mirror of
https://github.com/huggingface/diffusers.git
synced 2025-12-07 13:04:15 +08:00
Compare commits
181 Commits
migrate-lo
...
test-clean
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
de7cdf6287 | ||
|
|
73c5fe8bb1 | ||
|
|
595581d6ba | ||
|
|
d27b65411e | ||
|
|
cb9dca5523 | ||
|
|
79166dcb47 | ||
|
|
f95c320467 | ||
|
|
59abd9514b | ||
|
|
5f3ebef0d7 | ||
|
|
e6ffde2936 | ||
|
|
04171c7345 | ||
|
|
be5e10ae61 | ||
|
|
a2da0004ee | ||
|
|
863c7df543 | ||
|
|
e0083b29d5 | ||
|
|
6521f599b2 | ||
|
|
0fcce2acd8 | ||
|
|
ceeb3c1da3 | ||
|
|
0fcdd699cf | ||
|
|
5af003a9e1 | ||
|
|
179d6d958b | ||
|
|
229c4b355c | ||
|
|
0a4819a755 | ||
|
|
7cea9a3bb0 | ||
|
|
23de59e21a | ||
|
|
4f8b6f5a15 | ||
|
|
63e94cbc61 | ||
|
|
2c66fb3a85 | ||
|
|
284f827d6c | ||
|
|
b750c69859 | ||
|
|
13c51bb038 | ||
|
|
3e46c86a93 | ||
|
|
8cb5b084b5 | ||
|
|
13fe248152 | ||
|
|
2e2024152c | ||
|
|
1987c07899 | ||
|
|
4543d216ec | ||
|
|
b5db8aaa6f | ||
|
|
98ea5c9e86 | ||
|
|
f27fbceba1 | ||
|
|
4b12a60c93 | ||
|
|
abf28d55fb | ||
|
|
db4b54cfab | ||
|
|
0138e176ac | ||
|
|
bbd9340781 | ||
|
|
363737ec4b | ||
|
|
c5849ba9d5 | ||
|
|
f09b1ccfae | ||
|
|
285f877620 | ||
|
|
c75b88f86f | ||
|
|
b43e703fae | ||
|
|
9fae3828a7 | ||
|
|
3a3441cb45 | ||
|
|
fdd2bedae9 | ||
|
|
fedaa00bd5 | ||
|
|
8c680bc0b4 | ||
|
|
92b6b43805 | ||
|
|
49ea4d1bf5 | ||
|
|
58dbe0c29e | ||
|
|
9aaec5b9bc | ||
|
|
93760b1888 | ||
|
|
75540f42ee | ||
|
|
b543bcc661 | ||
|
|
885a596696 | ||
|
|
655512e2cf | ||
|
|
f63d62e091 | ||
|
|
7608d2eb9e | ||
|
|
449f299c63 | ||
|
|
84f4b27dfa | ||
|
|
9abac85f77 | ||
|
|
61772f0994 | ||
|
|
b92cda25e2 | ||
|
|
7492e331b4 | ||
|
|
ab6d63407a | ||
|
|
da4242d467 | ||
|
|
129d658da7 | ||
|
|
75e62385f5 | ||
|
|
a33206d22b | ||
|
|
a82e211f89 | ||
|
|
f3453f05ff | ||
|
|
c437ae72c6 | ||
|
|
9530245e17 | ||
|
|
74b908b7e2 | ||
|
|
7d2a633e02 | ||
|
|
cb328d3ff9 | ||
|
|
8c038f0e62 | ||
|
|
5917d7039f | ||
|
|
c0327e493e | ||
|
|
174628edf4 | ||
|
|
1c9f0a83c9 | ||
|
|
cdaaa40d31 | ||
|
|
ffbaa890ba | ||
|
|
e49413d87d | ||
|
|
48e4ff5c05 | ||
|
|
7c78fb1aad | ||
|
|
bb4044362e | ||
|
|
1ae591e817 | ||
|
|
42c06e90f4 | ||
|
|
085ade03be | ||
|
|
78d2454c7c | ||
|
|
19545fd3e1 | ||
|
|
d12531ddf7 | ||
|
|
4751d456f2 | ||
|
|
083479c365 | ||
|
|
04c16d0a56 | ||
|
|
9e58856b7a | ||
|
|
45392cce11 | ||
|
|
8913d59bf3 | ||
|
|
5a8c1b5f19 | ||
|
|
7ad01a6350 | ||
|
|
a8e853b791 | ||
|
|
6a509ba862 | ||
|
|
96795afc72 | ||
|
|
12650e1393 | ||
|
|
addaad013c | ||
|
|
485f8d1758 | ||
|
|
cff0fd6260 | ||
|
|
8ddb20bfb8 | ||
|
|
e5089d702b | ||
|
|
2c3e4eafa8 | ||
|
|
c7020df2cf | ||
|
|
4bed3e306e | ||
|
|
00a3bc9d6c | ||
|
|
ccb35acd81 | ||
|
|
00cae4e857 | ||
|
|
b3fb4188f5 | ||
|
|
71df1581f7 | ||
|
|
d046cf7d35 | ||
|
|
68a5185c86 | ||
|
|
6e2fe26bfd | ||
|
|
77b5fa59c5 | ||
|
|
a226920b52 | ||
|
|
7007f72409 | ||
|
|
a6804de4a2 | ||
|
|
7f897a9fc4 | ||
|
|
0966663d2a | ||
|
|
fb78f4f12d | ||
|
|
2220af6940 | ||
|
|
7a34832d52 | ||
|
|
e973de64f9 | ||
|
|
db94ca882d | ||
|
|
6985906a2e | ||
|
|
54f410db6c | ||
|
|
c12a05b9c1 | ||
|
|
2e0f5c86cc | ||
|
|
1d63306295 | ||
|
|
6c93626f6f | ||
|
|
72c5bf07c8 | ||
|
|
ed59f90f15 | ||
|
|
a09ca7f27e | ||
|
|
8c02572e16 | ||
|
|
27dde51de8 | ||
|
|
10d4a775f1 | ||
|
|
72d9a81d99 | ||
|
|
4fa85c7963 | ||
|
|
806e8e66fb | ||
|
|
0b90051db8 | ||
|
|
b305c779b2 | ||
|
|
2b3cd2d39c | ||
|
|
bc3d1c9ee6 | ||
|
|
e50d614636 | ||
|
|
a8df0f1ffb | ||
|
|
ace53e2d2f | ||
|
|
ffc2992fc2 | ||
|
|
c70a285c2c | ||
|
|
8b811feece | ||
|
|
37e8dc7a59 | ||
|
|
024a9f5de3 | ||
|
|
005195c23e | ||
|
|
6742f160df | ||
|
|
540d303250 | ||
|
|
f1b3036ca1 | ||
|
|
46ec1743a2 | ||
|
|
70272b1108 | ||
|
|
2b6dcbfa1d | ||
|
|
af9572d759 | ||
|
|
ddea157979 | ||
|
|
ad3f9a26c0 | ||
|
|
e8d0980f9f | ||
|
|
52a7f1cb97 | ||
|
|
33f85fadf6 |
2
.github/workflows/nightly_tests.yml
vendored
2
.github/workflows/nightly_tests.yml
vendored
@@ -248,7 +248,7 @@ jobs:
|
||||
BIG_GPU_MEMORY: 40
|
||||
run: |
|
||||
python -m pytest -n 1 --max-worker-restart=0 --dist=loadfile \
|
||||
-m "big_gpu_with_torch_cuda" \
|
||||
-m "big_accelerator" \
|
||||
--make-reports=tests_big_gpu_torch_cuda \
|
||||
--report-log=tests_big_gpu_torch_cuda.log \
|
||||
tests/
|
||||
|
||||
@@ -93,6 +93,16 @@
|
||||
- local: hybrid_inference/api_reference
|
||||
title: API Reference
|
||||
title: Hybrid Inference
|
||||
- sections:
|
||||
- local: modular_diffusers/getting_started
|
||||
title: Getting Started
|
||||
- local: modular_diffusers/components_manager
|
||||
title: Components Manager
|
||||
- local: modular_diffusers/write_own_pipeline_block
|
||||
title: Write your own pipeline block
|
||||
- local: modular_diffusers/end_to_end_guide
|
||||
title: End-to-End Developer Guide
|
||||
title: Modular Diffusers
|
||||
- sections:
|
||||
- local: using-diffusers/consisid
|
||||
title: ConsisID
|
||||
|
||||
@@ -28,3 +28,9 @@ Cache methods speedup diffusion transformers by storing and reusing intermediate
|
||||
[[autodoc]] FasterCacheConfig
|
||||
|
||||
[[autodoc]] apply_faster_cache
|
||||
|
||||
### FirstBlockCacheConfig
|
||||
|
||||
[[autodoc]] FirstBlockCacheConfig
|
||||
|
||||
[[autodoc]] apply_first_block_cache
|
||||
|
||||
510
docs/source/en/modular_diffusers/components_manager.md
Normal file
510
docs/source/en/modular_diffusers/components_manager.md
Normal file
@@ -0,0 +1,510 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Components Manager
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
🧪 **Experimental Feature**: This is an experimental feature we are actively developing. The API may be subject to breaking changes.
|
||||
|
||||
</Tip>
|
||||
|
||||
The Components Manager is a central model registry and management system in diffusers. It lets you add models then reuse them across multiple pipelines and workflows. It tracks all models in one place with useful metadata such as model size, device placement and loaded adapters (LoRA, IP-Adapter). It has mechanisms in place to prevent duplicate model instances, enables memory-efficient sharing. Most significantly, it offers offloading that works across pipelines — unlike regular DiffusionPipeline offloading which is limited to one pipeline with predefined sequences, the Components Manager automatically manages your device memory across all your models and workflows.
|
||||
|
||||
|
||||
## Basic Operations
|
||||
|
||||
Let's start with the fundamental operations. First, create a Components Manager:
|
||||
|
||||
```py
|
||||
from diffusers import ComponentsManager
|
||||
comp = ComponentsManager()
|
||||
```
|
||||
|
||||
Use the `add(name, component)` method to register a component. It returns a unique ID that combines the component name with the object's unique identifier (using Python's `id()` function):
|
||||
|
||||
```py
|
||||
from diffusers import AutoModel
|
||||
text_encoder = AutoModel.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", subfolder="text_encoder")
|
||||
# Returns component_id like 'text_encoder_139917733042864'
|
||||
component_id = comp.add("text_encoder", text_encoder)
|
||||
```
|
||||
|
||||
You can view all registered components and their metadata:
|
||||
|
||||
```py
|
||||
>>> comp
|
||||
Components:
|
||||
===============================================================================================================================================
|
||||
Models:
|
||||
-----------------------------------------------------------------------------------------------------------------------------------------------
|
||||
Name_ID | Class | Device: act(exec) | Dtype | Size (GB) | Load ID | Collection
|
||||
-----------------------------------------------------------------------------------------------------------------------------------------------
|
||||
text_encoder_139917733042864 | CLIPTextModel | cpu | torch.float32 | 0.46 | N/A | N/A
|
||||
-----------------------------------------------------------------------------------------------------------------------------------------------
|
||||
|
||||
Additional Component Info:
|
||||
==================================================
|
||||
```
|
||||
|
||||
And remove components using their unique ID:
|
||||
|
||||
```py
|
||||
comp.remove("text_encoder_139917733042864")
|
||||
```
|
||||
|
||||
## Duplicate Detection
|
||||
|
||||
The Components Manager automatically detects and prevents duplicate model instances to save memory and avoid confusion. Let's walk through how this works in practice.
|
||||
|
||||
When you try to add the same object twice, the manager will warn you and return the existing ID:
|
||||
|
||||
```py
|
||||
>>> comp.add("text_encoder", text_encoder)
|
||||
'text_encoder_139917733042864'
|
||||
>>> comp.add("text_encoder", text_encoder)
|
||||
ComponentsManager: component 'text_encoder' already exists as 'text_encoder_139917733042864'
|
||||
'text_encoder_139917733042864'
|
||||
```
|
||||
|
||||
Even if you add the same object under a different name, it will still be detected as a duplicate:
|
||||
|
||||
```py
|
||||
>>> comp.add("clip", text_encoder)
|
||||
ComponentsManager: adding component 'clip' as 'clip_139917733042864', but it is duplicate of 'text_encoder_139917733042864'
|
||||
To remove a duplicate, call `components_manager.remove('<component_id>')`.
|
||||
'clip_139917733042864'
|
||||
```
|
||||
|
||||
However, there's a more subtle case where duplicate detection becomes tricky. When you load the same model into different objects, the manager can't detect duplicates unless you use `ComponentSpec`. For example:
|
||||
|
||||
```py
|
||||
>>> text_encoder_2 = AutoModel.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", subfolder="text_encoder")
|
||||
>>> comp.add("text_encoder", text_encoder_2)
|
||||
'text_encoder_139917732983664'
|
||||
```
|
||||
|
||||
This creates a problem - you now have two copies of the same model consuming double the memory:
|
||||
|
||||
```py
|
||||
>>> comp
|
||||
Components:
|
||||
===============================================================================================================================================
|
||||
Models:
|
||||
-----------------------------------------------------------------------------------------------------------------------------------------------
|
||||
Name_ID | Class | Device: act(exec) | Dtype | Size (GB) | Load ID | Collection
|
||||
-----------------------------------------------------------------------------------------------------------------------------------------------
|
||||
text_encoder_139917733042864 | CLIPTextModel | cpu | torch.float32 | 0.46 | N/A | N/A
|
||||
clip_139917733042864 | CLIPTextModel | cpu | torch.float32 | 0.46 | N/A | N/A
|
||||
text_encoder_139917732983664 | CLIPTextModel | cpu | torch.float32 | 0.46 | N/A | N/A
|
||||
-----------------------------------------------------------------------------------------------------------------------------------------------
|
||||
|
||||
Additional Component Info:
|
||||
==================================================
|
||||
```
|
||||
|
||||
We recommend using `ComponentSpec` to load your models. Models loaded with `ComponentSpec` get tagged with a unique ID that encodes their loading parameters, allowing the Components Manager to detect when different objects represent the same underlying checkpoint:
|
||||
|
||||
```py
|
||||
from diffusers import ComponentSpec, ComponentsManager
|
||||
from transformers import CLIPTextModel
|
||||
comp = ComponentsManager()
|
||||
|
||||
# Create ComponentSpec for the first text encoder
|
||||
spec = ComponentSpec(name="text_encoder", repo="stabilityai/stable-diffusion-xl-base-1.0", subfolder="text_encoder", type_hint=AutoModel)
|
||||
# Create ComponentSpec for a duplicate text encoder (it is same checkpoint, from same repo/subfolder)
|
||||
spec_duplicated = ComponentSpec(name="text_encoder_duplicated", repo="stabilityai/stable-diffusion-xl-base-1.0", subfolder="text_encoder", type_hint=CLIPTextModel)
|
||||
|
||||
# Load and add both components - the manager will detect they're the same model
|
||||
comp.add("text_encoder", spec.load())
|
||||
comp.add("text_encoder_duplicated", spec_duplicated.load())
|
||||
```
|
||||
|
||||
Now the manager detects the duplicate and warns you:
|
||||
|
||||
```out
|
||||
ComponentsManager: adding component 'text_encoder_duplicated_139917580682672', but it has duplicate load_id 'stabilityai/stable-diffusion-xl-base-1.0|text_encoder|null|null' with existing components: text_encoder_139918506246832. To remove a duplicate, call `components_manager.remove('<component_id>')`.
|
||||
'text_encoder_duplicated_139917580682672'
|
||||
```
|
||||
|
||||
Both models now show the same `load_id`, making it clear they're the same model:
|
||||
|
||||
```py
|
||||
>>> comp
|
||||
Components:
|
||||
======================================================================================================================================================================================================
|
||||
Models:
|
||||
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
Name_ID | Class | Device: act(exec) | Dtype | Size (GB) | Load ID | Collection
|
||||
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
text_encoder_139918506246832 | CLIPTextModel | cpu | torch.float32 | 0.46 | stabilityai/stable-diffusion-xl-base-1.0|text_encoder|null|null | N/A
|
||||
text_encoder_duplicated_139917580682672 | CLIPTextModel | cpu | torch.float32 | 0.46 | stabilityai/stable-diffusion-xl-base-1.0|text_encoder|null|null | N/A
|
||||
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
|
||||
Additional Component Info:
|
||||
==================================================
|
||||
```
|
||||
|
||||
## Collections
|
||||
|
||||
Collections are labels you can assign to components for better organization and management. You add a component under a collection by passing the `collection=` parameter when you add the component to the manager, i.e. `add(name, component, collection=...)`. Within each collection, only one component per name is allowed - if you add a second component with the same name, the first one is automatically removed.
|
||||
|
||||
Here's how collections work in practice:
|
||||
|
||||
```py
|
||||
comp = ComponentsManager()
|
||||
# Create ComponentSpec for the first UNet (SDXL base)
|
||||
spec = ComponentSpec(name="unet", repo="stabilityai/stable-diffusion-xl-base-1.0", subfolder="unet", type_hint=AutoModel)
|
||||
# Create ComponentSpec for a different UNet (Juggernaut-XL)
|
||||
spec2 = ComponentSpec(name="unet", repo="RunDiffusion/Juggernaut-XL-v9", subfolder="unet", type_hint=AutoModel, variant="fp16")
|
||||
|
||||
# Add both UNets to the same collection - the second one will replace the first
|
||||
comp.add("unet", spec.load(), collection="sdxl")
|
||||
comp.add("unet", spec2.load(), collection="sdxl")
|
||||
```
|
||||
|
||||
The manager automatically removes the old UNet and adds the new one:
|
||||
|
||||
```out
|
||||
ComponentsManager: removing existing unet from collection 'sdxl': unet_139917723891888
|
||||
'unet_139917723893136'
|
||||
```
|
||||
|
||||
Only one UNet remains in the collection:
|
||||
|
||||
```py
|
||||
>>> comp
|
||||
Components:
|
||||
====================================================================================================================================================================
|
||||
Models:
|
||||
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
Name_ID | Class | Device: act(exec) | Dtype | Size (GB) | Load ID | Collection
|
||||
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
unet_139917723893136 | UNet2DConditionModel | cpu | torch.float32 | 9.56 | RunDiffusion/Juggernaut-XL-v9|unet|fp16|null | sdxl
|
||||
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
|
||||
Additional Component Info:
|
||||
==================================================
|
||||
```
|
||||
|
||||
For example, in node-based systems, you can mark all models loaded from one node with the same collection label, automatically replace models when user loads new checkpoints under same name, batch delete all models in a collection when a node is removed.
|
||||
|
||||
## Retrieving Components
|
||||
|
||||
The Components Manager provides several methods to retrieve registered components.
|
||||
|
||||
The `get_one()` method returns a single component and supports pattern matching for the `name` parameter. You can use:
|
||||
- exact matches like `comp.get_one(name="unet")`
|
||||
- wildcards like `comp.get_one(name="unet*")` for components starting with "unet"
|
||||
- exclusion patterns like `comp.get_one(name="!unet")` to exclude components named "unet"
|
||||
- OR patterns like `comp.get_one(name="unet|vae")` to match either "unet" OR "vae".
|
||||
|
||||
You can also filter by collection with `comp.get_one(name="unet", collection="sdxl")` or by load_id. If multiple components match, `get_one()` throws an error.
|
||||
|
||||
Another useful method is `get_components_by_names()`, which takes a list of names and returns a dictionary mapping names to components. This is particularly helpful with modular pipelines since they provide lists of required component names, and the returned dictionary can be directly passed to `pipeline.update_components()`.
|
||||
|
||||
```py
|
||||
# Get components by name list
|
||||
component_dict = comp.get_components_by_names(names=["text_encoder", "unet", "vae"])
|
||||
# Returns: {"text_encoder": component1, "unet": component2, "vae": component3}
|
||||
```
|
||||
|
||||
## Using Components Manager with Modular Pipelines
|
||||
|
||||
The Components Manager integrates seamlessly with Modular Pipelines. All you need to do is pass a Components Manager instance to `from_pretrained()` or `init_pipeline()` with an optional `collection` parameter:
|
||||
|
||||
```py
|
||||
from diffusers import ModularPipeline, ComponentsManager
|
||||
comp = ComponentsManager()
|
||||
pipe = ModularPipeline.from_pretrained("YiYiXu/modular-demo-auto", components_manager=comp, collection="test1")
|
||||
```
|
||||
|
||||
By default, modular pipelines don't load components immediately, so both the pipeline and Components Manager start empty:
|
||||
|
||||
```py
|
||||
>>> comp
|
||||
Components:
|
||||
==================================================
|
||||
No components registered.
|
||||
==================================================
|
||||
```
|
||||
|
||||
When you load components on the pipeline, they are automatically registered in the Components Manager:
|
||||
|
||||
```py
|
||||
>>> pipe.load_components(names="unet")
|
||||
>>> comp
|
||||
Components:
|
||||
==============================================================================================================================================================
|
||||
Models:
|
||||
--------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
Name_ID | Class | Device: act(exec) | Dtype | Size (GB) | Load ID | Collection
|
||||
--------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
unet_139917726686304 | UNet2DConditionModel | cpu | torch.float32 | 9.56 | SG161222/RealVisXL_V4.0|unet|null|null | test1
|
||||
--------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
|
||||
Additional Component Info:
|
||||
==================================================
|
||||
```
|
||||
|
||||
Now let's load all default components and then create a second pipeline that reuses all components from the first one. We pass the same Components Manager to the second pipeline but with a different collection:
|
||||
|
||||
```py
|
||||
# Load all default components
|
||||
>>> pipe.load_default_components()`
|
||||
|
||||
# Create a second pipeline using the same Components Manager but with a different collection
|
||||
>>> pipe2 = ModularPipeline.from_pretrained("YiYiXu/modular-demo-auto", components_manager=comp, collection="test2")
|
||||
```
|
||||
|
||||
As mentioned earlier, `ModularPipeline` has a property `null_component_names` that returns a list of component names it needs to load. We can conveniently use this list with the `get_components_by_names` method on the Components Manager:
|
||||
|
||||
```py
|
||||
# Get the list of components that pipe2 needs to load
|
||||
>>> pipe2.null_component_names
|
||||
['text_encoder', 'text_encoder_2', 'tokenizer', 'tokenizer_2', 'image_encoder', 'unet', 'vae', 'scheduler', 'controlnet']
|
||||
|
||||
# Retrieve all required components from the Components Manager
|
||||
>>> comp_dict = comp.get_components_by_names(names=pipe2.null_component_names)
|
||||
|
||||
# Update the pipeline with the retrieved components
|
||||
>>> pipe2.update_components(**comp_dict)
|
||||
```
|
||||
|
||||
The warnings that follow are expected and indicate that the Components Manager is correctly identifying that these components already exist and will be reused rather than creating duplicates:
|
||||
|
||||
```
|
||||
ComponentsManager: component 'text_encoder' already exists as 'text_encoder_139917586016400'
|
||||
ComponentsManager: component 'text_encoder_2' already exists as 'text_encoder_2_139917699973424'
|
||||
ComponentsManager: component 'tokenizer' already exists as 'tokenizer_139917580599504'
|
||||
ComponentsManager: component 'tokenizer_2' already exists as 'tokenizer_2_139915763443904'
|
||||
ComponentsManager: component 'image_encoder' already exists as 'image_encoder_139917722468304'
|
||||
ComponentsManager: component 'unet' already exists as 'unet_139917580609632'
|
||||
ComponentsManager: component 'vae' already exists as 'vae_139917722459040'
|
||||
ComponentsManager: component 'scheduler' already exists as 'scheduler_139916266559408'
|
||||
ComponentsManager: component 'controlnet' already exists as 'controlnet_139917722454432'
|
||||
```
|
||||
```
|
||||
|
||||
The pipeline is now fully loaded:
|
||||
|
||||
```py
|
||||
# null_component_names return empty list, meaning everything are loaded
|
||||
>>> pipe2.null_component_names
|
||||
[]
|
||||
```
|
||||
|
||||
No new components were added to the Components Manager - we're reusing everything. All models are now associated with both `test1` and `test2` collections, showing that these components are shared across multiple pipelines:
|
||||
```py
|
||||
>>> comp
|
||||
Components:
|
||||
========================================================================================================================================================================================
|
||||
Models:
|
||||
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
Name_ID | Class | Device: act(exec) | Dtype | Size (GB) | Load ID | Collection
|
||||
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
text_encoder_139917586016400 | CLIPTextModel | cpu | torch.float32 | 0.46 | SG161222/RealVisXL_V4.0|text_encoder|null|null | test1
|
||||
| | | | | | test2
|
||||
text_encoder_2_139917699973424 | CLIPTextModelWithProjection | cpu | torch.float32 | 2.59 | SG161222/RealVisXL_V4.0|text_encoder_2|null|null | test1
|
||||
| | | | | | test2
|
||||
unet_139917580609632 | UNet2DConditionModel | cpu | torch.float32 | 9.56 | SG161222/RealVisXL_V4.0|unet|null|null | test1
|
||||
| | | | | | test2
|
||||
controlnet_139917722454432 | ControlNetModel | cpu | torch.float32 | 4.66 | diffusers/controlnet-canny-sdxl-1.0|null|null|null | test1
|
||||
| | | | | | test2
|
||||
vae_139917722459040 | AutoencoderKL | cpu | torch.float32 | 0.31 | SG161222/RealVisXL_V4.0|vae|null|null | test1
|
||||
| | | | | | test2
|
||||
image_encoder_139917722468304 | CLIPVisionModelWithProjection | cpu | torch.float32 | 6.87 | h94/IP-Adapter|sdxl_models/image_encoder|null|null | test1
|
||||
| | | | | | test2
|
||||
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
|
||||
Other Components:
|
||||
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
ID | Class | Collection
|
||||
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
tokenizer_139917580599504 | CLIPTokenizer | test1
|
||||
| | test2
|
||||
scheduler_139916266559408 | EulerDiscreteScheduler | test1
|
||||
| | test2
|
||||
tokenizer_2_139915763443904 | CLIPTokenizer | test1
|
||||
| | test2
|
||||
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
|
||||
Additional Component Info:
|
||||
==================================================
|
||||
```
|
||||
|
||||
|
||||
## Automatic Memory Management
|
||||
|
||||
The Components Manager provides a global offloading strategy across all models, regardless of which pipeline is using them:
|
||||
|
||||
```py
|
||||
comp.enable_auto_cpu_offload(device="cuda")
|
||||
```
|
||||
|
||||
When enabled, all models start on CPU. The manager moves models to the device right before they're used and moves other models back to CPU when GPU memory runs low. You can set your own rules for which models to offload first. This works smoothly as you add or remove components. Once it's on, you don't need to worry about device placement - you can focus on your workflow.
|
||||
|
||||
|
||||
|
||||
## Practical Example: Building Modular Workflows with Component Reuse
|
||||
|
||||
Now that we've covered the basics of the Components Manager, let's walk through a practical example that shows how to build workflows in a modular setting and use the Components Manager to reuse components across multiple pipelines. This example demonstrates the true power of Modular Diffusers by working with multiple pipelines that can share components.
|
||||
|
||||
In this example, we'll generate latents from a text-to-image pipeline, then refine them with an image-to-image pipeline. We will also use Lora and IP-Adapter.
|
||||
|
||||
Let's create a modular text-to-image workflow by separating it into three components: `text_blocks` for encoding prompts, `t2i_blocks` for generating latents, and `decoder_blocks` for creating final images.
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers.modular_pipelines import SequentialPipelineBlocks
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl import ALL_BLOCKS
|
||||
|
||||
# Create modular blocks and separate text encoding and decoding steps
|
||||
t2i_blocks = SequentialPipelineBlocks.from_blocks_dict(ALL_BLOCKS["text2img"])
|
||||
text_blocks = t2i_blocks.sub_blocks.pop("text_encoder")
|
||||
decoder_blocks = t2i_blocks.sub_blocks.pop("decode")
|
||||
```
|
||||
|
||||
Now we will convert them into runnalbe pipelines and set up the Components Manager with auto offloading and organize components under a "t2i" collection:
|
||||
|
||||
```py
|
||||
from diffusers import ComponentsManager, ModularPipeline
|
||||
|
||||
# Set up Components Manager with auto offloading
|
||||
components = ComponentsManager()
|
||||
components.enable_auto_cpu_offload(device="cuda")
|
||||
|
||||
# Create pipelines and load components
|
||||
t2i_repo = "YiYiXu/modular-demo-auto"
|
||||
t2i_loader_pipe = ModularPipeline.from_pretrained(t2i_repo, components_manager=components, collection="t2i")
|
||||
|
||||
text_node = text_blocks.init_pipeline(t2i_repo, components_manager=components)
|
||||
decoder_node = decoder_blocks.init_pipeline(t2i_repo, components_manager=components)
|
||||
t2i_pipe = t2i_blocks.init_pipeline(t2i_repo, components_manager=components)
|
||||
```
|
||||
|
||||
Load all components into the Components Manager under the "t2i" collection:
|
||||
|
||||
```py
|
||||
# Load all components (including IP-Adapter and ControlNet for later use)
|
||||
t2i_loader_pipe.load_components(names=t2i_loader_pipe.pretrained_component_names, torch_dtype=torch.float16)
|
||||
```
|
||||
|
||||
Now distribute the loaded components to each pipeline:
|
||||
|
||||
```py
|
||||
# Get VAE for decoder (using get_one since there's only one)
|
||||
vae = components.get_one(load_id="SG161222/RealVisXL_V4.0|vae|null|null")
|
||||
decoder_node.update_components(vae=vae)
|
||||
|
||||
# Get text components for text node (using get_components_by_names for multiple components)
|
||||
text_components = components.get_components_by_names(text_node.null_component_names)
|
||||
text_node.update_components(**text_components)
|
||||
|
||||
# Get remaining components for t2i pipeline
|
||||
t2i_components = components.get_components_by_names(t2i_pipe.null_component_names)
|
||||
t2i_pipe.update_components(**t2i_components)
|
||||
```
|
||||
|
||||
Now we can generate images using our modular workflow:
|
||||
|
||||
```py
|
||||
# Generate text embeddings
|
||||
prompt = "an astronaut"
|
||||
text_embeddings = text_node(prompt=prompt, output=["prompt_embeds","negative_prompt_embeds", "pooled_prompt_embeds", "negative_pooled_prompt_embeds"])
|
||||
|
||||
# Generate latents and decode to image
|
||||
generator = torch.Generator(device="cuda").manual_seed(0)
|
||||
latents_t2i = t2i_pipe(**text_embeddings, num_inference_steps=25, generator=generator, output="latents")
|
||||
image = decoder_node(latents=latents_t2i, output="images")[0]
|
||||
image.save("modular_part2_t2i.png")
|
||||
```
|
||||
|
||||
Let's add a LoRA:
|
||||
|
||||
```py
|
||||
# Load LoRA weights - only the UNet gets the adapter
|
||||
>>> t2i_loader_pipe.load_lora_weights("CiroN2022/toy-face", weight_name="toy_face_sdxl.safetensors", adapter_name="toy_face")
|
||||
>>> components
|
||||
Components:
|
||||
============================================================================================================================================================
|
||||
...
|
||||
Additional Component Info:
|
||||
==================================================
|
||||
|
||||
unet:
|
||||
Adapters: ['toy_face']
|
||||
```
|
||||
|
||||
You can see that the Components Manager tracks adapters metadata for all models it manages, and in our case, only Unet has lora loaded. This means we can reuse existing text embeddings.
|
||||
|
||||
```py
|
||||
# Generate with LoRA (reusing existing text embeddings)
|
||||
generator = torch.Generator(device="cuda").manual_seed(0)
|
||||
latents_lora = t2i_pipe(**text_embeddings, num_inference_steps=25, generator=generator, output="latents")
|
||||
image = decoder_node(latents=latents_lora, output="images")[0]
|
||||
image.save("modular_part2_lora.png")
|
||||
```
|
||||
|
||||
|
||||
Now let's create a refiner pipeline that reuses components from our text-to-image workflow:
|
||||
|
||||
```py
|
||||
# Create refiner blocks (removing image_encoder and decode since we work with latents)
|
||||
refiner_blocks = SequentialPipelineBlocks.from_blocks_dict(ALL_BLOCKS["img2img"])
|
||||
refiner_blocks.sub_blocks.pop("image_encoder")
|
||||
refiner_blocks.sub_blocks.pop("decode")
|
||||
|
||||
# Create refiner pipeline with different repo and collection
|
||||
refiner_repo = "YiYiXu/modular_refiner"
|
||||
refiner_pipe = refiner_blocks.init_pipeline(refiner_repo, components_manager=components, collection="refiner")
|
||||
```
|
||||
|
||||
We pass the **same Components Manager** (`components`) to the refiner pipeline, but with a **different collection** (`"refiner"`). This allows the refiner to access and reuse components from the "t2i" collection while organizing its own components (like the refiner UNet) under the "refiner" collection.
|
||||
|
||||
```py
|
||||
# Load only the refiner UNet (different from t2i UNet)
|
||||
refiner_pipe.load_components(names="unet", torch_dtype=torch.float16)
|
||||
|
||||
# Reuse components from t2i pipeline using pattern matching
|
||||
reuse_components = components.search_components("text_encoder_2|scheduler|vae|tokenizer_2")
|
||||
refiner_pipe.update_components(**reuse_components)
|
||||
```
|
||||
|
||||
When we reuse components from the "t2i" collection, they automatically get added to the "refiner" collection as well. You can verify this by checking the Components Manager - you'll see components like `vae`, `scheduler`, etc. listed under both collections, indicating they're shared between workflows.
|
||||
|
||||
Now we can refine any of our generated latents:
|
||||
|
||||
```py
|
||||
# Refine all our different latents
|
||||
refined_latents = refiner_pipe(image_latents=latents_t2i, prompt=prompt, num_inference_steps=10, output="latents")
|
||||
refined_image = decoder_node(latents=refined_latents, output="images")[0]
|
||||
refined_image.save("modular_part2_t2i_refine_out.png")
|
||||
|
||||
refined_latents = refiner_pipe(image_latents=latents_lora, prompt=prompt, num_inference_steps=10, output="latents")
|
||||
refined_image = decoder_node(latents=refined_latents, output="images")[0]
|
||||
refined_image.save("modular_part2_lora_refine_out.png")
|
||||
```
|
||||
|
||||
|
||||
Here are the results from our modular pipeline examples.
|
||||
|
||||
#### Base Text-to-Image Generation
|
||||
| Base Text-to-Image | Base Text-to-Image (Refined) |
|
||||
|-------------------|------------------------------|
|
||||
|  |  |
|
||||
|
||||
#### LoRA
|
||||
| LoRA | LoRA (Refined) |
|
||||
|-------------------|------------------------------|
|
||||
|  |  |
|
||||
|
||||
648
docs/source/en/modular_diffusers/end_to_end_guide.md
Normal file
648
docs/source/en/modular_diffusers/end_to_end_guide.md
Normal file
@@ -0,0 +1,648 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# End-to-End Developer Guide: Building with Modular Diffusers
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
🧪 **Experimental Feature**: Modular Diffusers is an experimental feature we are actively developing. The API may be subject to breaking changes.
|
||||
|
||||
</Tip>
|
||||
|
||||
|
||||
In this tutorial we will walk through the process of adding a new pipeline to the modular framework using differential diffusion as our example. We'll cover the complete workflow from implementation to deployment: implementing the new pipeline, ensuring compatibility with existing tools, sharing the code on Hugging Face Hub, and deploying it as a UI node.
|
||||
|
||||
We'll also demonstrate the 4-step framework process we use for implementing new basic pipelines in the modular system.
|
||||
|
||||
1. **Start with an existing pipeline as a base**
|
||||
- Identify which existing pipeline is most similar to the one you want to implement
|
||||
- Determine what part of the pipeline needs modification
|
||||
|
||||
2. **Build a working pipeline structure first**
|
||||
- Assemble the complete pipeline structure
|
||||
- Use existing blocks wherever possible
|
||||
- For new blocks, create placeholders (e.g. you can copy from similar blocks and change the name) without implementing custom logic just yet
|
||||
|
||||
3. **Set up an example**
|
||||
- Create a simple inference script with expected inputs/outputs
|
||||
|
||||
4. **Implement your custom logic and test incrementally**
|
||||
- Add the custom logics the blocks you want to change
|
||||
- Test incrementally, and inspect pipeline states and debug as needed
|
||||
|
||||
Let's see how this works with the Differential Diffusion example.
|
||||
|
||||
|
||||
## Differential Diffusion Pipeline
|
||||
|
||||
### Start with an existing pipeline
|
||||
|
||||
Differential diffusion (https://differential-diffusion.github.io/) is an image-to-image workflow, so it makes sense for us to start with the preset of pipeline blocks used to build img2img pipeline (`IMAGE2IMAGE_BLOCKS`) and see how we can build this new pipeline with them.
|
||||
|
||||
```py
|
||||
>>> from diffusers.modular_pipelines.stable_diffusion_xl import IMAGE2IMAGE_BLOCKS
|
||||
>>> IMAGE2IMAGE_BLOCKS = InsertableDict([
|
||||
... ("text_encoder", StableDiffusionXLTextEncoderStep),
|
||||
... ("image_encoder", StableDiffusionXLVaeEncoderStep),
|
||||
... ("input", StableDiffusionXLInputStep),
|
||||
... ("set_timesteps", StableDiffusionXLImg2ImgSetTimestepsStep),
|
||||
... ("prepare_latents", StableDiffusionXLImg2ImgPrepareLatentsStep),
|
||||
... ("prepare_add_cond", StableDiffusionXLImg2ImgPrepareAdditionalConditioningStep),
|
||||
... ("denoise", StableDiffusionXLDenoiseStep),
|
||||
... ("decode", StableDiffusionXLDecodeStep)
|
||||
... ])
|
||||
```
|
||||
|
||||
Note that "denoise" (`StableDiffusionXLDenoiseStep`) is a `LoopSequentialPipelineBlocks` that contains 3 loop blocks (more on LoopSequentialPipelineBlocks [here](https://huggingface.co/docs/diffusers/modular_diffusers/write_own_pipeline_block#loopsequentialpipelineblocks))
|
||||
|
||||
```py
|
||||
>>> denoise_blocks = IMAGE2IMAGE_BLOCKS["denoise"]()
|
||||
>>> print(denoise_blocks)
|
||||
```
|
||||
|
||||
```out
|
||||
StableDiffusionXLDenoiseStep(
|
||||
Class: StableDiffusionXLDenoiseLoopWrapper
|
||||
|
||||
Description: Denoise step that iteratively denoise the latents.
|
||||
Its loop logic is defined in `StableDiffusionXLDenoiseLoopWrapper.__call__` method
|
||||
At each iteration, it runs blocks defined in `sub_blocks` sequencially:
|
||||
- `StableDiffusionXLLoopBeforeDenoiser`
|
||||
- `StableDiffusionXLLoopDenoiser`
|
||||
- `StableDiffusionXLLoopAfterDenoiser`
|
||||
This block supports both text2img and img2img tasks.
|
||||
|
||||
|
||||
Components:
|
||||
scheduler (`EulerDiscreteScheduler`)
|
||||
guider (`ClassifierFreeGuidance`)
|
||||
unet (`UNet2DConditionModel`)
|
||||
|
||||
Sub-Blocks:
|
||||
[0] before_denoiser (StableDiffusionXLLoopBeforeDenoiser)
|
||||
Description: step within the denoising loop that prepare the latent input for the denoiser. This block should be used to compose the `sub_blocks` attribute of a `LoopSequentialPipelineBlocks` object (e.g. `StableDiffusionXLDenoiseLoopWrapper`)
|
||||
|
||||
[1] denoiser (StableDiffusionXLLoopDenoiser)
|
||||
Description: Step within the denoising loop that denoise the latents with guidance. This block should be used to compose the `sub_blocks` attribute of a `LoopSequentialPipelineBlocks` object (e.g. `StableDiffusionXLDenoiseLoopWrapper`)
|
||||
|
||||
[2] after_denoiser (StableDiffusionXLLoopAfterDenoiser)
|
||||
Description: step within the denoising loop that update the latents. This block should be used to compose the `sub_blocks` attribute of a `LoopSequentialPipelineBlocks` object (e.g. `StableDiffusionXLDenoiseLoopWrapper`)
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
Let's compare standard image-to-image and differential diffusion! The key difference in algorithm is that standard image-to-image diffusion applies uniform noise across all pixels based on a single `strength` parameter, but differential diffusion uses a change map where each pixel value determines when that region starts denoising. Regions with lower values get "frozen" earlier by replacing them with noised original latents, preserving more of the original image.
|
||||
|
||||
Therefore, the key differences when it comes to pipeline implementation would be:
|
||||
1. The `prepare_latents` step (which prepares the change map and pre-computes noised latents for all timesteps)
|
||||
2. The `denoise` step (which selectively applies denoising based on the change map)
|
||||
3. Since differential diffusion doesn't use the `strength` parameter, we'll use the text-to-image `set_timesteps` step instead of the image-to-image version
|
||||
|
||||
To implement differntial diffusion, we can reuse most blocks from image-to-image and text-to-image workflows, only modifying the `prepare_latents` step and the first part of the `denoise` step (i.e. `before_denoiser (StableDiffusionXLLoopBeforeDenoiser)`).
|
||||
|
||||
Here's a flowchart showing the pipeline structure and the changes we need to make:
|
||||
|
||||
|
||||
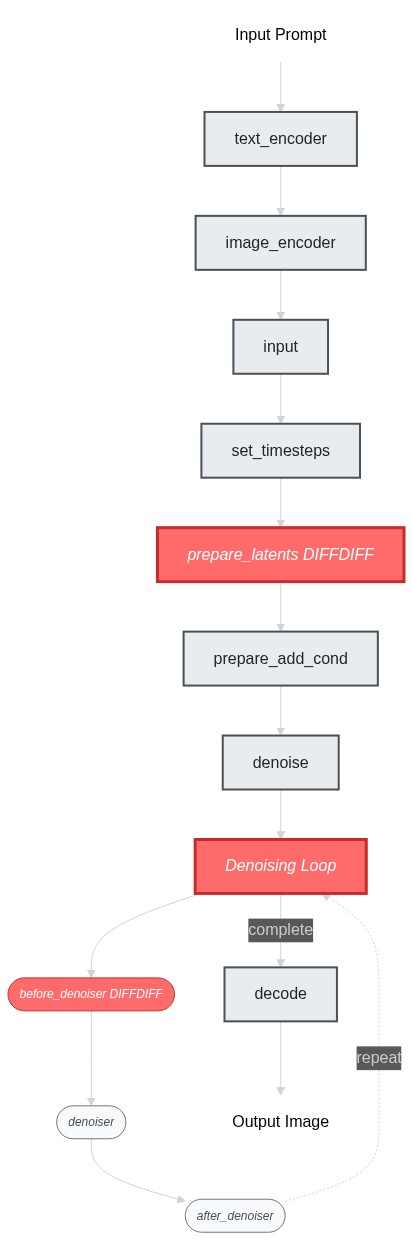
|
||||
|
||||
|
||||
### Build a Working Pipeline Structure
|
||||
|
||||
ok now we've identified the blocks to modify, let's build the pipeline skeleton first - at this stage, our goal is to get the pipeline struture working end-to-end (even though it's just doing the img2img behavior). I would simply create placeholder blocks by copying from existing ones:
|
||||
|
||||
```py
|
||||
>>> # Copy existing blocks as placeholders
|
||||
>>> class SDXLDiffDiffPrepareLatentsStep(PipelineBlock):
|
||||
... """Copied from StableDiffusionXLImg2ImgPrepareLatentsStep - will modify later"""
|
||||
... # ... same implementation as StableDiffusionXLImg2ImgPrepareLatentsStep
|
||||
...
|
||||
>>> class SDXLDiffDiffLoopBeforeDenoiser(PipelineBlock):
|
||||
... """Copied from StableDiffusionXLLoopBeforeDenoiser - will modify later"""
|
||||
... # ... same implementation as StableDiffusionXLLoopBeforeDenoiser
|
||||
```
|
||||
|
||||
`SDXLDiffDiffLoopBeforeDenoiser` is the be part of the denoise loop we need to change. Let's use it to assemble a `SDXLDiffDiffDenoiseStep`.
|
||||
|
||||
```py
|
||||
>>> class SDXLDiffDiffDenoiseStep(StableDiffusionXLDenoiseLoopWrapper):
|
||||
... block_classes = [SDXLDiffDiffLoopBeforeDenoiser, StableDiffusionXLLoopDenoiser, StableDiffusionXLLoopAfterDenoiser]
|
||||
... block_names = ["before_denoiser", "denoiser", "after_denoiser"]
|
||||
```
|
||||
|
||||
Now we can put together our differential diffusion pipeline.
|
||||
|
||||
```py
|
||||
>>> DIFFDIFF_BLOCKS = IMAGE2IMAGE_BLOCKS.copy()
|
||||
>>> DIFFDIFF_BLOCKS["set_timesteps"] = TEXT2IMAGE_BLOCKS["set_timesteps"]
|
||||
>>> DIFFDIFF_BLOCKS["prepare_latents"] = SDXLDiffDiffPrepareLatentsStep
|
||||
>>> DIFFDIFF_BLOCKS["denoise"] = SDXLDiffDiffDenoiseStep
|
||||
>>>
|
||||
>>> dd_blocks = SequentialPipelineBlocks.from_blocks_dict(DIFFDIFF_BLOCKS)
|
||||
>>> print(dd_blocks)
|
||||
>>> # At this point, the pipeline works exactly like img2img since our blocks are just copies
|
||||
```
|
||||
|
||||
### Set up an example
|
||||
|
||||
ok, so now our blocks should be able to compile without an error, we can move on to the next step. Let's setup a simple example so we can run the pipeline as we build it. diff-diff use same model checkpoints as SDXL so we can fetch the models from a regular SDXL repo.
|
||||
|
||||
```py
|
||||
>>> dd_pipeline = dd_blocks.init_pipeline("YiYiXu/modular-demo-auto", collection="diffdiff")
|
||||
>>> dd_pipeline.load_default_componenets(torch_dtype=torch.float16)
|
||||
>>> dd_pipeline.to("cuda")
|
||||
```
|
||||
|
||||
We will use this example script:
|
||||
|
||||
```py
|
||||
>>> image = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/20240329211129_4024911930.png?download=true")
|
||||
>>> mask = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/gradient_mask.png?download=true")
|
||||
>>>
|
||||
>>> prompt = "a green pear"
|
||||
>>> negative_prompt = "blurry"
|
||||
>>>
|
||||
>>> image = dd_pipeline(
|
||||
... prompt=prompt,
|
||||
... negative_prompt=negative_prompt,
|
||||
... num_inference_steps=25,
|
||||
... diffdiff_map=mask,
|
||||
... image=image,
|
||||
... output="images"
|
||||
... )[0]
|
||||
>>>
|
||||
>>> image.save("diffdiff_out.png")
|
||||
```
|
||||
|
||||
If you run the script right now, you will get a complaint about unexpected input `diffdiff_map`.
|
||||
and you would get the same result as the original img2img pipeline.
|
||||
|
||||
### implement your custom logic and test incrementally
|
||||
|
||||
Let's modify the pipeline so that we can get expected result with this example script.
|
||||
|
||||
We'll start with the `prepare_latents` step. The main changes are:
|
||||
- Requires a new user input `diffdiff_map`
|
||||
- Requires new component `mask_processor` to process the `diffdiff_map`
|
||||
- Requires new intermediate inputs:
|
||||
- Need `timestep` instead of `latent_timestep` to precompute all the latents
|
||||
- Need `num_inference_steps` to create the `diffdiff_masks`
|
||||
- create a new output `diffdiff_masks` and `original_latents`
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 use `print(dd_pipeline.doc)` to check compiled inputs and outputs of the built piepline.
|
||||
|
||||
e.g. after we added `diffdiff_map` as an input in this step, we can run `print(dd_pipeline.doc)` to verify that it shows up in the docstring as a user input.
|
||||
|
||||
</Tip>
|
||||
|
||||
Once we make sure all the variables we need are available in the block state, we can implement the diff-diff logic inside `__call__`. We created 2 new variables: the change map `diffdiff_mask` and the pre-computed noised latents for all timesteps `original_latents`.
|
||||
|
||||
<Tip>
|
||||
|
||||
💡 Implement incrementally! Run the example script as you go, and insert `print(state)` and `print(block_state)` everywhere inside the `__call__` method to inspect the intermediate results. This helps you understand what's going on and what each line you just added does.
|
||||
|
||||
</Tip>
|
||||
|
||||
Here are the key changes we made to implement differential diffusion:
|
||||
|
||||
**1. Modified `prepare_latents` step:**
|
||||
```diff
|
||||
class SDXLDiffDiffPrepareLatentsStep(PipelineBlock):
|
||||
@property
|
||||
def expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec("vae", AutoencoderKL),
|
||||
ComponentSpec("scheduler", EulerDiscreteScheduler),
|
||||
+ ComponentSpec("mask_processor", VaeImageProcessor, config=FrozenDict({"do_normalize": False, "do_convert_grayscale": True}))
|
||||
]
|
||||
|
||||
@property
|
||||
def inputs(self) -> List[Tuple[str, Any]]:
|
||||
return [
|
||||
+ InputParam("diffdiff_map", required=True),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self) -> List[InputParam]:
|
||||
return [
|
||||
InputParam("generator"),
|
||||
- InputParam("latent_timestep", required=True, type_hint=torch.Tensor),
|
||||
+ InputParam("timesteps", type_hint=torch.Tensor),
|
||||
+ InputParam("num_inference_steps", type_hint=int),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self) -> List[OutputParam]:
|
||||
return [
|
||||
+ OutputParam("original_latents", type_hint=torch.Tensor),
|
||||
+ OutputParam("diffdiff_masks", type_hint=torch.Tensor),
|
||||
]
|
||||
|
||||
def __call__(self, components, state: PipelineState):
|
||||
# ... existing logic ...
|
||||
+ # Process change map and create masks
|
||||
+ diffdiff_map = components.mask_processor.preprocess(block_state.diffdiff_map, height=latent_height, width=latent_width)
|
||||
+ thresholds = torch.arange(block_state.num_inference_steps, dtype=diffdiff_map.dtype) / block_state.num_inference_steps
|
||||
+ block_state.diffdiff_masks = diffdiff_map > (thresholds + (block_state.denoising_start or 0))
|
||||
+ block_state.original_latents = block_state.latents
|
||||
```
|
||||
|
||||
**2. Modified `before_denoiser` step:**
|
||||
```diff
|
||||
class SDXLDiffDiffLoopBeforeDenoiser(PipelineBlock):
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"Step within the denoising loop for differential diffusion that prepare the latent input for the denoiser"
|
||||
)
|
||||
|
||||
@property
|
||||
def inputs(self) -> List[Tuple[str, Any]]:
|
||||
return [
|
||||
InputParam("denoising_start"),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self) -> List[str]:
|
||||
return [
|
||||
InputParam("latents", required=True, type_hint=torch.Tensor),
|
||||
InputParam("original_latents", type_hint=torch.Tensor),
|
||||
InputParam("diffdiff_masks", type_hint=torch.Tensor),
|
||||
]
|
||||
|
||||
def __call__(self, components, block_state, i, t):
|
||||
# Apply differential diffusion logic
|
||||
if i == 0 and block_state.denoising_start is None:
|
||||
block_state.latents = block_state.original_latents[:1]
|
||||
else:
|
||||
block_state.mask = block_state.diffdiff_masks[i].unsqueeze(0).unsqueeze(1)
|
||||
block_state.latents = block_state.original_latents[i] * block_state.mask + block_state.latents * (1 - block_state.mask)
|
||||
|
||||
# ... rest of existing logic ...
|
||||
```
|
||||
|
||||
That's all there is to it! We've just created a simple sequential pipeline by mix-and-match some existing and new pipeline blocks.
|
||||
|
||||
Now we use the process we've prepred in step2 to build the pipeline and inspect it.
|
||||
|
||||
|
||||
```py
|
||||
>> dd_pipeline
|
||||
SequentialPipelineBlocks(
|
||||
Class: ModularPipelineBlocks
|
||||
|
||||
Description:
|
||||
|
||||
|
||||
Components:
|
||||
text_encoder (`CLIPTextModel`)
|
||||
text_encoder_2 (`CLIPTextModelWithProjection`)
|
||||
tokenizer (`CLIPTokenizer`)
|
||||
tokenizer_2 (`CLIPTokenizer`)
|
||||
guider (`ClassifierFreeGuidance`)
|
||||
vae (`AutoencoderKL`)
|
||||
image_processor (`VaeImageProcessor`)
|
||||
scheduler (`EulerDiscreteScheduler`)
|
||||
mask_processor (`VaeImageProcessor`)
|
||||
unet (`UNet2DConditionModel`)
|
||||
|
||||
Configs:
|
||||
force_zeros_for_empty_prompt (default: True)
|
||||
requires_aesthetics_score (default: False)
|
||||
|
||||
Blocks:
|
||||
[0] text_encoder (StableDiffusionXLTextEncoderStep)
|
||||
Description: Text Encoder step that generate text_embeddings to guide the image generation
|
||||
|
||||
[1] image_encoder (StableDiffusionXLVaeEncoderStep)
|
||||
Description: Vae Encoder step that encode the input image into a latent representation
|
||||
|
||||
[2] input (StableDiffusionXLInputStep)
|
||||
Description: Input processing step that:
|
||||
1. Determines `batch_size` and `dtype` based on `prompt_embeds`
|
||||
2. Adjusts input tensor shapes based on `batch_size` (number of prompts) and `num_images_per_prompt`
|
||||
|
||||
All input tensors are expected to have either batch_size=1 or match the batch_size
|
||||
of prompt_embeds. The tensors will be duplicated across the batch dimension to
|
||||
have a final batch_size of batch_size * num_images_per_prompt.
|
||||
|
||||
[3] set_timesteps (StableDiffusionXLSetTimestepsStep)
|
||||
Description: Step that sets the scheduler's timesteps for inference
|
||||
|
||||
[4] prepare_latents (SDXLDiffDiffPrepareLatentsStep)
|
||||
Description: Step that prepares the latents for the differential diffusion generation process
|
||||
|
||||
[5] prepare_add_cond (StableDiffusionXLImg2ImgPrepareAdditionalConditioningStep)
|
||||
Description: Step that prepares the additional conditioning for the image-to-image/inpainting generation process
|
||||
|
||||
[6] denoise (SDXLDiffDiffDenoiseStep)
|
||||
Description: Pipeline block that iteratively denoise the latents over `timesteps`. The specific steps with each iteration can be customized with `sub_blocks` attributes
|
||||
|
||||
[7] decode (StableDiffusionXLDecodeStep)
|
||||
Description: Step that decodes the denoised latents into images
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
Run the example now, you should see an apple with its right half transformed into a green pear.
|
||||
|
||||

|
||||
|
||||
|
||||
## Adding IP-adapter
|
||||
|
||||
We provide an auto IP-adapter block that you can plug-and-play into your modular workflow. It's an `AutoPipelineBlocks`, so it will only run when the user passes an IP adapter image. In this tutorial, we'll focus on how to package it into your differential diffusion workflow. To learn more about `AutoPipelineBlocks`, see [here](https://huggingface.co/docs/diffusers/modular_diffusers/write_own_pipeline_block#autopipelineblocks)
|
||||
|
||||
We talked about how to add IP-adapter into your workflow in the [getting-started guide](https://huggingface.co/docs/diffusers/modular_diffusers/quicktour#ip-adapter). Let's just go ahead to create the IP-adapter block.
|
||||
|
||||
```py
|
||||
>>> from diffusers.modular_pipelines.stable_diffusion_xl.encoders import StableDiffusionXLAutoIPAdapterStep
|
||||
>>> ip_adapter_block = StableDiffusionXLAutoIPAdapterStep()
|
||||
```
|
||||
|
||||
We can directly add the ip-adapter block instance to the `diffdiff_blocks` that we created before. The `sub_blocks` attribute is a `InsertableDict`, so we're able to insert the it at specific position (index `0` here).
|
||||
|
||||
```py
|
||||
>>> dd_blocks.sub_blocks.insert("ip_adapter", ip_adapter_block, 0)
|
||||
```
|
||||
|
||||
Take a look at the new diff-diff pipeline with ip-adapter!
|
||||
|
||||
```py
|
||||
>>> print(dd_blocks)
|
||||
```
|
||||
|
||||
The pipeline now lists ip-adapter as its first block, and tells you that it will run only if `ip_adapter_image` is provided. It also includes the two new components from ip-adpater: `image_encoder` and `feature_extractor`
|
||||
|
||||
```out
|
||||
SequentialPipelineBlocks(
|
||||
Class: ModularPipelineBlocks
|
||||
|
||||
====================================================================================================
|
||||
This pipeline contains blocks that are selected at runtime based on inputs.
|
||||
Trigger Inputs: {'ip_adapter_image'}
|
||||
Use `get_execution_blocks()` with input names to see selected blocks (e.g. `get_execution_blocks('ip_adapter_image')`).
|
||||
====================================================================================================
|
||||
|
||||
|
||||
Description:
|
||||
|
||||
|
||||
Components:
|
||||
image_encoder (`CLIPVisionModelWithProjection`)
|
||||
feature_extractor (`CLIPImageProcessor`)
|
||||
unet (`UNet2DConditionModel`)
|
||||
guider (`ClassifierFreeGuidance`)
|
||||
text_encoder (`CLIPTextModel`)
|
||||
text_encoder_2 (`CLIPTextModelWithProjection`)
|
||||
tokenizer (`CLIPTokenizer`)
|
||||
tokenizer_2 (`CLIPTokenizer`)
|
||||
vae (`AutoencoderKL`)
|
||||
image_processor (`VaeImageProcessor`)
|
||||
scheduler (`EulerDiscreteScheduler`)
|
||||
mask_processor (`VaeImageProcessor`)
|
||||
|
||||
Configs:
|
||||
force_zeros_for_empty_prompt (default: True)
|
||||
requires_aesthetics_score (default: False)
|
||||
|
||||
Blocks:
|
||||
[0] ip_adapter (StableDiffusionXLAutoIPAdapterStep)
|
||||
Description: Run IP Adapter step if `ip_adapter_image` is provided.
|
||||
|
||||
[1] text_encoder (StableDiffusionXLTextEncoderStep)
|
||||
Description: Text Encoder step that generate text_embeddings to guide the image generation
|
||||
|
||||
[2] image_encoder (StableDiffusionXLVaeEncoderStep)
|
||||
Description: Vae Encoder step that encode the input image into a latent representation
|
||||
|
||||
[3] input (StableDiffusionXLInputStep)
|
||||
Description: Input processing step that:
|
||||
1. Determines `batch_size` and `dtype` based on `prompt_embeds`
|
||||
2. Adjusts input tensor shapes based on `batch_size` (number of prompts) and `num_images_per_prompt`
|
||||
|
||||
All input tensors are expected to have either batch_size=1 or match the batch_size
|
||||
of prompt_embeds. The tensors will be duplicated across the batch dimension to
|
||||
have a final batch_size of batch_size * num_images_per_prompt.
|
||||
|
||||
[4] set_timesteps (StableDiffusionXLSetTimestepsStep)
|
||||
Description: Step that sets the scheduler's timesteps for inference
|
||||
|
||||
[5] prepare_latents (SDXLDiffDiffPrepareLatentsStep)
|
||||
Description: Step that prepares the latents for the differential diffusion generation process
|
||||
|
||||
[6] prepare_add_cond (StableDiffusionXLImg2ImgPrepareAdditionalConditioningStep)
|
||||
Description: Step that prepares the additional conditioning for the image-to-image/inpainting generation process
|
||||
|
||||
[7] denoise (SDXLDiffDiffDenoiseStep)
|
||||
Description: Pipeline block that iteratively denoise the latents over `timesteps`. The specific steps with each iteration can be customized with `sub_blocks` attributes
|
||||
|
||||
[8] decode (StableDiffusionXLDecodeStep)
|
||||
Description: Step that decodes the denoised latents into images
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
Let's test it out. We used an orange image to condition the generation via ip-addapter and we can see a slight orange color and texture in the final output.
|
||||
|
||||
|
||||
```py
|
||||
>>> ip_adapter_block = StableDiffusionXLAutoIPAdapterStep()
|
||||
>>> dd_blocks.sub_blocks.insert("ip_adapter", ip_adapter_block, 0)
|
||||
>>>
|
||||
>>> dd_pipeline = dd_blocks.init_pipeline("YiYiXu/modular-demo-auto", collection="diffdiff")
|
||||
>>> dd_pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
>>> dd_pipeline.loader.load_ip_adapter("h94/IP-Adapter", subfolder="sdxl_models", weight_name="ip-adapter_sdxl.bin")
|
||||
>>> dd_pipeline.loader.set_ip_adapter_scale(0.6)
|
||||
>>> dd_pipeline = dd_pipeline.to(device)
|
||||
>>>
|
||||
>>> ip_adapter_image = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/diffdiff_orange.jpeg")
|
||||
>>> image = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/20240329211129_4024911930.png?download=true")
|
||||
>>> mask = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/gradient_mask.png?download=true")
|
||||
>>>
|
||||
>>> prompt = "a green pear"
|
||||
>>> negative_prompt = "blurry"
|
||||
>>> generator = torch.Generator(device=device).manual_seed(42)
|
||||
>>>
|
||||
>>> image = dd_pipeline(
|
||||
... prompt=prompt,
|
||||
... negative_prompt=negative_prompt,
|
||||
... num_inference_steps=25,
|
||||
... generator=generator,
|
||||
... ip_adapter_image=ip_adapter_image,
|
||||
... diffdiff_map=mask,
|
||||
... image=image,
|
||||
... output="images"
|
||||
... )[0]
|
||||
```
|
||||
|
||||
## Working with ControlNets
|
||||
|
||||
What about controlnet? Can differential diffusion work with controlnet? The key differences between a regular pipeline and a ControlNet pipeline are:
|
||||
1. A ControlNet input step that prepares the control condition
|
||||
2. Inside the denoising loop, a modified denoiser step where the control image is first processed through ControlNet, then control information is injected into the UNet
|
||||
|
||||
From looking at the code workflow: differential diffusion only modifies the "before denoiser" step, while ControlNet operates within the "denoiser" itself. Since they intervene at different points in the pipeline, they should work together without conflicts.
|
||||
|
||||
Intuitively, these two techniques are orthogonal and should combine naturally: differential diffusion controls how much the inference process can deviate from the original in each region, while ControlNet controls in what direction that change occurs.
|
||||
|
||||
With this understanding, let's assemble the `SDXLDiffDiffControlNetDenoiseStep`:
|
||||
|
||||
```py
|
||||
>>> class SDXLDiffDiffControlNetDenoiseStep(StableDiffusionXLDenoiseLoopWrapper):
|
||||
... block_classes = [SDXLDiffDiffLoopBeforeDenoiser, StableDiffusionXLControlNetLoopDenoiser, StableDiffusionXLDenoiseLoopAfterDenoiser]
|
||||
... block_names = ["before_denoiser", "denoiser", "after_denoiser"]
|
||||
>>>
|
||||
>>> controlnet_denoise_block = SDXLDiffDiffControlNetDenoiseStep()
|
||||
>>> # print(controlnet_denoise)
|
||||
```
|
||||
|
||||
We provide a auto controlnet input block that you can directly put into your workflow to proceess the `control_image`: similar to auto ip-adapter block, this step will only run if `control_image` input is passed from user. It work with both controlnet and controlnet union.
|
||||
|
||||
|
||||
```py
|
||||
>>> from diffusers.modular_pipelines.stable_diffusion_xl.modular_blocks import StableDiffusionXLAutoControlNetInputStep
|
||||
>>> control_input_block = StableDiffusionXLAutoControlNetInputStep()
|
||||
>>> print(control_input_block)
|
||||
```
|
||||
|
||||
```out
|
||||
StableDiffusionXLAutoControlNetInputStep(
|
||||
Class: AutoPipelineBlocks
|
||||
|
||||
====================================================================================================
|
||||
This pipeline contains blocks that are selected at runtime based on inputs.
|
||||
Trigger Inputs: ['control_image', 'control_mode']
|
||||
====================================================================================================
|
||||
|
||||
|
||||
Description: Controlnet Input step that prepare the controlnet input.
|
||||
This is an auto pipeline block that works for both controlnet and controlnet_union.
|
||||
(it should be called right before the denoise step) - `StableDiffusionXLControlNetUnionInputStep` is called to prepare the controlnet input when `control_mode` and `control_image` are provided.
|
||||
- `StableDiffusionXLControlNetInputStep` is called to prepare the controlnet input when `control_image` is provided. - if neither `control_mode` nor `control_image` is provided, step will be skipped.
|
||||
|
||||
|
||||
Components:
|
||||
controlnet (`ControlNetUnionModel`)
|
||||
control_image_processor (`VaeImageProcessor`)
|
||||
|
||||
Sub-Blocks:
|
||||
• controlnet_union [trigger: control_mode] (StableDiffusionXLControlNetUnionInputStep)
|
||||
Description: step that prepares inputs for the ControlNetUnion model
|
||||
|
||||
• controlnet [trigger: control_image] (StableDiffusionXLControlNetInputStep)
|
||||
Description: step that prepare inputs for controlnet
|
||||
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
Let's assemble the blocks and run an example using controlnet + differential diffusion. We used a tomato as `control_image`, so you can see that in the output, the right half that transformed into a pear had a tomato-like shape.
|
||||
|
||||
```py
|
||||
>>> dd_blocks.sub_blocks.insert("controlnet_input", control_input_block, 7)
|
||||
>>> dd_blocks.sub_blocks["denoise"] = controlnet_denoise_block
|
||||
>>>
|
||||
>>> dd_pipeline = dd_blocks.init_pipeline("YiYiXu/modular-demo-auto", collection="diffdiff")
|
||||
>>> dd_pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
>>> dd_pipeline = dd_pipeline.to(device)
|
||||
>>>
|
||||
>>> control_image = load_image("https://huggingface.co/datasets/YiYiXu/testing-images/resolve/main/diffdiff_tomato_canny.jpeg")
|
||||
>>> image = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/20240329211129_4024911930.png?download=true")
|
||||
>>> mask = load_image("https://huggingface.co/datasets/OzzyGT/testing-resources/resolve/main/differential/gradient_mask.png?download=true")
|
||||
>>>
|
||||
>>> prompt = "a green pear"
|
||||
>>> negative_prompt = "blurry"
|
||||
>>> generator = torch.Generator(device=device).manual_seed(42)
|
||||
>>>
|
||||
>>> image = dd_pipeline(
|
||||
... prompt=prompt,
|
||||
... negative_prompt=negative_prompt,
|
||||
... num_inference_steps=25,
|
||||
... generator=generator,
|
||||
... control_image=control_image,
|
||||
... controlnet_conditioning_scale=0.5,
|
||||
... diffdiff_map=mask,
|
||||
... image=image,
|
||||
... output="images"
|
||||
... )[0]
|
||||
```
|
||||
|
||||
Optionally, We can combine `SDXLDiffDiffControlNetDenoiseStep` and `SDXLDiffDiffDenoiseStep` into a `AutoPipelineBlocks` so that same workflow can work with or without controlnet.
|
||||
|
||||
|
||||
```py
|
||||
>>> class SDXLDiffDiffAutoDenoiseStep(AutoPipelineBlocks):
|
||||
... block_classes = [SDXLDiffDiffControlNetDenoiseStep, SDXLDiffDiffDenoiseStep]
|
||||
... block_names = ["controlnet_denoise", "denoise"]
|
||||
... block_trigger_inputs = ["controlnet_cond", None]
|
||||
```
|
||||
|
||||
`SDXLDiffDiffAutoDenoiseStep` will run the ControlNet denoise step if `control_image` input is provided, otherwise it will run the regular denoise step.
|
||||
|
||||
<Tip>
|
||||
|
||||
Note that it's perfectly fine not to use `AutoPipelineBlocks`. In fact, we recommend only using `AutoPipelineBlocks` to package your workflow at the end once you've verified all your pipelines work as expected.
|
||||
|
||||
</Tip>
|
||||
|
||||
Now you can create the differential diffusion preset that works with ip-adapter & controlnet.
|
||||
|
||||
```py
|
||||
>>> DIFFDIFF_AUTO_BLOCKS = IMAGE2IMAGE_BLOCKS.copy()
|
||||
>>> DIFFDIFF_AUTO_BLOCKS["prepare_latents"] = SDXLDiffDiffPrepareLatentsStep
|
||||
>>> DIFFDIFF_AUTO_BLOCKS["set_timesteps"] = TEXT2IMAGE_BLOCKS["set_timesteps"]
|
||||
>>> DIFFDIFF_AUTO_BLOCKS["denoise"] = SDXLDiffDiffAutoDenoiseStep
|
||||
>>> DIFFDIFF_AUTO_BLOCKS.insert("ip_adapter", StableDiffusionXLAutoIPAdapterStep, 0)
|
||||
>>> DIFFDIFF_AUTO_BLOCKS.insert("controlnet_input",StableDiffusionXLControlNetAutoInput, 7)
|
||||
>>>
|
||||
>>> print(DIFFDIFF_AUTO_BLOCKS)
|
||||
```
|
||||
|
||||
to use
|
||||
|
||||
```py
|
||||
>>> dd_auto_blocks = SequentialPipelineBlocks.from_blocks_dict(DIFFDIFF_AUTO_BLOCKS)
|
||||
>>> dd_pipeline = dd_auto_blocks.init_pipeline(...)
|
||||
```
|
||||
## Creating a Modular Repo
|
||||
|
||||
You can easily share your differential diffusion workflow on the hub, by creating a modular repo like this https://huggingface.co/YiYiXu/modular-diffdiff
|
||||
|
||||
To create a Modular Repo and share on hub, you just need to run `save_pretrained()` along with the `push_to_hub=True` flag. Note that if your pipeline contains custom block, you need to manually upload the code to the hub. But we are working on a command line tool to help you upload it very easily.
|
||||
|
||||
```py
|
||||
dd_pipeline.save_pretrained("YiYiXu/test_modular_doc", push_to_hub=True)
|
||||
```
|
||||
|
||||
With a modular repo, it is very easy for the community to use the workflow you just created! Here is an example to use the differential-diffusion pipeline we just created and shared.
|
||||
|
||||
```py
|
||||
>>> from diffusers.modular_pipelines import ModularPipeline, ComponentsManager
|
||||
>>> import torch
|
||||
>>> from diffusers.utils import load_image
|
||||
>>>
|
||||
>>> repo_id = "YiYiXu/modular-diffdiff-0704"
|
||||
>>>
|
||||
>>> components = ComponentsManager()
|
||||
>>>
|
||||
>>> diffdiff_pipeline = ModularPipeline.from_pretrained(repo_id, trust_remote_code=True, components_manager=components, collection="diffdiff")
|
||||
>>> diffdiff_pipeline.load_default_components(torch_dtype=torch.float16)
|
||||
>>> components.enable_auto_cpu_offload()
|
||||
```
|
||||
|
||||
see more usage example on model card
|
||||
|
||||
## deploy a mellon node
|
||||
|
||||
[YIYI TODO: for now, here is an example of mellon node https://huggingface.co/YiYiXu/diff-diff-mellon]
|
||||
1210
docs/source/en/modular_diffusers/getting_started.md
Normal file
1210
docs/source/en/modular_diffusers/getting_started.md
Normal file
File diff suppressed because it is too large
Load Diff
817
docs/source/en/modular_diffusers/write_own_pipeline_block.md
Normal file
817
docs/source/en/modular_diffusers/write_own_pipeline_block.md
Normal file
@@ -0,0 +1,817 @@
|
||||
<!--Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
|
||||
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations under the License.
|
||||
-->
|
||||
|
||||
# Writing Your Own Pipeline Blocks
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
🧪 **Experimental Feature**: Modular Diffusers is an experimental feature we are actively developing. The API may be subject to breaking changes.
|
||||
|
||||
</Tip>
|
||||
|
||||
In Modular Diffusers, you build your workflow using `ModularPipelineBlocks`. We support 4 different types of blocks: `PipelineBlock`, `SequentialPipelineBlocks`, `LoopSequentialPipelineBlocks`, and `AutoPipelineBlocks`. Among them, `PipelineBlock` is the most fundamental building block of the whole system - it's like a brick in a Lego system. These blocks are designed to easily connect with each other, allowing for modular construction of creative and potentially very complex workflows.
|
||||
|
||||
In this tutorial, we will focus on how to write a basic `PipelineBlock` and how it interacts with other components in the system. We will also cover how to connect them together using the multi-blocks: `SequentialPipelineBlocks`, `LoopSequentialPipelineBlocks`, and `AutoPipelineBlocks`.
|
||||
|
||||
|
||||
## Understanding the Foundation: `PipelineState`
|
||||
|
||||
Before we dive into creating `PipelineBlock`s, we need to have a basic understanding of `PipelineState` - the core data structure that all blocks operate on. This concept is fundamental to understanding how blocks interact with each other and the pipeline system.
|
||||
|
||||
In the modular diffusers system, `PipelineState` acts as the global state container that `PipelineBlock`s operate on - each block gets a local view (`BlockState`) of the relevant variables it needs from `PipelineState`, performs its operations, and then updates `PipelineState` with any changes.
|
||||
|
||||
While `PipelineState` maintains the complete runtime state of the pipeline, `PipelineBlock`s define what parts of that state they can read from and write to through their `input`s, `intermediates_inputs`, and `intermediates_outputs` properties.
|
||||
|
||||
A `PipelineState` consists of two distinct states:
|
||||
- The **immutable state** (i.e. the `inputs` dict) contains a copy of values provided by users. Once a value is added to the immutable state, it cannot be changed. Blocks can read from the immutable state but cannot write to it.
|
||||
- The **mutable state** (i.e. the `intermediates` dict) contains variables that are passed between blocks and can be modified by them.
|
||||
|
||||
Here's an example of what a `PipelineState` looks like:
|
||||
|
||||
```
|
||||
PipelineState(
|
||||
inputs={
|
||||
prompt: 'a cat'
|
||||
guidance_scale: 7.0
|
||||
num_inference_steps: 25
|
||||
},
|
||||
intermediates={
|
||||
prompt_embeds: Tensor(dtype=torch.float32, shape=torch.Size([1, 1, 1, 1]))
|
||||
negative_prompt_embeds: None
|
||||
},
|
||||
```
|
||||
|
||||
## Creating a `PipelineBlock`
|
||||
|
||||
To write a `PipelineBlock` class, you need to define a few properties that determine how your block interacts with the pipeline state. Understanding these properties is crucial - they define what data your block can access and what it can produce.
|
||||
|
||||
The three main properties you need to define are:
|
||||
- `inputs`: Immutable values from the user that cannot be modified
|
||||
- `intermediate_inputs`: Mutable values from previous blocks that can be read and modified
|
||||
- `intermediate_outputs`: New values your block creates for subsequent blocks
|
||||
|
||||
Let's explore each one and understand how they work with the pipeline state.
|
||||
|
||||
**Inputs: Immutable User Values**
|
||||
|
||||
Inputs are variables your block needs from the immutable pipeline state - these are user-provided values that cannot be modified by any block. You define them using `InputParam`:
|
||||
|
||||
```py
|
||||
user_inputs = [
|
||||
InputParam(name="image", type_hint="PIL.Image", description="raw input image to process")
|
||||
]
|
||||
```
|
||||
|
||||
When you list something as an input, you're saying "I need this value directly from the end user, and I will talk to them directly, telling them what I need in the 'description' field. They will provide it and it will come to me unchanged."
|
||||
|
||||
This is especially useful for raw values that serve as the "source of truth" in your workflow. For example, with a raw image, many workflows require preprocessing steps like resizing that a previous block might have performed. But in many cases, you also want the raw PIL image. In some inpainting workflows, you need the original image to overlay with the generated result for better control and consistency.
|
||||
|
||||
**Intermediate Inputs: Mutable Values from Previous Blocks**
|
||||
|
||||
Intermediate inputs are variables your block needs from the mutable pipeline state - these are values that can be read and modified. They're typically created by previous blocks, but could also be directly provided by the user if not the case:
|
||||
|
||||
```py
|
||||
user_intermediate_inputs = [
|
||||
InputParam(name="processed_image", type_hint="torch.Tensor", description="image that has been preprocessed and normalized"),
|
||||
]
|
||||
```
|
||||
|
||||
When you list something as an intermediate input, you're saying "I need this value, but I want to work with a different block that has already created it. I already know for sure that I can get it from this other block, but it's okay if other developers want use something different."
|
||||
|
||||
**Intermediate Outputs: New Values for Subsequent Blocks**
|
||||
|
||||
Intermediate outputs are new variables your block creates and adds to the mutable pipeline state so they can be used by subsequent blocks:
|
||||
|
||||
```py
|
||||
user_intermediate_outputs = [
|
||||
OutputParam(name="image_latents", description="latents representing the image")
|
||||
]
|
||||
```
|
||||
|
||||
Intermediate inputs and intermediate outputs work together like Lego studs and anti-studs - they're the connection points that make blocks modular. When one block produces an intermediate output, it becomes available as an intermediate input for subsequent blocks. This is where the "modular" nature of the system really shines - blocks can be connected and reconnected in different ways as long as their inputs and outputs match. We will see more how they connect when we talk about multi-blocks.
|
||||
|
||||
**The `__call__` Method Structure**
|
||||
|
||||
Your `PipelineBlock`'s `__call__` method should follow this structure:
|
||||
|
||||
```py
|
||||
def __call__(self, components, state):
|
||||
# Get a local view of the state variables this block needs
|
||||
block_state = self.get_block_state(state)
|
||||
|
||||
# Your computation logic here
|
||||
# block_state contains all your inputs and intermediate_inputs
|
||||
# You can access them like: block_state.image, block_state.processed_image
|
||||
|
||||
# Update the pipeline state with your updated block_states
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
The `block_state` object contains all the variables you defined in `inputs` and `intermediate_inputs`, making them easily accessible for your computation.
|
||||
|
||||
**Components and Configs**
|
||||
|
||||
You can define the components and pipeline-level configs your block needs using `ComponentSpec` and `ConfigSpec`:
|
||||
|
||||
```py
|
||||
from diffusers import ComponentSpec, ConfigSpec
|
||||
|
||||
# Define components your block needs
|
||||
expected_components = [
|
||||
ComponentSpec(name="unet", type_hint=UNet2DConditionModel),
|
||||
ComponentSpec(name="scheduler", type_hint=EulerDiscreteScheduler)
|
||||
]
|
||||
|
||||
# Define pipeline-level configs
|
||||
expected_config = [
|
||||
ConfigSpec("force_zeros_for_empty_prompt", True)
|
||||
]
|
||||
```
|
||||
|
||||
**Components**: In the `ComponentSpec`, You must provide a `name` and ideally a `type_hint`. The actual loading details (`repo`, `subfolder`, `variant` and `revision` fields) are typically specified when creating the pipeline, as we covered in the [Getting Started Guide](https://huggingface.co/docs/diffusers/en/modular_diffusers/getting_started#loading-components-into-a-modularpipeline).
|
||||
|
||||
**Configs**: Simple pipeline-level settings that control behavior across all blocks.
|
||||
|
||||
When you convert your blocks into a pipeline using `blocks.init_pipeline()`, the pipeline collects all component requirements from the blocks and fetches the loading specs from the modular repository. The components are then made available to your block in the `components` argument of the `__call__` method.
|
||||
|
||||
That's all you need to define in order to create a `PipelineBlock`. There is no hidden complexity. In fact we are going to create a helper function that take exactly these variables as input and return a pipeline block. We will use this helper function through out the tutorial to create test blocks
|
||||
|
||||
Note that for `__call__` method, the only part you should implement differently is the part between `self.get_block_state()` and `self.set_block_state()`, which can be abstracted into a simple function that takes `block_state` and returns the updated state. Our helper function accepts a `block_fn` that does exactly that.
|
||||
|
||||
**Helper Function**
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import PipelineBlock, InputParam, OutputParam
|
||||
import torch
|
||||
|
||||
def make_block(inputs=[], intermediate_inputs=[], intermediate_outputs=[], block_fn=None, description=None):
|
||||
class TestBlock(PipelineBlock):
|
||||
model_name = "test"
|
||||
|
||||
@property
|
||||
def inputs(self):
|
||||
return inputs
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self):
|
||||
return intermediate_inputs
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self):
|
||||
return intermediate_outputs
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return description if description is not None else ""
|
||||
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
if block_fn is not None:
|
||||
block_state = block_fn(block_state, state)
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
|
||||
return TestBlock
|
||||
```
|
||||
|
||||
|
||||
Let's create a simple block to see how these definitions interact with the pipeline state. To better understand what's happening, we'll print out the states before and after updates to inspect them:
|
||||
|
||||
```py
|
||||
inputs = [
|
||||
InputParam(name="image", type_hint="PIL.Image", description="raw input image to process")
|
||||
]
|
||||
|
||||
intermediate_inputs = [InputParam(name="batch_size", type_hint=int)]
|
||||
|
||||
intermediate_outputs = [
|
||||
OutputParam(name="image_latents", description="latents representing the image")
|
||||
]
|
||||
|
||||
def image_encoder_block_fn(block_state, pipeline_state):
|
||||
print(f"pipeline_state (before update): {pipeline_state}")
|
||||
print(f"block_state (before update): {block_state}")
|
||||
|
||||
# Simulate processing the image
|
||||
block_state.image = torch.randn(1, 3, 512, 512)
|
||||
block_state.batch_size = block_state.batch_size * 2
|
||||
block_state.processed_image = [torch.randn(1, 3, 512, 512)] * block_state.batch_size
|
||||
block_state.image_latents = torch.randn(1, 4, 64, 64)
|
||||
|
||||
print(f"block_state (after update): {block_state}")
|
||||
return block_state
|
||||
|
||||
# Create a block with our definitions
|
||||
image_encoder_block_cls = make_block(
|
||||
inputs=inputs,
|
||||
intermediate_inputs=intermediate_inputs,
|
||||
intermediate_outputs=intermediate_outputs,
|
||||
block_fn=image_encoder_block_fn,
|
||||
description=" Encode raw image into its latent presentation"
|
||||
)
|
||||
image_encoder_block = image_encoder_block_cls()
|
||||
pipe = image_encoder_block.init_pipeline()
|
||||
```
|
||||
|
||||
Let's check the pipeline's docstring to see what inputs it expects:
|
||||
```py
|
||||
>>> print(pipe.doc)
|
||||
class TestBlock
|
||||
|
||||
Encode raw image into its latent presentation
|
||||
|
||||
Inputs:
|
||||
|
||||
image (`PIL.Image`, *optional*):
|
||||
raw input image to process
|
||||
|
||||
batch_size (`int`, *optional*):
|
||||
|
||||
Outputs:
|
||||
|
||||
image_latents (`None`):
|
||||
latents representing the image
|
||||
```
|
||||
|
||||
Notice that `batch_size` appears as an input even though we defined it as an intermediate input. This happens because no previous block provided it, so the pipeline makes it available as a user input. However, unlike regular inputs, this value goes directly into the mutable intermediate state.
|
||||
|
||||
Now let's run the pipeline:
|
||||
|
||||
```py
|
||||
from diffusers.utils import load_image
|
||||
|
||||
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/image_of_squirrel_painting.png")
|
||||
state = pipe(image=image, batch_size=2)
|
||||
print(f"pipeline_state (after update): {state}")
|
||||
```
|
||||
```out
|
||||
pipeline_state (before update): PipelineState(
|
||||
inputs={
|
||||
image: <PIL.Image.Image image mode=RGB size=512x512 at 0x7F3ECC494550>
|
||||
},
|
||||
intermediates={
|
||||
batch_size: 2
|
||||
},
|
||||
)
|
||||
block_state (before update): BlockState(
|
||||
image: <PIL.Image.Image image mode=RGB size=512x512 at 0x7F3ECC494640>
|
||||
batch_size: 2
|
||||
)
|
||||
|
||||
block_state (after update): BlockState(
|
||||
image: Tensor(dtype=torch.float32, shape=torch.Size([1, 3, 512, 512]))
|
||||
batch_size: 4
|
||||
processed_image: List[4] of Tensors with shapes [torch.Size([1, 3, 512, 512]), torch.Size([1, 3, 512, 512]), torch.Size([1, 3, 512, 512]), torch.Size([1, 3, 512, 512])]
|
||||
image_latents: Tensor(dtype=torch.float32, shape=torch.Size([1, 4, 64, 64]))
|
||||
)
|
||||
pipeline_state (after update): PipelineState(
|
||||
inputs={
|
||||
image: <PIL.Image.Image image mode=RGB size=512x512 at 0x7F3ECC494550>
|
||||
},
|
||||
intermediates={
|
||||
batch_size: 4
|
||||
image_latents: Tensor(dtype=torch.float32, shape=torch.Size([1, 4, 64, 64]))
|
||||
},
|
||||
)
|
||||
```
|
||||
**Key Observations:**
|
||||
|
||||
1. **Before the update**: `image` (the input) goes to the immutable inputs dict, while `batch_size` (the intermediate_input) goes to the mutable intermediates dict, and both are available in `block_state`.
|
||||
|
||||
2. **After the update**:
|
||||
- **`image` (inputs)** changed in `block_state` but not in `pipeline_state` - this change is local to the block only.
|
||||
- **`batch_size (intermediate_inputs)`** was updated in both `block_state` and `pipeline_state` - this change affects subsequent blocks (we didn't need to declare it as an intermediate output since it was already in the intermediates dict)
|
||||
- **`image_latents (intermediate_outputs)`** was added to `pipeline_state` because it was declared as an intermediate output
|
||||
- **`processed_image`** was not added to `pipeline_state` because it wasn't declared as an intermediate output
|
||||
|
||||
I hope by now you have a basic idea about how `PipelineBlock` manages state through inputs, intermediate inputs, and intermediate outputs. The real power comes when we connect multiple blocks together - their intermediate outputs become intermediate inputs for subsequent blocks, creating modular workflows. Let's explore how to build these connections using multi-blocks like `SequentialPipelineBlocks`.
|
||||
|
||||
## Create a `SequentialPipelineBlocks`
|
||||
|
||||
I assume that you're already familiar with `SequentialPipelineBlocks` and how to create them with the `from_blocks_dict` API. It's one of the most common ways to use Modular Diffusers, and we've covered it pretty well in the [Getting Started Guide](https://huggingface.co/docs/diffusers/pr_9672/en/modular_diffusers/getting_started#modularpipelineblocks).
|
||||
|
||||
But how do blocks actually connect and work together? Understanding this is crucial for building effective modular workflows. Let's explore this through an example.
|
||||
|
||||
**How Blocks Connect in SequentialPipelineBlocks:**
|
||||
|
||||
The key insight is that blocks connect through their intermediate inputs and outputs - the "studs and anti-studs" we discussed earlier. Let's expand on our example to create a new block that produces `batch_size`, which we'll call "input_block":
|
||||
|
||||
```py
|
||||
def input_block_fn(block_state, pipeline_state):
|
||||
|
||||
batch_size = len(block_state.prompt)
|
||||
block_state.batch_size = batch_size * block_state.num_images_per_prompt
|
||||
|
||||
return block_state
|
||||
|
||||
input_block_cls = make_block(
|
||||
inputs=[
|
||||
InputParam(name="prompt", type_hint=list, description="list of text prompts"),
|
||||
InputParam(name="num_images_per_prompt", type_hint=int, description="number of images per prompt")
|
||||
],
|
||||
intermediate_outputs=[
|
||||
OutputParam(name="batch_size", description="calculated batch size")
|
||||
],
|
||||
block_fn=input_block_fn,
|
||||
description="A block that determines batch_size based on the number of prompts and num_images_per_prompt argument."
|
||||
)
|
||||
input_block = input_block_cls()
|
||||
```
|
||||
|
||||
Now let's connect these blocks to create a pipeline:
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import SequentialPipelineBlocks, InsertableDict
|
||||
# define a dict map block names to block class
|
||||
blocks_dict = InsertableDict()
|
||||
blocks_dict["input"] = input_block
|
||||
blocks_dict["image_encoder"] = image_encoder_block
|
||||
# create the multi-block
|
||||
blocks = SequentialPipelineBlocks.from_blocks_dict(blocks_dict)
|
||||
# convert it to a runnable pipeline
|
||||
pipeline = blocks.init_pipeline()
|
||||
```
|
||||
|
||||
Now you have a pipeline with 2 blocks.
|
||||
|
||||
```py
|
||||
>>> pipeline.blocks
|
||||
SequentialPipelineBlocks(
|
||||
Class: ModularPipelineBlocks
|
||||
|
||||
Description:
|
||||
|
||||
|
||||
Sub-Blocks:
|
||||
[0] input (TestBlock)
|
||||
Description: A block that determines batch_size based on the number of prompts and num_images_per_prompt argument.
|
||||
|
||||
[1] image_encoder (TestBlock)
|
||||
Description: Encode raw image into its latent presentation
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
When you inspect `pipeline.doc`, you can see that `batch_size` is not listed as an input. The pipeline automatically detects that the `input_block` can produce `batch_size` for the `image_encoder_block`, so it doesn't ask the user to provide it.
|
||||
|
||||
```py
|
||||
>>> print(pipeline.doc)
|
||||
class SequentialPipelineBlocks
|
||||
|
||||
Inputs:
|
||||
|
||||
prompt (`None`, *optional*):
|
||||
|
||||
num_images_per_prompt (`None`, *optional*):
|
||||
|
||||
image (`PIL.Image`, *optional*):
|
||||
raw input image to process
|
||||
|
||||
Outputs:
|
||||
|
||||
batch_size (`None`):
|
||||
|
||||
image_latents (`None`):
|
||||
latents representing the image
|
||||
```
|
||||
|
||||
At runtime, you have data flow like this:
|
||||
|
||||

|
||||
|
||||
**How SequentialPipelineBlocks Works:**
|
||||
|
||||
1. Blocks are executed in the order they're registered in the `blocks_dict`
|
||||
2. Outputs from one block become available as intermediate inputs to all subsequent blocks
|
||||
3. The pipeline automatically figures out which values need to be provided by the user and which will be generated by previous blocks
|
||||
4. Each block maintains its own behavior and operates through its defined interface, while collectively these interfaces determine what the entire pipeline accepts and produces
|
||||
|
||||
What happens within each block follows the same pattern we described earlier: each block gets its own `block_state` with the relevant inputs and intermediate inputs, performs its computation, and updates the pipeline state with its intermediate outputs.
|
||||
|
||||
## `LoopSequentialPipelineBlocks`
|
||||
|
||||
To create a loop in Modular Diffusers, you could use a single `PipelineBlock` like this:
|
||||
|
||||
```python
|
||||
class DenoiseLoop(PipelineBlock):
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
for t in range(block_state.num_inference_steps):
|
||||
# ... loop logic here
|
||||
pass
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
Or you could create a `LoopSequentialPipelineBlocks`. The key difference is that with `LoopSequentialPipelineBlocks`, the loop itself is modular: you can add or remove blocks within the loop or reuse the same loop structure with different block combinations.
|
||||
|
||||
It involves two parts: a **loop wrapper** and **loop blocks**
|
||||
|
||||
* The **loop wrapper** (`LoopSequentialPipelineBlocks`) defines the loop structure, e.g. it defines the iteration variables, and loop configurations such as progress bar.
|
||||
|
||||
* The **loop blocks** are basically standard pipeline blocks you add to the loop wrapper.
|
||||
- they run sequentially for each iteration of the loop
|
||||
- they receive the current iteration index as an additional parameter
|
||||
- they share the same block_state throughout the entire loop
|
||||
|
||||
Unlike regular `SequentialPipelineBlocks` where each block gets its own state, loop blocks share a single state that persists and evolves across iterations.
|
||||
|
||||
We will build a simple loop block to demonstrate these concepts. Creating a loop block involves three steps:
|
||||
1. defining the loop wrapper class
|
||||
2. creating the loop blocks
|
||||
3. adding the loop blocks to the loop wrapper class to create the loop wrapper instance
|
||||
|
||||
**Step 1: Define the Loop Wrapper**
|
||||
|
||||
To create a `LoopSequentialPipelineBlocks` class, you need to define:
|
||||
|
||||
* `loop_inputs`: User input variables (equivalent to `PipelineBlock.inputs`)
|
||||
* `loop_intermediate_inputs`: Intermediate variables needed from the mutable pipeline state (equivalent to `PipelineBlock.intermediates_inputs`)
|
||||
* `loop_intermediate_outputs`: New intermediate variables this block will add to the mutable pipeline state (equivalent to `PipelineBlock.intermediates_outputs`)
|
||||
* `__call__` method: Defines the loop structure and iteration logic
|
||||
|
||||
Here is an example of a loop wrapper:
|
||||
|
||||
```py
|
||||
import torch
|
||||
from diffusers.modular_pipelines import LoopSequentialPipelineBlocks, PipelineBlock, InputParam, OutputParam
|
||||
|
||||
class LoopWrapper(LoopSequentialPipelineBlocks):
|
||||
model_name = "test"
|
||||
@property
|
||||
def description(self):
|
||||
return "I'm a loop!!"
|
||||
@property
|
||||
def loop_inputs(self):
|
||||
return [InputParam(name="num_steps")]
|
||||
@torch.no_grad()
|
||||
def __call__(self, components, state):
|
||||
block_state = self.get_block_state(state)
|
||||
# Loop structure - can be customized to your needs
|
||||
for i in range(block_state.num_steps):
|
||||
# loop_step executes all registered blocks in sequence
|
||||
components, block_state = self.loop_step(components, block_state, i=i)
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
```
|
||||
|
||||
**Step 2: Create Loop Blocks**
|
||||
|
||||
Loop blocks are standard `PipelineBlock`s, but their `__call__` method works differently:
|
||||
* It receives the iteration variable (e.g., `i`) passed by the loop wrapper
|
||||
* It works directly with `block_state` instead of pipeline state
|
||||
* No need to call `self.get_block_state()` or `self.set_block_state()`
|
||||
|
||||
```py
|
||||
class LoopBlock(PipelineBlock):
|
||||
# this is used to identify the model family, we won't worry about it in this example
|
||||
model_name = "test"
|
||||
@property
|
||||
def inputs(self):
|
||||
return [InputParam(name="x")]
|
||||
@property
|
||||
def intermediate_outputs(self):
|
||||
# outputs produced by this block
|
||||
return [OutputParam(name="x")]
|
||||
@property
|
||||
def description(self):
|
||||
return "I'm a block used inside the `LoopWrapper` class"
|
||||
def __call__(self, components, block_state, i: int):
|
||||
block_state.x += 1
|
||||
return components, block_state
|
||||
```
|
||||
|
||||
**Step 3: Combine Everything**
|
||||
|
||||
Finally, assemble your loop by adding the block(s) to the wrapper:
|
||||
|
||||
```py
|
||||
loop = LoopWrapper.from_blocks_dict({"block1": LoopBlock})
|
||||
```
|
||||
|
||||
Now you've created a loop with one step:
|
||||
|
||||
```py
|
||||
>>> loop
|
||||
LoopWrapper(
|
||||
Class: LoopSequentialPipelineBlocks
|
||||
|
||||
Description: I'm a loop!!
|
||||
|
||||
Sub-Blocks:
|
||||
[0] block1 (LoopBlock)
|
||||
Description: I'm a block used inside the `LoopWrapper` class
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
It has two inputs: `x` (used at each step within the loop) and `num_steps` used to define the loop.
|
||||
|
||||
```py
|
||||
>>> print(loop.doc)
|
||||
class LoopWrapper
|
||||
|
||||
I'm a loop!!
|
||||
|
||||
Inputs:
|
||||
|
||||
x (`None`, *optional*):
|
||||
|
||||
num_steps (`None`, *optional*):
|
||||
|
||||
Outputs:
|
||||
|
||||
x (`None`):
|
||||
```
|
||||
|
||||
**Running the Loop:**
|
||||
|
||||
```py
|
||||
# run the loop
|
||||
loop_pipeline = loop.init_pipeline()
|
||||
x = loop_pipeline(num_steps=10, x=0, output="x")
|
||||
assert x == 10
|
||||
```
|
||||
|
||||
**Adding Multiple Blocks:**
|
||||
|
||||
We can add multiple blocks to run within each iteration. Let's run the loop block twice within each iteration:
|
||||
|
||||
```py
|
||||
loop = LoopWrapper.from_blocks_dict({"block1": LoopBlock(), "block2": LoopBlock})
|
||||
loop_pipeline = loop.init_pipeline()
|
||||
x = loop_pipeline(num_steps=10, x=0, output="x")
|
||||
assert x == 20 # Each iteration runs 2 blocks, so 10 iterations * 2 = 20
|
||||
```
|
||||
|
||||
**Key Differences from SequentialPipelineBlocks:**
|
||||
|
||||
The main difference is that loop blocks share the same `block_state` across all iterations, allowing values to accumulate and evolve throughout the loop. Loop blocks could receive additional arguments (like the current iteration index) depending on the loop wrapper's implementation, since the wrapper defines how loop blocks are called. You can easily add, remove, or reorder blocks within the loop without changing the loop logic itself.
|
||||
|
||||
The officially supported denoising loops in Modular Diffusers are implemented using `LoopSequentialPipelineBlocks`. You can explore the actual implementation to see how these concepts work in practice:
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines.stable_diffusion_xl.denoise import StableDiffusionXLDenoiseStep
|
||||
StableDiffusionXLDenoiseStep()
|
||||
```
|
||||
|
||||
## `AutoPipelineBlocks`
|
||||
|
||||
`AutoPipelineBlocks` allows you to pack different pipelines into one and automatically select which one to run at runtime based on the inputs. The main purpose is convenience and portability - for developers, you can package everything into one workflow, making it easier to share and use.
|
||||
|
||||
For example, you might want to support text-to-image and image-to-image tasks. Instead of creating two separate pipelines, you can create an `AutoPipelineBlocks` that automatically chooses the workflow based on whether an `image` input is provided.
|
||||
|
||||
Let's see an example. Here we'll create a dummy `AutoPipelineBlocks` that includes dummy text-to-image, image-to-image, and inpaint pipelines.
|
||||
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import AutoPipelineBlocks
|
||||
|
||||
# These are dummy blocks and we only focus on "inputs" for our purpose
|
||||
inputs = [InputParam(name="prompt")]
|
||||
# block_fn prints out which workflow is running so we can see the execution order at runtime
|
||||
block_fn = lambda x, y: print("running the text-to-image workflow")
|
||||
block_t2i_cls = make_block(inputs=inputs, block_fn=block_fn, description="I'm a text-to-image workflow!")
|
||||
|
||||
inputs = [InputParam(name="prompt"), InputParam(name="image")]
|
||||
block_fn = lambda x, y: print("running the image-to-image workflow")
|
||||
block_i2i_cls = make_block(inputs=inputs, block_fn=block_fn, description="I'm a image-to-image workflow!")
|
||||
|
||||
inputs = [InputParam(name="prompt"), InputParam(name="image"), InputParam(name="mask")]
|
||||
block_fn = lambda x, y: print("running the inpaint workflow")
|
||||
block_inpaint_cls = make_block(inputs=inputs, block_fn=block_fn, description="I'm a inpaint workflow!")
|
||||
|
||||
class AutoImageBlocks(AutoPipelineBlocks):
|
||||
# List of sub-block classes to choose from
|
||||
block_classes = [block_inpaint_cls, block_i2i_cls, block_t2i_cls]
|
||||
# Names for each block in the same order
|
||||
block_names = ["inpaint", "img2img", "text2img"]
|
||||
# Trigger inputs that determine which block to run
|
||||
# - "mask" triggers inpaint workflow
|
||||
# - "image" triggers img2img workflow (but only if mask is not provided)
|
||||
# - if none of above, runs the text2img workflow (default)
|
||||
block_trigger_inputs = ["mask", "image", None]
|
||||
# Description is extremely important for AutoPipelineBlocks
|
||||
@property
|
||||
def description(self):
|
||||
return (
|
||||
"Pipeline generates images given different types of conditions!\n"
|
||||
+ "This is an auto pipeline block that works for text2img, img2img and inpainting tasks.\n"
|
||||
+ " - inpaint workflow is run when `mask` is provided.\n"
|
||||
+ " - img2img workflow is run when `image` is provided (but only when `mask` is not provided).\n"
|
||||
+ " - text2img workflow is run when neither `image` nor `mask` is provided.\n"
|
||||
)
|
||||
|
||||
# Create the blocks
|
||||
auto_blocks = AutoImageBlocks()
|
||||
# convert to pipeline
|
||||
auto_pipeline = auto_blocks.init_pipeline()
|
||||
```
|
||||
|
||||
Now we have created an `AutoPipelineBlocks` that contains 3 sub-blocks. Notice the warning message at the top - this automatically appears in every `ModularPipelineBlocks` that contains `AutoPipelineBlocks` to remind end users that dynamic block selection happens at runtime.
|
||||
|
||||
```py
|
||||
AutoImageBlocks(
|
||||
Class: AutoPipelineBlocks
|
||||
|
||||
====================================================================================================
|
||||
This pipeline contains blocks that are selected at runtime based on inputs.
|
||||
Trigger Inputs: ['mask', 'image']
|
||||
====================================================================================================
|
||||
|
||||
|
||||
Description: Pipeline generates images given different types of conditions!
|
||||
This is an auto pipeline block that works for text2img, img2img and inpainting tasks.
|
||||
- inpaint workflow is run when `mask` is provided.
|
||||
- img2img workflow is run when `image` is provided (but only when `mask` is not provided).
|
||||
- text2img workflow is run when neither `image` nor `mask` is provided.
|
||||
|
||||
|
||||
|
||||
Sub-Blocks:
|
||||
• inpaint [trigger: mask] (TestBlock)
|
||||
Description: I'm a inpaint workflow!
|
||||
|
||||
• img2img [trigger: image] (TestBlock)
|
||||
Description: I'm a image-to-image workflow!
|
||||
|
||||
• text2img [default] (TestBlock)
|
||||
Description: I'm a text-to-image workflow!
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
Check out the documentation with `print(auto_pipeline.doc)`:
|
||||
|
||||
```py
|
||||
>>> print(auto_pipeline.doc)
|
||||
class AutoImageBlocks
|
||||
|
||||
Pipeline generates images given different types of conditions!
|
||||
This is an auto pipeline block that works for text2img, img2img and inpainting tasks.
|
||||
- inpaint workflow is run when `mask` is provided.
|
||||
- img2img workflow is run when `image` is provided (but only when `mask` is not provided).
|
||||
- text2img workflow is run when neither `image` nor `mask` is provided.
|
||||
|
||||
Inputs:
|
||||
|
||||
prompt (`None`, *optional*):
|
||||
|
||||
image (`None`, *optional*):
|
||||
|
||||
mask (`None`, *optional*):
|
||||
```
|
||||
|
||||
There is a fundamental trade-off of AutoPipelineBlocks: it trades clarity for convenience. While it is really easy for packaging multiple workflows, it can become confusing without proper documentation. e.g. if we just throw a pipeline at you and tell you that it contains 3 sub-blocks and takes 3 inputs `prompt`, `image` and `mask`, and ask you to run an image-to-image workflow: if you don't have any prior knowledge on how these pipelines work, you would be pretty clueless, right?
|
||||
|
||||
This pipeline we just made though, has a docstring that shows all available inputs and workflows and explains how to use each with different inputs. So it's really helpful for users. For example, it's clear that you need to pass `image` to run img2img. This is why the description field is absolutely critical for AutoPipelineBlocks. We highly recommend you to explain the conditional logic very well for each `AutoPipelineBlocks` you would make. We also recommend to always test individual pipelines first before packaging them into AutoPipelineBlocks.
|
||||
|
||||
Let's run this auto pipeline with different inputs to see if the conditional logic works as described. Remember that we have added `print` in each `PipelineBlock`'s `__call__` method to print out its workflow name, so it should be easy to tell which one is running:
|
||||
|
||||
```py
|
||||
>>> _ = auto_pipeline(image="image", mask="mask")
|
||||
running the inpaint workflow
|
||||
>>> _ = auto_pipeline(image="image")
|
||||
running the image-to-image workflow
|
||||
>>> _ = auto_pipeline(prompt="prompt")
|
||||
running the text-to-image workflow
|
||||
>>> _ = auto_pipeline(image="prompt", mask="mask")
|
||||
running the inpaint workflow
|
||||
```
|
||||
|
||||
However, even with documentation, it can become very confusing when AutoPipelineBlocks are combined with other blocks. The complexity grows quickly when you have nested AutoPipelineBlocks or use them as sub-blocks in larger pipelines.
|
||||
|
||||
Let's make another `AutoPipelineBlocks` - this one only contains one block, and it does not include `None` in its `block_trigger_inputs` (which corresponds to the default block to run when none of the trigger inputs are provided). This means this block will be skipped if the trigger input (`ip_adapter_image`) is not provided at runtime.
|
||||
|
||||
```py
|
||||
from diffusers.modular_pipelines import SequentialPipelineBlocks, InsertableDict
|
||||
inputs = [InputParam(name="ip_adapter_image")]
|
||||
block_fn = lambda x, y: print("running the ip-adapter workflow")
|
||||
block_ipa_cls = make_block(inputs=inputs, block_fn=block_fn, description="I'm a IP-adapter workflow!")
|
||||
|
||||
class AutoIPAdapter(AutoPipelineBlocks):
|
||||
block_classes = [block_ipa_cls]
|
||||
block_names = ["ip-adapter"]
|
||||
block_trigger_inputs = ["ip_adapter_image"]
|
||||
@property
|
||||
def description(self):
|
||||
return "Run IP Adapter step if `ip_adapter_image` is provided."
|
||||
```
|
||||
|
||||
Now let's combine these 2 auto blocks together into a `SequentialPipelineBlocks`:
|
||||
|
||||
```py
|
||||
auto_ipa_blocks = AutoIPAdapter()
|
||||
blocks_dict = InsertableDict()
|
||||
blocks_dict["ip-adapter"] = auto_ipa_blocks
|
||||
blocks_dict["image-generation"] = auto_blocks
|
||||
all_blocks = SequentialPipelineBlocks.from_blocks_dict(blocks_dict)
|
||||
pipeline = all_blocks.init_pipeline()
|
||||
```
|
||||
|
||||
Let's take a look: now things get more confusing. In this particular example, you could still try to explain the conditional logic in the `description` field here - there are only 4 possible execution paths so it's doable. However, since this is a `SequentialPipelineBlocks` that could contain many more blocks, the complexity can quickly get out of hand as the number of blocks increases.
|
||||
|
||||
```py
|
||||
>>> all_blocks
|
||||
SequentialPipelineBlocks(
|
||||
Class: ModularPipelineBlocks
|
||||
|
||||
====================================================================================================
|
||||
This pipeline contains blocks that are selected at runtime based on inputs.
|
||||
Trigger Inputs: ['image', 'mask', 'ip_adapter_image']
|
||||
Use `get_execution_blocks()` with input names to see selected blocks (e.g. `get_execution_blocks('image')`).
|
||||
====================================================================================================
|
||||
|
||||
|
||||
Description:
|
||||
|
||||
|
||||
Sub-Blocks:
|
||||
[0] ip-adapter (AutoIPAdapter)
|
||||
Description: Run IP Adapter step if `ip_adapter_image` is provided.
|
||||
|
||||
|
||||
[1] image-generation (AutoImageBlocks)
|
||||
Description: Pipeline generates images given different types of conditions!
|
||||
This is an auto pipeline block that works for text2img, img2img and inpainting tasks.
|
||||
- inpaint workflow is run when `mask` is provided.
|
||||
- img2img workflow is run when `image` is provided (but only when `mask` is not provided).
|
||||
- text2img workflow is run when neither `image` nor `mask` is provided.
|
||||
|
||||
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
This is when the `get_execution_blocks()` method comes in handy - it basically extracts a `SequentialPipelineBlocks` that only contains the blocks that are actually run based on your inputs.
|
||||
|
||||
Let's try some examples:
|
||||
|
||||
`mask`: we expect it to skip the first ip-adapter since `ip_adapter_image` is not provided, and then run the inpaint for the second block.
|
||||
|
||||
```py
|
||||
>>> all_blocks.get_execution_blocks('mask')
|
||||
SequentialPipelineBlocks(
|
||||
Class: ModularPipelineBlocks
|
||||
|
||||
Description:
|
||||
|
||||
|
||||
Sub-Blocks:
|
||||
[0] image-generation (TestBlock)
|
||||
Description: I'm a inpaint workflow!
|
||||
|
||||
)
|
||||
```
|
||||
|
||||
Let's also actually run the pipeline to confirm:
|
||||
|
||||
```py
|
||||
>>> _ = pipeline(mask="mask")
|
||||
skipping auto block: AutoIPAdapter
|
||||
running the inpaint workflow
|
||||
```
|
||||
|
||||
Try a few more:
|
||||
|
||||
```py
|
||||
print(f"inputs: ip_adapter_image:")
|
||||
blocks_select = all_blocks.get_execution_blocks('ip_adapter_image')
|
||||
print(f"expected_execution_blocks: {blocks_select}")
|
||||
print(f"actual execution blocks:")
|
||||
_ = pipeline(ip_adapter_image="ip_adapter_image", prompt="prompt")
|
||||
# expect to see ip-adapter + text2img
|
||||
|
||||
print(f"inputs: image:")
|
||||
blocks_select = all_blocks.get_execution_blocks('image')
|
||||
print(f"expected_execution_blocks: {blocks_select}")
|
||||
print(f"actual execution blocks:")
|
||||
_ = pipeline(image="image", prompt="prompt")
|
||||
# expect to see img2img
|
||||
|
||||
print(f"inputs: prompt:")
|
||||
blocks_select = all_blocks.get_execution_blocks('prompt')
|
||||
print(f"expected_execution_blocks: {blocks_select}")
|
||||
print(f"actual execution blocks:")
|
||||
_ = pipeline(prompt="prompt")
|
||||
# expect to see text2img (prompt is not a trigger input so fallback to default)
|
||||
|
||||
print(f"inputs: mask + ip_adapter_image:")
|
||||
blocks_select = all_blocks.get_execution_blocks('mask','ip_adapter_image')
|
||||
print(f"expected_execution_blocks: {blocks_select}")
|
||||
print(f"actual execution blocks:")
|
||||
_ = pipeline(mask="mask", ip_adapter_image="ip_adapter_image")
|
||||
# expect to see ip-adapter + inpaint
|
||||
```
|
||||
|
||||
In summary, `AutoPipelineBlocks` is a good tool for packaging multiple workflows into a single, convenient interface and it can greatly simplify the user experience. However, always provide clear descriptions explaining the conditional logic, test individual pipelines first before combining them, and use `get_execution_blocks()` to understand runtime behavior in complex compositions.
|
||||
@@ -34,9 +34,11 @@ from .utils import (
|
||||
|
||||
_import_structure = {
|
||||
"configuration_utils": ["ConfigMixin"],
|
||||
"guiders": [],
|
||||
"hooks": [],
|
||||
"loaders": ["FromOriginalModelMixin"],
|
||||
"models": [],
|
||||
"modular_pipelines": [],
|
||||
"pipelines": [],
|
||||
"quantizers.quantization_config": [],
|
||||
"schedulers": [],
|
||||
@@ -130,12 +132,29 @@ except OptionalDependencyNotAvailable:
|
||||
_import_structure["utils.dummy_pt_objects"] = [name for name in dir(dummy_pt_objects) if not name.startswith("_")]
|
||||
|
||||
else:
|
||||
_import_structure["guiders"].extend(
|
||||
[
|
||||
"AdaptiveProjectedGuidance",
|
||||
"AutoGuidance",
|
||||
"ClassifierFreeGuidance",
|
||||
"ClassifierFreeZeroStarGuidance",
|
||||
"PerturbedAttentionGuidance",
|
||||
"SkipLayerGuidance",
|
||||
"SmoothedEnergyGuidance",
|
||||
"TangentialClassifierFreeGuidance",
|
||||
]
|
||||
)
|
||||
_import_structure["hooks"].extend(
|
||||
[
|
||||
"FasterCacheConfig",
|
||||
"FirstBlockCacheConfig",
|
||||
"HookRegistry",
|
||||
"LayerSkipConfig",
|
||||
"PyramidAttentionBroadcastConfig",
|
||||
"SmoothedEnergyGuidanceConfig",
|
||||
"apply_faster_cache",
|
||||
"apply_first_block_cache",
|
||||
"apply_layer_skip",
|
||||
"apply_pyramid_attention_broadcast",
|
||||
]
|
||||
)
|
||||
@@ -219,6 +238,14 @@ else:
|
||||
"WanVACETransformer3DModel",
|
||||
]
|
||||
)
|
||||
_import_structure["modular_pipelines"].extend(
|
||||
[
|
||||
"ComponentsManager",
|
||||
"ComponentSpec",
|
||||
"ModularPipeline",
|
||||
"ModularPipelineBlocks",
|
||||
]
|
||||
)
|
||||
_import_structure["optimization"] = [
|
||||
"get_constant_schedule",
|
||||
"get_constant_schedule_with_warmup",
|
||||
@@ -331,6 +358,12 @@ except OptionalDependencyNotAvailable:
|
||||
]
|
||||
|
||||
else:
|
||||
_import_structure["modular_pipelines"].extend(
|
||||
[
|
||||
"StableDiffusionXLAutoBlocks",
|
||||
"StableDiffusionXLModularPipeline",
|
||||
]
|
||||
)
|
||||
_import_structure["pipelines"].extend(
|
||||
[
|
||||
"AllegroPipeline",
|
||||
@@ -543,6 +576,7 @@ else:
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
try:
|
||||
if not (is_torch_available() and is_transformers_available() and is_opencv_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
@@ -749,11 +783,26 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
except OptionalDependencyNotAvailable:
|
||||
from .utils.dummy_pt_objects import * # noqa F403
|
||||
else:
|
||||
from .guiders import (
|
||||
AdaptiveProjectedGuidance,
|
||||
AutoGuidance,
|
||||
ClassifierFreeGuidance,
|
||||
ClassifierFreeZeroStarGuidance,
|
||||
PerturbedAttentionGuidance,
|
||||
SkipLayerGuidance,
|
||||
SmoothedEnergyGuidance,
|
||||
TangentialClassifierFreeGuidance,
|
||||
)
|
||||
from .hooks import (
|
||||
FasterCacheConfig,
|
||||
FirstBlockCacheConfig,
|
||||
HookRegistry,
|
||||
LayerSkipConfig,
|
||||
PyramidAttentionBroadcastConfig,
|
||||
SmoothedEnergyGuidanceConfig,
|
||||
apply_faster_cache,
|
||||
apply_first_block_cache,
|
||||
apply_layer_skip,
|
||||
apply_pyramid_attention_broadcast,
|
||||
)
|
||||
from .models import (
|
||||
@@ -833,6 +882,12 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
WanTransformer3DModel,
|
||||
WanVACETransformer3DModel,
|
||||
)
|
||||
from .modular_pipelines import (
|
||||
ComponentsManager,
|
||||
ComponentSpec,
|
||||
ModularPipeline,
|
||||
ModularPipelineBlocks,
|
||||
)
|
||||
from .optimization import (
|
||||
get_constant_schedule,
|
||||
get_constant_schedule_with_warmup,
|
||||
@@ -929,6 +984,10 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
except OptionalDependencyNotAvailable:
|
||||
from .utils.dummy_torch_and_transformers_objects import * # noqa F403
|
||||
else:
|
||||
from .modular_pipelines import (
|
||||
StableDiffusionXLAutoBlocks,
|
||||
StableDiffusionXLModularPipeline,
|
||||
)
|
||||
from .pipelines import (
|
||||
AllegroPipeline,
|
||||
AltDiffusionImg2ImgPipeline,
|
||||
|
||||
134
src/diffusers/commands/custom_blocks.py
Normal file
134
src/diffusers/commands/custom_blocks.py
Normal file
@@ -0,0 +1,134 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""
|
||||
Usage example:
|
||||
TODO
|
||||
"""
|
||||
|
||||
import ast
|
||||
import importlib.util
|
||||
import os
|
||||
from argparse import ArgumentParser, Namespace
|
||||
from pathlib import Path
|
||||
|
||||
from ..utils import logging
|
||||
from . import BaseDiffusersCLICommand
|
||||
|
||||
|
||||
EXPECTED_PARENT_CLASSES = ["ModularPipelineBlocks"]
|
||||
CONFIG = "config.json"
|
||||
|
||||
|
||||
def conversion_command_factory(args: Namespace):
|
||||
return CustomBlocksCommand(args.block_module_name, args.block_class_name)
|
||||
|
||||
|
||||
class CustomBlocksCommand(BaseDiffusersCLICommand):
|
||||
@staticmethod
|
||||
def register_subcommand(parser: ArgumentParser):
|
||||
conversion_parser = parser.add_parser("custom_blocks")
|
||||
conversion_parser.add_argument(
|
||||
"--block_module_name",
|
||||
type=str,
|
||||
default="block.py",
|
||||
help="Module filename in which the custom block will be implemented.",
|
||||
)
|
||||
conversion_parser.add_argument(
|
||||
"--block_class_name",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Name of the custom block. If provided None, we will try to infer it.",
|
||||
)
|
||||
conversion_parser.set_defaults(func=conversion_command_factory)
|
||||
|
||||
def __init__(self, block_module_name: str = "block.py", block_class_name: str = None):
|
||||
self.logger = logging.get_logger("diffusers-cli/custom_blocks")
|
||||
self.block_module_name = Path(block_module_name)
|
||||
self.block_class_name = block_class_name
|
||||
|
||||
def run(self):
|
||||
# determine the block to be saved.
|
||||
out = self._get_class_names(self.block_module_name)
|
||||
classes_found = list({cls for cls, _ in out})
|
||||
|
||||
if self.block_class_name is not None:
|
||||
child_class, parent_class = self._choose_block(out, self.block_class_name)
|
||||
if child_class is None and parent_class is None:
|
||||
raise ValueError(
|
||||
"`block_class_name` could not be retrieved. Available classes from "
|
||||
f"{self.block_module_name}:\n{classes_found}"
|
||||
)
|
||||
else:
|
||||
self.logger.info(
|
||||
f"Found classes: {classes_found} will be using {classes_found[0]}. "
|
||||
"If this needs to be changed, re-run the command specifying `block_class_name`."
|
||||
)
|
||||
child_class, parent_class = out[0][0], out[0][1]
|
||||
|
||||
# dynamically get the custom block and initialize it to call `save_pretrained` in the current directory.
|
||||
# the user is responsible for running it, so I guess that is safe?
|
||||
module_name = f"__dynamic__{self.block_module_name.stem}"
|
||||
spec = importlib.util.spec_from_file_location(module_name, str(self.block_module_name))
|
||||
module = importlib.util.module_from_spec(spec)
|
||||
spec.loader.exec_module(module)
|
||||
getattr(module, child_class)().save_pretrained(os.getcwd())
|
||||
|
||||
# or, we could create it manually.
|
||||
# automap = self._create_automap(parent_class=parent_class, child_class=child_class)
|
||||
# with open(CONFIG, "w") as f:
|
||||
# json.dump(automap, f)
|
||||
with open("requirements.txt", "w") as f:
|
||||
f.write("")
|
||||
|
||||
def _choose_block(self, candidates, chosen=None):
|
||||
for cls, base in candidates:
|
||||
if cls == chosen:
|
||||
return cls, base
|
||||
return None, None
|
||||
|
||||
def _get_class_names(self, file_path):
|
||||
source = file_path.read_text(encoding="utf-8")
|
||||
try:
|
||||
tree = ast.parse(source, filename=file_path)
|
||||
except SyntaxError as e:
|
||||
raise ValueError(f"Could not parse {file_path!r}: {e}") from e
|
||||
|
||||
results: list[tuple[str, str]] = []
|
||||
for node in tree.body:
|
||||
if not isinstance(node, ast.ClassDef):
|
||||
continue
|
||||
|
||||
# extract all base names for this class
|
||||
base_names = [bname for b in node.bases if (bname := self._get_base_name(b)) is not None]
|
||||
|
||||
# for each allowed base that appears in the class's bases, emit a tuple
|
||||
for allowed in EXPECTED_PARENT_CLASSES:
|
||||
if allowed in base_names:
|
||||
results.append((node.name, allowed))
|
||||
|
||||
return results
|
||||
|
||||
def _get_base_name(self, node: ast.expr):
|
||||
if isinstance(node, ast.Name):
|
||||
return node.id
|
||||
elif isinstance(node, ast.Attribute):
|
||||
val = self._get_base_name(node.value)
|
||||
return f"{val}.{node.attr}" if val else node.attr
|
||||
return None
|
||||
|
||||
def _create_automap(self, parent_class, child_class):
|
||||
module = str(self.block_module_name).replace(".py", "").rsplit(".", 1)[-1]
|
||||
auto_map = {f"{parent_class}": f"{module}.{child_class}"}
|
||||
return {"auto_map": auto_map}
|
||||
@@ -15,6 +15,7 @@
|
||||
|
||||
from argparse import ArgumentParser
|
||||
|
||||
from .custom_blocks import CustomBlocksCommand
|
||||
from .env import EnvironmentCommand
|
||||
from .fp16_safetensors import FP16SafetensorsCommand
|
||||
|
||||
@@ -26,6 +27,7 @@ def main():
|
||||
# Register commands
|
||||
EnvironmentCommand.register_subcommand(commands_parser)
|
||||
FP16SafetensorsCommand.register_subcommand(commands_parser)
|
||||
CustomBlocksCommand.register_subcommand(commands_parser)
|
||||
|
||||
# Let's go
|
||||
args = parser.parse_args()
|
||||
|
||||
@@ -176,6 +176,7 @@ class ConfigMixin:
|
||||
token = kwargs.pop("token", None)
|
||||
repo_id = kwargs.pop("repo_id", save_directory.split(os.path.sep)[-1])
|
||||
repo_id = create_repo(repo_id, exist_ok=True, private=private, token=token).repo_id
|
||||
subfolder = kwargs.pop("subfolder", None)
|
||||
|
||||
self._upload_folder(
|
||||
save_directory,
|
||||
@@ -183,6 +184,7 @@ class ConfigMixin:
|
||||
token=token,
|
||||
commit_message=commit_message,
|
||||
create_pr=create_pr,
|
||||
subfolder=subfolder,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
@@ -601,6 +603,10 @@ class ConfigMixin:
|
||||
value = value.tolist()
|
||||
elif isinstance(value, Path):
|
||||
value = value.as_posix()
|
||||
elif hasattr(value, "to_dict") and callable(value.to_dict):
|
||||
value = value.to_dict()
|
||||
elif isinstance(value, list):
|
||||
value = [to_json_saveable(v) for v in value]
|
||||
return value
|
||||
|
||||
if "quantization_config" in config_dict:
|
||||
|
||||
39
src/diffusers/guiders/__init__.py
Normal file
39
src/diffusers/guiders/__init__.py
Normal file
@@ -0,0 +1,39 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from typing import Union
|
||||
|
||||
from ..utils import is_torch_available
|
||||
|
||||
|
||||
if is_torch_available():
|
||||
from .adaptive_projected_guidance import AdaptiveProjectedGuidance
|
||||
from .auto_guidance import AutoGuidance
|
||||
from .classifier_free_guidance import ClassifierFreeGuidance
|
||||
from .classifier_free_zero_star_guidance import ClassifierFreeZeroStarGuidance
|
||||
from .perturbed_attention_guidance import PerturbedAttentionGuidance
|
||||
from .skip_layer_guidance import SkipLayerGuidance
|
||||
from .smoothed_energy_guidance import SmoothedEnergyGuidance
|
||||
from .tangential_classifier_free_guidance import TangentialClassifierFreeGuidance
|
||||
|
||||
GuiderType = Union[
|
||||
AdaptiveProjectedGuidance,
|
||||
AutoGuidance,
|
||||
ClassifierFreeGuidance,
|
||||
ClassifierFreeZeroStarGuidance,
|
||||
PerturbedAttentionGuidance,
|
||||
SkipLayerGuidance,
|
||||
SmoothedEnergyGuidance,
|
||||
TangentialClassifierFreeGuidance,
|
||||
]
|
||||
188
src/diffusers/guiders/adaptive_projected_guidance.py
Normal file
188
src/diffusers/guiders/adaptive_projected_guidance.py
Normal file
@@ -0,0 +1,188 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import math
|
||||
from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ..configuration_utils import register_to_config
|
||||
from .guider_utils import BaseGuidance, rescale_noise_cfg
|
||||
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from ..modular_pipelines.modular_pipeline import BlockState
|
||||
|
||||
|
||||
class AdaptiveProjectedGuidance(BaseGuidance):
|
||||
"""
|
||||
Adaptive Projected Guidance (APG): https://huggingface.co/papers/2410.02416
|
||||
|
||||
Args:
|
||||
guidance_scale (`float`, defaults to `7.5`):
|
||||
The scale parameter for classifier-free guidance. Higher values result in stronger conditioning on the text
|
||||
prompt, while lower values allow for more freedom in generation. Higher values may lead to saturation and
|
||||
deterioration of image quality.
|
||||
adaptive_projected_guidance_momentum (`float`, defaults to `None`):
|
||||
The momentum parameter for the adaptive projected guidance. Disabled if set to `None`.
|
||||
adaptive_projected_guidance_rescale (`float`, defaults to `15.0`):
|
||||
The rescale factor applied to the noise predictions. This is used to improve image quality and fix
|
||||
guidance_rescale (`float`, defaults to `0.0`):
|
||||
The rescale factor applied to the noise predictions. This is used to improve image quality and fix
|
||||
overexposure. Based on Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
|
||||
Flawed](https://huggingface.co/papers/2305.08891).
|
||||
use_original_formulation (`bool`, defaults to `False`):
|
||||
Whether to use the original formulation of classifier-free guidance as proposed in the paper. By default,
|
||||
we use the diffusers-native implementation that has been in the codebase for a long time. See
|
||||
[~guiders.classifier_free_guidance.ClassifierFreeGuidance] for more details.
|
||||
start (`float`, defaults to `0.0`):
|
||||
The fraction of the total number of denoising steps after which guidance starts.
|
||||
stop (`float`, defaults to `1.0`):
|
||||
The fraction of the total number of denoising steps after which guidance stops.
|
||||
"""
|
||||
|
||||
_input_predictions = ["pred_cond", "pred_uncond"]
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
guidance_scale: float = 7.5,
|
||||
adaptive_projected_guidance_momentum: Optional[float] = None,
|
||||
adaptive_projected_guidance_rescale: float = 15.0,
|
||||
eta: float = 1.0,
|
||||
guidance_rescale: float = 0.0,
|
||||
use_original_formulation: bool = False,
|
||||
start: float = 0.0,
|
||||
stop: float = 1.0,
|
||||
):
|
||||
super().__init__(start, stop)
|
||||
|
||||
self.guidance_scale = guidance_scale
|
||||
self.adaptive_projected_guidance_momentum = adaptive_projected_guidance_momentum
|
||||
self.adaptive_projected_guidance_rescale = adaptive_projected_guidance_rescale
|
||||
self.eta = eta
|
||||
self.guidance_rescale = guidance_rescale
|
||||
self.use_original_formulation = use_original_formulation
|
||||
self.momentum_buffer = None
|
||||
|
||||
def prepare_inputs(
|
||||
self, data: "BlockState", input_fields: Optional[Dict[str, Union[str, Tuple[str, str]]]] = None
|
||||
) -> List["BlockState"]:
|
||||
if input_fields is None:
|
||||
input_fields = self._input_fields
|
||||
|
||||
if self._step == 0:
|
||||
if self.adaptive_projected_guidance_momentum is not None:
|
||||
self.momentum_buffer = MomentumBuffer(self.adaptive_projected_guidance_momentum)
|
||||
tuple_indices = [0] if self.num_conditions == 1 else [0, 1]
|
||||
data_batches = []
|
||||
for i in range(self.num_conditions):
|
||||
data_batch = self._prepare_batch(input_fields, data, tuple_indices[i], self._input_predictions[i])
|
||||
data_batches.append(data_batch)
|
||||
return data_batches
|
||||
|
||||
def forward(self, pred_cond: torch.Tensor, pred_uncond: Optional[torch.Tensor] = None) -> torch.Tensor:
|
||||
pred = None
|
||||
|
||||
if not self._is_apg_enabled():
|
||||
pred = pred_cond
|
||||
else:
|
||||
pred = normalized_guidance(
|
||||
pred_cond,
|
||||
pred_uncond,
|
||||
self.guidance_scale,
|
||||
self.momentum_buffer,
|
||||
self.eta,
|
||||
self.adaptive_projected_guidance_rescale,
|
||||
self.use_original_formulation,
|
||||
)
|
||||
|
||||
if self.guidance_rescale > 0.0:
|
||||
pred = rescale_noise_cfg(pred, pred_cond, self.guidance_rescale)
|
||||
|
||||
return pred, {}
|
||||
|
||||
@property
|
||||
def is_conditional(self) -> bool:
|
||||
return self._count_prepared == 1
|
||||
|
||||
@property
|
||||
def num_conditions(self) -> int:
|
||||
num_conditions = 1
|
||||
if self._is_apg_enabled():
|
||||
num_conditions += 1
|
||||
return num_conditions
|
||||
|
||||
def _is_apg_enabled(self) -> bool:
|
||||
if not self._enabled:
|
||||
return False
|
||||
|
||||
is_within_range = True
|
||||
if self._num_inference_steps is not None:
|
||||
skip_start_step = int(self._start * self._num_inference_steps)
|
||||
skip_stop_step = int(self._stop * self._num_inference_steps)
|
||||
is_within_range = skip_start_step <= self._step < skip_stop_step
|
||||
|
||||
is_close = False
|
||||
if self.use_original_formulation:
|
||||
is_close = math.isclose(self.guidance_scale, 0.0)
|
||||
else:
|
||||
is_close = math.isclose(self.guidance_scale, 1.0)
|
||||
|
||||
return is_within_range and not is_close
|
||||
|
||||
|
||||
class MomentumBuffer:
|
||||
def __init__(self, momentum: float):
|
||||
self.momentum = momentum
|
||||
self.running_average = 0
|
||||
|
||||
def update(self, update_value: torch.Tensor):
|
||||
new_average = self.momentum * self.running_average
|
||||
self.running_average = update_value + new_average
|
||||
|
||||
|
||||
def normalized_guidance(
|
||||
pred_cond: torch.Tensor,
|
||||
pred_uncond: torch.Tensor,
|
||||
guidance_scale: float,
|
||||
momentum_buffer: Optional[MomentumBuffer] = None,
|
||||
eta: float = 1.0,
|
||||
norm_threshold: float = 0.0,
|
||||
use_original_formulation: bool = False,
|
||||
):
|
||||
diff = pred_cond - pred_uncond
|
||||
dim = [-i for i in range(1, len(diff.shape))]
|
||||
|
||||
if momentum_buffer is not None:
|
||||
momentum_buffer.update(diff)
|
||||
diff = momentum_buffer.running_average
|
||||
|
||||
if norm_threshold > 0:
|
||||
ones = torch.ones_like(diff)
|
||||
diff_norm = diff.norm(p=2, dim=dim, keepdim=True)
|
||||
scale_factor = torch.minimum(ones, norm_threshold / diff_norm)
|
||||
diff = diff * scale_factor
|
||||
|
||||
v0, v1 = diff.double(), pred_cond.double()
|
||||
v1 = torch.nn.functional.normalize(v1, dim=dim)
|
||||
v0_parallel = (v0 * v1).sum(dim=dim, keepdim=True) * v1
|
||||
v0_orthogonal = v0 - v0_parallel
|
||||
diff_parallel, diff_orthogonal = v0_parallel.type_as(diff), v0_orthogonal.type_as(diff)
|
||||
normalized_update = diff_orthogonal + eta * diff_parallel
|
||||
|
||||
pred = pred_cond if use_original_formulation else pred_uncond
|
||||
pred = pred + guidance_scale * normalized_update
|
||||
|
||||
return pred
|
||||
190
src/diffusers/guiders/auto_guidance.py
Normal file
190
src/diffusers/guiders/auto_guidance.py
Normal file
@@ -0,0 +1,190 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import math
|
||||
from typing import TYPE_CHECKING, Any, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ..configuration_utils import register_to_config
|
||||
from ..hooks import HookRegistry, LayerSkipConfig
|
||||
from ..hooks.layer_skip import _apply_layer_skip_hook
|
||||
from .guider_utils import BaseGuidance, rescale_noise_cfg
|
||||
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from ..modular_pipelines.modular_pipeline import BlockState
|
||||
|
||||
|
||||
class AutoGuidance(BaseGuidance):
|
||||
"""
|
||||
AutoGuidance: https://huggingface.co/papers/2406.02507
|
||||
|
||||
Args:
|
||||
guidance_scale (`float`, defaults to `7.5`):
|
||||
The scale parameter for classifier-free guidance. Higher values result in stronger conditioning on the text
|
||||
prompt, while lower values allow for more freedom in generation. Higher values may lead to saturation and
|
||||
deterioration of image quality.
|
||||
auto_guidance_layers (`int` or `List[int]`, *optional*):
|
||||
The layer indices to apply skip layer guidance to. Can be a single integer or a list of integers. If not
|
||||
provided, `skip_layer_config` must be provided.
|
||||
auto_guidance_config (`LayerSkipConfig` or `List[LayerSkipConfig]`, *optional*):
|
||||
The configuration for the skip layer guidance. Can be a single `LayerSkipConfig` or a list of
|
||||
`LayerSkipConfig`. If not provided, `skip_layer_guidance_layers` must be provided.
|
||||
dropout (`float`, *optional*):
|
||||
The dropout probability for autoguidance on the enabled skip layers (either with `auto_guidance_layers` or
|
||||
`auto_guidance_config`). If not provided, the dropout probability will be set to 1.0.
|
||||
guidance_rescale (`float`, defaults to `0.0`):
|
||||
The rescale factor applied to the noise predictions. This is used to improve image quality and fix
|
||||
overexposure. Based on Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
|
||||
Flawed](https://huggingface.co/papers/2305.08891).
|
||||
use_original_formulation (`bool`, defaults to `False`):
|
||||
Whether to use the original formulation of classifier-free guidance as proposed in the paper. By default,
|
||||
we use the diffusers-native implementation that has been in the codebase for a long time. See
|
||||
[~guiders.classifier_free_guidance.ClassifierFreeGuidance] for more details.
|
||||
start (`float`, defaults to `0.0`):
|
||||
The fraction of the total number of denoising steps after which guidance starts.
|
||||
stop (`float`, defaults to `1.0`):
|
||||
The fraction of the total number of denoising steps after which guidance stops.
|
||||
"""
|
||||
|
||||
_input_predictions = ["pred_cond", "pred_uncond"]
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
guidance_scale: float = 7.5,
|
||||
auto_guidance_layers: Optional[Union[int, List[int]]] = None,
|
||||
auto_guidance_config: Union[LayerSkipConfig, List[LayerSkipConfig], Dict[str, Any]] = None,
|
||||
dropout: Optional[float] = None,
|
||||
guidance_rescale: float = 0.0,
|
||||
use_original_formulation: bool = False,
|
||||
start: float = 0.0,
|
||||
stop: float = 1.0,
|
||||
):
|
||||
super().__init__(start, stop)
|
||||
|
||||
self.guidance_scale = guidance_scale
|
||||
self.auto_guidance_layers = auto_guidance_layers
|
||||
self.auto_guidance_config = auto_guidance_config
|
||||
self.dropout = dropout
|
||||
self.guidance_rescale = guidance_rescale
|
||||
self.use_original_formulation = use_original_formulation
|
||||
|
||||
if auto_guidance_layers is None and auto_guidance_config is None:
|
||||
raise ValueError(
|
||||
"Either `auto_guidance_layers` or `auto_guidance_config` must be provided to enable Skip Layer Guidance."
|
||||
)
|
||||
if auto_guidance_layers is not None and auto_guidance_config is not None:
|
||||
raise ValueError("Only one of `auto_guidance_layers` or `auto_guidance_config` can be provided.")
|
||||
if (dropout is None and auto_guidance_layers is not None) or (
|
||||
dropout is not None and auto_guidance_layers is None
|
||||
):
|
||||
raise ValueError("`dropout` must be provided if `auto_guidance_layers` is provided.")
|
||||
|
||||
if auto_guidance_layers is not None:
|
||||
if isinstance(auto_guidance_layers, int):
|
||||
auto_guidance_layers = [auto_guidance_layers]
|
||||
if not isinstance(auto_guidance_layers, list):
|
||||
raise ValueError(
|
||||
f"Expected `auto_guidance_layers` to be an int or a list of ints, but got {type(auto_guidance_layers)}."
|
||||
)
|
||||
auto_guidance_config = [
|
||||
LayerSkipConfig(layer, fqn="auto", dropout=dropout) for layer in auto_guidance_layers
|
||||
]
|
||||
|
||||
if isinstance(auto_guidance_config, dict):
|
||||
auto_guidance_config = LayerSkipConfig.from_dict(auto_guidance_config)
|
||||
|
||||
if isinstance(auto_guidance_config, LayerSkipConfig):
|
||||
auto_guidance_config = [auto_guidance_config]
|
||||
|
||||
if not isinstance(auto_guidance_config, list):
|
||||
raise ValueError(
|
||||
f"Expected `auto_guidance_config` to be a LayerSkipConfig or a list of LayerSkipConfig, but got {type(auto_guidance_config)}."
|
||||
)
|
||||
elif isinstance(next(iter(auto_guidance_config), None), dict):
|
||||
auto_guidance_config = [LayerSkipConfig.from_dict(config) for config in auto_guidance_config]
|
||||
|
||||
self.auto_guidance_config = auto_guidance_config
|
||||
self._auto_guidance_hook_names = [f"AutoGuidance_{i}" for i in range(len(self.auto_guidance_config))]
|
||||
|
||||
def prepare_models(self, denoiser: torch.nn.Module) -> None:
|
||||
self._count_prepared += 1
|
||||
if self._is_ag_enabled() and self.is_unconditional:
|
||||
for name, config in zip(self._auto_guidance_hook_names, self.auto_guidance_config):
|
||||
_apply_layer_skip_hook(denoiser, config, name=name)
|
||||
|
||||
def cleanup_models(self, denoiser: torch.nn.Module) -> None:
|
||||
if self._is_ag_enabled() and self.is_unconditional:
|
||||
for name in self._auto_guidance_hook_names:
|
||||
registry = HookRegistry.check_if_exists_or_initialize(denoiser)
|
||||
registry.remove_hook(name, recurse=True)
|
||||
|
||||
def prepare_inputs(
|
||||
self, data: "BlockState", input_fields: Optional[Dict[str, Union[str, Tuple[str, str]]]] = None
|
||||
) -> List["BlockState"]:
|
||||
if input_fields is None:
|
||||
input_fields = self._input_fields
|
||||
|
||||
tuple_indices = [0] if self.num_conditions == 1 else [0, 1]
|
||||
data_batches = []
|
||||
for i in range(self.num_conditions):
|
||||
data_batch = self._prepare_batch(input_fields, data, tuple_indices[i], self._input_predictions[i])
|
||||
data_batches.append(data_batch)
|
||||
return data_batches
|
||||
|
||||
def forward(self, pred_cond: torch.Tensor, pred_uncond: Optional[torch.Tensor] = None) -> torch.Tensor:
|
||||
pred = None
|
||||
|
||||
if not self._is_ag_enabled():
|
||||
pred = pred_cond
|
||||
else:
|
||||
shift = pred_cond - pred_uncond
|
||||
pred = pred_cond if self.use_original_formulation else pred_uncond
|
||||
pred = pred + self.guidance_scale * shift
|
||||
|
||||
if self.guidance_rescale > 0.0:
|
||||
pred = rescale_noise_cfg(pred, pred_cond, self.guidance_rescale)
|
||||
|
||||
return pred, {}
|
||||
|
||||
@property
|
||||
def is_conditional(self) -> bool:
|
||||
return self._count_prepared == 1
|
||||
|
||||
@property
|
||||
def num_conditions(self) -> int:
|
||||
num_conditions = 1
|
||||
if self._is_ag_enabled():
|
||||
num_conditions += 1
|
||||
return num_conditions
|
||||
|
||||
def _is_ag_enabled(self) -> bool:
|
||||
if not self._enabled:
|
||||
return False
|
||||
|
||||
is_within_range = True
|
||||
if self._num_inference_steps is not None:
|
||||
skip_start_step = int(self._start * self._num_inference_steps)
|
||||
skip_stop_step = int(self._stop * self._num_inference_steps)
|
||||
is_within_range = skip_start_step <= self._step < skip_stop_step
|
||||
|
||||
is_close = False
|
||||
if self.use_original_formulation:
|
||||
is_close = math.isclose(self.guidance_scale, 0.0)
|
||||
else:
|
||||
is_close = math.isclose(self.guidance_scale, 1.0)
|
||||
|
||||
return is_within_range and not is_close
|
||||
141
src/diffusers/guiders/classifier_free_guidance.py
Normal file
141
src/diffusers/guiders/classifier_free_guidance.py
Normal file
@@ -0,0 +1,141 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import math
|
||||
from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ..configuration_utils import register_to_config
|
||||
from .guider_utils import BaseGuidance, rescale_noise_cfg
|
||||
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from ..modular_pipelines.modular_pipeline import BlockState
|
||||
|
||||
|
||||
class ClassifierFreeGuidance(BaseGuidance):
|
||||
"""
|
||||
Classifier-free guidance (CFG): https://huggingface.co/papers/2207.12598
|
||||
|
||||
CFG is a technique used to improve generation quality and condition-following in diffusion models. It works by
|
||||
jointly training a model on both conditional and unconditional data, and using a weighted sum of the two during
|
||||
inference. This allows the model to tradeoff between generation quality and sample diversity. The original paper
|
||||
proposes scaling and shifting the conditional distribution based on the difference between conditional and
|
||||
unconditional predictions. [x_pred = x_cond + scale * (x_cond - x_uncond)]
|
||||
|
||||
Diffusers implemented the scaling and shifting on the unconditional prediction instead based on the [Imagen
|
||||
paper](https://huggingface.co/papers/2205.11487), which is equivalent to what the original paper proposed in
|
||||
theory. [x_pred = x_uncond + scale * (x_cond - x_uncond)]
|
||||
|
||||
The intution behind the original formulation can be thought of as moving the conditional distribution estimates
|
||||
further away from the unconditional distribution estimates, while the diffusers-native implementation can be
|
||||
thought of as moving the unconditional distribution towards the conditional distribution estimates to get rid of
|
||||
the unconditional predictions (usually negative features like "bad quality, bad anotomy, watermarks", etc.)
|
||||
|
||||
The `use_original_formulation` argument can be set to `True` to use the original CFG formulation mentioned in the
|
||||
paper. By default, we use the diffusers-native implementation that has been in the codebase for a long time.
|
||||
|
||||
Args:
|
||||
guidance_scale (`float`, defaults to `7.5`):
|
||||
The scale parameter for classifier-free guidance. Higher values result in stronger conditioning on the text
|
||||
prompt, while lower values allow for more freedom in generation. Higher values may lead to saturation and
|
||||
deterioration of image quality.
|
||||
guidance_rescale (`float`, defaults to `0.0`):
|
||||
The rescale factor applied to the noise predictions. This is used to improve image quality and fix
|
||||
overexposure. Based on Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
|
||||
Flawed](https://huggingface.co/papers/2305.08891).
|
||||
use_original_formulation (`bool`, defaults to `False`):
|
||||
Whether to use the original formulation of classifier-free guidance as proposed in the paper. By default,
|
||||
we use the diffusers-native implementation that has been in the codebase for a long time. See
|
||||
[~guiders.classifier_free_guidance.ClassifierFreeGuidance] for more details.
|
||||
start (`float`, defaults to `0.0`):
|
||||
The fraction of the total number of denoising steps after which guidance starts.
|
||||
stop (`float`, defaults to `1.0`):
|
||||
The fraction of the total number of denoising steps after which guidance stops.
|
||||
"""
|
||||
|
||||
_input_predictions = ["pred_cond", "pred_uncond"]
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
guidance_scale: float = 7.5,
|
||||
guidance_rescale: float = 0.0,
|
||||
use_original_formulation: bool = False,
|
||||
start: float = 0.0,
|
||||
stop: float = 1.0,
|
||||
):
|
||||
super().__init__(start, stop)
|
||||
|
||||
self.guidance_scale = guidance_scale
|
||||
self.guidance_rescale = guidance_rescale
|
||||
self.use_original_formulation = use_original_formulation
|
||||
|
||||
def prepare_inputs(
|
||||
self, data: "BlockState", input_fields: Optional[Dict[str, Union[str, Tuple[str, str]]]] = None
|
||||
) -> List["BlockState"]:
|
||||
if input_fields is None:
|
||||
input_fields = self._input_fields
|
||||
|
||||
tuple_indices = [0] if self.num_conditions == 1 else [0, 1]
|
||||
data_batches = []
|
||||
for i in range(self.num_conditions):
|
||||
data_batch = self._prepare_batch(input_fields, data, tuple_indices[i], self._input_predictions[i])
|
||||
data_batches.append(data_batch)
|
||||
return data_batches
|
||||
|
||||
def forward(self, pred_cond: torch.Tensor, pred_uncond: Optional[torch.Tensor] = None) -> torch.Tensor:
|
||||
pred = None
|
||||
|
||||
if not self._is_cfg_enabled():
|
||||
pred = pred_cond
|
||||
else:
|
||||
shift = pred_cond - pred_uncond
|
||||
pred = pred_cond if self.use_original_formulation else pred_uncond
|
||||
pred = pred + self.guidance_scale * shift
|
||||
|
||||
if self.guidance_rescale > 0.0:
|
||||
pred = rescale_noise_cfg(pred, pred_cond, self.guidance_rescale)
|
||||
|
||||
return pred, {}
|
||||
|
||||
@property
|
||||
def is_conditional(self) -> bool:
|
||||
return self._count_prepared == 1
|
||||
|
||||
@property
|
||||
def num_conditions(self) -> int:
|
||||
num_conditions = 1
|
||||
if self._is_cfg_enabled():
|
||||
num_conditions += 1
|
||||
return num_conditions
|
||||
|
||||
def _is_cfg_enabled(self) -> bool:
|
||||
if not self._enabled:
|
||||
return False
|
||||
|
||||
is_within_range = True
|
||||
if self._num_inference_steps is not None:
|
||||
skip_start_step = int(self._start * self._num_inference_steps)
|
||||
skip_stop_step = int(self._stop * self._num_inference_steps)
|
||||
is_within_range = skip_start_step <= self._step < skip_stop_step
|
||||
|
||||
is_close = False
|
||||
if self.use_original_formulation:
|
||||
is_close = math.isclose(self.guidance_scale, 0.0)
|
||||
else:
|
||||
is_close = math.isclose(self.guidance_scale, 1.0)
|
||||
|
||||
return is_within_range and not is_close
|
||||
152
src/diffusers/guiders/classifier_free_zero_star_guidance.py
Normal file
152
src/diffusers/guiders/classifier_free_zero_star_guidance.py
Normal file
@@ -0,0 +1,152 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import math
|
||||
from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ..configuration_utils import register_to_config
|
||||
from .guider_utils import BaseGuidance, rescale_noise_cfg
|
||||
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from ..modular_pipelines.modular_pipeline import BlockState
|
||||
|
||||
|
||||
class ClassifierFreeZeroStarGuidance(BaseGuidance):
|
||||
"""
|
||||
Classifier-free Zero* (CFG-Zero*): https://huggingface.co/papers/2503.18886
|
||||
|
||||
This is an implementation of the Classifier-Free Zero* guidance technique, which is a variant of classifier-free
|
||||
guidance. It proposes zero initialization of the noise predictions for the first few steps of the diffusion
|
||||
process, and also introduces an optimal rescaling factor for the noise predictions, which can help in improving the
|
||||
quality of generated images.
|
||||
|
||||
The authors of the paper suggest setting zero initialization in the first 4% of the inference steps.
|
||||
|
||||
Args:
|
||||
guidance_scale (`float`, defaults to `7.5`):
|
||||
The scale parameter for classifier-free guidance. Higher values result in stronger conditioning on the text
|
||||
prompt, while lower values allow for more freedom in generation. Higher values may lead to saturation and
|
||||
deterioration of image quality.
|
||||
zero_init_steps (`int`, defaults to `1`):
|
||||
The number of inference steps for which the noise predictions are zeroed out (see Section 4.2).
|
||||
guidance_rescale (`float`, defaults to `0.0`):
|
||||
The rescale factor applied to the noise predictions. This is used to improve image quality and fix
|
||||
overexposure. Based on Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
|
||||
Flawed](https://huggingface.co/papers/2305.08891).
|
||||
use_original_formulation (`bool`, defaults to `False`):
|
||||
Whether to use the original formulation of classifier-free guidance as proposed in the paper. By default,
|
||||
we use the diffusers-native implementation that has been in the codebase for a long time. See
|
||||
[~guiders.classifier_free_guidance.ClassifierFreeGuidance] for more details.
|
||||
start (`float`, defaults to `0.01`):
|
||||
The fraction of the total number of denoising steps after which guidance starts.
|
||||
stop (`float`, defaults to `0.2`):
|
||||
The fraction of the total number of denoising steps after which guidance stops.
|
||||
"""
|
||||
|
||||
_input_predictions = ["pred_cond", "pred_uncond"]
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
guidance_scale: float = 7.5,
|
||||
zero_init_steps: int = 1,
|
||||
guidance_rescale: float = 0.0,
|
||||
use_original_formulation: bool = False,
|
||||
start: float = 0.0,
|
||||
stop: float = 1.0,
|
||||
):
|
||||
super().__init__(start, stop)
|
||||
|
||||
self.guidance_scale = guidance_scale
|
||||
self.zero_init_steps = zero_init_steps
|
||||
self.guidance_rescale = guidance_rescale
|
||||
self.use_original_formulation = use_original_formulation
|
||||
|
||||
def prepare_inputs(
|
||||
self, data: "BlockState", input_fields: Optional[Dict[str, Union[str, Tuple[str, str]]]] = None
|
||||
) -> List["BlockState"]:
|
||||
if input_fields is None:
|
||||
input_fields = self._input_fields
|
||||
|
||||
tuple_indices = [0] if self.num_conditions == 1 else [0, 1]
|
||||
data_batches = []
|
||||
for i in range(self.num_conditions):
|
||||
data_batch = self._prepare_batch(input_fields, data, tuple_indices[i], self._input_predictions[i])
|
||||
data_batches.append(data_batch)
|
||||
return data_batches
|
||||
|
||||
def forward(self, pred_cond: torch.Tensor, pred_uncond: Optional[torch.Tensor] = None) -> torch.Tensor:
|
||||
pred = None
|
||||
|
||||
if self._step < self.zero_init_steps:
|
||||
pred = torch.zeros_like(pred_cond)
|
||||
elif not self._is_cfg_enabled():
|
||||
pred = pred_cond
|
||||
else:
|
||||
pred_cond_flat = pred_cond.flatten(1)
|
||||
pred_uncond_flat = pred_uncond.flatten(1)
|
||||
alpha = cfg_zero_star_scale(pred_cond_flat, pred_uncond_flat)
|
||||
alpha = alpha.view(-1, *(1,) * (len(pred_cond.shape) - 1))
|
||||
pred_uncond = pred_uncond * alpha
|
||||
shift = pred_cond - pred_uncond
|
||||
pred = pred_cond if self.use_original_formulation else pred_uncond
|
||||
pred = pred + self.guidance_scale * shift
|
||||
|
||||
if self.guidance_rescale > 0.0:
|
||||
pred = rescale_noise_cfg(pred, pred_cond, self.guidance_rescale)
|
||||
|
||||
return pred, {}
|
||||
|
||||
@property
|
||||
def is_conditional(self) -> bool:
|
||||
return self._count_prepared == 1
|
||||
|
||||
@property
|
||||
def num_conditions(self) -> int:
|
||||
num_conditions = 1
|
||||
if self._is_cfg_enabled():
|
||||
num_conditions += 1
|
||||
return num_conditions
|
||||
|
||||
def _is_cfg_enabled(self) -> bool:
|
||||
if not self._enabled:
|
||||
return False
|
||||
|
||||
is_within_range = True
|
||||
if self._num_inference_steps is not None:
|
||||
skip_start_step = int(self._start * self._num_inference_steps)
|
||||
skip_stop_step = int(self._stop * self._num_inference_steps)
|
||||
is_within_range = skip_start_step <= self._step < skip_stop_step
|
||||
|
||||
is_close = False
|
||||
if self.use_original_formulation:
|
||||
is_close = math.isclose(self.guidance_scale, 0.0)
|
||||
else:
|
||||
is_close = math.isclose(self.guidance_scale, 1.0)
|
||||
|
||||
return is_within_range and not is_close
|
||||
|
||||
|
||||
def cfg_zero_star_scale(cond: torch.Tensor, uncond: torch.Tensor, eps: float = 1e-8) -> torch.Tensor:
|
||||
cond_dtype = cond.dtype
|
||||
cond = cond.float()
|
||||
uncond = uncond.float()
|
||||
dot_product = torch.sum(cond * uncond, dim=1, keepdim=True)
|
||||
squared_norm = torch.sum(uncond**2, dim=1, keepdim=True) + eps
|
||||
# st_star = v_cond^T * v_uncond / ||v_uncond||^2
|
||||
scale = dot_product / squared_norm
|
||||
return scale.to(dtype=cond_dtype)
|
||||
309
src/diffusers/guiders/guider_utils.py
Normal file
309
src/diffusers/guiders/guider_utils.py
Normal file
@@ -0,0 +1,309 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import os
|
||||
from typing import TYPE_CHECKING, Any, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
from huggingface_hub.utils import validate_hf_hub_args
|
||||
from typing_extensions import Self
|
||||
|
||||
from ..configuration_utils import ConfigMixin
|
||||
from ..utils import PushToHubMixin, get_logger
|
||||
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from ..modular_pipelines.modular_pipeline import BlockState
|
||||
|
||||
|
||||
GUIDER_CONFIG_NAME = "guider_config.json"
|
||||
|
||||
|
||||
logger = get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
class BaseGuidance(ConfigMixin, PushToHubMixin):
|
||||
r"""Base class providing the skeleton for implementing guidance techniques."""
|
||||
|
||||
config_name = GUIDER_CONFIG_NAME
|
||||
_input_predictions = None
|
||||
_identifier_key = "__guidance_identifier__"
|
||||
|
||||
def __init__(self, start: float = 0.0, stop: float = 1.0):
|
||||
self._start = start
|
||||
self._stop = stop
|
||||
self._step: int = None
|
||||
self._num_inference_steps: int = None
|
||||
self._timestep: torch.LongTensor = None
|
||||
self._count_prepared = 0
|
||||
self._input_fields: Dict[str, Union[str, Tuple[str, str]]] = None
|
||||
self._enabled = True
|
||||
|
||||
if not (0.0 <= start < 1.0):
|
||||
raise ValueError(f"Expected `start` to be between 0.0 and 1.0, but got {start}.")
|
||||
if not (start <= stop <= 1.0):
|
||||
raise ValueError(f"Expected `stop` to be between {start} and 1.0, but got {stop}.")
|
||||
|
||||
if self._input_predictions is None or not isinstance(self._input_predictions, list):
|
||||
raise ValueError(
|
||||
"`_input_predictions` must be a list of required prediction names for the guidance technique."
|
||||
)
|
||||
|
||||
def disable(self):
|
||||
self._enabled = False
|
||||
|
||||
def enable(self):
|
||||
self._enabled = True
|
||||
|
||||
def set_state(self, step: int, num_inference_steps: int, timestep: torch.LongTensor) -> None:
|
||||
self._step = step
|
||||
self._num_inference_steps = num_inference_steps
|
||||
self._timestep = timestep
|
||||
self._count_prepared = 0
|
||||
|
||||
def set_input_fields(self, **kwargs: Dict[str, Union[str, Tuple[str, str]]]) -> None:
|
||||
"""
|
||||
Set the input fields for the guidance technique. The input fields are used to specify the names of the returned
|
||||
attributes containing the prepared data after `prepare_inputs` is called. The prepared data is obtained from
|
||||
the values of the provided keyword arguments to this method.
|
||||
|
||||
Args:
|
||||
**kwargs (`Dict[str, Union[str, Tuple[str, str]]]`):
|
||||
A dictionary where the keys are the names of the fields that will be used to store the data once it is
|
||||
prepared with `prepare_inputs`. The values can be either a string or a tuple of length 2, which is used
|
||||
to look up the required data provided for preparation.
|
||||
|
||||
If a string is provided, it will be used as the conditional data (or unconditional if used with a
|
||||
guidance method that requires it). If a tuple of length 2 is provided, the first element must be the
|
||||
conditional data identifier and the second element must be the unconditional data identifier or None.
|
||||
|
||||
Example:
|
||||
```
|
||||
data = {"prompt_embeds": <some tensor>, "negative_prompt_embeds": <some tensor>, "latents": <some tensor>}
|
||||
|
||||
BaseGuidance.set_input_fields(
|
||||
latents="latents",
|
||||
prompt_embeds=("prompt_embeds", "negative_prompt_embeds"),
|
||||
)
|
||||
```
|
||||
"""
|
||||
for key, value in kwargs.items():
|
||||
is_string = isinstance(value, str)
|
||||
is_tuple_of_str_with_len_2 = (
|
||||
isinstance(value, tuple) and len(value) == 2 and all(isinstance(v, str) for v in value)
|
||||
)
|
||||
if not (is_string or is_tuple_of_str_with_len_2):
|
||||
raise ValueError(
|
||||
f"Expected `set_input_fields` to be called with a string or a tuple of string with length 2, but got {type(value)} for key {key}."
|
||||
)
|
||||
self._input_fields = kwargs
|
||||
|
||||
def prepare_models(self, denoiser: torch.nn.Module) -> None:
|
||||
"""
|
||||
Prepares the models for the guidance technique on a given batch of data. This method should be overridden in
|
||||
subclasses to implement specific model preparation logic.
|
||||
"""
|
||||
self._count_prepared += 1
|
||||
|
||||
def cleanup_models(self, denoiser: torch.nn.Module) -> None:
|
||||
"""
|
||||
Cleans up the models for the guidance technique after a given batch of data. This method should be overridden
|
||||
in subclasses to implement specific model cleanup logic. It is useful for removing any hooks or other stateful
|
||||
modifications made during `prepare_models`.
|
||||
"""
|
||||
pass
|
||||
|
||||
def prepare_inputs(self, data: "BlockState") -> List["BlockState"]:
|
||||
raise NotImplementedError("BaseGuidance::prepare_inputs must be implemented in subclasses.")
|
||||
|
||||
def __call__(self, data: List["BlockState"]) -> Any:
|
||||
if not all(hasattr(d, "noise_pred") for d in data):
|
||||
raise ValueError("Expected all data to have `noise_pred` attribute.")
|
||||
if len(data) != self.num_conditions:
|
||||
raise ValueError(
|
||||
f"Expected {self.num_conditions} data items, but got {len(data)}. Please check the input data."
|
||||
)
|
||||
forward_inputs = {getattr(d, self._identifier_key): d.noise_pred for d in data}
|
||||
return self.forward(**forward_inputs)
|
||||
|
||||
def forward(self, *args, **kwargs) -> Any:
|
||||
raise NotImplementedError("BaseGuidance::forward must be implemented in subclasses.")
|
||||
|
||||
@property
|
||||
def is_conditional(self) -> bool:
|
||||
raise NotImplementedError("BaseGuidance::is_conditional must be implemented in subclasses.")
|
||||
|
||||
@property
|
||||
def is_unconditional(self) -> bool:
|
||||
return not self.is_conditional
|
||||
|
||||
@property
|
||||
def num_conditions(self) -> int:
|
||||
raise NotImplementedError("BaseGuidance::num_conditions must be implemented in subclasses.")
|
||||
|
||||
@classmethod
|
||||
def _prepare_batch(
|
||||
cls,
|
||||
input_fields: Dict[str, Union[str, Tuple[str, str]]],
|
||||
data: "BlockState",
|
||||
tuple_index: int,
|
||||
identifier: str,
|
||||
) -> "BlockState":
|
||||
"""
|
||||
Prepares a batch of data for the guidance technique. This method is used in the `prepare_inputs` method of the
|
||||
`BaseGuidance` class. It prepares the batch based on the provided tuple index.
|
||||
|
||||
Args:
|
||||
input_fields (`Dict[str, Union[str, Tuple[str, str]]]`):
|
||||
A dictionary where the keys are the names of the fields that will be used to store the data once it is
|
||||
prepared with `prepare_inputs`. The values can be either a string or a tuple of length 2, which is used
|
||||
to look up the required data provided for preparation. If a string is provided, it will be used as the
|
||||
conditional data (or unconditional if used with a guidance method that requires it). If a tuple of
|
||||
length 2 is provided, the first element must be the conditional data identifier and the second element
|
||||
must be the unconditional data identifier or None.
|
||||
data (`BlockState`):
|
||||
The input data to be prepared.
|
||||
tuple_index (`int`):
|
||||
The index to use when accessing input fields that are tuples.
|
||||
|
||||
Returns:
|
||||
`BlockState`: The prepared batch of data.
|
||||
"""
|
||||
from ..modular_pipelines.modular_pipeline import BlockState
|
||||
|
||||
if input_fields is None:
|
||||
raise ValueError(
|
||||
"Input fields cannot be None. Please pass `input_fields` to `prepare_inputs` or call `set_input_fields` before preparing inputs."
|
||||
)
|
||||
data_batch = {}
|
||||
for key, value in input_fields.items():
|
||||
try:
|
||||
if isinstance(value, str):
|
||||
data_batch[key] = getattr(data, value)
|
||||
elif isinstance(value, tuple):
|
||||
data_batch[key] = getattr(data, value[tuple_index])
|
||||
else:
|
||||
# We've already checked that value is a string or a tuple of strings with length 2
|
||||
pass
|
||||
except AttributeError:
|
||||
logger.debug(f"`data` does not have attribute(s) {value}, skipping.")
|
||||
data_batch[cls._identifier_key] = identifier
|
||||
return BlockState(**data_batch)
|
||||
|
||||
@classmethod
|
||||
@validate_hf_hub_args
|
||||
def from_pretrained(
|
||||
cls,
|
||||
pretrained_model_name_or_path: Optional[Union[str, os.PathLike]] = None,
|
||||
subfolder: Optional[str] = None,
|
||||
return_unused_kwargs=False,
|
||||
**kwargs,
|
||||
) -> Self:
|
||||
r"""
|
||||
Instantiate a guider from a pre-defined JSON configuration file in a local directory or Hub repository.
|
||||
|
||||
Parameters:
|
||||
pretrained_model_name_or_path (`str` or `os.PathLike`, *optional*):
|
||||
Can be either:
|
||||
|
||||
- A string, the *model id* (for example `google/ddpm-celebahq-256`) of a pretrained model hosted on
|
||||
the Hub.
|
||||
- A path to a *directory* (for example `./my_model_directory`) containing the guider configuration
|
||||
saved with [`~BaseGuidance.save_pretrained`].
|
||||
subfolder (`str`, *optional*):
|
||||
The subfolder location of a model file within a larger model repository on the Hub or locally.
|
||||
return_unused_kwargs (`bool`, *optional*, defaults to `False`):
|
||||
Whether kwargs that are not consumed by the Python class should be returned or not.
|
||||
cache_dir (`Union[str, os.PathLike]`, *optional*):
|
||||
Path to a directory where a downloaded pretrained model configuration is cached if the standard cache
|
||||
is not used.
|
||||
force_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
|
||||
cached versions if they exist.
|
||||
|
||||
proxies (`Dict[str, str]`, *optional*):
|
||||
A dictionary of proxy servers to use by protocol or endpoint, for example, `{'http': 'foo.bar:3128',
|
||||
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
|
||||
output_loading_info(`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to also return a dictionary containing missing keys, unexpected keys and error messages.
|
||||
local_files_only(`bool`, *optional*, defaults to `False`):
|
||||
Whether to only load local model weights and configuration files or not. If set to `True`, the model
|
||||
won't be downloaded from the Hub.
|
||||
token (`str` or *bool*, *optional*):
|
||||
The token to use as HTTP bearer authorization for remote files. If `True`, the token generated from
|
||||
`diffusers-cli login` (stored in `~/.huggingface`) is used.
|
||||
revision (`str`, *optional*, defaults to `"main"`):
|
||||
The specific model version to use. It can be a branch name, a tag name, a commit id, or any identifier
|
||||
allowed by Git.
|
||||
|
||||
<Tip>
|
||||
|
||||
To use private or [gated models](https://huggingface.co/docs/hub/models-gated#gated-models), log-in with
|
||||
`huggingface-cli login`. You can also activate the special
|
||||
["offline-mode"](https://huggingface.co/diffusers/installation.html#offline-mode) to use this method in a
|
||||
firewalled environment.
|
||||
|
||||
</Tip>
|
||||
|
||||
"""
|
||||
config, kwargs, commit_hash = cls.load_config(
|
||||
pretrained_model_name_or_path=pretrained_model_name_or_path,
|
||||
subfolder=subfolder,
|
||||
return_unused_kwargs=True,
|
||||
return_commit_hash=True,
|
||||
**kwargs,
|
||||
)
|
||||
return cls.from_config(config, return_unused_kwargs=return_unused_kwargs, **kwargs)
|
||||
|
||||
def save_pretrained(self, save_directory: Union[str, os.PathLike], push_to_hub: bool = False, **kwargs):
|
||||
"""
|
||||
Save a guider configuration object to a directory so that it can be reloaded using the
|
||||
[`~BaseGuidance.from_pretrained`] class method.
|
||||
|
||||
Args:
|
||||
save_directory (`str` or `os.PathLike`):
|
||||
Directory where the configuration JSON file will be saved (will be created if it does not exist).
|
||||
push_to_hub (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to push your model to the Hugging Face Hub after saving it. You can specify the
|
||||
repository you want to push to with `repo_id` (will default to the name of `save_directory` in your
|
||||
namespace).
|
||||
kwargs (`Dict[str, Any]`, *optional*):
|
||||
Additional keyword arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
|
||||
"""
|
||||
self.save_config(save_directory=save_directory, push_to_hub=push_to_hub, **kwargs)
|
||||
|
||||
|
||||
def rescale_noise_cfg(noise_cfg, noise_pred_text, guidance_rescale=0.0):
|
||||
r"""
|
||||
Rescales `noise_cfg` tensor based on `guidance_rescale` to improve image quality and fix overexposure. Based on
|
||||
Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
|
||||
Flawed](https://arxiv.org/pdf/2305.08891.pdf).
|
||||
|
||||
Args:
|
||||
noise_cfg (`torch.Tensor`):
|
||||
The predicted noise tensor for the guided diffusion process.
|
||||
noise_pred_text (`torch.Tensor`):
|
||||
The predicted noise tensor for the text-guided diffusion process.
|
||||
guidance_rescale (`float`, *optional*, defaults to 0.0):
|
||||
A rescale factor applied to the noise predictions.
|
||||
Returns:
|
||||
noise_cfg (`torch.Tensor`): The rescaled noise prediction tensor.
|
||||
"""
|
||||
std_text = noise_pred_text.std(dim=list(range(1, noise_pred_text.ndim)), keepdim=True)
|
||||
std_cfg = noise_cfg.std(dim=list(range(1, noise_cfg.ndim)), keepdim=True)
|
||||
# rescale the results from guidance (fixes overexposure)
|
||||
noise_pred_rescaled = noise_cfg * (std_text / std_cfg)
|
||||
# mix with the original results from guidance by factor guidance_rescale to avoid "plain looking" images
|
||||
noise_cfg = guidance_rescale * noise_pred_rescaled + (1 - guidance_rescale) * noise_cfg
|
||||
return noise_cfg
|
||||
271
src/diffusers/guiders/perturbed_attention_guidance.py
Normal file
271
src/diffusers/guiders/perturbed_attention_guidance.py
Normal file
@@ -0,0 +1,271 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import math
|
||||
from typing import TYPE_CHECKING, Any, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ..configuration_utils import register_to_config
|
||||
from ..hooks import HookRegistry, LayerSkipConfig
|
||||
from ..hooks.layer_skip import _apply_layer_skip_hook
|
||||
from ..utils import get_logger
|
||||
from .guider_utils import BaseGuidance, rescale_noise_cfg
|
||||
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from ..modular_pipelines.modular_pipeline import BlockState
|
||||
|
||||
|
||||
logger = get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
class PerturbedAttentionGuidance(BaseGuidance):
|
||||
"""
|
||||
Perturbed Attention Guidance (PAG): https://huggingface.co/papers/2403.17377
|
||||
|
||||
The intution behind PAG can be thought of as moving the CFG predicted distribution estimates further away from
|
||||
worse versions of the conditional distribution estimates. PAG was one of the first techniques to introduce the idea
|
||||
of using a worse version of the trained model for better guiding itself in the denoising process. It perturbs the
|
||||
attention scores of the latent stream by replacing the score matrix with an identity matrix for selectively chosen
|
||||
layers.
|
||||
|
||||
Additional reading:
|
||||
- [Guiding a Diffusion Model with a Bad Version of Itself](https://huggingface.co/papers/2406.02507)
|
||||
|
||||
PAG is implemented with similar implementation to SkipLayerGuidance due to overlap in the configuration parameters
|
||||
and implementation details.
|
||||
|
||||
Args:
|
||||
guidance_scale (`float`, defaults to `7.5`):
|
||||
The scale parameter for classifier-free guidance. Higher values result in stronger conditioning on the text
|
||||
prompt, while lower values allow for more freedom in generation. Higher values may lead to saturation and
|
||||
deterioration of image quality.
|
||||
perturbed_guidance_scale (`float`, defaults to `2.8`):
|
||||
The scale parameter for perturbed attention guidance.
|
||||
perturbed_guidance_start (`float`, defaults to `0.01`):
|
||||
The fraction of the total number of denoising steps after which perturbed attention guidance starts.
|
||||
perturbed_guidance_stop (`float`, defaults to `0.2`):
|
||||
The fraction of the total number of denoising steps after which perturbed attention guidance stops.
|
||||
perturbed_guidance_layers (`int` or `List[int]`, *optional*):
|
||||
The layer indices to apply perturbed attention guidance to. Can be a single integer or a list of integers.
|
||||
If not provided, `perturbed_guidance_config` must be provided.
|
||||
perturbed_guidance_config (`LayerSkipConfig` or `List[LayerSkipConfig]`, *optional*):
|
||||
The configuration for the perturbed attention guidance. Can be a single `LayerSkipConfig` or a list of
|
||||
`LayerSkipConfig`. If not provided, `perturbed_guidance_layers` must be provided.
|
||||
guidance_rescale (`float`, defaults to `0.0`):
|
||||
The rescale factor applied to the noise predictions. This is used to improve image quality and fix
|
||||
overexposure. Based on Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
|
||||
Flawed](https://huggingface.co/papers/2305.08891).
|
||||
use_original_formulation (`bool`, defaults to `False`):
|
||||
Whether to use the original formulation of classifier-free guidance as proposed in the paper. By default,
|
||||
we use the diffusers-native implementation that has been in the codebase for a long time. See
|
||||
[~guiders.classifier_free_guidance.ClassifierFreeGuidance] for more details.
|
||||
start (`float`, defaults to `0.01`):
|
||||
The fraction of the total number of denoising steps after which guidance starts.
|
||||
stop (`float`, defaults to `0.2`):
|
||||
The fraction of the total number of denoising steps after which guidance stops.
|
||||
"""
|
||||
|
||||
# NOTE: The current implementation does not account for joint latent conditioning (text + image/video tokens in
|
||||
# the same latent stream). It assumes the entire latent is a single stream of visual tokens. It would be very
|
||||
# complex to support joint latent conditioning in a model-agnostic manner without specializing the implementation
|
||||
# for each model architecture.
|
||||
|
||||
_input_predictions = ["pred_cond", "pred_uncond", "pred_cond_skip"]
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
guidance_scale: float = 7.5,
|
||||
perturbed_guidance_scale: float = 2.8,
|
||||
perturbed_guidance_start: float = 0.01,
|
||||
perturbed_guidance_stop: float = 0.2,
|
||||
perturbed_guidance_layers: Optional[Union[int, List[int]]] = None,
|
||||
perturbed_guidance_config: Union[LayerSkipConfig, List[LayerSkipConfig], Dict[str, Any]] = None,
|
||||
guidance_rescale: float = 0.0,
|
||||
use_original_formulation: bool = False,
|
||||
start: float = 0.0,
|
||||
stop: float = 1.0,
|
||||
):
|
||||
super().__init__(start, stop)
|
||||
|
||||
self.guidance_scale = guidance_scale
|
||||
self.skip_layer_guidance_scale = perturbed_guidance_scale
|
||||
self.skip_layer_guidance_start = perturbed_guidance_start
|
||||
self.skip_layer_guidance_stop = perturbed_guidance_stop
|
||||
self.guidance_rescale = guidance_rescale
|
||||
self.use_original_formulation = use_original_formulation
|
||||
|
||||
if perturbed_guidance_config is None:
|
||||
if perturbed_guidance_layers is None:
|
||||
raise ValueError(
|
||||
"`perturbed_guidance_layers` must be provided if `perturbed_guidance_config` is not specified."
|
||||
)
|
||||
perturbed_guidance_config = LayerSkipConfig(
|
||||
indices=perturbed_guidance_layers,
|
||||
fqn="auto",
|
||||
skip_attention=False,
|
||||
skip_attention_scores=True,
|
||||
skip_ff=False,
|
||||
)
|
||||
else:
|
||||
if perturbed_guidance_layers is not None:
|
||||
raise ValueError(
|
||||
"`perturbed_guidance_layers` should not be provided if `perturbed_guidance_config` is specified."
|
||||
)
|
||||
|
||||
if isinstance(perturbed_guidance_config, dict):
|
||||
perturbed_guidance_config = LayerSkipConfig.from_dict(perturbed_guidance_config)
|
||||
|
||||
if isinstance(perturbed_guidance_config, LayerSkipConfig):
|
||||
perturbed_guidance_config = [perturbed_guidance_config]
|
||||
|
||||
if not isinstance(perturbed_guidance_config, list):
|
||||
raise ValueError(
|
||||
"`perturbed_guidance_config` must be a `LayerSkipConfig`, a list of `LayerSkipConfig`, or a dict that can be converted to a `LayerSkipConfig`."
|
||||
)
|
||||
elif isinstance(next(iter(perturbed_guidance_config), None), dict):
|
||||
perturbed_guidance_config = [LayerSkipConfig.from_dict(config) for config in perturbed_guidance_config]
|
||||
|
||||
for config in perturbed_guidance_config:
|
||||
if config.skip_attention or not config.skip_attention_scores or config.skip_ff:
|
||||
logger.warning(
|
||||
"Perturbed Attention Guidance is designed to perturb attention scores, so `skip_attention` should be False, `skip_attention_scores` should be True, and `skip_ff` should be False. "
|
||||
"Please check your configuration. Modifying the config to match the expected values."
|
||||
)
|
||||
config.skip_attention = False
|
||||
config.skip_attention_scores = True
|
||||
config.skip_ff = False
|
||||
|
||||
self.skip_layer_config = perturbed_guidance_config
|
||||
self._skip_layer_hook_names = [f"SkipLayerGuidance_{i}" for i in range(len(self.skip_layer_config))]
|
||||
|
||||
# Copied from diffusers.guiders.skip_layer_guidance.SkipLayerGuidance.prepare_models
|
||||
def prepare_models(self, denoiser: torch.nn.Module) -> None:
|
||||
self._count_prepared += 1
|
||||
if self._is_slg_enabled() and self.is_conditional and self._count_prepared > 1:
|
||||
for name, config in zip(self._skip_layer_hook_names, self.skip_layer_config):
|
||||
_apply_layer_skip_hook(denoiser, config, name=name)
|
||||
|
||||
# Copied from diffusers.guiders.skip_layer_guidance.SkipLayerGuidance.cleanup_models
|
||||
def cleanup_models(self, denoiser: torch.nn.Module) -> None:
|
||||
if self._is_slg_enabled() and self.is_conditional and self._count_prepared > 1:
|
||||
registry = HookRegistry.check_if_exists_or_initialize(denoiser)
|
||||
# Remove the hooks after inference
|
||||
for hook_name in self._skip_layer_hook_names:
|
||||
registry.remove_hook(hook_name, recurse=True)
|
||||
|
||||
# Copied from diffusers.guiders.skip_layer_guidance.SkipLayerGuidance.prepare_inputs
|
||||
def prepare_inputs(
|
||||
self, data: "BlockState", input_fields: Optional[Dict[str, Union[str, Tuple[str, str]]]] = None
|
||||
) -> List["BlockState"]:
|
||||
if input_fields is None:
|
||||
input_fields = self._input_fields
|
||||
|
||||
if self.num_conditions == 1:
|
||||
tuple_indices = [0]
|
||||
input_predictions = ["pred_cond"]
|
||||
elif self.num_conditions == 2:
|
||||
tuple_indices = [0, 1]
|
||||
input_predictions = (
|
||||
["pred_cond", "pred_uncond"] if self._is_cfg_enabled() else ["pred_cond", "pred_cond_skip"]
|
||||
)
|
||||
else:
|
||||
tuple_indices = [0, 1, 0]
|
||||
input_predictions = ["pred_cond", "pred_uncond", "pred_cond_skip"]
|
||||
data_batches = []
|
||||
for i in range(self.num_conditions):
|
||||
data_batch = self._prepare_batch(input_fields, data, tuple_indices[i], input_predictions[i])
|
||||
data_batches.append(data_batch)
|
||||
return data_batches
|
||||
|
||||
# Copied from diffusers.guiders.skip_layer_guidance.SkipLayerGuidance.forward
|
||||
def forward(
|
||||
self,
|
||||
pred_cond: torch.Tensor,
|
||||
pred_uncond: Optional[torch.Tensor] = None,
|
||||
pred_cond_skip: Optional[torch.Tensor] = None,
|
||||
) -> torch.Tensor:
|
||||
pred = None
|
||||
|
||||
if not self._is_cfg_enabled() and not self._is_slg_enabled():
|
||||
pred = pred_cond
|
||||
elif not self._is_cfg_enabled():
|
||||
shift = pred_cond - pred_cond_skip
|
||||
pred = pred_cond if self.use_original_formulation else pred_cond_skip
|
||||
pred = pred + self.skip_layer_guidance_scale * shift
|
||||
elif not self._is_slg_enabled():
|
||||
shift = pred_cond - pred_uncond
|
||||
pred = pred_cond if self.use_original_formulation else pred_uncond
|
||||
pred = pred + self.guidance_scale * shift
|
||||
else:
|
||||
shift = pred_cond - pred_uncond
|
||||
shift_skip = pred_cond - pred_cond_skip
|
||||
pred = pred_cond if self.use_original_formulation else pred_uncond
|
||||
pred = pred + self.guidance_scale * shift + self.skip_layer_guidance_scale * shift_skip
|
||||
|
||||
if self.guidance_rescale > 0.0:
|
||||
pred = rescale_noise_cfg(pred, pred_cond, self.guidance_rescale)
|
||||
|
||||
return pred, {}
|
||||
|
||||
@property
|
||||
# Copied from diffusers.guiders.skip_layer_guidance.SkipLayerGuidance.is_conditional
|
||||
def is_conditional(self) -> bool:
|
||||
return self._count_prepared == 1 or self._count_prepared == 3
|
||||
|
||||
@property
|
||||
# Copied from diffusers.guiders.skip_layer_guidance.SkipLayerGuidance.num_conditions
|
||||
def num_conditions(self) -> int:
|
||||
num_conditions = 1
|
||||
if self._is_cfg_enabled():
|
||||
num_conditions += 1
|
||||
if self._is_slg_enabled():
|
||||
num_conditions += 1
|
||||
return num_conditions
|
||||
|
||||
# Copied from diffusers.guiders.skip_layer_guidance.SkipLayerGuidance._is_cfg_enabled
|
||||
def _is_cfg_enabled(self) -> bool:
|
||||
if not self._enabled:
|
||||
return False
|
||||
|
||||
is_within_range = True
|
||||
if self._num_inference_steps is not None:
|
||||
skip_start_step = int(self._start * self._num_inference_steps)
|
||||
skip_stop_step = int(self._stop * self._num_inference_steps)
|
||||
is_within_range = skip_start_step <= self._step < skip_stop_step
|
||||
|
||||
is_close = False
|
||||
if self.use_original_formulation:
|
||||
is_close = math.isclose(self.guidance_scale, 0.0)
|
||||
else:
|
||||
is_close = math.isclose(self.guidance_scale, 1.0)
|
||||
|
||||
return is_within_range and not is_close
|
||||
|
||||
# Copied from diffusers.guiders.skip_layer_guidance.SkipLayerGuidance._is_slg_enabled
|
||||
def _is_slg_enabled(self) -> bool:
|
||||
if not self._enabled:
|
||||
return False
|
||||
|
||||
is_within_range = True
|
||||
if self._num_inference_steps is not None:
|
||||
skip_start_step = int(self.skip_layer_guidance_start * self._num_inference_steps)
|
||||
skip_stop_step = int(self.skip_layer_guidance_stop * self._num_inference_steps)
|
||||
is_within_range = skip_start_step < self._step < skip_stop_step
|
||||
|
||||
is_zero = math.isclose(self.skip_layer_guidance_scale, 0.0)
|
||||
|
||||
return is_within_range and not is_zero
|
||||
262
src/diffusers/guiders/skip_layer_guidance.py
Normal file
262
src/diffusers/guiders/skip_layer_guidance.py
Normal file
@@ -0,0 +1,262 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import math
|
||||
from typing import TYPE_CHECKING, Any, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ..configuration_utils import register_to_config
|
||||
from ..hooks import HookRegistry, LayerSkipConfig
|
||||
from ..hooks.layer_skip import _apply_layer_skip_hook
|
||||
from .guider_utils import BaseGuidance, rescale_noise_cfg
|
||||
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from ..modular_pipelines.modular_pipeline import BlockState
|
||||
|
||||
|
||||
class SkipLayerGuidance(BaseGuidance):
|
||||
"""
|
||||
Skip Layer Guidance (SLG): https://github.com/Stability-AI/sd3.5
|
||||
|
||||
Spatio-Temporal Guidance (STG): https://huggingface.co/papers/2411.18664
|
||||
|
||||
SLG was introduced by StabilityAI for improving structure and anotomy coherence in generated images. It works by
|
||||
skipping the forward pass of specified transformer blocks during the denoising process on an additional conditional
|
||||
batch of data, apart from the conditional and unconditional batches already used in CFG
|
||||
([~guiders.classifier_free_guidance.ClassifierFreeGuidance]), and then scaling and shifting the CFG predictions
|
||||
based on the difference between conditional without skipping and conditional with skipping predictions.
|
||||
|
||||
The intution behind SLG can be thought of as moving the CFG predicted distribution estimates further away from
|
||||
worse versions of the conditional distribution estimates (because skipping layers is equivalent to using a worse
|
||||
version of the model for the conditional prediction).
|
||||
|
||||
STG is an improvement and follow-up work combining ideas from SLG, PAG and similar techniques for improving
|
||||
generation quality in video diffusion models.
|
||||
|
||||
Additional reading:
|
||||
- [Guiding a Diffusion Model with a Bad Version of Itself](https://huggingface.co/papers/2406.02507)
|
||||
|
||||
The values for `skip_layer_guidance_scale`, `skip_layer_guidance_start`, and `skip_layer_guidance_stop` are
|
||||
defaulted to the recommendations by StabilityAI for Stable Diffusion 3.5 Medium.
|
||||
|
||||
Args:
|
||||
guidance_scale (`float`, defaults to `7.5`):
|
||||
The scale parameter for classifier-free guidance. Higher values result in stronger conditioning on the text
|
||||
prompt, while lower values allow for more freedom in generation. Higher values may lead to saturation and
|
||||
deterioration of image quality.
|
||||
skip_layer_guidance_scale (`float`, defaults to `2.8`):
|
||||
The scale parameter for skip layer guidance. Anatomy and structure coherence may improve with higher
|
||||
values, but it may also lead to overexposure and saturation.
|
||||
skip_layer_guidance_start (`float`, defaults to `0.01`):
|
||||
The fraction of the total number of denoising steps after which skip layer guidance starts.
|
||||
skip_layer_guidance_stop (`float`, defaults to `0.2`):
|
||||
The fraction of the total number of denoising steps after which skip layer guidance stops.
|
||||
skip_layer_guidance_layers (`int` or `List[int]`, *optional*):
|
||||
The layer indices to apply skip layer guidance to. Can be a single integer or a list of integers. If not
|
||||
provided, `skip_layer_config` must be provided. The recommended values are `[7, 8, 9]` for Stable Diffusion
|
||||
3.5 Medium.
|
||||
skip_layer_config (`LayerSkipConfig` or `List[LayerSkipConfig]`, *optional*):
|
||||
The configuration for the skip layer guidance. Can be a single `LayerSkipConfig` or a list of
|
||||
`LayerSkipConfig`. If not provided, `skip_layer_guidance_layers` must be provided.
|
||||
guidance_rescale (`float`, defaults to `0.0`):
|
||||
The rescale factor applied to the noise predictions. This is used to improve image quality and fix
|
||||
overexposure. Based on Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
|
||||
Flawed](https://huggingface.co/papers/2305.08891).
|
||||
use_original_formulation (`bool`, defaults to `False`):
|
||||
Whether to use the original formulation of classifier-free guidance as proposed in the paper. By default,
|
||||
we use the diffusers-native implementation that has been in the codebase for a long time. See
|
||||
[~guiders.classifier_free_guidance.ClassifierFreeGuidance] for more details.
|
||||
start (`float`, defaults to `0.01`):
|
||||
The fraction of the total number of denoising steps after which guidance starts.
|
||||
stop (`float`, defaults to `0.2`):
|
||||
The fraction of the total number of denoising steps after which guidance stops.
|
||||
"""
|
||||
|
||||
_input_predictions = ["pred_cond", "pred_uncond", "pred_cond_skip"]
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
guidance_scale: float = 7.5,
|
||||
skip_layer_guidance_scale: float = 2.8,
|
||||
skip_layer_guidance_start: float = 0.01,
|
||||
skip_layer_guidance_stop: float = 0.2,
|
||||
skip_layer_guidance_layers: Optional[Union[int, List[int]]] = None,
|
||||
skip_layer_config: Union[LayerSkipConfig, List[LayerSkipConfig], Dict[str, Any]] = None,
|
||||
guidance_rescale: float = 0.0,
|
||||
use_original_formulation: bool = False,
|
||||
start: float = 0.0,
|
||||
stop: float = 1.0,
|
||||
):
|
||||
super().__init__(start, stop)
|
||||
|
||||
self.guidance_scale = guidance_scale
|
||||
self.skip_layer_guidance_scale = skip_layer_guidance_scale
|
||||
self.skip_layer_guidance_start = skip_layer_guidance_start
|
||||
self.skip_layer_guidance_stop = skip_layer_guidance_stop
|
||||
self.guidance_rescale = guidance_rescale
|
||||
self.use_original_formulation = use_original_formulation
|
||||
|
||||
if not (0.0 <= skip_layer_guidance_start < 1.0):
|
||||
raise ValueError(
|
||||
f"Expected `skip_layer_guidance_start` to be between 0.0 and 1.0, but got {skip_layer_guidance_start}."
|
||||
)
|
||||
if not (skip_layer_guidance_start <= skip_layer_guidance_stop <= 1.0):
|
||||
raise ValueError(
|
||||
f"Expected `skip_layer_guidance_stop` to be between 0.0 and 1.0, but got {skip_layer_guidance_stop}."
|
||||
)
|
||||
|
||||
if skip_layer_guidance_layers is None and skip_layer_config is None:
|
||||
raise ValueError(
|
||||
"Either `skip_layer_guidance_layers` or `skip_layer_config` must be provided to enable Skip Layer Guidance."
|
||||
)
|
||||
if skip_layer_guidance_layers is not None and skip_layer_config is not None:
|
||||
raise ValueError("Only one of `skip_layer_guidance_layers` or `skip_layer_config` can be provided.")
|
||||
|
||||
if skip_layer_guidance_layers is not None:
|
||||
if isinstance(skip_layer_guidance_layers, int):
|
||||
skip_layer_guidance_layers = [skip_layer_guidance_layers]
|
||||
if not isinstance(skip_layer_guidance_layers, list):
|
||||
raise ValueError(
|
||||
f"Expected `skip_layer_guidance_layers` to be an int or a list of ints, but got {type(skip_layer_guidance_layers)}."
|
||||
)
|
||||
skip_layer_config = [LayerSkipConfig(layer, fqn="auto") for layer in skip_layer_guidance_layers]
|
||||
|
||||
if isinstance(skip_layer_config, dict):
|
||||
skip_layer_config = LayerSkipConfig.from_dict(skip_layer_config)
|
||||
|
||||
if isinstance(skip_layer_config, LayerSkipConfig):
|
||||
skip_layer_config = [skip_layer_config]
|
||||
|
||||
if not isinstance(skip_layer_config, list):
|
||||
raise ValueError(
|
||||
f"Expected `skip_layer_config` to be a LayerSkipConfig or a list of LayerSkipConfig, but got {type(skip_layer_config)}."
|
||||
)
|
||||
elif isinstance(next(iter(skip_layer_config), None), dict):
|
||||
skip_layer_config = [LayerSkipConfig.from_dict(config) for config in skip_layer_config]
|
||||
|
||||
self.skip_layer_config = skip_layer_config
|
||||
self._skip_layer_hook_names = [f"SkipLayerGuidance_{i}" for i in range(len(self.skip_layer_config))]
|
||||
|
||||
def prepare_models(self, denoiser: torch.nn.Module) -> None:
|
||||
self._count_prepared += 1
|
||||
if self._is_slg_enabled() and self.is_conditional and self._count_prepared > 1:
|
||||
for name, config in zip(self._skip_layer_hook_names, self.skip_layer_config):
|
||||
_apply_layer_skip_hook(denoiser, config, name=name)
|
||||
|
||||
def cleanup_models(self, denoiser: torch.nn.Module) -> None:
|
||||
if self._is_slg_enabled() and self.is_conditional and self._count_prepared > 1:
|
||||
registry = HookRegistry.check_if_exists_or_initialize(denoiser)
|
||||
# Remove the hooks after inference
|
||||
for hook_name in self._skip_layer_hook_names:
|
||||
registry.remove_hook(hook_name, recurse=True)
|
||||
|
||||
def prepare_inputs(
|
||||
self, data: "BlockState", input_fields: Optional[Dict[str, Union[str, Tuple[str, str]]]] = None
|
||||
) -> List["BlockState"]:
|
||||
if input_fields is None:
|
||||
input_fields = self._input_fields
|
||||
|
||||
if self.num_conditions == 1:
|
||||
tuple_indices = [0]
|
||||
input_predictions = ["pred_cond"]
|
||||
elif self.num_conditions == 2:
|
||||
tuple_indices = [0, 1]
|
||||
input_predictions = (
|
||||
["pred_cond", "pred_uncond"] if self._is_cfg_enabled() else ["pred_cond", "pred_cond_skip"]
|
||||
)
|
||||
else:
|
||||
tuple_indices = [0, 1, 0]
|
||||
input_predictions = ["pred_cond", "pred_uncond", "pred_cond_skip"]
|
||||
data_batches = []
|
||||
for i in range(self.num_conditions):
|
||||
data_batch = self._prepare_batch(input_fields, data, tuple_indices[i], input_predictions[i])
|
||||
data_batches.append(data_batch)
|
||||
return data_batches
|
||||
|
||||
def forward(
|
||||
self,
|
||||
pred_cond: torch.Tensor,
|
||||
pred_uncond: Optional[torch.Tensor] = None,
|
||||
pred_cond_skip: Optional[torch.Tensor] = None,
|
||||
) -> torch.Tensor:
|
||||
pred = None
|
||||
|
||||
if not self._is_cfg_enabled() and not self._is_slg_enabled():
|
||||
pred = pred_cond
|
||||
elif not self._is_cfg_enabled():
|
||||
shift = pred_cond - pred_cond_skip
|
||||
pred = pred_cond if self.use_original_formulation else pred_cond_skip
|
||||
pred = pred + self.skip_layer_guidance_scale * shift
|
||||
elif not self._is_slg_enabled():
|
||||
shift = pred_cond - pred_uncond
|
||||
pred = pred_cond if self.use_original_formulation else pred_uncond
|
||||
pred = pred + self.guidance_scale * shift
|
||||
else:
|
||||
shift = pred_cond - pred_uncond
|
||||
shift_skip = pred_cond - pred_cond_skip
|
||||
pred = pred_cond if self.use_original_formulation else pred_uncond
|
||||
pred = pred + self.guidance_scale * shift + self.skip_layer_guidance_scale * shift_skip
|
||||
|
||||
if self.guidance_rescale > 0.0:
|
||||
pred = rescale_noise_cfg(pred, pred_cond, self.guidance_rescale)
|
||||
|
||||
return pred, {}
|
||||
|
||||
@property
|
||||
def is_conditional(self) -> bool:
|
||||
return self._count_prepared == 1 or self._count_prepared == 3
|
||||
|
||||
@property
|
||||
def num_conditions(self) -> int:
|
||||
num_conditions = 1
|
||||
if self._is_cfg_enabled():
|
||||
num_conditions += 1
|
||||
if self._is_slg_enabled():
|
||||
num_conditions += 1
|
||||
return num_conditions
|
||||
|
||||
def _is_cfg_enabled(self) -> bool:
|
||||
if not self._enabled:
|
||||
return False
|
||||
|
||||
is_within_range = True
|
||||
if self._num_inference_steps is not None:
|
||||
skip_start_step = int(self._start * self._num_inference_steps)
|
||||
skip_stop_step = int(self._stop * self._num_inference_steps)
|
||||
is_within_range = skip_start_step <= self._step < skip_stop_step
|
||||
|
||||
is_close = False
|
||||
if self.use_original_formulation:
|
||||
is_close = math.isclose(self.guidance_scale, 0.0)
|
||||
else:
|
||||
is_close = math.isclose(self.guidance_scale, 1.0)
|
||||
|
||||
return is_within_range and not is_close
|
||||
|
||||
def _is_slg_enabled(self) -> bool:
|
||||
if not self._enabled:
|
||||
return False
|
||||
|
||||
is_within_range = True
|
||||
if self._num_inference_steps is not None:
|
||||
skip_start_step = int(self.skip_layer_guidance_start * self._num_inference_steps)
|
||||
skip_stop_step = int(self.skip_layer_guidance_stop * self._num_inference_steps)
|
||||
is_within_range = skip_start_step < self._step < skip_stop_step
|
||||
|
||||
is_zero = math.isclose(self.skip_layer_guidance_scale, 0.0)
|
||||
|
||||
return is_within_range and not is_zero
|
||||
251
src/diffusers/guiders/smoothed_energy_guidance.py
Normal file
251
src/diffusers/guiders/smoothed_energy_guidance.py
Normal file
@@ -0,0 +1,251 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import math
|
||||
from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ..configuration_utils import register_to_config
|
||||
from ..hooks import HookRegistry
|
||||
from ..hooks.smoothed_energy_guidance_utils import SmoothedEnergyGuidanceConfig, _apply_smoothed_energy_guidance_hook
|
||||
from .guider_utils import BaseGuidance, rescale_noise_cfg
|
||||
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from ..modular_pipelines.modular_pipeline import BlockState
|
||||
|
||||
|
||||
class SmoothedEnergyGuidance(BaseGuidance):
|
||||
"""
|
||||
Smoothed Energy Guidance (SEG): https://huggingface.co/papers/2408.00760
|
||||
|
||||
SEG is only supported as an experimental prototype feature for now, so the implementation may be modified in the
|
||||
future without warning or guarantee of reproducibility. This implementation assumes:
|
||||
- Generated images are square (height == width)
|
||||
- The model does not combine different modalities together (e.g., text and image latent streams are not combined
|
||||
together such as Flux)
|
||||
|
||||
Args:
|
||||
guidance_scale (`float`, defaults to `7.5`):
|
||||
The scale parameter for classifier-free guidance. Higher values result in stronger conditioning on the text
|
||||
prompt, while lower values allow for more freedom in generation. Higher values may lead to saturation and
|
||||
deterioration of image quality.
|
||||
seg_guidance_scale (`float`, defaults to `3.0`):
|
||||
The scale parameter for smoothed energy guidance. Anatomy and structure coherence may improve with higher
|
||||
values, but it may also lead to overexposure and saturation.
|
||||
seg_blur_sigma (`float`, defaults to `9999999.0`):
|
||||
The amount by which we blur the attention weights. Setting this value greater than 9999.0 results in
|
||||
infinite blur, which means uniform queries. Controlling it exponentially is empirically effective.
|
||||
seg_blur_threshold_inf (`float`, defaults to `9999.0`):
|
||||
The threshold above which the blur is considered infinite.
|
||||
seg_guidance_start (`float`, defaults to `0.0`):
|
||||
The fraction of the total number of denoising steps after which smoothed energy guidance starts.
|
||||
seg_guidance_stop (`float`, defaults to `1.0`):
|
||||
The fraction of the total number of denoising steps after which smoothed energy guidance stops.
|
||||
seg_guidance_layers (`int` or `List[int]`, *optional*):
|
||||
The layer indices to apply smoothed energy guidance to. Can be a single integer or a list of integers. If
|
||||
not provided, `seg_guidance_config` must be provided. The recommended values are `[7, 8, 9]` for Stable
|
||||
Diffusion 3.5 Medium.
|
||||
seg_guidance_config (`SmoothedEnergyGuidanceConfig` or `List[SmoothedEnergyGuidanceConfig]`, *optional*):
|
||||
The configuration for the smoothed energy layer guidance. Can be a single `SmoothedEnergyGuidanceConfig` or
|
||||
a list of `SmoothedEnergyGuidanceConfig`. If not provided, `seg_guidance_layers` must be provided.
|
||||
guidance_rescale (`float`, defaults to `0.0`):
|
||||
The rescale factor applied to the noise predictions. This is used to improve image quality and fix
|
||||
overexposure. Based on Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
|
||||
Flawed](https://huggingface.co/papers/2305.08891).
|
||||
use_original_formulation (`bool`, defaults to `False`):
|
||||
Whether to use the original formulation of classifier-free guidance as proposed in the paper. By default,
|
||||
we use the diffusers-native implementation that has been in the codebase for a long time. See
|
||||
[~guiders.classifier_free_guidance.ClassifierFreeGuidance] for more details.
|
||||
start (`float`, defaults to `0.01`):
|
||||
The fraction of the total number of denoising steps after which guidance starts.
|
||||
stop (`float`, defaults to `0.2`):
|
||||
The fraction of the total number of denoising steps after which guidance stops.
|
||||
"""
|
||||
|
||||
_input_predictions = ["pred_cond", "pred_uncond", "pred_cond_seg"]
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
guidance_scale: float = 7.5,
|
||||
seg_guidance_scale: float = 2.8,
|
||||
seg_blur_sigma: float = 9999999.0,
|
||||
seg_blur_threshold_inf: float = 9999.0,
|
||||
seg_guidance_start: float = 0.0,
|
||||
seg_guidance_stop: float = 1.0,
|
||||
seg_guidance_layers: Optional[Union[int, List[int]]] = None,
|
||||
seg_guidance_config: Union[SmoothedEnergyGuidanceConfig, List[SmoothedEnergyGuidanceConfig]] = None,
|
||||
guidance_rescale: float = 0.0,
|
||||
use_original_formulation: bool = False,
|
||||
start: float = 0.0,
|
||||
stop: float = 1.0,
|
||||
):
|
||||
super().__init__(start, stop)
|
||||
|
||||
self.guidance_scale = guidance_scale
|
||||
self.seg_guidance_scale = seg_guidance_scale
|
||||
self.seg_blur_sigma = seg_blur_sigma
|
||||
self.seg_blur_threshold_inf = seg_blur_threshold_inf
|
||||
self.seg_guidance_start = seg_guidance_start
|
||||
self.seg_guidance_stop = seg_guidance_stop
|
||||
self.guidance_rescale = guidance_rescale
|
||||
self.use_original_formulation = use_original_formulation
|
||||
|
||||
if not (0.0 <= seg_guidance_start < 1.0):
|
||||
raise ValueError(f"Expected `seg_guidance_start` to be between 0.0 and 1.0, but got {seg_guidance_start}.")
|
||||
if not (seg_guidance_start <= seg_guidance_stop <= 1.0):
|
||||
raise ValueError(f"Expected `seg_guidance_stop` to be between 0.0 and 1.0, but got {seg_guidance_stop}.")
|
||||
|
||||
if seg_guidance_layers is None and seg_guidance_config is None:
|
||||
raise ValueError(
|
||||
"Either `seg_guidance_layers` or `seg_guidance_config` must be provided to enable Smoothed Energy Guidance."
|
||||
)
|
||||
if seg_guidance_layers is not None and seg_guidance_config is not None:
|
||||
raise ValueError("Only one of `seg_guidance_layers` or `seg_guidance_config` can be provided.")
|
||||
|
||||
if seg_guidance_layers is not None:
|
||||
if isinstance(seg_guidance_layers, int):
|
||||
seg_guidance_layers = [seg_guidance_layers]
|
||||
if not isinstance(seg_guidance_layers, list):
|
||||
raise ValueError(
|
||||
f"Expected `seg_guidance_layers` to be an int or a list of ints, but got {type(seg_guidance_layers)}."
|
||||
)
|
||||
seg_guidance_config = [SmoothedEnergyGuidanceConfig(layer, fqn="auto") for layer in seg_guidance_layers]
|
||||
|
||||
if isinstance(seg_guidance_config, dict):
|
||||
seg_guidance_config = SmoothedEnergyGuidanceConfig.from_dict(seg_guidance_config)
|
||||
|
||||
if isinstance(seg_guidance_config, SmoothedEnergyGuidanceConfig):
|
||||
seg_guidance_config = [seg_guidance_config]
|
||||
|
||||
if not isinstance(seg_guidance_config, list):
|
||||
raise ValueError(
|
||||
f"Expected `seg_guidance_config` to be a SmoothedEnergyGuidanceConfig or a list of SmoothedEnergyGuidanceConfig, but got {type(seg_guidance_config)}."
|
||||
)
|
||||
elif isinstance(next(iter(seg_guidance_config), None), dict):
|
||||
seg_guidance_config = [SmoothedEnergyGuidanceConfig.from_dict(config) for config in seg_guidance_config]
|
||||
|
||||
self.seg_guidance_config = seg_guidance_config
|
||||
self._seg_layer_hook_names = [f"SmoothedEnergyGuidance_{i}" for i in range(len(self.seg_guidance_config))]
|
||||
|
||||
def prepare_models(self, denoiser: torch.nn.Module) -> None:
|
||||
if self._is_seg_enabled() and self.is_conditional and self._count_prepared > 1:
|
||||
for name, config in zip(self._seg_layer_hook_names, self.seg_guidance_config):
|
||||
_apply_smoothed_energy_guidance_hook(denoiser, config, self.seg_blur_sigma, name=name)
|
||||
|
||||
def cleanup_models(self, denoiser: torch.nn.Module):
|
||||
if self._is_seg_enabled() and self.is_conditional and self._count_prepared > 1:
|
||||
registry = HookRegistry.check_if_exists_or_initialize(denoiser)
|
||||
# Remove the hooks after inference
|
||||
for hook_name in self._seg_layer_hook_names:
|
||||
registry.remove_hook(hook_name, recurse=True)
|
||||
|
||||
def prepare_inputs(
|
||||
self, data: "BlockState", input_fields: Optional[Dict[str, Union[str, Tuple[str, str]]]] = None
|
||||
) -> List["BlockState"]:
|
||||
if input_fields is None:
|
||||
input_fields = self._input_fields
|
||||
|
||||
if self.num_conditions == 1:
|
||||
tuple_indices = [0]
|
||||
input_predictions = ["pred_cond"]
|
||||
elif self.num_conditions == 2:
|
||||
tuple_indices = [0, 1]
|
||||
input_predictions = (
|
||||
["pred_cond", "pred_uncond"] if self._is_cfg_enabled() else ["pred_cond", "pred_cond_seg"]
|
||||
)
|
||||
else:
|
||||
tuple_indices = [0, 1, 0]
|
||||
input_predictions = ["pred_cond", "pred_uncond", "pred_cond_seg"]
|
||||
data_batches = []
|
||||
for i in range(self.num_conditions):
|
||||
data_batch = self._prepare_batch(input_fields, data, tuple_indices[i], input_predictions[i])
|
||||
data_batches.append(data_batch)
|
||||
return data_batches
|
||||
|
||||
def forward(
|
||||
self,
|
||||
pred_cond: torch.Tensor,
|
||||
pred_uncond: Optional[torch.Tensor] = None,
|
||||
pred_cond_seg: Optional[torch.Tensor] = None,
|
||||
) -> torch.Tensor:
|
||||
pred = None
|
||||
|
||||
if not self._is_cfg_enabled() and not self._is_seg_enabled():
|
||||
pred = pred_cond
|
||||
elif not self._is_cfg_enabled():
|
||||
shift = pred_cond - pred_cond_seg
|
||||
pred = pred_cond if self.use_original_formulation else pred_cond_seg
|
||||
pred = pred + self.seg_guidance_scale * shift
|
||||
elif not self._is_seg_enabled():
|
||||
shift = pred_cond - pred_uncond
|
||||
pred = pred_cond if self.use_original_formulation else pred_uncond
|
||||
pred = pred + self.guidance_scale * shift
|
||||
else:
|
||||
shift = pred_cond - pred_uncond
|
||||
shift_seg = pred_cond - pred_cond_seg
|
||||
pred = pred_cond if self.use_original_formulation else pred_uncond
|
||||
pred = pred + self.guidance_scale * shift + self.seg_guidance_scale * shift_seg
|
||||
|
||||
if self.guidance_rescale > 0.0:
|
||||
pred = rescale_noise_cfg(pred, pred_cond, self.guidance_rescale)
|
||||
|
||||
return pred, {}
|
||||
|
||||
@property
|
||||
def is_conditional(self) -> bool:
|
||||
return self._count_prepared == 1 or self._count_prepared == 3
|
||||
|
||||
@property
|
||||
def num_conditions(self) -> int:
|
||||
num_conditions = 1
|
||||
if self._is_cfg_enabled():
|
||||
num_conditions += 1
|
||||
if self._is_seg_enabled():
|
||||
num_conditions += 1
|
||||
return num_conditions
|
||||
|
||||
def _is_cfg_enabled(self) -> bool:
|
||||
if not self._enabled:
|
||||
return False
|
||||
|
||||
is_within_range = True
|
||||
if self._num_inference_steps is not None:
|
||||
skip_start_step = int(self._start * self._num_inference_steps)
|
||||
skip_stop_step = int(self._stop * self._num_inference_steps)
|
||||
is_within_range = skip_start_step <= self._step < skip_stop_step
|
||||
|
||||
is_close = False
|
||||
if self.use_original_formulation:
|
||||
is_close = math.isclose(self.guidance_scale, 0.0)
|
||||
else:
|
||||
is_close = math.isclose(self.guidance_scale, 1.0)
|
||||
|
||||
return is_within_range and not is_close
|
||||
|
||||
def _is_seg_enabled(self) -> bool:
|
||||
if not self._enabled:
|
||||
return False
|
||||
|
||||
is_within_range = True
|
||||
if self._num_inference_steps is not None:
|
||||
skip_start_step = int(self.seg_guidance_start * self._num_inference_steps)
|
||||
skip_stop_step = int(self.seg_guidance_stop * self._num_inference_steps)
|
||||
is_within_range = skip_start_step < self._step < skip_stop_step
|
||||
|
||||
is_zero = math.isclose(self.seg_guidance_scale, 0.0)
|
||||
|
||||
return is_within_range and not is_zero
|
||||
143
src/diffusers/guiders/tangential_classifier_free_guidance.py
Normal file
143
src/diffusers/guiders/tangential_classifier_free_guidance.py
Normal file
@@ -0,0 +1,143 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import math
|
||||
from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ..configuration_utils import register_to_config
|
||||
from .guider_utils import BaseGuidance, rescale_noise_cfg
|
||||
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from ..modular_pipelines.modular_pipeline import BlockState
|
||||
|
||||
|
||||
class TangentialClassifierFreeGuidance(BaseGuidance):
|
||||
"""
|
||||
Tangential Classifier Free Guidance (TCFG): https://huggingface.co/papers/2503.18137
|
||||
|
||||
Args:
|
||||
guidance_scale (`float`, defaults to `7.5`):
|
||||
The scale parameter for classifier-free guidance. Higher values result in stronger conditioning on the text
|
||||
prompt, while lower values allow for more freedom in generation. Higher values may lead to saturation and
|
||||
deterioration of image quality.
|
||||
guidance_rescale (`float`, defaults to `0.0`):
|
||||
The rescale factor applied to the noise predictions. This is used to improve image quality and fix
|
||||
overexposure. Based on Section 3.4 from [Common Diffusion Noise Schedules and Sample Steps are
|
||||
Flawed](https://huggingface.co/papers/2305.08891).
|
||||
use_original_formulation (`bool`, defaults to `False`):
|
||||
Whether to use the original formulation of classifier-free guidance as proposed in the paper. By default,
|
||||
we use the diffusers-native implementation that has been in the codebase for a long time. See
|
||||
[~guiders.classifier_free_guidance.ClassifierFreeGuidance] for more details.
|
||||
start (`float`, defaults to `0.0`):
|
||||
The fraction of the total number of denoising steps after which guidance starts.
|
||||
stop (`float`, defaults to `1.0`):
|
||||
The fraction of the total number of denoising steps after which guidance stops.
|
||||
"""
|
||||
|
||||
_input_predictions = ["pred_cond", "pred_uncond"]
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
guidance_scale: float = 7.5,
|
||||
guidance_rescale: float = 0.0,
|
||||
use_original_formulation: bool = False,
|
||||
start: float = 0.0,
|
||||
stop: float = 1.0,
|
||||
):
|
||||
super().__init__(start, stop)
|
||||
|
||||
self.guidance_scale = guidance_scale
|
||||
self.guidance_rescale = guidance_rescale
|
||||
self.use_original_formulation = use_original_formulation
|
||||
|
||||
def prepare_inputs(
|
||||
self, data: "BlockState", input_fields: Optional[Dict[str, Union[str, Tuple[str, str]]]] = None
|
||||
) -> List["BlockState"]:
|
||||
if input_fields is None:
|
||||
input_fields = self._input_fields
|
||||
|
||||
tuple_indices = [0] if self.num_conditions == 1 else [0, 1]
|
||||
data_batches = []
|
||||
for i in range(self.num_conditions):
|
||||
data_batch = self._prepare_batch(input_fields, data, tuple_indices[i], self._input_predictions[i])
|
||||
data_batches.append(data_batch)
|
||||
return data_batches
|
||||
|
||||
def forward(self, pred_cond: torch.Tensor, pred_uncond: Optional[torch.Tensor] = None) -> torch.Tensor:
|
||||
pred = None
|
||||
|
||||
if not self._is_tcfg_enabled():
|
||||
pred = pred_cond
|
||||
else:
|
||||
pred = normalized_guidance(pred_cond, pred_uncond, self.guidance_scale, self.use_original_formulation)
|
||||
|
||||
if self.guidance_rescale > 0.0:
|
||||
pred = rescale_noise_cfg(pred, pred_cond, self.guidance_rescale)
|
||||
|
||||
return pred, {}
|
||||
|
||||
@property
|
||||
def is_conditional(self) -> bool:
|
||||
return self._num_outputs_prepared == 1
|
||||
|
||||
@property
|
||||
def num_conditions(self) -> int:
|
||||
num_conditions = 1
|
||||
if self._is_tcfg_enabled():
|
||||
num_conditions += 1
|
||||
return num_conditions
|
||||
|
||||
def _is_tcfg_enabled(self) -> bool:
|
||||
if not self._enabled:
|
||||
return False
|
||||
|
||||
is_within_range = True
|
||||
if self._num_inference_steps is not None:
|
||||
skip_start_step = int(self._start * self._num_inference_steps)
|
||||
skip_stop_step = int(self._stop * self._num_inference_steps)
|
||||
is_within_range = skip_start_step <= self._step < skip_stop_step
|
||||
|
||||
is_close = False
|
||||
if self.use_original_formulation:
|
||||
is_close = math.isclose(self.guidance_scale, 0.0)
|
||||
else:
|
||||
is_close = math.isclose(self.guidance_scale, 1.0)
|
||||
|
||||
return is_within_range and not is_close
|
||||
|
||||
|
||||
def normalized_guidance(
|
||||
pred_cond: torch.Tensor, pred_uncond: torch.Tensor, guidance_scale: float, use_original_formulation: bool = False
|
||||
) -> torch.Tensor:
|
||||
cond_dtype = pred_cond.dtype
|
||||
preds = torch.stack([pred_cond, pred_uncond], dim=1).float()
|
||||
preds = preds.flatten(2)
|
||||
U, S, Vh = torch.linalg.svd(preds, full_matrices=False)
|
||||
Vh_modified = Vh.clone()
|
||||
Vh_modified[:, 1] = 0
|
||||
|
||||
uncond_flat = pred_uncond.reshape(pred_uncond.size(0), 1, -1).float()
|
||||
x_Vh = torch.matmul(uncond_flat, Vh.transpose(-2, -1))
|
||||
x_Vh_V = torch.matmul(x_Vh, Vh_modified)
|
||||
pred_uncond = x_Vh_V.reshape(pred_uncond.shape).to(cond_dtype)
|
||||
|
||||
pred = pred_cond if use_original_formulation else pred_uncond
|
||||
shift = pred_cond - pred_uncond
|
||||
pred = pred + guidance_scale * shift
|
||||
|
||||
return pred
|
||||
@@ -1,9 +1,26 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from ..utils import is_torch_available
|
||||
|
||||
|
||||
if is_torch_available():
|
||||
from .faster_cache import FasterCacheConfig, apply_faster_cache
|
||||
from .first_block_cache import FirstBlockCacheConfig, apply_first_block_cache
|
||||
from .group_offloading import apply_group_offloading
|
||||
from .hooks import HookRegistry, ModelHook
|
||||
from .layer_skip import LayerSkipConfig, apply_layer_skip
|
||||
from .layerwise_casting import apply_layerwise_casting, apply_layerwise_casting_hook
|
||||
from .pyramid_attention_broadcast import PyramidAttentionBroadcastConfig, apply_pyramid_attention_broadcast
|
||||
from .smoothed_energy_guidance_utils import SmoothedEnergyGuidanceConfig
|
||||
|
||||
43
src/diffusers/hooks/_common.py
Normal file
43
src/diffusers/hooks/_common.py
Normal file
@@ -0,0 +1,43 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
|
||||
from ..models.attention import FeedForward, LuminaFeedForward
|
||||
from ..models.attention_processor import Attention, MochiAttention
|
||||
|
||||
|
||||
_ATTENTION_CLASSES = (Attention, MochiAttention)
|
||||
_FEEDFORWARD_CLASSES = (FeedForward, LuminaFeedForward)
|
||||
|
||||
_SPATIAL_TRANSFORMER_BLOCK_IDENTIFIERS = ("blocks", "transformer_blocks", "single_transformer_blocks", "layers")
|
||||
_TEMPORAL_TRANSFORMER_BLOCK_IDENTIFIERS = ("temporal_transformer_blocks",)
|
||||
_CROSS_TRANSFORMER_BLOCK_IDENTIFIERS = ("blocks", "transformer_blocks", "layers")
|
||||
|
||||
_ALL_TRANSFORMER_BLOCK_IDENTIFIERS = tuple(
|
||||
{
|
||||
*_SPATIAL_TRANSFORMER_BLOCK_IDENTIFIERS,
|
||||
*_TEMPORAL_TRANSFORMER_BLOCK_IDENTIFIERS,
|
||||
*_CROSS_TRANSFORMER_BLOCK_IDENTIFIERS,
|
||||
}
|
||||
)
|
||||
|
||||
|
||||
def _get_submodule_from_fqn(module: torch.nn.Module, fqn: str) -> Optional[torch.nn.Module]:
|
||||
for submodule_name, submodule in module.named_modules():
|
||||
if submodule_name == fqn:
|
||||
return submodule
|
||||
return None
|
||||
264
src/diffusers/hooks/_helpers.py
Normal file
264
src/diffusers/hooks/_helpers.py
Normal file
@@ -0,0 +1,264 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import inspect
|
||||
from dataclasses import dataclass
|
||||
from typing import Any, Callable, Dict, Type
|
||||
|
||||
|
||||
@dataclass
|
||||
class AttentionProcessorMetadata:
|
||||
skip_processor_output_fn: Callable[[Any], Any]
|
||||
|
||||
|
||||
@dataclass
|
||||
class TransformerBlockMetadata:
|
||||
return_hidden_states_index: int = None
|
||||
return_encoder_hidden_states_index: int = None
|
||||
|
||||
_cls: Type = None
|
||||
_cached_parameter_indices: Dict[str, int] = None
|
||||
|
||||
def _get_parameter_from_args_kwargs(self, identifier: str, args=(), kwargs=None):
|
||||
kwargs = kwargs or {}
|
||||
if identifier in kwargs:
|
||||
return kwargs[identifier]
|
||||
if self._cached_parameter_indices is not None:
|
||||
return args[self._cached_parameter_indices[identifier]]
|
||||
if self._cls is None:
|
||||
raise ValueError("Model class is not set for metadata.")
|
||||
parameters = list(inspect.signature(self._cls.forward).parameters.keys())
|
||||
parameters = parameters[1:] # skip `self`
|
||||
self._cached_parameter_indices = {param: i for i, param in enumerate(parameters)}
|
||||
if identifier not in self._cached_parameter_indices:
|
||||
raise ValueError(f"Parameter '{identifier}' not found in function signature but was requested.")
|
||||
index = self._cached_parameter_indices[identifier]
|
||||
if index >= len(args):
|
||||
raise ValueError(f"Expected {index} arguments but got {len(args)}.")
|
||||
return args[index]
|
||||
|
||||
|
||||
class AttentionProcessorRegistry:
|
||||
_registry = {}
|
||||
# TODO(aryan): this is only required for the time being because we need to do the registrations
|
||||
# for classes. If we do it eagerly, i.e. call the functions in global scope, we will get circular
|
||||
# import errors because of the models imported in this file.
|
||||
_is_registered = False
|
||||
|
||||
@classmethod
|
||||
def register(cls, model_class: Type, metadata: AttentionProcessorMetadata):
|
||||
cls._register()
|
||||
cls._registry[model_class] = metadata
|
||||
|
||||
@classmethod
|
||||
def get(cls, model_class: Type) -> AttentionProcessorMetadata:
|
||||
cls._register()
|
||||
if model_class not in cls._registry:
|
||||
raise ValueError(f"Model class {model_class} not registered.")
|
||||
return cls._registry[model_class]
|
||||
|
||||
@classmethod
|
||||
def _register(cls):
|
||||
if cls._is_registered:
|
||||
return
|
||||
cls._is_registered = True
|
||||
_register_attention_processors_metadata()
|
||||
|
||||
|
||||
class TransformerBlockRegistry:
|
||||
_registry = {}
|
||||
# TODO(aryan): this is only required for the time being because we need to do the registrations
|
||||
# for classes. If we do it eagerly, i.e. call the functions in global scope, we will get circular
|
||||
# import errors because of the models imported in this file.
|
||||
_is_registered = False
|
||||
|
||||
@classmethod
|
||||
def register(cls, model_class: Type, metadata: TransformerBlockMetadata):
|
||||
cls._register()
|
||||
metadata._cls = model_class
|
||||
cls._registry[model_class] = metadata
|
||||
|
||||
@classmethod
|
||||
def get(cls, model_class: Type) -> TransformerBlockMetadata:
|
||||
cls._register()
|
||||
if model_class not in cls._registry:
|
||||
raise ValueError(f"Model class {model_class} not registered.")
|
||||
return cls._registry[model_class]
|
||||
|
||||
@classmethod
|
||||
def _register(cls):
|
||||
if cls._is_registered:
|
||||
return
|
||||
cls._is_registered = True
|
||||
_register_transformer_blocks_metadata()
|
||||
|
||||
|
||||
def _register_attention_processors_metadata():
|
||||
from ..models.attention_processor import AttnProcessor2_0
|
||||
from ..models.transformers.transformer_cogview4 import CogView4AttnProcessor
|
||||
|
||||
# AttnProcessor2_0
|
||||
AttentionProcessorRegistry.register(
|
||||
model_class=AttnProcessor2_0,
|
||||
metadata=AttentionProcessorMetadata(
|
||||
skip_processor_output_fn=_skip_proc_output_fn_Attention_AttnProcessor2_0,
|
||||
),
|
||||
)
|
||||
|
||||
# CogView4AttnProcessor
|
||||
AttentionProcessorRegistry.register(
|
||||
model_class=CogView4AttnProcessor,
|
||||
metadata=AttentionProcessorMetadata(
|
||||
skip_processor_output_fn=_skip_proc_output_fn_Attention_CogView4AttnProcessor,
|
||||
),
|
||||
)
|
||||
|
||||
|
||||
def _register_transformer_blocks_metadata():
|
||||
from ..models.attention import BasicTransformerBlock
|
||||
from ..models.transformers.cogvideox_transformer_3d import CogVideoXBlock
|
||||
from ..models.transformers.transformer_cogview4 import CogView4TransformerBlock
|
||||
from ..models.transformers.transformer_flux import FluxSingleTransformerBlock, FluxTransformerBlock
|
||||
from ..models.transformers.transformer_hunyuan_video import (
|
||||
HunyuanVideoSingleTransformerBlock,
|
||||
HunyuanVideoTokenReplaceSingleTransformerBlock,
|
||||
HunyuanVideoTokenReplaceTransformerBlock,
|
||||
HunyuanVideoTransformerBlock,
|
||||
)
|
||||
from ..models.transformers.transformer_ltx import LTXVideoTransformerBlock
|
||||
from ..models.transformers.transformer_mochi import MochiTransformerBlock
|
||||
from ..models.transformers.transformer_wan import WanTransformerBlock
|
||||
|
||||
# BasicTransformerBlock
|
||||
TransformerBlockRegistry.register(
|
||||
model_class=BasicTransformerBlock,
|
||||
metadata=TransformerBlockMetadata(
|
||||
return_hidden_states_index=0,
|
||||
return_encoder_hidden_states_index=None,
|
||||
),
|
||||
)
|
||||
|
||||
# CogVideoX
|
||||
TransformerBlockRegistry.register(
|
||||
model_class=CogVideoXBlock,
|
||||
metadata=TransformerBlockMetadata(
|
||||
return_hidden_states_index=0,
|
||||
return_encoder_hidden_states_index=1,
|
||||
),
|
||||
)
|
||||
|
||||
# CogView4
|
||||
TransformerBlockRegistry.register(
|
||||
model_class=CogView4TransformerBlock,
|
||||
metadata=TransformerBlockMetadata(
|
||||
return_hidden_states_index=0,
|
||||
return_encoder_hidden_states_index=1,
|
||||
),
|
||||
)
|
||||
|
||||
# Flux
|
||||
TransformerBlockRegistry.register(
|
||||
model_class=FluxTransformerBlock,
|
||||
metadata=TransformerBlockMetadata(
|
||||
return_hidden_states_index=1,
|
||||
return_encoder_hidden_states_index=0,
|
||||
),
|
||||
)
|
||||
TransformerBlockRegistry.register(
|
||||
model_class=FluxSingleTransformerBlock,
|
||||
metadata=TransformerBlockMetadata(
|
||||
return_hidden_states_index=1,
|
||||
return_encoder_hidden_states_index=0,
|
||||
),
|
||||
)
|
||||
|
||||
# HunyuanVideo
|
||||
TransformerBlockRegistry.register(
|
||||
model_class=HunyuanVideoTransformerBlock,
|
||||
metadata=TransformerBlockMetadata(
|
||||
return_hidden_states_index=0,
|
||||
return_encoder_hidden_states_index=1,
|
||||
),
|
||||
)
|
||||
TransformerBlockRegistry.register(
|
||||
model_class=HunyuanVideoSingleTransformerBlock,
|
||||
metadata=TransformerBlockMetadata(
|
||||
return_hidden_states_index=0,
|
||||
return_encoder_hidden_states_index=1,
|
||||
),
|
||||
)
|
||||
TransformerBlockRegistry.register(
|
||||
model_class=HunyuanVideoTokenReplaceTransformerBlock,
|
||||
metadata=TransformerBlockMetadata(
|
||||
return_hidden_states_index=0,
|
||||
return_encoder_hidden_states_index=1,
|
||||
),
|
||||
)
|
||||
TransformerBlockRegistry.register(
|
||||
model_class=HunyuanVideoTokenReplaceSingleTransformerBlock,
|
||||
metadata=TransformerBlockMetadata(
|
||||
return_hidden_states_index=0,
|
||||
return_encoder_hidden_states_index=1,
|
||||
),
|
||||
)
|
||||
|
||||
# LTXVideo
|
||||
TransformerBlockRegistry.register(
|
||||
model_class=LTXVideoTransformerBlock,
|
||||
metadata=TransformerBlockMetadata(
|
||||
return_hidden_states_index=0,
|
||||
return_encoder_hidden_states_index=None,
|
||||
),
|
||||
)
|
||||
|
||||
# Mochi
|
||||
TransformerBlockRegistry.register(
|
||||
model_class=MochiTransformerBlock,
|
||||
metadata=TransformerBlockMetadata(
|
||||
return_hidden_states_index=0,
|
||||
return_encoder_hidden_states_index=1,
|
||||
),
|
||||
)
|
||||
|
||||
# Wan
|
||||
TransformerBlockRegistry.register(
|
||||
model_class=WanTransformerBlock,
|
||||
metadata=TransformerBlockMetadata(
|
||||
return_hidden_states_index=0,
|
||||
return_encoder_hidden_states_index=None,
|
||||
),
|
||||
)
|
||||
|
||||
|
||||
# fmt: off
|
||||
def _skip_attention___ret___hidden_states(self, *args, **kwargs):
|
||||
hidden_states = kwargs.get("hidden_states", None)
|
||||
if hidden_states is None and len(args) > 0:
|
||||
hidden_states = args[0]
|
||||
return hidden_states
|
||||
|
||||
|
||||
def _skip_attention___ret___hidden_states___encoder_hidden_states(self, *args, **kwargs):
|
||||
hidden_states = kwargs.get("hidden_states", None)
|
||||
encoder_hidden_states = kwargs.get("encoder_hidden_states", None)
|
||||
if hidden_states is None and len(args) > 0:
|
||||
hidden_states = args[0]
|
||||
if encoder_hidden_states is None and len(args) > 1:
|
||||
encoder_hidden_states = args[1]
|
||||
return hidden_states, encoder_hidden_states
|
||||
|
||||
|
||||
_skip_proc_output_fn_Attention_AttnProcessor2_0 = _skip_attention___ret___hidden_states
|
||||
_skip_proc_output_fn_Attention_CogView4AttnProcessor = _skip_attention___ret___hidden_states___encoder_hidden_states
|
||||
# fmt: on
|
||||
227
src/diffusers/hooks/first_block_cache.py
Normal file
227
src/diffusers/hooks/first_block_cache.py
Normal file
@@ -0,0 +1,227 @@
|
||||
# Copyright 2024 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from dataclasses import dataclass
|
||||
from typing import Tuple, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ..utils import get_logger
|
||||
from ..utils.torch_utils import unwrap_module
|
||||
from ._common import _ALL_TRANSFORMER_BLOCK_IDENTIFIERS
|
||||
from ._helpers import TransformerBlockRegistry
|
||||
from .hooks import BaseState, HookRegistry, ModelHook, StateManager
|
||||
|
||||
|
||||
logger = get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
_FBC_LEADER_BLOCK_HOOK = "fbc_leader_block_hook"
|
||||
_FBC_BLOCK_HOOK = "fbc_block_hook"
|
||||
|
||||
|
||||
@dataclass
|
||||
class FirstBlockCacheConfig:
|
||||
r"""
|
||||
Configuration for [First Block
|
||||
Cache](https://github.com/chengzeyi/ParaAttention/blob/7a266123671b55e7e5a2fe9af3121f07a36afc78/README.md#first-block-cache-our-dynamic-caching).
|
||||
|
||||
Args:
|
||||
threshold (`float`, defaults to `0.05`):
|
||||
The threshold to determine whether or not a forward pass through all layers of the model is required. A
|
||||
higher threshold usually results in a forward pass through a lower number of layers and faster inference,
|
||||
but might lead to poorer generation quality. A lower threshold may not result in significant generation
|
||||
speedup. The threshold is compared against the absmean difference of the residuals between the current and
|
||||
cached outputs from the first transformer block. If the difference is below the threshold, the forward pass
|
||||
is skipped.
|
||||
"""
|
||||
|
||||
threshold: float = 0.05
|
||||
|
||||
|
||||
class FBCSharedBlockState(BaseState):
|
||||
def __init__(self) -> None:
|
||||
super().__init__()
|
||||
|
||||
self.head_block_output: Union[torch.Tensor, Tuple[torch.Tensor, ...]] = None
|
||||
self.head_block_residual: torch.Tensor = None
|
||||
self.tail_block_residuals: Union[torch.Tensor, Tuple[torch.Tensor, ...]] = None
|
||||
self.should_compute: bool = True
|
||||
|
||||
def reset(self):
|
||||
self.tail_block_residuals = None
|
||||
self.should_compute = True
|
||||
|
||||
|
||||
class FBCHeadBlockHook(ModelHook):
|
||||
_is_stateful = True
|
||||
|
||||
def __init__(self, state_manager: StateManager, threshold: float):
|
||||
self.state_manager = state_manager
|
||||
self.threshold = threshold
|
||||
self._metadata = None
|
||||
|
||||
def initialize_hook(self, module):
|
||||
unwrapped_module = unwrap_module(module)
|
||||
self._metadata = TransformerBlockRegistry.get(unwrapped_module.__class__)
|
||||
return module
|
||||
|
||||
def new_forward(self, module: torch.nn.Module, *args, **kwargs):
|
||||
original_hidden_states = self._metadata._get_parameter_from_args_kwargs("hidden_states", args, kwargs)
|
||||
|
||||
output = self.fn_ref.original_forward(*args, **kwargs)
|
||||
is_output_tuple = isinstance(output, tuple)
|
||||
|
||||
if is_output_tuple:
|
||||
hidden_states_residual = output[self._metadata.return_hidden_states_index] - original_hidden_states
|
||||
else:
|
||||
hidden_states_residual = output - original_hidden_states
|
||||
|
||||
shared_state: FBCSharedBlockState = self.state_manager.get_state()
|
||||
hidden_states = encoder_hidden_states = None
|
||||
should_compute = self._should_compute_remaining_blocks(hidden_states_residual)
|
||||
shared_state.should_compute = should_compute
|
||||
|
||||
if not should_compute:
|
||||
# Apply caching
|
||||
if is_output_tuple:
|
||||
hidden_states = (
|
||||
shared_state.tail_block_residuals[0] + output[self._metadata.return_hidden_states_index]
|
||||
)
|
||||
else:
|
||||
hidden_states = shared_state.tail_block_residuals[0] + output
|
||||
|
||||
if self._metadata.return_encoder_hidden_states_index is not None:
|
||||
assert is_output_tuple
|
||||
encoder_hidden_states = (
|
||||
shared_state.tail_block_residuals[1] + output[self._metadata.return_encoder_hidden_states_index]
|
||||
)
|
||||
|
||||
if is_output_tuple:
|
||||
return_output = [None] * len(output)
|
||||
return_output[self._metadata.return_hidden_states_index] = hidden_states
|
||||
return_output[self._metadata.return_encoder_hidden_states_index] = encoder_hidden_states
|
||||
return_output = tuple(return_output)
|
||||
else:
|
||||
return_output = hidden_states
|
||||
output = return_output
|
||||
else:
|
||||
if is_output_tuple:
|
||||
head_block_output = [None] * len(output)
|
||||
head_block_output[0] = output[self._metadata.return_hidden_states_index]
|
||||
head_block_output[1] = output[self._metadata.return_encoder_hidden_states_index]
|
||||
else:
|
||||
head_block_output = output
|
||||
shared_state.head_block_output = head_block_output
|
||||
shared_state.head_block_residual = hidden_states_residual
|
||||
|
||||
return output
|
||||
|
||||
def reset_state(self, module):
|
||||
self.state_manager.reset()
|
||||
return module
|
||||
|
||||
@torch.compiler.disable
|
||||
def _should_compute_remaining_blocks(self, hidden_states_residual: torch.Tensor) -> bool:
|
||||
shared_state = self.state_manager.get_state()
|
||||
if shared_state.head_block_residual is None:
|
||||
return True
|
||||
prev_hidden_states_residual = shared_state.head_block_residual
|
||||
absmean = (hidden_states_residual - prev_hidden_states_residual).abs().mean()
|
||||
prev_hidden_states_absmean = prev_hidden_states_residual.abs().mean()
|
||||
diff = (absmean / prev_hidden_states_absmean).item()
|
||||
return diff > self.threshold
|
||||
|
||||
|
||||
class FBCBlockHook(ModelHook):
|
||||
def __init__(self, state_manager: StateManager, is_tail: bool = False):
|
||||
super().__init__()
|
||||
self.state_manager = state_manager
|
||||
self.is_tail = is_tail
|
||||
self._metadata = None
|
||||
|
||||
def initialize_hook(self, module):
|
||||
unwrapped_module = unwrap_module(module)
|
||||
self._metadata = TransformerBlockRegistry.get(unwrapped_module.__class__)
|
||||
return module
|
||||
|
||||
def new_forward(self, module: torch.nn.Module, *args, **kwargs):
|
||||
original_hidden_states = self._metadata._get_parameter_from_args_kwargs("hidden_states", args, kwargs)
|
||||
original_encoder_hidden_states = None
|
||||
if self._metadata.return_encoder_hidden_states_index is not None:
|
||||
original_encoder_hidden_states = self._metadata._get_parameter_from_args_kwargs(
|
||||
"encoder_hidden_states", args, kwargs
|
||||
)
|
||||
|
||||
shared_state = self.state_manager.get_state()
|
||||
|
||||
if shared_state.should_compute:
|
||||
output = self.fn_ref.original_forward(*args, **kwargs)
|
||||
if self.is_tail:
|
||||
hidden_states_residual = encoder_hidden_states_residual = None
|
||||
if isinstance(output, tuple):
|
||||
hidden_states_residual = (
|
||||
output[self._metadata.return_hidden_states_index] - shared_state.head_block_output[0]
|
||||
)
|
||||
encoder_hidden_states_residual = (
|
||||
output[self._metadata.return_encoder_hidden_states_index] - shared_state.head_block_output[1]
|
||||
)
|
||||
else:
|
||||
hidden_states_residual = output - shared_state.head_block_output
|
||||
shared_state.tail_block_residuals = (hidden_states_residual, encoder_hidden_states_residual)
|
||||
return output
|
||||
|
||||
if original_encoder_hidden_states is None:
|
||||
return_output = original_hidden_states
|
||||
else:
|
||||
return_output = [None, None]
|
||||
return_output[self._metadata.return_hidden_states_index] = original_hidden_states
|
||||
return_output[self._metadata.return_encoder_hidden_states_index] = original_encoder_hidden_states
|
||||
return_output = tuple(return_output)
|
||||
return return_output
|
||||
|
||||
|
||||
def apply_first_block_cache(module: torch.nn.Module, config: FirstBlockCacheConfig) -> None:
|
||||
state_manager = StateManager(FBCSharedBlockState, (), {})
|
||||
remaining_blocks = []
|
||||
|
||||
for name, submodule in module.named_children():
|
||||
if name not in _ALL_TRANSFORMER_BLOCK_IDENTIFIERS or not isinstance(submodule, torch.nn.ModuleList):
|
||||
continue
|
||||
for index, block in enumerate(submodule):
|
||||
remaining_blocks.append((f"{name}.{index}", block))
|
||||
|
||||
head_block_name, head_block = remaining_blocks.pop(0)
|
||||
tail_block_name, tail_block = remaining_blocks.pop(-1)
|
||||
|
||||
logger.debug(f"Applying FBCHeadBlockHook to '{head_block_name}'")
|
||||
_apply_fbc_head_block_hook(head_block, state_manager, config.threshold)
|
||||
|
||||
for name, block in remaining_blocks:
|
||||
logger.debug(f"Applying FBCBlockHook to '{name}'")
|
||||
_apply_fbc_block_hook(block, state_manager)
|
||||
|
||||
logger.debug(f"Applying FBCBlockHook to tail block '{tail_block_name}'")
|
||||
_apply_fbc_block_hook(tail_block, state_manager, is_tail=True)
|
||||
|
||||
|
||||
def _apply_fbc_head_block_hook(block: torch.nn.Module, state_manager: StateManager, threshold: float) -> None:
|
||||
registry = HookRegistry.check_if_exists_or_initialize(block)
|
||||
hook = FBCHeadBlockHook(state_manager, threshold)
|
||||
registry.register_hook(hook, _FBC_LEADER_BLOCK_HOOK)
|
||||
|
||||
|
||||
def _apply_fbc_block_hook(block: torch.nn.Module, state_manager: StateManager, is_tail: bool = False) -> None:
|
||||
registry = HookRegistry.check_if_exists_or_initialize(block)
|
||||
hook = FBCBlockHook(state_manager, is_tail)
|
||||
registry.register_hook(hook, _FBC_BLOCK_HOOK)
|
||||
@@ -18,11 +18,44 @@ from typing import Any, Dict, Optional, Tuple
|
||||
import torch
|
||||
|
||||
from ..utils.logging import get_logger
|
||||
from ..utils.torch_utils import unwrap_module
|
||||
|
||||
|
||||
logger = get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
class BaseState:
|
||||
def reset(self, *args, **kwargs) -> None:
|
||||
raise NotImplementedError(
|
||||
"BaseState::reset is not implemented. Please implement this method in the derived class."
|
||||
)
|
||||
|
||||
|
||||
class StateManager:
|
||||
def __init__(self, state_cls: BaseState, init_args=None, init_kwargs=None):
|
||||
self._state_cls = state_cls
|
||||
self._init_args = init_args if init_args is not None else ()
|
||||
self._init_kwargs = init_kwargs if init_kwargs is not None else {}
|
||||
self._state_cache = {}
|
||||
self._current_context = None
|
||||
|
||||
def get_state(self):
|
||||
if self._current_context is None:
|
||||
raise ValueError("No context is set. Please set a context before retrieving the state.")
|
||||
if self._current_context not in self._state_cache.keys():
|
||||
self._state_cache[self._current_context] = self._state_cls(*self._init_args, **self._init_kwargs)
|
||||
return self._state_cache[self._current_context]
|
||||
|
||||
def set_context(self, name: str) -> None:
|
||||
self._current_context = name
|
||||
|
||||
def reset(self, *args, **kwargs) -> None:
|
||||
for name, state in list(self._state_cache.items()):
|
||||
state.reset(*args, **kwargs)
|
||||
self._state_cache.pop(name)
|
||||
self._current_context = None
|
||||
|
||||
|
||||
class ModelHook:
|
||||
r"""
|
||||
A hook that contains callbacks to be executed just before and after the forward method of a model.
|
||||
@@ -99,6 +132,14 @@ class ModelHook:
|
||||
raise NotImplementedError("This hook is stateful and needs to implement the `reset_state` method.")
|
||||
return module
|
||||
|
||||
def _set_context(self, module: torch.nn.Module, name: str) -> None:
|
||||
# Iterate over all attributes of the hook to see if any of them have the type `StateManager`. If so, call `set_context` on them.
|
||||
for attr_name in dir(self):
|
||||
attr = getattr(self, attr_name)
|
||||
if isinstance(attr, StateManager):
|
||||
attr.set_context(name)
|
||||
return module
|
||||
|
||||
|
||||
class HookFunctionReference:
|
||||
def __init__(self) -> None:
|
||||
@@ -211,9 +252,10 @@ class HookRegistry:
|
||||
hook.reset_state(self._module_ref)
|
||||
|
||||
if recurse:
|
||||
for module_name, module in self._module_ref.named_modules():
|
||||
for module_name, module in unwrap_module(self._module_ref).named_modules():
|
||||
if module_name == "":
|
||||
continue
|
||||
module = unwrap_module(module)
|
||||
if hasattr(module, "_diffusers_hook"):
|
||||
module._diffusers_hook.reset_stateful_hooks(recurse=False)
|
||||
|
||||
@@ -223,6 +265,19 @@ class HookRegistry:
|
||||
module._diffusers_hook = cls(module)
|
||||
return module._diffusers_hook
|
||||
|
||||
def _set_context(self, name: Optional[str] = None) -> None:
|
||||
for hook_name in reversed(self._hook_order):
|
||||
hook = self.hooks[hook_name]
|
||||
if hook._is_stateful:
|
||||
hook._set_context(self._module_ref, name)
|
||||
|
||||
for module_name, module in unwrap_module(self._module_ref).named_modules():
|
||||
if module_name == "":
|
||||
continue
|
||||
module = unwrap_module(module)
|
||||
if hasattr(module, "_diffusers_hook"):
|
||||
module._diffusers_hook._set_context(name)
|
||||
|
||||
def __repr__(self) -> str:
|
||||
registry_repr = ""
|
||||
for i, hook_name in enumerate(self._hook_order):
|
||||
|
||||
254
src/diffusers/hooks/layer_skip.py
Normal file
254
src/diffusers/hooks/layer_skip.py
Normal file
@@ -0,0 +1,254 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import math
|
||||
from dataclasses import asdict, dataclass
|
||||
from typing import Callable, List, Optional
|
||||
|
||||
import torch
|
||||
|
||||
from ..utils import get_logger
|
||||
from ..utils.torch_utils import unwrap_module
|
||||
from ._common import (
|
||||
_ALL_TRANSFORMER_BLOCK_IDENTIFIERS,
|
||||
_ATTENTION_CLASSES,
|
||||
_FEEDFORWARD_CLASSES,
|
||||
_get_submodule_from_fqn,
|
||||
)
|
||||
from ._helpers import AttentionProcessorRegistry, TransformerBlockRegistry
|
||||
from .hooks import HookRegistry, ModelHook
|
||||
|
||||
|
||||
logger = get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
_LAYER_SKIP_HOOK = "layer_skip_hook"
|
||||
|
||||
|
||||
# Aryan/YiYi TODO: we need to make guider class a config mixin so I think this is not needed
|
||||
# either remove or make it serializable
|
||||
@dataclass
|
||||
class LayerSkipConfig:
|
||||
r"""
|
||||
Configuration for skipping internal transformer blocks when executing a transformer model.
|
||||
|
||||
Args:
|
||||
indices (`List[int]`):
|
||||
The indices of the layer to skip. This is typically the first layer in the transformer block.
|
||||
fqn (`str`, defaults to `"auto"`):
|
||||
The fully qualified name identifying the stack of transformer blocks. Typically, this is
|
||||
`transformer_blocks`, `single_transformer_blocks`, `blocks`, `layers`, or `temporal_transformer_blocks`.
|
||||
For automatic detection, set this to `"auto"`. "auto" only works on DiT models. For UNet models, you must
|
||||
provide the correct fqn.
|
||||
skip_attention (`bool`, defaults to `True`):
|
||||
Whether to skip attention blocks.
|
||||
skip_ff (`bool`, defaults to `True`):
|
||||
Whether to skip feed-forward blocks.
|
||||
skip_attention_scores (`bool`, defaults to `False`):
|
||||
Whether to skip attention score computation in the attention blocks. This is equivalent to using `value`
|
||||
projections as the output of scaled dot product attention.
|
||||
dropout (`float`, defaults to `1.0`):
|
||||
The dropout probability for dropping the outputs of the skipped layers. By default, this is set to `1.0`,
|
||||
meaning that the outputs of the skipped layers are completely ignored. If set to `0.0`, the outputs of the
|
||||
skipped layers are fully retained, which is equivalent to not skipping any layers.
|
||||
"""
|
||||
|
||||
indices: List[int]
|
||||
fqn: str = "auto"
|
||||
skip_attention: bool = True
|
||||
skip_attention_scores: bool = False
|
||||
skip_ff: bool = True
|
||||
dropout: float = 1.0
|
||||
|
||||
def __post_init__(self):
|
||||
if not (0 <= self.dropout <= 1):
|
||||
raise ValueError(f"Expected `dropout` to be between 0.0 and 1.0, but got {self.dropout}.")
|
||||
if not math.isclose(self.dropout, 1.0) and self.skip_attention_scores:
|
||||
raise ValueError(
|
||||
"Cannot set `skip_attention_scores` to True when `dropout` is not 1.0. Please set `dropout` to 1.0."
|
||||
)
|
||||
|
||||
def to_dict(self):
|
||||
return asdict(self)
|
||||
|
||||
@staticmethod
|
||||
def from_dict(data: dict) -> "LayerSkipConfig":
|
||||
return LayerSkipConfig(**data)
|
||||
|
||||
|
||||
class AttentionScoreSkipFunctionMode(torch.overrides.TorchFunctionMode):
|
||||
def __torch_function__(self, func, types, args=(), kwargs=None):
|
||||
if kwargs is None:
|
||||
kwargs = {}
|
||||
if func is torch.nn.functional.scaled_dot_product_attention:
|
||||
value = kwargs.get("value", None)
|
||||
if value is None:
|
||||
value = args[2]
|
||||
return value
|
||||
return func(*args, **kwargs)
|
||||
|
||||
|
||||
class AttentionProcessorSkipHook(ModelHook):
|
||||
def __init__(self, skip_processor_output_fn: Callable, skip_attention_scores: bool = False, dropout: float = 1.0):
|
||||
self.skip_processor_output_fn = skip_processor_output_fn
|
||||
self.skip_attention_scores = skip_attention_scores
|
||||
self.dropout = dropout
|
||||
|
||||
def new_forward(self, module: torch.nn.Module, *args, **kwargs):
|
||||
if self.skip_attention_scores:
|
||||
if not math.isclose(self.dropout, 1.0):
|
||||
raise ValueError(
|
||||
"Cannot set `skip_attention_scores` to True when `dropout` is not 1.0. Please set `dropout` to 1.0."
|
||||
)
|
||||
with AttentionScoreSkipFunctionMode():
|
||||
output = self.fn_ref.original_forward(*args, **kwargs)
|
||||
else:
|
||||
if math.isclose(self.dropout, 1.0):
|
||||
output = self.skip_processor_output_fn(module, *args, **kwargs)
|
||||
else:
|
||||
output = self.fn_ref.original_forward(*args, **kwargs)
|
||||
output = torch.nn.functional.dropout(output, p=self.dropout)
|
||||
return output
|
||||
|
||||
|
||||
class FeedForwardSkipHook(ModelHook):
|
||||
def __init__(self, dropout: float):
|
||||
super().__init__()
|
||||
self.dropout = dropout
|
||||
|
||||
def new_forward(self, module: torch.nn.Module, *args, **kwargs):
|
||||
if math.isclose(self.dropout, 1.0):
|
||||
output = kwargs.get("hidden_states", None)
|
||||
if output is None:
|
||||
output = kwargs.get("x", None)
|
||||
if output is None and len(args) > 0:
|
||||
output = args[0]
|
||||
else:
|
||||
output = self.fn_ref.original_forward(*args, **kwargs)
|
||||
output = torch.nn.functional.dropout(output, p=self.dropout)
|
||||
return output
|
||||
|
||||
|
||||
class TransformerBlockSkipHook(ModelHook):
|
||||
def __init__(self, dropout: float):
|
||||
super().__init__()
|
||||
self.dropout = dropout
|
||||
|
||||
def initialize_hook(self, module):
|
||||
self._metadata = TransformerBlockRegistry.get(unwrap_module(module).__class__)
|
||||
return module
|
||||
|
||||
def new_forward(self, module: torch.nn.Module, *args, **kwargs):
|
||||
if math.isclose(self.dropout, 1.0):
|
||||
original_hidden_states = self._metadata._get_parameter_from_args_kwargs("hidden_states", args, kwargs)
|
||||
if self._metadata.return_encoder_hidden_states_index is None:
|
||||
output = original_hidden_states
|
||||
else:
|
||||
original_encoder_hidden_states = self._metadata._get_parameter_from_args_kwargs(
|
||||
"encoder_hidden_states", args, kwargs
|
||||
)
|
||||
output = (original_hidden_states, original_encoder_hidden_states)
|
||||
else:
|
||||
output = self.fn_ref.original_forward(*args, **kwargs)
|
||||
output = torch.nn.functional.dropout(output, p=self.dropout)
|
||||
return output
|
||||
|
||||
|
||||
def apply_layer_skip(module: torch.nn.Module, config: LayerSkipConfig) -> None:
|
||||
r"""
|
||||
Apply layer skipping to internal layers of a transformer.
|
||||
|
||||
Args:
|
||||
module (`torch.nn.Module`):
|
||||
The transformer model to which the layer skip hook should be applied.
|
||||
config (`LayerSkipConfig`):
|
||||
The configuration for the layer skip hook.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
>>> from diffusers import apply_layer_skip_hook, CogVideoXTransformer3DModel, LayerSkipConfig
|
||||
|
||||
>>> transformer = CogVideoXTransformer3DModel.from_pretrained("THUDM/CogVideoX-5b", torch_dtype=torch.bfloat16)
|
||||
>>> config = LayerSkipConfig(layer_index=[10, 20], fqn="transformer_blocks")
|
||||
>>> apply_layer_skip_hook(transformer, config)
|
||||
```
|
||||
"""
|
||||
_apply_layer_skip_hook(module, config)
|
||||
|
||||
|
||||
def _apply_layer_skip_hook(module: torch.nn.Module, config: LayerSkipConfig, name: Optional[str] = None) -> None:
|
||||
name = name or _LAYER_SKIP_HOOK
|
||||
|
||||
if config.skip_attention and config.skip_attention_scores:
|
||||
raise ValueError("Cannot set both `skip_attention` and `skip_attention_scores` to True. Please choose one.")
|
||||
if not math.isclose(config.dropout, 1.0) and config.skip_attention_scores:
|
||||
raise ValueError(
|
||||
"Cannot set `skip_attention_scores` to True when `dropout` is not 1.0. Please set `dropout` to 1.0."
|
||||
)
|
||||
|
||||
if config.fqn == "auto":
|
||||
for identifier in _ALL_TRANSFORMER_BLOCK_IDENTIFIERS:
|
||||
if hasattr(module, identifier):
|
||||
config.fqn = identifier
|
||||
break
|
||||
else:
|
||||
raise ValueError(
|
||||
"Could not find a suitable identifier for the transformer blocks automatically. Please provide a valid "
|
||||
"`fqn` (fully qualified name) that identifies a stack of transformer blocks."
|
||||
)
|
||||
|
||||
transformer_blocks = _get_submodule_from_fqn(module, config.fqn)
|
||||
if transformer_blocks is None or not isinstance(transformer_blocks, torch.nn.ModuleList):
|
||||
raise ValueError(
|
||||
f"Could not find {config.fqn} in the provided module, or configured `fqn` (fully qualified name) does not identify "
|
||||
f"a `torch.nn.ModuleList`. Please provide a valid `fqn` that identifies a stack of transformer blocks."
|
||||
)
|
||||
if len(config.indices) == 0:
|
||||
raise ValueError("Layer index list is empty. Please provide a non-empty list of layer indices to skip.")
|
||||
|
||||
blocks_found = False
|
||||
for i, block in enumerate(transformer_blocks):
|
||||
if i not in config.indices:
|
||||
continue
|
||||
|
||||
blocks_found = True
|
||||
|
||||
if config.skip_attention and config.skip_ff:
|
||||
logger.debug(f"Applying TransformerBlockSkipHook to '{config.fqn}.{i}'")
|
||||
registry = HookRegistry.check_if_exists_or_initialize(block)
|
||||
hook = TransformerBlockSkipHook(config.dropout)
|
||||
registry.register_hook(hook, name)
|
||||
|
||||
elif config.skip_attention or config.skip_attention_scores:
|
||||
for submodule_name, submodule in block.named_modules():
|
||||
if isinstance(submodule, _ATTENTION_CLASSES) and not submodule.is_cross_attention:
|
||||
logger.debug(f"Applying AttentionProcessorSkipHook to '{config.fqn}.{i}.{submodule_name}'")
|
||||
output_fn = AttentionProcessorRegistry.get(submodule.processor.__class__).skip_processor_output_fn
|
||||
registry = HookRegistry.check_if_exists_or_initialize(submodule)
|
||||
hook = AttentionProcessorSkipHook(output_fn, config.skip_attention_scores, config.dropout)
|
||||
registry.register_hook(hook, name)
|
||||
|
||||
if config.skip_ff:
|
||||
for submodule_name, submodule in block.named_modules():
|
||||
if isinstance(submodule, _FEEDFORWARD_CLASSES):
|
||||
logger.debug(f"Applying FeedForwardSkipHook to '{config.fqn}.{i}.{submodule_name}'")
|
||||
registry = HookRegistry.check_if_exists_or_initialize(submodule)
|
||||
hook = FeedForwardSkipHook(config.dropout)
|
||||
registry.register_hook(hook, name)
|
||||
|
||||
if not blocks_found:
|
||||
raise ValueError(
|
||||
f"Could not find any transformer blocks matching the provided indices {config.indices} and "
|
||||
f"fully qualified name '{config.fqn}'. Please check the indices and fqn for correctness."
|
||||
)
|
||||
167
src/diffusers/hooks/smoothed_energy_guidance_utils.py
Normal file
167
src/diffusers/hooks/smoothed_energy_guidance_utils.py
Normal file
@@ -0,0 +1,167 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import math
|
||||
from dataclasses import asdict, dataclass
|
||||
from typing import List, Optional
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
from ..utils import get_logger
|
||||
from ._common import _ALL_TRANSFORMER_BLOCK_IDENTIFIERS, _ATTENTION_CLASSES, _get_submodule_from_fqn
|
||||
from .hooks import HookRegistry, ModelHook
|
||||
|
||||
|
||||
logger = get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
_SMOOTHED_ENERGY_GUIDANCE_HOOK = "smoothed_energy_guidance_hook"
|
||||
|
||||
|
||||
@dataclass
|
||||
class SmoothedEnergyGuidanceConfig:
|
||||
r"""
|
||||
Configuration for skipping internal transformer blocks when executing a transformer model.
|
||||
|
||||
Args:
|
||||
indices (`List[int]`):
|
||||
The indices of the layer to skip. This is typically the first layer in the transformer block.
|
||||
fqn (`str`, defaults to `"auto"`):
|
||||
The fully qualified name identifying the stack of transformer blocks. Typically, this is
|
||||
`transformer_blocks`, `single_transformer_blocks`, `blocks`, `layers`, or `temporal_transformer_blocks`.
|
||||
For automatic detection, set this to `"auto"`. "auto" only works on DiT models. For UNet models, you must
|
||||
provide the correct fqn.
|
||||
_query_proj_identifiers (`List[str]`, defaults to `None`):
|
||||
The identifiers for the query projection layers. Typically, these are `to_q`, `query`, or `q_proj`. If
|
||||
`None`, `to_q` is used by default.
|
||||
"""
|
||||
|
||||
indices: List[int]
|
||||
fqn: str = "auto"
|
||||
_query_proj_identifiers: List[str] = None
|
||||
|
||||
def to_dict(self):
|
||||
return asdict(self)
|
||||
|
||||
@staticmethod
|
||||
def from_dict(data: dict) -> "SmoothedEnergyGuidanceConfig":
|
||||
return SmoothedEnergyGuidanceConfig(**data)
|
||||
|
||||
|
||||
class SmoothedEnergyGuidanceHook(ModelHook):
|
||||
def __init__(self, blur_sigma: float = 1.0, blur_threshold_inf: float = 9999.9) -> None:
|
||||
super().__init__()
|
||||
self.blur_sigma = blur_sigma
|
||||
self.blur_threshold_inf = blur_threshold_inf
|
||||
|
||||
def post_forward(self, module: torch.nn.Module, output: torch.Tensor) -> torch.Tensor:
|
||||
# Copied from https://github.com/SusungHong/SEG-SDXL/blob/cf8256d640d5373541cfea3b3b6caf93272cf986/pipeline_seg.py#L172C31-L172C102
|
||||
kernel_size = math.ceil(6 * self.blur_sigma) + 1 - math.ceil(6 * self.blur_sigma) % 2
|
||||
smoothed_output = _gaussian_blur_2d(output, kernel_size, self.blur_sigma, self.blur_threshold_inf)
|
||||
return smoothed_output
|
||||
|
||||
|
||||
def _apply_smoothed_energy_guidance_hook(
|
||||
module: torch.nn.Module, config: SmoothedEnergyGuidanceConfig, blur_sigma: float, name: Optional[str] = None
|
||||
) -> None:
|
||||
name = name or _SMOOTHED_ENERGY_GUIDANCE_HOOK
|
||||
|
||||
if config.fqn == "auto":
|
||||
for identifier in _ALL_TRANSFORMER_BLOCK_IDENTIFIERS:
|
||||
if hasattr(module, identifier):
|
||||
config.fqn = identifier
|
||||
break
|
||||
else:
|
||||
raise ValueError(
|
||||
"Could not find a suitable identifier for the transformer blocks automatically. Please provide a valid "
|
||||
"`fqn` (fully qualified name) that identifies a stack of transformer blocks."
|
||||
)
|
||||
|
||||
if config._query_proj_identifiers is None:
|
||||
config._query_proj_identifiers = ["to_q"]
|
||||
|
||||
transformer_blocks = _get_submodule_from_fqn(module, config.fqn)
|
||||
blocks_found = False
|
||||
for i, block in enumerate(transformer_blocks):
|
||||
if i not in config.indices:
|
||||
continue
|
||||
|
||||
blocks_found = True
|
||||
|
||||
for submodule_name, submodule in block.named_modules():
|
||||
if not isinstance(submodule, _ATTENTION_CLASSES) or submodule.is_cross_attention:
|
||||
continue
|
||||
for identifier in config._query_proj_identifiers:
|
||||
query_proj = getattr(submodule, identifier, None)
|
||||
if query_proj is None or not isinstance(query_proj, torch.nn.Linear):
|
||||
continue
|
||||
logger.debug(
|
||||
f"Registering smoothed energy guidance hook on {config.fqn}.{i}.{submodule_name}.{identifier}"
|
||||
)
|
||||
registry = HookRegistry.check_if_exists_or_initialize(query_proj)
|
||||
hook = SmoothedEnergyGuidanceHook(blur_sigma)
|
||||
registry.register_hook(hook, name)
|
||||
|
||||
if not blocks_found:
|
||||
raise ValueError(
|
||||
f"Could not find any transformer blocks matching the provided indices {config.indices} and "
|
||||
f"fully qualified name '{config.fqn}'. Please check the indices and fqn for correctness."
|
||||
)
|
||||
|
||||
|
||||
# Modified from https://github.com/SusungHong/SEG-SDXL/blob/cf8256d640d5373541cfea3b3b6caf93272cf986/pipeline_seg.py#L71
|
||||
def _gaussian_blur_2d(query: torch.Tensor, kernel_size: int, sigma: float, sigma_threshold_inf: float) -> torch.Tensor:
|
||||
"""
|
||||
This implementation assumes that the input query is for visual (image/videos) tokens to apply the 2D gaussian blur.
|
||||
However, some models use joint text-visual token attention for which this may not be suitable. Additionally, this
|
||||
implementation also assumes that the visual tokens come from a square image/video. In practice, despite these
|
||||
assumptions, applying the 2D square gaussian blur on the query projections generates reasonable results for
|
||||
Smoothed Energy Guidance.
|
||||
|
||||
SEG is only supported as an experimental prototype feature for now, so the implementation may be modified in the
|
||||
future without warning or guarantee of reproducibility.
|
||||
"""
|
||||
assert query.ndim == 3
|
||||
|
||||
is_inf = sigma > sigma_threshold_inf
|
||||
batch_size, seq_len, embed_dim = query.shape
|
||||
|
||||
seq_len_sqrt = int(math.sqrt(seq_len))
|
||||
num_square_tokens = seq_len_sqrt * seq_len_sqrt
|
||||
query_slice = query[:, :num_square_tokens, :]
|
||||
query_slice = query_slice.permute(0, 2, 1)
|
||||
query_slice = query_slice.reshape(batch_size, embed_dim, seq_len_sqrt, seq_len_sqrt)
|
||||
|
||||
if is_inf:
|
||||
kernel_size = min(kernel_size, seq_len_sqrt - (seq_len_sqrt % 2 - 1))
|
||||
kernel_size_half = (kernel_size - 1) / 2
|
||||
|
||||
x = torch.linspace(-kernel_size_half, kernel_size_half, steps=kernel_size)
|
||||
pdf = torch.exp(-0.5 * (x / sigma).pow(2))
|
||||
kernel1d = pdf / pdf.sum()
|
||||
kernel1d = kernel1d.to(query)
|
||||
kernel2d = torch.matmul(kernel1d[:, None], kernel1d[None, :])
|
||||
kernel2d = kernel2d.expand(embed_dim, 1, kernel2d.shape[0], kernel2d.shape[1])
|
||||
|
||||
padding = [kernel_size // 2, kernel_size // 2, kernel_size // 2, kernel_size // 2]
|
||||
query_slice = F.pad(query_slice, padding, mode="reflect")
|
||||
query_slice = F.conv2d(query_slice, kernel2d, groups=embed_dim)
|
||||
else:
|
||||
query_slice[:] = query_slice.mean(dim=(-2, -1), keepdim=True)
|
||||
|
||||
query_slice = query_slice.reshape(batch_size, embed_dim, num_square_tokens)
|
||||
query_slice = query_slice.permute(0, 2, 1)
|
||||
query[:, :num_square_tokens, :] = query_slice.clone()
|
||||
|
||||
return query
|
||||
@@ -84,6 +84,7 @@ if is_torch_available():
|
||||
"IPAdapterMixin",
|
||||
"FluxIPAdapterMixin",
|
||||
"SD3IPAdapterMixin",
|
||||
"ModularIPAdapterMixin",
|
||||
]
|
||||
|
||||
_import_structure["peft"] = ["PeftAdapterMixin"]
|
||||
@@ -101,6 +102,7 @@ if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
from .ip_adapter import (
|
||||
FluxIPAdapterMixin,
|
||||
IPAdapterMixin,
|
||||
ModularIPAdapterMixin,
|
||||
SD3IPAdapterMixin,
|
||||
)
|
||||
from .lora_pipeline import (
|
||||
|
||||
@@ -354,6 +354,256 @@ class IPAdapterMixin:
|
||||
self.unet.set_attn_processor(attn_procs)
|
||||
|
||||
|
||||
class ModularIPAdapterMixin:
|
||||
"""Mixin for handling IP Adapters."""
|
||||
|
||||
@validate_hf_hub_args
|
||||
def load_ip_adapter(
|
||||
self,
|
||||
pretrained_model_name_or_path_or_dict: Union[str, List[str], Dict[str, torch.Tensor]],
|
||||
subfolder: Union[str, List[str]],
|
||||
weight_name: Union[str, List[str]],
|
||||
**kwargs,
|
||||
):
|
||||
"""
|
||||
Parameters:
|
||||
pretrained_model_name_or_path_or_dict (`str` or `List[str]` or `os.PathLike` or `List[os.PathLike]` or `dict` or `List[dict]`):
|
||||
Can be either:
|
||||
|
||||
- A string, the *model id* (for example `google/ddpm-celebahq-256`) of a pretrained model hosted on
|
||||
the Hub.
|
||||
- A path to a *directory* (for example `./my_model_directory`) containing the model weights saved
|
||||
with [`ModelMixin.save_pretrained`].
|
||||
- A [torch state
|
||||
dict](https://pytorch.org/tutorials/beginner/saving_loading_models.html#what-is-a-state-dict).
|
||||
subfolder (`str` or `List[str]`):
|
||||
The subfolder location of a model file within a larger model repository on the Hub or locally. If a
|
||||
list is passed, it should have the same length as `weight_name`.
|
||||
weight_name (`str` or `List[str]`):
|
||||
The name of the weight file to load. If a list is passed, it should have the same length as
|
||||
`subfolder`.
|
||||
cache_dir (`Union[str, os.PathLike]`, *optional*):
|
||||
Path to a directory where a downloaded pretrained model configuration is cached if the standard cache
|
||||
is not used.
|
||||
force_download (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to force the (re-)download of the model weights and configuration files, overriding the
|
||||
cached versions if they exist.
|
||||
|
||||
proxies (`Dict[str, str]`, *optional*):
|
||||
A dictionary of proxy servers to use by protocol or endpoint, for example, `{'http': 'foo.bar:3128',
|
||||
'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
|
||||
local_files_only (`bool`, *optional*, defaults to `False`):
|
||||
Whether to only load local model weights and configuration files or not. If set to `True`, the model
|
||||
won't be downloaded from the Hub.
|
||||
token (`str` or *bool*, *optional*):
|
||||
The token to use as HTTP bearer authorization for remote files. If `True`, the token generated from
|
||||
`diffusers-cli login` (stored in `~/.huggingface`) is used.
|
||||
revision (`str`, *optional*, defaults to `"main"`):
|
||||
The specific model version to use. It can be a branch name, a tag name, a commit id, or any identifier
|
||||
allowed by Git.
|
||||
low_cpu_mem_usage (`bool`, *optional*, defaults to `True` if torch version >= 1.9.0 else `False`):
|
||||
Speed up model loading only loading the pretrained weights and not initializing the weights. This also
|
||||
tries to not use more than 1x model size in CPU memory (including peak memory) while loading the model.
|
||||
Only supported for PyTorch >= 1.9.0. If you are using an older version of PyTorch, setting this
|
||||
argument to `True` will raise an error.
|
||||
"""
|
||||
|
||||
# handle the list inputs for multiple IP Adapters
|
||||
if not isinstance(weight_name, list):
|
||||
weight_name = [weight_name]
|
||||
|
||||
if not isinstance(pretrained_model_name_or_path_or_dict, list):
|
||||
pretrained_model_name_or_path_or_dict = [pretrained_model_name_or_path_or_dict]
|
||||
if len(pretrained_model_name_or_path_or_dict) == 1:
|
||||
pretrained_model_name_or_path_or_dict = pretrained_model_name_or_path_or_dict * len(weight_name)
|
||||
|
||||
if not isinstance(subfolder, list):
|
||||
subfolder = [subfolder]
|
||||
if len(subfolder) == 1:
|
||||
subfolder = subfolder * len(weight_name)
|
||||
|
||||
if len(weight_name) != len(pretrained_model_name_or_path_or_dict):
|
||||
raise ValueError("`weight_name` and `pretrained_model_name_or_path_or_dict` must have the same length.")
|
||||
|
||||
if len(weight_name) != len(subfolder):
|
||||
raise ValueError("`weight_name` and `subfolder` must have the same length.")
|
||||
|
||||
# Load the main state dict first.
|
||||
cache_dir = kwargs.pop("cache_dir", None)
|
||||
force_download = kwargs.pop("force_download", False)
|
||||
proxies = kwargs.pop("proxies", None)
|
||||
local_files_only = kwargs.pop("local_files_only", None)
|
||||
token = kwargs.pop("token", None)
|
||||
revision = kwargs.pop("revision", None)
|
||||
low_cpu_mem_usage = kwargs.pop("low_cpu_mem_usage", _LOW_CPU_MEM_USAGE_DEFAULT)
|
||||
|
||||
if low_cpu_mem_usage and not is_accelerate_available():
|
||||
low_cpu_mem_usage = False
|
||||
logger.warning(
|
||||
"Cannot initialize model with low cpu memory usage because `accelerate` was not found in the"
|
||||
" environment. Defaulting to `low_cpu_mem_usage=False`. It is strongly recommended to install"
|
||||
" `accelerate` for faster and less memory-intense model loading. You can do so with: \n```\npip"
|
||||
" install accelerate\n```\n."
|
||||
)
|
||||
|
||||
if low_cpu_mem_usage is True and not is_torch_version(">=", "1.9.0"):
|
||||
raise NotImplementedError(
|
||||
"Low memory initialization requires torch >= 1.9.0. Please either update your PyTorch version or set"
|
||||
" `low_cpu_mem_usage=False`."
|
||||
)
|
||||
|
||||
user_agent = {
|
||||
"file_type": "attn_procs_weights",
|
||||
"framework": "pytorch",
|
||||
}
|
||||
state_dicts = []
|
||||
for pretrained_model_name_or_path_or_dict, weight_name, subfolder in zip(
|
||||
pretrained_model_name_or_path_or_dict, weight_name, subfolder
|
||||
):
|
||||
if not isinstance(pretrained_model_name_or_path_or_dict, dict):
|
||||
model_file = _get_model_file(
|
||||
pretrained_model_name_or_path_or_dict,
|
||||
weights_name=weight_name,
|
||||
cache_dir=cache_dir,
|
||||
force_download=force_download,
|
||||
proxies=proxies,
|
||||
local_files_only=local_files_only,
|
||||
token=token,
|
||||
revision=revision,
|
||||
subfolder=subfolder,
|
||||
user_agent=user_agent,
|
||||
)
|
||||
if weight_name.endswith(".safetensors"):
|
||||
state_dict = {"image_proj": {}, "ip_adapter": {}}
|
||||
with safe_open(model_file, framework="pt", device="cpu") as f:
|
||||
for key in f.keys():
|
||||
if key.startswith("image_proj."):
|
||||
state_dict["image_proj"][key.replace("image_proj.", "")] = f.get_tensor(key)
|
||||
elif key.startswith("ip_adapter."):
|
||||
state_dict["ip_adapter"][key.replace("ip_adapter.", "")] = f.get_tensor(key)
|
||||
else:
|
||||
state_dict = load_state_dict(model_file)
|
||||
else:
|
||||
state_dict = pretrained_model_name_or_path_or_dict
|
||||
|
||||
keys = list(state_dict.keys())
|
||||
if "image_proj" not in keys and "ip_adapter" not in keys:
|
||||
raise ValueError("Required keys are (`image_proj` and `ip_adapter`) missing from the state dict.")
|
||||
|
||||
state_dicts.append(state_dict)
|
||||
|
||||
unet_name = getattr(self, "unet_name", "unet")
|
||||
unet = getattr(self, unet_name)
|
||||
unet._load_ip_adapter_weights(state_dicts, low_cpu_mem_usage=low_cpu_mem_usage)
|
||||
|
||||
extra_loras = unet._load_ip_adapter_loras(state_dicts)
|
||||
if extra_loras != {}:
|
||||
if not USE_PEFT_BACKEND:
|
||||
logger.warning("PEFT backend is required to load these weights.")
|
||||
else:
|
||||
# apply the IP Adapter Face ID LoRA weights
|
||||
peft_config = getattr(unet, "peft_config", {})
|
||||
for k, lora in extra_loras.items():
|
||||
if f"faceid_{k}" not in peft_config:
|
||||
self.load_lora_weights(lora, adapter_name=f"faceid_{k}")
|
||||
self.set_adapters([f"faceid_{k}"], adapter_weights=[1.0])
|
||||
|
||||
def set_ip_adapter_scale(self, scale):
|
||||
"""
|
||||
Set IP-Adapter scales per-transformer block. Input `scale` could be a single config or a list of configs for
|
||||
granular control over each IP-Adapter behavior. A config can be a float or a dictionary.
|
||||
|
||||
Example:
|
||||
|
||||
```py
|
||||
# To use original IP-Adapter
|
||||
scale = 1.0
|
||||
pipeline.set_ip_adapter_scale(scale)
|
||||
|
||||
# To use style block only
|
||||
scale = {
|
||||
"up": {"block_0": [0.0, 1.0, 0.0]},
|
||||
}
|
||||
pipeline.set_ip_adapter_scale(scale)
|
||||
|
||||
# To use style+layout blocks
|
||||
scale = {
|
||||
"down": {"block_2": [0.0, 1.0]},
|
||||
"up": {"block_0": [0.0, 1.0, 0.0]},
|
||||
}
|
||||
pipeline.set_ip_adapter_scale(scale)
|
||||
|
||||
# To use style and layout from 2 reference images
|
||||
scales = [{"down": {"block_2": [0.0, 1.0]}}, {"up": {"block_0": [0.0, 1.0, 0.0]}}]
|
||||
pipeline.set_ip_adapter_scale(scales)
|
||||
```
|
||||
"""
|
||||
unet_name = getattr(self, "unet_name", "unet")
|
||||
unet = getattr(self, unet_name)
|
||||
if not isinstance(scale, list):
|
||||
scale = [scale]
|
||||
scale_configs = _maybe_expand_lora_scales(unet, scale, default_scale=0.0)
|
||||
|
||||
for attn_name, attn_processor in unet.attn_processors.items():
|
||||
if isinstance(
|
||||
attn_processor, (IPAdapterAttnProcessor, IPAdapterAttnProcessor2_0, IPAdapterXFormersAttnProcessor)
|
||||
):
|
||||
if len(scale_configs) != len(attn_processor.scale):
|
||||
raise ValueError(
|
||||
f"Cannot assign {len(scale_configs)} scale_configs to {len(attn_processor.scale)} IP-Adapter."
|
||||
)
|
||||
elif len(scale_configs) == 1:
|
||||
scale_configs = scale_configs * len(attn_processor.scale)
|
||||
for i, scale_config in enumerate(scale_configs):
|
||||
if isinstance(scale_config, dict):
|
||||
for k, s in scale_config.items():
|
||||
if attn_name.startswith(k):
|
||||
attn_processor.scale[i] = s
|
||||
else:
|
||||
attn_processor.scale[i] = scale_config
|
||||
|
||||
def unload_ip_adapter(self):
|
||||
"""
|
||||
Unloads the IP Adapter weights
|
||||
|
||||
Examples:
|
||||
|
||||
```python
|
||||
>>> # Assuming `pipeline` is already loaded with the IP Adapter weights.
|
||||
>>> pipeline.unload_ip_adapter()
|
||||
>>> ...
|
||||
```
|
||||
"""
|
||||
|
||||
# remove hidden encoder
|
||||
if self.unet is None:
|
||||
return
|
||||
|
||||
self.unet.encoder_hid_proj = None
|
||||
self.unet.config.encoder_hid_dim_type = None
|
||||
|
||||
# Kolors: restore `encoder_hid_proj` with `text_encoder_hid_proj`
|
||||
if hasattr(self.unet, "text_encoder_hid_proj") and self.unet.text_encoder_hid_proj is not None:
|
||||
self.unet.encoder_hid_proj = self.unet.text_encoder_hid_proj
|
||||
self.unet.text_encoder_hid_proj = None
|
||||
self.unet.config.encoder_hid_dim_type = "text_proj"
|
||||
|
||||
# restore original Unet attention processors layers
|
||||
attn_procs = {}
|
||||
for name, value in self.unet.attn_processors.items():
|
||||
attn_processor_class = (
|
||||
AttnProcessor2_0() if hasattr(F, "scaled_dot_product_attention") else AttnProcessor()
|
||||
)
|
||||
attn_procs[name] = (
|
||||
attn_processor_class
|
||||
if isinstance(
|
||||
value, (IPAdapterAttnProcessor, IPAdapterAttnProcessor2_0, IPAdapterXFormersAttnProcessor)
|
||||
)
|
||||
else value.__class__()
|
||||
)
|
||||
self.unet.set_attn_processor(attn_procs)
|
||||
|
||||
|
||||
class FluxIPAdapterMixin:
|
||||
"""Mixin for handling Flux IP Adapters."""
|
||||
|
||||
|
||||
@@ -25,7 +25,6 @@ import torch.nn as nn
|
||||
from huggingface_hub import model_info
|
||||
from huggingface_hub.constants import HF_HUB_OFFLINE
|
||||
|
||||
from ..hooks.group_offloading import _is_group_offload_enabled, _maybe_remove_and_reapply_group_offloading
|
||||
from ..models.modeling_utils import ModelMixin, load_state_dict
|
||||
from ..utils import (
|
||||
USE_PEFT_BACKEND,
|
||||
@@ -331,6 +330,8 @@ def _load_lora_into_text_encoder(
|
||||
hotswap: bool = False,
|
||||
metadata=None,
|
||||
):
|
||||
from ..hooks.group_offloading import _maybe_remove_and_reapply_group_offloading
|
||||
|
||||
if not USE_PEFT_BACKEND:
|
||||
raise ValueError("PEFT backend is required for this method.")
|
||||
|
||||
@@ -442,6 +443,8 @@ def _func_optionally_disable_offloading(_pipeline):
|
||||
tuple:
|
||||
A tuple indicating if `is_model_cpu_offload` or `is_sequential_cpu_offload` or `is_group_offload` is True.
|
||||
"""
|
||||
from ..hooks.group_offloading import _is_group_offload_enabled
|
||||
|
||||
is_model_cpu_offload = False
|
||||
is_sequential_cpu_offload = False
|
||||
is_group_offload = False
|
||||
|
||||
@@ -22,7 +22,6 @@ from typing import Dict, List, Literal, Optional, Union
|
||||
import safetensors
|
||||
import torch
|
||||
|
||||
from ..hooks.group_offloading import _maybe_remove_and_reapply_group_offloading
|
||||
from ..utils import (
|
||||
MIN_PEFT_VERSION,
|
||||
USE_PEFT_BACKEND,
|
||||
@@ -164,6 +163,8 @@ class PeftAdapterMixin:
|
||||
from peft import inject_adapter_in_model, set_peft_model_state_dict
|
||||
from peft.tuners.tuners_utils import BaseTunerLayer
|
||||
|
||||
from ..hooks.group_offloading import _maybe_remove_and_reapply_group_offloading
|
||||
|
||||
cache_dir = kwargs.pop("cache_dir", None)
|
||||
force_download = kwargs.pop("force_download", False)
|
||||
proxies = kwargs.pop("proxies", None)
|
||||
@@ -695,6 +696,7 @@ class PeftAdapterMixin:
|
||||
if not USE_PEFT_BACKEND:
|
||||
raise ValueError("PEFT backend is required for `unload_lora()`.")
|
||||
|
||||
from ..hooks.group_offloading import _maybe_remove_and_reapply_group_offloading
|
||||
from ..utils import recurse_remove_peft_layers
|
||||
|
||||
recurse_remove_peft_layers(self)
|
||||
|
||||
@@ -22,7 +22,6 @@ import torch
|
||||
import torch.nn.functional as F
|
||||
from huggingface_hub.utils import validate_hf_hub_args
|
||||
|
||||
from ..hooks.group_offloading import _maybe_remove_and_reapply_group_offloading
|
||||
from ..models.embeddings import (
|
||||
ImageProjection,
|
||||
IPAdapterFaceIDImageProjection,
|
||||
@@ -132,6 +131,8 @@ class UNet2DConditionLoadersMixin:
|
||||
)
|
||||
```
|
||||
"""
|
||||
from ..hooks.group_offloading import _maybe_remove_and_reapply_group_offloading
|
||||
|
||||
cache_dir = kwargs.pop("cache_dir", None)
|
||||
force_download = kwargs.pop("force_download", False)
|
||||
proxies = kwargs.pop("proxies", None)
|
||||
|
||||
@@ -12,6 +12,8 @@
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from contextlib import contextmanager
|
||||
|
||||
from ..utils.logging import get_logger
|
||||
|
||||
|
||||
@@ -25,6 +27,7 @@ class CacheMixin:
|
||||
Supported caching techniques:
|
||||
- [Pyramid Attention Broadcast](https://huggingface.co/papers/2408.12588)
|
||||
- [FasterCache](https://huggingface.co/papers/2410.19355)
|
||||
- [FirstBlockCache](https://github.com/chengzeyi/ParaAttention/blob/7a266123671b55e7e5a2fe9af3121f07a36afc78/README.md#first-block-cache-our-dynamic-caching)
|
||||
"""
|
||||
|
||||
_cache_config = None
|
||||
@@ -62,8 +65,10 @@ class CacheMixin:
|
||||
|
||||
from ..hooks import (
|
||||
FasterCacheConfig,
|
||||
FirstBlockCacheConfig,
|
||||
PyramidAttentionBroadcastConfig,
|
||||
apply_faster_cache,
|
||||
apply_first_block_cache,
|
||||
apply_pyramid_attention_broadcast,
|
||||
)
|
||||
|
||||
@@ -72,31 +77,36 @@ class CacheMixin:
|
||||
f"Caching has already been enabled with {type(self._cache_config)}. To apply a new caching technique, please disable the existing one first."
|
||||
)
|
||||
|
||||
if isinstance(config, PyramidAttentionBroadcastConfig):
|
||||
apply_pyramid_attention_broadcast(self, config)
|
||||
elif isinstance(config, FasterCacheConfig):
|
||||
if isinstance(config, FasterCacheConfig):
|
||||
apply_faster_cache(self, config)
|
||||
elif isinstance(config, FirstBlockCacheConfig):
|
||||
apply_first_block_cache(self, config)
|
||||
elif isinstance(config, PyramidAttentionBroadcastConfig):
|
||||
apply_pyramid_attention_broadcast(self, config)
|
||||
else:
|
||||
raise ValueError(f"Cache config {type(config)} is not supported.")
|
||||
|
||||
self._cache_config = config
|
||||
|
||||
def disable_cache(self) -> None:
|
||||
from ..hooks import FasterCacheConfig, HookRegistry, PyramidAttentionBroadcastConfig
|
||||
from ..hooks import FasterCacheConfig, FirstBlockCacheConfig, HookRegistry, PyramidAttentionBroadcastConfig
|
||||
from ..hooks.faster_cache import _FASTER_CACHE_BLOCK_HOOK, _FASTER_CACHE_DENOISER_HOOK
|
||||
from ..hooks.first_block_cache import _FBC_BLOCK_HOOK, _FBC_LEADER_BLOCK_HOOK
|
||||
from ..hooks.pyramid_attention_broadcast import _PYRAMID_ATTENTION_BROADCAST_HOOK
|
||||
|
||||
if self._cache_config is None:
|
||||
logger.warning("Caching techniques have not been enabled, so there's nothing to disable.")
|
||||
return
|
||||
|
||||
if isinstance(self._cache_config, PyramidAttentionBroadcastConfig):
|
||||
registry = HookRegistry.check_if_exists_or_initialize(self)
|
||||
registry.remove_hook(_PYRAMID_ATTENTION_BROADCAST_HOOK, recurse=True)
|
||||
elif isinstance(self._cache_config, FasterCacheConfig):
|
||||
registry = HookRegistry.check_if_exists_or_initialize(self)
|
||||
registry = HookRegistry.check_if_exists_or_initialize(self)
|
||||
if isinstance(self._cache_config, FasterCacheConfig):
|
||||
registry.remove_hook(_FASTER_CACHE_DENOISER_HOOK, recurse=True)
|
||||
registry.remove_hook(_FASTER_CACHE_BLOCK_HOOK, recurse=True)
|
||||
elif isinstance(self._cache_config, FirstBlockCacheConfig):
|
||||
registry.remove_hook(_FBC_LEADER_BLOCK_HOOK, recurse=True)
|
||||
registry.remove_hook(_FBC_BLOCK_HOOK, recurse=True)
|
||||
elif isinstance(self._cache_config, PyramidAttentionBroadcastConfig):
|
||||
registry.remove_hook(_PYRAMID_ATTENTION_BROADCAST_HOOK, recurse=True)
|
||||
else:
|
||||
raise ValueError(f"Cache config {type(self._cache_config)} is not supported.")
|
||||
|
||||
@@ -106,3 +116,15 @@ class CacheMixin:
|
||||
from ..hooks import HookRegistry
|
||||
|
||||
HookRegistry.check_if_exists_or_initialize(self).reset_stateful_hooks(recurse=recurse)
|
||||
|
||||
@contextmanager
|
||||
def cache_context(self, name: str):
|
||||
r"""Context manager that provides additional methods for cache management."""
|
||||
from ..hooks import HookRegistry
|
||||
|
||||
registry = HookRegistry.check_if_exists_or_initialize(self)
|
||||
registry._set_context(name)
|
||||
|
||||
yield
|
||||
|
||||
registry._set_context(None)
|
||||
|
||||
@@ -343,25 +343,25 @@ class FluxControlNetModel(ModelMixin, ConfigMixin, PeftAdapterMixin):
|
||||
)
|
||||
block_samples = block_samples + (hidden_states,)
|
||||
|
||||
hidden_states = torch.cat([encoder_hidden_states, hidden_states], dim=1)
|
||||
|
||||
single_block_samples = ()
|
||||
for index_block, block in enumerate(self.single_transformer_blocks):
|
||||
if torch.is_grad_enabled() and self.gradient_checkpointing:
|
||||
hidden_states = self._gradient_checkpointing_func(
|
||||
encoder_hidden_states, hidden_states = self._gradient_checkpointing_func(
|
||||
block,
|
||||
hidden_states,
|
||||
encoder_hidden_states,
|
||||
temb,
|
||||
image_rotary_emb,
|
||||
)
|
||||
|
||||
else:
|
||||
hidden_states = block(
|
||||
encoder_hidden_states, hidden_states = block(
|
||||
hidden_states=hidden_states,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
temb=temb,
|
||||
image_rotary_emb=image_rotary_emb,
|
||||
)
|
||||
single_block_samples = single_block_samples + (hidden_states[:, encoder_hidden_states.shape[1] :],)
|
||||
single_block_samples = single_block_samples + (hidden_states,)
|
||||
|
||||
# controlnet block
|
||||
controlnet_block_samples = ()
|
||||
|
||||
@@ -21,6 +21,7 @@ import torch.nn.functional as F
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...loaders import PeftAdapterMixin
|
||||
from ...utils import USE_PEFT_BACKEND, logging, scale_lora_layers, unscale_lora_layers
|
||||
from ...utils.torch_utils import maybe_allow_in_graph
|
||||
from ..attention import FeedForward
|
||||
from ..attention_processor import Attention
|
||||
from ..cache_utils import CacheMixin
|
||||
@@ -453,6 +454,7 @@ class CogView4TrainingAttnProcessor:
|
||||
return hidden_states, encoder_hidden_states
|
||||
|
||||
|
||||
@maybe_allow_in_graph
|
||||
class CogView4TransformerBlock(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
|
||||
@@ -79,10 +79,14 @@ class FluxSingleTransformerBlock(nn.Module):
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
encoder_hidden_states: torch.Tensor,
|
||||
temb: torch.Tensor,
|
||||
image_rotary_emb: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
|
||||
joint_attention_kwargs: Optional[Dict[str, Any]] = None,
|
||||
) -> torch.Tensor:
|
||||
text_seq_len = encoder_hidden_states.shape[1]
|
||||
hidden_states = torch.cat([encoder_hidden_states, hidden_states], dim=1)
|
||||
|
||||
residual = hidden_states
|
||||
norm_hidden_states, gate = self.norm(hidden_states, emb=temb)
|
||||
mlp_hidden_states = self.act_mlp(self.proj_mlp(norm_hidden_states))
|
||||
@@ -100,7 +104,8 @@ class FluxSingleTransformerBlock(nn.Module):
|
||||
if hidden_states.dtype == torch.float16:
|
||||
hidden_states = hidden_states.clip(-65504, 65504)
|
||||
|
||||
return hidden_states
|
||||
encoder_hidden_states, hidden_states = hidden_states[:, :text_seq_len], hidden_states[:, text_seq_len:]
|
||||
return encoder_hidden_states, hidden_states
|
||||
|
||||
|
||||
@maybe_allow_in_graph
|
||||
@@ -507,20 +512,21 @@ class FluxTransformer2DModel(
|
||||
)
|
||||
else:
|
||||
hidden_states = hidden_states + controlnet_block_samples[index_block // interval_control]
|
||||
hidden_states = torch.cat([encoder_hidden_states, hidden_states], dim=1)
|
||||
|
||||
for index_block, block in enumerate(self.single_transformer_blocks):
|
||||
if torch.is_grad_enabled() and self.gradient_checkpointing:
|
||||
hidden_states = self._gradient_checkpointing_func(
|
||||
encoder_hidden_states, hidden_states = self._gradient_checkpointing_func(
|
||||
block,
|
||||
hidden_states,
|
||||
encoder_hidden_states,
|
||||
temb,
|
||||
image_rotary_emb,
|
||||
)
|
||||
|
||||
else:
|
||||
hidden_states = block(
|
||||
encoder_hidden_states, hidden_states = block(
|
||||
hidden_states=hidden_states,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
temb=temb,
|
||||
image_rotary_emb=image_rotary_emb,
|
||||
joint_attention_kwargs=joint_attention_kwargs,
|
||||
@@ -530,12 +536,7 @@ class FluxTransformer2DModel(
|
||||
if controlnet_single_block_samples is not None:
|
||||
interval_control = len(self.single_transformer_blocks) / len(controlnet_single_block_samples)
|
||||
interval_control = int(np.ceil(interval_control))
|
||||
hidden_states[:, encoder_hidden_states.shape[1] :, ...] = (
|
||||
hidden_states[:, encoder_hidden_states.shape[1] :, ...]
|
||||
+ controlnet_single_block_samples[index_block // interval_control]
|
||||
)
|
||||
|
||||
hidden_states = hidden_states[:, encoder_hidden_states.shape[1] :, ...]
|
||||
hidden_states = hidden_states + controlnet_single_block_samples[index_block // interval_control]
|
||||
|
||||
hidden_states = self.norm_out(hidden_states, temb)
|
||||
output = self.proj_out(hidden_states)
|
||||
|
||||
@@ -22,6 +22,7 @@ import torch.nn.functional as F
|
||||
from ...configuration_utils import ConfigMixin, register_to_config
|
||||
from ...loaders import FromOriginalModelMixin, PeftAdapterMixin
|
||||
from ...utils import USE_PEFT_BACKEND, logging, scale_lora_layers, unscale_lora_layers
|
||||
from ...utils.torch_utils import maybe_allow_in_graph
|
||||
from ..attention import FeedForward
|
||||
from ..attention_processor import Attention
|
||||
from ..cache_utils import CacheMixin
|
||||
@@ -249,6 +250,7 @@ class WanRotaryPosEmbed(nn.Module):
|
||||
return freqs_cos, freqs_sin
|
||||
|
||||
|
||||
@maybe_allow_in_graph
|
||||
class WanTransformerBlock(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
|
||||
84
src/diffusers/modular_pipelines/__init__.py
Normal file
84
src/diffusers/modular_pipelines/__init__.py
Normal file
@@ -0,0 +1,84 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ..utils import (
|
||||
DIFFUSERS_SLOW_IMPORT,
|
||||
OptionalDependencyNotAvailable,
|
||||
_LazyModule,
|
||||
get_objects_from_module,
|
||||
is_torch_available,
|
||||
is_transformers_available,
|
||||
)
|
||||
|
||||
|
||||
# These modules contain pipelines from multiple libraries/frameworks
|
||||
_dummy_objects = {}
|
||||
_import_structure = {}
|
||||
|
||||
try:
|
||||
if not is_torch_available():
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ..utils import dummy_pt_objects # noqa F403
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_pt_objects))
|
||||
else:
|
||||
_import_structure["modular_pipeline"] = [
|
||||
"ModularPipelineBlocks",
|
||||
"ModularPipeline",
|
||||
"PipelineBlock",
|
||||
"AutoPipelineBlocks",
|
||||
"SequentialPipelineBlocks",
|
||||
"LoopSequentialPipelineBlocks",
|
||||
"PipelineState",
|
||||
"BlockState",
|
||||
]
|
||||
_import_structure["modular_pipeline_utils"] = [
|
||||
"ComponentSpec",
|
||||
"ConfigSpec",
|
||||
"InputParam",
|
||||
"OutputParam",
|
||||
"InsertableDict",
|
||||
]
|
||||
_import_structure["stable_diffusion_xl"] = ["StableDiffusionXLAutoBlocks", "StableDiffusionXLModularPipeline"]
|
||||
_import_structure["components_manager"] = ["ComponentsManager"]
|
||||
|
||||
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
try:
|
||||
if not is_torch_available():
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ..utils.dummy_pt_objects import * # noqa F403
|
||||
else:
|
||||
from .components_manager import ComponentsManager
|
||||
from .modular_pipeline import (
|
||||
AutoPipelineBlocks,
|
||||
BlockState,
|
||||
LoopSequentialPipelineBlocks,
|
||||
ModularPipeline,
|
||||
ModularPipelineBlocks,
|
||||
PipelineBlock,
|
||||
PipelineState,
|
||||
SequentialPipelineBlocks,
|
||||
)
|
||||
from .modular_pipeline_utils import (
|
||||
ComponentSpec,
|
||||
ConfigSpec,
|
||||
InputParam,
|
||||
InsertableDict,
|
||||
OutputParam,
|
||||
)
|
||||
from .stable_diffusion_xl import (
|
||||
StableDiffusionXLAutoBlocks,
|
||||
StableDiffusionXLModularPipeline,
|
||||
)
|
||||
else:
|
||||
import sys
|
||||
|
||||
sys.modules[__name__] = _LazyModule(
|
||||
__name__,
|
||||
globals()["__file__"],
|
||||
_import_structure,
|
||||
module_spec=__spec__,
|
||||
)
|
||||
for name, value in _dummy_objects.items():
|
||||
setattr(sys.modules[__name__], name, value)
|
||||
1046
src/diffusers/modular_pipelines/components_manager.py
Normal file
1046
src/diffusers/modular_pipelines/components_manager.py
Normal file
File diff suppressed because it is too large
Load Diff
2827
src/diffusers/modular_pipelines/modular_pipeline.py
Normal file
2827
src/diffusers/modular_pipelines/modular_pipeline.py
Normal file
File diff suppressed because it is too large
Load Diff
671
src/diffusers/modular_pipelines/modular_pipeline_utils.py
Normal file
671
src/diffusers/modular_pipelines/modular_pipeline_utils.py
Normal file
@@ -0,0 +1,671 @@
|
||||
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import inspect
|
||||
import re
|
||||
from collections import OrderedDict
|
||||
from dataclasses import dataclass, field, fields
|
||||
from typing import Any, Dict, List, Literal, Optional, Type, Union
|
||||
|
||||
import torch
|
||||
|
||||
from ..configuration_utils import ConfigMixin, FrozenDict
|
||||
from ..utils import is_torch_available, logging
|
||||
|
||||
|
||||
if is_torch_available():
|
||||
pass
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
class InsertableDict(OrderedDict):
|
||||
def insert(self, key, value, index):
|
||||
items = list(self.items())
|
||||
|
||||
# Remove key if it already exists to avoid duplicates
|
||||
items = [(k, v) for k, v in items if k != key]
|
||||
|
||||
# Insert at the specified index
|
||||
items.insert(index, (key, value))
|
||||
|
||||
# Clear and update self
|
||||
self.clear()
|
||||
self.update(items)
|
||||
|
||||
# Return self for method chaining
|
||||
return self
|
||||
|
||||
def __repr__(self):
|
||||
if not self:
|
||||
return "InsertableDict()"
|
||||
|
||||
items = []
|
||||
for i, (key, value) in enumerate(self.items()):
|
||||
if isinstance(value, type):
|
||||
# For classes, show class name and <class ...>
|
||||
obj_repr = f"<class '{value.__module__}.{value.__name__}'>"
|
||||
else:
|
||||
# For objects (instances) and other types, show class name and module
|
||||
obj_repr = f"<obj '{value.__class__.__module__}.{value.__class__.__name__}'>"
|
||||
items.append(f"{i}: ({repr(key)}, {obj_repr})")
|
||||
|
||||
return "InsertableDict([\n " + ",\n ".join(items) + "\n])"
|
||||
|
||||
|
||||
# YiYi TODO:
|
||||
# 1. validate the dataclass fields
|
||||
# 2. improve the docstring and potentially add a validator for load methods, make sure they are valid inputs to pass to from_pretrained()
|
||||
@dataclass
|
||||
class ComponentSpec:
|
||||
"""Specification for a pipeline component.
|
||||
|
||||
A component can be created in two ways:
|
||||
1. From scratch using __init__ with a config dict
|
||||
2. using `from_pretrained`
|
||||
|
||||
Attributes:
|
||||
name: Name of the component
|
||||
type_hint: Type of the component (e.g. UNet2DConditionModel)
|
||||
description: Optional description of the component
|
||||
config: Optional config dict for __init__ creation
|
||||
repo: Optional repo path for from_pretrained creation
|
||||
subfolder: Optional subfolder in repo
|
||||
variant: Optional variant in repo
|
||||
revision: Optional revision in repo
|
||||
default_creation_method: Preferred creation method - "from_config" or "from_pretrained"
|
||||
"""
|
||||
|
||||
name: Optional[str] = None
|
||||
type_hint: Optional[Type] = None
|
||||
description: Optional[str] = None
|
||||
config: Optional[FrozenDict] = None
|
||||
# YiYi Notes: should we change it to pretrained_model_name_or_path for consistency? a bit long for a field name
|
||||
repo: Optional[Union[str, List[str]]] = field(default=None, metadata={"loading": True})
|
||||
subfolder: Optional[str] = field(default=None, metadata={"loading": True})
|
||||
variant: Optional[str] = field(default=None, metadata={"loading": True})
|
||||
revision: Optional[str] = field(default=None, metadata={"loading": True})
|
||||
default_creation_method: Literal["from_config", "from_pretrained"] = "from_pretrained"
|
||||
|
||||
def __hash__(self):
|
||||
"""Make ComponentSpec hashable, using load_id as the hash value."""
|
||||
return hash((self.name, self.load_id, self.default_creation_method))
|
||||
|
||||
def __eq__(self, other):
|
||||
"""Compare ComponentSpec objects based on name and load_id."""
|
||||
if not isinstance(other, ComponentSpec):
|
||||
return False
|
||||
return (
|
||||
self.name == other.name
|
||||
and self.load_id == other.load_id
|
||||
and self.default_creation_method == other.default_creation_method
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_component(cls, name: str, component: Any) -> Any:
|
||||
"""Create a ComponentSpec from a Component.
|
||||
|
||||
Currently supports:
|
||||
- Components created with `ComponentSpec.load()` method
|
||||
- Components that are ConfigMixin subclasses but not nn.Modules (e.g. schedulers, guiders)
|
||||
|
||||
Args:
|
||||
name: Name of the component
|
||||
component: Component object to create spec from
|
||||
|
||||
Returns:
|
||||
ComponentSpec object
|
||||
|
||||
Raises:
|
||||
ValueError: If component is not supported (e.g. nn.Module without load_id, non-ConfigMixin)
|
||||
"""
|
||||
|
||||
# Check if component was created with ComponentSpec.load()
|
||||
if hasattr(component, "_diffusers_load_id") and component._diffusers_load_id != "null":
|
||||
# component has a usable load_id -> from_pretrained, no warning needed
|
||||
default_creation_method = "from_pretrained"
|
||||
else:
|
||||
# Component doesn't have a usable load_id, check if it's a nn.Module
|
||||
if isinstance(component, torch.nn.Module):
|
||||
raise ValueError(
|
||||
"Cannot create ComponentSpec from a nn.Module that was not created with `ComponentSpec.load()` method."
|
||||
)
|
||||
# ConfigMixin objects without weights (e.g. scheduler & guider) can be recreated with from_config
|
||||
elif isinstance(component, ConfigMixin):
|
||||
# warn if component was not created with `ComponentSpec`
|
||||
if not hasattr(component, "_diffusers_load_id"):
|
||||
logger.warning(
|
||||
"Component was not created using `ComponentSpec`, defaulting to `from_config` creation method"
|
||||
)
|
||||
default_creation_method = "from_config"
|
||||
else:
|
||||
# Not a ConfigMixin and not created with `ComponentSpec.load()` method -> throw error
|
||||
raise ValueError(
|
||||
f"Cannot create ComponentSpec from {name}({component.__class__.__name__}). Currently ComponentSpec.from_component() only supports: "
|
||||
f" - components created with `ComponentSpec.load()` method"
|
||||
f" - components that are a subclass of ConfigMixin but not a nn.Module (e.g. guider, scheduler)."
|
||||
)
|
||||
|
||||
type_hint = component.__class__
|
||||
|
||||
if isinstance(component, ConfigMixin) and default_creation_method == "from_config":
|
||||
config = component.config
|
||||
else:
|
||||
config = None
|
||||
if hasattr(component, "_diffusers_load_id") and component._diffusers_load_id != "null":
|
||||
load_spec = cls.decode_load_id(component._diffusers_load_id)
|
||||
else:
|
||||
load_spec = {}
|
||||
|
||||
return cls(
|
||||
name=name, type_hint=type_hint, config=config, default_creation_method=default_creation_method, **load_spec
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def loading_fields(cls) -> List[str]:
|
||||
"""
|
||||
Return the names of all loading‐related fields (i.e. those whose field.metadata["loading"] is True).
|
||||
"""
|
||||
return [f.name for f in fields(cls) if f.metadata.get("loading", False)]
|
||||
|
||||
@property
|
||||
def load_id(self) -> str:
|
||||
"""
|
||||
Unique identifier for this spec's pretrained load, composed of repo|subfolder|variant|revision (no empty
|
||||
segments).
|
||||
"""
|
||||
parts = [getattr(self, k) for k in self.loading_fields()]
|
||||
parts = ["null" if p is None else p for p in parts]
|
||||
return "|".join(p for p in parts if p)
|
||||
|
||||
@classmethod
|
||||
def decode_load_id(cls, load_id: str) -> Dict[str, Optional[str]]:
|
||||
"""
|
||||
Decode a load_id string back into a dictionary of loading fields and values.
|
||||
|
||||
Args:
|
||||
load_id: The load_id string to decode, format: "repo|subfolder|variant|revision"
|
||||
where None values are represented as "null"
|
||||
|
||||
Returns:
|
||||
Dict mapping loading field names to their values. e.g. {
|
||||
"repo": "path/to/repo", "subfolder": "subfolder", "variant": "variant", "revision": "revision"
|
||||
} If a segment value is "null", it's replaced with None. Returns None if load_id is "null" (indicating
|
||||
component not created with `load` method).
|
||||
"""
|
||||
|
||||
# Get all loading fields in order
|
||||
loading_fields = cls.loading_fields()
|
||||
result = {f: None for f in loading_fields}
|
||||
|
||||
if load_id == "null":
|
||||
return result
|
||||
|
||||
# Split the load_id
|
||||
parts = load_id.split("|")
|
||||
|
||||
# Map parts to loading fields by position
|
||||
for i, part in enumerate(parts):
|
||||
if i < len(loading_fields):
|
||||
# Convert "null" string back to None
|
||||
result[loading_fields[i]] = None if part == "null" else part
|
||||
|
||||
return result
|
||||
|
||||
# YiYi TODO: I think we should only support ConfigMixin for this method (after we make guider and image_processors config mixin)
|
||||
# otherwise we cannot do spec -> spec.create() -> component -> ComponentSpec.from_component(component)
|
||||
# the config info is lost in the process
|
||||
# remove error check in from_component spec and ModularPipeline.update_components() if we remove support for non configmixin in `create()` method
|
||||
def create(self, config: Optional[Union[FrozenDict, Dict[str, Any]]] = None, **kwargs) -> Any:
|
||||
"""Create component using from_config with config."""
|
||||
|
||||
if self.type_hint is None or not isinstance(self.type_hint, type):
|
||||
raise ValueError("`type_hint` is required when using from_config creation method.")
|
||||
|
||||
config = config or self.config or {}
|
||||
|
||||
if issubclass(self.type_hint, ConfigMixin):
|
||||
component = self.type_hint.from_config(config, **kwargs)
|
||||
else:
|
||||
signature_params = inspect.signature(self.type_hint.__init__).parameters
|
||||
init_kwargs = {}
|
||||
for k, v in config.items():
|
||||
if k in signature_params:
|
||||
init_kwargs[k] = v
|
||||
for k, v in kwargs.items():
|
||||
if k in signature_params:
|
||||
init_kwargs[k] = v
|
||||
component = self.type_hint(**init_kwargs)
|
||||
|
||||
component._diffusers_load_id = "null"
|
||||
if hasattr(component, "config"):
|
||||
self.config = component.config
|
||||
|
||||
return component
|
||||
|
||||
# YiYi TODO: add guard for type of model, if it is supported by from_pretrained
|
||||
def load(self, **kwargs) -> Any:
|
||||
"""Load component using from_pretrained."""
|
||||
|
||||
# select loading fields from kwargs passed from user: e.g. repo, subfolder, variant, revision, note the list could change
|
||||
passed_loading_kwargs = {key: kwargs.pop(key) for key in self.loading_fields() if key in kwargs}
|
||||
# merge loading field value in the spec with user passed values to create load_kwargs
|
||||
load_kwargs = {key: passed_loading_kwargs.get(key, getattr(self, key)) for key in self.loading_fields()}
|
||||
# repo is a required argument for from_pretrained, a.k.a. pretrained_model_name_or_path
|
||||
repo = load_kwargs.pop("repo", None)
|
||||
if repo is None:
|
||||
raise ValueError(
|
||||
"`repo` info is required when using `load` method (you can directly set it in `repo` field of the ComponentSpec or pass it as an argument)"
|
||||
)
|
||||
|
||||
if self.type_hint is None:
|
||||
try:
|
||||
from diffusers import AutoModel
|
||||
|
||||
component = AutoModel.from_pretrained(repo, **load_kwargs, **kwargs)
|
||||
except Exception as e:
|
||||
raise ValueError(f"Unable to load {self.name} without `type_hint`: {e}")
|
||||
# update type_hint if AutoModel load successfully
|
||||
self.type_hint = component.__class__
|
||||
else:
|
||||
try:
|
||||
component = self.type_hint.from_pretrained(repo, **load_kwargs, **kwargs)
|
||||
except Exception as e:
|
||||
raise ValueError(f"Unable to load {self.name} using load method: {e}")
|
||||
|
||||
self.repo = repo
|
||||
for k, v in load_kwargs.items():
|
||||
setattr(self, k, v)
|
||||
component._diffusers_load_id = self.load_id
|
||||
|
||||
return component
|
||||
|
||||
|
||||
@dataclass
|
||||
class ConfigSpec:
|
||||
"""Specification for a pipeline configuration parameter."""
|
||||
|
||||
name: str
|
||||
default: Any
|
||||
description: Optional[str] = None
|
||||
|
||||
|
||||
# YiYi Notes: both inputs and intermediate_inputs are InputParam objects
|
||||
# however some fields are not relevant for intermediate_inputs
|
||||
# e.g. unlike inputs, required only used in docstring for intermediate_inputs, we do not check if a required intermediate inputs is passed
|
||||
# default is not used for intermediate_inputs, we only use default from inputs, so it is ignored if it is set for intermediate_inputs
|
||||
# -> should we use different class for inputs and intermediate_inputs?
|
||||
@dataclass
|
||||
class InputParam:
|
||||
"""Specification for an input parameter."""
|
||||
|
||||
name: str = None
|
||||
type_hint: Any = None
|
||||
default: Any = None
|
||||
required: bool = False
|
||||
description: str = ""
|
||||
kwargs_type: str = None # YiYi Notes: remove this feature (maybe)
|
||||
|
||||
def __repr__(self):
|
||||
return f"<{self.name}: {'required' if self.required else 'optional'}, default={self.default}>"
|
||||
|
||||
|
||||
@dataclass
|
||||
class OutputParam:
|
||||
"""Specification for an output parameter."""
|
||||
|
||||
name: str
|
||||
type_hint: Any = None
|
||||
description: str = ""
|
||||
kwargs_type: str = None # YiYi notes: remove this feature (maybe)
|
||||
|
||||
def __repr__(self):
|
||||
return (
|
||||
f"<{self.name}: {self.type_hint.__name__ if hasattr(self.type_hint, '__name__') else str(self.type_hint)}>"
|
||||
)
|
||||
|
||||
|
||||
def format_inputs_short(inputs):
|
||||
"""
|
||||
Format input parameters into a string representation, with required params first followed by optional ones.
|
||||
|
||||
Args:
|
||||
inputs: List of input parameters with 'required' and 'name' attributes, and 'default' for optional params
|
||||
|
||||
Returns:
|
||||
str: Formatted string of input parameters
|
||||
|
||||
Example:
|
||||
>>> inputs = [ ... InputParam(name="prompt", required=True), ... InputParam(name="image", required=True), ...
|
||||
InputParam(name="guidance_scale", required=False, default=7.5), ... InputParam(name="num_inference_steps",
|
||||
required=False, default=50) ... ] >>> format_inputs_short(inputs) 'prompt, image, guidance_scale=7.5,
|
||||
num_inference_steps=50'
|
||||
"""
|
||||
required_inputs = [param for param in inputs if param.required]
|
||||
optional_inputs = [param for param in inputs if not param.required]
|
||||
|
||||
required_str = ", ".join(param.name for param in required_inputs)
|
||||
optional_str = ", ".join(f"{param.name}={param.default}" for param in optional_inputs)
|
||||
|
||||
inputs_str = required_str
|
||||
if optional_str:
|
||||
inputs_str = f"{inputs_str}, {optional_str}" if required_str else optional_str
|
||||
|
||||
return inputs_str
|
||||
|
||||
|
||||
def format_intermediates_short(intermediate_inputs, required_intermediate_inputs, intermediate_outputs):
|
||||
"""
|
||||
Formats intermediate inputs and outputs of a block into a string representation.
|
||||
|
||||
Args:
|
||||
intermediate_inputs: List of intermediate input parameters
|
||||
required_intermediate_inputs: List of required intermediate input names
|
||||
intermediate_outputs: List of intermediate output parameters
|
||||
|
||||
Returns:
|
||||
str: Formatted string like:
|
||||
Intermediates:
|
||||
- inputs: Required(latents), dtype
|
||||
- modified: latents # variables that appear in both inputs and outputs
|
||||
- outputs: images # new outputs only
|
||||
"""
|
||||
# Handle inputs
|
||||
input_parts = []
|
||||
for inp in intermediate_inputs:
|
||||
if inp.name in required_intermediate_inputs:
|
||||
input_parts.append(f"Required({inp.name})")
|
||||
else:
|
||||
if inp.name is None and inp.kwargs_type is not None:
|
||||
inp_name = "*_" + inp.kwargs_type
|
||||
else:
|
||||
inp_name = inp.name
|
||||
input_parts.append(inp_name)
|
||||
|
||||
# Handle modified variables (appear in both inputs and outputs)
|
||||
inputs_set = {inp.name for inp in intermediate_inputs}
|
||||
modified_parts = []
|
||||
new_output_parts = []
|
||||
|
||||
for out in intermediate_outputs:
|
||||
if out.name in inputs_set:
|
||||
modified_parts.append(out.name)
|
||||
else:
|
||||
new_output_parts.append(out.name)
|
||||
|
||||
result = []
|
||||
if input_parts:
|
||||
result.append(f" - inputs: {', '.join(input_parts)}")
|
||||
if modified_parts:
|
||||
result.append(f" - modified: {', '.join(modified_parts)}")
|
||||
if new_output_parts:
|
||||
result.append(f" - outputs: {', '.join(new_output_parts)}")
|
||||
|
||||
return "\n".join(result) if result else " (none)"
|
||||
|
||||
|
||||
def format_params(params, header="Args", indent_level=4, max_line_length=115):
|
||||
"""Format a list of InputParam or OutputParam objects into a readable string representation.
|
||||
|
||||
Args:
|
||||
params: List of InputParam or OutputParam objects to format
|
||||
header: Header text to use (e.g. "Args" or "Returns")
|
||||
indent_level: Number of spaces to indent each parameter line (default: 4)
|
||||
max_line_length: Maximum length for each line before wrapping (default: 115)
|
||||
|
||||
Returns:
|
||||
A formatted string representing all parameters
|
||||
"""
|
||||
if not params:
|
||||
return ""
|
||||
|
||||
base_indent = " " * indent_level
|
||||
param_indent = " " * (indent_level + 4)
|
||||
desc_indent = " " * (indent_level + 8)
|
||||
formatted_params = []
|
||||
|
||||
def get_type_str(type_hint):
|
||||
if hasattr(type_hint, "__origin__") and type_hint.__origin__ is Union:
|
||||
types = [t.__name__ if hasattr(t, "__name__") else str(t) for t in type_hint.__args__]
|
||||
return f"Union[{', '.join(types)}]"
|
||||
return type_hint.__name__ if hasattr(type_hint, "__name__") else str(type_hint)
|
||||
|
||||
def wrap_text(text, indent, max_length):
|
||||
"""Wrap text while preserving markdown links and maintaining indentation."""
|
||||
words = text.split()
|
||||
lines = []
|
||||
current_line = []
|
||||
current_length = 0
|
||||
|
||||
for word in words:
|
||||
word_length = len(word) + (1 if current_line else 0)
|
||||
|
||||
if current_line and current_length + word_length > max_length:
|
||||
lines.append(" ".join(current_line))
|
||||
current_line = [word]
|
||||
current_length = len(word)
|
||||
else:
|
||||
current_line.append(word)
|
||||
current_length += word_length
|
||||
|
||||
if current_line:
|
||||
lines.append(" ".join(current_line))
|
||||
|
||||
return f"\n{indent}".join(lines)
|
||||
|
||||
# Add the header
|
||||
formatted_params.append(f"{base_indent}{header}:")
|
||||
|
||||
for param in params:
|
||||
# Format parameter name and type
|
||||
type_str = get_type_str(param.type_hint) if param.type_hint != Any else ""
|
||||
# YiYi Notes: remove this line if we remove kwargs_type
|
||||
name = f"**{param.kwargs_type}" if param.name is None and param.kwargs_type is not None else param.name
|
||||
param_str = f"{param_indent}{name} (`{type_str}`"
|
||||
|
||||
# Add optional tag and default value if parameter is an InputParam and optional
|
||||
if hasattr(param, "required"):
|
||||
if not param.required:
|
||||
param_str += ", *optional*"
|
||||
if param.default is not None:
|
||||
param_str += f", defaults to {param.default}"
|
||||
param_str += "):"
|
||||
|
||||
# Add description on a new line with additional indentation and wrapping
|
||||
if param.description:
|
||||
desc = re.sub(r"\[(.*?)\]\((https?://[^\s\)]+)\)", r"[\1](\2)", param.description)
|
||||
wrapped_desc = wrap_text(desc, desc_indent, max_line_length)
|
||||
param_str += f"\n{desc_indent}{wrapped_desc}"
|
||||
|
||||
formatted_params.append(param_str)
|
||||
|
||||
return "\n\n".join(formatted_params)
|
||||
|
||||
|
||||
def format_input_params(input_params, indent_level=4, max_line_length=115):
|
||||
"""Format a list of InputParam objects into a readable string representation.
|
||||
|
||||
Args:
|
||||
input_params: List of InputParam objects to format
|
||||
indent_level: Number of spaces to indent each parameter line (default: 4)
|
||||
max_line_length: Maximum length for each line before wrapping (default: 115)
|
||||
|
||||
Returns:
|
||||
A formatted string representing all input parameters
|
||||
"""
|
||||
return format_params(input_params, "Inputs", indent_level, max_line_length)
|
||||
|
||||
|
||||
def format_output_params(output_params, indent_level=4, max_line_length=115):
|
||||
"""Format a list of OutputParam objects into a readable string representation.
|
||||
|
||||
Args:
|
||||
output_params: List of OutputParam objects to format
|
||||
indent_level: Number of spaces to indent each parameter line (default: 4)
|
||||
max_line_length: Maximum length for each line before wrapping (default: 115)
|
||||
|
||||
Returns:
|
||||
A formatted string representing all output parameters
|
||||
"""
|
||||
return format_params(output_params, "Outputs", indent_level, max_line_length)
|
||||
|
||||
|
||||
def format_components(components, indent_level=4, max_line_length=115, add_empty_lines=True):
|
||||
"""Format a list of ComponentSpec objects into a readable string representation.
|
||||
|
||||
Args:
|
||||
components: List of ComponentSpec objects to format
|
||||
indent_level: Number of spaces to indent each component line (default: 4)
|
||||
max_line_length: Maximum length for each line before wrapping (default: 115)
|
||||
add_empty_lines: Whether to add empty lines between components (default: True)
|
||||
|
||||
Returns:
|
||||
A formatted string representing all components
|
||||
"""
|
||||
if not components:
|
||||
return ""
|
||||
|
||||
base_indent = " " * indent_level
|
||||
component_indent = " " * (indent_level + 4)
|
||||
formatted_components = []
|
||||
|
||||
# Add the header
|
||||
formatted_components.append(f"{base_indent}Components:")
|
||||
if add_empty_lines:
|
||||
formatted_components.append("")
|
||||
|
||||
# Add each component with optional empty lines between them
|
||||
for i, component in enumerate(components):
|
||||
# Get type name, handling special cases
|
||||
type_name = (
|
||||
component.type_hint.__name__ if hasattr(component.type_hint, "__name__") else str(component.type_hint)
|
||||
)
|
||||
|
||||
component_desc = f"{component_indent}{component.name} (`{type_name}`)"
|
||||
if component.description:
|
||||
component_desc += f": {component.description}"
|
||||
|
||||
# Get the loading fields dynamically
|
||||
loading_field_values = []
|
||||
for field_name in component.loading_fields():
|
||||
field_value = getattr(component, field_name)
|
||||
if field_value is not None:
|
||||
loading_field_values.append(f"{field_name}={field_value}")
|
||||
|
||||
# Add loading field information if available
|
||||
if loading_field_values:
|
||||
component_desc += f" [{', '.join(loading_field_values)}]"
|
||||
|
||||
formatted_components.append(component_desc)
|
||||
|
||||
# Add an empty line after each component except the last one
|
||||
if add_empty_lines and i < len(components) - 1:
|
||||
formatted_components.append("")
|
||||
|
||||
return "\n".join(formatted_components)
|
||||
|
||||
|
||||
def format_configs(configs, indent_level=4, max_line_length=115, add_empty_lines=True):
|
||||
"""Format a list of ConfigSpec objects into a readable string representation.
|
||||
|
||||
Args:
|
||||
configs: List of ConfigSpec objects to format
|
||||
indent_level: Number of spaces to indent each config line (default: 4)
|
||||
max_line_length: Maximum length for each line before wrapping (default: 115)
|
||||
add_empty_lines: Whether to add empty lines between configs (default: True)
|
||||
|
||||
Returns:
|
||||
A formatted string representing all configs
|
||||
"""
|
||||
if not configs:
|
||||
return ""
|
||||
|
||||
base_indent = " " * indent_level
|
||||
config_indent = " " * (indent_level + 4)
|
||||
formatted_configs = []
|
||||
|
||||
# Add the header
|
||||
formatted_configs.append(f"{base_indent}Configs:")
|
||||
if add_empty_lines:
|
||||
formatted_configs.append("")
|
||||
|
||||
# Add each config with optional empty lines between them
|
||||
for i, config in enumerate(configs):
|
||||
config_desc = f"{config_indent}{config.name} (default: {config.default})"
|
||||
if config.description:
|
||||
config_desc += f": {config.description}"
|
||||
formatted_configs.append(config_desc)
|
||||
|
||||
# Add an empty line after each config except the last one
|
||||
if add_empty_lines and i < len(configs) - 1:
|
||||
formatted_configs.append("")
|
||||
|
||||
return "\n".join(formatted_configs)
|
||||
|
||||
|
||||
def make_doc_string(
|
||||
inputs,
|
||||
intermediate_inputs,
|
||||
outputs,
|
||||
description="",
|
||||
class_name=None,
|
||||
expected_components=None,
|
||||
expected_configs=None,
|
||||
):
|
||||
"""
|
||||
Generates a formatted documentation string describing the pipeline block's parameters and structure.
|
||||
|
||||
Args:
|
||||
inputs: List of input parameters
|
||||
intermediate_inputs: List of intermediate input parameters
|
||||
outputs: List of output parameters
|
||||
description (str, *optional*): Description of the block
|
||||
class_name (str, *optional*): Name of the class to include in the documentation
|
||||
expected_components (List[ComponentSpec], *optional*): List of expected components
|
||||
expected_configs (List[ConfigSpec], *optional*): List of expected configurations
|
||||
|
||||
Returns:
|
||||
str: A formatted string containing information about components, configs, call parameters,
|
||||
intermediate inputs/outputs, and final outputs.
|
||||
"""
|
||||
output = ""
|
||||
|
||||
# Add class name if provided
|
||||
if class_name:
|
||||
output += f"class {class_name}\n\n"
|
||||
|
||||
# Add description
|
||||
if description:
|
||||
desc_lines = description.strip().split("\n")
|
||||
aligned_desc = "\n".join(" " + line for line in desc_lines)
|
||||
output += aligned_desc + "\n\n"
|
||||
|
||||
# Add components section if provided
|
||||
if expected_components and len(expected_components) > 0:
|
||||
components_str = format_components(expected_components, indent_level=2)
|
||||
output += components_str + "\n\n"
|
||||
|
||||
# Add configs section if provided
|
||||
if expected_configs and len(expected_configs) > 0:
|
||||
configs_str = format_configs(expected_configs, indent_level=2)
|
||||
output += configs_str + "\n\n"
|
||||
|
||||
# Add inputs section
|
||||
output += format_input_params(inputs + intermediate_inputs, indent_level=2)
|
||||
|
||||
# Add outputs section
|
||||
output += "\n\n"
|
||||
output += format_output_params(outputs, indent_level=2)
|
||||
|
||||
return output
|
||||
665
src/diffusers/modular_pipelines/node_utils.py
Normal file
665
src/diffusers/modular_pipelines/node_utils.py
Normal file
@@ -0,0 +1,665 @@
|
||||
import json
|
||||
import logging
|
||||
import os
|
||||
from pathlib import Path
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import numpy as np
|
||||
import PIL
|
||||
import torch
|
||||
|
||||
from ..configuration_utils import ConfigMixin
|
||||
from ..image_processor import PipelineImageInput
|
||||
from .modular_pipeline import ModularPipelineBlocks, SequentialPipelineBlocks
|
||||
from .modular_pipeline_utils import InputParam
|
||||
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# YiYi Notes: this is actually for SDXL, put it here for now
|
||||
SDXL_INPUTS_SCHEMA = {
|
||||
"prompt": InputParam(
|
||||
"prompt", type_hint=Union[str, List[str]], description="The prompt or prompts to guide the image generation"
|
||||
),
|
||||
"prompt_2": InputParam(
|
||||
"prompt_2",
|
||||
type_hint=Union[str, List[str]],
|
||||
description="The prompt or prompts to be sent to the tokenizer_2 and text_encoder_2",
|
||||
),
|
||||
"negative_prompt": InputParam(
|
||||
"negative_prompt",
|
||||
type_hint=Union[str, List[str]],
|
||||
description="The prompt or prompts not to guide the image generation",
|
||||
),
|
||||
"negative_prompt_2": InputParam(
|
||||
"negative_prompt_2",
|
||||
type_hint=Union[str, List[str]],
|
||||
description="The negative prompt or prompts for text_encoder_2",
|
||||
),
|
||||
"cross_attention_kwargs": InputParam(
|
||||
"cross_attention_kwargs",
|
||||
type_hint=Optional[dict],
|
||||
description="Kwargs dictionary passed to the AttentionProcessor",
|
||||
),
|
||||
"clip_skip": InputParam(
|
||||
"clip_skip", type_hint=Optional[int], description="Number of layers to skip in CLIP text encoder"
|
||||
),
|
||||
"image": InputParam(
|
||||
"image",
|
||||
type_hint=PipelineImageInput,
|
||||
required=True,
|
||||
description="The image(s) to modify for img2img or inpainting",
|
||||
),
|
||||
"mask_image": InputParam(
|
||||
"mask_image",
|
||||
type_hint=PipelineImageInput,
|
||||
required=True,
|
||||
description="Mask image for inpainting, white pixels will be repainted",
|
||||
),
|
||||
"generator": InputParam(
|
||||
"generator",
|
||||
type_hint=Optional[Union[torch.Generator, List[torch.Generator]]],
|
||||
description="Generator(s) for deterministic generation",
|
||||
),
|
||||
"height": InputParam("height", type_hint=Optional[int], description="Height in pixels of the generated image"),
|
||||
"width": InputParam("width", type_hint=Optional[int], description="Width in pixels of the generated image"),
|
||||
"num_images_per_prompt": InputParam(
|
||||
"num_images_per_prompt", type_hint=int, default=1, description="Number of images to generate per prompt"
|
||||
),
|
||||
"num_inference_steps": InputParam(
|
||||
"num_inference_steps", type_hint=int, default=50, description="Number of denoising steps"
|
||||
),
|
||||
"timesteps": InputParam(
|
||||
"timesteps", type_hint=Optional[torch.Tensor], description="Custom timesteps for the denoising process"
|
||||
),
|
||||
"sigmas": InputParam(
|
||||
"sigmas", type_hint=Optional[torch.Tensor], description="Custom sigmas for the denoising process"
|
||||
),
|
||||
"denoising_end": InputParam(
|
||||
"denoising_end",
|
||||
type_hint=Optional[float],
|
||||
description="Fraction of denoising process to complete before termination",
|
||||
),
|
||||
# YiYi Notes: img2img defaults to 0.3, inpainting defaults to 0.9999
|
||||
"strength": InputParam(
|
||||
"strength", type_hint=float, default=0.3, description="How much to transform the reference image"
|
||||
),
|
||||
"denoising_start": InputParam(
|
||||
"denoising_start", type_hint=Optional[float], description="Starting point of the denoising process"
|
||||
),
|
||||
"latents": InputParam(
|
||||
"latents", type_hint=Optional[torch.Tensor], description="Pre-generated noisy latents for image generation"
|
||||
),
|
||||
"padding_mask_crop": InputParam(
|
||||
"padding_mask_crop",
|
||||
type_hint=Optional[Tuple[int, int]],
|
||||
description="Size of margin in crop for image and mask",
|
||||
),
|
||||
"original_size": InputParam(
|
||||
"original_size",
|
||||
type_hint=Optional[Tuple[int, int]],
|
||||
description="Original size of the image for SDXL's micro-conditioning",
|
||||
),
|
||||
"target_size": InputParam(
|
||||
"target_size", type_hint=Optional[Tuple[int, int]], description="Target size for SDXL's micro-conditioning"
|
||||
),
|
||||
"negative_original_size": InputParam(
|
||||
"negative_original_size",
|
||||
type_hint=Optional[Tuple[int, int]],
|
||||
description="Negative conditioning based on image resolution",
|
||||
),
|
||||
"negative_target_size": InputParam(
|
||||
"negative_target_size",
|
||||
type_hint=Optional[Tuple[int, int]],
|
||||
description="Negative conditioning based on target resolution",
|
||||
),
|
||||
"crops_coords_top_left": InputParam(
|
||||
"crops_coords_top_left",
|
||||
type_hint=Tuple[int, int],
|
||||
default=(0, 0),
|
||||
description="Top-left coordinates for SDXL's micro-conditioning",
|
||||
),
|
||||
"negative_crops_coords_top_left": InputParam(
|
||||
"negative_crops_coords_top_left",
|
||||
type_hint=Tuple[int, int],
|
||||
default=(0, 0),
|
||||
description="Negative conditioning crop coordinates",
|
||||
),
|
||||
"aesthetic_score": InputParam(
|
||||
"aesthetic_score", type_hint=float, default=6.0, description="Simulates aesthetic score of generated image"
|
||||
),
|
||||
"negative_aesthetic_score": InputParam(
|
||||
"negative_aesthetic_score", type_hint=float, default=2.0, description="Simulates negative aesthetic score"
|
||||
),
|
||||
"eta": InputParam("eta", type_hint=float, default=0.0, description="Parameter η in the DDIM paper"),
|
||||
"output_type": InputParam(
|
||||
"output_type", type_hint=str, default="pil", description="Output format (pil/tensor/np.array)"
|
||||
),
|
||||
"ip_adapter_image": InputParam(
|
||||
"ip_adapter_image",
|
||||
type_hint=PipelineImageInput,
|
||||
required=True,
|
||||
description="Image(s) to be used as IP adapter",
|
||||
),
|
||||
"control_image": InputParam(
|
||||
"control_image", type_hint=PipelineImageInput, required=True, description="ControlNet input condition"
|
||||
),
|
||||
"control_guidance_start": InputParam(
|
||||
"control_guidance_start",
|
||||
type_hint=Union[float, List[float]],
|
||||
default=0.0,
|
||||
description="When ControlNet starts applying",
|
||||
),
|
||||
"control_guidance_end": InputParam(
|
||||
"control_guidance_end",
|
||||
type_hint=Union[float, List[float]],
|
||||
default=1.0,
|
||||
description="When ControlNet stops applying",
|
||||
),
|
||||
"controlnet_conditioning_scale": InputParam(
|
||||
"controlnet_conditioning_scale",
|
||||
type_hint=Union[float, List[float]],
|
||||
default=1.0,
|
||||
description="Scale factor for ControlNet outputs",
|
||||
),
|
||||
"guess_mode": InputParam(
|
||||
"guess_mode",
|
||||
type_hint=bool,
|
||||
default=False,
|
||||
description="Enables ControlNet encoder to recognize input without prompts",
|
||||
),
|
||||
"control_mode": InputParam(
|
||||
"control_mode", type_hint=List[int], required=True, description="Control mode for union controlnet"
|
||||
),
|
||||
}
|
||||
|
||||
SDXL_INTERMEDIATE_INPUTS_SCHEMA = {
|
||||
"prompt_embeds": InputParam(
|
||||
"prompt_embeds",
|
||||
type_hint=torch.Tensor,
|
||||
required=True,
|
||||
description="Text embeddings used to guide image generation",
|
||||
),
|
||||
"negative_prompt_embeds": InputParam(
|
||||
"negative_prompt_embeds", type_hint=torch.Tensor, description="Negative text embeddings"
|
||||
),
|
||||
"pooled_prompt_embeds": InputParam(
|
||||
"pooled_prompt_embeds", type_hint=torch.Tensor, required=True, description="Pooled text embeddings"
|
||||
),
|
||||
"negative_pooled_prompt_embeds": InputParam(
|
||||
"negative_pooled_prompt_embeds", type_hint=torch.Tensor, description="Negative pooled text embeddings"
|
||||
),
|
||||
"batch_size": InputParam("batch_size", type_hint=int, required=True, description="Number of prompts"),
|
||||
"dtype": InputParam("dtype", type_hint=torch.dtype, description="Data type of model tensor inputs"),
|
||||
"preprocess_kwargs": InputParam(
|
||||
"preprocess_kwargs", type_hint=Optional[dict], description="Kwargs for ImageProcessor"
|
||||
),
|
||||
"latents": InputParam(
|
||||
"latents", type_hint=torch.Tensor, required=True, description="Initial latents for denoising process"
|
||||
),
|
||||
"timesteps": InputParam("timesteps", type_hint=torch.Tensor, required=True, description="Timesteps for inference"),
|
||||
"num_inference_steps": InputParam(
|
||||
"num_inference_steps", type_hint=int, required=True, description="Number of denoising steps"
|
||||
),
|
||||
"latent_timestep": InputParam(
|
||||
"latent_timestep", type_hint=torch.Tensor, required=True, description="Initial noise level timestep"
|
||||
),
|
||||
"image_latents": InputParam(
|
||||
"image_latents", type_hint=torch.Tensor, required=True, description="Latents representing reference image"
|
||||
),
|
||||
"mask": InputParam("mask", type_hint=torch.Tensor, required=True, description="Mask for inpainting"),
|
||||
"masked_image_latents": InputParam(
|
||||
"masked_image_latents", type_hint=torch.Tensor, description="Masked image latents for inpainting"
|
||||
),
|
||||
"add_time_ids": InputParam(
|
||||
"add_time_ids", type_hint=torch.Tensor, required=True, description="Time ids for conditioning"
|
||||
),
|
||||
"negative_add_time_ids": InputParam(
|
||||
"negative_add_time_ids", type_hint=torch.Tensor, description="Negative time ids"
|
||||
),
|
||||
"timestep_cond": InputParam("timestep_cond", type_hint=torch.Tensor, description="Timestep conditioning for LCM"),
|
||||
"noise": InputParam("noise", type_hint=torch.Tensor, description="Noise added to image latents"),
|
||||
"crops_coords": InputParam("crops_coords", type_hint=Optional[Tuple[int]], description="Crop coordinates"),
|
||||
"ip_adapter_embeds": InputParam(
|
||||
"ip_adapter_embeds", type_hint=List[torch.Tensor], description="Image embeddings for IP-Adapter"
|
||||
),
|
||||
"negative_ip_adapter_embeds": InputParam(
|
||||
"negative_ip_adapter_embeds",
|
||||
type_hint=List[torch.Tensor],
|
||||
description="Negative image embeddings for IP-Adapter",
|
||||
),
|
||||
"images": InputParam(
|
||||
"images",
|
||||
type_hint=Union[List[PIL.Image.Image], List[torch.Tensor], List[np.array]],
|
||||
required=True,
|
||||
description="Generated images",
|
||||
),
|
||||
}
|
||||
|
||||
SDXL_PARAM_SCHEMA = {**SDXL_INPUTS_SCHEMA, **SDXL_INTERMEDIATE_INPUTS_SCHEMA}
|
||||
|
||||
|
||||
DEFAULT_PARAM_MAPS = {
|
||||
"prompt": {
|
||||
"label": "Prompt",
|
||||
"type": "string",
|
||||
"default": "a bear sitting in a chair drinking a milkshake",
|
||||
"display": "textarea",
|
||||
},
|
||||
"negative_prompt": {
|
||||
"label": "Negative Prompt",
|
||||
"type": "string",
|
||||
"default": "deformed, ugly, wrong proportion, low res, bad anatomy, worst quality, low quality",
|
||||
"display": "textarea",
|
||||
},
|
||||
"num_inference_steps": {
|
||||
"label": "Steps",
|
||||
"type": "int",
|
||||
"default": 25,
|
||||
"min": 1,
|
||||
"max": 1000,
|
||||
},
|
||||
"seed": {
|
||||
"label": "Seed",
|
||||
"type": "int",
|
||||
"default": 0,
|
||||
"min": 0,
|
||||
"display": "random",
|
||||
},
|
||||
"width": {
|
||||
"label": "Width",
|
||||
"type": "int",
|
||||
"display": "text",
|
||||
"default": 1024,
|
||||
"min": 8,
|
||||
"max": 8192,
|
||||
"step": 8,
|
||||
"group": "dimensions",
|
||||
},
|
||||
"height": {
|
||||
"label": "Height",
|
||||
"type": "int",
|
||||
"display": "text",
|
||||
"default": 1024,
|
||||
"min": 8,
|
||||
"max": 8192,
|
||||
"step": 8,
|
||||
"group": "dimensions",
|
||||
},
|
||||
"images": {
|
||||
"label": "Images",
|
||||
"type": "image",
|
||||
"display": "output",
|
||||
},
|
||||
"image": {
|
||||
"label": "Image",
|
||||
"type": "image",
|
||||
"display": "input",
|
||||
},
|
||||
}
|
||||
|
||||
DEFAULT_TYPE_MAPS = {
|
||||
"int": {
|
||||
"type": "int",
|
||||
"default": 0,
|
||||
"min": 0,
|
||||
},
|
||||
"float": {
|
||||
"type": "float",
|
||||
"default": 0.0,
|
||||
"min": 0.0,
|
||||
},
|
||||
"str": {
|
||||
"type": "string",
|
||||
"default": "",
|
||||
},
|
||||
"bool": {
|
||||
"type": "boolean",
|
||||
"default": False,
|
||||
},
|
||||
"image": {
|
||||
"type": "image",
|
||||
},
|
||||
}
|
||||
|
||||
DEFAULT_MODEL_KEYS = ["unet", "vae", "text_encoder", "tokenizer", "controlnet", "transformer", "image_encoder"]
|
||||
DEFAULT_CATEGORY = "Modular Diffusers"
|
||||
DEFAULT_EXCLUDE_MODEL_KEYS = ["processor", "feature_extractor", "safety_checker"]
|
||||
DEFAULT_PARAMS_GROUPS_KEYS = {
|
||||
"text_encoders": ["text_encoder", "tokenizer"],
|
||||
"ip_adapter_embeds": ["ip_adapter_embeds"],
|
||||
"prompt_embeddings": ["prompt_embeds"],
|
||||
}
|
||||
|
||||
|
||||
def get_group_name(name, group_params_keys=DEFAULT_PARAMS_GROUPS_KEYS):
|
||||
"""
|
||||
Get the group name for a given parameter name, if not part of a group, return None e.g. "prompt_embeds" ->
|
||||
"text_embeds", "text_encoder" -> "text_encoders", "prompt" -> None
|
||||
"""
|
||||
if name is None:
|
||||
return None
|
||||
for group_name, group_keys in group_params_keys.items():
|
||||
for group_key in group_keys:
|
||||
if group_key in name:
|
||||
return group_name
|
||||
return None
|
||||
|
||||
|
||||
class ModularNode(ConfigMixin):
|
||||
"""
|
||||
A ModularNode is a base class to build UI nodes using diffusers. Currently only supports Mellon. It is a wrapper
|
||||
around a ModularPipelineBlocks object.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This is an experimental feature and is likely to change in the future.
|
||||
|
||||
</Tip>
|
||||
"""
|
||||
|
||||
config_name = "node_config.json"
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(
|
||||
cls,
|
||||
pretrained_model_name_or_path: str,
|
||||
trust_remote_code: Optional[bool] = None,
|
||||
**kwargs,
|
||||
):
|
||||
blocks = ModularPipelineBlocks.from_pretrained(
|
||||
pretrained_model_name_or_path, trust_remote_code=trust_remote_code, **kwargs
|
||||
)
|
||||
return cls(blocks, **kwargs)
|
||||
|
||||
def __init__(self, blocks, category=DEFAULT_CATEGORY, label=None, **kwargs):
|
||||
self.blocks = blocks
|
||||
|
||||
if label is None:
|
||||
label = self.blocks.__class__.__name__
|
||||
# blocks param name -> mellon param name
|
||||
self.name_mapping = {}
|
||||
|
||||
input_params = {}
|
||||
# pass or create a default param dict for each input
|
||||
# e.g. for prompt,
|
||||
# prompt = {
|
||||
# "name": "text_input", # the name of the input in node defination, could be different from the input name in diffusers
|
||||
# "label": "Prompt",
|
||||
# "type": "string",
|
||||
# "default": "a bear sitting in a chair drinking a milkshake",
|
||||
# "display": "textarea"}
|
||||
# if type is not specified, it'll be a "custom" param of its own type
|
||||
# e.g. you can pass ModularNode(scheduler = {name :"scheduler"})
|
||||
# it will get this spec in node defination {"scheduler": {"label": "Scheduler", "type": "scheduler", "display": "input"}}
|
||||
# name can be a dict, in that case, it is part of a "dict" input in mellon nodes, e.g. text_encoder= {name: {"text_encoders": "text_encoder"}}
|
||||
inputs = self.blocks.inputs + self.blocks.intermediate_inputs
|
||||
for inp in inputs:
|
||||
param = kwargs.pop(inp.name, None)
|
||||
if param:
|
||||
# user can pass a param dict for all inputs, e.g. ModularNode(prompt = {...})
|
||||
input_params[inp.name] = param
|
||||
mellon_name = param.pop("name", inp.name)
|
||||
if mellon_name != inp.name:
|
||||
self.name_mapping[inp.name] = mellon_name
|
||||
continue
|
||||
|
||||
if inp.name not in DEFAULT_PARAM_MAPS and not inp.required and not get_group_name(inp.name):
|
||||
continue
|
||||
|
||||
if inp.name in DEFAULT_PARAM_MAPS:
|
||||
# first check if it's in the default param map, if so, directly use that
|
||||
param = DEFAULT_PARAM_MAPS[inp.name].copy()
|
||||
elif get_group_name(inp.name):
|
||||
param = get_group_name(inp.name)
|
||||
if inp.name not in self.name_mapping:
|
||||
self.name_mapping[inp.name] = param
|
||||
else:
|
||||
# if not, check if it's in the SDXL input schema, if so,
|
||||
# 1. use the type hint to determine the type
|
||||
# 2. use the default param dict for the type e.g. if "steps" is a "int" type, {"steps": {"type": "int", "default": 0, "min": 0}}
|
||||
if inp.type_hint is not None:
|
||||
type_str = str(inp.type_hint).lower()
|
||||
else:
|
||||
inp_spec = SDXL_PARAM_SCHEMA.get(inp.name, None)
|
||||
type_str = str(inp_spec.type_hint).lower() if inp_spec else ""
|
||||
for type_key, type_param in DEFAULT_TYPE_MAPS.items():
|
||||
if type_key in type_str:
|
||||
param = type_param.copy()
|
||||
param["label"] = inp.name
|
||||
param["display"] = "input"
|
||||
break
|
||||
else:
|
||||
param = inp.name
|
||||
# add the param dict to the inp_params dict
|
||||
input_params[inp.name] = param
|
||||
|
||||
component_params = {}
|
||||
for comp in self.blocks.expected_components:
|
||||
param = kwargs.pop(comp.name, None)
|
||||
if param:
|
||||
component_params[comp.name] = param
|
||||
mellon_name = param.pop("name", comp.name)
|
||||
if mellon_name != comp.name:
|
||||
self.name_mapping[comp.name] = mellon_name
|
||||
continue
|
||||
|
||||
to_exclude = False
|
||||
for exclude_key in DEFAULT_EXCLUDE_MODEL_KEYS:
|
||||
if exclude_key in comp.name:
|
||||
to_exclude = True
|
||||
break
|
||||
if to_exclude:
|
||||
continue
|
||||
|
||||
if get_group_name(comp.name):
|
||||
param = get_group_name(comp.name)
|
||||
if comp.name not in self.name_mapping:
|
||||
self.name_mapping[comp.name] = param
|
||||
elif comp.name in DEFAULT_MODEL_KEYS:
|
||||
param = {"label": comp.name, "type": "diffusers_auto_model", "display": "input"}
|
||||
else:
|
||||
param = comp.name
|
||||
# add the param dict to the model_params dict
|
||||
component_params[comp.name] = param
|
||||
|
||||
output_params = {}
|
||||
if isinstance(self.blocks, SequentialPipelineBlocks):
|
||||
last_block_name = list(self.blocks.sub_blocks.keys())[-1]
|
||||
outputs = self.blocks.sub_blocks[last_block_name].intermediate_outputs
|
||||
else:
|
||||
outputs = self.blocks.intermediate_outputs
|
||||
|
||||
for out in outputs:
|
||||
param = kwargs.pop(out.name, None)
|
||||
if param:
|
||||
output_params[out.name] = param
|
||||
mellon_name = param.pop("name", out.name)
|
||||
if mellon_name != out.name:
|
||||
self.name_mapping[out.name] = mellon_name
|
||||
continue
|
||||
|
||||
if out.name in DEFAULT_PARAM_MAPS:
|
||||
param = DEFAULT_PARAM_MAPS[out.name].copy()
|
||||
param["display"] = "output"
|
||||
else:
|
||||
group_name = get_group_name(out.name)
|
||||
if group_name:
|
||||
param = group_name
|
||||
if out.name not in self.name_mapping:
|
||||
self.name_mapping[out.name] = param
|
||||
else:
|
||||
param = out.name
|
||||
# add the param dict to the outputs dict
|
||||
output_params[out.name] = param
|
||||
|
||||
if len(kwargs) > 0:
|
||||
logger.warning(f"Unused kwargs: {kwargs}")
|
||||
|
||||
register_dict = {
|
||||
"category": category,
|
||||
"label": label,
|
||||
"input_params": input_params,
|
||||
"component_params": component_params,
|
||||
"output_params": output_params,
|
||||
"name_mapping": self.name_mapping,
|
||||
}
|
||||
self.register_to_config(**register_dict)
|
||||
|
||||
def setup(self, components_manager, collection=None):
|
||||
self.pipeline = self.blocks.init_pipeline(components_manager=components_manager, collection=collection)
|
||||
self._components_manager = components_manager
|
||||
|
||||
@property
|
||||
def mellon_config(self):
|
||||
return self._convert_to_mellon_config()
|
||||
|
||||
def _convert_to_mellon_config(self):
|
||||
node = {}
|
||||
node["label"] = self.config.label
|
||||
node["category"] = self.config.category
|
||||
|
||||
node_param = {}
|
||||
for inp_name, inp_param in self.config.input_params.items():
|
||||
if inp_name in self.name_mapping:
|
||||
mellon_name = self.name_mapping[inp_name]
|
||||
else:
|
||||
mellon_name = inp_name
|
||||
if isinstance(inp_param, str):
|
||||
param = {
|
||||
"label": inp_param,
|
||||
"type": inp_param,
|
||||
"display": "input",
|
||||
}
|
||||
else:
|
||||
param = inp_param
|
||||
|
||||
if mellon_name not in node_param:
|
||||
node_param[mellon_name] = param
|
||||
else:
|
||||
logger.debug(f"Input param {mellon_name} already exists in node_param, skipping {inp_name}")
|
||||
|
||||
for comp_name, comp_param in self.config.component_params.items():
|
||||
if comp_name in self.name_mapping:
|
||||
mellon_name = self.name_mapping[comp_name]
|
||||
else:
|
||||
mellon_name = comp_name
|
||||
if isinstance(comp_param, str):
|
||||
param = {
|
||||
"label": comp_param,
|
||||
"type": comp_param,
|
||||
"display": "input",
|
||||
}
|
||||
else:
|
||||
param = comp_param
|
||||
|
||||
if mellon_name not in node_param:
|
||||
node_param[mellon_name] = param
|
||||
else:
|
||||
logger.debug(f"Component param {comp_param} already exists in node_param, skipping {comp_name}")
|
||||
|
||||
for out_name, out_param in self.config.output_params.items():
|
||||
if out_name in self.name_mapping:
|
||||
mellon_name = self.name_mapping[out_name]
|
||||
else:
|
||||
mellon_name = out_name
|
||||
if isinstance(out_param, str):
|
||||
param = {
|
||||
"label": out_param,
|
||||
"type": out_param,
|
||||
"display": "output",
|
||||
}
|
||||
else:
|
||||
param = out_param
|
||||
|
||||
if mellon_name not in node_param:
|
||||
node_param[mellon_name] = param
|
||||
else:
|
||||
logger.debug(f"Output param {out_param} already exists in node_param, skipping {out_name}")
|
||||
node["params"] = node_param
|
||||
return node
|
||||
|
||||
def save_mellon_config(self, file_path):
|
||||
"""
|
||||
Save the Mellon configuration to a JSON file.
|
||||
|
||||
Args:
|
||||
file_path (str or Path): Path where the JSON file will be saved
|
||||
|
||||
Returns:
|
||||
Path: Path to the saved config file
|
||||
"""
|
||||
file_path = Path(file_path)
|
||||
|
||||
# Create directory if it doesn't exist
|
||||
os.makedirs(file_path.parent, exist_ok=True)
|
||||
|
||||
# Create a combined dictionary with module definition and name mapping
|
||||
config = {"module": self.mellon_config, "name_mapping": self.name_mapping}
|
||||
|
||||
# Save the config to file
|
||||
with open(file_path, "w", encoding="utf-8") as f:
|
||||
json.dump(config, f, indent=2)
|
||||
|
||||
logger.info(f"Mellon config and name mapping saved to {file_path}")
|
||||
|
||||
return file_path
|
||||
|
||||
@classmethod
|
||||
def load_mellon_config(cls, file_path):
|
||||
"""
|
||||
Load a Mellon configuration from a JSON file.
|
||||
|
||||
Args:
|
||||
file_path (str or Path): Path to the JSON file containing Mellon config
|
||||
|
||||
Returns:
|
||||
dict: The loaded combined configuration containing 'module' and 'name_mapping'
|
||||
"""
|
||||
file_path = Path(file_path)
|
||||
|
||||
if not file_path.exists():
|
||||
raise FileNotFoundError(f"Config file not found: {file_path}")
|
||||
|
||||
with open(file_path, "r", encoding="utf-8") as f:
|
||||
config = json.load(f)
|
||||
|
||||
logger.info(f"Mellon config loaded from {file_path}")
|
||||
|
||||
return config
|
||||
|
||||
def process_inputs(self, **kwargs):
|
||||
params_components = {}
|
||||
for comp_name, comp_param in self.config.component_params.items():
|
||||
logger.debug(f"component: {comp_name}")
|
||||
mellon_comp_name = self.name_mapping.get(comp_name, comp_name)
|
||||
if mellon_comp_name in kwargs:
|
||||
if isinstance(kwargs[mellon_comp_name], dict) and comp_name in kwargs[mellon_comp_name]:
|
||||
comp = kwargs[mellon_comp_name].pop(comp_name)
|
||||
else:
|
||||
comp = kwargs.pop(mellon_comp_name)
|
||||
if comp:
|
||||
params_components[comp_name] = self._components_manager.get_one(comp["model_id"])
|
||||
|
||||
params_run = {}
|
||||
for inp_name, inp_param in self.config.input_params.items():
|
||||
logger.debug(f"input: {inp_name}")
|
||||
mellon_inp_name = self.name_mapping.get(inp_name, inp_name)
|
||||
if mellon_inp_name in kwargs:
|
||||
if isinstance(kwargs[mellon_inp_name], dict) and inp_name in kwargs[mellon_inp_name]:
|
||||
inp = kwargs[mellon_inp_name].pop(inp_name)
|
||||
else:
|
||||
inp = kwargs.pop(mellon_inp_name)
|
||||
if inp is not None:
|
||||
params_run[inp_name] = inp
|
||||
|
||||
return_output_names = list(self.config.output_params.keys())
|
||||
|
||||
return params_components, params_run, return_output_names
|
||||
|
||||
def execute(self, **kwargs):
|
||||
params_components, params_run, return_output_names = self.process_inputs(**kwargs)
|
||||
|
||||
self.pipeline.update_components(**params_components)
|
||||
output = self.pipeline(**params_run, output=return_output_names)
|
||||
return output
|
||||
@@ -0,0 +1,77 @@
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
from ...utils import (
|
||||
DIFFUSERS_SLOW_IMPORT,
|
||||
OptionalDependencyNotAvailable,
|
||||
_LazyModule,
|
||||
get_objects_from_module,
|
||||
is_torch_available,
|
||||
is_transformers_available,
|
||||
)
|
||||
|
||||
|
||||
_dummy_objects = {}
|
||||
_import_structure = {}
|
||||
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils import dummy_torch_and_transformers_objects # noqa F403
|
||||
|
||||
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
|
||||
else:
|
||||
_import_structure["encoders"] = ["StableDiffusionXLTextEncoderStep"]
|
||||
_import_structure["modular_blocks"] = [
|
||||
"ALL_BLOCKS",
|
||||
"AUTO_BLOCKS",
|
||||
"CONTROLNET_BLOCKS",
|
||||
"IMAGE2IMAGE_BLOCKS",
|
||||
"INPAINT_BLOCKS",
|
||||
"IP_ADAPTER_BLOCKS",
|
||||
"TEXT2IMAGE_BLOCKS",
|
||||
"StableDiffusionXLAutoBlocks",
|
||||
"StableDiffusionXLAutoControlnetStep",
|
||||
"StableDiffusionXLAutoDecodeStep",
|
||||
"StableDiffusionXLAutoIPAdapterStep",
|
||||
"StableDiffusionXLAutoVaeEncoderStep",
|
||||
]
|
||||
_import_structure["modular_pipeline"] = ["StableDiffusionXLModularPipeline"]
|
||||
|
||||
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
|
||||
try:
|
||||
if not (is_transformers_available() and is_torch_available()):
|
||||
raise OptionalDependencyNotAvailable()
|
||||
except OptionalDependencyNotAvailable:
|
||||
from ...utils.dummy_torch_and_transformers_objects import * # noqa F403
|
||||
else:
|
||||
from .encoders import (
|
||||
StableDiffusionXLTextEncoderStep,
|
||||
)
|
||||
from .modular_blocks import (
|
||||
ALL_BLOCKS,
|
||||
AUTO_BLOCKS,
|
||||
CONTROLNET_BLOCKS,
|
||||
IMAGE2IMAGE_BLOCKS,
|
||||
INPAINT_BLOCKS,
|
||||
IP_ADAPTER_BLOCKS,
|
||||
TEXT2IMAGE_BLOCKS,
|
||||
StableDiffusionXLAutoBlocks,
|
||||
StableDiffusionXLAutoControlnetStep,
|
||||
StableDiffusionXLAutoDecodeStep,
|
||||
StableDiffusionXLAutoIPAdapterStep,
|
||||
StableDiffusionXLAutoVaeEncoderStep,
|
||||
)
|
||||
from .modular_pipeline import StableDiffusionXLModularPipeline
|
||||
else:
|
||||
import sys
|
||||
|
||||
sys.modules[__name__] = _LazyModule(
|
||||
__name__,
|
||||
globals()["__file__"],
|
||||
_import_structure,
|
||||
module_spec=__spec__,
|
||||
)
|
||||
|
||||
for name, value in _dummy_objects.items():
|
||||
setattr(sys.modules[__name__], name, value)
|
||||
File diff suppressed because it is too large
Load Diff
217
src/diffusers/modular_pipelines/stable_diffusion_xl/decoders.py
Normal file
217
src/diffusers/modular_pipelines/stable_diffusion_xl/decoders.py
Normal file
@@ -0,0 +1,217 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from typing import Any, List, Tuple, Union
|
||||
|
||||
import numpy as np
|
||||
import PIL
|
||||
import torch
|
||||
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...image_processor import VaeImageProcessor
|
||||
from ...models import AutoencoderKL
|
||||
from ...models.attention_processor import AttnProcessor2_0, XFormersAttnProcessor
|
||||
from ...utils import logging
|
||||
from ..modular_pipeline import (
|
||||
PipelineBlock,
|
||||
PipelineState,
|
||||
)
|
||||
from ..modular_pipeline_utils import ComponentSpec, InputParam, OutputParam
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
class StableDiffusionXLDecodeStep(PipelineBlock):
|
||||
model_name = "stable-diffusion-xl"
|
||||
|
||||
@property
|
||||
def expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec("vae", AutoencoderKL),
|
||||
ComponentSpec(
|
||||
"image_processor",
|
||||
VaeImageProcessor,
|
||||
config=FrozenDict({"vae_scale_factor": 8}),
|
||||
default_creation_method="from_config",
|
||||
),
|
||||
]
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return "Step that decodes the denoised latents into images"
|
||||
|
||||
@property
|
||||
def inputs(self) -> List[Tuple[str, Any]]:
|
||||
return [
|
||||
InputParam("output_type", default="pil"),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self) -> List[str]:
|
||||
return [
|
||||
InputParam(
|
||||
"latents",
|
||||
required=True,
|
||||
type_hint=torch.Tensor,
|
||||
description="The denoised latents from the denoising step",
|
||||
)
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self) -> List[str]:
|
||||
return [
|
||||
OutputParam(
|
||||
"images",
|
||||
type_hint=Union[List[PIL.Image.Image], List[torch.Tensor], List[np.array]],
|
||||
description="The generated images, can be a PIL.Image.Image, torch.Tensor or a numpy array",
|
||||
)
|
||||
]
|
||||
|
||||
@staticmethod
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_upscale.StableDiffusionUpscalePipeline.upcast_vae with self->components
|
||||
def upcast_vae(components):
|
||||
dtype = components.vae.dtype
|
||||
components.vae.to(dtype=torch.float32)
|
||||
use_torch_2_0_or_xformers = isinstance(
|
||||
components.vae.decoder.mid_block.attentions[0].processor,
|
||||
(
|
||||
AttnProcessor2_0,
|
||||
XFormersAttnProcessor,
|
||||
),
|
||||
)
|
||||
# if xformers or torch_2_0 is used attention block does not need
|
||||
# to be in float32 which can save lots of memory
|
||||
if use_torch_2_0_or_xformers:
|
||||
components.vae.post_quant_conv.to(dtype)
|
||||
components.vae.decoder.conv_in.to(dtype)
|
||||
components.vae.decoder.mid_block.to(dtype)
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, components, state: PipelineState) -> PipelineState:
|
||||
block_state = self.get_block_state(state)
|
||||
|
||||
if not block_state.output_type == "latent":
|
||||
latents = block_state.latents
|
||||
# make sure the VAE is in float32 mode, as it overflows in float16
|
||||
block_state.needs_upcasting = components.vae.dtype == torch.float16 and components.vae.config.force_upcast
|
||||
|
||||
if block_state.needs_upcasting:
|
||||
self.upcast_vae(components)
|
||||
latents = latents.to(next(iter(components.vae.post_quant_conv.parameters())).dtype)
|
||||
elif latents.dtype != components.vae.dtype:
|
||||
if torch.backends.mps.is_available():
|
||||
# some platforms (eg. apple mps) misbehave due to a pytorch bug: https://github.com/pytorch/pytorch/pull/99272
|
||||
components.vae = components.vae.to(latents.dtype)
|
||||
|
||||
# unscale/denormalize the latents
|
||||
# denormalize with the mean and std if available and not None
|
||||
block_state.has_latents_mean = (
|
||||
hasattr(components.vae.config, "latents_mean") and components.vae.config.latents_mean is not None
|
||||
)
|
||||
block_state.has_latents_std = (
|
||||
hasattr(components.vae.config, "latents_std") and components.vae.config.latents_std is not None
|
||||
)
|
||||
if block_state.has_latents_mean and block_state.has_latents_std:
|
||||
block_state.latents_mean = (
|
||||
torch.tensor(components.vae.config.latents_mean).view(1, 4, 1, 1).to(latents.device, latents.dtype)
|
||||
)
|
||||
block_state.latents_std = (
|
||||
torch.tensor(components.vae.config.latents_std).view(1, 4, 1, 1).to(latents.device, latents.dtype)
|
||||
)
|
||||
latents = (
|
||||
latents * block_state.latents_std / components.vae.config.scaling_factor + block_state.latents_mean
|
||||
)
|
||||
else:
|
||||
latents = latents / components.vae.config.scaling_factor
|
||||
|
||||
block_state.images = components.vae.decode(latents, return_dict=False)[0]
|
||||
|
||||
# cast back to fp16 if needed
|
||||
if block_state.needs_upcasting:
|
||||
components.vae.to(dtype=torch.float16)
|
||||
else:
|
||||
block_state.images = block_state.latents
|
||||
|
||||
# apply watermark if available
|
||||
if hasattr(components, "watermark") and components.watermark is not None:
|
||||
block_state.images = components.watermark.apply_watermark(block_state.images)
|
||||
|
||||
block_state.images = components.image_processor.postprocess(
|
||||
block_state.images, output_type=block_state.output_type
|
||||
)
|
||||
|
||||
self.set_block_state(state, block_state)
|
||||
|
||||
return components, state
|
||||
|
||||
|
||||
class StableDiffusionXLInpaintOverlayMaskStep(PipelineBlock):
|
||||
model_name = "stable-diffusion-xl"
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"A post-processing step that overlays the mask on the image (inpainting task only).\n"
|
||||
+ "only needed when you are using the `padding_mask_crop` option when pre-processing the image and mask"
|
||||
)
|
||||
|
||||
@property
|
||||
def inputs(self) -> List[Tuple[str, Any]]:
|
||||
return [
|
||||
InputParam("image"),
|
||||
InputParam("mask_image"),
|
||||
InputParam("padding_mask_crop"),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self) -> List[str]:
|
||||
return [
|
||||
InputParam(
|
||||
"images",
|
||||
type_hint=Union[List[PIL.Image.Image], List[torch.Tensor], List[np.array]],
|
||||
description="The generated images from the decode step",
|
||||
),
|
||||
InputParam(
|
||||
"crops_coords",
|
||||
type_hint=Tuple[int, int],
|
||||
description="The crop coordinates to use for preprocess/postprocess the image and mask, for inpainting task only. Can be generated in vae_encode step.",
|
||||
),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self) -> List[str]:
|
||||
return [
|
||||
OutputParam(
|
||||
"images",
|
||||
type_hint=Union[List[PIL.Image.Image], List[torch.Tensor], List[np.array]],
|
||||
description="The generated images with the mask overlayed",
|
||||
)
|
||||
]
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, components, state: PipelineState) -> PipelineState:
|
||||
block_state = self.get_block_state(state)
|
||||
|
||||
if block_state.padding_mask_crop is not None and block_state.crops_coords is not None:
|
||||
block_state.images = [
|
||||
components.image_processor.apply_overlay(
|
||||
block_state.mask_image, block_state.image, i, block_state.crops_coords
|
||||
)
|
||||
for i in block_state.images
|
||||
]
|
||||
|
||||
self.set_block_state(state, block_state)
|
||||
|
||||
return components, state
|
||||
791
src/diffusers/modular_pipelines/stable_diffusion_xl/denoise.py
Normal file
791
src/diffusers/modular_pipelines/stable_diffusion_xl/denoise.py
Normal file
@@ -0,0 +1,791 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
import inspect
|
||||
from typing import Any, List, Optional, Tuple
|
||||
|
||||
import torch
|
||||
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...guiders import ClassifierFreeGuidance
|
||||
from ...models import ControlNetModel, UNet2DConditionModel
|
||||
from ...schedulers import EulerDiscreteScheduler
|
||||
from ...utils import logging
|
||||
from ..modular_pipeline import (
|
||||
BlockState,
|
||||
LoopSequentialPipelineBlocks,
|
||||
PipelineBlock,
|
||||
PipelineState,
|
||||
)
|
||||
from ..modular_pipeline_utils import ComponentSpec, InputParam, OutputParam
|
||||
from .modular_pipeline import StableDiffusionXLModularPipeline
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
# YiYi experimenting composible denoise loop
|
||||
# loop step (1): prepare latent input for denoiser
|
||||
class StableDiffusionXLLoopBeforeDenoiser(PipelineBlock):
|
||||
model_name = "stable-diffusion-xl"
|
||||
|
||||
@property
|
||||
def expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec("scheduler", EulerDiscreteScheduler),
|
||||
]
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"step within the denoising loop that prepare the latent input for the denoiser. "
|
||||
"This block should be used to compose the `sub_blocks` attribute of a `LoopSequentialPipelineBlocks` "
|
||||
"object (e.g. `StableDiffusionXLDenoiseLoopWrapper`)"
|
||||
)
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self) -> List[str]:
|
||||
return [
|
||||
InputParam(
|
||||
"latents",
|
||||
required=True,
|
||||
type_hint=torch.Tensor,
|
||||
description="The initial latents to use for the denoising process. Can be generated in prepare_latent step.",
|
||||
),
|
||||
]
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, components: StableDiffusionXLModularPipeline, block_state: BlockState, i: int, t: int):
|
||||
block_state.scaled_latents = components.scheduler.scale_model_input(block_state.latents, t)
|
||||
|
||||
return components, block_state
|
||||
|
||||
|
||||
# loop step (1): prepare latent input for denoiser (with inpainting)
|
||||
class StableDiffusionXLInpaintLoopBeforeDenoiser(PipelineBlock):
|
||||
model_name = "stable-diffusion-xl"
|
||||
|
||||
@property
|
||||
def expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec("scheduler", EulerDiscreteScheduler),
|
||||
ComponentSpec("unet", UNet2DConditionModel),
|
||||
]
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"step within the denoising loop that prepare the latent input for the denoiser (for inpainting workflow only). "
|
||||
"This block should be used to compose the `sub_blocks` attribute of a `LoopSequentialPipelineBlocks` object"
|
||||
)
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self) -> List[str]:
|
||||
return [
|
||||
InputParam(
|
||||
"latents",
|
||||
required=True,
|
||||
type_hint=torch.Tensor,
|
||||
description="The initial latents to use for the denoising process. Can be generated in prepare_latent step.",
|
||||
),
|
||||
InputParam(
|
||||
"mask",
|
||||
type_hint=Optional[torch.Tensor],
|
||||
description="The mask to use for the denoising process, for inpainting task only. Can be generated in vae_encode or prepare_latent step.",
|
||||
),
|
||||
InputParam(
|
||||
"masked_image_latents",
|
||||
type_hint=Optional[torch.Tensor],
|
||||
description="The masked image latents to use for the denoising process, for inpainting task only. Can be generated in vae_encode or prepare_latent step.",
|
||||
),
|
||||
]
|
||||
|
||||
@staticmethod
|
||||
def check_inputs(components, block_state):
|
||||
num_channels_unet = components.num_channels_unet
|
||||
if num_channels_unet == 9:
|
||||
# default case for runwayml/stable-diffusion-inpainting
|
||||
if block_state.mask is None or block_state.masked_image_latents is None:
|
||||
raise ValueError("mask and masked_image_latents must be provided for inpainting-specific Unet")
|
||||
num_channels_latents = block_state.latents.shape[1]
|
||||
num_channels_mask = block_state.mask.shape[1]
|
||||
num_channels_masked_image = block_state.masked_image_latents.shape[1]
|
||||
if num_channels_latents + num_channels_mask + num_channels_masked_image != num_channels_unet:
|
||||
raise ValueError(
|
||||
f"Incorrect configuration settings! The config of `components.unet`: {components.unet.config} expects"
|
||||
f" {components.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
|
||||
f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
|
||||
f" = {num_channels_latents + num_channels_masked_image + num_channels_mask}. Please verify the config of"
|
||||
" `components.unet` or your `mask_image` or `image` input."
|
||||
)
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, components: StableDiffusionXLModularPipeline, block_state: BlockState, i: int, t: int):
|
||||
self.check_inputs(components, block_state)
|
||||
|
||||
block_state.scaled_latents = components.scheduler.scale_model_input(block_state.latents, t)
|
||||
if components.num_channels_unet == 9:
|
||||
block_state.scaled_latents = torch.cat(
|
||||
[block_state.scaled_latents, block_state.mask, block_state.masked_image_latents], dim=1
|
||||
)
|
||||
|
||||
return components, block_state
|
||||
|
||||
|
||||
# loop step (2): denoise the latents with guidance
|
||||
class StableDiffusionXLLoopDenoiser(PipelineBlock):
|
||||
model_name = "stable-diffusion-xl"
|
||||
|
||||
@property
|
||||
def expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec(
|
||||
"guider",
|
||||
ClassifierFreeGuidance,
|
||||
config=FrozenDict({"guidance_scale": 7.5}),
|
||||
default_creation_method="from_config",
|
||||
),
|
||||
ComponentSpec("unet", UNet2DConditionModel),
|
||||
]
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"Step within the denoising loop that denoise the latents with guidance. "
|
||||
"This block should be used to compose the `sub_blocks` attribute of a `LoopSequentialPipelineBlocks` "
|
||||
"object (e.g. `StableDiffusionXLDenoiseLoopWrapper`)"
|
||||
)
|
||||
|
||||
@property
|
||||
def inputs(self) -> List[Tuple[str, Any]]:
|
||||
return [
|
||||
InputParam("cross_attention_kwargs"),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self) -> List[str]:
|
||||
return [
|
||||
InputParam(
|
||||
"num_inference_steps",
|
||||
required=True,
|
||||
type_hint=int,
|
||||
description="The number of inference steps to use for the denoising process. Can be generated in set_timesteps step.",
|
||||
),
|
||||
InputParam(
|
||||
"timestep_cond",
|
||||
type_hint=Optional[torch.Tensor],
|
||||
description="The guidance scale embedding to use for Latent Consistency Models(LCMs). Can be generated in prepare_additional_conditioning step.",
|
||||
),
|
||||
InputParam(
|
||||
kwargs_type="guider_input_fields",
|
||||
description=(
|
||||
"All conditional model inputs that need to be prepared with guider. "
|
||||
"It should contain prompt_embeds/negative_prompt_embeds, "
|
||||
"add_time_ids/negative_add_time_ids, "
|
||||
"pooled_prompt_embeds/negative_pooled_prompt_embeds, "
|
||||
"and ip_adapter_embeds/negative_ip_adapter_embeds (optional)."
|
||||
"please add `kwargs_type=guider_input_fields` to their parameter spec (`OutputParam`) when they are created and added to the pipeline state"
|
||||
),
|
||||
),
|
||||
]
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(
|
||||
self, components: StableDiffusionXLModularPipeline, block_state: BlockState, i: int, t: int
|
||||
) -> PipelineState:
|
||||
# Map the keys we'll see on each `guider_state_batch` (e.g. guider_state_batch.prompt_embeds)
|
||||
# to the corresponding (cond, uncond) fields on block_state. (e.g. block_state.prompt_embeds, block_state.negative_prompt_embeds)
|
||||
guider_input_fields = {
|
||||
"prompt_embeds": ("prompt_embeds", "negative_prompt_embeds"),
|
||||
"time_ids": ("add_time_ids", "negative_add_time_ids"),
|
||||
"text_embeds": ("pooled_prompt_embeds", "negative_pooled_prompt_embeds"),
|
||||
"image_embeds": ("ip_adapter_embeds", "negative_ip_adapter_embeds"),
|
||||
}
|
||||
|
||||
components.guider.set_state(step=i, num_inference_steps=block_state.num_inference_steps, timestep=t)
|
||||
|
||||
# Prepare mini‐batches according to guidance method and `guider_input_fields`
|
||||
# Each guider_state_batch will have .prompt_embeds, .time_ids, text_embeds, image_embeds.
|
||||
# e.g. for CFG, we prepare two batches: one for uncond, one for cond
|
||||
# for first batch, guider_state_batch.prompt_embeds correspond to block_state.prompt_embeds
|
||||
# for second batch, guider_state_batch.prompt_embeds correspond to block_state.negative_prompt_embeds
|
||||
guider_state = components.guider.prepare_inputs(block_state, guider_input_fields)
|
||||
|
||||
# run the denoiser for each guidance batch
|
||||
for guider_state_batch in guider_state:
|
||||
components.guider.prepare_models(components.unet)
|
||||
cond_kwargs = guider_state_batch.as_dict()
|
||||
cond_kwargs = {k: v for k, v in cond_kwargs.items() if k in guider_input_fields}
|
||||
prompt_embeds = cond_kwargs.pop("prompt_embeds")
|
||||
|
||||
# Predict the noise residual
|
||||
# store the noise_pred in guider_state_batch so that we can apply guidance across all batches
|
||||
guider_state_batch.noise_pred = components.unet(
|
||||
block_state.scaled_latents,
|
||||
t,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep_cond=block_state.timestep_cond,
|
||||
cross_attention_kwargs=block_state.cross_attention_kwargs,
|
||||
added_cond_kwargs=cond_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
components.guider.cleanup_models(components.unet)
|
||||
|
||||
# Perform guidance
|
||||
block_state.noise_pred, block_state.scheduler_step_kwargs = components.guider(guider_state)
|
||||
|
||||
return components, block_state
|
||||
|
||||
|
||||
# loop step (2): denoise the latents with guidance (with controlnet)
|
||||
class StableDiffusionXLControlNetLoopDenoiser(PipelineBlock):
|
||||
model_name = "stable-diffusion-xl"
|
||||
|
||||
@property
|
||||
def expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec(
|
||||
"guider",
|
||||
ClassifierFreeGuidance,
|
||||
config=FrozenDict({"guidance_scale": 7.5}),
|
||||
default_creation_method="from_config",
|
||||
),
|
||||
ComponentSpec("unet", UNet2DConditionModel),
|
||||
ComponentSpec("controlnet", ControlNetModel),
|
||||
]
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"step within the denoising loop that denoise the latents with guidance (with controlnet). "
|
||||
"This block should be used to compose the `sub_blocks` attribute of a `LoopSequentialPipelineBlocks` "
|
||||
"object (e.g. `StableDiffusionXLDenoiseLoopWrapper`)"
|
||||
)
|
||||
|
||||
@property
|
||||
def inputs(self) -> List[Tuple[str, Any]]:
|
||||
return [
|
||||
InputParam("cross_attention_kwargs"),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self) -> List[str]:
|
||||
return [
|
||||
InputParam(
|
||||
"controlnet_cond",
|
||||
required=True,
|
||||
type_hint=torch.Tensor,
|
||||
description="The control image to use for the denoising process. Can be generated in prepare_controlnet_inputs step.",
|
||||
),
|
||||
InputParam(
|
||||
"conditioning_scale",
|
||||
type_hint=float,
|
||||
description="The controlnet conditioning scale value to use for the denoising process. Can be generated in prepare_controlnet_inputs step.",
|
||||
),
|
||||
InputParam(
|
||||
"guess_mode",
|
||||
required=True,
|
||||
type_hint=bool,
|
||||
description="The guess mode value to use for the denoising process. Can be generated in prepare_controlnet_inputs step.",
|
||||
),
|
||||
InputParam(
|
||||
"controlnet_keep",
|
||||
required=True,
|
||||
type_hint=List[float],
|
||||
description="The controlnet keep values to use for the denoising process. Can be generated in prepare_controlnet_inputs step.",
|
||||
),
|
||||
InputParam(
|
||||
"timestep_cond",
|
||||
type_hint=Optional[torch.Tensor],
|
||||
description="The guidance scale embedding to use for Latent Consistency Models(LCMs), can be generated by prepare_additional_conditioning step",
|
||||
),
|
||||
InputParam(
|
||||
"num_inference_steps",
|
||||
required=True,
|
||||
type_hint=int,
|
||||
description="The number of inference steps to use for the denoising process. Can be generated in set_timesteps step.",
|
||||
),
|
||||
InputParam(
|
||||
kwargs_type="guider_input_fields",
|
||||
description=(
|
||||
"All conditional model inputs that need to be prepared with guider. "
|
||||
"It should contain prompt_embeds/negative_prompt_embeds, "
|
||||
"add_time_ids/negative_add_time_ids, "
|
||||
"pooled_prompt_embeds/negative_pooled_prompt_embeds, "
|
||||
"and ip_adapter_embeds/negative_ip_adapter_embeds (optional)."
|
||||
"please add `kwargs_type=guider_input_fields` to their parameter spec (`OutputParam`) when they are created and added to the pipeline state"
|
||||
),
|
||||
),
|
||||
InputParam(
|
||||
kwargs_type="controlnet_kwargs",
|
||||
description=(
|
||||
"additional kwargs for controlnet (e.g. control_type_idx and control_type from the controlnet union input step )"
|
||||
"please add `kwargs_type=controlnet_kwargs` to their parameter spec (`OutputParam`) when they are created and added to the pipeline state"
|
||||
),
|
||||
),
|
||||
]
|
||||
|
||||
@staticmethod
|
||||
def prepare_extra_kwargs(func, exclude_kwargs=[], **kwargs):
|
||||
accepted_kwargs = set(inspect.signature(func).parameters.keys())
|
||||
extra_kwargs = {}
|
||||
for key, value in kwargs.items():
|
||||
if key in accepted_kwargs and key not in exclude_kwargs:
|
||||
extra_kwargs[key] = value
|
||||
|
||||
return extra_kwargs
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, components: StableDiffusionXLModularPipeline, block_state: BlockState, i: int, t: int):
|
||||
extra_controlnet_kwargs = self.prepare_extra_kwargs(
|
||||
components.controlnet.forward, **block_state.controlnet_kwargs
|
||||
)
|
||||
|
||||
# Map the keys we'll see on each `guider_state_batch` (e.g. guider_state_batch.prompt_embeds)
|
||||
# to the corresponding (cond, uncond) fields on block_state. (e.g. block_state.prompt_embeds, block_state.negative_prompt_embeds)
|
||||
guider_input_fields = {
|
||||
"prompt_embeds": ("prompt_embeds", "negative_prompt_embeds"),
|
||||
"time_ids": ("add_time_ids", "negative_add_time_ids"),
|
||||
"text_embeds": ("pooled_prompt_embeds", "negative_pooled_prompt_embeds"),
|
||||
"image_embeds": ("ip_adapter_embeds", "negative_ip_adapter_embeds"),
|
||||
}
|
||||
|
||||
# cond_scale for the timestep (controlnet input)
|
||||
if isinstance(block_state.controlnet_keep[i], list):
|
||||
block_state.cond_scale = [
|
||||
c * s for c, s in zip(block_state.conditioning_scale, block_state.controlnet_keep[i])
|
||||
]
|
||||
else:
|
||||
controlnet_cond_scale = block_state.conditioning_scale
|
||||
if isinstance(controlnet_cond_scale, list):
|
||||
controlnet_cond_scale = controlnet_cond_scale[0]
|
||||
block_state.cond_scale = controlnet_cond_scale * block_state.controlnet_keep[i]
|
||||
|
||||
# default controlnet output/unet input for guess mode + conditional path
|
||||
block_state.down_block_res_samples_zeros = None
|
||||
block_state.mid_block_res_sample_zeros = None
|
||||
|
||||
# guided denoiser step
|
||||
components.guider.set_state(step=i, num_inference_steps=block_state.num_inference_steps, timestep=t)
|
||||
|
||||
# Prepare mini‐batches according to guidance method and `guider_input_fields`
|
||||
# Each guider_state_batch will have .prompt_embeds, .time_ids, text_embeds, image_embeds.
|
||||
# e.g. for CFG, we prepare two batches: one for uncond, one for cond
|
||||
# for first batch, guider_state_batch.prompt_embeds correspond to block_state.prompt_embeds
|
||||
# for second batch, guider_state_batch.prompt_embeds correspond to block_state.negative_prompt_embeds
|
||||
guider_state = components.guider.prepare_inputs(block_state, guider_input_fields)
|
||||
|
||||
# run the denoiser for each guidance batch
|
||||
for guider_state_batch in guider_state:
|
||||
components.guider.prepare_models(components.unet)
|
||||
|
||||
# Prepare additional conditionings
|
||||
added_cond_kwargs = {
|
||||
"text_embeds": guider_state_batch.text_embeds,
|
||||
"time_ids": guider_state_batch.time_ids,
|
||||
}
|
||||
if hasattr(guider_state_batch, "image_embeds") and guider_state_batch.image_embeds is not None:
|
||||
added_cond_kwargs["image_embeds"] = guider_state_batch.image_embeds
|
||||
|
||||
# Prepare controlnet additional conditionings
|
||||
controlnet_added_cond_kwargs = {
|
||||
"text_embeds": guider_state_batch.text_embeds,
|
||||
"time_ids": guider_state_batch.time_ids,
|
||||
}
|
||||
# run controlnet for the guidance batch
|
||||
if block_state.guess_mode and not components.guider.is_conditional:
|
||||
# guider always run uncond batch first, so these tensors should be set already
|
||||
down_block_res_samples = block_state.down_block_res_samples_zeros
|
||||
mid_block_res_sample = block_state.mid_block_res_sample_zeros
|
||||
else:
|
||||
down_block_res_samples, mid_block_res_sample = components.controlnet(
|
||||
block_state.scaled_latents,
|
||||
t,
|
||||
encoder_hidden_states=guider_state_batch.prompt_embeds,
|
||||
controlnet_cond=block_state.controlnet_cond,
|
||||
conditioning_scale=block_state.cond_scale,
|
||||
guess_mode=block_state.guess_mode,
|
||||
added_cond_kwargs=controlnet_added_cond_kwargs,
|
||||
return_dict=False,
|
||||
**extra_controlnet_kwargs,
|
||||
)
|
||||
|
||||
# assign it to block_state so it will be available for the uncond guidance batch
|
||||
if block_state.down_block_res_samples_zeros is None:
|
||||
block_state.down_block_res_samples_zeros = [torch.zeros_like(d) for d in down_block_res_samples]
|
||||
if block_state.mid_block_res_sample_zeros is None:
|
||||
block_state.mid_block_res_sample_zeros = torch.zeros_like(mid_block_res_sample)
|
||||
|
||||
# Predict the noise
|
||||
# store the noise_pred in guider_state_batch so we can apply guidance across all batches
|
||||
guider_state_batch.noise_pred = components.unet(
|
||||
block_state.scaled_latents,
|
||||
t,
|
||||
encoder_hidden_states=guider_state_batch.prompt_embeds,
|
||||
timestep_cond=block_state.timestep_cond,
|
||||
cross_attention_kwargs=block_state.cross_attention_kwargs,
|
||||
added_cond_kwargs=added_cond_kwargs,
|
||||
down_block_additional_residuals=down_block_res_samples,
|
||||
mid_block_additional_residual=mid_block_res_sample,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
components.guider.cleanup_models(components.unet)
|
||||
|
||||
# Perform guidance
|
||||
block_state.noise_pred, block_state.scheduler_step_kwargs = components.guider(guider_state)
|
||||
|
||||
return components, block_state
|
||||
|
||||
|
||||
# loop step (3): scheduler step to update latents
|
||||
class StableDiffusionXLLoopAfterDenoiser(PipelineBlock):
|
||||
model_name = "stable-diffusion-xl"
|
||||
|
||||
@property
|
||||
def expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec("scheduler", EulerDiscreteScheduler),
|
||||
]
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"step within the denoising loop that update the latents. "
|
||||
"This block should be used to compose the `sub_blocks` attribute of a `LoopSequentialPipelineBlocks` "
|
||||
"object (e.g. `StableDiffusionXLDenoiseLoopWrapper`)"
|
||||
)
|
||||
|
||||
@property
|
||||
def inputs(self) -> List[Tuple[str, Any]]:
|
||||
return [
|
||||
InputParam("eta", default=0.0),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self) -> List[str]:
|
||||
return [
|
||||
InputParam("generator"),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self) -> List[OutputParam]:
|
||||
return [OutputParam("latents", type_hint=torch.Tensor, description="The denoised latents")]
|
||||
|
||||
# YiYi TODO: move this out of here
|
||||
@staticmethod
|
||||
def prepare_extra_kwargs(func, exclude_kwargs=[], **kwargs):
|
||||
accepted_kwargs = set(inspect.signature(func).parameters.keys())
|
||||
extra_kwargs = {}
|
||||
for key, value in kwargs.items():
|
||||
if key in accepted_kwargs and key not in exclude_kwargs:
|
||||
extra_kwargs[key] = value
|
||||
|
||||
return extra_kwargs
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, components: StableDiffusionXLModularPipeline, block_state: BlockState, i: int, t: int):
|
||||
# Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
||||
block_state.extra_step_kwargs = self.prepare_extra_kwargs(
|
||||
components.scheduler.step, generator=block_state.generator, eta=block_state.eta
|
||||
)
|
||||
|
||||
# Perform scheduler step using the predicted output
|
||||
block_state.latents_dtype = block_state.latents.dtype
|
||||
block_state.latents = components.scheduler.step(
|
||||
block_state.noise_pred,
|
||||
t,
|
||||
block_state.latents,
|
||||
**block_state.extra_step_kwargs,
|
||||
**block_state.scheduler_step_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
if block_state.latents.dtype != block_state.latents_dtype:
|
||||
if torch.backends.mps.is_available():
|
||||
# some platforms (eg. apple mps) misbehave due to a pytorch bug: https://github.com/pytorch/pytorch/pull/99272
|
||||
block_state.latents = block_state.latents.to(block_state.latents_dtype)
|
||||
|
||||
return components, block_state
|
||||
|
||||
|
||||
# loop step (3): scheduler step to update latents (with inpainting)
|
||||
class StableDiffusionXLInpaintLoopAfterDenoiser(PipelineBlock):
|
||||
model_name = "stable-diffusion-xl"
|
||||
|
||||
@property
|
||||
def expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec("scheduler", EulerDiscreteScheduler),
|
||||
ComponentSpec("unet", UNet2DConditionModel),
|
||||
]
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"step within the denoising loop that update the latents (for inpainting workflow only). "
|
||||
"This block should be used to compose the `sub_blocks` attribute of a `LoopSequentialPipelineBlocks` "
|
||||
"object (e.g. `StableDiffusionXLDenoiseLoopWrapper`)"
|
||||
)
|
||||
|
||||
@property
|
||||
def inputs(self) -> List[Tuple[str, Any]]:
|
||||
return [
|
||||
InputParam("eta", default=0.0),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self) -> List[str]:
|
||||
return [
|
||||
InputParam("generator"),
|
||||
InputParam(
|
||||
"timesteps",
|
||||
required=True,
|
||||
type_hint=torch.Tensor,
|
||||
description="The timesteps to use for the denoising process. Can be generated in set_timesteps step.",
|
||||
),
|
||||
InputParam(
|
||||
"mask",
|
||||
type_hint=Optional[torch.Tensor],
|
||||
description="The mask to use for the denoising process, for inpainting task only. Can be generated in vae_encode or prepare_latent step.",
|
||||
),
|
||||
InputParam(
|
||||
"noise",
|
||||
type_hint=Optional[torch.Tensor],
|
||||
description="The noise added to the image latents, for inpainting task only. Can be generated in prepare_latent step.",
|
||||
),
|
||||
InputParam(
|
||||
"image_latents",
|
||||
type_hint=Optional[torch.Tensor],
|
||||
description="The image latents to use for the denoising process, for inpainting/image-to-image task only. Can be generated in vae_encode or prepare_latent step.",
|
||||
),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self) -> List[OutputParam]:
|
||||
return [OutputParam("latents", type_hint=torch.Tensor, description="The denoised latents")]
|
||||
|
||||
@staticmethod
|
||||
def prepare_extra_kwargs(func, exclude_kwargs=[], **kwargs):
|
||||
accepted_kwargs = set(inspect.signature(func).parameters.keys())
|
||||
extra_kwargs = {}
|
||||
for key, value in kwargs.items():
|
||||
if key in accepted_kwargs and key not in exclude_kwargs:
|
||||
extra_kwargs[key] = value
|
||||
|
||||
return extra_kwargs
|
||||
|
||||
def check_inputs(self, components, block_state):
|
||||
if components.num_channels_unet == 4:
|
||||
if block_state.image_latents is None:
|
||||
raise ValueError(f"image_latents is required for this step {self.__class__.__name__}")
|
||||
if block_state.mask is None:
|
||||
raise ValueError(f"mask is required for this step {self.__class__.__name__}")
|
||||
if block_state.noise is None:
|
||||
raise ValueError(f"noise is required for this step {self.__class__.__name__}")
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, components: StableDiffusionXLModularPipeline, block_state: BlockState, i: int, t: int):
|
||||
self.check_inputs(components, block_state)
|
||||
|
||||
# Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
|
||||
block_state.extra_step_kwargs = self.prepare_extra_kwargs(
|
||||
components.scheduler.step, generator=block_state.generator, eta=block_state.eta
|
||||
)
|
||||
|
||||
# Perform scheduler step using the predicted output
|
||||
block_state.latents_dtype = block_state.latents.dtype
|
||||
block_state.latents = components.scheduler.step(
|
||||
block_state.noise_pred,
|
||||
t,
|
||||
block_state.latents,
|
||||
**block_state.extra_step_kwargs,
|
||||
**block_state.scheduler_step_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
if block_state.latents.dtype != block_state.latents_dtype:
|
||||
if torch.backends.mps.is_available():
|
||||
# some platforms (eg. apple mps) misbehave due to a pytorch bug: https://github.com/pytorch/pytorch/pull/99272
|
||||
block_state.latents = block_state.latents.to(block_state.latents_dtype)
|
||||
|
||||
# adjust latent for inpainting
|
||||
if components.num_channels_unet == 4:
|
||||
block_state.init_latents_proper = block_state.image_latents
|
||||
if i < len(block_state.timesteps) - 1:
|
||||
block_state.noise_timestep = block_state.timesteps[i + 1]
|
||||
block_state.init_latents_proper = components.scheduler.add_noise(
|
||||
block_state.init_latents_proper, block_state.noise, torch.tensor([block_state.noise_timestep])
|
||||
)
|
||||
|
||||
block_state.latents = (
|
||||
1 - block_state.mask
|
||||
) * block_state.init_latents_proper + block_state.mask * block_state.latents
|
||||
|
||||
return components, block_state
|
||||
|
||||
|
||||
# the loop wrapper that iterates over the timesteps
|
||||
class StableDiffusionXLDenoiseLoopWrapper(LoopSequentialPipelineBlocks):
|
||||
model_name = "stable-diffusion-xl"
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"Pipeline block that iteratively denoise the latents over `timesteps`. "
|
||||
"The specific steps with each iteration can be customized with `sub_blocks` attributes"
|
||||
)
|
||||
|
||||
@property
|
||||
def loop_expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec(
|
||||
"guider",
|
||||
ClassifierFreeGuidance,
|
||||
config=FrozenDict({"guidance_scale": 7.5}),
|
||||
default_creation_method="from_config",
|
||||
),
|
||||
ComponentSpec("scheduler", EulerDiscreteScheduler),
|
||||
ComponentSpec("unet", UNet2DConditionModel),
|
||||
]
|
||||
|
||||
@property
|
||||
def loop_intermediate_inputs(self) -> List[InputParam]:
|
||||
return [
|
||||
InputParam(
|
||||
"timesteps",
|
||||
required=True,
|
||||
type_hint=torch.Tensor,
|
||||
description="The timesteps to use for the denoising process. Can be generated in set_timesteps step.",
|
||||
),
|
||||
InputParam(
|
||||
"num_inference_steps",
|
||||
required=True,
|
||||
type_hint=int,
|
||||
description="The number of inference steps to use for the denoising process. Can be generated in set_timesteps step.",
|
||||
),
|
||||
]
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, components: StableDiffusionXLModularPipeline, state: PipelineState) -> PipelineState:
|
||||
block_state = self.get_block_state(state)
|
||||
|
||||
block_state.disable_guidance = True if components.unet.config.time_cond_proj_dim is not None else False
|
||||
if block_state.disable_guidance:
|
||||
components.guider.disable()
|
||||
else:
|
||||
components.guider.enable()
|
||||
|
||||
block_state.num_warmup_steps = max(
|
||||
len(block_state.timesteps) - block_state.num_inference_steps * components.scheduler.order, 0
|
||||
)
|
||||
|
||||
with self.progress_bar(total=block_state.num_inference_steps) as progress_bar:
|
||||
for i, t in enumerate(block_state.timesteps):
|
||||
components, block_state = self.loop_step(components, block_state, i=i, t=t)
|
||||
if i == len(block_state.timesteps) - 1 or (
|
||||
(i + 1) > block_state.num_warmup_steps and (i + 1) % components.scheduler.order == 0
|
||||
):
|
||||
progress_bar.update()
|
||||
|
||||
self.set_block_state(state, block_state)
|
||||
|
||||
return components, state
|
||||
|
||||
|
||||
# composing the denoising loops
|
||||
class StableDiffusionXLDenoiseStep(StableDiffusionXLDenoiseLoopWrapper):
|
||||
block_classes = [
|
||||
StableDiffusionXLLoopBeforeDenoiser,
|
||||
StableDiffusionXLLoopDenoiser,
|
||||
StableDiffusionXLLoopAfterDenoiser,
|
||||
]
|
||||
block_names = ["before_denoiser", "denoiser", "after_denoiser"]
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"Denoise step that iteratively denoise the latents. \n"
|
||||
"Its loop logic is defined in `StableDiffusionXLDenoiseLoopWrapper.__call__` method \n"
|
||||
"At each iteration, it runs blocks defined in `sub_blocks` sequencially:\n"
|
||||
" - `StableDiffusionXLLoopBeforeDenoiser`\n"
|
||||
" - `StableDiffusionXLLoopDenoiser`\n"
|
||||
" - `StableDiffusionXLLoopAfterDenoiser`\n"
|
||||
"This block supports both text2img and img2img tasks."
|
||||
)
|
||||
|
||||
|
||||
# control_cond
|
||||
class StableDiffusionXLControlNetDenoiseStep(StableDiffusionXLDenoiseLoopWrapper):
|
||||
block_classes = [
|
||||
StableDiffusionXLLoopBeforeDenoiser,
|
||||
StableDiffusionXLControlNetLoopDenoiser,
|
||||
StableDiffusionXLLoopAfterDenoiser,
|
||||
]
|
||||
block_names = ["before_denoiser", "denoiser", "after_denoiser"]
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"Denoise step that iteratively denoise the latents with controlnet. \n"
|
||||
"Its loop logic is defined in `StableDiffusionXLDenoiseLoopWrapper.__call__` method \n"
|
||||
"At each iteration, it runs blocks defined in `sub_blocks` sequencially:\n"
|
||||
" - `StableDiffusionXLLoopBeforeDenoiser`\n"
|
||||
" - `StableDiffusionXLControlNetLoopDenoiser`\n"
|
||||
" - `StableDiffusionXLLoopAfterDenoiser`\n"
|
||||
"This block supports using controlnet for both text2img and img2img tasks."
|
||||
)
|
||||
|
||||
|
||||
# mask
|
||||
class StableDiffusionXLInpaintDenoiseStep(StableDiffusionXLDenoiseLoopWrapper):
|
||||
block_classes = [
|
||||
StableDiffusionXLInpaintLoopBeforeDenoiser,
|
||||
StableDiffusionXLLoopDenoiser,
|
||||
StableDiffusionXLInpaintLoopAfterDenoiser,
|
||||
]
|
||||
block_names = ["before_denoiser", "denoiser", "after_denoiser"]
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"Denoise step that iteratively denoise the latents(for inpainting task only). \n"
|
||||
"Its loop logic is defined in `StableDiffusionXLDenoiseLoopWrapper.__call__` method \n"
|
||||
"At each iteration, it runs blocks defined in `sub_blocks` sequencially:\n"
|
||||
" - `StableDiffusionXLInpaintLoopBeforeDenoiser`\n"
|
||||
" - `StableDiffusionXLLoopDenoiser`\n"
|
||||
" - `StableDiffusionXLInpaintLoopAfterDenoiser`\n"
|
||||
"This block onlysupports inpainting tasks."
|
||||
)
|
||||
|
||||
|
||||
# control_cond + mask
|
||||
class StableDiffusionXLInpaintControlNetDenoiseStep(StableDiffusionXLDenoiseLoopWrapper):
|
||||
block_classes = [
|
||||
StableDiffusionXLInpaintLoopBeforeDenoiser,
|
||||
StableDiffusionXLControlNetLoopDenoiser,
|
||||
StableDiffusionXLInpaintLoopAfterDenoiser,
|
||||
]
|
||||
block_names = ["before_denoiser", "denoiser", "after_denoiser"]
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"Denoise step that iteratively denoise the latents(for inpainting task only) with controlnet. \n"
|
||||
"Its loop logic is defined in `StableDiffusionXLDenoiseLoopWrapper.__call__` method \n"
|
||||
"At each iteration, it runs blocks defined in `sub_blocks` sequencially:\n"
|
||||
" - `StableDiffusionXLInpaintLoopBeforeDenoiser`\n"
|
||||
" - `StableDiffusionXLControlNetLoopDenoiser`\n"
|
||||
" - `StableDiffusionXLInpaintLoopAfterDenoiser`\n"
|
||||
"This block only supports using controlnet for inpainting tasks."
|
||||
)
|
||||
902
src/diffusers/modular_pipelines/stable_diffusion_xl/encoders.py
Normal file
902
src/diffusers/modular_pipelines/stable_diffusion_xl/encoders.py
Normal file
@@ -0,0 +1,902 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from typing import List, Optional, Tuple
|
||||
|
||||
import torch
|
||||
from transformers import (
|
||||
CLIPImageProcessor,
|
||||
CLIPTextModel,
|
||||
CLIPTextModelWithProjection,
|
||||
CLIPTokenizer,
|
||||
CLIPVisionModelWithProjection,
|
||||
)
|
||||
|
||||
from ...configuration_utils import FrozenDict
|
||||
from ...guiders import ClassifierFreeGuidance
|
||||
from ...image_processor import PipelineImageInput, VaeImageProcessor
|
||||
from ...loaders import StableDiffusionXLLoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...models import AutoencoderKL, ImageProjection, UNet2DConditionModel
|
||||
from ...models.lora import adjust_lora_scale_text_encoder
|
||||
from ...utils import (
|
||||
USE_PEFT_BACKEND,
|
||||
logging,
|
||||
scale_lora_layers,
|
||||
unscale_lora_layers,
|
||||
)
|
||||
from ..modular_pipeline import PipelineBlock, PipelineState
|
||||
from ..modular_pipeline_utils import ComponentSpec, ConfigSpec, InputParam, OutputParam
|
||||
from .modular_pipeline import StableDiffusionXLModularPipeline
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.retrieve_latents
|
||||
def retrieve_latents(
|
||||
encoder_output: torch.Tensor, generator: Optional[torch.Generator] = None, sample_mode: str = "sample"
|
||||
):
|
||||
if hasattr(encoder_output, "latent_dist") and sample_mode == "sample":
|
||||
return encoder_output.latent_dist.sample(generator)
|
||||
elif hasattr(encoder_output, "latent_dist") and sample_mode == "argmax":
|
||||
return encoder_output.latent_dist.mode()
|
||||
elif hasattr(encoder_output, "latents"):
|
||||
return encoder_output.latents
|
||||
else:
|
||||
raise AttributeError("Could not access latents of provided encoder_output")
|
||||
|
||||
|
||||
class StableDiffusionXLIPAdapterStep(PipelineBlock):
|
||||
model_name = "stable-diffusion-xl"
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"IP Adapter step that prepares ip adapter image embeddings.\n"
|
||||
"Note that this step only prepares the embeddings - in order for it to work correctly, "
|
||||
"you need to load ip adapter weights into unet via ModularPipeline.load_ip_adapter() and pipeline.set_ip_adapter_scale().\n"
|
||||
"See [ModularIPAdapterMixin](https://huggingface.co/docs/diffusers/api/loaders/ip_adapter#diffusers.loaders.ModularIPAdapterMixin)"
|
||||
" for more details"
|
||||
)
|
||||
|
||||
@property
|
||||
def expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec("image_encoder", CLIPVisionModelWithProjection),
|
||||
ComponentSpec(
|
||||
"feature_extractor",
|
||||
CLIPImageProcessor,
|
||||
config=FrozenDict({"size": 224, "crop_size": 224}),
|
||||
default_creation_method="from_config",
|
||||
),
|
||||
ComponentSpec("unet", UNet2DConditionModel),
|
||||
ComponentSpec(
|
||||
"guider",
|
||||
ClassifierFreeGuidance,
|
||||
config=FrozenDict({"guidance_scale": 7.5}),
|
||||
default_creation_method="from_config",
|
||||
),
|
||||
]
|
||||
|
||||
@property
|
||||
def inputs(self) -> List[InputParam]:
|
||||
return [
|
||||
InputParam(
|
||||
"ip_adapter_image",
|
||||
PipelineImageInput,
|
||||
required=True,
|
||||
description="The image(s) to be used as ip adapter",
|
||||
)
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self) -> List[OutputParam]:
|
||||
return [
|
||||
OutputParam("ip_adapter_embeds", type_hint=torch.Tensor, description="IP adapter image embeddings"),
|
||||
OutputParam(
|
||||
"negative_ip_adapter_embeds",
|
||||
type_hint=torch.Tensor,
|
||||
description="Negative IP adapter image embeddings",
|
||||
),
|
||||
]
|
||||
|
||||
@staticmethod
|
||||
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.encode_image with self->components
|
||||
def encode_image(components, image, device, num_images_per_prompt, output_hidden_states=None):
|
||||
dtype = next(components.image_encoder.parameters()).dtype
|
||||
|
||||
if not isinstance(image, torch.Tensor):
|
||||
image = components.feature_extractor(image, return_tensors="pt").pixel_values
|
||||
|
||||
image = image.to(device=device, dtype=dtype)
|
||||
if output_hidden_states:
|
||||
image_enc_hidden_states = components.image_encoder(image, output_hidden_states=True).hidden_states[-2]
|
||||
image_enc_hidden_states = image_enc_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
uncond_image_enc_hidden_states = components.image_encoder(
|
||||
torch.zeros_like(image), output_hidden_states=True
|
||||
).hidden_states[-2]
|
||||
uncond_image_enc_hidden_states = uncond_image_enc_hidden_states.repeat_interleave(
|
||||
num_images_per_prompt, dim=0
|
||||
)
|
||||
return image_enc_hidden_states, uncond_image_enc_hidden_states
|
||||
else:
|
||||
image_embeds = components.image_encoder(image).image_embeds
|
||||
image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
|
||||
uncond_image_embeds = torch.zeros_like(image_embeds)
|
||||
|
||||
return image_embeds, uncond_image_embeds
|
||||
|
||||
# modified from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_ip_adapter_image_embeds
|
||||
def prepare_ip_adapter_image_embeds(
|
||||
self,
|
||||
components,
|
||||
ip_adapter_image,
|
||||
ip_adapter_image_embeds,
|
||||
device,
|
||||
num_images_per_prompt,
|
||||
prepare_unconditional_embeds,
|
||||
):
|
||||
image_embeds = []
|
||||
if prepare_unconditional_embeds:
|
||||
negative_image_embeds = []
|
||||
if ip_adapter_image_embeds is None:
|
||||
if not isinstance(ip_adapter_image, list):
|
||||
ip_adapter_image = [ip_adapter_image]
|
||||
|
||||
if len(ip_adapter_image) != len(components.unet.encoder_hid_proj.image_projection_layers):
|
||||
raise ValueError(
|
||||
f"`ip_adapter_image` must have same length as the number of IP Adapters. Got {len(ip_adapter_image)} images and {len(components.unet.encoder_hid_proj.image_projection_layers)} IP Adapters."
|
||||
)
|
||||
|
||||
for single_ip_adapter_image, image_proj_layer in zip(
|
||||
ip_adapter_image, components.unet.encoder_hid_proj.image_projection_layers
|
||||
):
|
||||
output_hidden_state = not isinstance(image_proj_layer, ImageProjection)
|
||||
single_image_embeds, single_negative_image_embeds = self.encode_image(
|
||||
components, single_ip_adapter_image, device, 1, output_hidden_state
|
||||
)
|
||||
|
||||
image_embeds.append(single_image_embeds[None, :])
|
||||
if prepare_unconditional_embeds:
|
||||
negative_image_embeds.append(single_negative_image_embeds[None, :])
|
||||
else:
|
||||
for single_image_embeds in ip_adapter_image_embeds:
|
||||
if prepare_unconditional_embeds:
|
||||
single_negative_image_embeds, single_image_embeds = single_image_embeds.chunk(2)
|
||||
negative_image_embeds.append(single_negative_image_embeds)
|
||||
image_embeds.append(single_image_embeds)
|
||||
|
||||
ip_adapter_image_embeds = []
|
||||
for i, single_image_embeds in enumerate(image_embeds):
|
||||
single_image_embeds = torch.cat([single_image_embeds] * num_images_per_prompt, dim=0)
|
||||
if prepare_unconditional_embeds:
|
||||
single_negative_image_embeds = torch.cat([negative_image_embeds[i]] * num_images_per_prompt, dim=0)
|
||||
single_image_embeds = torch.cat([single_negative_image_embeds, single_image_embeds], dim=0)
|
||||
|
||||
single_image_embeds = single_image_embeds.to(device=device)
|
||||
ip_adapter_image_embeds.append(single_image_embeds)
|
||||
|
||||
return ip_adapter_image_embeds
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, components: StableDiffusionXLModularPipeline, state: PipelineState) -> PipelineState:
|
||||
block_state = self.get_block_state(state)
|
||||
|
||||
block_state.prepare_unconditional_embeds = components.guider.num_conditions > 1
|
||||
block_state.device = components._execution_device
|
||||
|
||||
block_state.ip_adapter_embeds = self.prepare_ip_adapter_image_embeds(
|
||||
components,
|
||||
ip_adapter_image=block_state.ip_adapter_image,
|
||||
ip_adapter_image_embeds=None,
|
||||
device=block_state.device,
|
||||
num_images_per_prompt=1,
|
||||
prepare_unconditional_embeds=block_state.prepare_unconditional_embeds,
|
||||
)
|
||||
if block_state.prepare_unconditional_embeds:
|
||||
block_state.negative_ip_adapter_embeds = []
|
||||
for i, image_embeds in enumerate(block_state.ip_adapter_embeds):
|
||||
negative_image_embeds, image_embeds = image_embeds.chunk(2)
|
||||
block_state.negative_ip_adapter_embeds.append(negative_image_embeds)
|
||||
block_state.ip_adapter_embeds[i] = image_embeds
|
||||
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
|
||||
|
||||
class StableDiffusionXLTextEncoderStep(PipelineBlock):
|
||||
model_name = "stable-diffusion-xl"
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return "Text Encoder step that generate text_embeddings to guide the image generation"
|
||||
|
||||
@property
|
||||
def expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec("text_encoder", CLIPTextModel),
|
||||
ComponentSpec("text_encoder_2", CLIPTextModelWithProjection),
|
||||
ComponentSpec("tokenizer", CLIPTokenizer),
|
||||
ComponentSpec("tokenizer_2", CLIPTokenizer),
|
||||
ComponentSpec(
|
||||
"guider",
|
||||
ClassifierFreeGuidance,
|
||||
config=FrozenDict({"guidance_scale": 7.5}),
|
||||
default_creation_method="from_config",
|
||||
),
|
||||
]
|
||||
|
||||
@property
|
||||
def expected_configs(self) -> List[ConfigSpec]:
|
||||
return [ConfigSpec("force_zeros_for_empty_prompt", True)]
|
||||
|
||||
@property
|
||||
def inputs(self) -> List[InputParam]:
|
||||
return [
|
||||
InputParam("prompt"),
|
||||
InputParam("prompt_2"),
|
||||
InputParam("negative_prompt"),
|
||||
InputParam("negative_prompt_2"),
|
||||
InputParam("cross_attention_kwargs"),
|
||||
InputParam("clip_skip"),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self) -> List[OutputParam]:
|
||||
return [
|
||||
OutputParam(
|
||||
"prompt_embeds",
|
||||
type_hint=torch.Tensor,
|
||||
kwargs_type="guider_input_fields",
|
||||
description="text embeddings used to guide the image generation",
|
||||
),
|
||||
OutputParam(
|
||||
"negative_prompt_embeds",
|
||||
type_hint=torch.Tensor,
|
||||
kwargs_type="guider_input_fields",
|
||||
description="negative text embeddings used to guide the image generation",
|
||||
),
|
||||
OutputParam(
|
||||
"pooled_prompt_embeds",
|
||||
type_hint=torch.Tensor,
|
||||
kwargs_type="guider_input_fields",
|
||||
description="pooled text embeddings used to guide the image generation",
|
||||
),
|
||||
OutputParam(
|
||||
"negative_pooled_prompt_embeds",
|
||||
type_hint=torch.Tensor,
|
||||
kwargs_type="guider_input_fields",
|
||||
description="negative pooled text embeddings used to guide the image generation",
|
||||
),
|
||||
]
|
||||
|
||||
@staticmethod
|
||||
def check_inputs(block_state):
|
||||
if block_state.prompt is not None and (
|
||||
not isinstance(block_state.prompt, str) and not isinstance(block_state.prompt, list)
|
||||
):
|
||||
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(block_state.prompt)}")
|
||||
elif block_state.prompt_2 is not None and (
|
||||
not isinstance(block_state.prompt_2, str) and not isinstance(block_state.prompt_2, list)
|
||||
):
|
||||
raise ValueError(f"`prompt_2` has to be of type `str` or `list` but is {type(block_state.prompt_2)}")
|
||||
|
||||
@staticmethod
|
||||
def encode_prompt(
|
||||
components,
|
||||
prompt: str,
|
||||
prompt_2: Optional[str] = None,
|
||||
device: Optional[torch.device] = None,
|
||||
num_images_per_prompt: int = 1,
|
||||
prepare_unconditional_embeds: bool = True,
|
||||
negative_prompt: Optional[str] = None,
|
||||
negative_prompt_2: Optional[str] = None,
|
||||
prompt_embeds: Optional[torch.Tensor] = None,
|
||||
negative_prompt_embeds: Optional[torch.Tensor] = None,
|
||||
pooled_prompt_embeds: Optional[torch.Tensor] = None,
|
||||
negative_pooled_prompt_embeds: Optional[torch.Tensor] = None,
|
||||
lora_scale: Optional[float] = None,
|
||||
clip_skip: Optional[int] = None,
|
||||
):
|
||||
r"""
|
||||
Encodes the prompt into text encoder hidden states.
|
||||
|
||||
Args:
|
||||
prompt (`str` or `List[str]`, *optional*):
|
||||
prompt to be encoded
|
||||
prompt_2 (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts to be sent to the `tokenizer_2` and `text_encoder_2`. If not defined, `prompt` is
|
||||
used in both text-encoders
|
||||
device: (`torch.device`):
|
||||
torch device
|
||||
num_images_per_prompt (`int`):
|
||||
number of images that should be generated per prompt
|
||||
prepare_unconditional_embeds (`bool`):
|
||||
whether to use prepare unconditional embeddings or not
|
||||
negative_prompt (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts not to guide the image generation. If not defined, one has to pass
|
||||
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
|
||||
less than `1`).
|
||||
negative_prompt_2 (`str` or `List[str]`, *optional*):
|
||||
The prompt or prompts not to guide the image generation to be sent to `tokenizer_2` and
|
||||
`text_encoder_2`. If not defined, `negative_prompt` is used in both text-encoders
|
||||
prompt_embeds (`torch.Tensor`, *optional*):
|
||||
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
|
||||
provided, text embeddings will be generated from `prompt` input argument.
|
||||
negative_prompt_embeds (`torch.Tensor`, *optional*):
|
||||
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
|
||||
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
|
||||
argument.
|
||||
pooled_prompt_embeds (`torch.Tensor`, *optional*):
|
||||
Pre-generated pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting.
|
||||
If not provided, pooled text embeddings will be generated from `prompt` input argument.
|
||||
negative_pooled_prompt_embeds (`torch.Tensor`, *optional*):
|
||||
Pre-generated negative pooled text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
|
||||
weighting. If not provided, pooled negative_prompt_embeds will be generated from `negative_prompt`
|
||||
input argument.
|
||||
lora_scale (`float`, *optional*):
|
||||
A lora scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
|
||||
clip_skip (`int`, *optional*):
|
||||
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
|
||||
the output of the pre-final layer will be used for computing the prompt embeddings.
|
||||
"""
|
||||
device = device or components._execution_device
|
||||
|
||||
# set lora scale so that monkey patched LoRA
|
||||
# function of text encoder can correctly access it
|
||||
if lora_scale is not None and isinstance(components, StableDiffusionXLLoraLoaderMixin):
|
||||
components._lora_scale = lora_scale
|
||||
|
||||
# dynamically adjust the LoRA scale
|
||||
if components.text_encoder is not None:
|
||||
if not USE_PEFT_BACKEND:
|
||||
adjust_lora_scale_text_encoder(components.text_encoder, lora_scale)
|
||||
else:
|
||||
scale_lora_layers(components.text_encoder, lora_scale)
|
||||
|
||||
if components.text_encoder_2 is not None:
|
||||
if not USE_PEFT_BACKEND:
|
||||
adjust_lora_scale_text_encoder(components.text_encoder_2, lora_scale)
|
||||
else:
|
||||
scale_lora_layers(components.text_encoder_2, lora_scale)
|
||||
|
||||
prompt = [prompt] if isinstance(prompt, str) else prompt
|
||||
|
||||
if prompt is not None:
|
||||
batch_size = len(prompt)
|
||||
else:
|
||||
batch_size = prompt_embeds.shape[0]
|
||||
|
||||
# Define tokenizers and text encoders
|
||||
tokenizers = (
|
||||
[components.tokenizer, components.tokenizer_2]
|
||||
if components.tokenizer is not None
|
||||
else [components.tokenizer_2]
|
||||
)
|
||||
text_encoders = (
|
||||
[components.text_encoder, components.text_encoder_2]
|
||||
if components.text_encoder is not None
|
||||
else [components.text_encoder_2]
|
||||
)
|
||||
|
||||
if prompt_embeds is None:
|
||||
prompt_2 = prompt_2 or prompt
|
||||
prompt_2 = [prompt_2] if isinstance(prompt_2, str) else prompt_2
|
||||
|
||||
# textual inversion: process multi-vector tokens if necessary
|
||||
prompt_embeds_list = []
|
||||
prompts = [prompt, prompt_2]
|
||||
for prompt, tokenizer, text_encoder in zip(prompts, tokenizers, text_encoders):
|
||||
if isinstance(components, TextualInversionLoaderMixin):
|
||||
prompt = components.maybe_convert_prompt(prompt, tokenizer)
|
||||
|
||||
text_inputs = tokenizer(
|
||||
prompt,
|
||||
padding="max_length",
|
||||
max_length=tokenizer.model_max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
|
||||
text_input_ids = text_inputs.input_ids
|
||||
untruncated_ids = tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
|
||||
|
||||
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
|
||||
text_input_ids, untruncated_ids
|
||||
):
|
||||
removed_text = tokenizer.batch_decode(untruncated_ids[:, tokenizer.model_max_length - 1 : -1])
|
||||
logger.warning(
|
||||
"The following part of your input was truncated because CLIP can only handle sequences up to"
|
||||
f" {tokenizer.model_max_length} tokens: {removed_text}"
|
||||
)
|
||||
|
||||
prompt_embeds = text_encoder(text_input_ids.to(device), output_hidden_states=True)
|
||||
|
||||
# We are only ALWAYS interested in the pooled output of the final text encoder
|
||||
pooled_prompt_embeds = prompt_embeds[0]
|
||||
if clip_skip is None:
|
||||
prompt_embeds = prompt_embeds.hidden_states[-2]
|
||||
else:
|
||||
# "2" because SDXL always indexes from the penultimate layer.
|
||||
prompt_embeds = prompt_embeds.hidden_states[-(clip_skip + 2)]
|
||||
|
||||
prompt_embeds_list.append(prompt_embeds)
|
||||
|
||||
prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
|
||||
|
||||
# get unconditional embeddings for classifier free guidance
|
||||
zero_out_negative_prompt = negative_prompt is None and components.config.force_zeros_for_empty_prompt
|
||||
if prepare_unconditional_embeds and negative_prompt_embeds is None and zero_out_negative_prompt:
|
||||
negative_prompt_embeds = torch.zeros_like(prompt_embeds)
|
||||
negative_pooled_prompt_embeds = torch.zeros_like(pooled_prompt_embeds)
|
||||
elif prepare_unconditional_embeds and negative_prompt_embeds is None:
|
||||
negative_prompt = negative_prompt or ""
|
||||
negative_prompt_2 = negative_prompt_2 or negative_prompt
|
||||
|
||||
# normalize str to list
|
||||
negative_prompt = batch_size * [negative_prompt] if isinstance(negative_prompt, str) else negative_prompt
|
||||
negative_prompt_2 = (
|
||||
batch_size * [negative_prompt_2] if isinstance(negative_prompt_2, str) else negative_prompt_2
|
||||
)
|
||||
|
||||
uncond_tokens: List[str]
|
||||
if prompt is not None and type(prompt) is not type(negative_prompt):
|
||||
raise TypeError(
|
||||
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
|
||||
f" {type(prompt)}."
|
||||
)
|
||||
elif batch_size != len(negative_prompt):
|
||||
raise ValueError(
|
||||
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
|
||||
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
|
||||
" the batch size of `prompt`."
|
||||
)
|
||||
else:
|
||||
uncond_tokens = [negative_prompt, negative_prompt_2]
|
||||
|
||||
negative_prompt_embeds_list = []
|
||||
for negative_prompt, tokenizer, text_encoder in zip(uncond_tokens, tokenizers, text_encoders):
|
||||
if isinstance(components, TextualInversionLoaderMixin):
|
||||
negative_prompt = components.maybe_convert_prompt(negative_prompt, tokenizer)
|
||||
|
||||
max_length = prompt_embeds.shape[1]
|
||||
uncond_input = tokenizer(
|
||||
negative_prompt,
|
||||
padding="max_length",
|
||||
max_length=max_length,
|
||||
truncation=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
|
||||
negative_prompt_embeds = text_encoder(
|
||||
uncond_input.input_ids.to(device),
|
||||
output_hidden_states=True,
|
||||
)
|
||||
# We are only ALWAYS interested in the pooled output of the final text encoder
|
||||
negative_pooled_prompt_embeds = negative_prompt_embeds[0]
|
||||
negative_prompt_embeds = negative_prompt_embeds.hidden_states[-2]
|
||||
|
||||
negative_prompt_embeds_list.append(negative_prompt_embeds)
|
||||
|
||||
negative_prompt_embeds = torch.concat(negative_prompt_embeds_list, dim=-1)
|
||||
|
||||
if components.text_encoder_2 is not None:
|
||||
prompt_embeds = prompt_embeds.to(dtype=components.text_encoder_2.dtype, device=device)
|
||||
else:
|
||||
prompt_embeds = prompt_embeds.to(dtype=components.unet.dtype, device=device)
|
||||
|
||||
bs_embed, seq_len, _ = prompt_embeds.shape
|
||||
# duplicate text embeddings for each generation per prompt, using mps friendly method
|
||||
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
|
||||
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
|
||||
|
||||
if prepare_unconditional_embeds:
|
||||
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
|
||||
seq_len = negative_prompt_embeds.shape[1]
|
||||
|
||||
if components.text_encoder_2 is not None:
|
||||
negative_prompt_embeds = negative_prompt_embeds.to(
|
||||
dtype=components.text_encoder_2.dtype, device=device
|
||||
)
|
||||
else:
|
||||
negative_prompt_embeds = negative_prompt_embeds.to(dtype=components.unet.dtype, device=device)
|
||||
|
||||
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
|
||||
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
|
||||
|
||||
pooled_prompt_embeds = pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
|
||||
bs_embed * num_images_per_prompt, -1
|
||||
)
|
||||
if prepare_unconditional_embeds:
|
||||
negative_pooled_prompt_embeds = negative_pooled_prompt_embeds.repeat(1, num_images_per_prompt).view(
|
||||
bs_embed * num_images_per_prompt, -1
|
||||
)
|
||||
|
||||
if components.text_encoder is not None:
|
||||
if isinstance(components, StableDiffusionXLLoraLoaderMixin) and USE_PEFT_BACKEND:
|
||||
# Retrieve the original scale by scaling back the LoRA layers
|
||||
unscale_lora_layers(components.text_encoder, lora_scale)
|
||||
|
||||
if components.text_encoder_2 is not None:
|
||||
if isinstance(components, StableDiffusionXLLoraLoaderMixin) and USE_PEFT_BACKEND:
|
||||
# Retrieve the original scale by scaling back the LoRA layers
|
||||
unscale_lora_layers(components.text_encoder_2, lora_scale)
|
||||
|
||||
return prompt_embeds, negative_prompt_embeds, pooled_prompt_embeds, negative_pooled_prompt_embeds
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, components: StableDiffusionXLModularPipeline, state: PipelineState) -> PipelineState:
|
||||
# Get inputs and intermediates
|
||||
block_state = self.get_block_state(state)
|
||||
self.check_inputs(block_state)
|
||||
|
||||
block_state.prepare_unconditional_embeds = components.guider.num_conditions > 1
|
||||
block_state.device = components._execution_device
|
||||
|
||||
# Encode input prompt
|
||||
block_state.text_encoder_lora_scale = (
|
||||
block_state.cross_attention_kwargs.get("scale", None)
|
||||
if block_state.cross_attention_kwargs is not None
|
||||
else None
|
||||
)
|
||||
(
|
||||
block_state.prompt_embeds,
|
||||
block_state.negative_prompt_embeds,
|
||||
block_state.pooled_prompt_embeds,
|
||||
block_state.negative_pooled_prompt_embeds,
|
||||
) = self.encode_prompt(
|
||||
components,
|
||||
block_state.prompt,
|
||||
block_state.prompt_2,
|
||||
block_state.device,
|
||||
1,
|
||||
block_state.prepare_unconditional_embeds,
|
||||
block_state.negative_prompt,
|
||||
block_state.negative_prompt_2,
|
||||
prompt_embeds=None,
|
||||
negative_prompt_embeds=None,
|
||||
pooled_prompt_embeds=None,
|
||||
negative_pooled_prompt_embeds=None,
|
||||
lora_scale=block_state.text_encoder_lora_scale,
|
||||
clip_skip=block_state.clip_skip,
|
||||
)
|
||||
# Add outputs
|
||||
self.set_block_state(state, block_state)
|
||||
return components, state
|
||||
|
||||
|
||||
class StableDiffusionXLVaeEncoderStep(PipelineBlock):
|
||||
model_name = "stable-diffusion-xl"
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return "Vae Encoder step that encode the input image into a latent representation"
|
||||
|
||||
@property
|
||||
def expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec("vae", AutoencoderKL),
|
||||
ComponentSpec(
|
||||
"image_processor",
|
||||
VaeImageProcessor,
|
||||
config=FrozenDict({"vae_scale_factor": 8}),
|
||||
default_creation_method="from_config",
|
||||
),
|
||||
]
|
||||
|
||||
@property
|
||||
def inputs(self) -> List[InputParam]:
|
||||
return [
|
||||
InputParam("image", required=True),
|
||||
InputParam("height"),
|
||||
InputParam("width"),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self) -> List[InputParam]:
|
||||
return [
|
||||
InputParam("generator"),
|
||||
InputParam("dtype", type_hint=torch.dtype, description="Data type of model tensor inputs"),
|
||||
InputParam(
|
||||
"preprocess_kwargs",
|
||||
type_hint=Optional[dict],
|
||||
description="A kwargs dictionary that if specified is passed along to the `ImageProcessor` as defined under `self.image_processor` in [diffusers.image_processor.VaeImageProcessor]",
|
||||
),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self) -> List[OutputParam]:
|
||||
return [
|
||||
OutputParam(
|
||||
"image_latents",
|
||||
type_hint=torch.Tensor,
|
||||
description="The latents representing the reference image for image-to-image/inpainting generation",
|
||||
)
|
||||
]
|
||||
|
||||
# Modified from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl_inpaint.StableDiffusionXLInpaintPipeline._encode_vae_image with self -> components
|
||||
# YiYi TODO: update the _encode_vae_image so that we can use #Coped from
|
||||
def _encode_vae_image(self, components, image: torch.Tensor, generator: torch.Generator):
|
||||
latents_mean = latents_std = None
|
||||
if hasattr(components.vae.config, "latents_mean") and components.vae.config.latents_mean is not None:
|
||||
latents_mean = torch.tensor(components.vae.config.latents_mean).view(1, 4, 1, 1)
|
||||
if hasattr(components.vae.config, "latents_std") and components.vae.config.latents_std is not None:
|
||||
latents_std = torch.tensor(components.vae.config.latents_std).view(1, 4, 1, 1)
|
||||
|
||||
dtype = image.dtype
|
||||
if components.vae.config.force_upcast:
|
||||
image = image.float()
|
||||
components.vae.to(dtype=torch.float32)
|
||||
|
||||
if isinstance(generator, list):
|
||||
image_latents = [
|
||||
retrieve_latents(components.vae.encode(image[i : i + 1]), generator=generator[i])
|
||||
for i in range(image.shape[0])
|
||||
]
|
||||
image_latents = torch.cat(image_latents, dim=0)
|
||||
else:
|
||||
image_latents = retrieve_latents(components.vae.encode(image), generator=generator)
|
||||
|
||||
if components.vae.config.force_upcast:
|
||||
components.vae.to(dtype)
|
||||
|
||||
image_latents = image_latents.to(dtype)
|
||||
if latents_mean is not None and latents_std is not None:
|
||||
latents_mean = latents_mean.to(device=image_latents.device, dtype=dtype)
|
||||
latents_std = latents_std.to(device=image_latents.device, dtype=dtype)
|
||||
image_latents = (image_latents - latents_mean) * components.vae.config.scaling_factor / latents_std
|
||||
else:
|
||||
image_latents = components.vae.config.scaling_factor * image_latents
|
||||
|
||||
return image_latents
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, components: StableDiffusionXLModularPipeline, state: PipelineState) -> PipelineState:
|
||||
block_state = self.get_block_state(state)
|
||||
block_state.preprocess_kwargs = block_state.preprocess_kwargs or {}
|
||||
block_state.device = components._execution_device
|
||||
block_state.dtype = block_state.dtype if block_state.dtype is not None else components.vae.dtype
|
||||
|
||||
block_state.image = components.image_processor.preprocess(
|
||||
block_state.image, height=block_state.height, width=block_state.width, **block_state.preprocess_kwargs
|
||||
)
|
||||
block_state.image = block_state.image.to(device=block_state.device, dtype=block_state.dtype)
|
||||
|
||||
block_state.batch_size = block_state.image.shape[0]
|
||||
|
||||
# if generator is a list, make sure the length of it matches the length of images (both should be batch_size)
|
||||
if isinstance(block_state.generator, list) and len(block_state.generator) != block_state.batch_size:
|
||||
raise ValueError(
|
||||
f"You have passed a list of generators of length {len(block_state.generator)}, but requested an effective batch"
|
||||
f" size of {block_state.batch_size}. Make sure the batch size matches the length of the generators."
|
||||
)
|
||||
|
||||
block_state.image_latents = self._encode_vae_image(
|
||||
components, image=block_state.image, generator=block_state.generator
|
||||
)
|
||||
|
||||
self.set_block_state(state, block_state)
|
||||
|
||||
return components, state
|
||||
|
||||
|
||||
class StableDiffusionXLInpaintVaeEncoderStep(PipelineBlock):
|
||||
model_name = "stable-diffusion-xl"
|
||||
|
||||
@property
|
||||
def expected_components(self) -> List[ComponentSpec]:
|
||||
return [
|
||||
ComponentSpec("vae", AutoencoderKL),
|
||||
ComponentSpec(
|
||||
"image_processor",
|
||||
VaeImageProcessor,
|
||||
config=FrozenDict({"vae_scale_factor": 8}),
|
||||
default_creation_method="from_config",
|
||||
),
|
||||
ComponentSpec(
|
||||
"mask_processor",
|
||||
VaeImageProcessor,
|
||||
config=FrozenDict(
|
||||
{"do_normalize": False, "vae_scale_factor": 8, "do_binarize": True, "do_convert_grayscale": True}
|
||||
),
|
||||
default_creation_method="from_config",
|
||||
),
|
||||
]
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return "Vae encoder step that prepares the image and mask for the inpainting process"
|
||||
|
||||
@property
|
||||
def inputs(self) -> List[InputParam]:
|
||||
return [
|
||||
InputParam("height"),
|
||||
InputParam("width"),
|
||||
InputParam("image", required=True),
|
||||
InputParam("mask_image", required=True),
|
||||
InputParam("padding_mask_crop"),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_inputs(self) -> List[InputParam]:
|
||||
return [
|
||||
InputParam("dtype", type_hint=torch.dtype, description="The dtype of the model inputs"),
|
||||
InputParam("generator"),
|
||||
]
|
||||
|
||||
@property
|
||||
def intermediate_outputs(self) -> List[OutputParam]:
|
||||
return [
|
||||
OutputParam(
|
||||
"image_latents", type_hint=torch.Tensor, description="The latents representation of the input image"
|
||||
),
|
||||
OutputParam("mask", type_hint=torch.Tensor, description="The mask to use for the inpainting process"),
|
||||
OutputParam(
|
||||
"masked_image_latents",
|
||||
type_hint=torch.Tensor,
|
||||
description="The masked image latents to use for the inpainting process (only for inpainting-specifid unet)",
|
||||
),
|
||||
OutputParam(
|
||||
"crops_coords",
|
||||
type_hint=Optional[Tuple[int, int]],
|
||||
description="The crop coordinates to use for the preprocess/postprocess of the image and mask",
|
||||
),
|
||||
]
|
||||
|
||||
# Modified from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl_inpaint.StableDiffusionXLInpaintPipeline._encode_vae_image with self -> components
|
||||
# YiYi TODO: update the _encode_vae_image so that we can use #Coped from
|
||||
def _encode_vae_image(self, components, image: torch.Tensor, generator: torch.Generator):
|
||||
latents_mean = latents_std = None
|
||||
if hasattr(components.vae.config, "latents_mean") and components.vae.config.latents_mean is not None:
|
||||
latents_mean = torch.tensor(components.vae.config.latents_mean).view(1, 4, 1, 1)
|
||||
if hasattr(components.vae.config, "latents_std") and components.vae.config.latents_std is not None:
|
||||
latents_std = torch.tensor(components.vae.config.latents_std).view(1, 4, 1, 1)
|
||||
|
||||
dtype = image.dtype
|
||||
if components.vae.config.force_upcast:
|
||||
image = image.float()
|
||||
components.vae.to(dtype=torch.float32)
|
||||
|
||||
if isinstance(generator, list):
|
||||
image_latents = [
|
||||
retrieve_latents(components.vae.encode(image[i : i + 1]), generator=generator[i])
|
||||
for i in range(image.shape[0])
|
||||
]
|
||||
image_latents = torch.cat(image_latents, dim=0)
|
||||
else:
|
||||
image_latents = retrieve_latents(components.vae.encode(image), generator=generator)
|
||||
|
||||
if components.vae.config.force_upcast:
|
||||
components.vae.to(dtype)
|
||||
|
||||
image_latents = image_latents.to(dtype)
|
||||
if latents_mean is not None and latents_std is not None:
|
||||
latents_mean = latents_mean.to(device=image_latents.device, dtype=dtype)
|
||||
latents_std = latents_std.to(device=image_latents.device, dtype=dtype)
|
||||
image_latents = (image_latents - latents_mean) * self.vae.config.scaling_factor / latents_std
|
||||
else:
|
||||
image_latents = components.vae.config.scaling_factor * image_latents
|
||||
|
||||
return image_latents
|
||||
|
||||
# modified from diffusers.pipelines.stable_diffusion_xl.pipeline_stable_diffusion_xl_inpaint.StableDiffusionXLInpaintPipeline.prepare_mask_latents
|
||||
# do not accept do_classifier_free_guidance
|
||||
def prepare_mask_latents(
|
||||
self, components, mask, masked_image, batch_size, height, width, dtype, device, generator
|
||||
):
|
||||
# resize the mask to latents shape as we concatenate the mask to the latents
|
||||
# we do that before converting to dtype to avoid breaking in case we're using cpu_offload
|
||||
# and half precision
|
||||
mask = torch.nn.functional.interpolate(
|
||||
mask, size=(height // components.vae_scale_factor, width // components.vae_scale_factor)
|
||||
)
|
||||
mask = mask.to(device=device, dtype=dtype)
|
||||
|
||||
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
|
||||
if mask.shape[0] < batch_size:
|
||||
if not batch_size % mask.shape[0] == 0:
|
||||
raise ValueError(
|
||||
"The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
|
||||
f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
|
||||
" of masks that you pass is divisible by the total requested batch size."
|
||||
)
|
||||
mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
|
||||
|
||||
if masked_image is not None and masked_image.shape[1] == 4:
|
||||
masked_image_latents = masked_image
|
||||
else:
|
||||
masked_image_latents = None
|
||||
|
||||
if masked_image is not None:
|
||||
if masked_image_latents is None:
|
||||
masked_image = masked_image.to(device=device, dtype=dtype)
|
||||
masked_image_latents = self._encode_vae_image(components, masked_image, generator=generator)
|
||||
|
||||
if masked_image_latents.shape[0] < batch_size:
|
||||
if not batch_size % masked_image_latents.shape[0] == 0:
|
||||
raise ValueError(
|
||||
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
|
||||
f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
|
||||
" Make sure the number of images that you pass is divisible by the total requested batch size."
|
||||
)
|
||||
masked_image_latents = masked_image_latents.repeat(
|
||||
batch_size // masked_image_latents.shape[0], 1, 1, 1
|
||||
)
|
||||
|
||||
# aligning device to prevent device errors when concating it with the latent model input
|
||||
masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
|
||||
|
||||
return mask, masked_image_latents
|
||||
|
||||
@torch.no_grad()
|
||||
def __call__(self, components: StableDiffusionXLModularPipeline, state: PipelineState) -> PipelineState:
|
||||
block_state = self.get_block_state(state)
|
||||
|
||||
block_state.dtype = block_state.dtype if block_state.dtype is not None else components.vae.dtype
|
||||
block_state.device = components._execution_device
|
||||
|
||||
if block_state.height is None:
|
||||
block_state.height = components.default_height
|
||||
if block_state.width is None:
|
||||
block_state.width = components.default_width
|
||||
|
||||
if block_state.padding_mask_crop is not None:
|
||||
block_state.crops_coords = components.mask_processor.get_crop_region(
|
||||
block_state.mask_image, block_state.width, block_state.height, pad=block_state.padding_mask_crop
|
||||
)
|
||||
block_state.resize_mode = "fill"
|
||||
else:
|
||||
block_state.crops_coords = None
|
||||
block_state.resize_mode = "default"
|
||||
|
||||
block_state.image = components.image_processor.preprocess(
|
||||
block_state.image,
|
||||
height=block_state.height,
|
||||
width=block_state.width,
|
||||
crops_coords=block_state.crops_coords,
|
||||
resize_mode=block_state.resize_mode,
|
||||
)
|
||||
block_state.image = block_state.image.to(dtype=torch.float32)
|
||||
|
||||
block_state.mask = components.mask_processor.preprocess(
|
||||
block_state.mask_image,
|
||||
height=block_state.height,
|
||||
width=block_state.width,
|
||||
resize_mode=block_state.resize_mode,
|
||||
crops_coords=block_state.crops_coords,
|
||||
)
|
||||
block_state.masked_image = block_state.image * (block_state.mask < 0.5)
|
||||
|
||||
block_state.batch_size = block_state.image.shape[0]
|
||||
block_state.image = block_state.image.to(device=block_state.device, dtype=block_state.dtype)
|
||||
block_state.image_latents = self._encode_vae_image(
|
||||
components, image=block_state.image, generator=block_state.generator
|
||||
)
|
||||
|
||||
# 7. Prepare mask latent variables
|
||||
block_state.mask, block_state.masked_image_latents = self.prepare_mask_latents(
|
||||
components,
|
||||
block_state.mask,
|
||||
block_state.masked_image,
|
||||
block_state.batch_size,
|
||||
block_state.height,
|
||||
block_state.width,
|
||||
block_state.dtype,
|
||||
block_state.device,
|
||||
block_state.generator,
|
||||
)
|
||||
|
||||
self.set_block_state(state, block_state)
|
||||
|
||||
return components, state
|
||||
@@ -0,0 +1,380 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from ...utils import logging
|
||||
from ..modular_pipeline import AutoPipelineBlocks, SequentialPipelineBlocks
|
||||
from ..modular_pipeline_utils import InsertableDict
|
||||
from .before_denoise import (
|
||||
StableDiffusionXLControlNetInputStep,
|
||||
StableDiffusionXLControlNetUnionInputStep,
|
||||
StableDiffusionXLImg2ImgPrepareAdditionalConditioningStep,
|
||||
StableDiffusionXLImg2ImgPrepareLatentsStep,
|
||||
StableDiffusionXLImg2ImgSetTimestepsStep,
|
||||
StableDiffusionXLInpaintPrepareLatentsStep,
|
||||
StableDiffusionXLInputStep,
|
||||
StableDiffusionXLPrepareAdditionalConditioningStep,
|
||||
StableDiffusionXLPrepareLatentsStep,
|
||||
StableDiffusionXLSetTimestepsStep,
|
||||
)
|
||||
from .decoders import (
|
||||
StableDiffusionXLDecodeStep,
|
||||
StableDiffusionXLInpaintOverlayMaskStep,
|
||||
)
|
||||
from .denoise import (
|
||||
StableDiffusionXLControlNetDenoiseStep,
|
||||
StableDiffusionXLDenoiseStep,
|
||||
StableDiffusionXLInpaintControlNetDenoiseStep,
|
||||
StableDiffusionXLInpaintDenoiseStep,
|
||||
)
|
||||
from .encoders import (
|
||||
StableDiffusionXLInpaintVaeEncoderStep,
|
||||
StableDiffusionXLIPAdapterStep,
|
||||
StableDiffusionXLTextEncoderStep,
|
||||
StableDiffusionXLVaeEncoderStep,
|
||||
)
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
# auto blocks & sequential blocks & mappings
|
||||
|
||||
|
||||
# vae encoder (run before before_denoise)
|
||||
class StableDiffusionXLAutoVaeEncoderStep(AutoPipelineBlocks):
|
||||
block_classes = [StableDiffusionXLInpaintVaeEncoderStep, StableDiffusionXLVaeEncoderStep]
|
||||
block_names = ["inpaint", "img2img"]
|
||||
block_trigger_inputs = ["mask_image", "image"]
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return (
|
||||
"Vae encoder step that encode the image inputs into their latent representations.\n"
|
||||
+ "This is an auto pipeline block that works for both inpainting and img2img tasks.\n"
|
||||
+ " - `StableDiffusionXLInpaintVaeEncoderStep` (inpaint) is used when `mask_image` is provided.\n"
|
||||
+ " - `StableDiffusionXLVaeEncoderStep` (img2img) is used when only `image` is provided."
|
||||
+ " - if neither `mask_image` nor `image` is provided, step will be skipped."
|
||||
)
|
||||
|
||||
|
||||
# optional ip-adapter (run before input step)
|
||||
class StableDiffusionXLAutoIPAdapterStep(AutoPipelineBlocks):
|
||||
block_classes = [StableDiffusionXLIPAdapterStep]
|
||||
block_names = ["ip_adapter"]
|
||||
block_trigger_inputs = ["ip_adapter_image"]
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return "Run IP Adapter step if `ip_adapter_image` is provided. This step should be placed before the 'input' step.\n"
|
||||
|
||||
|
||||
# before_denoise: text2img
|
||||
class StableDiffusionXLBeforeDenoiseStep(SequentialPipelineBlocks):
|
||||
block_classes = [
|
||||
StableDiffusionXLInputStep,
|
||||
StableDiffusionXLSetTimestepsStep,
|
||||
StableDiffusionXLPrepareLatentsStep,
|
||||
StableDiffusionXLPrepareAdditionalConditioningStep,
|
||||
]
|
||||
block_names = ["input", "set_timesteps", "prepare_latents", "prepare_add_cond"]
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return (
|
||||
"Before denoise step that prepare the inputs for the denoise step.\n"
|
||||
+ "This is a sequential pipeline blocks:\n"
|
||||
+ " - `StableDiffusionXLInputStep` is used to adjust the batch size of the model inputs\n"
|
||||
+ " - `StableDiffusionXLSetTimestepsStep` is used to set the timesteps\n"
|
||||
+ " - `StableDiffusionXLPrepareLatentsStep` is used to prepare the latents\n"
|
||||
+ " - `StableDiffusionXLPrepareAdditionalConditioningStep` is used to prepare the additional conditioning\n"
|
||||
)
|
||||
|
||||
|
||||
# before_denoise: img2img
|
||||
class StableDiffusionXLImg2ImgBeforeDenoiseStep(SequentialPipelineBlocks):
|
||||
block_classes = [
|
||||
StableDiffusionXLInputStep,
|
||||
StableDiffusionXLImg2ImgSetTimestepsStep,
|
||||
StableDiffusionXLImg2ImgPrepareLatentsStep,
|
||||
StableDiffusionXLImg2ImgPrepareAdditionalConditioningStep,
|
||||
]
|
||||
block_names = ["input", "set_timesteps", "prepare_latents", "prepare_add_cond"]
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return (
|
||||
"Before denoise step that prepare the inputs for the denoise step for img2img task.\n"
|
||||
+ "This is a sequential pipeline blocks:\n"
|
||||
+ " - `StableDiffusionXLInputStep` is used to adjust the batch size of the model inputs\n"
|
||||
+ " - `StableDiffusionXLImg2ImgSetTimestepsStep` is used to set the timesteps\n"
|
||||
+ " - `StableDiffusionXLImg2ImgPrepareLatentsStep` is used to prepare the latents\n"
|
||||
+ " - `StableDiffusionXLImg2ImgPrepareAdditionalConditioningStep` is used to prepare the additional conditioning\n"
|
||||
)
|
||||
|
||||
|
||||
# before_denoise: inpainting
|
||||
class StableDiffusionXLInpaintBeforeDenoiseStep(SequentialPipelineBlocks):
|
||||
block_classes = [
|
||||
StableDiffusionXLInputStep,
|
||||
StableDiffusionXLImg2ImgSetTimestepsStep,
|
||||
StableDiffusionXLInpaintPrepareLatentsStep,
|
||||
StableDiffusionXLImg2ImgPrepareAdditionalConditioningStep,
|
||||
]
|
||||
block_names = ["input", "set_timesteps", "prepare_latents", "prepare_add_cond"]
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return (
|
||||
"Before denoise step that prepare the inputs for the denoise step for inpainting task.\n"
|
||||
+ "This is a sequential pipeline blocks:\n"
|
||||
+ " - `StableDiffusionXLInputStep` is used to adjust the batch size of the model inputs\n"
|
||||
+ " - `StableDiffusionXLImg2ImgSetTimestepsStep` is used to set the timesteps\n"
|
||||
+ " - `StableDiffusionXLInpaintPrepareLatentsStep` is used to prepare the latents\n"
|
||||
+ " - `StableDiffusionXLImg2ImgPrepareAdditionalConditioningStep` is used to prepare the additional conditioning\n"
|
||||
)
|
||||
|
||||
|
||||
# before_denoise: all task (text2img, img2img, inpainting)
|
||||
class StableDiffusionXLAutoBeforeDenoiseStep(AutoPipelineBlocks):
|
||||
block_classes = [
|
||||
StableDiffusionXLInpaintBeforeDenoiseStep,
|
||||
StableDiffusionXLImg2ImgBeforeDenoiseStep,
|
||||
StableDiffusionXLBeforeDenoiseStep,
|
||||
]
|
||||
block_names = ["inpaint", "img2img", "text2img"]
|
||||
block_trigger_inputs = ["mask", "image_latents", None]
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return (
|
||||
"Before denoise step that prepare the inputs for the denoise step.\n"
|
||||
+ "This is an auto pipeline block that works for text2img, img2img and inpainting tasks as well as controlnet, controlnet_union.\n"
|
||||
+ " - `StableDiffusionXLInpaintBeforeDenoiseStep` (inpaint) is used when both `mask` and `image_latents` are provided.\n"
|
||||
+ " - `StableDiffusionXLImg2ImgBeforeDenoiseStep` (img2img) is used when only `image_latents` is provided.\n"
|
||||
+ " - `StableDiffusionXLBeforeDenoiseStep` (text2img) is used when both `image_latents` and `mask` are not provided.\n"
|
||||
)
|
||||
|
||||
|
||||
# optional controlnet input step (after before_denoise, before denoise)
|
||||
# works for both controlnet and controlnet_union
|
||||
class StableDiffusionXLAutoControlNetInputStep(AutoPipelineBlocks):
|
||||
block_classes = [StableDiffusionXLControlNetUnionInputStep, StableDiffusionXLControlNetInputStep]
|
||||
block_names = ["controlnet_union", "controlnet"]
|
||||
block_trigger_inputs = ["control_mode", "control_image"]
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return (
|
||||
"Controlnet Input step that prepare the controlnet input.\n"
|
||||
+ "This is an auto pipeline block that works for both controlnet and controlnet_union.\n"
|
||||
+ " (it should be called right before the denoise step)"
|
||||
+ " - `StableDiffusionXLControlNetUnionInputStep` is called to prepare the controlnet input when `control_mode` and `control_image` are provided.\n"
|
||||
+ " - `StableDiffusionXLControlNetInputStep` is called to prepare the controlnet input when `control_image` is provided."
|
||||
+ " - if neither `control_mode` nor `control_image` is provided, step will be skipped."
|
||||
)
|
||||
|
||||
|
||||
# denoise: controlnet (text2img, img2img, inpainting)
|
||||
class StableDiffusionXLAutoControlNetDenoiseStep(AutoPipelineBlocks):
|
||||
block_classes = [StableDiffusionXLInpaintControlNetDenoiseStep, StableDiffusionXLControlNetDenoiseStep]
|
||||
block_names = ["inpaint_controlnet_denoise", "controlnet_denoise"]
|
||||
block_trigger_inputs = ["mask", "controlnet_cond"]
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"Denoise step that iteratively denoise the latents with controlnet. "
|
||||
"This is a auto pipeline block that using controlnet for text2img, img2img and inpainting tasks."
|
||||
"This block should not be used without a controlnet_cond input"
|
||||
" - `StableDiffusionXLInpaintControlNetDenoiseStep` (inpaint_controlnet_denoise) is used when mask is provided."
|
||||
" - `StableDiffusionXLControlNetDenoiseStep` (controlnet_denoise) is used when mask is not provided but controlnet_cond is provided."
|
||||
" - If neither mask nor controlnet_cond are provided, step will be skipped."
|
||||
)
|
||||
|
||||
|
||||
# denoise: all task with or without controlnet (text2img, img2img, inpainting)
|
||||
class StableDiffusionXLAutoDenoiseStep(AutoPipelineBlocks):
|
||||
block_classes = [
|
||||
StableDiffusionXLAutoControlNetDenoiseStep,
|
||||
StableDiffusionXLInpaintDenoiseStep,
|
||||
StableDiffusionXLDenoiseStep,
|
||||
]
|
||||
block_names = ["controlnet_denoise", "inpaint_denoise", "denoise"]
|
||||
block_trigger_inputs = ["controlnet_cond", "mask", None]
|
||||
|
||||
@property
|
||||
def description(self) -> str:
|
||||
return (
|
||||
"Denoise step that iteratively denoise the latents. "
|
||||
"This is a auto pipeline block that works for text2img, img2img and inpainting tasks. And can be used with or without controlnet."
|
||||
" - `StableDiffusionXLAutoControlNetDenoiseStep` (controlnet_denoise) is used when controlnet_cond is provided (support controlnet withtext2img, img2img and inpainting tasks)."
|
||||
" - `StableDiffusionXLInpaintDenoiseStep` (inpaint_denoise) is used when mask is provided (support inpainting tasks)."
|
||||
" - `StableDiffusionXLDenoiseStep` (denoise) is used when neither mask nor controlnet_cond are provided (support text2img and img2img tasks)."
|
||||
)
|
||||
|
||||
|
||||
# decode: inpaint
|
||||
class StableDiffusionXLInpaintDecodeStep(SequentialPipelineBlocks):
|
||||
block_classes = [StableDiffusionXLDecodeStep, StableDiffusionXLInpaintOverlayMaskStep]
|
||||
block_names = ["decode", "mask_overlay"]
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return (
|
||||
"Inpaint decode step that decode the denoised latents into images outputs.\n"
|
||||
+ "This is a sequential pipeline blocks:\n"
|
||||
+ " - `StableDiffusionXLDecodeStep` is used to decode the denoised latents into images\n"
|
||||
+ " - `StableDiffusionXLInpaintOverlayMaskStep` is used to overlay the mask on the image"
|
||||
)
|
||||
|
||||
|
||||
# decode: all task (text2img, img2img, inpainting)
|
||||
class StableDiffusionXLAutoDecodeStep(AutoPipelineBlocks):
|
||||
block_classes = [StableDiffusionXLInpaintDecodeStep, StableDiffusionXLDecodeStep]
|
||||
block_names = ["inpaint", "non-inpaint"]
|
||||
block_trigger_inputs = ["padding_mask_crop", None]
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return (
|
||||
"Decode step that decode the denoised latents into images outputs.\n"
|
||||
+ "This is an auto pipeline block that works for inpainting and non-inpainting tasks.\n"
|
||||
+ " - `StableDiffusionXLInpaintDecodeStep` (inpaint) is used when `padding_mask_crop` is provided.\n"
|
||||
+ " - `StableDiffusionXLDecodeStep` (non-inpaint) is used when `padding_mask_crop` is not provided."
|
||||
)
|
||||
|
||||
|
||||
# ip-adapter, controlnet, text2img, img2img, inpainting
|
||||
class StableDiffusionXLAutoBlocks(SequentialPipelineBlocks):
|
||||
block_classes = [
|
||||
StableDiffusionXLTextEncoderStep,
|
||||
StableDiffusionXLAutoIPAdapterStep,
|
||||
StableDiffusionXLAutoVaeEncoderStep,
|
||||
StableDiffusionXLAutoBeforeDenoiseStep,
|
||||
StableDiffusionXLAutoControlNetInputStep,
|
||||
StableDiffusionXLAutoDenoiseStep,
|
||||
StableDiffusionXLAutoDecodeStep,
|
||||
]
|
||||
block_names = [
|
||||
"text_encoder",
|
||||
"ip_adapter",
|
||||
"image_encoder",
|
||||
"before_denoise",
|
||||
"controlnet_input",
|
||||
"denoise",
|
||||
"decoder",
|
||||
]
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return (
|
||||
"Auto Modular pipeline for text-to-image, image-to-image, inpainting, and controlnet tasks using Stable Diffusion XL.\n"
|
||||
+ "- for image-to-image generation, you need to provide either `image` or `image_latents`\n"
|
||||
+ "- for inpainting, you need to provide `mask_image` and `image`, optionally you can provide `padding_mask_crop` \n"
|
||||
+ "- to run the controlnet workflow, you need to provide `control_image`\n"
|
||||
+ "- to run the controlnet_union workflow, you need to provide `control_image` and `control_mode`\n"
|
||||
+ "- to run the ip_adapter workflow, you need to provide `ip_adapter_image`\n"
|
||||
+ "- for text-to-image generation, all you need to provide is `prompt`"
|
||||
)
|
||||
|
||||
|
||||
# controlnet (input + denoise step)
|
||||
class StableDiffusionXLAutoControlnetStep(SequentialPipelineBlocks):
|
||||
block_classes = [
|
||||
StableDiffusionXLAutoControlNetInputStep,
|
||||
StableDiffusionXLAutoControlNetDenoiseStep,
|
||||
]
|
||||
block_names = ["controlnet_input", "controlnet_denoise"]
|
||||
|
||||
@property
|
||||
def description(self):
|
||||
return (
|
||||
"Controlnet auto step that prepare the controlnet input and denoise the latents. "
|
||||
+ "It works for both controlnet and controlnet_union and supports text2img, img2img and inpainting tasks."
|
||||
+ " (it should be replace at 'denoise' step)"
|
||||
)
|
||||
|
||||
|
||||
TEXT2IMAGE_BLOCKS = InsertableDict(
|
||||
[
|
||||
("text_encoder", StableDiffusionXLTextEncoderStep),
|
||||
("input", StableDiffusionXLInputStep),
|
||||
("set_timesteps", StableDiffusionXLSetTimestepsStep),
|
||||
("prepare_latents", StableDiffusionXLPrepareLatentsStep),
|
||||
("prepare_add_cond", StableDiffusionXLPrepareAdditionalConditioningStep),
|
||||
("denoise", StableDiffusionXLDenoiseStep),
|
||||
("decode", StableDiffusionXLDecodeStep),
|
||||
]
|
||||
)
|
||||
|
||||
IMAGE2IMAGE_BLOCKS = InsertableDict(
|
||||
[
|
||||
("text_encoder", StableDiffusionXLTextEncoderStep),
|
||||
("image_encoder", StableDiffusionXLVaeEncoderStep),
|
||||
("input", StableDiffusionXLInputStep),
|
||||
("set_timesteps", StableDiffusionXLImg2ImgSetTimestepsStep),
|
||||
("prepare_latents", StableDiffusionXLImg2ImgPrepareLatentsStep),
|
||||
("prepare_add_cond", StableDiffusionXLImg2ImgPrepareAdditionalConditioningStep),
|
||||
("denoise", StableDiffusionXLDenoiseStep),
|
||||
("decode", StableDiffusionXLDecodeStep),
|
||||
]
|
||||
)
|
||||
|
||||
INPAINT_BLOCKS = InsertableDict(
|
||||
[
|
||||
("text_encoder", StableDiffusionXLTextEncoderStep),
|
||||
("image_encoder", StableDiffusionXLInpaintVaeEncoderStep),
|
||||
("input", StableDiffusionXLInputStep),
|
||||
("set_timesteps", StableDiffusionXLImg2ImgSetTimestepsStep),
|
||||
("prepare_latents", StableDiffusionXLInpaintPrepareLatentsStep),
|
||||
("prepare_add_cond", StableDiffusionXLImg2ImgPrepareAdditionalConditioningStep),
|
||||
("denoise", StableDiffusionXLInpaintDenoiseStep),
|
||||
("decode", StableDiffusionXLInpaintDecodeStep),
|
||||
]
|
||||
)
|
||||
|
||||
CONTROLNET_BLOCKS = InsertableDict(
|
||||
[
|
||||
("denoise", StableDiffusionXLAutoControlnetStep),
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
IP_ADAPTER_BLOCKS = InsertableDict(
|
||||
[
|
||||
("ip_adapter", StableDiffusionXLAutoIPAdapterStep),
|
||||
]
|
||||
)
|
||||
|
||||
AUTO_BLOCKS = InsertableDict(
|
||||
[
|
||||
("text_encoder", StableDiffusionXLTextEncoderStep),
|
||||
("ip_adapter", StableDiffusionXLAutoIPAdapterStep),
|
||||
("image_encoder", StableDiffusionXLAutoVaeEncoderStep),
|
||||
("before_denoise", StableDiffusionXLAutoBeforeDenoiseStep),
|
||||
("controlnet_input", StableDiffusionXLAutoControlNetInputStep),
|
||||
("denoise", StableDiffusionXLAutoDenoiseStep),
|
||||
("decode", StableDiffusionXLAutoDecodeStep),
|
||||
]
|
||||
)
|
||||
|
||||
|
||||
ALL_BLOCKS = {
|
||||
"text2img": TEXT2IMAGE_BLOCKS,
|
||||
"img2img": IMAGE2IMAGE_BLOCKS,
|
||||
"inpaint": INPAINT_BLOCKS,
|
||||
"controlnet": CONTROLNET_BLOCKS,
|
||||
"ip_adapter": IP_ADAPTER_BLOCKS,
|
||||
"auto": AUTO_BLOCKS,
|
||||
}
|
||||
@@ -0,0 +1,375 @@
|
||||
# Copyright 2025 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import numpy as np
|
||||
import PIL
|
||||
import torch
|
||||
|
||||
from ...image_processor import PipelineImageInput
|
||||
from ...loaders import ModularIPAdapterMixin, StableDiffusionXLLoraLoaderMixin, TextualInversionLoaderMixin
|
||||
from ...pipelines.pipeline_utils import StableDiffusionMixin
|
||||
from ...pipelines.stable_diffusion_xl.pipeline_output import StableDiffusionXLPipelineOutput
|
||||
from ...utils import logging
|
||||
from ..modular_pipeline import ModularPipeline
|
||||
from ..modular_pipeline_utils import InputParam, OutputParam
|
||||
|
||||
|
||||
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
|
||||
# YiYi TODO: move to a different file? stable_diffusion_xl_module should have its own folder?
|
||||
# YiYi Notes: model specific components:
|
||||
## (1) it should inherit from ModularPipeline
|
||||
## (2) acts like a container that holds components and configs
|
||||
## (3) define default config (related to components), e.g. default_sample_size, vae_scale_factor, num_channels_unet, num_channels_latents
|
||||
## (4) inherit from model-specic loader class (e.g. StableDiffusionXLLoraLoaderMixin)
|
||||
## (5) how to use together with Components_manager?
|
||||
class StableDiffusionXLModularPipeline(
|
||||
ModularPipeline,
|
||||
StableDiffusionMixin,
|
||||
TextualInversionLoaderMixin,
|
||||
StableDiffusionXLLoraLoaderMixin,
|
||||
ModularIPAdapterMixin,
|
||||
):
|
||||
"""
|
||||
A ModularPipeline for Stable Diffusion XL.
|
||||
|
||||
<Tip warning={true}>
|
||||
|
||||
This is an experimental feature and is likely to change in the future.
|
||||
|
||||
</Tip>
|
||||
"""
|
||||
|
||||
@property
|
||||
def default_height(self):
|
||||
return self.default_sample_size * self.vae_scale_factor
|
||||
|
||||
@property
|
||||
def default_width(self):
|
||||
return self.default_sample_size * self.vae_scale_factor
|
||||
|
||||
@property
|
||||
def default_sample_size(self):
|
||||
default_sample_size = 128
|
||||
if hasattr(self, "unet") and self.unet is not None:
|
||||
default_sample_size = self.unet.config.sample_size
|
||||
return default_sample_size
|
||||
|
||||
@property
|
||||
def vae_scale_factor(self):
|
||||
vae_scale_factor = 8
|
||||
if hasattr(self, "vae") and self.vae is not None:
|
||||
vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
|
||||
return vae_scale_factor
|
||||
|
||||
@property
|
||||
def num_channels_unet(self):
|
||||
num_channels_unet = 4
|
||||
if hasattr(self, "unet") and self.unet is not None:
|
||||
num_channels_unet = self.unet.config.in_channels
|
||||
return num_channels_unet
|
||||
|
||||
@property
|
||||
def num_channels_latents(self):
|
||||
num_channels_latents = 4
|
||||
if hasattr(self, "vae") and self.vae is not None:
|
||||
num_channels_latents = self.vae.config.latent_channels
|
||||
return num_channels_latents
|
||||
|
||||
|
||||
# YiYi Notes: not used yet, maintain a list of schema that can be used across all pipeline blocks
|
||||
SDXL_INPUTS_SCHEMA = {
|
||||
"prompt": InputParam(
|
||||
"prompt", type_hint=Union[str, List[str]], description="The prompt or prompts to guide the image generation"
|
||||
),
|
||||
"prompt_2": InputParam(
|
||||
"prompt_2",
|
||||
type_hint=Union[str, List[str]],
|
||||
description="The prompt or prompts to be sent to the tokenizer_2 and text_encoder_2",
|
||||
),
|
||||
"negative_prompt": InputParam(
|
||||
"negative_prompt",
|
||||
type_hint=Union[str, List[str]],
|
||||
description="The prompt or prompts not to guide the image generation",
|
||||
),
|
||||
"negative_prompt_2": InputParam(
|
||||
"negative_prompt_2",
|
||||
type_hint=Union[str, List[str]],
|
||||
description="The negative prompt or prompts for text_encoder_2",
|
||||
),
|
||||
"cross_attention_kwargs": InputParam(
|
||||
"cross_attention_kwargs",
|
||||
type_hint=Optional[dict],
|
||||
description="Kwargs dictionary passed to the AttentionProcessor",
|
||||
),
|
||||
"clip_skip": InputParam(
|
||||
"clip_skip", type_hint=Optional[int], description="Number of layers to skip in CLIP text encoder"
|
||||
),
|
||||
"image": InputParam(
|
||||
"image",
|
||||
type_hint=PipelineImageInput,
|
||||
required=True,
|
||||
description="The image(s) to modify for img2img or inpainting",
|
||||
),
|
||||
"mask_image": InputParam(
|
||||
"mask_image",
|
||||
type_hint=PipelineImageInput,
|
||||
required=True,
|
||||
description="Mask image for inpainting, white pixels will be repainted",
|
||||
),
|
||||
"generator": InputParam(
|
||||
"generator",
|
||||
type_hint=Optional[Union[torch.Generator, List[torch.Generator]]],
|
||||
description="Generator(s) for deterministic generation",
|
||||
),
|
||||
"height": InputParam("height", type_hint=Optional[int], description="Height in pixels of the generated image"),
|
||||
"width": InputParam("width", type_hint=Optional[int], description="Width in pixels of the generated image"),
|
||||
"num_images_per_prompt": InputParam(
|
||||
"num_images_per_prompt", type_hint=int, default=1, description="Number of images to generate per prompt"
|
||||
),
|
||||
"num_inference_steps": InputParam(
|
||||
"num_inference_steps", type_hint=int, default=50, description="Number of denoising steps"
|
||||
),
|
||||
"timesteps": InputParam(
|
||||
"timesteps", type_hint=Optional[torch.Tensor], description="Custom timesteps for the denoising process"
|
||||
),
|
||||
"sigmas": InputParam(
|
||||
"sigmas", type_hint=Optional[torch.Tensor], description="Custom sigmas for the denoising process"
|
||||
),
|
||||
"denoising_end": InputParam(
|
||||
"denoising_end",
|
||||
type_hint=Optional[float],
|
||||
description="Fraction of denoising process to complete before termination",
|
||||
),
|
||||
# YiYi Notes: img2img defaults to 0.3, inpainting defaults to 0.9999
|
||||
"strength": InputParam(
|
||||
"strength", type_hint=float, default=0.3, description="How much to transform the reference image"
|
||||
),
|
||||
"denoising_start": InputParam(
|
||||
"denoising_start", type_hint=Optional[float], description="Starting point of the denoising process"
|
||||
),
|
||||
"latents": InputParam(
|
||||
"latents", type_hint=Optional[torch.Tensor], description="Pre-generated noisy latents for image generation"
|
||||
),
|
||||
"padding_mask_crop": InputParam(
|
||||
"padding_mask_crop",
|
||||
type_hint=Optional[Tuple[int, int]],
|
||||
description="Size of margin in crop for image and mask",
|
||||
),
|
||||
"original_size": InputParam(
|
||||
"original_size",
|
||||
type_hint=Optional[Tuple[int, int]],
|
||||
description="Original size of the image for SDXL's micro-conditioning",
|
||||
),
|
||||
"target_size": InputParam(
|
||||
"target_size", type_hint=Optional[Tuple[int, int]], description="Target size for SDXL's micro-conditioning"
|
||||
),
|
||||
"negative_original_size": InputParam(
|
||||
"negative_original_size",
|
||||
type_hint=Optional[Tuple[int, int]],
|
||||
description="Negative conditioning based on image resolution",
|
||||
),
|
||||
"negative_target_size": InputParam(
|
||||
"negative_target_size",
|
||||
type_hint=Optional[Tuple[int, int]],
|
||||
description="Negative conditioning based on target resolution",
|
||||
),
|
||||
"crops_coords_top_left": InputParam(
|
||||
"crops_coords_top_left",
|
||||
type_hint=Tuple[int, int],
|
||||
default=(0, 0),
|
||||
description="Top-left coordinates for SDXL's micro-conditioning",
|
||||
),
|
||||
"negative_crops_coords_top_left": InputParam(
|
||||
"negative_crops_coords_top_left",
|
||||
type_hint=Tuple[int, int],
|
||||
default=(0, 0),
|
||||
description="Negative conditioning crop coordinates",
|
||||
),
|
||||
"aesthetic_score": InputParam(
|
||||
"aesthetic_score", type_hint=float, default=6.0, description="Simulates aesthetic score of generated image"
|
||||
),
|
||||
"negative_aesthetic_score": InputParam(
|
||||
"negative_aesthetic_score", type_hint=float, default=2.0, description="Simulates negative aesthetic score"
|
||||
),
|
||||
"eta": InputParam("eta", type_hint=float, default=0.0, description="Parameter η in the DDIM paper"),
|
||||
"output_type": InputParam(
|
||||
"output_type", type_hint=str, default="pil", description="Output format (pil/tensor/np.array)"
|
||||
),
|
||||
"ip_adapter_image": InputParam(
|
||||
"ip_adapter_image",
|
||||
type_hint=PipelineImageInput,
|
||||
required=True,
|
||||
description="Image(s) to be used as IP adapter",
|
||||
),
|
||||
"control_image": InputParam(
|
||||
"control_image", type_hint=PipelineImageInput, required=True, description="ControlNet input condition"
|
||||
),
|
||||
"control_guidance_start": InputParam(
|
||||
"control_guidance_start",
|
||||
type_hint=Union[float, List[float]],
|
||||
default=0.0,
|
||||
description="When ControlNet starts applying",
|
||||
),
|
||||
"control_guidance_end": InputParam(
|
||||
"control_guidance_end",
|
||||
type_hint=Union[float, List[float]],
|
||||
default=1.0,
|
||||
description="When ControlNet stops applying",
|
||||
),
|
||||
"controlnet_conditioning_scale": InputParam(
|
||||
"controlnet_conditioning_scale",
|
||||
type_hint=Union[float, List[float]],
|
||||
default=1.0,
|
||||
description="Scale factor for ControlNet outputs",
|
||||
),
|
||||
"guess_mode": InputParam(
|
||||
"guess_mode",
|
||||
type_hint=bool,
|
||||
default=False,
|
||||
description="Enables ControlNet encoder to recognize input without prompts",
|
||||
),
|
||||
"control_mode": InputParam(
|
||||
"control_mode", type_hint=List[int], required=True, description="Control mode for union controlnet"
|
||||
),
|
||||
}
|
||||
|
||||
|
||||
SDXL_INTERMEDIATE_INPUTS_SCHEMA = {
|
||||
"prompt_embeds": InputParam(
|
||||
"prompt_embeds",
|
||||
type_hint=torch.Tensor,
|
||||
required=True,
|
||||
description="Text embeddings used to guide image generation",
|
||||
),
|
||||
"negative_prompt_embeds": InputParam(
|
||||
"negative_prompt_embeds", type_hint=torch.Tensor, description="Negative text embeddings"
|
||||
),
|
||||
"pooled_prompt_embeds": InputParam(
|
||||
"pooled_prompt_embeds", type_hint=torch.Tensor, required=True, description="Pooled text embeddings"
|
||||
),
|
||||
"negative_pooled_prompt_embeds": InputParam(
|
||||
"negative_pooled_prompt_embeds", type_hint=torch.Tensor, description="Negative pooled text embeddings"
|
||||
),
|
||||
"batch_size": InputParam("batch_size", type_hint=int, required=True, description="Number of prompts"),
|
||||
"dtype": InputParam("dtype", type_hint=torch.dtype, description="Data type of model tensor inputs"),
|
||||
"preprocess_kwargs": InputParam(
|
||||
"preprocess_kwargs", type_hint=Optional[dict], description="Kwargs for ImageProcessor"
|
||||
),
|
||||
"latents": InputParam(
|
||||
"latents", type_hint=torch.Tensor, required=True, description="Initial latents for denoising process"
|
||||
),
|
||||
"timesteps": InputParam("timesteps", type_hint=torch.Tensor, required=True, description="Timesteps for inference"),
|
||||
"num_inference_steps": InputParam(
|
||||
"num_inference_steps", type_hint=int, required=True, description="Number of denoising steps"
|
||||
),
|
||||
"latent_timestep": InputParam(
|
||||
"latent_timestep", type_hint=torch.Tensor, required=True, description="Initial noise level timestep"
|
||||
),
|
||||
"image_latents": InputParam(
|
||||
"image_latents", type_hint=torch.Tensor, required=True, description="Latents representing reference image"
|
||||
),
|
||||
"mask": InputParam("mask", type_hint=torch.Tensor, required=True, description="Mask for inpainting"),
|
||||
"masked_image_latents": InputParam(
|
||||
"masked_image_latents", type_hint=torch.Tensor, description="Masked image latents for inpainting"
|
||||
),
|
||||
"add_time_ids": InputParam(
|
||||
"add_time_ids", type_hint=torch.Tensor, required=True, description="Time ids for conditioning"
|
||||
),
|
||||
"negative_add_time_ids": InputParam(
|
||||
"negative_add_time_ids", type_hint=torch.Tensor, description="Negative time ids"
|
||||
),
|
||||
"timestep_cond": InputParam("timestep_cond", type_hint=torch.Tensor, description="Timestep conditioning for LCM"),
|
||||
"noise": InputParam("noise", type_hint=torch.Tensor, description="Noise added to image latents"),
|
||||
"crops_coords": InputParam("crops_coords", type_hint=Optional[Tuple[int]], description="Crop coordinates"),
|
||||
"ip_adapter_embeds": InputParam(
|
||||
"ip_adapter_embeds", type_hint=List[torch.Tensor], description="Image embeddings for IP-Adapter"
|
||||
),
|
||||
"negative_ip_adapter_embeds": InputParam(
|
||||
"negative_ip_adapter_embeds",
|
||||
type_hint=List[torch.Tensor],
|
||||
description="Negative image embeddings for IP-Adapter",
|
||||
),
|
||||
"images": InputParam(
|
||||
"images",
|
||||
type_hint=Union[List[PIL.Image.Image], List[torch.Tensor], List[np.array]],
|
||||
required=True,
|
||||
description="Generated images",
|
||||
),
|
||||
}
|
||||
|
||||
|
||||
SDXL_INTERMEDIATE_OUTPUTS_SCHEMA = {
|
||||
"prompt_embeds": OutputParam(
|
||||
"prompt_embeds", type_hint=torch.Tensor, description="Text embeddings used to guide image generation"
|
||||
),
|
||||
"negative_prompt_embeds": OutputParam(
|
||||
"negative_prompt_embeds", type_hint=torch.Tensor, description="Negative text embeddings"
|
||||
),
|
||||
"pooled_prompt_embeds": OutputParam(
|
||||
"pooled_prompt_embeds", type_hint=torch.Tensor, description="Pooled text embeddings"
|
||||
),
|
||||
"negative_pooled_prompt_embeds": OutputParam(
|
||||
"negative_pooled_prompt_embeds", type_hint=torch.Tensor, description="Negative pooled text embeddings"
|
||||
),
|
||||
"batch_size": OutputParam("batch_size", type_hint=int, description="Number of prompts"),
|
||||
"dtype": OutputParam("dtype", type_hint=torch.dtype, description="Data type of model tensor inputs"),
|
||||
"image_latents": OutputParam(
|
||||
"image_latents", type_hint=torch.Tensor, description="Latents representing reference image"
|
||||
),
|
||||
"mask": OutputParam("mask", type_hint=torch.Tensor, description="Mask for inpainting"),
|
||||
"masked_image_latents": OutputParam(
|
||||
"masked_image_latents", type_hint=torch.Tensor, description="Masked image latents for inpainting"
|
||||
),
|
||||
"crops_coords": OutputParam("crops_coords", type_hint=Optional[Tuple[int]], description="Crop coordinates"),
|
||||
"timesteps": OutputParam("timesteps", type_hint=torch.Tensor, description="Timesteps for inference"),
|
||||
"num_inference_steps": OutputParam("num_inference_steps", type_hint=int, description="Number of denoising steps"),
|
||||
"latent_timestep": OutputParam(
|
||||
"latent_timestep", type_hint=torch.Tensor, description="Initial noise level timestep"
|
||||
),
|
||||
"add_time_ids": OutputParam("add_time_ids", type_hint=torch.Tensor, description="Time ids for conditioning"),
|
||||
"negative_add_time_ids": OutputParam(
|
||||
"negative_add_time_ids", type_hint=torch.Tensor, description="Negative time ids"
|
||||
),
|
||||
"timestep_cond": OutputParam("timestep_cond", type_hint=torch.Tensor, description="Timestep conditioning for LCM"),
|
||||
"latents": OutputParam("latents", type_hint=torch.Tensor, description="Denoised latents"),
|
||||
"noise": OutputParam("noise", type_hint=torch.Tensor, description="Noise added to image latents"),
|
||||
"ip_adapter_embeds": OutputParam(
|
||||
"ip_adapter_embeds", type_hint=List[torch.Tensor], description="Image embeddings for IP-Adapter"
|
||||
),
|
||||
"negative_ip_adapter_embeds": OutputParam(
|
||||
"negative_ip_adapter_embeds",
|
||||
type_hint=List[torch.Tensor],
|
||||
description="Negative image embeddings for IP-Adapter",
|
||||
),
|
||||
"images": OutputParam(
|
||||
"images",
|
||||
type_hint=Union[List[PIL.Image.Image], List[torch.Tensor], List[np.array]],
|
||||
description="Generated images",
|
||||
),
|
||||
}
|
||||
|
||||
|
||||
SDXL_OUTPUTS_SCHEMA = {
|
||||
"images": OutputParam(
|
||||
"images",
|
||||
type_hint=Union[
|
||||
Tuple[Union[List[PIL.Image.Image], List[torch.Tensor], List[np.array]]], StableDiffusionXLPipelineOutput
|
||||
],
|
||||
description="The final generated images",
|
||||
)
|
||||
}
|
||||
@@ -248,14 +248,15 @@ def _get_connected_pipeline(pipeline_cls):
|
||||
return _get_task_class(AUTO_INPAINT_PIPELINES_MAPPING, pipeline_cls.__name__, throw_error_if_not_exist=False)
|
||||
|
||||
|
||||
def _get_task_class(mapping, pipeline_class_name, throw_error_if_not_exist: bool = True):
|
||||
def get_model(pipeline_class_name):
|
||||
for task_mapping in SUPPORTED_TASKS_MAPPINGS:
|
||||
for model_name, pipeline in task_mapping.items():
|
||||
if pipeline.__name__ == pipeline_class_name:
|
||||
return model_name
|
||||
def _get_model(pipeline_class_name):
|
||||
for task_mapping in SUPPORTED_TASKS_MAPPINGS:
|
||||
for model_name, pipeline in task_mapping.items():
|
||||
if pipeline.__name__ == pipeline_class_name:
|
||||
return model_name
|
||||
|
||||
model_name = get_model(pipeline_class_name)
|
||||
|
||||
def _get_task_class(mapping, pipeline_class_name, throw_error_if_not_exist: bool = True):
|
||||
model_name = _get_model(pipeline_class_name)
|
||||
|
||||
if model_name is not None:
|
||||
task_class = mapping.get(model_name, None)
|
||||
|
||||
@@ -718,14 +718,15 @@ class CogVideoXPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
|
||||
timestep = t.expand(latent_model_input.shape[0])
|
||||
|
||||
# predict noise model_output
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
image_rotary_emb=image_rotary_emb,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
with self.transformer.cache_context("cond_uncond"):
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
image_rotary_emb=image_rotary_emb,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
noise_pred = noise_pred.float()
|
||||
|
||||
# perform guidance
|
||||
|
||||
@@ -784,14 +784,15 @@ class CogVideoXFunControlPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin):
|
||||
timestep = t.expand(latent_model_input.shape[0])
|
||||
|
||||
# predict noise model_output
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
image_rotary_emb=image_rotary_emb,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
with self.transformer.cache_context("cond_uncond"):
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
image_rotary_emb=image_rotary_emb,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
noise_pred = noise_pred.float()
|
||||
|
||||
# perform guidance
|
||||
|
||||
@@ -831,15 +831,16 @@ class CogVideoXImageToVideoPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin)
|
||||
timestep = t.expand(latent_model_input.shape[0])
|
||||
|
||||
# predict noise model_output
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
ofs=ofs_emb,
|
||||
image_rotary_emb=image_rotary_emb,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
with self.transformer.cache_context("cond_uncond"):
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
ofs=ofs_emb,
|
||||
image_rotary_emb=image_rotary_emb,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
noise_pred = noise_pred.float()
|
||||
|
||||
# perform guidance
|
||||
|
||||
@@ -799,14 +799,15 @@ class CogVideoXVideoToVideoPipeline(DiffusionPipeline, CogVideoXLoraLoaderMixin)
|
||||
timestep = t.expand(latent_model_input.shape[0])
|
||||
|
||||
# predict noise model_output
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
image_rotary_emb=image_rotary_emb,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
with self.transformer.cache_context("cond_uncond"):
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
image_rotary_emb=image_rotary_emb,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
noise_pred = noise_pred.float()
|
||||
|
||||
# perform guidance
|
||||
|
||||
@@ -619,22 +619,10 @@ class CogView4Pipeline(DiffusionPipeline, CogView4LoraLoaderMixin):
|
||||
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
||||
timestep = t.expand(latents.shape[0])
|
||||
|
||||
noise_pred_cond = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
original_size=original_size,
|
||||
target_size=target_size,
|
||||
crop_coords=crops_coords_top_left,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
# perform guidance
|
||||
if self.do_classifier_free_guidance:
|
||||
noise_pred_uncond = self.transformer(
|
||||
with self.transformer.cache_context("cond"):
|
||||
noise_pred_cond = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=negative_prompt_embeds,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
original_size=original_size,
|
||||
target_size=target_size,
|
||||
@@ -643,6 +631,19 @@ class CogView4Pipeline(DiffusionPipeline, CogView4LoraLoaderMixin):
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
# perform guidance
|
||||
if self.do_classifier_free_guidance:
|
||||
with self.transformer.cache_context("uncond"):
|
||||
noise_pred_uncond = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=negative_prompt_embeds,
|
||||
timestep=timestep,
|
||||
original_size=original_size,
|
||||
target_size=target_size,
|
||||
crop_coords=crops_coords_top_left,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
noise_pred = noise_pred_uncond + self.guidance_scale * (noise_pred_cond - noise_pred_uncond)
|
||||
else:
|
||||
noise_pred = noise_pred_cond
|
||||
|
||||
@@ -912,32 +912,35 @@ class FluxPipeline(
|
||||
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
||||
timestep = t.expand(latents.shape[0]).to(latents.dtype)
|
||||
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latents,
|
||||
timestep=timestep / 1000,
|
||||
guidance=guidance,
|
||||
pooled_projections=pooled_prompt_embeds,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
txt_ids=text_ids,
|
||||
img_ids=latent_image_ids,
|
||||
joint_attention_kwargs=self.joint_attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
if do_true_cfg:
|
||||
if negative_image_embeds is not None:
|
||||
self._joint_attention_kwargs["ip_adapter_image_embeds"] = negative_image_embeds
|
||||
neg_noise_pred = self.transformer(
|
||||
with self.transformer.cache_context("cond"):
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latents,
|
||||
timestep=timestep / 1000,
|
||||
guidance=guidance,
|
||||
pooled_projections=negative_pooled_prompt_embeds,
|
||||
encoder_hidden_states=negative_prompt_embeds,
|
||||
txt_ids=negative_text_ids,
|
||||
pooled_projections=pooled_prompt_embeds,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
txt_ids=text_ids,
|
||||
img_ids=latent_image_ids,
|
||||
joint_attention_kwargs=self.joint_attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
if do_true_cfg:
|
||||
if negative_image_embeds is not None:
|
||||
self._joint_attention_kwargs["ip_adapter_image_embeds"] = negative_image_embeds
|
||||
|
||||
with self.transformer.cache_context("uncond"):
|
||||
neg_noise_pred = self.transformer(
|
||||
hidden_states=latents,
|
||||
timestep=timestep / 1000,
|
||||
guidance=guidance,
|
||||
pooled_projections=negative_pooled_prompt_embeds,
|
||||
encoder_hidden_states=negative_prompt_embeds,
|
||||
txt_ids=negative_text_ids,
|
||||
img_ids=latent_image_ids,
|
||||
joint_attention_kwargs=self.joint_attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
noise_pred = neg_noise_pred + true_cfg_scale * (noise_pred - neg_noise_pred)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
|
||||
@@ -693,28 +693,30 @@ class HunyuanVideoPipeline(DiffusionPipeline, HunyuanVideoLoraLoaderMixin):
|
||||
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
||||
timestep = t.expand(latents.shape[0]).to(latents.dtype)
|
||||
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
timestep=timestep,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
encoder_attention_mask=prompt_attention_mask,
|
||||
pooled_projections=pooled_prompt_embeds,
|
||||
guidance=guidance,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
if do_true_cfg:
|
||||
neg_noise_pred = self.transformer(
|
||||
with self.transformer.cache_context("cond"):
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
timestep=timestep,
|
||||
encoder_hidden_states=negative_prompt_embeds,
|
||||
encoder_attention_mask=negative_prompt_attention_mask,
|
||||
pooled_projections=negative_pooled_prompt_embeds,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
encoder_attention_mask=prompt_attention_mask,
|
||||
pooled_projections=pooled_prompt_embeds,
|
||||
guidance=guidance,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
if do_true_cfg:
|
||||
with self.transformer.cache_context("uncond"):
|
||||
neg_noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
timestep=timestep,
|
||||
encoder_hidden_states=negative_prompt_embeds,
|
||||
encoder_attention_mask=negative_prompt_attention_mask,
|
||||
pooled_projections=negative_pooled_prompt_embeds,
|
||||
guidance=guidance,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
noise_pred = neg_noise_pred + true_cfg_scale * (noise_pred - neg_noise_pred)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
|
||||
@@ -757,18 +757,19 @@ class LTXPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraLoaderMixi
|
||||
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
||||
timestep = t.expand(latent_model_input.shape[0])
|
||||
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
encoder_attention_mask=prompt_attention_mask,
|
||||
num_frames=latent_num_frames,
|
||||
height=latent_height,
|
||||
width=latent_width,
|
||||
rope_interpolation_scale=rope_interpolation_scale,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
with self.transformer.cache_context("cond_uncond"):
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
encoder_attention_mask=prompt_attention_mask,
|
||||
num_frames=latent_num_frames,
|
||||
height=latent_height,
|
||||
width=latent_width,
|
||||
rope_interpolation_scale=rope_interpolation_scale,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
noise_pred = noise_pred.float()
|
||||
|
||||
if self.do_classifier_free_guidance:
|
||||
|
||||
@@ -1177,15 +1177,16 @@ class LTXConditionPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLoraL
|
||||
if is_conditioning_image_or_video:
|
||||
timestep = torch.min(timestep, (1 - conditioning_mask_model_input) * 1000.0)
|
||||
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
encoder_attention_mask=prompt_attention_mask,
|
||||
video_coords=video_coords,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
with self.transformer.cache_context("cond_uncond"):
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
encoder_attention_mask=prompt_attention_mask,
|
||||
video_coords=video_coords,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
if self.do_classifier_free_guidance:
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
|
||||
@@ -830,18 +830,19 @@ class LTXImageToVideoPipeline(DiffusionPipeline, FromSingleFileMixin, LTXVideoLo
|
||||
timestep = t.expand(latent_model_input.shape[0])
|
||||
timestep = timestep.unsqueeze(-1) * (1 - conditioning_mask)
|
||||
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
encoder_attention_mask=prompt_attention_mask,
|
||||
num_frames=latent_num_frames,
|
||||
height=latent_height,
|
||||
width=latent_width,
|
||||
rope_interpolation_scale=rope_interpolation_scale,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
with self.transformer.cache_context("cond_uncond"):
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
encoder_attention_mask=prompt_attention_mask,
|
||||
num_frames=latent_num_frames,
|
||||
height=latent_height,
|
||||
width=latent_width,
|
||||
rope_interpolation_scale=rope_interpolation_scale,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
noise_pred = noise_pred.float()
|
||||
|
||||
if self.do_classifier_free_guidance:
|
||||
|
||||
@@ -671,14 +671,15 @@ class MochiPipeline(DiffusionPipeline, Mochi1LoraLoaderMixin):
|
||||
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
||||
timestep = t.expand(latent_model_input.shape[0]).to(latents.dtype)
|
||||
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
encoder_attention_mask=prompt_attention_mask,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
with self.transformer.cache_context("cond_uncond"):
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
timestep=timestep,
|
||||
encoder_attention_mask=prompt_attention_mask,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
# Mochi CFG + Sampling runs in FP32
|
||||
noise_pred = noise_pred.to(torch.float32)
|
||||
|
||||
|
||||
@@ -371,6 +371,22 @@ def maybe_raise_or_warn(
|
||||
)
|
||||
|
||||
|
||||
# a simpler version of get_class_obj_and_candidates, it won't work with custom code
|
||||
def simple_get_class_obj(library_name, class_name):
|
||||
from diffusers import pipelines
|
||||
|
||||
is_pipeline_module = hasattr(pipelines, library_name)
|
||||
|
||||
if is_pipeline_module:
|
||||
pipeline_module = getattr(pipelines, library_name)
|
||||
class_obj = getattr(pipeline_module, class_name)
|
||||
else:
|
||||
library = importlib.import_module(library_name)
|
||||
class_obj = getattr(library, class_name)
|
||||
|
||||
return class_obj
|
||||
|
||||
|
||||
def get_class_obj_and_candidates(
|
||||
library_name, class_name, importable_classes, pipelines, is_pipeline_module, component_name=None, cache_dir=None
|
||||
):
|
||||
@@ -452,7 +468,7 @@ def _get_pipeline_class(
|
||||
revision=revision,
|
||||
)
|
||||
|
||||
if class_obj.__name__ != "DiffusionPipeline":
|
||||
if class_obj.__name__ != "DiffusionPipeline" and class_obj.__name__ != "ModularPipeline":
|
||||
return class_obj
|
||||
|
||||
diffusers_module = importlib.import_module(class_obj.__module__.split(".")[0])
|
||||
@@ -892,7 +908,10 @@ def _fetch_class_library_tuple(module):
|
||||
library = not_compiled_module.__module__
|
||||
|
||||
# retrieve class_name
|
||||
class_name = not_compiled_module.__class__.__name__
|
||||
if isinstance(not_compiled_module, type):
|
||||
class_name = not_compiled_module.__name__
|
||||
else:
|
||||
class_name = not_compiled_module.__class__.__name__
|
||||
|
||||
return (library, class_name)
|
||||
|
||||
|
||||
@@ -1986,11 +1986,13 @@ class DiffusionPipeline(ConfigMixin, PushToHubMixin):
|
||||
f"{'' if k.startswith('_') else '_'}{k}": v for k, v in original_config.items() if k not in pipeline_kwargs
|
||||
}
|
||||
|
||||
optional_components = (
|
||||
pipeline._optional_components
|
||||
if hasattr(pipeline, "_optional_components") and pipeline._optional_components
|
||||
else []
|
||||
)
|
||||
missing_modules = (
|
||||
set(expected_modules)
|
||||
- set(pipeline._optional_components)
|
||||
- set(pipeline_kwargs.keys())
|
||||
- set(true_optional_modules)
|
||||
set(expected_modules) - set(optional_components) - set(pipeline_kwargs.keys()) - set(true_optional_modules)
|
||||
)
|
||||
|
||||
if len(missing_modules) > 0:
|
||||
|
||||
@@ -533,22 +533,24 @@ class WanPipeline(DiffusionPipeline, WanLoraLoaderMixin):
|
||||
latent_model_input = latents.to(transformer_dtype)
|
||||
timestep = t.expand(latents.shape[0])
|
||||
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
timestep=timestep,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
if self.do_classifier_free_guidance:
|
||||
noise_uncond = self.transformer(
|
||||
with self.transformer.cache_context("cond"):
|
||||
noise_pred = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
timestep=timestep,
|
||||
encoder_hidden_states=negative_prompt_embeds,
|
||||
encoder_hidden_states=prompt_embeds,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
|
||||
if self.do_classifier_free_guidance:
|
||||
with self.transformer.cache_context("uncond"):
|
||||
noise_uncond = self.transformer(
|
||||
hidden_states=latent_model_input,
|
||||
timestep=timestep,
|
||||
encoder_hidden_states=negative_prompt_embeds,
|
||||
attention_kwargs=attention_kwargs,
|
||||
return_dict=False,
|
||||
)[0]
|
||||
noise_pred = noise_uncond + guidance_scale * (noise_pred - noise_uncond)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
|
||||
@@ -2,6 +2,126 @@
|
||||
from ..utils import DummyObject, requires_backends
|
||||
|
||||
|
||||
class AdaptiveProjectedGuidance(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class AutoGuidance(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class ClassifierFreeGuidance(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class ClassifierFreeZeroStarGuidance(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class PerturbedAttentionGuidance(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class SkipLayerGuidance(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class SmoothedEnergyGuidance(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class TangentialClassifierFreeGuidance(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class FasterCacheConfig(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
@@ -17,6 +137,21 @@ class FasterCacheConfig(metaclass=DummyObject):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class FirstBlockCacheConfig(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class HookRegistry(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
@@ -32,6 +167,21 @@ class HookRegistry(metaclass=DummyObject):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class LayerSkipConfig(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class PyramidAttentionBroadcastConfig(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
@@ -47,10 +197,33 @@ class PyramidAttentionBroadcastConfig(metaclass=DummyObject):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class SmoothedEnergyGuidanceConfig(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
def apply_faster_cache(*args, **kwargs):
|
||||
requires_backends(apply_faster_cache, ["torch"])
|
||||
|
||||
|
||||
def apply_first_block_cache(*args, **kwargs):
|
||||
requires_backends(apply_first_block_cache, ["torch"])
|
||||
|
||||
|
||||
def apply_layer_skip(*args, **kwargs):
|
||||
requires_backends(apply_layer_skip, ["torch"])
|
||||
|
||||
|
||||
def apply_pyramid_attention_broadcast(*args, **kwargs):
|
||||
requires_backends(apply_pyramid_attention_broadcast, ["torch"])
|
||||
|
||||
@@ -1180,6 +1353,66 @@ class WanVACETransformer3DModel(metaclass=DummyObject):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class ComponentsManager(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class ComponentSpec(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class ModularPipeline(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
class ModularPipelineBlocks(metaclass=DummyObject):
|
||||
_backends = ["torch"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch"])
|
||||
|
||||
|
||||
def get_constant_schedule(*args, **kwargs):
|
||||
requires_backends(get_constant_schedule, ["torch"])
|
||||
|
||||
|
||||
@@ -2,6 +2,36 @@
|
||||
from ..utils import DummyObject, requires_backends
|
||||
|
||||
|
||||
class StableDiffusionXLAutoBlocks(metaclass=DummyObject):
|
||||
_backends = ["torch", "transformers"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch", "transformers"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch", "transformers"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch", "transformers"])
|
||||
|
||||
|
||||
class StableDiffusionXLModularPipeline(metaclass=DummyObject):
|
||||
_backends = ["torch", "transformers"]
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
requires_backends(self, ["torch", "transformers"])
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch", "transformers"])
|
||||
|
||||
@classmethod
|
||||
def from_pretrained(cls, *args, **kwargs):
|
||||
requires_backends(cls, ["torch", "transformers"])
|
||||
|
||||
|
||||
class AllegroPipeline(metaclass=DummyObject):
|
||||
_backends = ["torch", "transformers"]
|
||||
|
||||
|
||||
@@ -20,8 +20,11 @@ import json
|
||||
import os
|
||||
import re
|
||||
import shutil
|
||||
import signal
|
||||
import sys
|
||||
import threading
|
||||
from pathlib import Path
|
||||
from types import ModuleType
|
||||
from typing import Dict, Optional, Union
|
||||
from urllib import request
|
||||
|
||||
@@ -37,6 +40,8 @@ logger = logging.get_logger(__name__) # pylint: disable=invalid-name
|
||||
|
||||
# See https://huggingface.co/datasets/diffusers/community-pipelines-mirror
|
||||
COMMUNITY_PIPELINES_MIRROR_ID = "diffusers/community-pipelines-mirror"
|
||||
TIME_OUT_REMOTE_CODE = int(os.getenv("DIFFUSERS_TIMEOUT_REMOTE_CODE", 15))
|
||||
_HF_REMOTE_CODE_LOCK = threading.Lock()
|
||||
|
||||
|
||||
def get_diffusers_versions():
|
||||
@@ -154,33 +159,87 @@ def check_imports(filename):
|
||||
return get_relative_imports(filename)
|
||||
|
||||
|
||||
def get_class_in_module(class_name, module_path, pretrained_model_name_or_path=None):
|
||||
def _raise_timeout_error(signum, frame):
|
||||
raise ValueError(
|
||||
"Loading this model requires you to execute custom code contained in the model repository on your local "
|
||||
"machine. Please set the option `trust_remote_code=True` to permit loading of this model."
|
||||
)
|
||||
|
||||
|
||||
def resolve_trust_remote_code(trust_remote_code, model_name, has_remote_code):
|
||||
if trust_remote_code is None:
|
||||
if has_remote_code and TIME_OUT_REMOTE_CODE > 0:
|
||||
prev_sig_handler = None
|
||||
try:
|
||||
prev_sig_handler = signal.signal(signal.SIGALRM, _raise_timeout_error)
|
||||
signal.alarm(TIME_OUT_REMOTE_CODE)
|
||||
while trust_remote_code is None:
|
||||
answer = input(
|
||||
f"The repository for {model_name} contains custom code which must be executed to correctly "
|
||||
f"load the model. You can inspect the repository content at https://hf.co/{model_name}.\n"
|
||||
f"You can avoid this prompt in future by passing the argument `trust_remote_code=True`.\n\n"
|
||||
f"Do you wish to run the custom code? [y/N] "
|
||||
)
|
||||
if answer.lower() in ["yes", "y", "1"]:
|
||||
trust_remote_code = True
|
||||
elif answer.lower() in ["no", "n", "0", ""]:
|
||||
trust_remote_code = False
|
||||
signal.alarm(0)
|
||||
except Exception:
|
||||
# OS which does not support signal.SIGALRM
|
||||
raise ValueError(
|
||||
f"The repository for {model_name} contains custom code which must be executed to correctly "
|
||||
f"load the model. You can inspect the repository content at https://hf.co/{model_name}.\n"
|
||||
f"Please pass the argument `trust_remote_code=True` to allow custom code to be run."
|
||||
)
|
||||
finally:
|
||||
if prev_sig_handler is not None:
|
||||
signal.signal(signal.SIGALRM, prev_sig_handler)
|
||||
signal.alarm(0)
|
||||
elif has_remote_code:
|
||||
# For the CI which puts the timeout at 0
|
||||
_raise_timeout_error(None, None)
|
||||
|
||||
if has_remote_code and not trust_remote_code:
|
||||
raise ValueError(
|
||||
f"Loading {model_name} requires you to execute the configuration file in that"
|
||||
" repo on your local machine. Make sure you have read the code there to avoid malicious use, then"
|
||||
" set the option `trust_remote_code=True` to remove this error."
|
||||
)
|
||||
|
||||
return trust_remote_code
|
||||
|
||||
|
||||
def get_class_in_module(class_name, module_path, force_reload=False):
|
||||
"""
|
||||
Import a module on the cache directory for modules and extract a class from it.
|
||||
"""
|
||||
module_path = module_path.replace(os.path.sep, ".")
|
||||
try:
|
||||
module = importlib.import_module(module_path)
|
||||
except ModuleNotFoundError as e:
|
||||
# This can happen when the repo id contains ".", which Python's import machinery interprets as a directory
|
||||
# separator. We do a bit of monkey patching to detect and fix this case.
|
||||
if not (
|
||||
pretrained_model_name_or_path is not None
|
||||
and "." in pretrained_model_name_or_path
|
||||
and module_path.startswith("diffusers_modules")
|
||||
and pretrained_model_name_or_path.replace("/", "--") in module_path
|
||||
):
|
||||
raise e # We can't figure this one out, just reraise the original error
|
||||
name = os.path.normpath(module_path)
|
||||
if name.endswith(".py"):
|
||||
name = name[:-3]
|
||||
name = name.replace(os.path.sep, ".")
|
||||
module_file: Path = Path(HF_MODULES_CACHE) / module_path
|
||||
|
||||
corrected_path = os.path.join(HF_MODULES_CACHE, module_path.replace(".", "/")) + ".py"
|
||||
corrected_path = corrected_path.replace(
|
||||
pretrained_model_name_or_path.replace("/", "--").replace(".", "/"),
|
||||
pretrained_model_name_or_path.replace("/", "--"),
|
||||
)
|
||||
module = importlib.machinery.SourceFileLoader(module_path, corrected_path).load_module()
|
||||
with _HF_REMOTE_CODE_LOCK:
|
||||
if force_reload:
|
||||
sys.modules.pop(name, None)
|
||||
importlib.invalidate_caches()
|
||||
cached_module: Optional[ModuleType] = sys.modules.get(name)
|
||||
module_spec = importlib.util.spec_from_file_location(name, location=module_file)
|
||||
|
||||
module: ModuleType
|
||||
if cached_module is None:
|
||||
module = importlib.util.module_from_spec(module_spec)
|
||||
# insert it into sys.modules before any loading begins
|
||||
sys.modules[name] = module
|
||||
else:
|
||||
module = cached_module
|
||||
|
||||
module_spec.loader.exec_module(module)
|
||||
|
||||
if class_name is None:
|
||||
return find_pipeline_class(module)
|
||||
|
||||
return getattr(module, class_name)
|
||||
|
||||
|
||||
@@ -472,4 +531,4 @@ def get_class_from_dynamic_module(
|
||||
revision=revision,
|
||||
local_files_only=local_files_only,
|
||||
)
|
||||
return get_class_in_module(class_name, final_module.replace(".py", ""), pretrained_model_name_or_path)
|
||||
return get_class_in_module(class_name, final_module)
|
||||
|
||||
@@ -467,6 +467,7 @@ class PushToHubMixin:
|
||||
token: Optional[str] = None,
|
||||
commit_message: Optional[str] = None,
|
||||
create_pr: bool = False,
|
||||
subfolder: Optional[str] = None,
|
||||
):
|
||||
"""
|
||||
Uploads all files in `working_dir` to `repo_id`.
|
||||
@@ -481,7 +482,12 @@ class PushToHubMixin:
|
||||
|
||||
logger.info(f"Uploading the files of {working_dir} to {repo_id}.")
|
||||
return upload_folder(
|
||||
repo_id=repo_id, folder_path=working_dir, token=token, commit_message=commit_message, create_pr=create_pr
|
||||
repo_id=repo_id,
|
||||
folder_path=working_dir,
|
||||
token=token,
|
||||
commit_message=commit_message,
|
||||
create_pr=create_pr,
|
||||
path_in_repo=subfolder,
|
||||
)
|
||||
|
||||
def push_to_hub(
|
||||
@@ -493,6 +499,7 @@ class PushToHubMixin:
|
||||
create_pr: bool = False,
|
||||
safe_serialization: bool = True,
|
||||
variant: Optional[str] = None,
|
||||
subfolder: Optional[str] = None,
|
||||
) -> str:
|
||||
"""
|
||||
Upload model, scheduler, or pipeline files to the 🤗 Hugging Face Hub.
|
||||
@@ -534,8 +541,9 @@ class PushToHubMixin:
|
||||
repo_id = create_repo(repo_id, private=private, token=token, exist_ok=True).repo_id
|
||||
|
||||
# Create a new empty model card and eventually tag it
|
||||
model_card = load_or_create_model_card(repo_id, token=token)
|
||||
model_card = populate_model_card(model_card)
|
||||
if not subfolder:
|
||||
model_card = load_or_create_model_card(repo_id, token=token)
|
||||
model_card = populate_model_card(model_card)
|
||||
|
||||
# Save all files.
|
||||
save_kwargs = {"safe_serialization": safe_serialization}
|
||||
@@ -546,7 +554,8 @@ class PushToHubMixin:
|
||||
self.save_pretrained(tmpdir, **save_kwargs)
|
||||
|
||||
# Update model card if needed:
|
||||
model_card.save(os.path.join(tmpdir, "README.md"))
|
||||
if not subfolder:
|
||||
model_card.save(os.path.join(tmpdir, "README.md"))
|
||||
|
||||
return self._upload_folder(
|
||||
tmpdir,
|
||||
@@ -554,4 +563,5 @@ class PushToHubMixin:
|
||||
token=token,
|
||||
commit_message=commit_message,
|
||||
create_pr=create_pr,
|
||||
subfolder=subfolder,
|
||||
)
|
||||
|
||||
@@ -421,6 +421,10 @@ def require_big_accelerator(test_case):
|
||||
Decorator marking a test that requires a bigger hardware accelerator (24GB) for execution. Some example pipelines:
|
||||
Flux, SD3, Cog, etc.
|
||||
"""
|
||||
import pytest
|
||||
|
||||
test_case = pytest.mark.big_accelerator(test_case)
|
||||
|
||||
if not is_torch_available():
|
||||
return unittest.skip("test requires PyTorch")(test_case)
|
||||
|
||||
|
||||
@@ -92,6 +92,11 @@ def is_compiled_module(module) -> bool:
|
||||
return isinstance(module, torch._dynamo.eval_frame.OptimizedModule)
|
||||
|
||||
|
||||
def unwrap_module(module):
|
||||
"""Unwraps a module if it was compiled with torch.compile()"""
|
||||
return module._orig_mod if is_compiled_module(module) else module
|
||||
|
||||
|
||||
def fourier_filter(x_in: "torch.Tensor", threshold: int, scale: int) -> "torch.Tensor":
|
||||
"""Fourier filter as introduced in FreeU (https://huggingface.co/papers/2309.11497).
|
||||
|
||||
|
||||
@@ -30,6 +30,10 @@ sys.path.insert(1, git_repo_path)
|
||||
warnings.simplefilter(action="ignore", category=FutureWarning)
|
||||
|
||||
|
||||
def pytest_configure(config):
|
||||
config.addinivalue_line("markers", "big_accelerator: marks tests as requiring big accelerator resources")
|
||||
|
||||
|
||||
def pytest_addoption(parser):
|
||||
from diffusers.utils.testing_utils import pytest_addoption_shared
|
||||
|
||||
|
||||
@@ -20,7 +20,6 @@ import tempfile
|
||||
import unittest
|
||||
|
||||
import numpy as np
|
||||
import pytest
|
||||
import safetensors.torch
|
||||
import torch
|
||||
from parameterized import parameterized
|
||||
@@ -813,7 +812,6 @@ class FluxControlLoRATests(unittest.TestCase, PeftLoraLoaderMixinTests):
|
||||
@require_torch_accelerator
|
||||
@require_peft_backend
|
||||
@require_big_accelerator
|
||||
@pytest.mark.big_accelerator
|
||||
class FluxLoRAIntegrationTests(unittest.TestCase):
|
||||
"""internal note: The integration slices were obtained on audace.
|
||||
|
||||
@@ -960,7 +958,6 @@ class FluxLoRAIntegrationTests(unittest.TestCase):
|
||||
@require_torch_accelerator
|
||||
@require_peft_backend
|
||||
@require_big_accelerator
|
||||
@pytest.mark.big_accelerator
|
||||
class FluxControlLoRAIntegrationTests(unittest.TestCase):
|
||||
num_inference_steps = 10
|
||||
seed = 0
|
||||
|
||||
@@ -17,7 +17,6 @@ import sys
|
||||
import unittest
|
||||
|
||||
import numpy as np
|
||||
import pytest
|
||||
import torch
|
||||
from transformers import CLIPTextModel, CLIPTokenizer, LlamaModel, LlamaTokenizerFast
|
||||
|
||||
@@ -198,7 +197,6 @@ class HunyuanVideoLoRATests(unittest.TestCase, PeftLoraLoaderMixinTests):
|
||||
@require_torch_accelerator
|
||||
@require_peft_backend
|
||||
@require_big_accelerator
|
||||
@pytest.mark.big_accelerator
|
||||
class HunyuanVideoLoRAIntegrationTests(unittest.TestCase):
|
||||
"""internal note: The integration slices were obtained on DGX.
|
||||
|
||||
|
||||
@@ -17,7 +17,6 @@ import sys
|
||||
import unittest
|
||||
|
||||
import numpy as np
|
||||
import pytest
|
||||
import torch
|
||||
from transformers import AutoTokenizer, CLIPTextModelWithProjection, CLIPTokenizer, T5EncoderModel
|
||||
|
||||
@@ -139,7 +138,6 @@ class SD3LoRATests(unittest.TestCase, PeftLoraLoaderMixinTests):
|
||||
@require_torch_accelerator
|
||||
@require_peft_backend
|
||||
@require_big_accelerator
|
||||
@pytest.mark.big_accelerator
|
||||
class SD3LoraIntegrationTests(unittest.TestCase):
|
||||
pipeline_class = StableDiffusion3Img2ImgPipeline
|
||||
repo_id = "stabilityai/stable-diffusion-3-medium-diffusers"
|
||||
|
||||
@@ -33,6 +33,7 @@ from diffusers.utils.testing_utils import (
|
||||
from ..pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_IMAGE_PARAMS, TEXT_TO_IMAGE_PARAMS
|
||||
from ..test_pipelines_common import (
|
||||
FasterCacheTesterMixin,
|
||||
FirstBlockCacheTesterMixin,
|
||||
PipelineTesterMixin,
|
||||
PyramidAttentionBroadcastTesterMixin,
|
||||
check_qkv_fusion_matches_attn_procs_length,
|
||||
@@ -45,7 +46,11 @@ enable_full_determinism()
|
||||
|
||||
|
||||
class CogVideoXPipelineFastTests(
|
||||
PipelineTesterMixin, PyramidAttentionBroadcastTesterMixin, FasterCacheTesterMixin, unittest.TestCase
|
||||
PipelineTesterMixin,
|
||||
PyramidAttentionBroadcastTesterMixin,
|
||||
FasterCacheTesterMixin,
|
||||
FirstBlockCacheTesterMixin,
|
||||
unittest.TestCase,
|
||||
):
|
||||
pipeline_class = CogVideoXPipeline
|
||||
params = TEXT_TO_IMAGE_PARAMS - {"cross_attention_kwargs"}
|
||||
|
||||
@@ -17,7 +17,6 @@ import gc
|
||||
import unittest
|
||||
|
||||
import numpy as np
|
||||
import pytest
|
||||
import torch
|
||||
from huggingface_hub import hf_hub_download
|
||||
from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer, T5EncoderModel, T5TokenizerFast
|
||||
@@ -211,7 +210,6 @@ class FluxControlNetPipelineFastTests(unittest.TestCase, PipelineTesterMixin, Fl
|
||||
|
||||
@nightly
|
||||
@require_big_accelerator
|
||||
@pytest.mark.big_accelerator
|
||||
class FluxControlNetPipelineSlowTests(unittest.TestCase):
|
||||
pipeline_class = FluxControlNetPipeline
|
||||
|
||||
|
||||
@@ -18,7 +18,6 @@ import unittest
|
||||
from typing import Optional
|
||||
|
||||
import numpy as np
|
||||
import pytest
|
||||
import torch
|
||||
from transformers import AutoTokenizer, CLIPTextConfig, CLIPTextModelWithProjection, CLIPTokenizer, T5EncoderModel
|
||||
|
||||
@@ -221,7 +220,6 @@ class StableDiffusion3ControlNetPipelineFastTests(unittest.TestCase, PipelineTes
|
||||
|
||||
@slow
|
||||
@require_big_accelerator
|
||||
@pytest.mark.big_accelerator
|
||||
class StableDiffusion3ControlNetPipelineSlowTests(unittest.TestCase):
|
||||
pipeline_class = StableDiffusion3ControlNetPipeline
|
||||
|
||||
|
||||
@@ -2,7 +2,6 @@ import gc
|
||||
import unittest
|
||||
|
||||
import numpy as np
|
||||
import pytest
|
||||
import torch
|
||||
from huggingface_hub import hf_hub_download
|
||||
from transformers import AutoTokenizer, CLIPTextConfig, CLIPTextModel, CLIPTokenizer, T5EncoderModel
|
||||
@@ -25,6 +24,7 @@ from diffusers.utils.testing_utils import (
|
||||
|
||||
from ..test_pipelines_common import (
|
||||
FasterCacheTesterMixin,
|
||||
FirstBlockCacheTesterMixin,
|
||||
FluxIPAdapterTesterMixin,
|
||||
PipelineTesterMixin,
|
||||
PyramidAttentionBroadcastTesterMixin,
|
||||
@@ -34,11 +34,12 @@ from ..test_pipelines_common import (
|
||||
|
||||
|
||||
class FluxPipelineFastTests(
|
||||
unittest.TestCase,
|
||||
PipelineTesterMixin,
|
||||
FluxIPAdapterTesterMixin,
|
||||
PyramidAttentionBroadcastTesterMixin,
|
||||
FasterCacheTesterMixin,
|
||||
FirstBlockCacheTesterMixin,
|
||||
unittest.TestCase,
|
||||
):
|
||||
pipeline_class = FluxPipeline
|
||||
params = frozenset(["prompt", "height", "width", "guidance_scale", "prompt_embeds", "pooled_prompt_embeds"])
|
||||
@@ -224,7 +225,6 @@ class FluxPipelineFastTests(
|
||||
|
||||
@nightly
|
||||
@require_big_accelerator
|
||||
@pytest.mark.big_accelerator
|
||||
class FluxPipelineSlowTests(unittest.TestCase):
|
||||
pipeline_class = FluxPipeline
|
||||
repo_id = "black-forest-labs/FLUX.1-schnell"
|
||||
@@ -312,7 +312,6 @@ class FluxPipelineSlowTests(unittest.TestCase):
|
||||
|
||||
@slow
|
||||
@require_big_accelerator
|
||||
@pytest.mark.big_accelerator
|
||||
class FluxIPAdapterPipelineSlowTests(unittest.TestCase):
|
||||
pipeline_class = FluxPipeline
|
||||
repo_id = "black-forest-labs/FLUX.1-dev"
|
||||
|
||||
@@ -2,7 +2,6 @@ import gc
|
||||
import unittest
|
||||
|
||||
import numpy as np
|
||||
import pytest
|
||||
import torch
|
||||
|
||||
from diffusers import FluxPipeline, FluxPriorReduxPipeline
|
||||
@@ -19,7 +18,6 @@ from diffusers.utils.testing_utils import (
|
||||
|
||||
@slow
|
||||
@require_big_accelerator
|
||||
@pytest.mark.big_accelerator
|
||||
class FluxReduxSlowTests(unittest.TestCase):
|
||||
pipeline_class = FluxPriorReduxPipeline
|
||||
repo_id = "black-forest-labs/FLUX.1-Redux-dev"
|
||||
|
||||
@@ -33,6 +33,7 @@ from diffusers.utils.testing_utils import (
|
||||
|
||||
from ..test_pipelines_common import (
|
||||
FasterCacheTesterMixin,
|
||||
FirstBlockCacheTesterMixin,
|
||||
PipelineTesterMixin,
|
||||
PyramidAttentionBroadcastTesterMixin,
|
||||
to_np,
|
||||
@@ -43,7 +44,11 @@ enable_full_determinism()
|
||||
|
||||
|
||||
class HunyuanVideoPipelineFastTests(
|
||||
PipelineTesterMixin, PyramidAttentionBroadcastTesterMixin, FasterCacheTesterMixin, unittest.TestCase
|
||||
PipelineTesterMixin,
|
||||
PyramidAttentionBroadcastTesterMixin,
|
||||
FasterCacheTesterMixin,
|
||||
FirstBlockCacheTesterMixin,
|
||||
unittest.TestCase,
|
||||
):
|
||||
pipeline_class = HunyuanVideoPipeline
|
||||
params = frozenset(["prompt", "height", "width", "guidance_scale", "prompt_embeds", "pooled_prompt_embeds"])
|
||||
|
||||
@@ -23,13 +23,13 @@ from diffusers import AutoencoderKLLTXVideo, FlowMatchEulerDiscreteScheduler, LT
|
||||
from diffusers.utils.testing_utils import enable_full_determinism, torch_device
|
||||
|
||||
from ..pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_IMAGE_PARAMS, TEXT_TO_IMAGE_PARAMS
|
||||
from ..test_pipelines_common import PipelineTesterMixin, to_np
|
||||
from ..test_pipelines_common import FirstBlockCacheTesterMixin, PipelineTesterMixin, to_np
|
||||
|
||||
|
||||
enable_full_determinism()
|
||||
|
||||
|
||||
class LTXPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
|
||||
class LTXPipelineFastTests(PipelineTesterMixin, FirstBlockCacheTesterMixin, unittest.TestCase):
|
||||
pipeline_class = LTXPipeline
|
||||
params = TEXT_TO_IMAGE_PARAMS - {"cross_attention_kwargs"}
|
||||
batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
|
||||
@@ -49,7 +49,7 @@ class LTXPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
|
||||
test_layerwise_casting = True
|
||||
test_group_offloading = True
|
||||
|
||||
def get_dummy_components(self):
|
||||
def get_dummy_components(self, num_layers: int = 1):
|
||||
torch.manual_seed(0)
|
||||
transformer = LTXVideoTransformer3DModel(
|
||||
in_channels=8,
|
||||
@@ -59,7 +59,7 @@ class LTXPipelineFastTests(PipelineTesterMixin, unittest.TestCase):
|
||||
num_attention_heads=4,
|
||||
attention_head_dim=8,
|
||||
cross_attention_dim=32,
|
||||
num_layers=1,
|
||||
num_layers=num_layers,
|
||||
caption_channels=32,
|
||||
)
|
||||
|
||||
|
||||
@@ -17,7 +17,6 @@ import inspect
|
||||
import unittest
|
||||
|
||||
import numpy as np
|
||||
import pytest
|
||||
import torch
|
||||
from transformers import AutoTokenizer, T5EncoderModel
|
||||
|
||||
@@ -33,13 +32,15 @@ from diffusers.utils.testing_utils import (
|
||||
)
|
||||
|
||||
from ..pipeline_params import TEXT_TO_IMAGE_BATCH_PARAMS, TEXT_TO_IMAGE_IMAGE_PARAMS, TEXT_TO_IMAGE_PARAMS
|
||||
from ..test_pipelines_common import FasterCacheTesterMixin, PipelineTesterMixin, to_np
|
||||
from ..test_pipelines_common import FasterCacheTesterMixin, FirstBlockCacheTesterMixin, PipelineTesterMixin, to_np
|
||||
|
||||
|
||||
enable_full_determinism()
|
||||
|
||||
|
||||
class MochiPipelineFastTests(PipelineTesterMixin, FasterCacheTesterMixin, unittest.TestCase):
|
||||
class MochiPipelineFastTests(
|
||||
PipelineTesterMixin, FasterCacheTesterMixin, FirstBlockCacheTesterMixin, unittest.TestCase
|
||||
):
|
||||
pipeline_class = MochiPipeline
|
||||
params = TEXT_TO_IMAGE_PARAMS - {"cross_attention_kwargs"}
|
||||
batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
|
||||
@@ -268,7 +269,6 @@ class MochiPipelineFastTests(PipelineTesterMixin, FasterCacheTesterMixin, unitte
|
||||
@nightly
|
||||
@require_torch_accelerator
|
||||
@require_big_accelerator
|
||||
@pytest.mark.big_accelerator
|
||||
class MochiPipelineIntegrationTests(unittest.TestCase):
|
||||
prompt = "A painting of a squirrel eating a burger."
|
||||
|
||||
|
||||
@@ -2,7 +2,6 @@ import gc
|
||||
import unittest
|
||||
|
||||
import numpy as np
|
||||
import pytest
|
||||
import torch
|
||||
from transformers import AutoTokenizer, CLIPTextConfig, CLIPTextModelWithProjection, CLIPTokenizer, T5EncoderModel
|
||||
|
||||
@@ -233,7 +232,6 @@ class StableDiffusion3PipelineFastTests(unittest.TestCase, PipelineTesterMixin):
|
||||
|
||||
@slow
|
||||
@require_big_accelerator
|
||||
@pytest.mark.big_accelerator
|
||||
class StableDiffusion3PipelineSlowTests(unittest.TestCase):
|
||||
pipeline_class = StableDiffusion3Pipeline
|
||||
repo_id = "stabilityai/stable-diffusion-3-medium-diffusers"
|
||||
|
||||
@@ -3,7 +3,6 @@ import random
|
||||
import unittest
|
||||
|
||||
import numpy as np
|
||||
import pytest
|
||||
import torch
|
||||
from transformers import AutoTokenizer, CLIPTextConfig, CLIPTextModelWithProjection, CLIPTokenizer, T5EncoderModel
|
||||
|
||||
@@ -168,7 +167,6 @@ class StableDiffusion3Img2ImgPipelineFastTests(PipelineLatentTesterMixin, unitte
|
||||
|
||||
@slow
|
||||
@require_big_accelerator
|
||||
@pytest.mark.big_accelerator
|
||||
class StableDiffusion3Img2ImgPipelineSlowTests(unittest.TestCase):
|
||||
pipeline_class = StableDiffusion3Img2ImgPipeline
|
||||
repo_id = "stabilityai/stable-diffusion-3-medium-diffusers"
|
||||
|
||||
@@ -33,6 +33,7 @@ from diffusers import (
|
||||
)
|
||||
from diffusers.hooks import apply_group_offloading
|
||||
from diffusers.hooks.faster_cache import FasterCacheBlockHook, FasterCacheDenoiserHook
|
||||
from diffusers.hooks.first_block_cache import FirstBlockCacheConfig
|
||||
from diffusers.hooks.pyramid_attention_broadcast import PyramidAttentionBroadcastHook
|
||||
from diffusers.image_processor import VaeImageProcessor
|
||||
from diffusers.loaders import FluxIPAdapterMixin, IPAdapterMixin
|
||||
@@ -2648,7 +2649,7 @@ class FasterCacheTesterMixin:
|
||||
self.faster_cache_config.current_timestep_callback = lambda: pipe.current_timestep
|
||||
pipe = create_pipe()
|
||||
pipe.transformer.enable_cache(self.faster_cache_config)
|
||||
output = run_forward(pipe).flatten().flatten()
|
||||
output = run_forward(pipe).flatten()
|
||||
image_slice_faster_cache_enabled = np.concatenate((output[:8], output[-8:]))
|
||||
|
||||
# Run inference with FasterCache disabled
|
||||
@@ -2755,6 +2756,55 @@ class FasterCacheTesterMixin:
|
||||
self.assertTrue(state.cache is None, "Cache should be reset to None.")
|
||||
|
||||
|
||||
# TODO(aryan, dhruv): the cache tester mixins should probably be rewritten so that more models can be tested out
|
||||
# of the box once there is better cache support/implementation
|
||||
class FirstBlockCacheTesterMixin:
|
||||
# threshold is intentionally set higher than usual values since we're testing with random unconverged models
|
||||
# that will not satisfy the expected properties of the denoiser for caching to be effective
|
||||
first_block_cache_config = FirstBlockCacheConfig(threshold=0.8)
|
||||
|
||||
def test_first_block_cache_inference(self, expected_atol: float = 0.1):
|
||||
device = "cpu" # ensure determinism for the device-dependent torch.Generator
|
||||
|
||||
def create_pipe():
|
||||
torch.manual_seed(0)
|
||||
num_layers = 2
|
||||
components = self.get_dummy_components(num_layers=num_layers)
|
||||
pipe = self.pipeline_class(**components)
|
||||
pipe = pipe.to(device)
|
||||
pipe.set_progress_bar_config(disable=None)
|
||||
return pipe
|
||||
|
||||
def run_forward(pipe):
|
||||
torch.manual_seed(0)
|
||||
inputs = self.get_dummy_inputs(device)
|
||||
inputs["num_inference_steps"] = 4
|
||||
return pipe(**inputs)[0]
|
||||
|
||||
# Run inference without FirstBlockCache
|
||||
pipe = create_pipe()
|
||||
output = run_forward(pipe).flatten()
|
||||
original_image_slice = np.concatenate((output[:8], output[-8:]))
|
||||
|
||||
# Run inference with FirstBlockCache enabled
|
||||
pipe = create_pipe()
|
||||
pipe.transformer.enable_cache(self.first_block_cache_config)
|
||||
output = run_forward(pipe).flatten()
|
||||
image_slice_fbc_enabled = np.concatenate((output[:8], output[-8:]))
|
||||
|
||||
# Run inference with FirstBlockCache disabled
|
||||
pipe.transformer.disable_cache()
|
||||
output = run_forward(pipe).flatten()
|
||||
image_slice_fbc_disabled = np.concatenate((output[:8], output[-8:]))
|
||||
|
||||
assert np.allclose(original_image_slice, image_slice_fbc_enabled, atol=expected_atol), (
|
||||
"FirstBlockCache outputs should not differ much."
|
||||
)
|
||||
assert np.allclose(original_image_slice, image_slice_fbc_disabled, atol=1e-4), (
|
||||
"Outputs from normal inference and after disabling cache should not differ."
|
||||
)
|
||||
|
||||
|
||||
# Some models (e.g. unCLIP) are extremely likely to significantly deviate depending on which hardware is used.
|
||||
# This helper function is used to check that the image doesn't deviate on average more than 10 pixels from a
|
||||
# reference image.
|
||||
|
||||
Reference in New Issue
Block a user