||
"portrait photo of the oldest warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes 50mm portrait photography, hard rim lighting photography--beta --ar 2:3 --beta --upbeta",
|
||||
"portrait photo of an old warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes 50mm portrait photography, hard rim lighting photography--beta --ar 2:3 --beta --upbeta",
|
||||
"portrait photo of a warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes 50mm portrait photography, hard rim lighting photography--beta --ar 2:3 --beta --upbeta",
|
||||
"portrait photo of a young warrior chief, tribal panther make up, blue on red, side profile, looking away, serious eyes 50mm portrait photography, hard rim lighting photography--beta --ar 2:3 --beta --upbeta",
|
||||
]
|
||||
|
||||
generator = [torch.Generator("cuda").manual_seed(1) for _ in range(len(prompts))]
|
||||
images = pipeline(prompt=prompts, generator=generator, num_inference_steps=25).images
|
||||
make_image_grid(images, 2, 2)
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/stable_diffusion_101/sd_101_8.png">
|
||||
</div>
|
||||
prompt = """
|
||||
cinematic film still of a cat sipping a margarita in a pool in Palm Springs, California
|
||||
highly detailed, high budget hollywood movie, cinemascope, moody, epic, gorgeous, film grain
|
||||
"""
|
||||
negative_prompt = "low quality, blurry, ugly, poor details"
|
||||
pipeline(prompt, negative_prompt=negative_prompt).images[0]
|
||||
```
|
||||
|
||||
## Next steps
|
||||
|
||||
In this tutorial, you learned how to optimize a [`DiffusionPipeline`] for computational and memory efficiency as well as improving the quality of generated outputs. If you're interested in making your pipeline even faster, take a look at the following resources:
|
||||
|
||||
- Learn how [PyTorch 2.0](./optimization/fp16) and [`torch.compile`](https://pytorch.org/docs/stable/generated/torch.compile.html) can yield 5 - 300% faster inference speed. On an A100 GPU, inference can be up to 50% faster!
|
||||
- If you can't use PyTorch 2, we recommend you install [xFormers](./optimization/xformers). Its memory-efficient attention mechanism works great with PyTorch 1.13.1 for faster speed and reduced memory consumption.
|
||||
- Other optimization techniques, such as model offloading, are covered in [this guide](./optimization/fp16).
|
||||
Diffusers offers more advanced and powerful optimizations such as [group-offloading](./optimization/memory#group-offloading) and [regional compilation](./optimization/fp16#regional-compilation). To learn more about how to maximize performance, take a look at the Inference Optimization section.
|
||||
@@ -12,52 +12,37 @@ specific language governing permissions and limitations under the License.
|
||||
|
||||
# Pipeline callbacks
|
||||
|
||||
The denoising loop of a pipeline can be modified with custom defined functions using the `callback_on_step_end` parameter. The callback function is executed at the end of each step, and modifies the pipeline attributes and variables for the next step. This is really useful for *dynamically* adjusting certain pipeline attributes or modifying tensor variables. This versatility allows for interesting use cases such as changing the prompt embeddings at each timestep, assigning different weights to the prompt embeddings, and editing the guidance scale. With callbacks, you can implement new features without modifying the underlying code!
|
||||
A callback is a function that modifies [`DiffusionPipeline`] behavior and it is executed at the end of a denoising step. The changes are propagated to subsequent steps in the denoising process. It is useful for adjusting pipeline attributes or tensor variables to support new features without rewriting the underlying pipeline code.
|
||||
|
||||
> [!TIP]
|
||||
> 🤗 Diffusers currently only supports `callback_on_step_end`, but feel free to open a [feature request](https://github.com/huggingface/diffusers/issues/new/choose) if you have a cool use-case and require a callback function with a different execution point!
|
||||
Diffusers provides several callbacks in the pipeline [overview](../api/pipelines/overview#callbacks).
|
||||
|
||||
This guide will demonstrate how callbacks work by a few features you can implement with them.
|
||||
To enable a callback, configure when the callback is executed after a certain number of denoising steps with one of the following arguments.
|
||||
|
||||
## Official callbacks
|
||||
- `cutoff_step_ratio` specifies when a callback is activated as a percentage of the total denoising steps.
|
||||
- `cutoff_step_index` specifies the exact step number a callback is activated.
|
||||
|
||||
We provide a list of callbacks you can plug into an existing pipeline and modify the denoising loop. This is the current list of official callbacks:
|
||||
The example below uses `cutoff_step_ratio=0.4`, which means the callback is activated once denoising reaches 40% of the total inference steps. [`~callbacks.SDXLCFGCutoffCallback`] disables classifier-free guidance (CFG) after a certain number of steps, which can help save compute without significantly affecting performance.
|
||||
|
||||
- `SDCFGCutoffCallback`: Disables the CFG after a certain number of steps for all SD 1.5 pipelines, including text-to-image, image-to-image, inpaint, and controlnet.
|
||||
- `SDXLCFGCutoffCallback`: Disables the CFG after a certain number of steps for all SDXL pipelines, including text-to-image, image-to-image, inpaint, and controlnet.
|
||||
- `IPAdapterScaleCutoffCallback`: Disables the IP Adapter after a certain number of steps for all pipelines supporting IP-Adapter.
|
||||
Define a callback with either of the `cutoff` arguments and pass it to the `callback_on_step_end` parameter in the pipeline.
|
||||
|
||||
> [!TIP]
|
||||
> If you want to add a new official callback, feel free to open a [feature request](https://github.com/huggingface/diffusers/issues/new/choose) or [submit a PR](https://huggingface.co/docs/diffusers/main/en/conceptual/contribution#how-to-open-a-pr).
|
||||
|
||||
To set up a callback, you need to specify the number of denoising steps after which the callback comes into effect. You can do so by using either one of these two arguments
|
||||
|
||||
- `cutoff_step_ratio`: Float number with the ratio of the steps.
|
||||
- `cutoff_step_index`: Integer number with the exact number of the step.
|
||||
|
||||
```python
|
||||
```py
|
||||
import torch
|
||||
|
||||
from diffusers import DPMSolverMultistepScheduler, StableDiffusionXLPipeline
|
||||
from diffusers.callbacks import SDXLCFGCutoffCallback
|
||||
|
||||
|
||||
callback = SDXLCFGCutoffCallback(cutoff_step_ratio=0.4)
|
||||
# can also be used with cutoff_step_index
|
||||
# if using cutoff_step_index
|
||||
# callback = SDXLCFGCutoffCallback(cutoff_step_ratio=None, cutoff_step_index=10)
|
||||
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.float16,
|
||||
variant="fp16",
|
||||
).to("cuda")
|
||||
device_map="cuda"
|
||||
)
|
||||
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config, use_karras_sigmas=True)
|
||||
|
||||
prompt = "a sports car at the road, best quality, high quality, high detail, 8k resolution"
|
||||
|
||||
generator = torch.Generator(device="cpu").manual_seed(2628670641)
|
||||
|
||||
out = pipeline(
|
||||
output = pipeline(
|
||||
prompt=prompt,
|
||||
negative_prompt="",
|
||||
guidance_scale=6.5,
|
||||
@@ -65,83 +50,16 @@ out = pipeline(
|
||||
generator=generator,
|
||||
callback_on_step_end=callback,
|
||||
)
|
||||
|
||||
out.images[0].save("official_callback.png")
|
||||
```
|
||||
|
||||
<div class="flex gap-4">
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/without_cfg_callback.png" alt="generated image of a sports car at the road" />
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">without SDXLCFGCutoffCallback</figcaption>
|
||||
</div>
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/with_cfg_callback.png" alt="generated image of a sports car at the road with cfg callback" />
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">with SDXLCFGCutoffCallback</figcaption>
|
||||
</div>
|
||||
</div>
|
||||
If you want to add a new official callback, feel free to open a [feature request](https://github.com/huggingface/diffusers/issues/new/choose) or [submit a PR](https://huggingface.co/docs/diffusers/main/en/conceptual/contribution#how-to-open-a-pr). Otherwise, you can also create your own callback as shown below.
|
||||
|
||||
## Dynamic classifier-free guidance
|
||||
## Early stopping
|
||||
|
||||
Dynamic classifier-free guidance (CFG) is a feature that allows you to disable CFG after a certain number of inference steps which can help you save compute with minimal cost to performance. The callback function for this should have the following arguments:
|
||||
|
||||
- `pipeline` (or the pipeline instance) provides access to important properties such as `num_timesteps` and `guidance_scale`. You can modify these properties by updating the underlying attributes. For this example, you'll disable CFG by setting `pipeline._guidance_scale=0.0`.
|
||||
- `step_index` and `timestep` tell you where you are in the denoising loop. Use `step_index` to turn off CFG after reaching 40% of `num_timesteps`.
|
||||
- `callback_kwargs` is a dict that contains tensor variables you can modify during the denoising loop. It only includes variables specified in the `callback_on_step_end_tensor_inputs` argument, which is passed to the pipeline's `__call__` method. Different pipelines may use different sets of variables, so please check a pipeline's `_callback_tensor_inputs` attribute for the list of variables you can modify. Some common variables include `latents` and `prompt_embeds`. For this function, change the batch size of `prompt_embeds` after setting `guidance_scale=0.0` in order for it to work properly.
|
||||
|
||||
Your callback function should look something like this:
|
||||
|
||||
```python
|
||||
def callback_dynamic_cfg(pipe, step_index, timestep, callback_kwargs):
|
||||
# adjust the batch_size of prompt_embeds according to guidance_scale
|
||||
if step_index == int(pipeline.num_timesteps * 0.4):
|
||||
prompt_embeds = callback_kwargs["prompt_embeds"]
|
||||
prompt_embeds = prompt_embeds.chunk(2)[-1]
|
||||
|
||||
# update guidance_scale and prompt_embeds
|
||||
pipeline._guidance_scale = 0.0
|
||||
callback_kwargs["prompt_embeds"] = prompt_embeds
|
||||
return callback_kwargs
|
||||
```
|
||||
|
||||
Now, you can pass the callback function to the `callback_on_step_end` parameter and the `prompt_embeds` to `callback_on_step_end_tensor_inputs`.
|
||||
Early stopping is useful if you aren't happy with the intermediate results during generation. This callback sets a hardcoded stop point after which the pipeline terminates by setting the `_interrupt` attribute to `True`.
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipeline = StableDiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", torch_dtype=torch.float16)
|
||||
pipeline = pipeline.to("cuda")
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
|
||||
generator = torch.Generator(device="cuda").manual_seed(1)
|
||||
out = pipeline(
|
||||
prompt,
|
||||
generator=generator,
|
||||
callback_on_step_end=callback_dynamic_cfg,
|
||||
callback_on_step_end_tensor_inputs=['prompt_embeds']
|
||||
)
|
||||
|
||||
out.images[0].save("out_custom_cfg.png")
|
||||
```
|
||||
|
||||
## Interrupt the diffusion process
|
||||
|
||||
> [!TIP]
|
||||
> The interruption callback is supported for text-to-image, image-to-image, and inpainting for the [StableDiffusionPipeline](../api/pipelines/stable_diffusion/overview) and [StableDiffusionXLPipeline](../api/pipelines/stable_diffusion/stable_diffusion_xl).
|
||||
|
||||
Stopping the diffusion process early is useful when building UIs that work with Diffusers because it allows users to stop the generation process if they're unhappy with the intermediate results. You can incorporate this into your pipeline with a callback.
|
||||
|
||||
This callback function should take the following arguments: `pipeline`, `i`, `t`, and `callback_kwargs` (this must be returned). Set the pipeline's `_interrupt` attribute to `True` to stop the diffusion process after a certain number of steps. You are also free to implement your own custom stopping logic inside the callback.
|
||||
|
||||
In this example, the diffusion process is stopped after 10 steps even though `num_inference_steps` is set to 50.
|
||||
|
||||
```python
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipeline = StableDiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5")
|
||||
pipeline.enable_model_cpu_offload()
|
||||
num_inference_steps = 50
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
|
||||
def interrupt_callback(pipeline, i, t, callback_kwargs):
|
||||
stop_idx = 10
|
||||
@@ -150,6 +68,11 @@ def interrupt_callback(pipeline, i, t, callback_kwargs):
|
||||
|
||||
return callback_kwargs
|
||||
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5"
|
||||
)
|
||||
num_inference_steps = 50
|
||||
|
||||
pipeline(
|
||||
"A photo of a cat",
|
||||
num_inference_steps=num_inference_steps,
|
||||
@@ -157,92 +80,11 @@ pipeline(
|
||||
)
|
||||
```
|
||||
|
||||
## IP Adapter Cutoff
|
||||
## Display intermediate images
|
||||
|
||||
IP Adapter is an image prompt adapter that can be used for diffusion models without any changes to the underlying model. We can use the IP Adapter Cutoff Callback to disable the IP Adapter after a certain number of steps. To set up the callback, you need to specify the number of denoising steps after which the callback comes into effect. You can do so by using either one of these two arguments:
|
||||
Visualizing the intermediate images is useful for progress monitoring and assessing the quality of the generated content. This callback decodes the latent tensors at each step and converts them to images.
|
||||
|
||||
- `cutoff_step_ratio`: Float number with the ratio of the steps.
|
||||
- `cutoff_step_index`: Integer number with the exact number of the step.
|
||||
|
||||
We need to download the diffusion model and load the ip_adapter for it as follows:
|
||||
|
||||
```py
|
||||
from diffusers import AutoPipelineForText2Image
|
||||
from diffusers.utils import load_image
|
||||
import torch
|
||||
|
||||
pipeline = AutoPipelineForText2Image.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16).to("cuda")
|
||||
pipeline.load_ip_adapter("h94/IP-Adapter", subfolder="sdxl_models", weight_name="ip-adapter_sdxl.bin")
|
||||
pipeline.set_ip_adapter_scale(0.6)
|
||||
```
|
||||
The setup for the callback should look something like this:
|
||||
|
||||
```py
|
||||
|
||||
from diffusers import AutoPipelineForText2Image
|
||||
from diffusers.callbacks import IPAdapterScaleCutoffCallback
|
||||
from diffusers.utils import load_image
|
||||
import torch
|
||||
|
||||
|
||||
pipeline = AutoPipelineForText2Image.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.float16
|
||||
).to("cuda")
|
||||
|
||||
|
||||
pipeline.load_ip_adapter(
|
||||
"h94/IP-Adapter",
|
||||
subfolder="sdxl_models",
|
||||
weight_name="ip-adapter_sdxl.bin"
|
||||
)
|
||||
|
||||
pipeline.set_ip_adapter_scale(0.6)
|
||||
|
||||
|
||||
callback = IPAdapterScaleCutoffCallback(
|
||||
cutoff_step_ratio=None,
|
||||
cutoff_step_index=5
|
||||
)
|
||||
|
||||
image = load_image(
|
||||
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/ip_adapter_diner.png"
|
||||
)
|
||||
|
||||
generator = torch.Generator(device="cuda").manual_seed(2628670641)
|
||||
|
||||
images = pipeline(
|
||||
prompt="a tiger sitting in a chair drinking orange juice",
|
||||
ip_adapter_image=image,
|
||||
negative_prompt="deformed, ugly, wrong proportion, low res, bad anatomy, worst quality, low quality",
|
||||
generator=generator,
|
||||
num_inference_steps=50,
|
||||
callback_on_step_end=callback,
|
||||
).images
|
||||
|
||||
images[0].save("custom_callback_img.png")
|
||||
```
|
||||
|
||||
<div class="flex gap-4">
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/without_callback.png" alt="generated image of a tiger sitting in a chair drinking orange juice" />
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">without IPAdapterScaleCutoffCallback</figcaption>
|
||||
</div>
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/with_callback2.png" alt="generated image of a tiger sitting in a chair drinking orange juice with ip adapter callback" />
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">with IPAdapterScaleCutoffCallback</figcaption>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
|
||||
## Display image after each generation step
|
||||
|
||||
> [!TIP]
|
||||
> This tip was contributed by [asomoza](https://github.com/asomoza).
|
||||
|
||||
Display an image after each generation step by accessing and converting the latents after each step into an image. The latent space is compressed to 128x128, so the images are also 128x128 which is useful for a quick preview.
|
||||
|
||||
1. Use the function below to convert the SDXL latents (4 channels) to RGB tensors (3 channels) as explained in the [Explaining the SDXL latent space](https://huggingface.co/blog/TimothyAlexisVass/explaining-the-sdxl-latent-space) blog post.
|
||||
[Convert](https://huggingface.co/blog/TimothyAlexisVass/explaining-the-sdxl-latent-space) the Stable Diffusion XL latents from latents (4 channels) to RGB tensors (3 tensors).
|
||||
|
||||
```py
|
||||
def latents_to_rgb(latents):
|
||||
@@ -260,7 +102,7 @@ def latents_to_rgb(latents):
|
||||
return Image.fromarray(image_array)
|
||||
```
|
||||
|
||||
2. Create a function to decode and save the latents into an image.
|
||||
Extract the latents and convert the first image in the batch to RGB. Save the image as a PNG file with the step number.
|
||||
|
||||
```py
|
||||
def decode_tensors(pipe, step, timestep, callback_kwargs):
|
||||
@@ -272,19 +114,18 @@ def decode_tensors(pipe, step, timestep, callback_kwargs):
|
||||
return callback_kwargs
|
||||
```
|
||||
|
||||
3. Pass the `decode_tensors` function to the `callback_on_step_end` parameter to decode the tensors after each step. You also need to specify what you want to modify in the `callback_on_step_end_tensor_inputs` parameter, which in this case are the latents.
|
||||
Use the `callback_on_step_end_tensor_inputs` parameter to specify what input type to modify, which in this case, are the latents.
|
||||
|
||||
```py
|
||||
from diffusers import AutoPipelineForText2Image
|
||||
import torch
|
||||
from PIL import Image
|
||||
from diffusers import AutoPipelineForText2Image
|
||||
|
||||
pipeline = AutoPipelineForText2Image.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.float16,
|
||||
variant="fp16",
|
||||
use_safetensors=True
|
||||
).to("cuda")
|
||||
device_map="cuda"
|
||||
)
|
||||
|
||||
image = pipeline(
|
||||
prompt="A croissant shaped like a cute bear.",
|
||||
@@ -293,27 +134,3 @@ image = pipeline(
|
||||
callback_on_step_end_tensor_inputs=["latents"],
|
||||
).images[0]
|
||||
```
|
||||
|
||||
<div class="flex gap-4 justify-center">
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/tips_step_0.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">step 0</figcaption>
|
||||
</div>
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/tips_step_19.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">step 19
|
||||
</figcaption>
|
||||
</div>
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/tips_step_29.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">step 29</figcaption>
|
||||
</div>
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/tips_step_39.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">step 39</figcaption>
|
||||
</div>
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/tips_step_49.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">step 49</figcaption>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
@@ -10,376 +10,163 @@ an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express o
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Load community pipelines and components
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
## Community pipelines
|
||||
# Community pipelines and components
|
||||
|
||||
> [!TIP] Take a look at GitHub Issue [#841](https://github.com/huggingface/diffusers/issues/841) for more context about why we're adding community pipelines to help everyone easily share their work without being slowed down.
|
||||
|
||||
Community pipelines are any [`DiffusionPipeline`] class that are different from the original paper implementation (for example, the [`StableDiffusionControlNetPipeline`] corresponds to the [Text-to-Image Generation with ControlNet Conditioning](https://huggingface.co/papers/2302.05543) paper). They provide additional functionality or extend the original implementation of a pipeline.
|
||||
|
||||
There are many cool community pipelines like [Marigold Depth Estimation](https://github.com/huggingface/diffusers/tree/main/examples/community#marigold-depth-estimation) or [InstantID](https://github.com/huggingface/diffusers/tree/main/examples/community#instantid-pipeline), and you can find all the official community pipelines [here](https://github.com/huggingface/diffusers/tree/main/examples/community).
|
||||
|
||||
There are two types of community pipelines, those stored on the Hugging Face Hub and those stored on Diffusers GitHub repository. Hub pipelines are completely customizable (scheduler, models, pipeline code, etc.) while Diffusers GitHub pipelines are only limited to custom pipeline code.
|
||||
|
||||
| | GitHub community pipeline | HF Hub community pipeline |
|
||||
|----------------|------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------|
|
||||
| usage | same | same |
|
||||
| review process | open a Pull Request on GitHub and undergo a review process from the Diffusers team before merging; may be slower | upload directly to a Hub repository without any review; this is the fastest workflow |
|
||||
| visibility | included in the official Diffusers repository and documentation | included on your HF Hub profile and relies on your own usage/promotion to gain visibility |
|
||||
|
||||
<hfoptions id="community">
|
||||
<hfoption id="Hub pipelines">
|
||||
|
||||
To load a Hugging Face Hub community pipeline, pass the repository id of the community pipeline to the `custom_pipeline` argument and the model repository where you'd like to load the pipeline weights and components from. For example, the example below loads a dummy pipeline from [hf-internal-testing/diffusers-dummy-pipeline](https://huggingface.co/hf-internal-testing/diffusers-dummy-pipeline/blob/main/pipeline.py) and the pipeline weights and components from [google/ddpm-cifar10-32](https://huggingface.co/google/ddpm-cifar10-32):
|
||||
|
||||
> [!WARNING]
|
||||
> By loading a community pipeline from the Hugging Face Hub, you are trusting that the code you are loading is safe. Make sure to inspect the code online before loading and running it automatically!
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"google/ddpm-cifar10-32", custom_pipeline="hf-internal-testing/diffusers-dummy-pipeline", use_safetensors=True
|
||||
)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="GitHub pipelines">
|
||||
|
||||
To load a GitHub community pipeline, pass the repository id of the community pipeline to the `custom_pipeline` argument and the model repository where you you'd like to load the pipeline weights and components from. You can also load model components directly. The example below loads the community [CLIP Guided Stable Diffusion](https://github.com/huggingface/diffusers/tree/main/examples/community#clip-guided-stable-diffusion) pipeline and the CLIP model components.
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
from transformers import CLIPImageProcessor, CLIPModel
|
||||
|
||||
clip_model_id = "laion/CLIP-ViT-B-32-laion2B-s34B-b79K"
|
||||
|
||||
feature_extractor = CLIPImageProcessor.from_pretrained(clip_model_id)
|
||||
clip_model = CLIPModel.from_pretrained(clip_model_id)
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5",
|
||||
custom_pipeline="clip_guided_stable_diffusion",
|
||||
clip_model=clip_model,
|
||||
feature_extractor=feature_extractor,
|
||||
use_safetensors=True,
|
||||
)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
### Load from a local file
|
||||
|
||||
Community pipelines can also be loaded from a local file if you pass a file path instead. The path to the passed directory must contain a pipeline.py file that contains the pipeline class.
|
||||
|
||||
```py
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5",
|
||||
custom_pipeline="./path/to/pipeline_directory/",
|
||||
clip_model=clip_model,
|
||||
feature_extractor=feature_extractor,
|
||||
use_safetensors=True,
|
||||
)
|
||||
```
|
||||
|
||||
### Load from a specific version
|
||||
|
||||
By default, community pipelines are loaded from the latest stable version of Diffusers. To load a community pipeline from another version, use the `custom_revision` parameter.
|
||||
|
||||
<hfoptions id="version">
|
||||
<hfoption id="main">
|
||||
|
||||
For example, to load from the main branch:
|
||||
|
||||
```py
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5",
|
||||
custom_pipeline="clip_guided_stable_diffusion",
|
||||
custom_revision="main",
|
||||
clip_model=clip_model,
|
||||
feature_extractor=feature_extractor,
|
||||
use_safetensors=True,
|
||||
)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="older version">
|
||||
|
||||
For example, to load from a previous version of Diffusers like v0.25.0:
|
||||
|
||||
```py
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5",
|
||||
custom_pipeline="clip_guided_stable_diffusion",
|
||||
custom_revision="v0.25.0",
|
||||
clip_model=clip_model,
|
||||
feature_extractor=feature_extractor,
|
||||
use_safetensors=True,
|
||||
)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
### Load with from_pipe
|
||||
|
||||
Community pipelines can also be loaded with the [`~DiffusionPipeline.from_pipe`] method which allows you to load and reuse multiple pipelines without any additional memory overhead (learn more in the [Reuse a pipeline](./loading#reuse-a-pipeline) guide). The memory requirement is determined by the largest single pipeline loaded.
|
||||
|
||||
For example, let's load a community pipeline that supports [long prompts with weighting](https://github.com/huggingface/diffusers/tree/main/examples/community#long-prompt-weighting-stable-diffusion) from a Stable Diffusion pipeline.
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipe_sd = DiffusionPipeline.from_pretrained("emilianJR/CyberRealistic_V3", torch_dtype=torch.float16)
|
||||
pipe_sd.to("cuda")
|
||||
# load long prompt weighting pipeline
|
||||
pipe_lpw = DiffusionPipeline.from_pipe(
|
||||
pipe_sd,
|
||||
custom_pipeline="lpw_stable_diffusion",
|
||||
).to("cuda")
|
||||
|
||||
prompt = "cat, hiding in the leaves, ((rain)), zazie rainyday, beautiful eyes, macro shot, colorful details, natural lighting, amazing composition, subsurface scattering, amazing textures, filmic, soft light, ultra-detailed eyes, intricate details, detailed texture, light source contrast, dramatic shadows, cinematic light, depth of field, film grain, noise, dark background, hyperrealistic dslr film still, dim volumetric cinematic lighting"
|
||||
neg_prompt = "(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime, mutated hands and fingers:1.4), (deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, disconnected limbs, mutation, mutated, ugly, disgusting, amputation"
|
||||
generator = torch.Generator(device="cpu").manual_seed(20)
|
||||
out_lpw = pipe_lpw(
|
||||
prompt,
|
||||
negative_prompt=neg_prompt,
|
||||
width=512,
|
||||
height=512,
|
||||
max_embeddings_multiples=3,
|
||||
num_inference_steps=50,
|
||||
generator=generator,
|
||||
).images[0]
|
||||
out_lpw
|
||||
```
|
||||
|
||||
<div class="flex gap-4">
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/from_pipe_lpw.png" />
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">Stable Diffusion with long prompt weighting</figcaption>
|
||||
</div>
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/from_pipe_non_lpw.png" />
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">Stable Diffusion</figcaption>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
## Example community pipelines
|
||||
|
||||
Community pipelines are a really fun and creative way to extend the capabilities of the original pipeline with new and unique features. You can find all community pipelines in the [diffusers/examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) folder with inference and training examples for how to use them.
|
||||
|
||||
This section showcases a couple of the community pipelines and hopefully it'll inspire you to create your own (feel free to open a PR for your community pipeline and ping us for a review)!
|
||||
Community pipelines are [`DiffusionPipeline`] classes that are different from the original paper implementation. They provide additional functionality or extend the original pipeline implementation.
|
||||
|
||||
> [!TIP]
|
||||
> The [`~DiffusionPipeline.from_pipe`] method is particularly useful for loading community pipelines because many of them don't have pretrained weights and add a feature on top of an existing pipeline like Stable Diffusion or Stable Diffusion XL. You can learn more about the [`~DiffusionPipeline.from_pipe`] method in the [Load with from_pipe](custom_pipeline_overview#load-with-from_pipe) section.
|
||||
> Check out the community pipelines in [diffusers/examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) with inference and training examples for how to use them.
|
||||
|
||||
<hfoptions id="community">
|
||||
<hfoption id="Marigold">
|
||||
Community pipelines are either stored on the Hub or the Diffusers' GitHub repository. Hub pipelines are completely customizable (scheduler, models, pipeline code, etc.) while GitHub pipelines are limited to only the custom pipeline code. Further compare the two community pipeline types in the table below.
|
||||
|
||||
[Marigold](https://marigoldmonodepth.github.io/) is a depth estimation diffusion pipeline that uses the rich existing and inherent visual knowledge in diffusion models. It takes an input image and denoises and decodes it into a depth map. Marigold performs well even on images it hasn't seen before.
|
||||
| | GitHub | Hub |
|
||||
|---|---|---|
|
||||
| Usage | Same. | Same. |
|
||||
| Review process | Open a Pull Request on GitHub and undergo a review process from the Diffusers team before merging. This option is slower. | Upload directly to a Hub repository without a review. This is the fastest option. |
|
||||
| Visibility | Included in the official Diffusers repository and docs. | Included on your Hub profile and relies on your own usage and promotion to gain visibility. |
|
||||
|
||||
## custom_pipeline
|
||||
|
||||
Load either community pipeline types by passing the `custom_pipeline` argument to [`~DiffusionPipeline.from_pretrained`].
|
||||
|
||||
```py
|
||||
import torch
|
||||
from PIL import Image
|
||||
from diffusers import DiffusionPipeline
|
||||
from diffusers.utils import load_image
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"prs-eth/marigold-lcm-v1-0",
|
||||
custom_pipeline="marigold_depth_estimation",
|
||||
"stabilityai/stable-diffusion-3-medium-diffusers",
|
||||
custom_pipeline="pipeline_stable_diffusion_3_instruct_pix2pix",
|
||||
torch_dtype=torch.float16,
|
||||
variant="fp16",
|
||||
device_map="cuda"
|
||||
)
|
||||
|
||||
pipeline.to("cuda")
|
||||
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/community-marigold.png")
|
||||
output = pipeline(
|
||||
image,
|
||||
denoising_steps=4,
|
||||
ensemble_size=5,
|
||||
processing_res=768,
|
||||
match_input_res=True,
|
||||
batch_size=0,
|
||||
seed=33,
|
||||
color_map="Spectral",
|
||||
show_progress_bar=True,
|
||||
)
|
||||
depth_colored: Image.Image = output.depth_colored
|
||||
depth_colored.save("./depth_colored.png")
|
||||
```
|
||||
|
||||
<div class="flex flex-row gap-4">
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/community-marigold.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">original image</figcaption>
|
||||
</div>
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/marigold-depth.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">colorized depth image</figcaption>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="HD-Painter">
|
||||
|
||||
[HD-Painter](https://hf.co/papers/2312.14091) is a high-resolution inpainting pipeline. It introduces a *Prompt-Aware Introverted Attention (PAIntA)* layer to better align a prompt with the area to be inpainted, and *Reweighting Attention Score Guidance (RASG)* to keep the latents more prompt-aligned and within their trained domain to generate realistc images.
|
||||
Add the `custom_revision` argument to [`~DiffusionPipeline.from_pretrained`] to load a community pipeline from a specific version (for example, `v0.30.0` or `main`). By default, community pipelines are loaded from the latest stable version of Diffusers.
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline, DDIMScheduler
|
||||
from diffusers.utils import load_image
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5-inpainting",
|
||||
custom_pipeline="hd_painter"
|
||||
"stabilityai/stable-diffusion-3-medium-diffusers",
|
||||
custom_pipeline="pipeline_stable_diffusion_3_instruct_pix2pix",
|
||||
custom_revision="main"
|
||||
torch_dtype=torch.float16,
|
||||
device_map="cuda"
|
||||
)
|
||||
pipeline.scheduler = DDIMScheduler.from_config(pipeline.scheduler.config)
|
||||
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/hd-painter.jpg")
|
||||
mask_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/hd-painter-mask.png")
|
||||
prompt = "football"
|
||||
image = pipeline(prompt, init_image, mask_image, use_rasg=True, use_painta=True, generator=torch.manual_seed(0)).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
<div class="flex flex-row gap-4">
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/hd-painter.jpg"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">original image</figcaption>
|
||||
</div>
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/hd-painter-output.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">generated image</figcaption>
|
||||
</div>
|
||||
</div>
|
||||
> [!WARNING]
|
||||
> While the Hugging Face Hub [scans](https://huggingface.co/docs/hub/security-malware) files, you should still inspect the Hub pipeline code and make sure it is safe.
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
There are a few ways to load a community pipeline.
|
||||
|
||||
- Pass a path to `custom_pipeline` to load a local community pipeline. The directory must contain a `pipeline.py` file containing the pipeline class.
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-3-medium-diffusers",
|
||||
custom_pipeline="path/to/pipeline_directory",
|
||||
torch_dtype=torch.float16,
|
||||
device_map="cuda"
|
||||
)
|
||||
```
|
||||
|
||||
- The `custom_pipeline` argument is also supported by [`~DiffusionPipeline.from_pipe`], which is useful for [reusing pipelines](./loading#reuse-a-pipeline) without using additional memory. It limits the memory usage to only the largest pipeline loaded.
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline_sd = DiffusionPipeline.from_pretrained("emilianJR/CyberRealistic_V3", torch_dtype=torch.float16, device_map="cuda")
|
||||
pipeline_lpw = DiffusionPipeline.from_pipe(
|
||||
pipeline_sd, custom_pipeline="lpw_stable_diffusion", device_map="cuda"
|
||||
)
|
||||
```
|
||||
|
||||
The [`~DiffusionPipeline.from_pipe`] method is especially useful for loading community pipelines because many of them don't have pretrained weights. Community pipelines generally add a feature on top of an existing pipeline.
|
||||
|
||||
## Community components
|
||||
|
||||
Community components allow users to build pipelines that may have customized components that are not a part of Diffusers. If your pipeline has custom components that Diffusers doesn't already support, you need to provide their implementations as Python modules. These customized components could be a VAE, UNet, and scheduler. In most cases, the text encoder is imported from the Transformers library. The pipeline code itself can also be customized.
|
||||
Community components let users build pipelines with custom transformers, UNets, VAEs, and schedulers not supported by Diffusers. These components require Python module implementations.
|
||||
|
||||
This section shows how users should use community components to build a community pipeline.
|
||||
This section shows how users can use community components to build a community pipeline using [showlab/show-1-base](https://huggingface.co/showlab/show-1-base) as an example.
|
||||
|
||||
You'll use the [showlab/show-1-base](https://huggingface.co/showlab/show-1-base) pipeline checkpoint as an example.
|
||||
|
||||
1. Import and load the text encoder from Transformers:
|
||||
|
||||
```python
|
||||
from transformers import T5Tokenizer, T5EncoderModel
|
||||
|
||||
pipe_id = "showlab/show-1-base"
|
||||
tokenizer = T5Tokenizer.from_pretrained(pipe_id, subfolder="tokenizer")
|
||||
text_encoder = T5EncoderModel.from_pretrained(pipe_id, subfolder="text_encoder")
|
||||
```
|
||||
|
||||
2. Load a scheduler:
|
||||
1. Load the required components, the scheduler and image processor. The text encoder is generally imported from [Transformers](https://huggingface.co/docs/transformers/index).
|
||||
|
||||
```python
|
||||
from transformers import T5Tokenizer, T5EncoderModel, CLIPImageProcessor
|
||||
from diffusers import DPMSolverMultistepScheduler
|
||||
|
||||
pipeline_id = "showlab/show-1-base"
|
||||
tokenizer = T5Tokenizer.from_pretrained(pipeline_id, subfolder="tokenizer")
|
||||
text_encoder = T5EncoderModel.from_pretrained(pipeline_id, subfolder="text_encoder")
|
||||
scheduler = DPMSolverMultistepScheduler.from_pretrained(pipe_id, subfolder="scheduler")
|
||||
```
|
||||
|
||||
3. Load an image processor:
|
||||
|
||||
```python
|
||||
from transformers import CLIPImageProcessor
|
||||
|
||||
feature_extractor = CLIPImageProcessor.from_pretrained(pipe_id, subfolder="feature_extractor")
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
> [!WARNING]
|
||||
> In steps 2 and 3, the custom [UNet](https://github.com/showlab/Show-1/blob/main/showone/models/unet_3d_condition.py) and [pipeline](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/unet/showone_unet_3d_condition.py) implementation must match the format shown in their files for this example to work.
|
||||
|
||||
In steps 4 and 5, the custom [UNet](https://github.com/showlab/Show-1/blob/main/showone/models/unet_3d_condition.py) and [pipeline](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/unet/showone_unet_3d_condition.py) implementation must match the format shown in their files for this example to work.
|
||||
|
||||
</Tip>
|
||||
|
||||
4. Now you'll load a [custom UNet](https://github.com/showlab/Show-1/blob/main/showone/models/unet_3d_condition.py), which in this example, has already been implemented in [showone_unet_3d_condition.py](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/unet/showone_unet_3d_condition.py) for your convenience. You'll notice the [`UNet3DConditionModel`] class name is changed to `ShowOneUNet3DConditionModel` because [`UNet3DConditionModel`] already exists in Diffusers. Any components needed for the `ShowOneUNet3DConditionModel` class should be placed in showone_unet_3d_condition.py.
|
||||
|
||||
Once this is done, you can initialize the UNet:
|
||||
|
||||
```python
|
||||
from showone_unet_3d_condition import ShowOneUNet3DConditionModel
|
||||
|
||||
unet = ShowOneUNet3DConditionModel.from_pretrained(pipe_id, subfolder="unet")
|
||||
```
|
||||
|
||||
5. Finally, you'll load the custom pipeline code. For this example, it has already been created for you in [pipeline_t2v_base_pixel.py](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/pipeline_t2v_base_pixel.py). This script contains a custom `TextToVideoIFPipeline` class for generating videos from text. Just like the custom UNet, any code needed for the custom pipeline to work should go in pipeline_t2v_base_pixel.py.
|
||||
|
||||
Once everything is in place, you can initialize the `TextToVideoIFPipeline` with the `ShowOneUNet3DConditionModel`:
|
||||
2. Load a [custom UNet](https://github.com/showlab/Show-1/blob/main/showone/models/unet_3d_condition.py) which is already implemented in [showone_unet_3d_condition.py](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/unet/showone_unet_3d_condition.py). The [`UNet3DConditionModel`] class name is renamed to the custom implementation, `ShowOneUNet3DConditionModel`, because [`UNet3DConditionModel`] already exists in Diffusers. Any components required for `ShowOneUNet3DConditionModel` class should be placed in `showone_unet_3d_condition.py`.
|
||||
|
||||
```python
|
||||
from showone_unet_3d_condition import ShowOneUNet3DConditionModel
|
||||
|
||||
unet = ShowOneUNet3DConditionModel.from_pretrained(pipeline_id, subfolder="unet")
|
||||
```
|
||||
|
||||
3. Load the custom pipeline code (already implemented in [pipeline_t2v_base_pixel.py](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/pipeline_t2v_base_pixel.py)). This script contains a custom `TextToVideoIFPipeline` class for generating videos from text. Like the custom UNet, any code required for `TextToVideIFPipeline` should be placed in `pipeline_t2v_base_pixel.py`.
|
||||
|
||||
Initialize `TextToVideoIFPipeline` with `ShowOneUNet3DConditionModel`.
|
||||
|
||||
```python
|
||||
from pipeline_t2v_base_pixel import TextToVideoIFPipeline
|
||||
import torch
|
||||
from pipeline_t2v_base_pixel import TextToVideoIFPipeline
|
||||
|
||||
pipeline = TextToVideoIFPipeline(
|
||||
unet=unet,
|
||||
text_encoder=text_encoder,
|
||||
tokenizer=tokenizer,
|
||||
scheduler=scheduler,
|
||||
feature_extractor=feature_extractor
|
||||
feature_extractor=feature_extractor,
|
||||
device_map="cuda",
|
||||
torch_dtype=torch.float16
|
||||
)
|
||||
pipeline = pipeline.to(device="cuda")
|
||||
pipeline.torch_dtype = torch.float16
|
||||
```
|
||||
|
||||
Push the pipeline to the Hub to share with the community!
|
||||
4. Push the pipeline to the Hub to share with the community.
|
||||
|
||||
```python
|
||||
pipeline.push_to_hub("custom-t2v-pipeline")
|
||||
```
|
||||
|
||||
After the pipeline is successfully pushed, you need to make a few changes:
|
||||
After the pipeline is successfully pushed, make the following changes.
|
||||
|
||||
1. Change the `_class_name` attribute in [model_index.json](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/model_index.json#L2) to `"pipeline_t2v_base_pixel"` and `"TextToVideoIFPipeline"`.
|
||||
2. Upload `showone_unet_3d_condition.py` to the [unet](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/unet/showone_unet_3d_condition.py) subfolder.
|
||||
3. Upload `pipeline_t2v_base_pixel.py` to the pipeline [repository](https://huggingface.co/sayakpaul/show-1-base-with-code/tree/main).
|
||||
- Change the `_class_name` attribute in [model_index.json](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/model_index.json#L2) to `"pipeline_t2v_base_pixel"` and `"TextToVideoIFPipeline"`.
|
||||
- Upload `showone_unet_3d_condition.py` to the [unet](https://huggingface.co/sayakpaul/show-1-base-with-code/blob/main/unet/showone_unet_3d_condition.py) subfolder.
|
||||
- Upload `pipeline_t2v_base_pixel.py` to the pipeline [repository](https://huggingface.co/sayakpaul/show-1-base-with-code/tree/main).
|
||||
|
||||
To run inference, add the `trust_remote_code` argument while initializing the pipeline to handle all the "magic" behind the scenes.
|
||||
|
||||
> [!WARNING]
|
||||
> As an additional precaution with `trust_remote_code=True`, we strongly encourage you to pass a commit hash to the `revision` parameter in [`~DiffusionPipeline.from_pretrained`] to make sure the code hasn't been updated with some malicious new lines of code (unless you fully trust the model owners).
|
||||
|
||||
```python
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"<change-username>/<change-id>", trust_remote_code=True, torch_dtype=torch.float16
|
||||
).to("cuda")
|
||||
|
||||
prompt = "hello"
|
||||
|
||||
# Text embeds
|
||||
prompt_embeds, negative_embeds = pipeline.encode_prompt(prompt)
|
||||
|
||||
# Keyframes generation (8x64x40, 2fps)
|
||||
video_frames = pipeline(
|
||||
prompt_embeds=prompt_embeds,
|
||||
negative_prompt_embeds=negative_embeds,
|
||||
num_frames=8,
|
||||
height=40,
|
||||
width=64,
|
||||
num_inference_steps=2,
|
||||
guidance_scale=9.0,
|
||||
output_type="pt"
|
||||
).frames
|
||||
```
|
||||
|
||||
As an additional reference, take a look at the repository structure of [stabilityai/japanese-stable-diffusion-xl](https://huggingface.co/stabilityai/japanese-stable-diffusion-xl/) which also uses the `trust_remote_code` feature.
|
||||
|
||||
```python
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stabilityai/japanese-stable-diffusion-xl", trust_remote_code=True
|
||||
)
|
||||
pipeline.to("cuda")
|
||||
```
|
||||
|
||||
> [!WARNING]
|
||||
> As an additional precaution with `trust_remote_code=True`, we strongly encourage passing a commit hash to the `revision` argument in [`~DiffusionPipeline.from_pretrained`] to make sure the code hasn't been updated with new malicious code (unless you fully trust the model owners).
|
||||
|
||||
## Resources
|
||||
|
||||
- Take a look at Issue [#841](https://github.com/huggingface/diffusers/issues/841) for more context about why we're adding community pipelines to help everyone easily share their work without being slowed down.
|
||||
- Check out the [stabilityai/japanese-stable-diffusion-xl](https://huggingface.co/stabilityai/japanese-stable-diffusion-xl/) repository for an additional example of a community pipeline that also uses the `trust_remote_code` feature.
|
||||
@@ -112,6 +112,30 @@ print(pipe.transformer.dtype, pipe.vae.dtype) # (torch.bfloat16, torch.float16)
|
||||
|
||||
If a component is not explicitly specified in the dictionary and no `default` is provided, it will be loaded with `torch.float32`.
|
||||
|
||||
### Parallel loading
|
||||
|
||||
Large models are often [sharded](../training/distributed_inference#model-sharding) into smaller files so that they are easier to load. Diffusers supports loading shards in parallel to speed up the loading process.
|
||||
|
||||
Set the environment variables below to enable parallel loading.
|
||||
|
||||
- Set `HF_ENABLE_PARALLEL_LOADING` to `"YES"` to enable parallel loading of shards.
|
||||
- Set `HF_PARALLEL_LOADING_WORKERS` to configure the number of parallel threads to use when loading shards. More workers loads a model faster but uses more memory.
|
||||
|
||||
The `device_map` argument should be set to `"cuda"` to pre-allocate a large chunk of memory based on the model size. This substantially reduces model load time because warming up the memory allocator now avoids many smaller calls to the allocator later.
|
||||
|
||||
```py
|
||||
import os
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
os.environ["HF_ENABLE_PARALLEL_LOADING"] = "YES"
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"Wan-AI/Wan2.2-I2V-A14B-Diffusers",
|
||||
torch_dtype=torch.bfloat16,
|
||||
device_map="cuda"
|
||||
)
|
||||
```
|
||||
|
||||
### Local pipeline
|
||||
|
||||
To load a pipeline locally, use [git-lfs](https://git-lfs.github.com/) to manually download a checkpoint to your local disk.
|
||||
|
||||
@@ -1,12 +1,150 @@
|
||||
- sections:
|
||||
- title: 开始Diffusers
|
||||
sections:
|
||||
- local: index
|
||||
title: 🧨 Diffusers
|
||||
title: Diffusers
|
||||
- local: installation
|
||||
title: 安装
|
||||
- local: quicktour
|
||||
title: 快速入门
|
||||
- local: stable_diffusion
|
||||
title: 有效和高效的扩散
|
||||
- local: consisid
|
||||
title: 身份保持的文本到视频生成
|
||||
- local: installation
|
||||
title: 安装
|
||||
title: 开始
|
||||
|
||||
- title: DiffusionPipeline
|
||||
isExpanded: false
|
||||
sections:
|
||||
- local: using-diffusers/schedulers
|
||||
title: Load schedulers and models
|
||||
|
||||
- title: Inference
|
||||
isExpanded: false
|
||||
sections:
|
||||
- local: training/distributed_inference
|
||||
title: Distributed inference
|
||||
|
||||
- title: Inference optimization
|
||||
isExpanded: false
|
||||
sections:
|
||||
- local: optimization/fp16
|
||||
title: Accelerate inference
|
||||
- local: optimization/cache
|
||||
title: Caching
|
||||
- local: optimization/memory
|
||||
title: Reduce memory usage
|
||||
- local: optimization/speed-memory-optims
|
||||
title: Compile and offloading quantized models
|
||||
- title: Community optimizations
|
||||
sections:
|
||||
- local: optimization/pruna
|
||||
title: Pruna
|
||||
- local: optimization/xformers
|
||||
title: xFormers
|
||||
- local: optimization/tome
|
||||
title: Token merging
|
||||
- local: optimization/deepcache
|
||||
title: DeepCache
|
||||
- local: optimization/tgate
|
||||
title: TGATE
|
||||
- local: optimization/xdit
|
||||
title: xDiT
|
||||
- local: optimization/para_attn
|
||||
title: ParaAttention
|
||||
|
||||
- title: Hybrid Inference
|
||||
isExpanded: false
|
||||
sections:
|
||||
- local: hybrid_inference/overview
|
||||
title: Overview
|
||||
- local: hybrid_inference/vae_encode
|
||||
title: VAE Encode
|
||||
- local: hybrid_inference/api_reference
|
||||
title: API Reference
|
||||
|
||||
- title: Modular Diffusers
|
||||
isExpanded: false
|
||||
sections:
|
||||
- local: modular_diffusers/overview
|
||||
title: Overview
|
||||
- local: modular_diffusers/quickstart
|
||||
title: Quickstart
|
||||
- local: modular_diffusers/modular_diffusers_states
|
||||
title: States
|
||||
- local: modular_diffusers/pipeline_block
|
||||
title: ModularPipelineBlocks
|
||||
- local: modular_diffusers/sequential_pipeline_blocks
|
||||
title: SequentialPipelineBlocks
|
||||
- local: modular_diffusers/loop_sequential_pipeline_blocks
|
||||
title: LoopSequentialPipelineBlocks
|
||||
- local: modular_diffusers/auto_pipeline_blocks
|
||||
title: AutoPipelineBlocks
|
||||
- local: modular_diffusers/modular_pipeline
|
||||
title: ModularPipeline
|
||||
- local: modular_diffusers/components_manager
|
||||
title: ComponentsManager
|
||||
- local: modular_diffusers/guiders
|
||||
title: Guiders
|
||||
|
||||
- title: Training
|
||||
isExpanded: false
|
||||
sections:
|
||||
- local: training/overview
|
||||
title: Overview
|
||||
- local: training/adapt_a_model
|
||||
title: Adapt a model to a new task
|
||||
- title: Models
|
||||
sections:
|
||||
- local: training/text2image
|
||||
title: Text-to-image
|
||||
- local: training/kandinsky
|
||||
title: Kandinsky 2.2
|
||||
- local: training/wuerstchen
|
||||
title: Wuerstchen
|
||||
- local: training/controlnet
|
||||
title: ControlNet
|
||||
- local: training/instructpix2pix
|
||||
title: InstructPix2Pix
|
||||
- title: Methods
|
||||
sections:
|
||||
- local: training/text_inversion
|
||||
title: Textual Inversion
|
||||
- local: training/dreambooth
|
||||
title: DreamBooth
|
||||
- local: training/lora
|
||||
title: LoRA
|
||||
|
||||
- title: Model accelerators and hardware
|
||||
isExpanded: false
|
||||
sections:
|
||||
- local: optimization/onnx
|
||||
title: ONNX
|
||||
- local: optimization/open_vino
|
||||
title: OpenVINO
|
||||
- local: optimization/coreml
|
||||
title: Core ML
|
||||
- local: optimization/mps
|
||||
title: Metal Performance Shaders (MPS)
|
||||
- local: optimization/habana
|
||||
title: Intel Gaudi
|
||||
- local: optimization/neuron
|
||||
title: AWS Neuron
|
||||
|
||||
- title: Specific pipeline examples
|
||||
isExpanded: false
|
||||
sections:
|
||||
- local: using-diffusers/consisid
|
||||
title: ConsisID
|
||||
|
||||
- title: Resources
|
||||
isExpanded: false
|
||||
sections:
|
||||
- title: Task recipes
|
||||
sections:
|
||||
- local: community_projects
|
||||
title: Projects built with Diffusers
|
||||
- local: conceptual/philosophy
|
||||
title: Philosophy
|
||||
- local: conceptual/contribution
|
||||
title: How to contribute?
|
||||
- local: conceptual/ethical_guidelines
|
||||
title: Diffusers' Ethical Guidelines
|
||||
- local: conceptual/evaluation
|
||||
title: Evaluating Diffusion Models
|
||||
|
||||
89
docs/source/zh/community_projects.md
Normal file
89
docs/source/zh/community_projects.md
Normal file
@@ -0,0 +1,89 @@
|
||||
<!--版权 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据Apache许可证,版本2.0("许可证")授权;除非符合许可证,否则不得使用此文件。您可以在
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
获取许可证的副本。
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件是按"原样"分发的,没有任何形式的明示或暗示的担保或条件。有关许可证的特定语言,请参阅许可证。
|
||||
-->
|
||||
|
||||
# 社区项目
|
||||
|
||||
欢迎来到社区项目。这个空间致力于展示我们充满活力的社区使用`diffusers`库创建的令人难以置信的工作和创新应用。
|
||||
|
||||
本节旨在:
|
||||
|
||||
- 突出使用`diffusers`构建的多样化和鼓舞人心的项目
|
||||
- 促进我们社区内的知识共享
|
||||
- 提供如何利用`diffusers`的实际例子
|
||||
|
||||
探索愉快,感谢您成为Diffusers社区的一部分!
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<th>项目名称</th>
|
||||
<th>描述</th>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td><a href="https://github.com/carson-katri/dream-textures"> dream-textures </a></td>
|
||||
<td>Stable Diffusion内置到Blender</td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td><a href="https://github.com/megvii-research/HiDiffusion"> HiDiffusion </a></td>
|
||||
<td>仅通过添加一行代码即可提高扩散模型的分辨率和速度</td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td><a href="https://github.com/lllyasviel/IC-Light"> IC-Light </a></td>
|
||||
<td>IC-Light是一个用于操作图像照明的项目</td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td><a href="https://github.com/InstantID/InstantID"> InstantID </a></td>
|
||||
<td>InstantID:零样本身份保留生成在几秒钟内</td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td><a href="https://github.com/Sanster/IOPaint"> IOPaint </a></td>
|
||||
<td>由SOTA AI模型驱动的图像修复工具。从您的图片中移除任何不需要的物体、缺陷、人物,或擦除并替换(由stable_diffusion驱动)图片上的任何内容。</td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td><a href="https://github.com/bmaltais/kohya_ss"> Kohya </a></td>
|
||||
<td>Kohya的Stable Diffusion训练器的Gradio GUI</td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td><a href="https://github.com/magic-research/magic-animate"> MagicAnimate </a></td>
|
||||
<td>MagicAnimate:使用扩散模型进行时间一致的人体图像动画</td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td><a href="https://github.com/levihsu/OOTDiffusion"> OOTDiffusion </a></td>
|
||||
<td>基于潜在扩散的虚拟试穿控制</td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td><a href="https://github.com/vladmandic/automatic"> SD.Next </a></td>
|
||||
<td>SD.Next: Stable Diffusion 和其他基于Diffusion的生成图像模型的高级实现</td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td><a href="https://github.com/ashawkey/stable-dreamfusion"> stable-dreamfusion </a></td>
|
||||
<td>使用 NeRF + Diffusion 进行文本到3D & 图像到3D & 网格导出</td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td><a href="https://github.com/HVision-NKU/StoryDiffusion"> StoryDiffusion </a></td>
|
||||
<td>StoryDiffusion 可以通过生成一致的图像和视频来创造一个神奇的故事。</td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td><a href="https://github.com/cumulo-autumn/StreamDiffusion"> StreamDiffusion </a></td>
|
||||
<td>实时交互生成的管道级解决方案</td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td><a href="https://github.com/Netwrck/stable-diffusion-server"> Stable Diffusion Server </a></td>
|
||||
<td>配置用于使用一个 stable diffusion 模型进行修复/生成/img2img 的服务器</td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td><a href="https://github.com/suzukimain/auto_diffusers"> Model Search </a></td>
|
||||
<td>在 Civitai 和 Hugging Face 上搜索模型</td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td><a href="https://github.com/beinsezii/skrample"> Skrample </a></td>
|
||||
<td>完全模块化的调度器功能,具有一流的 diffusers 集成。</td>
|
||||
</tr>
|
||||
</table>
|
||||
485
docs/source/zh/conceptual/contribution.md
Normal file
485
docs/source/zh/conceptual/contribution.md
Normal file
@@ -0,0 +1,485 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. 保留所有权利。
|
||||
|
||||
根据Apache许可证2.0版("许可证")授权;除非符合许可证要求,否则不得使用此文件。您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件均按"原样"分发,不附带任何明示或暗示的担保或条件。有关许可证下特定语言规定的权限和限制,请参阅许可证。
|
||||
-->
|
||||
|
||||
# 如何为Diffusers 🧨做贡献
|
||||
|
||||
我们❤️来自开源社区的贡献!欢迎所有人参与,所有类型的贡献——不仅仅是代码——都受到重视和赞赏。回答问题、帮助他人、主动交流以及改进文档对社区都极具价值,所以如果您愿意参与,请不要犹豫!
|
||||
|
||||
我们鼓励每个人先在公开Discord频道里打招呼👋。在那里我们讨论扩散模型的最新趋势、提出问题、展示个人项目、互相协助贡献,或者只是闲聊☕。<a href="https://Discord.gg/G7tWnz98XR"><img alt="加入Discord社区" src="https://img.shields.io/discord/823813159592001537?color=5865F2&logo=discord&logoColor=white"></a>
|
||||
|
||||
无论您选择以何种方式贡献,我们都致力于成为一个开放、友好、善良的社区。请阅读我们的[行为准则](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md),并在互动时注意遵守。我们也建议您了解指导本项目的[伦理准则](https://huggingface.co/docs/diffusers/conceptual/ethical_guidelines),并请您遵循同样的透明度和责任原则。
|
||||
|
||||
我们高度重视社区的反馈,所以如果您认为自己有能帮助改进库的有价值反馈,请不要犹豫说出来——每条消息、评论、issue和拉取请求(PR)都会被阅读和考虑。
|
||||
|
||||
## 概述
|
||||
|
||||
您可以通过多种方式做出贡献,从在issue和讨论区回答问题,到向核心库添加新的diffusion模型。
|
||||
|
||||
下面我们按难度升序列出不同的贡献方式,所有方式对社区都很有价值:
|
||||
|
||||
* 1. 在[Diffusers讨论论坛](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers)或[Discord](https://discord.gg/G7tWnz98XR)上提问和回答问题
|
||||
* 2. 在[GitHub Issues标签页](https://github.com/huggingface/diffusers/issues/new/choose)提交新issue,或在[GitHub Discussions标签页](https://github.com/huggingface/diffusers/discussions/new/choose)发起新讨论
|
||||
* 3. 在[GitHub Issues标签页](https://github.com/huggingface/diffusers/issues)解答issue,或在[GitHub Discussions标签页](https://github.com/huggingface/diffusers/discussions)参与讨论
|
||||
* 4. 解决标记为"Good first issue"的简单问题,详见[此处](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22)
|
||||
* 5. 参与[文档](https://github.com/huggingface/diffusers/tree/main/docs/source)建设
|
||||
* 6. 贡献[社区Pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3Acommunity-examples)
|
||||
* 7. 完善[示例代码](https://github.com/huggingface/diffusers/tree/main/examples)
|
||||
* 8. 解决标记为"Good second issue"的中等难度问题,详见[此处](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22)
|
||||
* 9. 添加新pipeline/模型/调度器,参见["New Pipeline/Model"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22)和["New scheduler"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22)类issue。此类贡献请先阅读[设计哲学](https://github.com/huggingface/diffusers/blob/main/PHILOSOPHY.md)
|
||||
|
||||
重申:**所有贡献对社区都具有重要价值。**下文将详细说明各类贡献方式。
|
||||
|
||||
对于4-9类贡献,您需要提交PR(拉取请求),具体操作详见[如何提交PR](#how-to-open-a-pr)章节。
|
||||
|
||||
### 1. 在Diffusers讨论区或Discord提问与解答
|
||||
|
||||
任何与Diffusers库相关的问题或讨论都可以发布在[官方论坛](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/)或[Discord频道](https://discord.gg/G7tWnz98XR),包括但不限于:
|
||||
- 分享训练/推理实验报告
|
||||
- 展示个人项目
|
||||
- 咨询非官方训练示例
|
||||
- 项目提案
|
||||
- 通用反馈
|
||||
- 论文解读
|
||||
- 基于Diffusers库的个人项目求助
|
||||
- 一般性问题
|
||||
- 关于diffusion模型的伦理讨论
|
||||
- ...
|
||||
|
||||
论坛/Discord上的每个问题都能促使社区公开分享知识,很可能帮助未来遇到相同问题的初学者。请务必提出您的疑问。
|
||||
同样地,通过回答问题您也在为社区创造公共知识文档,这种贡献极具价值。
|
||||
|
||||
**请注意**:提问/回答时投入的精力越多,产生的公共知识质量就越高。精心构建的问题与专业解答能形成高质量知识库,而表述不清的问题则可能降低讨论价值。
|
||||
|
||||
低质量的问题或回答会降低公共知识库的整体质量。
|
||||
简而言之,高质量的问题或回答应具备*精确性*、*简洁性*、*相关性*、*易于理解*、*可访问性*和*格式规范/表述清晰*等特质。更多详情请参阅[如何提交优质议题](#how-to-write-a-good-issue)章节。
|
||||
|
||||
**关于渠道的说明**:
|
||||
[*论坛*](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63)的内容能被谷歌等搜索引擎更好地收录,且帖子按热度而非时间排序,便于查找历史问答。此外,论坛内容更容易被直接链接引用。
|
||||
而*Discord*采用即时聊天模式,适合快速交流。虽然在Discord上可能更快获得解答,但信息会随时间淹没,且难以回溯历史讨论。因此我们强烈建议在论坛发布优质问答,以构建可持续的社区知识库。若Discord讨论产生有价值结论,建议将成果整理发布至论坛以惠及更多读者。
|
||||
|
||||
### 2. 在GitHub议题页提交新议题
|
||||
|
||||
🧨 Diffusers库的稳健性离不开用户的问题反馈,感谢您的报错。
|
||||
|
||||
请注意:GitHub议题仅限处理与Diffusers库代码直接相关的技术问题、错误报告、功能请求或库设计反馈。
|
||||
简言之,**与Diffusers库代码(含文档)无关**的内容应发布至[论坛](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63)或[Discord](https://discord.gg/G7tWnz98XR)。
|
||||
|
||||
**提交新议题时请遵循以下准则**:
|
||||
- 确认是否已有类似议题(使用GitHub议题页的搜索栏)
|
||||
- 请勿在现有议题下追加新问题。若存在高度关联议题,应新建议题并添加相关链接
|
||||
- 确保使用英文提交。非英语用户可通过[DeepL](https://www.deepl.com/translator)等免费工具翻译
|
||||
- 检查升级至最新Diffusers版本是否能解决问题。提交前请确认`python -c "import diffusers; print(diffusers.__version__)"`显示的版本号不低于最新版本
|
||||
- 记请记住,你在提交新issue时投入的精力越多,得到的回答质量就越高,Diffusers项目的整体issue质量也会越好。
|
||||
|
||||
新issue通常包含以下内容:
|
||||
|
||||
#### 2.1 可复现的最小化错误报告
|
||||
|
||||
错误报告应始终包含可复现的代码片段,并尽可能简洁明了。具体而言:
|
||||
- 尽量缩小问题范围,**不要直接粘贴整个代码文件**
|
||||
- 规范代码格式
|
||||
- 除Diffusers依赖库外,不要包含其他外部库
|
||||
- **务必**提供环境信息:可在终端运行`diffusers-cli env`命令,然后将显示的信息复制到issue中
|
||||
- 详细说明问题。如果读者不清楚问题所在及其影响,就无法解决问题
|
||||
- **确保**读者能以最小成本复现问题。如果代码片段因缺少库或未定义变量而无法运行,读者将无法提供帮助。请确保提供的可复现代码尽可能精简,可直接复制到Python shell运行
|
||||
- 如需特定模型/数据集复现问题,请确保读者能获取这些资源。可将模型/数据集上传至[Hub](https://huggingface.co)便于下载。尽量保持模型和数据集体积最小化,降低复现难度
|
||||
|
||||
更多信息请参阅[如何撰写优质issue](#how-to-write-a-good-issue)章节。
|
||||
|
||||
提交错误报告请点击[此处](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&projects=&template=bug-report.yml)。
|
||||
|
||||
#### 2.2 功能请求
|
||||
|
||||
优质的功能请求应包含以下要素:
|
||||
|
||||
1. 首先说明动机:
|
||||
* 是否与库的使用痛点相关?若是,请解释原因,最好提供演示问题的代码片段
|
||||
* 是否因项目需求产生?我们很乐意了解详情!
|
||||
* 是否是你已实现且认为对社区有价值的功能?请说明它为你解决了什么问题
|
||||
2. 用**完整段落**描述功能特性
|
||||
3. 提供**代码片段**演示预期用法
|
||||
4. 如涉及论文,请附上链接
|
||||
5. 可补充任何有助于理解的辅助材料(示意图、截图等)
|
||||
|
||||
提交功能请求请点击[此处](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=)。
|
||||
|
||||
#### 2.3 设计反馈
|
||||
|
||||
关于库设计的反馈(无论正面还是负面)能极大帮助核心维护者打造更友好的库。要了解当前设计理念,请参阅[此文档](https://huggingface.co/docs/diffusers/conceptual/philosophy)如果您认为某个设计选择与当前理念不符,请说明原因及改进建议。如果某个设计选择因过度遵循理念而限制了使用场景,也请解释原因并提出调整方案。
|
||||
若某个设计对您特别实用,请同样留下备注——这对未来的设计决策极具参考价值。
|
||||
|
||||
您可通过[此链接](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=)提交设计反馈。
|
||||
|
||||
#### 2.4 技术问题
|
||||
|
||||
技术问题主要涉及库代码的实现逻辑或特定功能模块的作用。提问时请务必:
|
||||
- 附上相关代码链接
|
||||
- 详细说明难以理解的具体原因
|
||||
|
||||
技术问题提交入口:[点击此处](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&template=bug-report.yml)
|
||||
|
||||
#### 2.5 新模型/调度器/pipeline提案
|
||||
|
||||
若diffusion模型社区发布了您希望集成到Diffusers库的新模型、pipeline或调度器,请提供以下信息:
|
||||
* 简要说明并附论文或发布链接
|
||||
* 开源实现链接(如有)
|
||||
* 模型权重下载链接(如已公开)
|
||||
|
||||
若您愿意参与开发,请告知我们以便指导。另请尝试通过GitHub账号标记原始组件作者。
|
||||
|
||||
提案提交地址:[新建请求](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=New+model%2Fpipeline%2Fscheduler&template=new-model-addition.yml)
|
||||
|
||||
### 3. 解答GitHub问题
|
||||
|
||||
回答GitHub问题可能需要Diffusers的技术知识,但我们鼓励所有人尝试参与——即使您对答案不完全正确。高质量回答的建议:
|
||||
- 保持简洁精炼
|
||||
- 严格聚焦问题本身
|
||||
- 提供代码/论文等佐证材料
|
||||
- 优先用代码说话:若代码片段能解决问题,请提供完整可复现代码
|
||||
|
||||
许多问题可能存在离题、重复或无关情况。您可以通过以下方式协助维护者:
|
||||
- 引导提问者精确描述问题
|
||||
- 标记重复issue并附原链接
|
||||
- 推荐用户至[论坛](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63)或[Discord](https://discord.gg/G7tWnz98XR)
|
||||
|
||||
在确认提交的Bug报告正确且需要修改源代码后,请继续阅读以下章节内容。
|
||||
|
||||
以下所有贡献都需要提交PR(拉取请求)。具体操作步骤详见[如何提交PR](#how-to-open-a-pr)章节。
|
||||
|
||||
### 4. 修复"Good first issue"类问题
|
||||
|
||||
标有[Good first issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22)标签的问题通常已说明解决方案建议,便于修复。若该问题尚未关闭且您想尝试解决,只需留言"我想尝试解决这个问题"。通常有三种情况:
|
||||
- a.) 问题描述已提出解决方案。若您认可该方案,可直接提交PR或草稿PR进行修复
|
||||
- b.) 问题描述未提出解决方案。您可询问修复建议,Diffusers团队会尽快回复。若有成熟解决方案,也可直接提交PR
|
||||
- c.) 已有PR但问题未关闭。若原PR停滞,可新开PR并关联原PR(开源社区常见现象)。若PR仍活跃,您可通过建议、审查或协作等方式帮助原作者
|
||||
|
||||
### 5. 文档贡献
|
||||
|
||||
优秀库**必然**拥有优秀文档!官方文档是新用户的首要接触点,因此文档贡献具有**极高价值**。贡献形式包括:
|
||||
- 修正拼写/语法错误
|
||||
- 修复文档字符串格式错误(如显示异常或链接失效)
|
||||
- 修正文档字符串中张量的形状/维度描述
|
||||
- 优化晦涩或错误的说明
|
||||
- 更新过时代码示例
|
||||
- 文档翻译
|
||||
|
||||
[官方文档页面](https://huggingface.co/docs/diffusers/index)所有内容均属可修改范围,对应[文档源文件](https://github.com/huggingface/diffusers/tree/main/docs/source)可进行编辑。修改前请查阅[验证说明](https://github.com/huggingface/diffusers/tree/main/docs)。
|
||||
|
||||
### 6. 贡献社区流程
|
||||
|
||||
> [!TIP]
|
||||
> 阅读[社区流程](../using-diffusers/custom_pipeline_overview#community-pipelines)指南了解GitHub与Hugging Face Hub社区流程的区别。若想了解我们设立社区流程的原因,请查看GitHub Issue [#841](https://github.com/huggingface/diffusers/issues/841)(简而言之,我们无法维护diffusion模型所有可能的推理使用方式,但也不希望限制社区构建这些流程)。
|
||||
|
||||
贡献社区流程是向社区分享创意与成果的绝佳方式。您可以在[`DiffusionPipeline`]基础上构建流程,任何人都能通过设置`custom_pipeline`参数加载使用。本节将指导您创建一个简单的"单步"流程——UNet仅执行单次前向传播并调用调度器一次。
|
||||
|
||||
1. 为社区流程创建one_step_unet.py文件。只要用户已安装相关包,该文件可包含任意所需包。确保仅有一个继承自[`DiffusionPipeline`]的流程类,用于从Hub加载模型权重和调度器配置。在`__init__`函数中添加UNet和调度器。
|
||||
|
||||
同时添加`register_modules`函数,确保您的流程及其组件可通过[`~DiffusionPipeline.save_pretrained`]保存。
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
|
||||
class UnetSchedulerOneForwardPipeline(DiffusionPipeline):
|
||||
def __init__(self, unet, scheduler):
|
||||
super().__init__()
|
||||
|
||||
self.register_modules(unet=unet, scheduler=scheduler)
|
||||
```
|
||||
|
||||
2. 在前向传播中(建议定义为`__call__`),可添加任意功能。对于"单步"流程,创建随机图像并通过设置`timestep=1`调用UNet和调度器一次。
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
|
||||
class UnetSchedulerOneForwardPipeline(DiffusionPipeline):
|
||||
def __init__(self, unet, scheduler):
|
||||
super().__init__()
|
||||
|
||||
self.register_modules(unet=unet, scheduler=scheduler)
|
||||
|
||||
def __call__(self):
|
||||
image = torch.randn(
|
||||
(1, self.unet.config.in_channels, self.unet.config.sample_size, self.unet.config.sample_size),
|
||||
)
|
||||
timestep = 1
|
||||
|
||||
model_output = self.unet(image, timestep).sample
|
||||
scheduler_output = self.scheduler.step(model_output, timestep, image).prev_sample
|
||||
|
||||
return scheduler_output
|
||||
```
|
||||
|
||||
现在您可以通过传入UNet和调度器来运行流程,若流程结构相同也可加载预训练权重。
|
||||
|
||||
```python
|
||||
from diffusers import DDPMScheduler, UNet2DModel
|
||||
|
||||
scheduler = DDPMScheduler()
|
||||
unet = UNet2DModel()
|
||||
|
||||
pipeline = UnetSchedulerOneForwardPipeline(unet=unet, scheduler=scheduler)
|
||||
output = pipeline()
|
||||
# 加载预训练权重
|
||||
pipeline = UnetSchedulerOneForwardPipeline.from_pretrained("google/ddpm-cifar10-32", use_safetensors=True)
|
||||
output = pipeline()
|
||||
```
|
||||
|
||||
您可以选择将pipeline作为GitHub社区pipeline或Hub社区pipeline进行分享。
|
||||
|
||||
<hfoptions id="pipeline类型">
|
||||
<hfoption id="GitHub pipeline">
|
||||
|
||||
通过向Diffusers[代码库](https://github.com/huggingface/diffusers)提交拉取请求来分享GitHub pipeline,将one_step_unet.py文件添加到[examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community)子文件夹中。
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="Hub pipeline">
|
||||
|
||||
通过在Hub上创建模型仓库并上传one_step_unet.py文件来分享Hub pipeline。
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
### 7. 贡献训练示例
|
||||
|
||||
Diffusers训练示例是位于[examples](https://github.com/huggingface/diffusers/tree/main/examples)目录下的训练脚本集合。
|
||||
|
||||
我们支持两种类型的训练示例:
|
||||
|
||||
- 官方训练示例
|
||||
- 研究型训练示例
|
||||
|
||||
研究型训练示例位于[examples/research_projects](https://github.com/huggingface/diffusers/tree/main/examples/research_projects),而官方训练示例包含[examples](https://github.com/huggingface/diffusers/tree/main/examples)目录下除`research_projects`和`community`外的所有文件夹。
|
||||
官方训练示例由Diffusers核心维护者维护,研究型训练示例则由社区维护。
|
||||
这与[6. 贡献社区pipeline](#6-contribute-a-community-pipeline)中关于官方pipeline与社区pipeline的原因相同:核心维护者不可能维护diffusion模型的所有可能训练方法。
|
||||
如果Diffusers核心维护者和社区认为某种训练范式过于实验性或不够普及,相应训练代码应放入`research_projects`文件夹并由作者维护。
|
||||
|
||||
官方训练和研究型示例都包含一个目录,其中含有一个或多个训练脚本、`requirements.txt`文件和`README.md`文件。用户使用时需要先克隆代码库:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers
|
||||
```
|
||||
|
||||
并安装训练所需的所有额外依赖:
|
||||
|
||||
```bash
|
||||
cd diffusers
|
||||
pip install -r examples/<your-example-folder>/requirements.txt
|
||||
```
|
||||
|
||||
因此添加示例时,`requirements.txt`文件应定义训练示例所需的所有pip依赖项,安装完成后用户即可运行示例训练脚本。可参考[DreamBooth的requirements.txt文件](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/requirements.txt)。
|
||||
- 运行示例所需的所有代码应集中在单个Python文件中
|
||||
- 用户应能通过命令行`python <your-example>.py --args`直接运行示例
|
||||
- **示例**应保持简洁,主要展示如何使用Diffusers进行训练。示例脚本的目的**不是**创建最先进的diffusion模型,而是复现已知训练方案,避免添加过多自定义逻辑。因此,这些示例也力求成为优质的教学材料。
|
||||
|
||||
提交示例时,强烈建议参考现有示例(如[dreambooth](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth.py))来了解规范格式。
|
||||
我们强烈建议贡献者使用[Accelerate库](https://github.com/huggingface/accelerate),因其与Diffusers深度集成。
|
||||
当示例脚本完成后,请确保添加详细的`README.md`说明使用方法,包括:
|
||||
- 运行示例的具体命令(示例参见[此处](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth#running-locally-with-pytorch))
|
||||
- 训练结果链接(日志/模型等),展示用户可预期的效果(示例参见[此处](https://api.wandb.ai/report/patrickvonplaten/xm6cd5q5))
|
||||
- 若添加非官方/研究性训练示例,**必须注明**维护者信息(含Git账号),格式参照[此处](https://github.com/huggingface/diffusers/tree/main/examples/research_projects/intel_opts#diffusers-examples-with-intel-optimizations)
|
||||
|
||||
贡献官方训练示例时,还需在对应目录添加测试文件(如[examples/dreambooth/test_dreambooth.py](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/test_dreambooth.py)),非官方示例无需此步骤。
|
||||
|
||||
### 8. 处理"Good second issue"类问题
|
||||
|
||||
标有[Good second issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22)标签的问题通常比[Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22)更复杂。
|
||||
这类问题的描述通常不会提供详细解决指引,需要贡献者对库有较深理解。
|
||||
若您想解决此类问题,可直接提交PR并关联对应issue。若已有未合并的PR,请分析原因后提交改进版。需注意,Good second issue类PR的合并难度通常高于good first issues。在需要帮助的时候请不要犹豫,大胆的向核心维护者询问。
|
||||
|
||||
### 9. 添加管道、模型和调度器
|
||||
|
||||
管道(pipelines)、模型(models)和调度器(schedulers)是Diffusers库中最重要的组成部分。它们提供了对最先进diffusion技术的便捷访问,使得社区能够构建强大的生成式AI应用。
|
||||
|
||||
通过添加新的模型、管道或调度器,您可能为依赖Diffusers的任何用户界面开启全新的强大用例,这对整个生成式AI生态系统具有巨大价值。
|
||||
|
||||
Diffusers针对这三类组件都有一些开放的功能请求——如果您还不确定要添加哪个具体组件,可以浏览以下链接:
|
||||
- [模型或管道](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22)
|
||||
- [调度器](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22)
|
||||
|
||||
在添加任何组件之前,强烈建议您阅读[设计哲学指南](philosophy),以更好地理解这三类组件的设计理念。请注意,如果添加的模型、调度器或管道与我们的设计理念存在严重分歧,我们将无法合并,因为这会导致API不一致。如果您从根本上不同意某个设计选择,请改为提交[反馈问题](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=),以便讨论是否应该更改库中的特定设计模式/选择,以及是否更新我们的设计哲学。保持库内的一致性对我们非常重要。
|
||||
|
||||
请确保在PR中添加原始代码库/论文的链接,并最好直接在PR中@原始作者,以便他们可以跟踪进展并在有疑问时提供帮助。
|
||||
|
||||
如果您在PR过程中遇到不确定或卡住的情况,请随时留言请求初步审查或帮助。
|
||||
|
||||
#### 复制机制(Copied from)
|
||||
|
||||
在添加任何管道、模型或调度器代码时,理解`# Copied from`机制是独特且重要的。您会在整个Diffusers代码库中看到这种机制,我们使用它的原因是为了保持代码库易于理解和维护。用`# Copied from`机制标记代码会强制标记的代码与复制来源的代码完全相同。这使得每当您运行`make fix-copies`时,可以轻松更新并将更改传播到多个文件。
|
||||
|
||||
例如,在下面的代码示例中,[`~diffusers.pipelines.stable_diffusion.StableDiffusionPipelineOutput`]是原始代码,而`AltDiffusionPipelineOutput`使用`# Copied from`机制来复制它。唯一的区别是将类前缀从`Stable`改为`Alt`。
|
||||
|
||||
```py
|
||||
# 从 diffusers.pipelines.stable_diffusion.pipeline_output.StableDiffusionPipelineOutput 复制并将 Stable 替换为 Alt
|
||||
class AltDiffusionPipelineOutput(BaseOutput):
|
||||
"""
|
||||
Output class for Alt Diffusion pipelines.
|
||||
|
||||
Args:
|
||||
images (`List[PIL.Image.Image]` or `np.ndarray`)
|
||||
List of denoised PIL images of length `batch_size` or NumPy array of shape `(batch_size, height, width,
|
||||
num_channels)`.
|
||||
nsfw_content_detected (`List[bool]`)
|
||||
List indicating whether the corresponding generated image contains "not-safe-for-work" (nsfw) content or
|
||||
`None` if safety checking could not be performed.
|
||||
"""
|
||||
```
|
||||
|
||||
要了解更多信息,请阅读[~不要~重复自己*](https://huggingface.co/blog/transformers-design-philosophy#4-machine-learning-models-are-static)博客文章的相应部分。
|
||||
|
||||
## 如何撰写优质问题
|
||||
|
||||
**问题描述越清晰,被快速解决的可能性就越高。**
|
||||
|
||||
1. 确保使用了正确的issue模板。您可以选择*错误报告*、*功能请求*、*API设计反馈*、*新模型/流水线/调度器添加*、*论坛*或空白issue。在[新建issue](https://github.com/huggingface/diffusers/issues/new/choose)时务必选择正确的模板。
|
||||
2. **精确描述**:为issue起一个恰当的标题。尽量用最简练的语言描述问题。提交issue时越精确,理解问题和潜在解决方案所需的时间就越少。确保一个issue只针对一个问题,不要将多个问题放在同一个issue中。如果发现多个问题,请分别创建多个issue。如果是错误报告,请尽可能精确描述错误类型——不应只写"diffusers出错"。
|
||||
3. **可复现性**:无法复现的代码片段 == 无法解决问题。如果遇到错误,维护人员必须能够**复现**它。确保包含一个可以复制粘贴到Python解释器中复现问题的代码片段。确保您的代码片段是可运行的,即没有缺少导入或图像链接等问题。issue应包含错误信息和可直接复制粘贴以复现相同错误的代码片段。如果issue涉及本地模型权重或无法被读者访问的本地数据,则问题无法解决。如果无法共享数据或模型,请尝试创建虚拟模型或虚拟数据。
|
||||
4. **最小化原则**:通过尽可能简洁的描述帮助读者快速理解问题。删除所有与问题无关的代码/信息。如果发现错误,请创建最简单的代码示例来演示问题,不要一发现错误就把整个工作流程都转储到issue中。例如,如果在训练模型时某个阶段出现错误或训练过程中遇到问题时,应首先尝试理解训练代码的哪部分导致了错误,并用少量代码尝试复现。建议使用模拟数据替代完整数据集进行测试。
|
||||
5. 添加引用链接。当提及特定命名、方法或模型时,请务必提供引用链接以便读者理解。若涉及具体PR或issue,请确保添加对应链接。不要假设读者了解你所指内容。issue中引用链接越丰富越好。
|
||||
6. 规范格式。请确保规范格式化issue内容:Python代码使用代码语法块,错误信息使用标准代码语法。详见[GitHub官方格式文档](https://docs.github.com/en/get-started/writing-on-github/getting-started-with-writing-and-formatting-on-github/basic-writing-and-formatting-syntax)。
|
||||
7. 请将issue视为百科全书的精美词条,而非待解决的工单。每个规范撰写的issue不仅是向维护者有效传递问题的方式,更是帮助社区深入理解库特性的公共知识贡献。
|
||||
|
||||
## 优质PR编写规范
|
||||
|
||||
1. 保持风格统一。理解现有设计模式和语法规范,确保新增代码与代码库现有结构无缝衔接。显著偏离现有设计模式或用户界面的PR将不予合并。
|
||||
2. 聚焦单一问题。每个PR应当只解决一个明确问题,避免"顺手修复其他问题"的陷阱。包含多个无关修改的PR会极大增加审查难度。
|
||||
3. 如适用,建议添加代码片段演示新增功能的使用方法。
|
||||
4. PR标题应准确概括其核心贡献。
|
||||
5. 若PR针对某个issue,请在描述中注明issue编号以建立关联(也让关注该issue的用户知晓有人正在处理);
|
||||
6. 进行中的PR请在标题添加`[WIP]`前缀。这既能避免重复劳动,也可与待合并PR明确区分;
|
||||
7. 文本表述与格式要求请参照[优质issue编写规范](#how-to-write-a-good-issue);
|
||||
8. 确保现有测试用例全部通过;
|
||||
9. 必须添加高覆盖率测试。未经充分测试的代码不予合并。
|
||||
- 若新增`@slow`测试,请使用`RUN_SLOW=1 python -m pytest tests/test_my_new_model.py`确保通过。
|
||||
CircleCI不执行慢速测试,但GitHub Actions会每日夜间运行!
|
||||
10. 所有公开方法必须包含格式规范、兼容markdown的说明文档。可参考[`pipeline_latent_diffusion.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py)
|
||||
11. 由于代码库快速增长,必须确保不会添加明显增加仓库体积的文件(如图片、视频等非文本文件)。建议优先使用托管在hf.co的`dataset`(例如[`hf-internal-testing`](https://huggingface.co/hf-internal-testing)或[huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images))存放这类文件。若为外部贡献,可将图片添加到PR中并请Hugging Face成员将其迁移至该数据集。
|
||||
|
||||
## 提交PR流程
|
||||
|
||||
编写代码前,强烈建议先搜索现有PR或issue,确认没有重复工作。如有疑问,建议先创建issue获取反馈。
|
||||
|
||||
贡献至🧨 Diffusers需要基本的`git`技能。虽然`git`学习曲线较高,但其拥有最完善的手册。在终端输入`git --help`即可查阅,或参考书籍[Pro Git](https://git-scm.com/book/en/v2)。
|
||||
|
||||
请按以下步骤操作([支持的Python版本](https://github.com/huggingface/diffusers/blob/83bc6c94eaeb6f7704a2a428931cf2d9ad973ae9/setup.py#L270)):
|
||||
|
||||
1. 在[仓库页面](https://github.com/huggingface/diffusers)点击"Fork"按钮创建代码副本至您的GitHub账户
|
||||
|
||||
2. 克隆fork到本地,并添加主仓库为远程源:
|
||||
```bash
|
||||
$ git clone git@github.com:<您的GitHub账号>/diffusers.git
|
||||
$ cd diffusers
|
||||
$ git remote add upstream https://github.com/huggingface/diffusers.git
|
||||
```
|
||||
|
||||
3. 创建新分支进行开发:
|
||||
```bash
|
||||
$ git checkout -b 您的开发分支名称
|
||||
```
|
||||
**禁止**直接在`main`分支上修改
|
||||
|
||||
4. 在虚拟环境中运行以下命令配置开发环境:
|
||||
```bash
|
||||
$ pip install -e ".[dev]"
|
||||
```
|
||||
若已克隆仓库,可能需要先执行`git pull`获取最新代码
|
||||
|
||||
5. 在您的分支上开发功能
|
||||
|
||||
开发过程中应确保测试通过。可运行受影响测试:
|
||||
```bash
|
||||
$ pytest tests/<待测文件>.py
|
||||
```
|
||||
执行测试前请安装测试依赖:
|
||||
```bash
|
||||
$ pip install -e ".[test]"
|
||||
```
|
||||
也可运行完整测试套件(需高性能机器):
|
||||
```bash
|
||||
$ make test
|
||||
```
|
||||
|
||||
🧨 Diffusers使用`black`和`isort`工具保持代码风格统一。修改后请执行自动化格式校正与代码验证,以下内容无法通过以下命令一次性自动化完成:
|
||||
|
||||
```bash
|
||||
$ make style
|
||||
```
|
||||
|
||||
🧨 Diffusers 还使用 `ruff` 和一些自定义脚本来检查代码错误。虽然质量控制流程会在 CI 中运行,但您也可以通过以下命令手动执行相同的检查:
|
||||
|
||||
```bash
|
||||
$ make quality
|
||||
```
|
||||
|
||||
当您对修改满意后,使用 `git add` 添加更改的文件,并通过 `git commit` 在本地记录这些更改:
|
||||
|
||||
```bash
|
||||
$ git add modified_file.py
|
||||
$ git commit -m "关于您所做更改的描述性信息。"
|
||||
```
|
||||
|
||||
定期将您的代码副本与原始仓库同步是一个好习惯。这样可以快速适应上游变更:
|
||||
|
||||
```bash
|
||||
$ git pull upstream main
|
||||
```
|
||||
|
||||
使用以下命令将更改推送到您的账户:
|
||||
|
||||
```bash
|
||||
$ git push -u origin 此处替换为您的描述性分支名称
|
||||
```
|
||||
|
||||
6. 确认无误后,请访问您 GitHub 账户中的派生仓库页面。点击「Pull request」将您的更改提交给项目维护者审核。
|
||||
|
||||
7. 如果维护者要求修改,这很正常——核心贡献者也会遇到这种情况!为了让所有人能在 Pull request 中看到变更,请在本地分支继续工作并将修改推送到您的派生仓库,这些变更会自动出现在 Pull request 中。
|
||||
|
||||
### 测试
|
||||
|
||||
我们提供了全面的测试套件来验证库行为和多个示例。库测试位于 [tests 文件夹](https://github.com/huggingface/diffusers/tree/main/tests)。
|
||||
|
||||
我们推荐使用 `pytest` 和 `pytest-xdist`,因为它们速度更快。在仓库根目录下运行以下命令执行库测试:
|
||||
|
||||
```bash
|
||||
$ python -m pytest -n auto --dist=loadfile -s -v ./tests/
|
||||
```
|
||||
|
||||
实际上,这就是 `make test` 的实现方式!
|
||||
|
||||
您可以指定更小的测试范围来仅验证您正在开发的功能。
|
||||
|
||||
默认情况下会跳过耗时测试。设置 `RUN_SLOW` 环境变量为 `yes` 可运行这些测试。注意:这将下载数十 GB 的模型文件——请确保您有足够的磁盘空间、良好的网络连接或充足的耐心!
|
||||
|
||||
```bash
|
||||
$ RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/
|
||||
```
|
||||
|
||||
我们也完全支持 `unittest`,运行方式如下:
|
||||
|
||||
```bash
|
||||
$ python -m unittest discover -s tests -t . -v
|
||||
$ python -m unittest discover -s examples -t examples -v
|
||||
```
|
||||
|
||||
### 将派生仓库的 main 分支与上游(HuggingFace)main 分支同步
|
||||
|
||||
为避免向上游仓库发送引用通知(这会给相关 PR 添加注释并向开发者发送不必要的通知),在同步派生仓库的 main 分支时,请遵循以下步骤:
|
||||
1. 尽可能避免通过派生仓库的分支和 PR 来同步上游,而是直接合并到派生仓库的 main 分支
|
||||
2. 如果必须使用 PR,请在检出分支后执行以下操作:
|
||||
```bash
|
||||
$ git checkout -b 您的同步分支名称
|
||||
$ git pull --squash --no-commit upstream main
|
||||
$ git commit -m '提交信息(不要包含 GitHub 引用)'
|
||||
$ git push --set-upstream origin 您的分支名称
|
||||
```
|
||||
|
||||
### 风格指南
|
||||
|
||||
对于文档字符串,🧨 Diffusers 遵循 [Google 风格指南](https://google.github.io/styleguide/pyguide.html)。
|
||||
56
docs/source/zh/conceptual/ethical_guidelines.md
Normal file
56
docs/source/zh/conceptual/ethical_guidelines.md
Normal file
@@ -0,0 +1,56 @@
|
||||
<!--版权归2025年HuggingFace团队所有。保留所有权利。
|
||||
|
||||
根据Apache许可证2.0版("许可证")授权;除非符合许可证要求,否则不得使用此文件。您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,本软件按"原样"分发,不附带任何明示或暗示的担保或条件。详见许可证中规定的特定语言权限和限制。
|
||||
-->
|
||||
|
||||
# 🧨 Diffusers伦理准则
|
||||
|
||||
## 前言
|
||||
|
||||
[Diffusers](https://huggingface.co/docs/diffusers/index)不仅提供预训练的diffusion模型,还是一个模块化工具箱,支持推理和训练功能。
|
||||
|
||||
鉴于该技术在实际场景中的应用及其可能对社会产生的负面影响,我们认为有必要制定项目伦理准则,以指导Diffusers库的开发、用户贡献和使用规范。
|
||||
|
||||
该技术涉及的风险仍在持续评估中,主要包括但不限于:艺术家版权问题、深度伪造滥用、不当情境下的色情内容生成、非自愿的人物模仿、以及加剧边缘群体压迫的有害社会偏见。我们将持续追踪风险,并根据社区反馈动态调整本准则。
|
||||
|
||||
## 适用范围
|
||||
|
||||
Diffusers社区将在项目开发中贯彻以下伦理准则,并协调社区贡献的整合方式,特别是在涉及伦理敏感议题的技术决策时。
|
||||
|
||||
## 伦理准则
|
||||
|
||||
以下准则具有普遍适用性,但我们主要在处理涉及伦理敏感问题的技术决策时实施。同时,我们承诺将根据技术发展带来的新兴风险持续调整这些原则:
|
||||
|
||||
- **透明度**:我们承诺以透明方式管理PR(拉取请求),向用户解释决策依据,并公开技术选择过程。
|
||||
|
||||
- **一致性**:我们承诺为用户提供统一标准的项目管理,保持技术稳定性和连贯性。
|
||||
|
||||
- **简洁性**:为了让Diffusers库更易使用和开发,我们承诺保持项目目标精简且逻辑自洽。
|
||||
|
||||
- **可及性**:本项目致力于降低贡献门槛,即使非技术人员也能参与运营,从而使研究资源更广泛地服务于社区。
|
||||
|
||||
- **可复现性**:对于通过Diffusers库发布的上游代码、模型和数据集,我们将明确说明其可复现性。
|
||||
|
||||
- **责任性**:作为社区和团队,我们共同承担用户责任,通过风险预判和缓解措施来应对技术潜在危害。
|
||||
|
||||
## 实施案例:安全功能与机制
|
||||
|
||||
团队持续开发技术和非技术工具,以应对diffusion技术相关的伦理与社会风险。社区反馈对于功能实施和风险意识提升具有不可替代的价值:
|
||||
|
||||
- [**社区讨论区**](https://huggingface.co/docs/hub/repositories-pull-requests-discussions):促进社区成员就项目开展协作讨论。
|
||||
|
||||
- **偏见探索与评估**:Hugging Face团队提供[交互空间](https://huggingface.co/spaces/society-ethics/DiffusionBiasExplorer)展示Stable Diffusion中的偏见。我们支持并鼓励此类偏见探索与评估工作。
|
||||
|
||||
- **部署安全强化**:
|
||||
|
||||
- [**Safe Stable Diffusion**](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_safe):解决Stable Diffusion等基于未过滤网络爬取数据训练的模型容易产生不当内容的问题。相关论文:[Safe Latent Diffusion:缓解diffusion模型中的不当退化](https://huggingface.co/papers/2211.05105)。
|
||||
|
||||
- [**安全检测器**](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py):通过比对图像生成后嵌入空间中硬编码有害概念集的类别概率进行检测。有害概念列表经特殊处理以防逆向工程。
|
||||
|
||||
- **分阶段模型发布**:对于高度敏感的仓库,采用分级访问控制。这种阶段性发布机制让作者能更好地管控使用场景。
|
||||
|
||||
- **许可证制度**:采用新型[OpenRAILs](https://huggingface.co/blog/open_rail)许可协议,在保障开放访问的同时设置使用限制以确保更负责任的应用。
|
||||
558
docs/source/zh/conceptual/evaluation.md
Normal file
558
docs/source/zh/conceptual/evaluation.md
Normal file
@@ -0,0 +1,558 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
根据 Apache License 2.0 版本("许可证")授权,除非符合许可证要求,否则不得使用本文件。
|
||||
您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,本软件按"原样"分发,不附带任何明示或暗示的担保或条件。详见许可证中规定的特定语言权限和限制。
|
||||
-->
|
||||
|
||||
# Diffusion模型评估指南
|
||||
|
||||
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/evaluation.ipynb">
|
||||
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="在 Colab 中打开"/>
|
||||
</a>
|
||||
|
||||
> [!TIP]
|
||||
> 鉴于当前已出现针对图像生成Diffusion模型的成熟评估框架(如[HEIM](https://crfm.stanford.edu/helm/heim/latest/)、[T2I-Compbench](https://huggingface.co/papers/2307.06350)、[GenEval](https://huggingface.co/papers/2310.11513)),本文档部分内容已过时。
|
||||
|
||||
像 [Stable Diffusion](https://huggingface.co/docs/diffusers/stable_diffusion) 这类生成模型的评估本质上是主观的。但作为开发者和研究者,我们经常需要在众多可能性中做出审慎选择。那么当面对不同生成模型(如 GANs、Diffusion 等)时,该如何决策?
|
||||
|
||||
定性评估容易产生偏差,可能导致错误结论;而定量指标又未必能准确反映图像质量。因此,通常需要结合定性与定量评估来获得更可靠的模型选择依据。
|
||||
|
||||
本文档将系统介绍扩散模型的定性与定量评估方法(非穷尽列举)。对于定量方法,我们将重点演示如何结合 `diffusers` 库实现这些评估。
|
||||
|
||||
文档所示方法同样适用于评估不同[噪声调度器](https://huggingface.co/docs/diffusers/main/en/api/schedulers/overview)在固定生成模型下的表现差异。
|
||||
|
||||
## 评估场景
|
||||
|
||||
我们涵盖以下Diffusion模型管线的评估:
|
||||
|
||||
- 文本引导图像生成(如 [`StableDiffusionPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/text2img))
|
||||
- 基于文本和输入图像的引导生成(如 [`StableDiffusionImg2ImgPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/img2img) 和 [`StableDiffusionInstructPix2PixPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/pix2pix))
|
||||
- 类别条件图像生成模型(如 [`DiTPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipe))
|
||||
|
||||
## 定性评估
|
||||
|
||||
定性评估通常涉及对生成图像的人工评判。评估维度包括构图质量、图文对齐度和空间关系等方面。标准化的提示词能为这些主观指标提供统一基准。DrawBench和PartiPrompts是常用的定性评估提示词数据集,分别由[Imagen](https://imagen.research.google/)和[Parti](https://parti.research.google/)团队提出。
|
||||
|
||||
根据[Parti官方网站](https://parti.research.google/)说明:
|
||||
|
||||
> PartiPrompts (P2)是我们发布的包含1600多个英文提示词的丰富集合,可用于测量模型在不同类别和挑战维度上的能力。
|
||||
|
||||
|
||||
|
||||
PartiPrompts包含以下字段:
|
||||
- Prompt(提示词)
|
||||
- Category(类别,如"抽象"、"世界知识"等)
|
||||
- Challenge(难度等级,如"基础"、"复杂"、"文字与符号"等)
|
||||
|
||||
这些基准测试支持对不同图像生成模型进行并排人工对比评估。为此,🧨 Diffusers团队构建了**Open Parti Prompts**——一个基于Parti Prompts的社区驱动型定性评估基准,用于比较顶尖开源diffusion模型:
|
||||
- [Open Parti Prompts游戏](https://huggingface.co/spaces/OpenGenAI/open-parti-prompts):展示10个parti提示词对应的4张生成图像,用户选择最符合提示的图片
|
||||
- [Open Parti Prompts排行榜](https://huggingface.co/spaces/OpenGenAI/parti-prompts-leaderboard):对比当前最优开源diffusion模型的性能榜单
|
||||
|
||||
为进行手动图像对比,我们演示如何使用`diffusers`处理部分PartiPrompts提示词。
|
||||
|
||||
以下是从不同挑战维度(基础、复杂、语言结构、想象力、文字与符号)采样的提示词示例(使用[PartiPrompts作为数据集](https://huggingface.co/datasets/nateraw/parti-prompts)):
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
|
||||
# prompts = load_dataset("nateraw/parti-prompts", split="train")
|
||||
# prompts = prompts.shuffle()
|
||||
# sample_prompts = [prompts[i]["Prompt"] for i in range(5)]
|
||||
|
||||
# Fixing these sample prompts in the interest of reproducibility.
|
||||
sample_prompts = [
|
||||
"a corgi",
|
||||
"a hot air balloon with a yin-yang symbol, with the moon visible in the daytime sky",
|
||||
"a car with no windows",
|
||||
"a cube made of porcupine",
|
||||
'The saying "BE EXCELLENT TO EACH OTHER" written on a red brick wall with a graffiti image of a green alien wearing a tuxedo. A yellow fire hydrant is on a sidewalk in the foreground.',
|
||||
]
|
||||
```
|
||||
|
||||
现在我们可以使用Stable Diffusion([v1-4 checkpoint](https://huggingface.co/CompVis/stable-diffusion-v1-4))生成这些提示词对应的图像:
|
||||
|
||||
```python
|
||||
import torch
|
||||
|
||||
seed = 0
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
images = sd_pipeline(sample_prompts, num_images_per_prompt=1, generator=generator).images
|
||||
```
|
||||
|
||||

|
||||
|
||||
我们也可以通过设置`num_images_per_prompt`参数来比较同一提示词生成的不同图像。使用不同检查点([v1-5](https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5))运行相同流程后,结果如下:
|
||||
|
||||

|
||||
|
||||
当使用多个待评估模型为所有提示词生成若干图像后,这些结果将提交给人类评估员进行打分。有关DrawBench和PartiPrompts基准测试的更多细节,请参阅各自的论文。
|
||||
|
||||
<Tip>
|
||||
|
||||
在模型训练过程中查看推理样本有助于评估训练进度。我们的[训练脚本](https://github.com/huggingface/diffusers/tree/main/examples/)支持此功能,并额外提供TensorBoard和Weights & Biases日志记录功能。
|
||||
|
||||
</Tip>
|
||||
|
||||
## 定量评估
|
||||
|
||||
本节将指导您如何评估三种不同的扩散流程,使用以下指标:
|
||||
- CLIP分数
|
||||
- CLIP方向相似度
|
||||
- FID(弗雷歇起始距离)
|
||||
|
||||
### 文本引导图像生成
|
||||
|
||||
[CLIP分数](https://huggingface.co/papers/2104.08718)用于衡量图像-标题对的匹配程度。CLIP分数越高表明匹配度越高🔼。该分数是对"匹配度"这一定性概念的量化测量,也可以理解为图像与标题之间的语义相似度。研究发现CLIP分数与人类判断具有高度相关性。
|
||||
|
||||
首先加载[`StableDiffusionPipeline`]:
|
||||
|
||||
```python
|
||||
from diffusers import StableDiffusionPipeline
|
||||
import torch
|
||||
|
||||
model_ckpt = "CompVis/stable-diffusion-v1-4"
|
||||
sd_pipeline = StableDiffusionPipeline.from_pretrained(model_ckpt, torch_dtype=torch.float16).to("cuda")
|
||||
```
|
||||
|
||||
使用多个提示词生成图像:
|
||||
|
||||
```python
|
||||
prompts = [
|
||||
"a photo of an astronaut riding a horse on mars",
|
||||
"A high tech solarpunk utopia in the Amazon rainforest",
|
||||
"A pikachu fine dining with a view to the Eiffel Tower",
|
||||
"A mecha robot in a favela in expressionist style",
|
||||
"an insect robot preparing a delicious meal",
|
||||
"A small cabin on top of a snowy mountain in the style of Disney, artstation",
|
||||
]
|
||||
|
||||
images = sd_pipeline(prompts, num_images_per_prompt=1, output_type="np").images
|
||||
|
||||
print(images.shape)
|
||||
# (6, 512, 512, 3)
|
||||
```
|
||||
|
||||
然后计算CLIP分数:
|
||||
|
||||
```python
|
||||
from torchmetrics.functional.multimodal import clip_score
|
||||
from functools import partial
|
||||
|
||||
clip_score_fn = partial(clip_score, model_name_or_path="openai/clip-vit-base-patch16")
|
||||
|
||||
def calculate_clip_score(images, prompts):
|
||||
images_int = (images * 255).astype("uint8")
|
||||
clip_score = clip_score_fn(torch.from_numpy(images_int).permute(0, 3, 1, 2), prompts).detach()
|
||||
return round(float(clip_score), 4)
|
||||
|
||||
sd_clip_score = calculate_clip_score(images, prompts)
|
||||
print(f"CLIP分数: {sd_clip_score}")
|
||||
# CLIP分数: 35.7038
|
||||
```
|
||||
|
||||
上述示例中,我们为每个提示生成一张图像。如果为每个提示生成多张图像,则需要计算每个提示生成图像的平均分数。
|
||||
|
||||
当需要比较两个兼容[`StableDiffusionPipeline`]的检查点时,应在调用管道时传入生成器。首先使用[v1-4 Stable Diffusion检查点](https://huggingface.co/CompVis/stable-diffusion-v1-4)以固定种子生成图像:
|
||||
|
||||
```python
|
||||
seed = 0
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
images = sd_pipeline(prompts, num_images_per_prompt=1, generator=generator, output_type="np").images
|
||||
```
|
||||
|
||||
然后加载[v1-5检查点](https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5)生成图像:
|
||||
|
||||
```python
|
||||
model_ckpt_1_5 = "stable-diffusion-v1-5/stable-diffusion-v1-5"
|
||||
sd_pipeline_1_5 = StableDiffusionPipeline.from_pretrained(model_ckpt_1_5, torch_dtype=torch.float16).to("cuda")
|
||||
|
||||
images_1_5 = sd_pipeline_1_5(prompts, num_images_per_prompt=1, generator=generator, output_type="np").images
|
||||
```
|
||||
|
||||
最后比较两者的CLIP分数:
|
||||
|
||||
```python
|
||||
sd_clip_score_1_4 = calculate_clip_score(images, prompts)
|
||||
print(f"v-1-4版本的CLIP分数: {sd_clip_score_1_4}")
|
||||
# v-1-4版本的CLIP分数: 34.9102
|
||||
|
||||
sd_clip_score_1_5 = calculate_clip_score(images_1_5, prompts)
|
||||
print(f"v-1-5版本的CLIP分数: {sd_clip_score_1_5}")
|
||||
# v-1-5版本的CLIP分数: 36.2137
|
||||
```
|
||||
|
||||
结果表明[v1-5](https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5)检查点性能优于前代。但需注意,我们用于计算CLIP分数的提示词数量较少。实际评估时应使用更多样化且数量更大的提示词集。
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
该分数存在固有局限性:训练数据中的标题是从网络爬取,并提取自图片关联的`alt`等标签。这些描述未必符合人类描述图像的方式,因此我们需要人工"设计"部分提示词。
|
||||
|
||||
</Tip>
|
||||
|
||||
### 图像条件式文本生成图像
|
||||
|
||||
这种情况下,生成管道同时接受输入图像和文本提示作为条件。以[`StableDiffusionInstructPix2PixPipeline`]为例,该管道接收编辑指令作为输入提示,并接受待编辑的输入图像。
|
||||
|
||||
示例图示:
|
||||
|
||||

|
||||
|
||||
评估此类模型的策略之一是测量两幅图像间变化的连贯性(通过[CLIP](https://huggingface.co/docs/transformers/model_doc/clip)定义)中两个图像之间的变化与两个图像描述之间的变化的一致性(如论文[《CLIP-Guided Domain Adaptation of Image Generators》](https://huggingface.co/papers/2108.00946)所示)。这被称为“**CLIP方向相似度**”。
|
||||
|
||||
- **描述1**对应输入图像(图像1),即待编辑的图像。
|
||||
- **描述2**对应编辑后的图像(图像2),应反映编辑指令。
|
||||
|
||||
以下是示意图:
|
||||
|
||||

|
||||
|
||||
我们准备了一个小型数据集来实现该指标。首先加载数据集:
|
||||
|
||||
```python
|
||||
from datasets import load_dataset
|
||||
|
||||
dataset = load_dataset("sayakpaul/instructpix2pix-demo", split="train")
|
||||
dataset.features
|
||||
```
|
||||
|
||||
```bash
|
||||
{'input': Value(dtype='string', id=None),
|
||||
'edit': Value(dtype='string', id=None),
|
||||
'output': Value(dtype='string', id=None),
|
||||
'image': Image(decode=True, id=None)}
|
||||
```
|
||||
|
||||
数据字段说明:
|
||||
|
||||
- `input`:与`image`对应的原始描述。
|
||||
- `edit`:编辑指令。
|
||||
- `output`:反映`edit`指令的修改后描述。
|
||||
|
||||
查看一个样本:
|
||||
|
||||
```python
|
||||
idx = 0
|
||||
print(f"Original caption: {dataset[idx]['input']}")
|
||||
print(f"Edit instruction: {dataset[idx]['edit']}")
|
||||
print(f"Modified caption: {dataset[idx]['output']}")
|
||||
```
|
||||
|
||||
```bash
|
||||
Original caption: 2. FAROE ISLANDS: An archipelago of 18 mountainous isles in the North Atlantic Ocean between Norway and Iceland, the Faroe Islands has 'everything you could hope for', according to Big 7 Travel. It boasts 'crystal clear waterfalls, rocky cliffs that seem to jut out of nowhere and velvety green hills'
|
||||
Edit instruction: make the isles all white marble
|
||||
Modified caption: 2. WHITE MARBLE ISLANDS: An archipelago of 18 mountainous white marble isles in the North Atlantic Ocean between Norway and Iceland, the White Marble Islands has 'everything you could hope for', according to Big 7 Travel. It boasts 'crystal clear waterfalls, rocky cliffs that seem to jut out of nowhere and velvety green hills'
|
||||
```
|
||||
|
||||
对应的图像:
|
||||
|
||||
```python
|
||||
dataset[idx]["image"]
|
||||
```
|
||||
|
||||

|
||||
|
||||
我们将根据编辑指令修改数据集中的图像,并计算方向相似度。
|
||||
|
||||
首先加载[`StableDiffusionInstructPix2PixPipeline`]:
|
||||
|
||||
```python
|
||||
from diffusers import StableDiffusionInstructPix2PixPipeline
|
||||
|
||||
instruct_pix2pix_pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained(
|
||||
"timbrooks/instruct-pix2pix", torch_dtype=torch.float16
|
||||
).to("cuda")
|
||||
```
|
||||
|
||||
执行编辑操作:
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
|
||||
def edit_image(input_image, instruction):
|
||||
image = instruct_pix2pix_pipeline(
|
||||
instruction,
|
||||
image=input_image,
|
||||
output_type="np",
|
||||
generator=generator,
|
||||
).images[0]
|
||||
return image
|
||||
|
||||
input_images = []
|
||||
original_captions = []
|
||||
modified_captions = []
|
||||
edited_images = []
|
||||
|
||||
for idx in range(len(dataset)):
|
||||
input_image = dataset[idx]["image"]
|
||||
edit_instruction = dataset[idx]["edit"]
|
||||
edited_image = edit_image(input_image, edit_instruction)
|
||||
|
||||
input_images.append(np.array(input_image))
|
||||
original_captions.append(dataset[idx]["input"])
|
||||
modified_captions.append(dataset[idx]["output"])
|
||||
edited_images.append(edited_image)
|
||||
```
|
||||
|
||||
为测量方向相似度,我们首先加载CLIP的图像和文本编码器:
|
||||
|
||||
```python
|
||||
from transformers import (
|
||||
CLIPTokenizer,
|
||||
CLIPTextModelWithProjection,
|
||||
CLIPVisionModelWithProjection,
|
||||
CLIPImageProcessor,
|
||||
)
|
||||
|
||||
clip_id = "openai/clip-vit-large-patch14"
|
||||
tokenizer = CLIPTokenizer.from_pretrained(clip_id)
|
||||
text_encoder = CLIPTextModelWithProjection.from_pretrained(clip_id).to("cuda")
|
||||
image_processor = CLIPImageProcessor.from_pretrained(clip_id)
|
||||
image_encoder = CLIPVisionModelWithProjection.from_pretrained(clip_id).to("cuda")
|
||||
```
|
||||
|
||||
注意我们使用的是特定CLIP检查点——`openai/clip-vit-large-patch14`,因为Stable Diffusion预训练正是基于此CLIP变体。详见[文档](https://huggingface.co/docs/transformers/model_doc/clip)。
|
||||
|
||||
接着准备计算方向相似度的PyTorch `nn.Module`:
|
||||
|
||||
```python
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
|
||||
class DirectionalSimilarity(nn.Module):
|
||||
def __init__(self, tokenizer, text_encoder, image_processor, image_encoder):
|
||||
super().__init__()
|
||||
self.tokenizer = tokenizer
|
||||
self.text_encoder = text_encoder
|
||||
self.image_processor = image_processor
|
||||
self.image_encoder = image_encoder
|
||||
|
||||
def preprocess_image(self, image):
|
||||
image = self.image_processor(image, return_tensors="pt")["pixel_values"]
|
||||
return {"pixel_values": image.to("cuda")}
|
||||
|
||||
def tokenize_text(self, text):
|
||||
inputs = self.tokenizer(
|
||||
text,
|
||||
max_length=self.tokenizer.model_max_length,
|
||||
padding="max_length",
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
return {"input_ids": inputs.input_ids.to("cuda")}
|
||||
|
||||
def encode_image(self, image):
|
||||
preprocessed_image = self.preprocess_image(image)
|
||||
image_features = self.image_encoder(**preprocessed_image).image_embeds
|
||||
image_features = image_features / image_features.norm(dim=1, keepdim=True)
|
||||
return image_features
|
||||
|
||||
def encode_text(self, text):
|
||||
tokenized_text = self.tokenize_text(text)
|
||||
text_features = self.text_encoder(**tokenized_text).text_embeds
|
||||
text_features = text_features / text_features.norm(dim=1, keepdim=True)
|
||||
return text_features
|
||||
|
||||
def compute_directional_similarity(self, img_feat_one, img_feat_two, text_feat_one, text_feat_two):
|
||||
sim_direction = F.cosine_similarity(img_feat_two - img_feat_one, text_feat_two - text_feat_one)
|
||||
return sim_direction
|
||||
|
||||
def forward(self, image_one, image_two, caption_one, caption_two):
|
||||
img_feat_one = self.encode_image(image_one)
|
||||
img_feat_two = self.encode_image(image_two)
|
||||
text_feat_one = self.encode_text(caption_one)
|
||||
text_feat_two = self.encode_text(caption_two)
|
||||
directional_similarity = self.compute_directional_similarity(
|
||||
img_feat_one, img_feat_two, text_feat_one, text_feat_two
|
||||
)
|
||||
return directional_similarity
|
||||
```
|
||||
|
||||
现在让我们使用`DirectionalSimilarity`模块:
|
||||
|
||||
```python
|
||||
dir_similarity = DirectionalSimilarity(tokenizer, text_encoder, image_processor, image_encoder)
|
||||
scores = []
|
||||
|
||||
for i in range(len(input_images)):
|
||||
original_image = input_images[i]
|
||||
original_caption = original_captions[i]
|
||||
edited_image = edited_images[i]
|
||||
modified_caption = modified_captions[i]
|
||||
|
||||
similarity_score = dir_similarity(original_image, edited_image, original_caption, modified_caption)
|
||||
scores.append(float(similarity_score.detach().cpu()))
|
||||
|
||||
print(f"CLIP方向相似度: {np.mean(scores)}")
|
||||
# CLIP方向相似度: 0.0797976553440094
|
||||
```
|
||||
|
||||
与CLIP分数类似,CLIP方向相似度数值越高越好。
|
||||
|
||||
需要注意的是,`StableDiffusionInstructPix2PixPipeline`提供了两个控制参数`image_guidance_scale`和`guidance_scale`来调节最终编辑图像的质量。建议您尝试调整这两个参数,观察它们对方向相似度的影响。
|
||||
|
||||
我们可以扩展这个度量标准来评估原始图像与编辑版本的相似度,只需计算`F.cosine_similarity(img_feat_two, img_feat_one)`。对于这类编辑任务,我们仍希望尽可能保留图像的主要语义特征(即保持较高的相似度分数)。
|
||||
|
||||
该度量方法同样适用于类似流程,例如[`StableDiffusionPix2PixZeroPipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/pix2pix_zero#diffusers.StableDiffusionPix2PixZeroPipeline)。
|
||||
|
||||
<Tip>
|
||||
|
||||
CLIP分数和CLIP方向相似度都依赖CLIP模型,可能导致评估结果存在偏差。
|
||||
|
||||
</Tip>
|
||||
|
||||
***扩展IS、FID(后文讨论)或KID等指标存在困难***,当被评估模型是在大型图文数据集(如[LAION-5B数据集](https://laion.ai/blog/laion-5b/))上预训练时。因为这些指标的底层都使用了在ImageNet-1k数据集上预训练的InceptionNet来提取图像特征。Stable Diffusion的预训练数据集与InceptionNet的预训练数据集可能重叠有限,因此不适合作为特征提取器。
|
||||
|
||||
***上述指标更适合评估类别条件模型***,例如[DiT](https://huggingface.co/docs/diffusers/main/en/api/pipelines/dit)。该模型是在ImageNet-1k类别条件下预训练的。
|
||||
这是9篇文档中的第8部分。
|
||||
|
||||
### 基于类别的图像生成
|
||||
|
||||
基于类别的生成模型通常是在带有类别标签的数据集(如[ImageNet-1k](https://huggingface.co/datasets/imagenet-1k))上进行预训练的。评估这些模型的常用指标包括Fréchet Inception Distance(FID)、Kernel Inception Distance(KID)和Inception Score(IS)。本文档重点介绍FID([Heusel等人](https://huggingface.co/papers/1706.08500)),并展示如何使用[`DiTPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/dit)计算该指标,该管道底层使用了[DiT模型](https://huggingface.co/papers/2212.09748)。
|
||||
|
||||
FID旨在衡量两组图像数据集的相似程度。根据[此资源](https://mmgeneration.readthedocs.io/en/latest/quick_run.html#fid):
|
||||
|
||||
> Fréchet Inception Distance是衡量两组图像数据集相似度的指标。研究表明其与人类对视觉质量的主观判断高度相关,因此最常用于评估生成对抗网络(GAN)生成样本的质量。FID通过计算Inception网络特征表示所拟合的两个高斯分布之间的Fréchet距离来实现。
|
||||
|
||||
这两个数据集本质上是真实图像数据集和生成图像数据集(本例中为人工生成的图像)。FID通常基于两个大型数据集计算,但本文档将使用两个小型数据集进行演示。
|
||||
|
||||
首先下载ImageNet-1k训练集中的部分图像:
|
||||
|
||||
```python
|
||||
from zipfile import ZipFile
|
||||
import requests
|
||||
|
||||
|
||||
def download(url, local_filepath):
|
||||
r = requests.get(url)
|
||||
with open(local_filepath, "wb") as f:
|
||||
f.write(r.content)
|
||||
return local_filepath
|
||||
|
||||
dummy_dataset_url = "https://hf.co/datasets/sayakpaul/sample-datasets/resolve/main/sample-imagenet-images.zip"
|
||||
local_filepath = download(dummy_dataset_url, dummy_dataset_url.split("/")[-1])
|
||||
|
||||
with ZipFile(local_filepath, "r") as zipper:
|
||||
zipper.extractall(".")
|
||||
```
|
||||
|
||||
```python
|
||||
from PIL import Image
|
||||
import os
|
||||
import numpy as np
|
||||
|
||||
dataset_path = "sample-imagenet-images"
|
||||
image_paths = sorted([os.path.join(dataset_path, x) for x in os.listdir(dataset_path)])
|
||||
|
||||
real_images = [np.array(Image.open(path).convert("RGB")) for path in image_paths]
|
||||
```
|
||||
|
||||
这些是来自以下ImageNet-1k类别的10张图像:"cassette_player"、"chain_saw"(2张)、"church"、"gas_pump"(3张)、"parachute"(2张)和"tench"。
|
||||
|
||||
<p align="center">
|
||||
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/evaluation_diffusion_models/real-images.png" alt="真实图像"><br>
|
||||
<em>真实图像</em>
|
||||
</p>
|
||||
|
||||
加载图像后,我们对其进行轻量级预处理以便用于FID计算:
|
||||
|
||||
```python
|
||||
from torchvision.transforms import functional as F
|
||||
import torch
|
||||
|
||||
|
||||
def preprocess_image(image):
|
||||
image = torch.tensor(image).unsqueeze(0)
|
||||
image = image.permute(0, 3, 1, 2) / 255.0
|
||||
return F.center_crop(image, (256, 256))
|
||||
|
||||
real_images = torch.stack([dit_pipeline.preprocess_image(image) for image in real_images])
|
||||
print(real_images.shape)
|
||||
# torch.Size([10, 3, 256, 256])
|
||||
```
|
||||
|
||||
我们现在加载[`DiTPipeline`](https://huggingface.co/docs/diffusers/api/pipelines/dit)来生成基于上述类别的条件图像。
|
||||
|
||||
```python
|
||||
from diffusers import DiTPipeline, DPMSolverMultistepScheduler
|
||||
|
||||
dit_pipeline = DiTPipeline.from_pretrained("facebook/DiT-XL-2-256", torch_dtype=torch.float16)
|
||||
dit_pipeline.scheduler = DPMSolverMultistepScheduler.from_config(dit_pipeline.scheduler.config)
|
||||
dit_pipeline = dit_pipeline.to("cuda")
|
||||
|
||||
seed = 0
|
||||
generator = torch.manual_seed(seed)
|
||||
|
||||
|
||||
words = [
|
||||
"cassette player",
|
||||
"chainsaw",
|
||||
"chainsaw",
|
||||
"church",
|
||||
"gas pump",
|
||||
"gas pump",
|
||||
"gas pump",
|
||||
"parachute",
|
||||
"parachute",
|
||||
"tench",
|
||||
]
|
||||
|
||||
class_ids = dit_pipeline.get_label_ids(words)
|
||||
output = dit_pipeline(class_labels=class_ids, generator=generator, output_type="np")
|
||||
|
||||
fake_images = output.images
|
||||
fake_images = torch.tensor(fake_images)
|
||||
fake_images = fake_images.permute(0, 3, 1, 2)
|
||||
print(fake_images.shape)
|
||||
# torch.Size([10, 3, 256, 256])
|
||||
```
|
||||
|
||||
现在,我们可以使用[`torchmetrics`](https://torchmetrics.readthedocs.io/)计算FID分数。
|
||||
|
||||
```python
|
||||
from torchmetrics.image.fid import FrechetInceptionDistance
|
||||
|
||||
fid = FrechetInceptionDistance(normalize=True)
|
||||
fid.update(real_images, real=True)
|
||||
fid.update(fake_images, real=False)
|
||||
|
||||
print(f"FID分数: {float(fid.compute())}")
|
||||
# FID分数: 177.7147216796875
|
||||
```
|
||||
|
||||
FID分数越低越好。以下因素会影响FID结果:
|
||||
|
||||
- 图像数量(包括真实图像和生成图像)
|
||||
- 扩散过程中引入的随机性
|
||||
- 扩散过程的推理步数
|
||||
- 扩散过程中使用的调度器
|
||||
|
||||
对于最后两点,最佳实践是使用不同的随机种子和推理步数进行多次评估,然后报告平均结果。
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
FID结果往往具有脆弱性,因为它依赖于许多因素:
|
||||
|
||||
* 计算过程中使用的特定Inception模型
|
||||
* 计算实现的准确性
|
||||
* 图像格式(PNG和JPG的起点不同)
|
||||
|
||||
需要注意的是,FID通常在比较相似实验时最有用,但除非作者仔细公开FID测量代码,否则很难复现论文结果。
|
||||
|
||||
这些注意事项同样适用于其他相关指标,如KID和IS。
|
||||
|
||||
</Tip>
|
||||
|
||||
最后,让我们可视化检查这些`fake_images`。
|
||||
|
||||
<p align="center">
|
||||
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/evaluation_diffusion_models/fake-images.png" alt="生成图像"><br>
|
||||
<em>生成图像示例</em>
|
||||
</p>
|
||||
104
docs/source/zh/conceptual/philosophy.md
Normal file
104
docs/source/zh/conceptual/philosophy.md
Normal file
@@ -0,0 +1,104 @@
|
||||
<!--版权 2025 HuggingFace 团队。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版本("许可证")授权;
|
||||
除非符合许可证要求,否则不得使用本文件。
|
||||
您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,本软件按"原样"分发,
|
||||
无任何明示或暗示的担保或条件。详见许可证中
|
||||
的特定语言规定和限制。
|
||||
-->
|
||||
|
||||
# 设计哲学
|
||||
|
||||
🧨 Diffusers 提供**最先进**的预训练扩散模型支持多模态任务。
|
||||
其目标是成为推理和训练通用的**模块化工具箱**。
|
||||
|
||||
我们致力于构建一个经得起时间考验的库,因此对API设计极为重视。
|
||||
|
||||
简而言之,Diffusers 被设计为 PyTorch 的自然延伸。因此,我们的多数设计决策都基于 [PyTorch 设计原则](https://pytorch.org/docs/stable/community/design.html#pytorch-design-philosophy)。以下是核心原则:
|
||||
|
||||
## 可用性优先于性能
|
||||
|
||||
- 尽管 Diffusers 包含众多性能优化特性(参见[内存与速度优化](https://huggingface.co/docs/diffusers/optimization/fp16)),模型默认总是以最高精度和最低优化级别加载。因此除非用户指定,扩散流程(pipeline)默认在CPU上以float32精度初始化。这确保了跨平台和加速器的可用性,意味着运行本库无需复杂安装。
|
||||
- Diffusers 追求**轻量化**,仅有少量必需依赖,但提供诸多可选依赖以提升性能(如`accelerate`、`safetensors`、`onnx`等)。我们竭力保持库的轻量级特性,使其能轻松作为其他包的依赖项。
|
||||
- Diffusers 偏好简单、自解释的代码而非浓缩的"魔法"代码。这意味着lambda函数等简写语法和高级PyTorch操作符通常不被采用。
|
||||
|
||||
## 简洁优于简易
|
||||
|
||||
正如PyTorch所言:**显式优于隐式**,**简洁优于复杂**。这一哲学体现在库的多个方面:
|
||||
- 我们遵循PyTorch的API设计,例如使用[`DiffusionPipeline.to`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.to)让用户自主管理设备。
|
||||
- 明确的错误提示优于静默纠正错误输入。Diffusers 旨在教育用户,而非单纯降低使用难度。
|
||||
- 暴露复杂的模型与调度器(scheduler)交互逻辑而非内部魔法处理。调度器/采样器与扩散模型分离且相互依赖最小化,迫使用户编写展开的去噪循环。但这种分离便于调试,并赋予用户更多控制权来调整去噪过程或切换模型/调度器。
|
||||
- 扩散流程中独立训练的组件(如文本编码器、UNet、变分自编码器)各有专属模型类。这要求用户处理组件间交互,且序列化格式将组件分存不同文件。但此举便于调试和定制,得益于组件分离,DreamBooth或Textual Inversion训练变得极为简单。
|
||||
|
||||
## 可定制与贡献友好优于抽象
|
||||
|
||||
库的大部分沿用了[Transformers库](https://github.com/huggingface/transformers)的重要设计原则:宁要重复代码,勿要仓促抽象。这一原则与[DRY原则](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself)形成鲜明对比。
|
||||
|
||||
简言之,正如Transformers对建模文件的做法,Diffusers对流程(pipeline)和调度器(scheduler)保持极低抽象度与高度自包含代码。函数、长代码块甚至类可能在多文件中重复,初看像是糟糕的松散设计。但该设计已被Transformers证明极其成功,对社区驱动的开源机器学习库意义重大:
|
||||
- 机器学习领域发展迅猛,范式、模型架构和算法快速迭代,难以定义长效代码抽象。
|
||||
- ML从业者常需快速修改现有代码进行研究,因此偏好自包含代码而非多重抽象。
|
||||
- 开源库依赖社区贡献,必须构建易于参与的代码库。抽象度越高、依赖越复杂、可读性越差,贡献难度越大。过度抽象的库会吓退贡献者。若贡献不会破坏核心功能,不仅吸引新贡献者,也更便于并行审查和修改。
|
||||
|
||||
Hugging Face称此设计为**单文件政策**——即某个类的几乎所有代码都应写在单一自包含文件中。更多哲学探讨可参阅[此博文](https://huggingface.co/blog/transformers-design-philosophy)。
|
||||
|
||||
Diffusers对流程和调度器完全遵循该哲学,但对diffusion模型仅部分适用。原因在于多数扩散流程(如[DDPM](https://huggingface.co/docs/diffusers/api/pipelines/ddpm)、[Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview#stable-diffusion-pipelines)、[unCLIP (DALL·E 2)](https://huggingface.co/docs/diffusers/api/pipelines/unclip)和[Imagen](https://imagen.research.google/))都基于相同扩散模型——[UNet](https://huggingface.co/docs/diffusers/api/models/unet2d-cond)。
|
||||
|
||||
现在您应已理解🧨 Diffusers的设计理念🤗。我们力求在全库贯彻这些原则,但仍存在少数例外或欠佳设计。如有反馈,我们❤️欢迎在[GitHub提交](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=)。
|
||||
|
||||
## 设计哲学细节
|
||||
|
||||
现在深入探讨设计细节。Diffusers主要包含三类:[流程(pipeline)](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines)、[模型](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models)和[调度器(scheduler)](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers)。以下是各类的具体设计决策。
|
||||
|
||||
### 流程(Pipelines)
|
||||
|
||||
流程设计追求易用性(因此不完全遵循[*简洁优于简易*](#简洁优于简易)),不要求功能完备,应视为使用[模型](#模型)和[调度器](#调度器schedulers)进行推理的示例。
|
||||
|
||||
遵循原则:
|
||||
- 采用单文件政策。所有流程位于src/diffusers/pipelines下的独立目录。一个流程文件夹对应一篇扩散论文/项目/发布。如[`src/diffusers/pipelines/stable-diffusion`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/stable_diffusion)可包含多个流程文件。若流程功能相似,可使用[# Copied from机制](https://github.com/huggingface/diffusers/blob/125d783076e5bd9785beb05367a2d2566843a271/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py#L251)。
|
||||
- 所有流程继承[`DiffusionPipeline`]。
|
||||
- 每个流程由不同模型和调度器组件构成,这些组件记录于[`model_index.json`文件](https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/blob/main/model_index.json),可通过同名属性访问,并可用[`DiffusionPipeline.components`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.components)在流程间共享。
|
||||
- 所有流程应能通过[`DiffusionPipeline.from_pretrained`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.from_pretrained)加载。
|
||||
- 流程**仅**用于推理。
|
||||
- 流程代码应具备高可读性、自解释性和易修改性。
|
||||
- 流程应设计为可相互构建,便于集成到高层API。
|
||||
- 流程**非**功能完备的用户界面。完整UI推荐[InvokeAI](https://github.com/invoke-ai/InvokeAI)、[Diffuzers](https://github.com/abhishekkrthakur/diffuzers)或[lama-cleaner](https://github.com/Sanster/lama-cleaner)。
|
||||
- 每个流程应通过唯一的`__call__`方法运行,且参数命名应跨流程统一。
|
||||
- 流程应以其解决的任务命名。
|
||||
- 几乎所有新diffusion流程都应在新文件夹/文件中实现。
|
||||
|
||||
### 模型
|
||||
|
||||
模型设计为可配置的工具箱,是[PyTorch Module类](https://pytorch.org/docs/stable/generated/torch.nn.Module.html)的自然延伸,仅部分遵循**单文件政策**。
|
||||
|
||||
遵循原则:
|
||||
- 模型对应**特定架构类型**。如[`UNet2DConditionModel`]类适用于所有需要2D图像输入且受上下文调节的UNet变体。
|
||||
- 所有模型位于[`src/diffusers/models`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models),每种架构应有独立文件,如[`unets/unet_2d_condition.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/unets/unet_2d_condition.py)、[`transformers/transformer_2d.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/transformers/transformer_2d.py)等。
|
||||
- 模型**不**采用单文件政策,应使用小型建模模块如[`attention.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention.py)、[`resnet.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/resnet.py)、[`embeddings.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/embeddings.py)等。**注意**:这与Transformers的建模文件截然不同,表明模型未完全遵循单文件政策。
|
||||
- 模型意图暴露复杂度(类似PyTorch的`Module`类),并提供明确错误提示。
|
||||
- 所有模型继承`ModelMixin`和`ConfigMixin`。
|
||||
- 当不涉及重大代码变更、保持向后兼容性且显著提升内存/计算效率时,可对模型进行性能优化。
|
||||
- 模型默认应具备最高精度和最低性能设置。
|
||||
- 若新模型检查点可归类为现有架构,应适配现有架构而非新建文件。仅当架构根本性不同时才创建新文件。
|
||||
- 模型设计应便于未来扩展。可通过限制公开函数参数、配置参数和"预见"变更实现。例如:优先采用可扩展的`string`类型参数而非布尔型`is_..._type`参数。对现有架构的修改应保持最小化。
|
||||
- 模型设计需在代码可读性与多检查点支持间权衡。多数情况下应适配现有类,但某些例外(如[UNet块](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/unets/unet_2d_blocks.py)和[注意力处理器](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py))需新建类以保证长期可读性。
|
||||
|
||||
### 调度器(Schedulers)
|
||||
|
||||
调度器负责引导推理去噪过程及定义训练噪声计划。它们设计为独立的可加载配置类,严格遵循**单文件政策**。
|
||||
|
||||
遵循原则:
|
||||
- 所有调度器位于[`src/diffusers/schedulers`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers)。
|
||||
- 调度器**禁止**从大型工具文件导入,必须保持高度自包含。
|
||||
- 一个调度器Python文件对应一种算法(如论文定义的算法)。
|
||||
- 若调度器功能相似,可使用`# Copied from`机制。
|
||||
- 所有调度器继承`SchedulerMixin`和`ConfigMixin`。
|
||||
- 调度器可通过[`ConfigMixin.from_config`](https://huggingface.co/docs/diffusers/main/en/api/configuration#diffusers.ConfigMixin.from_config)轻松切换(详见[此处](../using-diffusers/schedulers))。
|
||||
- 每个调度器必须包含`set_num_inference_steps`和`step`函数。在每次去噪过程前(即调用`step(...)`前)必须调用`set_num_inference_steps(...)`。
|
||||
- 每个调度器通过`timesteps`属性暴露需要"循环"的时间步,这是模型将被调用的时间步数组。
|
||||
- `step(...)`函数接收模型预测输出和"当前"样本(x_t),返回"前一个"略去噪的样本(x_t-1)。
|
||||
- 鉴于扩散调度器的复杂性,`step`函数不暴露全部细节,可视为"黑盒"。
|
||||
- 几乎所有新调度器都应在新文件中实现。
|
||||
9
docs/source/zh/hybrid_inference/api_reference.md
Normal file
9
docs/source/zh/hybrid_inference/api_reference.md
Normal file
@@ -0,0 +1,9 @@
|
||||
# 混合推理 API 参考
|
||||
|
||||
## 远程解码
|
||||
|
||||
[[autodoc]] utils.remote_utils.remote_decode
|
||||
|
||||
## 远程编码
|
||||
|
||||
[[autodoc]] utils.remote_utils.remote_encode
|
||||
55
docs/source/zh/hybrid_inference/overview.md
Normal file
55
docs/source/zh/hybrid_inference/overview.md
Normal file
@@ -0,0 +1,55 @@
|
||||
<!--版权 2025 HuggingFace 团队。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版本("许可证")授权;除非遵守许可证,否则不得使用此文件。
|
||||
您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,否则根据许可证分发的软件按"原样"分发,不附带任何明示或暗示的担保或条件。请参阅许可证以了解具体的语言管理权限和限制。
|
||||
-->
|
||||
|
||||
# 混合推理
|
||||
|
||||
**通过混合推理赋能本地 AI 构建者**
|
||||
|
||||
> [!TIP]
|
||||
> 混合推理是一项[实验性功能](https://huggingface.co/blog/remote_vae)。
|
||||
> 可以在此处提供反馈[此处](https://github.com/huggingface/diffusers/issues/new?template=remote-vae-pilot-feedback.yml)。
|
||||
|
||||
## 为什么使用混合推理?
|
||||
|
||||
混合推理提供了一种快速简单的方式来卸载本地生成需求。
|
||||
|
||||
- 🚀 **降低要求:** 无需昂贵硬件即可访问强大模型。
|
||||
- 💎 **无妥协:** 在不牺牲性能的情况下实现最高质量。
|
||||
- 💰 **成本效益高:** 它是免费的!🤑
|
||||
- 🎯 **多样化用例:** 与 Diffusers <20> 和更广泛的社区完全兼容。
|
||||
- 🔧 **开发者友好:** 简单请求,快速响应。
|
||||
|
||||
---
|
||||
|
||||
## 可用模型
|
||||
|
||||
* **VAE 解码 🖼️:** 快速将潜在表示解码为高质量图像,不影响性能或工作流速度。
|
||||
* **VAE 编码 🔢:** 高效将图像编码为潜在表示,用于生成和训练。
|
||||
* **文本编码器 📃(即将推出):** 快速准确地计算提示的文本嵌入,确保流畅高质量的工作流。
|
||||
|
||||
---
|
||||
|
||||
## 集成
|
||||
|
||||
* **[SD.Next](https://github.com/vladmandic/sdnext):** 一体化 UI,直接支持混合推理。
|
||||
* **[ComfyUI-HFRemoteVae](https://github.com/kijai/ComfyUI-HFRemoteVae):** 用于混合推理的 ComfyUI 节点。
|
||||
|
||||
## 更新日志
|
||||
|
||||
- 2025 年 3 月 10 日:添加了 VAE 编码
|
||||
- 2025 年 3 月 2 日:初始发布,包含 VAE 解码
|
||||
|
||||
## 内容
|
||||
|
||||
文档分为三个部分:
|
||||
|
||||
* **VAE 解码** 学习如何使用混合推理进行 VAE 解码的基础知识。
|
||||
* **VAE 编码** 学习如何使用混合推理进行 VAE 编码的基础知识。
|
||||
* **API 参考** 深入了解任务特定设置和参数。
|
||||
184
docs/source/zh/hybrid_inference/vae_encode.md
Normal file
184
docs/source/zh/hybrid_inference/vae_encode.md
Normal file
@@ -0,0 +1,184 @@
|
||||
# 入门:使用混合推理进行 VAE 编码
|
||||
|
||||
VAE 编码用于训练、图像到图像和图像到视频——将图像或视频转换为潜在表示。
|
||||
|
||||
## 内存
|
||||
|
||||
这些表格展示了在不同 GPU 上使用 SD v1 和 SD XL 进行 VAE 编码的 VRAM 需求。
|
||||
|
||||
对于这些 GPU 中的大多数,内存使用百分比决定了其他模型(文本编码器、UNet/Transformer)必须被卸载,或者必须使用分块编码,这会增加时间并影响质量。
|
||||
|
||||
<details><summary>SD v1.5</summary>
|
||||
|
||||
| GPU | 分辨率 | 时间(秒) | 内存(%) | 分块时间(秒) | 分块内存(%) |
|
||||
|:------------------------------|:-------------|-----------------:|-------------:|--------------------:|-------------------:|
|
||||
| NVIDIA GeForce RTX 4090 | 512x512 | 0.015 | 3.51901 | 0.015 | 3.51901 |
|
||||
| NVIDIA GeForce RTX 4090 | 256x256 | 0.004 | 1.3154 | 0.005 | 1.3154 |
|
||||
| NVIDIA GeForce RTX 4090 | 2048x2048 | 0.402 | 47.1852 | 0.496 | 3.51901 |
|
||||
| NVIDIA GeForce RTX 4090 | 1024x1024 | 0.078 | 12.2658 | 0.094 | 3.51901 |
|
||||
| NVIDIA GeForce RTX 4080 SUPER | 512x512 | 0.023 | 5.30105 | 0.023 | 5.30105 |
|
||||
| NVIDIA GeForce RTX 4080 SUPER | 256x256 | 0.006 | 1.98152 | 0.006 | 1.98152 |
|
||||
| NVIDIA GeForce RTX 4080 SUPER | 2048x2048 | 0.574 | 71.08 | 0.656 | 5.30105 |
|
||||
| NVIDIA GeForce RTX 4080 SUPER | 1024x1024 | 0.111 | 18.4772 | 0.14 | 5.30105 |
|
||||
| NVIDIA GeForce RTX 3090 | 512x512 | 0.032 | 3.52782 | 0.032 | 3.52782 |
|
||||
| NVIDIA GeForce RTX 3090 | 256x256 | 0.01 | 1.31869 | 0.009 | 1.31869 |
|
||||
| NVIDIA GeForce RTX 3090 | 2048x2048 | 0.742 | 47.3033 | 0.954 | 3.52782 |
|
||||
| NVIDIA GeForce RTX 3090 | 1024x1024 | 0.136 | 12.2965 | 0.207 | 3.52782 |
|
||||
| NVIDIA GeForce RTX 3080 | 512x512 | 0.036 | 8.51761 | 0.036 | 8.51761 |
|
||||
| NVIDIA GeForce RTX 3080 | 256x256 | 0.01 | 3.18387 | 0.01 | 3.18387 |
|
||||
| NVIDIA GeForce RTX 3080 | 2048x2048 | 0.863 | 86.7424 | 1.191 | 8.51761 |
|
||||
| NVIDIA GeForce RTX 3080 | 1024x1024 | 0.157 | 29.6888 | 0.227 | 8.51761 |
|
||||
| NVIDIA GeForce RTX 3070 | 512x512 | 0.051 | 10.6941 | 0.051 | 10.6941 |
|
||||
| NVIDIA GeForce RTX 3070 | 256x256 | 0.015 |
|
||||
| 3.99743 | 0.015 | 3.99743 |
|
||||
| NVIDIA GeForce RTX 3070 | 2048x2048 | 1.217 | 96.054 | 1.482 | 10.6941 |
|
||||
| NVIDIA GeForce RTX 3070 | 1024x1024 | 0.223 | 37.2751 | 0.327 | 10.6941 |
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary>SDXL</summary>
|
||||
|
||||
| GPU | Resolution | Time (seconds) | Memory Consumed (%) | Tiled Time (seconds) | Tiled Memory (%) |
|
||||
|:------------------------------|:-------------|-----------------:|----------------------:|-----------------------:|-------------------:|
|
||||
| NVIDIA GeForce RTX 4090 | 512x512 | 0.029 | 4.95707 | 0.029 | 4.95707 |
|
||||
| NVIDIA GeForce RTX 4090 | 256x256 | 0.007 | 2.29666 | 0.007 | 2.29666 |
|
||||
| NVIDIA GeForce RTX 4090 | 2048x2048 | 0.873 | 66.3452 | 0.863 | 15.5649 |
|
||||
| NVIDIA GeForce RTX 4090 | 1024x1024 | 0.142 | 15.5479 | 0.143 | 15.5479 |
|
||||
| NVIDIA GeForce RTX 4080 SUPER | 512x512 | 0.044 | 7.46735 | 0.044 | 7.46735 |
|
||||
| NVIDIA GeForce RTX 4080 SUPER | 256x256 | 0.01 | 3.4597 | 0.01 | 3.4597 |
|
||||
| NVIDIA GeForce RTX 4080 SUPER | 2048x2048 | 1.317 | 87.1615 | 1.291 | 23.447 |
|
||||
| NVIDIA GeForce RTX 4080 SUPER | 1024x1024 | 0.213 | 23.4215 | 0.214 | 23.4215 |
|
||||
| NVIDIA GeForce RTX 3090 | 512x512 | 0.058 | 5.65638 | 0.058 | 5.65638 |
|
||||
| NVIDIA GeForce RTX 3090 | 256x256 | 0.016 | 2.45081 | 0.016 | 2.45081 |
|
||||
| NVIDIA GeForce RTX 3090 | 2048x2048 | 1.755 | 77.8239 | 1.614 | 18.4193 |
|
||||
| NVIDIA GeForce RTX 3090 | 1024x1024 | 0.265 | 18.4023 | 0.265 | 18.4023 |
|
||||
| NVIDIA GeForce RTX 3080 | 512x512 | 0.064 | 13.6568 | 0.064 | 13.6568 |
|
||||
| NVIDIA GeForce RTX 3080 | 256x256 | 0.018 | 5.91728 | 0.018 | 5.91728 |
|
||||
| NVIDIA GeForce RTX 3080 | 2048x2048 | 内存不足 (OOM) | 内存不足 (OOM) | 1.866 | 44.4717 |
|
||||
| NVIDIA GeForce RTX 3080 | 1024x1024 | 0.302 | 44.4308 | 0.302 | 44.4308 |
|
||||
| NVIDIA GeForce RTX 3070 | 512x512 | 0.093 | 17.1465 | 0.093 | 17.1465 |
|
||||
| NVIDIA GeForce R
|
||||
| NVIDIA GeForce RTX 3070 | 256x256 | 0.025 | 7.42931 | 0.026 | 7.42931 |
|
||||
| NVIDIA GeForce RTX 3070 | 2048x2048 | OOM | OOM | 2.674 | 55.8355 |
|
||||
| NVIDIA GeForce RTX 3070 | 1024x1024 | 0.443 | 55.7841 | 0.443 | 55.7841 |
|
||||
|
||||
</details>
|
||||
|
||||
## 可用 VAE
|
||||
|
||||
| | **端点** | **模型** |
|
||||
|:-:|:-----------:|:--------:|
|
||||
| **Stable Diffusion v1** | [https://qc6479g0aac6qwy9.us-east-1.aws.endpoints.huggingface.cloud](https://qc6479g0aac6qwy9.us-east-1.aws.endpoints.huggingface.cloud) | [`stabilityai/sd-vae-ft-mse`](https://hf.co/stabilityai/sd-vae-ft-mse) |
|
||||
| **Stable Diffusion XL** | [https://xjqqhmyn62rog84g.us-east-1.aws.endpoints.huggingface.cloud](https://xjqqhmyn62rog84g.us-east-1.aws.endpoints.huggingface.cloud) | [`madebyollin/sdxl-vae-fp16-fix`](https://hf.co/madebyollin/sdxl-vae-fp16-fix) |
|
||||
| **Flux** | [https://ptccx55jz97f9zgo.us-east-1.aws.endpoints.huggingface.cloud](https://ptccx55jz97f9zgo.us-east-1.aws.endpoints.huggingface.cloud) | [`black-forest-labs/FLUX.1-schnell`](https://hf.co/black-forest-labs/FLUX.1-schnell) |
|
||||
|
||||
|
||||
> [!TIP]
|
||||
> 模型支持可以在此处请求:[这里](https://github.com/huggingface/diffusers/issues/new?template=remote-vae-pilot-feedback.yml)。
|
||||
|
||||
|
||||
## 代码
|
||||
|
||||
> [!TIP]
|
||||
> 从 `main` 安装 `diffusers` 以运行代码:`pip install git+https://github.com/huggingface/diffusers@main`
|
||||
|
||||
|
||||
一个辅助方法简化了与混合推理的交互。
|
||||
|
||||
```python
|
||||
from diffusers.utils.remote_utils import remote_encode
|
||||
```
|
||||
|
||||
### 基本示例
|
||||
|
||||
让我们编码一张图像,然后解码以演示。
|
||||
|
||||
<figure class="image flex flex-col items-center justify-center text-center m-0 w-full">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/astronaut.jpg"/>
|
||||
</figure>
|
||||
|
||||
<details><summary>代码</summary>
|
||||
|
||||
```python
|
||||
from diffusers.utils import load_image
|
||||
from diffusers.utils.remote_utils import remote_decode
|
||||
|
||||
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/astronaut.jpg?download=true")
|
||||
|
||||
latent = remote_encode(
|
||||
endpoint="https://ptccx55jz97f9zgo.us-east-1.aws.endpoints.huggingface.cloud/",
|
||||
scaling_factor=0.3611,
|
||||
shift_factor=0.1159,
|
||||
)
|
||||
|
||||
decoded = remote_decode(
|
||||
endpoint="https://whhx50ex1aryqvw6.us-east-1.aws.endpoints.huggingface.cloud/",
|
||||
tensor=latent,
|
||||
scaling_factor=0.3611,
|
||||
shift_factor=0.1159,
|
||||
)
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
<figure class="image flex flex-col items-center justify-center text-center m-0 w-full">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/remote_vae/decoded.png"/>
|
||||
</figure>
|
||||
|
||||
|
||||
### 生成
|
||||
|
||||
现在让我们看一个生成示例,我们将编码图像,生成,然后远程解码!
|
||||
|
||||
<details><summary>代码</summary>
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import StableDiffusionImg2ImgPip
|
||||
from diffusers.utils import load_image
|
||||
from diffusers.utils.remote_utils import remote_decode, remote_encode
|
||||
|
||||
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5",
|
||||
torch_dtype=torch.float16,
|
||||
variant="fp16",
|
||||
vae=None,
|
||||
).to("cuda")
|
||||
|
||||
init_image = load_image(
|
||||
"https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
|
||||
)
|
||||
init_image = init_image.resize((768, 512))
|
||||
|
||||
init_latent = remote_encode(
|
||||
endpoint="https://qc6479g0aac6qwy9.us-east-1.aws.endpoints.huggingface.cloud/",
|
||||
image=init_image,
|
||||
scaling_factor=0.18215,
|
||||
)
|
||||
|
||||
prompt = "A fantasy landscape, trending on artstation"
|
||||
latent = pipe(
|
||||
prompt=prompt,
|
||||
image=init_latent,
|
||||
strength=0.75,
|
||||
output_type="latent",
|
||||
).images
|
||||
|
||||
image = remote_decode(
|
||||
endpoint="https://q1bj3bpq6kzilnsu.us-east-1.aws.endpoints.huggingface.cloud/",
|
||||
tensor=latent,
|
||||
scaling_factor=0.18215,
|
||||
)
|
||||
image.save("fantasy_landscape.jpg")
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
<figure class="image flex flex-col items-center justify-center text-center m-0 w-full">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/remote_vae/fantasy_landscape.png"/>
|
||||
</figure>
|
||||
|
||||
## 集成
|
||||
|
||||
* **[SD.Next](https://github.com/vladmandic/sdnext):** 具有直接支持混合推理功能的一体化用户界面。
|
||||
* **[ComfyUI-HFRemoteVae](https://github.com/kijai/ComfyUI-HFRemoteVae):** 用于混合推理的 ComfyUI 节点。
|
||||
156
docs/source/zh/modular_diffusers/auto_pipeline_blocks.md
Normal file
156
docs/source/zh/modular_diffusers/auto_pipeline_blocks.md
Normal file
@@ -0,0 +1,156 @@
|
||||
<!--版权所有 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据Apache许可证2.0版("许可证")授权;除非符合许可证,否则不得使用此文件。您可以在
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
获取许可证的副本。
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件按"原样"分发,无任何明示或暗示的担保或条件。有关许可证的特定语言管理权限和限制,请参阅许可证。
|
||||
-->
|
||||
|
||||
# AutoPipelineBlocks
|
||||
|
||||
[`~modular_pipelines.AutoPipelineBlocks`] 是一种包含支持不同工作流程的块的多块类型。它根据运行时提供的输入自动选择要运行的子块。这通常用于将多个工作流程(文本到图像、图像到图像、修复)打包到一个管道中以便利。
|
||||
|
||||
本指南展示如何创建 [`~modular_pipelines.AutoPipelineBlocks`]。
|
||||
|
||||
创建三个 [`~modular_pipelines.ModularPipelineBlocks`] 用于文本到图像、图像到图像和修复。这些代表了管道中可用的不同工作流程。
|
||||
|
||||
<hfoptions id="auto">
|
||||
<hfoption id="text-to-image">
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers.modular_pipelines import ModularPipelineBlocks, InputParam, OutputParam
|
||||
|
||||
class TextToImageBlock(ModularPipelineBlocks):
|
||||
model_name = "text2img"
|
||||
|
||||
@property
|
||||
def inputs(self):
|
||||
return [InputParam(name="prompt")]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self):
|
||||
return []
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return "我是一个文本到图像的工作流程!"
|
||||
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
print("运行文本到图像工作流程")
|
||||
# 在这里添加你的文本到图像逻辑
|
||||
# 例如:根据提示生成图像
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="image-to-image">
|
||||
|
||||
```py
|
||||
class ImageToImageBlock(ModularPipelineBlocks):
|
||||
model_name = "img2img"
|
||||
|
||||
@property
|
||||
def inputs(self):
|
||||
return [InputParam(name="prompt"), InputParam(name="image")]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self):
|
||||
return []
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return "我是一个图像到图像的工作流程!"
|
||||
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
print("运行图像到图像工作流程")
|
||||
# 在这里添加你的图像到图像逻辑
|
||||
# 例如:根据提示转换输入图像
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="inpaint">
|
||||
|
||||
```py
|
||||
class InpaintBlock(ModularPipelineBlocks):
|
||||
model_name = "inpaint"
|
||||
|
||||
@property
|
||||
def inputs(self):
|
||||
return [InputParam(name="prompt"), InputParam(name="image"), InputParam(name="mask")]
|
||||
|
||||
@property
|
||||
|
||||
def intermediate_outputs(self):
|
||||
return []
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return "我是一个修复工作流!"
|
||||
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
print("运行修复工作流")
|
||||
# 在这里添加你的修复逻辑
|
||||
# 例如:根据提示填充被遮罩的区域
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
创建一个包含子块类及其对应块名称列表的[`~modular_pipelines.AutoPipelineBlocks`]类。
|
||||
|
||||
你还需要包括`block_trigger_inputs`,一个触发相应块的输入名称列表。如果在运行时提供了触发输入,则选择该块运行。使用`None`来指定如果未检测到触发输入时运行的默认块。
|
||||
|
||||
最后,重要的是包括一个`description`,清楚地解释哪些输入触发哪些工作流。这有助于用户理解如何运行特定的工作流。
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import AutoPipelineBlocks
|
||||
|
||||
class AutoImageBlocks(AutoPipelineBlocks):
|
||||
# 选择子块类的列表
|
||||
block_classes = [block_inpaint_cls, block_i2i_cls, block_t2i_cls]
|
||||
# 每个块的名称,顺序相同
|
||||
block_names = ["inpaint", "img2img", "text2img"]
|
||||
# 决定运行哪个块的触发输入
|
||||
# - "mask" 触发修复工作流
|
||||
# - "image" 触发img2img工作流(但仅在未提供mask时)
|
||||
# - 如果以上都没有,运行text2img工作流(默认)
|
||||
block_trigger_inputs = ["mask", "image", None]
|
||||
# 对于AutoPipelineBlocks来说,描述极其重要
|
||||
|
||||
def description(self):
|
||||
return (
|
||||
"Pipeline generates images given different types of conditions!\n"
|
||||
+ "This is an auto pipeline block that works for text2img, img2img and inpainting tasks.\n"
|
||||
+ " - inpaint workflow is run when `mask` is provided.\n"
|
||||
+ " - img2img workflow is run when `image` is provided (but only when `mask` is not provided).\n"
|
||||
+ " - text2img workflow is run when neither `image` nor `mask` is provided.\n"
|
||||
)
|
||||
```
|
||||
|
||||
包含`description`以避免任何关于如何运行块和需要什么输入的混淆**非常**重要。虽然[`~modular_pipelines.AutoPipelineBlocks`]很方便,但如果它没有正确解释,其条件逻辑可能难以理解。
|
||||
|
||||
创建`AutoImageBlocks`的一个实例。
|
||||
|
||||
```py
|
||||
auto_blocks = AutoImageBlocks()
|
||||
```
|
||||
|
||||
对于更复杂的组合,例如在更大的管道中作为子块使用的嵌套[`~modular_pipelines.AutoPipelineBlocks`]块,使用[`~modular_pipelines.SequentialPipelineBlocks.get_execution_blocks`]方法根据你的输入提取实际运行的块。
|
||||
|
||||
```py
|
||||
auto_blocks.get_execution_blocks("mask")
|
||||
```
|
||||
188
docs/source/zh/modular_diffusers/components_manager.md
Normal file
188
docs/source/zh/modular_diffusers/components_manager.md
Normal file
@@ -0,0 +1,188 @@
|
||||
<!--版权所有 2025 HuggingFace 团队。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版("许可证")授权;除非遵守许可证,否则不得使用此文件。您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件按"原样"分发,无任何明示或暗示的担保或条件。请参阅许可证以了解特定语言管理权限和限制。
|
||||
-->
|
||||
|
||||
# 组件管理器
|
||||
|
||||
[`ComponentsManager`] 是 Modular Diffusers 的模型注册和管理系统。它添加和跟踪模型,存储有用的元数据(模型大小、设备放置、适配器),防止重复模型实例,并支持卸载。
|
||||
|
||||
本指南将展示如何使用 [`ComponentsManager`] 来管理组件和设备内存。
|
||||
|
||||
## 添加组件
|
||||
|
||||
[`ComponentsManager`] 应与 [`ModularPipeline`] 一起创建,在 [`~ModularPipeline.from_pretrained`] 或 [`~ModularPipelineBlocks.init_pipeline`] 中。
|
||||
|
||||
> [!TIP]
|
||||
> `collection` 参数是可选的,但可以更轻松地组织和管理组件。
|
||||
|
||||
<hfoptions id="create">
|
||||
<hfoption id="from_pretrained">
|
||||
|
||||
```py
|
||||
from diffusers import ModularPipeline, ComponentsManager
|
||||
|
||||
comp = ComponentsManager()
|
||||
pipe = ModularPipeline.from_pretrained("YiYiXu/modular-demo-auto", components_manager=comp, collection="test1")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="init_pipeline">
|
||||
|
||||
```py
|
||||
from diffusers import ComponentsManager
|
||||
from diffusers.modular_pipelines import SequentialPipelineBlocks
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl import TEXT2IMAGE_BLOCKS
|
||||
|
||||
t2i_blocks = SequentialPipelineBlocks.from_blocks_dict(TEXT2IMAGE_BLOCKS)
|
||||
|
||||
modular_repo_id = "YiYiXu/modular-loader-t2i-0704"
|
||||
components = ComponentsManager()
|
||||
t2i_pipeline = t2i_blocks.init_pipeline(modular_repo_id, components_manager=components)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
组件仅在调用 [`~ModularPipeline.load_components`] 或 [`~ModularPipeline.load_default_components`] 时加载和注册。以下示例使用 [`~ModularPipeline.load_default_components`] 创建第二个管道,重用第一个管道的所有组件,并将其分配到不同的集合。
|
||||
|
||||
```py
|
||||
pipe.load_default_components()
|
||||
pipe2 = ModularPipeline.from_pretrained("YiYiXu/modular-demo-auto", components_manager=comp, collection="test2")
|
||||
```
|
||||
|
||||
使用 [`~ModularPipeline.null_component_names`] 属性来识别需要加载的任何组件,使用 [`~ComponentsManager.get_components_by_names`] 检索它们,然后调用 [`~ModularPipeline.update_components`] 来添加缺失的组件。
|
||||
|
||||
```py
|
||||
pipe2.null_component_names
|
||||
['text_encoder', 'text_encoder_2', 'tokenizer', 'tokenizer_2', 'image_encoder', 'unet', 'vae', 'scheduler', 'controlnet']
|
||||
|
||||
comp_dict = comp.get_components_by_names(names=pipe2.null_component_names)
|
||||
pipe2.update_components(**comp_dict)
|
||||
```
|
||||
|
||||
要添加单个组件,请使用 [`~ComponentsManager.add`] 方法。这会使用唯一 id 注册一个组件。
|
||||
|
||||
```py
|
||||
from diffusers import AutoModel
|
||||
|
||||
text_encoder = AutoModel.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", subfolder="text_encoder")
|
||||
component_id = comp.add("text_encoder", text_encoder)
|
||||
comp
|
||||
```
|
||||
|
||||
使用 [`~ComponentsManager.remove`] 通过其 id 移除一个组件。
|
||||
|
||||
```py
|
||||
comp.remove("text_encoder_139917733042864")
|
||||
```
|
||||
|
||||
## 检索组件
|
||||
|
||||
[`ComponentsManager`] 提供了几种方法来检索已注册的组件。
|
||||
|
||||
### get_one
|
||||
|
||||
[`~ComponentsManager.get_one`] 方法返回单个组件,并支持对 `name` 参数进行模式匹配。如果多个组件匹配,[`~ComponentsManager.get_one`] 会返回错误。
|
||||
|
||||
| 模式 | 示例 | 描述 |
|
||||
|-------------|----------------------------------|-------------------------------------------|
|
||||
| exact | `comp.get_one(name="unet")` | 精确名称匹配 |
|
||||
| wildcard | `comp.get_one(name="unet*")` | 名称以 "unet" 开头 |
|
||||
| exclusion | `comp.get_one(name="!unet")` | 排除名为 "unet" 的组件 |
|
||||
| or | `comp.get_one(name="unet|vae")` | 名称为 "unet" 或 "vae" |
|
||||
|
||||
[`~ComponentsManager.get_one`] 还通过 `collection` 参数或 `load_id` 参数过滤组件。
|
||||
|
||||
```py
|
||||
comp.get_one(name="unet", collection="sdxl")
|
||||
```
|
||||
|
||||
### get_components_by_names
|
||||
|
||||
[`~ComponentsManager.get_components_by_names`] 方法接受一个名称列表,并返回一个将名称映射到组件的字典。这在 [`ModularPipeline`] 中特别有用,因为它们提供了所需组件名称的列表,并且返回的字典可以直接传递给 [`~ModularPipeline.update_components`]。
|
||||
|
||||
```py
|
||||
component_dict = comp.get_components_by_names(names=["text_encoder", "unet", "vae"])
|
||||
{"text_encoder": component1, "unet": component2, "vae": component3}
|
||||
```
|
||||
|
||||
## 重复检测
|
||||
|
||||
建议使用 [`ComponentSpec`] 加载模型组件,以分配具有唯一 id 的组件,该 id 编码了它们的加载参数。这允许 [`ComponentsManager`] 自动检测并防止重复的模型实例,即使不同的对象代表相同的底层检查点。
|
||||
|
||||
```py
|
||||
from diffusers import ComponentSpec, ComponentsManager
|
||||
from transformers import CLIPTextModel
|
||||
|
||||
comp = ComponentsManager()
|
||||
|
||||
# 为第一个文本编码器创建 ComponentSpec
|
||||
spec = ComponentSpec(name="text_encoder", repo="stabilityai/stable-diffusion-xl-base-1.0", subfolder="text_encoder", type_hint=AutoModel)
|
||||
# 为重复的文本编码器创建 ComponentSpec(它是相同的检查点,来自相同的仓库/子文件夹)
|
||||
spec_duplicated = ComponentSpec(name="text_encoder_duplicated", repo="stabilityai/stable-diffusion-xl-base-1.0", subfolder="text_encoder", ty
|
||||
pe_hint=CLIPTextModel)
|
||||
|
||||
# 加载并添加两个组件 - 管理器会检测到它们是同一个模型
|
||||
comp.add("text_encoder", spec.load())
|
||||
comp.add("text_encoder_duplicated", spec_duplicated.load())
|
||||
```
|
||||
|
||||
这会返回一个警告,附带移除重复项的说明。
|
||||
|
||||
```py
|
||||
ComponentsManager: adding component 'text_encoder_duplicated_139917580682672', but it has duplicate load_id 'stabilityai/stable-diffusion-xl-base-1.0|text_encoder|null|null' with existing components: text_encoder_139918506246832. To remove a duplicate, call `components_manager.remove('<component_id>')`.
|
||||
'text_encoder_duplicated_139917580682672'
|
||||
```
|
||||
|
||||
您也可以不使用 [`ComponentSpec`] 添加组件,并且在大多数情况下,即使您以不同名称添加相同组件,重复检测仍然有效。
|
||||
|
||||
然而,当您将相同组件加载到不同对象时,[`ComponentManager`] 无法检测重复项。在这种情况下,您应该使用 [`ComponentSpec`] 加载模型。
|
||||
|
||||
```py
|
||||
text_encoder_2 = AutoModel.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", subfolder="text_encoder")
|
||||
comp.add("text_encoder", text_encoder_2)
|
||||
'text_encoder_139917732983664'
|
||||
```
|
||||
|
||||
## 集合
|
||||
|
||||
集合是为组件分配的标签,用于更好的组织和管理。使用 [`~ComponentsManager.add`] 中的 `collection` 参数将组件添加到集合中。
|
||||
|
||||
每个集合中只允许每个名称有一个组件。添加第二个同名组件会自动移除第一个组件。
|
||||
|
||||
```py
|
||||
from diffusers import ComponentSpec, ComponentsManager
|
||||
|
||||
comp = ComponentsManager()
|
||||
# 为第一个 UNet 创建 ComponentSpec
|
||||
spec = ComponentSpec(name="unet", repo="stabilityai/stable-diffusion-xl-base-1.0", subfolder="unet", type_hint=AutoModel)
|
||||
# 为另一个 UNet 创建 ComponentSpec
|
||||
spec2 = ComponentSpec(name="unet", repo="RunDiffusion/Juggernaut-XL-v9", subfolder="unet", type_hint=AutoModel, variant="fp16")
|
||||
|
||||
# 将两个 UNet 添加到同一个集合 - 第二个将替换第一个
|
||||
comp.add("unet", spec.load(), collection="sdxl")
|
||||
comp.add("unet", spec2.load(), collection="sdxl")
|
||||
```
|
||||
|
||||
这使得在基于节点的系统中工作变得方便,因为您可以:
|
||||
|
||||
- 使用 `collection` 标签标记所有从一个节点加载的模型。
|
||||
- 当新检查点以相同名称加载时自动替换模型。
|
||||
- 当节点被移除时批量删除集合中的所有模型。
|
||||
|
||||
## 卸载
|
||||
|
||||
[`~ComponentsManager.enable_auto_cpu_offload`] 方法是一种全局卸载策略,适用于所有模型,无论哪个管道在使用它们。一旦启用,您无需担心设备放置,如果您添加或移除组件。
|
||||
|
||||
```py
|
||||
comp.enable_auto_cpu_offload(device="cuda")
|
||||
```
|
||||
|
||||
所有模型开始时都在 CPU 上,[`ComponentsManager`] 在需要它们之前将它们移动到适当的设备,并在 GPU 内存不足时将其他模型移回 CPU。
|
||||
|
||||
您可以设置自己的规则来决定哪些模型要卸载。
|
||||
173
docs/source/zh/modular_diffusers/guiders.md
Normal file
173
docs/source/zh/modular_diffusers/guiders.md
Normal file
@@ -0,0 +1,173 @@
|
||||
<!--版权所有 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版("许可证")授权;除非遵守许可证,否则不得使用此文件。
|
||||
您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件按"原样"分发,不附带任何明示或暗示的担保或条件。请参阅许可证了解具体的语言管理权限和限制。
|
||||
-->
|
||||
|
||||
# 引导器
|
||||
|
||||
[Classifier-free guidance](https://huggingface.co/papers/2207.12598) 引导模型生成更好地匹配提示,通常用于提高生成质量、控制和提示的遵循度。有不同类型的引导方法,在 Diffusers 中,它们被称为*引导器*。与块类似,可以轻松切换和使用不同的引导器以适应不同的用例,而无需重写管道。
|
||||
|
||||
本指南将向您展示如何切换引导器、调整引导器参数,以及将它们加载并共享到 Hub。
|
||||
|
||||
## 切换引导器
|
||||
|
||||
[`ClassifierFreeGuidance`] 是默认引导器,在使用 [`~ModularPipelineBlocks.init_pipeline`] 初始化管道时创建。它通过 `from_config` 创建,这意味着它不需要从模块化存储库加载规范。引导器不会列在 `modular_model_index.json` 中。
|
||||
|
||||
使用 [`~ModularPipeline.get_component_spec`] 来检查引导器。
|
||||
|
||||
```py
|
||||
t2i_pipeline.get_component_spec("guider")
|
||||
ComponentSpec(name='guider', type_hint=<class 'diffusers.guiders.classifier_free_guidance.ClassifierFreeGuidance'>, description=None, config=FrozenDict([('guidance_scale', 7.5), ('guidance_rescale', 0.0), ('use_original_formulation', False), ('start', 0.0), ('stop', 1.0), ('_use_default_values', ['start', 'guidance_rescale', 'stop', 'use_original_formulation'])]), repo=None, subfolder=None, variant=None, revision=None, default_creation_method='from_config')
|
||||
```
|
||||
|
||||
通过将新引导器传递给 [`~ModularPipeline.update_components`] 来切换到不同的引导器。
|
||||
|
||||
> [!TIP]
|
||||
> 更改引导器将返回文本,让您知道您正在更改引导器类型。
|
||||
> ```bash
|
||||
> ModularPipeline.update_components: 添加具有新类型的引导器: PerturbedAttentionGuidance, 先前类型: ClassifierFreeGuidance
|
||||
> ```
|
||||
|
||||
```py
|
||||
from diffusers import LayerSkipConfig, PerturbedAttentionGuidance
|
||||
|
||||
config = LayerSkipConfig(indices=[2, 9], fqn="mid_block.attentions.0.transformer_blocks", skip_attention=False, skip_attention_scores=True, skip_ff=False)
|
||||
guider = PerturbedAttentionGuidance(
|
||||
guidance_scale=5.0, perturbed_guidance_scale=2.5, perturbed_guidance_config=config
|
||||
)
|
||||
t2i_pipeline.update_components(guider=guider)
|
||||
```
|
||||
|
||||
再次使用 [`~ModularPipeline.get_component_spec`] 来验证引导器类型是否不同。
|
||||
|
||||
```py
|
||||
t2i_pipeline.get_component_spec("guider")
|
||||
ComponentSpec(name='guider', type_hint=<class 'diffusers.guiders.perturbed_attention_guidance.PerturbedAttentionGuidance'>, description=None, config=FrozenDict([('guidance_scale', 5.0), ('perturbed_guidance_scale', 2.5), ('perturbed_guidance_start', 0.01), ('perturbed_guidance_stop', 0.2), ('perturbed_guidance_layers', None), ('perturbed_guidance_config', LayerSkipConfig(indices=[2, 9], fqn='mid_block.attentions.0.transformer_blocks', skip_attention=False, skip_attention_scores=True, skip_ff=False, dropout=1.0)), ('guidance_rescale', 0.0), ('use_original_formulation', False), ('start', 0.0), ('stop', 1.0), ('_use_default_values', ['perturbed_guidance_start', 'use_original_formulation', 'perturbed_guidance_layers', 'stop', 'start', 'guidance_rescale', 'perturbed_guidance_stop']), ('_class_name', 'PerturbedAttentionGuidance'), ('_diffusers_version', '0.35.0.dev0')]), repo=None, subfolder=None, variant=None, revision=None, default_creation_method='from_config')
|
||||
```
|
||||
|
||||
## 加载自定义引导器
|
||||
|
||||
已经在 Hub 上保存并带有 `modular_model_index.json` 文件的引导器现在被视为 `from_pretrained` 组件,而不是 `from_config` 组件。
|
||||
|
||||
```json
|
||||
{
|
||||
"guider": [
|
||||
null,
|
||||
null,
|
||||
{
|
||||
"repo": "YiYiXu/modular-loader-t2i-guider",
|
||||
"revision": null,
|
||||
"subfolder": "pag_guider",
|
||||
"type_hint": [
|
||||
"diffusers",
|
||||
"PerturbedAttentionGuidance"
|
||||
],
|
||||
"variant": null
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
引导器只有在调用 [`~ModularPipeline.load_default_components`] 之后才会创建,基于 `modular_model_index.json` 中的加载规范。
|
||||
|
||||
```py
|
||||
t2i_pipeline = t2i_blocks.init_pipeline("YiYiXu/modular-doc-guider")
|
||||
# 在初始化时未创建
|
||||
assert t2i_pipeline.guider is None
|
||||
t2i_pipeline.load_default_components()
|
||||
# 加载为 PAG 引导器
|
||||
t2i_pipeline.guider
|
||||
```
|
||||
|
||||
## 更改引导器参数
|
||||
|
||||
引导器参数可以通过 [`~ComponentSpec.create`] 方法或 [`~ModularPipeline.update_components`] 方法进行调整。下面的示例更改了 `guidance_scale` 值。
|
||||
|
||||
<hfoptions id="switch">
|
||||
<hfoption id="create">
|
||||
|
||||
```py
|
||||
guider_spec = t2i_pipeline.get_component_spec("guider")
|
||||
guider = guider_spec.create(guidance_scale=10)
|
||||
t2i_pipeline.update_components(guider=guider)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="update_components">
|
||||
|
||||
```py
|
||||
guider_spec = t2i_pipeline.get_component_spec("guider")
|
||||
guider_spec.config["guidance_scale"] = 10
|
||||
t2i_pipeline.update_components(guider=guider_spec)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## 上传自定义引导器
|
||||
|
||||
在自定义引导器上调用 [`~utils.PushToHubMixin.push_to_hub`] 方法,将其分享到 Hub。
|
||||
|
||||
```py
|
||||
guider.push_to_hub("YiYiXu/modular-loader-t2i-guider", subfolder="pag_guider")
|
||||
```
|
||||
|
||||
要使此引导器可用于管道,可以修改 `modular_model_index.json` 文件或使用 [`~ModularPipeline.update_components`] 方法。
|
||||
|
||||
<hfoptions id="upload">
|
||||
<hfoption id="modular_model_index.json">
|
||||
|
||||
编辑 `modular_model_index.json` 文件,并添加引导器的加载规范,指向包含引导器配置的文件夹
|
||||
例如。
|
||||
|
||||
```json
|
||||
{
|
||||
"guider": [
|
||||
"diffusers",
|
||||
"PerturbedAttentionGuidance",
|
||||
{
|
||||
"repo": "YiYiXu/modular-loader-t2i-guider",
|
||||
"revision": null,
|
||||
"subfolder": "pag_guider",
|
||||
"type_hint": [
|
||||
"diffusers",
|
||||
"PerturbedAttentionGuidance"
|
||||
],
|
||||
"variant": null
|
||||
}
|
||||
],
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="update_components">
|
||||
|
||||
将 [`~ComponentSpec.default_creation_method`] 更改为 `from_pretrained` 并使用 [`~ModularPipeline.update_components`] 来更新引导器和组件规范以及管道配置。
|
||||
|
||||
> [!TIP]
|
||||
> 更改创建方法将返回文本,告知您正在将创建类型更改为 `from_pretrained`。
|
||||
> ```bash
|
||||
> ModularPipeline.update_components: 将引导器的 default_creation_method 从 from_config 更改为 from_pretrained。
|
||||
> ```
|
||||
|
||||
```py
|
||||
guider_spec = t2i_pipeline.get_component_spec("guider")
|
||||
guider_spec.default_creation_method="from_pretrained"
|
||||
guider_spec.repo="YiYiXu/modular-loader-t2i-guider"
|
||||
guider_spec.subfolder="pag_guider"
|
||||
pag_guider = guider_spec.load()
|
||||
t2i_pipeline.update_components(guider=pag_guider)
|
||||
```
|
||||
|
||||
要使其成为管道的默认引导器,请调用 [`~utils.PushToHubMixin.push_to_hub`]。这是一个可选步骤,如果您仅在本地进行实验,则不需要。
|
||||
|
||||
```py
|
||||
t2i_pipeline.push_to_hub("YiYiXu/modular-doc-guider")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
@@ -0,0 +1,93 @@
|
||||
<!--版权 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版("许可证")授权;除非符合许可证,否则不得使用此文件。您可以在
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
获取许可证的副本。
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件按"原样"分发,无任何明示或暗示的担保或条件。请参阅许可证了解
|
||||
特定语言下的权限和限制。
|
||||
-->
|
||||
|
||||
# LoopSequentialPipelineBlocks
|
||||
|
||||
[`~modular_pipelines.LoopSequentialPipelineBlocks`] 是一种多块类型,它将其他 [`~modular_pipelines.ModularPipelineBlocks`] 以循环方式组合在一起。数据循环流动,使用 `intermediate_inputs` 和 `intermediate_outputs`,并且每个块都是迭代运行的。这通常用于创建一个默认是迭代的去噪循环。
|
||||
|
||||
本指南向您展示如何创建 [`~modular_pipelines.LoopSequentialPipelineBlocks`]。
|
||||
|
||||
## 循环包装器
|
||||
|
||||
[`~modular_pipelines.LoopSequentialPipelineBlocks`],也被称为 *循环包装器*,因为它定义了循环结构、迭代变量和配置。在循环包装器内,您需要以下变量。
|
||||
|
||||
- `loop_inputs` 是用户提供的值,等同于 [`~modular_pipelines.ModularPipelineBlocks.inputs`]。
|
||||
- `loop_intermediate_inputs` 是来自 [`~modular_pipelines.PipelineState`] 的中间变量,等同于 [`~modular_pipelines.ModularPipelineBlocks.intermediate_inputs`]。
|
||||
- `loop_intermediate_outputs` 是由块创建并添加到 [`~modular_pipelines.PipelineState`] 的新中间变量。它等同于 [`~modular_pipelines.ModularPipelineBlocks.intermediate_outputs`]。
|
||||
- `__call__` 方法定义了循环结构和迭代逻辑。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers.modular_pipelines import LoopSequentialPipelineBlocks, ModularPipelineBlocks, InputParam, OutputParam
|
||||
|
||||
class LoopWrapper(LoopSequentialPipelineBlocks):
|
||||
model_name = "test"
|
||||
@property
|
||||
def description(self):
|
||||
return "I'm a loop!!"
|
||||
@property
|
||||
def loop_inputs(self):
|
||||
return [InputParam(name="num_steps")]
|
||||
@torch.no_grad()
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
# 循环结构 - 可以根据您的需求定制
|
||||
for i in range(block_state.num_steps):
|
||||
# loop_step 按顺序执行所有注册的块
|
||||
components, block_state = self.loop_step(components, block_state, i=i)
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
循环包装器可以传递额外的参数,如当前迭代索引,到循环块。
|
||||
|
||||
## 循环块
|
||||
|
||||
循环块是一个 [`~modular_pipelines.ModularPipelineBlocks`],但 `__call__` 方法的行为不同。
|
||||
|
||||
- 它从循环包装器。
|
||||
- 它直接与[`~modular_pipelines.BlockState`]一起工作,而不是[`~modular_pipelines.PipelineState`]。
|
||||
- 它不需要检索或更新[`~modular_pipelines.BlockState`]。
|
||||
|
||||
循环块共享相同的[`~modular_pipelines.BlockState`],以允许值在循环的每次迭代中累积和变化。
|
||||
|
||||
```py
|
||||
class LoopBlock(ModularPipelineBlocks):
|
||||
model_name = "test"
|
||||
@property
|
||||
def inputs(self):
|
||||
return [InputParam(name="x")]
|
||||
@property
|
||||
def intermediate_outputs(self):
|
||||
# 这个块产生的输出
|
||||
return [OutputParam(name="x")]
|
||||
@property
|
||||
def description(self):
|
||||
return "我是一个在`LoopWrapper`类内部使用的块"
|
||||
def __call__(self, components, block_state, i: int):
|
||||
block_state.x += 1
|
||||
return components, block_state
|
||||
```
|
||||
|
||||
## LoopSequentialPipelineBlocks
|
||||
|
||||
使用[`~modular_pipelines.LoopSequentialPipelineBlocks.from_blocks_dict`]方法将循环块添加到循环包装器中,以创建[`~modular_pipelines.LoopSequentialPipelineBlocks`]。
|
||||
|
||||
```py
|
||||
loop = LoopWrapper.from_blocks_dict({"block1": LoopBlock})
|
||||
```
|
||||
|
||||
添加更多的循环块以在每次迭代中运行,使用[`~modular_pipelines.LoopSequentialPipelineBlocks.from_blocks_dict`]。这允许您在不改变循环逻辑本身的情况下修改块。
|
||||
|
||||
```py
|
||||
loop = LoopWrapper.from_blocks_dict({"block1": LoopBlock(), "block2": LoopBlock})
|
||||
```
|
||||
74
docs/source/zh/modular_diffusers/modular_diffusers_states.md
Normal file
74
docs/source/zh/modular_diffusers/modular_diffusers_states.md
Normal file
@@ -0,0 +1,74 @@
|
||||
<!--版权 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据Apache许可证2.0版("许可证")授权;除非符合许可证的规定,否则不得使用此文件。
|
||||
您可以在以下网址获取许可证的副本
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件是基于"按原样"分发的,没有任何形式的明示或暗示的担保或条件。有关许可证下特定的语言管理权限和限制,请参阅许可证。
|
||||
-->
|
||||
|
||||
# 状态
|
||||
|
||||
块依赖于[`~modular_pipelines.PipelineState`]和[`~modular_pipelines.BlockState`]数据结构进行通信和数据共享。
|
||||
|
||||
| 状态 | 描述 |
|
||||
|-------|-------------|
|
||||
| [`~modular_pipelines.PipelineState`] | 维护管道执行所需的整体数据,并允许块读取和更新其数据。 |
|
||||
| [`~modular_pipelines.BlockState`] | 允许每个块使用来自`inputs`的必要数据执行其计算 |
|
||||
|
||||
本指南解释了状态如何工作以及它们如何连接块。
|
||||
|
||||
## PipelineState
|
||||
|
||||
[`~modular_pipelines.PipelineState`]是所有块的全局状态容器。它维护管道的完整运行时状态,并为块提供了一种结构化的方式来读取和写入共享数据。
|
||||
|
||||
[`~modular_pipelines.PipelineState`]中有两个字典用于结构化数据。
|
||||
|
||||
- `values`字典是一个**可变**状态,包含用户提供的输入值的副本和由块生成的中间输出值。如果一个块修改了一个`input`,它将在调用`set_block_state`后反映在`values`字典中。
|
||||
|
||||
```py
|
||||
PipelineState(
|
||||
values={
|
||||
'prompt': 'a cat'
|
||||
'guidance_scale': 7.0
|
||||
'num_inference_steps': 25
|
||||
'prompt_embeds': Tensor(dtype=torch.float32, shape=torch.Size([1, 1, 1, 1]))
|
||||
'negative_prompt_embeds': None
|
||||
},
|
||||
)
|
||||
```
|
||||
|
||||
## BlockState
|
||||
|
||||
[`~modular_pipelines.BlockState`]是[`~modular_pipelines.PipelineState`]中相关变量的局部视图,单个块需要这些变量来执行其计算。
|
||||
|
||||
直接作为属性访问这些变量,如`block_state.image`。
|
||||
|
||||
```py
|
||||
BlockState(
|
||||
image: <PIL.Image.Image image mode=RGB size=512x512 at 0x7F3ECC494640>
|
||||
)
|
||||
```
|
||||
|
||||
当一个块的`__call__`方法被执行时,它用`self.get_block_state(state)`检索[`BlockState`],执行其操作,并用`self.set_block_state(state, block_state)`更新[`~modular_pipelines.PipelineState`]。
|
||||
|
||||
```py
|
||||
def __call__(self, components, state):
|
||||
# 检索BlockState
|
||||
block_state = self.get_block_state(state)
|
||||
|
||||
# 对输入进行计算的逻辑
|
||||
|
||||
# 更新PipelineState
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
## 状态交互
|
||||
|
||||
[`~modular_pipelines.PipelineState`]和[`~modular_pipelines.BlockState`]的交互由块的`inputs`和`intermediate_outputs`定义。
|
||||
|
||||
- `inputs`,
|
||||
一个块可以修改输入 - 比如 `block_state.image` - 并且这个改变可以通过调用 `set_block_state` 全局传播到 [`~modular_pipelines.PipelineState`]。
|
||||
- `intermediate_outputs`,是一个块创建的新变量。它被添加到 [`~modular_pipelines.PipelineState`] 的 `values` 字典中,并且可以作为后续块的可用变量,或者由用户作为管道的最终输出访问。
|
||||
358
docs/source/zh/modular_diffusers/modular_pipeline.md
Normal file
358
docs/source/zh/modular_diffusers/modular_pipeline.md
Normal file
@@ -0,0 +1,358 @@
|
||||
<!--版权 2025 HuggingFace 团队。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版(“许可证”)授权;除非符合许可证的规定,否则不得使用此文件。您可以在
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
获取许可证的副本。
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件是基于“按原样”分发的,没有任何形式的明示或暗示的保证或条件。有关许可证的特定语言,请参阅许可证。
|
||||
-->
|
||||
|
||||
# 模块化管道
|
||||
|
||||
[`ModularPipeline`] 将 [`~modular_pipelines.ModularPipelineBlocks`] 转换为可执行的管道,加载模型并执行块中定义的计算步骤。它是运行管道的主要接口,与 [`DiffusionPipeline`] API 非常相似。
|
||||
|
||||
主要区别在于在管道中包含了一个预期的 `output` 参数。
|
||||
|
||||
<hfoptions id="example">
|
||||
<hfoption id="text-to-image">
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers.modular_pipelines import SequentialPipelineBlocks
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl import TEXT2IMAGE_BLOCKS
|
||||
|
||||
blocks = SequentialPipelineBlocks.from_blocks_dict(TEXT2IMAGE_BLOCKS)
|
||||
|
||||
modular_repo_id = "YiYiXu/modular-loader-t2i-0704"
|
||||
pipeline = blocks.init_pipeline(modular_repo_id)
|
||||
|
||||
pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
pipeline.to("cuda")
|
||||
|
||||
image = pipeline(prompt="Astronaut in a jungle, cold color palette, muted colors, detailed, 8k", output="images")[0]
|
||||
image.save("modular_t2i_out.png")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="image-to-image">
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers.modular_pipelines import SequentialPipelineBlocks
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl import IMAGE2IMAGE_BLOCKS
|
||||
|
||||
blocks = SequentialPipelineBlocks.from_blocks_dict(IMAGE2IMAGE_BLOCKS)
|
||||
|
||||
modular_repo_id = "YiYiXu/modular-loader-t2i-0704"
|
||||
pipeline = blocks.init_pipeline(modular_repo_id)
|
||||
|
||||
pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
pipeline.to("cuda")
|
||||
|
||||
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-text2img.png"
|
||||
init_image = load_image(url)
|
||||
prompt = "a dog catching a frisbee in the jungle"
|
||||
image = pipeline(prompt=prompt, image=init_image, strength=0.8, output="images")[0]
|
||||
image.save("modular_i2i_out.png")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="inpainting">
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers.modular_pipelines import SequentialPipelineBlocks
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl import INPAINT_BLOCKS
|
||||
from diffusers.utils import load_image
|
||||
|
||||
blocks = SequentialPipelineBlocks.from_blocks_dict(INPAINT_BLOCKS)
|
||||
|
||||
modular_repo_id = "YiYiXu/modular-loader-t2i-0704"
|
||||
pipeline = blocks.init_pipeline(modular_repo_id)
|
||||
|
||||
pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
pipeline.to("cuda")
|
||||
|
||||
img_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-text2img.png"
|
||||
mask_url = "h
|
||||
ttps://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/sdxl-inpaint-mask.png"
|
||||
|
||||
init_image = load_image(img_url)
|
||||
mask_image = load_image(mask_url)
|
||||
|
||||
prompt = "A deep sea diver floating"
|
||||
image = pipeline(prompt=prompt, image=init_image, mask_image=mask_image, strength=0.85, output="images")[0]
|
||||
image.save("moduar_inpaint_out.png")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
本指南将向您展示如何创建一个[`ModularPipeline`]并管理其中的组件。
|
||||
|
||||
## 添加块
|
||||
|
||||
块是[`InsertableDict`]对象,可以在特定位置插入,提供了一种灵活的方式来混合和匹配块。
|
||||
|
||||
使用[`~modular_pipelines.modular_pipeline_utils.InsertableDict.insert`]在块类或`sub_blocks`属性上添加一个块。
|
||||
|
||||
```py
|
||||
# BLOCKS是块类的字典,您需要向其中添加类
|
||||
BLOCKS.insert("block_name", BlockClass, index)
|
||||
# sub_blocks属性包含实例,向该属性添加一个块实例
|
||||
t2i_blocks.sub_blocks.insert("block_name", block_instance, index)
|
||||
```
|
||||
|
||||
使用[`~modular_pipelines.modular_pipeline_utils.InsertableDict.pop`]在块类或`sub_blocks`属性上移除一个块。
|
||||
|
||||
```py
|
||||
# 从预设中移除一个块类
|
||||
BLOCKS.pop("text_encoder")
|
||||
# 分离出一个块实例
|
||||
text_encoder_block = t2i_blocks.sub_blocks.pop("text_encoder")
|
||||
```
|
||||
|
||||
通过将现有块设置为新块来交换块。
|
||||
|
||||
```py
|
||||
# 在预设中替换块类
|
||||
BLOCKS["prepare_latents"] = CustomPrepareLatents
|
||||
# 使用块实例在sub_blocks属性中替换
|
||||
t2i_blocks.sub_blocks["prepare_latents"] = CustomPrepareLatents()
|
||||
```
|
||||
|
||||
## 创建管道
|
||||
|
||||
有两种方法可以创建一个[`ModularPipeline`]。从[`ModularPipelineBlocks`]组装并创建管道,或使用[`~ModularPipeline.from_pretrained`]加载现有管道。
|
||||
|
||||
您还应该初始化一个[`ComponentsManager`]来处理设备放置和内存以及组件管理。
|
||||
|
||||
> [!TIP]
|
||||
> 有关它如何帮助管理不同工作流中的组件的更多详细信息,请参阅[ComponentsManager](./components_manager)文档。
|
||||
|
||||
<hfoptions id="create">
|
||||
<hfoption id="ModularPipelineBlocks">
|
||||
|
||||
使用[`~ModularPipelineBlocks.init_pipeline`]方法从组件和配置规范创建一个[`ModularPipeline`]。此方法从`modular_model_index.json`文件加载*规范*,但尚未加载*模型*。
|
||||
|
||||
```py
|
||||
from diffusers import ComponentsManager
|
||||
from diffusers.modular_pipelines import SequentialPipelineBlocks
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl import TEXT2IMAGE_BLOCKS
|
||||
|
||||
t2i_blocks = SequentialPipelineBlocks.from_blocks_dict(TEXT2IMAGE_BLOCKS)
|
||||
|
||||
modular_repo_id = "YiYiXu/modular-loader-t2i-0704"
|
||||
components = ComponentsManager()
|
||||
t2i_pipeline = t2i_blocks.init_pipeline(modular_repo_id, components_manager=components)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="from_pretrained">
|
||||
|
||||
[`~ModularPipeline.from_pretrained`]方法创建一个[`ModularPipeline`]从Hub上的模块化仓库加载。
|
||||
|
||||
```py
|
||||
from diffusers import ModularPipeline, ComponentsManager
|
||||
|
||||
components = ComponentsManager()
|
||||
pipeline = ModularPipeline.from_pretrained("YiYiXu/modular-loader-t2i-0704", components_manager=components)
|
||||
```
|
||||
|
||||
添加`trust_remote_code`参数以加载自定义的[`ModularPipeline`]。
|
||||
|
||||
```py
|
||||
from diffusers import ModularPipeline, ComponentsManager
|
||||
|
||||
components = ComponentsManager()
|
||||
modular_repo_id = "YiYiXu/modular-diffdiff-0704"
|
||||
diffdiff_pipeline = ModularPipeline.from_pretrained(modular_repo_id, trust_remote_code=True, components_manager=components)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## 加载组件
|
||||
|
||||
一个[`ModularPipeline`]不会自动实例化组件。它只加载配置和组件规范。您可以使用[`~ModularPipeline.load_default_components`]加载所有组件,或仅使用[`~ModularPipeline.load_components`]加载特定组件。
|
||||
|
||||
<hfoptions id="load">
|
||||
<hfoption id="load_default_components">
|
||||
|
||||
```py
|
||||
import torch
|
||||
|
||||
t2i_pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
t2i_pipeline.to("cuda")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="load_components">
|
||||
|
||||
下面的例子仅加载UNet和VAE。
|
||||
|
||||
```py
|
||||
import torch
|
||||
|
||||
t2i_pipeline.load_components(names=["unet", "vae"], torch_dtype=torch.float16)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
打印管道以检查加载的预训练组件。
|
||||
|
||||
```py
|
||||
t2i_pipeline
|
||||
```
|
||||
|
||||
这应该与管道初始化自的模块化仓库中的`modular_model_index.json`文件匹配。如果管道不需要某个组件,即使它在模块化仓库中存在,也不会被包含。
|
||||
|
||||
要修改组件加载的来源,编辑仓库中的`modular_model_index.json`文件,并将其更改为您希望的加载路径。下面的例子从不同的仓库加载UNet。
|
||||
|
||||
```json
|
||||
# 原始
|
||||
"unet": [
|
||||
null, null,
|
||||
{
|
||||
"repo": "stabilityai/stable-diffusion-xl-base-1.0",
|
||||
"subfolder": "unet",
|
||||
"variant": "fp16"
|
||||
}
|
||||
]
|
||||
|
||||
# 修改后
|
||||
"unet": [
|
||||
null, null,
|
||||
{
|
||||
"repo": "RunDiffusion/Juggernaut-XL-v9",
|
||||
"subfolder": "unet",
|
||||
"variant": "fp16"
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
### 组件加载状态
|
||||
|
||||
下面的管道属性提供了关于哪些组件被加载的更多信息。
|
||||
|
||||
使用`component_names`返回所有预期的组件。
|
||||
|
||||
```py
|
||||
t2i_pipeline.component_names
|
||||
['text_encoder', 'text_encoder_2', 'tokenizer', 'tokenizer_2', 'guider', 'scheduler', 'unet', 'vae', 'image_processor']
|
||||
```
|
||||
|
||||
使用`null_component_names`返回尚未加载的组件。使用[`~ModularPipeline.from_pretrained`]加载这些组件。
|
||||
|
||||
```py
|
||||
t2i_pipeline.null_component_names
|
||||
['text_encoder', 'text_encoder_2', 'tokenizer', 'tokenizer_2', 'scheduler']
|
||||
```
|
||||
|
||||
使用`pretrained_component_names`返回将从预训练模型加载的组件。
|
||||
|
||||
```py
|
||||
t2i_pipeline.pretrained_component_names
|
||||
['text_encoder', 'text_encoder_2', 'tokenizer', 'tokenizer_2', 'scheduler', 'unet', 'vae']
|
||||
```
|
||||
|
||||
使用 `config_component_names` 返回那些使用默认配置创建的组件(不是从模块化仓库加载的)。来自配置的组件不包括在内,因为它们已经在管道创建期间初始化。这就是为什么它们没有列在 `null_component_names` 中。
|
||||
|
||||
```py
|
||||
t2i_pipeline.config_component_names
|
||||
['guider', 'image_processor']
|
||||
```
|
||||
|
||||
## 更新组件
|
||||
|
||||
根据组件是*预训练组件*还是*配置组件*,组件可能会被更新。
|
||||
|
||||
> [!WARNING]
|
||||
> 在更新组件时,组件可能会从预训练变为配置。组件类型最初是在块的 `expected_components` 字段中定义的。
|
||||
|
||||
预训练组件通过 [`ComponentSpec`] 更新,而配置组件则通过直接传递对象或使用 [`ComponentSpec`] 更新。
|
||||
|
||||
[`ComponentSpec`] 对于预训练组件显示 `default_creation_method="from_pretrained"`,对于配置组件显示 `default_creation_method="from_config`。
|
||||
|
||||
要更新预训练组件,创建一个 [`ComponentSpec`],指定组件的名称和从哪里加载它。使用 [`~ComponentSpec.load`] 方法来加载组件。
|
||||
|
||||
```py
|
||||
from diffusers import ComponentSpec, UNet2DConditionModel
|
||||
|
||||
unet_spec = ComponentSpec(name="unet",type_hint=UNet2DConditionModel, repo="stabilityai/stable-diffusion-xl-base-1.0", subfolder="unet", variant="fp16")
|
||||
unet = unet_spec.load(torch_dtype=torch.float16)
|
||||
```
|
||||
|
||||
[`~ModularPipeline.update_components`] 方法用一个新的组件替换原来的组件。
|
||||
|
||||
```py
|
||||
t2i_pipeline.update_components(unet=unet2)
|
||||
```
|
||||
|
||||
当组件被更新时,加载规范也会在管道配置中更新。
|
||||
|
||||
### 组件提取和修改
|
||||
|
||||
当你使用 [`~ComponentSpec.load`] 时,新组件保持其加载规范。这使得提取规范并重新创建组件成为可能。
|
||||
|
||||
```py
|
||||
spec = ComponentSpec.from_component("unet", unet2)
|
||||
spec
|
||||
ComponentSpec(name='unet', type_hint=<class 'diffusers.models.unets.unet_2d_condition.UNet2DConditionModel'>, description=None, config=None, repo='stabilityai/stable-diffusion-xl-base-1.0', subfolder='unet', variant='fp16', revision=None, default_creation_method='from_pretrained')
|
||||
unet2_recreated = spec.load(torch_dtype=torch.float16)
|
||||
```
|
||||
|
||||
[`~ModularPipeline.get_component_spec`] 方法获取当前组件规范的副本以进行修改或更新。
|
||||
|
||||
```py
|
||||
unet_spec = t2i_pipeline.get_component_spec("unet")
|
||||
unet_spec
|
||||
ComponentSpec(
|
||||
name='unet',
|
||||
type_hint=<class 'diffusers.models.unets.unet_2d_condition.UNet2DConditionModel'>,
|
||||
repo='RunDiffusion/Juggernaut-XL-v9',
|
||||
subfolder='unet',
|
||||
variant='fp16',
|
||||
default_creation_method='from_pretrained'
|
||||
)
|
||||
|
||||
# 修改以从不同的仓库加载
|
||||
unet_spec.repo = "stabilityai/stable-diffusion-xl-base-1.0"
|
||||
|
||||
# 使用修改后的规范加载组件
|
||||
unet = unet_spec.load(torch_dtype=torch.float16)
|
||||
```
|
||||
|
||||
## 模块化仓库
|
||||
一个仓库
|
||||
如果管道块使用*预训练组件*,则需要y。该存储库提供了加载规范和元数据。
|
||||
|
||||
[`ModularPipeline`]特别需要*模块化存储库*(参见[示例存储库](https://huggingface.co/YiYiXu/modular-diffdiff)),这比典型的存储库更灵活。它包含一个`modular_model_index.json`文件,包含以下3个元素。
|
||||
|
||||
- `library`和`class`显示组件是从哪个库加载的及其类。如果是`null`,则表示组件尚未加载。
|
||||
- `loading_specs_dict`包含加载组件所需的信息,例如从中加载的存储库和子文件夹。
|
||||
|
||||
与标准存储库不同,模块化存储库可以根据`loading_specs_dict`从不同的存储库获取组件。组件不需要存在于同一个存储库中。
|
||||
|
||||
模块化存储库可能包含用于加载[`ModularPipeline`]的自定义代码。这允许您使用不是Diffusers原生的专用块。
|
||||
|
||||
```
|
||||
modular-diffdiff-0704/
|
||||
├── block.py # 自定义管道块实现
|
||||
├── config.json # 管道配置和auto_map
|
||||
└── modular_model_index.json # 组件加载规范
|
||||
```
|
||||
|
||||
[config.json](https://huggingface.co/YiYiXu/modular-diffdiff-0704/blob/main/config.json)文件包含一个`auto_map`键,指向`block.py`中定义自定义块的位置。
|
||||
|
||||
```json
|
||||
{
|
||||
"_class_name": "DiffDiffBlocks",
|
||||
"auto_map": {
|
||||
"ModularPipelineBlocks": "block.DiffDiffBlocks"
|
||||
}
|
||||
}
|
||||
```
|
||||
38
docs/source/zh/modular_diffusers/overview.md
Normal file
38
docs/source/zh/modular_diffusers/overview.md
Normal file
@@ -0,0 +1,38 @@
|
||||
<!--版权所有 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据Apache许可证2.0版("许可证")授权;除非符合许可证,否则不得使用此文件。您可以在以下位置获取许可证的副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件按"原样"分发,无任何明示或暗示的担保或条件。有关许可证下特定语言的权限和限制,请参阅许可证。
|
||||
-->
|
||||
|
||||
# 概述
|
||||
|
||||
> [!WARNING]
|
||||
> 模块化Diffusers正在积极开发中,其API可能会发生变化。
|
||||
|
||||
模块化Diffusers是一个统一的管道系统,通过*管道块*简化您的工作流程。
|
||||
|
||||
- 块是可重用的,您只需要为您的管道创建独特的块。
|
||||
- 块可以混合搭配,以适应或为特定工作流程或多个工作流程创建管道。
|
||||
|
||||
模块化Diffusers文档的组织如下所示。
|
||||
|
||||
## 快速开始
|
||||
|
||||
- 一个[快速开始](./quickstart)演示了如何使用模块化Diffusers实现一个示例工作流程。
|
||||
|
||||
## ModularPipelineBlocks
|
||||
|
||||
- [States](./modular_diffusers_states)解释了数据如何在块和[`ModularPipeline`]之间共享和通信。
|
||||
- [ModularPipelineBlocks](./pipeline_block)是[`ModularPipeline`]最基本的单位,本指南向您展示如何创建一个。
|
||||
- [SequentialPipelineBlocks](./sequential_pipeline_blocks)是一种类型的块,它将多个块链接起来,使它们一个接一个地运行,沿着链传递数据。本指南向您展示如何创建[`~modular_pipelines.SequentialPipelineBlocks`]以及它们如何连接和一起工作。
|
||||
- [LoopSequentialPipelineBlocks](./loop_sequential_pipeline_blocks)是一种类型的块,它在循环中运行一系列块。本指南向您展示如何创建[`~modular_pipelines.LoopSequentialPipelineBlocks`]。
|
||||
- [AutoPipelineBlocks](./auto_pipeline_blocks)是一种类型的块,它根据输入自动选择要运行的块。本指南向您展示如何创建[`~modular_pipelines.AutoPipelineBlocks`]。
|
||||
|
||||
## ModularPipeline
|
||||
|
||||
- [ModularPipeline](./modular_pipeline)向您展示如何创建并将管道块转换为可执行的[`ModularPipeline`]。
|
||||
- [ComponentsManager](./components_manager)向您展示如何跨多个管道管理和重用组件。
|
||||
- [Guiders](./guiders)向您展示如何在管道中使用不同的指导方法。
|
||||
114
docs/source/zh/modular_diffusers/pipeline_block.md
Normal file
114
docs/source/zh/modular_diffusers/pipeline_block.md
Normal file
@@ -0,0 +1,114 @@
|
||||
<!--版权 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据Apache许可证2.0版(“许可证”)授权;除非符合许可证,否则不得使用此文件。您可以在
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
获取许可证的副本。
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件是基于“按原样”基础分发的,没有任何明示或暗示的保证或条件。请参阅许可证了解特定语言管理权限和限制。
|
||||
-->
|
||||
|
||||
# ModularPipelineBlocks
|
||||
|
||||
[`~modular_pipelines.ModularPipelineBlocks`] 是构建 [`ModularPipeline`] 的基本块。它定义了管道中特定步骤应执行的组件、输入/输出和计算。一个 [`~modular_pipelines.ModularPipelineBlocks`] 与其他块连接,使用 [状态](./modular_diffusers_states),以实现工作流的模块化构建。
|
||||
|
||||
单独的 [`~modular_pipelines.ModularPipelineBlocks`] 无法执行。它是管道中步骤应执行的操作的蓝图。要实际运行和执行管道,需要将 [`~modular_pipelines.ModularPipelineBlocks`] 转换为 [`ModularPipeline`]。
|
||||
|
||||
本指南将向您展示如何创建 [`~modular_pipelines.ModularPipelineBlocks`]。
|
||||
|
||||
## 输入和输出
|
||||
|
||||
> [!TIP]
|
||||
> 如果您不熟悉Modular Diffusers中状态的工作原理,请参考 [States](./modular_diffusers_states) 指南。
|
||||
|
||||
一个 [`~modular_pipelines.ModularPipelineBlocks`] 需要 `inputs` 和 `intermediate_outputs`。
|
||||
|
||||
- `inputs` 是由用户提供并从 [`~modular_pipelines.PipelineState`] 中检索的值。这很有用,因为某些工作流会调整图像大小,但仍需要原始图像。 [`~modular_pipelines.PipelineState`] 维护原始图像。
|
||||
|
||||
使用 `InputParam` 定义 `inputs`。
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import InputParam
|
||||
|
||||
user_inputs = [
|
||||
InputParam(name="image", type_hint="PIL.Image", description="要处理的原始输入图像")
|
||||
]
|
||||
```
|
||||
|
||||
- `intermediate_inputs` 通常由前一个块创建的值,但如果前面的块没有生成它们,也可以直接提供。与 `inputs` 不同,`intermediate_inputs` 可以被修改。
|
||||
|
||||
使用 `InputParam` 定义 `intermediate_inputs`。
|
||||
|
||||
```py
|
||||
user_intermediate_inputs = [
|
||||
InputParam(name="processed_image", type_hint="torch.Tensor", description="image that has been preprocessed and normalized"),
|
||||
]
|
||||
```
|
||||
|
||||
- `intermediate_outputs` 是由块创建并添加到 [`~modular_pipelines.PipelineState`] 的新值。`intermediate_outputs` 可作为后续块的 `intermediate_inputs` 使用,或作为运行管道的最终输出使用。
|
||||
|
||||
使用 `OutputParam` 定义 `intermediate_outputs`。
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import OutputParam
|
||||
|
||||
user_intermediate_outputs = [
|
||||
OutputParam(name="image_latents", description="latents representing the image")
|
||||
]
|
||||
```
|
||||
|
||||
中间输入和输出共享数据以连接块。它们可以在任何时候访问,允许你跟踪工作流的进度。
|
||||
|
||||
## 计算逻辑
|
||||
|
||||
一个块执行的计算在`__call__`方法中定义,它遵循特定的结构。
|
||||
|
||||
1. 检索[`~modular_pipelines.BlockState`]以获取`inputs`和`intermediate_inputs`的局部视图。
|
||||
2. 在`inputs`和`intermediate_inputs`上实现计算逻辑。
|
||||
3. 更新[`~modular_pipelines.PipelineState`]以将局部[`~modular_pipelines.BlockState`]的更改推送回全局[`~modular_pipelines.PipelineState`]。
|
||||
4. 返回对下一个块可用的组件和状态。
|
||||
|
||||
```py
|
||||
def __call__(self, components, state):
|
||||
# 获取该块需要的状态变量的局部视图
|
||||
block_state = self.get_block_state(state)
|
||||
|
||||
# 你的计算逻辑在这里
|
||||
# block_state包含你所有的inputs和intermediate_inputs
|
||||
# 像这样访问它们: block_state.image, block_state.processed_image
|
||||
|
||||
# 用你更新的block_states更新管道状态
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
### 组件和配置
|
||||
|
||||
块需要的组件和管道级别的配置在[`ComponentSpec`]和[`~modular_pipelines.ConfigSpec`]中指定。
|
||||
|
||||
- [`ComponentSpec`]包含块使用的预期组件。你需要组件的`name`和理想情况下指定组件确切是什么的`type_hint`。
|
||||
- [`~modular_pipelines.ConfigSpec`]包含控制所有块行为的管道级别设置。
|
||||
|
||||
```py
|
||||
from diffusers import ComponentSpec, ConfigSpec
|
||||
|
||||
expected_components = [
|
||||
ComponentSpec(name="unet", type_hint=UNet2DConditionModel),
|
||||
ComponentSpec(name="scheduler", type_hint=EulerDiscreteScheduler)
|
||||
]
|
||||
|
||||
expected_config = [
|
||||
ConfigSpec("force_zeros_for_empty_prompt", True)
|
||||
]
|
||||
```
|
||||
|
||||
当块被转换为管道时,组件作为`__call__`中的第一个参数对块可用。
|
||||
|
||||
```py
|
||||
def __call__(self, components, state):
|
||||
# 使用点符号访问组件
|
||||
unet = components.unet
|
||||
vae = components.vae
|
||||
scheduler = components.scheduler
|
||||
```
|
||||
346
docs/source/zh/modular_diffusers/quickstart.md
Normal file
346
docs/source/zh/modular_diffusers/quickstart.md
Normal file
@@ -0,0 +1,346 @@
|
||||
<!--版权所有 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据Apache许可证2.0版("许可证")授权;除非符合许可证,否则不得使用此文件。您可以在
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
获取许可证的副本。
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件按"原样"分发,无任何明示或暗示的担保或条件。有关许可证下特定语言的管理权限和限制,请参阅许可证。
|
||||
-->
|
||||
|
||||
# 快速入门
|
||||
|
||||
模块化Diffusers是一个快速构建灵活和可定制管道的框架。模块化Diffusers的核心是[`ModularPipelineBlocks`],可以与其他块组合以适应新的工作流程。这些块被转换为[`ModularPipeline`],一个开发者可以使用的友好用户界面。
|
||||
|
||||
本文档将向您展示如何使用模块化框架实现[Differential Diffusion](https://differential-diffusion.github.io/)管道。
|
||||
|
||||
## ModularPipelineBlocks
|
||||
|
||||
[`ModularPipelineBlocks`]是*定义*,指定管道中单个步骤的组件、输入、输出和计算逻辑。有四种类型的块。
|
||||
|
||||
- [`ModularPipelineBlocks`]是最基本的单一步骤块。
|
||||
- [`SequentialPipelineBlocks`]是一个多块,线性组合其他块。一个块的输出是下一个块的输入。
|
||||
- [`LoopSequentialPipelineBlocks`]是一个多块,迭代运行,专为迭代工作流程设计。
|
||||
- [`AutoPipelineBlocks`]是一个针对不同工作流程的块集合,它根据输入选择运行哪个块。它旨在方便地将多个工作流程打包到单个管道中。
|
||||
|
||||
[Differential Diffusion](https://differential-diffusion.github.io/)是一个图像到图像的工作流程。从`IMAGE2IMAGE_BLOCKS`预设开始,这是一个用于图像到图像生成的`ModularPipelineBlocks`集合。
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl import IMAGE2IMAGE_BLOCKS
|
||||
IMAGE2IMAGE_BLOCKS = InsertableDict([
|
||||
("text_encoder", StableDiffusionXLTextEncoderStep),
|
||||
("image_encoder", StableDiffusionXLVaeEncoderStep),
|
||||
("input", StableDiffusionXLInputStep),
|
||||
("set_timesteps", StableDiffusionXLImg2ImgSetTimestepsStep),
|
||||
("prepare_latents", StableDiffusionXLImg2ImgPrepareLatentsStep),
|
||||
("prepare_add_cond", StableDiffusionXLImg2ImgPrepareAdditionalConditioningStep),
|
||||
("denoise", StableDiffusionXLDenoiseStep),
|
||||
("decode", StableDiffusionXLDecodeStep)
|
||||
])
|
||||
```
|
||||
|
||||
## 管道和块状态
|
||||
|
||||
模块化Diffusers使用*状态*在块之间通信数据。有两种类型的状态。
|
||||
|
||||
- [`PipelineState`]是一个全局状态,可用于跟踪所有块的所有输入和输出。
|
||||
- [`BlockState`]是[`PipelineState`]中相关变量的局部视图,用于单个块。
|
||||
|
||||
## 自定义块
|
||||
|
||||
[Differential Diffusion](https://differential-diffusion.github.io/) 与标准的图像到图像转换在其 `prepare_latents` 和 `denoise` 块上有所不同。所有其他块都可以重用,但你需要修改这两个。
|
||||
|
||||
通过复制和修改现有的块,为 `prepare_latents` 和 `denoise` 创建占位符 `ModularPipelineBlocks`。
|
||||
|
||||
打印 `denoise` 块,可以看到它由 [`LoopSequentialPipelineBlocks`] 组成,包含三个子块,`before_denoiser`、`denoiser` 和 `after_denoiser`。只需要修改 `before_denoiser` 子块,根据变化图为去噪器准备潜在输入。
|
||||
|
||||
```py
|
||||
denoise_blocks = IMAGE2IMAGE_BLOCKS["denoise"]()
|
||||
print(denoise_blocks)
|
||||
```
|
||||
|
||||
用新的 `SDXLDiffDiffLoopBeforeDenoiser` 块替换 `StableDiffusionXLLoopBeforeDenoiser` 子块。
|
||||
|
||||
```py
|
||||
# 复制现有块作为占位符
|
||||
class SDXLDiffDiffPrepareLatentsStep(ModularPipelineBlocks):
|
||||
"""Copied from StableDiffusionXLImg2ImgPrepareLatentsStep - will modify later"""
|
||||
# ... 与 StableDiffusionXLImg2ImgPrepareLatentsStep 相同的实现
|
||||
|
||||
class SDXLDiffDiffDenoiseStep(StableDiffusionXLDenoiseLoopWrapper):
|
||||
block_classes = [SDXLDiffDiffLoopBeforeDenoiser, StableDiffusionXLLoopDenoiser, StableDiffusionXLLoopAfterDenoiser]
|
||||
block_names = ["before_denoiser", "denoiser", "after_denoiser"]
|
||||
```
|
||||
|
||||
### prepare_latents
|
||||
|
||||
`prepare_latents` 块需要进行以下更改。
|
||||
|
||||
- 一个处理器来处理变化图
|
||||
- 一个新的 `inputs` 来接受用户提供的变化图,`timestep` 用于预计算所有潜在变量和 `num_inference_steps` 来创建更新图像区域的掩码
|
||||
- 更新 `__call__` 方法中的计算,用于处理变化图和创建掩码,并将其存储在 [`BlockState`] 中
|
||||
|
||||
```diff
|
||||
class SDXLDiffDiffPrepareLatentsStep(ModularPipelineBlocks):
|
||||
@property
|
||||
def expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec("vae", AutoencoderKL),
|
||||
ComponentSpec("scheduler", EulerDiscreteScheduler),
|
||||
+ ComponentSpec("mask_processor", VaeImageProcessor, config=FrozenDict({"do_normalize": False, "do_convert_grayscale": True}))
|
||||
]
|
||||
@property
|
||||
def inputs(self) -> List[Tuple[str, Any]]:
|
||||
return [
|
||||
InputParam("generator"),
|
||||
+ InputParam("diffdiff_map", required=True),
|
||||
- InputParam("latent_timestep", required=True, type_hint=torch.Tensor),
|
||||
+ InputParam("timesteps", type_hint=torch.Tensor),
|
||||
+ InputParam("num_inference_steps", type_hint=int),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self) -> List[OutputParam]:
|
||||
return [
|
||||
+ OutputParam("original_latents", type_hint=torch.Tensor),
|
||||
+ OutputParam("diffdiff_masks", type_hint=torch.Tensor),
|
||||
]
|
||||
def __call__(self, components, state: PipelineState):
|
||||
# ... existing logic ...
|
||||
+ # Process change map and create masks
|
||||
+ diffdiff_map = components.mask_processor.preprocess(block_state.diffdiff_map, height=latent_height, width=latent_width)
|
||||
+ thresholds = torch.arange(block_state.num_inference_steps, dtype=diffdiff_map.dtype) / block_state.num_inference_steps
|
||||
+ block_state.diffdiff_masks = diffdiff_map > (thresholds + (block_state.denoising_start or 0))
|
||||
+ block_state.original_latents = block_state.latents
|
||||
```
|
||||
|
||||
### 去噪
|
||||
|
||||
`before_denoiser` 子块需要进行以下更改。
|
||||
|
||||
- 新的 `inputs` 以接受 `denoising_start` 参数,`original_latents` 和 `diffdiff_masks` 来自 `prepare_latents` 块
|
||||
- 更新 `__call__` 方法中的计算以应用 Differential Diffusion
|
||||
|
||||
```diff
|
||||
class SDXLDiffDiffLoopBeforeDenoiser(ModularPipelineBlocks):
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"Step within the denoising loop for differential diffusion that prepare the latent input for the denoiser"
|
||||
)
|
||||
|
||||
@property
|
||||
def inputs(self) -> List[str]:
|
||||
return [
|
||||
InputParam("latents", required=True, type_hint=torch.Tensor),
|
||||
+ InputParam("denoising_start"),
|
||||
+ InputParam("original_latents", type_hint=torch.Tensor),
|
||||
+ InputParam("diffdiff_masks", type_hint=torch.Tensor),
|
||||
]
|
||||
|
||||
def __call__(self, components, block_state, i, t):
|
||||
+ # Apply differential diffusion logic
|
||||
+ if i == 0 and block_state.denoising_start is None:
|
||||
+ block_state.latents = block_state.original_latents[:1]
|
||||
+ else:
|
||||
+ block_state.mask = block_state.diffdiff_masks[i].unsqueeze(0).unsqueeze(1)
|
||||
+ block_state.latents = block_state.original_latents[i] * block_state.mask + block_state.latents * (1 - block_state.mask)
|
||||
|
||||
# ... rest of existing logic ...
|
||||
```
|
||||
|
||||
## 组装块
|
||||
|
||||
此时,您应该拥有创建 [`ModularPipeline`] 所需的所有块。
|
||||
|
||||
复制现有的 `IMAGE2IMAGE_BLOCKS` 预设,对于 `set_timesteps` 块,使用 `TEXT2IMAGE_BLOCKS` 中的 `set_timesteps`,因为 Differential Diffusion 不需要 `strength` 参数。
|
||||
|
||||
将 `prepare_latents` 和 `denoise` 块设置为您刚刚修改的 `SDXLDiffDiffPrepareLatentsStep` 和 `SDXLDiffDiffDenoiseStep` 块。
|
||||
|
||||
调用 [`SequentialPipelineBlocks.from_blocks_dict`] 在块上创建一个 `SequentialPipelineBlocks`。
|
||||
|
||||
```py
|
||||
DIFFDIFF_BLOCKS = IMAGE2IMAGE_BLOCKS.copy()
|
||||
DIFFDIFF_BLOCKS["set_timesteps"] = TEXT2IMAGE_BLOCKS["set_timesteps"]
|
||||
DIFFDIFF_BLOCKS["prepare_latents"] = SDXLDiffDiffPrepareLatentsStep
|
||||
DIFFDIFF_BLOCKS["denoise"] = SDXLDiffDiffDenoiseStep
|
||||
|
||||
dd_blocks = SequentialPipelineBlocks.from_blocks_dict(DIFFDIFF_BLOCKS)
|
||||
print(dd_blocks)
|
||||
```
|
||||
|
||||
## ModularPipeline
|
||||
|
||||
将 [`SequentialPipelineBlocks`] 转换为 [`ModularPipeline`],使用 [`ModularPipeline.init_pipeline`] 方法。这会初始化从 `modular_model_index.json` 文件加载的预期组件。通过调用 [`ModularPipeline.load_defau
|
||||
lt_components`]。
|
||||
|
||||
初始化[`ComponentManager`]时传入pipeline是一个好主意,以帮助管理不同的组件。一旦调用[`~ModularPipeline.load_default_components`],组件就会被注册到[`ComponentManager`]中,并且可以在工作流之间共享。下面的例子使用`collection`参数为组件分配了一个`"diffdiff"`标签,以便更好地组织。
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import ComponentsManager
|
||||
|
||||
components = ComponentManager()
|
||||
|
||||
dd_pipeline = dd_blocks.init_pipeline("YiYiXu/modular-demo-auto", components_manager=components, collection="diffdiff")
|
||||
dd_pipeline.load_default_componenets(torch_dtype=torch.float16)
|
||||
dd_pipeline.to("cuda")
|
||||
```
|
||||
|
||||
## 添加工作流
|
||||
|
||||
可以向[`ModularPipeline`]添加其他工作流以支持更多功能,而无需从头重写整个pipeline。
|
||||
|
||||
本节演示如何添加IP-Adapter或ControlNet。
|
||||
|
||||
### IP-Adapter
|
||||
|
||||
Stable Diffusion XL已经有一个预设的IP-Adapter块,你可以使用,并且不需要对现有的Differential Diffusion pipeline进行任何更改。
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl.encoders import StableDiffusionXLAutoIPAdapterStep
|
||||
|
||||
ip_adapter_block = StableDiffusionXLAutoIPAdapterStep()
|
||||
```
|
||||
|
||||
使用[`sub_blocks.insert`]方法将其插入到[`ModularPipeline`]中。下面的例子在位置`0`插入了`ip_adapter_block`。打印pipeline可以看到`ip_adapter_block`被添加了,并且它需要一个`ip_adapter_image`。这也向pipeline添加了两个组件,`image_encoder`和`feature_extractor`。
|
||||
|
||||
```py
|
||||
dd_blocks.sub_blocks.insert("ip_adapter", ip_adapter_block, 0)
|
||||
```
|
||||
|
||||
调用[`~ModularPipeline.init_pipeline`]来初始化一个[`ModularPipeline`],并使用[`~ModularPipeline.load_default_components`]加载模型组件。加载并设置IP-Adapter以运行pipeline。
|
||||
|
||||
```py
|
||||
dd_pipeline = dd_blocks.init_pipeline("YiYiXu/modular-demo-auto", collection="diffdiff")
|
||||
dd_pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
dd_pipeline.loader.load_ip_adapter("h94/IP-Adapter", subfolder="sdxl_models", weight_name="ip-adapter_sdxl.bin")
|
||||
dd_pipeline.loader.set_ip_adapter_scale(0.6)
|
||||
dd_pipeline = dd_pipeline.to(device)
|
||||
|
||||
ip_adapter_image = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/diffdiff_orange.jpeg")
|
||||
image = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/20240329211129_4024911930.png?download=true")
|
||||
mask = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/gradient_mask.png?download=true")
|
||||
|
||||
prompt = "a green pear"
|
||||
negative_prompt = "blurry"
|
||||
generator = torch.Generator(device=device).manual_seed(42)
|
||||
|
||||
image = dd_pipeline(
|
||||
prompt=prompt,
|
||||
negative_prompt=negative_prompt,
|
||||
num_inference_steps=25,
|
||||
generator=generator,
|
||||
ip_adapter_image=ip_adapter_image,
|
||||
diffdiff_map=mask,
|
||||
image=image,
|
||||
|
||||
output="images"
|
||||
)[0]
|
||||
```
|
||||
|
||||
### ControlNet
|
||||
|
||||
Stable Diffusion XL 已经预设了一个可以立即使用的 ControlNet 块。
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl.modular_blocks import StableDiffusionXLAutoControlNetInputStep
|
||||
|
||||
control_input_block = StableDiffusionXLAutoControlNetInputStep()
|
||||
```
|
||||
|
||||
然而,它需要修改 `denoise` 块,因为那是 ControlNet 将控制信息注入到 UNet 的地方。
|
||||
|
||||
通过将 `StableDiffusionXLLoopDenoiser` 子块替换为 `StableDiffusionXLControlNetLoopDenoiser` 来修改 `denoise` 块。
|
||||
|
||||
```py
|
||||
class SDXLDiffDiffControlNetDenoiseStep(StableDiffusionXLDenoiseLoopWrapper):
|
||||
block_classes = [SDXLDiffDiffLoopBeforeDenoiser, StableDiffusionXLControlNetLoopDenoiser, StableDiffusionXLDenoiseLoopAfterDenoiser]
|
||||
block_names = ["before_denoiser", "denoiser", "after_denoiser"]
|
||||
|
||||
controlnet_denoise_block = SDXLDiffDiffControlNetDenoiseStep()
|
||||
```
|
||||
|
||||
插入 `controlnet_input` 块并用新的 `controlnet_denoise_block` 替换 `denoise` 块。初始化一个 [`ModularPipeline`] 并将 [`~ModularPipeline.load_default_components`] 加载到其中。
|
||||
|
||||
```py
|
||||
dd_blocks.sub_blocks.insert("controlnet_input", control_input_block, 7)
|
||||
dd_blocks.sub_blocks["denoise"] = controlnet_denoise_block
|
||||
|
||||
dd_pipeline = dd_blocks.init_pipeline("YiYiXu/modular-demo-auto", collection="diffdiff")
|
||||
dd_pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
dd_pipeline = dd_pipeline.to(device)
|
||||
|
||||
control_image = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/diffdiff_tomato_canny.jpeg")
|
||||
image = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/20240329211129_4024911930.png?download=true")
|
||||
mask = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/gradient_mask.png?download=true")
|
||||
|
||||
prompt = "a green pear"
|
||||
negative_prompt = "blurry"
|
||||
generator = torch.Generator(device=device).manual_seed(42)
|
||||
|
||||
image = dd_pipeline(
|
||||
prompt=prompt,
|
||||
negative_prompt=negative_prompt,
|
||||
num_inference_steps=25,
|
||||
generator=generator,
|
||||
control_image=control_image,
|
||||
controlnet_conditioning_scale=0.5,
|
||||
diffdiff_map=mask,
|
||||
image=image,
|
||||
output="images"
|
||||
)[0]
|
||||
```
|
||||
|
||||
### AutoPipelineBlocks
|
||||
|
||||
差分扩散、IP-Adapter 和 ControlNet 工作流可以通过使用 [`AutoPipelineBlocks`] 捆绑到一个单一的 [`ModularPipeline`] 中。这允许根据输入如 `control_image` 或 `ip_adapter_image` 自动选择要运行的子块。如果没有传递这些输入,则默认为差分扩散。
|
||||
|
||||
使用 `block_trigger_inputs` 仅在提供 `control_image` 输入时运行 `SDXLDiffDiffControlNetDenoiseStep` 块。否则,使用 `SDXLDiffDiffDenoiseStep`。
|
||||
|
||||
```py
|
||||
class SDXLDiffDiffAutoDenoiseStep(AutoPipelineBlocks):
|
||||
block_classes = [SDXLDiffDiffControlNetDenoiseStep, SDXLDiffDiffDenoiseStep]
|
||||
block_names = ["contr
|
||||
olnet_denoise", "denoise"]
|
||||
block_trigger_inputs = ["controlnet_cond", None]
|
||||
```
|
||||
|
||||
添加 `ip_adapter` 和 `controlnet_input` 块。
|
||||
|
||||
```py
|
||||
DIFFDIFF_AUTO_BLOCKS = IMAGE2IMAGE_BLOCKS.copy()
|
||||
DIFFDIFF_AUTO_BLOCKS["prepare_latents"] = SDXLDiffDiffPrepareLatentsStep
|
||||
DIFFDIFF_AUTO_BLOCKS["set_timesteps"] = TEXT2IMAGE_BLOCKS["set_timesteps"]
|
||||
DIFFDIFF_AUTO_BLOCKS["denoise"] = SDXLDiffDiffAutoDenoiseStep
|
||||
DIFFDIFF_AUTO_BLOCKS.insert("ip_adapter", StableDiffusionXLAutoIPAdapterStep, 0)
|
||||
DIFFDIFF_AUTO_BLOCKS.insert("controlnet_input",StableDiffusionXLControlNetAutoInput, 7)
|
||||
```
|
||||
|
||||
调用 [`SequentialPipelineBlocks.from_blocks_dict`] 来创建一个 [`SequentialPipelineBlocks`] 并创建一个 [`ModularPipeline`] 并加载模型组件以运行。
|
||||
|
||||
```py
|
||||
dd_auto_blocks = SequentialPipelineBlocks.from_blocks_dict(DIFFDIFF_AUTO_BLOCKS)
|
||||
dd_pipeline = dd_auto_blocks.init_pipeline("YiYiXu/modular-demo-auto", collection="diffdiff")
|
||||
dd_pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
```
|
||||
|
||||
## 分享
|
||||
|
||||
使用 [`~ModularPipeline.save_pretrained`] 将您的 [`ModularPipeline`] 添加到 Hub,并将 `push_to_hub` 参数设置为 `True`。
|
||||
|
||||
```py
|
||||
dd_pipeline.save_pretrained("YiYiXu/test_modular_doc", push_to_hub=True)
|
||||
```
|
||||
|
||||
其他用户可以使用 [`~ModularPipeline.from_pretrained`] 加载 [`ModularPipeline`]。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers.modular_pipelines import ModularPipeline, ComponentsManager
|
||||
|
||||
components = ComponentsManager()
|
||||
|
||||
diffdiff_pipeline = ModularPipeline.from_pretrained("YiYiXu/modular-diffdiff-0704", trust_remote_code=True, components_manager=components, collection="diffdiff")
|
||||
diffdiff_pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
```
|
||||
112
docs/source/zh/modular_diffusers/sequential_pipeline_blocks.md
Normal file
112
docs/source/zh/modular_diffusers/sequential_pipeline_blocks.md
Normal file
@@ -0,0 +1,112 @@
|
||||
<!--版权 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据Apache许可证2.0版("许可证")授权;除非符合许可证,否则不得使用此文件。您可以在
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
获取许可证的副本。
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件是基于"按原样"基础分发的,没有任何形式的明示或暗示的保证或条件。有关许可证下特定语言的管理权限和限制,请参阅许可证。
|
||||
-->
|
||||
|
||||
# 顺序管道块
|
||||
|
||||
[`~modular_pipelines.SequentialPipelineBlocks`] 是一种多块类型,它将其他 [`~modular_pipelines.ModularPipelineBlocks`] 按顺序组合在一起。数据通过 `intermediate_inputs` 和 `intermediate_outputs` 线性地从一个块流向下一个块。[`~modular_pipelines.SequentialPipelineBlocks`] 中的每个块通常代表管道中的一个步骤,通过组合它们,您逐步构建一个管道。
|
||||
|
||||
本指南向您展示如何将两个块连接成一个 [`~modular_pipelines.SequentialPipelineBlocks`]。
|
||||
|
||||
创建两个 [`~modular_pipelines.ModularPipelineBlocks`]。第一个块 `InputBlock` 输出一个 `batch_size` 值,第二个块 `ImageEncoderBlock` 使用 `batch_size` 作为 `intermediate_inputs`。
|
||||
|
||||
<hfoptions id="sequential">
|
||||
<hfoption id="InputBlock">
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import ModularPipelineBlocks, InputParam, OutputParam
|
||||
|
||||
class InputBlock(ModularPipelineBlocks):
|
||||
|
||||
@property
|
||||
def inputs(self):
|
||||
return [
|
||||
InputParam(name="prompt", type_hint=list, description="list of text prompts"),
|
||||
InputParam(name="num_images_per_prompt", type_hint=int, description="number of images per prompt"),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self):
|
||||
return [
|
||||
OutputParam(name="batch_size", description="calculated batch size"),
|
||||
]
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return "A block that determines batch_size based on the number of prompts and num_images_per_prompt argument."
|
||||
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
batch_size = len(block_state.prompt)
|
||||
block_state.batch_size = batch_size * block_state.num_images_per_prompt
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="ImageEncoderBlock">
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers.modular_pipelines import ModularPipelineBlocks, InputParam, OutputParam
|
||||
|
||||
class ImageEncoderBlock(ModularPipelineBlocks):
|
||||
|
||||
@property
|
||||
def inputs(self):
|
||||
return [
|
||||
InputParam(name="image", type_hint="PIL.Image", description="raw input image to process"),
|
||||
InputParam(name="batch_size", type_hint=int),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self):
|
||||
return [
|
||||
OutputParam(name="image_latents", description="latents representing the image"
|
||||
]
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return "Encode raw image into its latent presentation"
|
||||
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
# 模拟处理图像
|
||||
# 这将改变所有块的图像状态,从PIL图像变为张量
|
||||
block_state.image = torch.randn(1, 3, 512, 512)
|
||||
block_state.batch_size = block_state.batch_size * 2
|
||||
block_state.image_latents = torch.randn(1, 4, 64, 64)
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
通过定义一个[`InsertableDict`]来连接两个块,将块名称映射到块实例。块按照它们在`blocks_dict`中注册的顺序执行。
|
||||
|
||||
使用[`~modular_pipelines.SequentialPipelineBlocks.from_blocks_dict`]来创建一个[`~modular_pipelines.SequentialPipelineBlocks`]。
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import SequentialPipelineBlocks, InsertableDict
|
||||
|
||||
blocks_dict = InsertableDict()
|
||||
blocks_dict["input"] = input_block
|
||||
blocks_dict["image_encoder"] = image_encoder_block
|
||||
|
||||
blocks = SequentialPipelineBlocks.from_blocks_dict(blocks_dict)
|
||||
```
|
||||
|
||||
通过调用`blocks`来检查[`~modular_pipelines.SequentialPipelineBlocks`]中的子块,要获取更多关于输入和输出的详细信息,可以访问`docs`属性。
|
||||
|
||||
```py
|
||||
print(blocks)
|
||||
print(blocks.doc)
|
||||
```
|
||||
67
docs/source/zh/optimization/cache.md
Normal file
67
docs/source/zh/optimization/cache.md
Normal file
@@ -0,0 +1,67 @@
|
||||
<!-- 版权所有 2025 HuggingFace 团队。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版本(“许可证”)授权;除非符合许可证,否则不得使用此文件。您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,否则根据许可证分发的软件按“原样”分发,不附带任何明示或暗示的担保或条件。请参阅许可证以了解具体的语言管理权限和限制。 -->
|
||||
|
||||
# 缓存
|
||||
|
||||
缓存通过存储和重用不同层的中间输出(如注意力层和前馈层)来加速推理,而不是在每个推理步骤执行整个计算。它显著提高了生成速度,但以更多内存为代价,并且不需要额外的训练。
|
||||
|
||||
本指南向您展示如何在 Diffusers 中使用支持的缓存方法。
|
||||
|
||||
## 金字塔注意力广播
|
||||
|
||||
[金字塔注意力广播 (PAB)](https://huggingface.co/papers/2408.12588) 基于这样一种观察:在生成过程的连续时间步之间,注意力输出差异不大。注意力差异在交叉注意力层中最小,并且通常在一个较长的时间步范围内被缓存。其次是时间注意力和空间注意力层。
|
||||
|
||||
> [!TIP]
|
||||
> 并非所有视频模型都有三种类型的注意力(交叉、时间和空间)!
|
||||
|
||||
PAB 可以与其他技术(如序列并行性和无分类器引导并行性(数据并行性))结合,实现近乎实时的视频生成。
|
||||
|
||||
设置并传递一个 [`PyramidAttentionBroadcastConfig`] 到管道的变换器以启用它。`spatial_attention_block_skip_range` 控制跳过空间注意力块中注意力计算的频率,`spatial_attention_timestep_skip_range` 是要跳过的时间步范围。注意选择一个合适的范围,因为较小的间隔可能导致推理速度变慢,而较大的间隔可能导致生成质量降低。
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import CogVideoXPipeline, PyramidAttentionBroadcastConfig
|
||||
|
||||
pipeline = CogVideoXPipeline.from_pretrained("THUDM/CogVideoX-5b", torch_dtype=torch.bfloat16)
|
||||
pipeline.to("cuda")
|
||||
|
||||
config = PyramidAttentionBroadcastConfig(
|
||||
spatial_attention_block_skip_range=2,
|
||||
spatial_attention_timestep_skip_range=(100, 800),
|
||||
current_timestep_callback=lambda: pipe.current_timestep,
|
||||
)
|
||||
pipeline.transformer.enable_cache(config)
|
||||
```
|
||||
|
||||
## FasterCache
|
||||
|
||||
[FasterCache](https://huggingface.co/papers/2410.19355) 缓存并重用注意力特征,类似于 [PAB](#pyramid-attention-broadcast),因为每个连续时间步的输出差异很小。
|
||||
|
||||
此方法在使用无分类器引导进行采样时(在大多数基础模型中常见),也可能选择跳过无条件分支预测,并且
|
||||
如果连续时间步之间的预测潜在输出存在显著冗余,则从条件分支预测中估计它。
|
||||
|
||||
设置并将 [`FasterCacheConfig`] 传递给管道的 transformer 以启用它。
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import CogVideoXPipeline, FasterCacheConfig
|
||||
|
||||
pipe line= CogVideoXPipeline.from_pretrained("THUDM/CogVideoX-5b", torch_dtype=torch.bfloat16)
|
||||
pipeline.to("cuda")
|
||||
|
||||
config = FasterCacheConfig(
|
||||
spatial_attention_block_skip_range=2,
|
||||
spatial_attention_timestep_skip_range=(-1, 681),
|
||||
current_timestep_callback=lambda: pipe.current_timestep,
|
||||
attention_weight_callback=lambda _: 0.3,
|
||||
unconditional_batch_skip_range=5,
|
||||
unconditional_batch_timestep_skip_range=(-1, 781),
|
||||
tensor_format="BFCHW",
|
||||
)
|
||||
pipeline.transformer.enable_cache(config)
|
||||
```
|
||||
163
docs/source/zh/optimization/coreml.md
Normal file
163
docs/source/zh/optimization/coreml.md
Normal file
@@ -0,0 +1,163 @@
|
||||
<!--版权所有 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版本("许可证")授权;除非符合许可证,否则不得使用此文件。您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件按"原样"分发,无任何明示或暗示的担保或条件。有关许可证的具体语言,请参阅许可证中的权限和限制。
|
||||
-->
|
||||
|
||||
# 如何使用 Core ML 运行 Stable Diffusion
|
||||
|
||||
[Core ML](https://developer.apple.com/documentation/coreml) 是 Apple 框架支持的模型格式和机器学习库。如果您有兴趣在 macOS 或 iOS/iPadOS 应用中运行 Stable Diffusion 模型,本指南将展示如何将现有的 PyTorch 检查点转换为 Core ML 格式,并使用 Python 或 Swift 进行推理。
|
||||
|
||||
Core ML 模型可以利用 Apple 设备中所有可用的计算引擎:CPU、GPU 和 Apple Neural Engine(或 ANE,一种在 Apple Silicon Mac 和现代 iPhone/iPad 中可用的张量优化加速器)。根据模型及其运行的设备,Core ML 还可以混合和匹配计算引擎,例如,模型的某些部分可能在 CPU 上运行,而其他部分在 GPU 上运行。
|
||||
|
||||
<Tip>
|
||||
|
||||
您还可以使用 PyTorch 内置的 `mps` 加速器在 Apple Silicon Mac 上运行 `diffusers` Python 代码库。这种方法在 [mps 指南](mps) 中有详细解释,但它与原生应用不兼容。
|
||||
|
||||
</Tip>
|
||||
|
||||
## Stable Diffusion Core ML 检查点
|
||||
|
||||
Stable Diffusion 权重(或检查点)以 PyTorch 格式存储,因此在使用它们之前,需要将它们转换为 Core ML 格式。
|
||||
|
||||
幸运的是,Apple 工程师基于 `diffusers` 开发了 [一个转换工具](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml),用于将 PyTorch 检查点转换为 Core ML。
|
||||
|
||||
但在转换模型之前,花点时间探索 Hugging Face Hub——很可能您感兴趣的模型已经以 Core ML 格式提供:
|
||||
|
||||
- [Apple](https://huggingface.co/apple) 组织包括 Stable Diffusion 版本 1.4、1.5、2.0 基础和 2.1 基础
|
||||
- [coreml community](https://huggingface.co/coreml-community) 包括自定义微调模型
|
||||
- 使用此 [过滤器](https://huggingface.co/models?pipeline_tag=text-to-image&library=coreml&p=2&sort=likes) 返回所有可用的 Core ML 检查点
|
||||
|
||||
如果您找不到感兴趣的模型,我们建议您遵循 Apple 的 [Converting Models to Core ML](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml) 说明。
|
||||
|
||||
## 选择要使用的 Core ML 变体
|
||||
|
||||
Stable Diffusion 模型可以转换为不同的 Core ML 变体,用于不同目的:
|
||||
|
||||
- 注意力类型
|
||||
使用了n个块。注意力操作用于“关注”图像表示中不同区域之间的关系,并理解图像和文本表示如何相关。注意力的计算和内存消耗很大,因此存在不同的实现方式,以适应不同设备的硬件特性。对于Core ML Stable Diffusion模型,有两种注意力变体:
|
||||
* `split_einsum`([由Apple引入](https://machinelearning.apple.com/research/neural-engine-transformers))针对ANE设备进行了优化,这些设备在现代iPhone、iPad和M系列计算机中可用。
|
||||
* “原始”注意力(在`diffusers`中使用的基础实现)仅与CPU/GPU兼容,不与ANE兼容。在CPU + GPU上使用`original`注意力运行模型可能比ANE*更快*。请参阅[此性能基准](https://huggingface.co/blog/fast-mac-diffusers#performance-benchmarks)以及社区提供的[一些额外测量](https://github.com/huggingface/swift-coreml-diffusers/issues/31)以获取更多细节。
|
||||
|
||||
- 支持的推理框架。
|
||||
* `packages`适用于Python推理。这可用于在尝试将转换后的Core ML模型集成到原生应用程序之前进行测试,或者如果您想探索Core ML性能但不需要支持原生应用程序。例如,具有Web UI的应用程序完全可以使用Python Core ML后端。
|
||||
* `compiled`模型是Swift代码所必需的。Hub中的`compiled`模型将大型UNet模型权重分成多个文件,以兼容iOS和iPadOS设备。这对应于[`--chunk-unet`转换选项](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml)。如果您想支持原生应用程序,则需要选择`compiled`变体。
|
||||
|
||||
官方的Core ML Stable Diffusion[模型](https://huggingface.co/apple/coreml-stable-diffusion-v1-4/tree/main)包括这些变体,但社区的可能有所不同:
|
||||
|
||||
```
|
||||
coreml-stable-diffusion-v1-4
|
||||
├── README.md
|
||||
├── original
|
||||
│ ├── compiled
|
||||
│ └── packages
|
||||
└── split_einsum
|
||||
├── compiled
|
||||
└── packages
|
||||
```
|
||||
|
||||
您可以下载并使用所需的变体,如下所示。
|
||||
|
||||
## Python中的Core ML推理
|
||||
|
||||
安装以下库以在Python中运行Core ML推理:
|
||||
|
||||
```bash
|
||||
pip install huggingface_hub
|
||||
pip install git+https://github.com/apple/ml-stable-diffusion
|
||||
```
|
||||
|
||||
### 下载模型检查点
|
||||
|
||||
要在Python中运行推理,请使用存储在`packages`文件夹中的版本之一,因为`compiled`版本仅与Swift兼容。您可以选择使用`original`或`split_einsum`注意力。
|
||||
|
||||
这是您如何从Hub下载`original`注意力变体到一个名为`models`的目录:
|
||||
|
||||
```Python
|
||||
from huggingface_hub import snapshot_download
|
||||
from pathlib import Path
|
||||
|
||||
repo_id = "apple/coreml-stable-diffusion-v1-4"
|
||||
variant = "original/packages"
|
||||
|
||||
mo
|
||||
del_path = Path("./models") / (repo_id.split("/")[-1] + "_" + variant.replace("/", "_"))
|
||||
snapshot_download(repo_id, allow_patterns=f"{variant}/*", local_dir=model_path, local_dir_use_symlinks=False)
|
||||
print(f"Model downloaded at {model_path}")
|
||||
```
|
||||
|
||||
### 推理[[python-inference]]
|
||||
|
||||
下载模型快照后,您可以使用 Apple 的 Python 脚本来测试它。
|
||||
|
||||
```shell
|
||||
python -m python_coreml_stable_diffusion.pipeline --prompt "a photo of an astronaut riding a horse on mars" -i ./models/coreml-stable-diffusion-v1-4_original_packages/original/packages -o </path/to/output/image> --compute-unit CPU_AND_GPU --seed 93
|
||||
```
|
||||
|
||||
使用 `-i` 标志将下载的检查点路径传递给脚本。`--compute-unit` 表示您希望允许用于推理的硬件。它必须是以下选项之一:`ALL`、`CPU_AND_GPU`、`CPU_ONLY`、`CPU_AND_NE`。您也可以提供可选的输出路径和用于可重现性的种子。
|
||||
|
||||
推理脚本假设您使用的是 Stable Diffusion 模型的原始版本,`CompVis/stable-diffusion-v1-4`。如果您使用另一个模型,您*必须*在推理命令行中使用 `--model-version` 选项指定其 Hub ID。这适用于已支持的模型以及您自己训练或微调的自定义模型。
|
||||
|
||||
例如,如果您想使用 [`stable-diffusion-v1-5/stable-diffusion-v1-5`](https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5):
|
||||
|
||||
```shell
|
||||
python -m python_coreml_stable_diffusion.pipeline --prompt "a photo of an astronaut riding a horse on mars" --compute-unit ALL -o output --seed 93 -i models/coreml-stable-diffusion-v1-5_original_packages --model-version stable-diffusion-v1-5/stable-diffusion-v1-5
|
||||
```
|
||||
|
||||
## Core ML 在 Swift 中的推理
|
||||
|
||||
在 Swift 中运行推理比在 Python 中稍快,因为模型已经以 `mlmodelc` 格式编译。这在应用启动时加载模型时很明显,但如果在之后运行多次生成,则不应明显。
|
||||
|
||||
### 下载
|
||||
|
||||
要在您的 Mac 上运行 Swift 推理,您需要一个 `compiled` 检查点版本。我们建议您使用类似于先前示例的 Python 代码在本地下载它们,但使用 `compiled` 变体之一:
|
||||
|
||||
```Python
|
||||
from huggingface_hub import snapshot_download
|
||||
from pathlib import Path
|
||||
|
||||
repo_id = "apple/coreml-stable-diffusion-v1-4"
|
||||
variant = "original/compiled"
|
||||
|
||||
model_path = Path("./models") / (repo_id.split("/")[-1] + "_" + variant.replace("/", "_"))
|
||||
snapshot_download(repo_id, allow_patterns=f"{variant}/*", local_dir=model_path, local_dir_use_symlinks=False)
|
||||
print(f"Model downloaded at {model_path}")
|
||||
```
|
||||
|
||||
### 推理[[swift-inference]]
|
||||
|
||||
要运行推理,请克隆 Apple 的仓库:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/apple/ml-stable-diffusion
|
||||
cd ml-stable-diffusion
|
||||
```
|
||||
|
||||
然后使用 Apple 的命令行工具,[Swift Package Manager](https://www.swift.org/package-manager/#):
|
||||
|
||||
```bash
|
||||
swift run StableDiffusionSample --resource-path models/coreml-stable-diffusion-v1-4_original_compiled --compute-units all "a photo of an astronaut riding a horse on mars"
|
||||
```
|
||||
|
||||
您必须在 `--resource-path` 中指定上一步下载的检查点之一,请确保它包含扩展名为 `.mlmodelc` 的已编译 Core ML 包。`--compute-units` 必须是以下值之一:`all`、`cpuOnly`、`cpuAndGPU`、`cpuAndNeuralEngine`。
|
||||
|
||||
有关更多详细信息,请参考 [Apple 仓库中的说明](https://github.com/apple/ml-stable-diffusion)。
|
||||
|
||||
## 支持的 Diffusers 功能
|
||||
|
||||
Core ML 模型和推理代码不支持 🧨 Diffusers 的许多功能、选项和灵活性。以下是一些需要注意的限制:
|
||||
|
||||
- Core ML 模型仅适用于推理。它们不能用于训练或微调。
|
||||
- 只有两个调度器已移植到 Swift:Stable Diffusion 使用的默认调度器和我们从 `diffusers` 实现移植到 Swift 的 `DPMSolverMultistepScheduler`。我们推荐您使用 `DPMSolverMultistepScheduler`,因为它在约一半的步骤中产生相同的质量。
|
||||
- 负面提示、无分类器引导尺度和图像到图像任务在推理代码中可用。高级功能如深度引导、ControlNet 和潜在上采样器尚不可用。
|
||||
|
||||
Apple 的 [转换和推理仓库](https://github.com/apple/ml-stable-diffusion) 和我们自己的 [swift-coreml-diffusers](https://github.com/huggingface/swift-coreml-diffusers) 仓库旨在作为技术演示,以帮助其他开发者在此基础上构建。
|
||||
|
||||
如果您对任何缺失功能有强烈需求,请随时提交功能请求或更好的是,贡献一个 PR 🙂。
|
||||
|
||||
## 原生 Diffusers Swift 应用
|
||||
|
||||
一个简单的方法来在您自己的 Apple 硬件上运行 Stable Diffusion 是使用 [我们的开源 Swift 仓库](https://github.com/huggingface/swift-coreml-diffusers),它基于 `diffusers` 和 Apple 的转换和推理仓库。您可以研究代码,使用 [Xcode](https://developer.apple.com/xcode/) 编译它,并根据您的需求进行适配。为了方便,[App Store 中还有一个独立 Mac 应用](https://apps.apple.com/app/diffusers/id1666309574),因此您无需处理代码或 IDE 即可使用它。如果您是开发者,并已确定 Core ML 是构建您的 Stable Diffusion 应用的最佳解决方案,那么您可以使用本指南的其余部分来开始您的项目。我们迫不及待想看看您会构建什么 🙂。
|
||||
59
docs/source/zh/optimization/deepcache.md
Normal file
59
docs/source/zh/optimization/deepcache.md
Normal file
@@ -0,0 +1,59 @@
|
||||
<!--版权所有 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版本("许可证")授权;除非遵守许可证,否则不得使用此文件。您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,否则根据许可证分发的软件按"原样"分发,无任何明示或暗示的担保或条件。有关许可证的具体语言,请参阅许可证中的权限和限制。
|
||||
-->
|
||||
|
||||
# DeepCache
|
||||
[DeepCache](https://huggingface.co/papers/2312.00858) 通过策略性地缓存和重用高级特征,同时利用 U-Net 架构高效更新低级特征,来加速 [`StableDiffusionPipeline`] 和 [`StableDiffusionXLPipeline`]。
|
||||
|
||||
首先安装 [DeepCache](https://github.com/horseee/DeepCache):
|
||||
```bash
|
||||
pip install DeepCache
|
||||
```
|
||||
|
||||
然后加载并启用 [`DeepCacheSDHelper`](https://github.com/horseee/DeepCache#usage):
|
||||
|
||||
```diff
|
||||
import torch
|
||||
from diffusers import StableDiffusionPipeline
|
||||
pipe = StableDiffusionPipeline.from_pretrained('stable-diffusion-v1-5/stable-diffusion-v1-5', torch_dtype=torch.float16).to("cuda")
|
||||
|
||||
+ from DeepCache import DeepCacheSDHelper
|
||||
+ helper = DeepCacheSDHelper(pipe=pipe)
|
||||
+ helper.set_params(
|
||||
+ cache_interval=3,
|
||||
+ cache_branch_id=0,
|
||||
+ )
|
||||
+ helper.enable()
|
||||
|
||||
image = pipe("a photo of an astronaut on a moon").images[0]
|
||||
```
|
||||
|
||||
`set_params` 方法接受两个参数:`cache_interval` 和 `cache_branch_id`。`cache_interval` 表示特征缓存的频率,指定为每次缓存操作之间的步数。`cache_branch_id` 标识网络的哪个分支(从最浅层到最深层排序)负责执行缓存过程。
|
||||
选择较低的 `cache_branch_id` 或较大的 `cache_interval` 可以加快推理速度,但会降低图像质量(这些超参数的消融实验可以在[论文](https://huggingface.co/papers/2312.00858)中找到)。一旦设置了这些参数,使用 `enable` 或 `disable` 方法来激活或停用 `DeepCacheSDHelper`。
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://github.com/horseee/Diffusion_DeepCache/raw/master/static/images/example.png">
|
||||
</div>
|
||||
|
||||
您可以在 [WandB 报告](https://wandb.ai/horseee/DeepCache/runs/jwlsqqgt?workspace=user-horseee) 中找到更多生成的样本(原始管道 vs DeepCache)和相应的推理延迟。提示是从 [MS-COCO 2017](https://cocodataset.org/#home) 数据集中随机选择的。
|
||||
|
||||
## 基准测试
|
||||
|
||||
我们在 NVIDIA RTX A5000 上测试了 DeepCache 使用 50 个推理步骤加速 [Stable Diffusion v2.1](https://huggingface.co/stabilityai/stable-diffusion-2-1) 的速度,使用不同的配置,包括分辨率、批处理大小、缓存间隔(I)和缓存分支(B)。
|
||||
|
||||
| **分辨率** | **批次大小** | **原始** | **DeepCache(I=3, B=0)** | **DeepCache(I=5, B=0)** | **DeepCache(I=5, B=1)** |
|
||||
|----------------|----------------|--------------|-------------------------|-------------------------|-------------------------|
|
||||
| 512| 8| 15.96| 6.88(2.32倍)| 5.03(3.18倍)| 7.27(2.20x)|
|
||||
| | 4| 8.39| 3.60(2.33倍)| 2.62(3.21倍)| 3.75(2.24x)|
|
||||
| | 1| 2.61| 1.12(2.33倍)| 0.81(3.24倍)| 1.11(2.35x)|
|
||||
| 768| 8| 43.58| 18.99(2.29倍)| 13.96(3.12倍)| 21.27(2.05x)|
|
||||
| | 4| 22.24| 9.67(2.30倍)| 7.10(3.13倍)| 10.74(2.07x)|
|
||||
| | 1| 6.33| 2.72(2.33倍)| 1.97(3.21倍)| 2.98(2.12x)|
|
||||
| 1024| 8| 101.95| 45.57(2.24倍)| 33.72(3.02倍)| 53.00(1.92x)|
|
||||
| | 4| 49.25| 21.86(2.25倍)| 16.19(3.04倍)| 25.78(1.91x)|
|
||||
| | 1| 13.83| 6.07(2.28倍)| 4.43(3.12倍)| 7.15(1.93x)|
|
||||
307
docs/source/zh/optimization/fp16.md
Normal file
307
docs/source/zh/optimization/fp16.md
Normal file
@@ -0,0 +1,307 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# 加速推理
|
||||
|
||||
Diffusion模型在推理时速度较慢,因为生成是一个迭代过程,需要经过一定数量的"步数"逐步将噪声细化为图像或视频。要加速这一过程,您可以尝试使用不同的[调度器](../api/schedulers/overview)、降低模型权重的精度以加快计算、使用更高效的内存注意力机制等方法。
|
||||
|
||||
将这些技术组合使用,可以比单独使用任何一种技术获得更快的推理速度。
|
||||
|
||||
本指南将介绍如何加速推理。
|
||||
|
||||
## 模型数据类型
|
||||
|
||||
模型权重的精度和数据类型会影响推理速度,因为更高的精度需要更多内存来加载,也需要更多时间进行计算。PyTorch默认以float32或全精度加载模型权重,因此更改数据类型是快速获得更快推理速度的简单方法。
|
||||
|
||||
<hfoptions id="dtypes">
|
||||
<hfoption id="bfloat16">
|
||||
|
||||
bfloat16与float16类似,但对数值误差更稳健。硬件对bfloat16的支持各不相同,但大多数现代GPU都能支持bfloat16。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
|
||||
).to("cuda")
|
||||
|
||||
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
|
||||
pipeline(prompt, num_inference_steps=30).images[0]
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="float16">
|
||||
|
||||
float16与bfloat16类似,但可能更容易出现数值误差。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
|
||||
).to("cuda")
|
||||
|
||||
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
|
||||
pipeline(prompt, num_inference_steps=30).images[0]
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="TensorFloat-32">
|
||||
|
||||
[TensorFloat-32 (tf32)](https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/)模式在NVIDIA Ampere GPU上受支持,它以tf32计算卷积和矩阵乘法运算。存储和其他操作保持在float32。与bfloat16或float16结合使用时,可以显著加快计算速度。
|
||||
|
||||
PyTorch默认仅对卷积启用tf32模式,您需要显式启用矩阵乘法的tf32模式。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
|
||||
torch.backends.cuda.matmul.allow_tf32 = True
|
||||
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
|
||||
).to("cuda")
|
||||
|
||||
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
|
||||
pipeline(prompt, num_inference_steps=30).images[0]
|
||||
```
|
||||
|
||||
更多详情请参阅[混合精度训练](https://huggingface.co/docs/transformers/en/perf_train_gpu_one#mixed-precision)文档。
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## 缩放点积注意力
|
||||
|
||||
> [!TIP]
|
||||
> 内存高效注意力优化了推理速度*和*[内存使用](./memory#memory-efficient-attention)!
|
||||
|
||||
[缩放点积注意力(SDPA)](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)实现了多种注意力后端,包括[FlashAttention](https://github.com/Dao-AILab/flash-attention)、[xFormers](https://github.com/facebookresearch/xformers)和原生C++实现。它会根据您的硬件自动选择最优的后端。
|
||||
|
||||
如果您使用的是PyTorch >= 2.0,SDPA默认启用,无需对代码进行任何额外更改。不过,您也可以尝试使用其他注意力后端来自行选择。下面的示例使用[torch.nn.attention.sdpa_kernel](https://pytorch.org/docs/stable/generated/torch.nn.attention.sdpa_kernel.html)上下文管理器来启用高效注意力。
|
||||
|
||||
```py
|
||||
from torch.nn.attention import SDPBackend, sdpa_kernel
|
||||
import torch
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
|
||||
).to("cuda")
|
||||
|
||||
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
|
||||
|
||||
with sdpa_kernel(SDPBackend.EFFICIENT_ATTENTION):
|
||||
image = pipeline(prompt, num_inference_steps=30).images[0]
|
||||
```
|
||||
|
||||
## torch.compile
|
||||
|
||||
[torch.compile](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html)通过将PyTorch代码和操作编译为优化的内核来加速推理。Diffusers通常会编译计算密集型的模型,如UNet、transformer或VAE。
|
||||
|
||||
启用以下编译器设置以获得最大速度(更多选项请参阅[完整列表](https://github.com/pytorch/pytorch/blob/main/torch/_inductor/config.py))。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
|
||||
torch._inductor.config.conv_1x1_as_mm = True
|
||||
torch._inductor.config.coordinate_descent_tuning = True
|
||||
torch._inductor.config.epilogue_fusion = False
|
||||
torch._inductor.config.coordinate_descent_check_all_directions = True
|
||||
```
|
||||
|
||||
加载并编译UNet和VAE。有几种不同的模式可供选择,但`"max-autotune"`通过编译为CUDA图来优化速度。CUDA图通过单个CPU操作启动多个GPU操作,有效减少了开销。
|
||||
|
||||
> [!TIP]
|
||||
> 在PyTorch 2.3.1中,您可以控制torch.compile的缓存行为。这对于像`"max-autotune"`这样的编译模式特别有用,它会通过网格搜索多个编译标志来找到最优配置。更多详情请参阅[torch.compile中的编译时间缓存](https://pytorch.org/tutorials/recipes/torch_compile_caching_tutorial.html)教程。
|
||||
|
||||
将内存布局更改为[channels_last](./memory#torchchannels_last)也可以优化内存和推理速度。
|
||||
|
||||
```py
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
|
||||
).to("cuda")
|
||||
pipeline.unet.to(memory_format=torch.channels_last)
|
||||
pipeline.vae.to(memory_format=torch.channels_last)
|
||||
pipeline.unet = torch.compile(
|
||||
pipeline.unet, mode="max-autotune", fullgraph=True
|
||||
)
|
||||
pipeline.vae.decode = torch.compile(
|
||||
pipeline.vae.decode,
|
||||
mode="max-autotune",
|
||||
fullgraph=True
|
||||
)
|
||||
|
||||
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
|
||||
pipeline(prompt, num_inference_steps=30).images[0]
|
||||
```
|
||||
|
||||
第一次编译时速度较慢,但一旦编译完成,速度会显著提升。尽量只在相同类型的推理操作上使用编译后的管道。在不同尺寸的图像上调用编译后的管道会重新触发编译,这会很慢且效率低下。
|
||||
|
||||
### 动态形状编译
|
||||
|
||||
> [!TIP]
|
||||
> 确保始终使用PyTorch的nightly版本以获得更好的支持。
|
||||
|
||||
`torch.compile`会跟踪输入形状和条件,如果这些不同,它会重新编译模型。例如,如果模型是在1024x1024分辨率的图像上编译的,而在不同分辨率的图像上使用,就会触发重新编译。
|
||||
|
||||
为避免重新编译,添加`dynamic=True`以尝试生成更动态的内核,避免条件变化时重新编译。
|
||||
|
||||
```diff
|
||||
+ torch.fx.experimental._config.use_duck_shape = False
|
||||
+ pipeline.unet = torch.compile(
|
||||
pipeline.unet, fullgraph=True, dynamic=True
|
||||
)
|
||||
```
|
||||
|
||||
指定`use_duck_shape=False`会指示编译器是否应使用相同的符号变量来表示相同大小的输入。更多详情请参阅此[评论](https://github.com/huggingface/diffusers/pull/11327#discussion_r2047659790)。
|
||||
|
||||
并非所有模型都能开箱即用地从动态编译中受益,可能需要更改。参考此[PR](https://github.com/huggingface/diffusers/pull/11297/),它改进了[`AuraFlowPipeline`]的实现以受益于动态编译。
|
||||
|
||||
如果动态编译对Diffusers模型的效果不如预期,请随时提出问题。
|
||||
|
||||
### 区域编译
|
||||
|
||||
[区域编译](https://docs.pytorch.org/tutorials/recipes/regional_compilation.html)通过仅编译模型中*小而频繁重复的块*(通常是transformer层)来减少冷启动延迟,并为每个后续出现的块重用编译后的工件。对于许多diffusion架构,这提供了与全图编译相同的运行时加速,并将编译时间减少了8-10倍。
|
||||
|
||||
使用[`~ModelMixin.compile_repeated_blocks`]方法(一个包装`torch.compile`的辅助函数)在任何组件(如transformer模型)上,如下所示。
|
||||
|
||||
```py
|
||||
# pip install -U diffusers
|
||||
import torch
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.float16,
|
||||
).to("cuda")
|
||||
|
||||
# 仅编译UNet中重复的transformer层
|
||||
pipeline.unet.compile_repeated_blocks(fullgraph=True)
|
||||
```
|
||||
|
||||
要为新模型启用区域编译,请在模型类中添加一个`_repeated_blocks`属性,包含您想要编译的块的类名(作为字符串)。
|
||||
|
||||
```py
|
||||
class MyUNet(ModelMixin):
|
||||
_repeated_blocks = ("Transformer2DModel",) # ← 默认编译
|
||||
```
|
||||
|
||||
> [!TIP]
|
||||
> 更多区域编译示例,请参阅参考[PR](https://github.com/huggingface/diffusers/pull/11705)。
|
||||
|
||||
[Accelerate](https://huggingface.co/docs/accelerate/index)中还有一个[compile_regions](https://github.com/huggingface/accelerate/blob/273799c85d849a1954a4f2e65767216eb37fa089/src/accelerate/utils/other.py#L78)方法,可以自动选择模型中的候选块进行编译。其余图会单独编译。这对于快速实验很有用,因为您不需要设置哪些块要编译或调整编译标志。
|
||||
|
||||
```py
|
||||
# pip install -U accelerate
|
||||
import torch
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
from accelerate.utils import compile regions
|
||||
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
|
||||
).to("cuda")
|
||||
pipeline.unet = compile_regions(pipeline.unet, mode="reduce-overhead", fullgraph=True)
|
||||
```
|
||||
|
||||
[`~ModelMixin.compile_repeated_blocks`]是故意显式的。在`_repeated_blocks`中列出要重复的块,辅助函数仅编译这些块。它提供了可预测的行为,并且只需一行代码即可轻松推理缓存重用。
|
||||
|
||||
### 图中断
|
||||
|
||||
在torch.compile中指定`fullgraph=True`非常重要,以确保底层模型中没有图中断。这使您可以充分利用torch.compile而不会降低性能。对于UNet和VAE,这会改变您访问返回变量的方式。
|
||||
|
||||
```diff
|
||||
- latents = unet(
|
||||
- latents, timestep=timestep, encoder_hidden_states=prompt_embeds
|
||||
-).sample
|
||||
|
||||
+ latents = unet(
|
||||
+ latents, timestep=timestep, encoder_hidden_states=prompt_embeds, return_dict=False
|
||||
+)[0]
|
||||
```
|
||||
|
||||
### GPU同步
|
||||
|
||||
每次去噪器做出预测后,调度器的`step()`函数会被[调用](https://github.com/huggingface/diffusers/blob/1d686bac8146037e97f3fd8c56e4063230f71751/src/diffusers/pipelines/stable_diffusion_xl/pipeline_stable_diffusion_xl.py#L1228),并且`sigmas`变量会被[索引](https://github.com/huggingface/diffusers/blob/1d686bac8146037e97f3fd8c56e4063230f71751/src/diffusers/schedulers/scheduling_euler_discrete.py#L476)。当放在GPU上时,这会引入延迟,因为CPU和GPU之间需要进行通信同步。当去噪器已经编译时,这一点会更加明显。
|
||||
|
||||
一般来说,`sigmas`应该[保持在CPU上](https://github.com/huggingface/diffusers/blob/35a969d297cba69110d175ee79c59312b9f49e1e/src/diffusers/schedulers/scheduling_euler_discrete.py#L240),以避免通信同步和延迟。
|
||||
|
||||
<Tip>
|
||||
|
||||
参阅[torch.compile和Diffusers:峰值性能实践指南](https://pytorch.org/blog/torch-compile-and-diffusers-a-hands-on-guide-to-peak-performance/)博客文章,了解如何为扩散模型最大化`torch.compile`的性能。
|
||||
|
||||
</Tip>
|
||||
|
||||
### 基准测试
|
||||
|
||||
参阅[diffusers/benchmarks](https://huggingface.co/datasets/diffusers/benchmarks)数据集,查看编译管道的推理延迟和内存使用数据。
|
||||
|
||||
[diffusers-torchao](https://github.com/sayakpaul/diffusers-torchao#benchmarking-results)仓库还包含Flux和CogVideoX编译版本的基准测试结果。
|
||||
|
||||
## 动态量化
|
||||
|
||||
[动态量化](https://pytorch.org/tutorials/recipes/recipes/dynamic_quantization.html)通过降低精度以加快数学运算来提高推理速度。这种特定类型的量化在运行时根据数据确定如何缩放激活,而不是使用固定的缩放因子。因此,缩放因子与数据更准确地匹配。
|
||||
|
||||
以下示例使用[torchao](../quantization/torchao)库对UNet和VAE应用[动态int8量化](https://pytorch.org/tutorials/recipes/recipes/dynamic_quantization.html)。
|
||||
|
||||
> [!TIP]
|
||||
> 参阅我们的[torchao](../quantization/torchao)文档,了解更多关于如何使用Diffusers torchao集成的信息。
|
||||
|
||||
配置编译器标志以获得最大速度。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from torchao import apply_dynamic_quant
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
|
||||
torch._inductor.config.conv_1x1_as_mm = True
|
||||
torch._inductor.config.coordinate_descent_tuning = True
|
||||
torch._inductor.config.epilogue_fusion = False
|
||||
torch._inductor.config.coordinate_descent_check_all_directions = True
|
||||
torch._inductor.config.force_fuse_int_mm_with_mul = True
|
||||
torch._inductor.config.use_mixed_mm = True
|
||||
```
|
||||
|
||||
使用[dynamic_quant_filter_fn](https://github.com/huggingface/diffusion-fast/blob/0f169640b1db106fe6a479f78c1ed3bfaeba3386/utils/pipeline_utils.py#L16)过滤掉UNet和VAE中一些不会从动态量化中受益的线性层。
|
||||
|
||||
```py
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.bfloat16
|
||||
).to("cuda")
|
||||
|
||||
apply_dynamic_quant(pipeline.unet, dynamic_quant_filter_fn)
|
||||
apply_dynamic_quant(pipeline.vae, dynamic_quant_filter_fn)
|
||||
|
||||
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
|
||||
pipeline(prompt, num_inference_steps=30).images[0]
|
||||
```
|
||||
|
||||
## 融合投影矩阵
|
||||
|
||||
> [!WARNING]
|
||||
> [fuse_qkv_projections](https://github.com/huggingface/diffusers/blob/58431f102cf39c3c8a569f32d71b2ea8caa461e1/src/diffusers/pipelines/pipeline_utils.py#L2034)方法是实验性的,目前主要支持Stable Diffusion管道。参阅此[PR](https://github.com/huggingface/diffusers/pull/6179)了解如何为其他管道启用它。
|
||||
|
||||
在注意力块中,输入被投影到三个子空间,分别由投影矩阵Q、K和V表示。这些投影通常单独计算,但您可以水平组合这些矩阵为一个矩阵,并在单步中执行投影。这会增加输入投影的矩阵乘法大小,并提高量化的效果。
|
||||
|
||||
```py
|
||||
pipeline.fuse_qkv_projections()
|
||||
```
|
||||
|
||||
## 资源
|
||||
|
||||
- 阅读[Presenting Flux Fast: Making Flux go brrr on H100s](https://pytorch.org/blog/presenting-flux-fast-making-flux-go-brrr-on-h100s/)博客文章,了解如何结合所有这些优化与[TorchInductor](https://docs.pytorch.org/docs/stable/torch.compiler.html)和[AOTInductor](https://docs.pytorch.org/docs/stable/torch.compiler_aot_inductor.html),使用[flux-fast](https://github.com/huggingface/flux-fast)的配方获得约2.5倍的加速。
|
||||
|
||||
这些配方支持AMD硬件和[Flux.1 Kontext Dev](https://huggingface.co/black-forest-labs/FLUX.1-Kontext-dev)。
|
||||
- 阅读[torch.compile和Diffusers:峰值性能实践指南](https://pytorch.org/blog/torch-compile-and-diffusers-a-hands-on-guide-to-peak-performance/)博客文章,了解如何在使用`torch.compile`时最大化性能。
|
||||
28
docs/source/zh/optimization/habana.md
Normal file
28
docs/source/zh/optimization/habana.md
Normal file
@@ -0,0 +1,28 @@
|
||||
<!--版权所有 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版本("许可证")授权;除非遵守许可证,否则不得使用此文件。您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件按"原样"分发,无任何明示或暗示的担保或条件。有关许可证管理权限和限制的具体语言,请参阅许可证。
|
||||
-->
|
||||
|
||||
# Intel Gaudi
|
||||
|
||||
Intel Gaudi AI 加速器系列包括 [Intel Gaudi 1](https://habana.ai/products/gaudi/)、[Intel Gaudi 2](https://habana.ai/products/gaudi2/) 和 [Intel Gaudi 3](https://habana.ai/products/gaudi3/)。每台服务器配备 8 个设备,称为 Habana 处理单元 (HPU),在 Gaudi 3 上提供 128GB 内存,在 Gaudi 2 上提供 96GB 内存,在第一代 Gaudi 上提供 32GB 内存。有关底层硬件架构的更多详细信息,请查看 [Gaudi 架构](https://docs.habana.ai/en/latest/Gaudi_Overview/Gaudi_Architecture.html) 概述。
|
||||
|
||||
Diffusers 管道可以利用 HPU 加速,即使管道尚未添加到 [Optimum for Intel Gaudi](https://huggingface.co/docs/optimum/main/en/habana/index),也可以通过 [GPU 迁移工具包](https://docs.habana.ai/en/latest/PyTorch/PyTorch_Model_Porting/GPU_Migration_Toolkit/GPU_Migration_Toolkit.html) 实现。
|
||||
|
||||
在您的管道上调用 `.to("hpu")` 以将其移动到 HPU 设备,如下所示为 Flux 示例:
|
||||
```py
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained("black-forest-labs/FLUX.1-schnell", torch_dtype=torch.bfloat16)
|
||||
pipeline.to("hpu")
|
||||
|
||||
image = pipeline("一张松鼠在毕加索风格中的图像").images[0]
|
||||
```
|
||||
|
||||
> [!TIP]
|
||||
> 对于 Gaudi 优化的扩散管道实现,我们推荐使用 [Optimum for Intel Gaudi](https://huggingface.co/docs/optimum/main/en/habana/index)。
|
||||
581
docs/source/zh/optimization/memory.md
Normal file
581
docs/source/zh/optimization/memory.md
Normal file
@@ -0,0 +1,581 @@
|
||||
<!--版权所有 2025 HuggingFace 团队。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版本(“许可证”)授权;除非遵守许可证,否则不得使用此文件。您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件按“原样”分发,无任何明示或暗示的担保或条件。有关许可证的特定语言管理权限和限制,请参阅许可证。
|
||||
-->
|
||||
|
||||
# 减少内存使用
|
||||
|
||||
现代diffusion models,如 [Flux](../api/pipelines/flux) 和 [Wan](../api/pipelines/wan),拥有数十亿参数,在您的硬件上进行推理时会占用大量内存。这是一个挑战,因为常见的 GPU 通常没有足够的内存。为了克服内存限制,您可以使用多个 GPU(如果可用)、将一些管道组件卸载到 CPU 等。
|
||||
|
||||
本指南将展示如何减少内存使用。
|
||||
|
||||
> [!TIP]
|
||||
> 请记住,这些技术可能需要根据模型进行调整。例如,基于 transformer 的扩散模型可能不会像基于 UNet 的模型那样从这些内存优化中同等受益。
|
||||
|
||||
## 多个 GPU
|
||||
|
||||
如果您有多个 GPU 的访问权限,有几种选项可以高效地在硬件上加载和分发大型模型。这些功能由 [Accelerate](https://huggingface.co/docs/accelerate/index) 库支持,因此请确保先安装它。
|
||||
|
||||
```bash
|
||||
pip install -U accelerate
|
||||
```
|
||||
|
||||
### 分片检查点
|
||||
|
||||
将大型检查点加载到多个分片中很有用,因为分片会逐个加载。这保持了低内存使用,只需要足够的内存来容纳模型大小和最大分片大小。我们建议当 fp32 检查点大于 5GB 时进行分片。默认分片大小为 5GB。
|
||||
|
||||
在 [`~DiffusionPipeline.save_pretrained`] 中使用 `max_shard_size` 参数对检查点进行分片。
|
||||
|
||||
```py
|
||||
from diffusers import AutoModel
|
||||
|
||||
unet = AutoModel.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0", subfolder="unet"
|
||||
)
|
||||
unet.save_pretrained("sdxl-unet-sharded", max_shard_size="5GB")
|
||||
```
|
||||
|
||||
现在您可以使用分片检查点,而不是常规检查点,以节省内存。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import AutoModel, StableDiffusionXLPipeline
|
||||
|
||||
unet = AutoModel.from_pretrained(
|
||||
"username/sdxl-unet-sharded", torch_dtype=torch.float16
|
||||
)
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
unet=unet,
|
||||
torch_dtype=torch.float16
|
||||
).to("cuda")
|
||||
```
|
||||
|
||||
### 设备放置
|
||||
|
||||
> [!WARNING]
|
||||
> 设备放置是一个实验性功能,API 可能会更改。目前仅支持 `balanced` 策略。我们计划在未来支持额外的映射策略。
|
||||
|
||||
`device_map` 参数控制管道或模型中的组件如何
|
||||
单个模型中的层分布在多个设备上。
|
||||
|
||||
<hfoptions id="device-map">
|
||||
<hfoption id="pipeline level">
|
||||
|
||||
`balanced` 设备放置策略将管道均匀分割到所有可用设备上。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import AutoModel, StableDiffusionXLPipeline
|
||||
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.float16,
|
||||
device_map="balanced"
|
||||
)
|
||||
```
|
||||
|
||||
您可以使用 `hf_device_map` 检查管道的设备映射。
|
||||
|
||||
```py
|
||||
print(pipeline.hf_device_map)
|
||||
{'unet': 1, 'vae': 1, 'safety_checker': 0, 'text_encoder': 0}
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="model level">
|
||||
|
||||
`device_map` 对于加载大型模型非常有用,例如具有 125 亿参数的 Flux diffusion transformer。将其设置为 `"auto"` 可以自动将模型首先分布到最快的设备上,然后再移动到较慢的设备。有关更多详细信息,请参阅 [模型分片](../training/distributed_inference#model-sharding) 文档。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import AutoModel
|
||||
|
||||
transformer = AutoModel.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-dev",
|
||||
subfolder="transformer",
|
||||
device_map="auto",
|
||||
torch_dtype=torch.bfloat16
|
||||
)
|
||||
```
|
||||
|
||||
您可以使用 `hf_device_map` 检查模型的设备映射。
|
||||
|
||||
```py
|
||||
print(transformer.hf_device_map)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
当设计您自己的 `device_map` 时,它应该是一个字典,包含模型的特定模块名称或层以及设备标识符(整数表示 GPU,`cpu` 表示 CPU,`disk` 表示磁盘)。
|
||||
|
||||
在模型上调用 `hf_device_map` 以查看模型层如何分布,然后设计您自己的映射。
|
||||
|
||||
```py
|
||||
print(transformer.hf_device_map)
|
||||
{'pos_embed': 0, 'time_text_embed': 0, 'context_embedder': 0, 'x_embedder': 0, 'transformer_blocks': 0, 'single_transformer_blocks.0': 0, 'single_transformer_blocks.1': 0, 'single_transformer_blocks.2': 0, 'single_transformer_blocks.3': 0, 'single_transformer_blocks.4': 0, 'single_transformer_blocks.5': 0, 'single_transformer_blocks.6': 0, 'single_transformer_blocks.7': 0, 'single_transformer_blocks.8': 0, 'single_transformer_blocks.9': 0, 'single_transformer_blocks.10': 'cpu', 'single_transformer_blocks.11': 'cpu', 'single_transformer_blocks.12': 'cpu', 'single_transformer_blocks.13': 'cpu', 'single_transformer_blocks.14': 'cpu', 'single_transformer_blocks.15': 'cpu', 'single_transformer_blocks.16': 'cpu', 'single_transformer_blocks.17': 'cpu', 'single_transformer_blocks.18': 'cpu', 'single_transformer_blocks.19': 'cpu', 'single_transformer_blocks.20': 'cpu', 'single_transformer_blocks.21': 'cpu', 'single_transformer_blocks.22': 'cpu', 'single_transformer_blocks.23': 'cpu', 'single_transformer_blocks.24': 'cpu', 'single_transformer_blocks.25': 'cpu', 'single_transformer_blocks.26': 'cpu', 'single_transformer_blocks.27': 'cpu', 'single_transformer_blocks.28': 'cpu', 'single_transformer_blocks.29': 'cpu', 'single_transformer_blocks.30': 'cpu', 'single_transformer_blocks.31': 'cpu', 'single_transformer_blocks.32': 'cpu', 'single_transformer_blocks.33': 'cpu', 'single_transformer_blocks.34': 'cpu', 'single_transformer_blocks.35': 'cpu', 'single_transformer_blocks.36': 'cpu', 'single_transformer_blocks.37': 'cpu', 'norm_out': 'cpu', 'proj_out': 'cpu'}
|
||||
```
|
||||
|
||||
例如,下面的 `device_map` 将 `single_transformer_blocks.10` 到 `single_transformer_blocks.20` 放置在第二个 GPU(`1`)上。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import AutoModel
|
||||
|
||||
device_map = {
|
||||
'pos_embed': 0, 'time_text_embed': 0, 'context_embedder': 0, 'x_embedder': 0, 'transformer_blocks': 0, 'single_transformer_blocks.0': 0, 'single_transformer_blocks.1': 0, 'single_transformer_blocks.2': 0, 'single_transformer_blocks.3': 0, 'single_transformer_blocks.4': 0, 'single_transformer_blocks.5': 0, 'single_transformer_blocks.6': 0, 'single_transformer_blocks.7': 0, 'single_transformer_blocks.8': 0, 'single_transformer_blocks.9': 0, 'single_transformer_blocks.10': 1, 'single_transformer_blocks.11': 1, 'single_transformer_blocks.12': 1, 'single_transformer_blocks.13': 1, 'single_transformer_blocks.14': 1, 'single_transformer_blocks.15': 1, 'single_transformer_blocks.16': 1, 'single_transformer_blocks.17': 1, 'single_transformer_blocks.18': 1, 'single_transformer_blocks.19': 1, 'single_transformer_blocks.20': 1, 'single_transformer_blocks.21': 'cpu', 'single_transformer_blocks.22': 'cpu', 'single_transformer_blocks.23': 'cpu', 'single_transformer_blocks.24': 'cpu', 'single_transformer_blocks.25': 'cpu', 'single_transformer_blocks.26': 'cpu', 'single_transformer_blocks.27': 'cpu', 'single_transformer_blocks.28': 'cpu', 'single_transformer_blocks.29': 'cpu', 'single_transformer_blocks.30': 'cpu', 'single_transformer_blocks.31': 'cpu', 'single_transformer_blocks.32': 'cpu', 'single_transformer_blocks.33': 'cpu', 'single_transformer_blocks.34': 'cpu', 'single_transformer_blocks.35': 'cpu', 'single_transformer_blocks.36': 'cpu', 'single_transformer_blocks.37': 'cpu', 'norm_out': 'cpu', 'proj_out': 'cpu'
|
||||
}
|
||||
|
||||
transformer = AutoModel.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-dev",
|
||||
subfolder="transformer",
|
||||
device_map=device_map,
|
||||
torch_dtype=torch.bfloat16
|
||||
)
|
||||
```
|
||||
|
||||
传递一个字典,将最大内存使用量映射到每个设备以强制执行限制。如果设备不在 `max_memory` 中,它将被忽略,管道组件不会分发到该设备。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import AutoModel, StableDiffusionXLPipeline
|
||||
|
||||
max_memory = {0:"1GB", 1:"1GB"}
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.float16,
|
||||
device_map="balanced",
|
||||
max_memory=max_memory
|
||||
)
|
||||
```
|
||||
|
||||
Diffusers 默认使用所有设备的最大内存,但如果它们无法适应 GPU,则需要使用单个 GPU 并通过以下方法卸载到 CPU。
|
||||
|
||||
- [`~DiffusionPipeline.enable_model_cpu_offload`] 仅适用于单个 GPU,但非常大的模型可能无法适应它
|
||||
- 使用 [`~DiffusionPipeline.enable_sequential_cpu_offload`] 可能有效,但它极其缓慢,并且仅限于单个 GPU。
|
||||
|
||||
使用 [`~DiffusionPipeline.reset_device_map`] 方法来重置 `device_map`。如果您想在已进行设备映射的管道上使用方法如 `.to()`、[`~DiffusionPipeline.enable_sequential_cpu_offload`] 和 [`~DiffusionPipeline.enable_model_cpu_offload`],这是必要的。
|
||||
|
||||
```py
|
||||
pipeline.reset_device_map()
|
||||
```
|
||||
|
||||
## VAE 切片
|
||||
|
||||
VAE 切片通过将大批次输入拆分为单个数据批次并分别处理它们来节省内存。这种方法在同时生成多个图像时效果最佳。
|
||||
|
||||
例如,如果您同时生成 4 个图像,解码会将峰值激活内存增加 4 倍。VAE 切片通过一次只解码 1 个图像而不是所有 4 个图像来减少这种情况。
|
||||
|
||||
调用 [`~StableDiffusionPipeline.enable_vae_slicing`] 来启用切片 VAE。您可以预期在解码多图像批次时性能会有小幅提升,而在单图像批次时没有性能影响。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import AutoModel, StableDiffusionXLPipeline
|
||||
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.float16,
|
||||
).to("cuda")
|
||||
pipeline.enable_vae_slicing()
|
||||
pipeline(["An astronaut riding a horse on Mars"]*32).images[0]
|
||||
print(f"Max memory reserved: {torch.cuda.max_memory_allocated() / 1024**3:.2f} GB")
|
||||
```
|
||||
|
||||
> [!WARNING]
|
||||
> [`AutoencoderKLWan`] 和 [`AsymmetricAutoencoderKL`] 类不支持切片。
|
||||
|
||||
## VAE 平铺
|
||||
|
||||
VAE 平铺通过将图像划分为较小的重叠图块而不是一次性处理整个图像来节省内存。这也减少了峰值内存使用量,因为 GPU 一次只处理一个图块。
|
||||
|
||||
调用 [`~StableDiffusionPipeline.enable_vae_tiling`] 来启用 VAE 平铺。生成的图像可能因图块到图块的色调变化而有所不同,因为它们被单独解码,但图块之间不应有明显的接缝。对于低于预设(但可配置)限制的分辨率,平铺被禁用。例如,对于 [`StableDiffusionPipeline`] 中的 VAE,此限制为 512x512。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import AutoPipelineForImage2Image
|
||||
from diffusers.utils import load_image
|
||||
|
||||
pipeline = AutoPipelineForImage2Image.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
|
||||
).to("cuda")
|
||||
pipeline.enable_vae_tiling()
|
||||
|
||||
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/img2img-sdxl-init.png")
|
||||
prompt = "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k"
|
||||
pipeline(prompt, image=init_image, strength=0.5).images[0]
|
||||
print(f"Max memory reserved: {torch.cuda.max_memory_allocated() / 1024**3:.2f} GB")
|
||||
```
|
||||
|
||||
> [!WARNING]
|
||||
> [`AutoencoderKLWan`] 和 [`AsymmetricAutoencoderKL`] 不支持平铺。
|
||||
|
||||
## 卸载
|
||||
|
||||
卸载策略将非当前活动层移动
|
||||
将模型移动到 CPU 以避免增加 GPU 内存。这些策略可以与量化和 torch.compile 结合使用,以平衡推理速度和内存使用。
|
||||
|
||||
有关更多详细信息,请参考 [编译和卸载量化模型](./speed-memory-optims) 指南。
|
||||
|
||||
### CPU 卸载
|
||||
|
||||
CPU 卸载选择性地将权重从 GPU 移动到 CPU。当需要某个组件时,它被传输到 GPU;当不需要时,它被移动到 CPU。此方法作用于子模块而非整个模型。它通过避免将整个模型存储在 GPU 上来节省内存。
|
||||
|
||||
CPU 卸载显著减少内存使用,但由于子模块在设备之间多次来回传递,它也非常慢。由于速度极慢,它通常不实用。
|
||||
|
||||
> [!WARNING]
|
||||
> 在调用 [`~DiffusionPipeline.enable_sequential_cpu_offload`] 之前,不要将管道移动到 CUDA,否则节省的内存非常有限(更多细节请参考此 [issue](https://github.com/huggingface/diffusers/issues/1934))。这是一个状态操作,会在模型上安装钩子。
|
||||
|
||||
调用 [`~DiffusionPipeline.enable_sequential_cpu_offload`] 以在管道上启用它。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-schnell", torch_dtype=torch.bfloat16
|
||||
)
|
||||
pipeline.enable_sequential_cpu_offload()
|
||||
|
||||
pipeline(
|
||||
prompt="An astronaut riding a horse on Mars",
|
||||
guidance_scale=0.,
|
||||
height=768,
|
||||
width=1360,
|
||||
num_inference_steps=4,
|
||||
max_sequence_length=256,
|
||||
).images[0]
|
||||
print(f"Max memory reserved: {torch.cuda.max_memory_allocated() / 1024**3:.2f} GB")
|
||||
```
|
||||
|
||||
### 模型卸载
|
||||
|
||||
模型卸载将整个模型移动到 GPU,而不是选择性地移动某些层或模型组件。一个主要管道模型,通常是文本编码器、UNet 和 VAE,被放置在 GPU 上,而其他组件保持在 CPU 上。像 UNet 这样运行多次的组件会一直留在 GPU 上,直到完全完成且不再需要。这消除了 [CPU 卸载](#cpu-offloading) 的通信开销,使模型卸载成为一个更快的替代方案。权衡是内存节省不会那么大。
|
||||
|
||||
> [!WARNING]
|
||||
> 请注意,如果在安装钩子后模型在管道外部被重用(更多细节请参考 [移除钩子](https://huggingface.co/docs/accelerate/en/package_reference/big_modeling#accelerate.hooks.remove_hook_from_module)),您需要按预期顺序运行整个管道和模型以正确卸载它们。这是一个状态操作,会在模型上安装钩子。
|
||||
|
||||
调用 [`~DiffusionPipeline.enable_model_cpu_offload`] 以在管道上启用它。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-schnell", torch_dtype=torch.bfloat16
|
||||
)
|
||||
pipeline.enable_model_cpu_offload()
|
||||
|
||||
pipeline(
|
||||
prompt="An astronaut riding a horse on Mars",
|
||||
guidance_scale=0.,
|
||||
height=768,
|
||||
width=1360,
|
||||
num_inference_steps=4,
|
||||
max_sequence_length=256,
|
||||
).images[0]
|
||||
print(f"最大内存保留: {torch.cuda.max_memory_allocated() / 1024**3:.2f} GB")
|
||||
```
|
||||
|
||||
[`~DiffusionPipeline.enable_model_cpu_offload`] 在您单独使用 [`~StableDiffusionXLPipeline.encode_prompt`] 方法生成文本编码器隐藏状态时也有帮助。
|
||||
|
||||
### 组卸载
|
||||
|
||||
组卸载将内部层组([torch.nn.ModuleList](https://pytorch.org/docs/stable/generated/torch.nn.ModuleList.html) 或 [torch.nn.Sequential](https://pytorch.org/docs/stable/generated/torch.nn.Sequential.html))移动到 CPU。它比[模型卸载](#model-offloading)使用更少的内存,并且比[CPU 卸载](#cpu-offloading)更快,因为它减少了通信开销。
|
||||
|
||||
> [!WARNING]
|
||||
> 如果前向实现包含权重相关的输入设备转换,组卸载可能不适用于所有模型,因为它可能与组卸载的设备转换机制冲突。
|
||||
|
||||
调用 [`~ModelMixin.enable_group_offload`] 为继承自 [`ModelMixin`] 的标准 Diffusers 模型组件启用它。对于不继承自 [`ModelMixin`] 的其他模型组件,例如通用 [torch.nn.Module](https://pytorch.org/docs/stable/generated/torch.nn.Module.html),使用 [`~hooks.apply_group_offloading`] 代替。
|
||||
|
||||
`offload_type` 参数可以设置为 `block_level` 或 `leaf_level`。
|
||||
|
||||
- `block_level` 基于 `num_blocks_per_group` 参数卸载层组。例如,如果 `num_blocks_per_group=2` 在一个有 40 层的模型上,每次加载和卸载 2 层(总共 20 次加载/卸载)。这大大减少了内存需求。
|
||||
- `leaf_level` 在最低级别卸载单个层,等同于[CPU 卸载](#cpu-offloading)。但如果您使用流而不放弃推理速度,它可以更快。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import CogVideoXPipeline
|
||||
from diffusers.hooks import apply_group_offloading
|
||||
from diffusers.utils import export_to_video
|
||||
|
||||
onload_device = torch.device("cuda")
|
||||
offload_device = torch.device("cpu")
|
||||
pipeline = CogVideoXPipeline.from_pretrained("THUDM/CogVideoX-5b", torch_dtype=torch.bfloat16)
|
||||
|
||||
# 对 Diffusers 模型实现使用 enable_group_offload 方法
|
||||
pipeline.transformer.enable_group_offload(onload_device=onload_device, offload_device=offload_device, offload_type="leaf_level")
|
||||
pipeline.vae.enable_group_offload(onload_device=onload_device, offload_type="leaf_level")
|
||||
|
||||
# 对其他模型组件使用 apply_group_offloading 方法
|
||||
apply_group_offloading(pipeline.text_encoder, onload_device=onload_device, offload_type="block_level", num_blocks_per_group=2)
|
||||
|
||||
prompt = (
|
||||
"A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. "
|
||||
"The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other "
|
||||
"pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, "
|
||||
"casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. "
|
||||
"The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical "
|
||||
"atmosphere of this unique musical performance."
|
||||
)
|
||||
video = pipeline(prompt=prompt, guidance_scale=6, num_inference_steps=50).frames[0]
|
||||
print(f"Max memory reserved: {torch.cuda.max_memory_allocated() / 1024**3:.2f} GB")
|
||||
export_to_video(video, "output.mp4", fps=8)
|
||||
```
|
||||
|
||||
#### CUDA 流
|
||||
`use_stream` 参数可以激活支持异步数据传输流的 CUDA 设备,以减少整体执行时间,与 [CPU 卸载](#cpu-offloading) 相比。它通过使用层预取重叠数据传输和计算。下一个要执行的层在当前层仍在执行时加载到 GPU 上。这会显著增加 CPU 内存,因此请确保您有模型大小的 2 倍内存。
|
||||
|
||||
设置 `record_stream=True` 以获得更多速度提升,代价是内存使用量略有增加。请参阅 [torch.Tensor.record_stream](https://pytorch.org/docs/stable/generated/torch.Tensor.record_stream.html) 文档了解更多信息。
|
||||
|
||||
> [!TIP]
|
||||
> 当 `use_stream=True` 在启用平铺的 VAEs 上时,确保在推理前进行虚拟前向传递(可以使用虚拟输入),以避免设备不匹配错误。这可能不适用于所有实现,因此如果遇到任何问题,请随时提出问题。
|
||||
|
||||
如果您在使用启用 `use_stream` 的 `block_level` 组卸载,`num_blocks_per_group` 参数应设置为 `1`,否则会引发警告。
|
||||
|
||||
```py
|
||||
pipeline.transformer.enable_group_offload(onload_device=onload_device, offload_device=offload_device, offload_type="leaf_level", use_stream=True, record_stream=True)
|
||||
```
|
||||
|
||||
`low_cpu_mem_usage` 参数可以设置为 `True`,以在使用流进行组卸载时减少 CPU 内存使用。它最适合 `leaf_level` 卸载和 CPU 内存瓶颈的情况。通过动态创建固定张量而不是预先固定它们来节省内存。然而,这可能会增加整体执行时间。
|
||||
|
||||
#### 卸载到磁盘
|
||||
组卸载可能会消耗大量系统内存,具体取决于模型大小。在内存有限的系统上,尝试将组卸载到磁盘作为辅助内存。
|
||||
|
||||
在 [`~ModelMixin.enable_group_offload`] 或 [`~hooks.apply_group_offloading`] 中设置 `offload_to_disk_path` 参数,将模型卸载到磁盘。
|
||||
|
||||
```py
|
||||
pipeline.transformer.enable_group_offload(onload_device=onload_device, offload_device=offload_device, offload_type="leaf_level", offload_to_disk_path="path/to/disk")
|
||||
|
||||
apply_group_offloading(pipeline.text_encoder, onload_device=onload_device, offload_type="block_level", num_blocks_per_group=2, offload_to_disk_path="path/to/disk")
|
||||
```
|
||||
|
||||
参考这些[两个](https://github.com/huggingface/diffusers/pull/11682#issue-3129365363)[表格](https://github.com/huggingface/diffusers/pull/11682#issuecomment-2955715126)来比较速度和内存的权衡。
|
||||
|
||||
## 分层类型转换
|
||||
|
||||
> [!TIP]
|
||||
> 将分层类型转换与[组卸载](#group-offloading)结合使用,以获得更多内存节省。
|
||||
|
||||
分层类型转换将权重存储在较小的数据格式中(例如 `torch.float8_e4m3fn` 和 `torch.float8_e5m2`),以使用更少的内存,并在计算时将那些权重上转换为更高精度如 `torch.float16` 或 `torch.bfloat16`。某些层(归一化和调制相关权重)被跳过,因为将它们存储在 fp8 中可能会降低生成质量。
|
||||
|
||||
> [!WARNING]
|
||||
> 如果前向实现包含权重的内部类型转换,分层类型转换可能不适用于所有模型。当前的分层类型转换实现假设前向传递独立于权重精度,并且输入数据类型始终在 `compute_dtype` 中指定(请参见[这里](https://github.com/huggingface/transformers/blob/7f5077e53682ca855afc826162b204ebf809f1f9/src/transformers/models/t5/modeling_t5.py#L294-L299)以获取不兼容的实现)。
|
||||
>
|
||||
> 分层类型转换也可能在使用[PEFT](https://huggingface.co/docs/peft/index)层的自定义建模实现上失败。有一些检查可用,但它们没有经过广泛测试或保证在所有情况下都能工作。
|
||||
|
||||
调用 [`~ModelMixin.enable_layerwise_casting`] 来设置存储和计算数据类型。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import CogVideoXPipeline, CogVideoXTransformer3DModel
|
||||
from diffusers.utils import export_to_video
|
||||
|
||||
transformer = CogVideoXTransformer3DModel.from_pretrained(
|
||||
"THUDM/CogVideoX-5b",
|
||||
subfolder="transformer",
|
||||
torch_dtype=torch.bfloat16
|
||||
)
|
||||
transformer.enable_layerwise_casting(storage_dtype=torch.float8_e4m3fn, compute_dtype=torch.bfloat16)
|
||||
|
||||
pipeline = CogVideoXPipeline.from_pretrained("THUDM/CogVideoX-5b",
|
||||
transformer=transformer,
|
||||
torch_dtype=torch.bfloat16
|
||||
).to("cuda")
|
||||
prompt = (
|
||||
"A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. "
|
||||
"The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other "
|
||||
"pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, "
|
||||
"casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. "
|
||||
"The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical "
|
||||
"atmosphere of this unique musical performance."
|
||||
)
|
||||
video = pipeline(prompt=prompt, guidance_scale=6, num_inference_steps=50).frames[0]
|
||||
print(f"Max memory reserved: {torch.cuda.max_memory_allocated() / 1024**3:.2f} GB")
|
||||
export_to_video(video, "output.mp4", fps=8)
|
||||
```
|
||||
|
||||
[`~hooks.apply_layerwise_casting`] 方法也可以在您需要更多控制和灵活性时使用。它可以通过在特定内部模块上调用它来部分应用于模型层。使用 `skip_modules_pattern` 或 `skip_modules_classes` 参数来指定要避免的模块,例如归一化和调制层。
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import CogVideoXTransformer3DModel
|
||||
from diffusers.hooks import apply_layerwise_casting
|
||||
|
||||
transformer = CogVideoXTransformer3DModel.from_pretrained(
|
||||
"THUDM/CogVideoX-5b",
|
||||
subfolder="transformer",
|
||||
torch_dtype=torch.bfloat16
|
||||
)
|
||||
|
||||
# 跳过归一化层
|
||||
apply_layerwise_casting(
|
||||
transformer,
|
||||
storage_dtype=torch.float8_e4m3fn,
|
||||
compute_dtype=torch.bfloat16,
|
||||
skip_modules_classes=["norm"],
|
||||
non_blocking=True,
|
||||
)
|
||||
```
|
||||
|
||||
## torch.channels_last
|
||||
|
||||
[torch.channels_last](https://pytorch.org/tutorials/intermediate/memory_format_tutorial.html) 将张量的存储方式从 `(批次大小, 通道数, 高度, 宽度)` 翻转为 `(批次大小, 高度, 宽度, 通道数)`。这使张量与硬件如何顺序访问存储在内存中的张量对齐,并避免了在内存中跳转以访问像素值。
|
||||
|
||||
并非所有运算符当前都支持通道最后格式,并且可能导致性能更差,但仍然值得尝试。
|
||||
|
||||
```py
|
||||
print(pipeline.unet.conv_out.state_dict()["weight"].stride()) # (2880, 9, 3, 1)
|
||||
pipeline.unet.to(memory_format=torch.channels_last) # 原地操作
|
||||
print(
|
||||
pipeline.unet.conv_out.state_dict()["weight"].stride()
|
||||
) # (2880, 1, 960, 320) 第二个维度的跨度为1证明它有效
|
||||
```
|
||||
|
||||
## torch.jit.trace
|
||||
|
||||
[torch.jit.trace](https://pytorch.org/docs/stable/generated/torch.jit.trace.html) 记录模型在样本输入上执行的操作,并根据记录的执行路径创建一个新的、优化的模型表示。在跟踪过程中,模型被优化以减少来自Python和动态控制流的开销,并且操作被融合在一起以提高效率。返回的可执行文件或 [ScriptFunction](https://pytorch.org/docs/stable/generated/torch.jit.ScriptFunction.html) 可以被编译。
|
||||
|
||||
```py
|
||||
import time
|
||||
import torch
|
||||
from diffusers import StableDiffusionPipeline
|
||||
import functools
|
||||
|
||||
# torch 禁用梯度
|
||||
torch.set_grad_enabled(False)
|
||||
|
||||
# 设置变量
|
||||
n_experiments = 2
|
||||
unet_runs_per_experiment = 50
|
||||
|
||||
# 加载样本输入
|
||||
def generate_inputs():
|
||||
sample = torch.randn((2, 4, 64, 64), device="cuda", dtype=torch.float16)
|
||||
timestep = torch.rand(1, device="cuda", dtype=torch.float16) * 999
|
||||
encoder_hidden_states = torch.randn((2, 77, 768), device="cuda", dtype=torch.float16)
|
||||
return sample, timestep, encoder_hidden_states
|
||||
|
||||
|
||||
pipeline = StableDiffusionPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5",
|
||||
torch_dtype=torch.float16,
|
||||
use_safetensors=True,
|
||||
).to("cuda")
|
||||
unet = pipeline.unet
|
||||
unet.eval()
|
||||
unet.to(memory
|
||||
_format=torch.channels_last) # 使用 channels_last 内存格式
|
||||
unet.forward = functools.partial(unet.forward, return_dict=False) # 设置 return_dict=False 为默认
|
||||
|
||||
# 预热
|
||||
for _ in range(3):
|
||||
with torch.inference_mode():
|
||||
inputs = generate_inputs()
|
||||
orig_output = unet(*inputs)
|
||||
|
||||
# 追踪
|
||||
print("tracing..")
|
||||
unet_traced = torch.jit.trace(unet, inputs)
|
||||
unet_traced.eval()
|
||||
print("done tracing")
|
||||
|
||||
# 预热和优化图
|
||||
for _ in range(5):
|
||||
with torch.inference_mode():
|
||||
inputs = generate_inputs()
|
||||
orig_output = unet_traced(*inputs)
|
||||
|
||||
# 基准测试
|
||||
with torch.inference_mode():
|
||||
for _ in range(n_experiments):
|
||||
torch.cuda.synchronize()
|
||||
start_time = time.time()
|
||||
for _ in range(unet_runs_per_experiment):
|
||||
orig_output = unet_traced(*inputs)
|
||||
torch.cuda.synchronize()
|
||||
print(f"unet traced inference took {time.time() - start_time:.2f} seconds")
|
||||
for _ in range(n_experiments):
|
||||
torch.cuda.synchronize()
|
||||
start_time = time.time()
|
||||
for _ in range(unet_runs_per_experiment):
|
||||
orig_output = unet(*inputs)
|
||||
torch.cuda.synchronize()
|
||||
print(f"unet inference took {time.time() - start_time:.2f} seconds")
|
||||
|
||||
# 保存模型
|
||||
unet_traced.save("unet_traced.pt")
|
||||
```
|
||||
|
||||
替换管道的 UNet 为追踪版本。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import StableDiffusionPipeline
|
||||
from dataclasses import dataclass
|
||||
|
||||
@dataclass
|
||||
class UNet2DConditionOutput:
|
||||
sample: torch.Tensor
|
||||
|
||||
pipeline = StableDiffusionPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5",
|
||||
torch_dtype=torch.float16,
|
||||
use_safetensors=True,
|
||||
).to("cuda")
|
||||
|
||||
# 使用 jitted unet
|
||||
unet_traced = torch.jit.load("unet_traced.pt")
|
||||
|
||||
# del pipeline.unet
|
||||
class TracedUNet(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.in_channels = pipe.unet.config.in_channels
|
||||
self.device = pipe.unet.device
|
||||
|
||||
def forward(self, latent_model_input, t, encoder_hidden_states):
|
||||
sample = unet_traced(latent_model_input, t, encoder_hidden_states)[0]
|
||||
return UNet2DConditionOutput(sample=sample)
|
||||
|
||||
pipeline.unet = TracedUNet()
|
||||
|
||||
with torch.inference_mode():
|
||||
image = pipe([prompt] * 1, num_inference_steps=50).images[0]
|
||||
```
|
||||
|
||||
## 内存高效注意力
|
||||
|
||||
> [!TIP]
|
||||
> 内存高效注意力优化内存使用 *和* [推理速度](./fp16#scaled-dot-product-attention)!
|
||||
|
||||
Transformers 注意力机制是内存密集型的,尤其对于长序列,因此您可以尝试使用不同且更内存高效的注意力类型。
|
||||
|
||||
默认情况下,如果安装了 PyTorch >= 2.0,则使用 [scaled dot-product attention (SDPA)](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)。您无需对代码进行任何额外更改。
|
||||
|
||||
SDPA 还支持 [FlashAttention](https://github.com/Dao-AILab/flash-attention) 和 [xFormers](https://github.com/facebookresearch/xformers),以及 a
|
||||
这是一个原生的 C++ PyTorch 实现。它会根据您的输入自动选择最优的实现。
|
||||
|
||||
您可以使用 [`~ModelMixin.enable_xformers_memory_efficient_attention`] 方法显式地使用 xFormers。
|
||||
|
||||
```py
|
||||
# pip install xformers
|
||||
import torch
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
|
||||
pipeline = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.float16,
|
||||
).to("cuda")
|
||||
pipeline.enable_xformers_memory_efficient_attention()
|
||||
```
|
||||
|
||||
调用 [`~ModelMixin.disable_xformers_memory_efficient_attention`] 来禁用它。
|
||||
|
||||
```py
|
||||
pipeline.disable_xformers_memory_efficient_attention()
|
||||
```
|
||||
82
docs/source/zh/optimization/mps.md
Normal file
82
docs/source/zh/optimization/mps.md
Normal file
@@ -0,0 +1,82 @@
|
||||
<!--版权所有 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版本("许可证")授权;除非遵守许可证,否则不得使用此文件。您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件按"原样"分发,无任何明示或暗示的担保或条件。请参阅许可证了解具体的语言管理权限和限制。
|
||||
-->
|
||||
|
||||
# Metal Performance Shaders (MPS)
|
||||
|
||||
> [!TIP]
|
||||
> 带有 <img alt="MPS" src="https://img.shields.io/badge/MPS-000000?style=flat&logo=apple&logoColor=white%22"> 徽章的管道表示模型可以利用 Apple silicon 设备上的 MPS 后端进行更快的推理。欢迎提交 [Pull Request](https://github.com/huggingface/diffusers/compare) 来为缺少此徽章的管道添加它。
|
||||
|
||||
🤗 Diffusers 与 Apple silicon(M1/M2 芯片)兼容,使用 PyTorch 的 [`mps`](https://pytorch.org/docs/stable/notes/mps.html) 设备,该设备利用 Metal 框架来发挥 MacOS 设备上 GPU 的性能。您需要具备:
|
||||
|
||||
- 配备 Apple silicon(M1/M2)硬件的 macOS 计算机
|
||||
- macOS 12.6 或更高版本(推荐 13.0 或更高)
|
||||
- arm64 版本的 Python
|
||||
- [PyTorch 2.0](https://pytorch.org/get-started/locally/)(推荐)或 1.13(支持 `mps` 的最低版本)
|
||||
|
||||
`mps` 后端使用 PyTorch 的 `.to()` 接口将 Stable Diffusion 管道移动到您的 M1 或 M2 设备上:
|
||||
|
||||
```python
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipe = DiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5")
|
||||
pipe = pipe.to("mps")
|
||||
|
||||
# 如果您的计算机内存小于 64 GB,推荐使用
|
||||
pipe.enable_attention_slicing()
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
image = pipe(prompt).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
PyTorch [mps](https://pytorch.org/docs/stable/notes/mps.html) 后端不支持大小超过 `2**32` 的 NDArray。如果您遇到此问题,请提交 [Issue](https://github.com/huggingface/diffusers/issues/new/choose) 以便我们调查。
|
||||
|
||||
</Tip>
|
||||
|
||||
如果您使用 **PyTorch 1.13**,您需要通过管道进行一次额外的"预热"传递。这是一个临时解决方法,用于解决首次推理传递产生的结果与后续传递略有不同的问题。您只需要执行此传递一次,并且在仅进行一次推理步骤后可以丢弃结果。
|
||||
|
||||
```diff
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipe = DiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5").to("mps")
|
||||
pipe.enable_attention_slicing()
|
||||
|
||||
prompt = "a photo of an astronaut riding a horse on mars"
|
||||
# 如果 PyTorch 版本是 1.13,进行首次"预热"传递
|
||||
+ _ = pipe(prompt, num_inference_steps=1)
|
||||
|
||||
# 预热传递后,结果与 CPU 设备上的结果匹配。
|
||||
image = pipe(prompt).images[0]
|
||||
```
|
||||
|
||||
## 故障排除
|
||||
|
||||
本节列出了使用 `mps` 后端时的一些常见问题及其解决方法。
|
||||
|
||||
### 注意力切片
|
||||
|
||||
M1/M2 性能对内存压力非常敏感。当发生这种情况时,系统会自动交换内存,这会显著降低性能。
|
||||
|
||||
为了防止这种情况发生,我们建议使用*注意力切片*来减少推理过程中的内存压力并防止交换。这在您的计算机系统内存少于 64GB 或生成非标准分辨率(大于 512×512 像素)的图像时尤其相关。在您的管道上调用 [`~DiffusionPipeline.enable_attention_slicing`] 函数:
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16", use_safetensors=True).to("mps")
|
||||
pipeline.enable_attention_slicing()
|
||||
```
|
||||
|
||||
注意力切片将昂贵的注意力操作分多个步骤执行,而不是一次性完成。在没有统一内存的计算机中,它通常能提高约 20% 的性能,但我们观察到在大多数 Apple 芯片计算机中,除非您有 64GB 或更多 RAM,否则性能会*更好*。
|
||||
|
||||
### 批量推理
|
||||
|
||||
批量生成多个提示可能会导致崩溃或无法可靠工作。如果是这种情况,请尝试迭代而不是批量处理。
|
||||
59
docs/source/zh/optimization/neuron.md
Normal file
59
docs/source/zh/optimization/neuron.md
Normal file
@@ -0,0 +1,59 @@
|
||||
<!--版权所有 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版(“许可证”)授权;除非遵守许可证,否则不得使用此文件。您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件按“原样”分发,无任何明示或暗示的担保或条件。请参阅许可证了解特定语言管理权限和限制。
|
||||
-->
|
||||
|
||||
# AWS Neuron
|
||||
|
||||
Diffusers 功能可在 [AWS Inf2 实例](https://aws.amazon.com/ec2/instance-types/inf2/)上使用,这些是由 [Neuron 机器学习加速器](https://aws.amazon.com/machine-learning/inferentia/)驱动的 EC2 实例。这些实例旨在提供更好的计算性能(更高的吞吐量、更低的延迟)和良好的成本效益,使其成为 AWS 用户将扩散模型部署到生产环境的良好选择。
|
||||
|
||||
[Optimum Neuron](https://huggingface.co/docs/optimum-neuron/en/index) 是 Hugging Face 库与 AWS 加速器之间的接口,包括 AWS [Trainium](https://aws.amazon.com/machine-learning/trainium/) 和 AWS [Inferentia](https://aws.amazon.com/machine-learning/inferentia/)。它支持 Diffusers 中的许多功能,并具有类似的 API,因此如果您已经熟悉 Diffusers,学习起来更容易。一旦您创建了 AWS Inf2 实例,请安装 Optimum Neuron。
|
||||
|
||||
```bash
|
||||
python -m pip install --upgrade-strategy eager optimum[neuronx]
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
我们提供预构建的 [Hugging Face Neuron 深度学习 AMI](https://aws.amazon.com/marketplace/pp/prodview-gr3e6yiscria2)(DLAMI)和用于 Amazon SageMaker 的 Optimum Neuron 容器。建议正确设置您的环境。
|
||||
|
||||
</Tip>
|
||||
|
||||
下面的示例演示了如何在 inf2.8xlarge 实例上使用 Stable Diffusion XL 模型生成图像(一旦模型编译完成,您可以切换到更便宜的 inf2.xlarge 实例)。要生成一些图像,请使用 [`~optimum.neuron.NeuronStableDiffusionXLPipeline`] 类,该类类似于 Diffusers 中的 [`StableDiffusionXLPipeline`] 类。
|
||||
|
||||
与 Diffusers 不同,您需要将管道中的模型编译为 Neuron 格式,即 `.neuron`。运行以下命令将模型导出为 `.neuron` 格式。
|
||||
|
||||
```bash
|
||||
optimum-cli export neuron --model stabilityai/stable-diffusion-xl-base-1.0 \
|
||||
--batch_size 1 \
|
||||
--height 1024 `# 生成图像的高度(像素),例如 768, 1024` \
|
||||
--width 1024 `# 生成图像的宽度(像素),例如 768, 1024` \
|
||||
--num_images_per_prompt 1 `# 每个提示生成的图像数量,默认为 1` \
|
||||
--auto_cast matmul `# 仅转换矩阵乘法操作` \
|
||||
--auto_cast_type bf16 `# 将操作从 FP32 转换为 BF16` \
|
||||
sd_neuron_xl/
|
||||
```
|
||||
|
||||
现在使用预编译的 SDXL 模型生成一些图像。
|
||||
|
||||
```python
|
||||
>>> from optimum.neuron import Neu
|
||||
ronStableDiffusionXLPipeline
|
||||
|
||||
>>> stable_diffusion_xl = NeuronStableDiffusionXLPipeline.from_pretrained("sd_neuron_xl/")
|
||||
>>> prompt = "a pig with wings flying in floating US dollar banknotes in the air, skyscrapers behind, warm color palette, muted colors, detailed, 8k"
|
||||
>>> image = stable_diffusion_xl(prompt).images[0]
|
||||
```
|
||||
|
||||
<img
|
||||
src="https://huggingface.co/datasets/Jingya/document_images/resolve/main/optimum/neuron/sdxl_pig.png"
|
||||
width="256"
|
||||
height="256"
|
||||
alt="peggy generated by sdxl on inf2"
|
||||
/>
|
||||
|
||||
欢迎查看Optimum Neuron [文档](https://huggingface.co/docs/optimum-neuron/en/inference_tutorials/stable_diffusion#generate-images-with-stable-diffusion-models-on-aws-inferentia)中更多不同用例的指南和示例!
|
||||
82
docs/source/zh/optimization/onnx.md
Normal file
82
docs/source/zh/optimization/onnx.md
Normal file
@@ -0,0 +1,82 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
根据 Apache License 2.0 许可证(以下简称"许可证")授权,除非符合许可证要求,否则不得使用本文件。您可以通过以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或以书面形式同意,本软件按"原样"分发,不附带任何明示或暗示的担保或条件。详见许可证中规定的特定语言权限和限制。
|
||||
-->
|
||||
|
||||
# ONNX Runtime
|
||||
|
||||
🤗 [Optimum](https://github.com/huggingface/optimum) 提供了兼容 ONNX Runtime 的 Stable Diffusion 流水线。您需要运行以下命令安装支持 ONNX Runtime 的 🤗 Optimum:
|
||||
|
||||
```bash
|
||||
pip install -q optimum["onnxruntime"]
|
||||
```
|
||||
|
||||
本指南将展示如何使用 ONNX Runtime 运行 Stable Diffusion 和 Stable Diffusion XL (SDXL) 流水线。
|
||||
|
||||
## Stable Diffusion
|
||||
|
||||
要加载并运行推理,请使用 [`~optimum.onnxruntime.ORTStableDiffusionPipeline`]。若需加载 PyTorch 模型并实时转换为 ONNX 格式,请设置 `export=True`:
|
||||
|
||||
```python
|
||||
from optimum.onnxruntime import ORTStableDiffusionPipeline
|
||||
|
||||
model_id = "stable-diffusion-v1-5/stable-diffusion-v1-5"
|
||||
pipeline = ORTStableDiffusionPipeline.from_pretrained(model_id, export=True)
|
||||
prompt = "sailing ship in storm by Leonardo da Vinci"
|
||||
image = pipeline(prompt).images[0]
|
||||
pipeline.save_pretrained("./onnx-stable-diffusion-v1-5")
|
||||
```
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
当前批量生成多个提示可能会占用过高内存。在问题修复前,建议采用迭代方式而非批量处理。
|
||||
|
||||
</Tip>
|
||||
|
||||
如需离线导出 ONNX 格式流水线供后续推理使用,请使用 [`optimum-cli export`](https://huggingface.co/docs/optimum/main/en/exporters/onnx/usage_guides/export_a_model#exporting-a-model-to-onnx-using-the-cli) 命令:
|
||||
|
||||
```bash
|
||||
optimum-cli export onnx --model stable-diffusion-v1-5/stable-diffusion-v1-5 sd_v15_onnx/
|
||||
```
|
||||
|
||||
随后进行推理时(无需再次指定 `export=True`):
|
||||
|
||||
```python
|
||||
from optimum.onnxruntime import ORTStableDiffusionPipeline
|
||||
|
||||
model_id = "sd_v15_onnx"
|
||||
pipeline = ORTStableDiffusionPipeline.from_pretrained(model_id)
|
||||
prompt = "sailing ship in storm by Leonardo da Vinci"
|
||||
image = pipeline(prompt).images[0]
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/optimum/documentation-images/resolve/main/onnxruntime/stable_diffusion_v1_5_ort_sail_boat.png">
|
||||
</div>
|
||||
|
||||
您可以在 🤗 Optimum [文档](https://huggingface.co/docs/optimum/) 中找到更多示例,Stable Diffusion 支持文生图、图生图和图像修复任务。
|
||||
|
||||
## Stable Diffusion XL
|
||||
|
||||
要加载并运行 SDXL 推理,请使用 [`~optimum.onnxruntime.ORTStableDiffusionXLPipeline`]:
|
||||
|
||||
```python
|
||||
from optimum.onnxruntime import ORTStableDiffusionXLPipeline
|
||||
|
||||
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
|
||||
pipeline = ORTStableDiffusionXLPipeline.from_pretrained(model_id)
|
||||
prompt = "sailing ship in storm by Leonardo da Vinci"
|
||||
image = pipeline(prompt).images[0]
|
||||
```
|
||||
|
||||
如需导出 ONNX 格式流水线供后续推理使用,请运行:
|
||||
|
||||
```bash
|
||||
optimum-cli export onnx --model stabilityai/stable-diffusion-xl-base-1.0 --task stable-diffusion-xl sd_xl_onnx/
|
||||
```
|
||||
|
||||
SDXL 的 ONNX 格式目前支持文生图和图生图任务。
|
||||
77
docs/source/zh/optimization/open_vino.md
Normal file
77
docs/source/zh/optimization/open_vino.md
Normal file
@@ -0,0 +1,77 @@
|
||||
<!--版权所有 2025 HuggingFace 团队。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版本("许可证")授权;除非遵守许可证,否则不得使用此文件。您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件按"原样"分发,无任何明示或暗示的担保或条件。请参阅许可证以了解具体的语言管理权限和限制。
|
||||
-->
|
||||
|
||||
# OpenVINO
|
||||
|
||||
🤗 [Optimum](https://github.com/huggingface/optimum-intel) 提供与 OpenVINO 兼容的 Stable Diffusion 管道,可在各种 Intel 处理器上执行推理(请参阅支持的设备[完整列表](https://docs.openvino.ai/latest/openvino_docs_OV_UG_supported_plugins_Supported_Devices.html))。
|
||||
|
||||
您需要安装 🤗 Optimum Intel,并使用 `--upgrade-strategy eager` 选项以确保 [`optimum-intel`](https://github.com/huggingface/optimum-intel) 使用最新版本:
|
||||
|
||||
```bash
|
||||
pip install --upgrade-strategy eager optimum["openvino"]
|
||||
```
|
||||
|
||||
本指南将展示如何使用 Stable Diffusion 和 Stable Diffusion XL (SDXL) 管道与 OpenVINO。
|
||||
|
||||
## Stable Diffusion
|
||||
|
||||
要加载并运行推理,请使用 [`~optimum.intel.OVStableDiffusionPipeline`]。如果您想加载 PyTorch 模型并即时转换为 OpenVINO 格式,请设置 `export=True`:
|
||||
|
||||
```python
|
||||
from optimum.intel import OVStableDiffusionPipeline
|
||||
|
||||
model_id = "stable-diffusion-v1-5/stable-diffusion-v1-5"
|
||||
pipeline = OVStableDiffusionPipeline.from_pretrained(model_id, export=True)
|
||||
prompt = "sailing ship in storm by Rembrandt"
|
||||
image = pipeline(prompt).images[0]
|
||||
|
||||
# 别忘了保存导出的模型
|
||||
pipeline.save_pretrained("openvino-sd-v1-5")
|
||||
```
|
||||
|
||||
为了进一步加速推理,静态重塑模型。如果您更改任何参数,例如输出高度或宽度,您需要再次静态重塑模型。
|
||||
|
||||
```python
|
||||
# 定义与输入和期望输出相关的形状
|
||||
batch_size, num_images, height, width = 1, 1, 512, 512
|
||||
|
||||
# 静态重塑模型
|
||||
pipeline.reshape(batch_size, height, width, num_images)
|
||||
# 在推理前编译模型
|
||||
pipeline.compile()
|
||||
|
||||
image = pipeline(
|
||||
prompt,
|
||||
height=height,
|
||||
width=width,
|
||||
num_images_per_prompt=num_images,
|
||||
).images[0]
|
||||
```
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/optimum/documentation-images/resolve/main/intel/openvino/stable_diffusion_v1_5_sail_boat_rembrandt.png">
|
||||
</div>
|
||||
|
||||
您可以在 🤗 Optimum [文档](https://huggingface.co/docs/optimum/intel/inference#stable-diffusion) 中找到更多示例,Stable Diffusion 支持文本到图像、图像到图像和修复。
|
||||
|
||||
## Stable Diffusion XL
|
||||
|
||||
要加载并运行 SDXL 推理,请使用 [`~optimum.intel.OVStableDiffusionXLPipeline`]:
|
||||
|
||||
```python
|
||||
from optimum.intel import OVStableDiffusionXLPipeline
|
||||
|
||||
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
|
||||
pipeline = OVStableDiffusionXLPipeline.from_pretrained(model_id)
|
||||
prompt = "sailing ship in storm by Rembrandt"
|
||||
image = pipeline(prompt).images[0]
|
||||
```
|
||||
|
||||
为了进一步加速推理,可以如Stable Diffusion部分所示[静态重塑](#stable-diffusion)模型。
|
||||
|
||||
您可以在🤗 Optimum[文档](https://huggingface.co/docs/optimum/intel/inference#stable-diffusion-xl)中找到更多示例,并且在OpenVINO中运行SDXL支持文本到图像和图像到图像。
|
||||
497
docs/source/zh/optimization/para_attn.md
Normal file
497
docs/source/zh/optimization/para_attn.md
Normal file
@@ -0,0 +1,497 @@
|
||||
# ParaAttention
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/para-attn/flux-performance.png">
|
||||
</div>
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/para-attn/hunyuan-video-performance.png">
|
||||
</div>
|
||||
|
||||
大型图像和视频生成模型,如 [FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev) 和 [HunyuanVideo](https://huggingface.co/tencent/HunyuanVideo),由于其规模,可能对实时应用和部署构成推理挑战。
|
||||
|
||||
[ParaAttention](https://github.com/chengzeyi/ParaAttention) 是一个实现了**上下文并行**和**第一块缓存**的库,可以与其他技术(如 torch.compile、fp8 动态量化)结合使用,以加速推理。
|
||||
|
||||
本指南将展示如何在 NVIDIA L20 GPU 上对 FLUX.1-dev 和 HunyuanVideo 应用 ParaAttention。
|
||||
在我们的基线基准测试中,除了 HunyuanVideo 为避免内存不足错误外,未应用任何优化。
|
||||
|
||||
我们的基线基准测试显示,FLUX.1-dev 能够在 28 步中生成 1024x1024 分辨率图像,耗时 26.36 秒;HunyuanVideo 能够在 30 步中生成 129 帧 720p 分辨率视频,耗时 3675.71 秒。
|
||||
|
||||
> [!TIP]
|
||||
> 对于更快的上下文并行推理,请尝试使用支持 NVLink 的 NVIDIA A100 或 H100 GPU(如果可用),尤其是在 GPU 数量较多时。
|
||||
|
||||
## 第一块缓存
|
||||
|
||||
缓存模型中 transformer 块的输出并在后续推理步骤中重用它们,可以降低计算成本并加速推理。
|
||||
|
||||
然而,很难决定何时重用缓存以确保生成图像或视频的质量。ParaAttention 直接使用**第一个 transformer 块输出的残差差异**来近似模型输出之间的差异。当差异足够小时,重用先前推理步骤的残差差异。换句话说,跳过去噪步骤。
|
||||
|
||||
这在 FLUX.1-dev 和 HunyuanVideo 推理上实现了 2 倍加速,且质量非常好。
|
||||
|
||||
<figure>
|
||||
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/para-attn/ada-cache.png" alt="Cache in Diffusion Transformer" />
|
||||
<figcaption>AdaCache 的工作原理,第一块缓存是其变体</figcaption>
|
||||
</figure>
|
||||
|
||||
<hfoptions id="first-block-cache">
|
||||
<hfoption id="FLUX-1.dev">
|
||||
|
||||
要在 FLUX.1-dev 上应用第一块缓存,请调用 `apply_cache_on_pipe`,如下所示。0.08 是 FLUX 模型的默认残差差异值。
|
||||
|
||||
```python
|
||||
import time
|
||||
import torch
|
||||
from diffusers import FluxPipeline
|
||||
|
||||
pipe = FluxPipeline.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-dev",
|
||||
torch_dtype=torch.bfloat16,
|
||||
).to("cuda")
|
||||
|
||||
from para_attn.first_block_cache.diffusers_adapters import apply_cache_on_pipe
|
||||
|
||||
apply_cache_on_pipe(pipe, residual_diff_thre
|
||||
shold=0.08)
|
||||
|
||||
# 启用内存节省
|
||||
# pipe.enable_model_cpu_offload()
|
||||
# pipe.enable_sequential_cpu_offload()
|
||||
|
||||
begin = time.time()
|
||||
image = pipe(
|
||||
"A cat holding a sign that says hello world",
|
||||
num_inference_steps=28,
|
||||
).images[0]
|
||||
end = time.time()
|
||||
print(f"Time: {end - begin:.2f}s")
|
||||
|
||||
print("Saving image to flux.png")
|
||||
image.save("flux.png")
|
||||
```
|
||||
|
||||
| 优化 | 原始 | FBCache rdt=0.06 | FBCache rdt=0.08 | FBCache rdt=0.10 | FBCache rdt=0.12 |
|
||||
| - | - | - | - | - | - |
|
||||
| 预览 |  |  |  |  |  |
|
||||
| 墙时间 (s) | 26.36 | 21.83 | 17.01 | 16.00 | 13.78 |
|
||||
|
||||
First Block Cache 将推理速度降低到 17.01 秒,与基线相比,或快 1.55 倍,同时保持几乎零质量损失。
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="HunyuanVideo">
|
||||
|
||||
要在 HunyuanVideo 上应用 First Block Cache,请使用 `apply_cache_on_pipe`,如下所示。0.06 是 HunyuanVideo 模型的默认残差差值。
|
||||
|
||||
```python
|
||||
import time
|
||||
import torch
|
||||
from diffusers import HunyuanVideoPipeline, HunyuanVideoTransformer3DModel
|
||||
from diffusers.utils import export_to_video
|
||||
|
||||
model_id = "tencent/HunyuanVideo"
|
||||
transformer = HunyuanVideoTransformer3DModel.from_pretrained(
|
||||
model_id,
|
||||
subfolder="transformer",
|
||||
torch_dtype=torch.bfloat16,
|
||||
revision="refs/pr/18",
|
||||
)
|
||||
pipe = HunyuanVideoPipeline.from_pretrained(
|
||||
model_id,
|
||||
transformer=transformer,
|
||||
torch_dtype=torch.float16,
|
||||
revision="refs/pr/18",
|
||||
).to("cuda")
|
||||
|
||||
from para_attn.first_block_cache.diffusers_adapters import apply_cache_on_pipe
|
||||
|
||||
apply_cache_on_pipe(pipe, residual_diff_threshold=0.6)
|
||||
|
||||
pipe.vae.enable_tiling()
|
||||
|
||||
begin = time.time()
|
||||
output = pipe(
|
||||
prompt="A cat walks on the grass, realistic",
|
||||
height=720,
|
||||
width=1280,
|
||||
num_frames=129,
|
||||
num_inference_steps=30,
|
||||
).frames[0]
|
||||
end = time.time()
|
||||
print(f"Time: {end - begin:.2f}s")
|
||||
|
||||
print("Saving video to hunyuan_video.mp4")
|
||||
export_to_video(output, "hunyuan_video.mp4", fps=15)
|
||||
```
|
||||
|
||||
<video controls>
|
||||
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/para-attn/hunyuan-video-original.mp4" type="video/mp4">
|
||||
您的浏览器不支持视频标签。
|
||||
</video>
|
||||
|
||||
<small> HunyuanVideo 无 FBCache </small>
|
||||
|
||||
<video controls>
|
||||
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/para-attn/hunyuan-video-fbc.mp4" type="video/mp4">
|
||||
Your browser does not support the video tag.
|
||||
</video>
|
||||
|
||||
<small> HunyuanVideo 与 FBCache </small>
|
||||
|
||||
First Block Cache 将推理速度降低至 2271.06 秒,相比基线快了 1.62 倍,同时保持了几乎为零的质量损失。
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## fp8 量化
|
||||
|
||||
fp8 动态量化进一步加速推理并减少内存使用。为了使用 8 位 [NVIDIA Tensor Cores](https://www.nvidia.com/en-us/data-center/tensor-cores/),必须对激活和权重进行量化。
|
||||
|
||||
使用 `float8_weight_only` 和 `float8_dynamic_activation_float8_weight` 来量化文本编码器和变换器模型。
|
||||
|
||||
默认量化方法是逐张量量化,但如果您的 GPU 支持逐行量化,您也可以尝试它以获得更好的准确性。
|
||||
|
||||
使用以下命令安装 [torchao](https://github.com/pytorch/ao/tree/main)。
|
||||
|
||||
```bash
|
||||
pip3 install -U torch torchao
|
||||
```
|
||||
|
||||
[torch.compile](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) 使用 `mode="max-autotune-no-cudagraphs"` 或 `mode="max-autotune"` 选择最佳内核以获得性能。如果是第一次调用模型,编译可能会花费很长时间,但一旦模型编译完成,这是值得的。
|
||||
|
||||
此示例仅量化变换器模型,但您也可以量化文本编码器以进一步减少内存使用。
|
||||
|
||||
> [!TIP]
|
||||
> 动态量化可能会显著改变模型输出的分布,因此您需要将 `residual_diff_threshold` 设置为更大的值以使其生效。
|
||||
|
||||
<hfoptions id="fp8-quantization">
|
||||
<hfoption id="FLUX-1.dev">
|
||||
|
||||
```python
|
||||
import time
|
||||
import torch
|
||||
from diffusers import FluxPipeline
|
||||
|
||||
pipe = FluxPipeline.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-dev",
|
||||
torch_dtype=torch.bfloat16,
|
||||
).to("cuda")
|
||||
|
||||
from para_attn.first_block_cache.diffusers_adapters import apply_cache_on_pipe
|
||||
|
||||
apply_cache_on_pipe(
|
||||
pipe,
|
||||
residual_diff_threshold=0.12, # 使用更大的值以使缓存生效
|
||||
)
|
||||
|
||||
from torchao.quantization import quantize_, float8_dynamic_activation_float8_weight, float8_weight_only
|
||||
|
||||
quantize_(pipe.text_encoder, float8_weight_only())
|
||||
quantize_(pipe.transformer, float8_dynamic_activation_float8_weight())
|
||||
pipe.transformer = torch.compile(
|
||||
pipe.transformer, mode="max-autotune-no-cudagraphs",
|
||||
)
|
||||
|
||||
# 启用内存节省
|
||||
# pipe.enable_model_cpu_offload()
|
||||
# pipe.enable_sequential_cpu_offload()
|
||||
|
||||
for i in range(2):
|
||||
begin = time.time()
|
||||
image = pipe(
|
||||
"A cat holding a sign that says hello world",
|
||||
num_inference_steps=28,
|
||||
).images[0]
|
||||
end = time.time()
|
||||
if i == 0:
|
||||
print(f"预热时间: {end - begin:.2f}s")
|
||||
else:
|
||||
print(f"时间: {end - begin:.2f}s")
|
||||
|
||||
print("保存图像到 flux.png")
|
||||
image.save("flux.png")
|
||||
```
|
||||
|
||||
fp8 动态量化和 torch.compile 将推理速度降低至 7.56 秒,相比基线快了 3.48 倍。
|
||||
</hfoption>
|
||||
<hfoption id="HunyuanVideo">
|
||||
|
||||
```python
|
||||
import time
|
||||
import torch
|
||||
from diffusers import HunyuanVideoPipeline, HunyuanVideoTransformer3DModel
|
||||
from diffusers.utils import export_to_video
|
||||
|
||||
model_id = "tencent/HunyuanVideo"
|
||||
transformer = HunyuanVideoTransformer3DModel.from_pretrained(
|
||||
model_id,
|
||||
subfolder="transformer",
|
||||
torch_dtype=torch.bfloat16,
|
||||
revision="refs/pr/18",
|
||||
)
|
||||
pipe = HunyuanVideoPipeline.from_pretrained(
|
||||
model_id,
|
||||
transformer=transformer,
|
||||
torch_dtype=torch.float16,
|
||||
revision="refs/pr/18",
|
||||
).to("cuda")
|
||||
|
||||
from para_attn.first_block_cache.diffusers_adapters import apply_cache_on_pipe
|
||||
|
||||
apply_cache_on_pipe(pipe)
|
||||
|
||||
from torchao.quantization import quantize_, float8_dynamic_activation_float8_weight, float8_weight_only
|
||||
|
||||
quantize_(pipe.text_encoder, float8_weight_only())
|
||||
quantize_(pipe.transformer, float8_dynamic_activation_float8_weight())
|
||||
pipe.transformer = torch.compile(
|
||||
pipe.transformer, mode="max-autotune-no-cudagraphs",
|
||||
)
|
||||
|
||||
# Enable memory savings
|
||||
pipe.vae.enable_tiling()
|
||||
# pipe.enable_model_cpu_offload()
|
||||
# pipe.enable_sequential_cpu_offload()
|
||||
|
||||
for i in range(2):
|
||||
begin = time.time()
|
||||
output = pipe(
|
||||
prompt="A cat walks on the grass, realistic",
|
||||
height=720,
|
||||
width=1280,
|
||||
num_frames=129,
|
||||
num_inference_steps=1 if i == 0 else 30,
|
||||
).frames[0]
|
||||
end = time.time()
|
||||
if i == 0:
|
||||
print(f"Warm up time: {end - begin:.2f}s")
|
||||
else:
|
||||
print(f"Time: {end - begin:.2f}s")
|
||||
|
||||
print("Saving video to hunyuan_video.mp4")
|
||||
export_to_video(output, "hunyuan_video.mp4", fps=15)
|
||||
```
|
||||
|
||||
NVIDIA L20 GPU 仅有 48GB 内存,在编译后且如果未调用 `enable_model_cpu_offload` 时,可能会遇到内存不足(OOM)错误,因为 HunyuanVideo 在高分辨率和大量帧数运行时具有非常大的激活张量。对于内存少于 80GB 的 GPU,可以尝试降低分辨率和帧数来避免 OOM 错误。
|
||||
|
||||
大型视频生成模型通常受注意力计算而非全连接层的瓶颈限制。这些模型不会从量化和 torch.compile 中显著受益。
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## 上下文并行性
|
||||
|
||||
上下文并行性并行化推理并随多个 GPU 扩展。ParaAttention 组合设计允许您将上下文并行性与第一块缓存和动态量化结合使用。
|
||||
|
||||
> [!TIP]
|
||||
> 请参考 [ParaAttention](https://github.com/chengzeyi/ParaAttention/tree/main) 仓库获取详细说明和如何使用多个 GPU 扩展推理的示例。
|
||||
|
||||
如果推理过程需要持久化和可服务,建议使用 [torch.multiprocessing](https://pytorch.org/docs/stable/multiprocessing.html) 编写您自己的推理处理器。这可以消除启动进程以及加载和重新编译模型的开销。
|
||||
|
||||
<hfoptions id="context-parallelism">
|
||||
<hfoption id="FLUX-1.dev">
|
||||
|
||||
以下代码示例结合了第一块缓存、fp8动态量化、torch.compile和上下文并行,以实现最快的推理速度。
|
||||
|
||||
```python
|
||||
import time
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from diffusers import FluxPipeline
|
||||
|
||||
dist.init_process_group()
|
||||
|
||||
torch.cuda.set_device(dist.get_rank())
|
||||
|
||||
pipe = FluxPipeline.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-dev",
|
||||
torch_dtype=torch.bfloat16,
|
||||
).to("cuda")
|
||||
|
||||
from para_attn.context_parallel import init_context_parallel_mesh
|
||||
from para_attn.context_parallel.diffusers_adapters import parallelize_pipe
|
||||
from para_attn.parallel_vae.diffusers_adapters import parallelize_vae
|
||||
|
||||
mesh = init_context_parallel_mesh(
|
||||
pipe.device.type,
|
||||
max_ring_dim_size=2,
|
||||
)
|
||||
parallelize_pipe(
|
||||
pipe,
|
||||
mesh=mesh,
|
||||
)
|
||||
parallelize_vae(pipe.vae, mesh=mesh._flatten())
|
||||
|
||||
from para_attn.first_block_cache.diffusers_adapters import apply_cache_on_pipe
|
||||
|
||||
apply_cache_on_pipe(
|
||||
pipe,
|
||||
residual_diff_threshold=0.12, # 使用较大的值以使缓存生效
|
||||
)
|
||||
|
||||
from torchao.quantization import quantize_, float8_dynamic_activation_float8_weight, float8_weight_only
|
||||
|
||||
quantize_(pipe.text_encoder, float8_weight_only())
|
||||
quantize_(pipe.transformer, float8_dynamic_activation_float8_weight())
|
||||
torch._inductor.config.reorder_for_compute_comm_overlap = True
|
||||
pipe.transformer = torch.compile(
|
||||
pipe.transformer, mode="max-autotune-no-cudagraphs",
|
||||
)
|
||||
|
||||
# 启用内存节省
|
||||
# pipe.enable_model_cpu_offload(gpu_id=dist.get_rank())
|
||||
# pipe.enable_sequential_cpu_offload(gpu_id=dist.get_rank())
|
||||
|
||||
for i in range(2):
|
||||
begin = time.time()
|
||||
image = pipe(
|
||||
"A cat holding a sign that says hello world",
|
||||
num_inference_steps=28,
|
||||
output_type="pil" if dist.get_rank() == 0 else "pt",
|
||||
).images[0]
|
||||
end = time.time()
|
||||
if dist.get_rank() == 0:
|
||||
if i == 0:
|
||||
print(f"预热时间: {end - begin:.2f}s")
|
||||
else:
|
||||
print(f"时间: {end - begin:.2f}s")
|
||||
|
||||
if dist.get_rank() == 0:
|
||||
print("将图像保存到flux.png")
|
||||
image.save("flux.png")
|
||||
|
||||
dist.destroy_process_group()
|
||||
```
|
||||
|
||||
保存到`run_flux.py`并使用[torchrun](https://pytorch.org/docs/stable/elastic/run.html)启动。
|
||||
|
||||
```bash
|
||||
# 使用--nproc_per_node指定GPU数量
|
||||
torchrun --nproc_per_node=2 run_flux.py
|
||||
```
|
||||
|
||||
推理速度降至8.20秒,相比基线快了3.21倍,使用2个NVIDIA L20 GPU。在4个L20上,推理速度为3.90秒,快了6.75倍。
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="HunyuanVideo">
|
||||
|
||||
以下代码示例结合了第一块缓存和上下文并行,以实现最快的推理速度。
|
||||
|
||||
```python
|
||||
import time
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from diffusers import HunyuanVideoPipeline, HunyuanVideoTransformer3DModel
|
||||
from diffusers.utils import export_to_video
|
||||
|
||||
dist.init_process_group()
|
||||
|
||||
torch.cuda.set_device(dist.get_rank())
|
||||
|
||||
model_id = "tencent/HunyuanVideo"
|
||||
transformer = HunyuanVideoTransformer3DModel.from_pretrained(
|
||||
model_id,
|
||||
subfolder="transformer",
|
||||
torch_dtype=torch.bfloat16,
|
||||
revision="refs/pr/18",
|
||||
)
|
||||
pipe = HunyuanVideoPipeline.from_pretrained(
|
||||
model_id,
|
||||
transformer=transformer,
|
||||
torch_dtype=torch.float16,
|
||||
revision="refs/pr/18",
|
||||
).to("cuda")
|
||||
|
||||
from para_attn.context_parallel import init_context_parallel_mesh
|
||||
from para_attn.context_parallel.diffusers_adapters import parallelize_pipe
|
||||
from para_attn.parallel_vae.diffusers_adapters import parallelize_vae
|
||||
|
||||
mesh = init_context_parallel_mesh(
|
||||
pipe.device.type,
|
||||
)
|
||||
parallelize_pipe(
|
||||
pipe,
|
||||
mesh=mesh,
|
||||
)
|
||||
parallelize_vae(pipe.vae, mesh=mesh._flatten())
|
||||
|
||||
from para_attn.first_block_cache.diffusers_adapters import apply_cache_on_pipe
|
||||
|
||||
apply_cache_on_pipe(pipe)
|
||||
|
||||
# from torchao.quantization import quantize_, float8_dynamic_activation_float8_weight, float8_weight_only
|
||||
#
|
||||
# torch._inductor.config.reorder_for_compute_comm_overlap = True
|
||||
#
|
||||
# quantize_(pipe.text_encoder, float8_weight_only())
|
||||
# quantize_(pipe.transformer, float8_dynamic_activation_float8_weight())
|
||||
# pipe.transformer = torch.compile(
|
||||
# pipe.transformer, mode="max-autotune-no-cudagraphs",
|
||||
# )
|
||||
|
||||
# 启用内存节省
|
||||
pipe.vae.enable_tiling()
|
||||
# pipe.enable_model_cpu_offload(gpu_id=dist.get_rank())
|
||||
# pipe.enable_sequential_cpu_offload(gpu_id=dist.get_rank())
|
||||
|
||||
for i in range(2):
|
||||
begin = time.time()
|
||||
output = pipe(
|
||||
prompt="A cat walks on the grass, realistic",
|
||||
height=720,
|
||||
width=1280,
|
||||
num_frames=129,
|
||||
num_inference_steps=1 if i == 0 else 30,
|
||||
output_type="pil" if dist.get_rank() == 0 else "pt",
|
||||
).frames[0]
|
||||
end = time.time()
|
||||
if dist.get_rank() == 0:
|
||||
if i == 0:
|
||||
print(f"预热时间: {end - begin:.2f}s")
|
||||
else:
|
||||
print(f"时间: {end - begin:.2f}s")
|
||||
|
||||
if dist.get_rank() == 0:
|
||||
print("保存视频到 hunyuan_video.mp4")
|
||||
export_to_video(output, "hunyuan_video.mp4", fps=15)
|
||||
|
||||
dist.destroy_process_group()
|
||||
```
|
||||
|
||||
保存到 `run_hunyuan_video.py` 并使用 [torchrun](https://pytorch.org/docs/stable/elastic/run.html) 启动。
|
||||
|
||||
```bash
|
||||
# 使用 --nproc_per_node 指定 GPU 数量
|
||||
torchrun --nproc_per_node=8 run_hunyuan_video.py
|
||||
```
|
||||
|
||||
推理速度降低到 649.23 秒,相比基线快 5.66 倍,使用 8 个 NVIDIA L20 GPU。
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## 基准测试
|
||||
|
||||
<hfoptions id="conclusion">
|
||||
<hfoption id="FLUX-1.dev">
|
||||
|
||||
| GPU 类型 | GPU 数量 | 优化 | 墙钟时间 (s) | 加速比 |
|
||||
| - | - | - | - | - |
|
||||
| NVIDIA L20 | 1 | 基线 | 26.36 | 1.00x |
|
||||
| NVIDIA L20 | 1 | FBCache (rdt=0.08) | 17.01 | 1.55x |
|
||||
| NVIDIA L20 | 1 | FP8 DQ | 13.40 | 1.96x |
|
||||
| NVIDIA L20 | 1 | FBCache (rdt=0.12) + FP8 DQ | 7.56 | 3.48x |
|
||||
| NVIDIA L20 | 2 | FBCache (rdt=0.12) + FP8 DQ + CP | 4.92 | 5.35x |
|
||||
| NVIDIA L20 | 4 | FBCache (rdt=0.12) + FP8 DQ + CP | 3.90 | 6.75x |
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="HunyuanVideo">
|
||||
|
||||
| GPU 类型 | GPU 数量 | 优化 | 墙钟时间 (s) | 加速比 |
|
||||
| - | - | - | - | - |
|
||||
| NVIDIA L20 | 1 | 基线 | 3675.71 | 1.00x |
|
||||
| NVIDIA
|
||||
L20 | 1 | FBCache | 2271.06 | 1.62x |
|
||||
| NVIDIA L20 | 2 | FBCache + CP | 1132.90 | 3.24x |
|
||||
| NVIDIA L20 | 4 | FBCache + CP | 718.15 | 5.12x |
|
||||
| NVIDIA L20 | 8 | FBCache + CP | 649.23 | 5.66x |
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
184
docs/source/zh/optimization/pruna.md
Normal file
184
docs/source/zh/optimization/pruna.md
Normal file
@@ -0,0 +1,184 @@
|
||||
# Pruna
|
||||
|
||||
[Pruna](https://github.com/PrunaAI/pruna) 是一个模型优化框架,提供多种优化方法——量化、剪枝、缓存、编译——以加速推理并减少内存使用。以下是优化方法的概览。
|
||||
|
||||
| 技术 | 描述 | 速度 | 内存 | 质量 |
|
||||
|------------|---------------------------------------------------------------------------------------|:----:|:----:|:----:|
|
||||
| `batcher` | 将多个输入分组在一起同时处理,提高计算效率并减少处理时间。 | ✅ | ❌ | ➖ |
|
||||
| `cacher` | 存储计算的中间结果以加速后续操作。 | ✅ | ➖ | ➖ |
|
||||
| `compiler` | 为特定硬件优化模型指令。 | ✅ | ➖ | ➖ |
|
||||
| `distiller`| 训练一个更小、更简单的模型来模仿一个更大、更复杂的模型。 | ✅ | ✅ | ❌ |
|
||||
| `quantizer`| 降低权重和激活的精度,减少内存需求。 | ✅ | ✅ | ❌ |
|
||||
| `pruner` | 移除不重要或冗余的连接和神经元,产生一个更稀疏、更高效的网络。 | ✅ | ✅ | ❌ |
|
||||
| `recoverer`| 在压缩后恢复模型的性能。 | ➖ | ➖ | ✅ |
|
||||
| `factorizer`| 将多个小矩阵乘法批处理为一个大型融合操作。 | ✅ | ➖ | ➖ |
|
||||
| `enhancer` | 通过应用后处理算法(如去噪或上采样)来增强模型输出。 | ❌ | - | ✅ |
|
||||
|
||||
✅ (改进), ➖ (大致相同), ❌ (恶化)
|
||||
|
||||
在 [Pruna 文档](https://docs.pruna.ai/en/stable/docs_pruna/user_manual/configure.html#configure-algorithms) 中探索所有优化方法。
|
||||
|
||||
## 安装
|
||||
|
||||
使用以下命令安装 Pruna。
|
||||
|
||||
```bash
|
||||
pip install pruna
|
||||
```
|
||||
|
||||
## 优化 Diffusers 模型
|
||||
|
||||
Diffusers 模型支持广泛的优化算法,如下所示。
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/PrunaAI/documentation-images/resolve/main/diffusers/diffusers_combinations.png" alt="Diffusers 模型支持的优化算法概览">
|
||||
</div>
|
||||
|
||||
下面的示例使用 factorizer、compiler 和 cacher 算法的组合优化 [black-forest-labs/FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev)。这种组合将推理速度加速高达 4.2 倍,并将峰值 GPU 内存使用从 34.7GB 减少到 28.0GB,同时几乎保持相同的输出质量。
|
||||
|
||||
> [!TIP]
|
||||
> 参考 [Pruna 优化](https://docs.pruna.ai/en/stable/docs_pruna/user_manual/configure.html) 文档以了解更多关于该操作的信息。
|
||||
本示例中使用的优化技术。
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/PrunaAI/documentation-images/resolve/main/diffusers/flux_combination.png" alt="用于FLUX.1-dev的优化技术展示,结合了因子分解器、编译器和缓存器算法">
|
||||
</div>
|
||||
|
||||
首先定义一个包含要使用的优化算法的`SmashConfig`。要优化模型,将管道和`SmashConfig`用`smash`包装,然后像往常一样使用管道进行推理。
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import FluxPipeline
|
||||
|
||||
from pruna import PrunaModel, SmashConfig, smash
|
||||
|
||||
# 加载模型
|
||||
# 使用小GPU内存尝试segmind/Segmind-Vega或black-forest-labs/FLUX.1-schnell
|
||||
pipe = FluxPipeline.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-dev",
|
||||
torch_dtype=torch.bfloat16
|
||||
).to("cuda")
|
||||
|
||||
# 定义配置
|
||||
smash_config = SmashConfig()
|
||||
smash_config["factorizer"] = "qkv_diffusers"
|
||||
smash_config["compiler"] = "torch_compile"
|
||||
smash_config["torch_compile_target"] = "module_list"
|
||||
smash_config["cacher"] = "fora"
|
||||
smash_config["fora_interval"] = 2
|
||||
|
||||
# 为了获得最佳速度结果,可以添加这些配置
|
||||
# 但它们会将预热时间从1.5分钟增加到10分钟
|
||||
# smash_config["torch_compile_mode"] = "max-autotune-no-cudagraphs"
|
||||
# smash_config["quantizer"] = "torchao"
|
||||
# smash_config["torchao_quant_type"] = "fp8dq"
|
||||
# smash_config["torchao_excluded_modules"] = "norm+embedding"
|
||||
|
||||
# 优化模型
|
||||
smashed_pipe = smash(pipe, smash_config)
|
||||
|
||||
# 运行模型
|
||||
smashed_pipe("a knitted purple prune").images[0]
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/PrunaAI/documentation-images/resolve/main/diffusers/flux_smashed_comparison.png">
|
||||
</div>
|
||||
|
||||
优化后,我们可以使用Hugging Face Hub共享和加载优化后的模型。
|
||||
|
||||
```python
|
||||
# 保存模型
|
||||
smashed_pipe.save_to_hub("<username>/FLUX.1-dev-smashed")
|
||||
|
||||
# 加载模型
|
||||
smashed_pipe = PrunaModel.from_hub("<username>/FLUX.1-dev-smashed")
|
||||
```
|
||||
|
||||
## 评估和基准测试Diffusers模型
|
||||
|
||||
Pruna提供了[EvaluationAgent](https://docs.pruna.ai/en/stable/docs_pruna/user_manual/evaluate.html)来评估优化后模型的质量。
|
||||
|
||||
我们可以定义我们关心的指标,如总时间和吞吐量,以及要评估的数据集。我们可以定义一个模型并将其传递给`EvaluationAgent`。
|
||||
|
||||
<hfoptions id="eval">
|
||||
<hfoption id="optimized model">
|
||||
|
||||
我们可以通过使用`EvaluationAgent`加载和评估优化后的模型,并将其传递给`Task`。
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import FluxPipeline
|
||||
|
||||
from pruna import PrunaModel
|
||||
from pruna.data.pruna_datamodule import PrunaDataModule
|
||||
from pruna.evaluation.evaluation_agent import EvaluationAgent
|
||||
from pruna.evaluation.metrics import (
|
||||
ThroughputMetric,
|
||||
TorchMetricWrapper,
|
||||
TotalTimeMetric,
|
||||
)
|
||||
from pruna.evaluation.task import Task
|
||||
|
||||
# define the device
|
||||
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
|
||||
|
||||
# 加载模型
|
||||
# 使用小GPU内存尝试 PrunaAI/Segmind-Vega-smashed 或 PrunaAI/FLUX.1-dev-smashed
|
||||
smashed_pipe = PrunaModel.from_hub("PrunaAI/FLUX.1-dev-smashed")
|
||||
|
||||
# 定义指标
|
||||
metrics = [
|
||||
TotalTimeMetric(n_iterations=20, n_warmup_iterations=5),
|
||||
ThroughputMetric(n_iterations=20, n_warmup_iterations=5),
|
||||
TorchMetricWrapper("clip"),
|
||||
]
|
||||
|
||||
# 定义数据模块
|
||||
datamodule = PrunaDataModule.from_string("LAION256")
|
||||
datamodule.limit_datasets(10)
|
||||
|
||||
# 定义任务和评估代理
|
||||
task = Task(metrics, datamodule=datamodule, device=device)
|
||||
eval_agent = EvaluationAgent(task)
|
||||
|
||||
# 评估优化模型并卸载到CPU
|
||||
smashed_pipe.move_to_device(device)
|
||||
smashed_pipe_results = eval_agent.evaluate(smashed_pipe)
|
||||
smashed_pipe.move_to_device("cpu")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="standalone model">
|
||||
|
||||
除了比较优化模型与基础模型,您还可以评估独立的 `diffusers` 模型。这在您想评估模型性能而不考虑优化时非常有用。我们可以通过使用 `PrunaModel` 包装器并运行 `EvaluationAgent` 来实现。
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import FluxPipeline
|
||||
|
||||
from pruna import PrunaModel
|
||||
|
||||
# 加载模型
|
||||
# 使用小GPU内存尝试 PrunaAI/Segmind-Vega-smashed 或 PrunaAI/FLUX.1-dev-smashed
|
||||
pipe = FluxPipeline.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-dev",
|
||||
torch_dtype=torch.bfloat16
|
||||
).to("cpu")
|
||||
wrapped_pipe = PrunaModel(model=pipe)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
现在您已经了解了如何优化和评估您的模型,可以开始使用 Pruna 来优化您自己的模型了。幸运的是,我们有许多示例来帮助您入门。
|
||||
|
||||
> [!TIP]
|
||||
> 有关基准测试 Flux 的更多详细信息,请查看 [宣布 FLUX-Juiced:最快的图像生成端点(快 2.6 倍)!](https://huggingface.co/blog/PrunaAI/flux-fastest-image-generation-endpoint) 博客文章和 [InferBench](https://huggingface.co/spaces/PrunaAI/InferBench) 空间。
|
||||
|
||||
## 参考
|
||||
|
||||
- [Pruna](https://github.com/pruna-ai/pruna)
|
||||
- [Pruna 优化](https://docs.pruna.ai/en/stable/docs_pruna/user_manual/configure.html#configure-algorithms)
|
||||
- [Pruna 评估](https://docs.pruna.ai/en/stable/docs_pruna/user_manual/evaluate.html)
|
||||
- [Pruna 教程](https://docs.pruna.ai/en/stable/docs_pruna/tutorials/index.html)
|
||||
200
docs/source/zh/optimization/speed-memory-optims.md
Normal file
200
docs/source/zh/optimization/speed-memory-optims.md
Normal file
@@ -0,0 +1,200 @@
|
||||
<!--版权所有 2024 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版(“许可证”)授权;除非符合许可证,否则不得使用此文件。
|
||||
您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件按“原样”分发,不附带任何明示或暗示的担保或条件。有关许可证的特定语言,请参阅许可证。
|
||||
-->
|
||||
|
||||
# 编译和卸载量化模型
|
||||
|
||||
优化模型通常涉及[推理速度](./fp16)和[内存使用](./memory)之间的权衡。例如,虽然[缓存](./cache)可以提高推理速度,但它也会增加内存消耗,因为它需要存储中间注意力层的输出。一种更平衡的优化策略结合了量化模型、[torch.compile](./fp16#torchcompile) 和各种[卸载方法](./memory#offloading)。
|
||||
|
||||
> [!TIP]
|
||||
> 查看 [torch.compile](./fp16#torchcompile) 指南以了解更多关于编译以及如何在此处应用的信息。例如,区域编译可以显著减少编译时间,而不会放弃任何加速。
|
||||
|
||||
对于图像生成,结合量化和[模型卸载](./memory#model-offloading)通常可以在质量、速度和内存之间提供最佳权衡。组卸载对于图像生成效果不佳,因为如果计算内核更快完成,通常不可能*完全*重叠数据传输。这会导致 CPU 和 GPU 之间的一些通信开销。
|
||||
|
||||
对于视频生成,结合量化和[组卸载](./memory#group-offloading)往往更好,因为视频模型更受计算限制。
|
||||
|
||||
下表提供了优化策略组合及其对 Flux 延迟和内存使用的影响的比较。
|
||||
|
||||
| 组合 | 延迟 (s) | 内存使用 (GB) |
|
||||
|---|---|---|
|
||||
| 量化 | 32.602 | 14.9453 |
|
||||
| 量化, torch.compile | 25.847 | 14.9448 |
|
||||
| 量化, torch.compile, 模型 CPU 卸载 | 32.312 | 12.2369 |
|
||||
<small>这些结果是在 Flux 上使用 RTX 4090 进行基准测试的。transformer 和 text_encoder 组件已量化。如果您有兴趣评估自己的模型,请参考[基准测试脚本](https://gist.github.com/sayakpaul/0db9d8eeeb3d2a0e5ed7cf0d9ca19b7d)。</small>
|
||||
|
||||
本指南将向您展示如何使用 [bitsandbytes](../quantization/bitsandbytes#torchcompile) 编译和卸载量化模型。确保您正在使用 [PyTorch nightly](https://pytorch.org/get-started/locally/) 和最新版本的 bitsandbytes。
|
||||
|
||||
```bash
|
||||
pip install -U bitsandbytes
|
||||
```
|
||||
|
||||
## 量化和 torch.compile
|
||||
|
||||
首先通过[量化](../quantization/overview)模型来减少存储所需的内存,并[编译](./fp16#torchcompile)它以加速推理。
|
||||
|
||||
配置 [Dynamo](https://docs.pytorch.org/docs/stable/torch.compiler_dynamo_overview.html) `capture_dynamic_output_shape_ops = True` 以在编译 bitsandbytes 模型时处理动态输出。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
from diffusers.quantizers import PipelineQuantizationConfig
|
||||
|
||||
torch._dynamo.config.capture_dynamic_output_shape_ops = True
|
||||
|
||||
# 量化
|
||||
pipeline_quant_config = PipelineQuantizationConfig(
|
||||
quant_backend="bitsandbytes_4bit",
|
||||
quant_kwargs={"load_in_4bit": True, "bnb_4bit_quant_type": "nf4", "bnb_4bit_compute_dtype": torch.bfloat16},
|
||||
components_to_quantize=["transformer", "text_encoder_2"],
|
||||
)
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-dev",
|
||||
quantization_config=pipeline_quant_config,
|
||||
torch_dtype=torch.bfloat16,
|
||||
).to("cuda")
|
||||
|
||||
# 编译
|
||||
pipeline.transformer.to(memory_format=torch.channels_last)
|
||||
pipeline.transformer.compile(mode="max-autotune", fullgraph=True)
|
||||
pipeline("""
|
||||
cinematic film still of a cat sipping a margarita in a pool in Palm Springs, California
|
||||
highly detailed, high budget hollywood movie, cinemascope, moody, epic, gorgeous, film grain
|
||||
"""
|
||||
).images[0]
|
||||
```
|
||||
|
||||
## 量化、torch.compile 和卸载
|
||||
|
||||
除了量化和 torch.compile,如果您需要进一步减少内存使用,可以尝试卸载。卸载根据需要将各种层或模型组件从 CPU 移动到 GPU 进行计算。
|
||||
|
||||
在卸载期间配置 [Dynamo](https://docs.pytorch.org/docs/stable/torch.compiler_dynamo_overview.html) `cache_size_limit` 以避免过多的重新编译,并设置 `capture_dynamic_output_shape_ops = True` 以在编译 bitsandbytes 模型时处理动态输出。
|
||||
|
||||
<hfoptions id="offloading">
|
||||
<hfoption id="model CPU offloading">
|
||||
|
||||
[模型 CPU 卸载](./memory#model-offloading) 将单个管道组件(如 transformer 模型)在需要计算时移动到 GPU。否则,它会被卸载到 CPU。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
from diffusers.quantizers import PipelineQuantizationConfig
|
||||
|
||||
torch._dynamo.config.cache_size_limit = 1000
|
||||
torch._dynamo.config.capture_dynamic_output_shape_ops = True
|
||||
|
||||
# 量化
|
||||
pipeline_quant_config = PipelineQuantizationConfig(
|
||||
quant_backend="bitsandbytes_4bit",
|
||||
quant_kwargs={"load_in_4bit": True, "bnb_4bit_quant_type": "nf4", "bnb_4bit_compute_dtype": torch.bfloat16},
|
||||
components_to_quantize=["transformer", "text_encoder_2"],
|
||||
)
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-dev",
|
||||
quantization_config=pipeline_quant_config,
|
||||
torch_dtype=torch.bfloat16,
|
||||
).to("cuda")
|
||||
|
||||
# 模型 CPU 卸载
|
||||
pipeline.enable_model_cpu_offload()
|
||||
|
||||
# 编译
|
||||
pipeline.transformer.compile()
|
||||
pipeline(
|
||||
"cinematic film still of a cat sipping a margarita in a pool in Palm Springs, California, highly detailed, high budget hollywood movie, cinemascope, moody, epic, gorgeous, film grain"
|
||||
).images[0]
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="group offloading">
|
||||
|
||||
[组卸载](./memory#group-offloading) 将单个管道组件(如变换器模型)的内部层移动到 GPU 进行计算,并在不需要时将其卸载。同时,它使用 [CUDA 流](./memory#cuda-stream) 功能来预取下一层以执行。
|
||||
|
||||
通过重叠计算和数据传输,它比模型 CPU 卸载更快,同时还能节省内存。
|
||||
|
||||
```py
|
||||
# pip install ftfy
|
||||
import torch
|
||||
from diffusers import AutoModel, DiffusionPipeline
|
||||
from diffusers.hooks import apply_group_offloading
|
||||
from diffusers.utils import export_to_video
|
||||
from diffusers.quantizers import PipelineQuantizationConfig
|
||||
from transformers import UMT5EncoderModel
|
||||
|
||||
torch._dynamo.config.cache_size_limit = 1000
|
||||
torch._dynamo.config.capture_dynamic_output_shape_ops = True
|
||||
|
||||
# 量化
|
||||
pipeline_quant_config = PipelineQuantizationConfig(
|
||||
quant_backend="bitsandbytes_4bit",
|
||||
quant_kwargs={"load_in_4bit": True, "bnb_4bit_quant_type": "nf4", "bnb_4bit_compute_dtype": torch.bfloat16},
|
||||
components_to_quantize=["transformer", "text_encoder"],
|
||||
)
|
||||
|
||||
text_encoder = UMT5EncoderModel.from_pretrained(
|
||||
"Wan-AI/Wan2.1-T2V-14B-Diffusers", subfolder="text_encoder", torch_dtype=torch.bfloat16
|
||||
)
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"Wan-AI/Wan2.1-T2V-14B-Diffusers",
|
||||
quantization_config=pipeline_quant_config,
|
||||
torch_dtype=torch.bfloat16,
|
||||
).to("cuda")
|
||||
|
||||
# 组卸载
|
||||
onload_device = torch.device("cuda")
|
||||
offload_device = torch.device("cpu")
|
||||
|
||||
pipeline.transformer.enable_group_offload(
|
||||
onload_device=onload_device,
|
||||
offload_device=offload_device,
|
||||
offload_type="leaf_level",
|
||||
use_stream=True,
|
||||
non_blocking=True
|
||||
)
|
||||
pipeline.vae.enable_group_offload(
|
||||
onload_device=onload_device,
|
||||
offload_device=offload_device,
|
||||
offload_type="leaf_level",
|
||||
use_stream=True,
|
||||
non_blocking=True
|
||||
)
|
||||
apply_group_offloading(
|
||||
pipeline.text_encoder,
|
||||
onload_device=onload_device,
|
||||
offload_type="leaf_level",
|
||||
use_stream=True,
|
||||
non_blocking=True
|
||||
)
|
||||
|
||||
# 编译
|
||||
pipeline.transformer.compile()
|
||||
|
||||
prompt = """
|
||||
The camera rushes from far to near in a low-angle shot,
|
||||
revealing a white ferret on a log. It plays, leaps into the water, and emerges, as the camera zooms in
|
||||
for a close-up. Water splashes berry bushes nearby, while moss, snow, and leaves blanket the ground.
|
||||
Birch trees and a light blue sky frame the scene, with ferns in the foreground. Side lighting casts dynamic
|
||||
shadows and warm highlights. Medium composition, front view, low angle, with depth of field.
|
||||
"""
|
||||
negative_prompt = """
|
||||
Bright tones, overexposed, static, blurred details, subtitles, style, works, paintings, images, static, overall gray, worst quality,
|
||||
low quality, JPEG compression residue, ugly, incomplete, extra fingers, poorly drawn hands, poorly drawn faces, deformed, disfigured,
|
||||
misshapen limbs, fused fingers, still picture, messy background, three legs, many people in the background, walking backwards
|
||||
"""
|
||||
|
||||
output = pipeline(
|
||||
prompt=prompt,
|
||||
negative_prompt=negative_prompt,
|
||||
num_frames=81,
|
||||
guidance_scale=5.0,
|
||||
).frames[0]
|
||||
export_to_video(output, "output.mp4", fps=16)
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
182
docs/source/zh/optimization/tgate.md
Normal file
182
docs/source/zh/optimization/tgate.md
Normal file
@@ -0,0 +1,182 @@
|
||||
# T-GATE
|
||||
|
||||
[T-GATE](https://github.com/HaozheLiu-ST/T-GATE/tree/main) 通过跳过交叉注意力计算一旦收敛,加速了 [Stable Diffusion](../api/pipelines/stable_diffusion/overview)、[PixArt](../api/pipelines/pixart) 和 [Latency Consistency Model](../api/pipelines/latent_consistency_models.md) 管道的推理。此方法不需要任何额外训练,可以将推理速度提高 10-50%。T-GATE 还与 [DeepCache](./deepcache) 等其他优化方法兼容。
|
||||
|
||||
开始之前,请确保安装 T-GATE。
|
||||
|
||||
```bash
|
||||
pip install tgate
|
||||
pip install -U torch diffusers transformers accelerate DeepCache
|
||||
```
|
||||
|
||||
要使用 T-GATE 与管道,您需要使用其对应的加载器。
|
||||
|
||||
| 管道 | T-GATE 加载器 |
|
||||
|---|---|
|
||||
| PixArt | TgatePixArtLoader |
|
||||
| Stable Diffusion XL | TgateSDXLLoader |
|
||||
| Stable Diffusion XL + DeepCache | TgateSDXLDeepCacheLoader |
|
||||
| Stable Diffusion | TgateSDLoader |
|
||||
| Stable Diffusion + DeepCache | TgateSDDeepCacheLoader |
|
||||
|
||||
接下来,创建一个 `TgateLoader`,包含管道、门限步骤(停止计算交叉注意力的时间步)和推理步骤数。然后在管道上调用 `tgate` 方法,提供提示、门限步骤和推理步骤数。
|
||||
|
||||
让我们看看如何为几个不同的管道启用此功能。
|
||||
|
||||
<hfoptions id="pipelines">
|
||||
<hfoption id="PixArt">
|
||||
|
||||
使用 T-GATE 加速 `PixArtAlphaPipeline`:
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import PixArtAlphaPipeline
|
||||
from tgate import TgatePixArtLoader
|
||||
|
||||
pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-XL-2-1024-MS", torch_dtype=torch.float16)
|
||||
|
||||
gate_step = 8
|
||||
inference_step = 25
|
||||
pipe = TgatePixArtLoader(
|
||||
pipe,
|
||||
gate_step=gate_step,
|
||||
num_inference_steps=inference_step,
|
||||
).to("cuda")
|
||||
|
||||
image = pipe.tgate(
|
||||
"An alpaca made of colorful building blocks, cyberpunk.",
|
||||
gate_step=gate_step,
|
||||
num_inference_steps=inference_step,
|
||||
).images[0]
|
||||
```
|
||||
</hfoption>
|
||||
<hfoption id="Stable Diffusion XL">
|
||||
|
||||
使用 T-GATE 加速 `StableDiffusionXLPipeline`:
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
from diffusers import DPMSolverMultistepScheduler
|
||||
from tgate import TgateSDXLLoader
|
||||
|
||||
pipe = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.float16,
|
||||
variant="fp16",
|
||||
use_safetensors=True,
|
||||
)
|
||||
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
|
||||
|
||||
gate_step = 10
|
||||
inference_step = 25
|
||||
pipe = TgateSDXLLoader(
|
||||
pipe,
|
||||
gate_step=gate_step,
|
||||
num_inference_steps=inference_step,
|
||||
).to("cuda")
|
||||
|
||||
image = pipe.tgate(
|
||||
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k.",
|
||||
gate_step=gate_step,
|
||||
num_inference_steps=inference_step
|
||||
).images[0]
|
||||
```
|
||||
</hfoption>
|
||||
<hfoption id="StableDiffusionXL with DeepCache">
|
||||
|
||||
使用 [DeepCache](https://github.co 加速 `StableDiffusionXLPipeline`
|
||||
m/horseee/DeepCache) 和 T-GATE:
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
from diffusers import DPMSolverMultistepScheduler
|
||||
from tgate import TgateSDXLDeepCacheLoader
|
||||
|
||||
pipe = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
torch_dtype=torch.float16,
|
||||
variant="fp16",
|
||||
use_safetensors=True,
|
||||
)
|
||||
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
|
||||
|
||||
gate_step = 10
|
||||
inference_step = 25
|
||||
pipe = TgateSDXLDeepCacheLoader(
|
||||
pipe,
|
||||
cache_interval=3,
|
||||
cache_branch_id=0,
|
||||
).to("cuda")
|
||||
|
||||
image = pipe.tgate(
|
||||
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k.",
|
||||
gate_step=gate_step,
|
||||
num_inference_steps=inference_step
|
||||
).images[0]
|
||||
```
|
||||
</hfoption>
|
||||
<hfoption id="Latent Consistency Model">
|
||||
|
||||
使用 T-GATE 加速 `latent-consistency/lcm-sdxl`:
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
from diffusers import UNet2DConditionModel, LCMScheduler
|
||||
from diffusers import DPMSolverMultistepScheduler
|
||||
from tgate import TgateSDXLLoader
|
||||
|
||||
unet = UNet2DConditionModel.from_pretrained(
|
||||
"latent-consistency/lcm-sdxl",
|
||||
torch_dtype=torch.float16,
|
||||
variant="fp16",
|
||||
)
|
||||
pipe = StableDiffusionXLPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0",
|
||||
unet=unet,
|
||||
torch_dtype=torch.float16,
|
||||
variant="fp16",
|
||||
)
|
||||
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
|
||||
|
||||
gate_step = 1
|
||||
inference_step = 4
|
||||
pipe = TgateSDXLLoader(
|
||||
pipe,
|
||||
gate_step=gate_step,
|
||||
num_inference_steps=inference_step,
|
||||
lcm=True
|
||||
).to("cuda")
|
||||
|
||||
image = pipe.tgate(
|
||||
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k.",
|
||||
gate_step=gate_step,
|
||||
num_inference_steps=inference_step
|
||||
).images[0]
|
||||
```
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
T-GATE 还支持 [`StableDiffusionPipeline`] 和 [PixArt-alpha/PixArt-LCM-XL-2-1024-MS](https://hf.co/PixArt-alpha/PixArt-LCM-XL-2-1024-MS)。
|
||||
|
||||
## 基准测试
|
||||
| 模型 | MACs | 参数 | 延迟 | 零样本 10K-FID on MS-COCO |
|
||||
|-----------------------|----------|-----------|---------|---------------------------|
|
||||
| SD-1.5 | 16.938T | 859.520M | 7.032s | 23.927 |
|
||||
| SD-1.5 w/ T-GATE | 9.875T | 815.557M | 4.313s | 20.789 |
|
||||
| SD-2.1 | 38.041T | 865.785M | 16.121s | 22.609 |
|
||||
| SD-2.1 w/ T-GATE | 22.208T | 815.433 M | 9.878s | 19.940 |
|
||||
| SD-XL | 149.438T | 2.570B | 53.187s | 24.628 |
|
||||
| SD-XL w/ T-GATE | 84.438T | 2.024B | 27.932s | 22.738 |
|
||||
| Pixart-Alpha | 107.031T | 611.350M | 61.502s | 38.669 |
|
||||
| Pixart-Alpha w/ T-GATE | 65.318T | 462.585M | 37.867s | 35.825 |
|
||||
| DeepCache (SD-XL) | 57.888T | - | 19.931s | 23.755 |
|
||||
| DeepCache 配合 T-GATE | 43.868T | - | 14.666秒 | 23.999 |
|
||||
| LCM (SD-XL) | 11.955T | 2.570B | 3.805秒 | 25.044 |
|
||||
| LCM 配合 T-GATE | 11.171T | 2.024B | 3.533秒 | 25.028 |
|
||||
| LCM (Pixart-Alpha) | 8.563T | 611.350M | 4.733秒 | 36.086 |
|
||||
| LCM 配合 T-GATE | 7.623T | 462.585M | 4.543秒 | 37.048 |
|
||||
|
||||
延迟测试基于 NVIDIA 1080TI,MACs 和 Params 使用 [calflops](https://github.com/MrYxJ/calculate-flops.pytorch) 计算,FID 使用 [PytorchFID](https://github.com/mseitzer/pytorch-fid) 计算。
|
||||
90
docs/source/zh/optimization/tome.md
Normal file
90
docs/source/zh/optimization/tome.md
Normal file
@@ -0,0 +1,90 @@
|
||||
<!--版权所有 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版(“许可证”)授权;除非遵守许可证,否则不得使用此文件。
|
||||
您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件按“原样”分发,不附带任何明示或暗示的担保或条件。请参阅许可证以了解具体的语言管理权限和限制。
|
||||
-->
|
||||
|
||||
# 令牌合并
|
||||
|
||||
[令牌合并](https://huggingface.co/papers/2303.17604)(ToMe)在基于 Transformer 的网络的前向传递中逐步合并冗余令牌/补丁,这可以加速 [`StableDiffusionPipeline`] 的推理延迟。
|
||||
|
||||
从 `pip` 安装 ToMe:
|
||||
|
||||
```bash
|
||||
pip install tomesd
|
||||
```
|
||||
|
||||
您可以使用 [`tomesd`](https://github.com/dbolya/tomesd) 库中的 [`apply_patch`](https://github.com/dbolya/tomesd?tab=readme-ov-file#usage) 函数:
|
||||
|
||||
```diff
|
||||
from diffusers import StableDiffusionPipeline
|
||||
import torch
|
||||
import tomesd
|
||||
|
||||
pipeline = StableDiffusionPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True,
|
||||
).to("cuda")
|
||||
+ tomesd.apply_patch(pipeline, ratio=0.5)
|
||||
|
||||
image = pipeline("a photo of an astronaut riding a horse on mars").images[0]
|
||||
```
|
||||
|
||||
`apply_patch` 函数公开了多个[参数](https://github.com/dbolya/tomesd#usage),以帮助在管道推理速度和生成令牌的质量之间取得平衡。最重要的参数是 `ratio`,它控制在前向传递期间合并的令牌数量。
|
||||
|
||||
如[论文](https://huggingface.co/papers/2303.17604)中所述,ToMe 可以在显著提升推理速度的同时,很大程度上保留生成图像的质量。通过增加 `ratio`,您可以进一步加速推理,但代价是图像质量有所下降。
|
||||
|
||||
为了测试生成图像的质量,我们从 [Parti Prompts](https://parti.research.google/) 中采样了一些提示,并使用 [`StableDiffusionPipeline`] 进行了推理,设置如下:
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/diffusers/docs-images/resolve/main/tome/tome_samples.png">
|
||||
</div>
|
||||
|
||||
我们没有注意到生成样本的质量有任何显著下降,您可以在此 [WandB 报告](https://wandb.ai/sayakpaul/tomesd-results/runs/23j4bj3i?workspace=)中查看生成的样本。如果您有兴趣重现此实验,请使用此[脚本](https://gist.github.com/sayakpaul/8cac98d7f22399085a060992f411ecbd)。
|
||||
|
||||
## 基准测试
|
||||
|
||||
我们还在启用 [xFormers](https://huggingface.co/docs/diffusers/optimization/xformers) 的情况下,对 [`StableDiffusionPipeline`] 上 `tomesd` 的影响进行了基准测试,涵盖了多个图像分辨率。结果
|
||||
结果是从以下开发环境中的A100和V100 GPU获得的:
|
||||
|
||||
```bash
|
||||
- `diffusers` 版本:0.15.1
|
||||
- Python 版本:3.8.16
|
||||
- PyTorch 版本(GPU?):1.13.1+cu116 (True)
|
||||
- Huggingface_hub 版本:0.13.2
|
||||
- Transformers 版本:4.27.2
|
||||
- Accelerate 版本:0.18.0
|
||||
- xFormers 版本:0.0.16
|
||||
- tomesd 版本:0.1.2
|
||||
```
|
||||
|
||||
要重现此基准测试,请随意使用此[脚本](https://gist.github.com/sayakpaul/27aec6bca7eb7b0e0aa4112205850335)。结果以秒为单位报告,并且在适用的情况下,我们报告了使用ToMe和ToMe + xFormers时相对于原始管道的加速百分比。
|
||||
|
||||
| **GPU** | **分辨率** | **批处理大小** | **原始** | **ToMe** | **ToMe + xFormers** |
|
||||
|----------|----------------|----------------|-------------|----------------|---------------------|
|
||||
| **A100** | 512 | 10 | 6.88 | 5.26 (+23.55%) | 4.69 (+31.83%) |
|
||||
| | 768 | 10 | OOM | 14.71 | 11 |
|
||||
| | | 8 | OOM | 11.56 | 8.84 |
|
||||
| | | 4 | OOM | 5.98 | 4.66 |
|
||||
| | | 2 | 4.99 | 3.24 (+35.07%) | 2.1 (+37.88%) |
|
||||
| | | 1 | 3.29 | 2.24 (+31.91%) | 2.03 (+38.3%) |
|
||||
| | 1024 | 10 | OOM | OOM | OOM |
|
||||
| | | 8 | OOM | OOM | OOM |
|
||||
| | | 4 | OOM | 12.51 | 9.09 |
|
||||
| | | 2 | OOM | 6.52 | 4.96 |
|
||||
| | | 1 | 6.4 | 3.61 (+43.59%) | 2.81 (+56.09%) |
|
||||
| **V100** | 512 | 10 | OOM | 10.03 | 9.29 |
|
||||
| | | 8 | OOM | 8.05 | 7.47 |
|
||||
| | | 4 | 5.7 | 4.3 (+24.56%) | 3.98 (+30.18%) |
|
||||
| | | 2 | 3.14 | 2.43 (+22.61%) | 2.27 (+27.71%) |
|
||||
| | | 1 | 1.88 | 1.57 (+16.49%) | 1.57 (+16.49%) |
|
||||
| | 768 | 10 | OOM | OOM | 23.67 |
|
||||
| | | 8 | OOM | OOM | 18.81 |
|
||||
| | | 4 | OOM | 11.81 | 9.7 |
|
||||
| | | 2 | OOM | 6.27 | 5.2 |
|
||||
| | | 1 | 5.43 | 3.38 (+37.75%) | 2.82 (+48.07%) |
|
||||
| | 1024 | 10 | OOM |
|
||||
如上表所示,`tomesd` 带来的加速效果在更大的图像分辨率下变得更加明显。有趣的是,使用 `tomesd` 可以在更高分辨率如 1024x1024 上运行管道。您可能还可以通过 [`torch.compile`](fp16#torchcompile) 进一步加速推理。
|
||||
119
docs/source/zh/optimization/xdit.md
Normal file
119
docs/source/zh/optimization/xdit.md
Normal file
@@ -0,0 +1,119 @@
|
||||
# xDiT
|
||||
|
||||
[xDiT](https://github.com/xdit-project/xDiT) 是一个推理引擎,专为大规模并行部署扩散变换器(DiTs)而设计。xDiT 提供了一套用于扩散模型的高效并行方法,以及 GPU 内核加速。
|
||||
|
||||
xDiT 支持四种并行方法,包括[统一序列并行](https://huggingface.co/papers/2405.07719)、[PipeFusion](https://huggingface.co/papers/2405.14430)、CFG 并行和数据并行。xDiT 中的这四种并行方法可以以混合方式配置,优化通信模式以最适合底层网络硬件。
|
||||
|
||||
与并行化正交的优化侧重于加速单个 GPU 的性能。除了利用知名的注意力优化库外,我们还利用编译加速技术,如 torch.compile 和 onediff。
|
||||
|
||||
xDiT 的概述如下所示。
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/xDiT/documentation-images/resolve/main/methods/xdit_overview.png">
|
||||
</div>
|
||||
您可以使用以下命令安装 xDiT:
|
||||
|
||||
```bash
|
||||
pip install xfuser
|
||||
```
|
||||
|
||||
以下是一个使用 xDiT 加速 Diffusers 模型推理的示例。
|
||||
|
||||
```diff
|
||||
import torch
|
||||
from diffusers import StableDiffusion3Pipeline
|
||||
|
||||
from xfuser import xFuserArgs, xDiTParallel
|
||||
from xfuser.config import FlexibleArgumentParser
|
||||
from xfuser.core.distributed import get_world_group
|
||||
|
||||
def main():
|
||||
+ parser = FlexibleArgumentParser(description="xFuser Arguments")
|
||||
+ args = xFuserArgs.add_cli_args(parser).parse_args()
|
||||
+ engine_args = xFuserArgs.from_cli_args(args)
|
||||
+ engine_config, input_config = engine_args.create_config()
|
||||
|
||||
local_rank = get_world_group().local_rank
|
||||
pipe = StableDiffusion3Pipeline.from_pretrained(
|
||||
pretrained_model_name_or_path=engine_config.model_config.model,
|
||||
torch_dtype=torch.float16,
|
||||
).to(f"cuda:{local_rank}")
|
||||
|
||||
# 在这里对管道进行任何操作
|
||||
|
||||
+ pipe = xDiTParallel(pipe, engine_config, input_config)
|
||||
|
||||
pipe(
|
||||
height=input_config.height,
|
||||
width=input_config.height,
|
||||
prompt=input_config.prompt,
|
||||
num_inference_steps=input_config.num_inference_steps,
|
||||
output_type=input_config.output_type,
|
||||
generator=torch.Generator(device="cuda").manual_seed(input_config.seed),
|
||||
)
|
||||
|
||||
+ if input_config.output_type == "pil":
|
||||
+ pipe.save("results", "stable_diffusion_3")
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
如您所见,我们只需要使用 xDiT 中的 xFuserArgs 来获取配置参数,并将这些参数与来自 Diffusers 库的管道对象一起传递给 xDiTParallel,即可完成对 Diffusers 中特定管道的并行化。
|
||||
|
||||
xDiT 运行时参数可以在命令行中使用 `-h` 查看,您可以参考此[使用](https://github.com/xdit-project/xDiT?tab=readme-ov-file#2-usage)示例以获取更多详细信息。
|
||||
ils。
|
||||
|
||||
xDiT 需要使用 torchrun 启动,以支持其多节点、多 GPU 并行能力。例如,以下命令可用于 8-GPU 并行推理:
|
||||
|
||||
```bash
|
||||
torchrun --nproc_per_node=8 ./inference.py --model models/FLUX.1-dev --data_parallel_degree 2 --ulysses_degree 2 --ring_degree 2 --prompt "A snowy mountain" "A small dog" --num_inference_steps 50
|
||||
```
|
||||
|
||||
## 支持的模型
|
||||
|
||||
在 xDiT 中支持 Diffusers 模型的一个子集,例如 Flux.1、Stable Diffusion 3 等。最新支持的模型可以在[这里](https://github.com/xdit-project/xDiT?tab=readme-ov-file#-supported-dits)找到。
|
||||
|
||||
## 基准测试
|
||||
我们在不同机器上测试了各种模型,以下是一些基准数据。
|
||||
|
||||
### Flux.1-schnell
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/xDiT/documentation-images/resolve/main/performance/flux/Flux-2k-L40.png">
|
||||
</div>
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/xDiT/documentation-images/resolve/main/performance/flux/Flux-2K-A100.png">
|
||||
</div>
|
||||
|
||||
### Stable Diffusion 3
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/xDiT/documentation-images/resolve/main/performance/sd3/L40-SD3.png">
|
||||
</div>
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/xDiT/documentation-images/resolve/main/performance/sd3/A100-SD3.png">
|
||||
</div>
|
||||
|
||||
### HunyuanDiT
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/xDiT/documentation-images/resolve/main/performance/hunuyuandit/L40-HunyuanDiT.png">
|
||||
</div>
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/xDiT/documentation-images/resolve/main/performance/hunuyuandit/V100-HunyuanDiT.png">
|
||||
</div>
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/xDiT/documentation-images/resolve/main/performance/hunuyuandit/T4-HunyuanDiT.png">
|
||||
</div>
|
||||
|
||||
更详细的性能指标可以在我们的 [GitHub 页面](https://github.com/xdit-project/xDiT?tab=readme-ov-file#perf) 上找到。
|
||||
|
||||
## 参考文献
|
||||
|
||||
[xDiT-project](https://github.com/xdit-project/xDiT)
|
||||
|
||||
[USP: A Unified Sequence Parallelism Approach for Long Context Generative AI](https://huggingface.co/papers/2405.07719)
|
||||
|
||||
[PipeFusion: Displaced Patch Pipeline Parallelism for Inference of Diffusion Transformer Models](https://huggingface.co/papers/2405.14430)
|
||||
32
docs/source/zh/optimization/xformers.md
Normal file
32
docs/source/zh/optimization/xformers.md
Normal file
@@ -0,0 +1,32 @@
|
||||
<!--版权归2025年HuggingFace团队所有。保留所有权利。
|
||||
|
||||
根据Apache许可证2.0版("许可证")授权;除非符合许可证要求,否则不得使用本文件。您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,本软件按"原样"分发,不附带任何明示或暗示的担保或条件。详见许可证中规定的特定语言及限制条款。
|
||||
-->
|
||||
|
||||
# xFormers
|
||||
|
||||
我们推荐在推理和训练过程中使用[xFormers](https://github.com/facebookresearch/xformers)。在我们的测试中,其对注意力模块的优化能同时提升运行速度并降低内存消耗。
|
||||
|
||||
通过`pip`安装xFormers:
|
||||
|
||||
```bash
|
||||
pip install xformers
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
xFormers的`pip`安装包需要最新版本的PyTorch。如需使用旧版PyTorch,建议[从源码安装xFormers](https://github.com/facebookresearch/xformers#installing-xformers)。
|
||||
|
||||
</Tip>
|
||||
|
||||
安装完成后,您可调用`enable_xformers_memory_efficient_attention()`来实现更快的推理速度和更低的内存占用,具体用法参见[此章节](memory#memory-efficient-attention)。
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
根据[此问题](https://github.com/huggingface/diffusers/issues/2234#issuecomment-1416931212)反馈,xFormers `v0.0.16`版本在某些GPU上无法用于训练(微调或DreamBooth)。如遇此问题,请按照该issue评论区指引安装开发版本。
|
||||
|
||||
</Tip>
|
||||
47
docs/source/zh/training/adapt_a_model.md
Normal file
47
docs/source/zh/training/adapt_a_model.md
Normal file
@@ -0,0 +1,47 @@
|
||||
# 将模型适配至新任务
|
||||
|
||||
许多扩散系统共享相同的组件架构,这使得您能够将针对某一任务预训练的模型调整适配至完全不同的新任务。
|
||||
|
||||
本指南将展示如何通过初始化并修改预训练 [`UNet2DConditionModel`] 的架构,将文生图预训练模型改造为图像修复(inpainting)模型。
|
||||
|
||||
## 配置 UNet2DConditionModel 参数
|
||||
|
||||
默认情况下,[`UNet2DConditionModel`] 的[输入样本](https://huggingface.co/docs/diffusers/v0.16.0/en/api/models#diffusers.UNet2DConditionModel.in_channels)接受4个通道。例如加载 [`stable-diffusion-v1-5/stable-diffusion-v1-5`](https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5) 这样的文生图预训练模型,查看其 `in_channels` 参数值:
|
||||
|
||||
```python
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipeline = StableDiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", use_safetensors=True)
|
||||
pipeline.unet.config["in_channels"]
|
||||
4
|
||||
```
|
||||
|
||||
而图像修复任务需要输入样本具有9个通道。您可以在 [`runwayml/stable-diffusion-inpainting`](https://huggingface.co/runwayml/stable-diffusion-inpainting) 这样的预训练修复模型中验证此参数:
|
||||
|
||||
```python
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
pipeline = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-inpainting", use_safetensors=True)
|
||||
pipeline.unet.config["in_channels"]
|
||||
9
|
||||
```
|
||||
|
||||
要将文生图模型改造为修复模型,您需要将 `in_channels` 参数从4调整为9。
|
||||
|
||||
初始化一个加载了文生图预训练权重的 [`UNet2DConditionModel`],并将 `in_channels` 设为9。由于输入通道数变化导致张量形状改变,需要设置 `ignore_mismatched_sizes=True` 和 `low_cpu_mem_usage=False` 来避免尺寸不匹配错误。
|
||||
|
||||
```python
|
||||
from diffusers import AutoModel
|
||||
|
||||
model_id = "stable-diffusion-v1-5/stable-diffusion-v1-5"
|
||||
unet = AutoModel.from_pretrained(
|
||||
model_id,
|
||||
subfolder="unet",
|
||||
in_channels=9,
|
||||
low_cpu_mem_usage=False,
|
||||
ignore_mismatched_sizes=True,
|
||||
use_safetensors=True,
|
||||
)
|
||||
```
|
||||
|
||||
此时文生图模型的其他组件权重仍保持预训练状态,但UNet的输入卷积层权重(`conv_in.weight`)会随机初始化。由于这一关键变化,必须对模型进行修复任务的微调,否则模型将仅会输出噪声。
|
||||
366
docs/source/zh/training/controlnet.md
Normal file
366
docs/source/zh/training/controlnet.md
Normal file
@@ -0,0 +1,366 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# ControlNet
|
||||
|
||||
[ControlNet](https://hf.co/papers/2302.05543) 是一种基于预训练模型的适配器架构。它通过额外输入的条件图像(如边缘检测图、深度图、人体姿态图等),实现对生成图像的精细化控制。
|
||||
|
||||
在显存有限的GPU上训练时,建议启用训练命令中的 `gradient_checkpointing`(梯度检查点)、`gradient_accumulation_steps`(梯度累积步数)和 `mixed_precision`(混合精度)参数。还可使用 [xFormers](../optimization/xformers) 的内存高效注意力机制进一步降低显存占用。虽然JAX/Flax训练支持在TPU和GPU上高效运行,但不支持梯度检查点和xFormers。若需通过Flax加速训练,建议使用显存大于30GB的GPU。
|
||||
|
||||
本指南将解析 [train_controlnet.py](https://github.com/huggingface/diffusers/blob/main/examples/controlnet/train_controlnet.py) 训练脚本,帮助您理解其逻辑并适配自定义需求。
|
||||
|
||||
运行脚本前,请确保从源码安装库:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers
|
||||
cd diffusers
|
||||
pip install .
|
||||
```
|
||||
|
||||
然后进入包含训练脚本的示例目录,安装所需依赖:
|
||||
|
||||
<hfoptions id="installation">
|
||||
<hfoption id="PyTorch">
|
||||
```bash
|
||||
cd examples/controlnet
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
</hfoption>
|
||||
<hfoption id="Flax">
|
||||
|
||||
若可访问TPU设备,Flax训练脚本将运行得更快!以下是在 [Google Cloud TPU VM](https://cloud.google.com/tpu/docs/run-calculation-jax) 上的配置流程。创建单个TPU v4-8虚拟机并连接:
|
||||
|
||||
```bash
|
||||
ZONE=us-central2-b
|
||||
TPU_TYPE=v4-8
|
||||
VM_NAME=hg_flax
|
||||
|
||||
gcloud alpha compute tpus tpu-vm create $VM_NAME \
|
||||
--zone $ZONE \
|
||||
--accelerator-type $TPU_TYPE \
|
||||
--version tpu-vm-v4-base
|
||||
|
||||
gcloud alpha compute tpus tpu-vm ssh $VM_NAME --zone $ZONE -- \
|
||||
```
|
||||
|
||||
安装JAX 0.4.5:
|
||||
|
||||
```bash
|
||||
pip install "jax[tpu]==0.4.5" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
|
||||
```
|
||||
|
||||
然后安装Flax脚本的依赖:
|
||||
|
||||
```bash
|
||||
cd examples/controlnet
|
||||
pip install -r requirements_flax.txt
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
<Tip>
|
||||
|
||||
🤗 Accelerate 是一个支持多GPU/TPU训练和混合精度的库,它能根据硬件环境自动配置训练方案。参阅 🤗 Accelerate [快速入门](https://huggingface.co/docs/accelerate/quicktour) 了解更多。
|
||||
|
||||
</Tip>
|
||||
|
||||
初始化🤗 Accelerate环境:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
若要创建默认配置(不进行交互式选择):
|
||||
|
||||
```bash
|
||||
accelerate config default
|
||||
```
|
||||
|
||||
若环境不支持交互式shell(如notebook),可使用:
|
||||
|
||||
```py
|
||||
from accelerate.utils import write_basic_config
|
||||
|
||||
write_basic_config()
|
||||
```
|
||||
|
||||
最后,如需训练自定义数据集,请参阅 [创建训练数据集](create_dataset) 指南了解数据准备方法。
|
||||
|
||||
<Tip>
|
||||
|
||||
下文重点解析脚本中的关键模块,但不会覆盖所有实现细节。如需深入了解,建议直接阅读 [脚本源码](https://github.com/huggingface/diffusers/blob/main/examples/controlnet/train_controlnet.py),如有疑问欢迎反馈。
|
||||
|
||||
</Tip>
|
||||
|
||||
## 脚本参数
|
||||
|
||||
训练脚本提供了丰富的可配置参数,所有参数及其说明详见 [`parse_args()`](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/controlnet/train_controlnet.py#L231) 函数。虽然该函数已为每个参数提供默认值(如训练批大小、学习率等),但您可以通过命令行参数覆盖这些默认值。
|
||||
|
||||
例如,使用fp16混合精度加速训练, 可使用`--mixed_precision`参数
|
||||
|
||||
```bash
|
||||
accelerate launch train_controlnet.py \
|
||||
--mixed_precision="fp16"
|
||||
```
|
||||
|
||||
基础参数说明可参考 [文生图](text2image#script-parameters) 训练指南,此处重点介绍ControlNet相关参数:
|
||||
|
||||
- `--max_train_samples`: 训练样本数量,减少该值可加快训练,但对超大数据集需配合 `--streaming` 参数使用
|
||||
- `--gradient_accumulation_steps`: 梯度累积步数,通过分步计算实现显存受限情况下的更大批次训练
|
||||
|
||||
### Min-SNR加权策略
|
||||
|
||||
[Min-SNR](https://huggingface.co/papers/2303.09556) 加权策略通过重新平衡损失函数加速模型收敛。虽然训练脚本支持预测 `epsilon`(噪声)或 `v_prediction`,但Min-SNR对两种预测类型均兼容。该策略仅适用于PyTorch版本,Flax训练脚本暂不支持。
|
||||
|
||||
推荐值设为5.0:
|
||||
|
||||
```bash
|
||||
accelerate launch train_controlnet.py \
|
||||
--snr_gamma=5.0
|
||||
```
|
||||
|
||||
## 训练脚本
|
||||
|
||||
与参数说明类似,训练流程的通用解析可参考 [文生图](text2image#training-script) 指南。此处重点分析ControlNet特有的实现。
|
||||
|
||||
脚本中的 [`make_train_dataset`](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/controlnet/train_controlnet.py#L582) 函数负责数据预处理,除常规的文本标注分词和图像变换外,还包含条件图像的特效处理:
|
||||
|
||||
<Tip>
|
||||
|
||||
在TPU上流式加载数据集时,🤗 Datasets库可能成为性能瓶颈(因其未针对图像数据优化)。建议考虑 [WebDataset](https://webdataset.github.io/webdataset/)、[TorchData](https://github.com/pytorch/data) 或 [TensorFlow Datasets](https://www.tensorflow.org/datasets/tfless_tfds) 等高效数据格式。
|
||||
|
||||
</Tip>
|
||||
|
||||
```py
|
||||
conditioning_image_transforms = transforms.Compose(
|
||||
[
|
||||
transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),
|
||||
transforms.CenterCrop(args.resolution),
|
||||
transforms.ToTensor(),
|
||||
]
|
||||
)
|
||||
```
|
||||
|
||||
在 [`main()`](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/controlnet/train_controlnet.py#L713) 函数中,代码会加载分词器、文本编码器、调度器和模型。此处也是ControlNet模型的加载点(支持从现有权重加载或从UNet随机初始化):
|
||||
|
||||
```py
|
||||
if args.controlnet_model_name_or_path:
|
||||
logger.info("Loading existing controlnet weights")
|
||||
controlnet = ControlNetModel.from_pretrained(args.controlnet_model_name_or_path)
|
||||
else:
|
||||
logger.info("Initializing controlnet weights from unet")
|
||||
controlnet = ControlNetModel.from_unet(unet)
|
||||
```
|
||||
|
||||
[优化器](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/controlnet/train_controlnet.py#L871) 专门针对ControlNet参数进行更新:
|
||||
|
||||
```py
|
||||
params_to_optimize = controlnet.parameters()
|
||||
optimizer = optimizer_class(
|
||||
params_to_optimize,
|
||||
lr=args.learning_rate,
|
||||
betas=(args.adam_beta1, args.adam_beta2),
|
||||
weight_decay=args.adam_weight_decay,
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
```
|
||||
|
||||
在 [训练循环](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/controlnet/train_controlnet.py#L943) 中,条件文本嵌入和图像被输入到ControlNet的下采样和中层模块:
|
||||
|
||||
```py
|
||||
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
|
||||
controlnet_image = batch["conditioning_pixel_values"].to(dtype=weight_dtype)
|
||||
|
||||
down_block_res_samples, mid_block_res_sample = controlnet(
|
||||
noisy_latents,
|
||||
timesteps,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
controlnet_cond=controlnet_image,
|
||||
return_dict=False,
|
||||
)
|
||||
```
|
||||
|
||||
若想深入理解训练循环机制,可参阅 [理解管道、模型与调度器](../using-diffusers/write_own_pipeline) 教程,该教程详细解析了去噪过程的基本原理。
|
||||
|
||||
## 启动训练
|
||||
|
||||
现在可以启动训练脚本了!🚀
|
||||
|
||||
本指南使用 [fusing/fill50k](https://huggingface.co/datasets/fusing/fill50k) 数据集,当然您也可以按照 [创建训练数据集](create_dataset) 指南准备自定义数据。
|
||||
|
||||
设置环境变量 `MODEL_NAME` 为Hub模型ID或本地路径,`OUTPUT_DIR` 为模型保存路径。
|
||||
|
||||
下载训练用的条件图像:
|
||||
|
||||
```bash
|
||||
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_1.png
|
||||
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_2.png
|
||||
```
|
||||
|
||||
根据GPU型号,可能需要启用特定优化。默认配置需要约38GB显存。若使用多GPU训练,请在 `accelerate launch` 命令中添加 `--multi_gpu` 参数。
|
||||
|
||||
<hfoptions id="gpu-select">
|
||||
<hfoption id="16GB">
|
||||
|
||||
16GB显卡可使用bitsandbytes 8-bit优化器和梯度检查点:
|
||||
|
||||
```py
|
||||
pip install bitsandbytes
|
||||
```
|
||||
|
||||
训练命令添加以下参数:
|
||||
|
||||
```bash
|
||||
accelerate launch train_controlnet.py \
|
||||
--gradient_checkpointing \
|
||||
--use_8bit_adam \
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="12GB">
|
||||
|
||||
12GB显卡需组合使用bitsandbytes 8-bit优化器、梯度检查点、xFormers,并将梯度置为None而非0:
|
||||
|
||||
```bash
|
||||
accelerate launch train_controlnet.py \
|
||||
--use_8bit_adam \
|
||||
--gradient_checkpointing \
|
||||
--enable_xformers_memory_efficient_attention \
|
||||
--set_grads_to_none \
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="8GB">
|
||||
|
||||
8GB显卡需使用 [DeepSpeed](https://www.deepspeed.ai/) 将张量卸载到CPU或NVME:
|
||||
|
||||
运行以下命令配置环境:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
选择DeepSpeed stage 2,结合fp16混合精度和参数卸载到CPU的方案。注意这会增加约25GB内存占用。配置示例如下:
|
||||
|
||||
```bash
|
||||
compute_environment: LOCAL_MACHINE
|
||||
deepspeed_config:
|
||||
gradient_accumulation_steps: 4
|
||||
offload_optimizer_device: cpu
|
||||
offload_param_device: cpu
|
||||
zero3_init_flag: false
|
||||
zero_stage: 2
|
||||
distributed_type: DEEPSPEED
|
||||
```
|
||||
|
||||
建议将优化器替换为DeepSpeed特化版 [`deepspeed.ops.adam.DeepSpeedCPUAdam`](https://deepspeed.readthedocs.io/en/latest/optimizers.html#adam-cpu),注意CUDA工具链版本需与PyTorch匹配。
|
||||
|
||||
当前bitsandbytes与DeepSpeed存在兼容性问题。
|
||||
|
||||
无需额外添加训练参数。
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
<hfoptions id="training-inference">
|
||||
<hfoption id="PyTorch">
|
||||
|
||||
```bash
|
||||
export MODEL_DIR="stable-diffusion-v1-5/stable-diffusion-v1-5"
|
||||
export OUTPUT_DIR="path/to/save/model"
|
||||
|
||||
accelerate launch train_controlnet.py \
|
||||
--pretrained_model_name_or_path=$MODEL_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--dataset_name=fusing/fill50k \
|
||||
--resolution=512 \
|
||||
--learning_rate=1e-5 \
|
||||
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
|
||||
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="Flax">
|
||||
|
||||
Flax版本支持通过 `--profile_steps==5` 参数进行性能分析:
|
||||
|
||||
```bash
|
||||
pip install tensorflow tensorboard-plugin-profile
|
||||
tensorboard --logdir runs/fill-circle-100steps-20230411_165612/
|
||||
```
|
||||
|
||||
在 [http://localhost:6006/#profile](http://localhost:6006/#profile) 查看分析结果。
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
若遇到插件版本冲突,建议重新安装TensorFlow和Tensorboard。注意性能分析插件仍处实验阶段,部分视图可能不完整。`trace_viewer` 会截断超过1M的事件记录,在编译步骤分析时可能导致设备轨迹丢失。
|
||||
|
||||
</Tip>
|
||||
|
||||
```bash
|
||||
python3 train_controlnet_flax.py \
|
||||
--pretrained_model_name_or_path=$MODEL_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--dataset_name=fusing/fill50k \
|
||||
--resolution=512 \
|
||||
--learning_rate=1e-5 \
|
||||
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
|
||||
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
|
||||
--validation_steps=1000 \
|
||||
--train_batch_size=2 \
|
||||
--revision="non-ema" \
|
||||
--from_pt \
|
||||
--report_to="wandb" \
|
||||
--tracker_project_name=$HUB_MODEL_ID \
|
||||
--num_train_epochs=11 \
|
||||
--push_to_hub \
|
||||
--hub_model_id=$HUB_MODEL_ID
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
训练完成后即可进行推理:
|
||||
|
||||
```py
|
||||
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
|
||||
from diffusers.utils import load_image
|
||||
import torch
|
||||
|
||||
controlnet = ControlNetModel.from_pretrained("path/to/controlnet", torch_dtype=torch.float16)
|
||||
pipeline = StableDiffusionControlNetPipeline.from_pretrained(
|
||||
"path/to/base/model", controlnet=controlnet, torch_dtype=torch.float16
|
||||
).to("cuda")
|
||||
|
||||
control_image = load_image("./conditioning_image_1.png")
|
||||
prompt = "pale golden rod circle with old lace background"
|
||||
|
||||
generator = torch.manual_seed(0)
|
||||
image = pipeline(prompt, num_inference_steps=20, generator=generator, image=control_image).images[0]
|
||||
image.save("./output.png")
|
||||
```
|
||||
|
||||
## Stable Diffusion XL
|
||||
|
||||
Stable Diffusion XL (SDXL) 是新一代文生图模型,通过添加第二文本编码器支持生成更高分辨率图像。使用 [`train_controlnet_sdxl.py`](https://github.com/huggingface/diffusers/blob/main/examples/controlnet/train_controlnet_sdxl.py) 脚本可为SDXL训练ControlNet适配器。
|
||||
|
||||
SDXL训练脚本的详细解析请参阅 [SDXL训练](sdxl) 指南。
|
||||
|
||||
## 后续步骤
|
||||
|
||||
恭喜完成ControlNet训练!如需进一步了解模型应用,以下指南可能有所帮助:
|
||||
|
||||
- 学习如何 [使用ControlNet](../using-diffusers/controlnet) 进行多样化任务的推理
|
||||
239
docs/source/zh/training/distributed_inference.md
Normal file
239
docs/source/zh/training/distributed_inference.md
Normal file
@@ -0,0 +1,239 @@
|
||||
<!--版权所有 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版本(“许可证”)授权;除非遵守许可证,否则不得使用此文件。您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,根据许可证分发的软件按“原样”分发,不附带任何明示或暗示的担保或条件。请参阅许可证了解具体的语言管理权限和限制。
|
||||
-->
|
||||
|
||||
# 分布式推理
|
||||
|
||||
在分布式设置中,您可以使用 🤗 [Accelerate](https://huggingface.co/docs/accelerate/index) 或 [PyTorch Distributed](https://pytorch.org/tutorials/beginner/dist_overview.html) 在多个 GPU 上运行推理,这对于并行生成多个提示非常有用。
|
||||
|
||||
本指南将向您展示如何使用 🤗 Accelerate 和 PyTorch Distributed 进行分布式推理。
|
||||
|
||||
## 🤗 Accelerate
|
||||
|
||||
🤗 [Accelerate](https://huggingface.co/docs/accelerate/index) 是一个旨在简化在分布式设置中训练或运行推理的库。它简化了设置分布式环境的过程,让您可以专注于您的 PyTorch 代码。
|
||||
|
||||
首先,创建一个 Python 文件并初始化一个 [`accelerate.PartialState`] 来创建分布式环境;您的设置会自动检测,因此您无需明确定义 `rank` 或 `world_size`。将 [`DiffusionPipeline`] 移动到 `distributed_state.device` 以为每个进程分配一个 GPU。
|
||||
|
||||
现在使用 [`~accelerate.PartialState.split_between_processes`] 实用程序作为上下文管理器,自动在进程数之间分发提示。
|
||||
|
||||
```py
|
||||
import torch
|
||||
from accelerate import PartialState
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True
|
||||
)
|
||||
distributed_state = PartialState()
|
||||
pipeline.to(distributed_state.device)
|
||||
|
||||
with distributed_state.split_between_processes(["a dog", "a cat"]) as prompt:
|
||||
result = pipeline(prompt).images[0]
|
||||
result.save(f"result_{distributed_state.process_index}.png")
|
||||
```
|
||||
|
||||
使用 `--num_processes` 参数指定要使用的 GPU 数量,并调用 `accelerate launch` 来运行脚本:
|
||||
|
||||
```bash
|
||||
accelerate launch run_distributed.py --num_processes=2
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
参考这个最小示例 [脚本](https://gist.github.com/sayakpaul/cfaebd221820d7b43fae638b4dfa01ba) 以在多个 GPU 上运行推理。要了解更多信息,请查看 [使用 🤗 Accelerate 进行分布式推理](https://huggingface.co/docs/accelerate/en/usage_guides/distributed_inference#distributed-inference-with-accelerate) 指南。
|
||||
|
||||
</Tip>
|
||||
|
||||
## PyTorch Distributed
|
||||
|
||||
PyTorch 支持 [`DistributedDataParallel`](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html),它启用了数据
|
||||
并行性。
|
||||
|
||||
首先,创建一个 Python 文件并导入 `torch.distributed` 和 `torch.multiprocessing` 来设置分布式进程组,并为每个 GPU 上的推理生成进程。您还应该初始化一个 [`DiffusionPipeline`]:
|
||||
|
||||
```py
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
import torch.multiprocessing as mp
|
||||
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
sd = DiffusionPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True
|
||||
)
|
||||
```
|
||||
|
||||
您需要创建一个函数来运行推理;[`init_process_group`](https://pytorch.org/docs/stable/distributed.html?highlight=init_process_group#torch.distributed.init_process_group) 处理创建一个分布式环境,指定要使用的后端类型、当前进程的 `rank` 以及参与进程的数量 `world_size`。如果您在 2 个 GPU 上并行运行推理,那么 `world_size` 就是 2。
|
||||
|
||||
将 [`DiffusionPipeline`] 移动到 `rank`,并使用 `get_rank` 为每个进程分配一个 GPU,其中每个进程处理不同的提示:
|
||||
|
||||
```py
|
||||
def run_inference(rank, world_size):
|
||||
dist.init_process_group("nccl", rank=rank, world_size=world_size)
|
||||
|
||||
sd.to(rank)
|
||||
|
||||
if torch.distributed.get_rank() == 0:
|
||||
prompt = "a dog"
|
||||
elif torch.distributed.get_rank() == 1:
|
||||
prompt = "a cat"
|
||||
|
||||
image = sd(prompt).images[0]
|
||||
image.save(f"./{'_'.join(prompt)}.png")
|
||||
```
|
||||
|
||||
要运行分布式推理,调用 [`mp.spawn`](https://pytorch.org/docs/stable/multiprocessing.html#torch.multiprocessing.spawn) 在 `world_size` 定义的 GPU 数量上运行 `run_inference` 函数:
|
||||
|
||||
```py
|
||||
def main():
|
||||
world_size = 2
|
||||
mp.spawn(run_inference, args=(world_size,), nprocs=world_size, join=True)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
```
|
||||
|
||||
完成推理脚本后,使用 `--nproc_per_node` 参数指定要使用的 GPU 数量,并调用 `torchrun` 来运行脚本:
|
||||
|
||||
```bash
|
||||
torchrun run_distributed.py --nproc_per_node=2
|
||||
```
|
||||
|
||||
> [!TIP]
|
||||
> 您可以在 [`DiffusionPipeline`] 中使用 `device_map` 将其模型级组件分布在多个设备上。请参考 [设备放置](../tutorials/inference_with_big_models#device-placement) 指南了解更多信息。
|
||||
|
||||
## 模型分片
|
||||
|
||||
现代扩散系统,如 [Flux](../api/pipelines/flux),非常大且包含多个模型。例如,[Flux.1-Dev](https://hf.co/black-forest-labs/FLUX.1-dev) 由两个文本编码器 - [T5-XXL](https://hf.co/google/t5-v1_1-xxl) 和 [CLIP-L](https://hf.co/openai/clip-vit-large-patch14) - 一个 [扩散变换器](../api/models/flux_transformer),以及一个 [VAE](../api/models/autoencoderkl) 组成。对于如此大的模型,在消费级 GPU 上运行推理可能具有挑战性。
|
||||
|
||||
模型分片是一种技术,当模型无法容纳在单个 GPU 上时,将模型分布在多个 GPU 上。下面的示例假设有两个 16GB GPU 可用于推理。
|
||||
|
||||
开始使用文本编码器计算文本嵌入。通过设置 `device_map="balanced"` 将文本编码器保持在两个GPU上。`balanced` 策略将模型均匀分布在所有可用GPU上。使用 `max_memory` 参数为每个GPU上的每个文本编码器分配最大内存量。
|
||||
|
||||
> [!TIP]
|
||||
> **仅** 在此步骤加载文本编码器!扩散变换器和VAE在后续步骤中加载以节省内存。
|
||||
|
||||
```py
|
||||
from diffusers import FluxPipeline
|
||||
import torch
|
||||
|
||||
prompt = "a photo of a dog with cat-like look"
|
||||
|
||||
pipeline = FluxPipeline.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-dev",
|
||||
transformer=None,
|
||||
vae=None,
|
||||
device_map="balanced",
|
||||
max_memory={0: "16GB", 1: "16GB"},
|
||||
torch_dtype=torch.bfloat16
|
||||
)
|
||||
with torch.no_grad():
|
||||
print("Encoding prompts.")
|
||||
prompt_embeds, pooled_prompt_embeds, text_ids = pipeline.encode_prompt(
|
||||
prompt=prompt, prompt_2=None, max_sequence_length=512
|
||||
)
|
||||
```
|
||||
|
||||
一旦文本嵌入计算完成,从GPU中移除它们以为扩散变换器腾出空间。
|
||||
|
||||
```py
|
||||
import gc
|
||||
|
||||
def flush():
|
||||
gc.collect()
|
||||
torch.cuda.empty_cache()
|
||||
torch.cuda.reset_max_memory_allocated()
|
||||
torch.cuda.reset_peak_memory_stats()
|
||||
|
||||
del pipeline.text_encoder
|
||||
del pipeline.text_encoder_2
|
||||
del pipeline.tokenizer
|
||||
del pipeline.tokenizer_2
|
||||
del pipeline
|
||||
|
||||
flush()
|
||||
```
|
||||
|
||||
接下来加载扩散变换器,它有125亿参数。这次,设置 `device_map="auto"` 以自动将模型分布在两个16GB GPU上。`auto` 策略由 [Accelerate](https://hf.co/docs/accelerate/index) 支持,并作为 [大模型推理](https://hf.co/docs/accelerate/concept_guides/big_model_inference) 功能的一部分可用。它首先将模型分布在最快的设备(GPU)上,然后在需要时移动到较慢的设备如CPU和硬盘。将模型参数存储在较慢设备上的权衡是推理延迟较慢。
|
||||
|
||||
```py
|
||||
from diffusers import AutoModel
|
||||
import torch
|
||||
|
||||
transformer = AutoModel.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-dev",
|
||||
subfolder="transformer",
|
||||
device_map="auto",
|
||||
torch_dtype=torch.bfloat16
|
||||
)
|
||||
```
|
||||
|
||||
> [!TIP]
|
||||
> 在任何时候,您可以尝试 `print(pipeline.hf_device_map)` 来查看各种模型如何在设备上分布。这对于跟踪模型的设备放置很有用。您也可以尝试 `print(transformer.hf_device_map)` 来查看变换器模型如何在设备上分片。
|
||||
|
||||
将变换器模型添加到管道中以进行去噪,但将其他模型级组件如文本编码器和VAE设置为 `None`,因为您还不需要它们。
|
||||
|
||||
```py
|
||||
pipeline = FluxPipeline.from_pretrained(
|
||||
"black-forest-labs/FLUX.1-dev",
|
||||
text_encoder=None,
|
||||
text_encoder_2=None,
|
||||
tokenizer=None,
|
||||
tokenizer_2=None,
|
||||
vae=None,
|
||||
transformer=transformer,
|
||||
torch_dtype=torch.bfloat16
|
||||
)
|
||||
|
||||
print("Running denoising.")
|
||||
height, width = 768, 1360
|
||||
latents = pipeline(
|
||||
|
||||
|
||||
prompt_embeds=prompt_embeds,
|
||||
pooled_prompt_embeds=pooled_prompt_embeds,
|
||||
num_inference_steps=50,
|
||||
guidance_scale=3.5,
|
||||
height=height,
|
||||
width=width,
|
||||
output_type="latent",
|
||||
).images
|
||||
```
|
||||
|
||||
从内存中移除管道和变换器,因为它们不再需要。
|
||||
|
||||
```py
|
||||
del pipeline.transformer
|
||||
del pipeline
|
||||
|
||||
flush()
|
||||
```
|
||||
|
||||
最后,使用变分自编码器(VAE)将潜在表示解码为图像。VAE通常足够小,可以在单个GPU上加载。
|
||||
|
||||
```py
|
||||
from diffusers import AutoencoderKL
|
||||
from diffusers.image_processor import VaeImageProcessor
|
||||
import torch
|
||||
|
||||
vae = AutoencoderKL.from_pretrained(ckpt_id, subfolder="vae", torch_dtype=torch.bfloat16).to("cuda")
|
||||
vae_scale_factor = 2 ** (len(vae.config.block_out_channels))
|
||||
image_processor = VaeImageProcessor(vae_scale_factor=vae_scale_factor)
|
||||
|
||||
with torch.no_grad():
|
||||
print("运行解码中。")
|
||||
latents = FluxPipeline._unpack_latents(latents, height, width, vae_scale_factor)
|
||||
latents = (latents / vae.config.scaling_factor) + vae.config.shift_factor
|
||||
|
||||
image = vae.decode(latents, return_dict=False)[0]
|
||||
image = image_processor.postprocess(image, output_type="pil")
|
||||
image[0].save("split_transformer.png")
|
||||
```
|
||||
|
||||
通过选择性加载和卸载在特定阶段所需的模型,并将最大模型分片到多个GPU上,可以在消费级GPU上运行大型模型的推理。
|
||||
643
docs/source/zh/training/dreambooth.md
Normal file
643
docs/source/zh/training/dreambooth.md
Normal file
@@ -0,0 +1,643 @@
|
||||
<!--版权所有 2025 The HuggingFace Team。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版(“许可证”)授权;除非遵守许可证,否则不得使用此文件。您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,否则根据许可证分发的软件按“原样”分发,不附带任何明示或暗示的担保或条件。请参阅许可证以了解特定的语言管理权限和限制。
|
||||
-->
|
||||
|
||||
# DreamBooth
|
||||
|
||||
[DreamBooth](https://huggingface.co/papers/2208.12242) 是一种训练技术,通过仅训练少数主题或风格的图像来更新整个扩散模型。它通过在提示中关联一个特殊词与示例图像来工作。
|
||||
|
||||
如果您在 vRAM 有限的 GPU 上训练,应尝试在训练命令中启用 `gradient_checkpointing` 和 `mixed_precision` 参数。您还可以通过使用 [xFormers](../optimization/xformers) 的内存高效注意力来减少内存占用。JAX/Flax 训练也支持在 TPU 和 GPU 上进行高效训练,但不支持梯度检查点或 xFormers。如果您想使用 Flax 更快地训练,应拥有内存 >30GB 的 GPU。
|
||||
|
||||
本指南将探索 [train_dreambooth.py](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth.py) 脚本,帮助您更熟悉它,以及如何根据您的用例进行适配。
|
||||
|
||||
在运行脚本之前,请确保从源代码安装库:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers
|
||||
cd diffusers
|
||||
pip install .
|
||||
```
|
||||
|
||||
导航到包含训练脚本的示例文件夹,并安装脚本所需的依赖项:
|
||||
|
||||
<hfoptions id="installation">
|
||||
<hfoption id="PyTorch">
|
||||
|
||||
```bash
|
||||
cd examples/dreambooth
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="Flax">
|
||||
|
||||
```bash
|
||||
cd examples/dreambooth
|
||||
pip install -r requirements_flax.txt
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
<Tip>
|
||||
|
||||
🤗 Accelerate 是一个库,用于帮助您在多个 GPU/TPU 上或使用混合精度进行训练。它会根据您的硬件和环境自动配置训练设置。查看 🤗 Accelerate [快速入门](https://huggingface.co/docs/accelerate/quicktour) 以了解更多信息。
|
||||
|
||||
</Tip>
|
||||
|
||||
初始化 🤗 Accelerate 环境:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
要设置默认的 🤗 Accelerate 环境而不选择任何配置:
|
||||
|
||||
```bash
|
||||
accelerate config default
|
||||
```
|
||||
|
||||
或者,如果您的环境不支持交互式 shell,例如笔记本,您可以使用:
|
||||
|
||||
```py
|
||||
from accelerate.utils import write_basic_config
|
||||
|
||||
write_basic_config()
|
||||
```
|
||||
|
||||
最后,如果您想在自己的数据集上训练模型,请查看 [创建用于训练的数据集](create_dataset) 指南,了解如何创建与
|
||||
训练脚本。
|
||||
|
||||
<Tip>
|
||||
|
||||
以下部分重点介绍了训练脚本中对于理解如何修改它很重要的部分,但并未详细涵盖脚本的每个方面。如果您有兴趣了解更多,请随时阅读[脚本](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth.py),并告诉我们如果您有任何问题或疑虑。
|
||||
|
||||
</Tip>
|
||||
|
||||
## 脚本参数
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
DreamBooth 对训练超参数非常敏感,容易过拟合。阅读 [使用 🧨 Diffusers 训练 Stable Diffusion 与 Dreambooth](https://huggingface.co/blog/dreambooth) 博客文章,了解针对不同主题的推荐设置,以帮助您选择合适的超参数。
|
||||
|
||||
</Tip>
|
||||
|
||||
训练脚本提供了许多参数来自定义您的训练运行。所有参数及其描述都可以在 [`parse_args()`](https://github.com/huggingface/diffusers/blob/072e00897a7cf4302c347a63ec917b4b8add16d4/examples/dreambooth/train_dreambooth.py#L228) 函数中找到。参数设置了默认值,这些默认值应该开箱即用效果不错,但如果您愿意,也可以在训练命令中设置自己的值。
|
||||
|
||||
例如,要以 bf16 格式进行训练:
|
||||
|
||||
```bash
|
||||
accelerate launch train_dreambooth.py \
|
||||
--mixed_precision="bf16"
|
||||
```
|
||||
|
||||
一些基本且重要的参数需要了解和指定:
|
||||
|
||||
- `--pretrained_model_name_or_path`: Hub 上的模型名称或预训练模型的本地路径
|
||||
- `--instance_data_dir`: 包含训练数据集(示例图像)的文件夹路径
|
||||
- `--instance_prompt`: 包含示例图像特殊单词的文本提示
|
||||
- `--train_text_encoder`: 是否也训练文本编码器
|
||||
- `--output_dir`: 保存训练后模型的位置
|
||||
- `--push_to_hub`: 是否将训练后的模型推送到 Hub
|
||||
- `--checkpointing_steps`: 模型训练时保存检查点的频率;这在训练因某种原因中断时很有用,您可以通过在训练命令中添加 `--resume_from_checkpoint` 来从该检查点继续训练
|
||||
|
||||
### Min-SNR 加权
|
||||
|
||||
[Min-SNR](https://huggingface.co/papers/2303.09556) 加权策略可以通过重新平衡损失来帮助训练,以实现更快的收敛。训练脚本支持预测 `epsilon`(噪声)或 `v_prediction`,但 Min-SNR 与两种预测类型都兼容。此加权策略仅由 PyTorch 支持,在 Flax 训练脚本中不可用。
|
||||
|
||||
添加 `--snr_gamma` 参数并将其设置为推荐值 5.0:
|
||||
|
||||
```bash
|
||||
accelerate launch train_dreambooth.py \
|
||||
--snr_gamma=5.0
|
||||
```
|
||||
|
||||
### 先验保持损失
|
||||
|
||||
先验保持损失是一种使用模型自身生成的样本来帮助它学习如何生成更多样化图像的方法。因为这些生成的样本图像属于您提供的图像相同的类别,它们帮助模型 r
|
||||
etain 它已经学到的关于类别的知识,以及它如何利用已经了解的类别信息来创建新的组合。
|
||||
|
||||
- `--with_prior_preservation`: 是否使用先验保留损失
|
||||
- `--prior_loss_weight`: 控制先验保留损失对模型的影响程度
|
||||
- `--class_data_dir`: 包含生成的类别样本图像的文件夹路径
|
||||
- `--class_prompt`: 描述生成的样本图像类别的文本提示
|
||||
|
||||
```bash
|
||||
accelerate launch train_dreambooth.py \
|
||||
--with_prior_preservation \
|
||||
--prior_loss_weight=1.0 \
|
||||
--class_data_dir="path/to/class/images" \
|
||||
--class_prompt="text prompt describing class"
|
||||
```
|
||||
|
||||
### 训练文本编码器
|
||||
|
||||
为了提高生成输出的质量,除了 UNet 之外,您还可以训练文本编码器。这需要额外的内存,并且您需要一个至少有 24GB 显存的 GPU。如果您拥有必要的硬件,那么训练文本编码器会产生更好的结果,尤其是在生成面部图像时。通过以下方式启用此选项:
|
||||
|
||||
```bash
|
||||
accelerate launch train_dreambooth.py \
|
||||
--train_text_encoder
|
||||
```
|
||||
|
||||
## 训练脚本
|
||||
|
||||
DreamBooth 附带了自己的数据集类:
|
||||
|
||||
- [`DreamBoothDataset`](https://github.com/huggingface/diffusers/blob/072e00897a7cf4302c347a63ec917b4b8add16d4/examples/dreambooth/train_dreambooth.py#L604): 预处理图像和类别图像,并对提示进行分词以用于训练
|
||||
- [`PromptDataset`](https://github.com/huggingface/diffusers/blob/072e00897a7cf4302c347a63ec917b4b8add16d4/examples/dreambooth/train_dreambooth.py#L738): 生成提示嵌入以生成类别图像
|
||||
|
||||
如果您启用了[先验保留损失](https://github.com/huggingface/diffusers/blob/072e00897a7cf4302c347a63ec917b4b8add16d4/examples/dreambooth/train_dreambooth.py#L842),类别图像在此处生成:
|
||||
|
||||
```py
|
||||
sample_dataset = PromptDataset(args.class_prompt, num_new_images)
|
||||
sample_dataloader = torch.utils.data.DataLoader(sample_dataset, batch_size=args.sample_batch_size)
|
||||
|
||||
sample_dataloader = accelerator.prepare(sample_dataloader)
|
||||
pipeline.to(accelerator.device)
|
||||
|
||||
for example in tqdm(
|
||||
sample_dataloader, desc="Generating class images", disable=not accelerator.is_local_main_process
|
||||
):
|
||||
images = pipeline(example["prompt"]).images
|
||||
```
|
||||
|
||||
接下来是 [`main()`](https://github.com/huggingface/diffusers/blob/072e00897a7cf4302c347a63ec917b4b8add16d4/examples/dreambooth/train_dreambooth.py#L799) 函数,它处理设置训练数据集和训练循环本身。脚本加载 [tokenizer](https://github.com/huggingface/diffusers/blob/072e00897a7cf4302c347a63ec917b4b8add16d4/examples/dreambooth/train_dreambooth.py#L898)、[scheduler 和 models](https://github.com/huggingface/diffusers/blob/072e00897a7cf4302c347a63ec917b4b8add16d4/examples/dreambooth/train_dreambooth.py#L912C1-L912C1):
|
||||
|
||||
```py
|
||||
# Load the tokenizer
|
||||
if args.tokenizer_name:
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name, revision=args.revision, use_fast=False)
|
||||
elif args.pretrained_model_name_or_path:
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
args.pretrained_model_name_or_path,
|
||||
subfolder="tokenizer",
|
||||
revision=args.revision,
|
||||
use_fast=False,
|
||||
)
|
||||
|
||||
# 加载调度器和模型
|
||||
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
|
||||
text_encoder = text_encoder_cls.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
|
||||
)
|
||||
|
||||
if model_has_vae(args):
|
||||
vae = AutoencoderKL.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision
|
||||
)
|
||||
else:
|
||||
vae = None
|
||||
|
||||
unet = UNet2DConditionModel.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
|
||||
)
|
||||
```
|
||||
|
||||
然后,是时候[创建训练数据集](https://github.com/huggingface/diffusers/blob/072e00897a7cf4302c347a63ec917b4b8add16d4/examples/dreambooth/train_dreambooth.py#L1073)和从`DreamBoothDataset`创建DataLoader:
|
||||
|
||||
```py
|
||||
train_dataset = DreamBoothDataset(
|
||||
instance_data_root=args.instance_data_dir,
|
||||
instance_prompt=args.instance_prompt,
|
||||
class_data_root=args.class_data_dir if args.with_prior_preservation else None,
|
||||
class_prompt=args.class_prompt,
|
||||
class_num=args.num_class_images,
|
||||
tokenizer=tokenizer,
|
||||
size=args.resolution,
|
||||
center_crop=args.center_crop,
|
||||
encoder_hidden_states=pre_computed_encoder_hidden_states,
|
||||
class_prompt_encoder_hidden_states=pre_computed_class_prompt_encoder_hidden_states,
|
||||
tokenizer_max_length=args.tokenizer_max_length,
|
||||
)
|
||||
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset,
|
||||
batch_size=args.train_batch_size,
|
||||
shuffle=True,
|
||||
collate_fn=lambda examples: collate_fn(examples, args.with_prior_preservation),
|
||||
num_workers=args.dataloader_num_workers,
|
||||
)
|
||||
```
|
||||
|
||||
最后,[训练循环](https://github.com/huggingface/diffusers/blob/072e00897a7cf4302c347a63ec917b4b8add16d4/examples/dreambooth/train_dreambooth.py#L1151)处理剩余步骤,例如将图像转换为潜在空间、向输入添加噪声、预测噪声残差和计算损失。
|
||||
|
||||
如果您想了解更多关于训练循环的工作原理,请查看[理解管道、模型和调度器](../using-diffusers/write_own_pipeline)教程,该教程分解了去噪过程的基本模式。
|
||||
|
||||
## 启动脚本
|
||||
|
||||
您现在准备好启动训练脚本了!🚀
|
||||
|
||||
对于本指南,您将下载一些[狗的图片](https://huggingface.co/datasets/diffusers/dog-example)的图像并将它们存储在一个目录中。但请记住,您可以根据需要创建和使用自己的数据集(请参阅[创建用于训练的数据集](create_dataset)指南)。
|
||||
|
||||
```py
|
||||
from huggingface_hub import snapshot_download
|
||||
|
||||
local_dir = "./dog"
|
||||
snapshot_download(
|
||||
"diffusers/dog-example",
|
||||
local_dir=local_dir,
|
||||
repo_type="dataset",
|
||||
ignore_patterns=".gitattributes",
|
||||
)
|
||||
```
|
||||
|
||||
设置环境变量 `MODEL_NAME` 为 Hub 上的模型 ID 或本地模型路径,`INSTANCE_DIR` 为您刚刚下载狗图像的路径,`OUTPUT_DIR` 为您想保存模型的位置。您将使用 `sks` 作为特殊词来绑定训练。
|
||||
|
||||
如果您有兴趣跟随训练过程,可以定期保存生成的图像作为训练进度。将以下参数添加到训练命令中:
|
||||
|
||||
```bash
|
||||
--validation_prompt="a photo of a sks dog"
|
||||
--num_validation_images=4
|
||||
--validation_steps=100
|
||||
```
|
||||
|
||||
在启动脚本之前,还有一件事!根据您拥有的 GPU,您可能需要启用某些优化来训练 DreamBooth。
|
||||
|
||||
<hfoptions id="gpu-select">
|
||||
<hfoption id="16GB">
|
||||
|
||||
在 16GB GPU 上,您可以使用 bitsandbytes 8 位优化器和梯度检查点来帮助训练 DreamBooth 模型。安装 bitsandbytes:
|
||||
|
||||
```py
|
||||
pip install bitsandbytes
|
||||
```
|
||||
|
||||
然后,将以下参数添加到您的训练命令中:
|
||||
|
||||
```bash
|
||||
accelerate launch train_dreambooth.py \
|
||||
--gradient_checkpointing \
|
||||
--use_8bit_adam \
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="12GB">
|
||||
|
||||
在 12GB GPU 上,您需要 bitsandbytes 8 位优化器、梯度检查点、xFormers,并将梯度设置为 `None` 而不是零以减少内存使用。
|
||||
|
||||
```bash
|
||||
accelerate launch train_dreambooth.py \
|
||||
--use_8bit_adam \
|
||||
--gradient_checkpointing \
|
||||
--enable_xformers_memory_efficient_attention \
|
||||
--set_grads_to_none \
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="8GB">
|
||||
|
||||
在 8GB GPU 上,您需要 [DeepSpeed](https://www.deepspeed.ai/) 将一些张量从 vRAM 卸载到 CPU 或 NVME,以便在更少的 GPU 内存下进行训练。
|
||||
|
||||
运行以下命令来配置您的 🤗 Accelerate 环境:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
在配置过程中,确认您想使用 DeepSpeed。现在,通过结合 DeepSpeed 阶段 2、fp16 混合精度以及将模型参数和优化器状态卸载到 CPU,应该可以在低于 8GB vRAM 的情况下进行训练。缺点是这需要更多的系统 RAM(约 25 GB)。有关更多配置选项,请参阅 [DeepSpeed 文档](https://huggingface.co/docs/accelerate/usage_guides/deepspeed)。
|
||||
|
||||
您还应将默认的 Adam 优化器更改为 DeepSpeed 的优化版本 [`deepspeed.ops.adam.DeepSpeedCPUAdam`](https://deepspeed.readthedocs.io/en/latest/optimizers.html#adam-cpu) 以获得显著的速度提升。启用 `DeepSpeedCPUAdam` 要求您的系统 CUDA 工具链版本与 PyTorch 安装的版本相同。
|
||||
|
||||
目前,bitsandbytes 8 位优化器似乎与 DeepSpeed 不兼容。
|
||||
|
||||
就是这样!您不需要向训练命令添加任何额外参数。
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
<hfoptions id="training-inference">
|
||||
<hfoption id="PyTorch">
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="stable-diffusion-v1-5/stable-diffusion-v1-5"
|
||||
export INSTANCE_DIR="./dog"
|
||||
export OUTPUT_DIR="path_to_
|
||||
saved_model"
|
||||
|
||||
accelerate launch train_dreambooth.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--instance_prompt="a photo of sks dog" \
|
||||
--resolution=512 \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=5e-6 \
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--max_train_steps=400 \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="Flax">
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
|
||||
export INSTANCE_DIR="./dog"
|
||||
export OUTPUT_DIR="path-to-save-model"
|
||||
|
||||
python train_dreambooth_flax.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--instance_prompt="a photo of sks dog" \
|
||||
--resolution=512 \
|
||||
--train_batch_size=1 \
|
||||
--learning_rate=5e-6 \
|
||||
--max_train_steps=400 \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
训练完成后,您可以使用新训练的模型进行推理!
|
||||
|
||||
<Tip>
|
||||
|
||||
等不及在训练完成前就尝试您的模型进行推理?🤭 请确保安装了最新版本的 🤗 Accelerate。
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline, UNet2DConditionModel
|
||||
from transformers import CLIPTextModel
|
||||
import torch
|
||||
|
||||
unet = UNet2DConditionModel.from_pretrained("path/to/model/checkpoint-100/unet")
|
||||
|
||||
# 如果您使用了 `--args.train_text_encoder` 进行训练,请确保也加载文本编码器
|
||||
text_encoder = CLIPTextModel.from_pretrained("path/to/model/checkpoint-100/checkpoint-100/text_encoder")
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5", unet=unet, text_encoder=text_encoder, dtype=torch.float16,
|
||||
).to("cuda")
|
||||
|
||||
image = pipeline("A photo of sks dog in a bucket", num_inference_steps=50, guidance_scale=7.5).images[0]
|
||||
image.save("dog-bucket.png")
|
||||
```
|
||||
|
||||
</Tip>
|
||||
|
||||
<hfoptions id="training-inference">
|
||||
<hfoption id="PyTorch">
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained("path_to_saved_model", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
|
||||
image = pipeline("A photo of sks dog in a bucket", num_inference_steps=50, guidance_scale=7.5).images[0]
|
||||
image.save("dog-bucket.png")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="Flax">
|
||||
|
||||
```py
|
||||
import jax
|
||||
import numpy as np
|
||||
from flax.jax_utils import replicate
|
||||
from flax.training.common_utils import shard
|
||||
from diffusers import FlaxStableDiffusionPipeline
|
||||
|
||||
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained("path-to-your-trained-model", dtype=jax.numpy.bfloat16)
|
||||
|
||||
prompt = "A photo of sks dog in a bucket"
|
||||
prng_seed = jax.random.PRNGKey(0)
|
||||
num_inference_steps = 50
|
||||
|
||||
num_samples = jax.device_count()
|
||||
prompt = num_samples * [prompt]
|
||||
prompt_ids = pipeline.prepare_inputs(prompt)
|
||||
|
||||
# 分片输入和随机数生成器
|
||||
params = replicate(params)
|
||||
prng_seed = jax.random.split(prng_seed, jax.device_count())
|
||||
prompt_ids = shard(prompt_ids)
|
||||
|
||||
images = pipeline(prompt_ids, params, prng_seed, num_inference_
|
||||
steps, jit=True).images
|
||||
images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
|
||||
image.save("dog-bucket.png")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## LoRA
|
||||
|
||||
LoRA 是一种训练技术,可显著减少可训练参数的数量。因此,训练速度更快,并且更容易存储生成的权重,因为它们小得多(约 100MB)。使用 [train_dreambooth_lora.py](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth_lora.py) 脚本通过 LoRA 进行训练。
|
||||
|
||||
LoRA 训练脚本在 [LoRA 训练](lora) 指南中有更详细的讨论。
|
||||
|
||||
## Stable Diffusion XL
|
||||
|
||||
Stable Diffusion XL (SDXL) 是一个强大的文本到图像模型,可生成高分辨率图像,并在其架构中添加了第二个文本编码器。使用 [train_dreambooth_lora_sdxl.py](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth_lora_sdxl.py) 脚本通过 LoRA 训练 SDXL 模型。
|
||||
|
||||
SDXL 训练脚本在 [SDXL 训练](sdxl) 指南中有更详细的讨论。
|
||||
|
||||
## DeepFloyd IF
|
||||
|
||||
DeepFloyd IF 是一个级联像素扩散模型,包含三个阶段。第一阶段生成基础图像,第二和第三阶段逐步将基础图像放大为高分辨率 1024x1024 图像。使用 [train_dreambooth_lora.py](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth_lora.py) 或 [train_dreambooth.py](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth.py) 脚本通过 LoRA 或完整模型训练 DeepFloyd IF 模型。
|
||||
|
||||
DeepFloyd IF 使用预测方差,但 Diffusers 训练脚本使用预测误差,因此训练的 DeepFloyd IF 模型被切换到固定方差调度。训练脚本将为您更新完全训练模型的调度器配置。但是,当您加载保存的 LoRA 权重时,还必须更新管道的调度器配置。
|
||||
|
||||
```py
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipe = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-XL-v1.0", use_safetensors=True)
|
||||
|
||||
pipe.load_lora_weights("<lora weights path>")
|
||||
|
||||
# 更新调度器配置为固定方差调度
|
||||
pipe.scheduler = pipe.scheduler.__class__.from_config(pipe.scheduler.config, variance_type="fixed_small")
|
||||
```
|
||||
|
||||
第二阶段模型需要额外的验证图像进行放大。您可以下载并使用训练图像的缩小版本。
|
||||
|
||||
```py
|
||||
from huggingface_hub import snapshot_download
|
||||
|
||||
local_dir = "./dog_downsized"
|
||||
snapshot_download(
|
||||
"diffusers/dog-example-downsized",
|
||||
local_dir=local_dir,
|
||||
repo_type="dataset",
|
||||
ignore_patterns=".gitattributes",
|
||||
)
|
||||
```
|
||||
|
||||
以下代码示例简要概述了如何结合 DreamBooth 和 LoRA 训练 DeepFloyd IF 模型。一些需要注意的重要参数包括:
|
||||
|
||||
* `--resolution=64`,需要更小的分辨率,因为 DeepFloyd IF 是
|
||||
一个像素扩散模型,用于处理未压缩的像素,输入图像必须更小
|
||||
* `--pre_compute_text_embeddings`,提前计算文本嵌入以节省内存,因为 [`~transformers.T5Model`] 可能占用大量内存
|
||||
* `--tokenizer_max_length=77`,您可以使用更长的默认文本长度与 T5 作为文本编码器,但默认模型编码过程使用较短的文本长度
|
||||
* `--text_encoder_use_attention_mask`,将注意力掩码传递给文本编码器
|
||||
|
||||
<hfoptions id="IF-DreamBooth">
|
||||
<hfoption id="Stage 1 LoRA DreamBooth">
|
||||
|
||||
使用 LoRA 和 DreamBooth 训练 DeepFloyd IF 的第 1 阶段需要约 28GB 内存。
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="DeepFloyd/IF-I-XL-v1.0"
|
||||
export INSTANCE_DIR="dog"
|
||||
export OUTPUT_DIR="dreambooth_dog_lora"
|
||||
|
||||
accelerate launch train_dreambooth_lora.py \
|
||||
--report_to wandb \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--instance_prompt="a sks dog" \
|
||||
--resolution=64 \
|
||||
--train_batch_size=4 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=5e-6 \
|
||||
--scale_lr \
|
||||
--max_train_steps=1200 \
|
||||
--validation_prompt="a sks dog" \
|
||||
--validation_epochs=25 \
|
||||
--checkpointing_steps=100 \
|
||||
--pre_compute_text_embeddings \
|
||||
--tokenizer_max_length=77 \
|
||||
--text_encoder_use_attention_mask
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="Stage 2 LoRA DreamBooth">
|
||||
|
||||
对于使用 LoRA 和 DreamBooth 的 DeepFloyd IF 第 2 阶段,请注意这些参数:
|
||||
|
||||
* `--validation_images`,验证期间用于上采样的图像
|
||||
* `--class_labels_conditioning=timesteps`,根据需要额外条件化 UNet,如第 2 阶段中所需
|
||||
* `--learning_rate=1e-6`,与第 1 阶段相比使用较低的学习率
|
||||
* `--resolution=256`,上采样器的预期分辨率
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="DeepFloyd/IF-II-L-v1.0"
|
||||
export INSTANCE_DIR="dog"
|
||||
export OUTPUT_DIR="dreambooth_dog_upscale"
|
||||
export VALIDATION_IMAGES="dog_downsized/image_1.png dog_downsized/image_2.png dog_downsized/image_3.png dog_downsized/image_4.png"
|
||||
|
||||
python train_dreambooth_lora.py \
|
||||
--report_to wandb \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--instance_prompt="a sks dog" \
|
||||
--resolution=256 \
|
||||
--train_batch_size=4 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=1e-6 \
|
||||
--max_train_steps=2000 \
|
||||
--validation_prompt="a sks dog" \
|
||||
--validation_epochs=100 \
|
||||
--checkpointing_steps=500 \
|
||||
--pre_compute_text_embeddings \
|
||||
--tokenizer_max_length=77 \
|
||||
--text_encoder_use_attention_mask \
|
||||
--validation_images $VALIDATION_IMAGES \
|
||||
--class_labels_conditioning=timesteps
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="Stage 1 DreamBooth">
|
||||
|
||||
对于使用 DreamBooth 的 DeepFloyd IF 第 1 阶段,请注意这些参数:
|
||||
|
||||
* `--skip_save_text_encoder`,跳过保存完整 T5 文本编码器与微调模型
|
||||
* `--use_8bit_adam`,使用 8 位 Adam 优化器以节省内存,因为
|
||||
|
||||
优化器状态的大小在训练完整模型时
|
||||
* `--learning_rate=1e-7`,对于完整模型训练应使用非常低的学习率,否则模型质量会下降(您可以使用更高的学习率和更大的批次大小)
|
||||
|
||||
使用8位Adam和批次大小为4进行训练,完整模型可以在约48GB内存下训练。
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="DeepFloyd/IF-I-XL-v1.0"
|
||||
export INSTANCE_DIR="dog"
|
||||
export OUTPUT_DIR="dreambooth_if"
|
||||
|
||||
accelerate launch train_dreambooth.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--instance_prompt="a photo of sks dog" \
|
||||
--resolution=64 \
|
||||
--train_batch_size=4 \
|
||||
--gradient_accumulation_steps=1 \
|
||||
--learning_rate=1e-7 \
|
||||
--max_train_steps=150 \
|
||||
--validation_prompt "a photo of sks dog" \
|
||||
--validation_steps 25 \
|
||||
--text_encoder_use_attention_mask \
|
||||
--tokenizer_max_length 77 \
|
||||
--pre_compute_text_embeddings \
|
||||
--use_8bit_adam \
|
||||
--set_grads_to_none \
|
||||
--skip_save_text_encoder \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="Stage 2 DreamBooth">
|
||||
|
||||
对于DeepFloyd IF的第二阶段DreamBooth,请注意这些参数:
|
||||
|
||||
* `--learning_rate=5e-6`,使用较低的学习率和较小的有效批次大小
|
||||
* `--resolution=256`,上采样器的预期分辨率
|
||||
* `--train_batch_size=2` 和 `--gradient_accumulation_steps=6`,为了有效训练包含面部的图像,需要更大的批次大小
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="DeepFloyd/IF-II-L-v1.0"
|
||||
export INSTANCE_DIR="dog"
|
||||
export OUTPUT_DIR="dreambooth_dog_upscale"
|
||||
export VALIDATION_IMAGES="dog_downsized/image_1.png dog_downsized/image_2.png dog_downsized/image_3.png dog_downsized/image_4.png"
|
||||
|
||||
accelerate launch train_dreambooth.py \
|
||||
--report_to wandb \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
--instance_prompt="a sks dog" \
|
||||
--resolution=256 \
|
||||
--train_batch_size=2 \
|
||||
--gradient_accumulation_steps=6 \
|
||||
--learning_rate=5e-6 \
|
||||
--max_train_steps=2000 \
|
||||
--validation_prompt="a sks dog" \
|
||||
--validation_steps=150 \
|
||||
--checkpointing_steps=500 \
|
||||
--pre_compute_text_embeddings \
|
||||
--tokenizer_max_length=77 \
|
||||
--text_encoder_use_attention_mask \
|
||||
--validation_images $VALIDATION_IMAGES \
|
||||
--class_labels_conditioning timesteps \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
### 训练技巧
|
||||
|
||||
训练DeepFloyd IF模型可能具有挑战性,但以下是我们发现有用的技巧:
|
||||
|
||||
- LoRA对于训练第一阶段模型已足够,因为模型的低分辨率使得表示更精细的细节变得困难,无论如何。
|
||||
- 对于常见或简单的对象,您不一定需要微调上采样器。确保传递给上采样器的提示被调整以移除实例提示中的新令牌。例如,如果您第一阶段提示是"a sks dog",那么您第二阶段的提示应该是"a dog"。
|
||||
- 对于更精细的细节,如面部,完全训练
|
||||
使用阶段2上采样器比使用LoRA训练阶段2模型更好。使用更大的批次大小和较低的学习率也有帮助。
|
||||
- 应使用较低的学习率来训练阶段2模型。
|
||||
- [`DDPMScheduler`] 比训练脚本中使用的DPMSolver效果更好。
|
||||
|
||||
## 下一步
|
||||
|
||||
恭喜您训练了您的DreamBooth模型!要了解更多关于如何使用您的新模型的信息,以下指南可能有所帮助:
|
||||
- 如果您使用LoRA训练了您的模型,请学习如何[加载DreamBooth](../using-diffusers/loading_adapters)模型进行推理。
|
||||
255
docs/source/zh/training/instructpix2pix.md
Normal file
255
docs/source/zh/training/instructpix2pix.md
Normal file
@@ -0,0 +1,255 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# InstructPix2Pix
|
||||
|
||||
[InstructPix2Pix](https://hf.co/papers/2211.09800) 是一个基于 Stable Diffusion 训练的模型,用于根据人类提供的指令编辑图像。例如,您的提示可以是“将云变成雨天”,模型将相应编辑输入图像。该模型以文本提示(或编辑指令)和输入图像为条件。
|
||||
|
||||
本指南将探索 [train_instruct_pix2pix.py](https://github.com/huggingface/diffusers/blob/main/examples/instruct_pix2pix/train_instruct_pix2pix.py) 训练脚本,帮助您熟悉它,以及如何将其适应您自己的用例。
|
||||
|
||||
在运行脚本之前,请确保从源代码安装库:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers
|
||||
cd diffusers
|
||||
pip install .
|
||||
```
|
||||
|
||||
然后导航到包含训练脚本的示例文件夹,并安装脚本所需的依赖项:
|
||||
|
||||
```bash
|
||||
cd examples/instruct_pix2pix
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
🤗 Accelerate 是一个库,用于帮助您在多个 GPU/TPU 上或使用混合精度进行训练。它将根据您的硬件和环境自动配置训练设置。查看 🤗 Accelerate [快速导览](https://huggingface.co/docs/accelerate/quicktour) 以了解更多信息。
|
||||
|
||||
</Tip>
|
||||
|
||||
初始化一个 🤗 Accelerate 环境:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
要设置一个默认的 🤗 Accelerate 环境,无需选择任何配置:
|
||||
|
||||
```bash
|
||||
accelerate config default
|
||||
```
|
||||
|
||||
或者,如果您的环境不支持交互式 shell,例如笔记本,您可以使用:
|
||||
|
||||
```py
|
||||
from accelerate.utils import write_basic_config
|
||||
|
||||
write_basic_config()
|
||||
```
|
||||
|
||||
最后,如果您想在自己的数据集上训练模型,请查看 [创建用于训练的数据集](create_dataset) 指南,了解如何创建与训练脚本兼容的数据集。
|
||||
|
||||
<Tip>
|
||||
|
||||
以下部分重点介绍了训练脚本中对于理解如何修改它很重要的部分,但并未详细涵盖脚本的每个方面。如果您有兴趣了解更多,请随时阅读 [脚本](https://github.com/huggingface/diffusers/blob/main/examples/instruct_pix2pix/train_instruct_pix2pix.py),并告诉我们如果您有任何问题或疑虑。
|
||||
|
||||
</Tip>
|
||||
|
||||
## 脚本参数
|
||||
|
||||
训练脚本有许多参数可帮助您自定义训练运行。所有
|
||||
参数及其描述可在 [`parse_args()`](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/instruct_pix2pix/train_instruct_pix2pix.py#L65) 函数中找到。大多数参数都提供了默认值,这些值效果相当不错,但如果您愿意,也可以在训练命令中设置自己的值。
|
||||
|
||||
例如,要增加输入图像的分辨率:
|
||||
|
||||
```bash
|
||||
accelerate launch train_instruct_pix2pix.py \
|
||||
--resolution=512 \
|
||||
```
|
||||
|
||||
许多基本和重要的参数在 [文本到图像](text2image#script-parameters) 训练指南中已有描述,因此本指南仅关注与 InstructPix2Pix 相关的参数:
|
||||
|
||||
- `--original_image_column`:编辑前的原始图像
|
||||
- `--edited_image_column`:编辑后的图像
|
||||
- `--edit_prompt_column`:编辑图像的指令
|
||||
- `--conditioning_dropout_prob`:训练期间编辑图像和编辑提示的 dropout 概率,这为一种或两种条件输入启用了无分类器引导(CFG)
|
||||
|
||||
## 训练脚本
|
||||
|
||||
数据集预处理代码和训练循环可在 [`main()`](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/instruct_pix2pix/train_instruct_pix2pix.py#L374) 函数中找到。这是您将修改训练脚本以适应自己用例的地方。
|
||||
|
||||
与脚本参数类似,[文本到图像](text2image#training-script) 训练指南提供了训练脚本的逐步说明。相反,本指南将查看脚本中与 InstructPix2Pix 相关的部分。
|
||||
|
||||
脚本首先修改 UNet 的第一个卷积层中的 [输入通道数](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/instruct_pix2pix/train_instruct_pix2pix.py#L445),以适应 InstructPix2Pix 的额外条件图像:
|
||||
|
||||
```py
|
||||
in_channels = 8
|
||||
out_channels = unet.conv_in.out_channels
|
||||
unet.register_to_config(in_channels=in_channels)
|
||||
|
||||
with torch.no_grad():
|
||||
new_conv_in = nn.Conv2d(
|
||||
in_channels, out_channels, unet.conv_in.kernel_size, unet.conv_in.stride, unet.conv_in.padding
|
||||
)
|
||||
new_conv_in.weight.zero_()
|
||||
new_conv_in.weight[:, :4, :, :].copy_(unet.conv_in.weight)
|
||||
unet.conv_in = new_conv_in
|
||||
```
|
||||
|
||||
这些 UNet 参数由优化器 [更新](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/instruct_pix2pix/train_instruct_pix2pix.py#L545C1-L551C6):
|
||||
|
||||
```py
|
||||
optimizer = optimizer_cls(
|
||||
unet.parameters(),
|
||||
lr=args.learning_rate,
|
||||
betas=(args.adam_beta1, args.adam_beta2),
|
||||
weight_decay=args.adam_weight_decay,
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
```
|
||||
|
||||
接下来,编辑后的图像和编辑指令被 [预处理](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/instruct_pix2pix/train_instruct_pix2pix.py#L624)并被[tokenized](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/instruct_pix2pix/train_instruct_pix2pix.py#L610C24-L610C24)。重要的是,对原始图像和编辑后的图像应用相同的图像变换。
|
||||
|
||||
```py
|
||||
def preprocess_train(examples):
|
||||
preprocessed_images = preprocess_images(examples)
|
||||
|
||||
original_images, edited_images = preprocessed_images.chunk(2)
|
||||
original_images = original_images.reshape(-1, 3, args.resolution, args.resolution)
|
||||
edited_images = edited_images.reshape(-1, 3, args.resolution, args.resolution)
|
||||
|
||||
examples["original_pixel_values"] = original_images
|
||||
examples["edited_pixel_values"] = edited_images
|
||||
|
||||
captions = list(examples[edit_prompt_column])
|
||||
examples["input_ids"] = tokenize_captions(captions)
|
||||
return examples
|
||||
```
|
||||
|
||||
最后,在[训练循环](https://github.com/huggingface/diffusers/blob/64603389da01082055a901f2883c4810d1144edb/examples/instruct_pix2pix/train_instruct_pix2pix.py#L730)中,它首先将编辑后的图像编码到潜在空间:
|
||||
|
||||
```py
|
||||
latents = vae.encode(batch["edited_pixel_values"].to(weight_dtype)).latent_dist.sample()
|
||||
latents = latents * vae.config.scaling_factor
|
||||
```
|
||||
|
||||
然后,脚本对原始图像和编辑指令嵌入应用 dropout 以支持 CFG(Classifier-Free Guidance)。这使得模型能够调节编辑指令和原始图像对编辑后图像的影响。
|
||||
|
||||
```py
|
||||
encoder_hidden_states = text_encoder(batch["input_ids"])[0]
|
||||
original_image_embeds = vae.encode(batch["original_pixel_values"].to(weight_dtype)).latent_dist.mode()
|
||||
|
||||
if args.conditioning_dropout_prob is not None:
|
||||
random_p = torch.rand(bsz, device=latents.device, generator=generator)
|
||||
prompt_mask = random_p < 2 * args.conditioning_dropout_prob
|
||||
prompt_mask = prompt_mask.reshape(bsz, 1, 1)
|
||||
null_conditioning = text_encoder(tokenize_captions([""]).to(accelerator.device))[0]
|
||||
encoder_hidden_states = torch.where(prompt_mask, null_conditioning, encoder_hidden_states)
|
||||
|
||||
image_mask_dtype = original_image_embeds.dtype
|
||||
image_mask = 1 - (
|
||||
(random_p >= args.conditioning_dropout_prob).to(image_mask_dtype)
|
||||
* (random_p < 3 * args.conditioning_dropout_prob).to(image_mask_dtype)
|
||||
)
|
||||
image_mask = image_mask.reshape(bsz, 1, 1, 1)
|
||||
original_image_embeds = image_mask * original_image_embeds
|
||||
```
|
||||
|
||||
差不多就是这样了!除了这里描述的不同之处,脚本的其余部分与[文本到图像](text2image#training-script)训练脚本非常相似,所以请随意查看以获取更多细节。如果您想了解更多关于训练循环如何工作的信息,请查看[理解管道、模型和调度器](../using-diffusers/write_own_pipeline)教程,该教程分解了去噪过程的基本模式。
|
||||
|
||||
## 启动脚本
|
||||
|
||||
一旦您对脚本的更改感到满意,或者如果您对默认配置没问题,您
|
||||
准备好启动训练脚本!🚀
|
||||
|
||||
本指南使用 [fusing/instructpix2pix-1000-samples](https://huggingface.co/datasets/fusing/instructpix2pix-1000-samples) 数据集,这是 [原始数据集](https://huggingface.co/datasets/timbrooks/instructpix2pix-clip-filtered) 的一个较小版本。您也可以创建并使用自己的数据集(请参阅 [创建用于训练的数据集](create_dataset) 指南)。
|
||||
|
||||
将 `MODEL_NAME` 环境变量设置为模型名称(可以是 Hub 上的模型 ID 或本地模型的路径),并将 `DATASET_ID` 设置为 Hub 上数据集的名称。脚本会创建并保存所有组件(特征提取器、调度器、文本编码器、UNet 等)到您的仓库中的一个子文件夹。
|
||||
|
||||
<Tip>
|
||||
|
||||
为了获得更好的结果,尝试使用更大的数据集进行更长时间的训练。我们只在较小规模的数据集上测试过此训练脚本。
|
||||
|
||||
<br>
|
||||
|
||||
要使用 Weights and Biases 监控训练进度,请将 `--report_to=wandb` 参数添加到训练命令中,并使用 `--val_image_url` 指定验证图像,使用 `--validation_prompt` 指定验证提示。这对于调试模型非常有用。
|
||||
|
||||
</Tip>
|
||||
|
||||
如果您在多个 GPU 上训练,请将 `--multi_gpu` 参数添加到 `accelerate launch` 命令中。
|
||||
|
||||
```bash
|
||||
accelerate launch --mixed_precision="fp16" train_instruct_pix2pix.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--dataset_name=$DATASET_ID \
|
||||
--enable_xformers_memory_efficient_attention \
|
||||
--resolution=256 \
|
||||
--random_flip \
|
||||
--train_batch_size=4 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--gradient_checkpointing \
|
||||
--max_train_steps=15000 \
|
||||
--checkpointing_steps=5000 \
|
||||
--checkpoints_total_limit=1 \
|
||||
--learning_rate=5e-05 \
|
||||
--max_grad_norm=1 \
|
||||
--lr_warmup_steps=0 \
|
||||
--conditioning_dropout_prob=0.05 \
|
||||
--mixed_precision=fp16 \
|
||||
--seed=42 \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
训练完成后,您可以使用您的新 InstructPix2Pix 进行推理:
|
||||
|
||||
```py
|
||||
import PIL
|
||||
import requests
|
||||
import torch
|
||||
from diffusers import StableDiffusionInstructPix2PixPipeline
|
||||
from diffusers.utils import load_image
|
||||
|
||||
pipeline = StableDiffusionInstructPix2PixPipeline.from_pretrained("your_cool_model", torch_dtype=torch.float16).to("cuda")
|
||||
generator = torch.Generator("cuda").manual_seed(0)
|
||||
|
||||
image = load_image("https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/test_pix2pix_4.png")
|
||||
prompt = "add some ducks to the lake"
|
||||
num_inference_steps = 20
|
||||
image_guidance_scale = 1.5
|
||||
guidance_scale = 10
|
||||
|
||||
edited_image = pipeline(
|
||||
prompt,
|
||||
image=image,
|
||||
num_inference_steps=num_inference_steps,
|
||||
image_guidance_scale=image_guidance_scale,
|
||||
guidance_scale=guidance_scale,
|
||||
generator=generator,
|
||||
).images[0]
|
||||
edited_image.save("edited_image.png")
|
||||
```
|
||||
|
||||
您应该尝试不同的 `num_inference_steps`、`image_guidance_scale` 和 `guidance_scale` 值,以查看它们如何影响推理速度和质量。指导比例参数
|
||||
这些参数尤其重要,因为它们控制原始图像和编辑指令对编辑后图像的影响程度。
|
||||
|
||||
## Stable Diffusion XL
|
||||
|
||||
Stable Diffusion XL (SDXL) 是一个强大的文本到图像模型,能够生成高分辨率图像,并在其架构中添加了第二个文本编码器。使用 [`train_instruct_pix2pix_sdxl.py`](https://github.com/huggingface/diffusers/blob/main/examples/instruct_pix2pix/train_instruct_pix2pix_sdxl.py) 脚本来训练 SDXL 模型以遵循图像编辑指令。
|
||||
|
||||
SDXL 训练脚本在 [SDXL 训练](sdxl) 指南中有更详细的讨论。
|
||||
|
||||
## 后续步骤
|
||||
|
||||
恭喜您训练了自己的 InstructPix2Pix 模型!🥳 要了解更多关于该模型的信息,可能有助于:
|
||||
|
||||
- 阅读 [Instruction-tuning Stable Diffusion with InstructPix2Pix](https://huggingface.co/blog/instruction-tuning-sd) 博客文章,了解更多我们使用 InstructPix2Pix 进行的一些实验、数据集准备以及不同指令的结果。
|
||||
328
docs/source/zh/training/kandinsky.md
Normal file
328
docs/source/zh/training/kandinsky.md
Normal file
@@ -0,0 +1,328 @@
|
||||
<!--版权所有 2025 HuggingFace 团队。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版本("许可证")授权;除非遵守许可证,否则您不得使用此文件。您可以在以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,否则根据许可证分发的软件按"原样"分发,不附带任何明示或暗示的担保或条件。请参阅许可证以了解具体的语言管理权限和限制。
|
||||
-->
|
||||
|
||||
# Kandinsky 2.2
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
此脚本是实验性的,容易过拟合并遇到灾难性遗忘等问题。尝试探索不同的超参数以在您的数据集上获得最佳结果。
|
||||
|
||||
</Tip>
|
||||
|
||||
Kandinsky 2.2 是一个多语言文本到图像模型,能够生成更逼真的图像。该模型包括一个图像先验模型,用于从文本提示创建图像嵌入,以及一个解码器模型,基于先验模型的嵌入生成图像。这就是为什么在 Diffusers 中您会找到两个独立的脚本用于 Kandinsky 2.2,一个用于训练先验模型,另一个用于训练解码器模型。您可以分别训练这两个模型,但为了获得最佳结果,您应该同时训练先验和解码器模型。
|
||||
|
||||
根据您的 GPU,您可能需要启用 `gradient_checkpointing`(⚠️ 不支持先验模型!)、`mixed_precision` 和 `gradient_accumulation_steps` 来帮助将模型装入内存并加速训练。您可以通过启用 [xFormers](../optimization/xformers) 的内存高效注意力来进一步减少内存使用(版本 [v0.0.16](https://github.com/huggingface/diffusers/issues/2234#issuecomment-1416931212) 在某些 GPU 上训练时失败,因此您可能需要安装开发版本)。
|
||||
|
||||
本指南探讨了 [train_text_to_image_prior.py](https://github.com/huggingface/diffusers/blob/main/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py) 和 [train_text_to_image_decoder.py](https://github.com/huggingface/diffusers/blob/main/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py) 脚本,以帮助您更熟悉它,以及如何根据您的用例进行调整。
|
||||
|
||||
在运行脚本之前,请确保从源代码安装库:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers
|
||||
cd diffusers
|
||||
pip install .
|
||||
```
|
||||
|
||||
然后导航到包含训练脚本的示例文件夹,并安装脚本所需的依赖项:
|
||||
|
||||
```bash
|
||||
cd examples/kandinsky2_2/text_to_image
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
🤗 Accelerate 是一个帮助您在多个 GPU/TPU 上或使用混合精度进行训练的库。它会根据您的硬件和环境自动配置训练设置。查看 🤗 Accelerate 的 [快速入门](https://huggingface.co/docs/accelerate/quicktour
|
||||
) 了解更多。
|
||||
|
||||
</Tip>
|
||||
|
||||
初始化一个 🤗 Accelerate 环境:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
要设置一个默认的 🤗 Accelerate 环境而不选择任何配置:
|
||||
|
||||
```bash
|
||||
accelerate config default
|
||||
```
|
||||
|
||||
或者,如果您的环境不支持交互式 shell,比如 notebook,您可以使用:
|
||||
|
||||
```py
|
||||
from accelerate.utils import write_basic_config
|
||||
|
||||
write_basic_config()
|
||||
```
|
||||
|
||||
最后,如果您想在自己的数据集上训练模型,请查看 [创建用于训练的数据集](create_dataset) 指南,了解如何创建与训练脚本兼容的数据集。
|
||||
|
||||
<Tip>
|
||||
|
||||
以下部分重点介绍了训练脚本中对于理解如何修改它很重要的部分,但并未详细涵盖脚本的每个方面。如果您有兴趣了解更多,请随时阅读脚本,并让我们知道您有任何疑问或顾虑。
|
||||
|
||||
</Tip>
|
||||
|
||||
## 脚本参数
|
||||
|
||||
训练脚本提供了许多参数来帮助您自定义训练运行。所有参数及其描述都可以在 [`parse_args()`](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py#L190) 函数中找到。训练脚本为每个参数提供了默认值,例如训练批次大小和学习率,但如果您愿意,也可以在训练命令中设置自己的值。
|
||||
|
||||
例如,要使用 fp16 格式的混合精度加速训练,请在训练命令中添加 `--mixed_precision` 参数:
|
||||
|
||||
```bash
|
||||
accelerate launch train_text_to_image_prior.py \
|
||||
--mixed_precision="fp16"
|
||||
```
|
||||
|
||||
大多数参数与 [文本到图像](text2image#script-parameters) 训练指南中的参数相同,所以让我们直接进入 Kandinsky 训练脚本的 walkthrough!
|
||||
|
||||
### Min-SNR 加权
|
||||
|
||||
[Min-SNR](https://huggingface.co/papers/2303.09556) 加权策略可以通过重新平衡损失来帮助训练,实现更快的收敛。训练脚本支持预测 `epsilon`(噪声)或 `v_prediction`,但 Min-SNR 与两种预测类型都兼容。此加权策略仅由 PyTorch 支持,在 Flax 训练脚本中不可用。
|
||||
|
||||
添加 `--snr_gamma` 参数并将其设置为推荐值 5.0:
|
||||
|
||||
```bash
|
||||
accelerate launch train_text_to_image_prior.py \
|
||||
--snr_gamma=5.0
|
||||
```
|
||||
|
||||
## 训练脚本
|
||||
|
||||
训练脚本也类似于 [文本到图像](text2image#training-script) 训练指南,但已修改以支持训练 prior 和 decoder 模型。本指南重点介绍 Kandinsky 2.2 训练脚本中独特的代码。
|
||||
|
||||
<hfoptions id="script">
|
||||
<hfoption id="prior model">
|
||||
|
||||
[`main()`](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py#L441) 函数包含代码 f
|
||||
或准备数据集和训练模型。
|
||||
|
||||
您会立即注意到的主要区别之一是,训练脚本除了调度器和分词器外,还加载了一个 [`~transformers.CLIPImageProcessor`] 用于预处理图像,以及一个 [`~transformers.CLIPVisionModelWithProjection`] 模型用于编码图像:
|
||||
|
||||
```py
|
||||
noise_scheduler = DDPMScheduler(beta_schedule="squaredcos_cap_v2", prediction_type="sample")
|
||||
image_processor = CLIPImageProcessor.from_pretrained(
|
||||
args.pretrained_prior_model_name_or_path, subfolder="image_processor"
|
||||
)
|
||||
tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_prior_model_name_or_path, subfolder="tokenizer")
|
||||
|
||||
with ContextManagers(deepspeed_zero_init_disabled_context_manager()):
|
||||
image_encoder = CLIPVisionModelWithProjection.from_pretrained(
|
||||
args.pretrained_prior_model_name_or_path, subfolder="image_encoder", torch_dtype=weight_dtype
|
||||
).eval()
|
||||
text_encoder = CLIPTextModelWithProjection.from_pretrained(
|
||||
args.pretrained_prior_model_name_or_path, subfolder="text_encoder", torch_dtype=weight_dtype
|
||||
).eval()
|
||||
```
|
||||
|
||||
Kandinsky 使用一个 [`PriorTransformer`] 来生成图像嵌入,因此您需要设置优化器来学习先验模型的参数。
|
||||
|
||||
```py
|
||||
prior = PriorTransformer.from_pretrained(args.pretrained_prior_model_name_or_path, subfolder="prior")
|
||||
prior.train()
|
||||
optimizer = optimizer_cls(
|
||||
prior.parameters(),
|
||||
lr=args.learning_rate,
|
||||
betas=(args.adam_beta1, args.adam_beta2),
|
||||
weight_decay=args.adam_weight_decay,
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
```
|
||||
|
||||
接下来,输入标题被分词,图像由 [`~transformers.CLIPImageProcessor`] [预处理](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py#L632):
|
||||
|
||||
```py
|
||||
def preprocess_train(examples):
|
||||
images = [image.convert("RGB") for image in examples[image_column]]
|
||||
examples["clip_pixel_values"] = image_processor(images, return_tensors="pt").pixel_values
|
||||
examples["text_input_ids"], examples["text_mask"] = tokenize_captions(examples)
|
||||
return examples
|
||||
```
|
||||
|
||||
最后,[训练循环](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_prior.py#L718) 将输入图像转换为潜在表示,向图像嵌入添加噪声,并进行预测:
|
||||
|
||||
```py
|
||||
model_pred = prior(
|
||||
noisy_latents,
|
||||
timestep=timesteps,
|
||||
proj_embedding=prompt_embeds,
|
||||
encoder_hidden_states=text_encoder_hidden_states,
|
||||
attention_mask=text_mask,
|
||||
).predicted_image_embedding
|
||||
```
|
||||
|
||||
如果您想了解更多关于训练循环的工作原理,请查看 [理解管道、模型和调度器](../using-diffusers/write_own_pipeline) 教程,该教程分解了去噪过程的基本模式。
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="decoder model">
|
||||
|
||||
The [`main()`](https://github.com/huggingface/di
|
||||
ffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py#L440) 函数包含准备数据集和训练模型的代码。
|
||||
|
||||
与之前的模型不同,解码器初始化一个 [`VQModel`] 来将潜在变量解码为图像,并使用一个 [`UNet2DConditionModel`]:
|
||||
|
||||
```py
|
||||
with ContextManagers(deepspeed_zero_init_disabled_context_manager()):
|
||||
vae = VQModel.from_pretrained(
|
||||
args.pretrained_decoder_model_name_or_path, subfolder="movq", torch_dtype=weight_dtype
|
||||
).eval()
|
||||
image_encoder = CLIPVisionModelWithProjection.from_pretrained(
|
||||
args.pretrained_prior_model_name_or_path, subfolder="image_encoder", torch_dtype=weight_dtype
|
||||
).eval()
|
||||
unet = UNet2DConditionModel.from_pretrained(args.pretrained_decoder_model_name_or_path, subfolder="unet")
|
||||
```
|
||||
|
||||
接下来,脚本包括几个图像变换和一个用于对图像应用变换并返回像素值的[预处理](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py#L622)函数:
|
||||
|
||||
```py
|
||||
def preprocess_train(examples):
|
||||
images = [image.convert("RGB") for image in examples[image_column]]
|
||||
examples["pixel_values"] = [train_transforms(image) for image in images]
|
||||
examples["clip_pixel_values"] = image_processor(images, return_tensors="pt").pixel_values
|
||||
return examples
|
||||
```
|
||||
|
||||
最后,[训练循环](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/kandinsky2_2/text_to_image/train_text_to_image_decoder.py#L706)处理将图像转换为潜在变量、添加噪声和预测噪声残差。
|
||||
|
||||
如果您想了解更多关于训练循环如何工作的信息,请查看[理解管道、模型和调度器](../using-diffusers/write_own_pipeline)教程,该教程分解了去噪过程的基本模式。
|
||||
|
||||
```py
|
||||
model_pred = unet(noisy_latents, timesteps, None, added_cond_kwargs=added_cond_kwargs).sample[:, :4]
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## 启动脚本
|
||||
|
||||
一旦您完成了所有更改或接受默认配置,就可以启动训练脚本了!🚀
|
||||
|
||||
您将在[Naruto BLIP 字幕](https://huggingface.co/datasets/lambdalabs/naruto-blip-captions)数据集上进行训练,以生成您自己的Naruto角色,但您也可以通过遵循[创建用于训练的数据集](create_dataset)指南来创建和训练您自己的数据集。将环境变量 `DATASET_NAME` 设置为Hub上数据集的名称,或者如果您在自己的文件上训练,将环境变量 `TRAIN_DIR` 设置为数据集的路径。
|
||||
|
||||
如果您在多个GPU上训练,请在 `accelerate launch` 命令中添加 `--multi_gpu` 参数。
|
||||
|
||||
<Tip>
|
||||
|
||||
要使用Weights & Biases监控训练进度,请在训练命令中添加 `--report_to=wandb` 参数。您还需要
|
||||
建议在训练命令中添加 `--validation_prompt` 以跟踪结果。这对于调试模型和查看中间结果非常有用。
|
||||
|
||||
</Tip>
|
||||
|
||||
<hfoptions id="training-inference">
|
||||
<hfoption id="prior model">
|
||||
|
||||
```bash
|
||||
export DATASET_NAME="lambdalabs/naruto-blip-captions"
|
||||
|
||||
accelerate launch --mixed_precision="fp16" train_text_to_image_prior.py \
|
||||
--dataset_name=$DATASET_NAME \
|
||||
--resolution=768 \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--max_train_steps=15000 \
|
||||
--learning_rate=1e-05 \
|
||||
--max_grad_norm=1 \
|
||||
--checkpoints_total_limit=3 \
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--validation_prompts="A robot naruto, 4k photo" \
|
||||
--report_to="wandb" \
|
||||
--push_to_hub \
|
||||
--output_dir="kandi2-prior-naruto-model"
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="decoder model">
|
||||
|
||||
```bash
|
||||
export DATASET_NAME="lambdalabs/naruto-blip-captions"
|
||||
|
||||
accelerate launch --mixed_precision="fp16" train_text_to_image_decoder.py \
|
||||
--dataset_name=$DATASET_NAME \
|
||||
--resolution=768 \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--gradient_checkpointing \
|
||||
--max_train_steps=15000 \
|
||||
--learning_rate=1e-05 \
|
||||
--max_grad_norm=1 \
|
||||
--checkpoints_total_limit=3 \
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--validation_prompts="A robot naruto, 4k photo" \
|
||||
--report_to="wandb" \
|
||||
--push_to_hub \
|
||||
--output_dir="kandi2-decoder-naruto-model"
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
训练完成后,您可以使用新训练的模型进行推理!
|
||||
|
||||
<hfoptions id="training-inference">
|
||||
<hfoption id="prior model">
|
||||
|
||||
```py
|
||||
from diffusers import AutoPipelineForText2Image, DiffusionPipeline
|
||||
import torch
|
||||
|
||||
prior_pipeline = DiffusionPipeline.from_pretrained(output_dir, torch_dtype=torch.float16)
|
||||
prior_components = {"prior_" + k: v for k,v in prior_pipeline.components.items()}
|
||||
pipeline = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", **prior_components, torch_dtype=torch.float16)
|
||||
|
||||
pipe.enable_model_cpu_offload()
|
||||
prompt="A robot naruto, 4k photo"
|
||||
image = pipeline(prompt=prompt, negative_prompt=negative_prompt).images[0]
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
可以随意将 `kandinsky-community/kandinsky-2-2-decoder` 替换为您自己训练的 decoder 检查点!
|
||||
|
||||
</Tip>
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="decoder model">
|
||||
|
||||
```py
|
||||
from diffusers import AutoPipelineForText2Image
|
||||
import torch
|
||||
|
||||
pipeline = AutoPipelineForText2Image.from_pretrained("path/to/saved/model", torch_dtype=torch.float16)
|
||||
pipeline.enable_model_cpu_offload()
|
||||
|
||||
prompt="A robot naruto, 4k photo"
|
||||
image = pipeline(prompt=prompt).images[0]
|
||||
```
|
||||
|
||||
对于 decoder 模型,您还可以从保存的检查点进行推理,这对于查看中间结果很有用。在这种情况下,将检查点加载到 UNet 中:
|
||||
|
||||
```py
|
||||
from diffusers import AutoPipelineForText2Image, UNet2DConditionModel
|
||||
|
||||
unet = UNet2DConditionModel.from_pretrained("path/to/saved/model" + "/checkpoint-<N>/unet")
|
||||
|
||||
pipeline = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", unet=unet, torch_dtype=torch.float16)
|
||||
pipeline.enable_model_cpu_offload()
|
||||
|
||||
image = pipeline(prompt="A robot naruto, 4k photo").images[0]
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## 后续步骤
|
||||
|
||||
恭喜您训练了一个 Kandinsky 2.2 模型!要了解更多关于如何使用您的新模型的信息,以下指南可能会有所帮助:
|
||||
|
||||
- 阅读 [Kandinsky](../using-diffusers/kandinsky) 指南,学习如何将其用于各种不同的任务(文本到图像、图像到图像、修复、插值),以及如何与 ControlNet 结合使用。
|
||||
- 查看 [DreamBooth](dreambooth) 和 [LoRA](lora) 训练指南,学习如何使用少量示例图像训练个性化的 Kandinsky 模型。这两种训练技术甚至可以结合使用!
|
||||
231
docs/source/zh/training/lora.md
Normal file
231
docs/source/zh/training/lora.md
Normal file
@@ -0,0 +1,231 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# LoRA 低秩适配
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
当前功能处于实验阶段,API可能在未来版本中变更。
|
||||
|
||||
</Tip>
|
||||
|
||||
[LoRA(大语言模型的低秩适配)](https://hf.co/papers/2106.09685) 是一种轻量级训练技术,能显著减少可训练参数量。其原理是通过向模型注入少量新权重参数,仅训练这些新增参数。这使得LoRA训练速度更快、内存效率更高,并生成更小的模型权重文件(通常仅数百MB),便于存储和分享。LoRA还可与DreamBooth等其他训练技术结合以加速训练过程。
|
||||
|
||||
<Tip>
|
||||
|
||||
LoRA具有高度通用性,目前已支持以下应用场景:[DreamBooth](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth_lora.py)、[Kandinsky 2.2](https://github.com/huggingface/diffusers/blob/main/examples/kandinsky2_2/text_to_image/train_text_to_image_lora_decoder.py)、[Stable Diffusion XL](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora_sdxl.py)、[文生图](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py)以及[Wuerstchen](https://github.com/huggingface/diffusers/blob/main/examples/wuerstchen/text_to_image/train_text_to_image_lora_prior.py)。
|
||||
|
||||
</Tip>
|
||||
|
||||
本指南将通过解析[train_text_to_image_lora.py](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py)脚本,帮助您深入理解其工作原理,并掌握如何针对具体需求进行定制化修改。
|
||||
|
||||
运行脚本前,请确保从源码安装库:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers
|
||||
cd diffusers
|
||||
pip install .
|
||||
```
|
||||
|
||||
进入包含训练脚本的示例目录,并安装所需依赖:
|
||||
|
||||
<hfoptions id="installation">
|
||||
<hfoption id="PyTorch">
|
||||
|
||||
```bash
|
||||
cd examples/text_to_image
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="Flax">
|
||||
|
||||
```bash
|
||||
cd examples/text_to_image
|
||||
pip install -r requirements_flax.txt
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
<Tip>
|
||||
|
||||
🤗 Accelerate是一个支持多GPU/TPU训练和混合精度计算的库,它能根据硬件环境自动配置训练方案。参阅🤗 Accelerate[快速入门](https://huggingface.co/docs/accelerate/quicktour)了解更多。
|
||||
|
||||
</Tip>
|
||||
|
||||
初始化🤗 Accelerate环境:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
若要创建默认配置环境(不进行交互式设置):
|
||||
|
||||
```bash
|
||||
accelerate config default
|
||||
```
|
||||
|
||||
若在非交互环境(如Jupyter notebook)中使用:
|
||||
|
||||
```py
|
||||
from accelerate.utils import write_basic_config
|
||||
|
||||
write_basic_config()
|
||||
```
|
||||
|
||||
如需训练自定义数据集,请参考[创建训练数据集指南](create_dataset)了解数据准备流程。
|
||||
|
||||
<Tip>
|
||||
|
||||
以下章节重点解析训练脚本中与LoRA相关的核心部分,但不会涵盖所有实现细节。如需完整理解,建议直接阅读[脚本源码](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py),如有疑问欢迎反馈。
|
||||
|
||||
</Tip>
|
||||
|
||||
## 脚本参数
|
||||
|
||||
训练脚本提供众多参数用于定制训练过程。所有参数及其说明均定义在[`parse_args()`](https://github.com/huggingface/diffusers/blob/dd9a5caf61f04d11c0fa9f3947b69ab0010c9a0f/examples/text_to_image/train_text_to_image_lora.py#L85)函数中。多数参数设有默认值,您也可以通过命令行参数覆盖:
|
||||
|
||||
例如增加训练轮次:
|
||||
|
||||
```bash
|
||||
accelerate launch train_text_to_image_lora.py \
|
||||
--num_train_epochs=150 \
|
||||
```
|
||||
|
||||
基础参数说明可参考[文生图训练指南](text2image#script-parameters),此处重点介绍LoRA相关参数:
|
||||
|
||||
- `--rank`:低秩矩阵的内部维度,数值越高可训练参数越多
|
||||
- `--learning_rate`:默认学习率为1e-4,但使用LoRA时可适当提高
|
||||
|
||||
## 训练脚本实现
|
||||
|
||||
数据集预处理和训练循环逻辑位于[`main()`](https://github.com/huggingface/diffusers/blob/dd9a5caf61f04d11c0fa9f3947b69ab0010c9a0f/examples/text_to_image/train_text_to_image_lora.py#L371)函数,如需定制训练流程,可在此处进行修改。
|
||||
|
||||
与参数说明类似,训练流程的完整解析请参考[文生图指南](text2image#training-script),下文重点介绍LoRA相关实现。
|
||||
|
||||
<hfoptions id="lora">
|
||||
<hfoption id="UNet">
|
||||
|
||||
Diffusers使用[PEFT](https://hf.co/docs/peft)库的[`~peft.LoraConfig`]配置LoRA适配器参数,包括秩(rank)、alpha值以及目标模块。适配器被注入UNet后,通过`lora_layers`筛选出需要优化的LoRA层。
|
||||
|
||||
```py
|
||||
unet_lora_config = LoraConfig(
|
||||
r=args.rank,
|
||||
lora_alpha=args.rank,
|
||||
init_lora_weights="gaussian",
|
||||
target_modules=["to_k", "to_q", "to_v", "to_out.0"],
|
||||
)
|
||||
|
||||
unet.add_adapter(unet_lora_config)
|
||||
lora_layers = filter(lambda p: p.requires_grad, unet.parameters())
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="text encoder">
|
||||
|
||||
当需要微调文本编码器时(如SDXL模型),Diffusers同样支持通过[PEFT](https://hf.co/docs/peft)库实现。[`~peft.LoraConfig`]配置适配器参数后注入文本编码器,并筛选LoRA层进行训练。
|
||||
|
||||
```py
|
||||
text_lora_config = LoraConfig(
|
||||
r=args.rank,
|
||||
lora_alpha=args.rank,
|
||||
init_lora_weights="gaussian",
|
||||
target_modules=["q_proj", "k_proj", "v_proj", "out_proj"],
|
||||
)
|
||||
|
||||
text_encoder_one.add_adapter(text_lora_config)
|
||||
text_encoder_two.add_adapter(text_lora_config)
|
||||
text_lora_parameters_one = list(filter(lambda p: p.requires_grad, text_encoder_one.parameters()))
|
||||
text_lora_parameters_two = list(filter(lambda p: p.requires_grad, text_encoder_two.parameters()))
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
[优化器](https://github.com/huggingface/diffusers/blob/e4b8f173b97731686e290b2eb98e7f5df2b1b322/examples/text_to_image/train_text_to_image_lora.py#L529)仅对`lora_layers`参数进行优化:
|
||||
|
||||
```py
|
||||
optimizer = optimizer_cls(
|
||||
lora_layers,
|
||||
lr=args.learning_rate,
|
||||
betas=(args.adam_beta1, args.adam_beta2),
|
||||
weight_decay=args.adam_weight_decay,
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
```
|
||||
|
||||
除LoRA层设置外,该训练脚本与标准train_text_to_image.py基本相同!
|
||||
|
||||
## 启动训练
|
||||
|
||||
完成所有配置后,即可启动训练脚本!🚀
|
||||
|
||||
以下示例使用[Naruto BLIP captions](https://huggingface.co/datasets/lambdalabs/naruto-blip-captions)训练生成火影角色。请设置环境变量`MODEL_NAME`和`DATASET_NAME`指定基础模型和数据集,`OUTPUT_DIR`设置输出目录,`HUB_MODEL_ID`指定Hub存储库名称。脚本运行后将生成以下文件:
|
||||
|
||||
- 模型检查点
|
||||
- `pytorch_lora_weights.safetensors`(训练好的LoRA权重)
|
||||
|
||||
多GPU训练请添加`--multi_gpu`参数。
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
在11GB显存的2080 Ti显卡上完整训练约需5小时。
|
||||
|
||||
</Tip>
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="stable-diffusion-v1-5/stable-diffusion-v1-5"
|
||||
export OUTPUT_DIR="/sddata/finetune/lora/naruto"
|
||||
export HUB_MODEL_ID="naruto-lora"
|
||||
export DATASET_NAME="lambdalabs/naruto-blip-captions"
|
||||
|
||||
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--dataset_name=$DATASET_NAME \
|
||||
--dataloader_num_workers=8 \
|
||||
--resolution=512 \
|
||||
--center_crop \
|
||||
--random_flip \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--max_train_steps=15000 \
|
||||
--learning_rate=1e-04 \
|
||||
--max_grad_norm=1 \
|
||||
--lr_scheduler="cosine" \
|
||||
--lr_warmup_steps=0 \
|
||||
--output_dir=${OUTPUT_DIR} \
|
||||
--push_to_hub \
|
||||
--hub_model_id=${HUB_MODEL_ID} \
|
||||
--report_to=wandb \
|
||||
--checkpointing_steps=500 \
|
||||
--validation_prompt="蓝色眼睛的火影忍者角色" \
|
||||
--seed=1337
|
||||
```
|
||||
|
||||
训练完成后,您可以通过以下方式进行推理:
|
||||
|
||||
```py
|
||||
from diffusers import AutoPipelineForText2Image
|
||||
import torch
|
||||
|
||||
pipeline = AutoPipelineForText2Image.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", torch_dtype=torch.float16).to("cuda")
|
||||
pipeline.load_lora_weights("path/to/lora/model", weight_name="pytorch_lora_weights.safetensors")
|
||||
image = pipeline("A naruto with blue eyes").images[0]
|
||||
```
|
||||
|
||||
## 后续步骤
|
||||
|
||||
恭喜完成LoRA模型训练!如需进一步了解模型使用方法,可参考以下指南:
|
||||
|
||||
- 学习如何加载[不同格式的LoRA权重](../using-diffusers/loading_adapters#LoRA)(如Kohya或TheLastBen训练的模型)
|
||||
- 掌握使用PEFT进行[多LoRA组合推理](../tutorials/using_peft_for_inference)的技巧
|
||||
60
docs/source/zh/training/overview.md
Normal file
60
docs/source/zh/training/overview.md
Normal file
@@ -0,0 +1,60 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
根据 Apache License 2.0 版本("许可证")授权,除非符合许可证要求,否则不得使用此文件。您可以通过以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,本软件按"原样"分发,不附带任何明示或暗示的担保或条件。详见许可证中规定的特定语言权限和限制。
|
||||
-->
|
||||
|
||||
# 概述
|
||||
|
||||
🤗 Diffusers 提供了一系列训练脚本供您训练自己的diffusion模型。您可以在 [diffusers/examples](https://github.com/huggingface/diffusers/tree/main/examples) 找到所有训练脚本。
|
||||
|
||||
每个训练脚本具有以下特点:
|
||||
|
||||
- **独立完整**:训练脚本不依赖任何本地文件,所有运行所需的包都通过 `requirements.txt` 文件安装
|
||||
- **易于调整**:这些脚本是针对特定任务的训练示例,并不能开箱即用地适用于所有训练场景。您可能需要根据具体用例调整脚本。为此,我们完全公开了数据预处理代码和训练循环,方便您进行修改
|
||||
- **新手友好**:脚本设计注重易懂性和入门友好性,而非包含最新最优方法以获得最具竞争力的结果。我们有意省略了过于复杂的训练方法
|
||||
- **单一用途**:每个脚本仅针对一个任务设计,确保代码可读性和可理解性
|
||||
|
||||
当前提供的训练脚本包括:
|
||||
|
||||
| 训练类型 | 支持SDXL | 支持LoRA | 支持Flax |
|
||||
|---|---|---|---|
|
||||
| [unconditional image generation](https://github.com/huggingface/diffusers/tree/main/examples/unconditional_image_generation) [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb) | | | |
|
||||
| [text-to-image](https://github.com/huggingface/diffusers/tree/main/examples/text_to_image) | 👍 | 👍 | 👍 |
|
||||
| [textual inversion](https://github.com/huggingface/diffusers/tree/main/examples/textual_inversion) [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb) | | | 👍 |
|
||||
| [DreamBooth](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth) [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb) | 👍 | 👍 | 👍 |
|
||||
| [ControlNet](https://github.com/huggingface/diffusers/tree/main/examples/controlnet) | 👍 | | 👍 |
|
||||
| [InstructPix2Pix](https://github.com/huggingface/diffusers/tree/main/examples/instruct_pix2pix) | 👍 | | |
|
||||
| [Custom Diffusion](https://github.com/huggingface/diffusers/tree/main/examples/custom_diffusion) | | | |
|
||||
| [T2I-Adapters](https://github.com/huggingface/diffusers/tree/main/examples/t2i_adapter) | 👍 | | |
|
||||
| [Kandinsky 2.2](https://github.com/huggingface/diffusers/tree/main/examples/kandinsky2_2/text_to_image) | | 👍 | |
|
||||
| [Wuerstchen](https://github.com/huggingface/diffusers/tree/main/examples/wuerstchen/text_to_image) | | 👍 | |
|
||||
|
||||
这些示例处于**积极维护**状态,如果遇到问题请随时提交issue。如果您认为应该添加其他训练示例,欢迎创建[功能请求](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=)与我们讨论,我们将评估其是否符合独立完整、易于调整、新手友好和单一用途的标准。
|
||||
|
||||
## 安装
|
||||
|
||||
请按照以下步骤在新虚拟环境中从源码安装库,确保能成功运行最新版本的示例脚本:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers
|
||||
cd diffusers
|
||||
pip install .
|
||||
```
|
||||
|
||||
然后进入具体训练脚本目录(例如[DreamBooth](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth)),安装对应的`requirements.txt`文件。部分脚本针对SDXL、LoRA或Flax有特定要求文件,使用时请确保安装对应文件。
|
||||
|
||||
```bash
|
||||
cd examples/dreambooth
|
||||
pip install -r requirements.txt
|
||||
# 如需用DreamBooth训练SDXL
|
||||
pip install -r requirements_sdxl.txt
|
||||
```
|
||||
|
||||
为加速训练并降低内存消耗,我们建议:
|
||||
|
||||
- 使用PyTorch 2.0或更高版本,自动启用[缩放点积注意力](../optimization/fp16#scaled-dot-product-attention)(无需修改训练代码)
|
||||
- 安装[xFormers](../optimization/xformers)以启用内存高效注意力机制
|
||||
275
docs/source/zh/training/text2image.md
Normal file
275
docs/source/zh/training/text2image.md
Normal file
@@ -0,0 +1,275 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# 文生图
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
文生图训练脚本目前处于实验阶段,容易出现过拟合和灾难性遗忘等问题。建议尝试不同超参数以获得最佳数据集适配效果。
|
||||
|
||||
</Tip>
|
||||
|
||||
Stable Diffusion 等文生图模型能够根据文本提示生成对应图像。
|
||||
|
||||
模型训练对硬件要求较高,但启用 `gradient_checkpointing` 和 `mixed_precision` 后,可在单块24GB显存GPU上完成训练。如需更大批次或更快训练速度,建议使用30GB以上显存的GPU设备。通过启用 [xFormers](../optimization/xformers) 内存高效注意力机制可降低显存占用。JAX/Flax 训练方案也支持TPU/GPU高效训练,但不支持梯度检查点、梯度累积和xFormers。使用Flax训练时建议配备30GB以上显存GPU或TPU v3。
|
||||
|
||||
本指南将详解 [train_text_to_image.py](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image.py) 训练脚本,助您掌握其原理并适配自定义需求。
|
||||
|
||||
运行脚本前请确保已从源码安装库:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers
|
||||
cd diffusers
|
||||
pip install .
|
||||
```
|
||||
|
||||
然后进入包含训练脚本的示例目录,安装对应依赖:
|
||||
|
||||
<hfoptions id="installation">
|
||||
<hfoption id="PyTorch">
|
||||
```bash
|
||||
cd examples/text_to_image
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
</hfoption>
|
||||
<hfoption id="Flax">
|
||||
```bash
|
||||
cd examples/text_to_image
|
||||
pip install -r requirements_flax.txt
|
||||
```
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
<Tip>
|
||||
|
||||
🤗 Accelerate 是支持多GPU/TPU训练和混合精度的工具库,能根据硬件环境自动配置训练参数。参阅 🤗 Accelerate [快速入门](https://huggingface.co/docs/accelerate/quicktour) 了解更多。
|
||||
|
||||
</Tip>
|
||||
|
||||
初始化 🤗 Accelerate 环境:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
要创建默认配置环境(不进行交互式选择):
|
||||
|
||||
```bash
|
||||
accelerate config default
|
||||
```
|
||||
|
||||
若环境不支持交互式shell(如notebook),可使用:
|
||||
|
||||
```py
|
||||
from accelerate.utils import write_basic_config
|
||||
|
||||
write_basic_config()
|
||||
```
|
||||
|
||||
最后,如需在自定义数据集上训练,请参阅 [创建训练数据集](create_dataset) 指南了解如何准备适配脚本的数据集。
|
||||
|
||||
## 脚本参数
|
||||
|
||||
<Tip>
|
||||
|
||||
以下重点介绍脚本中影响训练效果的关键参数,如需完整参数说明可查阅 [脚本源码](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image.py)。如有疑问欢迎反馈。
|
||||
|
||||
</Tip>
|
||||
|
||||
训练脚本提供丰富参数供自定义训练流程,所有参数及说明详见 [`parse_args()`](https://github.com/huggingface/diffusers/blob/8959c5b9dec1c94d6ba482c94a58d2215c5fd026/examples/text_to_image/train_text_to_image.py#L193) 函数。该函数为每个参数提供默认值(如批次大小、学习率等),也可通过命令行参数覆盖。
|
||||
|
||||
例如使用fp16混合精度加速训练:
|
||||
|
||||
```bash
|
||||
accelerate launch train_text_to_image.py \
|
||||
--mixed_precision="fp16"
|
||||
```
|
||||
|
||||
基础重要参数包括:
|
||||
|
||||
- `--pretrained_model_name_or_path`: Hub模型名称或本地预训练模型路径
|
||||
- `--dataset_name`: Hub数据集名称或本地训练数据集路径
|
||||
- `--image_column`: 数据集中图像列名
|
||||
- `--caption_column`: 数据集中文本列名
|
||||
- `--output_dir`: 模型保存路径
|
||||
- `--push_to_hub`: 是否将训练模型推送至Hub
|
||||
- `--checkpointing_steps`: 模型检查点保存步数;训练中断时可添加 `--resume_from_checkpoint` 从该检查点恢复训练
|
||||
|
||||
### Min-SNR加权策略
|
||||
|
||||
[Min-SNR](https://huggingface.co/papers/2303.09556) 加权策略通过重新平衡损失函数加速模型收敛。训练脚本支持预测 `epsilon`(噪声)或 `v_prediction`,而Min-SNR兼容两种预测类型。该策略仅限PyTorch版本,Flax训练脚本不支持。
|
||||
|
||||
添加 `--snr_gamma` 参数并设为推荐值5.0:
|
||||
|
||||
```bash
|
||||
accelerate launch train_text_to_image.py \
|
||||
--snr_gamma=5.0
|
||||
```
|
||||
|
||||
可通过此 [Weights and Biases](https://wandb.ai/sayakpaul/text2image-finetune-minsnr) 报告比较不同 `snr_gamma` 值的损失曲面。小数据集上Min-SNR效果可能不如大数据集显著。
|
||||
|
||||
## 训练脚本解析
|
||||
|
||||
数据集预处理代码和训练循环位于 [`main()`](https://github.com/huggingface/diffusers/blob/8959c5b9dec1c94d6ba482c94a58d2215c5fd026/examples/text_to_image/train_text_to_image.py#L490) 函数,自定义修改需在此处进行。
|
||||
|
||||
`train_text_to_image` 脚本首先 [加载调度器](https://github.com/huggingface/diffusers/blob/8959c5b9dec1c94d6ba482c94a58d2215c5fd026/examples/text_to_image/train_text_to_image.py#L543) 和分词器,此处可替换其他调度器:
|
||||
|
||||
```py
|
||||
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
|
||||
tokenizer = CLIPTokenizer.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="tokenizer", revision=args.revision
|
||||
)
|
||||
```
|
||||
|
||||
接着 [加载UNet模型](https://github.com/huggingface/diffusers/blob/8959c5b9dec1c94d6ba482c94a58d2215c5fd026/examples/text_to_image/train_text_to_image.py#L619):
|
||||
|
||||
```py
|
||||
load_model = UNet2DConditionModel.from_pretrained(input_dir, subfolder="unet")
|
||||
model.register_to_config(**load_model.config)
|
||||
|
||||
model.load_state_dict(load_model.state_dict())
|
||||
```
|
||||
|
||||
随后对数据集的文本和图像列进行预处理。[`tokenize_captions`](https://github.com/huggingface/diffusers/blob/8959c5b9dec1c94d6ba482c94a58d2215c5fd026/examples/text_to_image/train_text_to_image.py#L724) 函数处理文本分词,[`train_transforms`](https://github.com/huggingface/diffusers/blob/8959c5b9dec1c94d6ba482c94a58d2215c5fd026/examples/text_to_image/train_text_to_image.py#L742) 定义图像增强策略,二者集成于 `preprocess_train`:
|
||||
|
||||
```py
|
||||
def preprocess_train(examples):
|
||||
images = [image.convert("RGB") for image in examples[image_column]]
|
||||
examples["pixel_values"] = [train_transforms(image) for image in images]
|
||||
examples["input_ids"] = tokenize_captions(examples)
|
||||
return examples
|
||||
```
|
||||
|
||||
最后,[训练循环](https://github.com/huggingface/diffusers/blob/8959c5b9dec1c94d6ba482c94a58d2215c5fd026/examples/text_to_image/train_text_to_image.py#L878) 处理剩余流程:图像编码为潜空间、添加噪声、计算文本嵌入条件、更新模型参数、保存并推送模型至Hub。想深入了解训练循环原理,可参阅 [理解管道、模型与调度器](../using-diffusers/write_own_pipeline) 教程,该教程解析了去噪过程的核心逻辑。
|
||||
|
||||
## 启动脚本
|
||||
|
||||
完成所有配置后,即可启动训练脚本!🚀
|
||||
|
||||
<hfoptions id="training-inference">
|
||||
<hfoption id="PyTorch">
|
||||
|
||||
以 [火影忍者BLIP标注数据集](https://huggingface.co/datasets/lambdalabs/naruto-blip-captions) 为例训练生成火影角色。设置环境变量 `MODEL_NAME` 和 `dataset_name` 指定模型和数据集(Hub或本地路径)。多GPU训练需在 `accelerate launch` 命令中添加 `--multi_gpu` 参数。
|
||||
|
||||
<Tip>
|
||||
|
||||
使用本地数据集时,设置 `TRAIN_DIR` 和 `OUTPUT_DIR` 环境变量为数据集路径和模型保存路径。
|
||||
|
||||
</Tip>
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="stable-diffusion-v1-5/stable-diffusion-v1-5"
|
||||
export dataset_name="lambdalabs/naruto-blip-captions"
|
||||
|
||||
accelerate launch --mixed_precision="fp16" train_text_to_image.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--dataset_name=$dataset_name \
|
||||
--use_ema \
|
||||
--resolution=512 --center_crop --random_flip \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--gradient_checkpointing \
|
||||
--max_train_steps=15000 \
|
||||
--learning_rate=1e-05 \
|
||||
--max_grad_norm=1 \
|
||||
--enable_xformers_memory_efficient_attention \
|
||||
--lr_scheduler="constant" --lr_warmup_steps=0 \
|
||||
--output_dir="sd-naruto-model" \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="Flax">
|
||||
|
||||
Flax训练方案在TPU/GPU上效率更高(由 [@duongna211](https://github.com/duongna21) 实现),TPU性能更优但GPU表现同样出色。
|
||||
|
||||
设置环境变量 `MODEL_NAME` 和 `dataset_name` 指定模型和数据集(Hub或本地路径)。
|
||||
|
||||
<Tip>
|
||||
|
||||
使用本地数据集时,设置 `TRAIN_DIR` 和 `OUTPUT_DIR` 环境变量为数据集路径和模型保存路径。
|
||||
|
||||
</Tip>
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="stable-diffusion-v1-5/stable-diffusion-v1-5"
|
||||
export dataset_name="lambdalabs/naruto-blip-captions"
|
||||
|
||||
python train_text_to_image_flax.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--dataset_name=$dataset_name \
|
||||
--resolution=512 --center_crop --random_flip \
|
||||
--train_batch_size=1 \
|
||||
--max_train_steps=15000 \
|
||||
--learning_rate=1e-05 \
|
||||
--max_grad_norm=1 \
|
||||
--output_dir="sd-naruto-model" \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
训练完成后,即可使用新模型进行推理:
|
||||
|
||||
<hfoptions id="training-inference">
|
||||
<hfoption id="PyTorch">
|
||||
|
||||
```py
|
||||
from diffusers import StableDiffusionPipeline
|
||||
import torch
|
||||
|
||||
pipeline = StableDiffusionPipeline.from_pretrained("path/to/saved_model", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
|
||||
|
||||
image = pipeline(prompt="yoda").images[0]
|
||||
image.save("yoda-naruto.png")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="Flax">
|
||||
|
||||
```py
|
||||
import jax
|
||||
import numpy as np
|
||||
from flax.jax_utils import replicate
|
||||
from flax.training.common_utils import shard
|
||||
from diffusers import FlaxStableDiffusionPipeline
|
||||
|
||||
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained("path/to/saved_model", dtype=jax.numpy.bfloat16)
|
||||
|
||||
prompt = "yoda naruto"
|
||||
prng_seed = jax.random.PRNGKey(0)
|
||||
num_inference_steps = 50
|
||||
|
||||
num_samples = jax.device_count()
|
||||
prompt = num_samples * [prompt]
|
||||
prompt_ids = pipeline.prepare_inputs(prompt)
|
||||
|
||||
# 分片输入和随机数
|
||||
params = replicate(params)
|
||||
prng_seed = jax.random.split(prng_seed, jax.device_count())
|
||||
prompt_ids = shard(prompt_ids)
|
||||
|
||||
images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
|
||||
images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
|
||||
image.save("yoda-naruto.png")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## 后续步骤
|
||||
|
||||
恭喜完成文生图模型训练!如需进一步使用模型,以下指南可能有所帮助:
|
||||
|
||||
- 了解如何加载 [LoRA权重](../using-diffusers/loading_adapters#LoRA) 进行推理(如果训练时使用了LoRA)
|
||||
- 在 [文生图](../using-diffusers/conditional_image_generation) 任务指南中,了解引导尺度等参数或提示词加权等技术如何控制生成效果
|
||||
296
docs/source/zh/training/text_inversion.md
Normal file
296
docs/source/zh/training/text_inversion.md
Normal file
@@ -0,0 +1,296 @@
|
||||
<!--版权声明 2025 由 HuggingFace 团队所有。保留所有权利。
|
||||
|
||||
根据 Apache 许可证 2.0 版("许可证")授权;除非符合许可证要求,否则不得使用本文件。
|
||||
您可以通过以下网址获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,本软件按"原样"分发,不附带任何明示或暗示的担保或条件。详见许可证中规定的特定语言权限和限制。
|
||||
-->
|
||||
|
||||
# 文本反转(Textual Inversion)
|
||||
|
||||
[文本反转](https://hf.co/papers/2208.01618)是一种训练技术,仅需少量示例图像即可个性化图像生成模型。该技术通过学习和更新文本嵌入(新嵌入会绑定到提示中必须使用的特殊词汇)来匹配您提供的示例图像。
|
||||
|
||||
如果在显存有限的GPU上训练,建议在训练命令中启用`gradient_checkpointing`和`mixed_precision`参数。您还可以通过[xFormers](../optimization/xformers)使用内存高效注意力机制来减少内存占用。JAX/Flax训练也支持在TPU和GPU上进行高效训练,但不支持梯度检查点或xFormers。在配置与PyTorch相同的情况下,Flax训练脚本的速度至少应快70%!
|
||||
|
||||
本指南将探索[textual_inversion.py](https://github.com/huggingface/diffusers/blob/main/examples/textual_inversion/textual_inversion.py)脚本,帮助您更熟悉其工作原理,并了解如何根据自身需求进行调整。
|
||||
|
||||
运行脚本前,请确保从源码安装库:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers
|
||||
cd diffusers
|
||||
pip install .
|
||||
```
|
||||
|
||||
进入包含训练脚本的示例目录,并安装所需依赖:
|
||||
|
||||
<hfoptions id="installation">
|
||||
<hfoption id="PyTorch">
|
||||
|
||||
```bash
|
||||
cd examples/textual_inversion
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="Flax">
|
||||
|
||||
```bash
|
||||
cd examples/textual_inversion
|
||||
pip install -r requirements_flax.txt
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
<Tip>
|
||||
|
||||
🤗 Accelerate 是一个帮助您在多GPU/TPU或混合精度环境下训练的工具库。它会根据硬件和环境自动配置训练设置。查看🤗 Accelerate [快速入门](https://huggingface.co/docs/accelerate/quicktour)了解更多。
|
||||
|
||||
</Tip>
|
||||
|
||||
初始化🤗 Accelerate环境:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
要设置默认的🤗 Accelerate环境(不选择任何配置):
|
||||
|
||||
```bash
|
||||
accelerate config default
|
||||
```
|
||||
|
||||
如果您的环境不支持交互式shell(如notebook),可以使用:
|
||||
|
||||
```py
|
||||
from accelerate.utils import write_basic_config
|
||||
|
||||
write_basic_config()
|
||||
```
|
||||
|
||||
最后,如果想在自定义数据集上训练模型,请参阅[创建训练数据集](create_dataset)指南,了解如何创建适用于训练脚本的数据集。
|
||||
|
||||
<Tip>
|
||||
|
||||
以下部分重点介绍训练脚本中需要理解的关键修改点,但未涵盖脚本所有细节。如需深入了解,可随时查阅[脚本源码](https://github.com/huggingface/diffusers/blob/main/examples/textual_inversion/textual_inversion.py),如有疑问欢迎反馈。
|
||||
|
||||
</Tip>
|
||||
|
||||
## 脚本参数
|
||||
|
||||
训练脚本包含众多参数,便于您定制训练过程。所有参数及其说明都列在[`parse_args()`](https://github.com/huggingface/diffusers/blob/839c2a5ece0af4e75530cb520d77bc7ed8acf474/examples/textual_inversion/textual_inversion.py#L176)函数中。Diffusers为每个参数提供了默认值(如训练批次大小和学习率),但您可以通过训练命令自由调整这些值。
|
||||
|
||||
例如,将梯度累积步数增加到默认值1以上:
|
||||
|
||||
```bash
|
||||
accelerate launch textual_inversion.py \
|
||||
--gradient_accumulation_steps=4
|
||||
```
|
||||
|
||||
其他需要指定的基础重要参数包括:
|
||||
|
||||
- `--pretrained_model_name_or_path`:Hub上的模型名称或本地预训练模型路径
|
||||
- `--train_data_dir`:包含训练数据集(示例图像)的文件夹路径
|
||||
- `--output_dir`:训练模型保存位置
|
||||
- `--push_to_hub`:是否将训练好的模型推送至Hub
|
||||
- `--checkpointing_steps`:训练过程中保存检查点的频率;若训练意外中断,可通过在命令中添加`--resume_from_checkpoint`从该检查点恢复训练
|
||||
- `--num_vectors`:学习嵌入的向量数量;增加此参数可提升模型效果,但会提高训练成本
|
||||
- `--placeholder_token`:绑定学习嵌入的特殊词汇(推理时需在提示中使用该词)
|
||||
- `--initializer_token`:大致描述训练目标的单字词汇(如物体或风格)
|
||||
- `--learnable_property`:训练目标是学习新"风格"(如梵高画风)还是"物体"(如您的宠物狗)
|
||||
|
||||
## 训练脚本
|
||||
|
||||
与其他训练脚本不同,textual_inversion.py包含自定义数据集类[`TextualInversionDataset`](https://github.com/huggingface/diffusers/blob/b81c69e489aad3a0ba73798c459a33990dc4379c/examples/textual_inversion/textual_inversion.py#L487),用于创建数据集。您可以自定义图像尺寸、占位符词汇、插值方法、是否裁剪图像等。如需修改数据集创建方式,可调整`TextualInversionDataset`类。
|
||||
|
||||
接下来,在[`main()`](https://github.com/huggingface/diffusers/blob/839c2a5ece0af4e75530cb520d77bc7ed8acf474/examples/textual_inversion/textual_inversion.py#L573)函数中可找到数据集预处理代码和训练循环。
|
||||
|
||||
脚本首先加载[tokenizer](https://github.com/huggingface/diffusers/blob/b81c69e489aad3a0ba73798c459a33990dc4379c/examples/textual_inversion/textual_inversion.py#L616)、[scheduler和模型](https://github.com/huggingface/diffusers/blob/b81c69e489aad3a0ba73798c459a33990dc4379c/examples/textual_inversion/textual_inversion.py#L622):
|
||||
|
||||
```py
|
||||
# 加载tokenizer
|
||||
if args.tokenizer_name:
|
||||
tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
|
||||
elif args.pretrained_model_name_or_path:
|
||||
tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
|
||||
|
||||
# 加载scheduler和模型
|
||||
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
|
||||
text_encoder = CLIPTextModel.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision
|
||||
)
|
||||
vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae", revision=args.revision)
|
||||
unet = UNet2DConditionModel.from_pretrained(
|
||||
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision
|
||||
)
|
||||
```
|
||||
|
||||
随后将特殊[占位符词汇](https://github.com/huggingface/diffusers/blob/b81c69e489aad3a0ba73798c459a33990dc4379c/examples/textual_inversion/textual_inversion.py#L632)加入tokenizer,并调整嵌入层以适配新词汇。
|
||||
|
||||
接着,脚本通过`TextualInversionDataset`[创建数据集](https://github.com/huggingface/diffusers/blob/b81c69e489aad3a0ba73798c459a33990dc4379c/examples/textual_inversion/textual_inversion.py#L716):
|
||||
|
||||
```py
|
||||
train_dataset = TextualInversionDataset(
|
||||
data_root=args.train_data_dir,
|
||||
tokenizer=tokenizer,
|
||||
size=args.resolution,
|
||||
placeholder_token=(" ".join(tokenizer.convert_ids_to_tokens(placeholder_token_ids))),
|
||||
repeats=args.repeats,
|
||||
learnable_property=args.learnable_property,
|
||||
center_crop=args.center_crop,
|
||||
set="train",
|
||||
)
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset, batch_size=args.train_batch_size, shuffle=True, num_workers=args.dataloader_num_workers
|
||||
)
|
||||
```
|
||||
|
||||
最后,[训练循环](https://github.com/huggingface/diffusers/blob/b81c69e489aad3a0ba73798c459a33990dc4379c/examples/textual_inversion/textual_inversion.py#L784)处理从预测噪声残差到更新特殊占位符词汇嵌入权重的所有流程。
|
||||
|
||||
如需深入了解训练循环工作原理,请参阅[理解管道、模型与调度器](../using-diffusers/write_own_pipeline)教程,该教程解析了去噪过程的基本模式。
|
||||
|
||||
## 启动脚本
|
||||
|
||||
完成所有修改或确认默认配置后,即可启动训练脚本!🚀
|
||||
|
||||
本指南将下载[猫玩具](https://huggingface.co/datasets/diffusers/cat_toy_example)的示例图像并存储在目录中。当然,您也可以创建和使用自己的数据集(参见[创建训练数据集](create_dataset)指南)。
|
||||
|
||||
```py
|
||||
from huggingface_hub import snapshot_download
|
||||
|
||||
local_dir = "./cat"
|
||||
snapshot_download(
|
||||
"diffusers/cat_toy_example", local_dir=local_dir, repo_type="dataset", ignore_patterns=".gitattributes"
|
||||
)
|
||||
```
|
||||
|
||||
设置环境变量`MODEL_NAME`为Hub上的模型ID或本地模型路径,`DATA_DIR`为刚下载的猫图像路径。脚本会将以下文件保存至您的仓库:
|
||||
|
||||
- `learned_embeds.bin`:与示例图像对应的学习嵌入向量
|
||||
- `token_identifier.txt`:特殊占位符词汇
|
||||
- `type_of_concept.txt`:训练概念类型("object"或"style")
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
在单块V100 GPU上完整训练约需1小时。
|
||||
|
||||
</Tip>
|
||||
|
||||
启动脚本前还有最后一步。如果想实时观察训练过程,可以定期保存生成图像。在训练命令中添加以下参数:
|
||||
|
||||
```bash
|
||||
--validation_prompt="A <cat-toy> train"
|
||||
--num_validation_images=4
|
||||
--validation_steps=100
|
||||
```
|
||||
|
||||
<hfoptions id="training-inference">
|
||||
<hfoption id="PyTorch">
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="stable-diffusion-v1-5/stable-diffusion-v1-5"
|
||||
export DATA_DIR="./cat"
|
||||
|
||||
accelerate launch textual_inversion.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--train_data_dir=$DATA_DIR \
|
||||
--learnable_property="object" \
|
||||
--placeholder_token="<cat-toy>" \
|
||||
--initializer_token="toy" \
|
||||
--resolution=512 \
|
||||
--train_batch_size=1 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--max_train_steps=3000 \
|
||||
--learning_rate=5.0e-04 \
|
||||
--scale_lr \
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--output_dir="textual_inversion_cat" \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="Flax">
|
||||
|
||||
```bash
|
||||
export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
|
||||
export DATA_DIR="./cat"
|
||||
|
||||
python textual_inversion_flax.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--train_data_dir=$DATA_DIR \
|
||||
--learnable_property="object" \
|
||||
--placeholder_token="<cat-toy>" \
|
||||
--initializer_token="toy" \
|
||||
--resolution=512 \
|
||||
--train_batch_size=1 \
|
||||
--max_train_steps=3000 \
|
||||
--learning_rate=5.0e-04 \
|
||||
--scale_lr \
|
||||
--output_dir="textual_inversion_cat" \
|
||||
--push_to_hub
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
训练完成后,可以像这样使用新模型进行推理:
|
||||
|
||||
<hfoptions id="training-inference">
|
||||
<hfoption id="PyTorch">
|
||||
|
||||
```py
|
||||
from diffusers import StableDiffusionPipeline
|
||||
import torch
|
||||
|
||||
pipeline = StableDiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", torch_dtype=torch.float16).to("cuda")
|
||||
pipeline.load_textual_inversion("sd-concepts-library/cat-toy")
|
||||
image = pipeline("A <cat-toy> train", num_inference_steps=50).images[0]
|
||||
image.save("cat-train.png")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="Flax">
|
||||
|
||||
Flax不支持[`~loaders.TextualInversionLoaderMixin.load_textual_inversion`]方法,但textual_inversion_flax.py脚本会在训练后[保存](https://github.com/huggingface/diffusers/blob/c0f058265161178f2a88849e92b37ffdc81f1dcc/examples/textual_inversion/textual_inversion_flax.py#L636C2-L636C2)学习到的嵌入作为模型的一部分。这意味着您可以像使用其他Flax模型一样进行推理:
|
||||
|
||||
```py
|
||||
import jax
|
||||
import numpy as np
|
||||
from flax.jax_utils import replicate
|
||||
from flax.training.common_utils import shard
|
||||
from diffusers import FlaxStableDiffusionPipeline
|
||||
|
||||
model_path = "path-to-your-trained-model"
|
||||
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(model_path, dtype=jax.numpy.bfloat16)
|
||||
|
||||
prompt = "A <cat-toy> train"
|
||||
prng_seed = jax.random.PRNGKey(0)
|
||||
num_inference_steps = 50
|
||||
|
||||
num_samples = jax.device_count()
|
||||
prompt = num_samples * [prompt]
|
||||
prompt_ids = pipeline.prepare_inputs(prompt)
|
||||
|
||||
# 分片输入和随机数生成器
|
||||
params = replicate(params)
|
||||
prng_seed = jax.random.split(prng_seed, jax.device_count())
|
||||
prompt_ids = shard(prompt_ids)
|
||||
|
||||
images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
|
||||
images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
|
||||
image.save("cat-train.png")
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
## 后续步骤
|
||||
|
||||
恭喜您成功训练了自己的文本反转模型!🎉 如需了解更多使用技巧,以下指南可能会有所帮助:
|
||||
|
||||
- 学习如何[加载文本反转嵌入](../using-diffusers/loading_adapters),并将其用作负面嵌入
|
||||
- 学习如何将[文本反转](textual_inversion_inference)应用于Stable Diffusion 1/2和Stable Diffusion XL的推理
|
||||
191
docs/source/zh/training/wuerstchen.md
Normal file
191
docs/source/zh/training/wuerstchen.md
Normal file
@@ -0,0 +1,191 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Wuerstchen
|
||||
|
||||
[Wuerstchen](https://hf.co/papers/2306.00637) 模型通过将潜在空间压缩 42 倍,在不影响图像质量的情况下大幅降低计算成本并加速推理。在训练过程中,Wuerstchen 使用两个模型(VQGAN + 自动编码器)来压缩潜在表示,然后第三个模型(文本条件潜在扩散模型)在这个高度压缩的空间上进行条件化以生成图像。
|
||||
|
||||
为了将先验模型放入 GPU 内存并加速训练,尝试分别启用 `gradient_accumulation_steps`、`gradient_checkpointing` 和 `mixed_precision`。
|
||||
|
||||
本指南探讨 [train_text_to_image_prior.py](https://github.com/huggingface/diffusers/blob/main/examples/wuerstchen/text_to_image/train_text_to_image_prior.py) 脚本,帮助您更熟悉它,以及如何根据您的用例进行适配。
|
||||
|
||||
在运行脚本之前,请确保从源代码安装库:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers
|
||||
cd diffusers
|
||||
pip install .
|
||||
```
|
||||
|
||||
然后导航到包含训练脚本的示例文件夹,并安装脚本所需的依赖项:
|
||||
|
||||
```bash
|
||||
cd examples/wuerstchen/text_to_image
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
<Tip>
|
||||
|
||||
🤗 Accelerate 是一个帮助您在多个 GPU/TPU 上或使用混合精度进行训练的库。它会根据您的硬件和环境自动配置训练设置。查看 🤗 Accelerate [快速入门](https://huggingface.co/docs/accelerate/quicktour) 以了解更多信息。
|
||||
|
||||
</Tip>
|
||||
|
||||
初始化一个 🤗 Accelerate 环境:
|
||||
|
||||
```bash
|
||||
accelerate config
|
||||
```
|
||||
|
||||
要设置一个默认的 🤗 Accelerate 环境而不选择任何配置:
|
||||
|
||||
```bash
|
||||
accelerate config default
|
||||
```
|
||||
|
||||
或者,如果您的环境不支持交互式 shell,例如笔记本,您可以使用:
|
||||
|
||||
```py
|
||||
from accelerate.utils import write_basic_config
|
||||
|
||||
write_basic_config()
|
||||
```
|
||||
|
||||
最后,如果您想在自己的数据集上训练模型,请查看 [创建训练数据集](create_dataset) 指南,了解如何创建与训练脚本兼容的数据集。
|
||||
|
||||
<Tip>
|
||||
|
||||
以下部分重点介绍了训练脚本中对于理解如何修改它很重要的部分,但并未涵盖 [脚本](https://github.com/huggingface/diffusers/blob/main/examples/wuerstchen/text_to_image/train_text_to_image_prior.py) 的详细信息。如果您有兴趣了解更多,请随时阅读脚本,并告诉我们您是否有任何问题或疑虑。
|
||||
|
||||
</Tip>
|
||||
|
||||
## 脚本参数
|
||||
|
||||
训练脚本提供了许多参数来帮助您自定义训练运行。所有参数及其描述都可以在 [`parse_args()`](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/wuerstchen/text_to_image/train_text_to_image_prior.py#L192) 函数中找到。它为每个参数提供了默认值,例如训练批次大小和学习率,但如果您愿意,也可以在训练命令中设置自己的值。
|
||||
|
||||
例如,要使用 fp16 格式的混合精度加速训练,请在训练命令中添加 `--mixed_precision` 参数:
|
||||
|
||||
```bash
|
||||
accelerate launch train_text_to_image_prior.py \
|
||||
--mixed_precision="fp16"
|
||||
```
|
||||
|
||||
大多数参数与 [文本到图像](text2image#script-parameters) 训练指南中的参数相同,因此让我们直接深入 Wuerstchen 训练脚本!
|
||||
|
||||
## 训练脚本
|
||||
|
||||
训练脚本也与 [文本到图像](text2image#training-script) 训练指南类似,但已修改以支持 Wuerstchen。本指南重点介绍 Wuerstchen 训练脚本中独特的代码。
|
||||
|
||||
[`main()`](https://github.com/huggingface/diffusers/blob/6e68c71503682c8693cb5b06a4da4911dfd655ee/examples/wuerstchen/text_to_image/train_text_to_image_prior.py#L441) 函数首先初始化图像编码器 - 一个 [EfficientNet](https://github.com/huggingface/diffusers/blob/main/examples/wuerstchen/text_to_image/modeling_efficient_net_encoder.py) - 以及通常的调度器和分词器。
|
||||
|
||||
```py
|
||||
with ContextManagers(deepspeed_zero_init_disabled_context_manager()):
|
||||
pretrained_checkpoint_file = hf_hub_download("dome272/wuerstchen", filename="model_v2_stage_b.pt")
|
||||
state_dict = torch.load(pretrained_checkpoint_file, map_location="cpu")
|
||||
image_encoder = EfficientNetEncoder()
|
||||
image_encoder.load_state_dict(state_dict["effnet_state_dict"])
|
||||
image_encoder.eval()
|
||||
```
|
||||
|
||||
您还将加载 [`WuerstchenPrior`] 模型以进行优化。
|
||||
|
||||
```py
|
||||
prior = WuerstchenPrior.from_pretrained(args.pretrained_prior_model_name_or_path, subfolder="prior")
|
||||
|
||||
optimizer = optimizer_cls(
|
||||
prior.parameters(),
|
||||
lr=args.learning_rate,
|
||||
betas=(args.adam_beta1, args.adam_beta2),
|
||||
weight_decay=args.adam_weight_decay,
|
||||
eps=args.adam_epsilon,
|
||||
)
|
||||
```
|
||||
|
||||
接下来,您将对图像应用一些 [transforms](https://github.com/huggingface/diffusers/blob/65ef7a0c5c594b4f84092e328fbdd73183613b30/examples/wuerstchen/text_to_image/train_text_to_image_prior.py#L656) 并对标题进行 [tokenize](https://github.com/huggingface/diffusers/blob/65ef7a0c5c594b4f84092e328fbdd73183613b30/examples/wuerstchen/text_to_image/train_text_to_image_prior.py#L637):
|
||||
|
||||
```py
|
||||
def preprocess_train(examples):
|
||||
images = [image.conver
|
||||
t("RGB") for image in examples[image_column]]
|
||||
examples["effnet_pixel_values"] = [effnet_transforms(image) for image in images]
|
||||
examples["text_input_ids"], examples["text_mask"] = tokenize_captions(examples)
|
||||
return examples
|
||||
```
|
||||
|
||||
最后,[训练循环](https://github.com/huggingface/diffusers/blob/65ef7a0c5c594b4f84092e328fbdd73183613b30/examples/wuerstchen/text_to_image/train_text_to_image_prior.py#L656)处理使用`EfficientNetEncoder`将图像压缩到潜在空间,向潜在表示添加噪声,并使用[`WuerstchenPrior`]模型预测噪声残差。
|
||||
|
||||
```py
|
||||
pred_noise = prior(noisy_latents, timesteps, prompt_embeds)
|
||||
```
|
||||
|
||||
如果您想了解更多关于训练循环的工作原理,请查看[理解管道、模型和调度器](../using-diffusers/write_own_pipeline)教程,该教程分解了去噪过程的基本模式。
|
||||
|
||||
## 启动脚本
|
||||
|
||||
一旦您完成了所有更改或对默认配置满意,就可以启动训练脚本了!🚀
|
||||
|
||||
设置`DATASET_NAME`环境变量为Hub中的数据集名称。本指南使用[Naruto BLIP captions](https://huggingface.co/datasets/lambdalabs/naruto-blip-captions)数据集,但您也可以创建和训练自己的数据集(参见[创建用于训练的数据集](create_dataset)指南)。
|
||||
|
||||
<Tip>
|
||||
|
||||
要使用Weights & Biases监控训练进度,请在训练命令中添加`--report_to=wandb`参数。您还需要在训练命令中添加`--validation_prompt`以跟踪结果。这对于调试模型和查看中间结果非常有用。
|
||||
|
||||
</Tip>
|
||||
|
||||
```bash
|
||||
export DATASET_NAME="lambdalabs/naruto-blip-captions"
|
||||
|
||||
accelerate launch train_text_to_image_prior.py \
|
||||
--mixed_precision="fp16" \
|
||||
--dataset_name=$DATASET_NAME \
|
||||
--resolution=768 \
|
||||
--train_batch_size=4 \
|
||||
--gradient_accumulation_steps=4 \
|
||||
--gradient_checkpointing \
|
||||
--dataloader_num_workers=4 \
|
||||
--max_train_steps=15000 \
|
||||
--learning_rate=1e-05 \
|
||||
--max_grad_norm=1 \
|
||||
--checkpoints_total_limit=3 \
|
||||
--lr_scheduler="constant" \
|
||||
--lr_warmup_steps=0 \
|
||||
--validation_prompts="A robot naruto, 4k photo" \
|
||||
--report_to="wandb" \
|
||||
--push_to_hub \
|
||||
--output_dir="wuerstchen-prior-naruto-model"
|
||||
```
|
||||
|
||||
训练完成后,您可以使用新训练的模型进行推理!
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers import AutoPipelineForText2Image
|
||||
from diffusers.pipelines.wuerstchen import DEFAULT_STAGE_C_TIMESTEPS
|
||||
|
||||
pipeline = AutoPipelineForText2Image.from_pretrained("path/to/saved/model", torch_dtype=torch.float16).to("cuda")
|
||||
|
||||
caption = "A cute bird naruto holding a shield"
|
||||
images = pipeline(
|
||||
caption,
|
||||
width=1024,
|
||||
height=1536,
|
||||
prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS,
|
||||
prior_guidance_scale=4.0,
|
||||
num_images_per_prompt=2,
|
||||
).images
|
||||
```
|
||||
|
||||
## 下一步
|
||||
|
||||
恭喜您训练了一个Wuerstchen模型!要了解更多关于如何使用您的新模型的信息,请参
|
||||
以下内容可能有所帮助:
|
||||
|
||||
- 查看 [Wuerstchen](../api/pipelines/wuerstchen#text-to-image-generation) API 文档,了解更多关于如何使用该管道进行文本到图像生成及其限制的信息。
|
||||
256
docs/source/zh/using-diffusers/schedulers.md
Normal file
256
docs/source/zh/using-diffusers/schedulers.md
Normal file
@@ -0,0 +1,256 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
根据 Apache License 2.0 许可证(以下简称"许可证")授权;
|
||||
除非符合许可证要求,否则不得使用本文件。
|
||||
您可以通过以下链接获取许可证副本:
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
除非适用法律要求或书面同意,本软件按"原样"分发,
|
||||
无任何明示或暗示的担保或条件。详见许可证中关于权限和限制的具体规定。
|
||||
-->
|
||||
|
||||
# 加载调度器与模型
|
||||
|
||||
[[open-in-colab]]
|
||||
|
||||
Diffusion管道是由可互换的调度器(schedulers)和模型(models)组成的集合,可通过混合搭配来定制特定用例的流程。调度器封装了整个去噪过程(如去噪步数和寻找去噪样本的算法),其本身不包含可训练参数,因此内存占用极低。模型则主要负责从含噪输入到较纯净样本的前向传播过程。
|
||||
|
||||
本指南将展示如何加载调度器和模型来自定义流程。我们将全程使用[stable-diffusion-v1-5/stable-diffusion-v1-5](https://hf.co/stable-diffusion-v1-5/stable-diffusion-v1-5)检查点,首先加载基础管道:
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True
|
||||
).to("cuda")
|
||||
```
|
||||
|
||||
通过`pipeline.scheduler`属性可查看当前管道使用的调度器:
|
||||
|
||||
```python
|
||||
pipeline.scheduler
|
||||
PNDMScheduler {
|
||||
"_class_name": "PNDMScheduler",
|
||||
"_diffusers_version": "0.21.4",
|
||||
"beta_end": 0.012,
|
||||
"beta_schedule": "scaled_linear",
|
||||
"beta_start": 0.00085,
|
||||
"clip_sample": false,
|
||||
"num_train_timesteps": 1000,
|
||||
"set_alpha_to_one": false,
|
||||
"skip_prk_steps": true,
|
||||
"steps_offset": 1,
|
||||
"timestep_spacing": "leading",
|
||||
"trained_betas": null
|
||||
}
|
||||
```
|
||||
|
||||
## 加载调度器
|
||||
|
||||
调度器通过配置文件定义,同一配置文件可被多种调度器共享。使用[`SchedulerMixin.from_pretrained`]方法加载时,需指定`subfolder`参数以定位配置文件在仓库中的正确子目录。
|
||||
|
||||
例如加载[`DDIMScheduler`]:
|
||||
|
||||
```python
|
||||
from diffusers import DDIMScheduler, DiffusionPipeline
|
||||
|
||||
ddim = DDIMScheduler.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", subfolder="scheduler")
|
||||
```
|
||||
|
||||
然后将新调度器传入管道:
|
||||
|
||||
```python
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5", scheduler=ddim, torch_dtype=torch.float16, use_safetensors=True
|
||||
).to("cuda")
|
||||
```
|
||||
|
||||
## 调度器对比
|
||||
|
||||
不同调度器各有优劣,难以定量评估哪个最适合您的流程。通常需要在去噪速度与质量之间权衡。我们建议尝试多种调度器以找到最佳方案。通过`pipeline.scheduler.compatibles`属性可查看兼容当前管道的所有调度器。
|
||||
|
||||
下面我们使用相同提示词和随机种子,对比[`LMSDiscreteScheduler`]、[`EulerDiscreteScheduler`]、[`EulerAncestralDiscreteScheduler`]和[`DPMSolverMultistepScheduler`]的表现:
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5", torch_dtype=torch.float16, use_safetensors=True
|
||||
).to("cuda")
|
||||
|
||||
prompt = "A photograph of an astronaut riding a horse on Mars, high resolution, high definition."
|
||||
generator = torch.Generator(device="cuda").manual_seed(8)
|
||||
```
|
||||
|
||||
使用[`~ConfigMixin.from_config`]方法加载不同调度器的配置来切换管道调度器:
|
||||
|
||||
<hfoptions id="schedulers">
|
||||
<hfoption id="LMSDiscreteScheduler">
|
||||
|
||||
[`LMSDiscreteScheduler`]通常能生成比默认调度器更高质量的图像。
|
||||
|
||||
```python
|
||||
from diffusers import LMSDiscreteScheduler
|
||||
|
||||
pipeline.scheduler = LMSDiscreteScheduler.from_config(pipeline.scheduler.config)
|
||||
image = pipeline(prompt, generator=generator).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="EulerDiscreteScheduler">
|
||||
|
||||
[`EulerDiscreteScheduler`]仅需30步即可生成高质量图像。
|
||||
|
||||
```python
|
||||
from diffusers import EulerDiscreteScheduler
|
||||
|
||||
pipeline.scheduler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
|
||||
image = pipeline(prompt, generator=generator).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="EulerAncestralDiscreteScheduler">
|
||||
|
||||
[`EulerAncestralDiscreteScheduler`]同样可在30步内生成高质量图像。
|
||||
|
||||
```python
|
||||
from diffusers import EulerAncestralDiscreteScheduler
|
||||
|
||||
pipeline.scheduler = EulerAncestralDiscreteScheduler.from_config(pipeline.scheduler.config)
|
||||
image = pipeline(prompt, generator=generator).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
<hfoption id="DPMSolverMultistepScheduler">
|
||||
|
||||
[`DPMSolverMultistepScheduler`]在速度与质量间取得平衡,仅需20步即可生成优质图像。
|
||||
|
||||
```python
|
||||
from diffusers import DPMSolverMultistepScheduler
|
||||
|
||||
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(pipeline.scheduler.config)
|
||||
image = pipeline(prompt, generator=generator).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
</hfoption>
|
||||
</hfoptions>
|
||||
|
||||
<div class="flex gap-4">
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_lms.png" />
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">LMSDiscreteScheduler</figcaption>
|
||||
</div>
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_euler_discrete.png" />
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">EulerDiscreteScheduler</figcaption>
|
||||
</div>
|
||||
</div>
|
||||
<div class="flex gap-4">
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_euler_ancestral.png" />
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">EulerAncestralDiscreteScheduler</figcaption>
|
||||
</div>
|
||||
<div>
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/diffusers_docs/astronaut_dpm.png" />
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">DPMSolverMultistepScheduler</figcaption>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
多数生成图像质量相近,实际选择需根据具体场景测试多种调度器进行比较。
|
||||
|
||||
### Flax调度器
|
||||
|
||||
对比Flax调度器时,需额外将调度器状态加载到模型参数中。例如将[`FlaxStableDiffusionPipeline`]的默认调度器切换为超高效的[`FlaxDPMSolverMultistepScheduler`]:
|
||||
|
||||
> [!警告]
|
||||
> [`FlaxLMSDiscreteScheduler`]和[`FlaxDDPMScheduler`]目前暂不兼容[`FlaxStableDiffusionPipeline`]。
|
||||
|
||||
```python
|
||||
import jax
|
||||
import numpy as np
|
||||
from flax.jax_utils import replicate
|
||||
from flax.training.common_utils import shard
|
||||
from diffusers import FlaxStableDiffusionPipeline, FlaxDPMSolverMultistepScheduler
|
||||
|
||||
scheduler, scheduler_state = FlaxDPMSolverMultistepScheduler.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5",
|
||||
subfolder="scheduler"
|
||||
)
|
||||
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5",
|
||||
scheduler=scheduler,
|
||||
variant="bf16",
|
||||
dtype=jax.numpy.bfloat16,
|
||||
)
|
||||
params["scheduler"] = scheduler_state
|
||||
```
|
||||
|
||||
利用Flax对TPU的兼容性实现并行图像生成。需为每个设备复制模型参数,并分配输入数据:
|
||||
|
||||
```python
|
||||
# 每个并行设备生成1张图像(TPUv2-8/TPUv3-8支持8设备并行)
|
||||
prompt = "一张宇航员在火星上骑马的高清照片,高分辨率,高画质。"
|
||||
num_samples = jax.device_count()
|
||||
prompt_ids = pipeline.prepare_inputs([prompt] * num_samples)
|
||||
|
||||
prng_seed = jax.random.PRNGKey(0)
|
||||
num_inference_steps = 25
|
||||
|
||||
# 分配输入和随机种子
|
||||
params = replicate(params)
|
||||
prng_seed = jax.random.split(prng_seed, jax.device_count())
|
||||
prompt_ids = shard(prompt_ids)
|
||||
|
||||
images = pipeline(prompt_ids, params, prng_seed, num_inference_steps, jit=True).images
|
||||
images = pipeline.numpy_to_pil(np.asarray(images.reshape((num_samples,) + images.shape[-3:])))
|
||||
```
|
||||
|
||||
## 模型加载
|
||||
|
||||
通过[`ModelMixin.from_pretrained`]方法加载模型,该方法会下载并缓存模型权重和配置的最新版本。若本地缓存已存在最新文件,则直接复用缓存而非重复下载。
|
||||
|
||||
通过`subfolder`参数可从子目录加载模型。例如[stable-diffusion-v1-5/stable-diffusion-v1-5](https://hf.co/stable-diffusion-v1-5/stable-diffusion-v1-5)的模型权重存储在[unet](https://hf.co/stable-diffusion-v1-5/stable-diffusion-v1-5/tree/main/unet)子目录中:
|
||||
|
||||
```python
|
||||
from diffusers import UNet2DConditionModel
|
||||
|
||||
unet = UNet2DConditionModel.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", subfolder="unet", use_safetensors=True)
|
||||
```
|
||||
|
||||
也可直接从[仓库](https://huggingface.co/google/ddpm-cifar10-32/tree/main)加载:
|
||||
|
||||
```python
|
||||
from diffusers import UNet2DModel
|
||||
|
||||
unet = UNet2DModel.from_pretrained("google/ddpm-cifar10-32", use_safetensors=True)
|
||||
```
|
||||
|
||||
加载和保存模型变体时,需在[`ModelMixin.from_pretrained`]和[`ModelMixin.save_pretrained`]中指定`variant`参数:
|
||||
|
||||
```python
|
||||
from diffusers import UNet2DConditionModel
|
||||
|
||||
unet = UNet2DConditionModel.from_pretrained(
|
||||
"stable-diffusion-v1-5/stable-diffusion-v1-5", subfolder="unet", variant="non_ema", use_safetensors=True
|
||||
)
|
||||
unet.save_pretrained("./local-unet", variant="non_ema")
|
||||
```
|
||||
|
||||
使用[`~ModelMixin.from_pretrained`]的`torch_dtype`参数指定模型加载精度:
|
||||
|
||||
```python
|
||||
from diffusers import AutoModel
|
||||
|
||||
unet = AutoModel.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0", subfolder="unet", torch_dtype=torch.float16
|
||||
)
|
||||
```
|
||||
|
||||
也可使用[torch.Tensor.to](https://docs.pytorch.org/docs/stable/generated/torch.Tensor.to.html)方法即时转换精度,但会转换所有权重(不同于`torch_dtype`参数会保留`_keep_in_fp32_modules`中的层)。这对某些必须保持fp32精度的层尤为重要(参见[示例](https://github.com/huggingface/diffusers/blob/f864a9a352fa4a220d860bfdd1782e3e5af96382/src/diffusers/models/transformers/transformer_wan.py#L374))。
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# /// script
|
||||
# dependencies = [
|
||||
@@ -89,7 +90,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# /// script
|
||||
# dependencies = [
|
||||
@@ -87,7 +88,7 @@ from diffusers.utils.import_utils import is_xformers_available
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# /// script
|
||||
# dependencies = [
|
||||
@@ -94,7 +95,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
@@ -61,7 +61,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
@@ -52,7 +52,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import copy
|
||||
@@ -59,7 +60,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
@@ -43,7 +43,7 @@ from diffusers.utils import BaseOutput, check_min_version
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
|
||||
class MarigoldDepthOutput(BaseOutput):
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import functools
|
||||
@@ -73,7 +74,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import copy
|
||||
@@ -66,7 +67,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import copy
|
||||
@@ -79,7 +80,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import functools
|
||||
@@ -72,7 +73,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import copy
|
||||
@@ -78,7 +79,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import contextlib
|
||||
@@ -60,7 +61,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import logging
|
||||
@@ -60,7 +61,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import copy
|
||||
@@ -65,7 +66,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
if is_torch_npu_available():
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import contextlib
|
||||
@@ -61,7 +62,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import functools
|
||||
@@ -61,7 +62,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
if is_torch_npu_available():
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import itertools
|
||||
@@ -63,7 +64,7 @@ from diffusers.utils.import_utils import is_xformers_available
|
||||
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
@@ -19,8 +19,9 @@ cd diffusers
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
Then cd in the example folder and run
|
||||
Install the requirements in the `examples/dreambooth` folder as shown below.
|
||||
```bash
|
||||
cd examples/dreambooth
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
|
||||
@@ -75,9 +75,9 @@ Now, we can launch training using:
|
||||
```bash
|
||||
export MODEL_NAME="Qwen/Qwen-Image"
|
||||
export INSTANCE_DIR="dog"
|
||||
export OUTPUT_DIR="trained-sana-lora"
|
||||
export OUTPUT_DIR="trained-qwenimage-lora"
|
||||
|
||||
accelerate launch train_dreambooth_lora_sana.py \
|
||||
accelerate launch train_dreambooth_lora_qwenimage.py \
|
||||
--pretrained_model_name_or_path=$MODEL_NAME \
|
||||
--instance_data_dir=$INSTANCE_DIR \
|
||||
--output_dir=$OUTPUT_DIR \
|
||||
|
||||
@@ -12,6 +12,7 @@
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import argparse
|
||||
import copy
|
||||
@@ -63,7 +64,7 @@ if is_wandb_available():
|
||||
import wandb
|
||||
|
||||
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
|
||||
check_min_version("0.35.0.dev0")
|
||||
check_min_version("0.36.0.dev0")
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user