mirror of
https://github.com/huggingface/diffusers.git
synced 2026-02-17 08:15:36 +08:00
Compare commits
1 Commits
custom-blo
...
v0.0.2-rel
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
23a71cf184 |
110
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
110
.github/ISSUE_TEMPLATE/bug-report.yml
vendored
@@ -1,110 +0,0 @@
|
||||
name: "\U0001F41B Bug Report"
|
||||
description: Report a bug on Diffusers
|
||||
labels: [ "bug" ]
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thanks a lot for taking the time to file this issue 🤗.
|
||||
Issues do not only help to improve the library, but also publicly document common problems, questions, workflows for the whole community!
|
||||
Thus, issues are of the same importance as pull requests when contributing to this library ❤️.
|
||||
In order to make your issue as **useful for the community as possible**, let's try to stick to some simple guidelines:
|
||||
- 1. Please try to be as precise and concise as possible.
|
||||
*Give your issue a fitting title. Assume that someone which very limited knowledge of Diffusers can understand your issue. Add links to the source code, documentation other issues, pull requests etc...*
|
||||
- 2. If your issue is about something not working, **always** provide a reproducible code snippet. The reader should be able to reproduce your issue by **only copy-pasting your code snippet into a Python shell**.
|
||||
*The community cannot solve your issue if it cannot reproduce it. If your bug is related to training, add your training script and make everything needed to train public. Otherwise, just add a simple Python code snippet.*
|
||||
- 3. Add the **minimum** amount of code / context that is needed to understand, reproduce your issue.
|
||||
*Make the life of maintainers easy. `diffusers` is getting many issues every day. Make sure your issue is about one bug and one bug only. Make sure you add only the context, code needed to understand your issues - nothing more. Generally, every issue is a way of documenting this library, try to make it a good documentation entry.*
|
||||
- 4. For issues related to community pipelines (i.e., the pipelines located in the `examples/community` folder), please tag the author of the pipeline in your issue thread as those pipelines are not maintained.
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
For more in-detail information on how to write good issues you can have a look [here](https://huggingface.co/course/chapter8/5?fw=pt).
|
||||
- type: textarea
|
||||
id: bug-description
|
||||
attributes:
|
||||
label: Describe the bug
|
||||
description: A clear and concise description of what the bug is. If you intend to submit a pull request for this issue, tell us in the description. Thanks!
|
||||
placeholder: Bug description
|
||||
validations:
|
||||
required: true
|
||||
- type: textarea
|
||||
id: reproduction
|
||||
attributes:
|
||||
label: Reproduction
|
||||
description: Please provide a minimal reproducible code which we can copy/paste and reproduce the issue.
|
||||
placeholder: Reproduction
|
||||
validations:
|
||||
required: true
|
||||
- type: textarea
|
||||
id: logs
|
||||
attributes:
|
||||
label: Logs
|
||||
description: "Please include the Python logs if you can."
|
||||
render: shell
|
||||
- type: textarea
|
||||
id: system-info
|
||||
attributes:
|
||||
label: System Info
|
||||
description: Please share your system info with us. You can run the command `diffusers-cli env` and copy-paste its output below.
|
||||
placeholder: Diffusers version, platform, Python version, ...
|
||||
validations:
|
||||
required: true
|
||||
- type: textarea
|
||||
id: who-can-help
|
||||
attributes:
|
||||
label: Who can help?
|
||||
description: |
|
||||
Your issue will be replied to more quickly if you can figure out the right person to tag with @.
|
||||
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
|
||||
|
||||
All issues are read by one of the core maintainers, so if you don't know who to tag, just leave this blank and
|
||||
a core maintainer will ping the right person.
|
||||
|
||||
Please tag a maximum of 2 people.
|
||||
|
||||
Questions on DiffusionPipeline (Saving, Loading, From pretrained, ...): @sayakpaul @DN6
|
||||
|
||||
Questions on pipelines:
|
||||
- Stable Diffusion @yiyixuxu @asomoza
|
||||
- Stable Diffusion XL @yiyixuxu @sayakpaul @DN6
|
||||
- Stable Diffusion 3: @yiyixuxu @sayakpaul @DN6 @asomoza
|
||||
- Kandinsky @yiyixuxu
|
||||
- ControlNet @sayakpaul @yiyixuxu @DN6
|
||||
- T2I Adapter @sayakpaul @yiyixuxu @DN6
|
||||
- IF @DN6
|
||||
- Text-to-Video / Video-to-Video @DN6 @a-r-r-o-w
|
||||
- Wuerstchen @DN6
|
||||
- Other: @yiyixuxu @DN6
|
||||
- Improving generation quality: @asomoza
|
||||
|
||||
Questions on models:
|
||||
- UNet @DN6 @yiyixuxu @sayakpaul
|
||||
- VAE @sayakpaul @DN6 @yiyixuxu
|
||||
- Transformers/Attention @DN6 @yiyixuxu @sayakpaul
|
||||
|
||||
Questions on single file checkpoints: @DN6
|
||||
|
||||
Questions on Schedulers: @yiyixuxu
|
||||
|
||||
Questions on LoRA: @sayakpaul
|
||||
|
||||
Questions on Textual Inversion: @sayakpaul
|
||||
|
||||
Questions on Training:
|
||||
- DreamBooth @sayakpaul
|
||||
- Text-to-Image Fine-tuning @sayakpaul
|
||||
- Textual Inversion @sayakpaul
|
||||
- ControlNet @sayakpaul
|
||||
|
||||
Questions on Tests: @DN6 @sayakpaul @yiyixuxu
|
||||
|
||||
Questions on Documentation: @stevhliu
|
||||
|
||||
Questions on JAX- and MPS-related things: @pcuenca
|
||||
|
||||
Questions on audio pipelines: @sanchit-gandhi
|
||||
|
||||
|
||||
|
||||
placeholder: "@Username ..."
|
||||
4
.github/ISSUE_TEMPLATE/config.yml
vendored
4
.github/ISSUE_TEMPLATE/config.yml
vendored
@@ -1,4 +0,0 @@
|
||||
contact_links:
|
||||
- name: Questions / Discussions
|
||||
url: https://github.com/huggingface/diffusers/discussions
|
||||
about: General usage questions and community discussions
|
||||
20
.github/ISSUE_TEMPLATE/feature_request.md
vendored
20
.github/ISSUE_TEMPLATE/feature_request.md
vendored
@@ -1,20 +0,0 @@
|
||||
---
|
||||
name: "\U0001F680 Feature Request"
|
||||
about: Suggest an idea for this project
|
||||
title: ''
|
||||
labels: ''
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
**Is your feature request related to a problem? Please describe.**
|
||||
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...].
|
||||
|
||||
**Describe the solution you'd like.**
|
||||
A clear and concise description of what you want to happen.
|
||||
|
||||
**Describe alternatives you've considered.**
|
||||
A clear and concise description of any alternative solutions or features you've considered.
|
||||
|
||||
**Additional context.**
|
||||
Add any other context or screenshots about the feature request here.
|
||||
12
.github/ISSUE_TEMPLATE/feedback.md
vendored
12
.github/ISSUE_TEMPLATE/feedback.md
vendored
@@ -1,12 +0,0 @@
|
||||
---
|
||||
name: "💬 Feedback about API Design"
|
||||
about: Give feedback about the current API design
|
||||
title: ''
|
||||
labels: ''
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
**What API design would you like to have changed or added to the library? Why?**
|
||||
|
||||
**What use case would this enable or better enable? Can you give us a code example?**
|
||||
31
.github/ISSUE_TEMPLATE/new-model-addition.yml
vendored
31
.github/ISSUE_TEMPLATE/new-model-addition.yml
vendored
@@ -1,31 +0,0 @@
|
||||
name: "\U0001F31F New Model/Pipeline/Scheduler Addition"
|
||||
description: Submit a proposal/request to implement a new diffusion model/pipeline/scheduler
|
||||
labels: [ "New model/pipeline/scheduler" ]
|
||||
|
||||
body:
|
||||
- type: textarea
|
||||
id: description-request
|
||||
validations:
|
||||
required: true
|
||||
attributes:
|
||||
label: Model/Pipeline/Scheduler description
|
||||
description: |
|
||||
Put any and all important information relative to the model/pipeline/scheduler
|
||||
|
||||
- type: checkboxes
|
||||
id: information-tasks
|
||||
attributes:
|
||||
label: Open source status
|
||||
description: |
|
||||
Please note that if the model implementation isn't available or if the weights aren't open-source, we are less likely to implement it in `diffusers`.
|
||||
options:
|
||||
- label: "The model implementation is available."
|
||||
- label: "The model weights are available (Only relevant if addition is not a scheduler)."
|
||||
|
||||
- type: textarea
|
||||
id: additional-info
|
||||
attributes:
|
||||
label: Provide useful links for the implementation
|
||||
description: |
|
||||
Please provide information regarding the implementation, the weights, and the authors.
|
||||
Please mention the authors by @gh-username if you're aware of their usernames.
|
||||
@@ -1,38 +0,0 @@
|
||||
name: "\U0001F31F Remote VAE"
|
||||
description: Feedback for remote VAE pilot
|
||||
labels: [ "Remote VAE" ]
|
||||
|
||||
body:
|
||||
- type: textarea
|
||||
id: positive
|
||||
validations:
|
||||
required: true
|
||||
attributes:
|
||||
label: Did you like the remote VAE solution?
|
||||
description: |
|
||||
If you liked it, we would appreciate it if you could elaborate what you liked.
|
||||
|
||||
- type: textarea
|
||||
id: feedback
|
||||
validations:
|
||||
required: true
|
||||
attributes:
|
||||
label: What can be improved about the current solution?
|
||||
description: |
|
||||
Let us know the things you would like to see improved. Note that we will work optimizing the solution once the pilot is over and we have usage.
|
||||
|
||||
- type: textarea
|
||||
id: others
|
||||
validations:
|
||||
required: true
|
||||
attributes:
|
||||
label: What other VAEs you would like to see if the pilot goes well?
|
||||
description: |
|
||||
Provide a list of the VAEs you would like to see in the future if the pilot goes well.
|
||||
|
||||
- type: textarea
|
||||
id: additional-info
|
||||
attributes:
|
||||
label: Notify the members of the team
|
||||
description: |
|
||||
Tag the following folks when submitting this feedback: @hlky @sayakpaul
|
||||
29
.github/ISSUE_TEMPLATE/translate.md
vendored
29
.github/ISSUE_TEMPLATE/translate.md
vendored
@@ -1,29 +0,0 @@
|
||||
---
|
||||
name: 🌐 Translating a New Language?
|
||||
about: Start a new translation effort in your language
|
||||
title: '[<languageCode>] Translating docs to <languageName>'
|
||||
labels: WIP
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
<!--
|
||||
Note: Please search to see if an issue already exists for the language you are trying to translate.
|
||||
-->
|
||||
|
||||
Hi!
|
||||
|
||||
Let's bring the documentation to all the <languageName>-speaking community 🌐.
|
||||
|
||||
Who would want to translate? Please follow the 🤗 [TRANSLATING guide](https://github.com/huggingface/diffusers/blob/main/docs/TRANSLATING.md). Here is a list of the files ready for translation. Let us know in this issue if you'd like to translate any, and we'll add your name to the list.
|
||||
|
||||
Some notes:
|
||||
|
||||
* Please translate using an informal tone (imagine you are talking with a friend about Diffusers 🤗).
|
||||
* Please translate in a gender-neutral way.
|
||||
* Add your translations to the folder called `<languageCode>` inside the [source folder](https://github.com/huggingface/diffusers/tree/main/docs/source).
|
||||
* Register your translation in `<languageCode>/_toctree.yml`; please follow the order of the [English version](https://github.com/huggingface/diffusers/blob/main/docs/source/en/_toctree.yml).
|
||||
* Once you're finished, open a pull request and tag this issue by including #issue-number in the description, where issue-number is the number of this issue. Please ping @stevhliu for review.
|
||||
* 🙋 If you'd like others to help you with the translation, you can also post in the 🤗 [forums](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63).
|
||||
|
||||
Thank you so much for your help! 🤗
|
||||
61
.github/PULL_REQUEST_TEMPLATE.md
vendored
61
.github/PULL_REQUEST_TEMPLATE.md
vendored
@@ -1,61 +0,0 @@
|
||||
# What does this PR do?
|
||||
|
||||
<!--
|
||||
Congratulations! You've made it this far! You're not quite done yet though.
|
||||
|
||||
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
|
||||
|
||||
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
|
||||
|
||||
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
|
||||
-->
|
||||
|
||||
<!-- Remove if not applicable -->
|
||||
|
||||
Fixes # (issue)
|
||||
|
||||
|
||||
## Before submitting
|
||||
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
|
||||
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/diffusers/blob/main/CONTRIBUTING.md)?
|
||||
- [ ] Did you read our [philosophy doc](https://github.com/huggingface/diffusers/blob/main/PHILOSOPHY.md) (important for complex PRs)?
|
||||
- [ ] Was this discussed/approved via a GitHub issue or the [forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63)? Please add a link to it if that's the case.
|
||||
- [ ] Did you make sure to update the documentation with your changes? Here are the
|
||||
[documentation guidelines](https://github.com/huggingface/diffusers/tree/main/docs), and
|
||||
[here are tips on formatting docstrings](https://github.com/huggingface/diffusers/tree/main/docs#writing-source-documentation).
|
||||
- [ ] Did you write any new necessary tests?
|
||||
|
||||
|
||||
## Who can review?
|
||||
|
||||
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
|
||||
members/contributors who may be interested in your PR.
|
||||
|
||||
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @.
|
||||
|
||||
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
|
||||
Please tag fewer than 3 people.
|
||||
|
||||
Core library:
|
||||
|
||||
- Schedulers: @yiyixuxu
|
||||
- Pipelines and pipeline callbacks: @yiyixuxu and @asomoza
|
||||
- Training examples: @sayakpaul
|
||||
- Docs: @stevhliu and @sayakpaul
|
||||
- JAX and MPS: @pcuenca
|
||||
- Audio: @sanchit-gandhi
|
||||
- General functionalities: @sayakpaul @yiyixuxu @DN6
|
||||
|
||||
Integrations:
|
||||
|
||||
- deepspeed: HF Trainer/Accelerate: @SunMarc
|
||||
- PEFT: @sayakpaul @BenjaminBossan
|
||||
|
||||
HF projects:
|
||||
|
||||
- accelerate: [different repo](https://github.com/huggingface/accelerate)
|
||||
- datasets: [different repo](https://github.com/huggingface/datasets)
|
||||
- transformers: [different repo](https://github.com/huggingface/transformers)
|
||||
- safetensors: [different repo](https://github.com/huggingface/safetensors)
|
||||
|
||||
-->
|
||||
146
.github/actions/setup-miniconda/action.yml
vendored
146
.github/actions/setup-miniconda/action.yml
vendored
@@ -1,146 +0,0 @@
|
||||
name: Set up conda environment for testing
|
||||
|
||||
description: Sets up miniconda in your ${RUNNER_TEMP} environment and gives you the ${CONDA_RUN} environment variable so you don't have to worry about polluting non-empeheral runners anymore
|
||||
|
||||
inputs:
|
||||
python-version:
|
||||
description: If set to any value, don't use sudo to clean the workspace
|
||||
required: false
|
||||
type: string
|
||||
default: "3.9"
|
||||
miniconda-version:
|
||||
description: Miniconda version to install
|
||||
required: false
|
||||
type: string
|
||||
default: "4.12.0"
|
||||
environment-file:
|
||||
description: Environment file to install dependencies from
|
||||
required: false
|
||||
type: string
|
||||
default: ""
|
||||
|
||||
runs:
|
||||
using: composite
|
||||
steps:
|
||||
# Use the same trick from https://github.com/marketplace/actions/setup-miniconda
|
||||
# to refresh the cache daily. This is kind of optional though
|
||||
- name: Get date
|
||||
id: get-date
|
||||
shell: bash
|
||||
run: echo "today=$(/bin/date -u '+%Y%m%d')d" >> $GITHUB_OUTPUT
|
||||
- name: Setup miniconda cache
|
||||
id: miniconda-cache
|
||||
uses: actions/cache@v2
|
||||
with:
|
||||
path: ${{ runner.temp }}/miniconda
|
||||
key: miniconda-${{ runner.os }}-${{ runner.arch }}-${{ inputs.python-version }}-${{ steps.get-date.outputs.today }}
|
||||
- name: Install miniconda (${{ inputs.miniconda-version }})
|
||||
if: steps.miniconda-cache.outputs.cache-hit != 'true'
|
||||
env:
|
||||
MINICONDA_VERSION: ${{ inputs.miniconda-version }}
|
||||
shell: bash -l {0}
|
||||
run: |
|
||||
MINICONDA_INSTALL_PATH="${RUNNER_TEMP}/miniconda"
|
||||
mkdir -p "${MINICONDA_INSTALL_PATH}"
|
||||
case ${RUNNER_OS}-${RUNNER_ARCH} in
|
||||
Linux-X64)
|
||||
MINICONDA_ARCH="Linux-x86_64"
|
||||
;;
|
||||
macOS-ARM64)
|
||||
MINICONDA_ARCH="MacOSX-arm64"
|
||||
;;
|
||||
macOS-X64)
|
||||
MINICONDA_ARCH="MacOSX-x86_64"
|
||||
;;
|
||||
*)
|
||||
echo "::error::Platform ${RUNNER_OS}-${RUNNER_ARCH} currently unsupported using this action"
|
||||
exit 1
|
||||
;;
|
||||
esac
|
||||
MINICONDA_URL="https://repo.anaconda.com/miniconda/Miniconda3-py39_${MINICONDA_VERSION}-${MINICONDA_ARCH}.sh"
|
||||
curl -fsSL "${MINICONDA_URL}" -o "${MINICONDA_INSTALL_PATH}/miniconda.sh"
|
||||
bash "${MINICONDA_INSTALL_PATH}/miniconda.sh" -b -u -p "${MINICONDA_INSTALL_PATH}"
|
||||
rm -rf "${MINICONDA_INSTALL_PATH}/miniconda.sh"
|
||||
- name: Update GitHub path to include miniconda install
|
||||
shell: bash
|
||||
run: |
|
||||
MINICONDA_INSTALL_PATH="${RUNNER_TEMP}/miniconda"
|
||||
echo "${MINICONDA_INSTALL_PATH}/bin" >> $GITHUB_PATH
|
||||
- name: Setup miniconda env cache (with env file)
|
||||
id: miniconda-env-cache-env-file
|
||||
if: ${{ runner.os }} == 'macOS' && ${{ inputs.environment-file }} != ''
|
||||
uses: actions/cache@v2
|
||||
with:
|
||||
path: ${{ runner.temp }}/conda-python-${{ inputs.python-version }}
|
||||
key: miniconda-env-${{ runner.os }}-${{ runner.arch }}-${{ inputs.python-version }}-${{ steps.get-date.outputs.today }}-${{ hashFiles(inputs.environment-file) }}
|
||||
- name: Setup miniconda env cache (without env file)
|
||||
id: miniconda-env-cache
|
||||
if: ${{ runner.os }} == 'macOS' && ${{ inputs.environment-file }} == ''
|
||||
uses: actions/cache@v2
|
||||
with:
|
||||
path: ${{ runner.temp }}/conda-python-${{ inputs.python-version }}
|
||||
key: miniconda-env-${{ runner.os }}-${{ runner.arch }}-${{ inputs.python-version }}-${{ steps.get-date.outputs.today }}
|
||||
- name: Setup conda environment with python (v${{ inputs.python-version }})
|
||||
if: steps.miniconda-env-cache-env-file.outputs.cache-hit != 'true' && steps.miniconda-env-cache.outputs.cache-hit != 'true'
|
||||
shell: bash
|
||||
env:
|
||||
PYTHON_VERSION: ${{ inputs.python-version }}
|
||||
ENV_FILE: ${{ inputs.environment-file }}
|
||||
run: |
|
||||
CONDA_BASE_ENV="${RUNNER_TEMP}/conda-python-${PYTHON_VERSION}"
|
||||
ENV_FILE_FLAG=""
|
||||
if [[ -f "${ENV_FILE}" ]]; then
|
||||
ENV_FILE_FLAG="--file ${ENV_FILE}"
|
||||
elif [[ -n "${ENV_FILE}" ]]; then
|
||||
echo "::warning::Specified env file (${ENV_FILE}) not found, not going to include it"
|
||||
fi
|
||||
conda create \
|
||||
--yes \
|
||||
--prefix "${CONDA_BASE_ENV}" \
|
||||
"python=${PYTHON_VERSION}" \
|
||||
${ENV_FILE_FLAG} \
|
||||
cmake=3.22 \
|
||||
conda-build=3.21 \
|
||||
ninja=1.10 \
|
||||
pkg-config=0.29 \
|
||||
wheel=0.37
|
||||
- name: Clone the base conda environment and update GitHub env
|
||||
shell: bash
|
||||
env:
|
||||
PYTHON_VERSION: ${{ inputs.python-version }}
|
||||
CONDA_BASE_ENV: ${{ runner.temp }}/conda-python-${{ inputs.python-version }}
|
||||
run: |
|
||||
CONDA_ENV="${RUNNER_TEMP}/conda_environment_${GITHUB_RUN_ID}"
|
||||
conda create \
|
||||
--yes \
|
||||
--prefix "${CONDA_ENV}" \
|
||||
--clone "${CONDA_BASE_ENV}"
|
||||
# TODO: conda-build could not be cloned because it hardcodes the path, so it
|
||||
# could not be cached
|
||||
conda install --yes -p ${CONDA_ENV} conda-build=3.21
|
||||
echo "CONDA_ENV=${CONDA_ENV}" >> "${GITHUB_ENV}"
|
||||
echo "CONDA_RUN=conda run -p ${CONDA_ENV} --no-capture-output" >> "${GITHUB_ENV}"
|
||||
echo "CONDA_BUILD=conda run -p ${CONDA_ENV} conda-build" >> "${GITHUB_ENV}"
|
||||
echo "CONDA_INSTALL=conda install -p ${CONDA_ENV}" >> "${GITHUB_ENV}"
|
||||
- name: Get disk space usage and throw an error for low disk space
|
||||
shell: bash
|
||||
run: |
|
||||
echo "Print the available disk space for manual inspection"
|
||||
df -h
|
||||
# Set the minimum requirement space to 4GB
|
||||
MINIMUM_AVAILABLE_SPACE_IN_GB=4
|
||||
MINIMUM_AVAILABLE_SPACE_IN_KB=$(($MINIMUM_AVAILABLE_SPACE_IN_GB * 1024 * 1024))
|
||||
# Use KB to avoid floating point warning like 3.1GB
|
||||
df -k | tr -s ' ' | cut -d' ' -f 4,9 | while read -r LINE;
|
||||
do
|
||||
AVAIL=$(echo $LINE | cut -f1 -d' ')
|
||||
MOUNT=$(echo $LINE | cut -f2 -d' ')
|
||||
if [ "$MOUNT" = "/" ]; then
|
||||
if [ "$AVAIL" -lt "$MINIMUM_AVAILABLE_SPACE_IN_KB" ]; then
|
||||
echo "There is only ${AVAIL}KB free space left in $MOUNT, which is less than the minimum requirement of ${MINIMUM_AVAILABLE_SPACE_IN_KB}KB. Please help create an issue to PyTorch Release Engineering via https://github.com/pytorch/test-infra/issues and provide the link to the workflow run."
|
||||
exit 1;
|
||||
else
|
||||
echo "There is ${AVAIL}KB free space left in $MOUNT, continue"
|
||||
fi
|
||||
fi
|
||||
done
|
||||
88
.github/workflows/benchmark.yml
vendored
88
.github/workflows/benchmark.yml
vendored
@@ -1,88 +0,0 @@
|
||||
name: Benchmarking tests
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
schedule:
|
||||
- cron: "30 1 1,15 * *" # every 2 weeks on the 1st and the 15th of every month at 1:30 AM
|
||||
|
||||
env:
|
||||
DIFFUSERS_IS_CI: yes
|
||||
HF_XET_HIGH_PERFORMANCE: 1
|
||||
HF_HOME: /mnt/cache
|
||||
OMP_NUM_THREADS: 8
|
||||
MKL_NUM_THREADS: 8
|
||||
BASE_PATH: benchmark_outputs
|
||||
|
||||
jobs:
|
||||
torch_models_cuda_benchmark_tests:
|
||||
env:
|
||||
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL_BENCHMARK }}
|
||||
name: Torch Core Models CUDA Benchmarking Tests
|
||||
strategy:
|
||||
fail-fast: false
|
||||
max-parallel: 1
|
||||
runs-on:
|
||||
group: aws-g6e-4xlarge
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --shm-size "16gb" --ipc host --gpus all
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
apt update
|
||||
apt install -y libpq-dev postgresql-client
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip install -r benchmarks/requirements.txt
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: Diffusers Benchmarking
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
run: |
|
||||
cd benchmarks && python run_all.py
|
||||
|
||||
- name: Push results to the Hub
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_BOT_TOKEN }}
|
||||
run: |
|
||||
cd benchmarks && python push_results.py
|
||||
mkdir $BASE_PATH && cp *.csv $BASE_PATH
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: benchmark_test_reports
|
||||
path: benchmarks/${{ env.BASE_PATH }}
|
||||
|
||||
# TODO: enable this once the connection problem has been resolved.
|
||||
- name: Update benchmarking results to DB
|
||||
env:
|
||||
PGDATABASE: metrics
|
||||
PGHOST: ${{ secrets.DIFFUSERS_BENCHMARKS_PGHOST }}
|
||||
PGUSER: transformers_benchmarks
|
||||
PGPASSWORD: ${{ secrets.DIFFUSERS_BENCHMARKS_PGPASSWORD }}
|
||||
BRANCH_NAME: ${{ github.head_ref || github.ref_name }}
|
||||
run: |
|
||||
git config --global --add safe.directory /__w/diffusers/diffusers
|
||||
commit_id=$GITHUB_SHA
|
||||
commit_msg=$(git show -s --format=%s "$commit_id" | cut -c1-70)
|
||||
cd benchmarks && python populate_into_db.py "$BRANCH_NAME" "$commit_id" "$commit_msg"
|
||||
|
||||
- name: Report success status
|
||||
if: ${{ success() }}
|
||||
run: |
|
||||
pip install requests && python utils/notify_benchmarking_status.py --status=success
|
||||
|
||||
- name: Report failure status
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
pip install requests && python utils/notify_benchmarking_status.py --status=failure
|
||||
127
.github/workflows/build_docker_images.yml
vendored
127
.github/workflows/build_docker_images.yml
vendored
@@ -1,127 +0,0 @@
|
||||
name: Test, build, and push Docker images
|
||||
|
||||
on:
|
||||
pull_request: # During PRs, we just check if the changes Dockerfiles can be successfully built
|
||||
branches:
|
||||
- main
|
||||
paths:
|
||||
- "docker/**"
|
||||
workflow_dispatch:
|
||||
schedule:
|
||||
- cron: "0 0 * * *" # every day at midnight
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
env:
|
||||
REGISTRY: diffusers
|
||||
CI_SLACK_CHANNEL: ${{ secrets.CI_DOCKER_CHANNEL }}
|
||||
|
||||
jobs:
|
||||
test-build-docker-images:
|
||||
runs-on:
|
||||
group: aws-general-8-plus
|
||||
if: github.event_name == 'pull_request'
|
||||
steps:
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v1
|
||||
|
||||
- name: Check out code
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: Find Changed Dockerfiles
|
||||
id: file_changes
|
||||
uses: jitterbit/get-changed-files@v1
|
||||
with:
|
||||
format: "space-delimited"
|
||||
token: ${{ secrets.GITHUB_TOKEN }}
|
||||
|
||||
- name: Build Changed Docker Images
|
||||
env:
|
||||
CHANGED_FILES: ${{ steps.file_changes.outputs.all }}
|
||||
run: |
|
||||
echo "$CHANGED_FILES"
|
||||
ALLOWED_IMAGES=(
|
||||
diffusers-pytorch-cpu
|
||||
diffusers-pytorch-cuda
|
||||
diffusers-pytorch-xformers-cuda
|
||||
diffusers-pytorch-minimum-cuda
|
||||
diffusers-doc-builder
|
||||
)
|
||||
|
||||
declare -A IMAGES_TO_BUILD=()
|
||||
|
||||
for FILE in $CHANGED_FILES; do
|
||||
# skip anything that isn't still on disk
|
||||
if [[ ! -e "$FILE" ]]; then
|
||||
echo "Skipping removed file $FILE"
|
||||
continue
|
||||
fi
|
||||
|
||||
for IMAGE in "${ALLOWED_IMAGES[@]}"; do
|
||||
if [[ "$FILE" == docker/${IMAGE}/* ]]; then
|
||||
IMAGES_TO_BUILD["$IMAGE"]=1
|
||||
fi
|
||||
done
|
||||
done
|
||||
|
||||
if [[ ${#IMAGES_TO_BUILD[@]} -eq 0 ]]; then
|
||||
echo "No relevant Docker changes detected."
|
||||
exit 0
|
||||
fi
|
||||
|
||||
for IMAGE in "${!IMAGES_TO_BUILD[@]}"; do
|
||||
DOCKER_PATH="docker/${IMAGE}"
|
||||
echo "Building Docker image for $IMAGE"
|
||||
docker build -t "$IMAGE" "$DOCKER_PATH"
|
||||
done
|
||||
if: steps.file_changes.outputs.all != ''
|
||||
|
||||
build-and-push-docker-images:
|
||||
runs-on:
|
||||
group: aws-general-8-plus
|
||||
if: github.event_name != 'pull_request'
|
||||
|
||||
permissions:
|
||||
contents: read
|
||||
packages: write
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
image-name:
|
||||
- diffusers-pytorch-cpu
|
||||
- diffusers-pytorch-cuda
|
||||
- diffusers-pytorch-xformers-cuda
|
||||
- diffusers-pytorch-minimum-cuda
|
||||
- diffusers-doc-builder
|
||||
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v3
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v1
|
||||
- name: Login to Docker Hub
|
||||
uses: docker/login-action@v2
|
||||
with:
|
||||
username: ${{ env.REGISTRY }}
|
||||
password: ${{ secrets.DOCKERHUB_TOKEN }}
|
||||
- name: Build and push
|
||||
uses: docker/build-push-action@v3
|
||||
with:
|
||||
no-cache: true
|
||||
context: ./docker/${{ matrix.image-name }}
|
||||
push: true
|
||||
tags: ${{ env.REGISTRY }}/${{ matrix.image-name }}:latest
|
||||
|
||||
- name: Post to a Slack channel
|
||||
id: slack
|
||||
uses: huggingface/hf-workflows/.github/actions/post-slack@main
|
||||
with:
|
||||
# Slack channel id, channel name, or user id to post message.
|
||||
# See also: https://api.slack.com/methods/chat.postMessage#channels
|
||||
slack_channel: ${{ env.CI_SLACK_CHANNEL }}
|
||||
title: "🤗 Results of the ${{ matrix.image-name }} Docker Image build"
|
||||
status: ${{ job.status }}
|
||||
slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
27
.github/workflows/build_documentation.yml
vendored
27
.github/workflows/build_documentation.yml
vendored
@@ -1,27 +0,0 @@
|
||||
name: Build documentation
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
- doc-builder*
|
||||
- v*-release
|
||||
- v*-patch
|
||||
paths:
|
||||
- "src/diffusers/**.py"
|
||||
- "examples/**"
|
||||
- "docs/**"
|
||||
|
||||
jobs:
|
||||
build:
|
||||
uses: huggingface/doc-builder/.github/workflows/build_main_documentation.yml@main
|
||||
with:
|
||||
commit_sha: ${{ github.sha }}
|
||||
install_libgl1: true
|
||||
package: diffusers
|
||||
notebook_folder: diffusers_doc
|
||||
languages: en ko zh ja pt
|
||||
custom_container: diffusers/diffusers-doc-builder
|
||||
secrets:
|
||||
token: ${{ secrets.HUGGINGFACE_PUSH }}
|
||||
hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
|
||||
49
.github/workflows/build_pr_documentation.yml
vendored
49
.github/workflows/build_pr_documentation.yml
vendored
@@ -1,49 +0,0 @@
|
||||
name: Build PR Documentation
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
paths:
|
||||
- "src/diffusers/**.py"
|
||||
- "examples/**"
|
||||
- "docs/**"
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
check-links:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.10'
|
||||
|
||||
- name: Install uv
|
||||
run: |
|
||||
curl -LsSf https://astral.sh/uv/install.sh | sh
|
||||
echo "$HOME/.cargo/bin" >> $GITHUB_PATH
|
||||
|
||||
- name: Install doc-builder
|
||||
run: |
|
||||
uv pip install --system git+https://github.com/huggingface/doc-builder.git@main
|
||||
|
||||
- name: Check documentation links
|
||||
run: |
|
||||
uv run doc-builder check-links docs/source/en
|
||||
|
||||
build:
|
||||
needs: check-links
|
||||
uses: huggingface/doc-builder/.github/workflows/build_pr_documentation.yml@main
|
||||
with:
|
||||
commit_sha: ${{ github.event.pull_request.head.sha }}
|
||||
pr_number: ${{ github.event.number }}
|
||||
install_libgl1: true
|
||||
package: diffusers
|
||||
languages: en ko zh ja pt
|
||||
custom_container: diffusers/diffusers-doc-builder
|
||||
102
.github/workflows/mirror_community_pipeline.yml
vendored
102
.github/workflows/mirror_community_pipeline.yml
vendored
@@ -1,102 +0,0 @@
|
||||
name: Mirror Community Pipeline
|
||||
|
||||
on:
|
||||
# Push changes on the main branch
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
paths:
|
||||
- 'examples/community/**.py'
|
||||
|
||||
# And on tag creation (e.g. `v0.28.1`)
|
||||
tags:
|
||||
- '*'
|
||||
|
||||
# Manual trigger with ref input
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
ref:
|
||||
description: "Either 'main' or a tag ref"
|
||||
required: true
|
||||
default: 'main'
|
||||
|
||||
jobs:
|
||||
mirror_community_pipeline:
|
||||
env:
|
||||
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL_COMMUNITY_MIRROR }}
|
||||
|
||||
runs-on: ubuntu-22.04
|
||||
steps:
|
||||
# Checkout to correct ref
|
||||
# If workflow dispatch
|
||||
# If ref is 'main', set:
|
||||
# CHECKOUT_REF=refs/heads/main
|
||||
# PATH_IN_REPO=main
|
||||
# Else it must be a tag. Set:
|
||||
# CHECKOUT_REF=refs/tags/{tag}
|
||||
# PATH_IN_REPO={tag}
|
||||
# If not workflow dispatch
|
||||
# If ref is 'refs/heads/main' => set 'main'
|
||||
# Else it must be a tag => set {tag}
|
||||
- name: Set checkout_ref and path_in_repo
|
||||
run: |
|
||||
if [ "${{ github.event_name }}" == "workflow_dispatch" ]; then
|
||||
if [ -z "${{ github.event.inputs.ref }}" ]; then
|
||||
echo "Error: Missing ref input"
|
||||
exit 1
|
||||
elif [ "${{ github.event.inputs.ref }}" == "main" ]; then
|
||||
echo "CHECKOUT_REF=refs/heads/main" >> $GITHUB_ENV
|
||||
echo "PATH_IN_REPO=main" >> $GITHUB_ENV
|
||||
else
|
||||
echo "CHECKOUT_REF=refs/tags/${{ github.event.inputs.ref }}" >> $GITHUB_ENV
|
||||
echo "PATH_IN_REPO=${{ github.event.inputs.ref }}" >> $GITHUB_ENV
|
||||
fi
|
||||
elif [ "${{ github.ref }}" == "refs/heads/main" ]; then
|
||||
echo "CHECKOUT_REF=${{ github.ref }}" >> $GITHUB_ENV
|
||||
echo "PATH_IN_REPO=main" >> $GITHUB_ENV
|
||||
else
|
||||
# e.g. refs/tags/v0.28.1 -> v0.28.1
|
||||
echo "CHECKOUT_REF=${{ github.ref }}" >> $GITHUB_ENV
|
||||
echo "PATH_IN_REPO=$(echo ${{ github.ref }} | sed 's/^refs\/tags\///')" >> $GITHUB_ENV
|
||||
fi
|
||||
- name: Print env vars
|
||||
run: |
|
||||
echo "CHECKOUT_REF: ${{ env.CHECKOUT_REF }}"
|
||||
echo "PATH_IN_REPO: ${{ env.PATH_IN_REPO }}"
|
||||
- uses: actions/checkout@v3
|
||||
with:
|
||||
ref: ${{ env.CHECKOUT_REF }}
|
||||
|
||||
# Setup + install dependencies
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: "3.10"
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
pip install --upgrade pip
|
||||
pip install --upgrade huggingface_hub
|
||||
|
||||
# Check secret is set
|
||||
- name: whoami
|
||||
run: hf auth whoami
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.HF_TOKEN_MIRROR_COMMUNITY_PIPELINES }}
|
||||
|
||||
# Push to HF! (under subfolder based on checkout ref)
|
||||
# https://huggingface.co/datasets/diffusers/community-pipelines-mirror
|
||||
- name: Mirror community pipeline to HF
|
||||
run: hf upload diffusers/community-pipelines-mirror ./examples/community ${PATH_IN_REPO} --repo-type dataset
|
||||
env:
|
||||
PATH_IN_REPO: ${{ env.PATH_IN_REPO }}
|
||||
HF_TOKEN: ${{ secrets.HF_TOKEN_MIRROR_COMMUNITY_PIPELINES }}
|
||||
|
||||
- name: Report success status
|
||||
if: ${{ success() }}
|
||||
run: |
|
||||
pip install requests && python utils/notify_community_pipelines_mirror.py --status=success
|
||||
|
||||
- name: Report failure status
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
pip install requests && python utils/notify_community_pipelines_mirror.py --status=failure
|
||||
608
.github/workflows/nightly_tests.yml
vendored
608
.github/workflows/nightly_tests.yml
vendored
@@ -1,608 +0,0 @@
|
||||
name: Nightly and release tests on main/release branch
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
schedule:
|
||||
- cron: "0 0 * * *" # every day at midnight
|
||||
|
||||
env:
|
||||
DIFFUSERS_IS_CI: yes
|
||||
HF_XET_HIGH_PERFORMANCE: 1
|
||||
OMP_NUM_THREADS: 8
|
||||
MKL_NUM_THREADS: 8
|
||||
PYTEST_TIMEOUT: 600
|
||||
RUN_SLOW: yes
|
||||
RUN_NIGHTLY: yes
|
||||
PIPELINE_USAGE_CUTOFF: 0
|
||||
SLACK_API_TOKEN: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
CONSOLIDATED_REPORT_PATH: consolidated_test_report.md
|
||||
|
||||
jobs:
|
||||
setup_torch_cuda_pipeline_matrix:
|
||||
name: Setup Torch Pipelines CUDA Slow Tests Matrix
|
||||
runs-on:
|
||||
group: aws-general-8-plus
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
outputs:
|
||||
pipeline_test_matrix: ${{ steps.fetch_pipeline_matrix.outputs.pipeline_test_matrix }}
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
pip install -e .[test]
|
||||
pip install huggingface_hub
|
||||
- name: Fetch Pipeline Matrix
|
||||
id: fetch_pipeline_matrix
|
||||
run: |
|
||||
matrix=$(python utils/fetch_torch_cuda_pipeline_test_matrix.py)
|
||||
echo $matrix
|
||||
echo "pipeline_test_matrix=$matrix" >> $GITHUB_OUTPUT
|
||||
|
||||
- name: Pipeline Tests Artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: test-pipelines.json
|
||||
path: reports
|
||||
|
||||
run_nightly_tests_for_torch_pipelines:
|
||||
name: Nightly Torch Pipelines CUDA Tests
|
||||
needs: setup_torch_cuda_pipeline_matrix
|
||||
strategy:
|
||||
fail-fast: false
|
||||
max-parallel: 8
|
||||
matrix:
|
||||
module: ${{ fromJson(needs.setup_torch_cuda_pipeline_matrix.outputs.pipeline_test_matrix) }}
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --shm-size "16gb" --ipc host --gpus all
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
- name: NVIDIA-SMI
|
||||
run: nvidia-smi
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip uninstall accelerate && uv pip install -U accelerate@git+https://github.com/huggingface/accelerate.git
|
||||
uv pip install pytest-reportlog
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: Pipeline CUDA Test
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# https://pytorch.org/docs/stable/notes/randomness.html#avoiding-nondeterministic-algorithms
|
||||
CUBLAS_WORKSPACE_CONFIG: :16:8
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "not Flax and not Onnx" \
|
||||
--make-reports=tests_pipeline_${{ matrix.module }}_cuda \
|
||||
--report-log=tests_pipeline_${{ matrix.module }}_cuda.log \
|
||||
tests/pipelines/${{ matrix.module }}
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/tests_pipeline_${{ matrix.module }}_cuda_stats.txt
|
||||
cat reports/tests_pipeline_${{ matrix.module }}_cuda_failures_short.txt
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: pipeline_${{ matrix.module }}_test_reports
|
||||
path: reports
|
||||
|
||||
run_nightly_tests_for_other_torch_modules:
|
||||
name: Nightly Torch CUDA Tests
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --shm-size "16gb" --ipc host --gpus all
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
strategy:
|
||||
fail-fast: false
|
||||
max-parallel: 2
|
||||
matrix:
|
||||
module: [models, schedulers, lora, others, single_file, examples]
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip install peft@git+https://github.com/huggingface/peft.git
|
||||
uv pip uninstall accelerate && uv pip install -U accelerate@git+https://github.com/huggingface/accelerate.git
|
||||
uv pip install pytest-reportlog
|
||||
- name: Environment
|
||||
run: python utils/print_env.py
|
||||
|
||||
- name: Run nightly PyTorch CUDA tests for non-pipeline modules
|
||||
if: ${{ matrix.module != 'examples'}}
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# https://pytorch.org/docs/stable/notes/randomness.html#avoiding-nondeterministic-algorithms
|
||||
CUBLAS_WORKSPACE_CONFIG: :16:8
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "not Flax and not Onnx" \
|
||||
--make-reports=tests_torch_${{ matrix.module }}_cuda \
|
||||
--report-log=tests_torch_${{ matrix.module }}_cuda.log \
|
||||
tests/${{ matrix.module }}
|
||||
|
||||
- name: Run nightly example tests with Torch
|
||||
if: ${{ matrix.module == 'examples' }}
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# https://pytorch.org/docs/stable/notes/randomness.html#avoiding-nondeterministic-algorithms
|
||||
CUBLAS_WORKSPACE_CONFIG: :16:8
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v --make-reports=examples_torch_cuda \
|
||||
--report-log=examples_torch_cuda.log \
|
||||
examples/
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/tests_torch_${{ matrix.module }}_cuda_stats.txt
|
||||
cat reports/tests_torch_${{ matrix.module }}_cuda_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: torch_${{ matrix.module }}_cuda_test_reports
|
||||
path: reports
|
||||
|
||||
run_torch_compile_tests:
|
||||
name: PyTorch Compile CUDA tests
|
||||
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --gpus all --shm-size "16gb" --ipc host
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality,training]"
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: Run torch compile tests on GPU
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
RUN_COMPILE: yes
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile -s -v -k "compile" --make-reports=tests_torch_compile_cuda tests/
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: cat reports/tests_torch_compile_cuda_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: torch_compile_test_reports
|
||||
path: reports
|
||||
|
||||
run_big_gpu_torch_tests:
|
||||
name: Torch tests on big GPU
|
||||
strategy:
|
||||
fail-fast: false
|
||||
max-parallel: 2
|
||||
runs-on:
|
||||
group: aws-g6e-xlarge-plus
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --shm-size "16gb" --ipc host --gpus all
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
- name: NVIDIA-SMI
|
||||
run: nvidia-smi
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip install peft@git+https://github.com/huggingface/peft.git
|
||||
uv pip uninstall accelerate && uv pip install -U accelerate@git+https://github.com/huggingface/accelerate.git
|
||||
uv pip install pytest-reportlog
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: Selected Torch CUDA Test on big GPU
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# https://pytorch.org/docs/stable/notes/randomness.html#avoiding-nondeterministic-algorithms
|
||||
CUBLAS_WORKSPACE_CONFIG: :16:8
|
||||
BIG_GPU_MEMORY: 40
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-m "big_accelerator" \
|
||||
--make-reports=tests_big_gpu_torch_cuda \
|
||||
--report-log=tests_big_gpu_torch_cuda.log \
|
||||
tests/
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/tests_big_gpu_torch_cuda_stats.txt
|
||||
cat reports/tests_big_gpu_torch_cuda_failures_short.txt
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: torch_cuda_big_gpu_test_reports
|
||||
path: reports
|
||||
|
||||
torch_minimum_version_cuda_tests:
|
||||
name: Torch Minimum Version CUDA Tests
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-minimum-cuda
|
||||
options: --shm-size "16gb" --ipc host --gpus all
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip install peft@git+https://github.com/huggingface/peft.git
|
||||
uv pip uninstall accelerate && uv pip install -U accelerate@git+https://github.com/huggingface/accelerate.git
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run PyTorch CUDA tests
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# https://pytorch.org/docs/stable/notes/randomness.html#avoiding-nondeterministic-algorithms
|
||||
CUBLAS_WORKSPACE_CONFIG: :16:8
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "not Flax and not Onnx" \
|
||||
--make-reports=tests_torch_minimum_version_cuda \
|
||||
tests/models/test_modeling_common.py \
|
||||
tests/pipelines/test_pipelines_common.py \
|
||||
tests/pipelines/test_pipeline_utils.py \
|
||||
tests/pipelines/test_pipelines.py \
|
||||
tests/pipelines/test_pipelines_auto.py \
|
||||
tests/schedulers/test_schedulers.py \
|
||||
tests/others
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/tests_torch_minimum_version_cuda_stats.txt
|
||||
cat reports/tests_torch_minimum_version_cuda_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: torch_minimum_version_cuda_test_reports
|
||||
path: reports
|
||||
|
||||
run_nightly_quantization_tests:
|
||||
name: Torch quantization nightly tests
|
||||
strategy:
|
||||
fail-fast: false
|
||||
max-parallel: 2
|
||||
matrix:
|
||||
config:
|
||||
- backend: "bitsandbytes"
|
||||
test_location: "bnb"
|
||||
additional_deps: ["peft"]
|
||||
- backend: "gguf"
|
||||
test_location: "gguf"
|
||||
additional_deps: ["peft", "kernels"]
|
||||
- backend: "torchao"
|
||||
test_location: "torchao"
|
||||
additional_deps: []
|
||||
- backend: "optimum_quanto"
|
||||
test_location: "quanto"
|
||||
additional_deps: []
|
||||
- backend: "nvidia_modelopt"
|
||||
test_location: "modelopt"
|
||||
additional_deps: []
|
||||
runs-on:
|
||||
group: aws-g6e-xlarge-plus
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --shm-size "20gb" --ipc host --gpus all
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
- name: NVIDIA-SMI
|
||||
run: nvidia-smi
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip install -U ${{ matrix.config.backend }}
|
||||
if [ "${{ join(matrix.config.additional_deps, ' ') }}" != "" ]; then
|
||||
uv pip install ${{ join(matrix.config.additional_deps, ' ') }}
|
||||
fi
|
||||
uv pip install pytest-reportlog
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: ${{ matrix.config.backend }} quantization tests on GPU
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# https://pytorch.org/docs/stable/notes/randomness.html#avoiding-nondeterministic-algorithms
|
||||
CUBLAS_WORKSPACE_CONFIG: :16:8
|
||||
BIG_GPU_MEMORY: 40
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
--make-reports=tests_${{ matrix.config.backend }}_torch_cuda \
|
||||
--report-log=tests_${{ matrix.config.backend }}_torch_cuda.log \
|
||||
tests/quantization/${{ matrix.config.test_location }}
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/tests_${{ matrix.config.backend }}_torch_cuda_stats.txt
|
||||
cat reports/tests_${{ matrix.config.backend }}_torch_cuda_failures_short.txt
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: torch_cuda_${{ matrix.config.backend }}_reports
|
||||
path: reports
|
||||
|
||||
run_nightly_pipeline_level_quantization_tests:
|
||||
name: Torch quantization nightly tests
|
||||
strategy:
|
||||
fail-fast: false
|
||||
max-parallel: 2
|
||||
runs-on:
|
||||
group: aws-g6e-xlarge-plus
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --shm-size "20gb" --ipc host --gpus all
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
- name: NVIDIA-SMI
|
||||
run: nvidia-smi
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip install -U bitsandbytes optimum_quanto
|
||||
uv pip install pytest-reportlog
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: Pipeline-level quantization tests on GPU
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# https://pytorch.org/docs/stable/notes/randomness.html#avoiding-nondeterministic-algorithms
|
||||
CUBLAS_WORKSPACE_CONFIG: :16:8
|
||||
BIG_GPU_MEMORY: 40
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
--make-reports=tests_pipeline_level_quant_torch_cuda \
|
||||
--report-log=tests_pipeline_level_quant_torch_cuda.log \
|
||||
tests/quantization/test_pipeline_level_quantization.py
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/tests_pipeline_level_quant_torch_cuda_stats.txt
|
||||
cat reports/tests_pipeline_level_quant_torch_cuda_failures_short.txt
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: torch_cuda_pipeline_level_quant_reports
|
||||
path: reports
|
||||
|
||||
generate_consolidated_report:
|
||||
name: Generate Consolidated Test Report
|
||||
needs: [
|
||||
run_nightly_tests_for_torch_pipelines,
|
||||
run_nightly_tests_for_other_torch_modules,
|
||||
run_torch_compile_tests,
|
||||
run_big_gpu_torch_tests,
|
||||
run_nightly_quantization_tests,
|
||||
run_nightly_pipeline_level_quantization_tests,
|
||||
# run_nightly_onnx_tests,
|
||||
torch_minimum_version_cuda_tests,
|
||||
# run_flax_tpu_tests
|
||||
]
|
||||
if: always()
|
||||
runs-on:
|
||||
group: aws-general-8-plus
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Create reports directory
|
||||
run: mkdir -p combined_reports
|
||||
|
||||
- name: Download all test reports
|
||||
uses: actions/download-artifact@v4
|
||||
with:
|
||||
path: artifacts
|
||||
|
||||
- name: Prepare reports
|
||||
run: |
|
||||
# Move all report files to a single directory for processing
|
||||
find artifacts -name "*.txt" -exec cp {} combined_reports/ \;
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
pip install -e .[test]
|
||||
pip install slack_sdk tabulate
|
||||
|
||||
- name: Generate consolidated report
|
||||
run: |
|
||||
python utils/consolidated_test_report.py \
|
||||
--reports_dir combined_reports \
|
||||
--output_file $CONSOLIDATED_REPORT_PATH \
|
||||
--slack_channel_name diffusers-ci-nightly
|
||||
|
||||
- name: Show consolidated report
|
||||
run: |
|
||||
cat $CONSOLIDATED_REPORT_PATH >> $GITHUB_STEP_SUMMARY
|
||||
|
||||
- name: Upload consolidated report
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: consolidated_test_report
|
||||
path: ${{ env.CONSOLIDATED_REPORT_PATH }}
|
||||
|
||||
# M1 runner currently not well supported
|
||||
# TODO: (Dhruv) add these back when we setup better testing for Apple Silicon
|
||||
# run_nightly_tests_apple_m1:
|
||||
# name: Nightly PyTorch MPS tests on MacOS
|
||||
# runs-on: [ self-hosted, apple-m1 ]
|
||||
# if: github.event_name == 'schedule'
|
||||
#
|
||||
# steps:
|
||||
# - name: Checkout diffusers
|
||||
# uses: actions/checkout@v3
|
||||
# with:
|
||||
# fetch-depth: 2
|
||||
#
|
||||
# - name: Clean checkout
|
||||
# shell: arch -arch arm64 bash {0}
|
||||
# run: |
|
||||
# git clean -fxd
|
||||
# - name: Setup miniconda
|
||||
# uses: ./.github/actions/setup-miniconda
|
||||
# with:
|
||||
# python-version: 3.9
|
||||
#
|
||||
# - name: Install dependencies
|
||||
# shell: arch -arch arm64 bash {0}
|
||||
# run: |
|
||||
# ${CONDA_RUN} pip install --upgrade pip uv
|
||||
# ${CONDA_RUN} uv pip install -e ".[quality]"
|
||||
# ${CONDA_RUN} uv pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cpu
|
||||
# ${CONDA_RUN} uv pip install accelerate@git+https://github.com/huggingface/accelerate
|
||||
# ${CONDA_RUN} uv pip install pytest-reportlog
|
||||
# - name: Environment
|
||||
# shell: arch -arch arm64 bash {0}
|
||||
# run: |
|
||||
# ${CONDA_RUN} python utils/print_env.py
|
||||
# - name: Run nightly PyTorch tests on M1 (MPS)
|
||||
# shell: arch -arch arm64 bash {0}
|
||||
# env:
|
||||
# HF_HOME: /System/Volumes/Data/mnt/cache
|
||||
# HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# run: |
|
||||
# ${CONDA_RUN} pytest -n 1 -s -v --make-reports=tests_torch_mps \
|
||||
# --report-log=tests_torch_mps.log \
|
||||
# tests/
|
||||
# - name: Failure short reports
|
||||
# if: ${{ failure() }}
|
||||
# run: cat reports/tests_torch_mps_failures_short.txt
|
||||
#
|
||||
# - name: Test suite reports artifacts
|
||||
# if: ${{ always() }}
|
||||
# uses: actions/upload-artifact@v4
|
||||
# with:
|
||||
# name: torch_mps_test_reports
|
||||
# path: reports
|
||||
#
|
||||
# - name: Generate Report and Notify Channel
|
||||
# if: always()
|
||||
# run: |
|
||||
# pip install slack_sdk tabulate
|
||||
# python utils/log_reports.py >> $GITHUB_STEP_SUMMARY run_nightly_tests_apple_m1:
|
||||
# name: Nightly PyTorch MPS tests on MacOS
|
||||
# runs-on: [ self-hosted, apple-m1 ]
|
||||
# if: github.event_name == 'schedule'
|
||||
#
|
||||
# steps:
|
||||
# - name: Checkout diffusers
|
||||
# uses: actions/checkout@v3
|
||||
# with:
|
||||
# fetch-depth: 2
|
||||
#
|
||||
# - name: Clean checkout
|
||||
# shell: arch -arch arm64 bash {0}
|
||||
# run: |
|
||||
# git clean -fxd
|
||||
# - name: Setup miniconda
|
||||
# uses: ./.github/actions/setup-miniconda
|
||||
# with:
|
||||
# python-version: 3.9
|
||||
#
|
||||
# - name: Install dependencies
|
||||
# shell: arch -arch arm64 bash {0}
|
||||
# run: |
|
||||
# ${CONDA_RUN} pip install --upgrade pip uv
|
||||
# ${CONDA_RUN} uv pip install -e ".[quality]"
|
||||
# ${CONDA_RUN} uv pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cpu
|
||||
# ${CONDA_RUN} uv pip install accelerate@git+https://github.com/huggingface/accelerate
|
||||
# ${CONDA_RUN} uv pip install pytest-reportlog
|
||||
# - name: Environment
|
||||
# shell: arch -arch arm64 bash {0}
|
||||
# run: |
|
||||
# ${CONDA_RUN} python utils/print_env.py
|
||||
# - name: Run nightly PyTorch tests on M1 (MPS)
|
||||
# shell: arch -arch arm64 bash {0}
|
||||
# env:
|
||||
# HF_HOME: /System/Volumes/Data/mnt/cache
|
||||
# HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# run: |
|
||||
# ${CONDA_RUN} pytest -n 1 -s -v --make-reports=tests_torch_mps \
|
||||
# --report-log=tests_torch_mps.log \
|
||||
# tests/
|
||||
# - name: Failure short reports
|
||||
# if: ${{ failure() }}
|
||||
# run: cat reports/tests_torch_mps_failures_short.txt
|
||||
#
|
||||
# - name: Test suite reports artifacts
|
||||
# if: ${{ always() }}
|
||||
# uses: actions/upload-artifact@v4
|
||||
# with:
|
||||
# name: torch_mps_test_reports
|
||||
# path: reports
|
||||
#
|
||||
# - name: Generate Report and Notify Channel
|
||||
# if: always()
|
||||
# run: |
|
||||
# pip install slack_sdk tabulate
|
||||
# python utils/log_reports.py >> $GITHUB_STEP_SUMMARY
|
||||
23
.github/workflows/notify_slack_about_release.yml
vendored
23
.github/workflows/notify_slack_about_release.yml
vendored
@@ -1,23 +0,0 @@
|
||||
name: Notify Slack about a release
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
release:
|
||||
types: [published]
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-22.04
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: '3.8'
|
||||
|
||||
- name: Notify Slack about the release
|
||||
env:
|
||||
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }}
|
||||
run: pip install requests && python utils/notify_slack_about_release.py
|
||||
32
.github/workflows/pr_dependency_test.yml
vendored
32
.github/workflows/pr_dependency_test.yml
vendored
@@ -1,32 +0,0 @@
|
||||
name: Run dependency tests
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
branches:
|
||||
- main
|
||||
paths:
|
||||
- "src/diffusers/**.py"
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
check_dependencies:
|
||||
runs-on: ubuntu-22.04
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
pip install -e .
|
||||
pip install pytest
|
||||
- name: Check for soft dependencies
|
||||
run: |
|
||||
pytest tests/others/test_dependencies.py
|
||||
138
.github/workflows/pr_modular_tests.yml
vendored
138
.github/workflows/pr_modular_tests.yml
vendored
@@ -1,138 +0,0 @@
|
||||
name: Fast PR tests for Modular
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
branches: [main]
|
||||
paths:
|
||||
- "src/diffusers/modular_pipelines/**.py"
|
||||
- "src/diffusers/models/modeling_utils.py"
|
||||
- "src/diffusers/models/model_loading_utils.py"
|
||||
- "src/diffusers/pipelines/pipeline_utils.py"
|
||||
- "src/diffusers/pipeline_loading_utils.py"
|
||||
- "src/diffusers/loaders/lora_base.py"
|
||||
- "src/diffusers/loaders/lora_pipeline.py"
|
||||
- "src/diffusers/loaders/peft.py"
|
||||
- "tests/modular_pipelines/**.py"
|
||||
- ".github/**.yml"
|
||||
- "utils/**.py"
|
||||
- "setup.py"
|
||||
push:
|
||||
branches:
|
||||
- ci-*
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
env:
|
||||
DIFFUSERS_IS_CI: yes
|
||||
HF_XET_HIGH_PERFORMANCE: 1
|
||||
OMP_NUM_THREADS: 4
|
||||
MKL_NUM_THREADS: 4
|
||||
PYTEST_TIMEOUT: 60
|
||||
|
||||
jobs:
|
||||
check_code_quality:
|
||||
runs-on: ubuntu-22.04
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: "3.10"
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
pip install --upgrade pip
|
||||
pip install .[quality]
|
||||
- name: Check quality
|
||||
run: make quality
|
||||
- name: Check if failure
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
echo "Quality check failed. Please ensure the right dependency versions are installed with 'pip install -e .[quality]' and run 'make style && make quality'" >> $GITHUB_STEP_SUMMARY
|
||||
|
||||
check_repository_consistency:
|
||||
needs: check_code_quality
|
||||
runs-on: ubuntu-22.04
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: "3.10"
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
pip install --upgrade pip
|
||||
pip install .[quality]
|
||||
- name: Check repo consistency
|
||||
run: |
|
||||
python utils/check_copies.py
|
||||
python utils/check_dummies.py
|
||||
python utils/check_support_list.py
|
||||
make deps_table_check_updated
|
||||
- name: Check if failure
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
echo "Repo consistency check failed. Please ensure the right dependency versions are installed with 'pip install -e .[quality]' and run 'make fix-copies'" >> $GITHUB_STEP_SUMMARY
|
||||
|
||||
run_fast_tests:
|
||||
needs: [check_code_quality, check_repository_consistency]
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
config:
|
||||
- name: Fast PyTorch Modular Pipeline CPU tests
|
||||
framework: pytorch_pipelines
|
||||
runner: aws-highmemory-32-plus
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
report: torch_cpu_modular_pipelines
|
||||
|
||||
name: ${{ matrix.config.name }}
|
||||
|
||||
runs-on:
|
||||
group: ${{ matrix.config.runner }}
|
||||
|
||||
container:
|
||||
image: ${{ matrix.config.image }}
|
||||
options: --shm-size "16gb" --ipc host -v /mnt/hf_cache:/mnt/cache/
|
||||
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip uninstall transformers huggingface_hub && uv pip install --prerelease allow -U transformers@git+https://github.com/huggingface/transformers.git
|
||||
uv pip uninstall accelerate && uv pip install -U accelerate@git+https://github.com/huggingface/accelerate.git --no-deps
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run fast PyTorch Pipeline CPU tests
|
||||
if: ${{ matrix.config.framework == 'pytorch_pipelines' }}
|
||||
run: |
|
||||
pytest -n 8 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "not Flax and not Onnx" \
|
||||
--make-reports=tests_${{ matrix.config.report }} \
|
||||
tests/modular_pipelines
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: cat reports/tests_${{ matrix.config.report }}_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: pr_${{ matrix.config.framework }}_${{ matrix.config.report }}_test_reports
|
||||
path: reports
|
||||
|
||||
|
||||
17
.github/workflows/pr_style_bot.yml
vendored
17
.github/workflows/pr_style_bot.yml
vendored
@@ -1,17 +0,0 @@
|
||||
name: PR Style Bot
|
||||
|
||||
on:
|
||||
issue_comment:
|
||||
types: [created]
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
pull-requests: write
|
||||
|
||||
jobs:
|
||||
style:
|
||||
uses: huggingface/huggingface_hub/.github/workflows/style-bot-action.yml@main
|
||||
with:
|
||||
python_quality_dependencies: "[quality]"
|
||||
secrets:
|
||||
bot_token: ${{ secrets.HF_STYLE_BOT_ACTION }}
|
||||
170
.github/workflows/pr_test_fetcher.yml
vendored
170
.github/workflows/pr_test_fetcher.yml
vendored
@@ -1,170 +0,0 @@
|
||||
name: Fast tests for PRs - Test Fetcher
|
||||
|
||||
on: workflow_dispatch
|
||||
|
||||
env:
|
||||
DIFFUSERS_IS_CI: yes
|
||||
OMP_NUM_THREADS: 4
|
||||
MKL_NUM_THREADS: 4
|
||||
PYTEST_TIMEOUT: 60
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
setup_pr_tests:
|
||||
name: Setup PR Tests
|
||||
runs-on:
|
||||
group: aws-general-8-plus
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
options: --shm-size "16gb" --ipc host -v /mnt/hf_cache:/mnt/cache/
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
outputs:
|
||||
matrix: ${{ steps.set_matrix.outputs.matrix }}
|
||||
test_map: ${{ steps.set_matrix.outputs.test_map }}
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 0
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
echo $(git --version)
|
||||
- name: Fetch Tests
|
||||
run: |
|
||||
python utils/tests_fetcher.py | tee test_preparation.txt
|
||||
- name: Report fetched tests
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: test_fetched
|
||||
path: test_preparation.txt
|
||||
- id: set_matrix
|
||||
name: Create Test Matrix
|
||||
# The `keys` is used as GitHub actions matrix for jobs, i.e. `models`, `pipelines`, etc.
|
||||
# The `test_map` is used to get the actual identified test files under each key.
|
||||
# If no test to run (so no `test_map.json` file), create a dummy map (empty matrix will fail)
|
||||
run: |
|
||||
if [ -f test_map.json ]; then
|
||||
keys=$(python3 -c 'import json; fp = open("test_map.json"); test_map = json.load(fp); fp.close(); d = list(test_map.keys()); print(json.dumps(d))')
|
||||
test_map=$(python3 -c 'import json; fp = open("test_map.json"); test_map = json.load(fp); fp.close(); print(json.dumps(test_map))')
|
||||
else
|
||||
keys=$(python3 -c 'keys = ["dummy"]; print(keys)')
|
||||
test_map=$(python3 -c 'test_map = {"dummy": []}; print(test_map)')
|
||||
fi
|
||||
echo $keys
|
||||
echo $test_map
|
||||
echo "matrix=$keys" >> $GITHUB_OUTPUT
|
||||
echo "test_map=$test_map" >> $GITHUB_OUTPUT
|
||||
|
||||
run_pr_tests:
|
||||
name: Run PR Tests
|
||||
needs: setup_pr_tests
|
||||
if: contains(fromJson(needs.setup_pr_tests.outputs.matrix), 'dummy') != true
|
||||
strategy:
|
||||
fail-fast: false
|
||||
max-parallel: 2
|
||||
matrix:
|
||||
modules: ${{ fromJson(needs.setup_pr_tests.outputs.matrix) }}
|
||||
runs-on:
|
||||
group: aws-general-8-plus
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
options: --shm-size "16gb" --ipc host -v /mnt/hf_cache:/mnt/cache/
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip install accelerate
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run all selected tests on CPU
|
||||
run: |
|
||||
pytest -n 2 --dist=loadfile -v --make-reports=${{ matrix.modules }}_tests_cpu ${{ fromJson(needs.setup_pr_tests.outputs.test_map)[matrix.modules] }}
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
continue-on-error: true
|
||||
run: |
|
||||
cat reports/${{ matrix.modules }}_tests_cpu_stats.txt
|
||||
cat reports/${{ matrix.modules }}_tests_cpu_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: ${{ matrix.modules }}_test_reports
|
||||
path: reports
|
||||
|
||||
run_staging_tests:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
config:
|
||||
- name: Hub tests for models, schedulers, and pipelines
|
||||
framework: hub_tests_pytorch
|
||||
runner: aws-general-8-plus
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
report: torch_hub
|
||||
|
||||
name: ${{ matrix.config.name }}
|
||||
runs-on:
|
||||
group: ${{ matrix.config.runner }}
|
||||
container:
|
||||
image: ${{ matrix.config.image }}
|
||||
options: --shm-size "16gb" --ipc host -v /mnt/hf_cache:/mnt/cache/
|
||||
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
pip install -e [quality]
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run Hub tests for models, schedulers, and pipelines on a staging env
|
||||
if: ${{ matrix.config.framework == 'hub_tests_pytorch' }}
|
||||
run: |
|
||||
HUGGINGFACE_CO_STAGING=true pytest \
|
||||
-m "is_staging_test" \
|
||||
--make-reports=tests_${{ matrix.config.report }} \
|
||||
tests
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: cat reports/tests_${{ matrix.config.report }}_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: pr_${{ matrix.config.report }}_test_reports
|
||||
path: reports
|
||||
278
.github/workflows/pr_tests.yml
vendored
278
.github/workflows/pr_tests.yml
vendored
@@ -1,278 +0,0 @@
|
||||
name: Fast tests for PRs
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
branches: [main]
|
||||
paths:
|
||||
- "src/diffusers/**.py"
|
||||
- "benchmarks/**.py"
|
||||
- "examples/**.py"
|
||||
- "scripts/**.py"
|
||||
- "tests/**.py"
|
||||
- ".github/**.yml"
|
||||
- "utils/**.py"
|
||||
- "setup.py"
|
||||
push:
|
||||
branches:
|
||||
- ci-*
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
env:
|
||||
DIFFUSERS_IS_CI: yes
|
||||
HF_XET_HIGH_PERFORMANCE: 1
|
||||
OMP_NUM_THREADS: 4
|
||||
MKL_NUM_THREADS: 4
|
||||
PYTEST_TIMEOUT: 60
|
||||
|
||||
jobs:
|
||||
check_code_quality:
|
||||
runs-on: ubuntu-22.04
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
pip install --upgrade pip
|
||||
pip install .[quality]
|
||||
- name: Check quality
|
||||
run: make quality
|
||||
- name: Check if failure
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
echo "Quality check failed. Please ensure the right dependency versions are installed with 'pip install -e .[quality]' and run 'make style && make quality'" >> $GITHUB_STEP_SUMMARY
|
||||
|
||||
check_repository_consistency:
|
||||
needs: check_code_quality
|
||||
runs-on: ubuntu-22.04
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
pip install --upgrade pip
|
||||
pip install .[quality]
|
||||
- name: Check repo consistency
|
||||
run: |
|
||||
python utils/check_copies.py
|
||||
python utils/check_dummies.py
|
||||
python utils/check_support_list.py
|
||||
make deps_table_check_updated
|
||||
- name: Check if failure
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
echo "Repo consistency check failed. Please ensure the right dependency versions are installed with 'pip install -e .[quality]' and run 'make fix-copies'" >> $GITHUB_STEP_SUMMARY
|
||||
|
||||
run_fast_tests:
|
||||
needs: [check_code_quality, check_repository_consistency]
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
config:
|
||||
- name: Fast PyTorch Pipeline CPU tests
|
||||
framework: pytorch_pipelines
|
||||
runner: aws-highmemory-32-plus
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
report: torch_cpu_pipelines
|
||||
- name: Fast PyTorch Models & Schedulers CPU tests
|
||||
framework: pytorch_models
|
||||
runner: aws-general-8-plus
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
report: torch_cpu_models_schedulers
|
||||
- name: PyTorch Example CPU tests
|
||||
framework: pytorch_examples
|
||||
runner: aws-general-8-plus
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
report: torch_example_cpu
|
||||
|
||||
name: ${{ matrix.config.name }}
|
||||
|
||||
runs-on:
|
||||
group: ${{ matrix.config.runner }}
|
||||
|
||||
container:
|
||||
image: ${{ matrix.config.image }}
|
||||
options: --shm-size "16gb" --ipc host -v /mnt/hf_cache:/mnt/cache/
|
||||
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip uninstall transformers huggingface_hub && uv pip install --prerelease allow -U transformers@git+https://github.com/huggingface/transformers.git
|
||||
uv pip uninstall accelerate && uv pip install -U accelerate@git+https://github.com/huggingface/accelerate.git --no-deps
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run fast PyTorch Pipeline CPU tests
|
||||
if: ${{ matrix.config.framework == 'pytorch_pipelines' }}
|
||||
run: |
|
||||
pytest -n 8 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "not Flax and not Onnx" \
|
||||
--make-reports=tests_${{ matrix.config.report }} \
|
||||
tests/pipelines
|
||||
|
||||
- name: Run fast PyTorch Model Scheduler CPU tests
|
||||
if: ${{ matrix.config.framework == 'pytorch_models' }}
|
||||
run: |
|
||||
pytest -n 4 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "not Flax and not Onnx and not Dependency" \
|
||||
--make-reports=tests_${{ matrix.config.report }} \
|
||||
tests/models tests/schedulers tests/others
|
||||
|
||||
- name: Run example PyTorch CPU tests
|
||||
if: ${{ matrix.config.framework == 'pytorch_examples' }}
|
||||
run: |
|
||||
uv pip install ".[training]"
|
||||
pytest -n 4 --max-worker-restart=0 --dist=loadfile \
|
||||
--make-reports=tests_${{ matrix.config.report }} \
|
||||
examples
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: cat reports/tests_${{ matrix.config.report }}_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: pr_${{ matrix.config.framework }}_${{ matrix.config.report }}_test_reports
|
||||
path: reports
|
||||
|
||||
run_staging_tests:
|
||||
needs: [check_code_quality, check_repository_consistency]
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
config:
|
||||
- name: Hub tests for models, schedulers, and pipelines
|
||||
framework: hub_tests_pytorch
|
||||
runner:
|
||||
group: aws-general-8-plus
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
report: torch_hub
|
||||
|
||||
name: ${{ matrix.config.name }}
|
||||
|
||||
runs-on: ${{ matrix.config.runner }}
|
||||
|
||||
container:
|
||||
image: ${{ matrix.config.image }}
|
||||
options: --shm-size "16gb" --ipc host -v /mnt/hf_cache:/mnt/cache/
|
||||
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run Hub tests for models, schedulers, and pipelines on a staging env
|
||||
if: ${{ matrix.config.framework == 'hub_tests_pytorch' }}
|
||||
run: |
|
||||
HUGGINGFACE_CO_STAGING=true pytest \
|
||||
-m "is_staging_test" \
|
||||
--make-reports=tests_${{ matrix.config.report }} \
|
||||
tests
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: cat reports/tests_${{ matrix.config.report }}_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: pr_${{ matrix.config.report }}_test_reports
|
||||
path: reports
|
||||
|
||||
run_lora_tests:
|
||||
needs: [check_code_quality, check_repository_consistency]
|
||||
strategy:
|
||||
fail-fast: false
|
||||
|
||||
name: LoRA tests with PEFT main
|
||||
|
||||
runs-on:
|
||||
group: aws-general-8-plus
|
||||
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
options: --shm-size "16gb" --ipc host -v /mnt/hf_cache:/mnt/cache/
|
||||
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
# TODO (sayakpaul, DN6): revisit `--no-deps`
|
||||
uv pip install -U peft@git+https://github.com/huggingface/peft.git --no-deps
|
||||
uv pip install -U tokenizers
|
||||
uv pip uninstall accelerate && uv pip install -U accelerate@git+https://github.com/huggingface/accelerate.git --no-deps
|
||||
uv pip uninstall transformers huggingface_hub && uv pip install --prerelease allow -U transformers@git+https://github.com/huggingface/transformers.git
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run fast PyTorch LoRA tests with PEFT
|
||||
run: |
|
||||
pytest -n 4 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v \
|
||||
--make-reports=tests_peft_main \
|
||||
tests/lora/
|
||||
pytest -n 4 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v \
|
||||
--make-reports=tests_models_lora_peft_main \
|
||||
tests/models/ -k "lora"
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/tests_peft_main_failures_short.txt
|
||||
cat reports/tests_models_lora_peft_main_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: pr_main_test_reports
|
||||
path: reports
|
||||
|
||||
291
.github/workflows/pr_tests_gpu.yml
vendored
291
.github/workflows/pr_tests_gpu.yml
vendored
@@ -1,291 +0,0 @@
|
||||
name: Fast GPU Tests on PR
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
branches: main
|
||||
paths:
|
||||
- "src/diffusers/models/modeling_utils.py"
|
||||
- "src/diffusers/models/model_loading_utils.py"
|
||||
- "src/diffusers/pipelines/pipeline_utils.py"
|
||||
- "src/diffusers/pipeline_loading_utils.py"
|
||||
- "src/diffusers/loaders/lora_base.py"
|
||||
- "src/diffusers/loaders/lora_pipeline.py"
|
||||
- "src/diffusers/loaders/peft.py"
|
||||
- "tests/pipelines/test_pipelines_common.py"
|
||||
- "tests/models/test_modeling_common.py"
|
||||
- "examples/**/*.py"
|
||||
workflow_dispatch:
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
env:
|
||||
DIFFUSERS_IS_CI: yes
|
||||
OMP_NUM_THREADS: 8
|
||||
MKL_NUM_THREADS: 8
|
||||
HF_XET_HIGH_PERFORMANCE: 1
|
||||
PYTEST_TIMEOUT: 600
|
||||
PIPELINE_USAGE_CUTOFF: 1000000000 # set high cutoff so that only always-test pipelines run
|
||||
|
||||
jobs:
|
||||
check_code_quality:
|
||||
runs-on: ubuntu-22.04
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
pip install --upgrade pip
|
||||
pip install .[quality]
|
||||
- name: Check quality
|
||||
run: make quality
|
||||
- name: Check if failure
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
echo "Quality check failed. Please ensure the right dependency versions are installed with 'pip install -e .[quality]' and run 'make style && make quality'" >> $GITHUB_STEP_SUMMARY
|
||||
|
||||
check_repository_consistency:
|
||||
needs: check_code_quality
|
||||
runs-on: ubuntu-22.04
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
pip install --upgrade pip
|
||||
pip install .[quality]
|
||||
- name: Check repo consistency
|
||||
run: |
|
||||
python utils/check_copies.py
|
||||
python utils/check_dummies.py
|
||||
python utils/check_support_list.py
|
||||
make deps_table_check_updated
|
||||
- name: Check if failure
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
echo "Repo consistency check failed. Please ensure the right dependency versions are installed with 'pip install -e .[quality]' and run 'make fix-copies'" >> $GITHUB_STEP_SUMMARY
|
||||
|
||||
setup_torch_cuda_pipeline_matrix:
|
||||
needs: [check_code_quality, check_repository_consistency]
|
||||
name: Setup Torch Pipelines CUDA Slow Tests Matrix
|
||||
runs-on:
|
||||
group: aws-general-8-plus
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
outputs:
|
||||
pipeline_test_matrix: ${{ steps.fetch_pipeline_matrix.outputs.pipeline_test_matrix }}
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: Fetch Pipeline Matrix
|
||||
id: fetch_pipeline_matrix
|
||||
run: |
|
||||
matrix=$(python utils/fetch_torch_cuda_pipeline_test_matrix.py)
|
||||
echo $matrix
|
||||
echo "pipeline_test_matrix=$matrix" >> $GITHUB_OUTPUT
|
||||
- name: Pipeline Tests Artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: test-pipelines.json
|
||||
path: reports
|
||||
|
||||
torch_pipelines_cuda_tests:
|
||||
name: Torch Pipelines CUDA Tests
|
||||
needs: setup_torch_cuda_pipeline_matrix
|
||||
strategy:
|
||||
fail-fast: false
|
||||
max-parallel: 8
|
||||
matrix:
|
||||
module: ${{ fromJson(needs.setup_torch_cuda_pipeline_matrix.outputs.pipeline_test_matrix) }}
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --shm-size "16gb" --ipc host --gpus all
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip uninstall accelerate && uv pip install -U accelerate@git+https://github.com/huggingface/accelerate.git
|
||||
uv pip uninstall transformers huggingface_hub && uv pip install --prerelease allow -U transformers@git+https://github.com/huggingface/transformers.git
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: Extract tests
|
||||
id: extract_tests
|
||||
run: |
|
||||
pattern=$(python utils/extract_tests_from_mixin.py --type pipeline)
|
||||
echo "$pattern" > /tmp/test_pattern.txt
|
||||
echo "pattern_file=/tmp/test_pattern.txt" >> $GITHUB_OUTPUT
|
||||
|
||||
- name: PyTorch CUDA checkpoint tests on Ubuntu
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# https://pytorch.org/docs/stable/notes/randomness.html#avoiding-nondeterministic-algorithms
|
||||
CUBLAS_WORKSPACE_CONFIG: :16:8
|
||||
run: |
|
||||
if [ "${{ matrix.module }}" = "ip_adapters" ]; then
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "not Flax and not Onnx" \
|
||||
--make-reports=tests_pipeline_${{ matrix.module }}_cuda \
|
||||
tests/pipelines/${{ matrix.module }}
|
||||
else
|
||||
pattern=$(cat ${{ steps.extract_tests.outputs.pattern_file }})
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "not Flax and not Onnx and $pattern" \
|
||||
--make-reports=tests_pipeline_${{ matrix.module }}_cuda \
|
||||
tests/pipelines/${{ matrix.module }}
|
||||
fi
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/tests_pipeline_${{ matrix.module }}_cuda_stats.txt
|
||||
cat reports/tests_pipeline_${{ matrix.module }}_cuda_failures_short.txt
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: pipeline_${{ matrix.module }}_test_reports
|
||||
path: reports
|
||||
|
||||
torch_cuda_tests:
|
||||
name: Torch CUDA Tests
|
||||
needs: [check_code_quality, check_repository_consistency]
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --shm-size "16gb" --ipc host --gpus all
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
strategy:
|
||||
fail-fast: false
|
||||
max-parallel: 4
|
||||
matrix:
|
||||
module: [models, schedulers, lora, others]
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip install peft@git+https://github.com/huggingface/peft.git
|
||||
uv pip uninstall accelerate && uv pip install -U accelerate@git+https://github.com/huggingface/accelerate.git
|
||||
uv pip uninstall transformers huggingface_hub && uv pip install --prerelease allow -U transformers@git+https://github.com/huggingface/transformers.git
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Extract tests
|
||||
id: extract_tests
|
||||
run: |
|
||||
pattern=$(python utils/extract_tests_from_mixin.py --type ${{ matrix.module }})
|
||||
echo "$pattern" > /tmp/test_pattern.txt
|
||||
echo "pattern_file=/tmp/test_pattern.txt" >> $GITHUB_OUTPUT
|
||||
|
||||
- name: Run PyTorch CUDA tests
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# https://pytorch.org/docs/stable/notes/randomness.html#avoiding-nondeterministic-algorithms
|
||||
CUBLAS_WORKSPACE_CONFIG: :16:8
|
||||
run: |
|
||||
pattern=$(cat ${{ steps.extract_tests.outputs.pattern_file }})
|
||||
if [ -z "$pattern" ]; then
|
||||
pytest -n 1 -sv --max-worker-restart=0 --dist=loadfile -k "not Flax and not Onnx" tests/${{ matrix.module }} \
|
||||
--make-reports=tests_torch_cuda_${{ matrix.module }}
|
||||
else
|
||||
pytest -n 1 -sv --max-worker-restart=0 --dist=loadfile -k "not Flax and not Onnx and $pattern" tests/${{ matrix.module }} \
|
||||
--make-reports=tests_torch_cuda_${{ matrix.module }}
|
||||
fi
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/tests_torch_cuda_${{ matrix.module }}_stats.txt
|
||||
cat reports/tests_torch_cuda_${{ matrix.module }}_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: torch_cuda_test_reports_${{ matrix.module }}
|
||||
path: reports
|
||||
|
||||
run_examples_tests:
|
||||
name: Examples PyTorch CUDA tests on Ubuntu
|
||||
needs: [check_code_quality, check_repository_consistency]
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --gpus all --shm-size "16gb" --ipc host
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip uninstall transformers huggingface_hub && uv pip install --prerelease allow -U transformers@git+https://github.com/huggingface/transformers.git
|
||||
uv pip install -e ".[quality,training]"
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run example tests on GPU
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
run: |
|
||||
uv pip install ".[training]"
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile -s -v --make-reports=examples_torch_cuda examples/
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/examples_torch_cuda_stats.txt
|
||||
cat reports/examples_torch_cuda_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: examples_test_reports
|
||||
path: reports
|
||||
|
||||
32
.github/workflows/pr_torch_dependency_test.yml
vendored
32
.github/workflows/pr_torch_dependency_test.yml
vendored
@@ -1,32 +0,0 @@
|
||||
name: Run Torch dependency tests
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
branches:
|
||||
- main
|
||||
paths:
|
||||
- "src/diffusers/**.py"
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
check_torch_dependencies:
|
||||
runs-on: ubuntu-22.04
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: "3.8"
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
pip install -e .
|
||||
pip install torch torchvision torchaudio pytest
|
||||
- name: Check for soft dependencies
|
||||
run: |
|
||||
pytest tests/others/test_dependencies.py
|
||||
286
.github/workflows/push_tests.yml
vendored
286
.github/workflows/push_tests.yml
vendored
@@ -1,286 +0,0 @@
|
||||
name: Fast GPU Tests on main
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
paths:
|
||||
- "src/diffusers/**.py"
|
||||
- "examples/**.py"
|
||||
- "tests/**.py"
|
||||
|
||||
env:
|
||||
DIFFUSERS_IS_CI: yes
|
||||
OMP_NUM_THREADS: 8
|
||||
MKL_NUM_THREADS: 8
|
||||
HF_XET_HIGH_PERFORMANCE: 1
|
||||
PYTEST_TIMEOUT: 600
|
||||
PIPELINE_USAGE_CUTOFF: 50000
|
||||
|
||||
jobs:
|
||||
setup_torch_cuda_pipeline_matrix:
|
||||
name: Setup Torch Pipelines CUDA Slow Tests Matrix
|
||||
runs-on:
|
||||
group: aws-general-8-plus
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
outputs:
|
||||
pipeline_test_matrix: ${{ steps.fetch_pipeline_matrix.outputs.pipeline_test_matrix }}
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: Fetch Pipeline Matrix
|
||||
id: fetch_pipeline_matrix
|
||||
run: |
|
||||
matrix=$(python utils/fetch_torch_cuda_pipeline_test_matrix.py)
|
||||
echo $matrix
|
||||
echo "pipeline_test_matrix=$matrix" >> $GITHUB_OUTPUT
|
||||
- name: Pipeline Tests Artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: test-pipelines.json
|
||||
path: reports
|
||||
|
||||
torch_pipelines_cuda_tests:
|
||||
name: Torch Pipelines CUDA Tests
|
||||
needs: setup_torch_cuda_pipeline_matrix
|
||||
strategy:
|
||||
fail-fast: false
|
||||
max-parallel: 8
|
||||
matrix:
|
||||
module: ${{ fromJson(needs.setup_torch_cuda_pipeline_matrix.outputs.pipeline_test_matrix) }}
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --shm-size "16gb" --ipc host --gpus all
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip uninstall accelerate && uv pip install -U accelerate@git+https://github.com/huggingface/accelerate.git
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: PyTorch CUDA checkpoint tests on Ubuntu
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# https://pytorch.org/docs/stable/notes/randomness.html#avoiding-nondeterministic-algorithms
|
||||
CUBLAS_WORKSPACE_CONFIG: :16:8
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "not Flax and not Onnx" \
|
||||
--make-reports=tests_pipeline_${{ matrix.module }}_cuda \
|
||||
tests/pipelines/${{ matrix.module }}
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/tests_pipeline_${{ matrix.module }}_cuda_stats.txt
|
||||
cat reports/tests_pipeline_${{ matrix.module }}_cuda_failures_short.txt
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: pipeline_${{ matrix.module }}_test_reports
|
||||
path: reports
|
||||
|
||||
torch_cuda_tests:
|
||||
name: Torch CUDA Tests
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --shm-size "16gb" --ipc host --gpus all
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
strategy:
|
||||
fail-fast: false
|
||||
max-parallel: 2
|
||||
matrix:
|
||||
module: [models, schedulers, lora, others, single_file]
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip install peft@git+https://github.com/huggingface/peft.git
|
||||
uv pip uninstall accelerate && uv pip install -U accelerate@git+https://github.com/huggingface/accelerate.git
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run PyTorch CUDA tests
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# https://pytorch.org/docs/stable/notes/randomness.html#avoiding-nondeterministic-algorithms
|
||||
CUBLAS_WORKSPACE_CONFIG: :16:8
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "not Flax and not Onnx" \
|
||||
--make-reports=tests_torch_cuda_${{ matrix.module }} \
|
||||
tests/${{ matrix.module }}
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/tests_torch_cuda_${{ matrix.module }}_stats.txt
|
||||
cat reports/tests_torch_cuda_${{ matrix.module }}_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: torch_cuda_test_reports_${{ matrix.module }}
|
||||
path: reports
|
||||
|
||||
run_torch_compile_tests:
|
||||
name: PyTorch Compile CUDA tests
|
||||
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --gpus all --shm-size "16gb" --ipc host
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality,training]"
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: Run example tests on GPU
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
RUN_COMPILE: yes
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile -s -v -k "compile" --make-reports=tests_torch_compile_cuda tests/
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: cat reports/tests_torch_compile_cuda_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: torch_compile_test_reports
|
||||
path: reports
|
||||
|
||||
run_xformers_tests:
|
||||
name: PyTorch xformers CUDA tests
|
||||
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-xformers-cuda
|
||||
options: --gpus all --shm-size "16gb" --ipc host
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality,training]"
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: Run example tests on GPU
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile -s -v -k "xformers" --make-reports=tests_torch_xformers_cuda tests/
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: cat reports/tests_torch_xformers_cuda_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: torch_xformers_test_reports
|
||||
path: reports
|
||||
|
||||
run_examples_tests:
|
||||
name: Examples PyTorch CUDA tests on Ubuntu
|
||||
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --gpus all --shm-size "16gb" --ipc host
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality,training]"
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run example tests on GPU
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
run: |
|
||||
uv pip install ".[training]"
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile -s -v --make-reports=examples_torch_cuda examples/
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/examples_torch_cuda_stats.txt
|
||||
cat reports/examples_torch_cuda_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: examples_test_reports
|
||||
path: reports
|
||||
94
.github/workflows/push_tests_fast.yml
vendored
94
.github/workflows/push_tests_fast.yml
vendored
@@ -1,94 +0,0 @@
|
||||
name: Fast tests on main
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
paths:
|
||||
- "src/diffusers/**.py"
|
||||
- "examples/**.py"
|
||||
- "tests/**.py"
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
env:
|
||||
DIFFUSERS_IS_CI: yes
|
||||
HF_HOME: /mnt/cache
|
||||
OMP_NUM_THREADS: 8
|
||||
MKL_NUM_THREADS: 8
|
||||
HF_XET_HIGH_PERFORMANCE: 1
|
||||
PYTEST_TIMEOUT: 600
|
||||
RUN_SLOW: no
|
||||
|
||||
jobs:
|
||||
run_fast_tests:
|
||||
strategy:
|
||||
fail-fast: false
|
||||
matrix:
|
||||
config:
|
||||
- name: Fast PyTorch CPU tests on Ubuntu
|
||||
framework: pytorch
|
||||
runner: aws-general-8-plus
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
report: torch_cpu
|
||||
- name: PyTorch Example CPU tests on Ubuntu
|
||||
framework: pytorch_examples
|
||||
runner: aws-general-8-plus
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
report: torch_example_cpu
|
||||
|
||||
name: ${{ matrix.config.name }}
|
||||
|
||||
runs-on:
|
||||
group: ${{ matrix.config.runner }}
|
||||
|
||||
container:
|
||||
image: ${{ matrix.config.image }}
|
||||
options: --shm-size "16gb" --ipc host -v /mnt/hf_cache:/mnt/cache/
|
||||
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run fast PyTorch CPU tests
|
||||
if: ${{ matrix.config.framework == 'pytorch' }}
|
||||
run: |
|
||||
pytest -n 4 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "not Flax and not Onnx" \
|
||||
--make-reports=tests_${{ matrix.config.report }} \
|
||||
tests/
|
||||
|
||||
- name: Run example PyTorch CPU tests
|
||||
if: ${{ matrix.config.framework == 'pytorch_examples' }}
|
||||
run: |
|
||||
uv pip install ".[training]"
|
||||
pytest -n 4 --max-worker-restart=0 --dist=loadfile \
|
||||
--make-reports=tests_${{ matrix.config.report }} \
|
||||
examples
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: cat reports/tests_${{ matrix.config.report }}_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: pr_${{ matrix.config.report }}_test_reports
|
||||
path: reports
|
||||
71
.github/workflows/push_tests_mps.yml
vendored
71
.github/workflows/push_tests_mps.yml
vendored
@@ -1,71 +0,0 @@
|
||||
name: Fast mps tests on main
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
|
||||
env:
|
||||
DIFFUSERS_IS_CI: yes
|
||||
HF_HOME: /mnt/cache
|
||||
OMP_NUM_THREADS: 8
|
||||
MKL_NUM_THREADS: 8
|
||||
HF_XET_HIGH_PERFORMANCE: 1
|
||||
PYTEST_TIMEOUT: 600
|
||||
RUN_SLOW: no
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
run_fast_tests_apple_m1:
|
||||
name: Fast PyTorch MPS tests on MacOS
|
||||
runs-on: macos-13-xlarge
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Clean checkout
|
||||
shell: arch -arch arm64 bash {0}
|
||||
run: |
|
||||
git clean -fxd
|
||||
|
||||
- name: Setup miniconda
|
||||
uses: ./.github/actions/setup-miniconda
|
||||
with:
|
||||
python-version: 3.9
|
||||
|
||||
- name: Install dependencies
|
||||
shell: arch -arch arm64 bash {0}
|
||||
run: |
|
||||
${CONDA_RUN} python -m pip install --upgrade pip uv
|
||||
${CONDA_RUN} python -m uv pip install -e ".[quality,test]"
|
||||
${CONDA_RUN} python -m uv pip install torch torchvision torchaudio
|
||||
${CONDA_RUN} python -m uv pip install accelerate@git+https://github.com/huggingface/accelerate.git
|
||||
${CONDA_RUN} python -m uv pip install transformers --upgrade
|
||||
|
||||
- name: Environment
|
||||
shell: arch -arch arm64 bash {0}
|
||||
run: |
|
||||
${CONDA_RUN} python utils/print_env.py
|
||||
|
||||
- name: Run fast PyTorch tests on M1 (MPS)
|
||||
shell: arch -arch arm64 bash {0}
|
||||
env:
|
||||
HF_HOME: /System/Volumes/Data/mnt/cache
|
||||
HF_TOKEN: ${{ secrets.HF_TOKEN }}
|
||||
run: |
|
||||
${CONDA_RUN} python -m pytest -n 0 -s -v --make-reports=tests_torch_mps tests/
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: cat reports/tests_torch_mps_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: pr_torch_mps_test_reports
|
||||
path: reports
|
||||
81
.github/workflows/pypi_publish.yaml
vendored
81
.github/workflows/pypi_publish.yaml
vendored
@@ -1,81 +0,0 @@
|
||||
# Adapted from https://blog.deepjyoti30.dev/pypi-release-github-action
|
||||
|
||||
name: PyPI release
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
push:
|
||||
tags:
|
||||
- "*"
|
||||
|
||||
jobs:
|
||||
find-and-checkout-latest-branch:
|
||||
runs-on: ubuntu-22.04
|
||||
outputs:
|
||||
latest_branch: ${{ steps.set_latest_branch.outputs.latest_branch }}
|
||||
steps:
|
||||
- name: Checkout Repo
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: Set up Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: '3.8'
|
||||
|
||||
- name: Fetch latest branch
|
||||
id: fetch_latest_branch
|
||||
run: |
|
||||
pip install -U requests packaging
|
||||
LATEST_BRANCH=$(python utils/fetch_latest_release_branch.py)
|
||||
echo "Latest branch: $LATEST_BRANCH"
|
||||
echo "latest_branch=$LATEST_BRANCH" >> $GITHUB_ENV
|
||||
|
||||
- name: Set latest branch output
|
||||
id: set_latest_branch
|
||||
run: echo "::set-output name=latest_branch::${{ env.latest_branch }}"
|
||||
|
||||
release:
|
||||
needs: find-and-checkout-latest-branch
|
||||
runs-on: ubuntu-22.04
|
||||
|
||||
steps:
|
||||
- name: Checkout Repo
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
ref: ${{ needs.find-and-checkout-latest-branch.outputs.latest_branch }}
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: "3.8"
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install -U setuptools wheel twine
|
||||
pip install -U torch --index-url https://download.pytorch.org/whl/cpu
|
||||
pip install -U transformers
|
||||
|
||||
- name: Build the dist files
|
||||
run: python setup.py bdist_wheel && python setup.py sdist
|
||||
|
||||
- name: Publish to the test PyPI
|
||||
env:
|
||||
TWINE_USERNAME: ${{ secrets.TEST_PYPI_USERNAME }}
|
||||
TWINE_PASSWORD: ${{ secrets.TEST_PYPI_PASSWORD }}
|
||||
run: twine upload dist/* -r pypitest --repository-url=https://test.pypi.org/legacy/
|
||||
|
||||
- name: Test installing diffusers and importing
|
||||
run: |
|
||||
pip install diffusers && pip uninstall diffusers -y
|
||||
pip install -i https://test.pypi.org/simple/ diffusers
|
||||
python -c "from diffusers import __version__; print(__version__)"
|
||||
python -c "from diffusers import DiffusionPipeline; pipe = DiffusionPipeline.from_pretrained('fusing/unet-ldm-dummy-update'); pipe()"
|
||||
python -c "from diffusers import DiffusionPipeline; pipe = DiffusionPipeline.from_pretrained('hf-internal-testing/tiny-stable-diffusion-pipe', safety_checker=None); pipe('ah suh du')"
|
||||
python -c "from diffusers import *"
|
||||
|
||||
- name: Publish to PyPI
|
||||
env:
|
||||
TWINE_USERNAME: ${{ secrets.PYPI_USERNAME }}
|
||||
TWINE_PASSWORD: ${{ secrets.PYPI_PASSWORD }}
|
||||
run: twine upload dist/* -r pypi
|
||||
342
.github/workflows/release_tests_fast.yml
vendored
342
.github/workflows/release_tests_fast.yml
vendored
@@ -1,342 +0,0 @@
|
||||
# Duplicate workflow to push_tests.yml that is meant to run on release/patch branches as a final check
|
||||
# Creating a duplicate workflow here is simpler than adding complex path/branch parsing logic to push_tests.yml
|
||||
# Needs to be updated if push_tests.yml updated
|
||||
name: (Release) Fast GPU Tests on main
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- "v*.*.*-release"
|
||||
- "v*.*.*-patch"
|
||||
|
||||
env:
|
||||
DIFFUSERS_IS_CI: yes
|
||||
OMP_NUM_THREADS: 8
|
||||
MKL_NUM_THREADS: 8
|
||||
PYTEST_TIMEOUT: 600
|
||||
PIPELINE_USAGE_CUTOFF: 50000
|
||||
|
||||
jobs:
|
||||
setup_torch_cuda_pipeline_matrix:
|
||||
name: Setup Torch Pipelines CUDA Slow Tests Matrix
|
||||
runs-on:
|
||||
group: aws-general-8-plus
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cpu
|
||||
outputs:
|
||||
pipeline_test_matrix: ${{ steps.fetch_pipeline_matrix.outputs.pipeline_test_matrix }}
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: Fetch Pipeline Matrix
|
||||
id: fetch_pipeline_matrix
|
||||
run: |
|
||||
matrix=$(python utils/fetch_torch_cuda_pipeline_test_matrix.py)
|
||||
echo $matrix
|
||||
echo "pipeline_test_matrix=$matrix" >> $GITHUB_OUTPUT
|
||||
- name: Pipeline Tests Artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: test-pipelines.json
|
||||
path: reports
|
||||
|
||||
torch_pipelines_cuda_tests:
|
||||
name: Torch Pipelines CUDA Tests
|
||||
needs: setup_torch_cuda_pipeline_matrix
|
||||
strategy:
|
||||
fail-fast: false
|
||||
max-parallel: 8
|
||||
matrix:
|
||||
module: ${{ fromJson(needs.setup_torch_cuda_pipeline_matrix.outputs.pipeline_test_matrix) }}
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --shm-size "16gb" --ipc host --gpus all
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip uninstall accelerate && uv pip install -U accelerate@git+https://github.com/huggingface/accelerate.git
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: Slow PyTorch CUDA checkpoint tests on Ubuntu
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# https://pytorch.org/docs/stable/notes/randomness.html#avoiding-nondeterministic-algorithms
|
||||
CUBLAS_WORKSPACE_CONFIG: :16:8
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "not Flax and not Onnx" \
|
||||
--make-reports=tests_pipeline_${{ matrix.module }}_cuda \
|
||||
tests/pipelines/${{ matrix.module }}
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/tests_pipeline_${{ matrix.module }}_cuda_stats.txt
|
||||
cat reports/tests_pipeline_${{ matrix.module }}_cuda_failures_short.txt
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: pipeline_${{ matrix.module }}_test_reports
|
||||
path: reports
|
||||
|
||||
torch_cuda_tests:
|
||||
name: Torch CUDA Tests
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --shm-size "16gb" --ipc host --gpus all
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
strategy:
|
||||
fail-fast: false
|
||||
max-parallel: 2
|
||||
matrix:
|
||||
module: [models, schedulers, lora, others, single_file]
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip install peft@git+https://github.com/huggingface/peft.git
|
||||
uv pip uninstall accelerate && uv pip install -U accelerate@git+https://github.com/huggingface/accelerate.git
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run PyTorch CUDA tests
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# https://pytorch.org/docs/stable/notes/randomness.html#avoiding-nondeterministic-algorithms
|
||||
CUBLAS_WORKSPACE_CONFIG: :16:8
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "not Flax and not Onnx" \
|
||||
--make-reports=tests_torch_${{ matrix.module }}_cuda \
|
||||
tests/${{ matrix.module }}
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/tests_torch_${{ matrix.module }}_cuda_stats.txt
|
||||
cat reports/tests_torch_${{ matrix.module }}_cuda_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: torch_cuda_${{ matrix.module }}_test_reports
|
||||
path: reports
|
||||
|
||||
torch_minimum_version_cuda_tests:
|
||||
name: Torch Minimum Version CUDA Tests
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-minimum-cuda
|
||||
options: --shm-size "16gb" --ipc host --gpus all
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip install peft@git+https://github.com/huggingface/peft.git
|
||||
uv pip uninstall accelerate && uv pip install -U accelerate@git+https://github.com/huggingface/accelerate.git
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run PyTorch CUDA tests
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
# https://pytorch.org/docs/stable/notes/randomness.html#avoiding-nondeterministic-algorithms
|
||||
CUBLAS_WORKSPACE_CONFIG: :16:8
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-s -v -k "not Flax and not Onnx" \
|
||||
--make-reports=tests_torch_minimum_cuda \
|
||||
tests/models/test_modeling_common.py \
|
||||
tests/pipelines/test_pipelines_common.py \
|
||||
tests/pipelines/test_pipeline_utils.py \
|
||||
tests/pipelines/test_pipelines.py \
|
||||
tests/pipelines/test_pipelines_auto.py \
|
||||
tests/schedulers/test_schedulers.py \
|
||||
tests/others
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/tests_torch_minimum_version_cuda_stats.txt
|
||||
cat reports/tests_torch_minimum_version_cuda_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: torch_minimum_version_cuda_test_reports
|
||||
path: reports
|
||||
|
||||
run_torch_compile_tests:
|
||||
name: PyTorch Compile CUDA tests
|
||||
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --gpus all --shm-size "16gb" --ipc host
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality,training]"
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: Run torch compile tests on GPU
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
RUN_COMPILE: yes
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile -s -v -k "compile" --make-reports=tests_torch_compile_cuda tests/
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: cat reports/tests_torch_compile_cuda_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: torch_compile_test_reports
|
||||
path: reports
|
||||
|
||||
run_xformers_tests:
|
||||
name: PyTorch xformers CUDA tests
|
||||
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-xformers-cuda
|
||||
options: --gpus all --shm-size "16gb" --ipc host
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality,training]"
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
- name: Run example tests on GPU
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
run: |
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile -s -v -k "xformers" --make-reports=tests_torch_xformers_cuda tests/
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: cat reports/tests_torch_xformers_cuda_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: torch_xformers_test_reports
|
||||
path: reports
|
||||
|
||||
run_examples_tests:
|
||||
name: Examples PyTorch CUDA tests on Ubuntu
|
||||
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
|
||||
container:
|
||||
image: diffusers/diffusers-pytorch-cuda
|
||||
options: --gpus all --shm-size "16gb" --ipc host
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
uv pip install -e ".[quality,training]"
|
||||
|
||||
- name: Environment
|
||||
run: |
|
||||
python utils/print_env.py
|
||||
|
||||
- name: Run example tests on GPU
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.DIFFUSERS_HF_HUB_READ_TOKEN }}
|
||||
run: |
|
||||
uv pip install ".[training]"
|
||||
pytest -n 1 --max-worker-restart=0 --dist=loadfile -s -v --make-reports=examples_torch_cuda examples/
|
||||
|
||||
- name: Failure short reports
|
||||
if: ${{ failure() }}
|
||||
run: |
|
||||
cat reports/examples_torch_cuda_stats.txt
|
||||
cat reports/examples_torch_cuda_failures_short.txt
|
||||
|
||||
- name: Test suite reports artifacts
|
||||
if: ${{ always() }}
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: examples_test_reports
|
||||
path: reports
|
||||
73
.github/workflows/run_tests_from_a_pr.yml
vendored
73
.github/workflows/run_tests_from_a_pr.yml
vendored
@@ -1,73 +0,0 @@
|
||||
name: Check running SLOW tests from a PR (only GPU)
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
docker_image:
|
||||
default: 'diffusers/diffusers-pytorch-cuda'
|
||||
description: 'Name of the Docker image'
|
||||
required: true
|
||||
pr_number:
|
||||
description: 'PR number to test on'
|
||||
required: true
|
||||
test:
|
||||
description: 'Tests to run (e.g.: `tests/models`).'
|
||||
required: true
|
||||
|
||||
env:
|
||||
DIFFUSERS_IS_CI: yes
|
||||
IS_GITHUB_CI: "1"
|
||||
HF_HOME: /mnt/cache
|
||||
OMP_NUM_THREADS: 8
|
||||
MKL_NUM_THREADS: 8
|
||||
PYTEST_TIMEOUT: 600
|
||||
RUN_SLOW: yes
|
||||
|
||||
jobs:
|
||||
run_tests:
|
||||
name: "Run a test on our runner from a PR"
|
||||
runs-on:
|
||||
group: aws-g4dn-2xlarge
|
||||
container:
|
||||
image: ${{ github.event.inputs.docker_image }}
|
||||
options: --gpus all --privileged --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
|
||||
|
||||
steps:
|
||||
- name: Validate test files input
|
||||
id: validate_test_files
|
||||
env:
|
||||
PY_TEST: ${{ github.event.inputs.test }}
|
||||
run: |
|
||||
if [[ ! "$PY_TEST" =~ ^tests/ ]]; then
|
||||
echo "Error: The input string must start with 'tests/'."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [[ ! "$PY_TEST" =~ ^tests/(models|pipelines|lora) ]]; then
|
||||
echo "Error: The input string must contain either 'models', 'pipelines', or 'lora' after 'tests/'."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [[ "$PY_TEST" == *";"* ]]; then
|
||||
echo "Error: The input string must not contain ';'."
|
||||
exit 1
|
||||
fi
|
||||
echo "$PY_TEST"
|
||||
|
||||
shell: bash -e {0}
|
||||
|
||||
- name: Checkout PR branch
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
ref: refs/pull/${{ inputs.pr_number }}/head
|
||||
|
||||
- name: Install pytest
|
||||
run: |
|
||||
uv pip install -e ".[quality]"
|
||||
uv pip install peft
|
||||
|
||||
- name: Run tests
|
||||
env:
|
||||
PY_TEST: ${{ github.event.inputs.test }}
|
||||
run: |
|
||||
pytest "$PY_TEST"
|
||||
40
.github/workflows/ssh-pr-runner.yml
vendored
40
.github/workflows/ssh-pr-runner.yml
vendored
@@ -1,40 +0,0 @@
|
||||
name: SSH into PR runners
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
docker_image:
|
||||
description: 'Name of the Docker image'
|
||||
required: true
|
||||
|
||||
env:
|
||||
IS_GITHUB_CI: "1"
|
||||
HF_HUB_READ_TOKEN: ${{ secrets.HF_HUB_READ_TOKEN }}
|
||||
HF_HOME: /mnt/cache
|
||||
DIFFUSERS_IS_CI: yes
|
||||
OMP_NUM_THREADS: 8
|
||||
MKL_NUM_THREADS: 8
|
||||
RUN_SLOW: yes
|
||||
|
||||
jobs:
|
||||
ssh_runner:
|
||||
name: "SSH"
|
||||
runs-on:
|
||||
group: aws-highmemory-32-plus
|
||||
container:
|
||||
image: ${{ github.event.inputs.docker_image }}
|
||||
options: --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface/diffusers:/mnt/cache/ --privileged
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: Tailscale # In order to be able to SSH when a test fails
|
||||
uses: huggingface/tailscale-action@main
|
||||
with:
|
||||
authkey: ${{ secrets.TAILSCALE_SSH_AUTHKEY }}
|
||||
slackChannel: ${{ secrets.SLACK_CIFEEDBACK_CHANNEL }}
|
||||
slackToken: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
waitForSSH: true
|
||||
52
.github/workflows/ssh-runner.yml
vendored
52
.github/workflows/ssh-runner.yml
vendored
@@ -1,52 +0,0 @@
|
||||
name: SSH into GPU runners
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
runner_type:
|
||||
description: 'Type of runner to test (aws-g6-4xlarge-plus: a10, aws-g4dn-2xlarge: t4, aws-g6e-xlarge-plus: L40)'
|
||||
type: choice
|
||||
required: true
|
||||
options:
|
||||
- aws-g6-4xlarge-plus
|
||||
- aws-g4dn-2xlarge
|
||||
- aws-g6e-xlarge-plus
|
||||
docker_image:
|
||||
description: 'Name of the Docker image'
|
||||
required: true
|
||||
|
||||
env:
|
||||
IS_GITHUB_CI: "1"
|
||||
HF_HUB_READ_TOKEN: ${{ secrets.HF_HUB_READ_TOKEN }}
|
||||
HF_HOME: /mnt/cache
|
||||
DIFFUSERS_IS_CI: yes
|
||||
OMP_NUM_THREADS: 8
|
||||
MKL_NUM_THREADS: 8
|
||||
RUN_SLOW: yes
|
||||
|
||||
jobs:
|
||||
ssh_runner:
|
||||
name: "SSH"
|
||||
runs-on:
|
||||
group: "${{ github.event.inputs.runner_type }}"
|
||||
container:
|
||||
image: ${{ github.event.inputs.docker_image }}
|
||||
options: --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface/diffusers:/mnt/cache/ --gpus all --privileged
|
||||
|
||||
steps:
|
||||
- name: Checkout diffusers
|
||||
uses: actions/checkout@v3
|
||||
with:
|
||||
fetch-depth: 2
|
||||
|
||||
- name: NVIDIA-SMI
|
||||
run: |
|
||||
nvidia-smi
|
||||
|
||||
- name: Tailscale # In order to be able to SSH when a test fails
|
||||
uses: huggingface/tailscale-action@main
|
||||
with:
|
||||
authkey: ${{ secrets.TAILSCALE_SSH_AUTHKEY }}
|
||||
slackChannel: ${{ secrets.SLACK_CIFEEDBACK_CHANNEL }}
|
||||
slackToken: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
|
||||
waitForSSH: true
|
||||
30
.github/workflows/stale.yml
vendored
30
.github/workflows/stale.yml
vendored
@@ -1,30 +0,0 @@
|
||||
name: Stale Bot
|
||||
|
||||
on:
|
||||
schedule:
|
||||
- cron: "0 15 * * *"
|
||||
|
||||
jobs:
|
||||
close_stale_issues:
|
||||
name: Close Stale Issues
|
||||
if: github.repository == 'huggingface/diffusers'
|
||||
runs-on: ubuntu-22.04
|
||||
permissions:
|
||||
issues: write
|
||||
pull-requests: write
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v1
|
||||
with:
|
||||
python-version: 3.8
|
||||
|
||||
- name: Install requirements
|
||||
run: |
|
||||
pip install PyGithub
|
||||
- name: Close stale issues
|
||||
run: |
|
||||
python utils/stale.py
|
||||
18
.github/workflows/trufflehog.yml
vendored
18
.github/workflows/trufflehog.yml
vendored
@@ -1,18 +0,0 @@
|
||||
on:
|
||||
push:
|
||||
|
||||
name: Secret Leaks
|
||||
|
||||
jobs:
|
||||
trufflehog:
|
||||
runs-on: ubuntu-22.04
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
fetch-depth: 0
|
||||
- name: Secret Scanning
|
||||
uses: trufflesecurity/trufflehog@main
|
||||
with:
|
||||
extra_args: --results=verified,unknown
|
||||
|
||||
14
.github/workflows/typos.yml
vendored
14
.github/workflows/typos.yml
vendored
@@ -1,14 +0,0 @@
|
||||
name: Check typos
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-22.04
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
- name: typos-action
|
||||
uses: crate-ci/typos@v1.12.4
|
||||
30
.github/workflows/update_metadata.yml
vendored
30
.github/workflows/update_metadata.yml
vendored
@@ -1,30 +0,0 @@
|
||||
name: Update Diffusers metadata
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
- update_diffusers_metadata*
|
||||
|
||||
jobs:
|
||||
update_metadata:
|
||||
runs-on: ubuntu-22.04
|
||||
defaults:
|
||||
run:
|
||||
shell: bash -l {0}
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
- name: Setup environment
|
||||
run: |
|
||||
pip install --upgrade pip
|
||||
pip install datasets pandas
|
||||
pip install .[torch]
|
||||
|
||||
- name: Update metadata
|
||||
env:
|
||||
HF_TOKEN: ${{ secrets.SAYAK_HF_TOKEN }}
|
||||
run: |
|
||||
python utils/update_metadata.py --commit_sha ${{ github.sha }}
|
||||
16
.github/workflows/upload_pr_documentation.yml
vendored
16
.github/workflows/upload_pr_documentation.yml
vendored
@@ -1,16 +0,0 @@
|
||||
name: Upload PR Documentation
|
||||
|
||||
on:
|
||||
workflow_run:
|
||||
workflows: ["Build PR Documentation"]
|
||||
types:
|
||||
- completed
|
||||
|
||||
jobs:
|
||||
build:
|
||||
uses: huggingface/doc-builder/.github/workflows/upload_pr_documentation.yml@main
|
||||
with:
|
||||
package_name: diffusers
|
||||
secrets:
|
||||
hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
|
||||
comment_bot_token: ${{ secrets.COMMENT_BOT_TOKEN }}
|
||||
23
.gitignore
vendored
23
.gitignore
vendored
@@ -1,4 +1,4 @@
|
||||
# Initially taken from GitHub's Python gitignore file
|
||||
# Initially taken from Github's Python gitignore file
|
||||
|
||||
# Byte-compiled / optimized / DLL files
|
||||
__pycache__/
|
||||
@@ -34,7 +34,7 @@ wheels/
|
||||
MANIFEST
|
||||
|
||||
# PyInstaller
|
||||
# Usually these files are written by a Python script from a template
|
||||
# Usually these files are written by a python script from a template
|
||||
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||
*.manifest
|
||||
*.spec
|
||||
@@ -125,9 +125,6 @@ dmypy.json
|
||||
.vs
|
||||
.vscode
|
||||
|
||||
# Cursor
|
||||
.cursor
|
||||
|
||||
# Pycharm
|
||||
.idea
|
||||
|
||||
@@ -156,7 +153,7 @@ debug.env
|
||||
# vim
|
||||
.*.swp
|
||||
|
||||
# ctags
|
||||
#ctags
|
||||
tags
|
||||
|
||||
# pre-commit
|
||||
@@ -166,16 +163,4 @@ tags
|
||||
*.lock
|
||||
|
||||
# DS_Store (MacOS)
|
||||
.DS_Store
|
||||
|
||||
# RL pipelines may produce mp4 outputs
|
||||
*.mp4
|
||||
|
||||
# dependencies
|
||||
/transformers
|
||||
|
||||
# ruff
|
||||
.ruff_cache
|
||||
|
||||
# wandb
|
||||
wandb
|
||||
.DS_Store
|
||||
52
CITATION.cff
52
CITATION.cff
@@ -1,52 +0,0 @@
|
||||
cff-version: 1.2.0
|
||||
title: 'Diffusers: State-of-the-art diffusion models'
|
||||
message: >-
|
||||
If you use this software, please cite it using the
|
||||
metadata from this file.
|
||||
type: software
|
||||
authors:
|
||||
- given-names: Patrick
|
||||
family-names: von Platen
|
||||
- given-names: Suraj
|
||||
family-names: Patil
|
||||
- given-names: Anton
|
||||
family-names: Lozhkov
|
||||
- given-names: Pedro
|
||||
family-names: Cuenca
|
||||
- given-names: Nathan
|
||||
family-names: Lambert
|
||||
- given-names: Kashif
|
||||
family-names: Rasul
|
||||
- given-names: Mishig
|
||||
family-names: Davaadorj
|
||||
- given-names: Dhruv
|
||||
family-names: Nair
|
||||
- given-names: Sayak
|
||||
family-names: Paul
|
||||
- given-names: Steven
|
||||
family-names: Liu
|
||||
- given-names: William
|
||||
family-names: Berman
|
||||
- given-names: Yiyi
|
||||
family-names: Xu
|
||||
- given-names: Thomas
|
||||
family-names: Wolf
|
||||
repository-code: 'https://github.com/huggingface/diffusers'
|
||||
abstract: >-
|
||||
Diffusers provides pretrained diffusion models across
|
||||
multiple modalities, such as vision and audio, and serves
|
||||
as a modular toolbox for inference and training of
|
||||
diffusion models.
|
||||
keywords:
|
||||
- deep-learning
|
||||
- pytorch
|
||||
- image-generation
|
||||
- hacktoberfest
|
||||
- diffusion
|
||||
- text2image
|
||||
- image2image
|
||||
- score-based-generative-modeling
|
||||
- stable-diffusion
|
||||
- stable-diffusion-diffusers
|
||||
license: Apache-2.0
|
||||
version: 0.12.1
|
||||
@@ -1,130 +0,0 @@
|
||||
|
||||
# Contributor Covenant Code of Conduct
|
||||
|
||||
## Our Pledge
|
||||
|
||||
We as members, contributors, and leaders pledge to make participation in our
|
||||
community a harassment-free experience for everyone, regardless of age, body
|
||||
size, visible or invisible disability, ethnicity, sex characteristics, gender
|
||||
identity and expression, level of experience, education, socio-economic status,
|
||||
nationality, personal appearance, race, caste, color, religion, or sexual identity
|
||||
and orientation.
|
||||
|
||||
We pledge to act and interact in ways that contribute to an open, welcoming,
|
||||
diverse, inclusive, and healthy community.
|
||||
|
||||
## Our Standards
|
||||
|
||||
Examples of behavior that contributes to a positive environment for our
|
||||
community include:
|
||||
|
||||
* Demonstrating empathy and kindness toward other people
|
||||
* Being respectful of differing opinions, viewpoints, and experiences
|
||||
* Giving and gracefully accepting constructive feedback
|
||||
* Accepting responsibility and apologizing to those affected by our mistakes,
|
||||
and learning from the experience
|
||||
* Focusing on what is best not just for us as individuals, but for the
|
||||
overall Diffusers community
|
||||
|
||||
Examples of unacceptable behavior include:
|
||||
|
||||
* The use of sexualized language or imagery, and sexual attention or
|
||||
advances of any kind
|
||||
* Trolling, insulting or derogatory comments, and personal or political attacks
|
||||
* Public or private harassment
|
||||
* Publishing others' private information, such as a physical or email
|
||||
address, without their explicit permission
|
||||
* Spamming issues or PRs with links to projects unrelated to this library
|
||||
* Other conduct which could reasonably be considered inappropriate in a
|
||||
professional setting
|
||||
|
||||
## Enforcement Responsibilities
|
||||
|
||||
Community leaders are responsible for clarifying and enforcing our standards of
|
||||
acceptable behavior and will take appropriate and fair corrective action in
|
||||
response to any behavior that they deem inappropriate, threatening, offensive,
|
||||
or harmful.
|
||||
|
||||
Community leaders have the right and responsibility to remove, edit, or reject
|
||||
comments, commits, code, wiki edits, issues, and other contributions that are
|
||||
not aligned to this Code of Conduct, and will communicate reasons for moderation
|
||||
decisions when appropriate.
|
||||
|
||||
## Scope
|
||||
|
||||
This Code of Conduct applies within all community spaces, and also applies when
|
||||
an individual is officially representing the community in public spaces.
|
||||
Examples of representing our community include using an official e-mail address,
|
||||
posting via an official social media account, or acting as an appointed
|
||||
representative at an online or offline event.
|
||||
|
||||
## Enforcement
|
||||
|
||||
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
||||
reported to the community leaders responsible for enforcement at
|
||||
feedback@huggingface.co.
|
||||
All complaints will be reviewed and investigated promptly and fairly.
|
||||
|
||||
All community leaders are obligated to respect the privacy and security of the
|
||||
reporter of any incident.
|
||||
|
||||
## Enforcement Guidelines
|
||||
|
||||
Community leaders will follow these Community Impact Guidelines in determining
|
||||
the consequences for any action they deem in violation of this Code of Conduct:
|
||||
|
||||
### 1. Correction
|
||||
|
||||
**Community Impact**: Use of inappropriate language or other behavior deemed
|
||||
unprofessional or unwelcome in the community.
|
||||
|
||||
**Consequence**: A private, written warning from community leaders, providing
|
||||
clarity around the nature of the violation and an explanation of why the
|
||||
behavior was inappropriate. A public apology may be requested.
|
||||
|
||||
### 2. Warning
|
||||
|
||||
**Community Impact**: A violation through a single incident or series
|
||||
of actions.
|
||||
|
||||
**Consequence**: A warning with consequences for continued behavior. No
|
||||
interaction with the people involved, including unsolicited interaction with
|
||||
those enforcing the Code of Conduct, for a specified period of time. This
|
||||
includes avoiding interactions in community spaces as well as external channels
|
||||
like social media. Violating these terms may lead to a temporary or
|
||||
permanent ban.
|
||||
|
||||
### 3. Temporary Ban
|
||||
|
||||
**Community Impact**: A serious violation of community standards, including
|
||||
sustained inappropriate behavior.
|
||||
|
||||
**Consequence**: A temporary ban from any sort of interaction or public
|
||||
communication with the community for a specified period of time. No public or
|
||||
private interaction with the people involved, including unsolicited interaction
|
||||
with those enforcing the Code of Conduct, is allowed during this period.
|
||||
Violating these terms may lead to a permanent ban.
|
||||
|
||||
### 4. Permanent Ban
|
||||
|
||||
**Community Impact**: Demonstrating a pattern of violation of community
|
||||
standards, including sustained inappropriate behavior, harassment of an
|
||||
individual, or aggression toward or disparagement of classes of individuals.
|
||||
|
||||
**Consequence**: A permanent ban from any sort of public interaction within
|
||||
the community.
|
||||
|
||||
## Attribution
|
||||
|
||||
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
|
||||
version 2.1, available at
|
||||
https://www.contributor-covenant.org/version/2/1/code_of_conduct.html.
|
||||
|
||||
Community Impact Guidelines were inspired by [Mozilla's code of conduct
|
||||
enforcement ladder](https://github.com/mozilla/diversity).
|
||||
|
||||
[homepage]: https://www.contributor-covenant.org
|
||||
|
||||
For answers to common questions about this code of conduct, see the FAQ at
|
||||
https://www.contributor-covenant.org/faq. Translations are available at
|
||||
https://www.contributor-covenant.org/translations.
|
||||
506
CONTRIBUTING.md
506
CONTRIBUTING.md
@@ -1,506 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# How to contribute to Diffusers 🧨
|
||||
|
||||
We ❤️ contributions from the open-source community! Everyone is welcome, and all types of participation –not just code– are valued and appreciated. Answering questions, helping others, reaching out, and improving the documentation are all immensely valuable to the community, so don't be afraid and get involved if you're up for it!
|
||||
|
||||
Everyone is encouraged to start by saying 👋 in our public Discord channel. We discuss the latest trends in diffusion models, ask questions, show off personal projects, help each other with contributions, or just hang out ☕. <a href="https://discord.gg/G7tWnz98XR"><img alt="Join us on Discord" src="https://img.shields.io/discord/823813159592001537?color=5865F2&logo=Discord&logoColor=white"></a>
|
||||
|
||||
Whichever way you choose to contribute, we strive to be part of an open, welcoming, and kind community. Please, read our [code of conduct](https://github.com/huggingface/diffusers/blob/main/CODE_OF_CONDUCT.md) and be mindful to respect it during your interactions. We also recommend you become familiar with the [ethical guidelines](https://huggingface.co/docs/diffusers/conceptual/ethical_guidelines) that guide our project and ask you to adhere to the same principles of transparency and responsibility.
|
||||
|
||||
We enormously value feedback from the community, so please do not be afraid to speak up if you believe you have valuable feedback that can help improve the library - every message, comment, issue, and pull request (PR) is read and considered.
|
||||
|
||||
## Overview
|
||||
|
||||
You can contribute in many ways ranging from answering questions on issues to adding new diffusion models to
|
||||
the core library.
|
||||
|
||||
In the following, we give an overview of different ways to contribute, ranked by difficulty in ascending order. All of them are valuable to the community.
|
||||
|
||||
* 1. Asking and answering questions on [the Diffusers discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers) or on [Discord](https://discord.gg/G7tWnz98XR).
|
||||
* 2. Opening new issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues/new/choose).
|
||||
* 3. Answering issues on [the GitHub Issues tab](https://github.com/huggingface/diffusers/issues).
|
||||
* 4. Fix a simple issue, marked by the "Good first issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
|
||||
* 5. Contribute to the [documentation](https://github.com/huggingface/diffusers/tree/main/docs/source).
|
||||
* 6. Contribute a [Community Pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3Acommunity-examples).
|
||||
* 7. Contribute to the [examples](https://github.com/huggingface/diffusers/tree/main/examples).
|
||||
* 8. Fix a more difficult issue, marked by the "Good second issue" label, see [here](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22).
|
||||
* 9. Add a new pipeline, model, or scheduler, see ["New Pipeline/Model"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) and ["New scheduler"](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22) issues. For this contribution, please have a look at [Design Philosophy](https://github.com/huggingface/diffusers/blob/main/PHILOSOPHY.md).
|
||||
|
||||
As said before, **all contributions are valuable to the community**.
|
||||
In the following, we will explain each contribution a bit more in detail.
|
||||
|
||||
For all contributions 4-9, you will need to open a PR. It is explained in detail how to do so in [Opening a pull request](#how-to-open-a-pr).
|
||||
|
||||
### 1. Asking and answering questions on the Diffusers discussion forum or on the Diffusers Discord
|
||||
|
||||
Any question or comment related to the Diffusers library can be asked on the [discussion forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/) or on [Discord](https://discord.gg/G7tWnz98XR). Such questions and comments include (but are not limited to):
|
||||
- Reports of training or inference experiments in an attempt to share knowledge
|
||||
- Presentation of personal projects
|
||||
- Questions to non-official training examples
|
||||
- Project proposals
|
||||
- General feedback
|
||||
- Paper summaries
|
||||
- Asking for help on personal projects that build on top of the Diffusers library
|
||||
- General questions
|
||||
- Ethical questions regarding diffusion models
|
||||
- ...
|
||||
|
||||
Every question that is asked on the forum or on Discord actively encourages the community to publicly
|
||||
share knowledge and might very well help a beginner in the future who has the same question you're
|
||||
having. Please do pose any questions you might have.
|
||||
In the same spirit, you are of immense help to the community by answering such questions because this way you are publicly documenting knowledge for everybody to learn from.
|
||||
|
||||
**Please** keep in mind that the more effort you put into asking or answering a question, the higher
|
||||
the quality of the publicly documented knowledge. In the same way, well-posed and well-answered questions create a high-quality knowledge database accessible to everybody, while badly posed questions or answers reduce the overall quality of the public knowledge database.
|
||||
In short, a high quality question or answer is *precise*, *concise*, *relevant*, *easy-to-understand*, *accessible*, and *well-formatted/well-posed*. For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
|
||||
|
||||
**NOTE about channels**:
|
||||
[*The forum*](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) is much better indexed by search engines, such as Google. Posts are ranked by popularity rather than chronologically. Hence, it's easier to look up questions and answers that we posted some time ago.
|
||||
In addition, questions and answers posted in the forum can easily be linked to.
|
||||
In contrast, *Discord* has a chat-like format that invites fast back-and-forth communication.
|
||||
While it will most likely take less time for you to get an answer to your question on Discord, your
|
||||
question won't be visible anymore over time. Also, it's much harder to find information that was posted a while back on Discord. We therefore strongly recommend using the forum for high-quality questions and answers in an attempt to create long-lasting knowledge for the community. If discussions on Discord lead to very interesting answers and conclusions, we recommend posting the results on the forum to make the information more available for future readers.
|
||||
|
||||
### 2. Opening new issues on the GitHub issues tab
|
||||
|
||||
The 🧨 Diffusers library is robust and reliable thanks to the users who notify us of
|
||||
the problems they encounter. So thank you for reporting an issue.
|
||||
|
||||
Remember, GitHub issues are reserved for technical questions directly related to the Diffusers library, bug reports, feature requests, or feedback on the library design.
|
||||
|
||||
In a nutshell, this means that everything that is **not** related to the **code of the Diffusers library** (including the documentation) should **not** be asked on GitHub, but rather on either the [forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR).
|
||||
|
||||
**Please consider the following guidelines when opening a new issue**:
|
||||
- Make sure you have searched whether your issue has already been asked before (use the search bar on GitHub under Issues).
|
||||
- Please never report a new issue on another (related) issue. If another issue is highly related, please
|
||||
open a new issue nevertheless and link to the related issue.
|
||||
- Make sure your issue is written in English. Please use one of the great, free online translation services, such as [DeepL](https://www.deepl.com/translator) to translate from your native language to English if you are not comfortable in English.
|
||||
- Check whether your issue might be solved by updating to the newest Diffusers version. Before posting your issue, please make sure that `python -c "import diffusers; print(diffusers.__version__)"` is higher or matches the latest Diffusers version.
|
||||
- Remember that the more effort you put into opening a new issue, the higher the quality of your answer will be and the better the overall quality of the Diffusers issues.
|
||||
|
||||
New issues usually include the following.
|
||||
|
||||
#### 2.1. Reproducible, minimal bug reports
|
||||
|
||||
A bug report should always have a reproducible code snippet and be as minimal and concise as possible.
|
||||
This means in more detail:
|
||||
- Narrow the bug down as much as you can, **do not just dump your whole code file**.
|
||||
- Format your code.
|
||||
- Do not include any external libraries except for Diffusers depending on them.
|
||||
- **Always** provide all necessary information about your environment; for this, you can run: `diffusers-cli env` in your shell and copy-paste the displayed information to the issue.
|
||||
- Explain the issue. If the reader doesn't know what the issue is and why it is an issue, she cannot solve it.
|
||||
- **Always** make sure the reader can reproduce your issue with as little effort as possible. If your code snippet cannot be run because of missing libraries or undefined variables, the reader cannot help you. Make sure your reproducible code snippet is as minimal as possible and can be copy-pasted into a simple Python shell.
|
||||
- If in order to reproduce your issue a model and/or dataset is required, make sure the reader has access to that model or dataset. You can always upload your model or dataset to the [Hub](https://huggingface.co) to make it easily downloadable. Try to keep your model and dataset as small as possible, to make the reproduction of your issue as effortless as possible.
|
||||
|
||||
For more information, please have a look through the [How to write a good issue](#how-to-write-a-good-issue) section.
|
||||
|
||||
You can open a bug report [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&projects=&template=bug-report.yml).
|
||||
|
||||
#### 2.2. Feature requests
|
||||
|
||||
A world-class feature request addresses the following points:
|
||||
|
||||
1. Motivation first:
|
||||
* Is it related to a problem/frustration with the library? If so, please explain
|
||||
why. Providing a code snippet that demonstrates the problem is best.
|
||||
* Is it related to something you would need for a project? We'd love to hear
|
||||
about it!
|
||||
* Is it something you worked on and think could benefit the community?
|
||||
Awesome! Tell us what problem it solved for you.
|
||||
2. Write a *full paragraph* describing the feature;
|
||||
3. Provide a **code snippet** that demonstrates its future use;
|
||||
4. In case this is related to a paper, please attach a link;
|
||||
5. Attach any additional information (drawings, screenshots, etc.) you think may help.
|
||||
|
||||
You can open a feature request [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feature_request.md&title=).
|
||||
|
||||
#### 2.3 Feedback
|
||||
|
||||
Feedback about the library design and why it is good or not good helps the core maintainers immensely to build a user-friendly library. To understand the philosophy behind the current design philosophy, please have a look [here](https://huggingface.co/docs/diffusers/conceptual/philosophy). If you feel like a certain design choice does not fit with the current design philosophy, please explain why and how it should be changed. If a certain design choice follows the design philosophy too much, hence restricting use cases, explain why and how it should be changed.
|
||||
If a certain design choice is very useful for you, please also leave a note as this is great feedback for future design decisions.
|
||||
|
||||
You can open an issue about feedback [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
|
||||
|
||||
#### 2.4 Technical questions
|
||||
|
||||
Technical questions are mainly about why certain code of the library was written in a certain way, or what a certain part of the code does. Please make sure to link to the code in question and please provide detail on
|
||||
why this part of the code is difficult to understand.
|
||||
|
||||
You can open an issue about a technical question [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=bug&template=bug-report.yml).
|
||||
|
||||
#### 2.5 Proposal to add a new model, scheduler, or pipeline
|
||||
|
||||
If the diffusion model community released a new model, pipeline, or scheduler that you would like to see in the Diffusers library, please provide the following information:
|
||||
|
||||
* Short description of the diffusion pipeline, model, or scheduler and link to the paper or public release.
|
||||
* Link to any of its open-source implementation.
|
||||
* Link to the model weights if they are available.
|
||||
|
||||
If you are willing to contribute to the model yourself, let us know so we can best guide you. Also, don't forget
|
||||
to tag the original author of the component (model, scheduler, pipeline, etc.) by GitHub handle if you can find it.
|
||||
|
||||
You can open a request for a model/pipeline/scheduler [here](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=New+model%2Fpipeline%2Fscheduler&template=new-model-addition.yml).
|
||||
|
||||
### 3. Answering issues on the GitHub issues tab
|
||||
|
||||
Answering issues on GitHub might require some technical knowledge of Diffusers, but we encourage everybody to give it a try even if you are not 100% certain that your answer is correct.
|
||||
Some tips to give a high-quality answer to an issue:
|
||||
- Be as concise and minimal as possible.
|
||||
- Stay on topic. An answer to the issue should concern the issue and only the issue.
|
||||
- Provide links to code, papers, or other sources that prove or encourage your point.
|
||||
- Answer in code. If a simple code snippet is the answer to the issue or shows how the issue can be solved, please provide a fully reproducible code snippet.
|
||||
|
||||
Also, many issues tend to be simply off-topic, duplicates of other issues, or irrelevant. It is of great
|
||||
help to the maintainers if you can answer such issues, encouraging the author of the issue to be
|
||||
more precise, provide the link to a duplicated issue or redirect them to [the forum](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63) or [Discord](https://discord.gg/G7tWnz98XR).
|
||||
|
||||
If you have verified that the issued bug report is correct and requires a correction in the source code,
|
||||
please have a look at the next sections.
|
||||
|
||||
For all of the following contributions, you will need to open a PR. It is explained in detail how to do so in the [Opening a pull request](#how-to-open-a-pr) section.
|
||||
|
||||
### 4. Fixing a "Good first issue"
|
||||
|
||||
*Good first issues* are marked by the [Good first issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) label. Usually, the issue already
|
||||
explains how a potential solution should look so that it is easier to fix.
|
||||
If the issue hasn't been closed and you would like to try to fix this issue, you can just leave a message "I would like to try this issue.". There are usually three scenarios:
|
||||
- a.) The issue description already proposes a fix. In this case and if the solution makes sense to you, you can open a PR or draft PR to fix it.
|
||||
- b.) The issue description does not propose a fix. In this case, you can ask what a proposed fix could look like and someone from the Diffusers team should answer shortly. If you have a good idea of how to fix it, feel free to directly open a PR.
|
||||
- c.) There is already an open PR to fix the issue, but the issue hasn't been closed yet. If the PR has gone stale, you can simply open a new PR and link to the stale PR. PRs often go stale if the original contributor who wanted to fix the issue suddenly cannot find the time anymore to proceed. This often happens in open-source and is very normal. In this case, the community will be very happy if you give it a new try and leverage the knowledge of the existing PR. If there is already a PR and it is active, you can help the author by giving suggestions, reviewing the PR or even asking whether you can contribute to the PR.
|
||||
|
||||
|
||||
### 5. Contribute to the documentation
|
||||
|
||||
A good library **always** has good documentation! The official documentation is often one of the first points of contact for new users of the library, and therefore contributing to the documentation is a **highly
|
||||
valuable contribution**.
|
||||
|
||||
Contributing to the library can have many forms:
|
||||
|
||||
- Correcting spelling or grammatical errors.
|
||||
- Correct incorrect formatting of the docstring. If you see that the official documentation is weirdly displayed or a link is broken, we are very happy if you take some time to correct it.
|
||||
- Correct the shape or dimensions of a docstring input or output tensor.
|
||||
- Clarify documentation that is hard to understand or incorrect.
|
||||
- Update outdated code examples.
|
||||
- Translating the documentation to another language.
|
||||
|
||||
Anything displayed on [the official Diffusers doc page](https://huggingface.co/docs/diffusers/index) is part of the official documentation and can be corrected, adjusted in the respective [documentation source](https://github.com/huggingface/diffusers/tree/main/docs/source).
|
||||
|
||||
Please have a look at [this page](https://github.com/huggingface/diffusers/tree/main/docs) on how to verify changes made to the documentation locally.
|
||||
|
||||
|
||||
### 6. Contribute a community pipeline
|
||||
|
||||
[Pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) are usually the first point of contact between the Diffusers library and the user.
|
||||
Pipelines are examples of how to use Diffusers [models](https://huggingface.co/docs/diffusers/api/models/overview) and [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview).
|
||||
We support two types of pipelines:
|
||||
|
||||
- Official Pipelines
|
||||
- Community Pipelines
|
||||
|
||||
Both official and community pipelines follow the same design and consist of the same type of components.
|
||||
|
||||
Official pipelines are tested and maintained by the core maintainers of Diffusers. Their code
|
||||
resides in [src/diffusers/pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines).
|
||||
In contrast, community pipelines are contributed and maintained purely by the **community** and are **not** tested.
|
||||
They reside in [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and while they can be accessed via the [PyPI diffusers package](https://pypi.org/project/diffusers/), their code is not part of the PyPI distribution.
|
||||
|
||||
The reason for the distinction is that the core maintainers of the Diffusers library cannot maintain and test all
|
||||
possible ways diffusion models can be used for inference, but some of them may be of interest to the community.
|
||||
Officially released diffusion pipelines,
|
||||
such as Stable Diffusion are added to the core src/diffusers/pipelines package which ensures
|
||||
high quality of maintenance, no backward-breaking code changes, and testing.
|
||||
More bleeding edge pipelines should be added as community pipelines. If usage for a community pipeline is high, the pipeline can be moved to the official pipelines upon request from the community. This is one of the ways we strive to be a community-driven library.
|
||||
|
||||
To add a community pipeline, one should add a <name-of-the-community>.py file to [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) and adapt the [examples/community/README.md](https://github.com/huggingface/diffusers/tree/main/examples/community/README.md) to include an example of the new pipeline.
|
||||
|
||||
An example can be seen [here](https://github.com/huggingface/diffusers/pull/2400).
|
||||
|
||||
Community pipeline PRs are only checked at a superficial level and ideally they should be maintained by their original authors.
|
||||
|
||||
Contributing a community pipeline is a great way to understand how Diffusers models and schedulers work. Having contributed a community pipeline is usually the first stepping stone to contributing an official pipeline to the
|
||||
core package.
|
||||
|
||||
### 7. Contribute to training examples
|
||||
|
||||
Diffusers examples are a collection of training scripts that reside in [examples](https://github.com/huggingface/diffusers/tree/main/examples).
|
||||
|
||||
We support two types of training examples:
|
||||
|
||||
- Official training examples
|
||||
- Research training examples
|
||||
|
||||
Research training examples are located in [examples/research_projects](https://github.com/huggingface/diffusers/tree/main/examples/research_projects) whereas official training examples include all folders under [examples](https://github.com/huggingface/diffusers/tree/main/examples) except the `research_projects` and `community` folders.
|
||||
The official training examples are maintained by the Diffusers' core maintainers whereas the research training examples are maintained by the community.
|
||||
This is because of the same reasons put forward in [6. Contribute a community pipeline](#6-contribute-a-community-pipeline) for official pipelines vs. community pipelines: It is not feasible for the core maintainers to maintain all possible training methods for diffusion models.
|
||||
If the Diffusers core maintainers and the community consider a certain training paradigm to be too experimental or not popular enough, the corresponding training code should be put in the `research_projects` folder and maintained by the author.
|
||||
|
||||
Both official training and research examples consist of a directory that contains one or more training scripts, a `requirements.txt` file, and a `README.md` file. In order for the user to make use of the
|
||||
training examples, it is required to clone the repository:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/huggingface/diffusers
|
||||
```
|
||||
|
||||
as well as to install all additional dependencies required for training:
|
||||
|
||||
```bash
|
||||
cd diffusers
|
||||
pip install -r examples/<your-example-folder>/requirements.txt
|
||||
```
|
||||
|
||||
Therefore when adding an example, the `requirements.txt` file shall define all pip dependencies required for your training example so that once all those are installed, the user can run the example's training script. See, for example, the [DreamBooth `requirements.txt` file](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/requirements.txt).
|
||||
|
||||
Training examples of the Diffusers library should adhere to the following philosophy:
|
||||
- All the code necessary to run the examples should be found in a single Python file.
|
||||
- One should be able to run the example from the command line with `python <your-example>.py --args`.
|
||||
- Examples should be kept simple and serve as **an example** on how to use Diffusers for training. The purpose of example scripts is **not** to create state-of-the-art diffusion models, but rather to reproduce known training schemes without adding too much custom logic. As a byproduct of this point, our examples also strive to serve as good educational materials.
|
||||
|
||||
To contribute an example, it is highly recommended to look at already existing examples such as [dreambooth](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/train_dreambooth.py) to get an idea of how they should look like.
|
||||
We strongly advise contributors to make use of the [Accelerate library](https://github.com/huggingface/accelerate) as it's tightly integrated
|
||||
with Diffusers.
|
||||
Once an example script works, please make sure to add a comprehensive `README.md` that states how to use the example exactly. This README should include:
|
||||
- An example command on how to run the example script as shown [here e.g.](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth#running-locally-with-pytorch).
|
||||
- A link to some training results (logs, models, ...) that show what the user can expect as shown [here e.g.](https://api.wandb.ai/report/patrickvonplaten/xm6cd5q5).
|
||||
- If you are adding a non-official/research training example, **please don't forget** to add a sentence that you are maintaining this training example which includes your git handle as shown [here](https://github.com/huggingface/diffusers/tree/main/examples/research_projects/intel_opts#diffusers-examples-with-intel-optimizations).
|
||||
|
||||
If you are contributing to the official training examples, please also make sure to add a test to [examples/test_examples.py](https://github.com/huggingface/diffusers/blob/main/examples/test_examples.py). This is not necessary for non-official training examples.
|
||||
|
||||
### 8. Fixing a "Good second issue"
|
||||
|
||||
*Good second issues* are marked by the [Good second issue](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22Good+second+issue%22) label. Good second issues are
|
||||
usually more complicated to solve than [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22).
|
||||
The issue description usually gives less guidance on how to fix the issue and requires
|
||||
a decent understanding of the library by the interested contributor.
|
||||
If you are interested in tackling a good second issue, feel free to open a PR to fix it and link the PR to the issue. If you see that a PR has already been opened for this issue but did not get merged, have a look to understand why it wasn't merged and try to open an improved PR.
|
||||
Good second issues are usually more difficult to get merged compared to good first issues, so don't hesitate to ask for help from the core maintainers. If your PR is almost finished the core maintainers can also jump into your PR and commit to it in order to get it merged.
|
||||
|
||||
### 9. Adding pipelines, models, schedulers
|
||||
|
||||
Pipelines, models, and schedulers are the most important pieces of the Diffusers library.
|
||||
They provide easy access to state-of-the-art diffusion technologies and thus allow the community to
|
||||
build powerful generative AI applications.
|
||||
|
||||
By adding a new model, pipeline, or scheduler you might enable a new powerful use case for any of the user interfaces relying on Diffusers which can be of immense value for the whole generative AI ecosystem.
|
||||
|
||||
Diffusers has a couple of open feature requests for all three components - feel free to gloss over them
|
||||
if you don't know yet what specific component you would like to add:
|
||||
- [Model or pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22)
|
||||
- [Scheduler](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22)
|
||||
|
||||
Before adding any of the three components, it is strongly recommended that you give the [Philosophy guide](https://github.com/huggingface/diffusers/blob/main/PHILOSOPHY.md) a read to better understand the design of any of the three components. Please be aware that
|
||||
we cannot merge model, scheduler, or pipeline additions that strongly diverge from our design philosophy
|
||||
as it will lead to API inconsistencies. If you fundamentally disagree with a design choice, please
|
||||
open a [Feedback issue](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=) instead so that it can be discussed whether a certain design
|
||||
pattern/design choice shall be changed everywhere in the library and whether we shall update our design philosophy. Consistency across the library is very important for us.
|
||||
|
||||
Please make sure to add links to the original codebase/paper to the PR and ideally also ping the
|
||||
original author directly on the PR so that they can follow the progress and potentially help with questions.
|
||||
|
||||
If you are unsure or stuck in the PR, don't hesitate to leave a message to ask for a first review or help.
|
||||
|
||||
## How to write a good issue
|
||||
|
||||
**The better your issue is written, the higher the chances that it will be quickly resolved.**
|
||||
|
||||
1. Make sure that you've used the correct template for your issue. You can pick between *Bug Report*, *Feature Request*, *Feedback about API Design*, *New model/pipeline/scheduler addition*, *Forum*, or a blank issue. Make sure to pick the correct one when opening [a new issue](https://github.com/huggingface/diffusers/issues/new/choose).
|
||||
2. **Be precise**: Give your issue a fitting title. Try to formulate your issue description as simple as possible. The more precise you are when submitting an issue, the less time it takes to understand the issue and potentially solve it. Make sure to open an issue for one issue only and not for multiple issues. If you found multiple issues, simply open multiple issues. If your issue is a bug, try to be as precise as possible about what bug it is - you should not just write "Error in diffusers".
|
||||
3. **Reproducibility**: No reproducible code snippet == no solution. If you encounter a bug, maintainers **have to be able to reproduce** it. Make sure that you include a code snippet that can be copy-pasted into a Python interpreter to reproduce the issue. Make sure that your code snippet works, *i.e.* that there are no missing imports or missing links to images, ... Your issue should contain an error message **and** a code snippet that can be copy-pasted without any changes to reproduce the exact same error message. If your issue is using local model weights or local data that cannot be accessed by the reader, the issue cannot be solved. If you cannot share your data or model, try to make a dummy model or dummy data.
|
||||
4. **Minimalistic**: Try to help the reader as much as you can to understand the issue as quickly as possible by staying as concise as possible. Remove all code / all information that is irrelevant to the issue. If you have found a bug, try to create the easiest code example you can to demonstrate your issue, do not just dump your whole workflow into the issue as soon as you have found a bug. E.g., if you train a model and get an error at some point during the training, you should first try to understand what part of the training code is responsible for the error and try to reproduce it with a couple of lines. Try to use dummy data instead of full datasets.
|
||||
5. Add links. If you are referring to a certain naming, method, or model make sure to provide a link so that the reader can better understand what you mean. If you are referring to a specific PR or issue, make sure to link it to your issue. Do not assume that the reader knows what you are talking about. The more links you add to your issue the better.
|
||||
6. Formatting. Make sure to nicely format your issue by formatting code into Python code syntax, and error messages into normal code syntax. See the [official GitHub formatting docs](https://docs.github.com/en/get-started/writing-on-github/getting-started-with-writing-and-formatting-on-github/basic-writing-and-formatting-syntax) for more information.
|
||||
7. Think of your issue not as a ticket to be solved, but rather as a beautiful entry to a well-written encyclopedia. Every added issue is a contribution to publicly available knowledge. By adding a nicely written issue you not only make it easier for maintainers to solve your issue, but you are helping the whole community to better understand a certain aspect of the library.
|
||||
|
||||
## How to write a good PR
|
||||
|
||||
1. Be a chameleon. Understand existing design patterns and syntax and make sure your code additions flow seamlessly into the existing code base. Pull requests that significantly diverge from existing design patterns or user interfaces will not be merged.
|
||||
2. Be laser focused. A pull request should solve one problem and one problem only. Make sure to not fall into the trap of "also fixing another problem while we're adding it". It is much more difficult to review pull requests that solve multiple, unrelated problems at once.
|
||||
3. If helpful, try to add a code snippet that displays an example of how your addition can be used.
|
||||
4. The title of your pull request should be a summary of its contribution.
|
||||
5. If your pull request addresses an issue, please mention the issue number in
|
||||
the pull request description to make sure they are linked (and people
|
||||
consulting the issue know you are working on it);
|
||||
6. To indicate a work in progress please prefix the title with `[WIP]`. These
|
||||
are useful to avoid duplicated work, and to differentiate it from PRs ready
|
||||
to be merged;
|
||||
7. Try to formulate and format your text as explained in [How to write a good issue](#how-to-write-a-good-issue).
|
||||
8. Make sure existing tests pass;
|
||||
9. Add high-coverage tests. No quality testing = no merge.
|
||||
- If you are adding new `@slow` tests, make sure they pass using
|
||||
`RUN_SLOW=1 python -m pytest tests/test_my_new_model.py`.
|
||||
CircleCI does not run the slow tests, but GitHub Actions does every night!
|
||||
10. All public methods must have informative docstrings that work nicely with markdown. See [`pipeline_latent_diffusion.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/latent_diffusion/pipeline_latent_diffusion.py) for an example.
|
||||
11. Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos, and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
|
||||
[`hf-internal-testing`](https://huggingface.co/hf-internal-testing) or [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images) to place these files.
|
||||
If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
|
||||
to this dataset.
|
||||
|
||||
## How to open a PR
|
||||
|
||||
Before writing code, we strongly advise you to search through the existing PRs or
|
||||
issues to make sure that nobody is already working on the same thing. If you are
|
||||
unsure, it is always a good idea to open an issue to get some feedback.
|
||||
|
||||
You will need basic `git` proficiency to be able to contribute to
|
||||
🧨 Diffusers. `git` is not the easiest tool to use but it has the greatest
|
||||
manual. Type `git --help` in a shell and enjoy. If you prefer books, [Pro
|
||||
Git](https://git-scm.com/book/en/v2) is a very good reference.
|
||||
|
||||
Follow these steps to start contributing ([supported Python versions](https://github.com/huggingface/diffusers/blob/42f25d601a910dceadaee6c44345896b4cfa9928/setup.py#L270)):
|
||||
|
||||
1. Fork the [repository](https://github.com/huggingface/diffusers) by
|
||||
clicking on the 'Fork' button on the repository's page. This creates a copy of the code
|
||||
under your GitHub user account.
|
||||
|
||||
2. Clone your fork to your local disk, and add the base repository as a remote:
|
||||
|
||||
```bash
|
||||
$ git clone git@github.com:<your GitHub handle>/diffusers.git
|
||||
$ cd diffusers
|
||||
$ git remote add upstream https://github.com/huggingface/diffusers.git
|
||||
```
|
||||
|
||||
3. Create a new branch to hold your development changes:
|
||||
|
||||
```bash
|
||||
$ git checkout -b a-descriptive-name-for-my-changes
|
||||
```
|
||||
|
||||
**Do not** work on the `main` branch.
|
||||
|
||||
4. Set up a development environment by running the following command in a virtual environment:
|
||||
|
||||
```bash
|
||||
$ pip install -e ".[dev]"
|
||||
```
|
||||
|
||||
If you have already cloned the repo, you might need to `git pull` to get the most recent changes in the
|
||||
library.
|
||||
|
||||
5. Develop the features on your branch.
|
||||
|
||||
As you work on the features, you should make sure that the test suite
|
||||
passes. You should run the tests impacted by your changes like this:
|
||||
|
||||
```bash
|
||||
$ pytest tests/<TEST_TO_RUN>.py
|
||||
```
|
||||
|
||||
Before you run the tests, please make sure you install the dependencies required for testing. You can do so
|
||||
with this command:
|
||||
|
||||
```bash
|
||||
$ pip install -e ".[test]"
|
||||
```
|
||||
|
||||
You can also run the full test suite with the following command, but it takes
|
||||
a beefy machine to produce a result in a decent amount of time now that
|
||||
Diffusers has grown a lot. Here is the command for it:
|
||||
|
||||
```bash
|
||||
$ make test
|
||||
```
|
||||
|
||||
🧨 Diffusers relies on `ruff` and `isort` to format its source code
|
||||
consistently. After you make changes, apply automatic style corrections and code verifications
|
||||
that can't be automated in one go with:
|
||||
|
||||
```bash
|
||||
$ make style
|
||||
```
|
||||
|
||||
🧨 Diffusers also uses `ruff` and a few custom scripts to check for coding mistakes. Quality
|
||||
control runs in CI, however, you can also run the same checks with:
|
||||
|
||||
```bash
|
||||
$ make quality
|
||||
```
|
||||
|
||||
Once you're happy with your changes, add changed files using `git add` and
|
||||
make a commit with `git commit` to record your changes locally:
|
||||
|
||||
```bash
|
||||
$ git add modified_file.py
|
||||
$ git commit -m "A descriptive message about your changes."
|
||||
```
|
||||
|
||||
It is a good idea to sync your copy of the code with the original
|
||||
repository regularly. This way you can quickly account for changes:
|
||||
|
||||
```bash
|
||||
$ git pull upstream main
|
||||
```
|
||||
|
||||
Push the changes to your account using:
|
||||
|
||||
```bash
|
||||
$ git push -u origin a-descriptive-name-for-my-changes
|
||||
```
|
||||
|
||||
6. Once you are satisfied, go to the
|
||||
webpage of your fork on GitHub. Click on 'Pull request' to send your changes
|
||||
to the project maintainers for review.
|
||||
|
||||
7. It's ok if maintainers ask you for changes. It happens to core contributors
|
||||
too! So everyone can see the changes in the Pull request, work in your local
|
||||
branch and push the changes to your fork. They will automatically appear in
|
||||
the pull request.
|
||||
|
||||
### Tests
|
||||
|
||||
An extensive test suite is included to test the library behavior and several examples. Library tests can be found in
|
||||
the [tests folder](https://github.com/huggingface/diffusers/tree/main/tests).
|
||||
|
||||
We like `pytest` and `pytest-xdist` because it's faster. From the root of the
|
||||
repository, here's how to run tests with `pytest` for the library:
|
||||
|
||||
```bash
|
||||
$ python -m pytest -n auto --dist=loadfile -s -v ./tests/
|
||||
```
|
||||
|
||||
In fact, that's how `make test` is implemented!
|
||||
|
||||
You can specify a smaller set of tests in order to test only the feature
|
||||
you're working on.
|
||||
|
||||
By default, slow tests are skipped. Set the `RUN_SLOW` environment variable to
|
||||
`yes` to run them. This will download many gigabytes of models — make sure you
|
||||
have enough disk space and a good Internet connection, or a lot of patience!
|
||||
|
||||
```bash
|
||||
$ RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/
|
||||
```
|
||||
|
||||
`unittest` is fully supported, here's how to run tests with it:
|
||||
|
||||
```bash
|
||||
$ python -m unittest discover -s tests -t . -v
|
||||
$ python -m unittest discover -s examples -t examples -v
|
||||
```
|
||||
|
||||
### Syncing forked main with upstream (HuggingFace) main
|
||||
|
||||
To avoid pinging the upstream repository which adds reference notes to each upstream PR and sends unnecessary notifications to the developers involved in these PRs,
|
||||
when syncing the main branch of a forked repository, please, follow these steps:
|
||||
1. When possible, avoid syncing with the upstream using a branch and PR on the forked repository. Instead, merge directly into the forked main.
|
||||
2. If a PR is absolutely necessary, use the following steps after checking out your branch:
|
||||
```bash
|
||||
$ git checkout -b your-branch-for-syncing
|
||||
$ git pull --squash --no-commit upstream main
|
||||
$ git commit -m '<your message without GitHub references>'
|
||||
$ git push --set-upstream origin your-branch-for-syncing
|
||||
```
|
||||
|
||||
### Style guide
|
||||
|
||||
For documentation strings, 🧨 Diffusers follows the [Google style](https://google.github.io/styleguide/pyguide.html).
|
||||
@@ -1,2 +0,0 @@
|
||||
include LICENSE
|
||||
include src/diffusers/utils/model_card_template.md
|
||||
37
Makefile
37
Makefile
@@ -3,14 +3,15 @@
|
||||
# make sure to test the local checkout in scripts and not the pre-installed one (don't use quotes!)
|
||||
export PYTHONPATH = src
|
||||
|
||||
check_dirs := examples scripts src tests utils benchmarks
|
||||
check_dirs := models tests src utils
|
||||
|
||||
modified_only_fixup:
|
||||
$(eval modified_py_files := $(shell python utils/get_modified_files.py $(check_dirs)))
|
||||
@if test -n "$(modified_py_files)"; then \
|
||||
echo "Checking/fixing $(modified_py_files)"; \
|
||||
ruff check $(modified_py_files) --fix; \
|
||||
ruff format $(modified_py_files);\
|
||||
black --preview $(modified_py_files); \
|
||||
isort $(modified_py_files); \
|
||||
flake8 $(modified_py_files); \
|
||||
else \
|
||||
echo "No library .py files were modified"; \
|
||||
fi
|
||||
@@ -33,30 +34,36 @@ autogenerate_code: deps_table_update
|
||||
# Check that the repo is in a good state
|
||||
|
||||
repo-consistency:
|
||||
python utils/check_copies.py
|
||||
python utils/check_table.py
|
||||
python utils/check_dummies.py
|
||||
python utils/check_repo.py
|
||||
python utils/check_inits.py
|
||||
python utils/check_config_docstrings.py
|
||||
python utils/tests_fetcher.py --sanity_check
|
||||
|
||||
# this target runs checks on all files
|
||||
|
||||
quality:
|
||||
ruff check $(check_dirs) setup.py
|
||||
ruff format --check $(check_dirs) setup.py
|
||||
doc-builder style src/diffusers docs/source --max_len 119 --check_only
|
||||
python utils/check_doc_toc.py
|
||||
black --check --preview $(check_dirs)
|
||||
isort --check-only $(check_dirs)
|
||||
python utils/custom_init_isort.py --check_only
|
||||
python utils/sort_auto_mappings.py --check_only
|
||||
flake8 $(check_dirs)
|
||||
doc-builder style src/transformers docs/source --max_len 119 --check_only --path_to_docs docs/source
|
||||
|
||||
# Format source code automatically and check is there are any problems left that need manual fixing
|
||||
|
||||
extra_style_checks:
|
||||
python utils/custom_init_isort.py
|
||||
python utils/check_doc_toc.py --fix_and_overwrite
|
||||
python utils/sort_auto_mappings.py
|
||||
doc-builder style src/transformers docs/source --max_len 119 --path_to_docs docs/source
|
||||
|
||||
# this target runs checks on all files and potentially modifies some of them
|
||||
|
||||
style:
|
||||
ruff check $(check_dirs) setup.py --fix
|
||||
ruff format $(check_dirs) setup.py
|
||||
doc-builder style src/diffusers docs/source --max_len 119
|
||||
black --preview $(check_dirs)
|
||||
isort $(check_dirs)
|
||||
${MAKE} autogenerate_code
|
||||
${MAKE} extra_style_checks
|
||||
|
||||
@@ -68,6 +75,7 @@ fixup: modified_only_fixup extra_style_checks autogenerate_code repo-consistency
|
||||
|
||||
fix-copies:
|
||||
python utils/check_copies.py --fix_and_overwrite
|
||||
python utils/check_table.py --fix_and_overwrite
|
||||
python utils/check_dummies.py --fix_and_overwrite
|
||||
|
||||
# Run tests for the library
|
||||
@@ -78,7 +86,12 @@ test:
|
||||
# Run tests for examples
|
||||
|
||||
test-examples:
|
||||
python -m pytest -n auto --dist=loadfile -s -v ./examples/
|
||||
python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/
|
||||
|
||||
# Run tests for SageMaker DLC release
|
||||
|
||||
test-sagemaker: # install sagemaker dependencies in advance with pip install .[sagemaker]
|
||||
TEST_SAGEMAKER=True python -m pytest -n auto -s -v ./tests/sagemaker
|
||||
|
||||
|
||||
# Release stuff
|
||||
|
||||
110
PHILOSOPHY.md
110
PHILOSOPHY.md
@@ -1,110 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Philosophy
|
||||
|
||||
🧨 Diffusers provides **state-of-the-art** pretrained diffusion models across multiple modalities.
|
||||
Its purpose is to serve as a **modular toolbox** for both inference and training.
|
||||
|
||||
We aim to build a library that stands the test of time and therefore take API design very seriously.
|
||||
|
||||
In a nutshell, Diffusers is built to be a natural extension of PyTorch. Therefore, most of our design choices are based on [PyTorch's Design Principles](https://pytorch.org/docs/stable/community/design.html#pytorch-design-philosophy). Let's go over the most important ones:
|
||||
|
||||
## Usability over Performance
|
||||
|
||||
- While Diffusers has many built-in performance-enhancing features (see [Memory and Speed](https://huggingface.co/docs/diffusers/optimization/fp16)), models are always loaded with the highest precision and lowest optimization. Therefore, by default diffusion pipelines are always instantiated on CPU with float32 precision if not otherwise defined by the user. This ensures usability across different platforms and accelerators and means that no complex installations are required to run the library.
|
||||
- Diffusers aims to be a **light-weight** package and therefore has very few required dependencies, but many soft dependencies that can improve performance (such as `accelerate`, `safetensors`, `onnx`, etc...). We strive to keep the library as lightweight as possible so that it can be added without much concern as a dependency on other packages.
|
||||
- Diffusers prefers simple, self-explainable code over condensed, magic code. This means that short-hand code syntaxes such as lambda functions, and advanced PyTorch operators are often not desired.
|
||||
|
||||
## Simple over easy
|
||||
|
||||
As PyTorch states, **explicit is better than implicit** and **simple is better than complex**. This design philosophy is reflected in multiple parts of the library:
|
||||
- We follow PyTorch's API with methods like [`DiffusionPipeline.to`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.to) to let the user handle device management.
|
||||
- Raising concise error messages is preferred to silently correct erroneous input. Diffusers aims at teaching the user, rather than making the library as easy to use as possible.
|
||||
- Complex model vs. scheduler logic is exposed instead of magically handled inside. Schedulers/Samplers are separated from diffusion models with minimal dependencies on each other. This forces the user to write the unrolled denoising loop. However, the separation allows for easier debugging and gives the user more control over adapting the denoising process or switching out diffusion models or schedulers.
|
||||
- Separately trained components of the diffusion pipeline, *e.g.* the text encoder, the UNet, and the variational autoencoder, each has their own model class. This forces the user to handle the interaction between the different model components, and the serialization format separates the model components into different files. However, this allows for easier debugging and customization. DreamBooth or Textual Inversion training
|
||||
is very simple thanks to Diffusers' ability to separate single components of the diffusion pipeline.
|
||||
|
||||
## Tweakable, contributor-friendly over abstraction
|
||||
|
||||
For large parts of the library, Diffusers adopts an important design principle of the [Transformers library](https://github.com/huggingface/transformers), which is to prefer copy-pasted code over hasty abstractions. This design principle is very opinionated and stands in stark contrast to popular design principles such as [Don't repeat yourself (DRY)](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself).
|
||||
In short, just like Transformers does for modeling files, Diffusers prefers to keep an extremely low level of abstraction and very self-contained code for pipelines and schedulers.
|
||||
Functions, long code blocks, and even classes can be copied across multiple files which at first can look like a bad, sloppy design choice that makes the library unmaintainable.
|
||||
**However**, this design has proven to be extremely successful for Transformers and makes a lot of sense for community-driven, open-source machine learning libraries because:
|
||||
- Machine Learning is an extremely fast-moving field in which paradigms, model architectures, and algorithms are changing rapidly, which therefore makes it very difficult to define long-lasting code abstractions.
|
||||
- Machine Learning practitioners like to be able to quickly tweak existing code for ideation and research and therefore prefer self-contained code over one that contains many abstractions.
|
||||
- Open-source libraries rely on community contributions and therefore must build a library that is easy to contribute to. The more abstract the code, the more dependencies, the harder to read, and the harder to contribute to. Contributors simply stop contributing to very abstract libraries out of fear of breaking vital functionality. If contributing to a library cannot break other fundamental code, not only is it more inviting for potential new contributors, but it is also easier to review and contribute to multiple parts in parallel.
|
||||
|
||||
At Hugging Face, we call this design the **single-file policy** which means that almost all of the code of a certain class should be written in a single, self-contained file. To read more about the philosophy, you can have a look
|
||||
at [this blog post](https://huggingface.co/blog/transformers-design-philosophy).
|
||||
|
||||
In Diffusers, we follow this philosophy for both pipelines and schedulers, but only partly for diffusion models. The reason we don't follow this design fully for diffusion models is because almost all diffusion pipelines, such
|
||||
as [DDPM](https://huggingface.co/docs/diffusers/api/pipelines/ddpm), [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview#stable-diffusion-pipelines), [unCLIP (DALL·E 2)](https://huggingface.co/docs/diffusers/api/pipelines/unclip) and [Imagen](https://imagen.research.google/) all rely on the same diffusion model, the [UNet](https://huggingface.co/docs/diffusers/api/models/unet2d-cond).
|
||||
|
||||
Great, now you should have generally understood why 🧨 Diffusers is designed the way it is 🤗.
|
||||
We try to apply these design principles consistently across the library. Nevertheless, there are some minor exceptions to the philosophy or some unlucky design choices. If you have feedback regarding the design, we would ❤️ to hear it [directly on GitHub](https://github.com/huggingface/diffusers/issues/new?assignees=&labels=&template=feedback.md&title=).
|
||||
|
||||
## Design Philosophy in Details
|
||||
|
||||
Now, let's look a bit into the nitty-gritty details of the design philosophy. Diffusers essentially consists of three major classes: [pipelines](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines), [models](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models), and [schedulers](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers).
|
||||
Let's walk through more detailed design decisions for each class.
|
||||
|
||||
### Pipelines
|
||||
|
||||
Pipelines are designed to be easy to use (therefore do not follow [*Simple over easy*](#simple-over-easy) 100%), are not feature complete, and should loosely be seen as examples of how to use [models](#models) and [schedulers](#schedulers) for inference.
|
||||
|
||||
The following design principles are followed:
|
||||
- Pipelines follow the single-file policy. All pipelines can be found in individual directories under src/diffusers/pipelines. One pipeline folder corresponds to one diffusion paper/project/release. Multiple pipeline files can be gathered in one pipeline folder, as it’s done for [`src/diffusers/pipelines/stable-diffusion`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/pipelines/stable_diffusion). If pipelines share similar functionality, one can make use of the [# Copied from mechanism](https://github.com/huggingface/diffusers/blob/125d783076e5bd9785beb05367a2d2566843a271/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion_img2img.py#L251).
|
||||
- Pipelines all inherit from [`DiffusionPipeline`].
|
||||
- Every pipeline consists of different model and scheduler components, that are documented in the [`model_index.json` file](https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/blob/main/model_index.json), are accessible under the same name as attributes of the pipeline and can be shared between pipelines with [`DiffusionPipeline.components`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.components) function.
|
||||
- Every pipeline should be loadable via the [`DiffusionPipeline.from_pretrained`](https://huggingface.co/docs/diffusers/main/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.from_pretrained) function.
|
||||
- Pipelines should be used **only** for inference.
|
||||
- Pipelines should be very readable, self-explanatory, and easy to tweak.
|
||||
- Pipelines should be designed to build on top of each other and be easy to integrate into higher-level APIs.
|
||||
- Pipelines are **not** intended to be feature-complete user interfaces. For feature-complete user interfaces one should rather have a look at [InvokeAI](https://github.com/invoke-ai/InvokeAI), [Diffuzers](https://github.com/abhishekkrthakur/diffuzers), and [lama-cleaner](https://github.com/Sanster/lama-cleaner).
|
||||
- Every pipeline should have one and only one way to run it via a `__call__` method. The naming of the `__call__` arguments should be shared across all pipelines.
|
||||
- Pipelines should be named after the task they are intended to solve.
|
||||
- In almost all cases, novel diffusion pipelines shall be implemented in a new pipeline folder/file.
|
||||
|
||||
### Models
|
||||
|
||||
Models are designed as configurable toolboxes that are natural extensions of [PyTorch's Module class](https://pytorch.org/docs/stable/generated/torch.nn.Module.html). They only partly follow the **single-file policy**.
|
||||
|
||||
The following design principles are followed:
|
||||
- Models correspond to **a type of model architecture**. *E.g.* the [`UNet2DConditionModel`] class is used for all UNet variations that expect 2D image inputs and are conditioned on some context.
|
||||
- All models can be found in [`src/diffusers/models`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/models) and every model architecture shall be defined in its file, e.g. [`unets/unet_2d_condition.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/unets/unet_2d_condition.py), [`transformers/transformer_2d.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/transformers/transformer_2d.py), etc...
|
||||
- Models **do not** follow the single-file policy and should make use of smaller model building blocks, such as [`attention.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention.py), [`resnet.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/resnet.py), [`embeddings.py`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/embeddings.py), etc... **Note**: This is in stark contrast to Transformers' modeling files and shows that models do not really follow the single-file policy.
|
||||
- Models intend to expose complexity, just like PyTorch's `Module` class, and give clear error messages.
|
||||
- Models all inherit from `ModelMixin` and `ConfigMixin`.
|
||||
- Models can be optimized for performance when it doesn’t demand major code changes, keep backward compatibility, and give significant memory or compute gain.
|
||||
- Models should by default have the highest precision and lowest performance setting.
|
||||
- To integrate new model checkpoints whose general architecture can be classified as an architecture that already exists in Diffusers, the existing model architecture shall be adapted to make it work with the new checkpoint. One should only create a new file if the model architecture is fundamentally different.
|
||||
- Models should be designed to be easily extendable to future changes. This can be achieved by limiting public function arguments, configuration arguments, and "foreseeing" future changes, *e.g.* it is usually better to add `string` "...type" arguments that can easily be extended to new future types instead of boolean `is_..._type` arguments. Only the minimum amount of changes shall be made to existing architectures to make a new model checkpoint work.
|
||||
- The model design is a difficult trade-off between keeping code readable and concise and supporting many model checkpoints. For most parts of the modeling code, classes shall be adapted for new model checkpoints, while there are some exceptions where it is preferred to add new classes to make sure the code is kept concise and
|
||||
readable long-term, such as [UNet blocks](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/unets/unet_2d_blocks.py) and [Attention processors](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
|
||||
|
||||
### Schedulers
|
||||
|
||||
Schedulers are responsible to guide the denoising process for inference as well as to define a noise schedule for training. They are designed as individual classes with loadable configuration files and strongly follow the **single-file policy**.
|
||||
|
||||
The following design principles are followed:
|
||||
- All schedulers are found in [`src/diffusers/schedulers`](https://github.com/huggingface/diffusers/tree/main/src/diffusers/schedulers).
|
||||
- Schedulers are **not** allowed to import from large utils files and shall be kept very self-contained.
|
||||
- One scheduler Python file corresponds to one scheduler algorithm (as might be defined in a paper).
|
||||
- If schedulers share similar functionalities, we can make use of the `# Copied from` mechanism.
|
||||
- Schedulers all inherit from `SchedulerMixin` and `ConfigMixin`.
|
||||
- Schedulers can be easily swapped out with the [`ConfigMixin.from_config`](https://huggingface.co/docs/diffusers/main/en/api/configuration#diffusers.ConfigMixin.from_config) method as explained in detail [here](./docs/source/en/using-diffusers/schedulers.md).
|
||||
- Every scheduler has to have a `set_num_inference_steps`, and a `step` function. `set_num_inference_steps(...)` has to be called before every denoising process, *i.e.* before `step(...)` is called.
|
||||
- Every scheduler exposes the timesteps to be "looped over" via a `timesteps` attribute, which is an array of timesteps the model will be called upon.
|
||||
- The `step(...)` function takes a predicted model output and the "current" sample (x_t) and returns the "previous", slightly more denoised sample (x_t-1).
|
||||
- Given the complexity of diffusion schedulers, the `step` function does not expose all the complexity and can be a bit of a "black box".
|
||||
- In almost all cases, novel schedulers shall be implemented in a new scheduling file.
|
||||
343
README.md
343
README.md
@@ -1,231 +1,160 @@
|
||||
<!---
|
||||
Copyright 2022 - The HuggingFace Team. All rights reserved.
|
||||
# Diffusers
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
## Definitions
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
**Models**: Single neural network that models p_θ(x_t-1|x_t) and is trained to “denoise” to image
|
||||
*Examples: UNet, Conditioned UNet, 3D UNet, Transformer UNet*
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
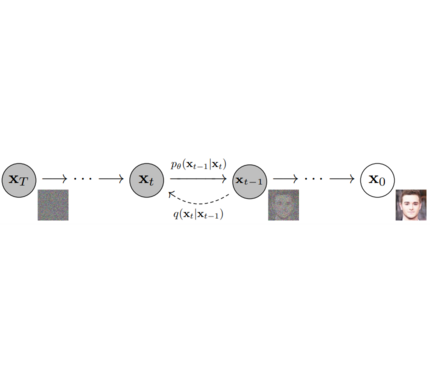
|
||||
|
||||
<p align="center">
|
||||
<br>
|
||||
<img src="https://raw.githubusercontent.com/huggingface/diffusers/main/docs/source/en/imgs/diffusers_library.jpg" width="400"/>
|
||||
<br>
|
||||
<p>
|
||||
<p align="center">
|
||||
<a href="https://github.com/huggingface/diffusers/blob/main/LICENSE"><img alt="GitHub" src="https://img.shields.io/github/license/huggingface/datasets.svg?color=blue"></a>
|
||||
<a href="https://github.com/huggingface/diffusers/releases"><img alt="GitHub release" src="https://img.shields.io/github/release/huggingface/diffusers.svg"></a>
|
||||
<a href="https://pepy.tech/project/diffusers"><img alt="GitHub release" src="https://static.pepy.tech/badge/diffusers/month"></a>
|
||||
<a href="CODE_OF_CONDUCT.md"><img alt="Contributor Covenant" src="https://img.shields.io/badge/Contributor%20Covenant-2.1-4baaaa.svg"></a>
|
||||
<a href="https://twitter.com/diffuserslib"><img alt="X account" src="https://img.shields.io/twitter/url/https/twitter.com/diffuserslib.svg?style=social&label=Follow%20%40diffuserslib"></a>
|
||||
</p>
|
||||
**Schedulers**: Algorithm to sample noise schedule for both *training* and *inference*. Defines alpha and beta schedule, timesteps, etc..
|
||||
*Example: Gaussian DDPM, DDIM, PMLS, DEIN*
|
||||
|
||||
🤗 Diffusers is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules. Whether you're looking for a simple inference solution or training your own diffusion models, 🤗 Diffusers is a modular toolbox that supports both. Our library is designed with a focus on [usability over performance](https://huggingface.co/docs/diffusers/conceptual/philosophy#usability-over-performance), [simple over easy](https://huggingface.co/docs/diffusers/conceptual/philosophy#simple-over-easy), and [customizability over abstractions](https://huggingface.co/docs/diffusers/conceptual/philosophy#tweakable-contributorfriendly-over-abstraction).
|
||||

|
||||

|
||||
|
||||
🤗 Diffusers offers three core components:
|
||||
**Diffusion Pipeline**: End-to-end pipeline that includes multiple diffusion models, possible text encoders, CLIP
|
||||
*Example: GLIDE,CompVis/Latent-Diffusion, Imagen, DALL-E*
|
||||
|
||||
- State-of-the-art [diffusion pipelines](https://huggingface.co/docs/diffusers/api/pipelines/overview) that can be run in inference with just a few lines of code.
|
||||
- Interchangeable noise [schedulers](https://huggingface.co/docs/diffusers/api/schedulers/overview) for different diffusion speeds and output quality.
|
||||
- Pretrained [models](https://huggingface.co/docs/diffusers/api/models/overview) that can be used as building blocks, and combined with schedulers, for creating your own end-to-end diffusion systems.
|
||||
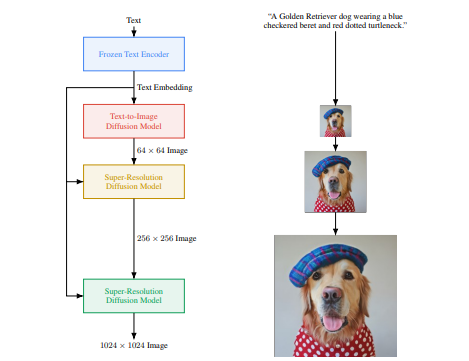
|
||||
|
||||
## Installation
|
||||
## 1. `diffusers` as a central modular diffusion and sampler library
|
||||
|
||||
We recommend installing 🤗 Diffusers in a virtual environment from PyPI or Conda. For more details about installing [PyTorch](https://pytorch.org/get-started/locally/), please refer to their official documentation.
|
||||
`diffusers` is more modularized than `transformers`. The idea is that researchers and engineers can use only parts of the library easily for the own use cases.
|
||||
It could become a central place for all kinds of models, schedulers, training utils and processors that one can mix and match for one's own use case.
|
||||
Both models and scredulers should be load- and saveable from the Hub.
|
||||
|
||||
### PyTorch
|
||||
Example:
|
||||
|
||||
With `pip` (official package):
|
||||
```python
|
||||
import torch
|
||||
from diffusers import UNetModel, GaussianDDPMScheduler
|
||||
import PIL
|
||||
import numpy as np
|
||||
|
||||
```bash
|
||||
pip install --upgrade diffusers[torch]
|
||||
generator = torch.Generator()
|
||||
generator = generator.manual_seed(6694729458485568)
|
||||
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
|
||||
|
||||
# 1. Load models
|
||||
scheduler = GaussianDDPMScheduler.from_config("fusing/ddpm-lsun-church")
|
||||
model = UNetModel.from_pretrained("fusing/ddpm-lsun-church").to(torch_device)
|
||||
|
||||
# 2. Sample gaussian noise
|
||||
image = scheduler.sample_noise((1, model.in_channels, model.resolution, model.resolution), device=torch_device, generator=generator)
|
||||
|
||||
# 3. Denoise
|
||||
for t in reversed(range(len(scheduler))):
|
||||
# i) define coefficients for time step t
|
||||
clipped_image_coeff = 1 / torch.sqrt(scheduler.get_alpha_prod(t))
|
||||
clipped_noise_coeff = torch.sqrt(1 / scheduler.get_alpha_prod(t) - 1)
|
||||
image_coeff = (1 - scheduler.get_alpha_prod(t - 1)) * torch.sqrt(scheduler.get_alpha(t)) / (1 - scheduler.get_alpha_prod(t))
|
||||
clipped_coeff = torch.sqrt(scheduler.get_alpha_prod(t - 1)) * scheduler.get_beta(t) / (1 - scheduler.get_alpha_prod(t))
|
||||
|
||||
# ii) predict noise residual
|
||||
with torch.no_grad():
|
||||
noise_residual = model(image, t)
|
||||
|
||||
# iii) compute predicted image from residual
|
||||
# See 2nd formula at https://github.com/hojonathanho/diffusion/issues/5#issue-896554416 for comparison
|
||||
pred_mean = clipped_image_coeff * image - clipped_noise_coeff * noise_residual
|
||||
pred_mean = torch.clamp(pred_mean, -1, 1)
|
||||
prev_image = clipped_coeff * pred_mean + image_coeff * image
|
||||
|
||||
# iv) sample variance
|
||||
prev_variance = scheduler.sample_variance(t, prev_image.shape, device=torch_device, generator=generator)
|
||||
|
||||
# v) sample x_{t-1} ~ N(prev_image, prev_variance)
|
||||
sampled_prev_image = prev_image + prev_variance
|
||||
image = sampled_prev_image
|
||||
|
||||
# process image to PIL
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = (image_processed + 1.0) * 127.5
|
||||
image_processed = image_processed.numpy().astype(np.uint8)
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# save image
|
||||
image_pil.save("test.png")
|
||||
```
|
||||
|
||||
With `conda` (maintained by the community):
|
||||
## 2. `diffusers` as a collection of most important Diffusion systems (GLIDE, Dalle, ...)
|
||||
`models` directory in repository hosts the complete code necessary for running a diffusion system as well as to train it. A `DiffusionPipeline` class allows to easily run the diffusion model in inference:
|
||||
|
||||
```sh
|
||||
conda install -c conda-forge diffusers
|
||||
```
|
||||
|
||||
### Apple Silicon (M1/M2) support
|
||||
|
||||
Please refer to the [How to use Stable Diffusion in Apple Silicon](https://huggingface.co/docs/diffusers/optimization/mps) guide.
|
||||
|
||||
## Quickstart
|
||||
|
||||
Generating outputs is super easy with 🤗 Diffusers. To generate an image from text, use the `from_pretrained` method to load any pretrained diffusion model (browse the [Hub](https://huggingface.co/models?library=diffusers&sort=downloads) for 30,000+ checkpoints):
|
||||
Example:
|
||||
|
||||
```python
|
||||
from diffusers import DiffusionPipeline
|
||||
import torch
|
||||
import PIL.Image
|
||||
import numpy as np
|
||||
|
||||
pipeline = DiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", torch_dtype=torch.float16)
|
||||
pipeline.to("cuda")
|
||||
pipeline("An image of a squirrel in Picasso style").images[0]
|
||||
# load model and scheduler
|
||||
ddpm = DiffusionPipeline.from_pretrained("fusing/ddpm-lsun-bedroom")
|
||||
|
||||
# run pipeline in inference (sample random noise and denoise)
|
||||
image = ddpm()
|
||||
|
||||
# process image to PIL
|
||||
image_processed = image.cpu().permute(0, 2, 3, 1)
|
||||
image_processed = (image_processed + 1.0) * 127.5
|
||||
image_processed = image_processed.numpy().astype(np.uint8)
|
||||
image_pil = PIL.Image.fromarray(image_processed[0])
|
||||
|
||||
# save image
|
||||
image_pil.save("test.png")
|
||||
```
|
||||
|
||||
You can also dig into the models and schedulers toolbox to build your own diffusion system:
|
||||
## Library structure:
|
||||
|
||||
```python
|
||||
from diffusers import DDPMScheduler, UNet2DModel
|
||||
from PIL import Image
|
||||
import torch
|
||||
|
||||
scheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256")
|
||||
model = UNet2DModel.from_pretrained("google/ddpm-cat-256").to("cuda")
|
||||
scheduler.set_timesteps(50)
|
||||
|
||||
sample_size = model.config.sample_size
|
||||
noise = torch.randn((1, 3, sample_size, sample_size), device="cuda")
|
||||
input = noise
|
||||
|
||||
for t in scheduler.timesteps:
|
||||
with torch.no_grad():
|
||||
noisy_residual = model(input, t).sample
|
||||
prev_noisy_sample = scheduler.step(noisy_residual, t, input).prev_sample
|
||||
input = prev_noisy_sample
|
||||
|
||||
image = (input / 2 + 0.5).clamp(0, 1)
|
||||
image = image.cpu().permute(0, 2, 3, 1).numpy()[0]
|
||||
image = Image.fromarray((image * 255).round().astype("uint8"))
|
||||
image
|
||||
```
|
||||
|
||||
Check out the [Quickstart](https://huggingface.co/docs/diffusers/quicktour) to launch your diffusion journey today!
|
||||
|
||||
## How to navigate the documentation
|
||||
|
||||
| **Documentation** | **What can I learn?** |
|
||||
|---------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| [Tutorial](https://huggingface.co/docs/diffusers/tutorials/tutorial_overview) | A basic crash course for learning how to use the library's most important features like using models and schedulers to build your own diffusion system, and training your own diffusion model. |
|
||||
| [Loading](https://huggingface.co/docs/diffusers/using-diffusers/loading) | Guides for how to load and configure all the components (pipelines, models, and schedulers) of the library, as well as how to use different schedulers. |
|
||||
| [Pipelines for inference](https://huggingface.co/docs/diffusers/using-diffusers/overview_techniques) | Guides for how to use pipelines for different inference tasks, batched generation, controlling generated outputs and randomness, and how to contribute a pipeline to the library. |
|
||||
| [Optimization](https://huggingface.co/docs/diffusers/optimization/fp16) | Guides for how to optimize your diffusion model to run faster and consume less memory. |
|
||||
| [Training](https://huggingface.co/docs/diffusers/training/overview) | Guides for how to train a diffusion model for different tasks with different training techniques. |
|
||||
## Contribution
|
||||
|
||||
We ❤️ contributions from the open-source community!
|
||||
If you want to contribute to this library, please check out our [Contribution guide](https://github.com/huggingface/diffusers/blob/main/CONTRIBUTING.md).
|
||||
You can look out for [issues](https://github.com/huggingface/diffusers/issues) you'd like to tackle to contribute to the library.
|
||||
- See [Good first issues](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22good+first+issue%22) for general opportunities to contribute
|
||||
- See [New model/pipeline](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+pipeline%2Fmodel%22) to contribute exciting new diffusion models / diffusion pipelines
|
||||
- See [New scheduler](https://github.com/huggingface/diffusers/issues?q=is%3Aopen+is%3Aissue+label%3A%22New+scheduler%22)
|
||||
|
||||
Also, say 👋 in our public Discord channel <a href="https://discord.gg/G7tWnz98XR"><img alt="Join us on Discord" src="https://img.shields.io/discord/823813159592001537?color=5865F2&logo=discord&logoColor=white"></a>. We discuss the hottest trends about diffusion models, help each other with contributions, personal projects or just hang out ☕.
|
||||
|
||||
|
||||
## Popular Tasks & Pipelines
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<th>Task</th>
|
||||
<th>Pipeline</th>
|
||||
<th>🤗 Hub</th>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td>Unconditional Image Generation</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/ddpm"> DDPM </a></td>
|
||||
<td><a href="https://huggingface.co/google/ddpm-ema-church-256"> google/ddpm-ema-church-256 </a></td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td>Text-to-Image</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/text2img">Stable Diffusion Text-to-Image</a></td>
|
||||
<td><a href="https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5"> stable-diffusion-v1-5/stable-diffusion-v1-5 </a></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Text-to-Image</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/unclip">unCLIP</a></td>
|
||||
<td><a href="https://huggingface.co/kakaobrain/karlo-v1-alpha"> kakaobrain/karlo-v1-alpha </a></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Text-to-Image</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/deepfloyd_if">DeepFloyd IF</a></td>
|
||||
<td><a href="https://huggingface.co/DeepFloyd/IF-I-XL-v1.0"> DeepFloyd/IF-I-XL-v1.0 </a></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Text-to-Image</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/kandinsky">Kandinsky</a></td>
|
||||
<td><a href="https://huggingface.co/kandinsky-community/kandinsky-2-2-decoder"> kandinsky-community/kandinsky-2-2-decoder </a></td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td>Text-guided Image-to-Image</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/controlnet">ControlNet</a></td>
|
||||
<td><a href="https://huggingface.co/lllyasviel/sd-controlnet-canny"> lllyasviel/sd-controlnet-canny </a></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Text-guided Image-to-Image</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/pix2pix">InstructPix2Pix</a></td>
|
||||
<td><a href="https://huggingface.co/timbrooks/instruct-pix2pix"> timbrooks/instruct-pix2pix </a></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Text-guided Image-to-Image</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/img2img">Stable Diffusion Image-to-Image</a></td>
|
||||
<td><a href="https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5"> stable-diffusion-v1-5/stable-diffusion-v1-5 </a></td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td>Text-guided Image Inpainting</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/inpaint">Stable Diffusion Inpainting</a></td>
|
||||
<td><a href="https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-inpainting"> stable-diffusion-v1-5/stable-diffusion-inpainting </a></td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td>Image Variation</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/image_variation">Stable Diffusion Image Variation</a></td>
|
||||
<td><a href="https://huggingface.co/lambdalabs/sd-image-variations-diffusers"> lambdalabs/sd-image-variations-diffusers </a></td>
|
||||
</tr>
|
||||
<tr style="border-top: 2px solid black">
|
||||
<td>Super Resolution</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/upscale">Stable Diffusion Upscale</a></td>
|
||||
<td><a href="https://huggingface.co/stabilityai/stable-diffusion-x4-upscaler"> stabilityai/stable-diffusion-x4-upscaler </a></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Super Resolution</td>
|
||||
<td><a href="https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/latent_upscale">Stable Diffusion Latent Upscale</a></td>
|
||||
<td><a href="https://huggingface.co/stabilityai/sd-x2-latent-upscaler"> stabilityai/sd-x2-latent-upscaler </a></td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
## Popular libraries using 🧨 Diffusers
|
||||
|
||||
- https://github.com/microsoft/TaskMatrix
|
||||
- https://github.com/invoke-ai/InvokeAI
|
||||
- https://github.com/InstantID/InstantID
|
||||
- https://github.com/apple/ml-stable-diffusion
|
||||
- https://github.com/Sanster/lama-cleaner
|
||||
- https://github.com/IDEA-Research/Grounded-Segment-Anything
|
||||
- https://github.com/ashawkey/stable-dreamfusion
|
||||
- https://github.com/deep-floyd/IF
|
||||
- https://github.com/bentoml/BentoML
|
||||
- https://github.com/bmaltais/kohya_ss
|
||||
- +14,000 other amazing GitHub repositories 💪
|
||||
|
||||
Thank you for using us ❤️.
|
||||
|
||||
## Credits
|
||||
|
||||
This library concretizes previous work by many different authors and would not have been possible without their great research and implementations. We'd like to thank, in particular, the following implementations which have helped us in our development and without which the API could not have been as polished today:
|
||||
|
||||
- @CompVis' latent diffusion models library, available [here](https://github.com/CompVis/latent-diffusion)
|
||||
- @hojonathanho original DDPM implementation, available [here](https://github.com/hojonathanho/diffusion) as well as the extremely useful translation into PyTorch by @pesser, available [here](https://github.com/pesser/pytorch_diffusion)
|
||||
- @ermongroup's DDIM implementation, available [here](https://github.com/ermongroup/ddim)
|
||||
- @yang-song's Score-VE and Score-VP implementations, available [here](https://github.com/yang-song/score_sde_pytorch)
|
||||
|
||||
We also want to thank @heejkoo for the very helpful overview of papers, code and resources on diffusion models, available [here](https://github.com/heejkoo/Awesome-Diffusion-Models) as well as @crowsonkb and @rromb for useful discussions and insights.
|
||||
|
||||
## Citation
|
||||
|
||||
```bibtex
|
||||
@misc{von-platen-etal-2022-diffusers,
|
||||
author = {Patrick von Platen and Suraj Patil and Anton Lozhkov and Pedro Cuenca and Nathan Lambert and Kashif Rasul and Mishig Davaadorj and Dhruv Nair and Sayak Paul and William Berman and Yiyi Xu and Steven Liu and Thomas Wolf},
|
||||
title = {Diffusers: State-of-the-art diffusion models},
|
||||
year = {2022},
|
||||
publisher = {GitHub},
|
||||
journal = {GitHub repository},
|
||||
howpublished = {\url{https://github.com/huggingface/diffusers}}
|
||||
}
|
||||
├── models
|
||||
│ ├── audio
|
||||
│ │ └── fastdiff
|
||||
│ │ ├── modeling_fastdiff.py
|
||||
│ │ ├── README.md
|
||||
│ │ └── run_fastdiff.py
|
||||
│ ├── __init__.py
|
||||
│ └── vision
|
||||
│ ├── dalle2
|
||||
│ │ ├── modeling_dalle2.py
|
||||
│ │ ├── README.md
|
||||
│ │ └── run_dalle2.py
|
||||
│ ├── ddpm
|
||||
│ │ ├── example.py
|
||||
│ │ ├── modeling_ddpm.py
|
||||
│ │ ├── README.md
|
||||
│ │ └── run_ddpm.py
|
||||
│ ├── glide
|
||||
│ │ ├── modeling_glide.py
|
||||
│ │ ├── modeling_vqvae.py.py
|
||||
│ │ ├── README.md
|
||||
│ │ └── run_glide.py
|
||||
│ ├── imagen
|
||||
│ │ ├── modeling_dalle2.py
|
||||
│ │ ├── README.md
|
||||
│ │ └── run_dalle2.py
|
||||
│ ├── __init__.py
|
||||
│ └── latent_diffusion
|
||||
│ ├── modeling_latent_diffusion.py
|
||||
│ ├── README.md
|
||||
│ └── run_latent_diffusion.py
|
||||
├── pyproject.toml
|
||||
├── README.md
|
||||
├── setup.cfg
|
||||
├── setup.py
|
||||
├── src
|
||||
│ └── diffusers
|
||||
│ ├── configuration_utils.py
|
||||
│ ├── __init__.py
|
||||
│ ├── modeling_utils.py
|
||||
│ ├── models
|
||||
│ │ ├── __init__.py
|
||||
│ │ ├── unet_glide.py
|
||||
│ │ └── unet.py
|
||||
│ ├── pipeline_utils.py
|
||||
│ └── schedulers
|
||||
│ ├── gaussian_ddpm.py
|
||||
│ ├── __init__.py
|
||||
├── tests
|
||||
│ └── test_modeling_utils.py
|
||||
```
|
||||
|
||||
13
_typos.toml
13
_typos.toml
@@ -1,13 +0,0 @@
|
||||
# Files for typos
|
||||
# Instruction: https://github.com/marketplace/actions/typos-action#getting-started
|
||||
|
||||
[default.extend-identifiers]
|
||||
|
||||
[default.extend-words]
|
||||
NIN="NIN" # NIN is used in scripts/convert_ncsnpp_original_checkpoint_to_diffusers.py
|
||||
nd="np" # nd may be np (numpy)
|
||||
parms="parms" # parms is used in scripts/convert_original_stable_diffusion_to_diffusers.py
|
||||
|
||||
|
||||
[files]
|
||||
extend-exclude = ["_typos.toml"]
|
||||
@@ -1,69 +0,0 @@
|
||||
# Diffusers Benchmarks
|
||||
|
||||
Welcome to Diffusers Benchmarks. These benchmarks are use to obtain latency and memory information of the most popular models across different scenarios such as:
|
||||
|
||||
* Base case i.e., when using `torch.bfloat16` and `torch.nn.functional.scaled_dot_product_attention`.
|
||||
* Base + `torch.compile()`
|
||||
* NF4 quantization
|
||||
* Layerwise upcasting
|
||||
|
||||
Instead of full diffusion pipelines, only the forward pass of the respective model classes (such as `FluxTransformer2DModel`) is tested with the real checkpoints (such as `"black-forest-labs/FLUX.1-dev"`).
|
||||
|
||||
The entrypoint to running all the currently available benchmarks is in `run_all.py`. However, one can run the individual benchmarks, too, e.g., `python benchmarking_flux.py`. It should produce a CSV file containing various information about the benchmarks run.
|
||||
|
||||
The benchmarks are run on a weekly basis and the CI is defined in [benchmark.yml](../.github/workflows/benchmark.yml).
|
||||
|
||||
## Running the benchmarks manually
|
||||
|
||||
First set up `torch` and install `diffusers` from the root of the directory:
|
||||
|
||||
```py
|
||||
pip install -e ".[quality,test]"
|
||||
```
|
||||
|
||||
Then make sure the other dependencies are installed:
|
||||
|
||||
```sh
|
||||
cd benchmarks/
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
We need to be authenticated to access some of the checkpoints used during benchmarking:
|
||||
|
||||
```sh
|
||||
hf auth login
|
||||
```
|
||||
|
||||
We use an L40 GPU with 128GB RAM to run the benchmark CI. As such, the benchmarks are configured to run on NVIDIA GPUs. So, make sure you have access to a similar machine (or modify the benchmarking scripts accordingly).
|
||||
|
||||
Then you can either launch the entire benchmarking suite by running:
|
||||
|
||||
```sh
|
||||
python run_all.py
|
||||
```
|
||||
|
||||
Or, you can run the individual benchmarks.
|
||||
|
||||
## Customizing the benchmarks
|
||||
|
||||
We define "scenarios" to cover the most common ways in which these models are used. You can
|
||||
define a new scenario, modifying an existing benchmark file:
|
||||
|
||||
```py
|
||||
BenchmarkScenario(
|
||||
name=f"{CKPT_ID}-bnb-8bit",
|
||||
model_cls=FluxTransformer2DModel,
|
||||
model_init_kwargs={
|
||||
"pretrained_model_name_or_path": CKPT_ID,
|
||||
"torch_dtype": torch.bfloat16,
|
||||
"subfolder": "transformer",
|
||||
"quantization_config": BitsAndBytesConfig(load_in_8bit=True),
|
||||
},
|
||||
get_model_input_dict=partial(get_input_dict, device=torch_device, dtype=torch.bfloat16),
|
||||
model_init_fn=model_init_fn,
|
||||
)
|
||||
```
|
||||
|
||||
You can also configure a new model-level benchmark and add it to the existing suite. To do so, just defining a valid benchmarking file like `benchmarking_flux.py` should be enough.
|
||||
|
||||
Happy benchmarking 🧨
|
||||
@@ -1,98 +0,0 @@
|
||||
from functools import partial
|
||||
|
||||
import torch
|
||||
from benchmarking_utils import BenchmarkMixin, BenchmarkScenario, model_init_fn
|
||||
|
||||
from diffusers import BitsAndBytesConfig, FluxTransformer2DModel
|
||||
from diffusers.utils.testing_utils import torch_device
|
||||
|
||||
|
||||
CKPT_ID = "black-forest-labs/FLUX.1-dev"
|
||||
RESULT_FILENAME = "flux.csv"
|
||||
|
||||
|
||||
def get_input_dict(**device_dtype_kwargs):
|
||||
# resolution: 1024x1024
|
||||
# maximum sequence length 512
|
||||
hidden_states = torch.randn(1, 4096, 64, **device_dtype_kwargs)
|
||||
encoder_hidden_states = torch.randn(1, 512, 4096, **device_dtype_kwargs)
|
||||
pooled_prompt_embeds = torch.randn(1, 768, **device_dtype_kwargs)
|
||||
image_ids = torch.ones(512, 3, **device_dtype_kwargs)
|
||||
text_ids = torch.ones(4096, 3, **device_dtype_kwargs)
|
||||
timestep = torch.tensor([1.0], **device_dtype_kwargs)
|
||||
guidance = torch.tensor([1.0], **device_dtype_kwargs)
|
||||
|
||||
return {
|
||||
"hidden_states": hidden_states,
|
||||
"encoder_hidden_states": encoder_hidden_states,
|
||||
"img_ids": image_ids,
|
||||
"txt_ids": text_ids,
|
||||
"pooled_projections": pooled_prompt_embeds,
|
||||
"timestep": timestep,
|
||||
"guidance": guidance,
|
||||
}
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
scenarios = [
|
||||
BenchmarkScenario(
|
||||
name=f"{CKPT_ID}-bf16",
|
||||
model_cls=FluxTransformer2DModel,
|
||||
model_init_kwargs={
|
||||
"pretrained_model_name_or_path": CKPT_ID,
|
||||
"torch_dtype": torch.bfloat16,
|
||||
"subfolder": "transformer",
|
||||
},
|
||||
get_model_input_dict=partial(get_input_dict, device=torch_device, dtype=torch.bfloat16),
|
||||
model_init_fn=model_init_fn,
|
||||
compile_kwargs={"fullgraph": True},
|
||||
),
|
||||
BenchmarkScenario(
|
||||
name=f"{CKPT_ID}-bnb-nf4",
|
||||
model_cls=FluxTransformer2DModel,
|
||||
model_init_kwargs={
|
||||
"pretrained_model_name_or_path": CKPT_ID,
|
||||
"torch_dtype": torch.bfloat16,
|
||||
"subfolder": "transformer",
|
||||
"quantization_config": BitsAndBytesConfig(
|
||||
load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16, bnb_4bit_quant_type="nf4"
|
||||
),
|
||||
},
|
||||
get_model_input_dict=partial(get_input_dict, device=torch_device, dtype=torch.bfloat16),
|
||||
model_init_fn=model_init_fn,
|
||||
),
|
||||
BenchmarkScenario(
|
||||
name=f"{CKPT_ID}-layerwise-upcasting",
|
||||
model_cls=FluxTransformer2DModel,
|
||||
model_init_kwargs={
|
||||
"pretrained_model_name_or_path": CKPT_ID,
|
||||
"torch_dtype": torch.bfloat16,
|
||||
"subfolder": "transformer",
|
||||
},
|
||||
get_model_input_dict=partial(get_input_dict, device=torch_device, dtype=torch.bfloat16),
|
||||
model_init_fn=partial(model_init_fn, layerwise_upcasting=True),
|
||||
),
|
||||
BenchmarkScenario(
|
||||
name=f"{CKPT_ID}-group-offload-leaf",
|
||||
model_cls=FluxTransformer2DModel,
|
||||
model_init_kwargs={
|
||||
"pretrained_model_name_or_path": CKPT_ID,
|
||||
"torch_dtype": torch.bfloat16,
|
||||
"subfolder": "transformer",
|
||||
},
|
||||
get_model_input_dict=partial(get_input_dict, device=torch_device, dtype=torch.bfloat16),
|
||||
model_init_fn=partial(
|
||||
model_init_fn,
|
||||
group_offload_kwargs={
|
||||
"onload_device": torch_device,
|
||||
"offload_device": torch.device("cpu"),
|
||||
"offload_type": "leaf_level",
|
||||
"use_stream": True,
|
||||
"non_blocking": True,
|
||||
},
|
||||
),
|
||||
),
|
||||
]
|
||||
|
||||
runner = BenchmarkMixin()
|
||||
runner.run_bencmarks_and_collate(scenarios, filename=RESULT_FILENAME)
|
||||
@@ -1,80 +0,0 @@
|
||||
from functools import partial
|
||||
|
||||
import torch
|
||||
from benchmarking_utils import BenchmarkMixin, BenchmarkScenario, model_init_fn
|
||||
|
||||
from diffusers import LTXVideoTransformer3DModel
|
||||
from diffusers.utils.testing_utils import torch_device
|
||||
|
||||
|
||||
CKPT_ID = "Lightricks/LTX-Video-0.9.7-dev"
|
||||
RESULT_FILENAME = "ltx.csv"
|
||||
|
||||
|
||||
def get_input_dict(**device_dtype_kwargs):
|
||||
# 512x704 (161 frames)
|
||||
# `max_sequence_length`: 256
|
||||
hidden_states = torch.randn(1, 7392, 128, **device_dtype_kwargs)
|
||||
encoder_hidden_states = torch.randn(1, 256, 4096, **device_dtype_kwargs)
|
||||
encoder_attention_mask = torch.ones(1, 256, **device_dtype_kwargs)
|
||||
timestep = torch.tensor([1.0], **device_dtype_kwargs)
|
||||
video_coords = torch.randn(1, 3, 7392, **device_dtype_kwargs)
|
||||
|
||||
return {
|
||||
"hidden_states": hidden_states,
|
||||
"encoder_hidden_states": encoder_hidden_states,
|
||||
"encoder_attention_mask": encoder_attention_mask,
|
||||
"timestep": timestep,
|
||||
"video_coords": video_coords,
|
||||
}
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
scenarios = [
|
||||
BenchmarkScenario(
|
||||
name=f"{CKPT_ID}-bf16",
|
||||
model_cls=LTXVideoTransformer3DModel,
|
||||
model_init_kwargs={
|
||||
"pretrained_model_name_or_path": CKPT_ID,
|
||||
"torch_dtype": torch.bfloat16,
|
||||
"subfolder": "transformer",
|
||||
},
|
||||
get_model_input_dict=partial(get_input_dict, device=torch_device, dtype=torch.bfloat16),
|
||||
model_init_fn=model_init_fn,
|
||||
compile_kwargs={"fullgraph": True},
|
||||
),
|
||||
BenchmarkScenario(
|
||||
name=f"{CKPT_ID}-layerwise-upcasting",
|
||||
model_cls=LTXVideoTransformer3DModel,
|
||||
model_init_kwargs={
|
||||
"pretrained_model_name_or_path": CKPT_ID,
|
||||
"torch_dtype": torch.bfloat16,
|
||||
"subfolder": "transformer",
|
||||
},
|
||||
get_model_input_dict=partial(get_input_dict, device=torch_device, dtype=torch.bfloat16),
|
||||
model_init_fn=partial(model_init_fn, layerwise_upcasting=True),
|
||||
),
|
||||
BenchmarkScenario(
|
||||
name=f"{CKPT_ID}-group-offload-leaf",
|
||||
model_cls=LTXVideoTransformer3DModel,
|
||||
model_init_kwargs={
|
||||
"pretrained_model_name_or_path": CKPT_ID,
|
||||
"torch_dtype": torch.bfloat16,
|
||||
"subfolder": "transformer",
|
||||
},
|
||||
get_model_input_dict=partial(get_input_dict, device=torch_device, dtype=torch.bfloat16),
|
||||
model_init_fn=partial(
|
||||
model_init_fn,
|
||||
group_offload_kwargs={
|
||||
"onload_device": torch_device,
|
||||
"offload_device": torch.device("cpu"),
|
||||
"offload_type": "leaf_level",
|
||||
"use_stream": True,
|
||||
"non_blocking": True,
|
||||
},
|
||||
),
|
||||
),
|
||||
]
|
||||
|
||||
runner = BenchmarkMixin()
|
||||
runner.run_bencmarks_and_collate(scenarios, filename=RESULT_FILENAME)
|
||||
@@ -1,82 +0,0 @@
|
||||
from functools import partial
|
||||
|
||||
import torch
|
||||
from benchmarking_utils import BenchmarkMixin, BenchmarkScenario, model_init_fn
|
||||
|
||||
from diffusers import UNet2DConditionModel
|
||||
from diffusers.utils.testing_utils import torch_device
|
||||
|
||||
|
||||
CKPT_ID = "stabilityai/stable-diffusion-xl-base-1.0"
|
||||
RESULT_FILENAME = "sdxl.csv"
|
||||
|
||||
|
||||
def get_input_dict(**device_dtype_kwargs):
|
||||
# height: 1024
|
||||
# width: 1024
|
||||
# max_sequence_length: 77
|
||||
hidden_states = torch.randn(1, 4, 128, 128, **device_dtype_kwargs)
|
||||
encoder_hidden_states = torch.randn(1, 77, 2048, **device_dtype_kwargs)
|
||||
timestep = torch.tensor([1.0], **device_dtype_kwargs)
|
||||
added_cond_kwargs = {
|
||||
"text_embeds": torch.randn(1, 1280, **device_dtype_kwargs),
|
||||
"time_ids": torch.ones(1, 6, **device_dtype_kwargs),
|
||||
}
|
||||
|
||||
return {
|
||||
"sample": hidden_states,
|
||||
"encoder_hidden_states": encoder_hidden_states,
|
||||
"timestep": timestep,
|
||||
"added_cond_kwargs": added_cond_kwargs,
|
||||
}
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
scenarios = [
|
||||
BenchmarkScenario(
|
||||
name=f"{CKPT_ID}-bf16",
|
||||
model_cls=UNet2DConditionModel,
|
||||
model_init_kwargs={
|
||||
"pretrained_model_name_or_path": CKPT_ID,
|
||||
"torch_dtype": torch.bfloat16,
|
||||
"subfolder": "unet",
|
||||
},
|
||||
get_model_input_dict=partial(get_input_dict, device=torch_device, dtype=torch.bfloat16),
|
||||
model_init_fn=model_init_fn,
|
||||
compile_kwargs={"fullgraph": True},
|
||||
),
|
||||
BenchmarkScenario(
|
||||
name=f"{CKPT_ID}-layerwise-upcasting",
|
||||
model_cls=UNet2DConditionModel,
|
||||
model_init_kwargs={
|
||||
"pretrained_model_name_or_path": CKPT_ID,
|
||||
"torch_dtype": torch.bfloat16,
|
||||
"subfolder": "unet",
|
||||
},
|
||||
get_model_input_dict=partial(get_input_dict, device=torch_device, dtype=torch.bfloat16),
|
||||
model_init_fn=partial(model_init_fn, layerwise_upcasting=True),
|
||||
),
|
||||
BenchmarkScenario(
|
||||
name=f"{CKPT_ID}-group-offload-leaf",
|
||||
model_cls=UNet2DConditionModel,
|
||||
model_init_kwargs={
|
||||
"pretrained_model_name_or_path": CKPT_ID,
|
||||
"torch_dtype": torch.bfloat16,
|
||||
"subfolder": "unet",
|
||||
},
|
||||
get_model_input_dict=partial(get_input_dict, device=torch_device, dtype=torch.bfloat16),
|
||||
model_init_fn=partial(
|
||||
model_init_fn,
|
||||
group_offload_kwargs={
|
||||
"onload_device": torch_device,
|
||||
"offload_device": torch.device("cpu"),
|
||||
"offload_type": "leaf_level",
|
||||
"use_stream": True,
|
||||
"non_blocking": True,
|
||||
},
|
||||
),
|
||||
),
|
||||
]
|
||||
|
||||
runner = BenchmarkMixin()
|
||||
runner.run_bencmarks_and_collate(scenarios, filename=RESULT_FILENAME)
|
||||
@@ -1,244 +0,0 @@
|
||||
import gc
|
||||
import inspect
|
||||
import logging
|
||||
import os
|
||||
import queue
|
||||
import threading
|
||||
from contextlib import nullcontext
|
||||
from dataclasses import dataclass
|
||||
from typing import Any, Callable, Dict, Optional, Union
|
||||
|
||||
import pandas as pd
|
||||
import torch
|
||||
import torch.utils.benchmark as benchmark
|
||||
|
||||
from diffusers.models.modeling_utils import ModelMixin
|
||||
from diffusers.utils.testing_utils import require_torch_gpu, torch_device
|
||||
|
||||
|
||||
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)s %(name)s: %(message)s")
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
NUM_WARMUP_ROUNDS = 5
|
||||
|
||||
|
||||
def benchmark_fn(f, *args, **kwargs):
|
||||
t0 = benchmark.Timer(
|
||||
stmt="f(*args, **kwargs)",
|
||||
globals={"args": args, "kwargs": kwargs, "f": f},
|
||||
num_threads=1,
|
||||
)
|
||||
return float(f"{(t0.blocked_autorange().mean):.3f}")
|
||||
|
||||
|
||||
def flush():
|
||||
gc.collect()
|
||||
torch.cuda.empty_cache()
|
||||
torch.cuda.reset_max_memory_allocated()
|
||||
torch.cuda.reset_peak_memory_stats()
|
||||
|
||||
|
||||
# Adapted from https://github.com/lucasb-eyer/cnn_vit_benchmarks/blob/15b665ff758e8062131353076153905cae00a71f/main.py
|
||||
def calculate_flops(model, input_dict):
|
||||
try:
|
||||
from torchprofile import profile_macs
|
||||
except ModuleNotFoundError:
|
||||
raise
|
||||
|
||||
# This is a hacky way to convert the kwargs to args as `profile_macs` cries about kwargs.
|
||||
sig = inspect.signature(model.forward)
|
||||
param_names = [
|
||||
p.name
|
||||
for p in sig.parameters.values()
|
||||
if p.kind
|
||||
in (
|
||||
inspect.Parameter.POSITIONAL_ONLY,
|
||||
inspect.Parameter.POSITIONAL_OR_KEYWORD,
|
||||
)
|
||||
and p.name != "self"
|
||||
]
|
||||
bound = sig.bind_partial(**input_dict)
|
||||
bound.apply_defaults()
|
||||
args = tuple(bound.arguments[name] for name in param_names)
|
||||
|
||||
model.eval()
|
||||
with torch.no_grad():
|
||||
macs = profile_macs(model, args)
|
||||
flops = 2 * macs # 1 MAC operation = 2 FLOPs (1 multiplication + 1 addition)
|
||||
return flops
|
||||
|
||||
|
||||
def calculate_params(model):
|
||||
return sum(p.numel() for p in model.parameters())
|
||||
|
||||
|
||||
# Users can define their own in case this doesn't suffice. For most cases,
|
||||
# it should be sufficient.
|
||||
def model_init_fn(model_cls, group_offload_kwargs=None, layerwise_upcasting=False, **init_kwargs):
|
||||
model = model_cls.from_pretrained(**init_kwargs).eval()
|
||||
if group_offload_kwargs and isinstance(group_offload_kwargs, dict):
|
||||
model.enable_group_offload(**group_offload_kwargs)
|
||||
else:
|
||||
model.to(torch_device)
|
||||
if layerwise_upcasting:
|
||||
model.enable_layerwise_casting(
|
||||
storage_dtype=torch.float8_e4m3fn, compute_dtype=init_kwargs.get("torch_dtype", torch.bfloat16)
|
||||
)
|
||||
return model
|
||||
|
||||
|
||||
@dataclass
|
||||
class BenchmarkScenario:
|
||||
name: str
|
||||
model_cls: ModelMixin
|
||||
model_init_kwargs: Dict[str, Any]
|
||||
model_init_fn: Callable
|
||||
get_model_input_dict: Callable
|
||||
compile_kwargs: Optional[Dict[str, Any]] = None
|
||||
|
||||
|
||||
@require_torch_gpu
|
||||
class BenchmarkMixin:
|
||||
def pre_benchmark(self):
|
||||
flush()
|
||||
torch.compiler.reset()
|
||||
|
||||
def post_benchmark(self, model):
|
||||
model.cpu()
|
||||
flush()
|
||||
torch.compiler.reset()
|
||||
|
||||
@torch.no_grad()
|
||||
def run_benchmark(self, scenario: BenchmarkScenario):
|
||||
# 0) Basic stats
|
||||
logger.info(f"Running scenario: {scenario.name}.")
|
||||
try:
|
||||
model = model_init_fn(scenario.model_cls, **scenario.model_init_kwargs)
|
||||
num_params = round(calculate_params(model) / 1e9, 2)
|
||||
try:
|
||||
flops = round(calculate_flops(model, input_dict=scenario.get_model_input_dict()) / 1e9, 2)
|
||||
except Exception as e:
|
||||
logger.info(f"Problem in calculating FLOPs:\n{e}")
|
||||
flops = None
|
||||
model.cpu()
|
||||
del model
|
||||
except Exception as e:
|
||||
logger.info(f"Error while initializing the model and calculating FLOPs:\n{e}")
|
||||
return {}
|
||||
self.pre_benchmark()
|
||||
|
||||
# 1) plain stats
|
||||
results = {}
|
||||
plain = None
|
||||
try:
|
||||
plain = self._run_phase(
|
||||
model_cls=scenario.model_cls,
|
||||
init_fn=scenario.model_init_fn,
|
||||
init_kwargs=scenario.model_init_kwargs,
|
||||
get_input_fn=scenario.get_model_input_dict,
|
||||
compile_kwargs=None,
|
||||
)
|
||||
except Exception as e:
|
||||
logger.info(f"Benchmark could not be run with the following error:\n{e}")
|
||||
return results
|
||||
|
||||
# 2) compiled stats (if any)
|
||||
compiled = {"time": None, "memory": None}
|
||||
if scenario.compile_kwargs:
|
||||
try:
|
||||
compiled = self._run_phase(
|
||||
model_cls=scenario.model_cls,
|
||||
init_fn=scenario.model_init_fn,
|
||||
init_kwargs=scenario.model_init_kwargs,
|
||||
get_input_fn=scenario.get_model_input_dict,
|
||||
compile_kwargs=scenario.compile_kwargs,
|
||||
)
|
||||
except Exception as e:
|
||||
logger.info(f"Compilation benchmark could not be run with the following error\n: {e}")
|
||||
if plain is None:
|
||||
return results
|
||||
|
||||
# 3) merge
|
||||
result = {
|
||||
"scenario": scenario.name,
|
||||
"model_cls": scenario.model_cls.__name__,
|
||||
"num_params_B": num_params,
|
||||
"flops_G": flops,
|
||||
"time_plain_s": plain["time"],
|
||||
"mem_plain_GB": plain["memory"],
|
||||
"time_compile_s": compiled["time"],
|
||||
"mem_compile_GB": compiled["memory"],
|
||||
}
|
||||
if scenario.compile_kwargs:
|
||||
result["fullgraph"] = scenario.compile_kwargs.get("fullgraph", False)
|
||||
result["mode"] = scenario.compile_kwargs.get("mode", "default")
|
||||
else:
|
||||
result["fullgraph"], result["mode"] = None, None
|
||||
return result
|
||||
|
||||
def run_bencmarks_and_collate(self, scenarios: Union[BenchmarkScenario, list[BenchmarkScenario]], filename: str):
|
||||
if not isinstance(scenarios, list):
|
||||
scenarios = [scenarios]
|
||||
record_queue = queue.Queue()
|
||||
stop_signal = object()
|
||||
|
||||
def _writer_thread():
|
||||
while True:
|
||||
item = record_queue.get()
|
||||
if item is stop_signal:
|
||||
break
|
||||
df_row = pd.DataFrame([item])
|
||||
write_header = not os.path.exists(filename)
|
||||
df_row.to_csv(filename, mode="a", header=write_header, index=False)
|
||||
record_queue.task_done()
|
||||
|
||||
record_queue.task_done()
|
||||
|
||||
writer = threading.Thread(target=_writer_thread, daemon=True)
|
||||
writer.start()
|
||||
|
||||
for s in scenarios:
|
||||
try:
|
||||
record = self.run_benchmark(s)
|
||||
if record:
|
||||
record_queue.put(record)
|
||||
else:
|
||||
logger.info(f"Record empty from scenario: {s.name}.")
|
||||
except Exception as e:
|
||||
logger.info(f"Running scenario ({s.name}) led to error:\n{e}")
|
||||
record_queue.put(stop_signal)
|
||||
logger.info(f"Results serialized to {filename=}.")
|
||||
|
||||
def _run_phase(
|
||||
self,
|
||||
*,
|
||||
model_cls: ModelMixin,
|
||||
init_fn: Callable,
|
||||
init_kwargs: Dict[str, Any],
|
||||
get_input_fn: Callable,
|
||||
compile_kwargs: Optional[Dict[str, Any]],
|
||||
) -> Dict[str, float]:
|
||||
# setup
|
||||
self.pre_benchmark()
|
||||
|
||||
# init & (optional) compile
|
||||
model = init_fn(model_cls, **init_kwargs)
|
||||
if compile_kwargs:
|
||||
model.compile(**compile_kwargs)
|
||||
|
||||
# build inputs
|
||||
inp = get_input_fn()
|
||||
|
||||
# measure
|
||||
run_ctx = torch._inductor.utils.fresh_inductor_cache() if compile_kwargs else nullcontext()
|
||||
with run_ctx:
|
||||
for _ in range(NUM_WARMUP_ROUNDS):
|
||||
_ = model(**inp)
|
||||
time_s = benchmark_fn(lambda m, d: m(**d), model, inp)
|
||||
mem_gb = torch.cuda.max_memory_allocated() / (1024**3)
|
||||
mem_gb = round(mem_gb, 2)
|
||||
|
||||
# teardown
|
||||
self.post_benchmark(model)
|
||||
del model
|
||||
return {"time": time_s, "memory": mem_gb}
|
||||
@@ -1,74 +0,0 @@
|
||||
from functools import partial
|
||||
|
||||
import torch
|
||||
from benchmarking_utils import BenchmarkMixin, BenchmarkScenario, model_init_fn
|
||||
|
||||
from diffusers import WanTransformer3DModel
|
||||
from diffusers.utils.testing_utils import torch_device
|
||||
|
||||
|
||||
CKPT_ID = "Wan-AI/Wan2.1-T2V-14B-Diffusers"
|
||||
RESULT_FILENAME = "wan.csv"
|
||||
|
||||
|
||||
def get_input_dict(**device_dtype_kwargs):
|
||||
# height: 480
|
||||
# width: 832
|
||||
# num_frames: 81
|
||||
# max_sequence_length: 512
|
||||
hidden_states = torch.randn(1, 16, 21, 60, 104, **device_dtype_kwargs)
|
||||
encoder_hidden_states = torch.randn(1, 512, 4096, **device_dtype_kwargs)
|
||||
timestep = torch.tensor([1.0], **device_dtype_kwargs)
|
||||
|
||||
return {"hidden_states": hidden_states, "encoder_hidden_states": encoder_hidden_states, "timestep": timestep}
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
scenarios = [
|
||||
BenchmarkScenario(
|
||||
name=f"{CKPT_ID}-bf16",
|
||||
model_cls=WanTransformer3DModel,
|
||||
model_init_kwargs={
|
||||
"pretrained_model_name_or_path": CKPT_ID,
|
||||
"torch_dtype": torch.bfloat16,
|
||||
"subfolder": "transformer",
|
||||
},
|
||||
get_model_input_dict=partial(get_input_dict, device=torch_device, dtype=torch.bfloat16),
|
||||
model_init_fn=model_init_fn,
|
||||
compile_kwargs={"fullgraph": True},
|
||||
),
|
||||
BenchmarkScenario(
|
||||
name=f"{CKPT_ID}-layerwise-upcasting",
|
||||
model_cls=WanTransformer3DModel,
|
||||
model_init_kwargs={
|
||||
"pretrained_model_name_or_path": CKPT_ID,
|
||||
"torch_dtype": torch.bfloat16,
|
||||
"subfolder": "transformer",
|
||||
},
|
||||
get_model_input_dict=partial(get_input_dict, device=torch_device, dtype=torch.bfloat16),
|
||||
model_init_fn=partial(model_init_fn, layerwise_upcasting=True),
|
||||
),
|
||||
BenchmarkScenario(
|
||||
name=f"{CKPT_ID}-group-offload-leaf",
|
||||
model_cls=WanTransformer3DModel,
|
||||
model_init_kwargs={
|
||||
"pretrained_model_name_or_path": CKPT_ID,
|
||||
"torch_dtype": torch.bfloat16,
|
||||
"subfolder": "transformer",
|
||||
},
|
||||
get_model_input_dict=partial(get_input_dict, device=torch_device, dtype=torch.bfloat16),
|
||||
model_init_fn=partial(
|
||||
model_init_fn,
|
||||
group_offload_kwargs={
|
||||
"onload_device": torch_device,
|
||||
"offload_device": torch.device("cpu"),
|
||||
"offload_type": "leaf_level",
|
||||
"use_stream": True,
|
||||
"non_blocking": True,
|
||||
},
|
||||
),
|
||||
),
|
||||
]
|
||||
|
||||
runner = BenchmarkMixin()
|
||||
runner.run_bencmarks_and_collate(scenarios, filename=RESULT_FILENAME)
|
||||
@@ -1,166 +0,0 @@
|
||||
import argparse
|
||||
import os
|
||||
import sys
|
||||
|
||||
import gpustat
|
||||
import pandas as pd
|
||||
import psycopg2
|
||||
import psycopg2.extras
|
||||
from psycopg2.extensions import register_adapter
|
||||
from psycopg2.extras import Json
|
||||
|
||||
|
||||
register_adapter(dict, Json)
|
||||
|
||||
FINAL_CSV_FILENAME = "collated_results.csv"
|
||||
# https://github.com/huggingface/transformers/blob/593e29c5e2a9b17baec010e8dc7c1431fed6e841/benchmark/init_db.sql#L27
|
||||
BENCHMARKS_TABLE_NAME = "benchmarks"
|
||||
MEASUREMENTS_TABLE_NAME = "model_measurements"
|
||||
|
||||
|
||||
def _init_benchmark(conn, branch, commit_id, commit_msg):
|
||||
gpu_stats = gpustat.GPUStatCollection.new_query()
|
||||
metadata = {"gpu_name": gpu_stats[0]["name"]}
|
||||
repository = "huggingface/diffusers"
|
||||
with conn.cursor() as cur:
|
||||
cur.execute(
|
||||
f"INSERT INTO {BENCHMARKS_TABLE_NAME} (repository, branch, commit_id, commit_message, metadata) VALUES (%s, %s, %s, %s, %s) RETURNING benchmark_id",
|
||||
(repository, branch, commit_id, commit_msg, metadata),
|
||||
)
|
||||
benchmark_id = cur.fetchone()[0]
|
||||
print(f"Initialised benchmark #{benchmark_id}")
|
||||
return benchmark_id
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"branch",
|
||||
type=str,
|
||||
help="The branch name on which the benchmarking is performed.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"commit_id",
|
||||
type=str,
|
||||
help="The commit hash on which the benchmarking is performed.",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"commit_msg",
|
||||
type=str,
|
||||
help="The commit message associated with the commit, truncated to 70 characters.",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
return args
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = parse_args()
|
||||
try:
|
||||
conn = psycopg2.connect(
|
||||
host=os.getenv("PGHOST"),
|
||||
database=os.getenv("PGDATABASE"),
|
||||
user=os.getenv("PGUSER"),
|
||||
password=os.getenv("PGPASSWORD"),
|
||||
)
|
||||
print("DB connection established successfully.")
|
||||
except Exception as e:
|
||||
print(f"Problem during DB init: {e}")
|
||||
sys.exit(1)
|
||||
|
||||
try:
|
||||
benchmark_id = _init_benchmark(
|
||||
conn=conn,
|
||||
branch=args.branch,
|
||||
commit_id=args.commit_id,
|
||||
commit_msg=args.commit_msg,
|
||||
)
|
||||
except Exception as e:
|
||||
print(f"Problem during initializing benchmark: {e}")
|
||||
sys.exit(1)
|
||||
|
||||
cur = conn.cursor()
|
||||
|
||||
df = pd.read_csv(FINAL_CSV_FILENAME)
|
||||
|
||||
# Helper to cast values (or None) given a dtype
|
||||
def _cast_value(val, dtype: str):
|
||||
if pd.isna(val):
|
||||
return None
|
||||
|
||||
if dtype == "text":
|
||||
return str(val).strip()
|
||||
|
||||
if dtype == "float":
|
||||
try:
|
||||
return float(val)
|
||||
except ValueError:
|
||||
return None
|
||||
|
||||
if dtype == "bool":
|
||||
s = str(val).strip().lower()
|
||||
if s in ("true", "t", "yes", "1"):
|
||||
return True
|
||||
if s in ("false", "f", "no", "0"):
|
||||
return False
|
||||
if val in (1, 1.0):
|
||||
return True
|
||||
if val in (0, 0.0):
|
||||
return False
|
||||
return None
|
||||
|
||||
return val
|
||||
|
||||
try:
|
||||
rows_to_insert = []
|
||||
for _, row in df.iterrows():
|
||||
scenario = _cast_value(row.get("scenario"), "text")
|
||||
model_cls = _cast_value(row.get("model_cls"), "text")
|
||||
num_params_B = _cast_value(row.get("num_params_B"), "float")
|
||||
flops_G = _cast_value(row.get("flops_G"), "float")
|
||||
time_plain_s = _cast_value(row.get("time_plain_s"), "float")
|
||||
mem_plain_GB = _cast_value(row.get("mem_plain_GB"), "float")
|
||||
time_compile_s = _cast_value(row.get("time_compile_s"), "float")
|
||||
mem_compile_GB = _cast_value(row.get("mem_compile_GB"), "float")
|
||||
fullgraph = _cast_value(row.get("fullgraph"), "bool")
|
||||
mode = _cast_value(row.get("mode"), "text")
|
||||
|
||||
# If "github_sha" column exists in the CSV, cast it; else default to None
|
||||
if "github_sha" in df.columns:
|
||||
github_sha = _cast_value(row.get("github_sha"), "text")
|
||||
else:
|
||||
github_sha = None
|
||||
|
||||
measurements = {
|
||||
"scenario": scenario,
|
||||
"model_cls": model_cls,
|
||||
"num_params_B": num_params_B,
|
||||
"flops_G": flops_G,
|
||||
"time_plain_s": time_plain_s,
|
||||
"mem_plain_GB": mem_plain_GB,
|
||||
"time_compile_s": time_compile_s,
|
||||
"mem_compile_GB": mem_compile_GB,
|
||||
"fullgraph": fullgraph,
|
||||
"mode": mode,
|
||||
"github_sha": github_sha,
|
||||
}
|
||||
rows_to_insert.append((benchmark_id, measurements))
|
||||
|
||||
# Batch-insert all rows
|
||||
insert_sql = f"""
|
||||
INSERT INTO {MEASUREMENTS_TABLE_NAME} (
|
||||
benchmark_id,
|
||||
measurements
|
||||
)
|
||||
VALUES (%s, %s);
|
||||
"""
|
||||
|
||||
psycopg2.extras.execute_batch(cur, insert_sql, rows_to_insert)
|
||||
conn.commit()
|
||||
|
||||
cur.close()
|
||||
conn.close()
|
||||
except Exception as e:
|
||||
print(f"Exception: {e}")
|
||||
sys.exit(1)
|
||||
@@ -1,76 +0,0 @@
|
||||
import os
|
||||
|
||||
import pandas as pd
|
||||
from huggingface_hub import hf_hub_download, upload_file
|
||||
from huggingface_hub.utils import EntryNotFoundError
|
||||
|
||||
|
||||
REPO_ID = "diffusers/benchmarks"
|
||||
|
||||
|
||||
def has_previous_benchmark() -> str:
|
||||
from run_all import FINAL_CSV_FILENAME
|
||||
|
||||
csv_path = None
|
||||
try:
|
||||
csv_path = hf_hub_download(repo_id=REPO_ID, repo_type="dataset", filename=FINAL_CSV_FILENAME)
|
||||
except EntryNotFoundError:
|
||||
csv_path = None
|
||||
return csv_path
|
||||
|
||||
|
||||
def filter_float(value):
|
||||
if isinstance(value, str):
|
||||
return float(value.split()[0])
|
||||
return value
|
||||
|
||||
|
||||
def push_to_hf_dataset():
|
||||
from run_all import FINAL_CSV_FILENAME, GITHUB_SHA
|
||||
|
||||
csv_path = has_previous_benchmark()
|
||||
if csv_path is not None:
|
||||
current_results = pd.read_csv(FINAL_CSV_FILENAME)
|
||||
previous_results = pd.read_csv(csv_path)
|
||||
|
||||
numeric_columns = current_results.select_dtypes(include=["float64", "int64"]).columns
|
||||
|
||||
for column in numeric_columns:
|
||||
# get previous values as floats, aligned to current index
|
||||
prev_vals = previous_results[column].map(filter_float).reindex(current_results.index)
|
||||
|
||||
# get current values as floats
|
||||
curr_vals = current_results[column].astype(float)
|
||||
|
||||
# stringify the current values
|
||||
curr_str = curr_vals.map(str)
|
||||
|
||||
# build an appendage only when prev exists and differs
|
||||
append_str = prev_vals.where(prev_vals.notnull() & (prev_vals != curr_vals), other=pd.NA).map(
|
||||
lambda x: f" ({x})" if pd.notnull(x) else ""
|
||||
)
|
||||
|
||||
# combine
|
||||
current_results[column] = curr_str + append_str
|
||||
os.remove(FINAL_CSV_FILENAME)
|
||||
current_results.to_csv(FINAL_CSV_FILENAME, index=False)
|
||||
|
||||
commit_message = f"upload from sha: {GITHUB_SHA}" if GITHUB_SHA is not None else "upload benchmark results"
|
||||
upload_file(
|
||||
repo_id=REPO_ID,
|
||||
path_in_repo=FINAL_CSV_FILENAME,
|
||||
path_or_fileobj=FINAL_CSV_FILENAME,
|
||||
repo_type="dataset",
|
||||
commit_message=commit_message,
|
||||
)
|
||||
upload_file(
|
||||
repo_id="diffusers/benchmark-analyzer",
|
||||
path_in_repo=FINAL_CSV_FILENAME,
|
||||
path_or_fileobj=FINAL_CSV_FILENAME,
|
||||
repo_type="space",
|
||||
commit_message=commit_message,
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
push_to_hf_dataset()
|
||||
@@ -1,6 +0,0 @@
|
||||
pandas
|
||||
psutil
|
||||
gpustat
|
||||
torchprofile
|
||||
bitsandbytes
|
||||
psycopg2==2.9.9
|
||||
@@ -1,84 +0,0 @@
|
||||
import glob
|
||||
import logging
|
||||
import os
|
||||
import subprocess
|
||||
|
||||
import pandas as pd
|
||||
|
||||
|
||||
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)s %(name)s: %(message)s")
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
PATTERN = "benchmarking_*.py"
|
||||
FINAL_CSV_FILENAME = "collated_results.csv"
|
||||
GITHUB_SHA = os.getenv("GITHUB_SHA", None)
|
||||
|
||||
|
||||
class SubprocessCallException(Exception):
|
||||
pass
|
||||
|
||||
|
||||
def run_command(command: list[str], return_stdout=False):
|
||||
try:
|
||||
output = subprocess.check_output(command, stderr=subprocess.STDOUT)
|
||||
if return_stdout and hasattr(output, "decode"):
|
||||
return output.decode("utf-8")
|
||||
except subprocess.CalledProcessError as e:
|
||||
raise SubprocessCallException(f"Command `{' '.join(command)}` failed with:\n{e.output.decode()}") from e
|
||||
|
||||
|
||||
def merge_csvs(final_csv: str = "collated_results.csv"):
|
||||
all_csvs = glob.glob("*.csv")
|
||||
all_csvs = [f for f in all_csvs if f != final_csv]
|
||||
if not all_csvs:
|
||||
logger.info("No result CSVs found to merge.")
|
||||
return
|
||||
|
||||
df_list = []
|
||||
for f in all_csvs:
|
||||
try:
|
||||
d = pd.read_csv(f)
|
||||
except pd.errors.EmptyDataError:
|
||||
# If a file existed but was zero‐bytes or corrupted, skip it
|
||||
continue
|
||||
df_list.append(d)
|
||||
|
||||
if not df_list:
|
||||
logger.info("All result CSVs were empty or invalid; nothing to merge.")
|
||||
return
|
||||
|
||||
final_df = pd.concat(df_list, ignore_index=True)
|
||||
if GITHUB_SHA is not None:
|
||||
final_df["github_sha"] = GITHUB_SHA
|
||||
final_df.to_csv(final_csv, index=False)
|
||||
logger.info(f"Merged {len(all_csvs)} partial CSVs → {final_csv}.")
|
||||
|
||||
|
||||
def run_scripts():
|
||||
python_files = sorted(glob.glob(PATTERN))
|
||||
python_files = [f for f in python_files if f != "benchmarking_utils.py"]
|
||||
|
||||
for file in python_files:
|
||||
script_name = file.split(".py")[0].split("_")[-1] # example: benchmarking_foo.py -> foo
|
||||
logger.info(f"\n****** Running file: {file} ******")
|
||||
|
||||
partial_csv = f"{script_name}.csv"
|
||||
if os.path.exists(partial_csv):
|
||||
logger.info(f"Found {partial_csv}. Removing for safer numbers and duplication.")
|
||||
os.remove(partial_csv)
|
||||
|
||||
command = ["python", file]
|
||||
try:
|
||||
run_command(command)
|
||||
logger.info(f"→ {file} finished normally.")
|
||||
except SubprocessCallException as e:
|
||||
logger.info(f"Error running {file}:\n{e}")
|
||||
finally:
|
||||
logger.info(f"→ Merging partial CSVs after {file} …")
|
||||
merge_csvs(final_csv=FINAL_CSV_FILENAME)
|
||||
|
||||
logger.info(f"\nAll scripts attempted. Final collated CSV: {FINAL_CSV_FILENAME}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
run_scripts()
|
||||
@@ -1,45 +0,0 @@
|
||||
FROM python:3.10-slim
|
||||
ENV PYTHONDONTWRITEBYTECODE=1
|
||||
LABEL maintainer="Hugging Face"
|
||||
LABEL repository="diffusers"
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
RUN apt-get -y update && apt-get install -y bash \
|
||||
build-essential \
|
||||
git \
|
||||
git-lfs \
|
||||
curl \
|
||||
ca-certificates \
|
||||
libglib2.0-0 \
|
||||
libsndfile1-dev \
|
||||
libgl1 \
|
||||
zip \
|
||||
wget
|
||||
|
||||
ENV UV_PYTHON=/usr/local/bin/python
|
||||
|
||||
# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
|
||||
RUN pip install uv
|
||||
RUN uv pip install --no-cache-dir \
|
||||
torch \
|
||||
torchvision \
|
||||
torchaudio \
|
||||
--extra-index-url https://download.pytorch.org/whl/cpu
|
||||
|
||||
RUN uv pip install --no-cache-dir "git+https://github.com/huggingface/diffusers.git@main#egg=diffusers[test]"
|
||||
|
||||
# Extra dependencies
|
||||
RUN uv pip install --no-cache-dir \
|
||||
accelerate \
|
||||
numpy==1.26.4 \
|
||||
hf_xet \
|
||||
setuptools==69.5.1 \
|
||||
bitsandbytes \
|
||||
torchao \
|
||||
gguf \
|
||||
optimum-quanto
|
||||
|
||||
RUN apt-get clean && rm -rf /var/lib/apt/lists/* && apt-get autoremove && apt-get autoclean
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
@@ -1,49 +0,0 @@
|
||||
FROM ubuntu:20.04
|
||||
LABEL maintainer="Hugging Face"
|
||||
LABEL repository="diffusers"
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
RUN apt-get -y update \
|
||||
&& apt-get install -y software-properties-common \
|
||||
&& add-apt-repository ppa:deadsnakes/ppa
|
||||
|
||||
RUN apt install -y bash \
|
||||
build-essential \
|
||||
git \
|
||||
git-lfs \
|
||||
curl \
|
||||
ca-certificates \
|
||||
libsndfile1-dev \
|
||||
libgl1 \
|
||||
python3.10 \
|
||||
python3-pip \
|
||||
python3.10-venv && \
|
||||
rm -rf /var/lib/apt/lists
|
||||
|
||||
# make sure to use venv
|
||||
RUN python3.10 -m venv /opt/venv
|
||||
ENV PATH="/opt/venv/bin:$PATH"
|
||||
|
||||
# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
|
||||
RUN python3 -m pip install --no-cache-dir --upgrade pip uv==0.1.11 && \
|
||||
python3 -m uv pip install --no-cache-dir \
|
||||
torch \
|
||||
torchvision \
|
||||
torchaudio\
|
||||
onnxruntime \
|
||||
--extra-index-url https://download.pytorch.org/whl/cpu && \
|
||||
python3 -m uv pip install --no-cache-dir \
|
||||
accelerate \
|
||||
datasets \
|
||||
hf-doc-builder \
|
||||
huggingface-hub \
|
||||
Jinja2 \
|
||||
librosa \
|
||||
numpy==1.26.4 \
|
||||
scipy \
|
||||
tensorboard \
|
||||
transformers \
|
||||
hf_xet
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
@@ -1,49 +0,0 @@
|
||||
FROM nvidia/cuda:12.1.0-runtime-ubuntu20.04
|
||||
LABEL maintainer="Hugging Face"
|
||||
LABEL repository="diffusers"
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
RUN apt-get -y update \
|
||||
&& apt-get install -y software-properties-common \
|
||||
&& add-apt-repository ppa:deadsnakes/ppa
|
||||
|
||||
RUN apt install -y bash \
|
||||
build-essential \
|
||||
git \
|
||||
git-lfs \
|
||||
curl \
|
||||
ca-certificates \
|
||||
libsndfile1-dev \
|
||||
libgl1 \
|
||||
python3.10 \
|
||||
python3-pip \
|
||||
python3.10-venv && \
|
||||
rm -rf /var/lib/apt/lists
|
||||
|
||||
# make sure to use venv
|
||||
RUN python3.10 -m venv /opt/venv
|
||||
ENV PATH="/opt/venv/bin:$PATH"
|
||||
|
||||
# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
|
||||
RUN python3.10 -m pip install --no-cache-dir --upgrade pip uv==0.1.11 && \
|
||||
python3.10 -m uv pip install --no-cache-dir \
|
||||
torch \
|
||||
torchvision \
|
||||
torchaudio \
|
||||
"onnxruntime-gpu>=1.13.1" \
|
||||
--extra-index-url https://download.pytorch.org/whl/cu117 && \
|
||||
python3.10 -m uv pip install --no-cache-dir \
|
||||
accelerate \
|
||||
datasets \
|
||||
hf-doc-builder \
|
||||
huggingface-hub \
|
||||
hf_xet \
|
||||
Jinja2 \
|
||||
librosa \
|
||||
numpy==1.26.4 \
|
||||
scipy \
|
||||
tensorboard \
|
||||
transformers
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
@@ -1,38 +0,0 @@
|
||||
FROM python:3.10-slim
|
||||
ENV PYTHONDONTWRITEBYTECODE=1
|
||||
LABEL maintainer="Hugging Face"
|
||||
LABEL repository="diffusers"
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
RUN apt-get -y update && apt-get install -y bash \
|
||||
build-essential \
|
||||
git \
|
||||
git-lfs \
|
||||
curl \
|
||||
ca-certificates \
|
||||
libglib2.0-0 \
|
||||
libsndfile1-dev \
|
||||
libgl1
|
||||
|
||||
ENV UV_PYTHON=/usr/local/bin/python
|
||||
|
||||
# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
|
||||
RUN pip install uv
|
||||
RUN uv pip install --no-cache-dir \
|
||||
torch \
|
||||
torchvision \
|
||||
torchaudio \
|
||||
--extra-index-url https://download.pytorch.org/whl/cpu
|
||||
|
||||
RUN uv pip install --no-cache-dir "git+https://github.com/huggingface/diffusers.git@main#egg=diffusers[test]"
|
||||
|
||||
# Extra dependencies
|
||||
RUN uv pip install --no-cache-dir \
|
||||
accelerate \
|
||||
numpy==1.26.4 \
|
||||
hf_xet
|
||||
|
||||
RUN apt-get clean && rm -rf /var/lib/apt/lists/* && apt-get autoremove && apt-get autoclean
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
@@ -1,49 +0,0 @@
|
||||
FROM nvidia/cuda:12.1.0-runtime-ubuntu20.04
|
||||
LABEL maintainer="Hugging Face"
|
||||
LABEL repository="diffusers"
|
||||
|
||||
ARG PYTHON_VERSION=3.12
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
RUN apt-get -y update \
|
||||
&& apt-get install -y software-properties-common \
|
||||
&& add-apt-repository ppa:deadsnakes/ppa && \
|
||||
apt-get update
|
||||
|
||||
RUN apt install -y bash \
|
||||
build-essential \
|
||||
git \
|
||||
git-lfs \
|
||||
curl \
|
||||
ca-certificates \
|
||||
libglib2.0-0 \
|
||||
libsndfile1-dev \
|
||||
libgl1 \
|
||||
python3 \
|
||||
python3-pip \
|
||||
&& apt-get clean \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
|
||||
RUN curl -LsSf https://astral.sh/uv/install.sh | sh
|
||||
ENV PATH="/root/.local/bin:$PATH"
|
||||
ENV VIRTUAL_ENV="/opt/venv"
|
||||
ENV UV_PYTHON_INSTALL_DIR=/opt/uv/python
|
||||
RUN uv venv --python ${PYTHON_VERSION} --seed ${VIRTUAL_ENV}
|
||||
ENV PATH="$VIRTUAL_ENV/bin:$PATH"
|
||||
|
||||
# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
|
||||
RUN uv pip install --no-cache-dir \
|
||||
torch \
|
||||
torchvision \
|
||||
torchaudio
|
||||
|
||||
RUN uv pip install --no-cache-dir "git+https://github.com/huggingface/diffusers.git@main#egg=diffusers[test]"
|
||||
|
||||
# Extra dependencies
|
||||
RUN uv pip install --no-cache-dir \
|
||||
accelerate \
|
||||
numpy==1.26.4 \
|
||||
pytorch-lightning \
|
||||
hf_xet
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
@@ -1,52 +0,0 @@
|
||||
FROM nvidia/cuda:12.1.0-runtime-ubuntu20.04
|
||||
LABEL maintainer="Hugging Face"
|
||||
LABEL repository="diffusers"
|
||||
|
||||
ARG PYTHON_VERSION=3.10
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
ENV MINIMUM_SUPPORTED_TORCH_VERSION="2.1.0"
|
||||
ENV MINIMUM_SUPPORTED_TORCHVISION_VERSION="0.16.0"
|
||||
ENV MINIMUM_SUPPORTED_TORCHAUDIO_VERSION="2.1.0"
|
||||
|
||||
RUN apt-get -y update \
|
||||
&& apt-get install -y software-properties-common \
|
||||
&& add-apt-repository ppa:deadsnakes/ppa && \
|
||||
apt-get update
|
||||
|
||||
RUN apt install -y bash \
|
||||
build-essential \
|
||||
git \
|
||||
git-lfs \
|
||||
curl \
|
||||
ca-certificates \
|
||||
libglib2.0-0 \
|
||||
libsndfile1-dev \
|
||||
libgl1 \
|
||||
python3 \
|
||||
python3-pip \
|
||||
&& apt-get clean \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
|
||||
RUN curl -LsSf https://astral.sh/uv/install.sh | sh
|
||||
ENV PATH="/root/.local/bin:$PATH"
|
||||
ENV VIRTUAL_ENV="/opt/venv"
|
||||
ENV UV_PYTHON_INSTALL_DIR=/opt/uv/python
|
||||
RUN uv venv --python ${PYTHON_VERSION} --seed ${VIRTUAL_ENV}
|
||||
ENV PATH="$VIRTUAL_ENV/bin:$PATH"
|
||||
|
||||
# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
|
||||
RUN uv pip install --no-cache-dir \
|
||||
torch==$MINIMUM_SUPPORTED_TORCH_VERSION \
|
||||
torchvision==$MINIMUM_SUPPORTED_TORCHVISION_VERSION \
|
||||
torchaudio==$MINIMUM_SUPPORTED_TORCHAUDIO_VERSION
|
||||
|
||||
RUN uv pip install --no-cache-dir "git+https://github.com/huggingface/diffusers.git@main#egg=diffusers[test]"
|
||||
|
||||
# Extra dependencies
|
||||
RUN uv pip install --no-cache-dir \
|
||||
accelerate \
|
||||
numpy==1.26.4 \
|
||||
pytorch-lightning \
|
||||
hf_xet
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
@@ -1,50 +0,0 @@
|
||||
FROM nvidia/cuda:12.1.0-runtime-ubuntu20.04
|
||||
LABEL maintainer="Hugging Face"
|
||||
LABEL repository="diffusers"
|
||||
|
||||
ARG PYTHON_VERSION=3.12
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
RUN apt-get -y update \
|
||||
&& apt-get install -y software-properties-common \
|
||||
&& add-apt-repository ppa:deadsnakes/ppa && \
|
||||
apt-get update
|
||||
|
||||
RUN apt install -y bash \
|
||||
build-essential \
|
||||
git \
|
||||
git-lfs \
|
||||
curl \
|
||||
ca-certificates \
|
||||
libglib2.0-0 \
|
||||
libsndfile1-dev \
|
||||
libgl1 \
|
||||
python3 \
|
||||
python3-pip \
|
||||
&& apt-get clean \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
|
||||
RUN curl -LsSf https://astral.sh/uv/install.sh | sh
|
||||
ENV PATH="/root/.local/bin:$PATH"
|
||||
ENV VIRTUAL_ENV="/opt/venv"
|
||||
ENV UV_PYTHON_INSTALL_DIR=/opt/uv/python
|
||||
RUN uv venv --python ${PYTHON_VERSION} --seed ${VIRTUAL_ENV}
|
||||
ENV PATH="$VIRTUAL_ENV/bin:$PATH"
|
||||
|
||||
# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
|
||||
RUN uv pip install --no-cache-dir \
|
||||
torch \
|
||||
torchvision \
|
||||
torchaudio
|
||||
|
||||
RUN uv pip install --no-cache-dir "git+https://github.com/huggingface/diffusers.git@main#egg=diffusers[test]"
|
||||
|
||||
# Extra dependencies
|
||||
RUN uv pip install --no-cache-dir \
|
||||
accelerate \
|
||||
numpy==1.26.4 \
|
||||
pytorch-lightning \
|
||||
hf_xet \
|
||||
xformers
|
||||
|
||||
CMD ["/bin/bash"]
|
||||
268
docs/README.md
268
docs/README.md
@@ -1,268 +0,0 @@
|
||||
<!---
|
||||
Copyright 2024- The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
|
||||
# Generating the documentation
|
||||
|
||||
To generate the documentation, you first have to build it. Several packages are necessary to build the doc,
|
||||
you can install them with the following command, at the root of the code repository:
|
||||
|
||||
```bash
|
||||
pip install -e ".[docs]"
|
||||
```
|
||||
|
||||
Then you need to install our open source documentation builder tool:
|
||||
|
||||
```bash
|
||||
pip install git+https://github.com/huggingface/doc-builder
|
||||
```
|
||||
|
||||
---
|
||||
**NOTE**
|
||||
|
||||
You only need to generate the documentation to inspect it locally (if you're planning changes and want to
|
||||
check how they look before committing for instance). You don't have to commit the built documentation.
|
||||
|
||||
---
|
||||
|
||||
## Previewing the documentation
|
||||
|
||||
To preview the docs, first install the `watchdog` module with:
|
||||
|
||||
```bash
|
||||
pip install watchdog
|
||||
```
|
||||
|
||||
Then run the following command:
|
||||
|
||||
```bash
|
||||
doc-builder preview {package_name} {path_to_docs}
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```bash
|
||||
doc-builder preview diffusers docs/source/en
|
||||
```
|
||||
|
||||
The docs will be viewable at [http://localhost:3000](http://localhost:3000). You can also preview the docs once you have opened a PR. You will see a bot add a comment to a link where the documentation with your changes lives.
|
||||
|
||||
---
|
||||
**NOTE**
|
||||
|
||||
The `preview` command only works with existing doc files. When you add a completely new file, you need to update `_toctree.yml` & restart `preview` command (`ctrl-c` to stop it & call `doc-builder preview ...` again).
|
||||
|
||||
---
|
||||
|
||||
## Adding a new element to the navigation bar
|
||||
|
||||
Accepted files are Markdown (.md).
|
||||
|
||||
Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
|
||||
the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/diffusers/blob/main/docs/source/en/_toctree.yml) file.
|
||||
|
||||
## Renaming section headers and moving sections
|
||||
|
||||
It helps to keep the old links working when renaming the section header and/or moving sections from one document to another. This is because the old links are likely to be used in Issues, Forums, and Social media and it'd make for a much more superior user experience if users reading those months later could still easily navigate to the originally intended information.
|
||||
|
||||
Therefore, we simply keep a little map of moved sections at the end of the document where the original section was. The key is to preserve the original anchor.
|
||||
|
||||
So if you renamed a section from: "Section A" to "Section B", then you can add at the end of the file:
|
||||
|
||||
```md
|
||||
Sections that were moved:
|
||||
|
||||
[ <a href="#section-b">Section A</a><a id="section-a"></a> ]
|
||||
```
|
||||
and of course, if you moved it to another file, then:
|
||||
|
||||
```md
|
||||
Sections that were moved:
|
||||
|
||||
[ <a href="../new-file#section-b">Section A</a><a id="section-a"></a> ]
|
||||
```
|
||||
|
||||
Use the relative style to link to the new file so that the versioned docs continue to work.
|
||||
|
||||
For an example of a rich moved section set please see the very end of [the transformers Trainer doc](https://github.com/huggingface/transformers/blob/main/docs/source/en/main_classes/trainer.md).
|
||||
|
||||
|
||||
## Writing Documentation - Specification
|
||||
|
||||
The `huggingface/diffusers` documentation follows the
|
||||
[Google documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html) style for docstrings,
|
||||
although we can write them directly in Markdown.
|
||||
|
||||
### Adding a new tutorial
|
||||
|
||||
Adding a new tutorial or section is done in two steps:
|
||||
|
||||
- Add a new Markdown (.md) file under `docs/source/<languageCode>`.
|
||||
- Link that file in `docs/source/<languageCode>/_toctree.yml` on the correct toc-tree.
|
||||
|
||||
Make sure to put your new file under the proper section. It's unlikely to go in the first section (*Get Started*), so
|
||||
depending on the intended targets (beginners, more advanced users, or researchers) it should go in sections two, three, or four.
|
||||
|
||||
### Adding a new pipeline/scheduler
|
||||
|
||||
When adding a new pipeline:
|
||||
|
||||
- Create a file `xxx.md` under `docs/source/<languageCode>/api/pipelines` (don't hesitate to copy an existing file as template).
|
||||
- Link that file in (*Diffusers Summary*) section in `docs/source/api/pipelines/overview.md`, along with the link to the paper, and a colab notebook (if available).
|
||||
- Write a short overview of the diffusion model:
|
||||
- Overview with paper & authors
|
||||
- Paper abstract
|
||||
- Tips and tricks and how to use it best
|
||||
- Possible an end-to-end example of how to use it
|
||||
- Add all the pipeline classes that should be linked in the diffusion model. These classes should be added using our Markdown syntax. By default as follows:
|
||||
|
||||
```
|
||||
[[autodoc]] XXXPipeline
|
||||
- all
|
||||
- __call__
|
||||
```
|
||||
|
||||
This will include every public method of the pipeline that is documented, as well as the `__call__` method that is not documented by default. If you just want to add additional methods that are not documented, you can put the list of all methods to add in a list that contains `all`.
|
||||
|
||||
```
|
||||
[[autodoc]] XXXPipeline
|
||||
- all
|
||||
- __call__
|
||||
- enable_attention_slicing
|
||||
- disable_attention_slicing
|
||||
- enable_xformers_memory_efficient_attention
|
||||
- disable_xformers_memory_efficient_attention
|
||||
```
|
||||
|
||||
You can follow the same process to create a new scheduler under the `docs/source/<languageCode>/api/schedulers` folder.
|
||||
|
||||
### Writing source documentation
|
||||
|
||||
Values that should be put in `code` should either be surrounded by backticks: \`like so\`. Note that argument names
|
||||
and objects like True, None, or any strings should usually be put in `code`.
|
||||
|
||||
When mentioning a class, function, or method, it is recommended to use our syntax for internal links so that our tool
|
||||
adds a link to its documentation with this syntax: \[\`XXXClass\`\] or \[\`function\`\]. This requires the class or
|
||||
function to be in the main package.
|
||||
|
||||
If you want to create a link to some internal class or function, you need to
|
||||
provide its path. For instance: \[\`pipelines.ImagePipelineOutput\`\]. This will be converted into a link with
|
||||
`pipelines.ImagePipelineOutput` in the description. To get rid of the path and only keep the name of the object you are
|
||||
linking to in the description, add a ~: \[\`~pipelines.ImagePipelineOutput\`\] will generate a link with `ImagePipelineOutput` in the description.
|
||||
|
||||
The same works for methods so you can either use \[\`XXXClass.method\`\] or \[\`~XXXClass.method\`\].
|
||||
|
||||
#### Defining arguments in a method
|
||||
|
||||
Arguments should be defined with the `Args:` (or `Arguments:` or `Parameters:`) prefix, followed by a line return and
|
||||
an indentation. The argument should be followed by its type, with its shape if it is a tensor, a colon, and its
|
||||
description:
|
||||
|
||||
```
|
||||
Args:
|
||||
n_layers (`int`): The number of layers of the model.
|
||||
```
|
||||
|
||||
If the description is too long to fit in one line, another indentation is necessary before writing the description
|
||||
after the argument.
|
||||
|
||||
Here's an example showcasing everything so far:
|
||||
|
||||
```
|
||||
Args:
|
||||
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
||||
Indices of input sequence tokens in the vocabulary.
|
||||
|
||||
Indices can be obtained using [`AlbertTokenizer`]. See [`~PreTrainedTokenizer.encode`] and
|
||||
[`~PreTrainedTokenizer.__call__`] for details.
|
||||
|
||||
[What are input IDs?](../glossary#input-ids)
|
||||
```
|
||||
|
||||
For optional arguments or arguments with defaults we follow the following syntax: imagine we have a function with the
|
||||
following signature:
|
||||
|
||||
```py
|
||||
def my_function(x: str=None, a: float=3.14):
|
||||
```
|
||||
|
||||
then its documentation should look like this:
|
||||
|
||||
```
|
||||
Args:
|
||||
x (`str`, *optional*):
|
||||
This argument controls ...
|
||||
a (`float`, *optional*, defaults to `3.14`):
|
||||
This argument is used to ...
|
||||
```
|
||||
|
||||
Note that we always omit the "defaults to \`None\`" when None is the default for any argument. Also note that even
|
||||
if the first line describing your argument type and its default gets long, you can't break it on several lines. You can
|
||||
however write as many lines as you want in the indented description (see the example above with `input_ids`).
|
||||
|
||||
#### Writing a multi-line code block
|
||||
|
||||
Multi-line code blocks can be useful for displaying examples. They are done between two lines of three backticks as usual in Markdown:
|
||||
|
||||
|
||||
````
|
||||
```
|
||||
# first line of code
|
||||
# second line
|
||||
# etc
|
||||
```
|
||||
````
|
||||
|
||||
#### Writing a return block
|
||||
|
||||
The return block should be introduced with the `Returns:` prefix, followed by a line return and an indentation.
|
||||
The first line should be the type of the return, followed by a line return. No need to indent further for the elements
|
||||
building the return.
|
||||
|
||||
Here's an example of a single value return:
|
||||
|
||||
```
|
||||
Returns:
|
||||
`List[int]`: A list of integers in the range [0, 1] --- 1 for a special token, 0 for a sequence token.
|
||||
```
|
||||
|
||||
Here's an example of a tuple return, comprising several objects:
|
||||
|
||||
```
|
||||
Returns:
|
||||
`tuple(torch.Tensor)` comprising various elements depending on the configuration ([`BertConfig`]) and inputs:
|
||||
- ** loss** (*optional*, returned when `masked_lm_labels` is provided) `torch.Tensor` of shape `(1,)` --
|
||||
Total loss is the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
|
||||
- **prediction_scores** (`torch.Tensor` of shape `(batch_size, sequence_length, config.vocab_size)`) --
|
||||
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
|
||||
```
|
||||
|
||||
#### Adding an image
|
||||
|
||||
Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos, and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
|
||||
the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
|
||||
them by URL. We recommend putting them in the following dataset: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
|
||||
If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
|
||||
to this dataset.
|
||||
|
||||
## Styling the docstring
|
||||
|
||||
We have an automatic script running with the `make style` command that will make sure that:
|
||||
- the docstrings fully take advantage of the line width
|
||||
- all code examples are formatted using black, like the code of the Transformers library
|
||||
|
||||
This script may have some weird failures if you made a syntax mistake or if you uncover a bug. Therefore, it's
|
||||
recommended to commit your changes before running `make style`, so you can revert the changes done by that script
|
||||
easily.
|
||||
@@ -1,69 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
### Translating the Diffusers documentation into your language
|
||||
|
||||
As part of our mission to democratize machine learning, we'd love to make the Diffusers library available in many more languages! Follow the steps below if you want to help translate the documentation into your language 🙏.
|
||||
|
||||
**🗞️ Open an issue**
|
||||
|
||||
To get started, navigate to the [Issues](https://github.com/huggingface/diffusers/issues) page of this repo and check if anyone else has opened an issue for your language. If not, open a new issue by selecting the "🌐 Translating a New Language?" from the "New issue" button.
|
||||
|
||||
Once an issue exists, post a comment to indicate which chapters you'd like to work on, and we'll add your name to the list.
|
||||
|
||||
|
||||
**🍴 Fork the repository**
|
||||
|
||||
First, you'll need to [fork the Diffusers repo](https://docs.github.com/en/get-started/quickstart/fork-a-repo). You can do this by clicking on the **Fork** button on the top-right corner of this repo's page.
|
||||
|
||||
Once you've forked the repo, you'll want to get the files on your local machine for editing. You can do that by cloning the fork with Git as follows:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/<YOUR-USERNAME>/diffusers.git
|
||||
```
|
||||
|
||||
**📋 Copy-paste the English version with a new language code**
|
||||
|
||||
The documentation files are in one leading directory:
|
||||
|
||||
- [`docs/source`](https://github.com/huggingface/diffusers/tree/main/docs/source): All the documentation materials are organized here by language.
|
||||
|
||||
You'll only need to copy the files in the [`docs/source/en`](https://github.com/huggingface/diffusers/tree/main/docs/source/en) directory, so first navigate to your fork of the repo and run the following:
|
||||
|
||||
```bash
|
||||
cd ~/path/to/diffusers/docs
|
||||
cp -r source/en source/<LANG-ID>
|
||||
```
|
||||
|
||||
Here, `<LANG-ID>` should be one of the ISO 639-1 or ISO 639-2 language codes -- see [here](https://www.loc.gov/standards/iso639-2/php/code_list.php) for a handy table.
|
||||
|
||||
**✍️ Start translating**
|
||||
|
||||
The fun part comes - translating the text!
|
||||
|
||||
The first thing we recommend is translating the part of the `_toctree.yml` file that corresponds to your doc chapter. This file is used to render the table of contents on the website.
|
||||
|
||||
> 🙋 If the `_toctree.yml` file doesn't yet exist for your language, you can create one by copy-pasting from the English version and deleting the sections unrelated to your chapter. Just make sure it exists in the `docs/source/<LANG-ID>/` directory!
|
||||
|
||||
The fields you should add are `local` (with the name of the file containing the translation; e.g. `autoclass_tutorial`), and `title` (with the title of the doc in your language; e.g. `Load pretrained instances with an AutoClass`) -- as a reference, here is the `_toctree.yml` for [English](https://github.com/huggingface/diffusers/blob/main/docs/source/en/_toctree.yml):
|
||||
|
||||
```yaml
|
||||
- sections:
|
||||
- local: pipeline_tutorial # Do not change this! Use the same name for your .md file
|
||||
title: Pipelines for inference # Translate this!
|
||||
...
|
||||
title: Tutorials # Translate this!
|
||||
```
|
||||
|
||||
Once you have translated the `_toctree.yml` file, you can start translating the [MDX](https://mdxjs.com/) files associated with your docs chapter.
|
||||
|
||||
> 🙋 If you'd like others to help you with the translation, you should [open an issue](https://github.com/huggingface/diffusers/issues) and tag @patrickvonplaten.
|
||||
@@ -1,9 +0,0 @@
|
||||
# docstyle-ignore
|
||||
INSTALL_CONTENT = """
|
||||
# Diffusers installation
|
||||
! pip install diffusers transformers datasets accelerate
|
||||
# To install from source instead of the last release, comment the command above and uncomment the following one.
|
||||
# ! pip install git+https://github.com/huggingface/diffusers.git
|
||||
"""
|
||||
|
||||
notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
|
||||
@@ -1,749 +0,0 @@
|
||||
- sections:
|
||||
- local: index
|
||||
title: Diffusers
|
||||
- local: installation
|
||||
title: Installation
|
||||
- local: quicktour
|
||||
title: Quickstart
|
||||
- local: stable_diffusion
|
||||
title: Basic performance
|
||||
title: Get started
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: using-diffusers/loading
|
||||
title: DiffusionPipeline
|
||||
- local: tutorials/autopipeline
|
||||
title: AutoPipeline
|
||||
- local: using-diffusers/custom_pipeline_overview
|
||||
title: Community pipelines and components
|
||||
- local: using-diffusers/callback
|
||||
title: Pipeline callbacks
|
||||
- local: using-diffusers/reusing_seeds
|
||||
title: Reproducibility
|
||||
- local: using-diffusers/schedulers
|
||||
title: Schedulers
|
||||
- local: using-diffusers/other-formats
|
||||
title: Model formats
|
||||
- local: using-diffusers/push_to_hub
|
||||
title: Sharing pipelines and models
|
||||
title: Pipelines
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: tutorials/using_peft_for_inference
|
||||
title: LoRA
|
||||
- local: using-diffusers/ip_adapter
|
||||
title: IP-Adapter
|
||||
- local: using-diffusers/controlnet
|
||||
title: ControlNet
|
||||
- local: using-diffusers/t2i_adapter
|
||||
title: T2I-Adapter
|
||||
- local: using-diffusers/dreambooth
|
||||
title: DreamBooth
|
||||
- local: using-diffusers/textual_inversion_inference
|
||||
title: Textual inversion
|
||||
title: Adapters
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: using-diffusers/weighted_prompts
|
||||
title: Prompting
|
||||
- local: using-diffusers/create_a_server
|
||||
title: Create a server
|
||||
- local: using-diffusers/batched_inference
|
||||
title: Batch inference
|
||||
- local: training/distributed_inference
|
||||
title: Distributed inference
|
||||
title: Inference
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: optimization/fp16
|
||||
title: Accelerate inference
|
||||
- local: optimization/cache
|
||||
title: Caching
|
||||
- local: optimization/attention_backends
|
||||
title: Attention backends
|
||||
- local: optimization/memory
|
||||
title: Reduce memory usage
|
||||
- local: optimization/speed-memory-optims
|
||||
title: Compiling and offloading quantized models
|
||||
- sections:
|
||||
- local: optimization/pruna
|
||||
title: Pruna
|
||||
- local: optimization/xformers
|
||||
title: xFormers
|
||||
- local: optimization/tome
|
||||
title: Token merging
|
||||
- local: optimization/deepcache
|
||||
title: DeepCache
|
||||
- local: optimization/cache_dit
|
||||
title: CacheDiT
|
||||
- local: optimization/tgate
|
||||
title: TGATE
|
||||
- local: optimization/xdit
|
||||
title: xDiT
|
||||
- local: optimization/para_attn
|
||||
title: ParaAttention
|
||||
- local: using-diffusers/image_quality
|
||||
title: FreeU
|
||||
title: Community optimizations
|
||||
title: Inference optimization
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: hybrid_inference/overview
|
||||
title: Overview
|
||||
- local: hybrid_inference/vae_decode
|
||||
title: VAE Decode
|
||||
- local: hybrid_inference/vae_encode
|
||||
title: VAE Encode
|
||||
- local: hybrid_inference/api_reference
|
||||
title: API Reference
|
||||
title: Hybrid Inference
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: modular_diffusers/overview
|
||||
title: Overview
|
||||
- local: modular_diffusers/quickstart
|
||||
title: Quickstart
|
||||
- local: modular_diffusers/modular_diffusers_states
|
||||
title: States
|
||||
- local: modular_diffusers/pipeline_block
|
||||
title: ModularPipelineBlocks
|
||||
- local: modular_diffusers/sequential_pipeline_blocks
|
||||
title: SequentialPipelineBlocks
|
||||
- local: modular_diffusers/loop_sequential_pipeline_blocks
|
||||
title: LoopSequentialPipelineBlocks
|
||||
- local: modular_diffusers/auto_pipeline_blocks
|
||||
title: AutoPipelineBlocks
|
||||
- local: modular_diffusers/modular_pipeline
|
||||
title: ModularPipeline
|
||||
- local: modular_diffusers/components_manager
|
||||
title: ComponentsManager
|
||||
- local: modular_diffusers/guiders
|
||||
title: Guiders
|
||||
title: Modular Diffusers
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: training/overview
|
||||
title: Overview
|
||||
- local: training/create_dataset
|
||||
title: Create a dataset for training
|
||||
- local: training/adapt_a_model
|
||||
title: Adapt a model to a new task
|
||||
- local: tutorials/basic_training
|
||||
title: Train a diffusion model
|
||||
- sections:
|
||||
- local: training/unconditional_training
|
||||
title: Unconditional image generation
|
||||
- local: training/text2image
|
||||
title: Text-to-image
|
||||
- local: training/sdxl
|
||||
title: Stable Diffusion XL
|
||||
- local: training/kandinsky
|
||||
title: Kandinsky 2.2
|
||||
- local: training/wuerstchen
|
||||
title: Wuerstchen
|
||||
- local: training/controlnet
|
||||
title: ControlNet
|
||||
- local: training/t2i_adapters
|
||||
title: T2I-Adapters
|
||||
- local: training/instructpix2pix
|
||||
title: InstructPix2Pix
|
||||
- local: training/cogvideox
|
||||
title: CogVideoX
|
||||
title: Models
|
||||
- sections:
|
||||
- local: training/text_inversion
|
||||
title: Textual Inversion
|
||||
- local: training/dreambooth
|
||||
title: DreamBooth
|
||||
- local: training/lora
|
||||
title: LoRA
|
||||
- local: training/custom_diffusion
|
||||
title: Custom Diffusion
|
||||
- local: training/lcm_distill
|
||||
title: Latent Consistency Distillation
|
||||
- local: training/ddpo
|
||||
title: Reinforcement learning training with DDPO
|
||||
title: Methods
|
||||
title: Training
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: quantization/overview
|
||||
title: Getting started
|
||||
- local: quantization/bitsandbytes
|
||||
title: bitsandbytes
|
||||
- local: quantization/gguf
|
||||
title: gguf
|
||||
- local: quantization/torchao
|
||||
title: torchao
|
||||
- local: quantization/quanto
|
||||
title: quanto
|
||||
- local: quantization/modelopt
|
||||
title: NVIDIA ModelOpt
|
||||
title: Quantization
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: optimization/onnx
|
||||
title: ONNX
|
||||
- local: optimization/open_vino
|
||||
title: OpenVINO
|
||||
- local: optimization/coreml
|
||||
title: Core ML
|
||||
- local: optimization/mps
|
||||
title: Metal Performance Shaders (MPS)
|
||||
- local: optimization/habana
|
||||
title: Intel Gaudi
|
||||
- local: optimization/neuron
|
||||
title: AWS Neuron
|
||||
title: Model accelerators and hardware
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- local: using-diffusers/consisid
|
||||
title: ConsisID
|
||||
- local: using-diffusers/sdxl
|
||||
title: Stable Diffusion XL
|
||||
- local: using-diffusers/sdxl_turbo
|
||||
title: SDXL Turbo
|
||||
- local: using-diffusers/kandinsky
|
||||
title: Kandinsky
|
||||
- local: using-diffusers/omnigen
|
||||
title: OmniGen
|
||||
- local: using-diffusers/pag
|
||||
title: PAG
|
||||
- local: using-diffusers/inference_with_lcm
|
||||
title: Latent Consistency Model
|
||||
- local: using-diffusers/shap-e
|
||||
title: Shap-E
|
||||
- local: using-diffusers/diffedit
|
||||
title: DiffEdit
|
||||
- local: using-diffusers/inference_with_tcd_lora
|
||||
title: Trajectory Consistency Distillation-LoRA
|
||||
- local: using-diffusers/svd
|
||||
title: Stable Video Diffusion
|
||||
- local: using-diffusers/marigold_usage
|
||||
title: Marigold Computer Vision
|
||||
title: Specific pipeline examples
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- sections:
|
||||
- local: using-diffusers/unconditional_image_generation
|
||||
title: Unconditional image generation
|
||||
- local: using-diffusers/conditional_image_generation
|
||||
title: Text-to-image
|
||||
- local: using-diffusers/img2img
|
||||
title: Image-to-image
|
||||
- local: using-diffusers/inpaint
|
||||
title: Inpainting
|
||||
- local: advanced_inference/outpaint
|
||||
title: Outpainting
|
||||
- local: using-diffusers/text-img2vid
|
||||
title: Video generation
|
||||
- local: using-diffusers/depth2img
|
||||
title: Depth-to-image
|
||||
title: Task recipes
|
||||
- local: using-diffusers/write_own_pipeline
|
||||
title: Understanding pipelines, models and schedulers
|
||||
- local: community_projects
|
||||
title: Projects built with Diffusers
|
||||
- local: conceptual/philosophy
|
||||
title: Philosophy
|
||||
- local: using-diffusers/controlling_generation
|
||||
title: Controlled generation
|
||||
- local: conceptual/contribution
|
||||
title: How to contribute?
|
||||
- local: conceptual/ethical_guidelines
|
||||
title: Diffusers' Ethical Guidelines
|
||||
- local: conceptual/evaluation
|
||||
title: Evaluating Diffusion Models
|
||||
title: Resources
|
||||
- isExpanded: false
|
||||
sections:
|
||||
- sections:
|
||||
- local: api/configuration
|
||||
title: Configuration
|
||||
- local: api/logging
|
||||
title: Logging
|
||||
- local: api/outputs
|
||||
title: Outputs
|
||||
- local: api/quantization
|
||||
title: Quantization
|
||||
- local: api/parallel
|
||||
title: Parallel inference
|
||||
title: Main Classes
|
||||
- sections:
|
||||
- local: api/modular_diffusers/pipeline
|
||||
title: Pipeline
|
||||
- local: api/modular_diffusers/pipeline_blocks
|
||||
title: Blocks
|
||||
- local: api/modular_diffusers/pipeline_states
|
||||
title: States
|
||||
- local: api/modular_diffusers/pipeline_components
|
||||
title: Components and configs
|
||||
- local: api/modular_diffusers/guiders
|
||||
title: Guiders
|
||||
title: Modular
|
||||
- sections:
|
||||
- local: api/loaders/ip_adapter
|
||||
title: IP-Adapter
|
||||
- local: api/loaders/lora
|
||||
title: LoRA
|
||||
- local: api/loaders/single_file
|
||||
title: Single files
|
||||
- local: api/loaders/textual_inversion
|
||||
title: Textual Inversion
|
||||
- local: api/loaders/unet
|
||||
title: UNet
|
||||
- local: api/loaders/transformer_sd3
|
||||
title: SD3Transformer2D
|
||||
- local: api/loaders/peft
|
||||
title: PEFT
|
||||
title: Loaders
|
||||
- sections:
|
||||
- local: api/models/overview
|
||||
title: Overview
|
||||
- local: api/models/auto_model
|
||||
title: AutoModel
|
||||
- sections:
|
||||
- local: api/models/controlnet
|
||||
title: ControlNetModel
|
||||
- local: api/models/controlnet_union
|
||||
title: ControlNetUnionModel
|
||||
- local: api/models/controlnet_flux
|
||||
title: FluxControlNetModel
|
||||
- local: api/models/controlnet_hunyuandit
|
||||
title: HunyuanDiT2DControlNetModel
|
||||
- local: api/models/controlnet_sana
|
||||
title: SanaControlNetModel
|
||||
- local: api/models/controlnet_sd3
|
||||
title: SD3ControlNetModel
|
||||
- local: api/models/controlnet_sparsectrl
|
||||
title: SparseControlNetModel
|
||||
title: ControlNets
|
||||
- sections:
|
||||
- local: api/models/allegro_transformer3d
|
||||
title: AllegroTransformer3DModel
|
||||
- local: api/models/aura_flow_transformer2d
|
||||
title: AuraFlowTransformer2DModel
|
||||
- local: api/models/transformer_bria_fibo
|
||||
title: BriaFiboTransformer2DModel
|
||||
- local: api/models/bria_transformer
|
||||
title: BriaTransformer2DModel
|
||||
- local: api/models/chroma_transformer
|
||||
title: ChromaTransformer2DModel
|
||||
- local: api/models/cogvideox_transformer3d
|
||||
title: CogVideoXTransformer3DModel
|
||||
- local: api/models/cogview3plus_transformer2d
|
||||
title: CogView3PlusTransformer2DModel
|
||||
- local: api/models/cogview4_transformer2d
|
||||
title: CogView4Transformer2DModel
|
||||
- local: api/models/consisid_transformer3d
|
||||
title: ConsisIDTransformer3DModel
|
||||
- local: api/models/cosmos_transformer3d
|
||||
title: CosmosTransformer3DModel
|
||||
- local: api/models/dit_transformer2d
|
||||
title: DiTTransformer2DModel
|
||||
- local: api/models/easyanimate_transformer3d
|
||||
title: EasyAnimateTransformer3DModel
|
||||
- local: api/models/flux_transformer
|
||||
title: FluxTransformer2DModel
|
||||
- local: api/models/hidream_image_transformer
|
||||
title: HiDreamImageTransformer2DModel
|
||||
- local: api/models/hunyuan_transformer2d
|
||||
title: HunyuanDiT2DModel
|
||||
- local: api/models/hunyuanimage_transformer_2d
|
||||
title: HunyuanImageTransformer2DModel
|
||||
- local: api/models/hunyuan_video_transformer_3d
|
||||
title: HunyuanVideoTransformer3DModel
|
||||
- local: api/models/latte_transformer3d
|
||||
title: LatteTransformer3DModel
|
||||
- local: api/models/ltx_video_transformer3d
|
||||
title: LTXVideoTransformer3DModel
|
||||
- local: api/models/lumina2_transformer2d
|
||||
title: Lumina2Transformer2DModel
|
||||
- local: api/models/lumina_nextdit2d
|
||||
title: LuminaNextDiT2DModel
|
||||
- local: api/models/mochi_transformer3d
|
||||
title: MochiTransformer3DModel
|
||||
- local: api/models/omnigen_transformer
|
||||
title: OmniGenTransformer2DModel
|
||||
- local: api/models/pixart_transformer2d
|
||||
title: PixArtTransformer2DModel
|
||||
- local: api/models/prior_transformer
|
||||
title: PriorTransformer
|
||||
- local: api/models/qwenimage_transformer2d
|
||||
title: QwenImageTransformer2DModel
|
||||
- local: api/models/sana_transformer2d
|
||||
title: SanaTransformer2DModel
|
||||
- local: api/models/sd3_transformer2d
|
||||
title: SD3Transformer2DModel
|
||||
- local: api/models/skyreels_v2_transformer_3d
|
||||
title: SkyReelsV2Transformer3DModel
|
||||
- local: api/models/stable_audio_transformer
|
||||
title: StableAudioDiTModel
|
||||
- local: api/models/transformer2d
|
||||
title: Transformer2DModel
|
||||
- local: api/models/transformer_temporal
|
||||
title: TransformerTemporalModel
|
||||
- local: api/models/wan_transformer_3d
|
||||
title: WanTransformer3DModel
|
||||
title: Transformers
|
||||
- sections:
|
||||
- local: api/models/stable_cascade_unet
|
||||
title: StableCascadeUNet
|
||||
- local: api/models/unet
|
||||
title: UNet1DModel
|
||||
- local: api/models/unet2d-cond
|
||||
title: UNet2DConditionModel
|
||||
- local: api/models/unet2d
|
||||
title: UNet2DModel
|
||||
- local: api/models/unet3d-cond
|
||||
title: UNet3DConditionModel
|
||||
- local: api/models/unet-motion
|
||||
title: UNetMotionModel
|
||||
- local: api/models/uvit2d
|
||||
title: UViT2DModel
|
||||
title: UNets
|
||||
- sections:
|
||||
- local: api/models/asymmetricautoencoderkl
|
||||
title: AsymmetricAutoencoderKL
|
||||
- local: api/models/autoencoder_dc
|
||||
title: AutoencoderDC
|
||||
- local: api/models/autoencoderkl
|
||||
title: AutoencoderKL
|
||||
- local: api/models/autoencoderkl_allegro
|
||||
title: AutoencoderKLAllegro
|
||||
- local: api/models/autoencoderkl_cogvideox
|
||||
title: AutoencoderKLCogVideoX
|
||||
- local: api/models/autoencoderkl_cosmos
|
||||
title: AutoencoderKLCosmos
|
||||
- local: api/models/autoencoder_kl_hunyuanimage
|
||||
title: AutoencoderKLHunyuanImage
|
||||
- local: api/models/autoencoder_kl_hunyuanimage_refiner
|
||||
title: AutoencoderKLHunyuanImageRefiner
|
||||
- local: api/models/autoencoder_kl_hunyuan_video
|
||||
title: AutoencoderKLHunyuanVideo
|
||||
- local: api/models/autoencoderkl_ltx_video
|
||||
title: AutoencoderKLLTXVideo
|
||||
- local: api/models/autoencoderkl_magvit
|
||||
title: AutoencoderKLMagvit
|
||||
- local: api/models/autoencoderkl_mochi
|
||||
title: AutoencoderKLMochi
|
||||
- local: api/models/autoencoderkl_qwenimage
|
||||
title: AutoencoderKLQwenImage
|
||||
- local: api/models/autoencoder_kl_wan
|
||||
title: AutoencoderKLWan
|
||||
- local: api/models/consistency_decoder_vae
|
||||
title: ConsistencyDecoderVAE
|
||||
- local: api/models/autoencoder_oobleck
|
||||
title: Oobleck AutoEncoder
|
||||
- local: api/models/autoencoder_tiny
|
||||
title: Tiny AutoEncoder
|
||||
- local: api/models/vq
|
||||
title: VQModel
|
||||
title: VAEs
|
||||
title: Models
|
||||
- sections:
|
||||
- local: api/pipelines/overview
|
||||
title: Overview
|
||||
- sections:
|
||||
- local: api/pipelines/audioldm
|
||||
title: AudioLDM
|
||||
- local: api/pipelines/audioldm2
|
||||
title: AudioLDM 2
|
||||
- local: api/pipelines/dance_diffusion
|
||||
title: Dance Diffusion
|
||||
- local: api/pipelines/musicldm
|
||||
title: MusicLDM
|
||||
- local: api/pipelines/stable_audio
|
||||
title: Stable Audio
|
||||
title: Audio
|
||||
- local: api/pipelines/auto_pipeline
|
||||
title: AutoPipeline
|
||||
- sections:
|
||||
- local: api/pipelines/amused
|
||||
title: aMUSEd
|
||||
- local: api/pipelines/animatediff
|
||||
title: AnimateDiff
|
||||
- local: api/pipelines/attend_and_excite
|
||||
title: Attend-and-Excite
|
||||
- local: api/pipelines/aura_flow
|
||||
title: AuraFlow
|
||||
- local: api/pipelines/blip_diffusion
|
||||
title: BLIP-Diffusion
|
||||
- local: api/pipelines/bria_3_2
|
||||
title: Bria 3.2
|
||||
- local: api/pipelines/bria_fibo
|
||||
title: Bria Fibo
|
||||
- local: api/pipelines/chroma
|
||||
title: Chroma
|
||||
- local: api/pipelines/cogview3
|
||||
title: CogView3
|
||||
- local: api/pipelines/cogview4
|
||||
title: CogView4
|
||||
- local: api/pipelines/consistency_models
|
||||
title: Consistency Models
|
||||
- local: api/pipelines/controlnet
|
||||
title: ControlNet
|
||||
- local: api/pipelines/controlnet_flux
|
||||
title: ControlNet with Flux.1
|
||||
- local: api/pipelines/controlnet_hunyuandit
|
||||
title: ControlNet with Hunyuan-DiT
|
||||
- local: api/pipelines/controlnet_sd3
|
||||
title: ControlNet with Stable Diffusion 3
|
||||
- local: api/pipelines/controlnet_sdxl
|
||||
title: ControlNet with Stable Diffusion XL
|
||||
- local: api/pipelines/controlnet_sana
|
||||
title: ControlNet-Sana
|
||||
- local: api/pipelines/controlnetxs
|
||||
title: ControlNet-XS
|
||||
- local: api/pipelines/controlnetxs_sdxl
|
||||
title: ControlNet-XS with Stable Diffusion XL
|
||||
- local: api/pipelines/controlnet_union
|
||||
title: ControlNetUnion
|
||||
- local: api/pipelines/cosmos
|
||||
title: Cosmos
|
||||
- local: api/pipelines/ddim
|
||||
title: DDIM
|
||||
- local: api/pipelines/ddpm
|
||||
title: DDPM
|
||||
- local: api/pipelines/deepfloyd_if
|
||||
title: DeepFloyd IF
|
||||
- local: api/pipelines/diffedit
|
||||
title: DiffEdit
|
||||
- local: api/pipelines/dit
|
||||
title: DiT
|
||||
- local: api/pipelines/easyanimate
|
||||
title: EasyAnimate
|
||||
- local: api/pipelines/flux
|
||||
title: Flux
|
||||
- local: api/pipelines/control_flux_inpaint
|
||||
title: FluxControlInpaint
|
||||
- local: api/pipelines/hidream
|
||||
title: HiDream-I1
|
||||
- local: api/pipelines/hunyuandit
|
||||
title: Hunyuan-DiT
|
||||
- local: api/pipelines/pix2pix
|
||||
title: InstructPix2Pix
|
||||
- local: api/pipelines/kandinsky
|
||||
title: Kandinsky 2.1
|
||||
- local: api/pipelines/kandinsky_v22
|
||||
title: Kandinsky 2.2
|
||||
- local: api/pipelines/kandinsky3
|
||||
title: Kandinsky 3
|
||||
- local: api/pipelines/kandinsky5
|
||||
title: Kandinsky 5
|
||||
- local: api/pipelines/kolors
|
||||
title: Kolors
|
||||
- local: api/pipelines/latent_consistency_models
|
||||
title: Latent Consistency Models
|
||||
- local: api/pipelines/latent_diffusion
|
||||
title: Latent Diffusion
|
||||
- local: api/pipelines/ledits_pp
|
||||
title: LEDITS++
|
||||
- local: api/pipelines/lumina2
|
||||
title: Lumina 2.0
|
||||
- local: api/pipelines/lumina
|
||||
title: Lumina-T2X
|
||||
- local: api/pipelines/marigold
|
||||
title: Marigold
|
||||
- local: api/pipelines/panorama
|
||||
title: MultiDiffusion
|
||||
- local: api/pipelines/omnigen
|
||||
title: OmniGen
|
||||
- local: api/pipelines/pag
|
||||
title: PAG
|
||||
- local: api/pipelines/paint_by_example
|
||||
title: Paint by Example
|
||||
- local: api/pipelines/pixart
|
||||
title: PixArt-α
|
||||
- local: api/pipelines/pixart_sigma
|
||||
title: PixArt-Σ
|
||||
- local: api/pipelines/prx
|
||||
title: PRX
|
||||
- local: api/pipelines/qwenimage
|
||||
title: QwenImage
|
||||
- local: api/pipelines/sana
|
||||
title: Sana
|
||||
- local: api/pipelines/sana_sprint
|
||||
title: Sana Sprint
|
||||
- local: api/pipelines/self_attention_guidance
|
||||
title: Self-Attention Guidance
|
||||
- local: api/pipelines/semantic_stable_diffusion
|
||||
title: Semantic Guidance
|
||||
- local: api/pipelines/shap_e
|
||||
title: Shap-E
|
||||
- local: api/pipelines/stable_cascade
|
||||
title: Stable Cascade
|
||||
- sections:
|
||||
- local: api/pipelines/stable_diffusion/overview
|
||||
title: Overview
|
||||
- local: api/pipelines/stable_diffusion/depth2img
|
||||
title: Depth-to-image
|
||||
- local: api/pipelines/stable_diffusion/gligen
|
||||
title: GLIGEN (Grounded Language-to-Image Generation)
|
||||
- local: api/pipelines/stable_diffusion/image_variation
|
||||
title: Image variation
|
||||
- local: api/pipelines/stable_diffusion/img2img
|
||||
title: Image-to-image
|
||||
- local: api/pipelines/stable_diffusion/inpaint
|
||||
title: Inpainting
|
||||
- local: api/pipelines/stable_diffusion/k_diffusion
|
||||
title: K-Diffusion
|
||||
- local: api/pipelines/stable_diffusion/latent_upscale
|
||||
title: Latent upscaler
|
||||
- local: api/pipelines/stable_diffusion/ldm3d_diffusion
|
||||
title: LDM3D Text-to-(RGB, Depth), Text-to-(RGB-pano, Depth-pano), LDM3D
|
||||
Upscaler
|
||||
- local: api/pipelines/stable_diffusion/stable_diffusion_safe
|
||||
title: Safe Stable Diffusion
|
||||
- local: api/pipelines/stable_diffusion/sdxl_turbo
|
||||
title: SDXL Turbo
|
||||
- local: api/pipelines/stable_diffusion/stable_diffusion_2
|
||||
title: Stable Diffusion 2
|
||||
- local: api/pipelines/stable_diffusion/stable_diffusion_3
|
||||
title: Stable Diffusion 3
|
||||
- local: api/pipelines/stable_diffusion/stable_diffusion_xl
|
||||
title: Stable Diffusion XL
|
||||
- local: api/pipelines/stable_diffusion/upscale
|
||||
title: Super-resolution
|
||||
- local: api/pipelines/stable_diffusion/adapter
|
||||
title: T2I-Adapter
|
||||
- local: api/pipelines/stable_diffusion/text2img
|
||||
title: Text-to-image
|
||||
title: Stable Diffusion
|
||||
- local: api/pipelines/stable_unclip
|
||||
title: Stable unCLIP
|
||||
- local: api/pipelines/unclip
|
||||
title: unCLIP
|
||||
- local: api/pipelines/unidiffuser
|
||||
title: UniDiffuser
|
||||
- local: api/pipelines/value_guided_sampling
|
||||
title: Value-guided sampling
|
||||
- local: api/pipelines/visualcloze
|
||||
title: VisualCloze
|
||||
- local: api/pipelines/wuerstchen
|
||||
title: Wuerstchen
|
||||
title: Image
|
||||
- sections:
|
||||
- local: api/pipelines/allegro
|
||||
title: Allegro
|
||||
- local: api/pipelines/cogvideox
|
||||
title: CogVideoX
|
||||
- local: api/pipelines/consisid
|
||||
title: ConsisID
|
||||
- local: api/pipelines/framepack
|
||||
title: Framepack
|
||||
- local: api/pipelines/hunyuanimage21
|
||||
title: HunyuanImage2.1
|
||||
- local: api/pipelines/hunyuan_video
|
||||
title: HunyuanVideo
|
||||
- local: api/pipelines/i2vgenxl
|
||||
title: I2VGen-XL
|
||||
- local: api/pipelines/latte
|
||||
title: Latte
|
||||
- local: api/pipelines/ltx_video
|
||||
title: LTXVideo
|
||||
- local: api/pipelines/mochi
|
||||
title: Mochi
|
||||
- local: api/pipelines/pia
|
||||
title: Personalized Image Animator (PIA)
|
||||
- local: api/pipelines/skyreels_v2
|
||||
title: SkyReels-V2
|
||||
- local: api/pipelines/stable_diffusion/svd
|
||||
title: Stable Video Diffusion
|
||||
- local: api/pipelines/text_to_video
|
||||
title: Text-to-video
|
||||
- local: api/pipelines/text_to_video_zero
|
||||
title: Text2Video-Zero
|
||||
- local: api/pipelines/wan
|
||||
title: Wan
|
||||
title: Video
|
||||
title: Pipelines
|
||||
- sections:
|
||||
- local: api/schedulers/overview
|
||||
title: Overview
|
||||
- local: api/schedulers/cm_stochastic_iterative
|
||||
title: CMStochasticIterativeScheduler
|
||||
- local: api/schedulers/ddim_cogvideox
|
||||
title: CogVideoXDDIMScheduler
|
||||
- local: api/schedulers/multistep_dpm_solver_cogvideox
|
||||
title: CogVideoXDPMScheduler
|
||||
- local: api/schedulers/consistency_decoder
|
||||
title: ConsistencyDecoderScheduler
|
||||
- local: api/schedulers/cosine_dpm
|
||||
title: CosineDPMSolverMultistepScheduler
|
||||
- local: api/schedulers/ddim_inverse
|
||||
title: DDIMInverseScheduler
|
||||
- local: api/schedulers/ddim
|
||||
title: DDIMScheduler
|
||||
- local: api/schedulers/ddpm
|
||||
title: DDPMScheduler
|
||||
- local: api/schedulers/deis
|
||||
title: DEISMultistepScheduler
|
||||
- local: api/schedulers/multistep_dpm_solver_inverse
|
||||
title: DPMSolverMultistepInverse
|
||||
- local: api/schedulers/multistep_dpm_solver
|
||||
title: DPMSolverMultistepScheduler
|
||||
- local: api/schedulers/dpm_sde
|
||||
title: DPMSolverSDEScheduler
|
||||
- local: api/schedulers/singlestep_dpm_solver
|
||||
title: DPMSolverSinglestepScheduler
|
||||
- local: api/schedulers/edm_multistep_dpm_solver
|
||||
title: EDMDPMSolverMultistepScheduler
|
||||
- local: api/schedulers/edm_euler
|
||||
title: EDMEulerScheduler
|
||||
- local: api/schedulers/euler_ancestral
|
||||
title: EulerAncestralDiscreteScheduler
|
||||
- local: api/schedulers/euler
|
||||
title: EulerDiscreteScheduler
|
||||
- local: api/schedulers/flow_match_euler_discrete
|
||||
title: FlowMatchEulerDiscreteScheduler
|
||||
- local: api/schedulers/flow_match_heun_discrete
|
||||
title: FlowMatchHeunDiscreteScheduler
|
||||
- local: api/schedulers/heun
|
||||
title: HeunDiscreteScheduler
|
||||
- local: api/schedulers/ipndm
|
||||
title: IPNDMScheduler
|
||||
- local: api/schedulers/stochastic_karras_ve
|
||||
title: KarrasVeScheduler
|
||||
- local: api/schedulers/dpm_discrete_ancestral
|
||||
title: KDPM2AncestralDiscreteScheduler
|
||||
- local: api/schedulers/dpm_discrete
|
||||
title: KDPM2DiscreteScheduler
|
||||
- local: api/schedulers/lcm
|
||||
title: LCMScheduler
|
||||
- local: api/schedulers/lms_discrete
|
||||
title: LMSDiscreteScheduler
|
||||
- local: api/schedulers/pndm
|
||||
title: PNDMScheduler
|
||||
- local: api/schedulers/repaint
|
||||
title: RePaintScheduler
|
||||
- local: api/schedulers/score_sde_ve
|
||||
title: ScoreSdeVeScheduler
|
||||
- local: api/schedulers/score_sde_vp
|
||||
title: ScoreSdeVpScheduler
|
||||
- local: api/schedulers/tcd
|
||||
title: TCDScheduler
|
||||
- local: api/schedulers/unipc
|
||||
title: UniPCMultistepScheduler
|
||||
- local: api/schedulers/vq_diffusion
|
||||
title: VQDiffusionScheduler
|
||||
title: Schedulers
|
||||
- sections:
|
||||
- local: api/internal_classes_overview
|
||||
title: Overview
|
||||
- local: api/attnprocessor
|
||||
title: Attention Processor
|
||||
- local: api/activations
|
||||
title: Custom activation functions
|
||||
- local: api/cache
|
||||
title: Caching methods
|
||||
- local: api/normalization
|
||||
title: Custom normalization layers
|
||||
- local: api/utilities
|
||||
title: Utilities
|
||||
- local: api/image_processor
|
||||
title: VAE Image Processor
|
||||
- local: api/video_processor
|
||||
title: Video Processor
|
||||
title: Internal classes
|
||||
title: API
|
||||
@@ -1,231 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Outpainting
|
||||
|
||||
Outpainting extends an image beyond its original boundaries, allowing you to add, replace, or modify visual elements in an image while preserving the original image. Like [inpainting](../using-diffusers/inpaint), you want to fill the white area (in this case, the area outside of the original image) with new visual elements while keeping the original image (represented by a mask of black pixels). There are a couple of ways to outpaint, such as with a [ControlNet](https://hf.co/blog/OzzyGT/outpainting-controlnet) or with [Differential Diffusion](https://hf.co/blog/OzzyGT/outpainting-differential-diffusion).
|
||||
|
||||
This guide will show you how to outpaint with an inpainting model, ControlNet, and a ZoeDepth estimator.
|
||||
|
||||
Before you begin, make sure you have the [controlnet_aux](https://github.com/huggingface/controlnet_aux) library installed so you can use the ZoeDepth estimator.
|
||||
|
||||
```py
|
||||
!pip install -q controlnet_aux
|
||||
```
|
||||
|
||||
## Image preparation
|
||||
|
||||
Start by picking an image to outpaint with and remove the background with a Space like [BRIA-RMBG-1.4](https://hf.co/spaces/briaai/BRIA-RMBG-1.4).
|
||||
|
||||
<iframe
|
||||
src="https://briaai-bria-rmbg-1-4.hf.space"
|
||||
frameborder="0"
|
||||
width="850"
|
||||
height="450"
|
||||
></iframe>
|
||||
|
||||
For example, remove the background from this image of a pair of shoes.
|
||||
|
||||
<div class="flex flex-row gap-4">
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/stevhliu/testing-images/resolve/main/original-jordan.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">original image</figcaption>
|
||||
</div>
|
||||
<div class="flex-1">
|
||||
<img class="rounded-xl" src="https://huggingface.co/datasets/stevhliu/testing-images/resolve/main/no-background-jordan.png"/>
|
||||
<figcaption class="mt-2 text-center text-sm text-gray-500">background removed</figcaption>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
[Stable Diffusion XL (SDXL)](../using-diffusers/sdxl) models work best with 1024x1024 images, but you can resize the image to any size as long as your hardware has enough memory to support it. The transparent background in the image should also be replaced with a white background. Create a function (like the one below) that scales and pastes the image onto a white background.
|
||||
|
||||
```py
|
||||
import random
|
||||
|
||||
import requests
|
||||
import torch
|
||||
from controlnet_aux import ZoeDetector
|
||||
from PIL import Image, ImageOps
|
||||
|
||||
from diffusers import (
|
||||
AutoencoderKL,
|
||||
ControlNetModel,
|
||||
StableDiffusionXLControlNetPipeline,
|
||||
StableDiffusionXLInpaintPipeline,
|
||||
)
|
||||
|
||||
def scale_and_paste(original_image):
|
||||
aspect_ratio = original_image.width / original_image.height
|
||||
|
||||
if original_image.width > original_image.height:
|
||||
new_width = 1024
|
||||
new_height = round(new_width / aspect_ratio)
|
||||
else:
|
||||
new_height = 1024
|
||||
new_width = round(new_height * aspect_ratio)
|
||||
|
||||
resized_original = original_image.resize((new_width, new_height), Image.LANCZOS)
|
||||
white_background = Image.new("RGBA", (1024, 1024), "white")
|
||||
x = (1024 - new_width) // 2
|
||||
y = (1024 - new_height) // 2
|
||||
white_background.paste(resized_original, (x, y), resized_original)
|
||||
|
||||
return resized_original, white_background
|
||||
|
||||
original_image = Image.open(
|
||||
requests.get(
|
||||
"https://huggingface.co/datasets/stevhliu/testing-images/resolve/main/no-background-jordan.png",
|
||||
stream=True,
|
||||
).raw
|
||||
).convert("RGBA")
|
||||
resized_img, white_bg_image = scale_and_paste(original_image)
|
||||
```
|
||||
|
||||
To avoid adding unwanted extra details, use the ZoeDepth estimator to provide additional guidance during generation and to ensure the shoes remain consistent with the original image.
|
||||
|
||||
```py
|
||||
zoe = ZoeDetector.from_pretrained("lllyasviel/Annotators")
|
||||
image_zoe = zoe(white_bg_image, detect_resolution=512, image_resolution=1024)
|
||||
image_zoe
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/stevhliu/testing-images/resolve/main/zoedepth-jordan.png"/>
|
||||
</div>
|
||||
|
||||
## Outpaint
|
||||
|
||||
Once your image is ready, you can generate content in the white area around the shoes with [controlnet-inpaint-dreamer-sdxl](https://hf.co/destitech/controlnet-inpaint-dreamer-sdxl), a SDXL ControlNet trained for inpainting.
|
||||
|
||||
Load the inpainting ControlNet, ZoeDepth model, VAE and pass them to the [`StableDiffusionXLControlNetPipeline`]. Then you can create an optional `generate_image` function (for convenience) to outpaint an initial image.
|
||||
|
||||
```py
|
||||
controlnets = [
|
||||
ControlNetModel.from_pretrained(
|
||||
"destitech/controlnet-inpaint-dreamer-sdxl", torch_dtype=torch.float16, variant="fp16"
|
||||
),
|
||||
ControlNetModel.from_pretrained(
|
||||
"diffusers/controlnet-zoe-depth-sdxl-1.0", torch_dtype=torch.float16
|
||||
),
|
||||
]
|
||||
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16).to("cuda")
|
||||
pipeline = StableDiffusionXLControlNetPipeline.from_pretrained(
|
||||
"SG161222/RealVisXL_V4.0", torch_dtype=torch.float16, variant="fp16", controlnet=controlnets, vae=vae
|
||||
).to("cuda")
|
||||
|
||||
def generate_image(prompt, negative_prompt, inpaint_image, zoe_image, seed: int = None):
|
||||
if seed is None:
|
||||
seed = random.randint(0, 2**32 - 1)
|
||||
|
||||
generator = torch.Generator(device="cpu").manual_seed(seed)
|
||||
|
||||
image = pipeline(
|
||||
prompt,
|
||||
negative_prompt=negative_prompt,
|
||||
image=[inpaint_image, zoe_image],
|
||||
guidance_scale=6.5,
|
||||
num_inference_steps=25,
|
||||
generator=generator,
|
||||
controlnet_conditioning_scale=[0.5, 0.8],
|
||||
control_guidance_end=[0.9, 0.6],
|
||||
).images[0]
|
||||
|
||||
return image
|
||||
|
||||
prompt = "nike air jordans on a basketball court"
|
||||
negative_prompt = ""
|
||||
|
||||
temp_image = generate_image(prompt, negative_prompt, white_bg_image, image_zoe, 908097)
|
||||
```
|
||||
|
||||
Paste the original image over the initial outpainted image. You'll improve the outpainted background in a later step.
|
||||
|
||||
```py
|
||||
x = (1024 - resized_img.width) // 2
|
||||
y = (1024 - resized_img.height) // 2
|
||||
temp_image.paste(resized_img, (x, y), resized_img)
|
||||
temp_image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/stevhliu/testing-images/resolve/main/initial-outpaint.png"/>
|
||||
</div>
|
||||
|
||||
> [!TIP]
|
||||
> Now is a good time to free up some memory if you're running low!
|
||||
>
|
||||
> ```py
|
||||
> pipeline=None
|
||||
> torch.cuda.empty_cache()
|
||||
> ```
|
||||
|
||||
Now that you have an initial outpainted image, load the [`StableDiffusionXLInpaintPipeline`] with the [RealVisXL](https://hf.co/SG161222/RealVisXL_V4.0) model to generate the final outpainted image with better quality.
|
||||
|
||||
```py
|
||||
pipeline = StableDiffusionXLInpaintPipeline.from_pretrained(
|
||||
"OzzyGT/RealVisXL_V4.0_inpainting",
|
||||
torch_dtype=torch.float16,
|
||||
variant="fp16",
|
||||
vae=vae,
|
||||
).to("cuda")
|
||||
```
|
||||
|
||||
Prepare a mask for the final outpainted image. To create a more natural transition between the original image and the outpainted background, blur the mask to help it blend better.
|
||||
|
||||
```py
|
||||
mask = Image.new("L", temp_image.size)
|
||||
mask.paste(resized_img.split()[3], (x, y))
|
||||
mask = ImageOps.invert(mask)
|
||||
final_mask = mask.point(lambda p: p > 128 and 255)
|
||||
mask_blurred = pipeline.mask_processor.blur(final_mask, blur_factor=20)
|
||||
mask_blurred
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/stevhliu/testing-images/resolve/main/blurred-mask.png"/>
|
||||
</div>
|
||||
|
||||
Create a better prompt and pass it to the `generate_outpaint` function to generate the final outpainted image. Again, paste the original image over the final outpainted background.
|
||||
|
||||
```py
|
||||
def generate_outpaint(prompt, negative_prompt, image, mask, seed: int = None):
|
||||
if seed is None:
|
||||
seed = random.randint(0, 2**32 - 1)
|
||||
|
||||
generator = torch.Generator(device="cpu").manual_seed(seed)
|
||||
|
||||
image = pipeline(
|
||||
prompt,
|
||||
negative_prompt=negative_prompt,
|
||||
image=image,
|
||||
mask_image=mask,
|
||||
guidance_scale=10.0,
|
||||
strength=0.8,
|
||||
num_inference_steps=30,
|
||||
generator=generator,
|
||||
).images[0]
|
||||
|
||||
return image
|
||||
|
||||
prompt = "high quality photo of nike air jordans on a basketball court, highly detailed"
|
||||
negative_prompt = ""
|
||||
|
||||
final_image = generate_outpaint(prompt, negative_prompt, temp_image, mask_blurred, 7688778)
|
||||
x = (1024 - resized_img.width) // 2
|
||||
y = (1024 - resized_img.height) // 2
|
||||
final_image.paste(resized_img, (x, y), resized_img)
|
||||
final_image
|
||||
```
|
||||
|
||||
<div class="flex justify-center">
|
||||
<img src="https://huggingface.co/datasets/stevhliu/testing-images/resolve/main/final-outpaint.png"/>
|
||||
</div>
|
||||
@@ -1,40 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Activation functions
|
||||
|
||||
Customized activation functions for supporting various models in 🤗 Diffusers.
|
||||
|
||||
## GELU
|
||||
|
||||
[[autodoc]] models.activations.GELU
|
||||
|
||||
## GEGLU
|
||||
|
||||
[[autodoc]] models.activations.GEGLU
|
||||
|
||||
## ApproximateGELU
|
||||
|
||||
[[autodoc]] models.activations.ApproximateGELU
|
||||
|
||||
|
||||
## SwiGLU
|
||||
|
||||
[[autodoc]] models.activations.SwiGLU
|
||||
|
||||
## FP32SiLU
|
||||
|
||||
[[autodoc]] models.activations.FP32SiLU
|
||||
|
||||
## LinearActivation
|
||||
|
||||
[[autodoc]] models.activations.LinearActivation
|
||||
@@ -1,166 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Attention Processor
|
||||
|
||||
An attention processor is a class for applying different types of attention mechanisms.
|
||||
|
||||
## AttnProcessor
|
||||
|
||||
[[autodoc]] models.attention_processor.AttnProcessor
|
||||
|
||||
[[autodoc]] models.attention_processor.AttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.AttnAddedKVProcessor
|
||||
|
||||
[[autodoc]] models.attention_processor.AttnAddedKVProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.AttnProcessorNPU
|
||||
|
||||
[[autodoc]] models.attention_processor.FusedAttnProcessor2_0
|
||||
|
||||
## Allegro
|
||||
|
||||
[[autodoc]] models.attention_processor.AllegroAttnProcessor2_0
|
||||
|
||||
## AuraFlow
|
||||
|
||||
[[autodoc]] models.attention_processor.AuraFlowAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.FusedAuraFlowAttnProcessor2_0
|
||||
|
||||
## CogVideoX
|
||||
|
||||
[[autodoc]] models.attention_processor.CogVideoXAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.FusedCogVideoXAttnProcessor2_0
|
||||
|
||||
## CrossFrameAttnProcessor
|
||||
|
||||
[[autodoc]] pipelines.text_to_video_synthesis.pipeline_text_to_video_zero.CrossFrameAttnProcessor
|
||||
|
||||
## Custom Diffusion
|
||||
|
||||
[[autodoc]] models.attention_processor.CustomDiffusionAttnProcessor
|
||||
|
||||
[[autodoc]] models.attention_processor.CustomDiffusionAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.CustomDiffusionXFormersAttnProcessor
|
||||
|
||||
## Flux
|
||||
|
||||
[[autodoc]] models.attention_processor.FluxAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.FusedFluxAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.FluxSingleAttnProcessor2_0
|
||||
|
||||
## Hunyuan
|
||||
|
||||
[[autodoc]] models.attention_processor.HunyuanAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.FusedHunyuanAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.PAGHunyuanAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.PAGCFGHunyuanAttnProcessor2_0
|
||||
|
||||
## IdentitySelfAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.PAGIdentitySelfAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.PAGCFGIdentitySelfAttnProcessor2_0
|
||||
|
||||
## IP-Adapter
|
||||
|
||||
[[autodoc]] models.attention_processor.IPAdapterAttnProcessor
|
||||
|
||||
[[autodoc]] models.attention_processor.IPAdapterAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.SD3IPAdapterJointAttnProcessor2_0
|
||||
|
||||
## JointAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.JointAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.PAGJointAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.PAGCFGJointAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.FusedJointAttnProcessor2_0
|
||||
|
||||
## LoRA
|
||||
|
||||
[[autodoc]] models.attention_processor.LoRAAttnProcessor
|
||||
|
||||
[[autodoc]] models.attention_processor.LoRAAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.LoRAAttnAddedKVProcessor
|
||||
|
||||
[[autodoc]] models.attention_processor.LoRAXFormersAttnProcessor
|
||||
|
||||
## Lumina-T2X
|
||||
|
||||
[[autodoc]] models.attention_processor.LuminaAttnProcessor2_0
|
||||
|
||||
## Mochi
|
||||
|
||||
[[autodoc]] models.attention_processor.MochiAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.MochiVaeAttnProcessor2_0
|
||||
|
||||
## Sana
|
||||
|
||||
[[autodoc]] models.attention_processor.SanaLinearAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.SanaMultiscaleAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.PAGCFGSanaLinearAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.PAGIdentitySanaLinearAttnProcessor2_0
|
||||
|
||||
## Stable Audio
|
||||
|
||||
[[autodoc]] models.attention_processor.StableAudioAttnProcessor2_0
|
||||
|
||||
## SlicedAttnProcessor
|
||||
|
||||
[[autodoc]] models.attention_processor.SlicedAttnProcessor
|
||||
|
||||
[[autodoc]] models.attention_processor.SlicedAttnAddedKVProcessor
|
||||
|
||||
## XFormersAttnProcessor
|
||||
|
||||
[[autodoc]] models.attention_processor.XFormersAttnProcessor
|
||||
|
||||
[[autodoc]] models.attention_processor.XFormersAttnAddedKVProcessor
|
||||
|
||||
## XLAFlashAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.XLAFlashAttnProcessor2_0
|
||||
|
||||
## XFormersJointAttnProcessor
|
||||
|
||||
[[autodoc]] models.attention_processor.XFormersJointAttnProcessor
|
||||
|
||||
## IPAdapterXFormersAttnProcessor
|
||||
|
||||
[[autodoc]] models.attention_processor.IPAdapterXFormersAttnProcessor
|
||||
|
||||
## FluxIPAdapterJointAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.FluxIPAdapterJointAttnProcessor2_0
|
||||
|
||||
|
||||
## XLAFluxFlashAttnProcessor2_0
|
||||
|
||||
[[autodoc]] models.attention_processor.XLAFluxFlashAttnProcessor2_0
|
||||
@@ -1,36 +0,0 @@
|
||||
<!-- Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License. -->
|
||||
|
||||
# Caching methods
|
||||
|
||||
Cache methods speedup diffusion transformers by storing and reusing intermediate outputs of specific layers, such as attention and feedforward layers, instead of recalculating them at each inference step.
|
||||
|
||||
## CacheMixin
|
||||
|
||||
[[autodoc]] CacheMixin
|
||||
|
||||
## PyramidAttentionBroadcastConfig
|
||||
|
||||
[[autodoc]] PyramidAttentionBroadcastConfig
|
||||
|
||||
[[autodoc]] apply_pyramid_attention_broadcast
|
||||
|
||||
## FasterCacheConfig
|
||||
|
||||
[[autodoc]] FasterCacheConfig
|
||||
|
||||
[[autodoc]] apply_faster_cache
|
||||
|
||||
### FirstBlockCacheConfig
|
||||
|
||||
[[autodoc]] FirstBlockCacheConfig
|
||||
|
||||
[[autodoc]] apply_first_block_cache
|
||||
@@ -1,27 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Configuration
|
||||
|
||||
Schedulers from [`~schedulers.scheduling_utils.SchedulerMixin`] and models from [`ModelMixin`] inherit from [`ConfigMixin`] which stores all the parameters that are passed to their respective `__init__` methods in a JSON-configuration file.
|
||||
|
||||
> [!TIP]
|
||||
> To use private or [gated](https://huggingface.co/docs/hub/models-gated#gated-models) models, log-in with `hf auth login`.
|
||||
|
||||
## ConfigMixin
|
||||
|
||||
[[autodoc]] ConfigMixin
|
||||
- load_config
|
||||
- from_config
|
||||
- save_config
|
||||
- to_json_file
|
||||
- to_json_string
|
||||
@@ -1,41 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# VAE Image Processor
|
||||
|
||||
The [`VaeImageProcessor`] provides a unified API for [`StableDiffusionPipeline`]s to prepare image inputs for VAE encoding and post-processing outputs once they're decoded. This includes transformations such as resizing, normalization, and conversion between PIL Image, PyTorch, and NumPy arrays.
|
||||
|
||||
All pipelines with [`VaeImageProcessor`] accept PIL Image, PyTorch tensor, or NumPy arrays as image inputs and return outputs based on the `output_type` argument by the user. You can pass encoded image latents directly to the pipeline and return latents from the pipeline as a specific output with the `output_type` argument (for example `output_type="latent"`). This allows you to take the generated latents from one pipeline and pass it to another pipeline as input without leaving the latent space. It also makes it much easier to use multiple pipelines together by passing PyTorch tensors directly between different pipelines.
|
||||
|
||||
## VaeImageProcessor
|
||||
|
||||
[[autodoc]] image_processor.VaeImageProcessor
|
||||
|
||||
## InpaintProcessor
|
||||
|
||||
The [`InpaintProcessor`] accepts `mask` and `image` inputs and process them together. Optionally, it can accept padding_mask_crop and apply mask overlay.
|
||||
|
||||
[[autodoc]] image_processor.InpaintProcessor
|
||||
|
||||
## VaeImageProcessorLDM3D
|
||||
|
||||
The [`VaeImageProcessorLDM3D`] accepts RGB and depth inputs and returns RGB and depth outputs.
|
||||
|
||||
[[autodoc]] image_processor.VaeImageProcessorLDM3D
|
||||
|
||||
## PixArtImageProcessor
|
||||
|
||||
[[autodoc]] image_processor.PixArtImageProcessor
|
||||
|
||||
## IPAdapterMaskProcessor
|
||||
|
||||
[[autodoc]] image_processor.IPAdapterMaskProcessor
|
||||
@@ -1,15 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Overview
|
||||
|
||||
The APIs in this section are more experimental and prone to breaking changes. Most of them are used internally for development, but they may also be useful to you if you're interested in building a diffusion model with some custom parts or if you're interested in some of our helper utilities for working with 🤗 Diffusers.
|
||||
@@ -1,32 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# IP-Adapter
|
||||
|
||||
[IP-Adapter](https://hf.co/papers/2308.06721) is a lightweight adapter that enables prompting a diffusion model with an image. This method decouples the cross-attention layers of the image and text features. The image features are generated from an image encoder.
|
||||
|
||||
> [!TIP]
|
||||
> Learn how to load and use an IP-Adapter checkpoint and image in the [IP-Adapter](../../using-diffusers/ip_adapter) guide,.
|
||||
|
||||
## IPAdapterMixin
|
||||
|
||||
[[autodoc]] loaders.ip_adapter.IPAdapterMixin
|
||||
|
||||
## SD3IPAdapterMixin
|
||||
|
||||
[[autodoc]] loaders.ip_adapter.SD3IPAdapterMixin
|
||||
- all
|
||||
- is_ip_adapter_active
|
||||
|
||||
## IPAdapterMaskProcessor
|
||||
|
||||
[[autodoc]] image_processor.IPAdapterMaskProcessor
|
||||
@@ -1,115 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# LoRA
|
||||
|
||||
LoRA is a fast and lightweight training method that inserts and trains a significantly smaller number of parameters instead of all the model parameters. This produces a smaller file (~100 MBs) and makes it easier to quickly train a model to learn a new concept. LoRA weights are typically loaded into the denoiser, text encoder or both. The denoiser usually corresponds to a UNet ([`UNet2DConditionModel`], for example) or a Transformer ([`SD3Transformer2DModel`], for example). There are several classes for loading LoRA weights:
|
||||
|
||||
- [`StableDiffusionLoraLoaderMixin`] provides functions for loading and unloading, fusing and unfusing, enabling and disabling, and more functions for managing LoRA weights. This class can be used with any model.
|
||||
- [`StableDiffusionXLLoraLoaderMixin`] is a [Stable Diffusion (SDXL)](../../api/pipelines/stable_diffusion/stable_diffusion_xl) version of the [`StableDiffusionLoraLoaderMixin`] class for loading and saving LoRA weights. It can only be used with the SDXL model.
|
||||
- [`SD3LoraLoaderMixin`] provides similar functions for [Stable Diffusion 3](https://huggingface.co/blog/sd3).
|
||||
- [`FluxLoraLoaderMixin`] provides similar functions for [Flux](https://huggingface.co/docs/diffusers/main/en/api/pipelines/flux).
|
||||
- [`CogVideoXLoraLoaderMixin`] provides similar functions for [CogVideoX](https://huggingface.co/docs/diffusers/main/en/api/pipelines/cogvideox).
|
||||
- [`Mochi1LoraLoaderMixin`] provides similar functions for [Mochi](https://huggingface.co/docs/diffusers/main/en/api/pipelines/mochi).
|
||||
- [`AuraFlowLoraLoaderMixin`] provides similar functions for [AuraFlow](https://huggingface.co/fal/AuraFlow).
|
||||
- [`LTXVideoLoraLoaderMixin`] provides similar functions for [LTX-Video](https://huggingface.co/docs/diffusers/main/en/api/pipelines/ltx_video).
|
||||
- [`SanaLoraLoaderMixin`] provides similar functions for [Sana](https://huggingface.co/docs/diffusers/main/en/api/pipelines/sana).
|
||||
- [`HunyuanVideoLoraLoaderMixin`] provides similar functions for [HunyuanVideo](https://huggingface.co/docs/diffusers/main/en/api/pipelines/hunyuan_video).
|
||||
- [`Lumina2LoraLoaderMixin`] provides similar functions for [Lumina2](https://huggingface.co/docs/diffusers/main/en/api/pipelines/lumina2).
|
||||
- [`WanLoraLoaderMixin`] provides similar functions for [Wan](https://huggingface.co/docs/diffusers/main/en/api/pipelines/wan).
|
||||
- [`SkyReelsV2LoraLoaderMixin`] provides similar functions for [SkyReels-V2](https://huggingface.co/docs/diffusers/main/en/api/pipelines/skyreels_v2).
|
||||
- [`CogView4LoraLoaderMixin`] provides similar functions for [CogView4](https://huggingface.co/docs/diffusers/main/en/api/pipelines/cogview4).
|
||||
- [`AmusedLoraLoaderMixin`] is for the [`AmusedPipeline`].
|
||||
- [`HiDreamImageLoraLoaderMixin`] provides similar functions for [HiDream Image](https://huggingface.co/docs/diffusers/main/en/api/pipelines/hidream)
|
||||
- [`QwenImageLoraLoaderMixin`] provides similar functions for [Qwen Image](https://huggingface.co/docs/diffusers/main/en/api/pipelines/qwen)
|
||||
- [`LoraBaseMixin`] provides a base class with several utility methods to fuse, unfuse, unload, LoRAs and more.
|
||||
|
||||
> [!TIP]
|
||||
> To learn more about how to load LoRA weights, see the [LoRA](../../tutorials/using_peft_for_inference) loading guide.
|
||||
|
||||
## LoraBaseMixin
|
||||
|
||||
[[autodoc]] loaders.lora_base.LoraBaseMixin
|
||||
|
||||
## StableDiffusionLoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.StableDiffusionLoraLoaderMixin
|
||||
|
||||
## StableDiffusionXLLoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.StableDiffusionXLLoraLoaderMixin
|
||||
|
||||
## SD3LoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.SD3LoraLoaderMixin
|
||||
|
||||
## FluxLoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.FluxLoraLoaderMixin
|
||||
|
||||
## CogVideoXLoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.CogVideoXLoraLoaderMixin
|
||||
|
||||
## Mochi1LoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.Mochi1LoraLoaderMixin
|
||||
## AuraFlowLoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.AuraFlowLoraLoaderMixin
|
||||
|
||||
## LTXVideoLoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.LTXVideoLoraLoaderMixin
|
||||
|
||||
## SanaLoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.SanaLoraLoaderMixin
|
||||
|
||||
## HunyuanVideoLoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.HunyuanVideoLoraLoaderMixin
|
||||
|
||||
## Lumina2LoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.Lumina2LoraLoaderMixin
|
||||
|
||||
## CogView4LoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.CogView4LoraLoaderMixin
|
||||
|
||||
## WanLoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.WanLoraLoaderMixin
|
||||
|
||||
## SkyReelsV2LoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.SkyReelsV2LoraLoaderMixin
|
||||
|
||||
## AmusedLoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.AmusedLoraLoaderMixin
|
||||
|
||||
## HiDreamImageLoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.HiDreamImageLoraLoaderMixin
|
||||
|
||||
## QwenImageLoraLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.lora_pipeline.QwenImageLoraLoaderMixin
|
||||
|
||||
## KandinskyLoraLoaderMixin
|
||||
[[autodoc]] loaders.lora_pipeline.KandinskyLoraLoaderMixin
|
||||
|
||||
## LoraBaseMixin
|
||||
|
||||
[[autodoc]] loaders.lora_base.LoraBaseMixin
|
||||
@@ -1,22 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# PEFT
|
||||
|
||||
Diffusers supports loading adapters such as [LoRA](../../tutorials/using_peft_for_inference) with the [PEFT](https://huggingface.co/docs/peft/index) library with the [`~loaders.peft.PeftAdapterMixin`] class. This allows modeling classes in Diffusers like [`UNet2DConditionModel`], [`SD3Transformer2DModel`] to operate with an adapter.
|
||||
|
||||
> [!TIP]
|
||||
> Refer to the [Inference with PEFT](../../tutorials/using_peft_for_inference.md) tutorial for an overview of how to use PEFT in Diffusers for inference.
|
||||
|
||||
## PeftAdapterMixin
|
||||
|
||||
[[autodoc]] loaders.peft.PeftAdapterMixin
|
||||
@@ -1,62 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Single files
|
||||
|
||||
The [`~loaders.FromSingleFileMixin.from_single_file`] method allows you to load:
|
||||
|
||||
* a model stored in a single file, which is useful if you're working with models from the diffusion ecosystem, like Automatic1111, and commonly rely on a single-file layout to store and share models
|
||||
* a model stored in their originally distributed layout, which is useful if you're working with models finetuned with other services, and want to load it directly into Diffusers model objects and pipelines
|
||||
|
||||
> [!TIP]
|
||||
> Read the [Model files and layouts](../../using-diffusers/other-formats) guide to learn more about the Diffusers-multifolder layout versus the single-file layout, and how to load models stored in these different layouts.
|
||||
|
||||
## Supported pipelines
|
||||
|
||||
- [`StableDiffusionPipeline`]
|
||||
- [`StableDiffusionImg2ImgPipeline`]
|
||||
- [`StableDiffusionInpaintPipeline`]
|
||||
- [`StableDiffusionControlNetPipeline`]
|
||||
- [`StableDiffusionControlNetImg2ImgPipeline`]
|
||||
- [`StableDiffusionControlNetInpaintPipeline`]
|
||||
- [`StableDiffusionUpscalePipeline`]
|
||||
- [`StableDiffusionXLPipeline`]
|
||||
- [`StableDiffusionXLImg2ImgPipeline`]
|
||||
- [`StableDiffusionXLInpaintPipeline`]
|
||||
- [`StableDiffusionXLInstructPix2PixPipeline`]
|
||||
- [`StableDiffusionXLControlNetPipeline`]
|
||||
- [`StableDiffusionXLKDiffusionPipeline`]
|
||||
- [`StableDiffusion3Pipeline`]
|
||||
- [`LatentConsistencyModelPipeline`]
|
||||
- [`LatentConsistencyModelImg2ImgPipeline`]
|
||||
- [`StableDiffusionControlNetXSPipeline`]
|
||||
- [`StableDiffusionXLControlNetXSPipeline`]
|
||||
- [`LEditsPPPipelineStableDiffusion`]
|
||||
- [`LEditsPPPipelineStableDiffusionXL`]
|
||||
- [`PIAPipeline`]
|
||||
|
||||
## Supported models
|
||||
|
||||
- [`UNet2DConditionModel`]
|
||||
- [`StableCascadeUNet`]
|
||||
- [`AutoencoderKL`]
|
||||
- [`ControlNetModel`]
|
||||
- [`SD3Transformer2DModel`]
|
||||
- [`FluxTransformer2DModel`]
|
||||
|
||||
## FromSingleFileMixin
|
||||
|
||||
[[autodoc]] loaders.single_file.FromSingleFileMixin
|
||||
|
||||
## FromOriginalModelMixin
|
||||
|
||||
[[autodoc]] loaders.single_file_model.FromOriginalModelMixin
|
||||
@@ -1,24 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Textual Inversion
|
||||
|
||||
Textual Inversion is a training method for personalizing models by learning new text embeddings from a few example images. The file produced from training is extremely small (a few KBs) and the new embeddings can be loaded into the text encoder.
|
||||
|
||||
[`TextualInversionLoaderMixin`] provides a function for loading Textual Inversion embeddings from Diffusers and Automatic1111 into the text encoder and loading a special token to activate the embeddings.
|
||||
|
||||
> [!TIP]
|
||||
> To learn more about how to load Textual Inversion embeddings, see the [Textual Inversion](../../using-diffusers/textual_inversion_inference) loading guide.
|
||||
|
||||
## TextualInversionLoaderMixin
|
||||
|
||||
[[autodoc]] loaders.textual_inversion.TextualInversionLoaderMixin
|
||||
@@ -1,26 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# SD3Transformer2D
|
||||
|
||||
This class is useful when *only* loading weights into a [`SD3Transformer2DModel`]. If you need to load weights into the text encoder or a text encoder and SD3Transformer2DModel, check [`SD3LoraLoaderMixin`](lora#diffusers.loaders.SD3LoraLoaderMixin) class instead.
|
||||
|
||||
The [`SD3Transformer2DLoadersMixin`] class currently only loads IP-Adapter weights, but will be used in the future to save weights and load LoRAs.
|
||||
|
||||
> [!TIP]
|
||||
> To learn more about how to load LoRA weights, see the [LoRA](../../tutorials/using_peft_for_inference) loading guide.
|
||||
|
||||
## SD3Transformer2DLoadersMixin
|
||||
|
||||
[[autodoc]] loaders.transformer_sd3.SD3Transformer2DLoadersMixin
|
||||
- all
|
||||
- _load_ip_adapter_weights
|
||||
@@ -1,24 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# UNet
|
||||
|
||||
Some training methods - like LoRA and Custom Diffusion - typically target the UNet's attention layers, but these training methods can also target other non-attention layers. Instead of training all of a model's parameters, only a subset of the parameters are trained, which is faster and more efficient. This class is useful if you're *only* loading weights into a UNet. If you need to load weights into the text encoder or a text encoder and UNet, try using the [`~loaders.StableDiffusionLoraLoaderMixin.load_lora_weights`] function instead.
|
||||
|
||||
The [`UNet2DConditionLoadersMixin`] class provides functions for loading and saving weights, fusing and unfusing LoRAs, disabling and enabling LoRAs, and setting and deleting adapters.
|
||||
|
||||
> [!TIP]
|
||||
> To learn more about how to load LoRA weights, see the [LoRA](../../tutorials/using_peft_for_inference) guide.
|
||||
|
||||
## UNet2DConditionLoadersMixin
|
||||
|
||||
[[autodoc]] loaders.unet.UNet2DConditionLoadersMixin
|
||||
@@ -1,96 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Logging
|
||||
|
||||
🤗 Diffusers has a centralized logging system to easily manage the verbosity of the library. The default verbosity is set to `WARNING`.
|
||||
|
||||
To change the verbosity level, use one of the direct setters. For instance, to change the verbosity to the `INFO` level.
|
||||
|
||||
```python
|
||||
import diffusers
|
||||
|
||||
diffusers.logging.set_verbosity_info()
|
||||
```
|
||||
|
||||
You can also use the environment variable `DIFFUSERS_VERBOSITY` to override the default verbosity. You can set it
|
||||
to one of the following: `debug`, `info`, `warning`, `error`, `critical`. For example:
|
||||
|
||||
```bash
|
||||
DIFFUSERS_VERBOSITY=error ./myprogram.py
|
||||
```
|
||||
|
||||
Additionally, some `warnings` can be disabled by setting the environment variable
|
||||
`DIFFUSERS_NO_ADVISORY_WARNINGS` to a true value, like `1`. This disables any warning logged by
|
||||
[`logger.warning_advice`]. For example:
|
||||
|
||||
```bash
|
||||
DIFFUSERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
|
||||
```
|
||||
|
||||
Here is an example of how to use the same logger as the library in your own module or script:
|
||||
|
||||
```python
|
||||
from diffusers.utils import logging
|
||||
|
||||
logging.set_verbosity_info()
|
||||
logger = logging.get_logger("diffusers")
|
||||
logger.info("INFO")
|
||||
logger.warning("WARN")
|
||||
```
|
||||
|
||||
|
||||
All methods of the logging module are documented below. The main methods are
|
||||
[`logging.get_verbosity`] to get the current level of verbosity in the logger and
|
||||
[`logging.set_verbosity`] to set the verbosity to the level of your choice.
|
||||
|
||||
In order from the least verbose to the most verbose:
|
||||
|
||||
| Method | Integer value | Description |
|
||||
|----------------------------------------------------------:|--------------:|----------------------------------------------------:|
|
||||
| `diffusers.logging.CRITICAL` or `diffusers.logging.FATAL` | 50 | only report the most critical errors |
|
||||
| `diffusers.logging.ERROR` | 40 | only report errors |
|
||||
| `diffusers.logging.WARNING` or `diffusers.logging.WARN` | 30 | only report errors and warnings (default) |
|
||||
| `diffusers.logging.INFO` | 20 | only report errors, warnings, and basic information |
|
||||
| `diffusers.logging.DEBUG` | 10 | report all information |
|
||||
|
||||
By default, `tqdm` progress bars are displayed during model download. [`logging.disable_progress_bar`] and [`logging.enable_progress_bar`] are used to enable or disable this behavior.
|
||||
|
||||
## Base setters
|
||||
|
||||
[[autodoc]] utils.logging.set_verbosity_error
|
||||
|
||||
[[autodoc]] utils.logging.set_verbosity_warning
|
||||
|
||||
[[autodoc]] utils.logging.set_verbosity_info
|
||||
|
||||
[[autodoc]] utils.logging.set_verbosity_debug
|
||||
|
||||
## Other functions
|
||||
|
||||
[[autodoc]] utils.logging.get_verbosity
|
||||
|
||||
[[autodoc]] utils.logging.set_verbosity
|
||||
|
||||
[[autodoc]] utils.logging.get_logger
|
||||
|
||||
[[autodoc]] utils.logging.enable_default_handler
|
||||
|
||||
[[autodoc]] utils.logging.disable_default_handler
|
||||
|
||||
[[autodoc]] utils.logging.enable_explicit_format
|
||||
|
||||
[[autodoc]] utils.logging.reset_format
|
||||
|
||||
[[autodoc]] utils.logging.enable_progress_bar
|
||||
|
||||
[[autodoc]] utils.logging.disable_progress_bar
|
||||
@@ -1,30 +0,0 @@
|
||||
<!-- Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License. -->
|
||||
|
||||
# AllegroTransformer3DModel
|
||||
|
||||
A Diffusion Transformer model for 3D data from [Allegro](https://github.com/rhymes-ai/Allegro) was introduced in [Allegro: Open the Black Box of Commercial-Level Video Generation Model](https://huggingface.co/papers/2410.15458) by RhymesAI.
|
||||
|
||||
The model can be loaded with the following code snippet.
|
||||
|
||||
```python
|
||||
from diffusers import AllegroTransformer3DModel
|
||||
|
||||
transformer = AllegroTransformer3DModel.from_pretrained("rhymes-ai/Allegro", subfolder="transformer", torch_dtype=torch.bfloat16).to("cuda")
|
||||
```
|
||||
|
||||
## AllegroTransformer3DModel
|
||||
|
||||
[[autodoc]] AllegroTransformer3DModel
|
||||
|
||||
## Transformer2DModelOutput
|
||||
|
||||
[[autodoc]] models.modeling_outputs.Transformer2DModelOutput
|
||||
@@ -1,60 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# AsymmetricAutoencoderKL
|
||||
|
||||
Improved larger variational autoencoder (VAE) model with KL loss for inpainting task: [Designing a Better Asymmetric VQGAN for StableDiffusion](https://huggingface.co/papers/2306.04632) by Zixin Zhu, Xuelu Feng, Dongdong Chen, Jianmin Bao, Le Wang, Yinpeng Chen, Lu Yuan, Gang Hua.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*StableDiffusion is a revolutionary text-to-image generator that is causing a stir in the world of image generation and editing. Unlike traditional methods that learn a diffusion model in pixel space, StableDiffusion learns a diffusion model in the latent space via a VQGAN, ensuring both efficiency and quality. It not only supports image generation tasks, but also enables image editing for real images, such as image inpainting and local editing. However, we have observed that the vanilla VQGAN used in StableDiffusion leads to significant information loss, causing distortion artifacts even in non-edited image regions. To this end, we propose a new asymmetric VQGAN with two simple designs. Firstly, in addition to the input from the encoder, the decoder contains a conditional branch that incorporates information from task-specific priors, such as the unmasked image region in inpainting. Secondly, the decoder is much heavier than the encoder, allowing for more detailed recovery while only slightly increasing the total inference cost. The training cost of our asymmetric VQGAN is cheap, and we only need to retrain a new asymmetric decoder while keeping the vanilla VQGAN encoder and StableDiffusion unchanged. Our asymmetric VQGAN can be widely used in StableDiffusion-based inpainting and local editing methods. Extensive experiments demonstrate that it can significantly improve the inpainting and editing performance, while maintaining the original text-to-image capability. The code is available at https://github.com/buxiangzhiren/Asymmetric_VQGAN*
|
||||
|
||||
Evaluation results can be found in section 4.1 of the original paper.
|
||||
|
||||
## Available checkpoints
|
||||
|
||||
* [https://huggingface.co/cross-attention/asymmetric-autoencoder-kl-x-1-5](https://huggingface.co/cross-attention/asymmetric-autoencoder-kl-x-1-5)
|
||||
* [https://huggingface.co/cross-attention/asymmetric-autoencoder-kl-x-2](https://huggingface.co/cross-attention/asymmetric-autoencoder-kl-x-2)
|
||||
|
||||
## Example Usage
|
||||
|
||||
```python
|
||||
from diffusers import AsymmetricAutoencoderKL, StableDiffusionInpaintPipeline
|
||||
from diffusers.utils import load_image, make_image_grid
|
||||
|
||||
|
||||
prompt = "a photo of a person with beard"
|
||||
img_url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/repaint/celeba_hq_256.png"
|
||||
mask_url = "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/repaint/mask_256.png"
|
||||
|
||||
original_image = load_image(img_url).resize((512, 512))
|
||||
mask_image = load_image(mask_url).resize((512, 512))
|
||||
|
||||
pipe = StableDiffusionInpaintPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-inpainting")
|
||||
pipe.vae = AsymmetricAutoencoderKL.from_pretrained("cross-attention/asymmetric-autoencoder-kl-x-1-5")
|
||||
pipe.to("cuda")
|
||||
|
||||
image = pipe(prompt=prompt, image=original_image, mask_image=mask_image).images[0]
|
||||
make_image_grid([original_image, mask_image, image], rows=1, cols=3)
|
||||
```
|
||||
|
||||
## AsymmetricAutoencoderKL
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_asym_kl.AsymmetricAutoencoderKL
|
||||
|
||||
## AutoencoderKLOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_kl.AutoencoderKLOutput
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
@@ -1,19 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# AuraFlowTransformer2DModel
|
||||
|
||||
A Transformer model for image-like data from [AuraFlow](https://blog.fal.ai/auraflow/).
|
||||
|
||||
## AuraFlowTransformer2DModel
|
||||
|
||||
[[autodoc]] AuraFlowTransformer2DModel
|
||||
@@ -1,29 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# AutoModel
|
||||
|
||||
The `AutoModel` is designed to make it easy to load a checkpoint without needing to know the specific model class. `AutoModel` automatically retrieves the correct model class from the checkpoint `config.json` file.
|
||||
|
||||
```python
|
||||
from diffusers import AutoModel, AutoPipelineForText2Image
|
||||
|
||||
unet = AutoModel.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", subfolder="unet")
|
||||
pipe = AutoPipelineForText2Image.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", unet=unet)
|
||||
```
|
||||
|
||||
|
||||
## AutoModel
|
||||
|
||||
[[autodoc]] AutoModel
|
||||
- all
|
||||
- from_pretrained
|
||||
@@ -1,72 +0,0 @@
|
||||
<!-- Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License. -->
|
||||
|
||||
# AutoencoderDC
|
||||
|
||||
The 2D Autoencoder model used in [SANA](https://huggingface.co/papers/2410.10629) and introduced in [DCAE](https://huggingface.co/papers/2410.10733) by authors Junyu Chen\*, Han Cai\*, Junsong Chen, Enze Xie, Shang Yang, Haotian Tang, Muyang Li, Yao Lu, Song Han from MIT HAN Lab.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*We present Deep Compression Autoencoder (DC-AE), a new family of autoencoder models for accelerating high-resolution diffusion models. Existing autoencoder models have demonstrated impressive results at a moderate spatial compression ratio (e.g., 8x), but fail to maintain satisfactory reconstruction accuracy for high spatial compression ratios (e.g., 64x). We address this challenge by introducing two key techniques: (1) Residual Autoencoding, where we design our models to learn residuals based on the space-to-channel transformed features to alleviate the optimization difficulty of high spatial-compression autoencoders; (2) Decoupled High-Resolution Adaptation, an efficient decoupled three-phases training strategy for mitigating the generalization penalty of high spatial-compression autoencoders. With these designs, we improve the autoencoder's spatial compression ratio up to 128 while maintaining the reconstruction quality. Applying our DC-AE to latent diffusion models, we achieve significant speedup without accuracy drop. For example, on ImageNet 512x512, our DC-AE provides 19.1x inference speedup and 17.9x training speedup on H100 GPU for UViT-H while achieving a better FID, compared with the widely used SD-VAE-f8 autoencoder. Our code is available at [this https URL](https://github.com/mit-han-lab/efficientvit).*
|
||||
|
||||
The following DCAE models are released and supported in Diffusers.
|
||||
|
||||
| Diffusers format | Original format |
|
||||
|:----------------:|:---------------:|
|
||||
| [`mit-han-lab/dc-ae-f32c32-sana-1.0-diffusers`](https://huggingface.co/mit-han-lab/dc-ae-f32c32-sana-1.0-diffusers) | [`mit-han-lab/dc-ae-f32c32-sana-1.0`](https://huggingface.co/mit-han-lab/dc-ae-f32c32-sana-1.0)
|
||||
| [`mit-han-lab/dc-ae-f32c32-in-1.0-diffusers`](https://huggingface.co/mit-han-lab/dc-ae-f32c32-in-1.0-diffusers) | [`mit-han-lab/dc-ae-f32c32-in-1.0`](https://huggingface.co/mit-han-lab/dc-ae-f32c32-in-1.0)
|
||||
| [`mit-han-lab/dc-ae-f32c32-mix-1.0-diffusers`](https://huggingface.co/mit-han-lab/dc-ae-f32c32-mix-1.0-diffusers) | [`mit-han-lab/dc-ae-f32c32-mix-1.0`](https://huggingface.co/mit-han-lab/dc-ae-f32c32-mix-1.0)
|
||||
| [`mit-han-lab/dc-ae-f64c128-in-1.0-diffusers`](https://huggingface.co/mit-han-lab/dc-ae-f64c128-in-1.0-diffusers) | [`mit-han-lab/dc-ae-f64c128-in-1.0`](https://huggingface.co/mit-han-lab/dc-ae-f64c128-in-1.0)
|
||||
| [`mit-han-lab/dc-ae-f64c128-mix-1.0-diffusers`](https://huggingface.co/mit-han-lab/dc-ae-f64c128-mix-1.0-diffusers) | [`mit-han-lab/dc-ae-f64c128-mix-1.0`](https://huggingface.co/mit-han-lab/dc-ae-f64c128-mix-1.0)
|
||||
| [`mit-han-lab/dc-ae-f128c512-in-1.0-diffusers`](https://huggingface.co/mit-han-lab/dc-ae-f128c512-in-1.0-diffusers) | [`mit-han-lab/dc-ae-f128c512-in-1.0`](https://huggingface.co/mit-han-lab/dc-ae-f128c512-in-1.0)
|
||||
| [`mit-han-lab/dc-ae-f128c512-mix-1.0-diffusers`](https://huggingface.co/mit-han-lab/dc-ae-f128c512-mix-1.0-diffusers) | [`mit-han-lab/dc-ae-f128c512-mix-1.0`](https://huggingface.co/mit-han-lab/dc-ae-f128c512-mix-1.0)
|
||||
|
||||
This model was contributed by [lawrence-cj](https://github.com/lawrence-cj).
|
||||
|
||||
Load a model in Diffusers format with [`~ModelMixin.from_pretrained`].
|
||||
|
||||
```python
|
||||
from diffusers import AutoencoderDC
|
||||
|
||||
ae = AutoencoderDC.from_pretrained("mit-han-lab/dc-ae-f32c32-sana-1.0-diffusers", torch_dtype=torch.float32).to("cuda")
|
||||
```
|
||||
|
||||
## Load a model in Diffusers via `from_single_file`
|
||||
|
||||
```python
|
||||
from difusers import AutoencoderDC
|
||||
|
||||
ckpt_path = "https://huggingface.co/mit-han-lab/dc-ae-f32c32-sana-1.0/blob/main/model.safetensors"
|
||||
model = AutoencoderDC.from_single_file(ckpt_path)
|
||||
|
||||
```
|
||||
|
||||
The `AutoencoderDC` model has `in` and `mix` single file checkpoint variants that have matching checkpoint keys, but use different scaling factors. It is not possible for Diffusers to automatically infer the correct config file to use with the model based on just the checkpoint and will default to configuring the model using the `mix` variant config file. To override the automatically determined config, please use the `config` argument when using single file loading with `in` variant checkpoints.
|
||||
|
||||
```python
|
||||
from diffusers import AutoencoderDC
|
||||
|
||||
ckpt_path = "https://huggingface.co/mit-han-lab/dc-ae-f128c512-in-1.0/blob/main/model.safetensors"
|
||||
model = AutoencoderDC.from_single_file(ckpt_path, config="mit-han-lab/dc-ae-f128c512-in-1.0-diffusers")
|
||||
```
|
||||
|
||||
|
||||
## AutoencoderDC
|
||||
|
||||
[[autodoc]] AutoencoderDC
|
||||
- encode
|
||||
- decode
|
||||
- all
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
|
||||
@@ -1,32 +0,0 @@
|
||||
<!-- Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License. -->
|
||||
|
||||
# AutoencoderKLHunyuanVideo
|
||||
|
||||
The 3D variational autoencoder (VAE) model with KL loss used in [HunyuanVideo](https://github.com/Tencent/HunyuanVideo/), which was introduced in [HunyuanVideo: A Systematic Framework For Large Video Generative Models](https://huggingface.co/papers/2412.03603) by Tencent.
|
||||
|
||||
The model can be loaded with the following code snippet.
|
||||
|
||||
```python
|
||||
from diffusers import AutoencoderKLHunyuanVideo
|
||||
|
||||
vae = AutoencoderKLHunyuanVideo.from_pretrained("hunyuanvideo-community/HunyuanVideo", subfolder="vae", torch_dtype=torch.float16)
|
||||
```
|
||||
|
||||
## AutoencoderKLHunyuanVideo
|
||||
|
||||
[[autodoc]] AutoencoderKLHunyuanVideo
|
||||
- decode
|
||||
- all
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
@@ -1,32 +0,0 @@
|
||||
<!-- Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License. -->
|
||||
|
||||
# AutoencoderKLHunyuanImage
|
||||
|
||||
The 2D variational autoencoder (VAE) model with KL loss used in [HunyuanImage2.1].
|
||||
|
||||
The model can be loaded with the following code snippet.
|
||||
|
||||
```python
|
||||
from diffusers import AutoencoderKLHunyuanImage
|
||||
|
||||
vae = AutoencoderKLHunyuanImage.from_pretrained("hunyuanvideo-community/HunyuanImage-2.1-Diffusers", subfolder="vae", torch_dtype=torch.bfloat16)
|
||||
```
|
||||
|
||||
## AutoencoderKLHunyuanImage
|
||||
|
||||
[[autodoc]] AutoencoderKLHunyuanImage
|
||||
- decode
|
||||
- all
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
@@ -1,32 +0,0 @@
|
||||
<!-- Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License. -->
|
||||
|
||||
# AutoencoderKLHunyuanImageRefiner
|
||||
|
||||
The 3D variational autoencoder (VAE) model with KL loss used in [HunyuanImage2.1](https://github.com/Tencent-Hunyuan/HunyuanImage-2.1) for its refiner pipeline.
|
||||
|
||||
The model can be loaded with the following code snippet.
|
||||
|
||||
```python
|
||||
from diffusers import AutoencoderKLHunyuanImageRefiner
|
||||
|
||||
vae = AutoencoderKLHunyuanImageRefiner.from_pretrained("hunyuanvideo-community/HunyuanImage-2.1-Refiner-Diffusers", subfolder="vae", torch_dtype=torch.bfloat16)
|
||||
```
|
||||
|
||||
## AutoencoderKLHunyuanImageRefiner
|
||||
|
||||
[[autodoc]] AutoencoderKLHunyuanImageRefiner
|
||||
- decode
|
||||
- all
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
@@ -1,32 +0,0 @@
|
||||
<!-- Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License. -->
|
||||
|
||||
# AutoencoderKLWan
|
||||
|
||||
The 3D variational autoencoder (VAE) model with KL loss used in [Wan 2.1](https://github.com/Wan-Video/Wan2.1) by the Alibaba Wan Team.
|
||||
|
||||
The model can be loaded with the following code snippet.
|
||||
|
||||
```python
|
||||
from diffusers import AutoencoderKLWan
|
||||
|
||||
vae = AutoencoderKLWan.from_pretrained("Wan-AI/Wan2.1-T2V-1.3B-Diffusers", subfolder="vae", torch_dtype=torch.float32)
|
||||
```
|
||||
|
||||
## AutoencoderKLWan
|
||||
|
||||
[[autodoc]] AutoencoderKLWan
|
||||
- decode
|
||||
- all
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
@@ -1,38 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# AutoencoderOobleck
|
||||
|
||||
The Oobleck variational autoencoder (VAE) model with KL loss was introduced in [Stability-AI/stable-audio-tools](https://github.com/Stability-AI/stable-audio-tools) and [Stable Audio Open](https://huggingface.co/papers/2407.14358) by Stability AI. The model is used in 🤗 Diffusers to encode audio waveforms into latents and to decode latent representations into audio waveforms.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*Open generative models are vitally important for the community, allowing for fine-tunes and serving as baselines when presenting new models. However, most current text-to-audio models are private and not accessible for artists and researchers to build upon. Here we describe the architecture and training process of a new open-weights text-to-audio model trained with Creative Commons data. Our evaluation shows that the model's performance is competitive with the state-of-the-art across various metrics. Notably, the reported FDopenl3 results (measuring the realism of the generations) showcase its potential for high-quality stereo sound synthesis at 44.1kHz.*
|
||||
|
||||
## AutoencoderOobleck
|
||||
|
||||
[[autodoc]] AutoencoderOobleck
|
||||
- decode
|
||||
- encode
|
||||
- all
|
||||
|
||||
## OobleckDecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_oobleck.OobleckDecoderOutput
|
||||
|
||||
## OobleckDecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_oobleck.OobleckDecoderOutput
|
||||
|
||||
## AutoencoderOobleckOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_oobleck.AutoencoderOobleckOutput
|
||||
@@ -1,57 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Tiny AutoEncoder
|
||||
|
||||
Tiny AutoEncoder for Stable Diffusion (TAESD) was introduced in [madebyollin/taesd](https://github.com/madebyollin/taesd) by Ollin Boer Bohan. It is a tiny distilled version of Stable Diffusion's VAE that can quickly decode the latents in a [`StableDiffusionPipeline`] or [`StableDiffusionXLPipeline`] almost instantly.
|
||||
|
||||
To use with Stable Diffusion v-2.1:
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline, AutoencoderTiny
|
||||
|
||||
pipe = DiffusionPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-2-1-base", torch_dtype=torch.float16
|
||||
)
|
||||
pipe.vae = AutoencoderTiny.from_pretrained("madebyollin/taesd", torch_dtype=torch.float16)
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "slice of delicious New York-style berry cheesecake"
|
||||
image = pipe(prompt, num_inference_steps=25).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
To use with Stable Diffusion XL 1.0
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import DiffusionPipeline, AutoencoderTiny
|
||||
|
||||
pipe = DiffusionPipeline.from_pretrained(
|
||||
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
|
||||
)
|
||||
pipe.vae = AutoencoderTiny.from_pretrained("madebyollin/taesdxl", torch_dtype=torch.float16)
|
||||
pipe = pipe.to("cuda")
|
||||
|
||||
prompt = "slice of delicious New York-style berry cheesecake"
|
||||
image = pipe(prompt, num_inference_steps=25).images[0]
|
||||
image
|
||||
```
|
||||
|
||||
## AutoencoderTiny
|
||||
|
||||
[[autodoc]] AutoencoderTiny
|
||||
|
||||
## AutoencoderTinyOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_tiny.AutoencoderTinyOutput
|
||||
@@ -1,46 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# AutoencoderKL
|
||||
|
||||
The variational autoencoder (VAE) model with KL loss was introduced in [Auto-Encoding Variational Bayes](https://huggingface.co/papers/1312.6114v11) by Diederik P. Kingma and Max Welling. The model is used in 🤗 Diffusers to encode images into latents and to decode latent representations into images.
|
||||
|
||||
The abstract from the paper is:
|
||||
|
||||
*How can we perform efficient inference and learning in directed probabilistic models, in the presence of continuous latent variables with intractable posterior distributions, and large datasets? We introduce a stochastic variational inference and learning algorithm that scales to large datasets and, under some mild differentiability conditions, even works in the intractable case. Our contributions are two-fold. First, we show that a reparameterization of the variational lower bound yields a lower bound estimator that can be straightforwardly optimized using standard stochastic gradient methods. Second, we show that for i.i.d. datasets with continuous latent variables per datapoint, posterior inference can be made especially efficient by fitting an approximate inference model (also called a recognition model) to the intractable posterior using the proposed lower bound estimator. Theoretical advantages are reflected in experimental results.*
|
||||
|
||||
## Loading from the original format
|
||||
|
||||
By default the [`AutoencoderKL`] should be loaded with [`~ModelMixin.from_pretrained`], but it can also be loaded
|
||||
from the original format using [`FromOriginalModelMixin.from_single_file`] as follows:
|
||||
|
||||
```py
|
||||
from diffusers import AutoencoderKL
|
||||
|
||||
url = "https://huggingface.co/stabilityai/sd-vae-ft-mse-original/blob/main/vae-ft-mse-840000-ema-pruned.safetensors" # can also be a local file
|
||||
model = AutoencoderKL.from_single_file(url)
|
||||
```
|
||||
|
||||
## AutoencoderKL
|
||||
|
||||
[[autodoc]] AutoencoderKL
|
||||
- decode
|
||||
- encode
|
||||
- all
|
||||
|
||||
## AutoencoderKLOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_kl.AutoencoderKLOutput
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
@@ -1,37 +0,0 @@
|
||||
<!-- Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License. -->
|
||||
|
||||
# AutoencoderKLAllegro
|
||||
|
||||
The 3D variational autoencoder (VAE) model with KL loss used in [Allegro](https://github.com/rhymes-ai/Allegro) was introduced in [Allegro: Open the Black Box of Commercial-Level Video Generation Model](https://huggingface.co/papers/2410.15458) by RhymesAI.
|
||||
|
||||
The model can be loaded with the following code snippet.
|
||||
|
||||
```python
|
||||
from diffusers import AutoencoderKLAllegro
|
||||
|
||||
vae = AutoencoderKLAllegro.from_pretrained("rhymes-ai/Allegro", subfolder="vae", torch_dtype=torch.float32).to("cuda")
|
||||
```
|
||||
|
||||
## AutoencoderKLAllegro
|
||||
|
||||
[[autodoc]] AutoencoderKLAllegro
|
||||
- decode
|
||||
- encode
|
||||
- all
|
||||
|
||||
## AutoencoderKLOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_kl.AutoencoderKLOutput
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
@@ -1,37 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License. -->
|
||||
|
||||
# AutoencoderKLCogVideoX
|
||||
|
||||
The 3D variational autoencoder (VAE) model with KL loss used in [CogVideoX](https://github.com/THUDM/CogVideo) was introduced in [CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer](https://github.com/THUDM/CogVideo/blob/main/resources/CogVideoX.pdf) by Tsinghua University & ZhipuAI.
|
||||
|
||||
The model can be loaded with the following code snippet.
|
||||
|
||||
```python
|
||||
from diffusers import AutoencoderKLCogVideoX
|
||||
|
||||
vae = AutoencoderKLCogVideoX.from_pretrained("THUDM/CogVideoX-2b", subfolder="vae", torch_dtype=torch.float16).to("cuda")
|
||||
```
|
||||
|
||||
## AutoencoderKLCogVideoX
|
||||
|
||||
[[autodoc]] AutoencoderKLCogVideoX
|
||||
- decode
|
||||
- encode
|
||||
- all
|
||||
|
||||
## AutoencoderKLOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_kl.AutoencoderKLOutput
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
@@ -1,40 +0,0 @@
|
||||
<!-- Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License. -->
|
||||
|
||||
# AutoencoderKLCosmos
|
||||
|
||||
[Cosmos Tokenizers](https://github.com/NVIDIA/Cosmos-Tokenizer).
|
||||
|
||||
Supported models:
|
||||
- [nvidia/Cosmos-1.0-Tokenizer-CV8x8x8](https://huggingface.co/nvidia/Cosmos-1.0-Tokenizer-CV8x8x8)
|
||||
|
||||
The model can be loaded with the following code snippet.
|
||||
|
||||
```python
|
||||
from diffusers import AutoencoderKLCosmos
|
||||
|
||||
vae = AutoencoderKLCosmos.from_pretrained("nvidia/Cosmos-1.0-Tokenizer-CV8x8x8", subfolder="vae")
|
||||
```
|
||||
|
||||
## AutoencoderKLCosmos
|
||||
|
||||
[[autodoc]] AutoencoderKLCosmos
|
||||
- decode
|
||||
- encode
|
||||
- all
|
||||
|
||||
## AutoencoderKLOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_kl.AutoencoderKLOutput
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
@@ -1,37 +0,0 @@
|
||||
<!-- Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License. -->
|
||||
|
||||
# AutoencoderKLLTXVideo
|
||||
|
||||
The 3D variational autoencoder (VAE) model with KL loss used in [LTX](https://huggingface.co/Lightricks/LTX-Video) was introduced by Lightricks.
|
||||
|
||||
The model can be loaded with the following code snippet.
|
||||
|
||||
```python
|
||||
from diffusers import AutoencoderKLLTXVideo
|
||||
|
||||
vae = AutoencoderKLLTXVideo.from_pretrained("Lightricks/LTX-Video", subfolder="vae", torch_dtype=torch.float32).to("cuda")
|
||||
```
|
||||
|
||||
## AutoencoderKLLTXVideo
|
||||
|
||||
[[autodoc]] AutoencoderKLLTXVideo
|
||||
- decode
|
||||
- encode
|
||||
- all
|
||||
|
||||
## AutoencoderKLOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_kl.AutoencoderKLOutput
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
@@ -1,37 +0,0 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License. -->
|
||||
|
||||
# AutoencoderKLMagvit
|
||||
|
||||
The 3D variational autoencoder (VAE) model with KL loss used in [EasyAnimate](https://github.com/aigc-apps/EasyAnimate) was introduced by Alibaba PAI.
|
||||
|
||||
The model can be loaded with the following code snippet.
|
||||
|
||||
```python
|
||||
from diffusers import AutoencoderKLMagvit
|
||||
|
||||
vae = AutoencoderKLMagvit.from_pretrained("alibaba-pai/EasyAnimateV5.1-12b-zh", subfolder="vae", torch_dtype=torch.float16).to("cuda")
|
||||
```
|
||||
|
||||
## AutoencoderKLMagvit
|
||||
|
||||
[[autodoc]] AutoencoderKLMagvit
|
||||
- decode
|
||||
- encode
|
||||
- all
|
||||
|
||||
## AutoencoderKLOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_kl.AutoencoderKLOutput
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
@@ -1,32 +0,0 @@
|
||||
<!-- Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License. -->
|
||||
|
||||
# AutoencoderKLMochi
|
||||
|
||||
The 3D variational autoencoder (VAE) model with KL loss used in [Mochi](https://github.com/genmoai/models) was introduced in [Mochi 1 Preview](https://huggingface.co/genmo/mochi-1-preview) by Tsinghua University & ZhipuAI.
|
||||
|
||||
The model can be loaded with the following code snippet.
|
||||
|
||||
```python
|
||||
from diffusers import AutoencoderKLMochi
|
||||
|
||||
vae = AutoencoderKLMochi.from_pretrained("genmo/mochi-1-preview", subfolder="vae", torch_dtype=torch.float32).to("cuda")
|
||||
```
|
||||
|
||||
## AutoencoderKLMochi
|
||||
|
||||
[[autodoc]] AutoencoderKLMochi
|
||||
- decode
|
||||
- all
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
@@ -1,35 +0,0 @@
|
||||
<!-- Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License. -->
|
||||
|
||||
# AutoencoderKLQwenImage
|
||||
|
||||
The model can be loaded with the following code snippet.
|
||||
|
||||
```python
|
||||
from diffusers import AutoencoderKLQwenImage
|
||||
|
||||
vae = AutoencoderKLQwenImage.from_pretrained("Qwen/QwenImage-20B", subfolder="vae")
|
||||
```
|
||||
|
||||
## AutoencoderKLQwenImage
|
||||
|
||||
[[autodoc]] AutoencoderKLQwenImage
|
||||
- decode
|
||||
- encode
|
||||
- all
|
||||
|
||||
## AutoencoderKLOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.autoencoder_kl.AutoencoderKLOutput
|
||||
|
||||
## DecoderOutput
|
||||
|
||||
[[autodoc]] models.autoencoders.vae.DecoderOutput
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user